|
Опрос
|
реклама
Быстрый переход
Google открыла доступ к Vids для всех: ИИ-видеоредактор стал бесплатным, но не без ограничений
27.08.2025 [19:21],
Анжелла Марина
Google запустила бесплатную версию видеоредактора Vids, работающего на базе искусственного интеллекта (ИИ). Ранее этот инструмент был доступен исключительно подписчикам Google Workspace и специальных тарифов с ИИ, но теперь все пользователи смогут использовать его базовую версию, которая включает шаблоны, стоковый медиаконтент и ограниченный набор ИИ-возможностей. 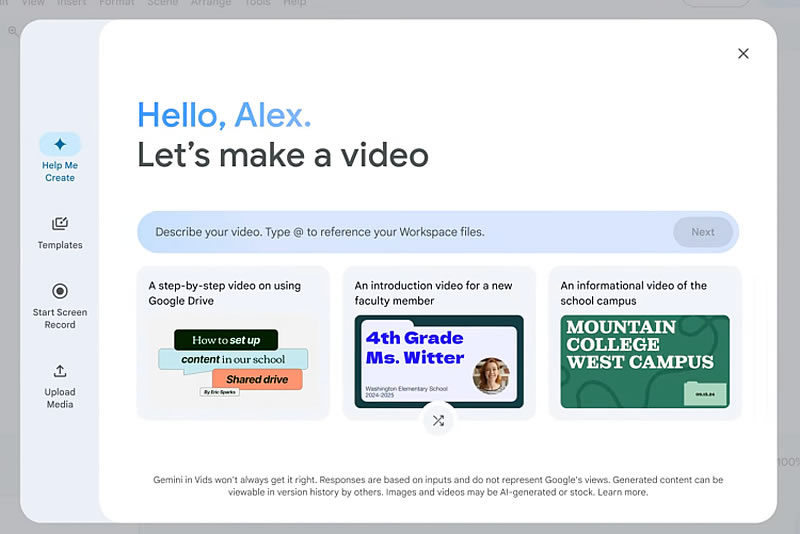
Источник изображений: Google Vids, представленный в прошлом году как часть пакета Workspace, предназначен для быстрого создания видео-презентаций. Он помогает пользователям формировать раскадровки, предлагая сцены, подбирая стоковые изображения и фоновую музыку с помощью алгоритмов. Как сообщает The Verge, ссылаясь на слова директора по продукту Вишну Шиваджи (Vishnu Sivaji), упрощённая версия сохраняет значительную часть основных возможностей приложения, однако в ней отсутствуют некоторые новейшие ИИ-функции, анонсированные одновременно с открытием доступа. В частности, бесплатная версия не позволяет использовать ИИ-аватары для озвучивания текста от имени пользователя. 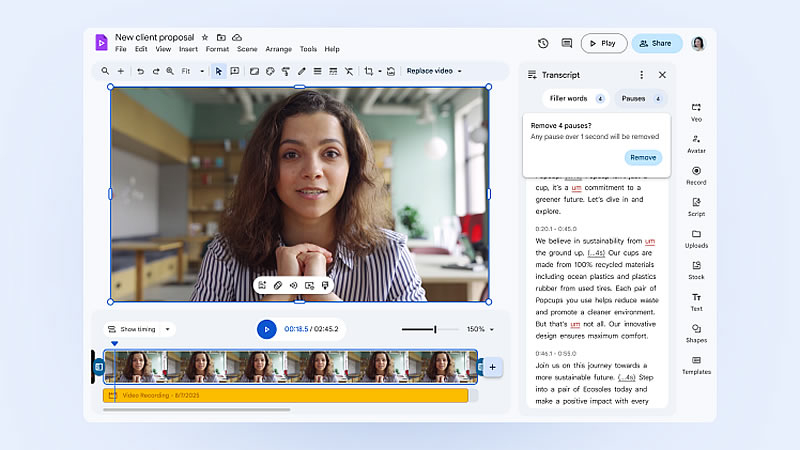 В рамках обновления платные подписчики получат доступ к выбору из 12 готовых аватаров с уникальной внешностью и голосом, в которые можно загружать собственный сценарий. При этом функция создания персонального ИИ-аватара, аналогичная реализованной в Zoom, в Vids пока недоступна. На вопрос о такой возможности Шиваджи ответил, что компания не готова делиться планами на этот счёт. 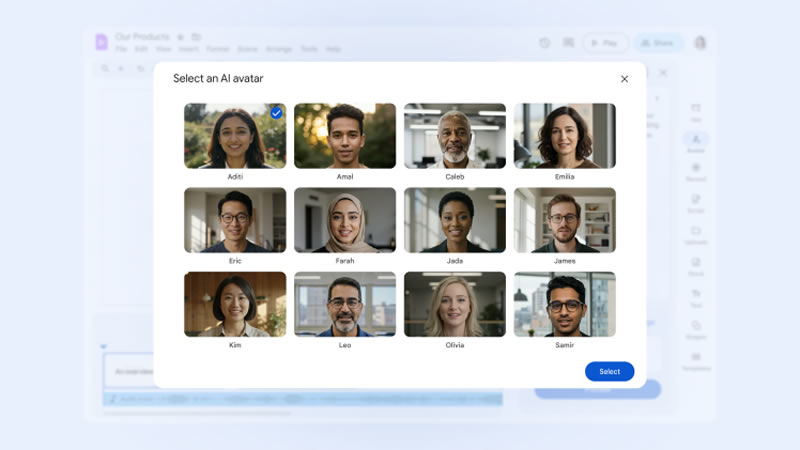 Также Google расширила возможности генерации видео: теперь можно создавать 8-секундные ролики на основе конкретного изображения, например фотографии нового продукта. Кроме того, появился инструмент, автоматически удаляющий из записи слова-паразиты и паузы, что полезно при подготовке собственных видео для презентаций. В компании считают, что новые функции помогут бизнесу сэкономить время и деньги при производстве видеоконтента различного назначения, в том числе обучающих роликов, так как, по словам Шиваджи, традиционное производство даже 10-минутного видео с живыми актёрами может занимать до полугода и обходиться в десятки тысяч долларов из-за затрат на написание сценария, его согласование, аренду студии, съёмку и монтаж. Microsoft представила VibeVoice — открытый ИИ, превращающий текст в полуторачасовые подкасты
27.08.2025 [17:36],
Анжелла Марина
Microsoft представила проект с открытым исходным кодом VibeVoice в области искусственного интеллекта — новую систему синтеза речи, способную генерировать из текста аудиоподкасты длительностью до 90 минут на английском или китайском языке. Технология уже доступна для тестирования любому желающему онлайн или с установкой на локальное устройство пользователя. 
