|
Опрос
|
реклама
Быстрый переход
По сравнению с декабрём выручка OpenAI в годовом выражении почти удвоилась до $10 млрд
10.06.2025 [09:26],
Алексей Разин
Компания OpenAI строит масштабные планы по развитию собственной вычислительной инфраструктуры, да и разработка языковых моделей требует серьёзных расходов, поэтому потенциальным инвесторам в этот стартап небезразлична динамика изменения его выручки. В этом месяце выручка OpenAI вышла на уровень, позволяющий рассчитывать на получение не менее $10 млрд в год. 
Источник изображения: OpenAI Для сравнения, как отмечает Reuters со ссылкой на CNBC, в декабре прошлого года этот показатель достигал $5,5 млрд. Преодоление рубежа в $10 млрд выручки в год в приведённом виде означает, что OpenAI наверняка удастся по итогам 2025 года в целом выручить $12,7 млрд, как она и рассчитывала. Текущая сумма в $10 млрд не учитывает поступлений от лицензионных отчислений крупнейшего партнёра Microsoft и вероятных разовых сделок, в результате которых OpenAI сможет получить дополнительную выручку. По сути, оценка в $10 млрд показывает, сколько компания способна получать в год главным образом от пользователей ChatGPT, оформивших платную подписку. Прошлый год OpenAI завершила с убытками в размере $5 млрд, поэтому высокая динамика наращивания выручки призвана успокоить инвесторов. В марте стало известно о намерениях компании привлечь ещё $40 млрд инвестиций, после чего её капитализация выросла бы до $300 млрд. По состоянию на конец марта OpenAI располагала ежемесячной аудиторией в 500 000 активных пользователей ChatGPT. Этот чат-бот компания вывела на рынок более двух лет назад, за доступ к его продвинутым возможностям пользователи ежемесячно вносят абонентскую плату. Основатель Huawei признал, что чипы компании на поколение отстают от западных, но назвал санкции неэффективными
10.06.2025 [07:01],
Алексей Разин
Весьма символично, что интервью основателя Huawei Жэнь Чжэнфэя (Ren Zhengfei) на страницах китайского издания People’s Daily было опубликовано именно в дни проведения торговых переговоров между США и КНР. Бывший глава китайского гиганта дал понять, что компания может выпускать передовые чипы и в условиях жёстких санкций. 
Источник изображения: Huawei Technologies С одной стороны, из уст Жэнь Чжэнфэя достаточно неожиданно прозвучали слова об очевидном отставании технологий самой Huawei от западных конкурентов. Как сообщает Reuters, он заявил о переоценке Западом технологических возможностей китайской компании: «США переоценили достижения Huawei, она не так хороша. Нам придётся усердно поработать, чтобы достичь того уровня, на который нас оценивают». Основатель Huawei добавил, что монолитные чипы разработки этой компании до сих пор на одно поколение отстают от американских. Чтобы устранить это отставание, компании приходится комбинировать физику и математику, находить способы обхода закона Мура, объединять чипы в вычислительные кластеры, чтобы добиться значимых практических результатов. Как дал понять Жэнь Чжэнфэй, Huawei запатентовала технологии упаковки чипов, которые позволят в конечном итоге добиться уровня производительности, сопоставимого с западными образцами. В сфере разработки ПО, главным образом полагающегося на принципы открытого исходного кода, у Китая есть ряд преимуществ вроде сотен миллионов молодых людей, способных заниматься разработкой, а также мощная энергетика и развитая сетевая инфраструктура. В будущем, по мнению основателя Huawei, Китай сможет использовать «сотни программ с открытым исходным кодом», которых хватит для покрытия всех потребностей китайского общества. В Китае, как подчеркнул основатель Huawei, достаточно разработчиков чипов, многие из них чувствуют себя хорошо, и в этом отношении концентрация США на одной Huawei немного удивляет Чжэнфэя. Сама Huawei ежегодно тратит по $25 млрд на исследования и разработки, и это должно позволить ей создать конкурентоспособные чипы с многокристальной компоновкой даже в условиях санкций. Apple призналась, что продолжит непублично совершенствовать Siri до следующего года
10.06.2025 [04:50],
Алексей Разин
На мероприятии WWDC 2025 представители Apple практически обошли стороной тему создания более персонализированного голосового ассистента Siri, опирающегося на искусственный интеллект. Было лишь мимоходом сказано, что на доводку Siri до стандартов качества компании уйдёт больше времени, и новости в этой сфере появятся не ранее следующего года. 
Источник изображения: Apple Старший вице-президент Apple по разработке ПО Крейг Федериги (Creig Federighi) буквально заявил: «Как мы и говорили, мы продолжаем работу над созданием функций, которые сделают Siri более персональной. Эта работа требует больше времени, чтобы достичь нашей высокой планки качества, и мы готовы будем поделиться новыми подробностями в следующем году». По меркам развития прочих проектов в сфере ИИ это достаточно большая пауза, что явно не идёт на пользу репутации Apple. Впервые о «более персональной Siri» компания заговорила ещё в прошлом году на WWDC 24, новое поколение голосового помощника должно было использовать искусственный интеллект, а потому рассматривалось как «следующий серьёзный шаг для Apple». Подразумевалось, что Siri после грядущего обновления сможет воспринимать более персонализированный контекст запросов, учитывая контакты и характер родственных связей пользователя, а также историю его активности. Планировалось также научить Siri работать с несколькими приложениями в сквозном режиме. Издание Bloomberg ранее сообщило, что на данном этапе новый вариант Siri вполне функционален, но у него нет стабильности в достигаемых результатах. Лишь две трети запросов обрабатываются корректно, что не позволяет выпустить эту версию голосового интерфейса на рынок в ближайшее время. В марте этого года Apple уже пришлось признать, что подготовка к выпуску нового варианта Siri задерживается. В руководстве компании на этом фоне даже произошли кадровые перестановки. Чтобы компенсировать собственное отставание в сфере ИИ, компания Apple скооперировалась с OpenAI, и теперь наиболее сложные вопросы в экосистеме первой из них адресуются ChatGPT. На нынешней конференции WWDC 2025 представители Apple демонстрировали прогресс во внедрении ИИ, но он не касался голосового помощника Siri. Figure похвалилась успехами человекоподобного робота Helix на работе, но посылки продолжают летать по складу
09.06.2025 [19:26],
Сергей Сурабекянц
Три месяца назад робототехнический стартап Figure «устроил на работу» в почтовое отделение своего передового гуманоидного робота Helix. Сегодня представители компании подробно рассказали о накопленном за это время опыте и успехах робота в сортировке посылок. Однако при просмотре опубликованного компанией почти часового видеоролика мы заметили множество ошибок, совершаемых Helix. Пожалуй, свои посылки мы ему пока доверить не готовы. 
