|
Опрос
|
реклама
Быстрый переход
Дженсен Хуанг отправил в Samsung гарантийное письмо — в компании не верят, что Nvidia захочет закупать её HBM3E
09.10.2025 [12:00],
Алексей Разин
В конце сентября стало известно, что после неоднократных попыток удовлетворить требования Nvidia к закупаемой памяти типа HBM3E, южнокорейская Samsung Electronics всё же добилась своего, и получила право снабжать ею данного заказчика. Теперь южнокорейские СМИ сообщают, что соответствующие намерения Nvidia подкрепила письменно в обращении к фактическому руководителю Samsung Ли Чжэ Ёну (Lee Jae-yong). 
Источник изображения: Nvidia Издание News1 Korea сообщает, что недавно основатель и руководитель Nvidia Дженсен Хуанг (Jensen Huang) направил председателю совета директоров Samsung Electronics письмо с заверениями о готовности на регулярной основе закупать у этого поставщика 12-ярусные микросхемы HBM3E для использования в составе ускорителей семейства GB300. По данным источника, попытки Samsung встроиться в цепочку поставок Nvidia с конкретным типом памяти длились около года и семи месяцев. Ещё в марте прошлого года Дженсен Хуанг оставил свой автограф с одобрением на символической пластине с чипом HBM3E производства Samsung, но фактически предлагаемая этой компанией продукция не могла удовлетворить требования Nvidia вплоть до прошлого месяца. Где-то в начале текущего года Samsung предложила Nvidia заметно переработанные чипы HBM3E, после чего процесс сертификации встал на путь к успеху. Впрочем, конкуренты Samsung в этой сфере оказались далеко впереди, поскольку SK hynix начала снабжать Nvidia своими 12-ярусными чипами ещё в сентябре прошлого года, а в феврале текущего к ней присоединилась американская Micron Technology. С точки зрения планов Nvidia, память типа HBM3E приближается к излёту своего жизненного цикла, поэтому много заработать на поставках своих микросхем этого типа Samsung не успеет. Зато Samsung уже предлагает своим клиентам образцы HBM4, и с их сертификацией она может добиться большего успеха, чем с HBM3E. Попутно стало известно, что Samsung закупила у Nvidia около 50 000 ускорителей вычислений. Предполагается, что они понадобятся для развития как собственных решений компании в сфере ИИ, так и реализации совместного проекта с OpenAI по строительству специализированного вычислительного центра на территории Южной Кореи. Карманный ИИ становится массовым: каждый третий смартфон в этом году получит ИИ-ускоритель
01.10.2025 [11:57],
Алексей Разин
Надежды производителей ПК на скорый рост продаж систем с возможностью локального ускорения ИИ пока не оправдываются, но вот в сегменте смартфонов в этом году количество устройств на основе процессоров с поддержкой генеративного ИИ вырастет на 74 % и достигнет 35 % годового объёма продаж. К такому выводу приходят специалисты Counterpoint Research. 
Источник изображения: Qualcomm Technologies В премиальном сегменте, как они утверждают, в этом году 88 % всех отгруженных в этом году чипов для смартфонов будут наделены функциями аппаратного ускорения работы с генеративным искусственным интеллектом. При этом подобные функции проникнут и в смартфоны в ценовом диапазоне от $300 до $499, которые в целом нарастят свою долю с 12 до 38 % рынка. Объёмы поставок ИИ-чипов для смартфонов в среднем ценовом диапазоне утроятся по сравнению с прошлым годом. Как отмечают аналитики, рост объёмов реализации ИИ-чипов по рынку смартфонов в целом на 74 % в текущем году во многом станет возможным именно благодаря распространению продвинутых функциональных возможностей на более низкие ценовые диапазоны. Среди поставщиков подобных процессоров лидировать будет Apple с 46 % рынка, хотя на программном уровне собственная экосистема ИИ у этой компании развита не так сильно, как она хотела бы. Тем не менее, формально процессоры семейства A19 позволяют работать с генеративным ИИ, что позволяет занять ведущие позиции на рынке. 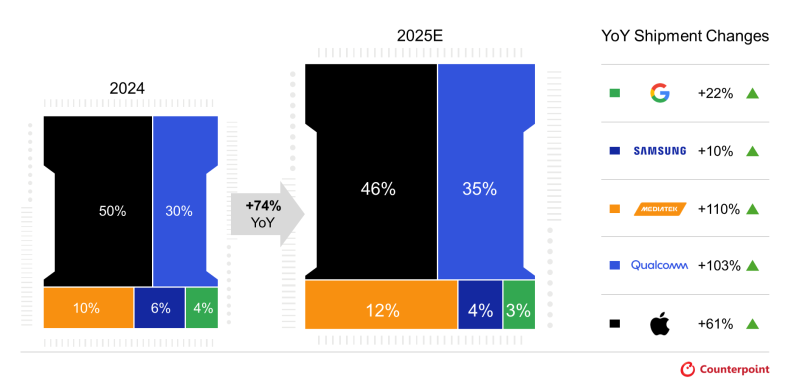
Источник изображения: Counterpoint Research На втором месте окажется Qualcomm с 35 % рынка, на третьем MediaTek с 12 %. Samsung с процессорами собственной разработки окажется на четвёртом месте с 4 % рынка, а Google достанутся 3 %. Год назад расстановка сил была другой: Apple (50 %), Qualcomm (35 %), MediaTek (10 %), Samsung (6 %) и Google (4 %) хоть и шли в том же порядке, продемонстрируют разную динамику по итогам текущего года в прогнозах авторов аналитической записки. Google увеличит объёмы поставок своих чипов на 22 %, Samsung прибавит только 10 %, Mediatek окажется лидером по темпам роста с 110 %, а Qualcomm лишь немного уступит ей с 103 %. В то же время, Apple с приростом на 61 % окажется крепким середнячком по динамике, но сохранит за собой лидирующие позиции по доле рынка. В сегменте Android-смартфонов лидером остаётся Qualcomm со своими процессорами, начиная с семейства Snapdragon 8 Gen 3. Компания постепенно проникает и в ценовой диапазон смартфонов от $100 до $299 со своими процессорами, наделёнными ИИ-функциями. В премиальном сегменте поставки ИИ-чипов для смартфонов вырастут на 53 % по итогам текущего года, их доля в сегменте достигнет 88 %. Здесь будут доминировать процессоры Apple A19 и A19 Pro, а также Qualcomm Snapdragon 8 Elite Gen 5 и MediaTek Dimensity 9500. В эту группу также входят процессоры Samsung Exynos, Google Tensor и HiSilicon Kirin 9000. Их внедрение вызовет рост средней цены реализации смартфонов в премиальном сегменте. Кроме того, смартфоны с такими функциональными возможностями в среднем содержат больше чипов. Китай попытается создать ИИ-чипы нового типа, так как подражать США «смертельно опасно»
11.09.2025 [21:13],
Сергей Сурабекянц
Главный советник китайского правительства профессор пекинского Университета Цинхуа Вэй Шаоцзюнь (Wei Shaojun), выступая на форуме в Сингапуре, заявил, что азиатским странам, включая Китай, следует снизить зависимость от универсальных графических процессоров, которые сейчас используются во всём мире для обучения ИИ платформ. По его словам, Китаю требуются чипы ИИ, построенные на собственной архитектуре и не зависящие от технологий Nvidia. 
Источник изображения: Samsung Вэй, который много лет консультировал высокопоставленных чиновников китайского правительства, признал, что «к сожалению, мы в Азии, включая Китай, подражаем США в разработке алгоритмов и больших моделей». Продолжение этого пути может быть «смертельно опасным» для региона, добавил он. Китаю следует сосредоточиться на создании нового типа чипа, специально предназначенного для разработки крупных моделей, а не продолжать полагаться на архитектуру, изначально разработанную для игр и промышленной графики, добавил Вэй. Он подчеркнул, что Китай по-прежнему активно развивает собственную индустрию по производству микросхем и располагает для этого достаточными средствами, несмотря на годы санкций США. Китайские компании столкнулись с нехваткой ИИ-ускорителей Nvidia из-за экспортных ограничений, введённых США, которые не позволяют китайским компаниям приобретать самые передовые чипы. Собственные технологии производства чипов в Китае пока не позволяют выпускать ускорители ИИ, сопоставимые по производительности с лучшими решениями Nvidia. Однако выход нейросети DeepSeek на мировую арену в начале этого года показал, что китайские компании способны совершенствовать свои алгоритмы ИИ даже на сравнительно слабом оборудовании. В конце июля китайские регуляторы обвинили Nvidia в том, что предназначенные для рынка КНР ускорители H20 имеют функции удалённой блокировки и отслеживания, из-за чего представителям компании пришлось неоднократно опровергать подобные обвинения. Между тем китайские СМИ продолжают продвигать тезис о том, что ускорители Nvidia H20 небезопасны для разработчиков в Китае. 
Источник изображения: Nvidia Китайская сторона усиливает работу над импортозамещением, а муниципальные власти крупных китайских городов присоединились к этой работе. Например, в Шанхае установлено требование к 2027 году довести долю китайских ускорителей в муниципальных ЦОД до 70 %, в Пекине этот уровень достигает 100 %, а для округа Гуйян, характеризуемого развитой вычислительной инфраструктурой, планка установлена на уровне 90 %. OpenAI выпустит свой первый ИИ-чип в 2026 году при поддержке Broadcom — последней это сулит $10 млрд
05.09.2025 [05:29],
Алексей Разин
Слухи о намерениях OpenAI представить чип для ускорения вычислений в системах ИИ получили новую жизнь на этой неделе, поскольку компания Broadcom открыто призналась в заключении контракта с таинственным новым клиентом на поставку подобных чипов на общую сумму $10 млрд. Данные чипы выйдут в следующем году. 
