|
Опрос
|
реклама
Быстрый переход
Google открыла бесплатный доступ к генератору видео Veo 3, но только на эти выходные
23.08.2025 [16:39],
Владимир Мироненко
В эти выходные чат-бот на основе искусственного интеллекта Google Gemini предоставит пользователям бесплатного приложения возможность опробовать версию новейшей модели генерации видео Google Veo 3, анонсированной в мае. С её помощью можно создавать на основе запросов 8-секундные клипы со звуком. Отметим для россиян, что эта услуга доступна только с зарубежного IP-адреса. 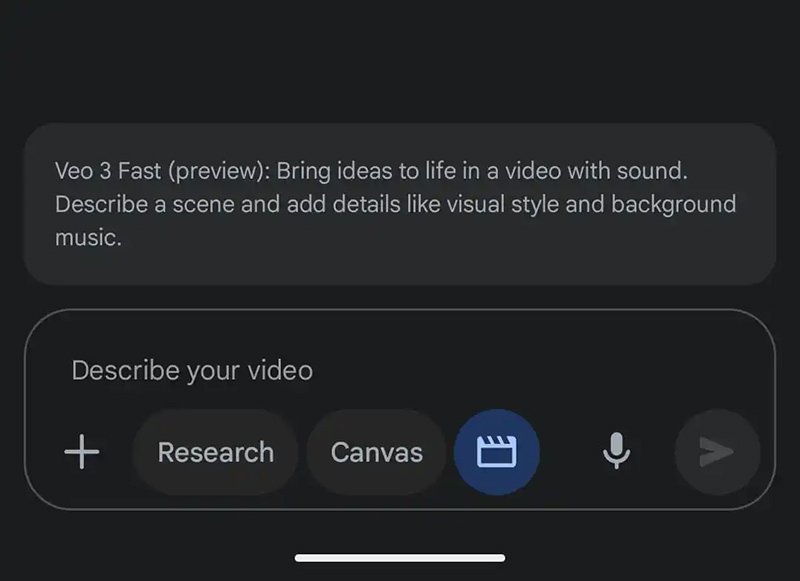
Источник изображения: 9to5google С июля платные подписчики Google AI Pro по всему миру могут создавать три видео в день с помощью более дешёвой, чем Veo 3, модели Veo 3 Fast, которая генерирует видео в два раза быстрее с разрешением 720p. При этом владельцы подписки Google AI Ultra имеют расширенный доступ к полной версии. Им также доступна функция преобразования фото в видео. Однако в рамках акции с текущего момента до 22:00 по тихоокеанскому времени воскресенья (понедельник, 9:00 мск) пользователи бесплатной версии Gemini смогут создать три видео с помощью модели Veo 3 Fast. Глава ИИ-сервиса Gemini Джош Вудворд (Josh Woodward) сообщил в четверг в соцсети X, что Google «настраивает массу TPU» перед пробным периодом, чтобы справиться с ожидаемым ростом запросов. При открытии приложения Gemini можно увидеть сообщение об акции. Если его нет, необходимо нажать на указатель с тремя точками на панели подсказок, чтобы открыть новый элемент «Видео: Генерация с Veo». Запрос пользователя должен «описывать сцену с добавленными деталями, такими как визуальный стиль и фоновая музыка». Можно также указать в описании диалоги и фоновый шум. Создание займёт несколько минут, после чего пользователи смогут скачать клип с водяным знаком (значок Veo в правом нижнем углу) или получить ссылку для общего доступа. Universal Pictures пригрозила ИИ-компаниям судом за незаконное использование фильмов студии для обучения нейросетей
07.08.2025 [07:56],
Владимир Фетисов
Одна из старейших голливудских киностудий Universal Pictures становится всё более агрессивной в защите своих фильмов от компаний, занимающихся разработкой генеративных нейросетей. В стремлении защитить свои фильмы от незаконного их использования для обучения нейросетей компания выбрала новый подход. 