Источник изображений: Figure «Теперь Helix может обрабатывать более широкий спектр упаковок и приближается к ловкости и скорости человеческого уровня, приближая нас к полностью автономной сортировке посылок. Этот быстрый прогресс подчёркивает масштабируемость основанного на обучении подхода Helix к робототехнике, который быстро переносится в реальное применение», — так оценил успехи робота представитель Figure. По его словам, за счёт масштабирования данных и усовершенствования архитектуры возможности Helix существенно повысились:
Помимо стандартных жёстких коробок система теперь обрабатывает полиэтиленовые пакеты, мягкие конверты и другие деформируемые или тонкие посылки. Эти предметы могут складываться, мяться или изгибаться, что затрудняет захват и распознавание этикеток. Helix решает эту задачу, корректируя стратегию захвата на лету — например, отбрасывая мягкий пакет для его динамического переворота или используя специальные захваты для плоских почтовых отправлений. 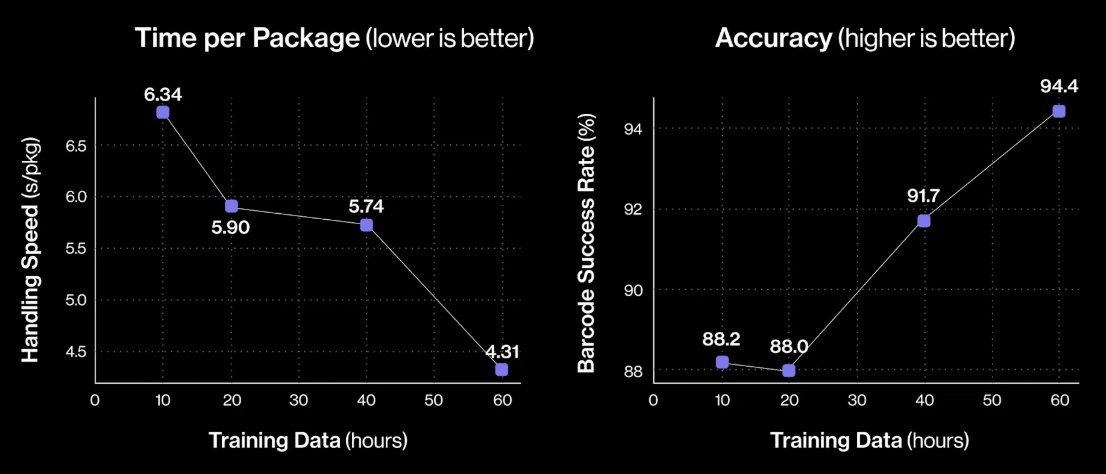 Робот должен поворачивать упаковку штрих-кодом вниз для сканирования. Helix старается расправить пластиковую упаковку, чтобы сканер смог успешно считать штрих-код. Такое адаптивное поведение подчёркивает преимущества сквозного обучения — робот выполняет действия, которые не были жёстко запрограммированы, чтобы компенсировать несовершенства упаковки. Многие достижения стали возможны благодаря целенаправленным улучшениям визуально-моторной политики робота. Он получил новые модули памяти и машинного зрения, что позволило ему лучше воспринимать состояние окружающей среды и быстро адаптироваться к изменениям ситуации. 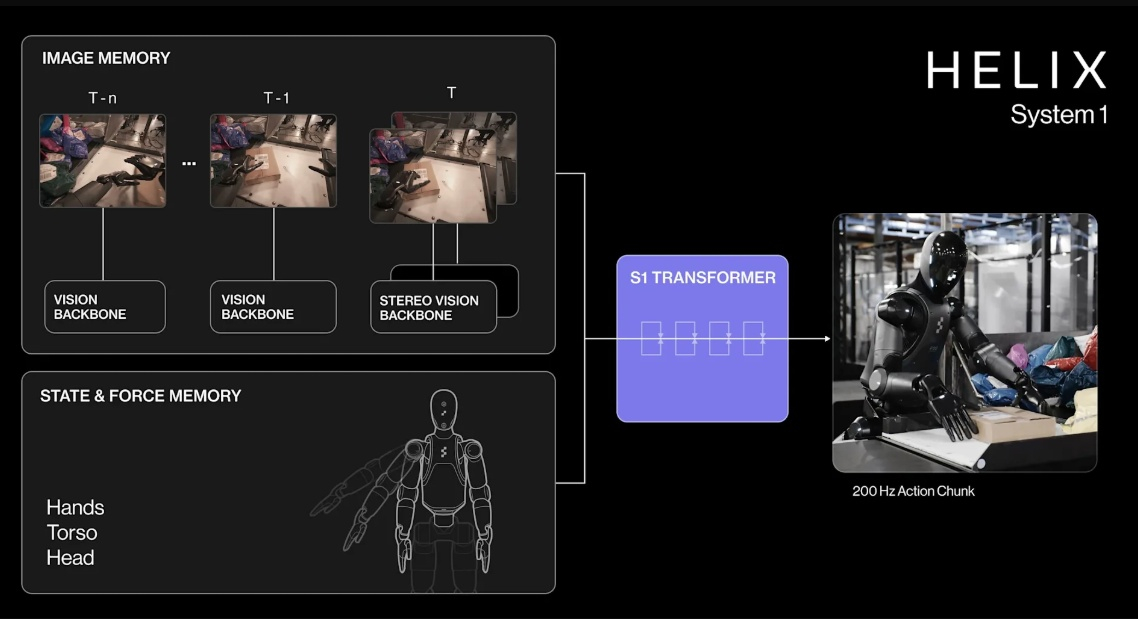 Helix оснащён модулем неявной визуальной памяти, который обеспечивает поведение с учётом текущего состояния — робот запоминает, какие стороны упаковки он уже осмотрел, либо какие зоны конвейера свободны. Модуль памяти помогает устранять избыточные движения, давая Helix ощущение временного контекста и позволяя ему действовать более стратегически при выполнении многошаговых манипуляций. Отслеживание истории недавних состояний позволяет роботу осуществлять более быстрое и реактивное управление. В результате ускоряется реакция на неожиданности и помехи: если пакет смещается или попытка захвата оказывается неудачной, Helix корректирует движение «на лету». Это значительно сократило время обработки каждого пакета. 