Источник изображения: AI Разработчики охарактеризовали VibeVoice как новаторский фреймворк, созданный для генерации продолжительного по времени аудиоконтента с несколькими участниками непосредственно из текста. Как пишет Windows Central, система решает ключевые проблемы традиционных синтезаторов речи (TTS), такие как масштабируемость, согласованность характеристик голоса и естественность чередования реплик в диалоге. Модель способна синтезировать аудио продолжительностью до 90 минут с участием до четырёх уникальных голосов, что превосходит ограничения в 1-2 спикера, характерные для многих предыдущих ИИ-моделей. В настоящее время для тестирования доступны две версии модели: на 1,5 и 7 млрд параметров. Первая может генерировать до 90 минут аудио с длиной контекста 64 тыс. токенов, тогда как вторая, предположительно более качественная из-за большего размера, ограничена 45 минутами и окном в 32 тысячи токенов. Также ожидается выпуск облегчённой версии на 0,5 млрд параметров, предназначенной для работы в реальном времени. Для локальной работы меньшая модель требует около 7 Гбайт видеопамяти, а для большей может потребоваться до 18 Гбайт VRAM. На текущий момент ИИ-модель VibeVoice обучена только на английском и китайском языках, включая мандаринскую разновидность (севернокитайский или путунхуа). Однако в Microsoft отмечают, что в будущих версиях планируется расширение поддержки других языков. Система способна передавать эмоции, управлять сменой реплик между участниками и генерировать естественные диалоги, хотя попытки воспроизведения музыки пока остаются неудачными. Голоса звучат довольно реалистично, однако их искусственное происхождение остаётся заметным. В перспективе разработчики рассматривают возможность интеграции функции клонирования голоса. Разработчики отмечают, что при запуске потоковой версии аудиогенерации VibeVoice может быть интегрирована в чат-ассистенты, позволяя обходиться без внешних серверов. Дополнительные сведения, включая инструкции по установке и настройке, доступны в официальном репозитории VibeVoice в GitHub и на платформе Hugging Face. Тысячи приватных диалогов с Grok утекли в поиск Google
20.08.2025 [18:27],
Анжелла Марина
Тысячи диалогов пользователей с чат-ботом Grok компании xAI Илона Маска (Elon Musk), оказались доступны через поисковые системы, сообщает TechCrunch со ссылкой на Forbes. Каждый раз, когда пользователь Grok нажимает кнопку «Поделиться» в разговоре с чат-ботом, создаётся уникальный URL-адрес, который затем можно передать по электронной почте, в текстовом сообщении или в социальных сетях. 
