|
Опрос
|
реклама
Быстрый переход
Модульная компактная экшн-камера DJI Osmo Nano показалась на фото до анонса
10.09.2025 [21:17],
Сергей Сурабекянц
Хотя DJI пока не делала официального заявления, утёкшие в интернет изображения подтверждают скорый выход модульной компактной экшн-камеры Osmo Nano, идейного продолжателя модели Action 2, дебютировавшей в 2021 году. Новинка DJI сохранила модульный принцип Action 2, например, экран с магнитным креплением, но при этом значительно меньше предшественницы — по размеру она ближе к Insta360 Go Ultra, анонсированной в прошлом месяце. 
Источник изображения: The Product Village Вчера инсайдер Роланд Квандт (Roland Quandt) опубликовал официальные фотографии DJI Osmo Nano, на которых показан модуль камеры без собственного экрана с дополнительным модулем для съёмок в реальном времени или показа уже отснятого материала. Игр с FSR 4 станет куда больше: AMD выпустила FidelityFX SDK 2.0, что упростит интеграцию новейшего ИИ-масштабирования
21.08.2025 [21:14],
Николай Хижняк
Компания AMD выпустила FidelityFX SDK 2.0, тем самым открыв разработчикам игр доступ к своей технологии ИИ-масштабирования FSR 4 (FidelityFX Super Resolution 4). Теперь разработчики могут напрямую интегрировать FSR 4 в свои проекты, используя готовые подписанные DLL-библиотеки. Однако в будущем API AMD FidelityFX позволит обновлять FSR 4 через драйверы с помощью функции AMD FSR Upgrade. 
Источник изображений: AMD Выпуск SDK открывает возможности для прямой интеграции AMD FSR 4 в игры. До сих пор поддержка FSR 4 зависела от API AMD FidelityFX, который использовался для обновления игр с FSR 3.1 до FSR 4. Вскоре игры смогут поддерживать технологию AMD FSR 4 по умолчанию. Это означает, что будущим проектам не потребуются драйверы, оптимизированные специально для FSR 4. 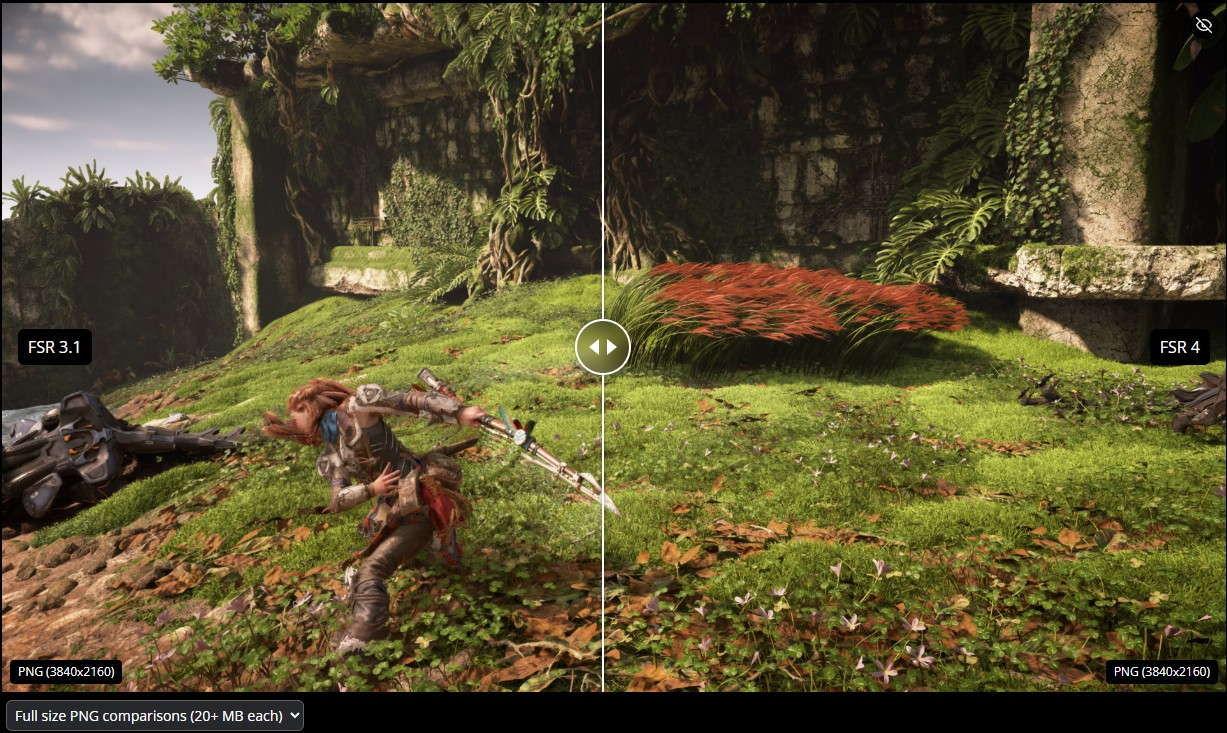
 Вместе с выпуском SDK для FSR 4 компания AMD представила новый плагин для Unreal Engine 5, который позволяет использовать FSR 4 в версиях Unreal Engine 5.1–5.6. «Обновление AMD FidelityFX SDK v2.0 включает в себя наш передовой алгоритм масштабирования на основе машинного обучения AMD FidelityFX Super Resolution 4 (FSR 4). Новый алгоритм масштабирования AMD FSR 4 с машинным обучением обучен на высококачественных игровых данных, полученных с помощью реального игрового процесса на графических процессорах AMD Instinct. FSR 4 использует аппаратно-ускоренные функции архитектуры AMD RDNA 4, разработанные для обеспечения максимального качества масштабирования и существенного прироста производительности. AMD FSR 4 обеспечивает значительное улучшение качества изображения по сравнению с масштабированием FSR 3.1 благодаря алгоритму на основе машинного обучения, разработанному для повышения временной стабильности, лучшей детализации и уменьшения ореолов. По сравнению с FSR 3.1 технология FSR 4 сокращает ореолы на движущихся объектах и устраняет артефакты на поверхностях, которые отсутствуют в исходном изображении. Это значительно улучшает качество картинки во время игры», — сообщает AMD в своём официальном блоге.  Для поддержки технологии FSR 4 требуются видеокарты Radeon RX 9000 на архитектуре RDNA 4. «Космический виноград»: древняя галактика сломала представления учёных о процессах в ранней Вселенной
11.08.2025 [23:08],
Николай Хижняк
Астрономы обнаружили далёкую галактику, в которой, по всей видимости, расположены дюжины плотно упакованных областей звездообразования, из-за чего она напоминает виноградную гроздь. Результаты исследования были опубликованы 7 августа в журнале Nature Astronomy, пишет Space.com. 
Художественное представление галактики «Космический виноград». Источник изображения: NSF/AUI/NSF NRAO/B.Saxton Из-за своей формы и структуры объект получил название «Космический виноград». Новое исследование показало, что во вращающемся диске галактики находится как минимум 15 массивных сгустков звездообразования, образующих нечто, напоминающее гроздь ярко-фиолетового винограда в космосе. Учёные полагают, что галактика сформировалась всего через 930 млн лет после Большого взрыва. Наблюдения проводились с помощью космического телескопа имени Джеймса Уэбба (JWST) и Атакамской большой миллиметровой/субмиллиметровой антенной решётки (ALMA) с применением метода гравитационного линзирования. В нём галактическое скопление RXCJ0600-2007, расположенное перед объектом, сыграло роль «увеличительного стекла» для более далёких структур. «Этот объект известен как одна из самых сильно гравитационно линзированных дальних галактик, когда-либо обнаруженных», — отметил руководитель исследования Сэйдзи Фудзимото (Seiji Fujimoto) в заявлении обсерватории Макдональда Техасского университета в Остине (UT Austin). «Благодаря этому мощному естественному увеличению в сочетании с наблюдениями, выполненными с помощью одних из самых современных телескопов мира, мы получили уникальную возможность изучить внутреннюю структуру далёкой галактики с беспрецедентной чувствительностью и разрешением», — добавил Фудзимото, начавший исследование в Техасском университете в Остине и ныне работающий в Университете Торонто. Для изучения «Космического винограда» учёные проанализировали более 100 часов телескопических наблюдений. Ранее полученные космическим телескопом «Хаббл» изображения предполагали наличие внутри неё гладкого вращающегося диска, однако высокое разрешение ALMA и JWST позволило увидеть гораздо более сложную картину — детальнейшее на сегодняшний день изображение внутренней структуры далёкой галактики и массивных сгустков плотного газа, готовых к звездообразованию. 
Источник изображения: NASA/ESA/CSA/Fujimoto и др. Выше представлены изображения скопления галактик RXCJ0600-2007, полученные телескопом JWST в ближнем инфракрасном диапазоне, демонстрирующие мощный эффект гравитационного линзирования. Эти наблюдения с рекордным разрешением раскрыли структуру далёкой галактики ранней Вселенной, состоящей более чем из 15 компактных сгустков звездообразования, расположенных подобно виноградной грозди. «Наши наблюдения показывают, что в свете молодых звёзд некоторых ранних галактик доминируют несколько массивных, плотных, компактных скоплений, а не однородная звёздная структура», — отметил соавтор исследования Майк Бойлан-Колчин (Mike Boylan-Kolchin), профессор астрономии Техасского университета в Остине. По мнению исследователей, это открытие меняет представления о раннем формировании галактик. Оно впервые демонстрирует чёткую связь между их малыми внутренними структурами — в данном случае массивными сгустками звездообразования — и общим вращением, что позволяет предположить: многие ранее наблюдавшиеся как гладкие галактики на самом деле могут быть заполнены подобными скрытыми скоплениями звёзд. Alibaba представила ИИ-генератор изображений Qwen-Image с высокой степенью грамотности
05.08.2025 [16:49],
Павел Котов
Alibaba представила модель искусственного интеллекта Qwen-Image 20B MMDiT, предназначенную для работы с изображениями — в ней разработчик значительно улучшил механизмы прорисовки сложных текстов и реализовал возможности точного редактирования изображений. 
Источник изображения: huggingface.co/Qwen Модель, доступ к которой откроется на платформе Qwen Chat в разделе «Генерация изображений», обладает расширенными возможностями рендеринга текста, в том числе многострочных макетов с семантикой на уровне абзацев и детализированными элементами. Поддерживаются языки на основе букв и иероглифов. Усовершенствованные механизмы многозадачного обучения помогли расширить возможности редактирования изображений с сохранением смыслового наполнения и визуального реализма. Новая Qwen-Image, уверяет Alibaba, обошла существующие решения в нескольких тестах по задачам на генерацию и редактирование изображений, включая GenEval, DPG, OneIG-Bench, GEdit, ImgEdit и GSO. Особых успехов удалось добиться в тестах на качество прорисовки текста, таких как LongText-Bench, ChineseWord и TextCraft — новая модель превзошла современные аналоги. Qwen-Image, в частности, справляется с точным отображением китайских иероглифов на вывесках магазинов с правильной глубиной резкости, с созданием детализированного английского текста на обложках книг и информационных слайдах, поддерживается работа с двуязычным контентом. Помимо обработки текста, модель свободно ориентируется в художественных жанрах от фотореализма до импрессионизма; поддерживаются различные операции при редактировании изображений, в том числе изменение стиля, добавление, удаление и улучшение деталей, а также редактирование текста и изменение поз у персонажей. В проекте Qwen-Image разработчики Alibaba, по их словам стремились способствовать развитию генерации изображений, снизить технические барьеры для создания визуальных материалов и вдохновить коллег на инновационные приложения. xAI запустила Grok Imagine — платный ИИ-генератор изображений и видео с «пикантным режимом»
04.08.2025 [19:36],
Сергей Сурабекянц
Компания xAI Илона Маска (Elon Musk) официально представила Grok Imagine — генератор изображений и видео, доступный для подписчиков тарифных планов SuperGrok и Premium+. Как и обещал Маск, позиционирующий Grok как ИИ, свободный от цензуры, Grok Imagine позволяет создавать контент, который обычно в интернете маркируется аббревиатурой NSFW (not safe/suitable for work — «небезопасно/неподходяще для демонстрации на работе»). 