Источник изображения: Broadcom Издание Financial Times подтвердило, что Broadcom помогла OpenAI разработать профильный чип, и на рынок он выйдет в 2026 году. Вторая из компаний собирается использовать этот компонент для собственных нужд и не предлагать сторонним клиентам. Сотрудничество с Broadcom в этой сфере началось ещё в прошлом году. До этого момента не было известно, когда начнётся массовое производство данного изделия. Для Broadcom стартап OpenAI станет уже четвёртым по счёту клиентом, для которого она разработала ИИ-чип. Акции Broadcom после этих заявлений в сочетании с в целом позитивной отчётностью выросли в цене на 4,5 %. Компания сотрудничала с Google при разработке специализированных тензорных процессоров последней. По мнению аналитиков HSBC, следующий год будет характеризоваться ростом продаж специализированных ИИ-чипов, тогда как универсальные решения типа предлагаемых Nvidia уже не смогут продемонстрировать высокой динамики роста выручки. Глава OpenAI Сэм Альтман (Sam Altman) в прошлом месяце выразил готовность увеличить вычислительные мощности компании вдвое за ближайшие пять месяцев. «Продажи HBM от Samsung достигли дна»: SK hynix стала крупнейшим производителем памяти в мире
31.07.2025 [14:29],
Анжелла Марина
SK hynix впервые обошла Samsung Electronics по объёму выручки от производства памяти, став крупнейшим в мире поставщиком, сообщает Bloomberg. Это произошло на фоне роста спроса на компоненты для систем искусственного интеллекта, где позиции SK hynix оказались более сильными. 
Источник изображения: SK hynix Выручка Samsung от продаж компьютерной памяти, включая DRAM и NAND, за период с апреля по июнь составила 21,2 триллиона вон (около $15,2 млрд), что ниже, чем 21,8 триллиона вон, зафиксированных у SK hynix неделей ранее. Основной вклад в успех компании, базирующейся в Ичхоне (Южная Корея) внесла высокопроизводительная память HBM (High-Bandwidth Memory), используемая в ИИ-чипах. По данным аналитической компании Counterpoint Research, доля SK hynix на рынке HBM достигла 62 %, в то время как Samsung контролирует лишь 17 % этого сегмента и до сих пор не получила одобрения от Nvidia на поставку своей самой передовой версии HBM. 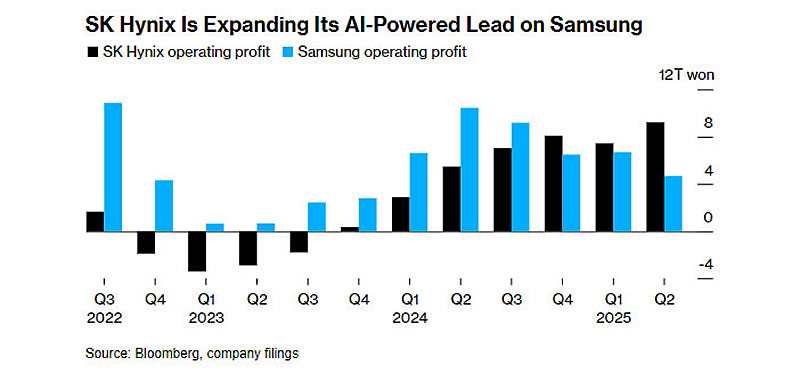
Источник изображения: Bloomberg МС Хван (MS Hwang), директор по исследованиям в Counterpoint, отметил, что траектории роста двух южнокорейских производителей начали расходиться в первой половине 2024 года на фоне повышенного спроса на продукцию Nvidia и связанную с ней память HBM. Он также указал, что падение продаж HBM у Samsung, вероятно, замедлилось. «Новость заключается в том, что продажи HBM-памяти Samsung, похоже, достигли своего дна», — сказал Хван. Для справки: HBM — это технология вертикального объединения нескольких слоёв DRAM, обеспечивающая высокую пропускную способность. Сегодня HBM рассматривается как критически важная составляющая для производительности современных компьютеров и серверов. Samsung предрекли падение прибыли на 39% из-за слабых продаж памяти для ИИ-систем
07.07.2025 [09:49],
Анжелла Марина
Аналитики ожидают от Samsung Electronics сильного снижения финансовых показателей. По итогам второго квартала операционная прибыль компании может упасть на 39 %, до 6,3 триллиона вон ($4,62 млрд). Это будет самый низкий уровень дохода за последние шесть кварталов и четвёртое подряд снижение, сообщает Reuters. Спад объясняется задержками в поставках передовой памяти HBM3E для Nvidia. 
Источник изображения: Samsung Electronics Аналитики отмечают, что Samsung столкнулась с растущим давлением со стороны таких конкурентов, как SK hynix и Micron, которые активно наращивают продажи чипов для ИИ-систем. В то же время Samsung остаётся зависимой от китайского рынка, где ограничения США на поставку высокотехнологичных компонентов замедляют рост выручки. Также процесс сертификации новых чипов HBM3E в Nvidia продолжается медленнее, чем ожидалось. Рю Ён Хо (Ryu Young-ho), старший аналитик NH Investment & Securities, заявил, что доходы от этих чипов во втором квартале, вероятно, остались на прежнем уровне и добавил, что массовые поставки новых чипов Samsung в Nvidia вряд ли начнутся в этом году. Ранее компания сообщала, что рассчитывала завершить тестирование своих HBM3E чипов к июню, однако официального подтверждения прохождения сертификации предоставлено не было. При этом в июне стало известно, что Samsung начала поставлять эти чипы американской компании AMD. Одновременно, несмотря на трудности в сегменте полупроводников, аналитики прогнозируют стабильные продажи смартфонов Samsung и, как отмечается, рост интереса к продукции не в малой степени связан с ожиданием возможных американских тарифов на импортные телефоны. В Китае начали выпускать первые в мире недвоичные ИИ-чипы, как ответ на санкции США
09.06.2025 [12:09],
Дмитрий Федоров
Китай начал первое в мире массовое производство недвоичных ИИ-чипов на базе гибридной логики, совмещающей бинарный и стохастический подход. Новые процессоры предназначены для смарт-дисплеев, авиационных систем и навигации, и представляют собой стратегический ответ на санкции США в сфере полупроводников. 
Источник изображения: Milad Fakurian / Unsplash Команда учёных под руководством профессора Ли Хунгэ (Li Hongge) из Пекинского аэрокосмического университета (Beihang University) официально представила первый в мире недвоичный ИИ-чип, ориентированный на массовое промышленное применение. Уникальность решения заключается в применении гибридной вычислительной архитектуры, что позволяет добиться высокой отказоустойчивости и энергоэффективности. Профессор Ли объясняет, что современные чипы сталкиваются с двумя критическими ограничениями: энергетическим и архитектурным барьером. Первый возникает из-за противоречия между высокой плотностью передачи данных и возросшими требованиями к энергозатратам, а второй обусловлен несовместимостью новых некремниевых решений с традиционными CMOS-архитектурами (комплементарными металл-оксидными полупроводниками). Именно эти фундаментальные ограничения не позволяют вычислительным системам эффективно масштабироваться и сдерживают внедрение новых парадигм в области ИИ. Решение, предложенное китайскими учёными, основывается на гибридной системе под названием Hybrid Stochastic Number (HSN). Она сочетает традиционные бинарные числа — основанные на жёстких логических 0 и 1 — с вероятностными величинами, используемыми в стохастической логике. Такой подход позволяет работать не с конкретными значениями, а с диапазонами вероятностей. В результате снижается аппаратная нагрузка, упрощается логика на уровне транзисторов и увеличивается устойчивость систем к ошибкам. Это особенно важно для управления в реальном времени, где очень важны отказоустойчивость, надёжность и энергоэффективность. В отличие от большинства существующих чипов, HSN-архитектура не требует строгой точности при обработке каждого бита информации. Это открывает путь к созданию интеллектуальных решений, способных работать в условиях высокой неопределённости, помех, сбоев в питании или неполных данных. Подобные характеристики востребованы в сенсорных интерфейсах, навигационных и системах управления полётами и даже в военной сфере. Использование стохастических алгоритмов в аппаратной логике делает возможным более глубокое моделирование процессов окружающей среды, чем традиционные системы. Производственные мощности размещены в провинции Хэбэй. Первая партия чипов уже прошла тестирование в авиационных тренажёрах, сенсорных платформах и экспериментальных навигационных системах. Массовое внедрение технологии ожидается во II квартале 2026 года. По информации издания Guangming Daily, переход к внедрению проходит поэтапно, с прицелом на интеграцию как в полностью новые, так и в существующие архитектуры. При этом адаптация возможна без полной переделки цифровой инфраструктуры, благодаря совместимости с протоколами передачи данных и гибкости логического слоя. Инженеры подчёркивают, что разработка китайского недвоичного ИИ-чипа не случайно совпала с жёсткими ограничениями США на экспорт полупроводниковых технологий. По сути, HSN-чип стал технополитическим ответом на санкционное давление и инструментом формирования цифрового суверенитета Китая. Технология позволяет Поднебесной снизить зависимость от поставок кремниевых чипов и выйти на путь создания собственной инфраструктуры для ИИ, которая может применяться не только в авиации и промышленности, но и в периферийных вычислениях, автономных автомобилях, робототехнике и даже в мобильных устройствах следующего поколения. Nvidia утверждает, что консоль Switch 2 использует ИИ для улучшения игрового процесса
04.06.2025 [05:04],
Алексей Разин
На этой неделе в продажу поступит долгожданная игровая консоль Nintendo Switch 2, и руководитель косвенно причастной к её созданию компании Nvidia Дженсен Хуанг (Jensen Huang) заранее поделился некоторыми её особенностями. По его словам, новинка получила выделенные ИИ-процессоры, которые в реальном времени улучшают игровой процесс. 
Источник изображения: Nintendo По словам основателя Nvidia, на которые ссылается CNBC, консоль Nintendo Switch 2 обеспечивает прорыв на трёх направлениях. Во-первых, это самая продвинутая графика для мобильного устройства, которая подразумевает полную аппаратную поддержку трассировки лучей. Во-вторых, это технология HDR для более ярких сцен и более глубоких теней. Наконец, Switch 2 наделена архитектурой, которая поддерживает обратную совместимость. Отдельно Дженсен Хуанг описал возможности консоли в сфере использования искусственного интеллекта: «Специальные процессоры чётче очерчивают, оживляют и улучшают игровой процесс в реальном времени». По словам главы Nvidia, Switch 2 является чем-то большим, чем новая игровая консоль. Он назвал её «новой главой, достойной видения Иваты-сан», имея в виду бывшего генерального директора Nintendo Сатору Ивату (Satoru Iwata), который не дожил до момента выхода исходной версии Switch. Nvidia выпустит ИИ-ускоритель B30 специально для Китая взамен запрещённого H20
02.06.2025 [16:52],
Дмитрий Федоров
Nvidia разрабатывает специализированный ИИ-ускоритель B30, соответствующий требованиям экспортного контроля США и предназначенный для поставок в Китай. Новый графический ускоритель (GPU) построен на архитектуре Blackwell и, вероятно, получит поддержку NVLink для объединения нескольких GPU в вычислительные кластеры. Эта разработка стала прямым ответом Nvidia на запрет, введённый правительством США на экспорт в КНР чипов линейки H20 на архитектуре Hopper. 
Источник изображений: Nvidia Главная особенность будущего B30 — поддержка масштабирования через объединение нескольких GPU. Эта функция, по мнению аналитиков, может быть реализована либо с применением технологии NVLink, либо посредством сетевых адаптеров ConnectX-8 SuperNIC с поддержкой PCIe 6.0. Несмотря на то, что Nvidia официально исключила NVLink из потребительских GPU начиная с предыдущего поколения, существует вероятность, что компания модифицировала кристаллы GB202, используемые в RTX 5090, и повторно активировала NVLink в их серверной конфигурации. Изначально будущий GPU фигурировал под различными названиями — от RTX Pro 6000D до B40, а теперь B30. Это, вероятно, указывает на наличие нескольких вариантов в рамках новой серии BXX, различающихся по уровню производительности и соответствию требованиям экспортного регулирования. Все модификации предполагается строить на чипах GB20X с использованием памяти GDDR7. Примечательно, что GB20X — это те же кристаллы, которые лежат в основе потребительских видеокарт линейки RTX 50. Таким образом, Nvidia не создаёт принципиально новый чип, а адаптирует уже существующую архитектуру для обхода ограничений. 
Nvidia RTX PRO 6000 Blackwell Workstation Edition На выставке Computex в Тайбэе Nvidia представила серверные системы RTX Pro Blackwell, рассчитанные на установку до восьми GPU RTX Pro 6000. Эти ускорители соединяются между собой через сетевые адаптеры ConnectX-8 SuperNIC, оснащённые встроенными PCIe 6.0-коммутаторами, обеспечивающими прямое взаимодействие между GPU. Та же схема коммуникации применяется при объединении двух суперчипов DGX Spark, которые служат основой для корпоративных и облачных ИИ-решений. Вероятнее всего, аналогичная архитектура будет использована и в B30. Комментируя запрет на экспорт H20, бессменный руководитель Nvidia Дженсен Хуанг (Jensen Huang) подчеркнул, что компания прекращает разработку альтернатив на архитектуре Hopper и сосредотачивается на Blackwell. Правительство США, в свою очередь, заявило, что у H20 — слишком высокая пропускная способность памяти и интерфейсных соединений, что делает чип неприемлемым для свободного экспорта. Эти параметры, по мнению регуляторов, создают риск использования ускорителей в составе китайских суперкомпьютеров, способных обслуживать оборонные и военные программы. 
Nvidia H200 Tensor Core GPU Ситуация с экспортными ограничениями не ограничивается только Nvidia. Американские регуляторы оказывают серьёзное влияние на весь рынок высокопроизводительных ИИ-решений. Компания AMD, например, оценивает потенциальные убытки от запрета на экспорт ускорителей MI308 в размере до $800 млн. Эта оценка была представлена сразу после вступления в силу новых ограничений. На протяжении последних лет Nvidia ведёт постоянную борьбу с регуляторами, сталкиваясь с чередой запретов и требований, где каждое новое поколение чипов, от A100 до H100 и H20, подвергается новым формам контроля. Хуанг, критикуя действующую экспортную политику США, назвал её «провалом» и предупредил о рисках стратегического отставания. По его мнению, такие меры лишь подталкивают китайские технологические компании, включая Huawei, к активному развитию собственных ИИ-решений. В результате они могут не только догнать, но и перегнать американских техногигантов, сформировав собственные стандарты, которые в будущем могут стать основой глобальной ИИ-инфраструктуры. Это создаёт угрозу потери влияния США не только в технологической, но и в военно-стратегической сфере. Нестабильность, перегрев и протечки заставили Nvidia упростить дизайн современных ИИ-серверов
28.05.2025 [14:16],
Алексей Разин
Технические проблемы преследовали семейство ускорителей Nvidia Blackwell с конца прошлого года, в результате чего партнёры компании не могли обеспечить довольно быструю рыночную экспансию решений серии GB200, но теперь все трудности позади. Nvidia сделала выводы из этого опыта, упростив конструкцию GB300 с целью предотвращения возможных проблем с наращиванием объёмов производства. 
Источник изображения: Nvidia Издание Financial Times напоминает, что стоечные системы на основе ускорителей Blackwell первого поколения страдали от целого ряда технических проблем. Во-первых, содержались дефекты в компоненте, отвечающем за скоростной обмен данными между отдельными чипами. Во-вторых, сообщалось о перегреве компонентов в плотно скомпонованных системах. В-третьих, жидкостная система охлаждения в некоторых случаях давала течь. По словам опрошенных Financial Times источников, наблюдавшиеся ещё два или три месяца назад технические проблемы с выпуском стоечных систем на базе Blackwell удалось решить при активном содействии партнёров Nvidia. Теперь объёмы их выпуска наращиваются без особых затруднений. В третьем квартале Nvidia собирается наладить выпуск систем следующего поколения, относящихся к серии GB300. От некоторых изначальных технических решений компания предпочла отказаться ради более высокой надёжности. В частности, перспективный дизайн печатных плат Cordelia предусматривал возможность простой замены отдельных графических процессоров при обслуживании системы. Тем не менее, сопутствующие риски вынудили Nvidia отказаться от него в пользу существующего дизайна печатных плат — Bianca, который уже применяется при производстве GB200 и проверен временем. В целом, Nvidia полна решимости когда-нибудь внедрить дизайн Cordelia, но пока этот шаг отложен до момента выхода на рынок ИИ-ускорителей следующего поколения. За счёт нынешних уступок в дизайне Nvidia рассчитывает быстрее нарастить объёмы выпуска GB300, и это позволит ей быстрее компенсировать потери на китайском рынке, вызванные запретом со стороны США на поставки ускорителей семейства H20. Аналитики Bank of America предположили, что квартальная норма прибыли Nvidia в результате санкций против Китая снизится с 71 до 58 %. Отчёт за первый квартал текущего фискального года компания опубликует на этой неделе. Со следующего года в школах и детских садах ОАЭ всех детей начнут готовить к ИИ-будущему
04.05.2025 [22:03],
Анжелла Марина
Объединённые Арабские Эмираты (ОАЭ) намерены внедрить искусственный интеллект в школьную и дошкольную программу уже в 2025 году, став одной из первых стран региона, которая начнёт обучать детей работе с ИИ с раннего возраста. Власти также активно инвестируют в ИИ-инфраструктуру с надеждой на то, что новые поколения специалистов укрепят позиции страны на мировой арене. 
Источник изображения: David Rodrigo / Unsplash С 2025–2026 учебного года в государственных школах ОАЭ появится курс по искусственному интеллекту для всех возрастов, начиная от детского сада и заканчивая выпускными классами. Как сообщает Bloomberg, программа включает как технические аспекты, так и практическое применение технологии. Таким образом, Эмираты присоединятся к растущему числу стран, активно внедряющих ИИ в систему образования. Месяцем ранее Китай также объявил о похожей инициативе для учащихся начальной и средней школы. Страна уже инвестировала миллиарды долларов в дата-центры для обучения ИИ-моделей и создала специальный фонд, который может вырасти до $100 млрд в ближайшие годы. Глава OpenAI Сэм Альтман (Sam Altman) при этом заявил, что ОАЭ могут стать «регуляторной песочницей» для тестирования ИИ-технологий, а затем задавать глобальные стандарты их использования. На международной арене также усиливается интерес к технологическому потенциалу Эмиратов. По данным СМИ, США рассматривают возможность смягчения ограничений на поставки чипов компании Nvidia в ОАЭ, что может значительно ускорить развитие местной ИИ-индустрии и усилить позиции страны в регионе. Решение может быть принято до визита президента Дональда Трампа (Donald Trump) в середине мая, который планирует остановиться в ОАЭ по пути в Саудовскую Аравию и Катар. В рамках более широкого стратегического сотрудничества ОАЭ ранее объявили о планах инвестировать до $1,4 трлн в течение следующего десятилетия в энергетику, полупроводники, ИИ-инфраструктуру и производство на территории США, а внедрение ИИ в систему школьного образования станет одним из элементов масштабной стратегии. Nvidia, AMD и другие американские чипмейкеры опасаются, что проиграют Huawei из-за антикитайских санкций США
19.04.2025 [17:29],
Владимир Мироненко
Несмотря на попытки американских производителей полупроводников убедить власти смягчить ограничения на поставки своей продукции в Китай, администрация Дональда Трампа (Donald Trump), наоборот, их ужесточила на этой неделе. Фактически это лишило такие компании, как Nvidia, Advanced Micro Devices и Intel, возможности развивать бизнес в Поднебесной, которая покупает больше чипов, чем любая другая страна в мире, пишет The New York Times. 
Источник изображения: Nvidia В частности, Nvidia из-за ввода ограничений на экспорт ускорителя вычислений H20, что на деле является запретом, потеряла заказы китайских клиентов на общую сумму $18 млрд. В течение двух дней после объявления о необходимости получения лицензий на экспорт в Китай передовых ИИ-чипов акции Nvidia упали на 8,4 %, AMD — на 7,4 %, Intel — на 6,8 %. «Для полупроводниковой промышленности США Китай ушёл», — отметил Хэндел Джонс (Handel Jones), консультант по полупроводникам в консалтинговой компании International Business Strategies. Согласно его прогнозу, к 2030 году китайские компании будут лидировать по доле в производстве чипов во всех основных категориях на ИИ-рынке в Китае. Американские компании выражают опасения, что проводимая предыдущей и нынешней администрацией Белого дома политика ограничений сыграет на руку Huawei, которая займёт лидирующие позиции на китайском рынке ИИ-чипов благодаря отсутствию конкуренции с их стороны. Если Huawei наберёт обороты, то Китай будет использовать чипы компании для строительства ЦОД ИИ по всему миру в рамках реализации инициативы «Один пояс, один путь». По словам Грегори Аллена (Gregory Allen), директора Центра ИИ и передовых технологий Вадхвани, ограничения властей США приведут к тому, что имеющееся отставание Huawei в производстве ИИ-ускорителей может сократиться. К тому же власти КНР помогут Huawei привлечь в качестве клиента перспективный ИИ-стартап DeepSeek. Это, в частности, позволит Huawei улучшить программное обеспечение для управления выпускаемыми чипами. Впрочем, некоторые из аналитиков выступают за дальнейшее ужесточение запретов. Например, Дилан Патель (Dylan Patel), главный аналитик исследовательской компании SemiAnalysis, считает, что власти США должны полностью запретить Китаю покупать американское оборудование для производства чипов. В настоящее время некоторые китайские компании имеют возможность покупать это оборудование для перепродажи его другим соотечественникам, которые находятся под санкциями. Google представила свой самый мощный ИИ-процессор Ironwood — до 4,6 квадриллиона операций в секунду
09.04.2025 [15:56],
Николай Хижняк
В рамках конференции Cloud Next на этой неделе компания Google представила новый специализированный ИИ-чип Ironwood. Это уже седьмое поколение ИИ-процессоров компании и первый TPU, оптимизированный для инференса — работы уже обученных ИИ-моделей. Процессор будет использоваться в Google Cloud и поставляться в системах двух конфигураций: серверах из 256 таких процессоров и кластеров из 9216 таких чипов. 
Источник изображений: Google «Ironwood — это наш самый мощный, самый производительный и самый энергоэффективный TPU. Он разработан для ускорения инференса ИИ-моделей в масштабах облачной инфраструктуры», — прокомментировал анонс процессора вице-президент Google Cloud Амин Вахдат (Amin Vahdat). Анонс Ironwood состоялся на фоне усиливающейся конкуренции в сегменте разработок проприетарных ИИ-ускорителей. Хотя Nvidia доминирует на этом рынке, свои технологические решения также продвигают Amazon и Microsoft. Первая разработала ИИ-процессоры Trainium, Inferentia и Graviton, которые используются в её облачной инфраструктуре AWS, а Microsoft применяет собственные ИИ-чипы Cobalt 100 в облачных инстансах Azure.  Google заявляет, что Ironwood обладает пиковой вычислительной производительностью 4614 Тфлопс или 4614 триллионов операций в секунду. Таким образом кластер из 9216 таких чипов предложит производительность в 42,5 Экзафлопс.  Каждый процессор оснащён 192 Гбайт выделенной оперативной памяти с пропускной способностью 7,4 Тбит/с. Также чип включает усовершенствованное специализированное ядро SparseCore для обработки типов данных, распространённых в рабочих нагрузках «расширенного ранжирования» и «рекомендательных систем» (например, алгоритм, предлагающий одежду, которая может вам понравиться). Архитектура TPU оптимизирована для минимизации перемещения данных и задержек, что, по утверждению Google, приводит к значительной экономии энергии. Компания планирует использовать Ironwood в своём модульном вычислительном кластере AI Hypercomputer в составе Google Cloud. Meta✴ собралась купить чипмейкера FuriosaAI для выпуска своих ИИ-чипов
13.02.2025 [00:18],
Анжелла Марина
Компания Meta✴, стремясь укрепить свою серверную инфраструктуру для систем искусственного интеллекта (ИИ), ведёт переговоры о покупке южнокорейского чипмейкера FuriosaAI, специализирующегося на разработке ускорителей искусственного интеллекта. Об этом сообщает TechCrunch. 