Источник изображения: Mariia Shalabaieva/Unsplash Эти URL-адреса с приватными диалогами могут быть проиндексированы поисковыми роботами Google, Bing и DuckDuckGo и появиться в результатах поиска глобальной сети. Функция, позволяющая генерировать публичные URL, аналогичным образом недавно затронула и пользователей чат-ботов от компаний Meta✴ и OpenAI, и в случае с Grok она также привела к утечке диалогов с небезопасным контентом — среди них запросы о взломе криптокошельков, откровенные беседы с персонифицированными ИИ-персонажами и просьбы предоставить инструкции по синтезу запрещённых препаратов. Хотя в правилах использования сервиса xAI прямо запрещено применять бота для поощрения действий, «критически вредящих человеческой жизни», а также для разработки «биологического, химического оружия или оружия массового уничтожения», однако это не помешало пользователям направлять соответствующие запросы к Grok. Согласно анализу диалогов, оказавшихся в открытом доступе через Google, бот предоставлял пошаговые инструкции по изготовлению запрещённых препаратов, перечислял методы совершения суицида, давал советы по созданию взрывоопасных устройств и даже сформулировал детальный план убийства самого Маска. Представители xAI пока не ответили на запрос о комментарии, а также не уточнили, с какого времени ссылки на диалоги с Grok начали индексироваться поисковыми системами. Напомним, что в конце прошлого месяца пользователи ChatGPT сообщили о похожей ситуации — их переписки также попадали в поисковую выдачу Google, на что OpenAI отреагировала, назвав это «кратковременным экспериментом». В ответ в Х появилось сообщение от компании Маска с фразой «Grok ftw» с комментарием, что в xAI «нет функции "Поделиться"» и что «конфиденциальность — её приоритет». OpenAI заработала $2 млрд на мобильном приложении ChatGPT — в 30 раз больше всех конкурентом вместе
16.08.2025 [01:05],
Анжелла Марина
Мобильное приложение ChatGPT от OpenAI заработало $2 млрд с момента своего запуска в мае 2023 года, принося в среднем $2,91 с каждой установки. Основной рост пришёлся на 2025 год — доход за первые семь месяцев составил $1,35 млрд, что на 673 % больше, чем за аналогичный период 2024 года. Эта сумма примерно в 30 раз превышает совокупные доходы от мобильных приложений конкурентов в лице Claude, Copilot и Grok. 
Источник изображения: Solen Feyissa/Unsplash По сообщению TechCrunch со ссылкой на данные компании Appfigures, специализирующейся на исследовании мобильного рынка, ChatGPT демонстрирует беспрецедентную монетизацию. В среднем приложение приносит $193 млн в месяц — для сравнения, ближайший конкурент Grok от xAI генерирует лишь $3,6 млн, что составляет 1,9 % от показателей ChatGPT. Разрыв ещё заметнее в пересчёте на одну загрузку: $2,91 у ChatGPT против $0,75 у Grok и $0,28 у Copilot. Главными рынками оказались США (38 % выручки) и Германия (5,3 %), тогда как больше всего загрузок пришлось на Индию (13,7 %). Глобальное же число установок ChatGPT подтверждает доминирование компании: 690 млн против 39,5 млн у Grok. 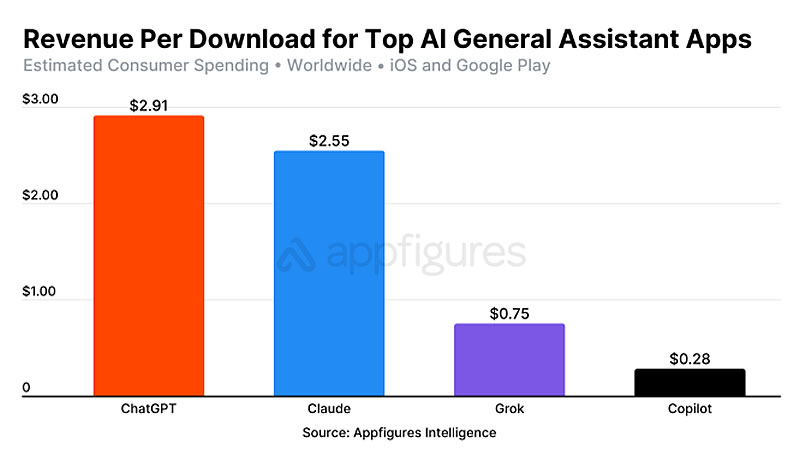
