|
Опрос
|
реклама
Быстрый переход
Лучшая роль второго плана: чипы AMD недостаточно хороши, чтобы стать ядром инфраструктуры OpenAI
07.10.2025 [14:59],
Алексей Разин
Даже по мнению главы AMD Лизы Су (Lisa Su), структура анонсированной вчера сделки с OpenAI получилась инновационной и замысловатой, поэтому анализ выгод и преимуществ, которые получат её участники, может занять много времени. По сути, ускорители AMD Instinct потребуются OpenAI для развития инфраструктуры для инференса, но в сфере обучения больших языковых моделей продукция Nvidia всё равно будет на первых ролях. 
Источник изображения: AMD Новые стороны сделки пытается раскрыть издание The Wall Street Journal, которое поясняет, что последний транш акций AMD может достаться OpenAI в рамках сделки в том случае, если их рыночная стоимость достигнет $600. По сути, при текущем курсе около $207 за акцию капитализация AMD уже приблизилась к $330 млрд после вчерашнего скачка котировок, поэтому участники сделки явно рассчитывают, что в определённый момент капитализация AMD вырастет почти до $1 трлн. Казалось бы, это приличная сумма, но в этом случае AMD всё равно остаётся в тени Nvidia, чья капитализация на нынешних уровнях выше почти в 14 раз и достигает $4,5 трлн, а в сегменте ускорителей вычислений и видеокарт её рыночная доля измеряется как минимум 75 %, по мнению многих аналитиков. Глава AMD Лиза Су на этой неделе заявила, что сделка с OpenAI станет «огромным расширением той работы, которую мы делаем», но хорошо известно, что ускорители AMD Instinct в большей мере заточены под инференс, а не обучение языковых моделей. По сути, OpenAI будет использовать сотрудничество с AMD, чтобы перераспределить вычислительные ресурсы оптимальным образом: под инференс будут использоваться ускорители этого партнёра, а для обучения языковых моделей удастся высвободить больше ускорителей Nvidia, с которой у OpenAI оформлена ещё более крупная сделка. Исторически ставка делалась на более производительные чипы, способные работать с обучением больших языковых моделей, использующих миллиарды или даже триллионы параметров. Сейчас же спрос в сфере ИИ постепенно смещается в сторону инференса, который не требует столь значительных вычислительных ресурсов, а потому сделка OpenAI и AMD может быть выгодна обеим компаниям. Клиентам ИИ-сервисов функции, связанные с инференсом, кажутся более полезными и практичными для применения, поэтому и коммерческий потенциал этого сектора рынка будет расти после того, как прогресс в сфере обучения больших языковых моделей достигнет фазы какого-то насыщения. Лиза Су неоднократно отмечала ориентацию решений AMD на инференс и подчёркивала, что пока спрос на решения для ИИ растёт, места на рынке хватит для всех компаний. Кроме того, ускорители AMD традиционно дешевле решений Nvidia и могут быть экономичнее в эксплуатации, а ещё их банально проще купить в условиях всеобъемлющего дефицита, сосредоточенного в сегменте продукции Nvidia. Президент и один из основателей OpenAI Грег Брокман (Greg Brockman) заявил: «Мы действительно верим, что в мире существует недооценка потребностей в инференсе, и что мы движемся к миру, в котором всего не хватает. Это рынок с выгодными условиями для всех участников (very positive-sum market — прим. автора), где люди просто не строят в достаточном количестве. Чипов не будет хватать». Новая ИИ-модель DeepSeek cделает работу с длинным контекстом вдвое дешевле и быстрее
30.09.2025 [10:46],
Владимир Мироненко
Инженеры DeepSeek представили новую экспериментальную модель V3.2-exp, которая обеспечивает вдвое меньшую стоимость инференса и значительное ускорение для сценариев с длинным контекстом. 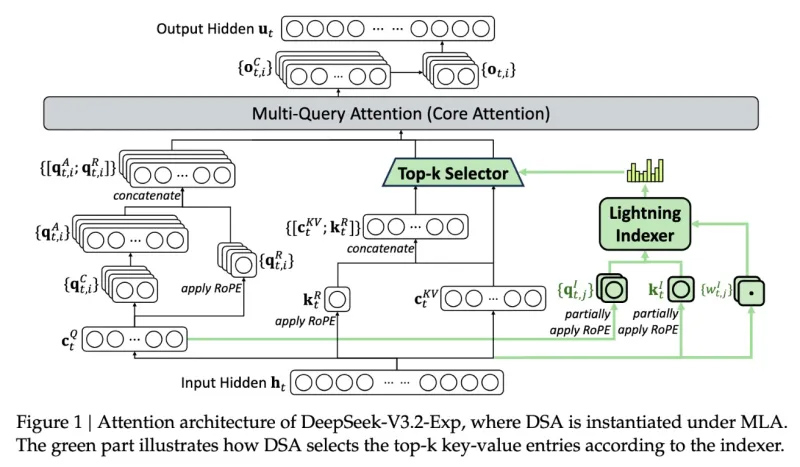
Источник изображения: DeepSeek/TechCrunch «В качестве промежуточного шага к архитектуре следующего поколения, V3.2-Exp дополняет V3.1-Terminus, внедряя DeepSeek Sparse Attention — механизм разреженного внимания, предназначенный для исследования и валидации оптимизаций эффективности обучения и вывода в сценариях с длинным контекстом», — сообщила компания в публикации на платформе Hugging Face, отметив в сообщении в соцсети X, что цены на API снижены более чем на 50 %. С помощью механизма DeepSeek Sparse Attention (DSA), который работает как интеллектуальный фильтр, модель выбирает наиболее важные фрагменты контекста, из которых с использованием системы точного выбора токенов выбирает определённые токены для загрузки в ограниченное окно внимания модуля. Метод сочетает крупнозернистое сжатие токенов с мелкозернистым отбором, гарантируя, что модель не теряет более широкий контекст. DeepSeek утверждает, что новый механизм отличается от представленной раннее в этом году технологии Native Sparse Attention и может быть модифицирован для предобученных моделей. В бенчмарках V3.2-Exp не уступает предыдущей версии ИИ-модели. В тестах на рассуждение, кодирование и использование инструментов различия были незначительными — часто в пределах одного-двух пунктов, — в то время как рост эффективности был значительным, пишет techstartups.com. Модель работала в 2–3 раза быстрее при инференсе с длинным контекстом, сократила потребление памяти на 30–40 % и вдвое повысила эффективность обучения. Для разработчиков это означает более быструю реакцию, снижение затрат на инфраструктуру и более плавный путь к развёртыванию. Для операций с длинным контекстом преимущества системы весьма существенны, отметил ресурс TechCrunch. Для более надёжной оценки модели потребуется дальнейшее тестирование, но, поскольку она имеет открытый вес и свободно доступна на площадке Hugging Face, пользователи сами могут оценить с помощью тестов, насколько эффективна новая разработка DeepSeek. Thinking Machines Lab намерена добиться, чтобы ИИ не отвечал по-разному на одинаковые вопросы
12.09.2025 [12:01],
Павел Котов
Бывшая технический директор OpenAI Мира Мурати (Mira Murati) учредила Thinking Machines Lab — собственный стартап в области искусственного интеллекта, который уже привлёк от инвесторов $2 млрд, не анонсировав ни одного продукта. В минувшую среду компания всё-таки рассказала об одном из своих проектов — она намеревается разработать модель ИИ, способную воспроизводить собственные ответы. Это оказалось не так просто. 
Источник изображения: Steve Johnson / unsplash.com В корпоративном блоге Thinking Machines Lab появилась публикация под заголовком «Преодоление нестабильности в ответах больших языковых моделей». Работающий в компании исследователь Хорас Хэ (Horace He) пытается раскрыть первопричину фактора случайности в ответах моделей ИИ: если задать, например, ChatGPT один и тот же вопрос несколько раз, чат-бот будет всегда отвечать по-разному. Сообщество ИИ приняло эту особенность как данность, современные модели считаются недетерминированными системами, но в Thinking Machines Lab считают проблему решаемой. Хорас Хэ указывает, что первопричина случайного фактора в работе моделей ИИ кроется в механизме взаимодействия между графическими ядрами — запущенными на чипах Nvidia алгоритмами — в процессе инференса, то есть вывода системы ИИ. Если обеспечить тщательный контроль над этим механизмом, можно повысить уровень определённости в работе моделей. В результате увеличится и надёжность ответов ИИ для потребителей, предприятий и учёных. Добившись воспроизводимости, можно повысить также качество обучения с подкреплением — процесса, при котором ИИ получает вознаграждение за правильные ответы: если все они имеют небольшие отличия, то в данных на выходе возникает информационный шум. Когда же ответы моделей ИИ оказываются более согласованными, то и процесс обучения с подкреплением становится более «гладким», рассуждает учёный. 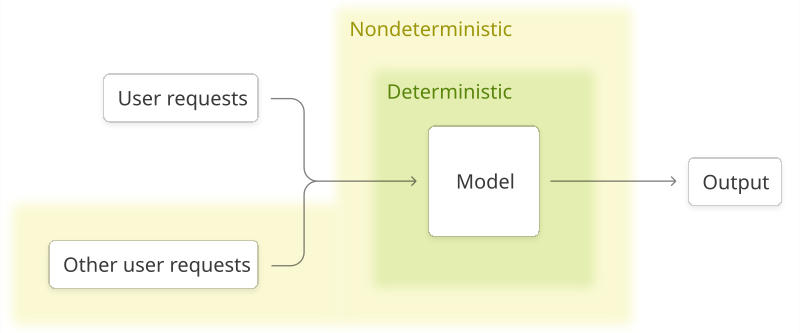
Источник изображения: thinkingmachines.ai Ранее Thinking Machines Lab сообщила инвесторам, что намеревается предлагать бизнесу модели ИИ, прошедшие настройку с помощью обучения с подкреплением. Первый продукт Мира Мурати пообещала представить в ближайшие месяцы, отметив, что он будет «полезен для исследователей и стартапов, разрабатывающих собственные модели». Что это за продукт, и будут ли применяться при его разработке указанные в новом материале методы повышения воспроизводимости результатов, ясности пока нет. Компания также заявила о планах часто публиковать в блоге записи с программным кодом и другой информацией о своих исследованиях, чтобы «приносить пользу обществу, а также повышать нашу собственную культуру научных разработок». На момент создания Thinking Machines Lab брала на себя обязательство проводить открытую политику в отношении собственных исследований, но по мере роста компания становилась всё более закрытой. Публикация даёт редкую возможность заглянуть за кулисы одного из самых засекреченных стартапов отрасли — точного направления развития технологии пока не даётся, но есть повод утверждать, что Thinking Machines Lab занялась решением одной из важнейших задач в области ИИ. Настоящей проверкой для неё будет ответ на вопрос, способна ли она решать такие задачи и создавать на основе этих исследований продукты, оправдывающие оценку компании в $12 млрд. «Торрент для запуска ИИ»: вышла утилита для распределённого запуска ИИ-моделей на любом оборудовании
27.02.2025 [18:30],
Павел Котов
Большие языковые модели искусственного интеллекта требуют значительных ресурсов не только при обучении, но и при запуске — необходимы существенные объёмы оперативной памяти и мощные графические процессоры. Альтернативу предложили создатели Exo — бесплатной программы для распределённого запуска ИИ на нескольких устройствах. Почти как торренты, только для запуска ИИ. 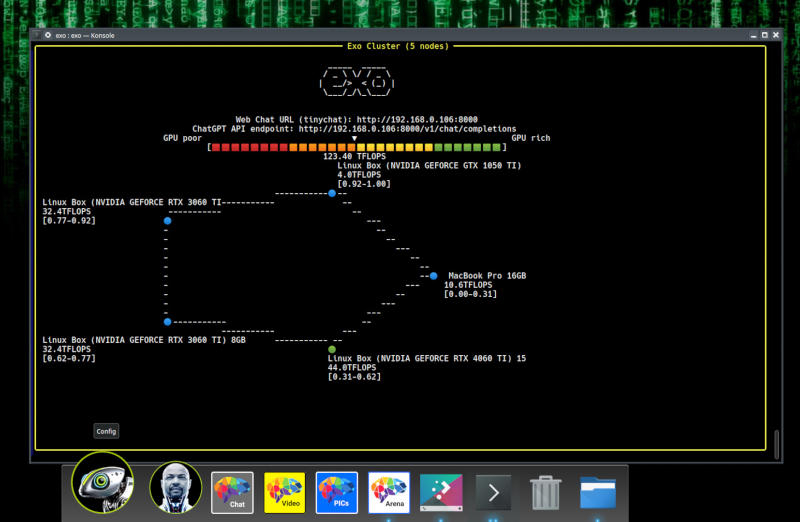
Источник изображения: github.com/exo-explore/exo Приложение позволяет объединять вычислительные ресурсы нескольких компьютеров, смартфонов и даже одноплатных компьютеров, в том числе Raspberry Pi, для запуска моделей, с которыми ни одна из имеющихся в распоряжении пользователя систем не справилась бы самостоятельно. Ресурсы устройств объединяются по одноранговой сети. Exo динамически распределяет нагрузку, создаваемую большой языковой моделью, по доступным в сети устройствам, размещая её слои, исходя из доступного объёма оперативной памяти и имеющейся вычислительной мощности. Поддерживаются LLaMA, Mistral, LlaVA, Qwen и DeepSeek. Программа устанавливается на устройства под управлением Linux, macOS, Android или iOS — версии под Windows пока нет. Для работы Exo требуется минимальная версия Python 3.12.0 и, в случае машин под Linux с графикой Nvidia, ряд других компонентов. Модель ИИ, требующую 16 Гбайт оперативной памяти, можно запустить на двух ноутбуках с 8 Гбайт на каждом; а мощную DeepSeek R1, которой нужны 1,3 Тбайт памяти, в теории можно запустить на кластере из 170 Raspberry Pi 5 с 8 Гбайт. Скорость сети и задержка могут снизить качество работы модели, и разработчики Exo предупреждают, что устройства небольшой производительности способны замедлить ИИ, но с каждым добавленным в сети устройством общая производительность увеличивается. Нельзя также забывать об угрозах безопасности, которые неизбежно возникают при совместном выполнении рабочих нагрузок на нескольких машинах. И даже с учётом этих оговорок Exo представляется перспективной альтернативой облачным ресурсам. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