Источник изображения: Julien Tromeur / Unsplash В июне этого года киностудия добавила в финальные титры фильма «Как приручить дракона» информацию о том, что незаконное использование этого контента грозит нарушителям судебными разбирательствами. Позднее аналогичные предупреждения появились в титрах фильмов «Мир юрского периода: Возрождение» и «Плохие парни 2». «Этот фильм защищён законами США и других стран. Несанкционированное копирование, распространение или демонстрация повлекут за собой гражданскую ответственность и уголовное преследование», — говорится в сообщении Universal Pictures. В компании считают, что добавление в титры такой формулировки создаст дополнительный уровень защиты от кражи кинофильмов с целью сбора данных для обучения ИИ-моделей. В некоторых странах в предупреждении компании упоминается вступивший в силу в Евросоюзе в 2019 году закон об авторском праве. Этот закон позволяет авторам контента отказаться от использования их материалов в научных целях. Быстрое развитие генеративных нейросетей несёт опасность для киноиндустрии, поскольку легко представить себе будущее, в котором многие зрители откажутся от просмотра традиционных фильмов в пользу того, что генерируют нейросети. При этом такие алгоритмы обычно обучаются на принадлежащей киностудиям интеллектуальной собственности. В настоящее время нейросети преимущественно задействованы для оптимизации отдельных процессов кинопроизводства, но уже сейчас есть игроки, которые верят в то, что будущее киноиндустрии за искусственным интеллектом. Например, в конце прошлого месяца студия Fable Studios Эдварда Саатчи (Edward Saatchi) объявила о получении неназванного объёма инвестиций от Amazon на создание платформы, которая позволит пользователям генерировать эпизоды шоу по простому текстовому описанию. У компании большие амбиции в этом направлении, она планирует выпустить в прокат свой первый сгенерированный ИИ полнометражный фильм в 2026 году. YouTube добавил ИИ-инструменты для создания роликов Shorts из фото или текста
23.07.2025 [22:02],
Николай Хижняк
Платформа YouTube начала внедрение инструментов на базе генеративного ИИ для упрощения процесса создания коротких вертикальных видео Shorts. Новые функции позволяют, например, преобразовывать фотографии в видео, а также предлагают целый арсенал видеоэффектов на базе ИИ. Кроме того, платформа представила инструмент генерации видео по подсказкам — AI Playground. 
Источник изображения: Christian Wiediger/unsplash.com Google представила три основные функции на базе ИИ для создателей Shorts. Одна из них позволяет превращать фото в видео — для создания клипа достаточно одного статичного изображения. Хотя Google не уточняет ограничения по длине таких роликов, вероятно, они будут довольно короткими. В инструментах редактирования Shorts также появились два новых ИИ-эффекта. Их можно выбрать перед началом записи. Первый — эффект «погружения в воду»: ИИ генерирует промежуточные кадры между реальными, создавая иллюзию, будто объект на видео погружается под воду. С примером этого эффекта можно ознакомиться ниже. Также в разделе эффектов появилась функция, позволяющая сделать грубый набросок прямо на экране смартфона, который затем будет преобразован в более красочное и проработанное изображение. Новые инструменты GenAI включают и платформу AI Playground — полноценную среду для генерации контента, а не просто наложения эффектов на видео и изображения. AI Playground позволяет создавать видео, изображения и музыку на основе текстовых описаний или готовых примеров. Получившийся контент можно публиковать в YouTube Shorts; он будет помечаться как созданный с использованием ИИ. По словам Google, развёртывание новых функций займёт несколько недель. На первом этапе они станут доступны пользователям в США, Канаде, Австралии и Новой Зеландии. В перспективе ожидается расширение географии их поддержки. Инструменты GenAI, представленные YouTube для Shorts, основаны на модели ИИ Veo 2. В будущем они будут переведены на новую модель Veo 3. Правда, сроки запуска пока не определены. Adobe Firefly научился добавлять звуковое сопровождение к генерируемым ИИ видео
17.07.2025 [19:57],
Владимир Фетисов
С тех пор как в апреле Adobe выпустила обновлённое приложение Firefly, для платформы генеративных ИИ-сервисов компании почти каждый месяц выходят крупные обновления. Сегодня разработчики представили несколько новых функций, которые будут полезны тем, кто использует сервис для создания видео. 