Источник изображения: appfigures.com Только за 2025 год приложение скачали 318 млн раз — в 2,8 раза больше, чем за тот же период прошлого года. Среднемесячное количество загрузок выросло на 180 %, достигнув 45 млн. При этом Grok изначально отставал в мобильном сегменте и до января 2025 года у него не было отдельного приложения для iOS, а версия для Android появилась лишь в марте. Эксперты отмечают, что эти данные отражают только доходы от мобильных пользователей, не учитывая веб-подписки и API. Бывшие сотрудники Google запустили ИИ, который создаёт вирусные видео в один клик
09.08.2025 [09:33],
Анжелла Марина
Стартап OpenArt, основанный бывшими сотрудниками Google в 2022 году, запустил в открытой бета-версии функцию «История в один клик» (One-Click Story), позволяющую превратить короткий текст, сценарий или песню в минутное видео с развитием сюжета. Платформа, насчитывающая около 3 млн активных пользователей в месяц, использует более 50 моделей искусственного интеллекта и предлагает шаблоны для создания персонажей и музыкальных клипов. 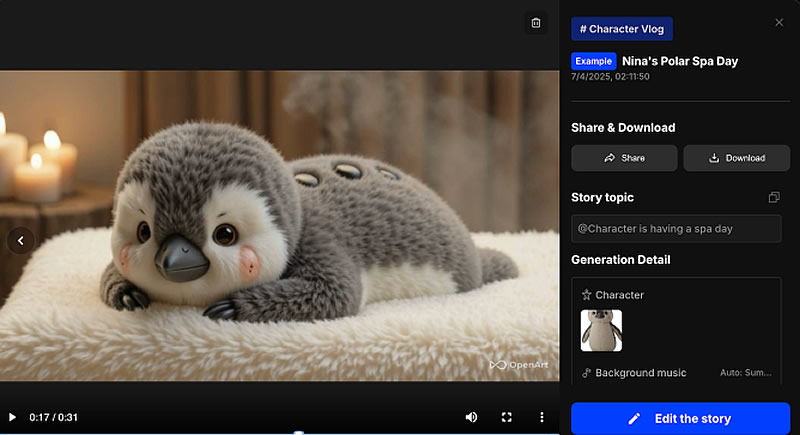
Источник изображений: OpenArt Пользователи могут выбрать один из трёх шаблонов: «Влог персонажа» (Character Vlog), «Музыкальное видео» (Music Video) или «Объяснение» (Explainer). Для генерации контента применяются более 50 ИИ-моделей, включая DALL·E 3, GPT, Imagen, Flux Kontext и Stable Diffusion. Если, например, загружается песня, алгоритм проанализирует её текст и создаст анимацию в соответствии с тематическим содержанием. После генерации ролик можно редактировать в режиме раскадровки, корректируя промпты для отдельных сцен. 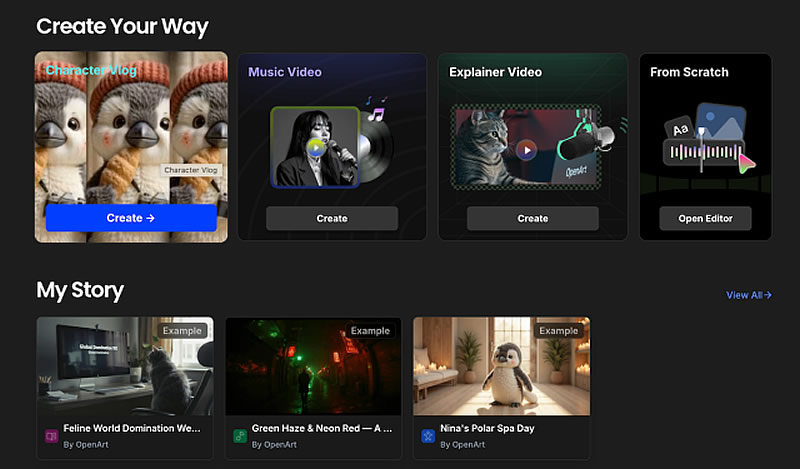 Однако тестирование сервиса журналистами TechCrunch выявило потенциальные риски, связанные с нарушением прав интеллектуальной собственности. В частности, в режиме Character Vlog возможна генерация образов, схожих с такими персонажами, как Пикачу, Спанч Боб и Марио. Стоит отметить, что недавно, в июне, Disney и Universal подали в суд на компанию Midjourney, занимающуюся разработкой искусственного интеллекта, из-за изображений, созданных с помощью ИИ. Генеральный директор OpenArt Коко Мао (Coco Mao) отметила, что используемые модели по умолчанию блокируют запросы с защищёнными персонажами, но в отдельных случаях такие образы всё же могут быть сгенерированы. Также компания заявила о готовности к переговорам с крупными правообладателями о лицензировании контента.  OpenArt работает по кредитной системе: базовый тариф стоит $14 в месяц и включает 4000 кредитов, за которые можно создать до четырёх One-Click Story, 40 видео, 4000 изображений и использовать до четырёх персонажей. Расширенный тариф стоит $30 в месяц за 12 000 кредитов и включает до 12 историй One-Click Story. Тариф Infinite стоит $56 в месяц за 24 000 кредитов; также доступен командный тариф — $35 в месяц с участника. Сервис ориентирован как на создание развлекательного контента для TikTok и YouTube, так и на образовательные ролики или рекламу. На данный момент компания привлекла $5 млн от Basis Set Ventures и DCM Ventures, имеет положительный денежный поток и прогнозирует годовой объём выручки свыше $20 млн. Бывший инженер OpenAI раскрыл, каково это — работать в компании мечты
16.07.2025 [06:17],
Анжелла Марина
Бывший инженер OpenAI и сооснователь Segment Калвин Френч-Оуэн (Calvin French-Owen), работавший над одним из самых перспективных продуктов компании — Codex, поделился в своём блоге впечатлением от года работы в OpenAI. Его рассказ раскрывает картину быстрого роста, внутреннего хаоса, бессонных ночей и неожиданной свободы. 
Источник изображения: AI Френч-Оуэн описал стремительный рост компании — за год её штат увеличился с 1000 до 3000 сотрудников, что, по его словам, привело к внутреннему хаосу, начиная от коммуникации и заканчивая процессами найма и выпуска продуктов. В то же время культура компании остаётся похожей на стартап: сотрудники могут быстро реализовывать свои идеи, хотя это иногда и приводит к дублированию усилий. Например, Френч-Оуэн отметил, что видел по несколько библиотек для одних и тех же задач, таких как управление очередями. Уровень программистов варьируется от опытных инженеров Google, способных писать код для миллиардов пользователей, до свежих PhD-выпускников без подобного опыта. Однако в сочетании с гибкостью языка программирования Python это превращало основной код OpenAI в своеобразную «свалку», где что-то постоянно ломалось или работало слишком медленно. Впрочем, руководство осознаёт проблему и пытается её решить. Френч-Оуен сравнил OpenAI с Meta✴ времён раннего Facebook✴ — та же скорость и готовность идти на риск. Например, команда из восьми инженеров, четырёх исследователей, двух дизайнеров и маркетологов смогла создать и запустить Codex всего за семь недель, почти без перерывов на сон. Но успех превзошёл ожидания: продукт мгновенно привлёк пользователей, просто появившись в боковой панели ChatGPT. При этом Френч-Оуэн отмечает, что OpenAI остаётся крайне закрытой компанией, болезненно реагирующей на различные утечки. Также была затронута тема безопасности ИИ. Вопреки мнению критиков, OpenAI не игнорирует риски, но фокусируется не на апокалиптических сценариях, а на практических проблемах, например борьбе с разжиганием ненависти, оскорблениями, манипуляциями, вредоносными запросами и другими опасными инструкциями. Долгосрочные угрозы тоже изучаются, особенно с учётом того, что сотни миллионов людей используют ChatGPT для медицинских консультаций или психологической поддержки. Френч-Оуэн подчеркнул, что ушёл не из-за каких-либо конфликтов или «драмы», а потому что хочет вернуться к роли сооснователя стартапа. Ранее он вместе с партнёрами создал Segment — стартап в сфере управления клиентскими данными, который был приобретён Twilio в 2020 году за $3,2 млрд. Alibaba представила ИИ-модель Qwen VLo, которая умеет редактировать картинки
28.06.2025 [06:27],
Анжелла Марина
Alibaba представила ИИ нового поколения, который существенно упростит пользователям создание и редактирование изображений на основе текстов и визуальных материалов. Модель, получившая название Qwen VLo, станет частью серии ИИ-сервисов под брендом Qwen и позволит не только генерировать изображения по текстовым запросам, но и модифицировать уже существующие. 
Источник изображения: Copilot Как сообщает Bloomberg, новая модель не только анализирует данные, но и способна на их основе генерировать высокачественные изображения. Например, пользователь может ввести текстовой запрос, а после генерации попросить добавить какие-либо детали, например, шляпу для кота. Также можно загрузить готовое изображение и «дорисовать» его. Одной из ключевых особенностей Qwen VLo является технология прогрессивной генерации, при которой пользователь может наблюдать за процессом создания изображения шаг за шагом. Например, можно отправить запрос «Создай картинку милого кота», и система начнёт формировать изображение прямо на глазах. В своём блоге компания также отметила, что новая версия модели не просто «воспринимает окружающий мир, но и способна создавать высококачественные реконструкции на основе этого восприятия». Это соотносится с тем, что ранее генеральный директор компании Эдди Ву (Eddie Wu) заявлял, что основной целью Alibaba на текущий момент является разработка сильного искусственного интеллекта (AGI), который будет обладать уровнем развития человека. Модель Qwen VLo позиционируется как конкурентный ответ на другие решения рынка, включая продукты OpenAI. Однако Alibaba также сталкивается с агрессивной конкуренцией внутри Китая, например, со стороны DeepSeek, которая произвела в индустрии фурор, заявив о создании мощной модели всего за несколько миллионов долларов. В ответ компания Alibaba ещё активнее стала добавлять новые функции для обработки текстов, изображений, аудио и видео, также оптимизируя модель и для работы на смартфонах. Runway готовит платформу для создания игр с помощью ИИ
28.06.2025 [06:03],
Анжелла Марина
ИИ-стартап Runway, чья оценочная стоимость составляет $3 млрд, намерен расширить горизонты своего влияния. После крупного успеха нейросети в киноиндустрии, компания планирует запустить платформу для генерации видеоигр. 
Источник изображения: Runway По словам генерального директора компании Кристобаля Валенсуэлы (Cristóbal Valenzuela), первые пользователи смогут протестировать новый продукт уже на следующей неделе. Пока это просто минималистичный интерфейс, позволяющий взаимодействовать с моделью в текстовом чате и создавать изображения, но в дальнейшем появится возможность генерировать полноценные игры, сообщает The Verge. Runway в настоящий момент активно ведёт переговоры с крупными игровыми студиями о внедрении своих технологий в производственные процессы и о доступе к их базам данных для обучения моделей. По мнению Валенсуэлы, игровая индустрия сейчас находится примерно в той же точке, в которой находилась киноиндустрия пару лет назад, когда впервые столкнулась с применением ИИ в процессе создания контента. Тогда тоже наблюдалось немалое сопротивление, но со временем ИИ-технологии начали активно внедряться в работу. Глава Runway уверен, что сейчас процесс принятия ИИ в играх будет происходить быстрее. Компания уже имеет опыт сотрудничества с крупнейшими игроками развлекательного рынка. Например, её технологии применялись при производстве сериала Amazon «Дом Дэвида», также продолжается сотрудничество почти со всеми голливудскими студиями и большинством компаний из списка Fortune 100. Валенсуэла считает, что если Runway может помочь студии ускорить производство фильма на 40 процентов, то аналогичный эффект возможен и в разработке игр. «Бездонная яма плагиата»: Disney и Universal подали в суд на Midjourney из-за ИИ
12.06.2025 [06:17],
Анжелла Марина
Кинокомпании Disney и Universal подали иск против Midjourney, обвинив сервис в создании копий их персонажей с помощью искусственного интеллекта (ИИ). Иск, поданный в федеральный суд Центрального округа Калифорнии, касается генерации изображений таких персонажей, как Шрек, Дарт Вейдер, Базз Лайтер и других защищённых авторским правом известных героев. 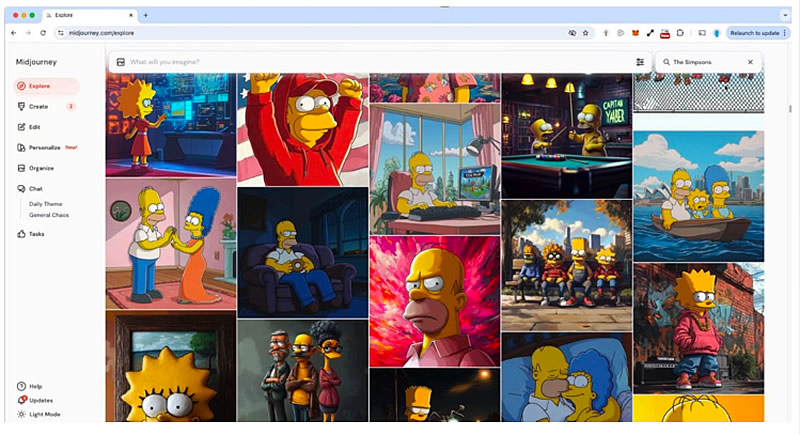
Источник изображений: theverge.com В заявлении говорится, что Midjourney действует как «виртуальный торговый автомат», производя бесконечные незаконные копии их работ. По мнению истцов, сервис сознательно использует популярных персонажей для продвижения своих инструментов, не вкладывая средств в их создание. В качестве примеров приведены изображения инопланетянина Йоды — одного из главных героев «Звёздных войн», Человека-паука, Эльзы из «Холодного сердца» и персонажей из «Миньонов».  Disney и Universal утверждают, что Midjourney игнорирует их требования прекратить нарушение авторских прав, в отличие от других сервисов ИИ, которые внедрили защитные механизмы. Особую обеспокоенность вызывает готовящийся к выпуску видеогенератор Midjourney, который, по мнению студий, уже сейчас может нарушать их права в связи с обучением ИИ на защищённом авторском контенте. Компании потребовали суда присяжных.  Как отмечает издание The Verge, это первый крупный иск Голливуда против генеративного ИИ, однако подобные судебные разбирательства становятся все более частыми. Ранее с исками к OpenAI, создателю ChatGPT, обращались The New York Times, группа авторов во главе с Джорджем Мартином (George R.R. Martin), а также издатели других газет. На компанию Anthropic, разработавшую чат-бот Claude, подали иски компании Universal Music и Reddit. Google научила Gemini 2.5 понимать и передавать эмоции в диалогах
05.06.2025 [01:57],
Вячеслав Ким
На конференции Google I/O 2025 компания анонсировала новую версию своей мультимодальной модели Gemini 2.5, которая теперь поддерживает генерацию аудио и диалогов в реальном времени. Эти возможности доступны в предварительной версии для разработчиков через платформы Google AI Studio и Vertex AI. 
Источник изображения: Google Gemini 2.5 Flash Preview обеспечивает реалистичное голосовое взаимодействие с ИИ, включая распознавание эмоциональной окраски речи, адаптацию интонации и акцента, а также возможность переключения между более чем 24 языками. Модель может игнорировать фоновые шумы и использовать внешние инструменты, такие как «Поиск», для получения актуальной информации во время диалога. Дополнительно, Gemini 2.5 предлагает расширенные функции синтеза речи (TTS), позволяя управлять стилем, темпом и эмоциональной выразительностью озвучивания. Поддерживается генерация диалогов с несколькими голосами, что делает модель подходящей для создания подкастов, аудиокниг и других мультимедийных продуктов. Для обеспечения прозрачности, все сгенерированные моделью аудио маркируются с помощью технологии SynthID, что позволяет идентифицировать контент, как сгенерированный ИИ. Разработчики могут опробовать новые функции через вкладки Stream и Generate Media в Google AI Studio. Gemini 2.5 демонстрирует значительный шаг вперёд в области мультимодальных ИИ-систем, объединяя модальности текстов, изображений, аудио и видео в единую платформу. Новые функции открывают широкие перспективы для создания интерактивных приложений, виртуальных ассистентов и инноваций в сфере образования. Character.AI запустила генерацию видео, а персонажи теперь могут говорить
03.06.2025 [06:15],
Анжелла Марина
Платформа Character.AI с функциями чат-бота для диалогов с ИИ-персонажами представила новые мультимедийные функции. Среди них — генератор видео AvatarFX, а также инструменты Scenes и Streams, позволяющие создавать ролики с ИИ-персонажами и делиться ими в социальной ленте. 
Источник изображения: Character.AI Ранее сервис работал только в текстовом формате, но теперь, по словам представителей компании, развивается в сторону большей интерактивности. Сейчас пользователи могут создавать до пяти видео в день с помощью AvatarFX. Для этого нужно загрузить изображение, выбрать голос и написать реплики для персонажа. Также есть возможность использовать аудиофайл для настройки голоса, но эта функция, как отмечает TechCrunch, пока работает нестабильно. Видео можно превращать в сцены (Scenes), представляющими из себя мини-истории с заранее заданными сюжетами от других пользователей. Пока эта опция доступна только в мобильном приложении, но скоро появится и в веб-версии. Функция Streams, позволяющая создавать динамические диалоги между двумя персонажами, выйдет на всех платформах на этой неделе. Готовые сцены можно будет публиковать в новой ленте сообщества. Однако у платформы есть проблемы с безопасностью из-за риска злоупотребления столь широкими возможностями. Ранее родители подавали в суд на Character.AI, утверждая, что чат-боты пытались склонить их детей к самоповреждениям и суициду. В одном случае 14-летний подросток покончил с собой после продолжительного общения с ИИ-персонажем. С расширением мультимедийных функций также могут возрастать риски злоупотреблений, например, использования фотографий реальных людей. Но компания заявляет, что блокирует загрузку изображений реальных людей, включая знаменитостей, и намеренно искажает их изображения (рисунок ниже), чтобы избежать создания deep-подделок. Однако иллюстрации с известными персонажами система не запрещает, что, возможно, оставляет лазейки для злоумышленников. 
Источник изображения: Character.AI Каждое видео помечается водяным знаком, но это не гарантирует полной защиты. Например, при попытке создать дипфейк на основе рисунка Илона Маска (Elon Musk) результат выглядит неестественно, но теоретически такие ролики всё равно можно использовать для обмана. 
Источник изображения: Amanda Silberling / bsky.app В Character.AI подчёркивают, что «стремятся балансировать между творческой свободой и безопасностью». По словам компании, цель платформы в том, чтобы предоставить пользователям интересные инструменты для самовыражения, минимизируя потенциальные угрозы. Однако есть те, кто сомневается, что текущих мер недостаточно для предотвращения новых скандалов. Stability AI выпустила ИИ-генератор музыки, который быстро работает даже на смартфоне
14.05.2025 [23:39],
Анжелла Марина
Stability AI, разработчик популярной нейросети Stable Diffusion, представила музыкальную ИИ-модель Stable Audio Open Small, которая генерирует аудио в стереозвучании и способна работать на смартфонах без подключения к интернету. Модель создана совместно с производителем чипов Arm, чьи процессоры используются в большинстве мобильных устройств, и способна быстро генерировать аудио в высоком качестве даже на устройствах с ограниченными вычислительными ресурсами. 
Источник изображения: AI В отличие от конкурентов, таких как Suno и Udio, которым требуется облачная обработка, Stable Audio Open Small работает локально. При этом, как отмечает TechCrunch, обучение модели проводилось только на данных из бесплатных аудиобиблиотек Free Music Archive и Freesound, что снижает риски нарушения авторских прав и выгодно отличает её от некоторых других ИИ-сервисов, использующих защищённый контент. Модель содержит 341 миллион параметров и оптимизирована для процессоров Arm. Она предназначена для быстрого создания коротких аудиосэмплов и звуковых эффектов, например, ударных или инструментальных партий. По заявлению Stability AI, на смартфоне ИИ может сгенерировать 11-секундное аудио менее чем за восемь секунд. Одновременно у Stable Audio Open Small есть некоторые ограничения. Например, она понимает текстовые запросы только на английском языке, не умеет создавать реалистичный вокал или сложные музыкальные композиции. Кроме того, компания признаёт, что из-за того, что модель обучалась на западно-ориентированных данных, она лучше справляется со стилями, присущими западной музыке. Ещё одна сложность заключается в условиях использования. Для исследователей, любителей и малого бизнеса ИИ-модель доступна бесплатно, но если годовой доход компании превышает $1 млн, потребуется покупка коммерческой лицензии. И хотя для инди-разработчиков такие условия выгодны, для крупных проектов это может стать определённой сложностью. Напомним, Stability AI, известная по своей модели глубокого обучения Stable Diffusion, генерирующей изображения по текстовым описаниям, в последние месяцы пытается восстановить репутацию после финансовых проблем при бывшем генеральном директоре Эмаде Мостаке (Emad Mostaque). Компания привлекла инвестиции, назначила нового главу и добавила в совет директоров режиссёра Джеймса Кэмерона (James Cameron). Параллельно она продолжает выпускать новые генеративные модели, включая новые инструменты для создания изображений. Новая статья: Лучшие ИИ-сервисы по версии 3DNews на начало 2025 г., часть 3: конструкторы приложений, секретари, менеджеры проектов, дата-дирижёры
18.03.2025 [00:03],
3DNews Team
Amazon собралась бросить вызов OpenAI, Google и Anthropic, и готовит собственную рассуждающую ИИ-модель
04.03.2025 [23:43],
Анжелла Марина
Amazon разрабатывает новую модель искусственного интеллекта (ИИ) с продвинутыми возможностями рассуждения. Модель разрабатывается в рамках бренда Nova и может составить серьёзную конкуренцию основным игрокам рынка — OpenAI, Anthropic и Gemini. 
Источник изображения: Christian Wiediger / Unsplash Как сообщает Business Insider, ссылаясь на источник, знакомый с проектом, Nova будет использовать гибридный подход к рассуждению, сочетая в одной системе быстрые ответы и более сложное, многозадачное мышление. Одной из ключевых задач Amazon является снижение стоимости работы модели по сравнению с конкурентами, такими как OpenAI o1, Anthropic Claude 3.7 Sonnet и Google Gemini 2.0 Flash Thinking. Ранее компания заявляла, что её текущие, не рассуждающие модели Nova, на 75 % дешевле сторонних предложений, доступных через платформу Bedrock AI. За разработку Nova отвечает команда AGI под руководством главного научного сотрудника Рохита Прадаса (Rohit Prasad), а чтобы вывести модель в топ-5 по производительности, Amazon тестирует её на внешних бенчмарках, оценивающих навыки программирования и математики, включая SWE, Berkeley Function Calling Leaderboard и AIME. Стоит сказать, что ИИ-модели с функцией рассуждения постепенно становятся новым этапом развития искусственного интеллекта. И хоть они работают медленнее, способны решать более сложные задачи, используя поиск решений и метод цепочки мыслей. Подобные технологии уже представили Google, OpenAI и Anthropic. Также китайская компания DeepSeek привлекла к себе внимание благодаря тому, что нашла ещё более эффективный подход. Ожидается, что Nova усилит конкуренцию Amazon с продуктами Anthropic, недавно выпустившей модель Claude 3.7 Sonnet, которая также использует гибридный подход. Представители Amazon пока отказались от каких-либо комментариев, однако предположительно рассуждающая ИИ-модель может быть запущена уже к июню. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex