Свежесгенерированных картинок в Сети также становится с каждым днём всё больше — но отыскать среди них действительно интересные, поражающие воображение; такие, что заставляли бы всерьёз обеспокоиться перспективами сохранения самой профессии художника за биологическими формами жизни, оказывается не так-то просто. Да, возможности генеративного ИИ в плане извлечения картинок из латентного пространства велики, — но привлекательность с человеческой точки зрения того, что в итоге оказывается оттуда добыто, сводится по сути к умению всё того же биологического оператора пользоваться наработанными к настоящему времени (его же белковыми собратьями, между прочим) инструментами.
Речь тут даже не об искусстве составления подсказок (prompt engineering) самом по себе: не менее важны понимание потенциала и ограничений избранного для генерации чекпойнта; умение оценить, как повлияет активация данной конкретной LoRA либо текстовой инверсии на создаваемое изображение; наличие сведений о дополнительных средствах повышения качества картинки вроде рассматривавшихся нами ранее Hires. fix, ADetalier и многое, многое другое. Плюс к тому огромную роль играет милость Фортуны: один и тот же набор параметров, исполненный с различными затравками (seed) и/или сочетанием CFG и числа шагов генерации, порождает порой разительно отличные по качеству картинки. Ну и как тут, спрашивается, оператору генеративной ИИ-модели тягаться с настоящим профессионалом изобразительных искусств, который — пусть с оговорками в плане индивидуально присущих ему таланта, усердия и иных чисто человеческих особенностей — способен гарантированно выдавать изображения стабильно высоких художественных достоинств?

И не такие ещё образы можно выловить из пучин латентного пространства, воспользовавшись рассматриваемым в настоящей статье расширением Dynamic Prompts (источник: ИИ-генерация на основе модели SD 1.5)
Проблему усугубляет неоглядная широта возможностей современных ИИ-моделей для рисования: если система способна изобразить пусть не всё, но очень многое, в том числе и воспроизводя стилистику лучших биологических художников, на работах которых (среди прочего) она обучена, — что же именно у неё затребовать такого, чтобы изображение вышло подлинно захватывающим? Увы, судя по регулярно обновляющейся галерее наиболее популярных работ на том же сайте Civitai, тематика скармливаемых генеративным моделям подсказок практически исчерпывается девушками различной степени одетости, котиками в смешных шляпах да мрачноватыми пейзажами. Изредка, впрочем, попадаются роботы. Не споспешествует росту разнообразия генерируемых ИИ картинок и тот факт, что Stable Diffusion (и, в чуть меньшей степени, коммерческие проекты с закрытым кодом вроде Midjourney или Dall-E) затрудняется адекватно изображать многофигурные композиции и динамичные сцены. Обещают, что грядущая буквально вот-вот (супер)модель SD 3 будет справляться с этим лучше, да и уже доступным чекпойнтам неплохо помогают дополнительные композиционные инструменты — вроде рассматривавшегося нами ранее расширения Tiled Diffusion.
Тем не менее в подавляющем большинстве случаев лучше всего генеративным моделям для ИИ-рисования удаются портреты, пейзажи, натюрморты, — словом, изображения с крайне статичной композицией. Стоит затребовать у системы чего-то менее тривиального — начинаются затруднения. «Тривиальность», конечно, понятие относительное — проиллюстрируем его на наглядном примере.
И возьмём для реализации этого примера чекпойнт CyberRealistic v. 4.2 — один из лучших на данный момент (если судить по качеству иллюстрирующих его применение генераций) в плане реалистичности среди всех основанных на SD 1.5. Кстати, с этой моделью предлагают использовать специально для неё оптимизированные текстовые инверсии для негативной подсказки — CyberRealistic Negative v. 1.0 и CyberRealistic_Negative_v3 (по какой-то причине вторая доступна только на HuggingFace, не на Civitai, — но это не проблема: загружаются из обоих источников они одинаково просто).
Для начала проверим, насколько оправданно применение двух этих инверсий именно вместе, — как раз таким образом их использует автор чекпойнта на иллюстрирующих тот примерах. Подходящий инструмент в составе рабочей среды AUTOMATIC1111, с которой мы снова будем иметь дело на этот раз, — уже хорошо знакомый давним читателям наших «Мастерских» скрипт «X/Y/Z plot», а точнее, сценарий «Prompt S/R» в его составе — и такая вот строка замен:
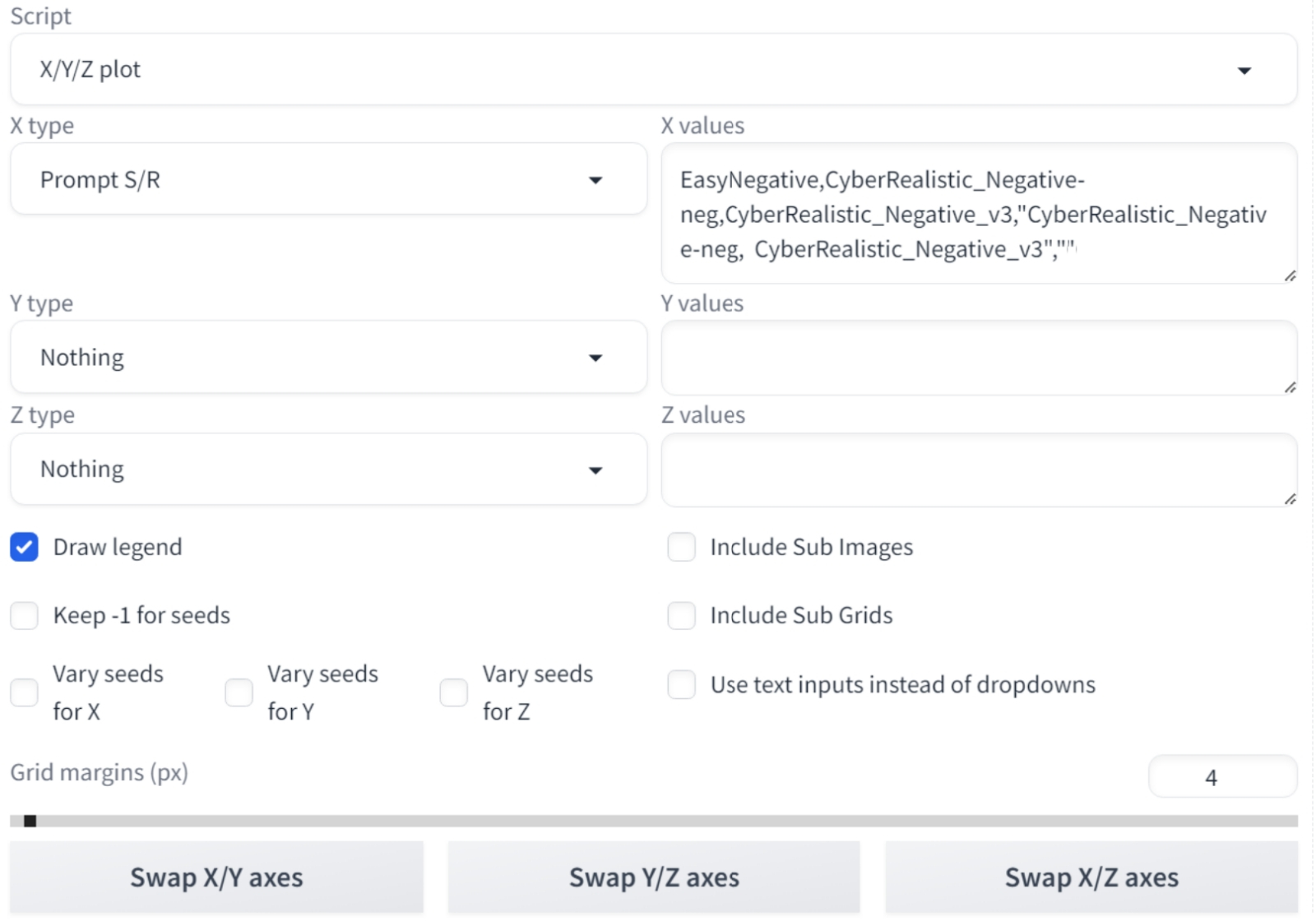
EasyNegative,CyberRealistic_Negative-neg,CyberRealistic_Negative_v3,"CyberRealistic_Negative-neg, CyberRealistic_Negative_v3"," "
В поле негативной подсказки укажем исходно «EasyNegative» без кавычек, и ничего больше: система сперва сгенерирует картинку с этой текстовой инверсией, а дальше при каждом новом проходе будет менять её на очередной элемент из строки замен сценария «Prompt S/R». Обратите внимание: чтобы передать в качестве очередного аргумента указание на две текстовые инверсии, разделённые запятыми, следует заключить их в прямые кавычки — "CyberRealistic_Negative-neg, CyberRealistic_Negative_v3". Последняя же пара кавычек, «" "», означает, что генерация в этом случае будет вестись вовсе без негативной подсказки. Для оригинальной модели SD 1.5 это наверняка вышло бы боком, но современные чекпойнты, дотренированные на тщательно отобранных картинках, даже совсем без негатива способны выдавать вполне приемлемые результаты.
Итак, позитивную подсказку задаём такой:
portrait of a ruggedly handsome paladin, soft hair, muscular, half body, masculine, mature, salt and pepper hair, leather, hairy, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
негативную, как и было сказано, просто
EasyNegative
Выбираем в качестве модели «SD VAE» стандартную для практически всех наших генераций с «Полуторкой» vae-ft-mse-840000-ema-pruned.safetensors; выставляем ползунок «Clip skip» в положение «2», «Sampling method» задаём «DPM++ 3M SDE Karras» (быстрый и в то же время высококачественный, напомним), значение «Sampling steps» пусть будет «35», «CFG Scale» — «7». С затравкой 85989958 получаем вот такое:

Источник: ИИ-генерация на основе модели SD 1.5
Как видно, даже при совершенно пустом поле негативной подсказки этот чекпойнт выдаёт вполне достойное изображение: пусть скорее напоминающее реалистичную иллюстрацию или 3D-рендер (особенно в части бликов на коже, которой явно недостаёт адекватного подповерхностного рассеяния), но всё-таки. Такова уж мощь современных усердно дотренированных чекпойнтов! Заметим также, что давно и широко применяемая текстовая инверсия EasyNegative уже сама по себе обеспечивает вполне приемлемое отображение кожи и волос; по сравнению с ней трудно сказать, что CyberRealistic_Negative — как 1-й, так и 3-й версии — однозначно выигрывает. Зато — по крайней мере, на субъективный взгляд, — сочетание двух последних инверсий как раз и обеспечивает наиболее достойное приближение портрета к реалистичности по всей совокупности параметров — черт лица, отображения волос и кожи, одежды из разнородных материалов, фона и проч. На этой комбинации текстовых инверсий в негативном поле пока и остановимся — она нам потребуется в дальнейшем.
Мы, собственно, собирались продемонстрировать слабость модели SD 1.5 в плане многофигурных композиций. Сделать это крайне просто с такой вот позитивной подсказкой:
Wide-angle shot of (Chinese panda) fiercely fighting with (American bald eagle), fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
Негативная подсказка, напомним, — «CyberRealistic_Negative-neg, CyberRealistic_Negative_v3»; холст на сей раз сделаем альбомным (768 × 512 точек — стандартные для SD 1.5 размеры сторон базового прямоугольника). Все остальные параметры пусть будут прежними, только в поле «Seed» установим значение «-1», задавая тем самым случайный выбор затравки. И с её значением, к примеру, 485257449 получим вот что:

Источник: ИИ-генерация на основе модели SD 1.5
Обратим внимание на «копирайт» и «подпись автора» в левом и правом нижних углах: без явного добавления «watermark, logo, signature» и иных подобных терминов в негативную подсказку подобные артефакты будут возникать довольно часто, поскольку значительная доля материала для тренировки Stable Diffusion как раз была снабжена подписями художников или логотипами различных франшиз, например. И всё же вовсе не это привлекает основное внимание, если сравнивать картинку с породившей её подсказкой: маловато здесь орлов, не находите? И это не случайность: в режиме «Generate forever», получив около полутора сотен изображений с этой подсказкой, мы так ни единого орла и не увидели. Хорошо, поменяем местами животных:
Wide-angle shot of (American bald eagle) fiercely fighting with (Chinese panda), fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration

Источник: ИИ-генерация на основе модели SD 1.5
А здесь мало того, что орёл на месте, — ещё и у панды внезапно прорезались когти и клюв. И такая дребедень, поверьте (а лучше — проверьте; благо даже на нашей тестовой машине с видеокартой GTX 1070 8 Gb каждая такая картинка генерируется за 6-7 с, не дольше), будет продолжаться и продолжаться. Изредка станут попадаться панды с орлиными крыльями и орлы с медвежьими лапами, и, только если вам невероятно повезёт, картинка выйдет более или менее подходящей — если не для непосредственного использования, то хотя бы для не слишком муторной обработки дорисовкой (методом inpainting во вкладке «img2img») либо во внешнем графическом редакторе. Вот, собственно, прямое свидетельство того, насколько «Полуторке» — точнее, даже самым современным чекпойнтам, основанным на модели SD 1.5, — сложно даются всего-то-навсего двухфигурные композиции.
Нельзя ли, однако, — как мы не раз уже проделывали в прошлых наших «Мастерских» по теме ИИ-рисования — обратить этот недуг во что-нибудь полезное? Да, разумеется: стремление генеративной модели сращивать воедино разнородные сущности, упомянутые в задаваемой ей подсказке, с готовностью пойдёт во благо ИИ-художнику — порождая вполне убедительно выглядящие химеры, которые так, с ходу, и не всякий умелый живописец изобразит.
Химеротворчеству в документации AUTOMATIC1111 посвящён целый раздел о чередующихся терминах, alternating words: синтаксис
[panda|eagle]
заставляет модель на каждом шаге (количество которых, напомним, определяется параметром «Sampling steps») менять целевой объект. То бишь на первой стадии генерации нейросеть будет силиться разглядеть в выловленной из латентного пространства зашумлённой картинке панду — и, соответственно, таким образом уменьшит количество шума в изображении, чтобы именно панда там в перспективе и появилась. На втором же шаге с точно таким же рвением нейросеть примется изображать орла — хотя буквально только что работала над пандой. На третьем этапе снова будет сделана попытка отыскать черты панды в уже начавшей формироваться химере — и так до тех пор, пока не будут исполнены все намеченные шаги.

Источник: ИИ-генерация на основе модели SD 1.5
Вот что выходит со всеми прежними параметрами генерации, включая затравку 485257449, и с модифицированной для чередования терминов позитивной подсказкой (негативная — та же, что и была):
Wide-angle shot of [panda|eagle] fiercely fighting, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
Пандорёл? Орланда? (И уж точно не Орландина…) Ради наглядности приведём пример того, что именно происходит с изображением в процессе чередования терминов, снова воспользовавшись для этого скриптом «X/Y/Z plot» и сделав одномерную таблицу с единственным меняющимся параметром — «Steps» — от 10 до 35 с шагом 5:

Источник: ИИ-генерация на основе модели SD 1.5
Видно, что где-то между 15-м и 20-м шагами зримые остатки латентной зашумлённости с изображения пропадают, а далее происходит всё более глубокая химеризация отображаемого объекта. И кстати, никто не запрещает добавлять в порождаемую генеративной моделью химеру больше компонентов:

Источник: ИИ-генерация на основе модели SD 1.5
Позитивная подсказка тут —
Wide-angle shot of [panda|eagle|ox|axolotl|pallas cat|squid] fiercely fighting, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
прочие же параметры прежние. Следует, впрочем, помнить, что такое прямолинейное химеротворение, требующее всего лишь квадратных скобочек и вертикального разделителя, не работает с дополнительными нейросетями, в частности с LoRA — на этот случай предусмотрено особое расширение sd-webui-loractl: LoRa Control - Dynamic Weights Controller.
Ещё одна полезная для продуктивного смешения сущностей возможность AUTOMATIC1111 — чуть более тонкое, чем последовательное чередование терминов, редактирование текста подсказки на лету: prompt editing. Синтаксис, используемый здесь, —
[from:to:when]
где слово (или слова), с которого начинается извлечение образа из латентного пространства (from), меняется на другие (to), не каждую итерацию поочерёдно, но лишь начиная с шага «when». При этом вместо точного номера шага можно задавать соответствующую ему долю от общего количества итераций: значит, в случае подсказки
Wide-angle shot of [colorful nebula:fantasy forest:0.3], intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
первые 30% цикла система будет изображать красочную туманность, а оставшиеся 70% — поневоле беря за основу уже почти на треть извлечённый из латентного пространства именно этот, вполне определённый, образ, — фэнтезийный лес. Вот что получается с разными значениями параметра «when» — 0.3,0.5,0.7,0.9 — при исполнении сценария «Prompt S/R» скрипта «X/Y/Z plot»:

Источник: ИИ-генерация на основе модели SD 1.5
Очевидно, чем больше шагов отводится на генерацию первой из заданных сущностей (в данном случае туманности), тем меньше латентного шума остаётся на изображении к моменту перехода ко второму термину. Зависимость выходит нелинейная — об этом следует помнить, экспериментируя с различными идеями.
Реализуем также более сложный пример многосоставного редактирования подсказки из описания AUTOMATIC1111:
[mountain:lake:0.25] and [an oak:a christmas tree:0.75][ in foreground::0.6][ in background:0.25] [shoddy:masterful:0.5]

Источник: ИИ-генерация на основе модели SD 1.5
Здесь первую четверть всего процесса генерации рисуется гора, оставшиеся 75% — озеро; первые 75% — дуб, оставшиеся 25% — рождественская ель; первые 60% указанный объект модели предписывается размещать на переднем плане, после чего данная инструкция попросту пропадает из подсказки (именно в этом смысл отсутствия чего-либо между двоеточиями во фрагменте [ in foreground::0.6]); после 25% шагов в подсказку добавляется указание ставить текущий объект и на задний план тоже ([ in background:0.25]); наконец, ровно на половине от общего числа генераций «низкопробное» в общей характеристике изображения сменяется на «мастерски исполненное». Как ни удивительно, полученная картинка не выглядит визуальной какофонией различных образов и стилей — в этом проявляется высокое качество тренировки модели, «стремящейся» (в кавычках, поскольку вместо осознания и воли тут работают зафиксированные в ходе обучения веса на входах перцептронов многослойной нейросети) выдать в итоге эстетически приемлемый результат. По крайней мере, не менее приемлемый, чем те примеры, на которых она тренировалась.
Эмма | Гектор | рябчик
Помимо химеризации объектов и даже разнообразных, включая формально несочетаемые, концепций редактирование подсказки на лету используется как один из способов получения устойчивых лиц (consistent faces). Одна удачная картинка — это прекрасно, но, если оператор желает получить целую серию, на которой присутствовал бы узнаваемо один и тот же персонаж (притом с привлечением различных затравок и подсказок — по крайней мере, в пределах одного и того же используемого чекпойнта), приходится прилагать немалые усилия. Редактирование подсказки даёт возможность создавать устойчивое лицо как химеру из двух или более других, заведомо известных генеративной модели, — это могут быть актёры, политики, прочие знаменитости и даже, к примеру, мультипликационные герои. Вот, скажем, такая подсказка —
portrait of a pretty sorceress girl, soft hair, fragile, half body, feminine, young, silver waivy hair, flowing silk, realistic skin, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
(прочие параметры прежние, включая затравку 485257449 и негативную подсказку с двумя текстовыми инверсиями) — выдаёт изображение довольно милой, но узнаваемо порождённой ИИ девушки с так называемым стандартным лицом. Да, от генерации к генерации человек, названный в подсказке просто «girl», будет выглядеть немного иначе, и, более того, при переходе от чекпойнта к чекпойнту перемены окажутся ещё разительнее, но в целом это усреднённо-безупречное, лишённое ярких выразительных черт лицо довольно быстро приедается.
![Слева направо в подсказке фигурируеют просто «girl», затем «(Emma Watson:1.0)» и, наконец, «Emma Watson|Thylane Blondeau]» (источник: ИИ-генерация на основе модели SD 1.5)](https://cdn.3dnews.ru/assets/external/illustrations/2024/05/03/1104253/aidraw08-11.jpg)
Слева направо в подсказке фигурирует просто «girl», затем «(Emma Watson:1.0)» и, наконец, «Emma Watson|Thylane Blondeau]» (источник: ИИ-генерация на основе модели SD 1.5)
Конечно же, можно вместо абстрактной «girl» указать всем известную Эмму Уотсон, к примеру, — и даже сделать замену на «(Emma Watson:1.0)», чтобы точнее связать для модели между собой имя и фамилию в единую сущность. Но это будет хотя и довольно уверенно воспроизводящееся от генерации к генерации, но вполне определённое — что называется, офлайновое — лицо! Как же сгенерировать такое, прямого соответствия которому в реальном мире нет? Да просто взять и соорудить химеру — например, [Emma Watson|Thylane Blondeau].
Как именно это будет выглядеть, изучим опять-таки с применением двухпараметрического скрипта «X/Y/Z plot»: по одной оси пусть меняются значения затравок, по другой — конкретный способ химеризации (с применением сценария «Prompt S/R» с параметрами
girl,(Emma Watson:1.0),[Emma Watson|Thylane Blondeau],[Emma Watson:Thylane Blondeau:0.3],[Emma Watson:Thylane Blondeau:0.5],[Emma Watson::0.5]
В последнем случае, напомним, модель будет извлекать из латентных пучин светлый облик актрисы, сыгравшей Гермиону Грейнджер, только до половины назначенных шагов генерации, — а после просто уберёт упоминание о ней из подсказки, не заменив его ничем и всего лишь дорисовывая абстрактную «sorceress» — но на основе, ранее тронутой образом Эммы Уотсон.
Немного скорректируем исходную подсказку:
close-up portrait of a pretty sorceress girl, soft wavy silver hair, fragile, feminine, young, flowing silk robes, realistic skin, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
Здесь специально вместо полуростового портрета (half-body) выбран крупный план, close-up, — чтобы нагляднее было видно, как меняется лицо. Негативную подсказку на всякий пожарный дополним парой подстраховочных в моральном плане терминов:
CyberRealistic_Negative-neg, CyberRealistic_Negative_v3, nude, nsfw

Источник: ИИ-генерация на основе модели SD 1.5
Действительно заметно, что от затравки к затравке лицо безымянной «girl» ощутимо меняется — по крайней мере, куда более ощутимо, чем лица, сгенерированные с опорой на изображения реальных людей. Особенно показательны в этом плане две последних строки приведённой таблицы: там, где после половины шагов генерации место «Emma Watson» заняла «Thylane Blondeau», лицо выходит в целом живее, чем когда освобождённую актрисой позицию никто не занял.
В принципе, уже теперь — используя чередование сущностей и редактирование подсказки на лету — можно надеяться получить от рабочей среды AUTOMATIC1111 дополнительное вдохновение, особенно если запускать создание картинок в режиме «Gernerate forever», да ещё и вручную менять по ходу дела отдельные параметры генерации в окнах ввода позитивной и негативной подсказок, перемещением различных ползунков и т. п., — в этом случае подхватывать изменения система будет по завершении генерации очередной картинки. Однако есть и более мощные способы разбудить задремавшую было фантазию ИИ-художника, реализованные в расширениях для рассматриваемой нами рабочей среды, — и прежде всего это динамические подсказки, Dynamic Prompts.
Как устанавливать расширения AUTOMATIC1111, читателям прежних наших «Мастерских» должно быть уже хорошо знакомо. Во вкладке «Extensions», в подвкладке «Available», обнаруживаем расширение «Dynamic Prompts» — оно располагается почти в самом низу списка. Нажимаем серую кнопку «Install»; затем, вернувшись в подвкладку «Installed», производим «Check for updates», — заодно обновятся ранее установленные расширения. Как вариант, можно запустить приложение командной строки (например, установленный в ходе самой первой «Мастерской» по ИИ-рисованию Git Bash) в инсталляционном каталоге stable-diffusion-webui и исполнить там команду
git clone https://github.com/adieyal/sd-dynamic-prompts/ extensions/sd-dynamic-prompts
после чего лучше всё равно перезагрузить графический интерфейс веб-сервера для надёжности. Кстати, для рабочей среды ComfyUI соответствующие кастомные ноды тоже имеются, — эта среда предпочтительна для SDXL (и, надо полагать, будет таковой и для SD 3), поэтому очень хорошо, что столь гибкий инструмент доступен в том числе и там.
Отныне во вкладке «txt2img» у нас появилось выпадающее меню «Dynamic Prompts», в данном случае — сразу под «Tiled VAE». Отметим, что установленное сейчас расширение сопровождают очень даже внятные авторские комментарии, доступные прямо в его же интерфейсе — в выпадающих подменю «Need help?» и «Help for Jinja2 templates» (внутри собственно «Jinja2 templates»).
Для начала удостоверимся, что опции «Dynamic Prompts enabled» и «Don't apply to negative prompts» помечены галочками, а в подменю «Advanced options» активируем «Fixed seed» — чтобы далее наблюдать, как различные подсказки срабатывают при одной и той же затравке. При запуске «Dynamic Prompts» в режиме, что называется, свободной охоты лучше давать системе как можно больше воли — тогда есть шанс наткнуться на что-то поистине неожиданное.
Суть динамических подсказок (реализуемых через расширение dynamic prompts; не путать с освещённым чуть выше редактированием подсказок на лету, prompt editing, интегрированным в AUTOMATIC1111) — в использовании подстановок (wildcards) вместо отдельных терминов с возможностью дальнейшего их комбинирования; раз за разом случайным образом — либо дотошным перебором всех возможных вариантов. После установки этого расширения вместо квадратных скобок для перечисления избранных вариантов через вертикальный разделитель по умолчанию используются фигурные — и это, подчеркнём, позволяет куда проще визуально различать чередование слов в подсказке от одного шага генерации к другому и выбор одной сущности из предложенных. Так, если фрагмент
[Emma Watson|Megan Fox|Audrey Hepburn]
означает, что в ходе генерации картинки на первом шаге система пытается создать химеру — извлечь из латентного пространства лицо первой из перечисленных актрис, на втором — второй, на третьем — третьей, на четвёртом — снова первой, то синтаксис
{Emma Watson|Megan Fox|Audrey Hepburn}
после установки «Dynamic Prompts» указывает на то, что для генерации при каждом очередном нажатии на кнопку «Generate» будет случайным образом выбрана только одна из перечисленных актрис.
Понятно, что если в голове оператора роится множество заслуживающих отвязного комбинирования сущностей, перечислять их все в единой подсказке неразумно: та выйдет чрезмерно громоздкой. Поэтому чаще расширение динамической подсказки используют иным, весьма логичным с программистской точки зрения образом — через обращение к заранее заготовленным перечням этих самых сущностей.