Источник изображения: Adobe Начнём с того, что Adobe упростила процесс добавления звуковых эффектов к клипам, созданным с помощью генеративных нейросетей. В настоящее время многие алгоритмы генерируют видео без звукового сопровождения. Adobe решает эту проблему с помощью новой функции, которая позволяет пользователю сначала описать звуковой эффект, который он хочет создать, а затем попытаться его воспроизвести. Вторая часть необходима не для того, чтобы ИИ-алгоритм имитировал звук, а для того, чтобы система лучше поняла, какую интенсивность и продолжительность звука ожидает пользователь. Во время демонстрации сотрудник Adobe использовал новую функцию, чтобы добавить звук расстёгивающейся молнии. Он произнёс «ззззттт», после чего алгоритм в точности воспроизвёл этот эффект с нужной громкостью. Отмечается, что не всегда генерация звука проходит безупречно, однако функция вполне подходит для создания черновых версий, как и задумывала Adobe. Ещё одной новой функцией стала Composition Reference. Она позволяет загрузить изображение или видео для управления процессом генерации. С помощью Video Presets можно задать стиль создаваемого ролика. Среди прочего на данный момент доступны стили аниме, чёрно-белое видео и видео с использованием векторной графики. Функция Keyframe Cropping позволяет загрузить первый и последний кадры и выбрать соотношение сторон, после чего Firefly сгенерирует видео, соответствующее заданному формату. В июне на платформе Adobe появилась поддержка ИИ-алгоритмов сторонних разработчиков, и в этом месяце их список расширился. Наиболее примечательным стало появление модели Google Veo 3, представленной в мае на конференции Google I/O 2025. В настоящее время Veo 3 — одна из немногих ИИ-моделей, способных генерировать видео со звуком. Каждое видео, созданное на платформе Firefly, имеет цифровую подпись, указывающую на то, что ролик был сгенерирован с помощью ИИ. «Сбер» представил нейросеть Kandinsky 4.1 Video для генерации 10-секундных HD-видео
25.06.2025 [15:40],
Владимир Фетисов
«Сбер» в рамках технологической конференции GigaConf анонсировал генеративную нейросеть Kandinsky 4.1 Video, которая позволяет создавать 10-секундные видео в формате HD по текстовому описанию или изображению. На данный момент опробовать новый алгоритм уже смогли участники конференции и профессиональные дизайнеры. 
Источник изображения: Steve Johnson / Unsplash «Kandinsky 4.1 Video обеспечивает качественно новый уровень генеративного видео. Модель стала в разы лучше по всем параметрам: по соответствию промпту, визуальному качеству, качеству генерации движений, а также способности моделировать физику мира. Такие разработки открывают беспрецедентные возможности как для дизайнеров, маркетологов, так и для представителей любых других креативных индустрий, работающих над созданием высококачественного видеоконтента», — рассказал старший вице-президент «Сбербанка» Андрей Белевцев. Согласно имеющимся данным, Kandinsky 4.1 Video генерирует видеоряд продолжительностью до 10 секунд в разрешении SD (720×576 пикселей) или HD (1280×720 пикселей). Разработчики дообучили новую архитектуру диффузионного трансформера на данных, подготовленных более чем 100 профессиональными фотографами и художниками. Особое внимание уделялось оптимизации вычислительных процессов. За счёт применения методов дистилляции и ускорения удалось более чем втрое сократить время генерации по сравнению с моделью предыдущего поколения. Kandinsky 1.4 Video поддерживает создание роликов с произвольным соотношением сторон, за счёт чего генерируемый контент можно адаптировать под разные платформы и маркетинговые задачи. Для всех желающих новая версия алгоритма станет доступна в ближайшее время. «Весёлая, простая и красивая»: Midjourney запустила V1 — свою первую ИИ-модель для генерации видео по изображениям
19.06.2025 [09:45],
Сергей Сурабекянц
Midjourney, один из самых популярных стартапов по генерации изображений на основе ИИ, объявил о запуске модели V1, генерирующей видеоролики из изображений. Как и другие модели компании, на момент запуска V1 доступна только через Discord и только онлайн. 