Источник изображения: @elonmusk Grok Imagine преобразовывает текстовые или графические запросы в 15-секундные видеоролики с оригинальным звуком и предлагает «пикантный режим», позволяющий пользователям создавать контент сексуального характера, включая частичную наготу. Пример такого видео опубликовал в своём аккаунте X Илон Маск. Журналисты TechCrunch сообщили, что многие из опробованных ими (во имя журналистики, конечно!) пикантных запросов привели к появлению «модерированных» размытых изображений, однако изображения полуобнажённых тел им получить удалось. NSFW-контент неудивителен для xAI, учитывая выход в прошлом месяце пикантного аниме-компаньона Ani с искусственным интеллектом. Но так же, как необузданная натура Grok была забавной, пока он не начал изрыгать оскорбительный, антисемитский и женоненавистнический контент, появление Grok Imagine может повлечь за собой свои непредвиденные последствия. При этом в Grok Imagine предусмотрены серьёзные ограничения, особенно учитывая, что модель позволяет создавать контент с изображениями знаменитостей. Так, попытки журналистов TechCrunch сгенерировать изображение беременного Дональда Трампа (Donald Trump) успехом не увенчались — Grok Imagine создавал либо изображения Трампа с младенцем на руках, либо рядом с беременной женщиной. Grok Imagine стремится конкурировать с такими игроками, как Google DeepMind, OpenAI, Runway и китайские нейросети, но пока находится на начальном этапе развития. По отзывам тестировщиков, генерируемые им изображения и видео людей нередко выглядят мультяшно, особенно из-за неестественной текстуры кожи. Тем не менее, генератор впечатляет: изображения создаются за считаные секунды и продолжают формироваться автоматически по мере прокрутки страницы. Затем их можно анимировать в стилизованные видеоролики. Пользовательский интерфейс удобен и интуитивно понятен. Недавно Маск заявил о намерении создать Baby Grok — чат-бот, пригодный для работы с детским контентом. Учитывая, насколько скандально развивается «взрослая версия» Grok, подобное направление экспансии довольно рискованно. Тем не менее, с точки зрения охвата аудитории эта ставка вполне может себя оправдать. Популярность Baby Grok может стать дополнительным источником дохода для xAI и новой статьёй расходов для родителей. Sony работает над трёхслойным датчиком изображения для фотокамер, который должен совершить революцию
02.08.2025 [13:11],
Владимир Фетисов
Подразделение Sony Imaging & Sensing Solution недавно провела встречу с инвесторами, в рамках которой представители направления Sony Semiconductor Solutions рассказали о перспективном трёхслойном датчике изображения, который обещает значительные улучшения при фото- и видеосъёмке. В настоящее время Sony выпускает матрицы для камер, основанные на двухслойной архитектуре. 
Источник изображений: petapixel.com По данным источника, в рамках прошедшей встречи с инвесторами компания подвела итоги 2024 финансового года, в ходе которого были зафиксированы рекордно высокие продажи и операционная прибыль. Вместе с этим представители компании рассказали о дальнейших планах по развитию бизнеса. Sony намерена инвестировать значительные средства в новые технологии, связанные с производством датчиков изображения. Одним из направлений станет развитие направления многослойных матриц для камер. 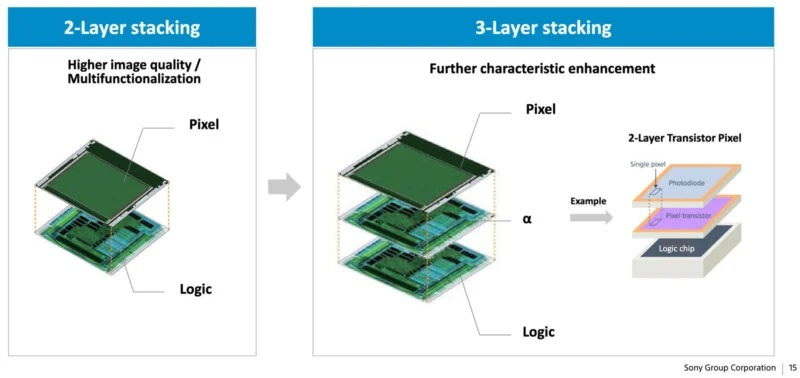 Sony уже использует многослойные датчики во многих камерах, но на данном этапе даже во флагманских моделях используются двухслойные матрицы. Речь идёт о датчиках, в которых один слой фотодиодов содержит все пиксели, используемые для съёмки изображений, а нижний транзисторный слой отвечает за обработку данных. Долгосрочные планы Sony по добавлению третьего слоя, по сути, означают расширение возможностей в плане обработки и повышения качества изображений. Чем выше вычислительная мощность матрицы, тем качественнее будут изображения при прочих равных условиях. 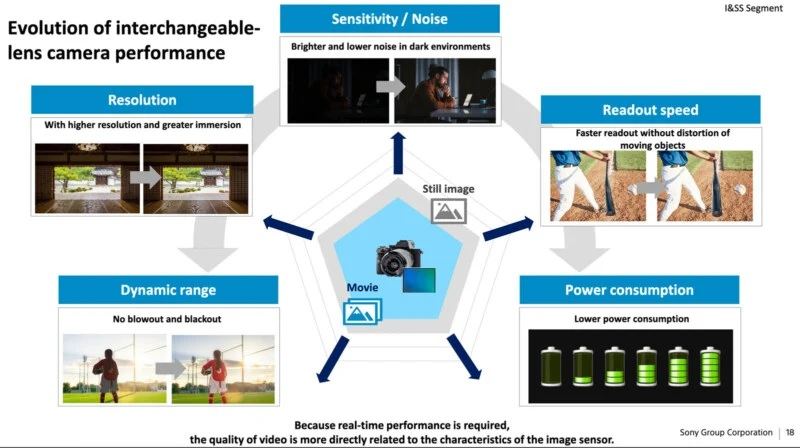 По данным Sony, увеличение вычислительной мощности на уровне сенсора может улучшить видимый динамический диапазон, чувствительность, шумоподавление, эффективность, скорость считывания и разрешение, хотя последнее больше касается видео, а не фотосъёмки. Появление нового слоя само по себе не изменит разрешение, но увеличение скорости считывания и производительности может дать возможность съёмки видео более высокого качества. Существующие камеры с датчиками высокого разрешения, как правило, не могут использовать его в полной мере при съёмке видео как раз из-за проблем со скоростью обработки данных. 