Dynamic Prompts — это страшная сила (источник: ИИ-генерация на основе модели SD 1.5)
Пояснить работу этого механизма проще всего на примере известной шутки: «„(Какая?) (что?) завела нас в (какой?) лес?“ — и как, по-вашему, нормальный второклассник должен раскрывать эти скобки, оставаясь в рамках приличия?!» В нашем случае за приличия будут отвечать параметры «nude, nsfw» в негативной подсказке, а вместо скобок синтаксис «Dynamic prompts» полагается по умолчанию (в настройках это можно изменить) на удвоенный символ подчёркивания: «__».
Составим такую переменную часть позитивной подсказки:
__type__ __creature__ drove us to a __characteristic__ forest
Добавим также к ней постоянную часть: довольно важный даже для самых свежих чекпойнтов SD 1.5 «словесный салат» (word salad — так энтузиасты снисходительно называют набор слабо связанных между собой на первый взгляд терминов, призванный полумагическим, т. е. труднообъяснимым, образом улучшить извлекаемое из латентного пространства изображение), уже использованный в только что проведённых генерациях:
d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
Далее составим в любом редакторе — notepad.exe подойдёт — три текстовых файла, в которых, собственно, и будут храниться различные ответы на вопросы «какая?», «какой?» и «что?». Ради наглядности сделаем эти файлы короткими, всего по три строчки в каждом, но в принципе они могут быть достаточно пространны. Сами разработчики рассматриваемого расширения дают в его описании ссылки на ряд внушительных, от десятков мегабайт до гигабайтов, коллекций подстановок (wildcards) по самым разным темам — от компендиумов эстетических особенностей изображений и стилей конкретных художников до перечней разнообразных поз, жестов, вариантов одежды, съедобных объектов и проч.
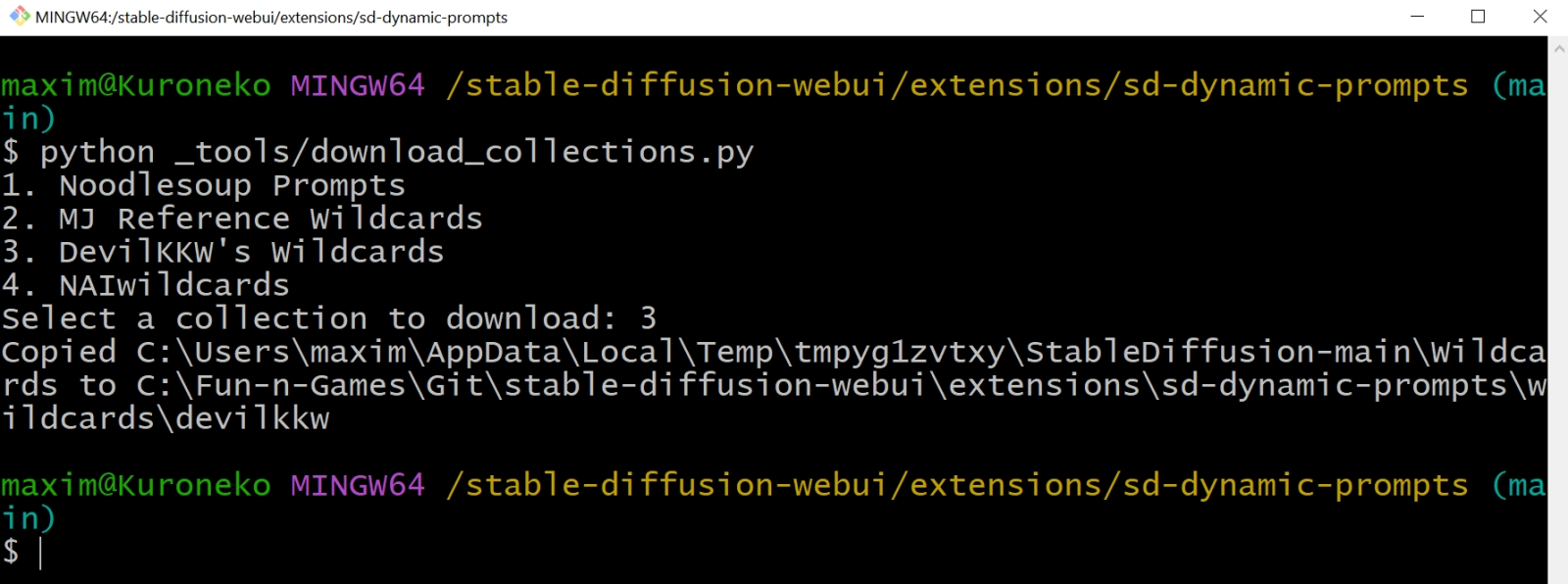
Загрузить соответствующие файлы можно и в автоматическом режиме — нужно через уже знакомый нам Git Bash исполнить в рабочем каталоге данного расширения (т. е. extensions/sd-dynamic-prompts/) команду
python _tools/download_collections.py
Вот, например, какие подстановки содержит файл gestures_one_hand_one_open_finger.txt из каталога C:\Fun-n-Games\Git\stable-diffusion-webui\extensions\sd-dynamic-prompts\collections\devilkkw\gesture:
akanbe
slit throat
index finger raised
middle finger
pinky out
beckoning
pointing
pointing at self
pointing at viewer
pointing down
pointing forward
pointing up
kamina pose
saturday night fever
shushing
thumbs down
thumbs up
Указанный здесь первым жест акамбэ хорошо знаком всем поклонникам аниме — это одновременное оттягивание указательным пальцем нижнего века и высовывание языка; выражает поддразнивание или в целом неуважительное отношение. Модели, натренированные на скриншотах из аниме и на рисунках мангак, уверенно будут ставить генерируемого персонажа в позицию akanbe, — но и не только они: множество актуальных сегодня чекпойнтов получены слиянием (merge) изначально фотореалистичных и мультяшных моделей, что существенно расширяет возможности интерпретации ими задаваемых оператором подсказок.
Однако прежде, чем переходить к использованию заготовленных кем-то подстановок, освоимся с самодельными. В каталоге C:\Fun-n-Games\Git\stable-diffusion-webui\extensions\sd-dynamic-prompts\wildcards создадим три файла:
первый, type.txt, с содержимым
grotesque
cute
ethereal
второй, creature.txt —
axolotl
cow
dragonfly
и третий, characteristic.txt:
eerie
sunny
flooded
Каждый файл состоит ровно из трёх строк; в каждой строке строго с первой позиции содержится только одно слово.
Теперь вернёмся к меню «Dynamic Prompts» и поставим галочку в позиции «Combinatorial generation»: эта команда заставит систему не просто брать случайные элементы подсказки из файлов подстановок, но перебирать все возможные их комбинации: в нашем случае — 3 раза по 3 и ещё по 3, т. е. 27. Переключим картинку в альбомный режим (768 × 512), прочие параметры генерации оставим прежними — и вперёд!

Источник: ИИ-генерация на основе модели SD 1.5
На нашей тестовой системе с GTX 1070 8 Gb генерация 27 картинок SD 1.5 безо всяких улучшений — ADetalier, Hires. fix и проч. — заняла менее 20 минут. В этом пакете выдачи встречаются действительно заслуживающие внимания композиции — и, что особенно приятно, их можно совершенствовать дальше.
Так, добавить генерации некоторую толику непредсказуемости поможет «подсказочное волшебство» — Prompt Magic. Реализуется оно через очередное выпадающее меню в «Dynamic Prompts»: всего-то нужно активировать опцию «Magic prompt». Ползунки «Max magic prompt length» и «Magic prompt creativity» на первых порах стоит оставить на позициях по умолчанию, как и «модель волшебства» — Gustavosta/MagicPrompt-Stable-Diffusion. В актуальную на момент написания настоящей статьи версию динамической подсказки интегрировано полтора десятка разнообразных моделей — интересующимся есть смысл лично их испробовать.

Источник: ИИ-генерация на основе модели SD 1.5
В поле «Magic prompt blocklist regex» пока вводить ничего не будем: оно полезно, если требуется исключить из генерации некоторые параметры. Скажем, вписав туда «yellow», мы отдадим системе команду не использовать жёлтый цвет (хотя в какой мере приказ будет исполнен, зависит от особенностей текущего чекпойнта, от значения CFG и многого другого), а комбинация «yellow|dog|future» будет интерпретирована как запрет на использование каждого из этих слов в модифицированной подсказке. В ходе первого запуска очередной модели «подсказочного волшебства» потребуется некоторое время на её загрузку, плюс она расположится в видеопамяти и тем самым сократит доступный её объём, — но в целом овчинка стоит выделки.
Вот, скажем, что мы получили с комбинацией подстановок cute, axolotl и eerie (т. е. с позитивной подсказкой cute axolotl drove us to a eerie forest, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration), — на следующей иллюстрации слева:

Источник: ИИ-генерация на основе модели SD 1.5
После же отработки «подсказочного волшебства» та же самая подсказка превратилась в
cute axolotl drove us to a eerie forest, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration art by greg rutkowski and alphonse mucha
и выглядит теперь так, — на иллюстрации выше справа. Вряд ли станет преувеличением сказать, что живописность изображения — как бы ту ни определять в культурологических терминах — в последнем случае явно выразительнее, чем в первом.
Если вместо сравнительно небольшой модели Gustavosta/MagicPrompt-Stable-Diffusion (510 Мбайт), которая в основном добавляет характерные для популярных художников стили, воспользоваться другой, Ar4ikov/gpt2-medium-650k-stable-diffusion-prompt-generator (1,44 Гбайт), да ещё и поднять лимит длины подсказки до 150 токенов (вдвое против стандартного блока на 75), то получится ещё занимательнее. Ну, точнее, может получиться, — фактор случайности тут немаловажен:

Источник: ИИ-генерация на основе модели SD 1.5
Заметим, что аксолотль превратился в данном случае — комбинация «cute, axolotl, eerie» воплощена в самой первой картинке этой серии, слева вверху, — в условную принцессу (латиноамериканская интерпретация «Царевны-лягушки»? Уже интересно!) потому, что тронутая волшебной 1,44-Гбайт палочкой из дополнительных токенов исходная подсказка преобразилась почти до неузнаваемости:
cute axolotl drove us to a eerie forest, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration art by artgerm and greg rutkowski and alphonse mucha, girl with long hair wearing a pink tank top, sitting on a hill, fantasy, intricate, elegant, highly detailed, digital painting, artstation, concept art, matte, sharp focus, illustration, hearthstone, art by artgerm and greg rutkowski and alphonse mucha, a beautiful 3 d render of a cat playing with a cat wearing a cat costume, unreal engine 5, 8 k, octane render, trending on art
В конце, как несложно заметить, произошла обрезка классической для «словесных салатов» эпохи SD 1.5 фразы — «trending on artstation» (имеется в виду популярный среди цифровых художников сайт), и это следует иметь в виду: если какой-то результат генерации динамической подсказки не слишком устраивает оператора, возможно, стоит удостовериться, что ничего важного система не обрезала. Да и вообще имеет смысл — если исходная подсказка действительно важна — ставить и лимит расширенной подсказки, и уровень влияния «волшебства» на неё (ползунок «Magic prompt creativity») поменьше.
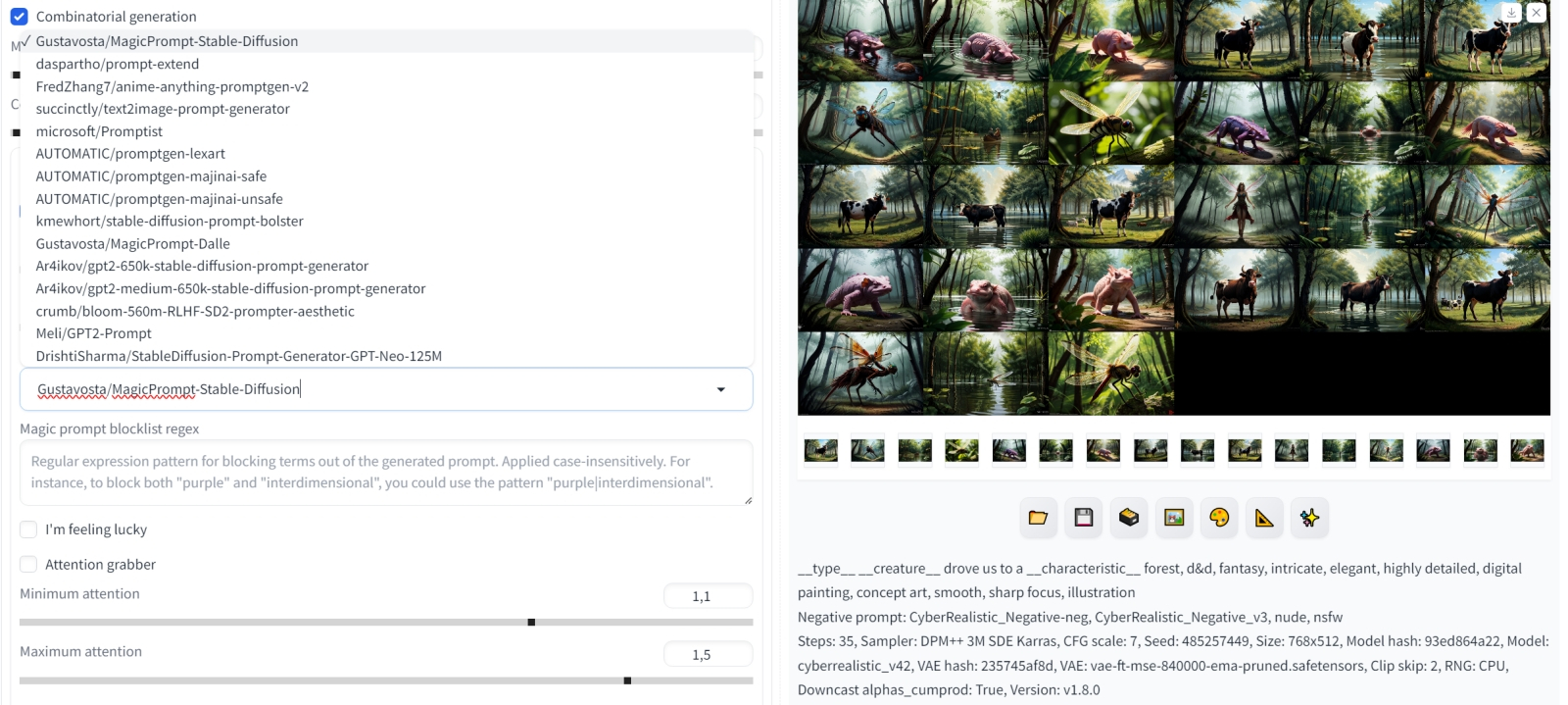
Выбор модели комбинационной генерации, равно как и предельной длины доработанной подсказки, существенно повлияет на результат
Рассмотрим ещё две возможности «Dynamic Prompts»: «Attention grabber» и «I'm feeling lucky», активируемые выставлением соответствующих галочек в подменю «Prompt Magic». Первая из них случайным образом выбирает в исходной подсказке некое слово и увеличивает его вес, придавая тем самым порой неожиданный акцент всему изображению. Запускать этот инструмент лучше с активной опцией «Fixed seed» — предварительно сняв галочку с опции «Combinatorial generation» уровнем выше, а заодно и с «Magic prompt» (иначе «словесный салат» продолжит неконтролируемо сыпаться в нашу подсказку). Выберем модель succinctly/text2image-prompt-generator (~600mb), специально натренированную, если верить описанию, на подсказках к удачным изображениям, выданным закрытой нейросетью Midjourney; вернём «Max magic prompt length» в 100, а «Magic prompt creativity» оставим исходным — 0,7.
Вот такая выразительная картинка, скажем, выходит, если акцентируется «sharp focus»:

Источник: ИИ-генерация на основе модели SD 1.5
cute axolotl drove us to a sunny forest, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, (sharp focus:1.24), illustration
Ну и наконец, если фантазия оператора уж совсем никак не взбадривается, можно поставить галочку в поле «I'm feeling lucky». Система будет обращаться к API известного сайта, коллекционирующего ИИ-сгенерированные изображения вместе с породившими их подсказками, — Lexica.art. Поскольку исходная подсказка в этом случае используется как поисковая строка в доступной базе, лучше минимизировать объём текста там (да даже просто оставить это поле пустым), — например, ограничиться одним только термином «axolotl». Кстати, предварительно можно проверить прямо на сайте Lexica, введя избранный термин в поисковую строку, какие с его применением порождаются картинки в принципе.
И вот что может таким образом выйти:

Источник: ИИ-генерация на основе модели SD 1.5
A large axolotl stone statue in the middle of a forest by Greg Rutkowski, Sung Choi, Mitchell Mohrhauser, Maciej Kuciara, Johnson Ting, Maxim Verehin, Peter Konig, final fantasy , 8k photorealistic, cinematic lighting, HD, high details, atmospheric,
Ну и следует помнить, конечно же, что обращение к веб-API оборачивается дополнительными задержками.
О подменю «Jinja2 templates», экспериментальной на данный момент возможности «Dynamic Prompts», говорить пока не будем — отметим только, что этот сравнительно примитивный, но всё же действенный скриптовый язык позволяет создавать такие, например, конструкции —
{% for colour in ["red", "blue", "green"] %}
{% if colour == "red" %}
{% prompt %}I love Нет данных roses{% endprompt %}
{% else %}
{% prompt %}I hate Нет данных roses{% endprompt %}
{% endif %}
{% endfor %}
В результате срабатывания конкретно этой будут получены три следующие подсказки:
I love red roses
I hate blue roses
I hate green roses
Желающие испробовать этот мощный инструмент всегда могут обратиться к соответствующей документации.
А мы пока разберёмся, как пользоваться уже имеющимися коллекциями подстановок, иные из которых содержат сотни и даже тысячи строк подмены. После инсталляции расширения «Dynamic Prompts» в каталоге C:\Fun-n-Games\Git\stable-diffusion-webui\extensions\sd-dynamic-prompts\collections образуется несколько папок с различными списками wildcards. Копируем/перемещаем оттуда, например, папку jumbo в C:\Fun-n-Games\Git\stable-diffusion-webui\extensions\sd-dynamic-prompts\wildcards — и делаем её видимой для системы.
В основном ряду вкладок рабочей среды — там же, где находятся «txt2img», «img2img» и иже с ними, — появилась теперь ещё одна, «Wildcards Manager». После перемещения коллекции jumbo и нажатия на расположенную в самом низу страницы кнопку обновления (ну или перезагрузки веб-интерфейса AUTOMATIC1111, кому как удобнее) новые файлы подстановок видны на этой вкладке — их можно просматривать и даже редактировать. В поле «Wildcards file» отображается точное наименование выбранного файла со всей прилагающейся структурой подкаталогов — именно его нужно будет включать в подсказку для генерации по подстановочным спискам.
Что же, попробуем задать максимально гибкую вариацию на тему «какая» и «что»:
__jumbo/appearance/adjectives__ __jumbo/creatures/animals__ brought us to a __jumbo/appearance/appearance__ __devilkkw/nature and elements/tree_habitats__ at __jumbo/time/timeofday__, in style of __jumbo/aesthetics/general_aesthetics__, __devilkkw/composition/image_composition_techniques__, masterpiece by __devilkkw/art/artists__, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration
Здесь вместо слова «drove», с которым, в частности, мы чуть выше извлекали из латентного пространства аксолотля, поставлено «brought» — поскольку первый из этих двух терминов, похоже, накрепко оказался связан в ходе тренировки ИИ-модели с автомобилями: слишком уж часто они появляются в выдаче, хотя никаких прямых указаний на них подсказка не содержит.
Чтобы в режиме «Generate forever» всякий раз производилась новая выборка строк в списках подмены, надо во вкладке «Settings» найти раздел «Dynamic Prompts» (слева в столбце, в категории «Uncategorized ») и отметить галочками параметры «Automatically purge wildcard cache on every generation» и «Shuffle wildcards before use for more random outputs».
После запуска режима «Generate forever» с таким образом сконфигурированными динамическими подсказками начинают уже попадаться по-настоящему впечатляющие картинки. Пусть и не слишком часто, да, — но далеко не всякий энтузиаст ИИ-рисования сумел бы с ходу, из головы, подобрать соответствующую комбинацию почти случайных параметров, чтобы получить на выходе такое:

Позитивная подсказка: harsh gopher brought us to a Flat shading rainforest at evening, in style of Drain, multiple monochrome, masterpiece by Chris Ware, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration (источник: ИИ-генерация на основе модели SD 1.5)
Или такое:

shiny mole brought us to a Skeuomorphic rainforest at noon, in style of Nerd, speed lines, masterpiece by Agnes Cecile, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration (источник: ИИ-генерация на основе модели SD 1.5)
Или вот такое:

glowing mule brought us to a Psychedelic jungle at afternoon, in style of Horror Academia, chiaroscuro, masterpiece by Ferdinand Knab, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration (источник: ИИ-генерация на основе модели SD 1.5)
Непредсказуемость срабатывания тех или иных терминов в подсказке, как водится, зашкаливает: «gopher» вообще никак себя не проявил, слово «mole» явно было воспринято в значении «родинка», а не «крот», — разве что вот «mule» вполне удался. И всё же в случае динамически сочиняемой и автоматически скармливаемой системе подсказки не так уже важно, что именно содержалось в поле текстового ввода, — имеют ценность картинки на выходе сами по себе.
Отметим также, что после обнаружения действительно интересной генерации есть смысл остановить бесконечный цикл (щёлкнуть правой кнопкой мыши на «Interrupt» и выбрать «Cancel generate forever»), загрузить приглянувшийся файл во вкладку «PNG Info», скопировать соответствующую позитивную подсказку и уже с ней запустить генерацию снова — деактивировав, разумеется, расширение «Dynamic Prompts». Разумно будет сразу же масштабировать картинку с повышением детализации — применяя уже знакомые инструменты Hires. fix и ADetaler. Причём для последнего, если на изображении много мелких человеческих фигур, желательно параметр «Denoising strength» брать побольше, 0,4-0,5, а в случае одиночного крупно (и удачно с эстетической точки зрения) изображённого лица ограничиваться величинами 0,15-0,25.

paradoxical rat brought us to a Skeuomorphic rainforest at dusk, in style of Bodikon, blending, masterpiece by Joan Miró, d&d, fantasy, intricate, elegant, highly detailed, digital painting, concept art, smooth, sharp focus, illustration (источник: ИИ-генерация на основе модели SD 1.5)
И тем не менее, возвращаясь к заданному в начале настоящей «Мастерской» вопросу: что же всё-таки делать, если оператору генеративной ИИ-модели страсть как хочется получить изображение панды, бьющейся с орлом, — ведь динамические подсказки при всех своих достоинствах именно эту задачу не решают? Не решают, верно; но на этот случай есть другие расширения для рабочей среды AUTOMATIC1111 — и это не только ControlNet и не Tiled Diffusion, о которых у нас шёл разговор ранее. Мощное средство регионализации подсказок открывает перед энтузиастами ИИ-рисования совершенно новые горизонты, но расскажем о нём мы уже в другой раз.