Источник изображения: Midjourney «Представляем нашу модель видео V1. Она весёлая, простая и красивая. Доступная за 10 долларов в месяц, это первая модель видео для всех и прямо сейчас», — говорится в аккаунте Midjourney в социальной сети X. V1 составит конкуренцию таким моделям видеогенерации, как Sora от OpenAI, Gen 4 от Runway, Firefly от Adobe и Veo 3 от Google. Midjourney подчеркнула, что в отличие от большинства компаний, сосредоточенных на разработке коммерческих моделей, она в первую очередь ориентирована на творческую аудиторию. По мнению экспертов, подобно сгенерированным изображениям Midjourney, видеоролики, созданные V1, выглядят «несколько потусторонними, а не гиперреалистичными». Хотя длительность видео, созданного с помощью V1, ограничена пятью секундами, пользователь может продлить его на четыре секунды до четырёх раз подряд, увеличив длительность финального ролика до 21 секунды. На момент запуска самым дешёвым способом опробовать V1 является подписка на базовый тариф Midjourney стоимостью $10 в месяц с ограниченным количеством генераций. Для безлимитного использования V1 придётся выбрать тариф Pro за $60 или Mega за $120 с дополнительным режимом Relax. Midjourney планирует в течение следующего месяца пересмотреть систему тарифных планов. Компания ставит перед собой более масштабные задачи, нежели генерация перебивок для голливудских фильмов или создание рекламных роликов. По словам главы Midjourney Дэвида Хольца (David Holz), конечная цель компании — модели ИИ, «способные к моделированию открытого мира в реальном времени». Также в дальнейших планах Midjourney — разработка ИИ-модели для полноценного 3D-рендеринга. Запуск V1 от Midjourney состоялся всего через неделю после того, как на стартап подали в суд две известные киностудии Голливуда —Disney и Universal. В иске утверждается, что модели Midjourney генерируют изображения персонажей студий, защищённых авторским правом, таких как Гомер Симпсон и Дарт Вейдер. 
Источник изображения: theverge.com Google интегрирует в YouTube Shorts свою новую ИИ-модель генерации видео Veo 3
19.06.2025 [08:30],
Сергей Сурабекянц
Генеральный директор YouTube Нил Мохан (Neal Mohan) сообщил, что новейшая модель генерации видео на основе искусственного интеллекта Google Veo 3 будет добавлена в раздел коротких вертикальных роликов Shorts «этим летом». Мохан также сообщил, что в настоящее среднее количество просмотров коротких видео превысило 200 миллиардов в день. 