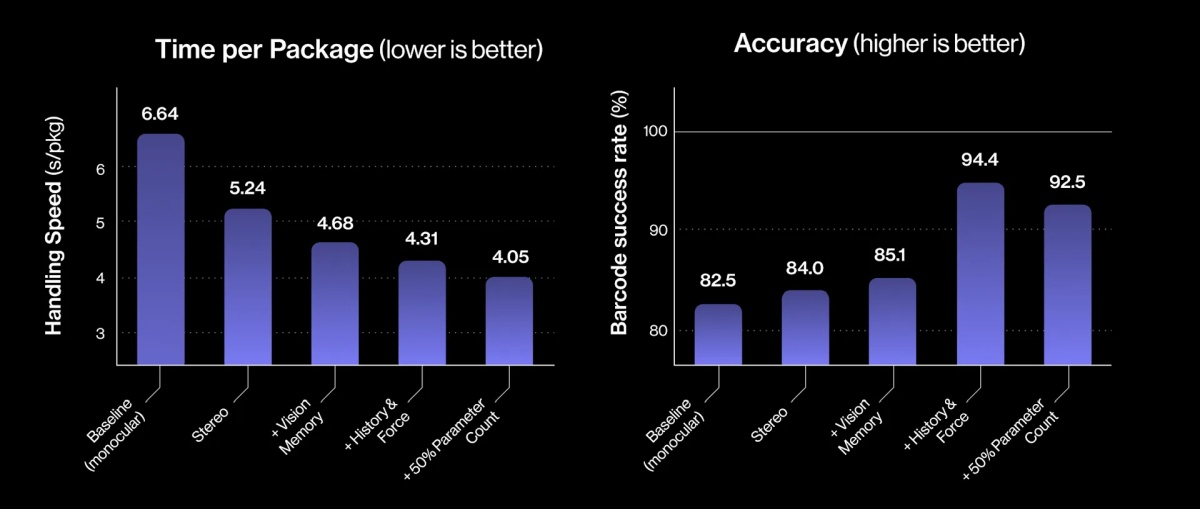 Helix использует аналог человеческого осязания благодаря интегрированной обратной связи по усилию. Робот способен определить момент соприкосновения с объектом и использовать это для модуляции движения, например, приостанавливая опускание при контакте с конвейерной лентой. Хотя основной задачей Helix в логистическом сценарии является автономная сортировка, он легко адаптируется к новым взаимодействиям. Например, протянутая к нему рука человека интерпретируется как сигнал к передаче предмета: робот отдаёт посылку, а не размещает её на конвейере — подобное поведение заранее явно не программировалось, система самостоятельно обучилась ему.  «Helix неуклонно масштабируется в плане ловкости и надёжности, сокращая разрыв между освоенными роботизированными манипуляциями и требованиями реальных задач. Мы продолжим расширять набор навыков и обеспечивать стабильность на ещё больших скоростях и рабочих нагрузках», — заявил представитель Figure. В реальности всё далеко не так радужно, как описывают маркетологи Figure — по следующим ссылкам можно увидеть, что робот совершает много ошибок, путается, роняет посылки и порой откровенно зависает. Так что какое-то время «кожаные мешки» на этой работе ещё будут востребованы. Но, учитывая нынешние темпы развития робототехники и бум искусственного интеллекта, почтовым служащим пора подумать о смене профессии. В Китае начали выпускать первые в мире недвоичные ИИ-чипы, как ответ на санкции США
09.06.2025 [12:09],
Дмитрий Федоров
Китай начал первое в мире массовое производство недвоичных ИИ-чипов на базе гибридной логики, совмещающей бинарный и стохастический подход. Новые процессоры предназначены для смарт-дисплеев, авиационных систем и навигации, и представляют собой стратегический ответ на санкции США в сфере полупроводников. 
Источник изображения: Milad Fakurian / Unsplash Команда учёных под руководством профессора Ли Хунгэ (Li Hongge) из Пекинского аэрокосмического университета (Beihang University) официально представила первый в мире недвоичный ИИ-чип, ориентированный на массовое промышленное применение. Уникальность решения заключается в применении гибридной вычислительной архитектуры, что позволяет добиться высокой отказоустойчивости и энергоэффективности. Профессор Ли объясняет, что современные чипы сталкиваются с двумя критическими ограничениями: энергетическим и архитектурным барьером. Первый возникает из-за противоречия между высокой плотностью передачи данных и возросшими требованиями к энергозатратам, а второй обусловлен несовместимостью новых некремниевых решений с традиционными CMOS-архитектурами (комплементарными металл-оксидными полупроводниками). Именно эти фундаментальные ограничения не позволяют вычислительным системам эффективно масштабироваться и сдерживают внедрение новых парадигм в области ИИ. Решение, предложенное китайскими учёными, основывается на гибридной системе под названием Hybrid Stochastic Number (HSN). Она сочетает традиционные бинарные числа — основанные на жёстких логических 0 и 1 — с вероятностными величинами, используемыми в стохастической логике. Такой подход позволяет работать не с конкретными значениями, а с диапазонами вероятностей. В результате снижается аппаратная нагрузка, упрощается логика на уровне транзисторов и увеличивается устойчивость систем к ошибкам. Это особенно важно для управления в реальном времени, где очень важны отказоустойчивость, надёжность и энергоэффективность. В отличие от большинства существующих чипов, HSN-архитектура не требует строгой точности при обработке каждого бита информации. Это открывает путь к созданию интеллектуальных решений, способных работать в условиях высокой неопределённости, помех, сбоев в питании или неполных данных. Подобные характеристики востребованы в сенсорных интерфейсах, навигационных и системах управления полётами и даже в военной сфере. Использование стохастических алгоритмов в аппаратной логике делает возможным более глубокое моделирование процессов окружающей среды, чем традиционные системы. Производственные мощности размещены в провинции Хэбэй. Первая партия чипов уже прошла тестирование в авиационных тренажёрах, сенсорных платформах и экспериментальных навигационных системах. Массовое внедрение технологии ожидается во II квартале 2026 года. По информации издания Guangming Daily, переход к внедрению проходит поэтапно, с прицелом на интеграцию как в полностью новые, так и в существующие архитектуры. При этом адаптация возможна без полной переделки цифровой инфраструктуры, благодаря совместимости с протоколами передачи данных и гибкости логического слоя. Инженеры подчёркивают, что разработка китайского недвоичного ИИ-чипа не случайно совпала с жёсткими ограничениями США на экспорт полупроводниковых технологий. По сути, HSN-чип стал технополитическим ответом на санкционное давление и инструментом формирования цифрового суверенитета Китая. Технология позволяет Поднебесной снизить зависимость от поставок кремниевых чипов и выйти на путь создания собственной инфраструктуры для ИИ, которая может применяться не только в авиации и промышленности, но и в периферийных вычислениях, автономных автомобилях, робототехнике и даже в мобильных устройствах следующего поколения. Nvidia выручит до $350 млрд на дата-центрах для ИИ только в этом году, несмотря на проблемы в Китае
09.06.2025 [09:42],
Алексей Разин
Представители Bank of America по итогам общения с руководством Nvidia пришли к выводу, что перспективы развития бизнеса этой компании в сфере центров обработки данных не особо омрачаются теми факторами, на которые предпочитают ссылаться пессимисты. Только в этом году она может выручить от $250 до $350 млрд. 
Источник изображения: Nvidia Как пояснил эксперт Вивек Арья (Vivek Arya), финансовый директор Nvidia Колетт Кресс (Colette Kress) весьма позитивно смотрит в будущее, поскольку спрос на решения этой марки высок как в корпоративном сегменте, так и на рынке облачных систем. Кроме того, переход от Blackwell к Blackwell Ultra будет более гладким по сравнению с переходом с Hopper на Blackwell, а сопутствующие расходы компании окажутся ниже. Руководство Nvidia, по словам представителей Bank of America, ожидает, что все крупнейшие государства заинтересованы в создании собственных языковых моделей и дальнейшем их развитии. Строительство вычислительного центра мощностью 1 ГВт в среднем позволит Nvidia выручить на проекте до $50 млрд. Если учесть, что только в этом году совокупная мощность вводимых в строй ЦОД будет варьироваться от 5 до 7 ГВт, то компания спокойно может претендовать на выручку от $250 до $350 млрд. Это значительно выше тех $175 млрд в год, на которые она могла рассчитывать ранее. Более того, антикитайские санкции оказывают не совсем предсказуемое влияние на бизнес Nvidia. Как отмечает The Information, китайские облачные гиганты типа Baidu и Alibaba не очень-то готовы активно переходить на ускорители китайского происхождения, включая продукцию Huawei, а потому у Nvidia сохраняется шанс на удержание своих рыночных позиций в Китае даже после усиления американских экспортных ограничений. Специалисты по ИИ решили, что современный ИИ — «зазубренный», потому что туповатый
08.06.2025 [21:59],
Анжелла Марина
Генеральный директор Google Сундар Пичаи (Sundar Pichai) заявил, что для обозначения текущей фазы развития искусственного интеллекта (ИИ) нужно ввести новый термин AJI, который необходим для обозначения противоречивой природы современных ИИ-моделей, способных решать сложнейшие задачи и совершать прорывы в науке, и одновременно допускать нелепые ошибки в простых заданиях, например в подсчёте слов. 
Источник изображения: AI Пичаи впервые упомянул об AJI на подкасте Лекса Фридмана (Lex Fridman), отметив, что он не уверен, кто именно придумал этот термин, но предположительно, это был бывший сотрудник OpenAI Андрей Карпати (Andrej Karpathy), специалист по глубокому обучению и компьютерному зрению. AJI расшифровывается примерно как «искусственный зазубренный интеллект» (Artificial Jagged Intelligence). Как пишет Business Insider, Карпати объяснил значение AJI в своём посте 2024 года в X, написав, что придумал его для описания странного факта при котором современные языковые модели могут справляться со сложными математическими задачами, но при этом могут не понять, что 9,9 больше, чем 9,11, допускают ошибки в игре «крестики-нолики» или неправильно считают буквы в словах. По словам Карпати, в отличие от человека, чьи когнитивные способности развиваются равномерно с детства, ИИ демонстрирует неравномерный прогресс, когда выдающиеся достижения в одних областях соседствуют с неожиданными провалами в других. Пичаи согласился с этой оценкой, отметив, что современные ИИ-системы обладают впечатляющими возможностями, но при этом спотыкаются на простых заданиях, например, при подсчёте букв в слове strawberry (клубника) или в сравнении чисел. По его мнению, сейчас ИИ находится именно в фазе AJI, когда прорывные достижения соседствуют с явными недостатками. Глава Google также затронул тему искусственного общего интеллекта (AGI). В 2010 году, когда появился DeepMind, специалисты прогнозировали появление AGI через 20 лет. Теперь Пичаи считает, что это займёт немного больше времени, но одновременно подчёркивает, что в любом случае к 2030 году благодаря технологии искусственного интеллекта мир будет наблюдать «умопомрачительный прогресс в различных областях». При этом Пичаи отметил необходимость систем маркировки контента, созданного ИИ, чтобы пользователи могли отличать реальную информацию от сгенерированной. На Саммите будущего ООН (UN Summit of the Future) в сентябре 2024 года Пичаи перечислил четыре ключевых направления, в которых ИИ может помочь человечеству: улучшение доступа к знаниям на родных языках, ускорение научных открытий, смягчение последствий климатических катастроф и содействие экономическому развитию. Однако ИИ сначала придётся научиться правильно писать слово strawberry. Сроки строительства гигаваттного ЦОД в ОАЭ растянутся из-за проблем в сфере безопасности
08.06.2025 [08:28],
Алексей Разин
В середине прошлого месяца президент Дональд Трамп (Donald Trump) посетил ОАЭ, в результате чего было заключено предварительное соглашение о строительстве на территории страны крупнейшего за пределами США центра обработки данных, связанного с искусственным интеллектом. Как выясняется, реализация этого проекта тормозится озабоченностью американской стороны вопросами безопасности, относящимися к Китаю. 
Источник изображения: Nvidia Готовность властей ОАЭ сотрудничать с китайскими компаниями, строго говоря, не является для американских чиновников неожиданностью и откровением, но экспорт в ближневосточный регион серьёзного количества передовых вычислительных компонентов таит особые риски, как отмечает Reuters со ссылкой на собственные источники. Представители Вашингтона выражают серьёзную обеспокоенность вероятностью получения Китаем доступа к соответствующим вычислительным мощностям на территории ОАЭ. На первом этапе на площади около 26 квадратных километров предполагается построить центр обработки данных, который будет потреблять 1 ГВт электроэнергии, вместит 100 000 передовых ускорителей Nvidia, и в дальнейшем может быть масштабирован до 5-гигаваттной мощности. Пользователями этого ЦОД и инвесторами в проект станут американские компании Nvidia, OpenAI, Oracle, Cisco и японская SoftBank, а арабская G42 будет отвечать за строительство необходимой инфраструктуры и дальнейшую эксплуатацию кампуса. Хотя последней в прошлом году и пришлось по требованию властей США прекратить использование китайского оборудования в своих проектах и отказаться от инвестиций в Китае, американские чиновники всё равно опасаются утечки технологий в Китай через территорию ОАЭ. Из-за этого одобрение проекта в США тормозится, поскольку американская сторона пытается наложить на представителей ОАЭ дополнительные обязательства в сфере безопасности. Этой ближневосточной стороне, например, предлагается отказаться от использования китайского оборудования в любых проектах, реализуемых на своей территории, а также запретить выходцам из Китая работать на территории ЦОД, который возводится совместно с американскими партнёрами. Сроки заключения соглашения по этому проекту в окончательном виде не определены, поэтому процедура может серьёзно затянуться, хотя изначально стороны намеревались ввести первую фазу ЦОД в строй в 2026 году. Предстоит также определить, как американская сторона сможет надёжно контролировать соблюдение предложенных условий. Nvidia планирует построить 100 новых ИИ-фабрик по всему миру
08.06.2025 [06:29],
Анжелла Марина
Nvidia приступила к реализации масштабного проекта по созданию 100 специализированных дата-центров для искусственного интеллекта (ИИ), которые получили название AI factories (ИИ-фабрики). По заявлению генерального директора компании Дженсена Хуанга (Jensen Huang), этот проект рассчитан на 50 лет и должен коренным образом изменить мировую ИИ-инфраструктуру. Тем более, что уже сейчас дата-центры приносят Nvidia почти 90 % выручки, тогда как доходы от игрового сегмента снизились до 9 %. 
