|
Опрос
|
реклама
Быстрый переход
YouTube запустит ИИ-дубляж уже в феврале, а в будущем ИИ будет определять возраст зрителей и защищать блогеров
11.02.2025 [20:21],
Сергей Сурабекянц
Сегодня генеральный директор YouTube Нил Мохан (Neal Mohan) назвал ИИ одной из четырёх «крупных ставок» компании на 2025 год. Он подчеркнул инвестиции компании в инструменты ИИ для создателей, в том числе для генерации идей, создания миниатюр и синхронного перевода. ИИ-дубляж станет доступен для создателей уже в этом месяце. Также ИИ будет определять возраст пользователей, чтобы предлагать соответствующий контент. А ещё ИИ будет защищать блогеров от ИИ. 
Источник изображения: Pixabay Мохан сообщил, что уже в этом месяце функция автоматического дубляжа станет доступной всем создателям в партнёрской программе YouTube. Этот инструмент поможет кардинально увеличить охват аудитории благодаря синхронному переводу на несколько языков с минимальными усилиями. YouTube планирует использовать ИИ в том числе и для контроля за использованием ИИ (как говорят следователи — «главное в процессе следствия не выйти на себя»). В первую очередь будет существенно расширена программа взаимодействия с агентством Creative Artists Agency (CAA). Она должна защитить людей творческих профессий, включая художников, актёров, музыкантов и спортсменов, от копирования их внешности или голоса. CAA расширит возможности существующей системы идентификации авторских прав Content ID, обнаруживая образы или голоса, созданные с помощью инструментов ИИ. Мохан рассказал, что уже в этом году YouTube начнёт использовать технологию машинного обучения для оценки возраста пользователей, чтобы показывать соответствующие возрасту рекомендации. Он не раскрыл способы, которыми новая технология будет определять возраст. Также он обошёл стороной вопрос о возможных ошибках ИИ, которые обязательно возникнут. За последний год YouTube развернул целый ряд ИИ-функций для создания изображений, фонов видео или генерации звукового сопровождения к коротким роликам. Однако добавление ИИ в сам процесс создания видео не обошлось без споров, поскольку противники этого процесса уверены, что некачественный контент, созданный ИИ, заполонит YouTube, вытеснив авторские произведения. Помимо дальнейшего безоглядного внедрения ИИ, YouTube в 2025 году ставит перед собой другие, довольно амбициозные задачи:
«Масштабы поразительны»: Meta✴ незаконно раздавала на торрентах терабайты файлов, заявили правообладатели
07.02.2025 [17:59],
Сергей Сурабекянц
Писатели и владельцы авторских прав подали иск против Meta✴. Они утверждают, что недавно раскрытые внутренние электронные письма работников компании предоставляют весомые доказательства масштабного нарушения Meta✴ авторских прав. По словам истцов, компания обучала свои модели ИИ на пиратских книгах и участвовала в гигантской незаконной торрент-раздаче, включающей в себя десятки миллионов произведений. 
Источник изображения: unsplash.com В исковом заявлении владельцы авторских прав утверждают, что Meta✴ участвовала в торрент-раздаче «не менее 81,7 терабайт данных из нескольких теневых библиотек через сайт Anna’s Archive, включая не менее 35,7 терабайт данных из Z-Library и LibGen, […] масштабы незаконной схемы торрентов Meta✴ поразительны». В исковом заявлении подчёркивается, что «гораздо меньшие акты пиратства данных — всего 0,008 процента от количества защищённых авторским правом работ, которые Meta✴ пиратски скопировала» приводили к уголовному преследованию. Meta✴ долгое время сопротивлялась попыткам раскрытия информации о нарушении компанией авторских прав и участии в незаконных торрент-раздачах. В ходатайстве об отклонении иска компания утверждала, что обучение ИИ на данных библиотеки LibGen является «добросовестным использованием». Юристы компании заявили суду, что «истцы не ссылаются ни на один случай, в котором какая-либо часть какой-либо книги была фактически загружена третьей стороной с Meta✴ через торрент, не говоря уже о том, что книги истцов каким-либо образом распространялись Meta✴». Тем не менее в распоряжение владельцев авторских прав попали внутренние электронные письма инженера-исследователя Meta✴ Николая Башлыкова, в которых он выражает озабоченность по поводу использования корпоративных компьютеров и IP-адресов Meta✴ «для загрузки пиратского контента через торренты». В сентябре 2023 года после консультаций с юристами Башлыков снова попытался привлечь внимание к проблеме, подчеркнув в письме, что «использование торрентов повлечёт за собой “раздачу” файлов, т. е. распространение контента за пределами компании, что может быть юридически недопустимо». Предупреждения Башлыкова, по-видимому, не были услышаны, поскольку Meta✴ продолжала загрузку и раздачу терабайтов данных из нескольких теневых библиотек вплоть до апреля 2024 года, приняв некоторые шаги для маскировки своей деятельности. Предположительно, Meta✴ пыталась скрыть раздачу, не используя серверы Facebook✴ при загрузке набора данных, чтобы избежать отслеживания источника раздачи. Компания также якобы изменила настройки торрент-клиента, чтобы минимизировать объём раздаваемой информации. Поскольку ограниченное раскрытие информации в настоящее время продолжается, компания уже не оспаривает сам факт нарушения авторских прав. Для Meta✴ ситуация теперь осложняется обвинениями в участии в массовом распространении пиратского контента. Тем не менее, представитель Meta✴ заявил в суде, что компания планирует «установить факты и развенчать это беспочвенное обвинение в порядке упрощённого судопроизводства». Российские медиа объявили войну пиратам: число заблокированных ссылок в поисковиках удвоилось за год
31.01.2025 [13:05],
Владимир Мироненко
В 2024 году резко выросло количество обращений российских медиахолдингов-правообладателей по поводу блокировки в выдаче поисковиков ссылок на пиратский контент, пишет «Коммерсантъ». 
Источник изображения: Glenn Carstens-Peters/unsplash.com Как сообщила «Коммерсанту» компания «Яндекс», число ссылок на сайты и страницы с пиратским контентом, которые российские правообладатели внесли в реестр в рамках антипиратского меморандума, в 2024 году составило 180 млн, более чем вдвое превысив показатель 2023 года в размере 89 млн ссылок. В 2022 году в реестр было внесено 76,5 млн ссылок, а с начала действия меморандума в 2018 году до марта 2021 года «Яндекс» добавила в реестр 15 млн ссылок на пиратский контент. Антипиратский меморандум был подписан поисковиками «Яндекс», Mail.ru, Rambler и правообладателями в РФ, включая производителей видеоконтента, 1 ноября 2018 года. Согласно документу, интернет-платформы обязаны удалять из выдачи ссылки на пиратские ресурсы во внесудебном порядке. В сентябре 2023 года Роскомнадзор сообщил о присоединении к меморандуму книжной и музыкальной отраслей. Впрочем, как утверждают издательства, включение в реестр пока не принесло ожидаемых результатов, поскольку он разрабатывался исключительно для нужд кинокомпаний. В «Газпром-медиа холдинге» (ГПМХ, включает телеканалы НТВ, ТНТ, ТВ-3, «Пятница!» и др.) рассказали, что в прошлом году инициировали блокировку около 17,4 тыс. сайтов. В частности, из выдачи «Яндекса» по его запросу было удалено более 6,2 млн ссылок, из выдачи Google — около 5 млн ссылок, что превышает показатель 2023 года на 17 %. Наибольшей популярностью у пиратов пользовались такие проекты, как «Жвачка», «Плевако», «Фарма», «Жуки», «Прелесть», «Красный 5», «Мир! Дружба! Жвачка!», «Бременские музыканты», «Сто лет тому вперед». В свою очередь, в «Национальной медиа группе» направили примерно на 60 % больше запросов, чем в 2023 году, на блокировку пиратского контента, включая такие проекты, как «Трудные подростки», «Слово пацана. Кровь на асфальте», «Библиотекарь», «Плакса». Также в 2024 году выросло число исков, в связи с нарушением авторских прав. Например, ГПМХ инициировал 904 судебных процесса, по 775 из них вынесены решения в пользу холдинга с возмещением ущерба в более чем 15,9 млн руб., что на 30 % больше, чем в 2023 году. Большие суммы взысканий заставляют нарушителей идти с ГПМХ на контакт в поисках путей урегулирования конфликта, говорит директор департамента обеспечения защиты интеллектуальной собственности «ГПМ Цифровые инновации» Павел Русаков. «Например, в 2024 году мы провели успешные переговоры с администраторами нескольких пиратских сайтов, по итогам которых с площадок был удалён контент компаний ГПМХ», — сообщил он. В Медиакоммуникационном союзе (объединяет телеком- и медиакомпании) связывают увеличение числа пиратских ссылок в реестре с ростом эффективности работы правообладателей по защите контента. При этом число охраняемых единиц контента не сильно выросло, утверждают источники на медиарынке. По данным «Индекса Кинопоиска Pro», российские онлайн-кинотеатры даже сократили в 2024 году число выпускаемых проектов на 25 %, с 201 до 151. Как полагает источник «Коммерсанта», такой рост показателей можно объяснить только двумя факторами: или крупные российские правообладатели резко увеличили число ссылок на одну охраняемую единицу контента, или же иностранные правообладатели (Sony, Universal, Warner, Disney) отказались от правовой охраны своего контента. — ИИ оставили без авторских прав на творчество, но есть и исключения
31.01.2025 [11:24],
Владимир Фетисов
Медиаконтент, созданный с помощью генеративных нейросетей и основанный только на текстовых подсказках автора, не защищён действующим в США законом об авторском праве. Об этом сказано в опубликованном на этой неделе документе Бюро авторского права США по вопросам политики ведомства в сфере ИИ и возможности защиты авторским правом контента, создаваемого с помощью нейросетей. 
Источник изображения: Copilot В ведомстве отметили, что при определении произведения, подлежащего защите авторским правом, основным моментом является творческая роль человека. Существует разница между искусственным интеллектом, используемым в качестве вспомогательного инструмента в творческом процессе, и искусственным интеллектом, заменяющим человеческое творчество. Это означает, что созданное с помощью ИИ произведение может быть защищено авторским правом, если алгоритм использовался для модификации работы человека. Для художников такими работами могут стать рисунки, которые обрабатывались ИИ-алгоритмами для добавления разных эффектов, например, эффекта 3D. Полностью сгенерированные ИИ изображения по-прежнему не будут защищены авторским правом, но это не касается работ, в которых после обработки остаётся узнаваема изначальная работа человека. Это также касается случаев, когда автор добавляет на принадлежащее ему изображение какие-то новые элементы с помощью ИИ. Аналогичным образом видео с добавленными с помощью ИИ эффектами по-прежнему будут защищены законом об авторском праве. Бюро авторского права США не исключает, что по мере развития технологий действующее законодательство потребует внесения изменений. Позднее в этом году ведомство планирует выпустить окончательную версию отчёта по результатам проведённых исследований в сфере генерации контента и произведений искусства с помощью ИИ. Telegram удалил официальный канал RuTracker
20.01.2025 [16:20],
Владимир Мироненко
Telegram заблокировал доступ к официальному каналу популярного в русскоязычном сегменте интернета торрент-трекера RuTracker за нарушение авторских прав, сообщил ресурс CNews. 
Источник изображения: Alex Kotliarskyi/unsplash.com Telegram-канал «RuTracker.org – официальный канал» (@rutracker_news) был создан в 2017 году, имел небольшую базу подписчиков в пределах 29 тыс. человек и не отличался особой активностью. Например, в 2024 году в нём не было ни одного сообщения, а за весь период деятельности Telegram-канала его администрация разместила всего два десятка сообщений. Сам торрент-трекер RuTracker («Рутрекер») начал работу в 2004 году под названием Torrents.ru. После того как мае 2015 года издательство «Эксмо» обратилось в Мосгорсуд с требованием полной блокировки сервиса на территории России в связи с нарушением авторских прав, суд удовлетворил его ходатайство, и сервис был заблокирован в январе 2016 года. Как пишет CNews, по состоянию на 20 января 2025 года, домен rutracker.org был включен в реестр Роскомнадзора на основании решений Мосгорсуда, вынесенных в ноябре и декабре 2015 года соответственно. В начале 2025 года Telegram также заблокировал по требованию правообладателей англоязычные каналы крупной теневой библиотеки Z-Library и метапоисковика Anna’s Archive. На момент блокировки аудитория Telegram-канала Z-Library Official превышала 629 тыс. человек. США включили «ВКонтакте» и «Авито» в список пиратов и продавцов контрафакта
13.01.2025 [12:02],
Владимир Мироненко
Соцсеть «ВКонтакте» и маркетплейс «Авито» внесли в ежегодный обзор рынков контрафакции и пиратства торгового представительства США (USTR) за 2024 год, поскольку они с 2022 года якобы отказываются удалять пиратский контент или нарушающие законы товары по запросу правообладателей из США. В «Авито» опровергли утверждение, что на платформе продаются товары, нарушающие авторские права, пишет «Коммерсант». 
Источник изображения: Anete Lūsiņa/unsplash.com USTR включало в свой список «ВКонтакте» и «Авито» и в 2023 году. Как утверждает американское ведомство, обе площадки не реагируют на обращения правообладателей из США, сообщающих о нарушении своих интеллектуальных прав. В частности, по словам USTR, «Авито» игнорирует множество запросов от правообладателей и не борется с продажей контрафакта. В списке USTR по итогам 2024 года также оказались такие IT-сервисы российского происхождения, как торрент-трекер Rutracker, файлообменик Rapidgator, библиотеки научной литературы LibGen и Sci-Hub. Также который год USTR включает в список российские рынки «Дубровка», «Садовод» и торговый центр «Горбушкин двор». Данный список, включающий страны и компании, публикуется с 2006 года и носит в первую очередь рекомендательный характер для тех, кто борется с продажей контрафакта. Для компаний, попавших в него, это несёт скорее репутационные риски, поскольку санкции не предусмотрены. В числе стран, где тоже наблюдаются проблемы с пиратством и контрафактом, ведомство назвало Китай, Индию, Турцию и т.д. В «Авито» отметили, что на платформе «предусмотрен налаженный процесс работы с любыми правообладателями вне зависимости от страны происхождения». В случае получения подтверждения нарушений прав контент блокируют. При этом удалённое объявление больше не появится на маркетплейсе. В «ВКонтакте» не стали комментировать действия американской организации. Как утверждает собеседник «Коммерсанта» на рынке цифровых платформ, включение сервисов в список «опасных» ресурсов, распространяющих пиратский контент и контрафакт, может быть вызвано, в том числе, недостаточным пониманием российского рынка западными исследователями. Вместе с тем исполнительный директор юридической компании «Медиа-НН» Георгий Давидьян отметил, что у администрации ресурсов «нет права не реагировать» на обращения правообладателей, которые сопровождаются документальным обоснованием. Собеседник «Коммерсанта» предупредил, что игнорирование требований зарубежных правообладателей может привести к удалению приложений таких сервисов из App Store или Google Play, хотя включение в список USTR на это не влияет. Эксперты также допускают, что отказ ресурсов реагировать на обоснованные обращения американских правообладателей может привести к тому, что те могут взыскать с них денежные компенсации. Anthropic договорилась с музыкальными издателями по иску о незаконном пересказывании песен ИИ
03.01.2025 [17:10],
Владимир Мироненко
Anthropic, разработчик ИИ-чат-бота Claude, заключила соглашение с тремя крупными музыкальными издателями для урегулирования части иска о нарушении авторских прав, связанного с предполагаемым использованием защищённых текстов песен. 
Источник изображения: Anthropic Окружной судья США Юми Ли (Eumi Lee) утвердила в четверг соглашение между сторонами, согласно которому Anthropic обязуется соблюдать существующие ограничения при обучении будущих моделей ИИ. Эти ограничения запрещают чат-боту Claude предоставлять пользователям тексты песен, принадлежащих музыкальным издателям, или создавать новые тексты на основе защищённых авторским правом материалов. Также соглашение определяет процедуру вмешательства музыкальных издателей при подозрении на нарушение Anthropic авторских прав. В октябре 2023 года несколько музыкальных издателей, включая Universal Music Group, ABKCO, Concord Music Group и Greg Nelson Music, подали в федеральный суд штата Теннесси иск против Anthropic, обвинив компанию в нарушении авторских прав. Согласно заявлению истцов, Anthropic якобы обучала свои ИИ-модели на текстах не менее 500 защищённых песен. В иске утверждается, что, когда Claude запрашивали тексты таких песен, как Halo Бейонсе, Uptown Funk Марка Ронсона (Mark Ronson) и Moves Like Jagger группы Maroon 5, чат-бот предоставлял ответы, «содержащие всё или значительную часть этих текстов». Музыкальные издатели подчеркнули, что существуют платформы, такие как Genius, которые легально распространяют тексты песен в интернете и выплачивают за это лицензионные сборы, в отличие от Anthropic. В иске также утверждается, что компания «намеренно удаляла или изменяла информацию об управлении авторскими правами» для песен, тексты которых были использованы для обучения её ИИ-моделей. Claude «не предназначен для использования в целях нарушения авторских прав, и у нас есть многочисленные инструменты, направленные на предотвращение таких нарушений, — указала Anthropic в заявлении для The Hollywood Reporter. — Наше решение заключить это соглашение соответствует этим приоритетам». Следует отметить, что урегулирование касается лишь части иска. В ближайшие месяцы суд должен вынести решение по вопросу о предварительном запрете на обучение ИИ-моделей компании на текстах песен, принадлежащих музыкальным издателям. OpenAI не выполнила обещание по созданию инструмента для защиты авторских прав к 2025 году
02.01.2025 [03:45],
Анжелла Марина
Компания OpenAI не смогла выпустить обещанный инструмент Media Manager до 2025 года, с помощью которого создатели контента смогли бы контролировать использование своих работ в обучении нейросетей. Media Manager, анонсированный в мае прошлого года, должен был идентифицировать защищённые авторским правом тексты, изображения, аудио и видео. 
Источник изображения: hdhai.com Инструмент должен был помочь OpenAI избежать юридических проблем, связанных с нарушением прав на интеллектуальную собственность, и в целом мог бы стать стандартом для всей индустрии искусственного интеллекта. Однако, как пишет издание TechCrunch, разработка Media Manager изначально не считалась в компании приоритетной. Один из бывших сотрудников OpenAI отметил: «Я не думаю, что это было приоритетом. Честно говоря, я и не помню, чтобы кто-то над этим работал». Другой источник, близкий к компании, подтвердил, что обсуждения инструмента были, но с конца 2024 года никакой новой информации, связанной с проектом, не поступало. Надо сказать, что в последнее время использование авторского контента для обучения ИИ неоднократно становилось причиной споров. Модели OpenAI, такие как ChatGPT и Sora, обучаются на огромных наборах данных, включающих тексты, изображения и видео из интернета. Это позволяет ИИ-моделями создавать новые работы, но зачастую они оказываются слишком похожи на оригинал. Например, Sora может генерировать видео с логотипом TikTok или персонажами из видеоигр, а ChatGPT был «пойман» на дословных цитатах из статей The New York Times. Такая практика вызывает волну возмущения со стороны авторов, чьи работы были использованы без их согласия. Против OpenAI уже поданы коллективные иски от художников, писателей и крупных медиа-компаний, включая The New York Times и Radio-Canada. Авторы, такие как американская актриса и сценарист Сара Сильверман (Sarah Silverman) и писатель Та-Нехиси Коутс (Ta-Nehisi Coates), также присоединились к судебным разбирательствам, обвинив OpenAI в незаконном использовании их работ. OpenAI предложила альтернативные решения проблемы, и на данный момент создателям контента предлагается несколько способов для исключения своих работы из обучения нейросетей. В частности, в сентябре 2024 года была запущена форма для подачи заявлений на удаление изображений из будущих наборов данных. Также компания ничего не имеет против того, чтобы веб-мастера прописывали блокировку для своих сайтов от сбора данных её ботами, например в файле «robots.txt». Однако эти методы подверглись критике как за их сложность (удаление контента из набора данных), так и за их несовершенство. Media Manager, напротив, преподносился как долгожданное комплексное решение. В мае 2024 года OpenAI заявила, что работает над инструментом совместно с регуляторами и использует передовые технологии машинного обучения для распознавания авторских прав. Тем не менее с момента анонса компания больше ни разу публично не упоминала об этом инструменте. И даже если Media Manager будет выпущен, эксперты сомневаются, что инструмент сможет решить все проблемы. Эдриан Сайхан (Adrian Cyhan), юрист в сфере интеллектуальной собственности, отмечает, что даже крупным платформам, таким как YouTube и TikTok, сложно справляться с идентификацией контента в больших масштабах. «Гарантировать соблюдение всех требований создателей контента и законов разных стран — крайне трудная задача», — заявил он. А основатель некоммерческой организации Fairly Trained Эд Ньютон-Рекс (Ed Newton-Rex) вообще считает, что Media Manager лишь переложит ответственность на самих создателей. При этом, даже если Media Manager будет запущен, он вряд ли сможет избавить OpenAI от юридической ответственности, считают эксперты. Эван Эверист (Evan Everist), специалист по авторскому праву, напомнил, что по закону владельцы авторских прав вообще не обязаны предупреждать о запрете на использование их работ и «базовые принципы авторского права остаются неизменными: нельзя использовать чужие материалы без разрешения». В отсутствие Media Manager, OpenAI пока внедрила фильтры, которые предотвращают дословное копирование чужих данных, а в судебных исках компания продолжает утверждать, что её ИИ-модели создают «компиляцию», а не плагиат, ссылаясь на принцип «добросовестного использования». Суды могут поддержать позицию OpenAI, как это произошло в деле Google Books, когда суд постановил, что копирование компанией Google миллионов книг для Google Books, своего рода цифрового архива, является допустимым. Однако, если суды признают, что OpenAI незаконно использует авторский контент, компании придётся пересмотреть свою стратегию, включая выпуск Media Manager. Фейковый юрист Nintendo запугивает блогеров, проходящих в игры на камеру — YouTube не может его остановить
27.12.2024 [22:07],
Анжелла Марина
Ютуберы, публикующие прохождения игр Nintendo, столкнулись с волной фальшивых жалоб на авторские права. Мошенник, выдающий себя за юриста Nintendo, требует удаление летсплеев под угрозой судебных исков. YouTube не может защитить своих пользователей. 
Источник изображения: Sean Do / Unsplash В конце сентября популярный YouTube-блогер Доминик Ноймайер (Dominik Neumayer) получил неприятное письмо. Его канал, которому уже 17 лет и на который подписаны более 1,5 миллиона человек, оказался под угрозой удаления из-за нескольких видео. Как объясняет издание The Verge, причиной стали жалобы о нарушении авторских прав, якобы поданные от имени Nintendo. По словам самого Domtendo, ситуация сразу показалась ему странной. Контент, который вызвал претензии, был частью популярного жанра Let’s Play, в котором блогеры проходят игры на камеру. Компания Nintendo хотя и известна своей жёсткой позицией по защите интеллектуальной собственности, обычно не предъявляет претензии к подобному контенту, так как он служит бесплатной рекламой для игр. Однако YouTube всё же удалил видео, ссылаясь на запрос, поданный якобы юристом компании Nintendo — неким Татсуми Масааки (Tatsumi Masaaki). Однако Domtendo обратил внимание на один подозрительный момент: запрос пришёл с личного адреса Масааки в домене protonmail.com, а не с официального домена Nintendo. Тем не менее, это не помешало YouTube отнестись к жалобе, как к законной. И подобные случаи не являются редкостью. По данным самой платформы, более 6 % всех заявок на удаление контента, поданных через публичную форму YouTube, предположительно ложные. Фальшивый юрист с каждым разом настаивал на удалении всё большего и большего количества видео, якобы нарушающего авторское право Nintendo. Однако угрозы становились всё более абсурдными. Так, в одном из писем утверждалось, что Nintendo уже получила личные данные Domtendo через немецкий офис компании, а в другом говорилось о немедленном запрете на использование любого контента, связанного с Nintendo. Domtendo начал подозревать, что за преследованием мог стоять не сотрудник Nintendo, а мошенник. Однако он не хотел рисковать каналом, поэтому удалил часть видео и обратился с запросом в компанию напрямую, чтобы подтвердить подлинность жалоб. 10 октября Nintendo ответила Domtendo, заявив, что предоставленный адрес в домене protonmail.com не принадлежит компании, а запросы не соответствуют их стандартной практике защиты авторских прав. Nintendo также объявила о начале расследования этой ситуации. Однако «юрист» продолжал преследовать блогера, и последнее его письмо было, как ни странно, отправлено с официального адреса Nintendo — nintendo.co.jp. Но проверив заголовки сообщения, Domtendo выяснил, что адрес был подделан с помощью доступного в интернете инструмента, что окончательно подтвердило ложность претензий. Domtendo и другие пострадавшие блогеры возмущены работой системы защиты авторских прав YouTube. По их словам, платформа слишком легко принимает запросы на удаление контента, даже не проверяя их подлинность. При том, что система DMCA, регулирующая авторские права, делает платформы ответственными за быстрое удаление контента, чтобы избежать судебных исков, это создаёт стимулы для YouTube действовать в интересах правообладателей, а не создателей контента. «Практически каждый может ударить по любому YouTube-каналу, и это почти не вызывает проблем. Это безумие», — заявил Domtendo. В свою очередь, YouTube подтвердил, что запросы Масааки были ложными, но не объяснил, почему платформа изначально приняла их без всякой проверки. Представитель компании Джек Мэлон (Jack Malone) отказался отвечать на вопросы о том, принимала ли платформа другие поддельные запросы от этого же лица, и какие меры будут предприняты для защиты блогеров в будущем. Корейцы натравят ИИ на пиратские кинотеатры по всему миру
25.12.2024 [22:45],
Анжелла Марина
Правительство Южной Кореи в рамках продвижения корейского контента на международной арене объявило о переходе на автоматизированные системы на базе искусственного интеллекта (ИИ), которые будут выявлять и блокировать нелегальные стриминговые сервисы и отслеживать нарушения авторского права. 
Источник изображения: Glenn Carstens-Peters / Unsplash По сообщению издания Comic Book Resources, министерство науки и информационно-коммуникационных технологий (MiST) Южной Кореи сообщило о планах перехода от ручных методов обнаружения нелегального контента к автоматическим на базе ИИ. В рамках этой инициативы правительство заявило, что будет поддерживать технологии, способные автоматически отслеживать и идентифицировать незаконные видеосервисы. Ожидается, что благодаря ИИ процесс обнаружения и проверки пиратских сайтов станет более эффективным по сравнению с ручными методами. Помимо этого, план включает создание совместного фонда объёмом 1 трлн вон (около $685 млн) для расширения влияния корейского контента за рубежом. Также компании этой страны увеличат своё присутствие на международных медиафестивалях, таких как Каннский кинофестиваль, а технологии Samsung и LG с их 600 миллионами телевизоров по всему миру будут использоваться для улучшения доступности K-Contents (корейский контент). Отмечается, что ИИ станет не только инструментом борьбы с пиратством, но и важным элементом создания контента. Среди запланированных нововведений значится использование технологий ИИ для автоматизированного перевода и дубляжа на иностранные языки, персонализированных рекомендаций на стриминговых платформах и разработки интерактивных сюжетов. Кроме того, правительство планирует обучить ИИ-модели на основе трёх миллионов часов видео, созданных за последние 70 лет, что позволит ускорить производство контента на всех этапах. Компании, работающие на стыке ИИ и цифровых технологий, таких как визуальные эффекты и монтаж, получат приоритетную поддержку, включая программы обучения специалистов. Стоит сказать, что другие страны, например Япония, также начали использовать ИИ для борьбы с пиратством. Недавно правительство этой страны объявило об открытии проекта, в рамках которого с помощью искусственного интеллекта будут выявлять пиратские сайты и нарушающие авторские права изображения и другой контент, а затем блокировать их посредством DMCA-запросов через Google. На грани авторского права: можно ли считать ИИ автором и как определить границы свободного использования
19.12.2024 [19:38],
Сергей Сурабекянц
С 5 по 8 декабря в Гостином дворе прошла Международная ярмарка интеллектуальной литературы non/fictioN №26. На круглом столе «Издательская деятельность, произведения изобразительного искусства и фотографические произведения: точки соприкосновения» речь шла о возможностях и подводных камнях свободного использования произведений, о разнице между переработкой оригинала и нарушением права на неприкосновенность и о регистрации авторских прав на продукцию ИИ. 
Источник изображения: non/fictioN Модератором встречи выступил Эрик Вальдес-Мартинес, директор «Ассоциации правообладателей по защите и управлению авторскими правами в сфере изобразительного искусства» (УПРАВИС) и член экспертного совета проекта Artists/ХУДОЖНИКИ.РФ, поддержанного Президентским фондом культурных инициатив. УПРАВИС занимается коллективным управлением исключительных прав фотографов, художников, скульпторов и других авторов произведений изобразительного искусства. 
Источник изображения: УПРАВИС Эрик Вальдес-Мартинес рассказал о двойственности и правовой неопределённости статьи 1276 Гражданского кодекса РФ, которая предусматривает свободное использование произведений архитектуры, градостроительства и фотографии, находящихся в местах, открытых для свободного посещения, если такое произведение не является основным объектом использования и не используется с целью извлечения прибыли. Например, фотография памятника, размещённая в путеводителе Екатеринбурга, была признана Верховным судом нарушением авторских прав, а Конституционный суд постановил, что фотография объекта не нарушает закон и не требует выплаты вознаграждения автору. Закон допускает использование произведений изобразительного искусства и фотографии для переработки. Если переделать часть фотографии, добавить к ней свой фон или произвести другие манипуляции, появляется новый объект права, созданный в результате переработки. При этом, как подчеркнул эксперт, правомерная переработка возможна только с разрешения автора оригинала или правообладателя. Если же взять часть фотографии и объединить её с другой, это нарушает неприкосновенность произведения — неимущественное право автора, которое не подлежит передаче. Неприкосновенность защищает изначальную форму произведения в том виде, в котором его создал автор. Нарушение этого права суд однозначно трактует как нарушение авторских прав. Не менее сложной остаётся ситуация с пародиями, создаваемыми без разрешения автора. По словам Вальдес-Мартинеса, «эта норма действует во всех странах мира, но важно, чтобы целью использования оригинала было именно создание пародийного эффекта». Суд может постановить, что мотивом создания «пародии» было желание заработать на популярности оригинального произведения, и признать это нарушением авторских прав. Говоря о возможности регистрации авторских прав на произведения, созданные ИИ, Вальдес-Мартинес подчеркнул, что официальная позиция большинства стран однозначно негативная. Например, Бюро по авторским правам США отозвало регистрацию прав на комикс «Рассветная заря» (Zarya of the Dawn) художницы Кристины Каштановой (Kristina Kashtanova), когда выяснилось, что иллюстрации были сгенерированы ИИ. 
Источник изображения: Kris Kashtanova Но не всё так просто: уже несколько лет учёный Стивен Талер (Stephen Thaler) создаёт свои изобретения при помощи созданной им ИИ-системы DABUS (Device for the autonomous bootstrapping of unified sentience — «Устройство автономной загрузки унифицированного сознания») и пытается зарегистрировать права в патентных офисах различных стран. Великобритания и США отклонили петиции Талера, но он добился успеха в таких странах, как Австралия и ЮАР. В ЮАР патентная система не предполагает экспертизы и там можно запатентовать даже колесо. В Австралии патентный суд решил, что DABUS может считаться автономным изобретателем, но все изобретения должны принадлежать Стивену Талеру. В июле 2024 года Федеральный верховный суд Германии постановил, что изобретение, созданное с помощью DABUS, может быть запатентовано, поскольку в качестве изобретателя был указан человек, хотя в заявке отмечено, что продукт был разработан ИИ. По мнению Вальдес-Мартинеса, «это переворачивает всё с ног на голову — если подобные решения будут становиться тенденцией, неизвестно, что нас ждёт». 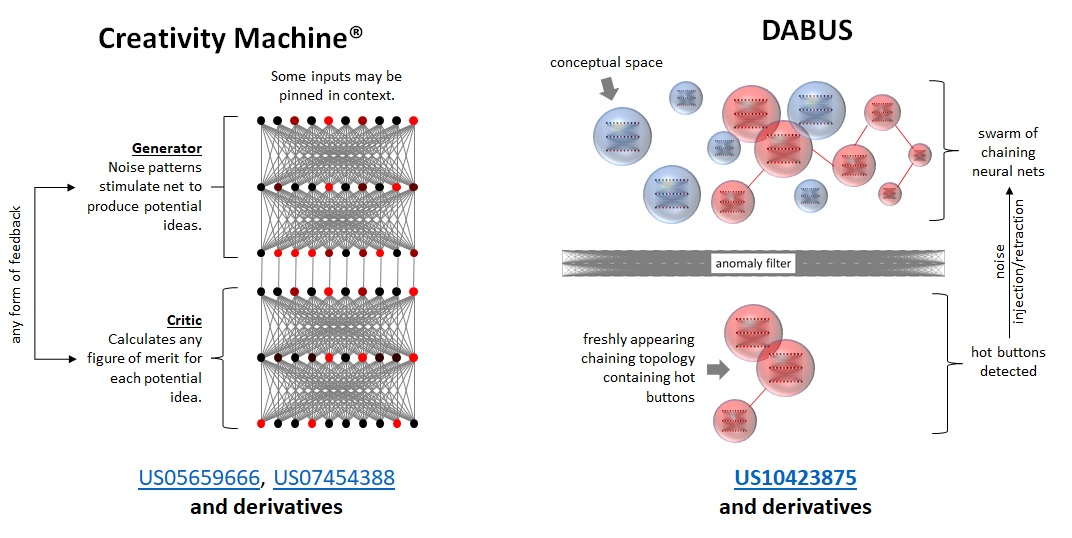
Источник изображения: DABUS Искусственный интеллект представляет угрозу не только в качестве потенциального «творца», но и в роли главного нарушителя авторских прав, по сравнению с которым все пиратские сайты и торрент-трекеры представляются просто малыми детишками. Активный сбор информации большими языковыми моделями из открытых источников уже давно нервирует правообладателей, а чувствительные к подобным проблемам средства массовой информации и вовсе при первой возможности пытаются защитить свои авторские права в суде. В августе группа художников, которая объединилась в коллективном иске против разработчиков наиболее популярных моделей искусственного интеллекта для генерации изображений, устроила празднование по случаю того, что судья дал ход этому делу и санкционировал раскрытие информации. 26 ноября бывший сотрудник OpenAI, 26-летний Сухир Баладжи (Suchir Balaji) был найден мёртвым в своей квартире в Сан-Франциско. Ранее Баладжи сообщил газете The New York Times, что OpenAI без разрешения использовала огромные объёмы интернет-данных для разработки ИИ-чат-бота ChatGPT, вышедшего в ноябре 2022 года. Он также обвинил компанию в создании собственного программного обеспечения для транскрибирования видео на YouTube для извлечения данных. В полиции заявили, что причиной его смерти стало самоубийство. Россия заняла третье место в мире по потреблению пиратского контента
16.12.2024 [12:05],
Дмитрий Федоров
Российские видеохостинги cтолкнулись с массовым распространением пиратского контента, особенно после ухода западных правообладателей. В результате Россия заняла третье место в мире по потреблению пиратского контента, уступив только США и Индии. 
Источник изображения: «VK Видео» На платформе «VK Видео» фиксируется ежемесячное удаление до 250 тыс. единиц пиратского контента, о чём сообщил технический директор бизнес-группы «Социальные платформы и медиаконтент» VK Сергей Ляджин. Ежемесячно платформа обрабатывает порядка 15 тыс. жалоб правообладателей, большинство из которых касается отечественного контента. Для автоматизации обработки обращений на «VK Видео» внедрена ИИ-система Content ID, использующая цифровые отпечатки видео- и аудиофайлов. Кроме того, правообладатели могут подавать запросы через форму DMCA. Другие крупные российские видеохостинги, такие как NUUM и RuTube, не предоставляют точных данных о количестве удалённого нелегального контента. Представители NUUM утверждают, что система обработки жалоб работает в штатном режиме, а материалы, нарушающие авторские права, удаляются в течение 24 часов. Однако, по словам участников медиарынка, именно на этих платформах наблюдается значительный рост объёма пиратских материалов после ухода из России западных правообладателей. Антипиратский меморандум, впервые подписанный 1 ноября 2018 года, был направлен на усиление борьбы с распространением нелегального видеоконтента в интернете. Документ обязывал правообладателей и интернет-платформы создавать реестры пиратских ресурсов и удалять ссылки на них из поисковой выдачи. Однако его эффективность снизилась, особенно после того как из меморандума вышли представители западных медиакомпаний, таких как Sony, Warner и Universal. В 2023 году меморандум был расширен за счёт включения книжной и музыкальной индустрий, но издательства отмечают, что результаты пока далеки от ожидаемых. Участники медиарынка полагают, что рост потребления пиратского контента в России был неизбежен после ухода западных правообладателей. Некоторые фильмы и сериалы появляются на пиратских платформах быстрее, чем на официальных площадках. При этом западные компании ограничиваются лишь уведомлением платформ о завершении сроков лицензий, что дополнительно усложняет борьбу с пиратством. По данным аналитических компаний MUSO и Kearney, Россия заняла третье место в мире по объёму трафика на пиратские ресурсы в 2023 году, уступив только США и Индии. На долю России пришлось 6 % мирового трафика на такие сайты. В целом по миру количество посещений пиратских ресурсов выросло на 10 % по сравнению с прошлым годом, что отражает глобальную тенденцию увеличения нелегального потребления контента. Проблема пиратского контента на российских видеохостингах является следствием как внешних, так и внутренних факторов. Для успешной борьбы с пиратством потребуется усиление законодательной базы, внедрение более продвинутых технологий контроля и активизация сотрудничества между платформами, правообладателями и государственными органами. Без этих шагов Россия рискует укрепить своё положение среди лидеров по нелегальному потреблению цифрового контента. Бывший сотрудник OpenAI, обвинявший компанию в нарушении авторских прав, найден мёртвым
14.12.2024 [12:45],
Владимир Мироненко
Бывший сотрудник OpenAI, 26-летний Сухир Баладжи (Suchir Balaji), 26 ноября был найден мёртвым в своей квартире в Сан-Франциско, сообщил ресурс TechCrunch. В полиции подтвердили личность Баладжи и заявили, что причиной его смерти стало самоубийство. В октябре в интервью The New York Times он выразил обеспокоенность по поводу нарушения OpenAI закона об авторском праве. 
Источник изображения: Levart_Photographer/unsplash.com Сухир Баладжи изучал информатику в Калифорнийском университете в Беркли. Во время учебы он стажировался в OpenAI и Scale AI. «Я проработал в OpenAI почти 4 года и последние 1,5 года работал над ChatGPT», — сообщил Баладжи в твите в октябре этого года. Баладжи рассказал, что заинтересовался вопросом защиты авторских прав, когда увидел все иски, поданные против компании GenAI. «Когда я попытался лучше разобраться в этом вопросе, я в конце концов пришёл к выводу, что добросовестное использование кажется довольно неправдоподобной защитой для многих продуктов генеративного ИИ по той простой причине, что они могут создавать заменители, которые конкурируют с данными, на которых они обучены», — сообщил он. Согласно описанию профиля в LinkedIn, первоначально Баладжи работал над WebGPT, доработанной версией GPT-3, которая могла осуществлять поиск в интернете. Это была ранняя версия SearchGPT, вышедшего в этом году. Впоследствии Баладжи работал в команде предварительного обучения GPT-4, а также в команде разработчиков ИИ-модели o1 со способностью рассуждать и команде постобучения ChatGPT. Баладжи сообщил газете The New York Times, что OpenAI без разрешения использовала огромные объёмы интернет-данных для разработки ИИ-чат-бота ChatGPT, вышедшего в ноябре 2022 года. Он также обвинил компанию в создании собственного программного обеспечения для транскрибирования видео на YouTube для извлечения данных. Из-за использования контента без разрешения со стороны издания, The New York Times подала в конце прошлого года на OpenAI и Microsoft в суд с обвинением в нарушении авторских прав. Трагическое происшествие с Баладжи привлекло дополнительное внимание к продолжающимся дебатам об этичном использовании данных при разработке технологий искусственного интеллекта. Apple и другие без разрешения обучали ИИ-модели на роликах YouTube
16.07.2024 [18:31],
Павел Котов
Несколько технологических гигантов, включая Apple, Anthropic, Nvidia и Salesforce, обучали свои модели искусственного интеллекта на видео с YouTube без согласия владеющей платформой компании Google и авторов этих видео, показало журналистское расследование Proof News. 
Источник изображения: Gerd Altmann / pixabay.com Предполагаемым нарушителем авторских прав оказалась некоммерческая организация EleutherAI, которая, по её собственному утверждению, помогает разработчикам в обучении моделей ИИ. Её целевой аудиторией является не технологические гиганты, а небольшие разработчики и учёные. EleutherAI выпустила массив данных Pile, значительная часть которого доступна и открыта для любого желающего в интернете — потребуются лишь ресурсы для их скачивания, хранения и обработки. В массив данных Pile оказались включены субтитры 173 536 видеороликов YouTube, которые были скачаны с более чем 48 000 каналов — файлы субтитров фактически являются расшифровками видеозаписей, а правила платформы YouTube запрещают скачивать её материалы без разрешения. Тем не менее, Apple, Nvidia и Salesforce — компании с капитализацией в сотни миллиардов и триллионы долларов — сами признавались в своих научных работах, что пользовались Pile при обучении ИИ. Apple, в частности, использовала Pile в обучении представленных в апреле моделей OpenELM, а уже в июне рассказала о новых функциях ИИ, которые появятся на iPhone и Mac. Если в ходе данного инцидента действительно было допущено нарушение авторского права, то сделала это в первую очередь некоммерческая организация EleutherAI, а технологические гиганты могли оказаться добросовестными пользователями общедоступного набора данных. Данный пример в очередной раз показывает, что сфера обучения ИИ до сих пор недостаточно отлажена с юридической позиции. YouTube научился удалять из видео защищённую авторским правом музыку с сохранением остального звука
05.07.2024 [16:33],
Павел Котов
Сервис YouTube выпустил обновлённый инструмент удаления музыки, защищённой авторским правом — функция основана на алгоритме искусственного интеллекта, который выполняет задачу, не затрагивая всего остального, в том числе диалогов и звуковых эффектов. 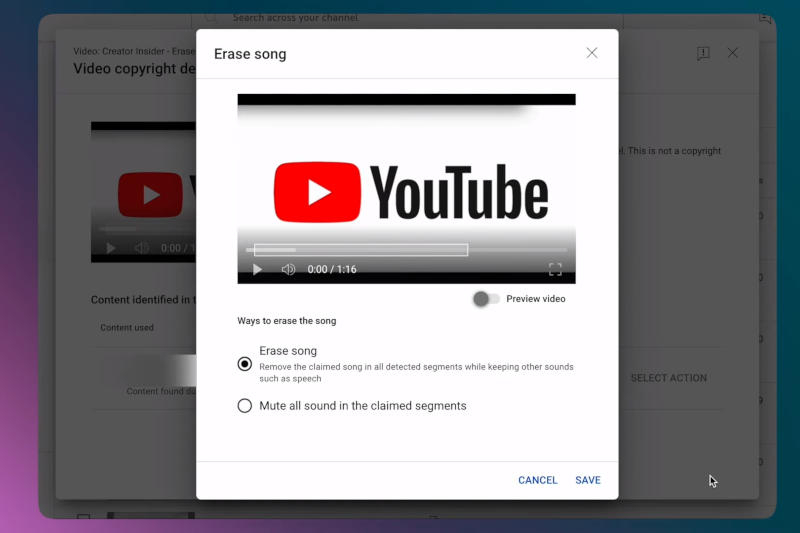
Источник изображения: youtube.com/@creatorinsider Гендиректор YouTube Нил Мохан (Neal Mohan) рассказал о нововведении в соцсети X: «Хорошие новости, авторы: наш обновлённый инструмент „Стереть песню“ (Erase Song) поможет вам легко удалить защищённую авторским правом музыку из вашего видео (оставив остальную часть аудио нетронутой)». Функция работает на основе алгоритма ИИ, который самостоятельно обнаруживает и удаляет композицию, не затрагивая остальной звук на ролике, предупредила администрация YouTube и добавила, что иногда алгоритм всё-таки даёт сбой и удаляет некоторые другие элементы аудио. «Это средство редактирования может не сработать, если песню сложно удалить. Если он не удаляет фрагмент аудио, вы можете попробовать другие варианты редактирования, например, отключить весь звук в указанных сегментах или вырезать эти сегменты», — говорится в анонсе новой функции. После успешного редактирования видео платформа снимает отметку идентификатора контента — системы, которая обнаруживает в загружаемых материалах защищённое авторским правом содержимое. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex