В прошлом мы рассказывали о технологии одновременной многопоточности (Simultaneous Multi-Threading - SMT), которая применяется в процессорах Intel. И хотя первоначально она создавалась под кодовым именем "технология Джексона" (Jackson Technology) как возможный, вероятный вариант, Intel официально анонсировала свою технологию на форуме IDF прошлой осенью. Кодовое имя Jackson было заменено более подходящим Hyper-Threading. Итак, для того чтобы разобраться, как работает новая технология, нам нужны кое-какие первоначальные знания. А именно, нам нужно знать, что такое поток, как выполняются эти потоки. Почему работает приложение? Как процессор узнает, какие операции и над какими данными он должен совершать? Вся эта информация содержится в откомпилированном коде выполняемого приложения. И как только приложение получает от пользователя какую-либо команду, какие-либо данные, – процессору сразу же отправляются потоки, в результате чего он и выполняет то, что должен выполнить в ответ на запрос пользователя. С точки зрения процессора, поток – это набор инструкций, которые необходимо выполнить. Когда в вас попадает снаряд в Quake III Arena, или когда вы открываете документ Microsoft Word, процессору посылается определенный набор инструкций, которые он должен выполнить.
Процессор точно знает, где брать эти инструкции. Для этой цели предназначен редко упоминаемый регистр, называемый счетчиком команд (Program Counter, PC). Этот регистр указывает на место в памяти, где хранится следующая для выполнения команда. Когда поток отправляется на процессор, адрес памяти потока загружается в этот счетчик команд, чтобы процессор знал, с какого именно места нужно начать выполнение. После каждой инструкции значение этого регистра увеличивается. Весь этот процесс выполняется до завершения потока. По окончании выполнения потока, в счетчик команд заносится адрес следующей инструкции, которую нужно выполнить. Потоки могут прерывать друг друга, при этом процессор запоминает значение счетчика команд в стеке и загружает в счетчик новое значение. Но ограничение в этом процессе все равно существует – в каждую единицу времени можно выполнять лишь один поток.
Существует общеизвестный способ решения данной проблемы. Заключается он в использовании двух процессоров – если один процессор в каждый момент времени может выполнять один поток, то два процессора за ту же единицу времени могут выполнять уже два потока. Отметим, что этот способ не идеален. При нем возникает множество других проблем. С некоторыми, вы уже, вероятно, знакомы. Во-первых, несколько процессоров всегда дороже, чем один. Во-вторых, управлять двумя процессорами тоже не так-то просто. Кроме того, не стоит забывать о разделении ресурсов между процессорами. Например, до появления чипсета AMD 760MP, все x86 платформы с поддержкой многопроцессорности разделяли всю пропускную способность системной шины между всеми имеющимися процессорами. Но основной недостаток в другом – для такой работы и приложения, и сама операционная система должны поддерживать многопроцессорность. Способность распределить выполнение нескольких потоков по ресурсам компьютера часто называют многопоточностью. При этом и операционная система должна поддерживать многопоточность. Приложения также должны поддерживать многопоточность, чтобы максимально эффективно использовать ресурсы компьютера. Не забывайте об этом, когда мы будем рассматривать ещё один подход решения проблемы многопоточности, новую технологию Hyper-Threading от Intel.
Об эффективности всегда много говорят. И не только в корпоративном окружении, в каких-то серьезных проектах, но и в повседневной жизни. Говорят, homo sapiens лишь частично задействуют возможности своего мозга. То же самое относится и к процессорам современных компьютеров.
Взять, к примеру, Pentium 4. Процессор обладает, в общей сложности, семью исполнительными устройствами, два из которых могут работать с удвоенной скоростью – две операции (микрооперации) за такт. Но в любом случае, вы бы не нашли программы, которая смогла бы заполнить инструкциями все эти устройства. Обычные программы обходятся несложными целочисленными вычислениями, да несколькими операциями загрузки и хранения данных, а операции с плавающей точкой остаются в стороне. Другие же программы (например, Maya) главным образом загружают работой устройства для операций с плавающей точкой.
Чтобы проиллюстрировать ситуацию, давайте вообразим себе процессор с тремя исполнительными устройствами: арифметико-логическим (целочисленным – ALU), устройством для работы с плавающей точкой (FPU), и устройством загрузки/хранения (для записи и чтения данных из памяти). Кроме того, предположим, что наш процессор может выполнять любую операцию за один такт и может распределять операции по всем трем устройствам одновременно. Давайте представим, что к этому процессору на выполнение отправляется поток из следующих инструкций:
1+1
10+1
Сохранить предыдущий результат
Рисунок ниже иллюстрирует уровень загруженности исполнительных устройств (серым цветом обозначается незадействованное устройство, синим – работающее устройство):
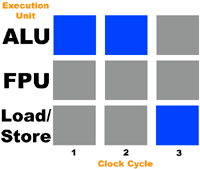
Итак, вы видите, что в каждый такт используется только 33% всех исполнительных устройств. В этот раз FPU остается вообще незадействованным. В соответствии с данными Intel, большинство программ для IA-32 x86 используют не более 35% исполнительных устройств процессора Pentium 4.
Представим себе ещё один поток, отправим его на выполнение процессору. На этот раз он будет состоять из операций загрузки данных, сложения и сохранения данных. Они будут выполняться в следующем порядке:
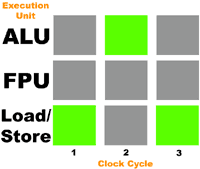
И снова загруженность исполнительных устройств составляет лишь на 33%.
Хорошим выходом из данной ситуации будет параллелизм на уровне инструкций (Instruction Level Parallelism - ILP). В этом случае одновременно выполняются сразу нескольких инструкций, поскольку процессор способен заполнять сразу несколько параллельных исполнительных устройств. К сожалению, большинство x86 программ не приспособлены к ILP в должной степени. Поэтому приходится изыскивать другие способы увеличения производительности. Так, например, если бы в системе использовалось сразу два процессора, то можно было бы одновременно выполнять сразу два потока. Такое решение называется параллелизмом на уровне потоков (thread-level parallelism, TLP). К слову сказать, такое решение достаточно дорогое.
Какие же ещё существуют способы увеличения исполнительной мощи современных процессоров архитектуры x86?
Проблема неполного использования исполнительных устройств связана с несколькими причинами. Вообще говоря, если процессор не может получать данные с желаемой скоростью (это происходит в результате недостаточной пропускной способности системной шины и шины памяти), то исполнительные устройства будут использоваться не так эффективно. Кроме того, существует ещё одна причина – недостаток параллелизма на уровне инструкций в большинстве потоков выполняемых команд.
В настоящее время большинство производителей улучшают скорость работы процессоров путем увеличения тактовой частоты и размеров кэша. Конечно, таким способом можно увеличить производительность, но все же потенциал процессора не будет полностью задействован. Если бы мы могли одновременно выполнять несколько потоков, то мы смогли бы использовать процессор куда более эффективно. Именно в этом и заключается суть технологии Hyper-Threading.
Hyper-Threading – это название технологии, существовавшей и ранее вне x86 мира, технологии одновременной многопоточности (Simultaneous Multi-Threading, SMT). Идея этой технологии проста. Один физический процессор представляется операционной системе как два логических процессора, и операционная система не видит разницы между одним SMT процессором или двумя обычными процессорами. В обоих случаях операционная система направляет потоки как на двухпроцессорную систему. Далее все вопросы решаются на аппаратном уровне.
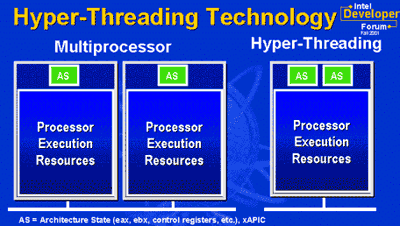
В процессоре с Hyper-Threading каждый логический процессор имеет свой собственный набор регистров (включая и отдельный счетчик команд), а чтобы не усложнять технологию, в ней не реализуется одновременное выполнение инструкций выборки/декодирования в двух потоках. То есть такие инструкции выполняются поочередно. Параллельно же выполняются лишь обычные команды.
Официально технология была объявлена на форуме Intel Developer Forum прошлой осенью. Технология демонстрировалась на процессоре Xeon, где проводился рендеринг с помощью Maya. В этом тесте Xeon с Hyper-Threading показал на 30% лучшие результаты, чем стандартный Xeon. Приятный прирост производительности, но больше всего интересно то, что технология уже присутствует в ядрах Pentium 4 и Xeon, только она выключена.
Технология пока ещё не выпущена, однако те из вас, кто приобрел 0,13 мкм Xeon, и установил этот процессор на платы с обновленным BIOS, наверняка были удивлены, увидев в BIOS опцию включения/отключения Hyper-Threading.
А пока Intel будет оставлять опцию Hyper-Threading отключенной по умолчанию. Впрочем, для ее включения достаточно просто обновить BIOS. Все это касается рабочих станций и серверов, что же до рынка персональных компьютеров, в ближайшем будущем у компании планов касательно этой технологии не имеется. Хотя возможно, производители материнских плат предоставят возможность включить Hyper-Threading с помощью специального BIOS.
Остается очень интересный вопрос, почему Intel хочет оставить эту опцию выключенной?
Помните те два потока из предыдущих примеров? Давайте на этот раз предположим, что наш процессор оснащен Hyper-Threading. Посмотрим, что получится, если мы попытаемся одновременно выполнить эти два потока:
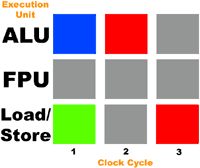
Как и ранее, синие прямоугольники указывают на выполнение инструкции первого потока, а зеленые - на выполнение инструкции второго потока. Серые прямоугольники показывают незадействованные исполнительные устройства, а красные - конфликт, когда на одно устройство пришло сразу две разных инструкции из разных потоков.
Итак, что же мы видим? Параллелизм на уровне потоков дал сбой – исполнительные устройства стали использоваться ещё менее эффективно. Вместо параллельного выполнения потоков, процессор выполняет их медленнее, чем если бы он выполнял их без Hyper-Threading. Причина довольно проста. Мы пытались одновременно выполнить сразу два очень похожих потока. Ведь оба они состоят из операций по загрузке/сохранению и операций сложения. Если бы мы параллельно запускали "целочисленное" приложение и приложение, работающее с плавающей точкой, мы бы оказались куда в лучшей ситуации. Как видим, эффективность Hyper-Threading сильно зависит от вида нагрузки на ПК.
В настоящий момент, большинство пользователей ПК используют свой компьютер примерно так, как описано в нашем примере. Процессор выполняет множество очень схожих операций. К сожалению, когда дело доходит до однотипных операций, возникают дополнительные сложности с управлением. Случаются ситуации, когда исполнительных устройств нужного типа уже не осталось, а инструкций, как назло, вдвое больше обычного. В большинстве случаев, если бы процессоры домашних компьютеров использовали технологию Hyper-Threading, то производительность бы от этого не увеличилась, а может быть, даже снизилась на 0-10%.
На рабочих же станциях возможностей для увеличения производительности у Hyper-Threading больше. Но с другой стороны, все зависит от конкретного использования компьютера. Рабочая станция может означать как high-end компьютер для обработки 3D графики, так и просто сильно нагруженный компьютер.
Наибольший же прирост в производительности от использования Hyper-Threading наблюдается в серверных приложениях. Главным образом это объясняется широким разнообразием посылаемых процессору операций. Сервер баз данных, использующих транзакции, может работать на 20-30% быстрее при включенной опции Hyper-Threading. Чуть меньший прирост производительности наблюдается на веб-серверах и в других сферах.
Вы думаете, Intel разработала Hyper-Threading только лишь для своей линейки серверных процессоров? Конечно же, нет. Если бы это было так, они бы не стали впустую тратить место на кристалле других своих процессоров. По сути, архитектура NetBurst, использующаяся в Pentium 4 и Xeon, как нельзя лучше подходит для ядра с поддержкой одновременной многопоточности. Давайте ещё раз представим себе процессор. На этот раз в нем будет ещё одно исполнительное устройство – второе целочисленное устройство. Посмотрим, что случится, если потоки будут выполняться обоими устройствами:
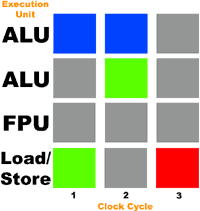
С использованием второго целочисленного устройства, единственный конфликт случился только на последней операции. Наш теоретический процессор в чем-то похож на Pentium 4. В нем имеется целых три целочисленных устройства (два ALU и одно медленное целочисленное устройство для циклических сдвигов). А что ещё более важно, оба целочисленных устройства Pentium 4 способны работать с двойной скоростью – выполнять по две микрооперации за такт. А это, в свою очередь, означает, что любое из этих двух целочисленных устройств Pentium 4/Xeon могло выполнить те две операции сложения из разных потоков за один такт.
Но это не решает нашей проблемы. Было бы мало смысла просто добавлять в процессор дополнительные исполнительные устройства с целью увеличения производительности от использования Hyper-Threading. С точки зрения занимаемого на кремнии пространства это было бы крайне дорого. Вместо этого, Intel предложила разработчикам оптимизировать программы под Hyper-Threading.
Используя инструкцию HALT, можно приостановить работу одного из логических процессоров, и тем самым увеличить производительность приложений, которые не выигрывают от Hyper-Threading. Итак, приложение не станет работать медленнее, вместо этого один из логических процессоров будет остановлен, и система будет работать на одном логическом процессоре – производительность будет такой же, что и на однопроцессорных компьютерах. Затем, когда приложение сочтет, что от Hyper-Threading оно выиграет в производительности, второй логический процессор просто возобновит свою работу.
На веб-сайте Intel имеется презентация, описывающая, как именно необходимо программировать, чтобы извлечь из Hyper-Threading максимум выгоды.
Хотя мы все были крайне обрадованы, когда до нас дошли слухи об использовании Hyper-Threading в ядрах всех современных Pentium 4/Xeon, все же это не будет бесплатной производительностью на все случаи жизни. Причины ясны, и технологии предстоит преодолеть ещё многое, прежде чем мы увидим Hyper-Threading, работающую на всех платформах, включая домашние компьютеры. А при поддержке разработчиков, технология определенно может оказаться хорошим союзником Pentium 4, Xeon, и процессорам будущего поколения от Intel.
При существующих ограничениях и при имеющейся технологии упаковки, Hyper-Threading кажется более разумным выбором для потребительского рынка, чем, например, подход AMD в SledgeHammer – в этих процессорах используется целых два ядра. И до тех пор, пока не станут совершенными технологии упаковки, такие как Bumpless Build-Up Layer, стоимость разработки многоядерных процессоров может оказаться слишком высокой.
Интересно заметить, насколько разными стали AMD и Intel за последние несколько лет. Ведь когда-то AMD практически копировала процессоры Intel. Теперь же компании выработали принципиально иные подходы к будущим процессорам для серверов и рабочих станций. AMD на самом деле проделала очень длинный путь. И если в процессорах Sledge Hammer действительно будут использоваться два ядра, то по производительности такое решение будет эффективнее, чем Hyper-Threading. Ведь в этом случае кроме удвоения количества всех исполнительных устройств снимаются проблемы, которые мы описали выше.
Hyper-Threading ещё некоторое время не появится на рынке обычных ПК, но при хорошей поддержке разработчиков, она может стать очередной технологией, которая опустится с серверного уровня до простых компьютеров.