Источник изображения: Nvidia Вместо того, чтобы просто продавать оборудование существующим владельцам дата-центров, Nvidia стала активно участвовать в проектировании и строительстве новых мощностей. Как сообщает Tom's Hardware, сейчас по всему миру разрабатывается около 100 таких объектов, приоритетом которых является запуск и обучение современных ИИ-моделей с возможностью масштабирования под будущие задачи. В отличие от игровых видеокарт, где пользователь видит результат в виде графики, в случае с ИИ вычислительная мощность напрямую трансформируется в экономический эффект. Nvidia рассчитывает, что её технологии станут основой глобальной ИИ-инфраструктуры, которая, по прогнозам Хуанга, будет развиваться на протяжении следующих 50 лет и со временем может стать неотъемлемой частью цифровой среды по всему миру, как это произошло с интернетом. Для реализации этих планов Nvidia заключила партнёрства с такими компаниями, как TSMC, Foxconn, Gigabyte, Asus, Humain в Саудовской Аравии и другими. Построение таких фабрик будет опираться на самые передовые решения, включая системы GB200 и GB300, объединяющие GPU и CPU. В дальнейшем ожидается внедрение более мощных архитектур, таких как Rubin, и систем охлаждения нового поколения. Также, по словам вице-президента и директора Nvidia по ускоренным вычислениям Йена Бака (Ian Buck), компания намерена сотрудничать и с разработчиками ИИ для того, чтобы её платформа оставалась актуальной и постоянно развивалась. Отмечается, что новые ИИ-фабрики смогут одновременно работать с несколькими моделями искусственного интеллекта и быстро адаптироваться к изменяющимся задачам. В целом глава компании сравнивает текущую ситуацию в отрасли с «золотой лихорадкой», в которой Nvidia выступает в роли не просто «поставщика лопат», а поставщика автоматизированных систем добычи и переработки. Хуанг подчёркивает, что производительность оборудования напрямую влияет на доходы клиентов. Например, улучшение энергоэффективности в четыре раза теоретически может увеличить прибыль дата-центра в той же пропорции. Одновременно эксперты указывают, что текущие затраты на развитие ИИ остаются крайне высокими, а некоторые крупные игроки в сфере ИИ несут убытки, исчисляемые десятизначными суммами. При этом перспективы масштабного внедрения ИИ всё ещё остаются прогнозом, а не реальностью. Высокий суд Англии вывел на чистую воду адвокатов, использующих ИИ, — они ссылались на фейковые прецеденты
08.06.2025 [00:47],
Анжелла Марина
Высокий суд Англии и Уэльса предупредил юристов, что использование в судебных материалах информации, созданной с помощью искусственного интеллекта, может привести к уголовной ответственности. Такое заявление последовало после выявления случаев, когда адвокаты ссылались на несуществующие судебные решения и цитировали вымышленные постановления, сообщает The New York Times. 
Источник изображения: AI Судья Виктория Шарп (Victoria Sharp) — президент Королевского суда (King's Bench Division), и судья Джереми Джонсон (Jeremy Johnson) рассмотрели два случая, в которых использовались ссылки на несуществующие дела. В одном из них истец вместе с адвокатом признали, что подготовили материалы иска против двух банков с помощью ИИ-инструментов. Суд обнаружил, что из 45 упомянутых ссылок 18 были вымышленными. Дело было закрыто в прошлом месяце. Во втором случае, завершившемся в апреле, юрист, подавший жалобу на местную администрацию от имени своего клиента, не смог объяснить происхождение пяти указанных примеров дел из судебной практики. «Могут быть серьёзные последствия для правосудия и доверия к системе, если использовать ИИ неправильно», — отметила судья Шарп. Она подчеркнула, что юристов могут привлечь к уголовной ответственности или лишить права заниматься профессиональной деятельностью за предоставление ложных данных, созданных ИИ. Также она указала, что такие инструменты, как ChatGPT, «не способны проводить надёжные правовые исследования» и могут давать хоть и уверенные, но полностью ложные утверждения или ссылки на несуществующие источники дел. В одном из дел мужчина потребовал выплатить ему сумму, исчисляемую миллионами, за якобы нарушенные банками условия договора. Позже он сам признал, что формировал ссылки на практику через ИИ-инструменты и интернет-ресурсы, поверив подлинности материалов. Его адвокат, в свою очередь, заявил, что опирался на исследования клиента и не проверил информацию самостоятельно. В другом деле юрист, представлявшая интересы человека, который был выселен из дома в Лондоне и нуждался в жилье, также использовала сгенерированные ссылки и не смогла объяснить их происхождение. При этом суд заподозрил применение ИИ из-за американского написания слов и шаблонного стиля текста. Сама юрист отрицала использование технологий искусственного интеллекта, но призналась, что в другом деле добавляла подобные ложные данные. Также она заявила, что использовала Google и Safari с ИИ-сводками результатов своего поиска. Интересно, что компания Vectara из Кремниевой долины (Калифорния, США), занимаясь с 2023 года исследованием ответов ИИ, выяснила, что даже лучшие чат-боты допускают ошибки в 0,7–2,2% случаев. При этом уровень «галлюцинаций» резко возрастает, когда от систем требуют генерировать большой текст с нуля. Недавно также и OpenAI сообщила, что её новые модели ошибаются в 51–79% случаев при ответах на общие вопросы. Несмотря на то, что судья Шарп признала, что искусственный интеллект является мощным инструментом, одновременно она заявила, что его использование сопряжено с рисками. Шарп также привела примеры из США, Австралии, Канады и Новой Зеландии, где ИИ некорректно интерпретировал законы или создавал вымышленные цитаты. Google Gemini научился выполнять задачи по расписанию
07.06.2025 [10:14],
Анжелла Марина
Google продолжает расширять возможности ИИ-ассистента Gemini, добавив функцию запланированных действий. Теперь подписчики Gemini Pro и Ultra могут настраивать автоматическое выполнение задач в заданное время. Например, ИИ будет отправлять сводку календаря в конце дня или предлагать идеи для блога еженедельно. 
Источник изображения: Solen Feyissa / Unsplash Как сообщает The Verge, пользователи также смогут поручать Gemini разовые задания. Например, запрашивать итоги прошедшего мероприятия на следующий день. Для работы функции достаточно указать искусственному интеллекту, что и когда нужно сделать, а чат-бот выполнит задачу самостоятельно. Управлять запланированными действиями можно в настройках приложения Gemini на странице Scheduled Actions. Ранее издание Android Authority сообщило, что предварительная версия этой функции была замечена ещё в апреле. Обновление является частью масштабных планов Google по превращению Gemini в цифрового помощника, обладающего более широкими автономными возможностями и способного выполнять команды без вмешательства пользователя. Интересно, что аналогичную функцию уже предлагает OpenAI в ChatGPT. В частности, подписчики могут настраивать «напоминалки» и повторяющиеся задачи. Суд «заблокировал» кнопку «Удалить» в ChatGPT
06.06.2025 [19:45],
Сергей Сурабекянц
OpenAI сообщила, что вынуждена хранить историю общения пользователей с ChatGPT «бессрочно» из-за постановления суда, вынесенного в рамках иска от издания The New York Times о защите авторских прав. Компания планирует обжаловать это решение, которое считает «чрезмерным вмешательством, отменяющим общепринятые нормы конфиденциальности и ослабляющим безопасность». 
Источник изображения: unsplash.com Издание The New York Times подало в суд на OpenAI и Microsoft за нарушение авторских прав в 2023 году, обвинив компании в «копировании и использовании миллионов» материалов для обучения моделей ИИ. Издание утверждает, что только сохранение данных пользователей до завершения судебного процесса сможет обеспечить предоставление необходимых доказательств в поддержку иска. В ноябре 2024 года стало известно, что инженеры OpenAI якобы случайно удалили данные, которые потенциально могли стать доказательством вины разработчика ИИ-алгоритмов в нарушении авторских прав. Компания признала ошибку и попыталась восстановить данные, но сделать это в полном объёме не удалось. Те же данные, что удалось восстановить, не позволяли определить, что публикации изданий были задействованы при обучении нейросетей. Поэтому в мае 2025 года суд обязал OpenAI сохранять «все выходные данные журнала, которые в противном случае были бы удалены», даже если пользователь запрашивает удаление чата или если законы о конфиденциальности требуют от OpenAI удаления данных. В соответствии с политикой OpenAI, если пользователь стирает чат, через 30 дней он удаляется без возможности восстановления. Теперь компании придётся хранить чаты до тех пор, пока суд не решит иначе. OpenAI сообщила, что постановление суда затронет пользователей бесплатной версии ChatGPT, а также владельцев подписок Pro, Plus и Team. Оно не повлияет на клиентов ChatGPT Enterprise или ChatGPT Edu, а также на компании, заключившие соглашение о нулевом хранении данных. OpenAI заверила, что данные не попадут в общий доступ, а работать с ними сможет «только небольшая проверенная юридическая и безопасная команда OpenAI» исключительно в юридических целях. «Мы считаем, что это был неуместный запрос, который создаёт плохой прецедент. Мы будем бороться с любым требованием, которое ставит под угрозу конфиденциальность наших пользователей; это основной принцип», — отреагировал генеральный директор OpenAI Сэм Альтман (Sam Altman). Ранее OpenAI обвинила The New York Times в «десятках тысяч попыток» получить эти «крайне аномальные результаты», «выявив и воспользовавшись ошибкой», которую сама OpenAI «стремится устранить». NYT якобы организовала эти атаки, чтобы собрать доказательства в поддержку утверждения, что продукты OpenAI ставят под угрозу журналистику, копируя авторские материалы и репортажи и тем самым отбирая аудиторию у создателей контента. The New York Times не одинока в своих претензиях в OpenAI. В мае 2024 года восемь интернет-изданий подали иск к OpenAI и Microsoft за незаконное использование статей для обучения ИИ. Истцы упрекают OpenAI в незаконном копировании миллионов статей, размещённых в изданиях New York Daily News, Chicago Tribune, Orlando Sentinel, Sun Sentinel, The Mercury News, The Denver Post, The Orange County Register и Pioneer Press для обучения своих языковых моделей. Apple разработала ИИ, выявляющий нетипичные аспекты устной речи — это поможет диагностировать заболевания
06.06.2025 [18:07],
Павел Котов
В рамках проекта, посвящённого голосовым и речевым моделям искусственного интеллекта, Apple опубликовала материалы (PDF) нового исследования, касающегося одной из сложных проблем машинного обучения: распознавание не только того, что было сказано человеком, но и того, как это было сказано. 
Источник изображения: Slavcho Malezan / unsplash.com В статье исследователи описывают схему анализа речи с использованием параметров качества голоса (Voice Quality Dimensions — VQD). Эти параметры указывают на разборчивость, резкость, монотонность речи, придыхание и другие аспекты. На них обращают внимание и логопеды, когда оценивают звучание голоса и влияние на него неврологических состояний и заболеваний. Apple работает над моделями ИИ, также способными их обнаруживать. Большинство речевых моделей обучается на здоровых и типичных для большинства голосах. Если голос человека звучит иначе, ИИ может дать сбой, и это большой недостаток системы, если ей пытается воспользоваться человек с ограниченными возможностями. В работе над этой проблемой исследователи Apple обучили несколько дополнительных моделей ИИ, предназначенных для работы совместно с основными речевыми системами, на большом общедоступном наборе данных аннотированной нетипичной речи, в том числе на голосах людей с болезнью Паркинсона, боковым амиотрофическим склерозом (БАС) и детским церебральным параличом (ДЦП). На этом инженеры компании не остановились — они не стали использовать эти модели для прямой расшифровки сказанного, а составили методику измерения того, как звучит голос, на основе семи основных критериев:

Источник изображения: Iluha Zavaley / unsplash.com Таким образом, ИИ научился «слушать как врач», а не просто регистрировать то, что говорят. Для извлечения звуковых характеристик Apple использовала пять моделей ИИ и обучила дополнительные легковесные алгоритмы, чтобы на основе этих характеристик предсказывать параметры качества голоса. Разработанные компанией дополнительные алгоритмы показали высокие результаты по большинству параметров, хотя качество срабатывания варьировалось в зависимости от конкретного признака и всей задачи. Важнейшим достоинством исследования стало то, что ответы моделей оказались объяснимыми — в отрасли ИИ это встречается нечасто. Вместо того, чтобы показывать условную оценку достоверности (confidence score), система указывает на конкретные характеристики голоса, что упрощает классификацию. Это поможет в клинической оценке и диагностике. Но и на клинической речи в Apple не остановились. Исследователи протестировали свои модели на образцах эмоциональной речи из набора данных RAVDESS: модели VQD не обучались на эмоциональных записях, но также давали прогнозы. Так, в сердитой речи отмечалась низкая «равномерность громкости», а грустные голоса воспринимались как монотонные. Возможно, это поможет улучшить и голосового помощника Apple Siri, который сможет корректировать свои интонации и речь в зависимости от того, как интерпретирует настроение и состояние пользователя, а не только сказанное им. ИИ можно полностью обучить только на бесплатных материалах, доказали исследователи
06.06.2025 [17:49],
Павел Котов
Специализирующиеся на разработке ИИ компании утверждают, что их проекты невозможно было бы создать без материалов, защищённых авторским правом. Группа учёных из США и других стран доказала, что разработка ИИ в таких условиях возможна, хотя и затруднительна. Они создали модель, обученную исключительно на общедоступном контенте и материалах с открытой лицензией. 
Источник изображения: Igor Omilaev / unsplash.com Проект стал результатом сотрудничества 14 учреждений, включая Массачусетский технологический институт, Университет Карнеги — Меллона и Торонтский университет. Исследователи составили массив данных для обучения, собранных только из этичных источников, — его объём достиг 8 Тбайт. В него, в частности, вошли 130 000 книг из Библиотеки Конгресса США. На этих материалах исследователи обучили большую языковую модель с 7 млрд параметров. Она работает примерно на уровне модели Meta✴ Llama 2-7B аналогичного размера, вышедшей в 2023 году. Тестов производительности модели в сравнении с ведущими отраслевыми проектами авторы исследования не привели. Качество работы системы на уровне модели двухлетней давности было не единственным недостатком — утомительным оказался и процесс перевода обучающего массива в надлежащий формат. Значительная часть данных не читалась машинами, поэтому людям приходилось участвовать в их подготовке. «Мы пользовались средствами автоматизации, но все наши материалы аннотировались вручную в конце дня и проверялись людьми. И это очень непросто», — рассказала одна из участниц проекта. Учёным пришлось определять, какая лицензия действует для каждого подвергшегося сканированию сайта. В 2024 году OpenAI заявила одному из комитетов британского парламента, что «обучать ведущие современные модели ИИ без использования защищённых авторским правом материалов невозможно». В прошлом году с этим тезисом согласился эксперт из Anthropic: «Больших языковых моделей, скорее всего, не было бы, если бы фирмы [специализирующиеся на] ИИ были обязаны лицензировать работы в своих наборах обучающих данных». Теперь есть доказательство, что оба утверждения не соответствуют действительности. Едва ли исследование что-то изменит в отрасли, но один из приводимых разработчиками ИИ распространённых аргументов оказался несостоятельным. Соцсеть X запретила использовать свой контент для обучения чужих ИИ
06.06.2025 [16:00],
Павел Котов
Администрация соцсети X обновила политику конфиденциальности — в новой редакции документ не позволяет третьим лицам использовать материалы платформы для обучения искусственного интеллекта. Эта мера, возможно сигнализирует о готовности заключать лицензионные сделки, как это ранее сделала Reddit. Источник изображения: Dima Solomin / unsplash.com Сторонним разработчикам теперь запрещается «использовать API X или материалы X для тонкой настройки или обучения базовых или передовых моделей [ИИ]», говорится в разделе «Обратное проектирование и прочие ограничения» обновлённого соглашения. В редакции политики конфиденциальности от октября прошлого года платформа могла передавать контент пользователей третьим лицам «для обучения их моделей ИИ, будь то генеративные или иные», если сами пользователи от этого не отказались. Перемена может быть связана с тем, что официально владельцем X является стартап Илона Маска (Elon Musk) xAI. Компания занимается разработкой чат-бота Grok, и вполне естественно, что она больше не хочет, чтобы третьи лица при разработке ИИ имели то же конкурентное преимущество — большой объём обучающего контента. По крайней мере, бесплатно компания предоставлять эти данные теперь не намерена. Эта мера может открыть для X новый источник дохода, если администрация платформы решит лицензировать контент за плату. Ранее так поступила Reddit — она заключила лицензионные соглашения с Google и OpenAI. Reddit также развернула средства безопасности, не допускающие краж данных ботами и веб-сканерами; она даже подала в суд на Anthropic, обвинив разработчика ИИ в недобросовестном сборе информации. Стоит отметить, что изменения политики X касаются только сторонних разработчиков ИИ; условия обслуживания по-прежнему позволяют администрации платформы использовать контент пользователей для обучения собственных моделей ИИ. Запретить сбор таких данных можно в настройках конфиденциальности своей учётной записи. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex