|
Опрос
|
реклама
Быстрый переход
Nvidia научит старые видеокарты GeForce повышать FPS с помощью ИИ, но потом
20.01.2025 [17:56],
Николай Хижняк
В интервью Digital Foundry Брайан Катандзаро (Bryan Catanzaro), вице-президент по исследованиям в области прикладного глубокого обучения в Nvidia сообщил, что не исключает возможности в будущем внедрения функции генерации кадров силами ИИ для повышения FPS, ставшей частью технологии DLSS, в старые видеокарты Nvidia GeForce. 
Источник изображений: Digital Foundry / Nvidia С момента своего дебюта в 2018 году технология масштабирования с глубоким обучением (DLSS) от Nvidia эволюционировала уже до четвёртой версии. Её последняя итерация перешла на ИИ-модель типа трансформер, что позволило реализовать ряд новых функций, включая мультикадровую генерацию (Multi Frame Generation, MFG). Последняя позволяет создавать до трёх дополнительных кадров на каждый традиционно отрисованный кадр для повышения FPS.  Nvidia смогла реализовать некоторые новые технологии, включая реконструкцию лучей (DLSS Ray Reconstruction), супер-разрешение (Super Resolution) и технологию сглаживания, опирающуюся на искусственный интеллект (Deep Learning Anti-Aliasing, DLAA) на всех видеокартах GeForce RTX, начиная с 20-й серии. Однако генератор кадров (Frame Generation) первого поколения, изначально представленный как эксклюзивная функция видеокарт GeForce RTX 40-й серии, не поддерживается моделями GeForce RTX 30-й и RTX 20-й серий. Новый мультикадровый генератор так и вовсе изначально заявлен только для новейших GeForce RTX 5000. В разговоре с журналистами Брайан Катандзаро отметил, что не исключает появления функции генерации кадров у старых моделей видеокарт Nvidia. «Я думаю, что ключевым здесь является вопрос проектирования и оптимизации, а также конечного пользовательского опыта. Мы запускаем этот генератор кадров, лучший генератор кадров, коим является технология Multi Frame Generation, с видеокартами 50-й серии. А в будущем посмотрим, сможем ли что-то выжать для старого поколения оборудования», — прокомментировал представитель Nvidia. 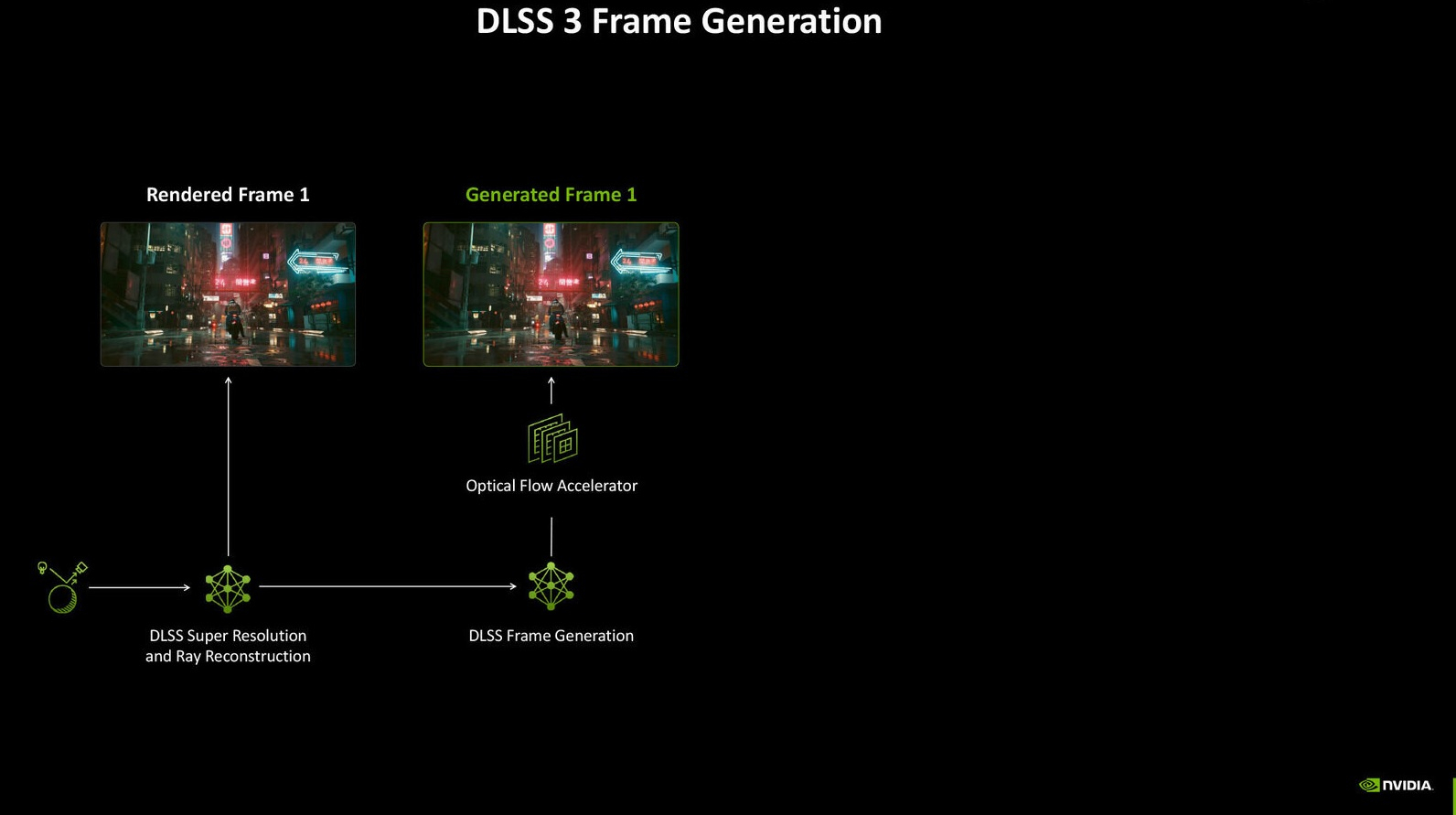 На фоне заявления Катандзаро можно предположить, что первая версия генератора кадров может в перспективе появиться на видеокартах GeForce RTX 30-й серии. Однако маловероятно, что она появится у моделей GeForce RTX 20-й серии. При этом, скорее всего, мультикадровый генератор кадров останется эксклюзивом видеокарт RTX 50-й серии, поскольку для его работы требуется значительно больше вычислительной мощности, заточенной под ИИ, которую у этих карт обеспечивают новые тензорные ядра. Один из ведущих разработчиков Nvidia также поделился некоторой информацией о разработке DLSS. «Когда мы создавали Nvidia DLSS 3 Frame Generation, нам было абсолютно необходимо аппаратное ускорение для вычислений Optical Flow. Но у нас не было достаточного количества тензорных ядер и не было достаточно хорошего алгоритма Optical Flow. Мы не создавали алгоритм Optical Flow для работы в реальном времени на тензорных ядрах, который мог бы вписаться в наш запас вычислительной мощности. У нас был аппаратный ускоритель Optical Flow, который Nvidia создавала годами как эволюцию нашей технологии видеокодирования. Он также был частью нашей технологии ускорения работы компьютерного зрения для беспилотных автомобилей. Казалось бы, для нас имело смысл использовать его и для Nvidia DLSS 3 Frame Generation. Но сложность в любой аппаратной реализации алгоритма типа Optical Flow заключается в том, что его действительно трудно улучшить. Он такой, какой он есть, и те сбои, которые возникли из-за этого аппаратного Optical Flow, мы не могли исправить с помощью более умной нейронной сети, пока не решили просто заменить его и перейти на решение, полностью основанное на ИИ. Именно это мы и сделали для Frame Generation в DLSS 4». Microsoft вернула старый ИИ-генератор картинок Bing Image Creator, потому что новый работал хуже
09.01.2025 [15:18],
Владимир Фетисов
Компания Microsoft решила откатить обновление ИИ-генератора изображений Bing Image Creator. Это произошло после того, как в течение нескольких недель пользователи сервиса активно жаловались на снижение качества его работы, которое возникло после обновления большой языковой модели DALL-E 3 18 декабря. Microsoft отказалась от комментариев по поводу причин решения откатить обновление. 
Источник изображения: Microsoft Сегодня корпоративный вице-президент Microsoft по поиску и искусственному интеллекту Жорди Рибас (Jordi Ribas) опубликовал пост в соцсети X, в котором сообщил, что разработчикам удалось воспроизвести «некоторые из обнаруженных проблем». Он также добавил, что было принято решение вернуться к использованию более старой версии модели DALL-E. В декабре Рибас сообщил о развёртывании обновления для модели DALL-E, которая является основой генератора изображений Bing Image Creator. Почти сразу после этого в интернете появились жалобы от пользователей сервиса, которые писали, что ИИ-генератор стал менее точно следовать текстовым подсказкам при создании изображений. На тот момент Рибас заявил, что качество работы обновлённого продукта «в среднем должно быть немного лучше», чем раньше. Жалобы пользователей стали появляться не только на форумах поддержки Microsoft, но и на других платформах, включая Reddit и форум OpenAI. Очевидно, что в конечном счёте Microsoft пришлось признать наличие проблемы и откатить обновление, чтобы вернуть Bing Image Creator к прежнему состоянию. Когда софтверный гигант может снова обновить языковую модель DALL-E, пока неизвестно. Google представила генератор картинок для тех, кто не любит писать — Whisk
17.12.2024 [12:54],
Павел Котов
Google анонсировала Whisk — основанный на искусственном интеллекте инструмент, который позволяет генерировать картинки, используя в качестве запроса другие изображения вместо длинных текстовых формулировок. 
Источник изображения: blog.google Работая с Whisk, можно загружать изображения, используя образцы картинок в качестве основной темы, сцены или стиля. При желании можно дополнить их текстовыми подсказками; а если нужных картинок не окажется под рукой, система предложит свои — вероятно, также сгенерированные ИИ. Получив результат, можно добавить его в избранное или скачать; либо улучшить его, дополнив или отредактировав текстовый запрос. Whisk предназначается для «быстрого создания визуального эскиза, а не дотошного редактирования с точностью до пикселя»; он может «промахнуться», признают в Google, поэтому позволяет редактировать исходные подсказки. В основу сервиса лёг последний вариант генератора изображений Imagen 3, который подразделение Google DeepMind анонсировало вместе с генератором видео Veo 2 — мощный конкурент OpenAI Sora пока доступен лишь ограниченному кругу пользователей экспериментальной платформы VideoFX. Чат-бот Grok от xAI Илона Маска обзавёлся генератором фотореалистичных изображений
08.12.2024 [06:24],
Алексей Разин
Концентрация нескольких динамично развивающихся компаний в руках Илона Маска (Elon Musk) приводит к их взаимной интеграции, а чат-бот Grok уже давно доступен подписчикам социальной сети X, а вчера он добрался и до бесплатных пользователей. Функциональность первого недавно дополнилась новым генератором изображений Aurora, который способен создавать фотореалистичные изображения, пусть и не лишённые недостатков. 
Источник изображения: X, EnsoMatt Бета-версия генератора изображений Aurora, как отмечает TechCrunch, стала доступна пользователям социальной сети X на вкладке Grok вчера. Доступ к этим возможностям не требует подписки, но имеет ограничения в бесплатном варианте. В частности, без подписки нельзя направить чат-боту Grok более 10 запросов за два часа, а количество генерируемых Aurora изображений ограничено тремя штуками в день. Кстати, некоторые пользователи X уже успели обнаружить, что лишены доступа к Aurora. Официально этот генератор изображений находится в бета-версии. Это уже второй генератор изображений для Grok компании xAI. Если в случае с первым, Flux, стартап Илона Маска сотрудничал с другими разработчиками, то история происхождения второго, Aurora, пока не раскрывается. По крайней мере, представители xAI только успели заявить, что принимали участие в настройке данной системы. Пользователи социальной сети X начали выкладывать образцы сгенерированных Aurora изображений, на одном из них можно лицезреть Адама Сэндлера (Adam Sandler) и его партнёра по сериалу Рэя Романо (Ray Romano), и если лица актёров на сгенерированных изображениях оказались похожими на настоящие, то с пальцами рук у генератора изображений возникли традиционные проблемы. Как отмечается, пейзажи и натюрморты у Aurora получаются гораздо лучше, но и там не обходится без дефектов. Google предложила помощь ИИ в создании клипартов для документов
16.11.2024 [12:22],
Павел Котов
На платформе Google Workspace появился генератор изображений на основе искусственного интеллекта Gemini прямо в приложении «Google Документы» — он позволяет быстро создавать иллюстрации к текстам. По сути, это генератор клипартов, схожий с аналогичной функцией в офисном пакете Microsoft. 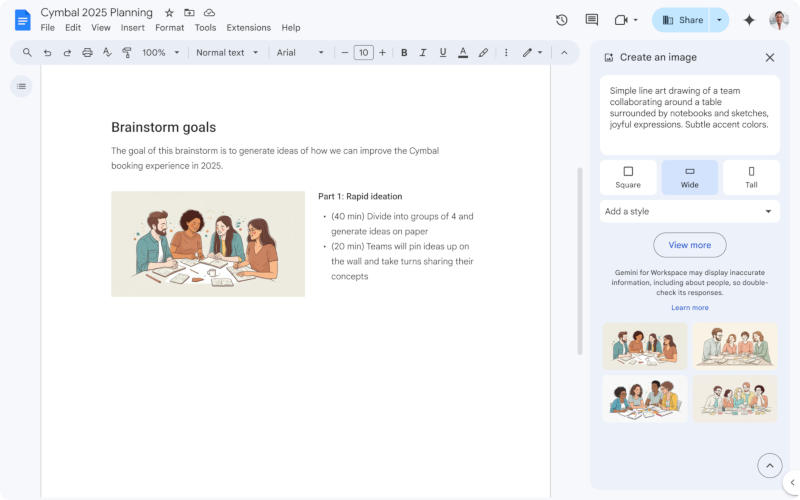
Источник изображения: workspaceupdates.googleblog.com Генератор изображений для «Google Документов» доступен для обладателей платных учётных записей Workspace, в том числе Gemini Business, Enterprise, Education, Education Premium и Google One AI Premium. Те, у кого новая функция уже заработала, могут открыть её через меню «Вставка», в котором требуется последовательно выбрать пункты «Изображение» и «Помогите мне создать изображение». Появляется боковая панель, на которой можно ввести описание требуемой иллюстрации; на ней же есть выпадающий список художественных стилей — например, «Фотография» или «Эскиз». Изображение будет квадратным либо вытянутым в горизонтальном или вертикальном направлении — можно выбрать то, что лучше впишется в макет документа. Доступно создание и изображения для обложки, которое протянется на всю страницу. За новую функцию отвечает новейший генератор Google Imagen 3 — он, по словам компании, обеспечивает «лучшую детализацию, более насыщенное освещение и меньше лишних артефактов». У части учётных записей новая функция появится в ближайшие 15 дней; для других она начнёт развёртываться 16 декабря. Представлена ИИ-модель YandexART 2.0 с поддержкой генерации текста на изображениях
10.10.2024 [17:09],
Павел Котов
«Яндекс» выпустил YandexART 2.0 — генератор картинок нового поколения. Нейросеть научилась создавать надписи на изображении и выдерживать на одной картинке сразу несколько стилей; объекты в пространстве и относительно друг друга теперь располагаются более естественно; а при создании изображений учитывается большее число деталей запроса. 
Источник изображений: «Яндекс» Отличительной особенностью YandexART 2.0 является гибридная архитектура нейросети, сочетающая черты свёрточной и трансформерной моделей. Свёрточная модель работает по принципу человеческого глаза, определяя ключевые признаки объекта, например, его форму, текстуру и края, но она ограничена в длине контекста, поэтому в длинных запросах ей помогает трансформер. Эта архитектура помогает YandexART 2.0 выдерживать несколько жанров в одном изображении — к примеру, она может изобразить анимешную этикетку на фотореалистичной бутылке лимонада.  Для обучения нейросети YandexART 2.0 использовались несколько сотен миллионов пар изображений и текстовых описаний к ним; более точное их соотношение обеспечила дополнительная VLM-модель, при помощи которой картинки анализировались и сопровождались подробными текстовыми описаниями. Массив обучающих данных был расширен за счёт нескольких сотен тысяч изображений с текстом — это помогло YandexART 2.0 дополнять картинки надписями латинскими буквами. 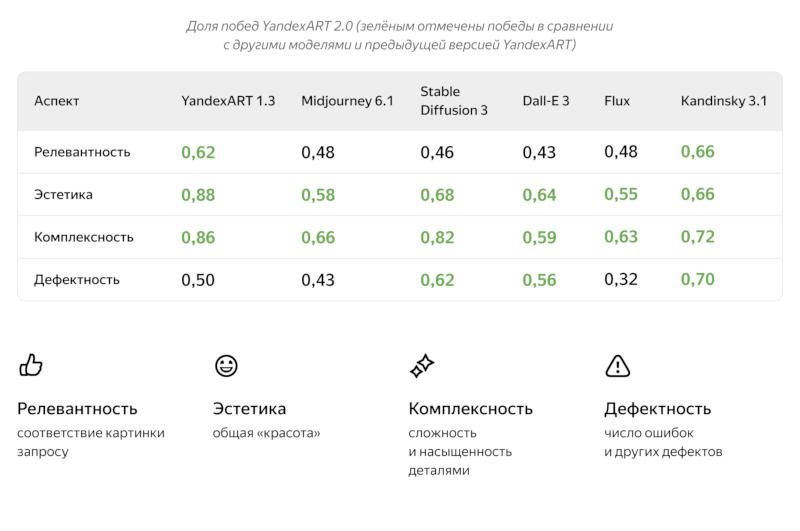 «Яндекс» также разработал собственную систему оценки качества работы для генератора изображений: новая модель выиграла у Midjourney v6.1 по критериям комплексности и эстетичности в 66 % и 58 % случаев соответственно, а также приблизилась к нему в аспекте релевантности запросам.  Бизнес-пользователи могут поработать с YandexART 2.0 на платформе Yandex Cloud — при помощи API можно интегрировать генератор изображений в любые приложения; есть возможность протестировать её работу в демонстрационном режиме для подбора оптимальных запросов. Корпоративные клиенты могут генерировать логотипы, иллюстрации для статей, презентаций или социальных сетей.  Визуальная нейросеть доступна также частным пользователям в веб-версии «Алисы» и собственном приложении виртуального помощника; владельцы бесплатных учётных записей могут запросить до пяти изображений в сутки, а у подписчиков опции «Алиса Про» такое ограничение отсутствует. С YandexART 2.0 можно создать аватарку для соцсетей, значок приложения, принт для футболки, открытку для друга или иллюстрацию для публикации. Google наконец починила ИИ-генератор изображений в Gemini — он перебарщивал с расовой инклюзивностью
29.08.2024 [00:41],
Николай Хижняк
Компания Google скоро вернёт пользователям доступ к генератору картинок в ИИ-чат-боте Gemini. Функция была удалена из чат-бота в феврале из-за того, что что она допускала серьёзные исторические ошибки в изображении людей, связанные с расовыми и гендерными вопросами. К примеру, расовое разнообразие солдат по запросу «римский легион» — явный анахронизм. 
Источник изображения: Google Ранний доступ к новому генератору изображений Imagen 3 от Google откроется платным пользователям Gemini на тарифах Advanced, Business и Enterprise в ближайшие дни, сообщил в официальном блоге Google Дэйв Ситрон (Dave Citron), старший директор по продуктам Gemini. Изначально функция будет поддерживать запросы только на английском языке. «Мы внесли технические исправления в продукт, а также поработали над более продвинутыми алгоритмами оценки и защитой от red-teaming-атак», — написал Ситрон. В феврале этого года Google приостановила работу функцию генерации изображений в Gemini, объяснив это тем, что она предлагает «неточности» при генерации исторических изображений. Компания приняла решение направить генератор изображений Gemini на доработку менее чем через сутки после поступления первых жалоб. По словам Ситрона, новый генератор Imagen 3 «не поддерживает создание фотореалистичных идентифицируемых лиц, изображений несовершеннолетний или чрезмерно кровавые, жестокие или сексуальные сцены». «Конечно, как и в случае с любым генеративным инструментом ИИ, не каждое изображение, создаваемое Gemini, будет идеальным, но мы продолжим прислушиваться к отзывам пользователей и будем совершенствовать наш продукт». Он также пообещал, что в дальнейшем пользоваться генератором изображений смогут больше людей, а сама функция получит поддержку дополнительных языков. Веб-версия генератора изображений Midjourney стала доступной для всех
24.08.2024 [13:07],
Павел Котов
Генеральный директор Midjourney Дэвид Хольц (David Holz) сообщил в Discord, что любой желающий теперь может открыть сайт сервиса и начать генерировать изображения. Бесплатная демо-версия платформы позволяет создать до 25 картинок. 
Источник изображения: Swello / unsplash.com Ранее для доступа к генератору Midjourney было необходимо пользоваться мессенджером Discord. Это было непросто, потому что приходилось особым образом составлять запросы. Чтобы привлечь пользователей, которым в Discord не нравилось, был запущен сайт платформы, но к работе в веб-интерфейсе допустили лишь тех, кто создал не менее 10 000 изображений через мессенджер. Теперь же сайт Midjourney открыт для всех желающих. Для регистрации потребуется учётная запись в Google или Discord — обладатели аккаунтов на обеих платформах могут подключить их к одной учётной записи в Midjourney и входить через любую их двух. После входа в систему набор основных инструментов доступен на левой боковой панели. Можно ознакомиться с изображениями, созданным по запросам других пользователей или попробовать сгенерировать картинку самостоятельно, предварительно посмотрев обучающий ролик. В верхней части страницы есть поле для ввода запроса, в ответ на который Midjourney предложит четыре изображения — качество наиболее удачного настраивается с помощью специальных инструментов: уменьшить, увеличить картинку или скорректировать ракурс. Есть и редактор изображений, где можно скорректировать запрос, изменить определённые области картинки, выбрать другое соотношение сторон и добавить новые элементы. Есть раздел, где собраны все созданные пользователем изображения. Картинку из коллекции можно посмотреть, изменить, скопировать или скачать. На сайте доступны чаты, где можно посмотреть, что создали другие люди, или разместить собственное изображение. По исчерпании лимита в 25 картинок Midjourney предложит оформить подписку на один из четырёх тарифных планов — они отличаются ценами и квотами на число изображений. Google открыла всем американским пользователям доступ к генератору изображений Imagen 3
16.08.2024 [17:31],
Павел Котов
Google без громких анонсов открыла всем пользователям из США доступ к последней модели генератора изображений с искусственным интеллектом Imagen 3 на платформе ImageFX. Компания также опубликовала исследовательскую работу, в которой подробно описывается эта технология. 
Источник изображения: deepmind.google Модель Imagen 3 была анонсирована в мае на конференции Google I/O и выпущена в ограниченный доступ для пользователей платформы Vertex AI. «Представляем Imagen 3 — модель скрытой диффузии, которая генерирует высококачественные изображения по текстовым запросам. На момент проведения оценки Imagen 3 является более предпочтительной, чем другие современные модели», — говорится в научной работе. Выпуск Google нового генератора изображений для широкой общественности в США — важный стратегический шаг для компании, вступившей в гонку технологий ИИ. С одной стороны, разработчику удалось повысить качестве её работы, с другой — модель подвергается критике за излишне строгие фильтры контента. Пользователи Reddit, в частности, сообщают, что генератор изображений отклоняет до половины запросов, даже если не предлагать ему «нарисовать» нечто сомнительное — дошло до того, что он отказался создать изображение киборга. Это резко контрастирует с подходом стартапа Илона Маска (Elon Musk) xAI, который на этой неделе выпустил модель Grok-2. Она генерирует изображения практически без ограничений, допуская создание картинок с общественными деятелями и деталями, которые на других платформах считаются недопустимыми. Это тоже вызвало недоумение общественности и породило предположения, что на xAI будет оказываться давление. Перед отраслью ИИ встаёт вопрос о балансе между творчеством и ответственностью, а также возможном влиянии генераторов изображений на публичный дискурс и достоверность информации. Художники одержали важную победу в деле об авторских правах против Stability AI и Midjourney
14.08.2024 [17:11],
Павел Котов
Группа художников, которая объединилась в коллективном иске против разработчиков наиболее популярных моделей искусственного интеллекта для генерации изображений, устроила празднование по случаю того, что судья дал ход этому делу и санкционировал раскрытие информации. 
Источник изображения: Alexandra_Koch / pixabay.com Ответчиками по делу выступают создатели сервисов Midjourney, Runway, Stability AI и DeviantArt — по версии истцов, разработчики систем на основе модели Stable Diffusion использовали их защищённые авторским правом работы для обучения ИИ. Судья Северного окружного суда Калифорнии Уильям Оррик (William H. Orrick), курирующий Сан-Франциско, где располагаются многие крупнейшие разработчики систем ИИ, пока не вынес окончательного решения по делу, но счёл, что предъявленных ответчикам обвинений достаточно, чтобы дело перешло к стадии раскрытия информации. Это значит, что представляющие истцов юристы могут изучить документы компаний — разработчиков генераторов изображений с ИИ; огласке будут преданы подробности о массивах обучающих данных, механизмах и внутренней работе систем. Модель Stable Diffusion предположительно обучалась на наборе данных LAION-5B из 5 млрд изображений, который был опубликован в 2022 году. Но, как отмечается в деле, эта база содержала только URL-адреса, то есть ссылки на изображения, а также их текстовые описания, то есть компаниям приходилось самостоятельно собирать эти изображения. Основанные на Stable Diffusion модели используют в работе механизм «CLIP-guided diffusion», помогающий им при генерации изображений отталкиваться от пользовательских запросов, которые могут включать имена художников. Метод CLIP (Contrastive Language-Image Pre-training) разработала и ещё в 2021 году опубликовала компания OpenAI — более чем за год до выпуска ChatGPT. Модель OpenAI CLIP способна работать как база данных по фирменному стилю, и если при обучении схожей с ней модели Midjourney использовались имена художников и их работы с сопоставленными с ними описаниями, то этот факт может представлять собой нарушение авторских прав. Стартап Black Forest Labs представил ИИ-генератор изображений FLUX.1 — он отлично справляется с прорисовкой рук человека
05.08.2024 [18:20],
Владимир Фетисов
В конце прошлой недели стартап Black Forest Labs объявил о начале своей деятельности в сфере разработки генеративных нейросетей. Вместе с этим компания, созданная выходцами из Stability AI, представила семейство моделей генерации изображений по текстовому описанию под названием FLUX.1, которые претендуют на звание лучших в своём классе. 
Источник изображений: FLUX.1 Запуск FLUX.1 произошёл примерно через семь недель после того, как в середине июня Stability AI выпустила ИИ-генератор Stable Diffusion 3 Medium, который собрал много критики из-за невысокого качества при создании изображений, на которых есть люди. Пользователи активно делились в соцсетях результатами генерации алгоритма с искажёнными конечностями и телами людей. Запуск Stable Diffusion 3 Medium последовал за уходом из Stability AI трёх ключевых сотрудников — Робина Ромбаха (Robin Rombach), Андреаса Блаттманна (Andreas Blattmann) и Доминика Лоренца (Dominik Lorenz). Именно они вместе с Патриком Эссером (Patrick Esser), который участвовал в разработке первой версии Stable Diffusion и с тех пор работал над разными ИИ-алгоритмами, а также другими инженерами, основали компанию Black Forest Lab.  На данный момент стартап представил три модели для генерации по текстовому описанию FLUX.1. ИИ-модель FLUX.1 pro представляет собой наиболее производительный генератор изображений, предназначенный для коммерческого использования через соответствующий API. Вместе с этим были выпущены FLUX.1 dev, доступная для некоммерческого использования, а также более лёгкая и быстрая FLUX.1 schnell (в переводе с немецкого — «быстрый» или «стремительный»).  Разработчики утверждают, что их ИИ-модели превосходят существующие аналоги, такие как Midjourney и DALL-E, по целому ряду показателей, включая качество создаваемых изображений и точность следования исходному описанию. В целом результаты генерации FLUX.1 сопоставимы с тем, что можно создать с помощью DALL-E 3 от OpenAI по точности следования описанию, и близки по фотореалистичности к Midjourney 6. При этом алгоритм явно более качественно работает по сравнению со Stable Diffusion XL, последним крупным релизом команды этих разработчиков, когда они ещё были частью Stability AI, не считая Stable Diffusion XL Turbo.  Модели Black Forest Lab построены на базе гибридной архитектуры, которая объединяет методы трансформации и диффузии, с масштабированием до 12 млрд параметров. Похоже, что такой подход делает нейросеть FLUX.1 способной качественно генерировать руки человека, что было слабым местом многих уже выпущенных на рынок аналогов. При этом разработчики не уточнили, на каких данных обучались модели FLUX.1. Отметим, что Black Forest Lab уже привлекла финансирование в размере $31 млн. Желающим опробовать FLUX.1 в действии можно воспользоваться сервисами Fal.ai или Replicate.com, где придётся платить деньги для работы с алгоритмами. AMD представила Amuse 2.0 — ПО для ИИ-генерации изображений для Ryzen и Radeon
29.07.2024 [00:20],
Николай Хижняк
AMD представила Amuse 2.0 — программный инструмент для ИИ-генерации изображений. Программа доступна в бета-версии. В перспективе её функциональность будет расширяться. Amuse 2.0 является своего рода аналогом инструмента AI Playground от Intel, использующего мощности видеокарт Intel Arc. Решение от AMD для генерации контента в свою очередь полагается на мощности процессоров Ryzen и видеокарт Radeon. 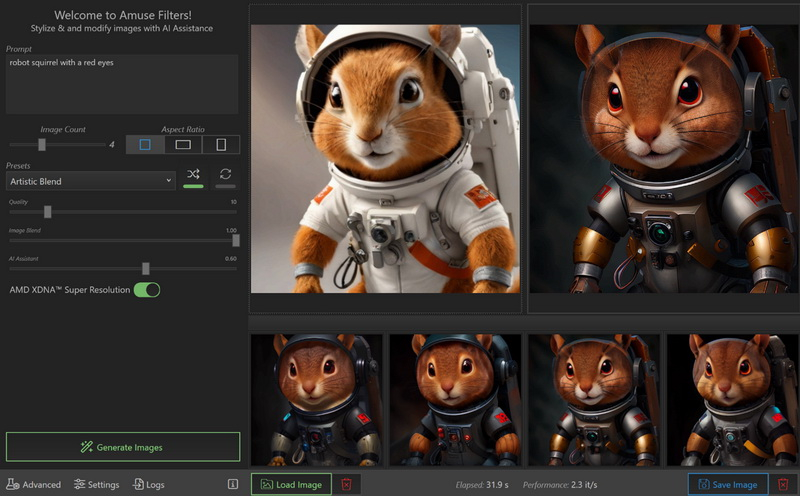
Источник изображений: AMD Приложение Amuse 2.0, разработанное с помощью TensorStack, отличается простотой использования, без необходимости загружать множество внешних компонентов, задействовать командные строки или запускать что-либо ещё. Для использования приложения достаточно лишь запустить исполняемый файл. 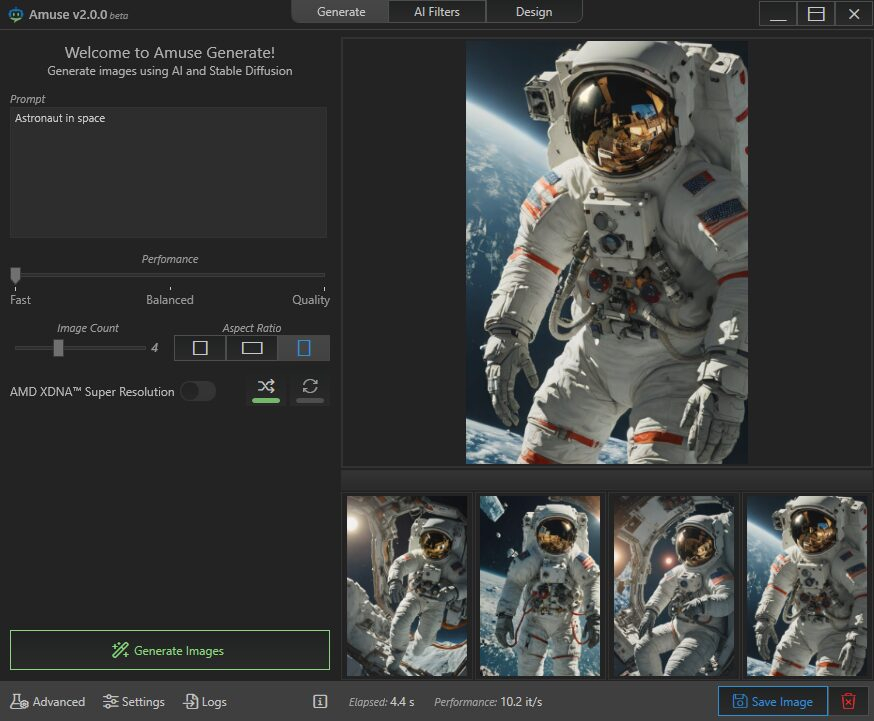 По сравнению с Intel AI Playground, Amuse 2.0 не поддерживает запуск чат-ботов на основе больших языковых моделей. В настоящее время приложение предназначено только для генерации изображений с помощью ИИ. Amuse 2.0 использует модели Stable Diffusion и поддерживает процессоры Ryzen AI 300 (Strix Point), Ryzen 8040 (Hawk Point) и серию видеокарт Radeon RX 7000. Почему компания не добавила поддержку видеокарт Radeon RX 6000 и более ранних моделей, а также процессоров Ryzen 7040 (Phoenix), обладающих практически идентичными характеристиками с Hawk Point, неизвестно. Возможно, это изменится в будущем. 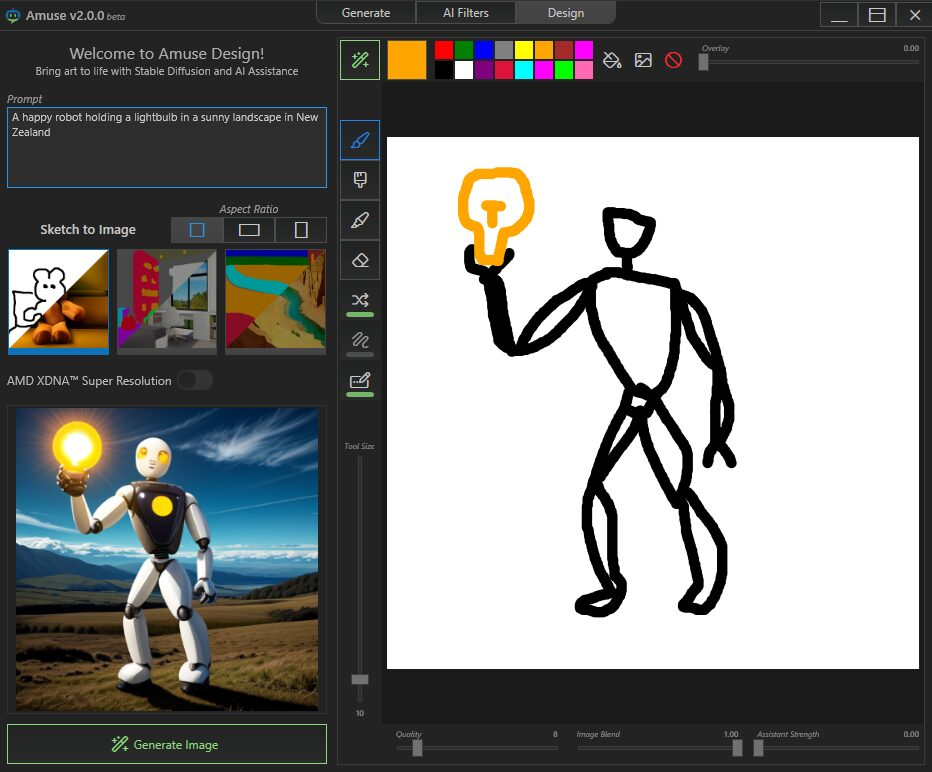 Для работы Amuse 2.0 AMD рекомендует использовать 24 Гбайт ОЗУ или больше для систем на базе процессоров Ryzen AI 300 и 32 Гбайт оперативной памяти для систем на базе Ryzen 8040. Для видеокарт Radeon RX 7000 требования к необходимому объёму памяти не указаны. 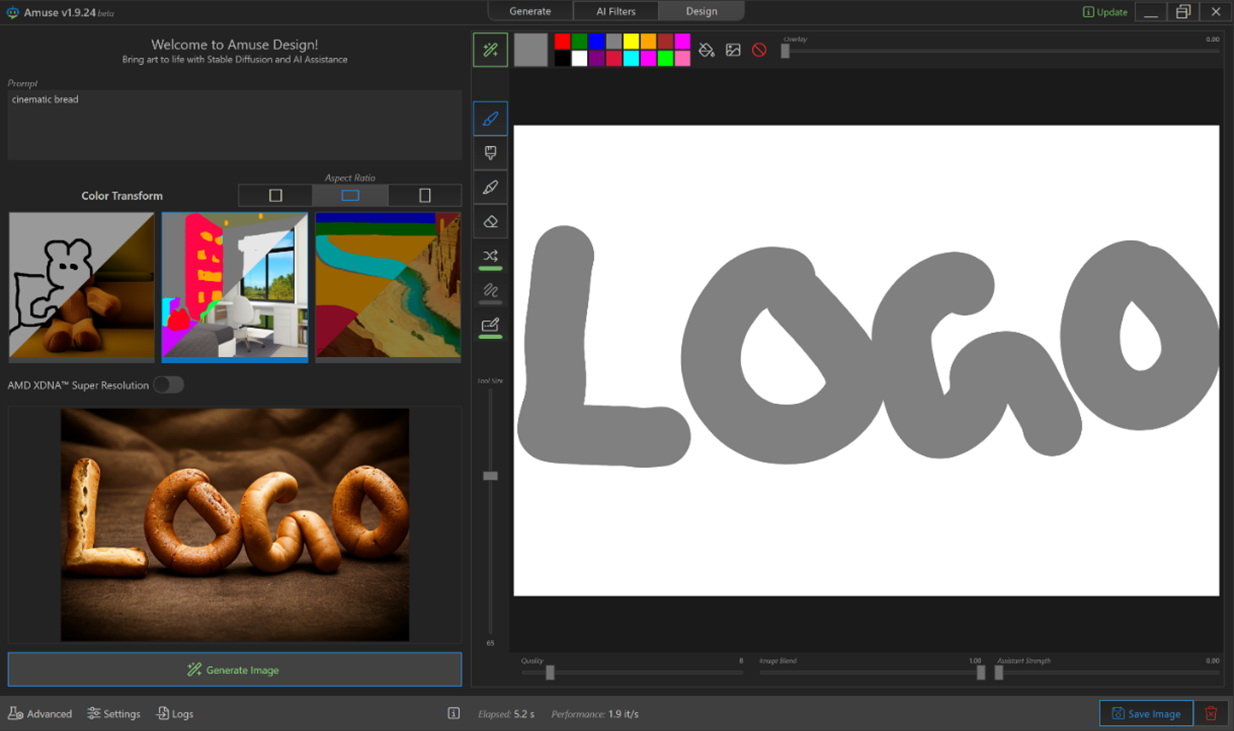 Возможности Amuse 2.0:
Стоит отметить, что инструмент поддерживает XDNA Super Resolution — технологию, позволяющую увеличивать масштаб изображений вдвое. Более подробно об Amuse 2.0 можно узнать по этой ссылке. Microsoft выпустила приложение Designer для создания изображений с помощью ИИ на iOS и Android
17.07.2024 [22:47],
Николай Хижняк
Компания Microsoft сообщила, что её приложение Designer на базе искусственного интеллекта вышло из предварительной версии и теперь доступно всем пользователям операционных систем iOS и Android. Приложение позволяет создавать изображения и дизайны на основе текстовых подсказок. С его помощью можно создавать, например, наклейки, поздравительные открытки, приглашения, коллажи и многое другое. 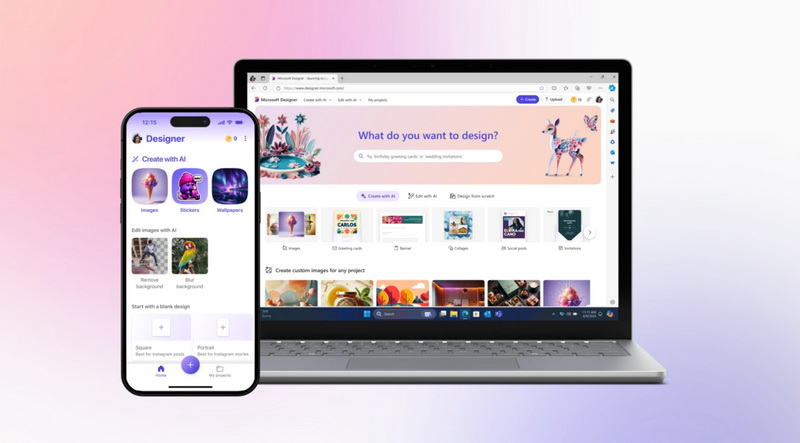
Источник изображений: Microsoft Веб-версия приложения Designer теперь поддерживает более 80 языков мира. Оно также доступно в виде бесплатного мобильного приложения, а также приложения в составе операционной системы Windows. В Designer есть «шаблоны подсказок», призванные помочь пользователям начать творческий процесс. Шаблоны включают стили и описания, которые можно настраивать и делиться с другими. Помимо стикеров, с помощью текстовых подсказок можно создавать смайлы, картинки, обои, монограммы, аватары и многое другое.  Кроме того, Designer можно использовать для редактирования стиля изображения с помощью ИИ. Например, в приложение можно загрузить селфи, а затем выбрать один из наборов стилей и добавить на изображение дополнительные детали. Скоро в Designer появится функция «замена фона», которая позволит с помощью текстовых подсказок заменять задний фон на изображениях.  Автономное приложение Designer совместимо с Word и PowerPoint через Copilot. Пользователи подписки Copilot Pro могут создавать с помощью Designer изображения прямо в своей рабочей среде. Вскоре компания добавит возможность создавать баннеры для того или иного документа на основе содержимого документов Word. Microsoft также сообщила, что приложение Designer получило более глубокую интеграцию в Microsoft Photos в составе Windows 11. Пользователи смогут использовать ИИ для редактирования фотографий, не выходя из приложения «Фото». У фотографий можно удалять объекты, фон и проводить автоматическую обрезку прямо в приложении. Figma отключила ИИ-помощника дизайнера — он копировал интерфейс приложений Apple
03.07.2024 [11:22],
Павел Котов
Администрация платформы Figma была вынуждена отключить основанный на генеративном искусственном интеллекте инструмент Make Designs — он начал разрабатывать для пользователей проекты, которые выглядели поразительно похожими на приложения из iOS. 
Источник изображения: Gerd Altmann / pixabay.com Генеральный директор Figma Дилан Филд (Dylan Field) подробно рассказал о проблеме на своей странице в соцсети X, возложил на себя вину за то, что торопил своих подчинённых выпустить продукт в общий доступ и выразил уверенность в правильности подхода компании в отношении ИИ. Он также процитировал гендиректора Not Boring Software Энди Аллена (Andy Allen), который наглядно продемонстрировал, как Figma Make Designs практически полностью копирует приложение погоды Apple, и предупредил пользователей платформы, что это чревато юридическими проблемами. «Мы не проводили обучения в рамках функций генеративного ИИ», — заявил ресурсу The Verge технический директор Figma Крис Расмуссен (Kris Rasmussen). Инструмент Make Designs, по его словам, был запущен на готовых моделях ИИ и созданной на заказ системе дизайна; на контенте пользователей или дизайнах готовых приложений обучение также не проводится, добавил Дилан Филд. В основе Make Designs лежат две модели ИИ: OpenAI GPT-4o и Amazon Titan Image Generator G1, рассказал технический директор, из чего можно сделать вывод, что дизайны Apple использовались для обучения ИИ в OpenAI или Amazon. От идеи обучать собственные модели ИИ на контенте пользователей Figma администрация платформы не отказывается, но и торопить события в компании не собираются. На минувшей неделе пользователям представили политику обучения ИИ и дали время до 15 августа решить, согласны ли они предоставлять свои материалы: в тарифных планах Starter и Professional это согласие по умолчанию дано, а в Organization и Enterprise — нет. Make Designs вернётся к пользователям Figma в обозримом будущем. «Мы проведём проверку данной системы дизайна, чтобы убедиться, что она предлагает достаточное разнообразие и отвечает нашим стандартам качества. <..> В этом основная причина проблемы. Но мы примем дополнительные меры предосторожности, прежде чем снова включить [Make Designs], чтобы убедиться, что функция в целом соответствует нашим стандартам качества и ценностям», — пообещал Расмуссен. Он также указал, что Make Designs находится в стадии бета-тестирования. «Бета-версии по определению несовершенны. Но можно сказать с уверенностью, как Дилан написал в своём твите, что мы просто не заметили эту конкретную проблему. А должны были», — заключил технический директор Figma. Intel представила AI Playground — бесплатный ИИ-генератор изображений, работающий локально
08.06.2024 [16:18],
Владимир Фетисов
На этой неделе состоялась ежегодная выставка Computex 2024, в рамках которой было представлено немало аппаратных и программных новинок. Одной из них стал генератор изображений AI Playground от Intel. Его основной является генеративная нейросеть, а главная особенность заключается в способности работать локально на пользовательском компьютере без подключения к облачным вычислительным мощностям. 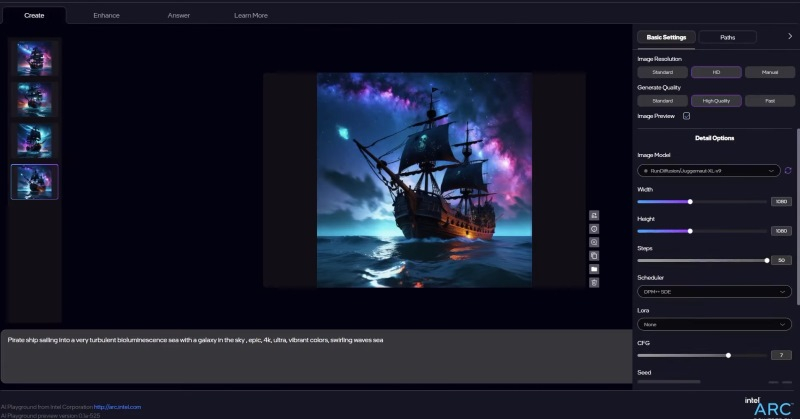
Источник изображения: Intel Приложение AI Playground для устройств с Windows требует наличия производительного процессора Intel Core Ultra, в составе которого есть встроенный ИИ-сопроцессор (NPU) для ускорения выполнения задач искусственного интеллекта. Также требуется наличие встроенной графики Intel Arc или дискретной видеокарты Intel с не менее чем 8 Гбайт видеопамяти. Ещё одна особенность приложения, которое станет доступно для скачивания позднее этим летом, в том, что использовать её можно бесплатно. «Мы не рассматриваем AI Playground как замену многим замечательным проектам и приложениям на основе ИИ, но мы рассматриваем AI Playground как лёгкий способ начать работу с ИИ», — говорится в сообщении Intel. AI Playground устанавливается на компьютер как стандартное приложение Windows. Пользовательский интерфейс выглядит достаточно простым. Для взаимодействия с разными функциями, такими как генерация или редактирование изображения, предлагается переключаться между вкладками в верхней части рабочего пространства. Для создания картинки достаточно ввести текстовое описание и запустить процесс генерации. Поддерживается возможность изменения качества и разрешения изображения, есть дополнительные опции, которые могут оказаться полезными при редактировании. Основой приложения стала большая языковая модель Answer. Хотя возможности AI Playground на данном этапе не слишком впечатляют, недостатки может компенсировать способность приложения работать локально. Это означает, что у разработчиков продукта не будет доступа к созданному пользователями контенту и текстовым подсказкам, которые они задействовали в процессе генерации. Кроме того, приложение можно использовать бесплатно, что также будет привлекательно для пользователей, которые только начинают знакомство с ИИ-генераторами изображений. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