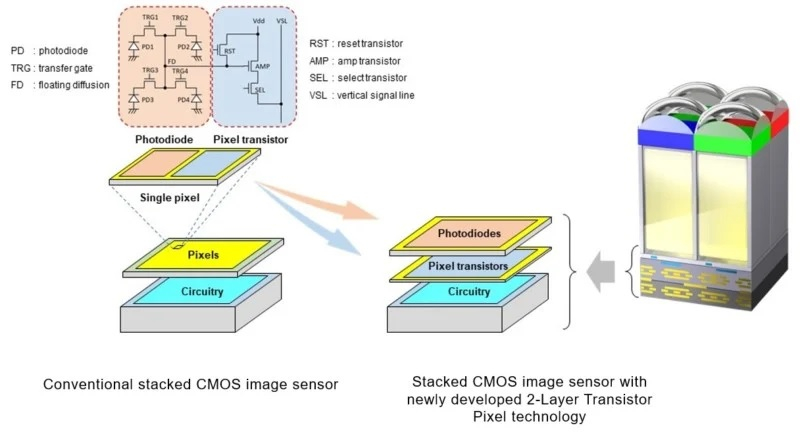 Более высокая скорость считывания благоприятно повлияет на многие аспекты работы камер, в том числе в режиме скользящего затвора, при скоростной серийной съёмке, а также повысит эффективность автофокуса. Повышение производительности может улучшить видимый динамический диапазон, но на практике динамический диапазон сенсора зависит от многих факторов, включая полную ёмкость пикселей матрицы и её шумовые характеристики. Хотя обработка и влияет на уровень шума, полная ёмкость пикселей остаётся неизменным физическим состоянием, из-за чего добавление ещё одного слоя может привести к снижению этого показателя в результате сжатия размеров пикселей.  Вопрос о том, когда трёхслойный датчик изображения может появиться в флагманских камерах Sony, остаётся открытым. Однако история компании говорит о том, что она умеет создавать инновационные матрицы и быстрые сенсоры с высоким разрешением. Sony остаётся привержена разработке полнокадровых датчиков, что позволяет с оптимизмом смотреть в будущее фото- и видеосъёмки. Photoshop сделал редактирование объектов и людей на фото удивительно простым
30.07.2025 [15:53],
Николай Хижняк
Компания Adobe запустила новые функции генеративного ИИ для Photoshop, упрощающие добавление и удаление людей и объектов на фотографиях. Обновление включает функции масштабирования изображений с помощью ИИ, улучшенный инструмент удаления объектов, а также средства автоматической композиции, которые позволяют плавно вписывать новые элементы в изображения всего за несколько кликов. 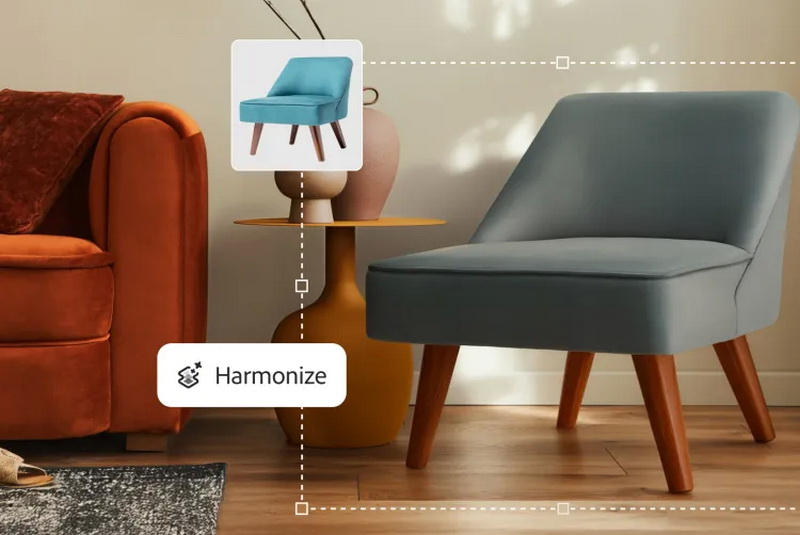
Источник изображений: Adobe Функция Harmonize основана на экспериментальной разработке Project Perfect Blend, представленной Adobe в прошлом году. При добавлении нового объекта на фотографию Harmonize автоматически корректирует цвет, освещение, тени и визуальный тон добавленного элемента, чтобы он естественным образом вписался в основное изображение. Обычно это требует определённых навыков и опыта работы с программами для редактирования фотографий. Бета-версия инструмента доступна для пользователей как веб-версии Photoshop, так и в приложении для ПК, а также в раннем доступе в мобильном приложении Photoshop для iOS.  Новый инструмент генеративного ИИ для масштабирования изображений также доступен в бета-версии для Photoshop в веб-версии и версии для ПК. По словам Adobe, он обеспечивает «высококачественное улучшение разрешения до восьми мегапикселей без ущерба для чёткости изображения», что позволяет улучшить детализацию изображений низкого качества. Это будет полезно, например, при восстановлении старых фотографий или адаптации изображений для различных платформ. Инструмент автоматического удаления объектов для пользователей настольных и веб-версий Photoshop также был обновлён. По словам разработчиков, он «очищает изображения с большей точностью». Улучшения должны привести к уменьшению количества нежелательных фоновых элементов на изображении и созданию более реалистичного контента для заполнения любых нежелательных пробелов. В частности, теперь он будет удалять нужный объект с изображения и редактировать получившийся пробел на снимке, добавляя максимально логичные детали.  В Photoshop уже были функции генеративного ИИ, которые позволяют добавлять новые объекты к изображениям на основе подсказок. Результаты могут быть непредсказуемыми, поэтому компания добавила меры предосторожности, предотвращающие создание чего-либо подозрительного, например, фейков известных публичных личностей, сцен насилия или материалов сексуального характера. Единственным ограничением той же новой функции Harmonize является то, что пользователю придётся найти изображения, которые он хочет объединить. Photoshop будет применять к отредактированным изображениям метки Content Credentials (учётные данные контента), содержащие информацию о том, как они были обработаны, но не предотвращать создание потенциально спорного контента. «Пользователи, использующие функцию Harmonize, должны соблюдать условия использования Adobe, которые запрещают создание незаконного или вредоносного контента. Adobe серьёзно относится к безопасности контента во всех своих продуктах и внедрила такие меры безопасности, как настройки Content Credentials, для защиты пользователей и борьбы с вредоносным и вводящим в заблуждение контентом. Учётные данные контента позволяют добросовестным пользователям добавлять историю редактирования к своей работе и создавать цифровую цепочку доверия и подлинности», — отметил в разговоре с порталом The Verge менеджер по продукту Photoshop Джоэл Баер (Joel Baer). Photoshop получил ИИ-инструмент для быстрого повышения качества старых фотографий
