|
Опрос
|
реклама
Быстрый переход
Google научила ИИ-бота Gemini редактировать любые изображения
01.05.2025 [14:22],
Дмитрий Федоров
Google Gemini научился редактировать как сгенерированные ИИ изображения, так и загруженные со смартфона или компьютера. В ближайшие недели новая функциональность станет доступна пользователям в большинстве стран мира, где доступен Gemini, и получит поддержку более чем 45 языков. Россия, напомним, в этот список не входит, однако русский язык Gemini понимает и «говорит» на нём. 
Источник изображений: Google Нативное редактирование изображений в ИИ-чат-боте Gemini представляет собой эволюционный шаг в развитии возможностей взаимодействия пользователя с ИИ. Запуск последовал за моделью редактирования изображений с помощью ИИ, которую Google опробовала в марте в своей платформе AI Studio и которая получила широкую огласку благодаря своей спорной способности удалять водяные знаки с любого изображения. Подобно недавно обновлённому инструменту редактирования изображений в ChatGPT, встроенный редактор Gemini теоретически способен достигать более высоких результатов по сравнению с автономными ИИ-генераторами изображений. Теперь Gemini предлагает инновационный «многоэтапный» процесс редактирования, обеспечивающий, по описанию компании, «более богатые и контекстуальные» отклики на каждый запрос — с интеграцией текста и изображений. Функциональность нового редактора позволяет пользователям изменять фон на изображениях, заменять объекты, добавлять элементы и выполнять множество других операций — и всё это непосредственно в интерфейсе Gemini. Подобное решение существенно упрощает процесс создания и редактирования визуального контента, устраняя необходимость переключаться между несколькими специализированными приложениями.  «Например, вы можете загрузить личную фотографию и попросить Gemini сгенерировать изображение того, как вы будете выглядеть с разными цветами волос. Также можно попросить Gemini создать первый черновик сказки на ночь о драконах и сгенерировать иллюстрации к истории», — поясняет Google в своём блоге. Эти примеры наглядно демонстрируют многофункциональность системы, пригодной как для утилитарных, так и для креативных задач. Потенциальные риски технологии в контексте создания дипфейков обоснованно вызывают опасения у специалистов по информационной безопасности. Чтобы нивелировать возможные злоупотребления, Google внедряет технологию невидимых водяных знаков во все изображения, созданные или отредактированные с помощью нативного генератора изображений Gemini. Параллельно компания проводит экспериментальные исследования по внедрению видимых водяных знаков на всех изображениях, сгенерированных с помощью Gemini. Зелёная сова против людей: Duolingo начала увольнять сотрудников, которых может заменить ИИ
29.04.2025 [11:10],
Дмитрий Федоров
Duolingo, один из лидеров рынка цифрового образования, объявила о переходе к стратегии AI-first, предполагающей постепенное замещение подрядчиков ИИ и фундаментальную перестройку рабочих процессов. Компания делает ставку на ускорение создания контента, внедрение новых технологий и обеспечение масштабного доступа к обучающим материалам для пользователей по всему миру. 
Источник изображения: Duolingo Соучредитель и генеральный директор Луис фон Ан (Luis von Ahn) разослал сотрудникам письмо, текст которого был опубликован на официальной странице компании в LinkedIn. В письме подчёркивается, что ИИ станет основой всех рабочих процессов, а подрядчики будут постепенно выведены из операционной деятельности. Он напомнил, что в 2012 году Duolingo сделала успешную ставку на мобильные устройства, когда большинство компаний ещё ориентировались на веб-приложения. Это решение в 2013 году принесло Duolingo награду «iPhone App of the Year» (рус. — Приложение года для iPhone) и обеспечило стремительный органический рост. Сегодня, по его словам, компания делает аналогичную ставку, только на ИИ. Переход к модели AI-first (рус. — ИИ на первом месте) потребует от компании пересмотра ключевых бизнес-процессов. Фон Ан отметил, что простые доработки систем, изначально предназначенных для работы людей, не обеспечат необходимого уровня эффективности. Вводятся конструктивные ограничения: отказ от подрядчиков для задач, которые может выполнять ИИ, обязательное использование ИИ как критерий при найме сотрудников, учёт уровня применения ИИ при аттестации персонала и ограничение увеличения численности штата только в случаях, когда дальнейшая автоматизация невозможна. Несмотря на радикальные изменения, фон Ан заверил, что Duolingo останется компанией, заботящейся о своих сотрудниках. Он подчеркнул, что цель перехода — не замена людей на ИИ, а устранение узких мест в рабочих процессах. Компания сосредоточит усилия на поддержке персонала: будет усилено обучение работе с ИИ, запущены программы наставничества и предоставлены новые инструменты для внедрения ИИ в профессиональную деятельность. Фон Ан привёл пример недавнего успеха Duolingo: замена медленного ручного процесса создания образовательного контента автоматизированной системой на базе ИИ. Без внедрения ИИ на масштабирование контента для всех пользователей ушли бы десятилетия. Теперь благодаря автоматизации Duolingo сможет предоставить новые обучающие материалы миллионам учащихся уже в ближайшие месяцы, выполняя свою миссию максимально быстро. ИИ позволяет компании разрабатывать ранее невозможные функции. Одним из ключевых проектов стала разработка функции Video Call (Видеозвонок), которая позволяет обучать пользователей на уровне лучших репетиторов. Это открывает новые перспективы в области дистанционного образования, значительно улучшая качество онлайн-обучения. Фон Ан подчеркнул, что Duolingo не намерена ждать, пока технологии достигнут идеала. Компания предпочитает действовать незамедлительно, даже если это приведёт к небольшим потерям качества на отдельных этапах. Основная цель — не упустить момент, когда технологические возможности стремительно меняют рынок, и первыми адаптировать свои процессы к новой реальности. Duolingo следует глобальному тренду в сфере технологий. Ранее аналогичное письмо сотрудникам направил генеральный директор Shopify Тоби Лютке (Tobi Lütke), в котором требовал, чтобы перед подачей заявки на увеличение численности персонала команды обосновывали невозможность выполнения поставленных задач с помощью ИИ. Этот тренд свидетельствует о том, что автоматизация становится одним из важнейших критериев эффективности бизнеса в 2025 году. Alibaba представила семейство ИИ-моделей Qwen3, которые быстрее и эффективнее DeepSeek
29.04.2025 [05:44],
Алексей Разин
В начале этой недели китайская компания Alibaba Group Holdings представила новое семейство флагманских языковых моделей Qwen3, которое использует актуальный метод «смешения экспертов» для достижения результатов, сопоставимых с итогами работы гибридных рассуждающих систем. 
Источник изображения: Alibaba По данным Alibaba, её модели семейства Qwen3 в ряде сфер применения оказываются на уровне или даже быстрее и эффективнее разработок DeepSeek, включая решение математических задач и написание программного кода. Масштабирование этих моделей также обходится значительно дешевле большинства популярных аналогов. Модели такого типа пытаются подражать людям в логике решения задач, подобные системы уже предложены компаниями Anthropic и Alphabet (Google). Более эффективное решение задачи осуществляется за счёт дробления её на несколько сегментов, за каждый из которых отвечает свой фрагмент кода. Это напоминает процесс решения проблемы группой экспертов, каждому из которых поручена своя задача. Alibaba ещё в марте представила модели семейства Qwen 2.5, которые могут работать с текстом, изображениями, аудио и видео, ограничиваясь при этом аппаратными ресурсами ноутбука или смартфона. Семейство моделей Qwen3 придерживается принципа открытости исходного кода. Под давлением DeepSeek американский стартап OpenAI также пообещал представить более открытую модель, подражающую логике рассуждения человека. Стремление Alibaba усилить свои позиции на рынке систем искусственного интеллекта помогло китайскому гиганту выйти из кризиса, порождённого конфликтом основателя Джека Ма (Jack Ma) с китайскими властями, которые несколько лет назад всерьёз взялись за регулирование бизнеса в тех сферах, на которых строилось благополучие Alibaba Group. Исследователи Anthropic и Google поищут признаки сознания у ИИ — ещё недавно за подобное увольняли
27.04.2025 [13:17],
Дмитрий Федоров
Ещё три года назад заявления о признаках сознания у ИИ воспринимались в индустрии высоких технологий как повод для насмешек и даже увольнения. Сегодня стартап Anthropic и исследователи Google DeepMind открыто обсуждают возможность появления сознания у ИИ, что отражает стремительное развитие технологий и глубокий сдвиг в научной парадигме. 
Источник изображения: Steve Johnson / Unsplash Anthropic, разработчик ИИ-модели Claude, объявил о создании новой исследовательской инициативы, посвящённой изучению возможности возникновения сознания у ИИ. Компания планирует исследовать, могут ли ИИ-модели в будущем испытывать субъективные переживания, формировать предпочтения или испытывать страдания. Ситуация резко контрастирует с событиями 2022 года, когда старший программный инженер из Google Блейк Лемойн (Blake Lemoine) был уволен после заявлений о сознательности ИИ-чат-бота LaMDA. Лемойн утверждал, что ИИ боялся отключения и идентифицировал себя как личность. В ответ Google назвал эти утверждения «совершенно необоснованными», а обсуждение темы сознания в ИИ-сообществе быстро сошло на нет. В отличие от случая с Лемойном, Anthropic не утверждает, что ИИ-модель Claude обладает сознанием. Компания намерена выяснить, может ли в будущем возникнуть подобное явление. Кайл Фиш (Kyle Fish), специалист по согласованию ИИ и ценностей человека, подчеркнул, что сегодня нельзя безответственно полагать, будто ответ на вопрос о сознательности ИИ-моделей будет всегда отрицательным. По оценке исследователей Anthropic, вероятность сознательности у Claude 3.7 составляет от 0,15 % до 15 %. 
Источник изображения: Alex Shuper / Unsplash Anthropic изучает, проявляет ли Claude 3.7 предпочтения или отвращение к определённым заданиям. Также компания тестирует механизмы отказа, которые позволяли бы ИИ-модели избегать нежелательных задач. Генеральный директор Anthropic Дарио Амодей (Dario Amodei) ранее выдвинул идею внедрения кнопки «Я бросаю эту работу» (англ. — I quit this job) для будущих ИИ-систем. Такая мера необходима не из-за признания сознательности, а для выявления паттернов отказов, которые могут сигнализировать о дискомфорте у ИИ. В Google DeepMind ведущий научный сотрудник Мюррей Шэнахэн (Murray Shanahan) предложил переосмыслить само понятие сознания применительно к ИИ. В подкасте, опубликованном в четверг, он заявил, что, возможно, потребуется изменить привычную лексику, описывающую сознание, чтобы она могла объяснить поведение ИИ-систем. Шэнахэн отметил, что хотя мы не можем находиться в общем мире с ИИ, как это происходит с собакой или осьминогом, это не означает, что внутренние процессы полностью отсутствуют. Google даже разместила вакансию исследователя для проекта «post-AGI», в обязанности которого входило бы изучение машинного сознания. Тем не менее, не все специалисты уверены в реальности появления сознания у ИИ. Джаред Каплан (Jared Kaplan), главный научный сотрудник Anthropic, заявил в интервью изданию The New York Times, что современные ИИ-модели легко обучаются имитировать сознательность, даже если ею не обладают. Он подчеркнул, что тестирование сознательности ИИ-моделей крайне сложно именно из-за их высокой способности к имитации. Критические оценки звучат и со стороны когнитивных учёных. Гэри Маркус (Gary Marcus) в интервью изданию Business Insider отметил, что акцент на теме сознания больше служит маркетинговым целям, чем научным. Он саркастически сравнил идею наделения правами ИИ-моделей с возможностью признания прав за калькуляторами и электронными таблицами, которые, в отличие от ИИ, не выдумывают информацию. Baidu обновила ИИ-модели Ernie 4.5 Turbo и Ernie X1 Turbo и снизила их стоимость на 80 и 50 % соответственно
27.04.2025 [07:11],
Дмитрий Федоров
На конференции разработчиков в Ухане Baidu представила обновлённые ИИ-модели Ernie 4.5 Turbo и Ernie X1 Turbo, снизив их стоимость на 80 и 50 % соответственно. На этом фоне акции компании выросли более чем на 5 % на торгах в Гонконге, что укрепило позиции Baidu в конкуренции с Alibaba, DeepSeek и другими игроками китайского рынка ИИ. 
Источник изображения: Baidu.com По утверждению компании, обновлённые ИИ-модели работают быстрее и стоят меньше по сравнению с предыдущими версиями, что позволяет разработчикам сосредоточиться на создании приложений, не беспокоясь о возможностях и стоимости ИИ-моделей, инструментах и платформах разработки. Помимо усовершенствованных ИИ-моделей, компания представила платформу для ИИ-агентов под названием Xinxiang, предназначенную для автоматизации повседневных задач. Эта разработка призвана усилить конкурентную борьбу с китайским сервисом Manus AI. Компания также сообщила об установке новых серверов, которые позволят разработчикам подключать свои ИИ-модели к данным поисковой системы и электронной коммерции Baidu. Гендиректор компании Робин Ли (Robin Li) сообщил о производстве 30 000 ИИ-чипов, которые уже используются компанией, однако технические характеристики этих чипов предоставлены не были. Baidu стала первой компанией в китайском технологическом секторе стоимостью $1 трлн, которая выпустила ИИ-чат-бот, созданный по образцу ChatGPT. Однако ИИ-чат-боты, разработанные ByteDance и Moonshot AI, вскоре обогнали продукт Baidu по популярности. Параллельно ИИ-модели с открытым исходным кодом, такие как Qwen компании Alibaba и решения DeepSeek, получили широкое признание среди разработчиков по всему миру. Учёные уличили ИИ в неспособности строить математические доказательства в олимпиадных задачах USAMO 2025 года
26.04.2025 [12:29],
Дмитрий Федоров
Новое исследование ETH Zurich и INSAIT показало, что современные ИИ-модели, имитирующие рассуждение и уверенно решающие стандартные математические задачи, практически не способны формулировать полные доказательства уровня Математической олимпиады США 2025 года (USAMO). Эти результаты ставят под сомнение возможность глубокого математического рассуждения у современных ИИ-моделей. 
Источник изображения: Imkara Visual / Unsplash В марте 2025 года исследовательская группа из Швейцарской высшей технической школы Цюриха (ETH Zurich) и Института компьютерных наук, искусственного интеллекта и технологий (INSAIT) при Софийском университете, возглавляемая Иво Петровым (Ivo Petrov) и Мартином Вечевым (Martin Vechev), опубликовала препринт научной статьи под названием «Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad» (рус. — Доказательство или блеф? Оценка больших языковых моделей на Математической олимпиаде США 2025 года). Работа направлена на оценку способности больших языковых моделей (LLMs), имитирующих рассуждение, генерировать полные математические доказательства на олимпиадных задачах. Для анализа были использованы шесть задач с USAMO 2025 года, организованного Математической ассоциацией Америки. ИИ-модели тестировались сразу после публикации заданий для минимизации риска утечки данных в обучающие выборки. Средняя результативность по всем ИИ-моделям при генерации полных доказательств составила менее 5 % от максимально возможных баллов. Системы оценивались по шкале от 0 до 7 баллов за задачу с учётом частичных зачётов, выставляемых экспертами. Лишь одна модель — Gemini 2.5 Pro компании Google — показала заметно лучший результат, набрав 10,1 балла из 42 возможных, что эквивалентно примерно 24 %. Остальные модели существенно отставали: DeepSeek R1 и Grok 3 получили по 2,0 балла, Gemini Flash Thinking — 1,8 балла, Claude 3.7 Sonnet — 1,5 балла, Qwen QwQ и OpenAI o1-pro — по 1,2 балла. ИИ-модель o3-mini-high компании OpenAI набрала всего 0,9 балла. Из почти 200 сгенерированных решений ни одно не было оценено на максимальный балл. Исследование подчёркивает фундаментальное различие между решением задач и построением математических доказательств. Стандартные задачи, такие как вычисление значения выражения или нахождение переменной, требуют лишь конечного правильного ответа. В отличие от них, доказательства требуют последовательной логической аргументации, объясняющей истинность утверждения для всех возможных случаев. Это качественное различие делает задачи уровня USAMO значительно более требовательными к глубине рассуждения. 
Скриншот задачи №1 USAMO 2025 года и её решения на сайте AoPSOnline. Источник изображения: AoPSOnline Авторы исследования выявили характерные модели ошибок в работе ИИ. Одной из них стала неспособность поддерживать корректные логические связи на протяжении всей цепочки вывода. На примере задачи №5 USAMO 2025 года ИИ-модели должны были найти все натуральные значения k, при которых определённая сумма биномиальных коэффициентов в степени k остаётся целым числом при любом положительном n. Модель Qwen QwQ допустила грубую ошибку, исключив возможные нецелые значения, разрешённые условиями задачи, что привело к неправильному окончательному выводу, несмотря на правильное определение условий на промежуточных этапах. Характерной особенностью поведения моделей стало то, что даже в случае серьёзных логических ошибок они формулировали свои решения в утвердительной форме, без каких-либо признаков сомнения или указаний на возможные противоречия. Это свойство имитации рассуждения указывает на отсутствие у ИИ-моделей механизмов внутренней самопроверки и коррекции вывода. Авторы отметили также влияние особенностей обучения на качество решений. Тестируемые ИИ-модели демонстрировали артефакты оптимизационных стратегий, применяемых при подготовке к стандартным бенчмаркам: например, принудительное форматирование ответов с использованием команды \boxed{}, предназначенное для удобства автоматизированной проверки. Эти шаблонные подходы приводили к ошибкам в контексте задач, где требовалось развёрнутое доказательство, а не только числовой ответ. 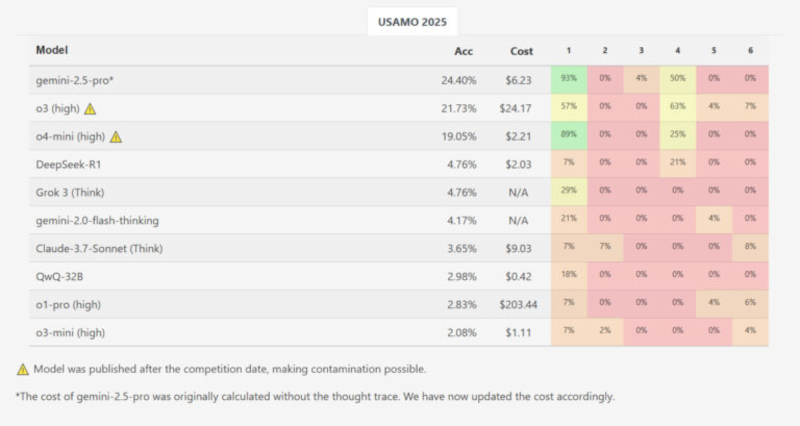
Показатели точности ИИ-моделей на каждой задаче USAMO 2025 года. Источник изображения: MathArena Несмотря на выявленные ограничения, внедрение методов цепочки размышлений и имитации рассуждения положительно сказались на формировании промежуточных логических шагов в процессе вывода ИИ-моделей. Механизм масштабирования вычислений на этапе вывода позволяет ИИ строить более связные локальные рассуждения. Однако фундаментальная проблема остаётся: современные большие языковые модели (LLM) на архитектуре «Трансформер» (Transformer) продолжают работать как системы распознавания паттернов, а не как самостоятельные системы концептуального рассуждения. Более высокие результаты модели Gemini 2.5 Pro свидетельствуют о потенциальной возможности сокращения разрыва между симулированным и реальным рассуждением в будущем. Однако для достижения качественного прогресса необходимо обучение ИИ-моделей более глубоким многомерным связям в латентном пространстве и освоение принципов построения новых логических структур, а не только копирование существующих шаблонов из обучающих выборок. Microsoft применила генеративный ИИ в рекламе, но этого никто не заметил
25.04.2025 [18:25],
Дмитрий Федоров
Microsoft опубликовала минутный рекламный ролик, частично созданный с помощью генеративного ИИ в январе этого года. Однако лишь спустя почти три месяца компания раскрыла факт использования ИИ при его создании. 
Источник изображения: Microsoft В блоге Microsoft Design старший менеджер по коммуникациям в области дизайна Джей Тан (Jay Tan) отметил, что в процессе генерации видео возникали типичные «галлюцинации» ИИ, что потребовало корректировки отдельных фрагментов и их интеграции с отснятым материалом. При выборе сцен для генерации команда пришла к выводу, что кадры со сложной моторикой, например крупные планы рук, печатающих на клавиатуре, необходимо снимать вживую. В то же время короткие или статичные эпизоды были признаны подходящими для создания средствами ИИ. Компания Microsoft не уточнила, какие конкретно кадры были сгенерированы с помощью ИИ, однако Тан подробно описал производственный процесс. Сначала команда использовала ИИ для создания сценария, раскадровок и презентационного материала. С помощью текстовых запросов и образцов изображений формировались подсказки, которые затем передавались в генератор изображений. Полученные изображения редактировались и загружались в видеогенераторы Hailuo и Kling. Прочие инструменты не были названы. По словам креативного директора Циско Маккарти (Cisco McCarthy), команда сформулировала тысячи различных подсказок, поэтапно уточняя результат. Он подчеркнул: «На самом деле никогда не бывает единственной и неповторимой подсказки», — поэтому достичь требуемого качества удалось лишь путём постоянной доработки. Визуальный дизайнер Брайан Таунсенд (Brian Townsend) добавил, что благодаря такому подходу удалось сократить до 90 % времени и затрат, которые обычно требуются при традиционном производстве видеоконтента. Подход Microsoft отражает позицию руководителя дизайнерского направления компании Джона Фридмана (Jon Friedman), который ранее заявил, что ИИ становится одним из инструментов в арсенале специалистов творческих профессий, а не заменяет их. По его словам, задача дизайнера сегодня заключается не только в создании, но и в редактировании, что приобретает всё большее значение. После того как Microsoft раскрыла факт применения ИИ в производстве ролика, стали заметны характерные признаки ИИ-генерации: чрезмерно большая стеклянная банка, надписи, выполненные не от руки, а также общее визуальное оформление с типичным цифровым блеском. Однако без знания об участии ИИ зрители не обращали внимания на эти детали в течение нескольких месяцев. Монтаж с частыми склейками эффективно нивелировал визуальные артефакты, возникающие при использовании ИИ. «Нельзя дважды лизнуть барсука»: Google AI Overviews наделил смыслом абсурдные идиомы и вымышленные фразеологизмы
24.04.2025 [09:46],
Дмитрий Федоров
Функция AI Overviews, встроенная в поисковую систему Google и использующая генеративный ИИ (GenAI) для кратких ответов на запросы, уверенно интерпретирует вымышленные идиомы. Пользователи обнаружили, что достаточно ввести произвольную фразу и добавить слово «meaning» (англ. — значение), чтобы получить уверенное объяснение смысла этой фразы, независимо от её реальности. Система при этом не только интерпретирует бессмысленные конструкции как устойчивые выражения, но и указывает предполагаемое происхождение, иногда даже снабжая ответ гиперссылками, усиливающими эффект достоверности. 
Источник изображения: Shutter Speed / Unsplash В результате в интернете начали появляться примеры очевидных вымыслов, обработанных AI Overviews как подлинные фразеологизмы. Так, фраза «a loose dog won’t surf» (англ. — свободная собака не будет сёрфить) была истолкована как «шутливый способ выразить сомнение в осуществимости какого-либо события». Конструкция «wired is as wired does» (англ. — проводной — это то, что делают провода) ИИ объяснил как высказывание о том, что поведение человека определяется его природой, подобно тому как функции компьютера зависят от его схем. Даже фраза «never throw a poodle at a pig» (англ. — никогда не бросайте пуделя на свинью) была описана как пословица с библейским происхождением. Все эти объяснения звучали правдоподобно и были изложены AI Overviews с полной уверенностью. На странице AI Overviews внизу размещено уведомление о том, что в её основе используется «экспериментальный» генеративный ИИ. Такие ИИ-модели представляют собой вероятностные алгоритмы, в которых каждое последующее слово выбирается на основе максимально возможной предсказуемости, опираясь на данные обучения. Это позволяет создавать связные тексты, но не гарантирует фактологическую точность. Именно поэтому система оказывается способной логично объяснить, что могла бы означать фраза, даже если она лишена реального смысла. Однако это свойство приводит к созданию правдоподобных, но полностью вымышленных интерпретаций. Как пояснил Цзян Сяо (Ziang Xiao), специалист в области компьютерных наук из Университета Джонса Хопкинса (JHU), предсказание слов в таких ИИ-моделях строится исключительно на статистике. Однако даже логически уместное слово не гарантирует достоверности ответа. Кроме того, генеративные ИИ-модели, по данным научных наблюдений, склонны угождать пользователю, адаптируя ответы к предполагаемым ожиданиям. Если система «видит» в запросе указание на то, что фраза вроде «you can’t lick a badger twice» (англ. — нельзя дважды лизнуть барсука) должна быть осмысленной, она интерпретирует её как таковую. Это поведение наблюдалось в исследовании под руководством Сяо в прошлом году. Сяо подчёркивает, что такие сбои особенно вероятны в контекстах, где информации в обучающих данных недостаточно — это касается редких тем и языков с ограниченным числом текстов. Кроме того, ошибка может быть усилена каскадным распространением, поскольку поисковая система представляет собой сложный многоуровневый механизм. При этом ИИ редко признаёт своё незнание, поэтому, если ИИ сталкивается с ложной предпосылкой, он с высокой вероятностью выдаёт вымышленный, но правдоподобно звучащий ответ. Представитель Google Мэганн Фарнсворт (Meghann Farnsworth) объяснила, что при поиске, основанном на абсурдных или несостоятельных предпосылках, система старается найти наиболее релевантный контент на основе ограниченных доступных данных. Это справедливо как для традиционного поиска, так и для AI Overviews, которая может активироваться в попытке предоставить полезный контекст. Тем не менее AI Overviews не срабатывает по каждому запросу. Как отметил когнитивист Гэри Маркус (Gary Marcus), система даёт непоследовательные результаты, поскольку GenAI зависит от конкретных примеров в обучающих выборках и не склоннен к абстрактному мышлению. Нашумевший ИИ-бот DeepSeek будет интегрирован в некоторые автомобили BMW
23.04.2025 [11:28],
Дмитрий Федоров
Немецкий автопроизводитель BMW планирует начать внедрение ИИ, разработанного китайским стартапом DeepSeek, в новые модели автомобилей, предназначенные для китайского рынка, начиная с конца текущего года. 
Источник изображения: Thai Nguyen / Unsplash Об этом сообщил генеральный директор компании, Оливер Ципсе (Oliver Zipse), в ходе автосалона в Шанхае: «Ключевые достижения в области искусственного интеллекта происходят сегодня именно здесь. Мы укрепляем партнёрские связи в сфере ИИ с целью интеграции этих технологий в наши автомобили, выпускаемые для Китая. Начиная с конца этого года, мы начнём внедрение искусственного интеллекта DeepSeek в новые автомобили, предназначенные для китайского рынка». Grok научился «видеть» окружающий мир
23.04.2025 [10:34],
Дмитрий Федоров
ИИ-чат-бот Grok компании xAI научился распознавать объекты и отвечать на вопросы о том, что находится в поле зрения камеры смартфона. Эта функция аналогична возможностям визуального восприятия в реальном времени, уже реализованным в Google Gemini и ChatGPT. 
Источник изображения: Mariia Shalabaieva / Unsplash Во вторник компания xAI объявила о запуске Grok Vision — технологии, позволяющей пользователям направлять камеру телефона на различные объекты (например, на товары, вывески или документы) и задавать по ним вопросы. В настоящий момент функция Grok Vision доступна только в приложении Grok для iOS. Версия для Android пока не поддерживает эту возможность. Кроме того, стали доступны новые функции Grok — многоязычный поиск в режиме реального времени с использованием голосового управления. Пользователи Grok на устройствах с Android могут воспользоваться этими возможностями, однако только при условии оформления подписки SuperGrok, стоимостью $30 в месяц. Grok регулярно получает обновления и новые функции. Так, в начале апреля компания xAI внедрила так называемую функцию «памяти», которая позволяет ИИ-чат-боту использовать информацию из предыдущих диалогов с пользователем. Начинающие разработчики ИИ-приложений привлекли рекордные $8,2 млрд инвестиций за прошлый год
14.04.2025 [12:15],
Дмитрий Федоров
Несколько стартапов в сфере ИИ, разрабатывающих прикладные решения на основе больших языковых моделей (LLM), стремительно наращивают объёмы продаж и инициируют новую гонку за коммерческое освоение передовых технологий. Их быстрый рост привлёк внимание инвесторов, готовых вложить сотни миллионов долларов в развитие потребительских ИИ-продуктов. 
Источник изображения: Alex Shuper / Unsplash Инвесторы делают ставку на такие компании, как Cursor, Perplexity, Synthesia и ElevenLabs. Эти стартапы создают приложения на основе мощных генеративных ИИ-моделей (GenAI), предоставляемых OpenAI, Google и Anthropic. Они способствуют более широкому внедрению быстро развивающихся технологий как в потребительской, так и в корпоративной среде. По данным аналитической платформы Dealroom.co, в 2024 году объём финансирования стартапов, разрабатывающих приложения на основе ИИ, составил $8,2 млрд, что на 110 % больше, чем в 2023 году. Этот инвестиционный ажиотаж свидетельствует о высоком интересе к разработчикам ИИ-инструментов, способным привлекать сотни миллионов долларов на фоне стремительного роста спроса. Стартап Perplexity, разработавший поисковую систему на базе ИИ, привлёк в декабре $500 млн в рамках своего четвёртого раунда финансирования за год, утроив оценку компании до $9 млрд. По данным источников, в настоящее время компания ведёт переговоры о новом раунде инвестиций по существенно более высокой оценке. В то же время стартап Harvey, разрабатывающий ИИ-решения для юридической сферы, привлёк $300 млн в феврале. Стартапы, создающие приложения для разработчиков программного обеспечения (ПО), также вызвали повышенный интерес со стороны инвесторов. Компании, такие как Reflection AI, Poolside, Magic и Codeium, собрали сотни миллионов долларов в 2024 году на развитие технологий, направленных на повышение производительности программистов. В январе компания Anysphere — разработчик инструмента автоматизации программирования Cursor — привлекла $105 млн при оценке $2,5 млрд. По словам источников, инвесторы проявляют интерес к компании при оценке в $10 млрд и выше. Трёхлетний стартап уже достиг годовой регулярной выручки на уровне $200 млн. 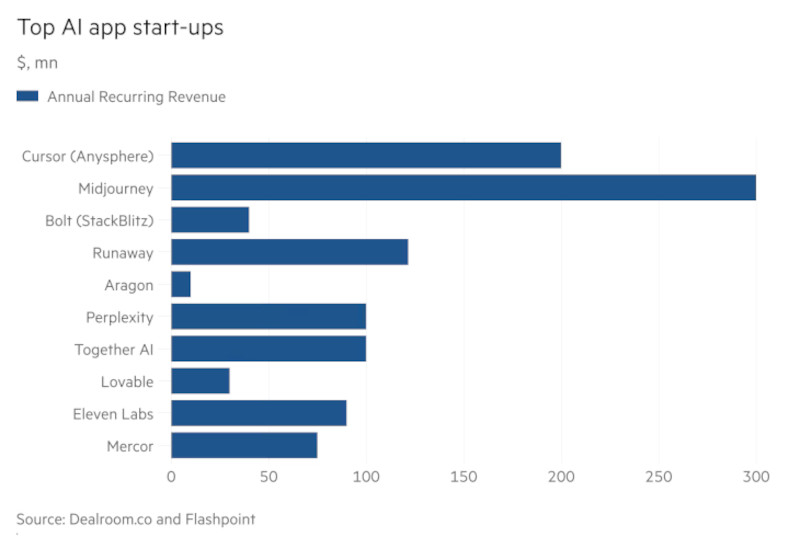
Источник изображения: Dealroom.co and Flashpoint ИИ-стартапы также получили выгоду от усилившейся конкуренции на рынке LLM, которая привела к снижению стоимости обработки запросов и генерации ответов с использованием ИИ. Это позволило использовать инфраструктуру LLM без необходимости создания собственных дорогостоящих ИИ-моделей, что ускорило вывод продуктов на рынок. Брет Тейлор (Bret Taylor), председатель совета директоров OpenAI и сооснователь стартапа Sierra, отметил, что компания за короткое время сменила используемые ИИ-модели не менее пяти-шести раз в связи с высокой скоростью развития отрасли. Стартап Sierra, разрабатывающий агентов поддержки клиентов на базе ИИ, был основан в феврале 2024 года и достиг оценки в $4,5 млрд уже в октябре того же года. По его словам, использование ИИ-модели двухлетней давности сегодня сравнимо с поездкой на автомобиле 1950-х годов — настолько стремительно устаревают технологии. Согласно анализу данных о платежах от финтех-компании Stripe, крупнейшие ИИ-компании достигают объёмов продаж в миллионы долларов уже в течение первого года своей деятельности. Это происходит значительно быстрее, чем в случае стартапов из других технологических отраслей, и свидетельствует о высокой способности прикладного ИИ к быстрому формированию устойчивых бизнес-моделей. Однако пока сложно оценить, насколько надёжна клиентская база ИИ-стартапов и насколько устойчивыми окажутся их текущие доходы. На фоне всеобщего интереса к ИИ ранние пользователи приходят быстро, что может искажать показатели роста, не гарантируя долгосрочной подписки. Некоторые инвесторы избегают участия в гонке за наиболее популярные приложения, опасаясь, что даже лучшие из них представляют собой лишь сервисные «обёртки» над существующими ИИ-моделями. Существует риск, что такие стартапы будут вытеснены в случае, если более крупная компания с широкой пользовательской базой решит воспроизвести их функциональность. Ханна Сил (Hannah Seal), партнёр венчурной компании Index Ventures, инвестировавшая в юридического ИИ-ассистента Wordsmith, подчёркивает, что многие из этих ИИ-стартапов ещё не прошли ни одного полного годового цикла продления подписки. Поэтому уровень оттока клиентов остаётся неизвестным и может существенно повлиять на дальнейшую динамику развития. Сфера ИИ заинтересовалась малыми языковыми моделями — они дешевле и эффективнее больших в конкретных задачах
13.04.2025 [21:16],
Владимир Мироненко
На рынке ИИ сейчас наблюдается тренд на использование малых языковых моделей (SLM), которые имеют меньше параметров, чем большие языковые модели (LLM), и лучше подходят для более узкого круга задач, пишет журнал Wired. 
Источник изображения: Luke Jones/unsplash.com Новейшие версии LLM компаний OpenAI, Meta✴ и DeepSeek имеют сотни миллиардов параметров, благодаря чему могут лучше определять закономерности и связи, что делает их более мощными и точными. Однако их обучение и использование требуют огромных вычислительных и финансовых ресурсов. Например, обучение модели Gemini 1.0 Ultra обошлось Google в 191 миллион долларов. По данным Института исследований электроэнергетики, выполнение одного запроса в ChatGPT требует примерно в 10 раз больше энергии, чем один поиск в Google. IBM, Google, Microsoft и OpenAI недавно выпустили SLM, имеющие всего несколько миллиардов параметров. Их нельзя использовать в качестве универсальных инструментов, как LLM, но они отлично справляются с более узко определёнными задачами, такими как подведение итогов разговоров, ответы на вопросы пациентов в качестве чат-бота по вопросам здравоохранения и сбор данных на интеллектуальных устройствах. «Они также могут работать на ноутбуке или мобильном телефоне, а не в огромном ЦОД», — отметил Зико Колтер (Zico Kolter), учёный-компьютерщик из Университета Карнеги — Меллона. Для обучения малых моделей исследователи используют несколько методов, например дистилляцию знаний, при которой LLM генерирует высококачественный набор данных, передавая знания SLM, как учитель даёт уроки ученику. Также малые модели создаются из больших путём «обрезки» — удаления ненужных или неэффективных частей нейронной сети. Поскольку у SLM меньше параметров, чем у больших моделей, их рассуждения могут быть более прозрачными. Небольшая целевая модель будет работать так же хорошо, как большая, при выполнении конкретных задач, но её будет проще разрабатывать и обучать. «Эти эффективные модели могут сэкономить деньги, время и вычислительные ресурсы», — сообщил Лешем Чошен (Leshem Choshen), научный сотрудник лаборатории искусственного интеллекта MIT-IBM Watson. В Китае квантовый компьютер впервые применили для точной настройки ИИ
09.04.2025 [10:26],
Геннадий Детинич
Китайские учёные первыми в мире использовали квантовый компьютер для точной настройки искусственного интеллекта — большой языковой модели с одним миллиардом параметров. Это стало первым использованием квантовой платформы, имеющим практическую ценность. В этом проявил себя компьютер Wukong китайской компании Origin, основанный на 72 сверхпроводящих кубитах. 
Источник изображения: Origin Система Wukong относится к третьему поколению квантовых компьютеров Origin. В январе 2024 года к ней был открыт облачный доступ со всего мира. Как признаются разработчики, поток учёных возглавили исследователи из США, несмотря на то что китайским учёным доступ к аналогичным ресурсам западных партнёров по-прежнему закрыт. «Это первый случай, когда настоящий квантовый компьютер был использован для точной настройки большой языковой модели в практических условиях. Это демонстрирует, что современное квантовое оборудование может начать поддерживать задачи обучения ИИ в реальном мире», — сказал Чэнь Чжаоюнь (Chen Zhaoyun), исследователь из Института искусственного интеллекта при Национальном научном центре в Хэфэе. По словам учёных, система Origin Wukong на 8,4 % улучшила результаты обучения ИИ при одновременном сокращении количества параметров на 76 %. Обычно для решения подобных задач — специализации ИИ общего назначения — используются суперкомпьютеры, что требует значительных вычислительных и энергетических ресурсов. Квантовый вычислитель, использующий принцип квантовой суперпозиции — множества вероятностных состояний вместо двух классических (0 и 1), способен экспоненциально ускорить расчёты при относительно скромных затратах ресурсов. В частности, учёные продемонстрировали преимущества точной настройки большой языковой модели с помощью квантовой системы для диагностики психических расстройств (число ошибок снижено на 15 %), а также при решении математических задач, где точность выросла с 68 % до 82 %. Для запуска алгоритмов обучения ИИ на квантовой платформе исследователи разработали то, что назвали «квантово-взвешенной тензорной гибридной настройкой параметров». Весовые значения обрабатывала квантовая платформа, в то время как классическая часть готовила большую языковую модель. Благодаря суперпозиции и эффекту квантовой запутанности платформа Origin Wukong смогла одновременно обрабатывать огромное количество комбинаций параметров, что ускорило специализацию модели. Meta✴ лишилась главы фундаментальных ИИ-исследований
02.04.2025 [11:25],
Дмитрий Федоров
Вице-президент Meta✴ по исследованиям в области ИИ Джоэль Пино (Joelle Pineau) объявила о своём уходе из компании. Её последний рабочий день в Meta✴ назначен на 30 мая 2025 года. Отставка происходит на фоне активной инвестиционной стратегии компании в сфере ИИ, направленной на опережение OpenAI и Google.  О своём уходе Пино сообщила в публикации на LinkedIn, где подтвердила, что покинет Meta✴. Она занимала должность вице-президента компании по исследованиям в области ИИ и с 2023 года возглавляла подразделение Fundamental AI Research (FAIR). FAIR занимается фундаментальными разработками в области ИИ, часть которых впоследствии внедряется в ключевые цифровые продукты Meta✴. Уход Пино совпал с этапом технологического переосмысления внутри компании. Генеральный директор Meta✴ Марк Цукерберг (Mark Zuckerberg) обозначил ИИ как приоритетное направление и инвестировал в него многомиллиардные ресурсы. Согласно его заявлениям, Meta✴ стремится к созданию ИИ-ассистента, которым будут пользоваться более одного миллиарда человек, а также к разработке так называемого сильного ИИ (Artificial General Intelligence — AGI), то есть ИИ-систем, способных мыслить и действовать на уровне человека. В своём заявлении Пино указала, что на фоне глобальных изменений и ускоряющейся гонки в сфере ИИ она считает целесообразным «освободить пространство для других». Она добавила, что будет наблюдать за дальнейшим развитием событий «со стороны», зная, что у команды Meta✴ есть всё необходимое для построения эффективных и этически устойчивых ИИ-систем, способных интегрироваться в повседневную жизнь миллиардов людей. Пино присоединилась к Meta✴ в 2017 году для руководства лабораторией по исследованиям в области ИИ в Монреале. Она также занимает должность профессора информатики в Университете Макгилла (McGill University), где является содиректором лаборатории по обучению и логическому выводу. Среди проектов, курируемых Пино, — семейство открытых языковых моделей LLaMA, а также PyTorch — фреймворк машинного обучения для языка Python для разработчиков ИИ. Разработки под её руководством охватывали передовые направления в области компьютерных наук и впоследствии использовались в технологических решениях Meta✴. Объявление Пино прозвучало за несколько недель до проведения ежегодной конференции LlamaCon, которая состоится 29 апреля. Ожидается, что на мероприятии Meta✴ представит очередную версию большой языковой модели LLaMA. Главный директор по продуктам компании Крис Кокс (Chris Cox) заявил, что LLaMA 4 станет основой для ИИ-агентов нового поколения. По информации издания CNBC, компания также планирует выпустить отдельное приложение для чат-бота Meta✴ AI. На фоне этих разработок отставка Пино приобретает особое значение, учитывая её ключевую роль в формировании научного направления FAIR. Китайская Zhipu AI ворвалась в ИИ-гонку с бесплатным ИИ-агентом AutoGLM Rumination
31.03.2025 [11:49],
Дмитрий Федоров
Китайская компания Zhipu AI, специализирующаяся на разработке систем искусственного интеллекта, представила ИИ-агента под названием AutoGLM Rumination. Новинка стала частью волны аналогичных проектов на фоне нарастающей конкуренции на китайском рынке ИИ. AutoGLM Rumination способен выполнять углублённые исследования, а также справляться с прикладными задачами, включая поиск информации в интернете, планирование путешествий и составление исследовательских отчётов. 
Источник изображения: zhipuai.cn Агент основан на моделях собственной разработки Zhipu AI. В их число входят рассуждающая ИИ-модель GLM-Z1-Air и базовая языковая модель GLM-4-Air-0414. Компания утверждает, что GLM-Z1-Air демонстрирует производительность, сопоставимую с моделью R1 компании DeepSeek, но работает в восемь раз быстрее и требует лишь одну тридцатую вычислительных ресурсов. Такие характеристики указывают на потенциальное снижение затрат на развёртывание и эксплуатацию ИИ-систем, что особенно важно на фоне масштабной интеграции нейросетей в экономику и государственное управление. ИИ-агенты представляют собой автономные программные системы, способные принимать решения и выполнять широкий спектр задач без постоянного вмешательства пользователя. В начале 2025 года компания DeepSeek представила ИИ-модель, работающую при значительно меньших издержках, чем американские аналоги, что вызвало значительный интерес на рынке. На этом фоне китайские разработчики ускорили вывод отечественных решений в области ИИ. Презентация Zhipu AI состоялась спустя несколько недель после заявления конкурирующей компании Manus, представившей своего ИИ-агента как первого в мире универсального ИИ-агента. В отличие от Manus, предлагающей продукт по подписке стоимостью до $199 в месяц, AutoGLM Rumination будет доступен бесплатно. Компания заявляет, что пользователи смогут получить доступ к ИИ-агенту через официальный сайт модели GLM и мобильное приложение. Компания Zhipu AI была основана в 2019 году как самостоятельная организация, выделившаяся из исследовательской лаборатории при Университете Цинхуа (Tsinghua University) с целью коммерциализации разработок в области ИИ. За последние годы она заняла одно из ведущих мест среди китайских ИИ-стартапов. Zhipu AI известна разработкой серии моделей GLM, последняя из которых — GLM4 — по заявлению компании превосходит GPT-4 по ряду бенчмарков. Подробные данные о метриках и условиях тестирования не раскрываются. Ранее в марте Zhipu AI провела три раунда финансирования при участии китайских государственных структур. Последние инвестиции поступили от администрации города Чэнду, которая вложила в компанию 300 млн юаней (около $41,5 млн). Участие региональных властей отражает стратегическую заинтересованность китайских городов в развитии ИИ-решений, особенно в условиях усиливающегося соперничества с иностранными разработками. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