Источник изображения: Igor Omilaev / Unsplash FuriosaAI, основанная бывшими сотрудниками Samsung и AMD, разрабатывает чипы, которые значительно ускоряют работу и обслуживание ИИ-моделей, включая модели генерации текста, такие как Llama 2 и Llama 3 от Meta✴. Ожидается, что Meta✴ может объявить о своих намерениях приобрести FuriosaAI уже в этом месяце. Согласно данным, FuriosaAI привлекла около 90 миллиардов корейских вон (примерно $61,94 млн) от инвесторов, включая южнокорейскую технологическую компанию Naver. Также ранее FuriosaAI заявляла о взаимодействии с потенциальными клиентами в США, Японии и Индии, не раскрывая их имён. По мнению экспертов, этот шаг, очевидно, направлен на снижение зависимости от доминирующей в области производства чипов компании Nvidia и является дополнением к собственным усилиям Meta✴ по созданию производительных и эффективных ИИ-ускорителей. Meta✴ заявила, что планирует потратить до $65 млрд в этом году на поддержку своих целей в области искусственного интеллекта. При этом приобретение FuriosaAI может значительно ускорить разработку и внедрение новых ИИ-технологий в собственные продукты Meta✴. Еврокомиссия раскритиковала новые правила США по поставкам ИИ-чипов — ограничения затронули большую часть ЕС
14.01.2025 [23:35],
Николай Хижняк
США, введя новые правила по контролю распространения ИИ, не только заблокировали поставки ИИ-чипов своим противникам, но также ограничили их экспорт в большинство стран мира. Такой радикальный подход администрации президента США Джо Байдена вызвал возмущение со стороны компании Nvidia, Ассоциации полупроводниковой промышленности (SIA), а теперь и Европейской комиссии (ЕК). 
Источник изображения: Nebius Новые правила экспортного контроля вступят в силу через 120 дней после их публикации — уже во время второго президентского срока Дональда Трампа. Это даст странам Евросоюза и другим заинтересованным сторонам время для консультаций с новой администрацией США, внесения возможных изменений в правила, их отсрочки или даже отмены. Согласно новым правилам, только 18 стран мира получат статус доверенных (Tier 1), из которых 10 являются членами ЕС: Бельгия, Дания, Финляндия, Франция, Германия, Ирландия, Италия, Нидерланды, Норвегия и Швеция. Это означает, что у них будет «практически неограниченный доступ» к передовым американским чипам для ИИ. Однако такие страны должны будут соблюдать требования безопасности США и размещать не менее 75 % своих вычислительных мощностей у себя или в других странах того же доверенного круга. Остальную часть мощностей разрешается размещать в странах, на которые не распространяется контроль над поставками вооружений со стороны США (Tier 2), при этом не более 7 % от общего объёма квоты может быть размещено в одной стране Tier 2. Для стран Tier 2, включая остальных 17 членов ЕС, вводится квота в 50 000 ИИ-чипов на страну. Возможны также сделки между правительствами, в результате которых квота может быть увеличена до 100 000 чипов, если цели стран в области возобновляемых источников энергии и технологической безопасности совпадают с целями США. Учреждения из некоторых стран могут подать заявку на получение особого статуса, который позволит им приобрести до 320 000 передовых ускорителей в течение двух лет. В ЕС резко раскритиковали такие экспортные ограничения. «Мы [ЕС] тесно сотрудничаем, в частности, в области безопасности, и представляем экономическую возможность для США, а не риск безопасности [...] Мы с нетерпением ждём конструктивного взаимодействия со следующей администрацией США. Мы уверены, что сможем найти способ сохранить безопасную трансатлантическую цепочку поставок технологий ИИ и суперкомпьютеров на благо наших компаний и граждан по обе стороны Атлантики», — говорится в совместном заявлении, опубликованном на сайте Еврокомиссии. Администрация президента Джо Байдена объявила о новых радикальных и противоречивых правилах экспортного контроля после сообщений о том, что предыдущие экспортные ограничения и санкции США в отношении противников оказались недостаточно эффективными. Новые меры в виде квот на поставки передовых чипов направлены на то, чтобы ещё больше затруднить доступ к ИИ-чипам для стран, находящихся под санкциями США, в частности Китая и России, даже через посредников. Стоит отметить, что с новыми экспортными ограничениями согласны не все даже в текущем составе руководства США. Так, министр торговли Джина Раймондо (Gina Raimondo) считает такие шаги пустой тратой времени. По её мнению, инвестиции в производство и исследования полупроводников гораздо важнее, так как именно они позволят США сохранить своё глобальное технологическое превосходство. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