Источник изображений: unsplash.com Создатели Shorts уже сейчас могут воспользоваться моделью Google Veo 2 предыдущего поколения для генерации динамических фоновых изображений с помощью инструмента Dream Screen. Мохан не уточнил, какие именно возможности предоставит развёртывание модели Veo 3 в Shorts, но упомянул об улучшенном качестве видео и возможности создания звуковой дорожки. Пока неясно, придётся ли создателям Shorts платить за использование Veo 3. Сейчас для создания видео при помощи Veo 3 требуется платная подписка на тарифные планы AI Pro или AI Ultra от Google. Далеко не все приветствуют всё более широкое распространение генераторов видео на основе искусственного интеллекта. Журналистка издания The Verge Эллисон Джонсон (Allison Johnson) недавно назвала генератор видео Google Veo 3 «мечтой торговца помоями».  Google расширила доступ к ИИ-генератору Veo 3 через приложение Gemini
26.05.2025 [17:01],
Владимир Фетисов
Всего несколько дней прошло с тех пор, как Google представила свой новый ИИ-генератор видео Veo 3, а он уже стал доступен пользователям из 71 страны. Опробовать новинку в деле смогут подписчики приложения Gemini из десятков стран, но на территории ЕС и в России сервис пока недоступен. Об этом в своём аккаунте в соцсети X сообщил глава Google Labs и Gemini Джош Вудворд (Josh Woodward). 
Источник изображения: Veo 3 / Google Согласно имеющимся данным, взаимодействовать с Veo 3 могут подписчики Gemini Pro, которые получат пробный пакет на 10 генераций видео через веб-интерфейс. На данном этапе пакет из десяти генераций является одноразовым, т.е. не будет обновлён после истечения какого-то периода времени. Обладатели подписки Ultra стоимостью $250 в месяц получат максимально разрешённое Google количество генераций, которые будут обновляться ежедневно. В режиме Flow, который ориентирован на создателей видеоконтента с помощью ИИ, подписчики Ultra смогу генерировать до 125 роликов в месяц, а подписчики Pro — до 10 роликов в месяц. На данном этапе не обошлось без некоторых ограничений. ИИ-генератор Veo 3 работает только в веб-версии Gemini Pro и поддерживает генерацию звукового сопровождения только на английском языке, хотя в некоторых случаях может появляться речь на других языках. Несмотря на это и ограниченную доступность, у Veo 3 есть все шансы стать вирусной сенсацией Google в сфере ИИ. Интернет уже наводнили созданные с помощью этого сервиса ролики, показывающие, как сочетание видео и аудио устанавливает новый стандарт качества для контента, генерируемого с помощью ИИ. Также отмечается, что Veo 3 с поразительной точностью следует подсказкам пользователей. Это повышает качество создаваемого контента, но в то же время позволяет генерировать фейковые видео, которые выглядят и звучат как настоящие. В одном из примеров пользователь сгенерировал видео с вымышленного автомобильного шоу, которое выглядит вполне реалистично. Однако злоумышленники могут задействовать сервис для генерации видео с высказываниями политиков, массовыми протестами и какими-то другими ситуациями для манипулирования общественным мнением. Veo 3 подтверждает опасения по поводу значимой роли ИИ в распространении дезинформации и одновременно демонстрирует, насколько далеко продвинулись технологии. Ещё несколько лет назад создание качественного фейкового видео с заменой лица требовало многочасовой работы и наличия серьёзных технических навыков. Сегодня несколько строчек теста позволяют генерировать реалистичные сцены с естественным звуком. Всё это говорит о том, что людям следует тщательнее проверять подлинность просматриваемого контента, не принимая всё увиденное за действительность. Смартфоны Honor 400 смогут анимировать фото с помощью ИИ-генератора от Google
12.05.2025 [17:47],
Владимир Фетисов
Разработанный Google ИИ-генератор видео из статических изображений станет доступен владельцам новых смартфонов Honor. Согласно имеющимся данным, опробовать ИИ-генератор видео в деле первыми смогут владельцы мобильных устройств Honor 400 и 400 Pro, продажи которых стартуют 22 мая. 
Источник изображения: Steve Johnson / Unsplash Новый ИИ-инструмент построен на базе большой языковой модели Google Veo 2. Он может генерировать пятисекундные видеоролики из статических изображений в портретной или альбомной ориентации. На создание одного такого ролика алгоритму требуется 1-2 минуты. Эта функция будет доступна в «Галерее» на новых смартфонах Honor, и она будет достаточно простой. Пользователь не сможет дополнить исходное изображение текстовой подсказкой, поэтому результат работы ИИ-алгоритма может оказаться неожиданным.  В некоторых случаях ИИ-генератор видео работает достаточно хорошо, особенно, когда на снимке запечатлён простой объект, например, человек или животное. В таком случае движения на видео выглядят вполне реалистично. С более сложными объектами ИИ-генератор справляется не так хорошо. Например, женский футбольный матч он представил как игру с участием не менее 27 человек в трёх командах и с двумя судьями. При обработке портрета Винсента Ван Гога генератор решил, что будет уместным, если из глаза художника вылетит голубь.  Отмечается, что доступный в новых смартфонах Honor ИИ-алгоритм создаёт видео в формате MP4. В течение первых двух месяцев владельцы Honor 400 и 400 Pro смогут бесплатно пользоваться новой функцией, создавая до 10 видео в день. Adobe обновила ИИ-генератор изображений Firefly и переработала его веб-приложение
24.04.2025 [14:11],
Владимир Фетисов
Adobe объявила о запуске новой версии ИИ-модели Firefly для генерации изображений, а также алгоритма генерации векторной графики и обновлённого веб-приложения, в котором собраны все генеративные модели компании, а также некоторые нейросети конкурентов. В дополнение к этому разработчики продолжают трудиться над созданием мобильного приложения Firefly. 
Источник изображения: Rubaitul Azad / Unsplash Большая языковая модель Firefly Image Model 4, по данным Adobe, превосходит своих предшественниц по качеству генерируемых изображений, скорости обработки запросов и возможностям по настройке параметров создаваемого контента. Поддерживается генерация изображений с разрешением до 2K. Существует также более производительная версия алгоритма Image Model 4 Ultra, которая может создавать сложные сцены с множеством мелких структур и большим количеством деталей. Представитель Adobe рассказал, что разработчики сделали новые ИИ-модели более производительными, чтобы они могли генерировать более детализированные изображения. Помимо прочего, более качественной стала генерация текста на изображениях, а также появилась возможность создавать несколько изображений в том же стиле, что и исходное. Вместе с этим компания открыла доступ всем желающим к своему ИИ-генератору видео Firefly, бета-тестирование которого началось в прошлом году. Алгоритм позволяет создавать видео на основе текстового описания или изображения, менять ракурсы камеры, указывать начальный и конечный кадры, настраивать элементы стиля анимации и др. ИИ-модель может создавать ролики в формате 1080p. ИИ-модель Firefly для создания векторной графики может генерировать пригодные для дальнейшего редактирования векторные иллюстрации, а также итерировать и генерировать варианты логотипов, паттернов и др. Доступ ко всем новым ИИ-моделям Adobe можно получить в обновлённом веб-приложении Firefly. Там также нашлось место генератору изображений GPT от OpenAI, моделям Imagen 3 и Veo 2 от Google, а также алгоритму Flux 1.1 Pro от Flux. Пользователи могут переключаться между этими алгоритмами по своему усмотрению. Adobe также проводит публичное тестирование нового продукта под названием Firefly Boards, который представляет собой холст для творчеств и реализации идей. С его помощью можно генерировать или импортировать изображения, редактировать их, в том числе совместно с другими пользователями платформы. Firefly Boards также будет доступен в веб-приложении Firefly. В дополнение к этому Adobe открыла доступ к API Text-to-Image и Avatar API, а также объявила о начале бета-тестирования API Text-to-Video. Получить доступ к этим и другим программным интерфейсам компании можно через платформу Firefly Services. Платные пользователи Google Gemini получили доступ к ИИ-генератору кинематографических видео Veo 2
15.04.2025 [22:35],
Владимир Фетисов
Google предложила подписчикам Gemini Advanced опробовать Veo 2 — свой генератор видео на базе искусственного интеллекта, который, по словам компании, способен на основе текстового описания создавать кинематографические ролики в высоком разрешении. Желающим испытать алгоритм достаточно выбрать его в списке доступных инструментов, после чего они смогут сгенерировать на основе текстовой подсказки 8-секундный ролик в разрешении 720p. 
Источник изображения: Google Предложение Google предусматривает ограничение на количество роликов, создаваемых с помощью Veo 2. В компании не предоставили более подробной информации, отметив лишь, что пользователи получат соответствующее уведомление при приближении к лимиту. Также известно, что Veo 2 генерирует ролики в формате MP4, а пользователи мобильных устройств смогут сразу загружать созданный контент в TikTok или на YouTube с помощью кнопки «Поделиться». По данным Google, обновлённая ИИ-модель «лучше понимает физику реального мира и движения человека», что позволяет ей передавать «плавные движения персонажей, реалистичные сцены и более тонкие визуальные детали в разных сюжетах и стилях». Генерируемые с помощью Veo 2 ролики дополняются цифровыми маркерами SynthID, которые указывают на то, что видео создано с использованием нейросети. Одновременно Google открывает для подписчиков One AI Premium доступ к инструменту Whisk Animate, который использует Veo 2 для создания 8-секундных роликов на основе изображения. Функция Whisk Animate доступна подписчикам по всему миру через Google Labs. Google представила Vertex AI Studio — набор ИИ-инструментов для создания готовых к публикации видео
09.04.2025 [17:47],
Владимир Фетисов
Компания Google объявила о запуске Vertex AI Media Studio — набора ИИ-инструментов, с помощью которых пользователи могут создавать видео на основе текстового описания. Сервис построен на базе платформы Vertex AI и объединяет несколько передовых ИИ-моделей для реализации всех аспектов видеопроизводства, включая визуальные эффекты, озвучку и фоновую музыку, не требуя от пользователей навыков в редактировании видео или написании программного кода. 
Источник изображения: Steve Johnson/unsplash.com Пользователям предлагается начать процесс работы с создания изображения с помощью ИИ-генератора Imagen 3. Затем полученное изображение можно превратить в видео с помощью алгоритма Veo 2, который также предлагает возможность настройки разных параметров. По данным Google, Veo позволяет выбрать тип движения камеры, например, съёмка с дрона или панорама, а также настроить частоту кадров и продолжительность ролика. Если алгоритм добавит в видео какие-то лишние элементы, их можно легко удалить с помощью инструмента Magic Eraser. После завершения работы над визуальными эффектами пользователю предлагается задействовать ИИ-синтезатор голоса Chirp для создания закадровой озвучки. В завершающей стадии ИИ-модель Lyria, являющаяся совместным творением DeepMind и YouTube, поможет сгенерировать музыкальное сопровождение, которое будет служить фоном для пользовательского видео. Теоретически в конце должно получиться готовое к публикации видео, которые не уступает профессиональному ни с точки зрения происходящего в кадре, ни с точки зрения озвучки. И всё это пользователь может создать в одном сервисе Vertex AI Studio, т.е. по сути том же сервисе, где разработчики тестируют новейшие версии ИИ-модели Gemini. Google раскрыла цену генерации видео в Veo 2 — в 64 000 раз дешевле «Мстителей»
24.02.2025 [14:44],
Владимир Фетисов
Компания Google без лишнего шума раскрыла стоимость использования своей новой генеративной нейросети Veo 2, которая предназначена для создания видео и была впервые анонсирована в декабре. Стоимость генерации видео с помощью ИИ-алгоритма составит $0,5 за секунду. 
Источник изображения: Google Это означает, что минута сгенерированного с помощью Veo 2 видео будет стоить $30, а за час придётся заплатить $1800. В подразделении Google DeepMind, занимающемся разработками в сфере искусственного интеллекта, эти цифры сравнили с блокбастером Marvel «Мстители: Финал», производственный бюджет которого составил $356 млн, т.е. примерно $32 000 за секунду видео. Конечно, пользователи Veo 2 не обязательно будут использовать каждую секунду сгенерированного алгоритмом видео, за которую они заплатят. Кроме того, в обозримом будущем нейросеть вряд ли сможет создать что-то подобное блокбастерам Marvel. В сообщении Google сказано, что алгоритм может генерировать видео продолжительностью более двух минут. Отметим, что OpenAI недавно сделала доступным свой ИИ-генератор видео Sora для подписчиков ChatGPT Pro, которые платят $200 в месяц. В YouTube появился ИИ-генератор полноценных роликов по текстовому описанию — их можно будет публиковать в Shorts
13.02.2025 [22:57],
Владимир Фетисов
На платформе YouTube появилась новая функция на основе искусственного интеллекта. Она предназначена для генерации небольших роликов, которые пользователи могут публиковать в Shorts. Речь идёт об инструменте YouTube Dream Screen, который построен на базе Google Veo 2. Эта функция и раньше позволяла генерировать ролики на основе текстового описания, но прежде пользователи могли лишь задействовать их в качестве фона. 
Источник изображения: Copilot Теперь же созданные с помощью Dream Screen видео можно публиковать в своём аккаунте в Shorts. Чтобы опробовать новые возможности пользователю нужно активировать камеру в Shorts, запустить функцию Dream Screen, открыть панель выбора медиафайлов и нажать на кнопку «Создать». После этого можно ввести текстовое описание будущего ролика, а также выбрать один из доступных стилей, объективов, кинематографических эффектов и указать продолжительность видео. По словам представителей YouTube, возможность публиковать сгенерированные ИИ ролики в Shorts на этой неделе появится у пользователей платформы из США, Канады, Австралии и Новой Зеландии. Позднее она также станет доступна в других странах, но более точные сроки озвучены не были. Это обновление стало несколько неожиданным, учитывая, что последняя версия нейросети Google Veo всё ещё находится в раннем доступе. По данным YouTube, интеграция нейросети с функцией Dream Screen позволит быстрее генерировать более «детальные и реалистичные» видео с учётом физики реального мира и естественных движений людей. При этом созданные с помощью ИИ видео будут помечаться, как видимыми визуальными метками, так и невидимыми водяными знаками Google SynthID, указывающими на то, что ролик создан или изменён с помощью нейросети. YouTube добавил в Shorts функцию Dream Screen — ИИ-генератор фонов для роликов
22.11.2024 [16:25],
Павел Котов
Администрация YouTube объявила, что в разделе коротких вертикальных роликов Shorts теперь доступна обновлённая функция Dream Screen — генерация динамических фоновых изображений с использованием искусственного интеллекта. Ранее функция Dream Screen позволяла генерировать в качестве фонов не видео, а неподвижные картинки. 
Источник изображения: YouTube Новая возможность появилась благодаря интеграции модели для генерации видео Google DeepMind Veo — она позволяет создавать ролики с разрешением 1080p в разных кинематографических стилях. Чтобы запустить новую функцию, необходимо перейти в камеру Shorts, выбрать значок «Зелёный экран» и опцию Dream Screen — здесь можно ввести текстовый запрос, например, «пейзаж из конфет» или «волшебный лес и ручей»; после чего останется выбрать стиль анимации и нажать кнопку «Создать». Dream Screen создаст несколько видеофонов, из которых нужно выбрать один, после чего можно записывать видео с этим изображением позади себя. Новая функция пригодится, например, чтобы погрузить зрителя в атмосферу любимой книги или подготовить анимированное вступление к основному ролику. В перспективе YouTube планирует предоставить авторам возможность создавать 6-секундные видеоролики, полностью сгенерированные Dream Screen. Крупнейшая в мире платформа коротких видео TikTok также поддерживает создание фоновых изображений с помощью ИИ, но эти картинки пока статические. Воспользоваться обновлённым вариантом Dream Screen могут пользователи YouTube из США, Канады, Австралии и Новой Зеландии. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex