Начинающим операторам генеративных моделей для преобразования текста в картинки непросто бывает сориентироваться в многообразии опций, которые предлагают AUTOMATIC1111 и иные рабочие среды (за исключением, пожалуй, наиболее скупой в плане доступных пользователю опций Fooocus). Удачное сочетание параметров, что порождает особенно привлекательную картинку, порой воспринимается как редчайшая находка,— не случайно в Сети уже немало онлайновых бирж для торговли подсказками. Да, всё верно: люди готовы платить за сочетания слов, что гарантируют получение заведомо высококачественных (что бы под этим словом каждый ни подразумевал) изображений. «Конструктор подсказок» (prompt engineer) — теперь профессия, обеспечивающая доход до 300 тыс. долл. США в год, — правда, пока не слишком ясно, каковы её хотя бы среднесрочные перспективы. Дело в том, что ChatGPT и его собратья (соботы?) по искусственному разуму сами довольно хороши в генерации подсказок для ИИ-рисования, — так что, вполне вероятно, хотя бы с позиций prompt engineers кожаных мешков роботы точно сумеют вытеснить.
Впрочем, помимо самой подсказки, других параметров — служебных — у любой генерации множество. Это и выбор дотренированного чекпойнта (если пользоваться не исходными моделями SD 1.5 или SDXL 1.0, первичной настройкой которых занимались сами разработчики из Stability.ai), и число шагов «расшумления» (denoising) численной репрезентации образа в латентном пространстве (steps), и конкретный планировщик/селектор (scheduler/sampler), и величина CFG (classifier free guidance, мера свободы действий классификатора), — и даже габариты холста: как размеры, так и соотношение длинной и короткой его сторон. Вот почему навигация в латентном пространстве — из которого, собственно, генеративная ИИ-модель и добывает изображения, отталкиваясь от всего набора заданных ей параметров, — представляет собой настолько сложную задачу: слишком много переменных. Убедительно достоверная в своей квазинатуральности (при определённом наборе входных величин) картинка может превратиться в сюрреалистическую фантасмагорию при изменении, допустим, CFG всего на 0,5 или steps на единичку.

Источник: ИИ-генерация на основе модели SDXL 1.0
Это, в свою очередь, делает саму процедуру оптимизации подсказок (текстовой и служебных) делом чрезвычайно трудозатратным: приходится оптимизировать систему по внушительному набору параметров одновременно, да ещё и с учётом того, что каждое изображение генерируется за десятки секунд, а то и за минуту-другую (на нашем тестовом ПК с ГП GTX 1070). Так что же остаётся: положиться на капризную Фортуну и просто вразнобой скармливать AUTOMATIC1111 самые разнообразные комбинации входных величин в надежде однажды добиться по-настоящему привлекательного результата? Да, можно и так, — но лучше по возможности организовать свои усилия, проводя поиск хотя бы с базовым уровнем систематизации. Это будет сродни не современному путешествию по спутниковому навигатору к вожделенной точке на карте, а, скорее, античному плаванию на утлой парусно-гребной лодчонке в виду берега (не изобретены ещё ни компас, ни секстант, — потому выход в открытое море грозит потерей ориентации) при постоянной сверке с составленным прежними мореходами периплом.
Попробуем?
Прежде чем отчаливать от берега, необходимо привести корабль в порядок. В нашем случае это будет означать обновление рабочей среды AUTOMATIC1111 до актуальной (на момент написания настоящей статьи) версии 1.6.0 — и заодно уж проверку того, насколько удачно в этом релизе организована хвалёная поддержка SDXL 1.0, раз мы в прошлой «Мастерской» посетовали на отсутствие этой опции в версии 1.5.1. Перипл, по которому мы в дальнейшем примемся бороздить латентное пространство, будет базироваться на модели SD 1.5, поскольку та наиболее хорошо к настоящему времени изучена сообществом энтузиастов ИИ-рисования (и исполняется на имеющемся «железе» существенно быстрее своей оверсайз-наследницы), но общие принципы и инструментарий такой навигации для всех моделей останутся корректными. По крайней мере, в рамках выбранной рабочей среды: для ComfyUI тех же самых результатов пришлось бы добиваться с применением «макаронных» циклограмм — которые сами по себе гораздо сложнее для восприятия неподготовленным оператором, чем привычные меню и вкладки веб-интерфейса AUTOMATIC1111.
Итак, первым делом обновим прямым запросом к GitHub свежую версию рабочей среды уже знакомым читателям прежних наших «Мастерских» способом, — надо только предварительно удостовериться, что это ПО в настоящее время не исполняется. Открыв в «Проводнике» Windows папку, в которую была ранее проинсталлирована AUTOMATIC1111, следует щёлкнуть правой кнопкой мыши и в появившемся меню выбрать «Git Bash Here». Запустится окно приложения командной строки, установленного вместе с рабочей средой, — и в него нужно будет ввести буквально два слова,
git pull
после чего нажать на Enter. Там же, в окне командной строки, система отчитается о произведённом обновлении — и, вероятно, в очередной раз предложит обновить служебное приложение pip. Если есть настроение, можно обновить — эту процедуру мы уже проделывали в ходе самой первой установки AUTOMATIC1111.
Прежде чем запускать сервер рабочей среды (и взаимодействовать с ним через локальный веб-интерфейс), следует удостовериться, что все необходимые чекпойнты загружены. В соответствующей папке models\stable-diffusion должны присутствовать базовая модель и доводчик для SDXL 1.0 (у тех, кто пробовал инсталлировать ComfyUI в рамках четвёртого занятия по ИИ в «Мастерской», они наверняка там и располагаются), а место для соответствующей модели VAE — в папке models\VAE. Этот вариационный автокодировщик (variational autoencoder) представляет собой дополнительную небольшую (по сравнению с основной моделью) нейросеть, специально натренированную на повышение качества итоговой картинки: усиление контраста, расширение динамического диапазона, выявление мелких деталей и придание им «ожидаемых» (т. е. присутствовавших в исходном наборе обучающих изображений) форм — чтобы, допустим, мелкие листочки дерева на фоне смотрелись именно как мелкие листочки (с более-менее узнаваемым и однотипным для всего этого дерева абрисом), а не просто как разнородные зеленоватые кляксы.
Напомним, что в ходе обучения моделей скрытого рассеяния (latent diffusion model) латентное пространство автокодировщика, что ставит в соответствие токенам (в которые преобразуется текстовый ввод) определённые образы, фиксировано. Именно поэтому при точном воспроизведении параметров генерации итоговый рисунок удаётся воспроизвести на другом ПК практически один в один, порой лишь за вычетом неизбежно добавляемой на отдельных шагах стохастики. Иными словами, теоретически латентное пространство всё-таки возможно точно картографировать, — проблема лишь в его поистине неохватном объёме. Грубая оценка общего числа образов, потенциально доступных для извлечения из латентного пространства модели SD 1.5, даёт величину 10^1010 — т. е. десятки, возведённой в степень 10 млрд. 10 в квадрате — это сто, 10 в девятой — миллиард, а тут — 10 в степени десять миллиардов. Вот почему энтузиастам ИИ-рисования приходится полагаться на периплы вместо карт — то бишь, по сути, на опыт первопроходцев. И самим становиться первопроходцами для тех, кто пойдёт следом.
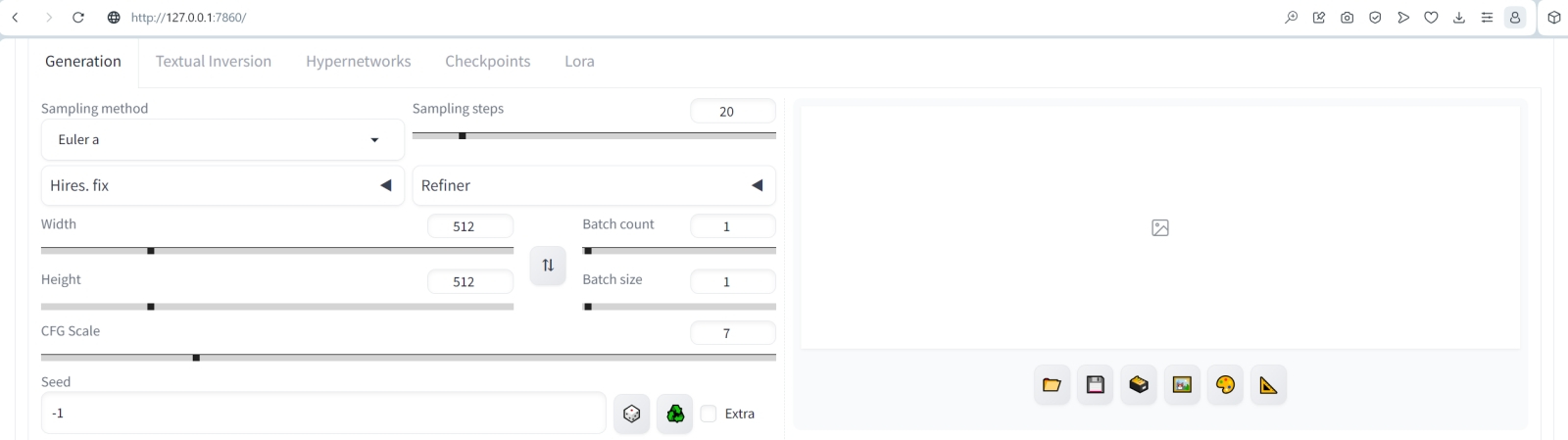
Сразу же видно, что в версии 1.6.0 рабочая среда AUTOMATIC1111 ориентирована на эксплуатацию SDXL-моделей: рядом с выпадающим меню «Highres. fix», которое присутствовало и прежде, появилось ещё одно, «Refiner», — для выбора модели доводчика.
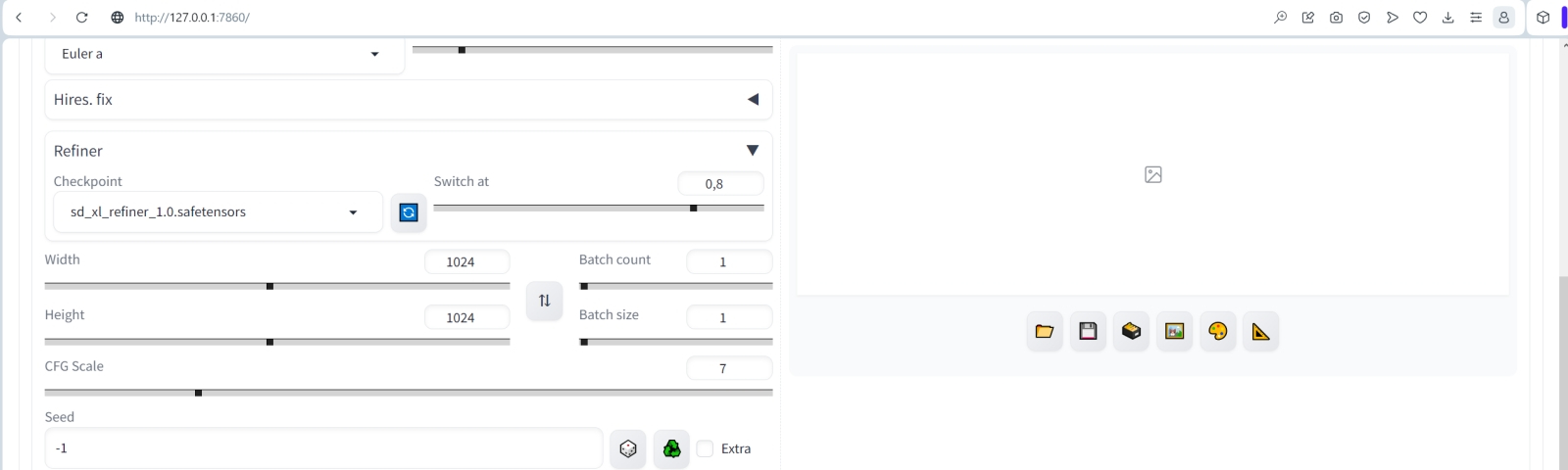
Чтобы проверить, как наша штатная рабочая среда оперирует с «Оверсайзом», зададим в выпадающих сверху меню базовую модель sd_xl_base_1.0.safetensors, VAE — sdxl_vae.safetensors, «Clip skip» установим пока в «1» (хотя для множества дотренированных чекпойнтов SD 1.5 их создатели рекомендуют применять «2»). Параметр «Switch at» оставляем в рекомендованном значении 0,8 — в прошлой «Мастерской» мы поясняли, по какой причине разработчики SDXL рекомендуют именно первые 80% шагов генерации отдавать на откуп базовой модели и только последние 20% — доводчику. Размерные параметры холста выставляем в стандартные для SDXL 1024 × 1024.
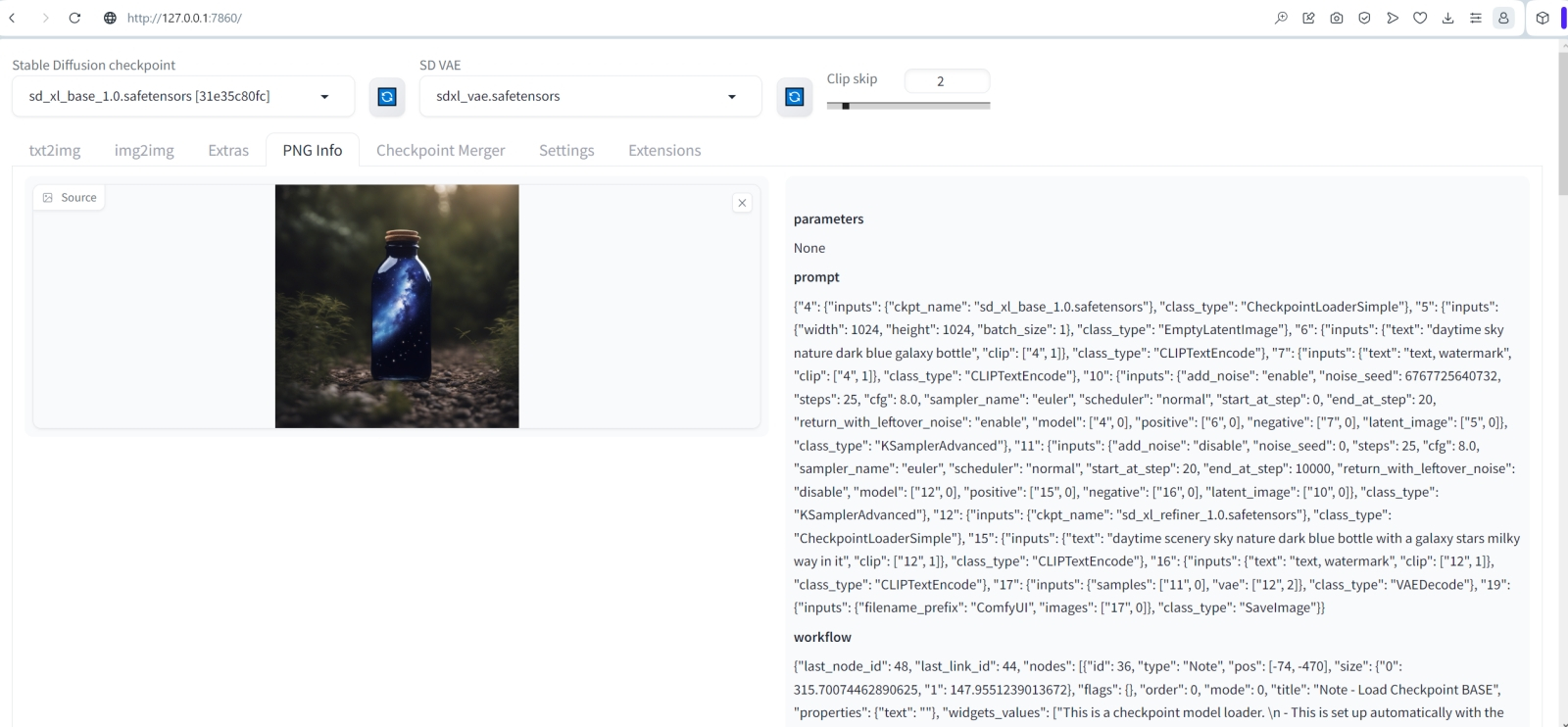
Теперь попробуем воспроизвести картинку sdxl_refiner_prompt_example, взятую из официальной подборки примеров генерации для ComfyUI + SDXL. Параметры, с которыми проводилась эта генерация, записаны в заголовок PNG-файла, и потому перетаскивание соответствующего изображения из «Проводника» мышкой в окно на вкладке «PNG Info» демонстрирует все эти параметры в доступном для изучения живым оператором виде. Правда, просто взять и нажатием кнопки «Send to txt2img» перебросить их на вкладку генерации не выйдет: формат текстовых полей у ComfyUI иной. Но это и не страшно: вручную несложно скопировать и перенести (либо вручную выставить подходящими ползунками в интерфейсе AUTOMATIC1111) следующие величины:
позитивная подсказка: daytime sky nature dark blue galaxy bottle (тут, правда, есть тонкость: в циклограмме ComfyUI для базы и для доводчика заданы разные позитивные подсказки: для первой — та, что приведена ранее; для второго — «daytime scenery sky nature dark blue bottle with a galaxy stars milky way in it». AUTOMATIC1111 раздельного указания подсказок не предусматривает, потому пока остановимся на первой, более короткой),
негативная: text, watermark,
затравка (seed): 6767725640732,
число шагов (steps): 25,
CFG: 8.0,
планировщик (sampler): euler.
И запускаем с такими параметрами на исполнение.

Слева — образцовая галактика в бутылке из руководства к использованию модели SDXL в рабочей среде ComfyUI (источник: GitHub), справа — генерация в AUTOMATIC1111 с той же моделью и указанными в тексте параметрами
Заняло всё около 6 минут, из которых заметное время — не менее полутора минут — ушло на подгрузку в видеопамять модели доводчика, а затем ещё примерно столько же — на обратную смену её на базовую. В целом изображения очень похожи, но деталей на том, что выполнено с AUTOMATIC1111, явно меньше. Испробуем теперь подсказку подлиннее — ту, что в оригинале скармливалась доводчику:
daytime scenery sky nature dark blue bottle with a galaxy stars milky way in it

Правая картинка — та же, что и прежде; левая — генерация в AUTOMATIC1111 с расширенной подсказкой
Деталей, пожалуй, прибавилось, но теперь картинки различаются очень сильно!
Отдать швартовы!
Значит, дело не в подсказке (доводчик в любом случае выполняет, по сути, ту же «отделочную» работу, что и VAE, поэтому принципиально на композицию изображения влиять не может), а, скорее всего, в реализации SDXL как таковой. Есть подозрение, что в версии 1.6.0 базовая модель передаёт доводчику по прохождении 80% шагов полностью готовую картинку — вместо того, чтобы оставлять на ней неудалённые следы латентного шума, которые при нормальной отработке циклограммы в той же ComfyUI становятся основой для более продуктивной работы refiner-модели.
Попробуем другой способ — реализацию сотворчества базы и доводчика внешним скриптом, Refiner (webui Extension). По приведённой ссылке, в принципе, можно и не переходить: это расширение устанавливается из самой рабочей среды. Достаточно на вкладке «Extensions» выбрать подвкладку «Available», нажать там на оранжевую кнопку «Load from:»,
и (после непродолжительного перерыва на обновление) отыскать на полученной странице с расширениями — просто через «Ctrl»+«F» в браузере — слово «refiner». На момент написания настоящей статьи такой скрипт там один-единственный, ошибиться невозможно: нажимаем на серенькую «Install» в соответствующей строке.
А затем, вернувшись на подвкладку «Installed», фиксируем факт успешной установки скрипта. Для верности можно проконтролировать, что ник автора, wcde, присутствующий в ссылке на домашнюю страницу данного проекта на GitHub, – тот же, что и в приведённом выше прямом адресе этого проекта. Теперь остаётся нажать «Apply and restart UI».
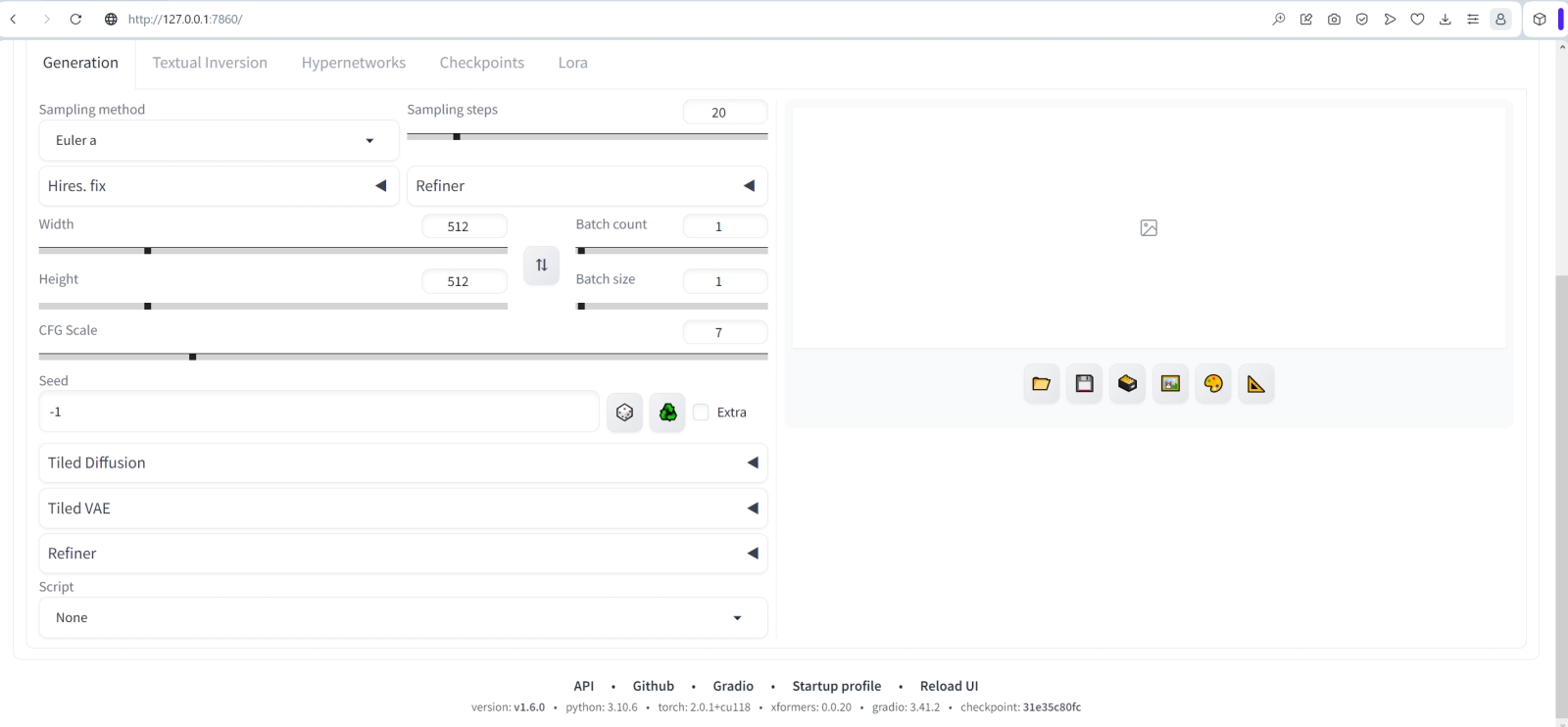
После обновления интерфейса в самом низу страницы на основной нашей рабочей вкладке «txt2img» появилось ещё одно выпадающее меню «Refiner» — им отныне и следует пользоваться. ВАЖНО: про штатную его реализацию, ту, что расположена рядом с «Highres. fix», надо забыть, как про страшный сон, — по крайней мере до тех пор, пока у автора AUTOMATIC1111 не дойдут руки заставить его работать как следует.
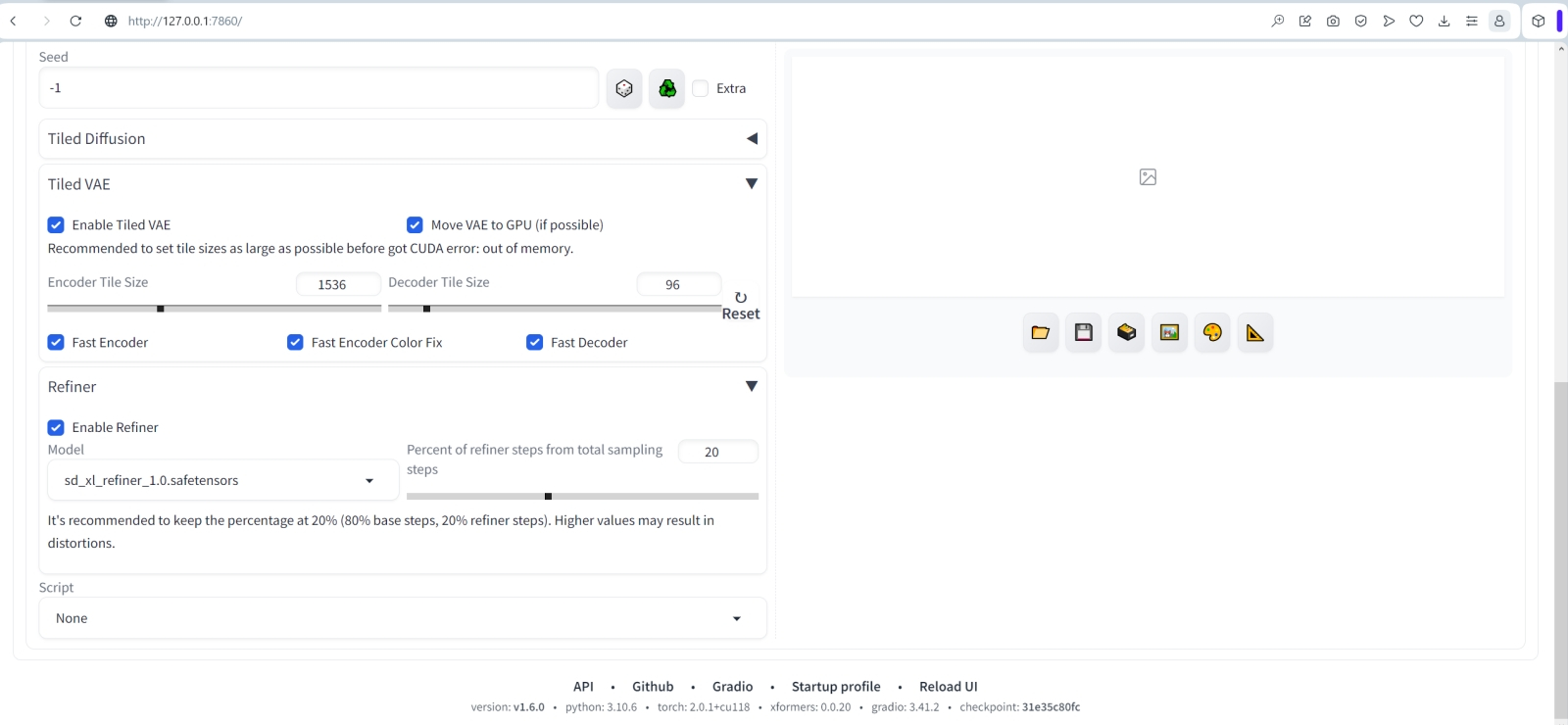
А как именно следует, сейчас нам продемонстрирует, хочется верить, Refiner (webui Extension). Активируем его, указывая теперь уже здесь модель доводчика, — и, разумеется, вручную восстанавливаем все прочие параметры. Кстати: автор скрипта рекомендует использовать с ним Tiled VAE на любых видеокартах менее чем с 12 Гбайт памяти, что в случае нашей тестовой системы (GTX 1070, 8 Гбайт) как раз справедливо. Чем хорош скрипт Tiled VAE, так это тем, что попусту ресурсы системы он не расходует. Если изображение слишком мало, чтобы загружать его в видеопамять, разрезая на куски (собственно тайлы), активированный Tiled VAE выдаст об этом сообщение в командной строке сервера и попросту пропустит исполнение данной задачи. Так что включим этот скрипт, не забыв поставить галочку ещё и у пункта «Fast Encoder Color Fix», — иначе велик шанс получить готовое изображение в несколько странноватой цветовой гамме.
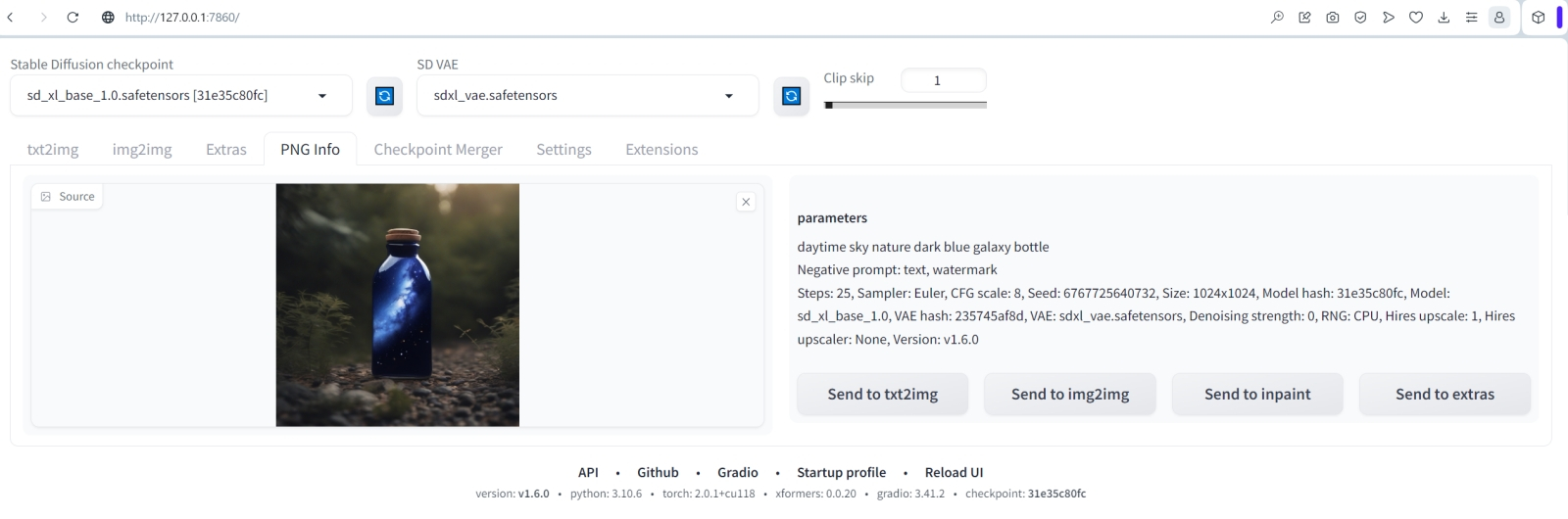
Как вариант, чтобы не прописывать снова вручную все параметры после обновления веб-интерфейса, можно загрузить на вкладке «PNG Info» созданную ранее в AUTOMATIC1111 с SDXL 1.0 и интегрированным вызовом доводчика картинку (с короткой позитивной подсказкой) — и отправить её на вкладку «txt2img». Интересно, что штатное выпадающее меню «Refiner» останется при этом деактивированным: чекпойнт автоматически не подгрузился — да и в текстовом описании PNG-файла он не указан. Ещё одно свидетельство того, что допиливание рабочей среды под совместимость с SDXL велось... ну, скажем, в спешке. Теперь остаётся ещё раз сверить все параметры, закрыть штатное выпадающее меню «Refiner», убедиться, что активны и нижний «Refiner», и «Tiled VAE», — после чего запустить генерацию.
Здесь сразу около минуты уходит на предварительную загрузку доводчика, зато дальше дело движется бодрее — примерно так же, как и в случае ComfyUI. В обоих рабочих средах (напомним, что у нашей тестовой системы — лишь 8 Гбайт видеоОЗУ, тогда как и base, и refiner для SDXL 1.0 занимают примерно по 6 Гбайт) реализация смены чекпойнта на лету явно производится не целиком, как это делает по умолчанию AUTOMATIC1111 версии 1.6.0 (убрать 6 Гбайт из видеоОЗУ — затянуть новые 6 Гбайт), а как-то более эффективно. В результате собственно отрисовка картинки полностью — без учёта первичной подгрузки доводчика — занимает примерно 2,5 минуты против почти 5,5 для штатной реализации этого скрипта.

Картинка слева сгенерирована в AUTOMATIC1111 с моделью SDXL 1.0 при помощи внешнего скрипта Refiner (webui Extension), тогда как правая, как и в предыдущих двух примерах, — с использованием встроенной в версию 1.6.0 реализации доводчика
И вот здесь уже деталей ощутимо больше, чем при реализации забега со штатным доводчиком, — и несколько больше даже, чем в ComfyUI (субъективно, но всё же). Тут разницу вносят наверняка и отсутствие раздельных подсказок для базы и доводчика, и применение параметра --medvram в batch-файле для запуска AUTOMATIC1111, — но в любом случае вариант со скриптом Refiner (webui Extension) явно более адекватно воспроизводит предложенную разработчиками из Stability.ai схему исполнения модели SDXL 1.0. То есть сперва — предварительная генерация картинки с базовым чекпойнтом, затем передача «непропечённой» (с остатками латентного шума) картинки доводчику — и уже в самом конце исполнение VAE на результате работы модели refiner. Так что будем официально считать рабочую среду AUTOMATIC1111 в версии 1.6.0 с дополнительно установленным скриптом Refiner (webui Extension) адекватно поддерживающей SDXL 1.0.

Источник: ИИ-генерация на основе модели SDXL 1.0
Тем не менее полного соответствия между реализациями SDXL здесь и в ComfyUI всё-таки нет. Попробуем ради примера воспроизвести более сложную картинку, созданную в «макаронной» рабочей среде. Параметры её создания можно изучить во вкладке «PNG Info»:
чекпойнт: protovisionXLHighFidelity3D_beta0520Bakedvae.safetensors,
размеры холста: 1344 × 768,
позитивная подсказка:
wide-angle photo of steampunk [spaceship|dirigible|sailingship] floating over picturesque islands in a vast ocean,
, shiny brass, oily copper, membranous sails, cogs and rivets, deconstructed clocks, geared wheels, mechanical, clockwork, lots of parts, rust, patina,
, wide depth of field, radiant mapping, reflections, light refraction, subsurface scattering, detailed shadows, ray tracing, high dynamic range, clear shadows and highlights,
, golden ratio, rule of thirds, unparalleled masterpiece, breathtaking, elaborate atmosphere, very complex, hyper realistic, colorful, mesmerizing, epic, dynamic, dramatic, vibrant, meticulously detailed, intricate, majestic)
(пустые строки и запятые в начале строк зрительно разделяют текстовые блоки, относящиеся к описанию сцены, деталям её композиции, особенностям воплощения и пр.; формат же записи spaceship|dirigible|sailingship означает, что перечисленные через вертикальные черты сущности чередуются: на первом шаге система генерирует космический корабль, на втором — дирижабль, на третьем — парусник, на четвёртом — снова космический корабль, так что в итоге выходит сравнительно органичная комбинация всех трёх),
негативная: canvas frame, USA, painting, drawing, sketch, cartoon, anime, manga, render, CG, 3d, watermark, signature, label (чем в данном случае провинились США — так это тем, что флаги на мачтах используемая модель предпочитает рисовать отчего-то по большей части американские),
затравка: 123456991,
число шагов: 50,
CFG: 8.0,
а вот дальше интересно: в параметрах ComfyUI раздельно заданы «sampler_name» — «dpmpp_sde_gpu» — и «scheduler» — «karras»; иными словами, понятия планировщика и селектора в рамках этой рабочей среды разнесены, тогда как в AUTOMATIC1111 задан ряд их предварительно составленных комбинаций, так что остаётся лишь выбрать максимально подходящую; в данном случае DPM++ 2M SDE Karras.
И посмотрим, что выйдет.

Источник: ИИ-генерация на основе модели SDXL 1.0
Времени ушло примерно столько же, сколько и на генерацию той же картинки в ComfyUI, — 7 с лишним минут. Но результат существенно иной, пусть и близкий. Возможно, это происходит от различий в реализации планировщика/селектора; возможно, оттого, что в подсказке задано чередование сущностей через оператор «|», и оно как-то по-своему реализуется в двух этих рабочих средах. Так или иначе, для экспериментов с SDXL 1.0 имеет смысл пока всё же оставить ComfyUI.
А мы тем временем вернёмся к AUTOMATIC1111 — и продолжим вести свой перипл, для чего изучим такой мощнейший встроенный инструментарий этой рабочей среды, как скрипты генерации.
Итак, с целью изучить базовые приёмы ориентирования в латентном пространстве по контурам береговой линии и поведению птиц (аналог античного мореплавания по периплу без компаса и карты) вернёмся к SD 1.5. Сделать это в интерфейсе AUTOMATIC1111 проще простого: снять галочку «Enable» в выпадающем меню Refiner (webui Extension) в нижней части основной веб-страницы, закрыть само это меню, затем поменять VAE на одну из тех, что разработаны для «Полуторки», — например, на классическую vae-ft-mse-840000-ema-pruned, — а также выбрать соответствующий чекпойнт. Вот только какой именно? И с каких служебных параметров начинать генерацию? Да, и едва ли не самое главное: как строить текстовую подсказку, чтобы хоть с минимальной гарантией получать эстетически приемлемые изображения?

К вопросу о тёмных глубинах латентного пространства. Обе подсказки для этой картинки состоят из одного слова: позитивная — nothing, негативная — anything (источник: ИИ-генерация на основе модели SD 1.5)
Начнём с того, что цель определяет средства: если от ИИ-модели требуется изобразить некую абстрактную или даже сюрреалистическую картинку, можно ограничиться базовым штатным чекпойнтом (который в инсталляции AUTOMATIC1111, как наверняка помнят читатели первой «Мастерской» на эту тему, переименован нами в model.safetensors) и дать полную волю фантазии в плане подсказок и выбора прочих параметров, после чего запустить систему в режиме «Generate forever»: что-нибудь подходящее за разумное время определённо изобразится. Другое дело, если нужна картинка в определённом стиле — пиксельная, скажем, или рисунок пером, или акварельный набросок, да ещё и с вполне узнаваемыми предметами либо существами: тут придётся повозиться серьёзнее. Но для таких случаев сегодня есть отличное подспорье — LoRA, которых на профильных сайтах вроде Civitai нетрудно отыскать множество, — вот, например.
Выходит, едва ли не самая сложная задача в приложении к ИИ-рисованию — генерация реалистичных изображений, словно бы снятых обычной (плёночной либо цифровой) фотокамерой, с правдоподобно выглядящими объектами и персонажами. Тезис, наверное, небесспорный, но — по внутренним ощущениям — стилизованных (под мангу/аниме, под средневековую книжную миниатюру, под манеру письма импрессионистов и пр.) удачных ИИ-изображений в Сети значительно больше, чем достоверно имитирующих банальные фотоснимки. Или не очень банальные — с эффектом парейдолии, например.

Не видите на этой — совсем не примечательной на первый взгляд — картинке никакого слова, составленного четырьмя довольно крупными буквами? А если отодвинуться от монитора подальше? (Источник: Reddit)
К настоящему времени в сообществе энтузиастов ИИ-рисования сложился довольно устойчивый консенсус: чем старше чекпойнт (условная граница между «старыми» и «новыми» проходит примерно по июлю-августу 2023-го), тем более развёрнутая и изощрённая подсказка нужна, чтобы удовлетворительные результаты на его основе появлялись чаще. Более поздние же модели тренируются, как правило, на аннотированных массивах изображений, тщательно подобранных именно с тем расчётом, чтобы выдача даже по короткой (3-5 слов) подсказке со случайной затравкой выходила бы с большой вероятностью достойной того, чтобы полученную картинку сохранить — а не отправить в «Корзину» (пожалуй, это единственный, хотя и во многом субъективный критерий для отличения «удачной» генерации от «неудачной»). Ещё один тонкий момент: выбор планировщика по сути определяет и предпочтительную длину текстовой подсказки, и оптимальное соотношение числа шагов генерации и CFG, так что всякий раз пришедшую вам в голову удачную идею для создания очередного ИИ-рисовального шедевра имеет смысл тестировать на широком спектре доступных для изменения служебных параметров модели.
А это значит, что для комфортного (счастливые обладатели ГП с объёмом видеопамяти 16 Гбайт и более могут с лёгким сердцем добавить тут «и быстрого») сравнения того, каким образом различные параметры влияют на реализацию тестируемой оператором подсказки, необходим соответствующий инструмент — который позволял бы не вручную менять раз за разом параметры генерации — а после долго и нудно сопоставлять одну картинку с другой, — а автоматизировать эту процедуру. К счастью, в этом отношении AUTOMATIC1111 полностью оправдывает своё наименование: такого рода инструмент в нём реализован штатно — и носит название «X/Y/Z script».

Инструмент «X/Y/Z script» позволяет автоматически генерировать серии картинок по одному и тому же в целом набору входных данных, варьируя лишь определённые параметры (в данном случае — steps и CFG) и представляя результаты в виде удобной таблицы (источник: ИИ-генерация на основе модели SD 1.5)
Итак, начнём с составления средних размеров подсказки: не самой простой («a robot chicken», скажем) и не самой громоздкой («1girl, masterpiece. best quality, solo, looking at viewer, realistic, 8k. sharp focus. long hair, smile, full body, highres, highly detailed, intricate, illustration, standing, blush. cinematic lighting, bangs, hdr.depth of field, extremely detailed, absurdres, high quality, blue eyes, raw photo, detailed eyes, short hair, black hair, cleavage, detailed face…» — и это только начало!), вдохновлённой вот этим постом:
a cheerful Celtic girl (in rusty armor) (walking a dragon:1.3) in front of a faraway castle, (closeup selfie:1.4), candid photo, elaborate atmosphere, meticulously detailed
а негативную сделаем такой:
anime, cartoon, painting, illustration, picture frame, signature, watermark, (worst quality, low quality, normal quality:1.5), nude
От добавления «nudе» в негативную подсказку мы технически могли бы и воздержаться, всё-таки рейтинг у издания «18+». Но сводить по умолчанию к минимуму возможность появления обнажёнки в ИИ-генерациях считается хорошим тоном — если оператор исходно не нацеливается именно на неё, конечно же. Да, многие чекпойнты (особенно в последнее время) тренируются так, чтобы порождать изображения людей без одежды лишь в случае прямого и явного указания на это в позитивной части подсказки, — но есть и противоположные примеры.
Так какой же, собственно, чекпойнт выбрать — ведь их уже существует множество, особенно для SD 1.5? Тут можно идти двумя путями. Первый: внимательно изучать уже упомянутый Civitai, где странички чекпойнтов сопровождают картинки, созданные с их помощью (и нередко вместе со всеми параметрами генерации: подсказками, планировщиком, CFG, числом шагов). Если нравящихся картинок много — скачать эту модель и испытать со своими подсказками. Кстати, обычно авторы (что делятся на тренеров, которые расходуют аппаратные ресурсы своих ПК на дотренировку не устраивающих их моделей на тщательно подобранных наборах картинок, и компиляторов, «сливающих» (merge) два уже готовых чекпойнта или более в один) в комментариях пишут, какие параметры генерации для их созданий оптимальны. Отталкиваясь от этих советов, можно приступать к подбору подходящих уже для своего случая — пусть и вручную, но на более узком поисковом поле.
Однако мы пойдём другим путём: автоматически составим перипл, который позволит выбрать оптимальную (либо близкую к ней) комбинацию — ну, для начала, чекпойнта и планировщика (sampler). Кстати, последних в AUTOMATIC1111 1.6.0 прибыло по сравнению с более ранними версиями этой рабочей среды — есть смысл испробовать их в деле.
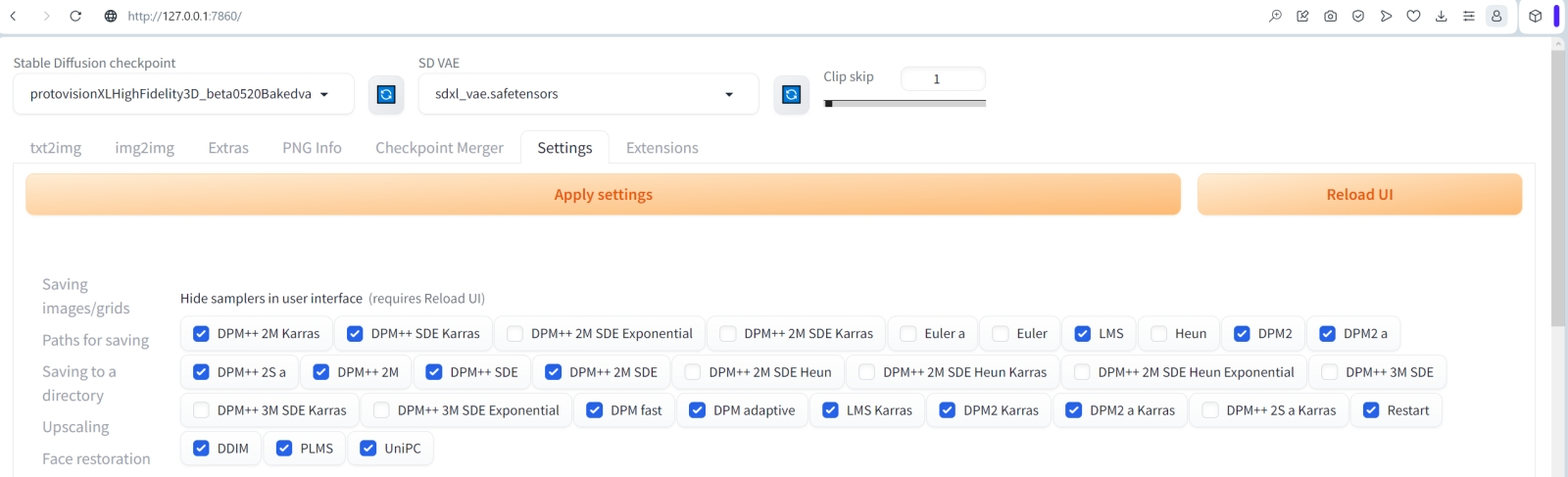
Чтобы не путаться с тем, какие планировщики испытывать, а какие нет, оставим доступными для выбора только те, что нас интересуют: самые новые и несколько хорошо зарекомендовавших себя старых. Для этого в соответствующем разделе настроек (см. первую «Мастерскую» по ИИ-рисованию) оставим непомеченными (а отмеченные галочками, наоборот, скроются) лишь следующие:
DPM++ 2M SDE Exponential
DPM++ 2M SDE Karras
Euler a
Euler
Heun
DPM++ 2M SDE Heun
DPM++ 2M SDE Heun Karras
DPM++ 2M SDE Heun Exponential
DPM++ 3M SDE
DPM++ 3M SDE Karras
DPM++ 3M SDE Exponential
DPM++ 2S a Karras
После переразметки нужно будет, как и всегда в случае изменения настроек, нажать «Apply settings», а затем «Reload UI».
И вот какие модели задействованы в грядущих испытаниях:
Какие же выбрать для предварительного тестирования служебные параметры — общие для всех сочетаний чекпойнтов с планировщиками? Да наиболее широко распространённые в приложении к SD 1.5:
число шагов — 25,
CFG — 6,
размеры — 512 × 768 (книжная ориентация).
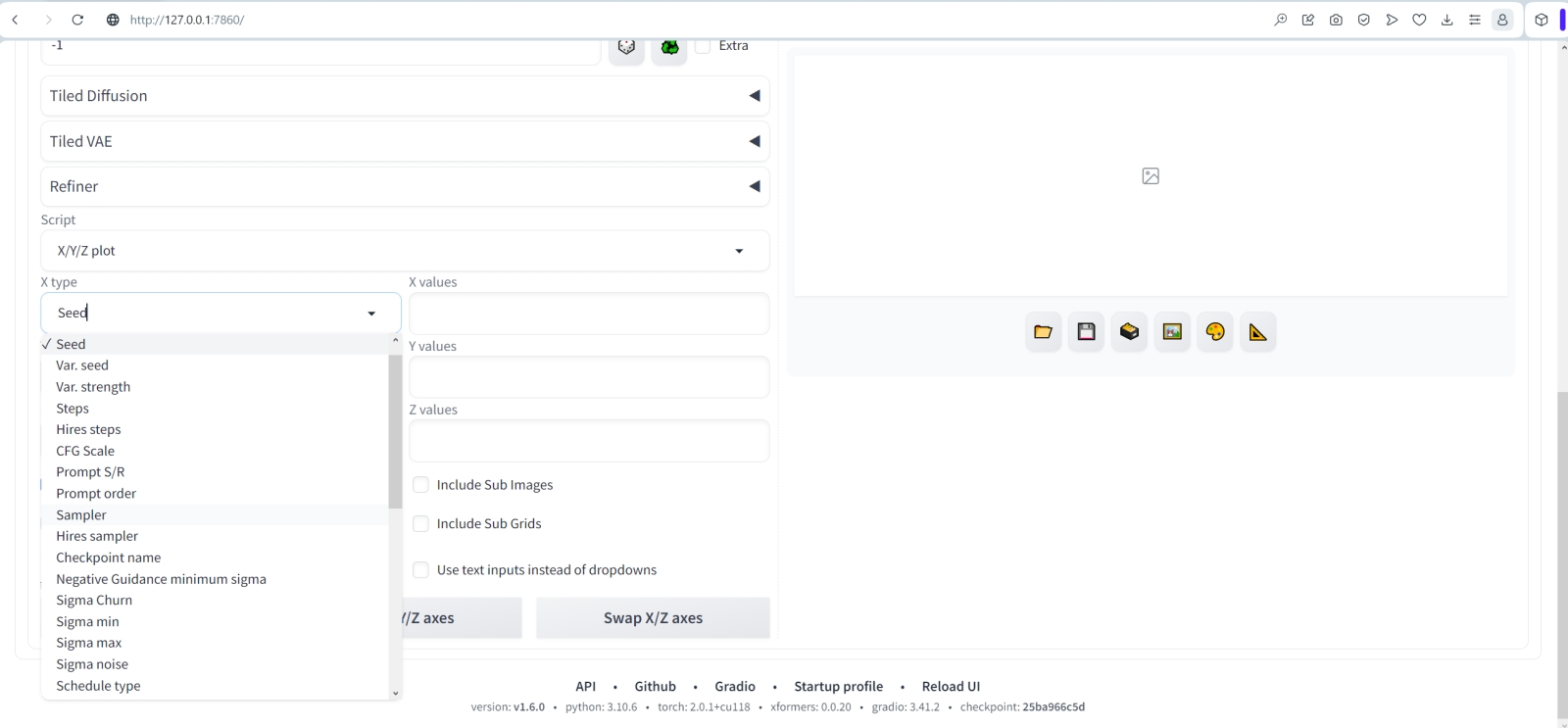
И вот теперь начинается самое интересное — собственно составление перипла: сейчас мы укажем рабочей среде ориентиры, по которым она отправится в плавание по бушующим волнам латентного пространства — и вернётся с картинками, полученными в процессе этого странствия. Прокручиваем веб-страницу до самого низа и открываем выпадающее меню «Script». Активируем в нём «X/Y/Z Plot», — откроется возможность выбрать ещё несколько параметров для каждой из переменных. По горизонтали («X type») пусть у нас будут чекпойнты, «Checkpioint name». Появится очередное выпадающее меню, что позволит вручную выбрать нужные из списка имеющихся.
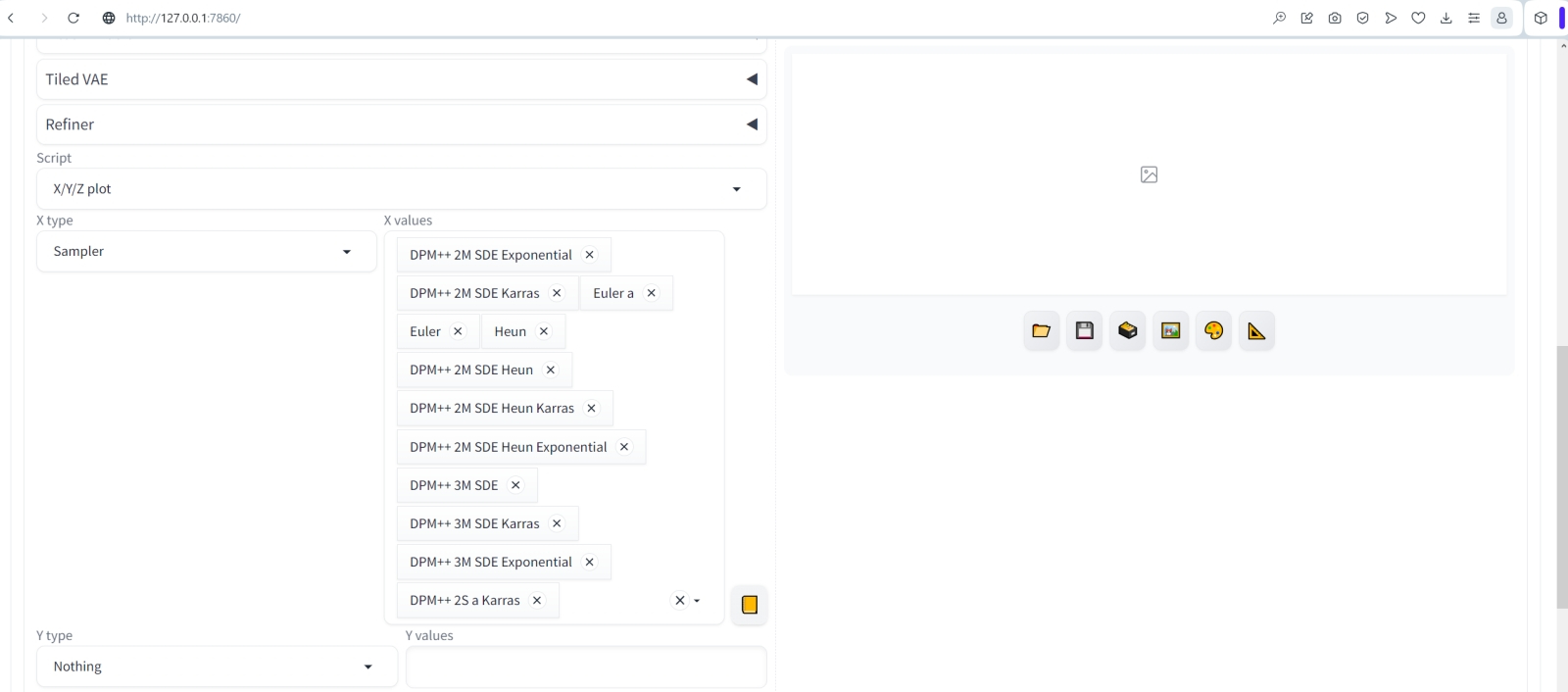
По вертикали («Y type») разместим планировщики. Поскольку нам нужны все доступные (только их мы оставили видимыми в настройках чуть ранее), просто нажмём на кнопку с оранжевым прямоугольником справа от поля «Y values», — полный их набор добавится автоматически.
Галочку с «Draw legend» не снимаем; «Grid margins (px)» устанавливаем в 4 — вполне разумная величина для зазора между соседними картинками в таблице. Прочие параметры пока не трогаем.
И — поехали! Система обещает намеченные 180 (12 × 15) картинок сгенерировать менее чем за пару часов. Если учесть, что каждая обсчитывается за 30-50 секунд, в зависимости от сэмплера, — вполне достоверная оценка. Загрузка ГП при этом менее 60% — и, кстати, есть смысл активировать «Silent mode», режим энергосбережения в панели управления графическим адаптером: это важный момент для энтузиастов ИИ-рисования. Часто и много работающий ГП потребляет порядком энергии, однако взвешенное суммирование (главная операция при обсчёте генеративных моделей) — процесс чисто арифметический и вовсе не требует оверклокинга. Именно поэтому рекомендуется снижать производительность видеокарты при длительной работе с SD/SDXL: время генерации изображений практически не вырастет, зато счета за электроэнергию будут хоть ненамного, но меньше. Да и нагрузка на графический процессор снизится — это только в плюс его долговечности.

Источник: ИИ-генерация на основе модели SD 1.5
Уже по этому чрезвычайно грубому периплу становится гораздо яснее, куда можно свободно плыть, изучая (почти) бескрайнюю гладь латентного пространства, а где незадачливого энтузиаста ожидают подводные камни, бури, штили и прочие цифровые Сциллы с Харибдами. Первый вывод, прямо-таки бросающийся в глаза: несколько картинок вышли «непропечёнными», испещрёнными пятнами неестественных форм и расцветок. Обычно это свидетельствует о недостаточном количестве шагов выборки (параметр steps): как видно, ряд сочетаний «чекпойнт + планировщик» требуют более значительного числа итераций. В других случаях фигуры девушки (и особенно дракона) слишком уж исковерканы, а кое-где одна из них и вовсе отсутствует. Это может говорить частично о недотренированности именно данного конкретного чекпойнта на аннотированных фотоснимках драконов (а откуда их, простите, брать в реальном мире в товарных количествах — если оставить за скобками комодских?), частично о недостаточной величине параметра CFG: возможно, при бóльших его значениях ситуация выправилась бы.
Выберем теперь одно из изображений с явными артефактами — ну, скажем, сгенерированное чекпойнтом Photon 1.0 с планировщиком (как раз из новодобавленных в AUTOMATIC1111) DPM++ 3M SDE. Там и девушка, и дракон, и замок на месте, и выражение её лица вполне жизнерадостное, и в целом композиция походит на селфи, — словом, подсказка воплощена практически идеально. Только вот сочетание steps/CFG подкачало. Попробуем составить ещё один перипл — теперь уже исследуя это сочетание в его разнообразных видах.
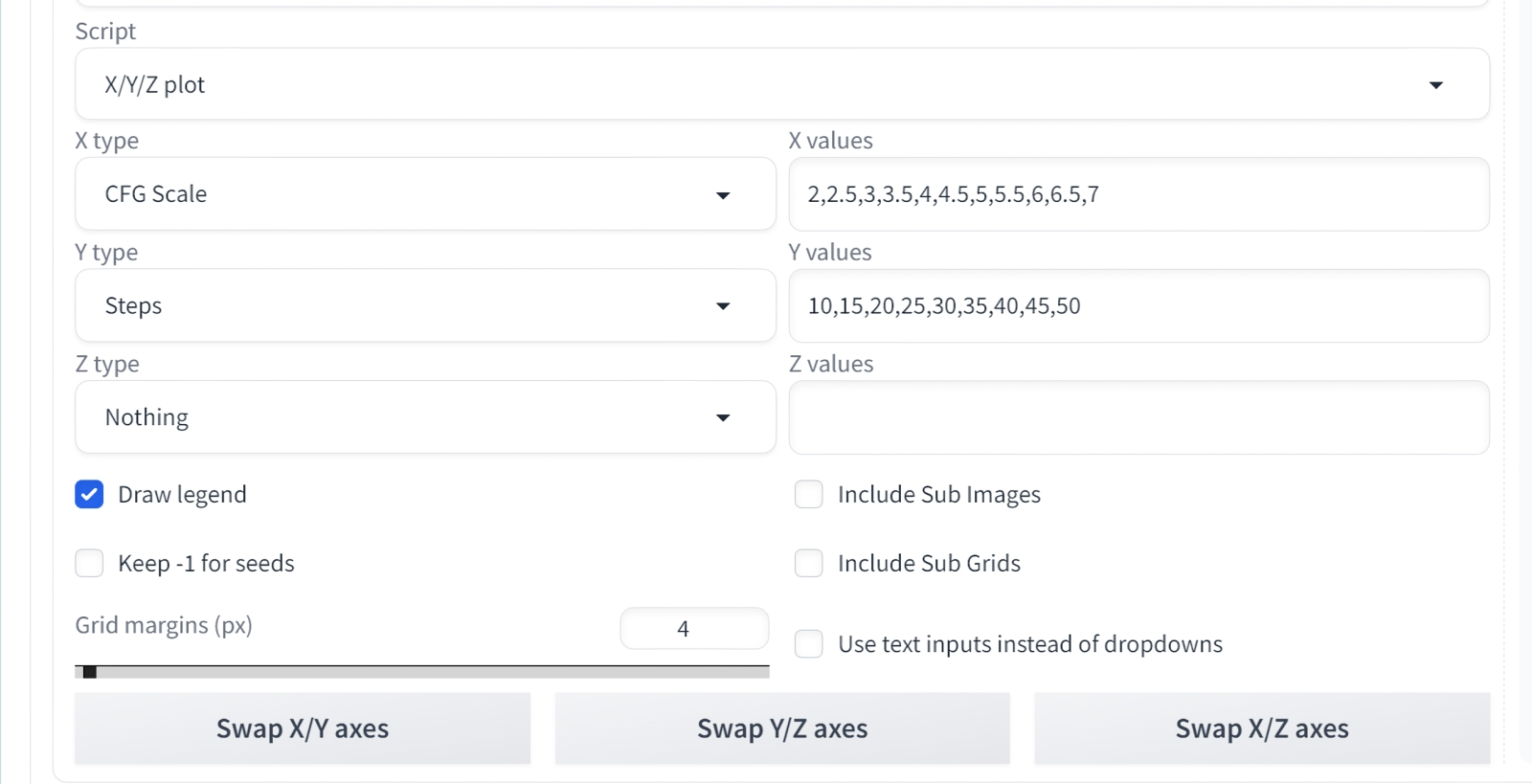
Оставляем подсказку прежней, чекпойнт выбираем Photon, назначаем Seed использованное при прежней генерации значение — 989666162 (его можно получить, загрузив картинку в «PNG Info», а можно просто взглянуть на название файла: если проделаны те шаги с настройками, что мы описывали в третьей «Мастерской», оно будет просто содержать эту самую затравку через дефис после порядкового номера файла в текущей папке), выбираем планировщик DPM++ 3M SDE. Снова прокручиваем страницу до конца и в настройках скрипта «X/Y/Z plot» меняем «X type» на CFG Scale с такими значениями:
2,2.5,3,3.5,4,4.5,5,5.5,6,6.5,7
А «Y type» — на Steps:
10,15,20,25,30,35,40,45,50
Здесь важно отсутствие пробелов: запятые разделяют непосредственно значения, а десятичные дроби по англо-американской традиции обозначаются точками. Вновь запускаем генерацию.

Источник: ИИ-генерация на основе модели SD 1.5
Сразу же видно, что большие CFG этому сочетанию «чекпойнт + планировщик» противопоказаны, а увеличение числа шагов начиная с определённого порога для каждого CFG не приводит к разительному росту качества изображения. Отчётливо виден своеобразный «клин адекватности»: прямоугольник CFG/Steps рассечён примерно по диагонали (в данном случае по линии, условно, от 4,0/10 до 7,0/25), левее и ниже которой находятся вполне приемлемые по качеству картинки, правее и выше — искажённые артефактами. Как видно, Photon в сотрудничестве с DPM++ 3M SDE позволяет очень быстро (10 итераций — это всего лишь около 10 с на видеокарте GTX 1070!) получать реалистичные и довольно проработанные изображения.
Дополнительный плюс такого подхода: при малых CFG «творческий потенциал» генеративного ИИ наиболее раскрепощён — т. е. следование подсказкам наименее буквалистское. А значит, запустив бесконечную генерацию с такими параметрами и со случайной затравкой по одной картинке за раз (режим «Generate forever»), можно навыловить из латентного пространства ох как много всякого неожиданного и нерядового. Понятно, что клин именно такого вида определён лишь для данного сочетания чекпойнта и планировщика, — у других комбинаций он окажется иным. Но с этим можно и нужно работать!
Возьмём теперь картинку с CFG=4 и steps=45 — уж больно там поворот головы героини динамичный — и посмотрим, какие ещё возможности по составлению периплов латентного пространства предлагает скрипт «X/Y/Z Plot».
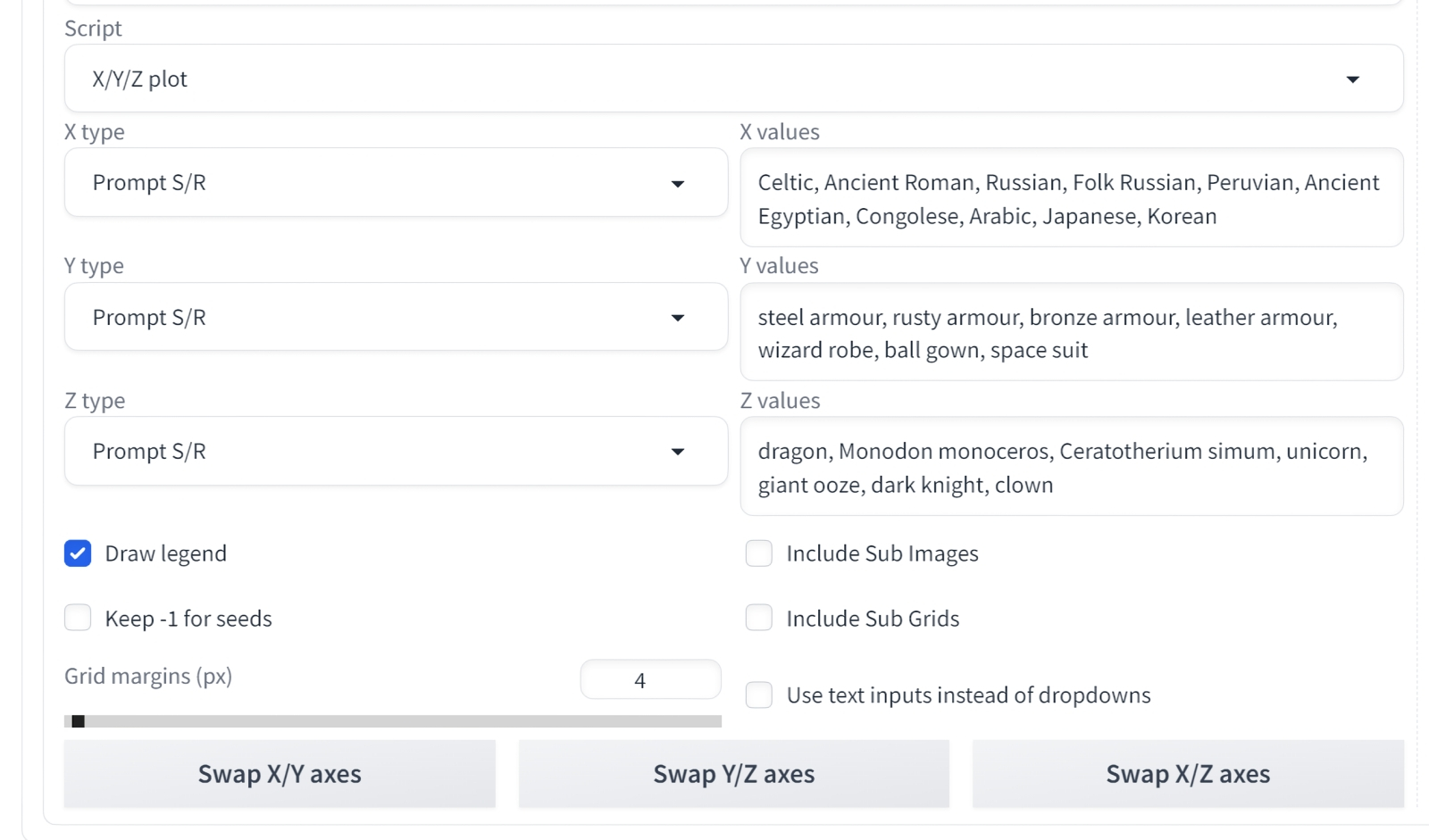
Испробуем ещё один тип переменной при составлении таблиц — «Prompt S/R». S в данном случае — search, R — replace. Имеется в виду, что система находит в исходной текстовой подсказке последовательность символов, совпадающую с первой из тех, что указаны здесь через запятую, и сперва производит генерацию именно с ней. А затем делает второй проход — взяв уже вторую последовательность и заменив ею первую. То есть если мы выберем в качестве «X type» вариант «Prompt S/R» и укажем, например, такую цепочку последовательностей, разделённых запятыми (тут всё зависит от фантазии), —
Celtic, Scandinavian, Russian, Peruvian, Ancient Egyptian, Congolese, Arabian, Korean
то первая генерация будет с позитивной подсказкой
a cheerful Celtic girl (in rusty armor) (walking a dragon:1.3) in front of a faraway castle, (closeup selfie:1.4), candid photo, elaborate atmosphere, meticulously detailed
вторая — с
a cheerful Scandinavian girl (in rusty armor) (walking a dragon:1.3) in front of a faraway castle, (closeup selfie:1.4), candid photo, elaborate atmosphere, meticulously detailed
третья — с
a cheerful Russian girl (in rusty armor) (walking a dragon:1.3) in front of a faraway castle, (closeup selfie:1.4), candid photo, elaborate atmosphere, meticulously detailed
и т. д.

Источник: ИИ-генерация на основе модели SD 1.5
Мало того! Скрипт не зря называется «X/Y/Z Plot»: он позволяет выстраивать наглядные таблицы-периплы по трём переменным. Прежде мы использовали лишь две — но почему не испробовать всю полноту предлагаемых возможностей? Выберем для «Y type» такие варианты «Prompt S/R»:
rusty armor, matted bronze armor, leather armor, revealing slik robe, glowing neon tight suit, frilly ball gown, shiny fantasy armor
а для «Z type» —
dragon, polar bear, clockwork robot, crazy pony, giant jellyfish, fiery burning phoenix, ghost clown

Все любят селфи с роботами! (Один из фрагментов предыдущей сетки изображений; источник — всё та же ИИ-генерация на основе модели SD 1.5)
Запустим, — исполнение займёт около пяти часов. В итоге получится, ясное дело, не кубическая таблица (как её отображать на плоском мониторе?), а удобно организованная последовательность прямоугольных. Плюс каждая из них по отдельности — чтобы удобнее было разглядывать.
Теперь вернёмся к выпадающему меню «Hires. fix», что находится рядом со штатным (и в версии 1.6.0 нефункциональным) меню «Refiner» для SDXL. По сути, апскейлер — автоматический «повышатель» разрешения с наращиванием детализации; под «high resolution fix» понимается именно он, — можно рассматривать как аналог доводчика для SD 1.5, только работающий с полностью готовым образом предыдущей итерации, а не с несущим на себе остаточные следы латентного шума. Подойдём к настройкам апскейлера именно с этой точки зрения: увеличивать картинку будем вдвое по обеим сторонам, а для имитации работы доводчика выставим соответствующее число шагов (11, поскольку 11+45=56, а 20% от 56 с округлением — как раз 11). Правда, верное значение силы шумоподавления (Denoising strength) угадать трудно, а «X/Y/Z Script» тут не помощник — нет в списке предлагаемых им параметров именно такого.
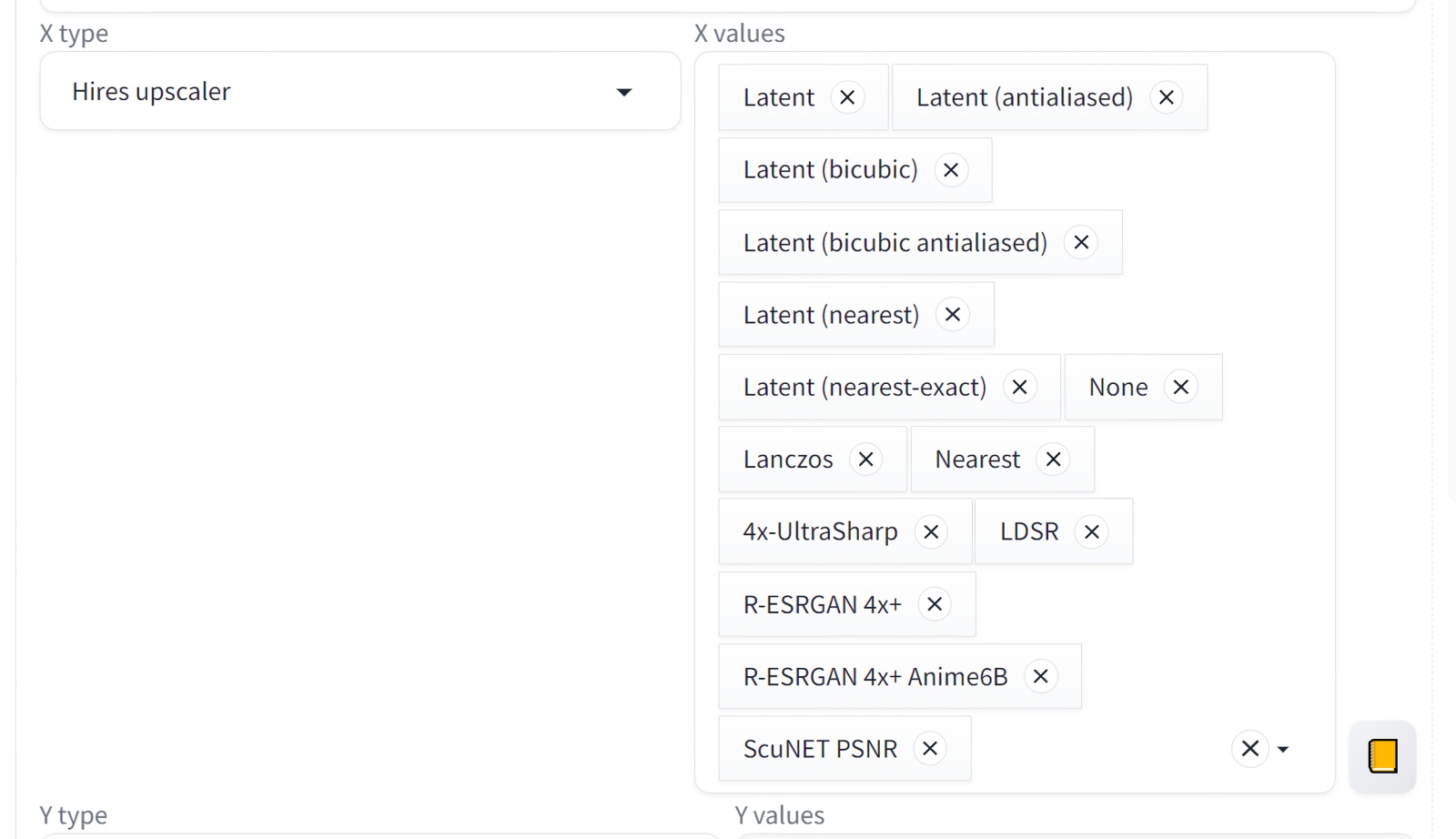
Что ж, попробуем вручную, меняя только сам алгоритм шумоподавления при масштабировании — это параметр «Hires. upscaler». В результате получится одномерная таблица (вектор) изображений с одинаковыми исходными параметрами, но разными апскейлерами. Вот такая — для Denoising strength = 0,45:

А такая — для Denoising strength = 0,15:

Даже на этих миниатюрах заметно, что при больших величинах шумоподавления особой разницы между алгоритмами апскейлинга нет; в целом все они работают хорошо — правда, точно так же все как один испортили кисть, держащую смартфон (куда-то подевался мизинец). Если же брать Denoising strength = 0,15, примерно половина картинок (с левой стороны ряда) испещряется артефактами. Выходит, если есть желание как можно точнее сохранить композицию и крупные детали исходного изображения, лучше брать алгоритмы из правой половины вектора.

Результаты масштабирования картинки с затравкой 989666162 и следующими парами параметров Upscaler/Denoising strength, слева направо: Latent/0,45; 4x-UltraSharp/0,45; Latent/0,15; 4x-UltraSharp/0,15 (источник: ИИ-генерация на основе модели SD 1.5)
Конкретно для картинки, на которой мы остановились, — с seed = 989666162 — ориентироваться можно по качеству отображения мизинчика: оптимальным следует считать сочетание силы шумоподавления 0,15 и алгоритма 4x-UltraSharp (хотя и SwinR, например, вполне себе тоже сгодится, а вот у Nearest, скажем, мизинчик выходит кривоват).
Как ещё можно облегчить себе навигацию в латентном пространстве? Оно — в отличие от реального моря — в определённом смысле готово подстраиваться под волю и целеполагание исследователя: иными словами, есть способы заранее повысить детерминированность создаваемой генеративным ИИ художественной композиции. Самый выдающийся на сегодня из этих способов, ControlNet, заслуживает особого обстоятельного рассмотрения, но уже среди встроенных в AUTOMATIC1111 инструментов есть грубое его подобие, а именно средство для набросков «Sketch».Реализовано оно в виде подвкладки на вкладке «img2img» и предназначено для того, чтобы по грубому наброску (понятие «грубый» здесь довольно расплывчато) система «уяснила» общие контуры намеченной композиции — и далее заполняла эти контуры подобающими порождениями латентного пространства.
Скетч можно сделать хоть в MS Paint, но мы поставим известный многим «Photoshop с открытым кодом», GIMP, вот отсюда: https://www.gimp.org/downloads/. Установка его простая и довольно быстрая.
После запуска создаём пустую канву 512 × 768, выбираем инструмент «Карандаш», меняем его размер с исходных 50 хотя бы на 3 и приступаем, собственно, к рисованию. Пусть это будет набросок в стиле эпического полотна «Сеятель» кисти товарища Бендера (который Остап), ничего страшного — ИИ нам поможет. Чуть позже.
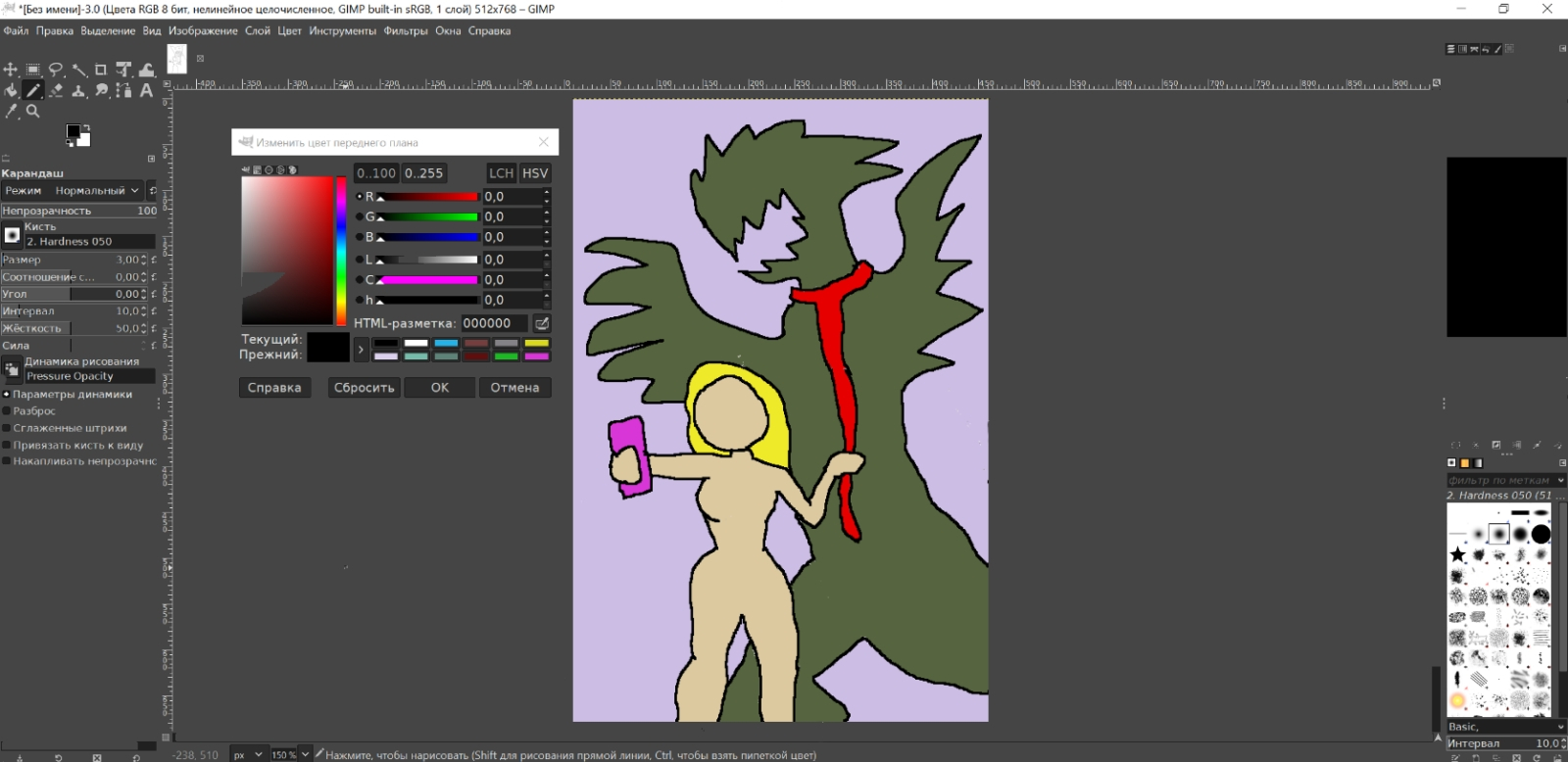
Мощь! Сила! Искусство композиции! В общем, умение рисовать принципиального значения не имеет: важно набросать в общих чертах то, что упоминается в текстовой подсказке (даже без особой детализации: замок на этом скетче отсутствует, к примеру). Кстати, разумно будет подбирать оттенки при раскраске таким образом, чтобы обеспечить максимальный контраст между соседними объектами. Если же вовсе не раскрашивать набросок, системе значительно труднее будет выделять на нём объекты, в особенности мелкие. Ну и детали самой подсказки необходимо принимать в расчёт: в частности, девушка на этом скетче не зря облачена в пустынное хаки — этот цвет в целом близок сочетанию коричневого и светло-серого (rusty armor: железо и кожа). Если же залить её, скажем, голубым, вместо брони (пусть и фэнтезийной) она с немалой вероятностью окажется облачена в какое-нибудь васильковое платье.
А теперь скормим этот шедевр AUTOMATIC1111, экспортировав его из GIMP в формате PNG и перетащив затем файл рисунка на соответствующее поле в подвкладке «Sketch» мышкой из «Проводника» Windows. Зададим число шагов 60, поскольку на вкладке «img2img» реальное число этих самых шагов, которые сделает система в процессе генерации, рассчитывается как произведение «Denoising strength» на «Steps», — и при рекомендованном значении этой силы 0,7 при 60 шагах как раз получим 42. Но какие же конкретно брать значения Denoising strength и CFG? «X/Y/Z Plot» снова нам поможет: по оси X пускаем CFG в таких вариантах:
1.5,2,2.5,3,3.5,4,4.5,5,5.5,6,6.5,7
а по Y — Denoising strength:
0.71,0.72,0.73,0.74,0.75,0.76,0.77,0.78,0.79,0.8

Источник: ИИ-генерация на основе модели SD 1.5
Занятный получается эффект — тоже своего рода «клин адекватности»: чем ниже CFG и сила шумоподавления, тем более рабски следует система предложенному ей наброску. Зато при высоких (правый нижний угол таблицы) всё более существенным образом от него отходит. Пожалуй, остановимся на варианте с CFG=6 и Denoising strength = 0,72. Но не потому, что там какая-то особенно выдающаяся картинка, а просто по причине субъективной сбалансированности следования наброску, с одной стороны, и привносимой генеративной моделью реалистичной детализации (небо, облака, замок и пр.) — с другой.
А теперь отключим скрипт, исправно рисовавший нам таблички (для чего следует просто свернуть выпадающее меню «X/Y/Z Plot»), и на этой же подвкладке «Sketch» запустим бесконечную генерацию, зафиксировав все с таким трудом подобранные параметры, кроме затравки, — seed выставим в позицию «-1» (случайная величина). И отправимся заниматься своими делами, а ИИ тем временем будет одну за другой выпекать всё новые вариации на тему нашего наброска, складывая их в папочку C:\Fun-n-Games\Git\stable-diffusion-webui\outputs\img2img-images\.

К вопросу о том, насколько велика роль случайности при создании картинок по скетчу. Все параметры генерации для приведённых изображений полностью идентичны, кроме затравки, — слева направо и сверху вниз: 2854953743, 775689019, 3263462885, 3189244609, 2918779236, 2036605733, 2504183938, 1064413415 (источник: ИИ-генерация на основе модели SD 1.5)
И вот — ВНЕЗАПНО! — удача: сгенерировалась картинка (seed = 1064413415), на которой практически всё в точности как на исходном скетче, — вплоть до ошейника и поводка. Да и пальцы вполне приличные! Можно теперь вволю заниматься доведением полученного шедевра до ума: через инструмент «Inpaint» править отдельные детали, в GIMP вручную скорректировать слишком длинный мизинец на держащей смартфон руке, потом произвести апскейл с повышением детализации и проч. Неважно: главное, что конечная цель нашего путешествия по латентному пространству с генерируемым прямо по ходу дела периплом достигнута. Текстовая подсказка стала графическим образом, достаточно адекватно соответствующим исходному замыслу, — пусть и с довольно неуклюжим костылём в виде грубого скетча. Счастливчики, умеющие рисовать, таким образом откроют для себя возможность быстрее и точнее добиваться от генеративной модели желаемого результата, — ну а нам, простым смертным, на радость изобретён ControlNet. О котором речь пойдёт уже в следующий раз.