29.07.2025 [19:37],
Сергей Сурабекянц
Adobe представила в последней бета-версии Photoshop серию новых инструментов, которые, по заявлению компании, устранят «утомительные шаги, снизят уровень сложности и сделают точное редактирование более быстрым и интуитивно понятным». Самой востребованной среди пользователей, по словам Adobe, является ИИ-функция Generative Upscale («Генеративное Масштабирование»), позволяющая увеличивать изображения до 8 мегапикселей без потери качества. 
Источник изображений: Adobe В последней версии программы также появился обновлённый инструмент Remove («Удаление»), созданный на основе последней ИИ-модели Adobe Firefly. Он выполняет все ожидаемые функции стирания и удаления объектов, но при этом, по утверждению Adobe, обеспечивает более реалистичное изображение — на фотографии остаётся «меньше артефактов от удалённых объектов». Этот инструмент, как и Generative Upscale, доступен в бета-версии для настольных компьютеров и в веб-приложении. Adobe также запускает функцию Harmonize («Гармонизация»), ранее анонсированную под названием Project Perfect Blend на конференции Max в октябре 2024 года. Используя ИИ-модель Adobe Firefly, Harmonize «интеллектуально анализирует окружающий контекст, автоматически корректируя цвет, освещение, тени и визуальный тон для создания бесшовных, цельных композиций». Adobe утверждает, что новая функция существенно сократит необходимость ручной корректировки. Помимо бета-версии на настольном компьютере или в веб-браузере, она также доступна для пользователей мобильных устройств iOS.  Теперь пользователи получили возможность переключаться между различными ИИ-моделями Adobe Firefly. Кроме того, в этой бета-версии Photoshop появилась функция Projects («Проекты»), которая обеспечит сохранение всех файлов пользователя в едином пространстве и позволит отправлять заказчику целые коллекции, а не одну версию за раз. «Лучший на сегодня» ИИ-генератор изображений Google Imagen 4 стал доступен бесплатно для всех
25.06.2025 [12:23],
Владимир Мироненко
Компания Google представила ИИ-генератор изображений следующего поколения — Imagen 4, назвав его «лучшей на сегодняшний день моделью преобразования текста в изображение». «Imagen 4 предлагает значительно улучшенную визуализацию текста по сравнению с нашими предыдущими моделями и расширяет границы качества генерации изображений по тексту», — сообщила компания. 
Источник изображений: Google Developers Blog Imagen 4 доступен в виде платной предварительной версии через API Gemini, а также для ограниченного бесплатного тестирования — в Google AI Studio. В настоящее время семейство Imagen 4 включает две модели: Imagen 4 и Imagen 4 Ultra. Модель преобразования текста в изображение Imagen 4 разработана для решения широкого спектра задач генерации изображений с существенным улучшением качества — особенно при работе с текстом — по сравнению с Imagen 3. Стоимость использования Imagen 4 составляет $0,04 за одно сгенерированное изображение.  Флагманская модель Imagen 4 Ultra предназначена для создания изображений, максимально точно соответствующих текстовым подсказкам пользователя, что позволяет добиться лучших результатов по сравнению с другими ведущими генеративными моделями. Стоимость одного изображения, созданного с помощью Imagen 4 Ultra, составляет $0,06. Все изображения, созданные моделями Imagen 4, получают маркировку в виде невидимого цифрового водяного знака SynthID. Adobe выпустила мобильное приложение со всеми генеративными ИИ-инструментами Firefly
17.06.2025 [18:08],
Владимир Фетисов
Платформа генеративных ИИ-сервисов Adobe Firefly теперь доступна на устройствах, работающих под управлением Android и iOS. Новое мобильное приложение Firefly позволяет пользователям генерировать изображения и видео по текстовому описанию, а также экспериментировать с популярными ИИ-инструментами для редактирования фотографий. 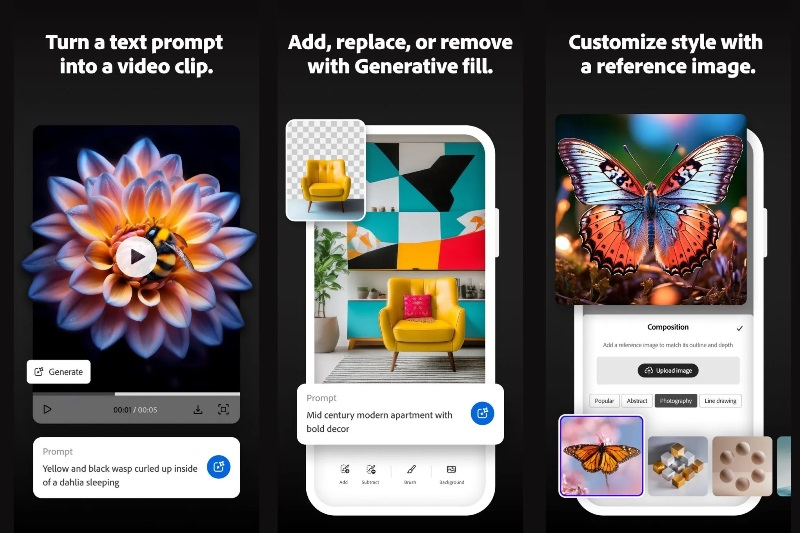
Источник изображения: Adobe Приложение Firefly для Android и iOS включает в себя фирменные алгоритмы Adobe для преобразования текста в изображения и видео, а также генеративные функции, такие как Generative Fill и Generative Expand, которые ранее были доступны в Photoshop. В дополнение к этому пользователи приложения могут взаимодействовать с ИИ-моделями сторонних разработчиков, такими как Google Imagen 3 и Imagen 4 для создания картинок, Veo 2 и Veo 3 для создания видео, а также генератором изображений OpenAI. Созданный в приложении Firefly контент автоматически синхронизируется с учётной записью пользователя на платформе Creative Cloud, что упрощает его дальнейшее размещение в интернете или обработку в других приложениях Adobe. Как и в случае с веб-приложением Firefly, для взаимодействия с некоторыми ИИ-инструментами необходимы кредиты Firefly, которые можно получить в рамках ежемесячных обновлений или путём оформления одного из платных тарифов Creative Cloud. Вместе с этим Adobe расширила возможности генерации видео в публичной бета-версии платформы интерактивных досок Firefly Boards. Теперь пользователи могут повторно микшировать загруженные клипы и генерировать новые кадры с помощью ИИ-модели Firefly, а также сторонних инструментов, таких как Veo 3 от Google. В ближайшее время разработчики также внедрят на платформу больше партнёрских ИИ-моделей от сторонних разработчиков для увеличения количества доступных функций. OpenAI пришлось идти на крайние меры, чтобы справиться с ажиотажем вокруг генерации картинок в стиле Ghibli
13.06.2025 [14:59],
Владимир Мироненко
Популярность ИИ-решений OpenAI среди пользователей сейчас зашкаливает, и каждый новый продукт пользуется буквально ажиотажным спросом. По словам главы OpenAI Сэма Альтмана (Sam Altman), компании пришлось пойти на необычные меры, чтобы справиться со спросом на создание изображений в стиле японской студии Ghibli Хаяо Миядзаки (Hayao Miyazaki) с помощью генератора изображений в ChatGPT. 
Источник изображения: Growtika/unsplash.com Сэм Альтман тогда пошутил, что шумиха вокруг этой функции чуть не расплавила графические процессоры компании, вынудив её на время ввести ограничения на частоту отправки запросов на генерацию изображений, чтобы смягчить проблему. Он буквально умолял пользователей снизить частоту генерации изображений, объясняя просьбу тем, что команде OpenAI нужна передышка и время для отдыха. Из-за всплеска спроса на картинки в стиле Ghibli от GPT-4o Image Generation аудитория чат-бота ChatGPT менее чем за час увеличилась на 1 млн пользователей. Популярность сервиса объясняется тем, что он позволяет получать более реалистичные изображения по сравнению с другими инструментами, такими как технология генерации изображений DALL-E 3. В недавнем интервью ресурсу Bloomberg Сэм Альтман признал, что компания была вынуждена идти на «неестественные» меры, чтобы справиться с вирусным эффектом Ghibli. «Я не думаю, что это случалось с какой-либо компанией раньше, — говорит Альтман. — Я видел вирусные моменты, но я никогда не видел, чтобы кто-то сталкивался с таким массовым наплывом использования продукта». Альтман рассказал, что создание изображения с помощью нового генератора изображений компании требует значительных вычислительных ресурсов, и чтобы справиться со всплеском спроса, OpenAI пришлось сделать много вещей, в том числе позаимствовать вычислительные мощности у исследовательского подразделения OpenAI, а также отсрочить запуск новых функций. «У нас нет сотен тысяч графических процессоров, которые просто простаивают без дела», — сообщил Альтман, добавив, что если бы у OpenAI было больше графических процессоров, она могла бы лучше справляться с резкими скачками спроса, и ей бы не пришлось прибегать к экстремальным мерам, таким как ограничения по скорости и задержка предоставления новых функций для бесплатных пользователей. Canon бросила вызов Sony, представив высокочувствительный датчик изображения для автомобилей
13.06.2025 [14:57],
Алексей Разин
Вполне объяснимо, что современный автомобиль по количеству бортовых камер превосходит среднестатистический смартфон, а потому для производителей датчиков изображений автомобильный рынок открывает новые перспективы сбыта продукции. Компания Canon отчётливо это понимает, а потому представила высокочувствительный датчик изображений для автомобильных камер. 
Источник изображения: Canon Как отмечает Nikkei Asian Review, новинка обладает высокой чувствительностью, позволяя бортовым системам машинного зрения определять пешеходов и другие объекты на вероятной траектории движения не только на значительном удалении, но и в условиях ограниченной для человеческого глаза видимости. Новый датчик устроен по принципу однофотонного лавинного диода (SPAD), до сих пор подобные элементы использовались главным образом в камерах видеонаблюдения, но развитие автомобильной электроники сделало данный сегмент привлекательным для подобных решений. Массовое производство новых датчиков изображений для бортовых систем автомобилей Canon развернёт к 2031 году. Датчики типа SPAD превосходят традиционные для автомобильного сектора CMOS-камеры по способности получать чёткие изображения объектов в условиях низкой освещённости. Над созданием таких датчиков Canon начала работать ещё в 2016 году, но ранние образцы плохо справлялись с обработкой изображений в светлых сценах и потребляли много энергии. Оптимизация помогла в четыре раза снизить энергопотребление датчика типа SPAD по сравнению с прототипом 2022 года. Свои сенсоры нового поколения Canon рассчитывает предлагать по той же цене, что и конкурирующие датчики типа CMOS. По прогнозам Yano Research Institute, к 2030 году ёмкость рынка датчиков для автомобильных систем увеличится более чем в два раза по сравнению с 2024 годом, до половины этого рынка будут формировать как раз датчики изображения. Главным конкурентом Canon на этом рынке остаётся корпорация Sony, хотя в США с ними обеими соперничают Onsemi и OmniVision. Последняя, кстати, формально принадлежит китайской Will Semiconductor. Корпорация Sony ставит перед собой задачу увеличить свою долю данного рынка с 32 до 43 % к концу марта 2027 года. Датчики типа SPAD разработки Sony найдут преимущественное применение в лидарах, а не камерах. Новое решение Sony позволяет в 2,7 раза увеличить разрешающую способность датчиков, при неизменном расстоянии оно определяет в три раза меньшие по размерам объекты по сравнению с датчиками текущего поколения. AMD представила ответ DLSS 4 — FSR Redstone с генерацией кадров, ИИ-освещением и регенерацией лучей
21.05.2025 [15:12],
Николай Хижняк
На выставке Computex 2025 компания AMD анонсировала следующую ступень в эволюции своей технологии FidelityFX Super Resolution (FSR). FSR 4, дебютировавшая вместе с видеокартами серии Radeon RX 9070 в начале года, была лишь очередным шагом к чему-то более масштабному. Теперь AMD представила FSR Redstone — технологию, объединяющую новые версии Super Resolution и генератора кадров, ещё теснее интегрированных с методами машинного обучения. 
Источник изображений: ComputerBase.de В новой технологии акцент сделан на трёх ключевых элементах: Neural Radiance Caching, регенерации лучей и генерации кадров, ускоренных с помощью машинного обучения и ИИ.  Суть технологии Neural Radiance Caching заключается в том, что нейросеть анализирует, как свет распределяется в трёхмерных сценах, и заранее предсказывает его воздействие на объекты. Это снижает объём вычислений для GPU и ускоряет рендеринг сложных эффектов — таких как отражения и рассеянное освещение.  Технология регенерации лучей (Ray Regeneration) — аналог функции реконструкции лучей (Ray Reconstruction), входящей в состав Nvidia DLSS 3.5 и выше. Она предназначена для устранения артефактов, возникающих при трассировке. Нейросеть в реальном времени устраняет шумы, сохраняя детализацию теней и бликов.  Наконец, новый генератор кадров, основанный на машинном обучении и входящий в состав FSR Redstone, отличается от версии в FSR 3.1 тем, что использует не интерполяцию, а промежуточные кадры, созданные ИИ с учётом движения объектов и изменений освещения. Это должно значительно уменьшить размытость в динамичных сценах. При этом AMD не заявляла о применении технологии мультикадрового генератора, аналогичной той, что используется в Nvidia DLSS 4.  FSR Redstone будет выпущена во второй половине этого года. К сожалению, поддержка технологии будет реализована только на видеокартах с архитектурой RDNA 4. FSR Redstone — это рабочее название. Возможно, финальная версия получит имя FSR 4.1 или, например, FSR 4.5. 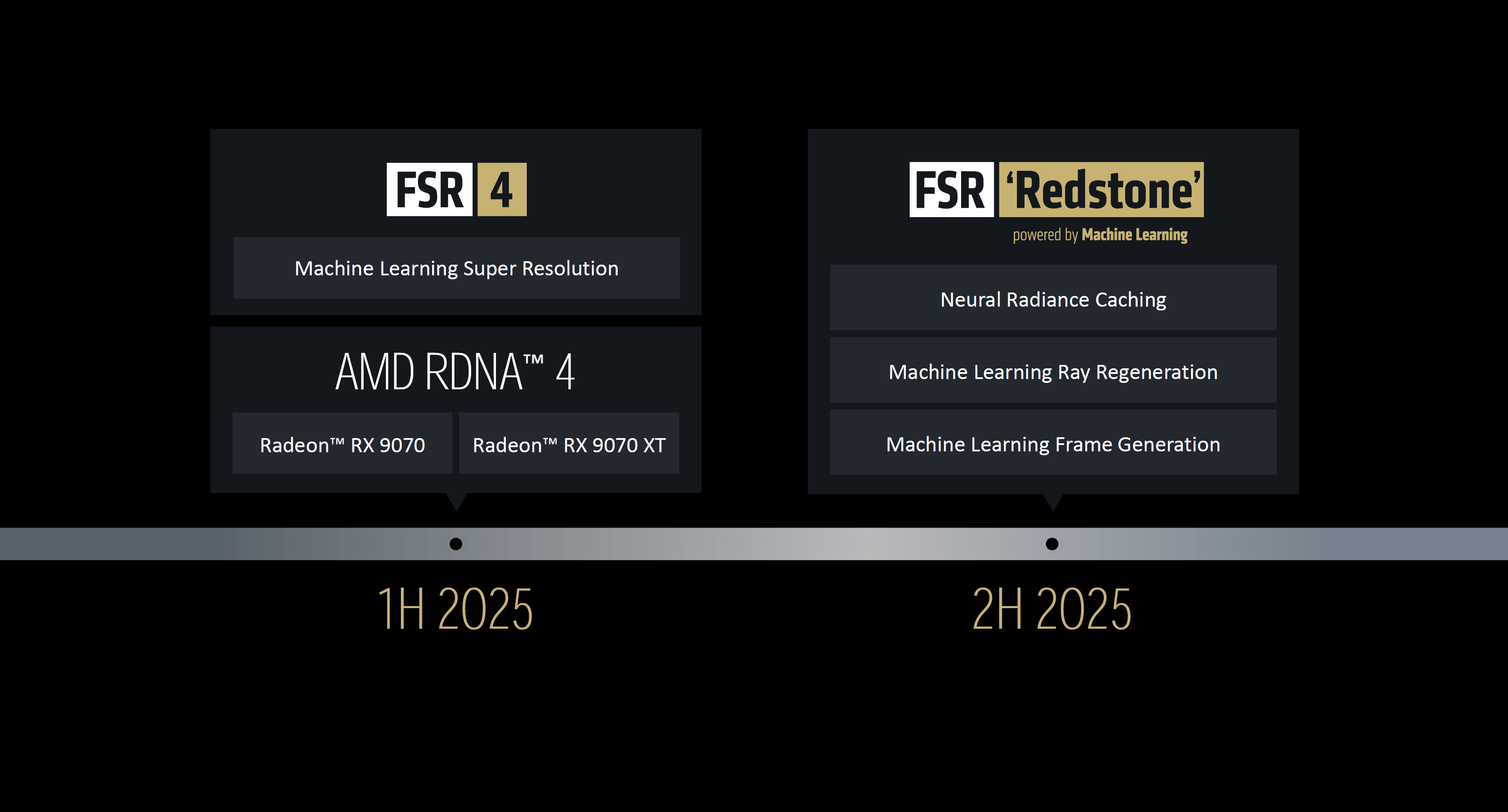 На Computex компания AMD не сделала никаких заявлений о внедрении поддержки FSR 4 для видеокарт предыдущих поколений. Однако компания отметила, что к 5 июня поддержку FSR 4 будут иметь 60 игр. Японцы изобрели камеру, способную снимать голограммы живых органов в реальном времени
21.05.2025 [12:25],
Геннадий Детинич
«Тайная жизнь мозга» — так могло называться первое видео мозга мыши, снятое научной камерой в 3D-разрешении сквозь кости черепа зверька. Это стало возможным благодаря японской разработке — однопиксельной камере для съёмок голографических видео. Созданная учёными Университета Кобе (Kobe University) камера, обещает малоинвазивное наблюдение за внутренними органами людей и другие применения, где нужна микро-3D-визуализация. 
Источник изображения: ИИ-генерация Grok 3/3DNews Сегодня голографические изображения без использования лазеров (когерентного освещения) получают двумя методами — это технология FINCH (Fresnel Incoherent Correlation Holography) в видимом диапазоне и технология OSH (Optical Scanning Holography) за пределами видимого света. Первая даёт возможность снимать движущиеся объекты, а вторая — только неподвижные, но в диапазонах, в которых нет доступных матриц изображения: ультрафиолетовом, инфракрасном и терагерцевом. Подчеркнём, оба метода работают на отражённом и рассеянном естественном свете или за счёт люминесценции, что делает работу платформ достаточно простой и доступной, в отличие от создания голограмм с помощью лазеров. Каждая из них имеет свои преимущества и недостатки, и японские учёные смогли объединить лучшее из каждого метода, создав однопиксельную платформу для съёмки голографических видео даже сквозь рассеивающие свет препятствия. Модернизированная установка OSH получила сканирующую зеркальную систему для проекции на объект специальных узоров, которые благодаря интерференции позволяют восстанавливать объёмное изображение. Отражённый свет собирается однопиксельным датчиком и обрабатывается на компьютере, а, в зависимости от момента, с привлечением искусственного интеллекта. 
Источник изображения: Kobe University Традиционные сканеры OSH работали с частотой 60 Гц. Модернизированная установка подсвечивала объект для обработки с частотой 22 кГц, что позволило приблизиться к созданию движущихся голографических изображений. Представленная в эксперименте камера снимала со скоростью один кадр в секунду. В перспективе учёные обещают довести скорость съёмки до 30 к/с, чтобы это было настоящее «киношное» видео. Разработка обещает погрузить учёных в мир голографической микроскопии, обещая упростить медицинские исследования в сфере биологии и здравоохранения. Google научила ИИ-бота Gemini редактировать любые изображения
01.05.2025 [14:22],
Дмитрий Федоров
Google Gemini научился редактировать как сгенерированные ИИ изображения, так и загруженные со смартфона или компьютера. В ближайшие недели новая функциональность станет доступна пользователям в большинстве стран мира, где доступен Gemini, и получит поддержку более чем 45 языков. Россия, напомним, в этот список не входит, однако русский язык Gemini понимает и «говорит» на нём. 
Источник изображений: Google Нативное редактирование изображений в ИИ-чат-боте Gemini представляет собой эволюционный шаг в развитии возможностей взаимодействия пользователя с ИИ. Запуск последовал за моделью редактирования изображений с помощью ИИ, которую Google опробовала в марте в своей платформе AI Studio и которая получила широкую огласку благодаря своей спорной способности удалять водяные знаки с любого изображения. Подобно недавно обновлённому инструменту редактирования изображений в ChatGPT, встроенный редактор Gemini теоретически способен достигать более высоких результатов по сравнению с автономными ИИ-генераторами изображений. Теперь Gemini предлагает инновационный «многоэтапный» процесс редактирования, обеспечивающий, по описанию компании, «более богатые и контекстуальные» отклики на каждый запрос — с интеграцией текста и изображений. Функциональность нового редактора позволяет пользователям изменять фон на изображениях, заменять объекты, добавлять элементы и выполнять множество других операций — и всё это непосредственно в интерфейсе Gemini. Подобное решение существенно упрощает процесс создания и редактирования визуального контента, устраняя необходимость переключаться между несколькими специализированными приложениями.  «Например, вы можете загрузить личную фотографию и попросить Gemini сгенерировать изображение того, как вы будете выглядеть с разными цветами волос. Также можно попросить Gemini создать первый черновик сказки на ночь о драконах и сгенерировать иллюстрации к истории», — поясняет Google в своём блоге. Эти примеры наглядно демонстрируют многофункциональность системы, пригодной как для утилитарных, так и для креативных задач. Потенциальные риски технологии в контексте создания дипфейков обоснованно вызывают опасения у специалистов по информационной безопасности. Чтобы нивелировать возможные злоупотребления, Google внедряет технологию невидимых водяных знаков во все изображения, созданные или отредактированные с помощью нативного генератора изображений Gemini. Параллельно компания проводит экспериментальные исследования по внедрению видимых водяных знаков на всех изображениях, сгенерированных с помощью Gemini. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex









