|
Опрос
|
реклама
Быстрый переход
YouTube объявил войну ИИ-дипфейкам, запустив функцию «Определение сходства»
21.10.2025 [22:29],
Николай Хижняк
Видеоплатформа YouTube объявила о полноценном запуске функции «Определение сходства». Она поможет авторам контента находить на YouTube видео с изображениями их лица или голоса, созданными с помощью искусственного интеллекта, управлять такими видео и отправлять запросы на их удаление. Подключение функции осуществляется в рамках партнёрской программы YouTube. 
Источник изображения: yousafbhutta/Pixabay В разговоре с TechCrunch представитель YouTube сообщил, что развёртывание функции «Определение сходства» началось, добавив, что авторы контента получили электронные письма с соответствующим уведомлением сегодня утром. Функция идентифицирует контент, в котором используется сходный образ оригинальных авторов (голос, лицо), будь то для рекламы продуктов и услуг, на поддержку которых они не давали согласия, или для распространения дезинформации. В качестве примера приводится случай компании Elecrow, которая с помощью ИИ имитировала голос YouTube-блогера Джеффа Гирлинга (Jeff Geerling) для продвижения своих продуктов. 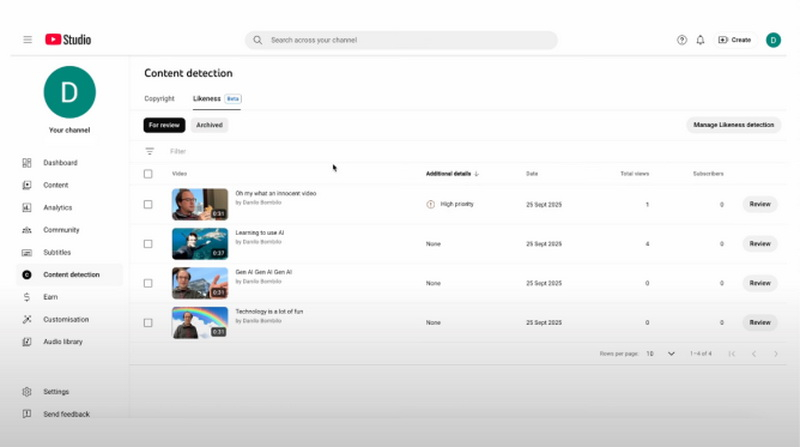
Источник изображения здесь и ниже: YouTube На своём канале Creator Insider платформа опубликовала инструкции о том, как авторы могут использовать новую функцию. Чтобы начать процесс регистрации, создателям контента необходимо перейти на вкладку «Определение сходства», дать согласие на обработку данных и отсканировать QR-код на экране смартфона, который перенаправит их на веб-страницу для подтверждения личности. Для этого требуется предъявить удостоверение личности с фотографией и снять короткое видео-селфи. После того как YouTube предоставит доступ к инструменту, создатели смогут просматривать все обнаруженные видео с их образами и отправлять запросы на их удаление в соответствии с политикой конфиденциальности YouTube, а также подавать запросы о нарушении авторских прав. Также доступна возможность архивировать видео. Авторы могут в любое время отказаться от использования этой функции — в этом случае YouTube прекратит поиск видео через 24 часа. 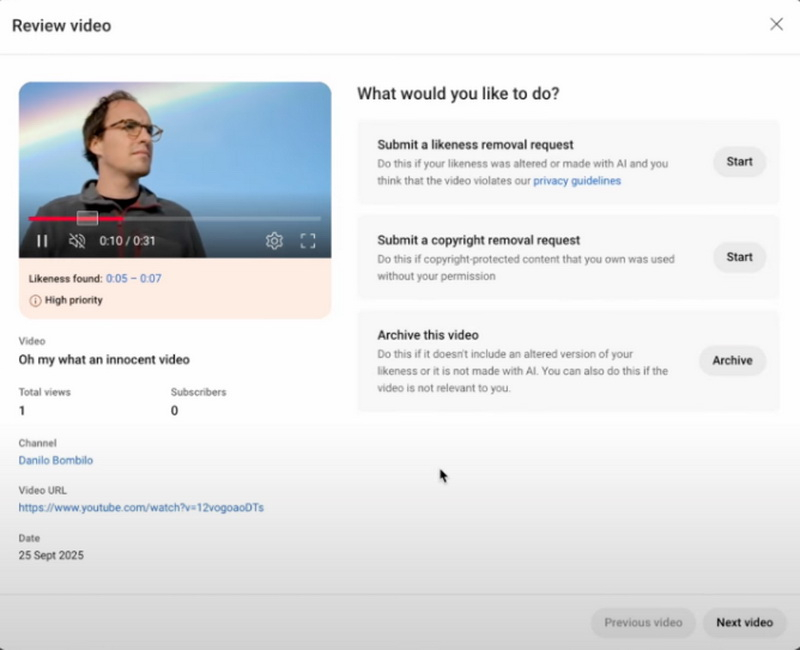 Функция «Определение сходства» находилась в пилотном режиме с начала этого года. В прошлом году видеохостинг впервые объявил о партнёрстве с американским агентством талантов Creative Artists Agency (CAA), чтобы помочь знаменитостям, спортсменам и авторам контента определять на платформе материалы, в которых используются их образы, сгенерированные искусственным интеллектом. В апреле YouTube выразил поддержку законопроекту под названием «Закон о запрете дипфейков», направленному на решение проблемы создаваемых искусственным интеллектом копий, имитирующих изображение или голос человека с целью обмана других и распространения вредоносного контента. Видеокарты GeForce RTX заставили работать с Apple MacBook, но поиграть на них не выйдет
21.10.2025 [19:02],
Сергей Сурабекянц
Специалистам компании TinyCorp удалось создать драйверы для работы графических ускорителей Nvidia серий GeForce RTX 3000, RTX 4000 и RTX 5000 с ноутбуками Apple MacBook при подключении через внешние док-станции по интерфейсу USB4 и Thunderbolt 4. Однако есть и ложка дёгтя: эти драйверы поддерживают исключительно работу ИИ на графических процессорах Nvidia — вывод видеосигнала не предусмотрен. 
Источник изображения: Tinycorp Заставить видеокарты Nvidia работать на устройствах Apple стало практически невозможно с тех пор, как компания отказалась от процессоров Intel и перешла на собственные чипы серии M на архитектуре ARM. После этого Apple перестала реализовывать поддержку графических процессоров Nvidia и AMD в ARM-версиях macOS. Это вынуждало разработчиков и пользователей вручную создавать собственные драйверы, чтобы хоть как-то обеспечить совместимость macOS с видеокартами Nvidia или AMD, подключёнными к внешним док-станциям. Стартап в области искусственного интеллекта TinyCorp уже имел опыт создания необходимых драйверов для работы внешних видеокарт на MacBook на базе ARM. Ранее компания первой в мире продемонстрировала док-станцию с графическим процессором AMD, подключённую к MacBook через порт USB3, который даже не поддерживает PCI Express. Теперь компания показала подключение видеокарты Nvidia, опубликовав изображение MacBook Pro на процессоре M3 Max с запущенным нейросетевым фреймворком собственной разработки Tinygrad на неназванной видеокарте GeForce RTX, подключённой к док-станции ADT-UT3G по USB4. Стандарт USB4/Thunderbolt 4 предусматривает поддержку, в том числе, таких устройств, как внешние док-станции для видеокарт, и совместим с PCIe. Кроме того, пропускная способность USB4/Thunderbolt 4 значительно превышает возможности классического USB3. На данный момент поддерживаются видеокарты Nvidia серий RTX 3000, 4000 и 5000. Разработчики отметили, что серия RTX 20 также может работать, но требует дополнительных действий со стороны пользователя. Видеокарты Nvidia серии GTX не поддерживаются. Возможно использование графических процессоров AMD на базе архитектур RDNA 2, 3 и 4. Разработчики полагают, что возможность применения графических процессоров Nvidia на компьютерах MacBook с архитектурой ARM будет крайне полезна для запуска локальных LLM и других моделей ИИ на таких картах, как GeForce RTX 5090, которые обеспечивают значительно более высокую производительность по сравнению со встроенным графическим ядром компьютеров Apple на базе чипов серии M. Создатели War Thunder анонсировали замену Roblox — платформу для создания игр EdenSpark с открытым исходным кодом
21.10.2025 [17:10],
Дмитрий Рудь
Венгерская студия с российскими корнями Gaijin Entertainment, известная по условно-бесплатному мультиплеерному боевику War Thunder, представила платформу EdenSpark — аналог Roblox, но с кардинальным отличием. 
Источник изображений: Gaijin Entertainment EdenSpark представляет собой платформу с открытым исходным кодом, которая позволяет независимым разработчикам делать свои игры и портировать их на консоли, не имея зарегистрированной компании и юридической документации. «Превратить идею в игру и поделиться ею с друзьями на PC, PlayStation или Xbox» — примерно так же это работает в Roblox или, например, редакторе Fortnite, но у EdenSpark есть важное преимущество — право собственности. В отличие от предлагающих схожий опыт закрытых экосистем, платформа Gaijin предполагает полноценное владение разработчиком кодом творений: это позволит, например, выпустить свою игру за пределами EdenSpark. По словам Gaijin, цель EdenSpark — сделать разработку игр доступнее. Опытные программисты смогут углубиться в код, а новички — обратиться к ИИ-инструментам для генерации художественных материалов, звуков и геймплейной логики. 
Показанные в трейлере игры можно будет попробовать со стартом закрытой «беты» Платформа базируется на разработанном Gaijin движке Dagor Engine (War Thunder, Enlisted, Active Matter). Как отмечают в студии, платформа уже используется для прототипирования разных игр (гоночных, симуляторов, AAA-шутеров). Закрытое бета-тестирование EdenSpark стартует в ноябре. Полноценный релиз ожидается летом 2026 года на PC (со стабильными API и полной интеграцией ИИ-ассистента), а осенью появится поддержка PS5, Xbox Series X и S. OpenAI не выпустит GPT-6 до конца 2025 года
19.10.2025 [20:00],
Владимир Фетисов
Компания OpenAI не намерена до конца года выпускать ИИ-модель следующего поколения — GPT-6, — но это не означает, что компания не будет выпускать новые большие языковые модели. Вполне вероятно, что разработчик обновит ИИ-модель GPT-5. 
Источник изображения: Bleeping Computer В настоящее время у OpenAI есть несколько версий модели GPT-5. По умолчанию в ChatGPT используется режим GPT-5 Auto, которая автоматически переключается между стандартной и рассуждающей версиями. В режиме рассуждений алгоритм тратит больше времени на подготовку ответов, но даёт более качественные результаты. В это же время модель GPT-5-instant не проводит глубокого анализа запросов, но даёт ответы быстрее. Автоматический режим GPT-5 выполняют функцию переключения между моделями и активируется только в случаях, когда система считает, что рассуждающая модель может дать более качественный ответ на вопрос пользователя. OpenAI несколько раз обновляла GPT-5 с момента запуска модели. Очевидно, что компания работает над GPT-6, но, когда эта нейросеть может стать общедоступным, пока неизвестно. В недавнем интервью для CNBC аналитик Evercore ISI Марк Махани (Mark Mahaney) заявил, что GPT-6 появится до конца года и OpenAI будет постепенно улучшать модель. Однако официальные представители компании вскоре опровергли это утверждение. Пользователи соцсети X с ником @tszzl, который является сотрудником OpenAI, заявил, что до конца года шестой версии GPT не будет. Это означает, что GPT-6 выйдет не слишком скоро. Дженсен Хуанг пожаловался на потерю китайского рынка ИИ-ускорителей — доля Nvidia снизилась с 95 до 0 %
18.10.2025 [18:22],
Николай Хижняк
Основатель и генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) пожаловался, что доля компании на рынке передовых чипов в Китае сократилась с 95 % до нуля, поскольку американский полупроводниковый гигант не имеет возможности продавать свою передовую продукцию компаниям материкового Китая из-за экспортных ограничений США. Об этом пишет South China Morning Post. 
Источник изображения: Nvidia «Мы продолжим разъяснять ситуацию, информировать, и будем надеяться на изменение политики. В настоящее время мы полностью покинули Китай», — заявил глава Nvidia на мероприятии Citadel Securities в Нью-Йорке 6 октября. Nvidia с 2022 года запрещено экспортировать свои передовые чипы для искусственного интеллекта, включая A100, H100 и H200. Хотя компания наконец-то получила разрешение Вашингтона на продажу менее мощного специализированного ускорителя H20, специально разработанного для Китая, китайское правительство начало расследование в отношении этого продукта из соображений безопасности, а китайским клиентам было рекомендовано избегать использования этого ускорителя со сниженными характеристиками. Комментарий Хуанга перекликается с его давней позицией, согласно которой, Nvidia должна продавать свою продукцию в Китай, иначе рынок будет отдан китайским конкурентам, таким как Huawei Technologies. Глава Nvidia заявил, что исключение компании с китайского рынка негативно сказывается на Китае, но ещё хуже — на США. По его мнению, «то, что вредит Китаю, зачастую может нанести более серьёзный вред Америке». Он отметил, что «разработчики жизненно важны» для любой индустрии программного обеспечения, и что в Китае сосредоточено «около 50 % мировых исследователей в области ИИ». «Не позволять этим исследователям создавать ИИ на основе американских технологий — ошибка. Вопрос в том, как сбалансировать достижение успеха, сохранение лидерства и, с другой стороны — обеспечить, чтобы весь мир развивался на базе американского технологического стека», — отметил Хуанг. Заявления главы Nvidia звучат на фоне продолжающегося общенационального стремления Китая к самодостаточности в области полупроводников. Китайские компании, специализирующиеся на ИИ и полупроводниках, поспешили выпустить отечественные альтернативы ускорителям Nvidia, подрывая некогда доминирующую позицию компании в стране. В сентябре находящийся под санкциями гигант телекоммуникационного оборудования Huawei Technologies представил свою дорожную карту по разработке ИИ-чипов, продемонстрировав методы кластеризации, разработанные для превосходства над Nvidia, а также передовые технологии производства, пока недоступные Китаю. Китайские интернет-гиганты Alibaba Group Holding, Tencent Holdings, ByteDance и Baidu, являющиеся также крупными поставщиками облачных услуг, вкладывают значительные средства в исследования и разработку как суверенных чипов, так и продуктов с привлечением внешних инвестиций, чтобы обеспечить больший контроль над своими цепочками поставок. В прошлом месяце Хуанг заявил, что Китай отстаёт от США всего на «наносекунды» в разработках ускорителей вычислений, подчеркнув прогресс страны в производстве чипов и её производственный потенциал. В сентябрьском выпуске подкаста BG2 он отметил богатый кадровый потенциал страны, активную рабочую культуру и внутреннюю конкуренцию. ИИ Meta✴ будет предлагать пользователям отредактировать и опубликовать фото из галереи смартфона
17.10.2025 [23:21],
Владимир Фетисов
Meta✴ Platforms объявила о запуске новой функции для своего ИИ-бота Meta✴ AI, который будет предлагать внести изменения в фотографии, хранящиеся на смартфоне пользователя и ещё не опубликованные в соцсети. Это нововведение распространяется на пользователей приложения на территории США и Канады. Пользователи смогут активировать опцию получения рекомендаций по редактированию фото, после чего их с внесёнными ИИ правками можно тут же публиковать в основной ленте Facebook✴ или Stories. 
Источник изображения: Paul Hanaoka / unsplash.com Запущенное летом в тестовом режиме приложение Meta✴ AI откроет диалоговое окно, с помощью которого пользователь может разрешить «облачную обработку». После этого алгоритм начнётвыдавать «креативные идеи», созданные на основе хранящихся в галерее снимков. В описании сказано, что новая функция может предложить создать коллаж, улучшить качество фото и многое другое. Для работы новой функции приложение будет постоянно загружать фото с пользовательского устройства в облако. Благодаря этому Meta✴ AI сможет предлагать разные варианты изменений для пользовательских фото. Компания заявила, что пользовательские медиафайлы не будут использоваться для таргетированной рекламы и обучения ИИ-алгоритмов компании, если только пользователь не воспользуется функцией ИИ-редактирования фото и не опубликует результат работы алгоритма в сети. При необходимости эту опцию можно отключить. Хотя Meta✴ Platforms, вероятно, не обучает свои нейросети на всех пользовательских фото, когда человек соглашается с условиями использования Meta✴ AI, он разрешает компании анализировать медиафайлы и черты лиц людей на фото с помощью ИИ. В условиях говорится, что компания имеет право «обобщать содержимое изображений, изменять их и генерировать новый контент на их основе». Компания также использует данные о времени создания снимков, людях и объектах на них для генерации творческих идей. Это даёт Meta✴ большое количество информации о пользователе, его знакомых и близких, его жизни и привычках. Кроме того, наличие доступа к ещё не опубликованным снимкам может дать компании преимущество в гонке ИИ, обеспечив разработчиков большим количеством данных, идей для новых функций и т.д. ИИ-модели и сервисы основного конкурента OpenAI стали доступны в Microsoft Office, Teams, Outlook и OneDrive
17.10.2025 [17:46],
Сергей Сурабекянц
Anthropic интегрировала своего ИИ-помощника Claude с сервисами Microsoft 365. Теперь Claude доступен контент из документов Word, сообщений Teams и электронных писем Outlook. Он может самостоятельно подключаться к SharePoint и OneDrive для поиска и анализа документов. Коннектор Microsoft 365 уже доступен для всех пользователей тарифных планов Claude Team и Enterprise, но требует разрешения IT-администраторов для подключения учётных записей конечных пользователей. 
Источник изображения: Anthropic Интеграция Microsoft Outlook с Claude позволяет чат-боту получать доступ к цепочкам электронных писем и анализировать сообщения, чтобы находить релевантный контекст в своих ответах. Claude также может выполнять поиск по чатам в Microsoft Teams, просматривать обсуждения каналов и сводки встреч. Anthropic также запустила корпоративный поиск по всем источникам данных компании. Как правило, организации используют разнообразные инструменты для управления HR-процессами, коммуникациями и другими аспектами бизнеса, поэтому данные часто хранятся во множестве различных приложений и сервисов. По словам Anthropic, «корпоративный поиск особенно ценен для адаптации новых членов команды, ответа на стратегические вопросы, такие как анализ закономерностей в отзывах клиентов, и быстрого поиска нужных внутренних экспертов для консультаций по любой теме». Интеграция Claude и Microsoft 365 работает с использованием коннектора Model Context Protocol (MCP) — стандарта Anthropic с открытым исходным кодом для подключения ИИ-приложений к другим источникам данных и приложениям. В настоящее время Microsoft внедряет MCP в свои продукты и планирует широко использовать его в своей ОС Windows. Microsoft всё больше полагается на ИИ-модели Anthropic для улучшения своих приложений Microsoft 365. Модели Anthropic используются в Copilot Researcher, GitHub Copilot, Copilot Studio и новом Office Agent, который умеет создавать документы Word и PowerPoint с помощью чат-интерфейса Copilot от Microsoft. Стремясь диверсифицировать подход к ИИ, Microsoft налаживает отношения с Anthropic, одновременно увеличивая инвестиции в собственные модели ИИ. Открытая ИИ-модель Google DeepMind Cell2Sentence-Scale 27B совершила прорыв в терапии рака, который подтвердили учёные
17.10.2025 [10:53],
Геннадий Детинич
Проблема с лечением онкологии заключается в том, что зачастую она остаётся невидимой для иммунной системы человека до тех пор, когда помощь уже мало что решает. Множество усилий учёных направлено на то, чтобы заставить опухоль проявить себя на ранних этапах — это почти наверняка спасёт пациентам здоровье и жизнь. Теперь к этому процессу подключили искусственный интеллект, который сходу обозначил прорыв в терапии рака. 
Источник изображения: ИИ-генерация Grok 4/3DNews Как сообщается в блоге компании Google, в ходе сотрудничества подразделения DeepMind и Йельского университета (Yale University) открытая модель искусственного интеллекта Gemma была адаптирована для анализа поведения раковых клеток, что привело к прорыву в лечении онкологии. Разработанная на базе Gemma версия Cell2Sentence-Scale 27B (C2S-Scale) с 27 млрд параметров позволила интерпретировать «язык» отдельных клеток, выявив скрытые связи в их взаимодействии. Что особенно важно, представленная модель не только оптимизировала решение предложенных ей задач, но и смогла выработать новые и неожиданные для учёных гипотезы. Исследование было сосредоточено на так называемых «холодных» опухолях — тех, которые слабо распознаются иммунной системой из-за недостаточной презентации антигенов. Виртуальный скрининг более 4000 потенциальных препаратов, проведённый моделью, выявил кандидатов, способных выборочно усиливать иммунный сигнал в таких опухолях, делая их «горячими» и, по сути, уязвимыми для иммунотерапии. Ключевым открытием стал ингибитор киназы CK2 — силмитасертиб (CX-4945), который в комбинации с низкой дозой интерферона продемонстрировал синергетический эффект: усиление презентации антигенов на 50 % в иммуноположительной среде с низким уровнем интерферона. Проще говоря, иммунная система уже ощущала, что в организме происходит что-то неладное, но количества враждебного биологического материала в виде клеток опухоли было недостаточно для её активации. Введение силмитасертиба усилило действие естественных защитных механизмов организма и стало своего рода спусковым крючком для атаки на раковые клетки. Ранее учёные не рассматривали подобный эффект и само это вещество, что стало настоящим открытием вне компетенции человека. ИИ «додумался» до этого самостоятельно — и это само по себе открытие. Эта гипотеза сразу же была подтверждена экспериментами в лаборатории на человеческих клетках, не использовавшихся при обучении модели. Тем самым можно сказать, что модель способна обобщать знания, распространяя их на ранее неизвестные области. Такой подход может радикально повысить эффективность иммунотерапии, превращая невидимые для иммунитета опухоли в цели для T-клеток, и открыть пути для персонализированного лечения. Модель C2S-Scale уже доступна бесплатно на платформе Hugging Face, что должно стимулировать международное научное сообщество к дальнейшим исследованиям. Команды Йеля продолжают изучать механизмы действия выявленных кандидатов и тестировать другие предсказания модели, потенциально расширяя её применение на другие типы рака и стратегии их лечения. Это хорошая иллюстрация того, как открытые ИИ-технологии ускоряют фундаментальные открытия, обеспечивая доступ к передовым инструментам биомедицины для более широкого круга исследователей. Также это исследование показало, что масштаб буквально имеет значение. Сравнительно небольшие модели ИИ не смогли справиться с той же задачей. Только значительное увеличение числа параметров модели привело к открытию. В данном случае масштаб стал фактором откровения, а не просто ускорения расчётов. Возникло совершенно новое знание — и это, само по себе, дорогого стоит. Intel представила Crescent Island — GPU для ИИ на архитектуре Xe3P и со 160 Гбайт LPDDR5X
14.10.2025 [21:52],
Николай Хижняк
Компания Intel анонсировала новый графический процессор, предназначенный для центров обработки данных, разработанный специально для выполнения задач логического вывода (ИИ). Новинка имеет кодовое название Crescent Island и построена на базе архитектуры Xe3P. 
Источник изображений: Intel Графический процессор Crescent Island основан на архитектуре Xe3P. Она представляет собой усовершенствованную версию графической архитектуры Xe3, анонсированной в составе процессоров Panther Lake для ноутбуков и компактных ПК. В перспективе Xe3P будет также использоваться в семействе потребительских видеокарт Arc следующего поколения — Arc C-Series. Новый графический процессор для ЦОД под кодовым названием Crescent Island разработан с учётом оптимизации энергопотребления и стоимости для корпоративных серверов с воздушным охлаждением, а также с акцентом на большой объём памяти и пропускную способность, оптимизированные для рабочих процессов вывода. Ключевые особенности Crescent Island:
Примечательно, что Intel выбрала память LPDDR5X для своего специализированного GPU. Конкуренты в лице Nvidia и AMD предлагают свои решения для ИИ-центров обработки данных с использованием высокоскоростной памяти HBM (например, HBM3E) и уже обсуждают применение ещё более производительной памяти HBM4 для решений будущих поколений, таких как Rubin и MI400. 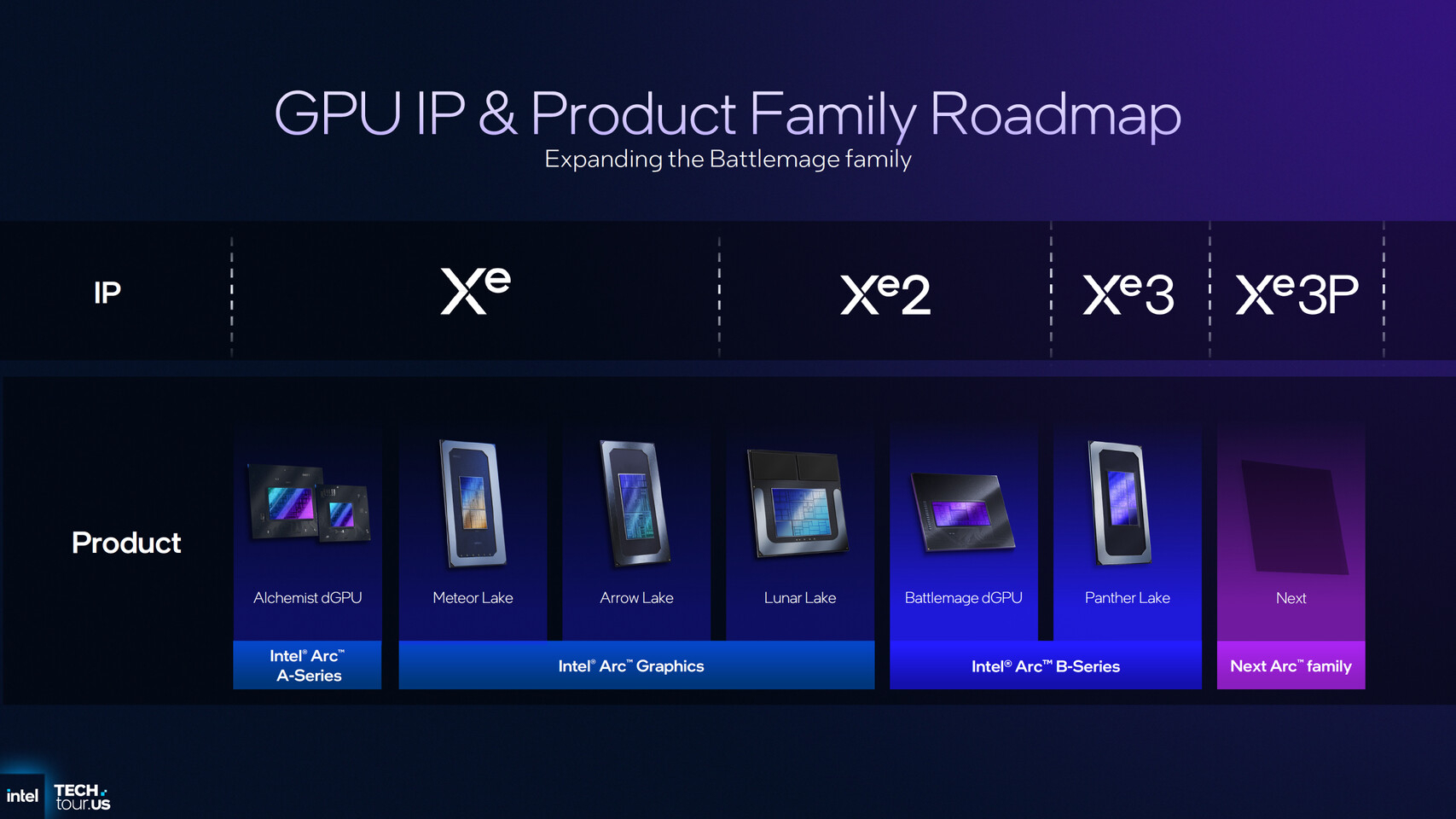 На фоне возросшего спроса и, как следствие, роста цен на память HBM использование LPDDR5X может предоставить решению Intel значительное преимущество в соотношении цены и производительности. Кроме того, поддержка широкого спектра типов данных делает архитектуру универсальной для различных задач, связанных с ИИ. Intel отмечает, что открытый и унифицированный программный стек для Crescent Island разрабатывается и тестируется на графических процессорах Arc Pro серии B для обеспечения ранней оптимизации и итераций. Ожидается, что образцы нового графического процессора для центров обработки данных под кодовым названием Crescent Island будут представлены клиентам во второй половине 2026 года. Итальянцы приделали ИИ к ветрякам — и те дали жару
14.10.2025 [20:52],
Геннадий Детинич
Итальянская компания Gevi Wind разработала систему ИИ-регулирования угла атаки лопастей ветряной турбины. Искусственный интеллект корректирует угол лопастей ветряного генератора каждые несколько миллисекунд, получая информацию не только о направлении и силе ветра, но даже о турбулентности, создаваемой соседними лопастями. Это заметно повышает эффективность выработки ветряной энергии, что может стать основой городской ветроэнергетики по всей Европе. 
Рендер полномасштабной турбины. Источник изображений: Gevi Wind Компания Gevi Wind с офисами в Пизе и Риме основана в 2022 году. Она разрабатывает ветрогенераторы с вертикально расположенными лопастями. Такие установки могут иметь относительно небольшие размеры и быть приспособлены для выработки энергии в городской черте. Фирменный генератор Gevi Wind высотой 3 м и диаметром ротора 5,4 м способен вырабатывать 3–5 кВт мощности при скорости ветра от 2,5 м/с. Благодаря компактным габаритам его можно устанавливать на крышах зданий и в других условиях плотной застройки. Заявлен низкий уровень шума — одно из ключевых требований к ветрякам, размещаемым рядом с жилыми домами. Так, система Gevi Wind не будет создавать шум выше 38 дБ на расстоянии около 10 м. Кроме того, небольшие размеры конструкции позволят монтировать её без привлечения высотных кранов — обязательного элемента при установке башенных ветряков. Обслуживание таких установок также будет значительно проще и дешевле. Эксперименты с моделями «умных» ветряков небольших размеров показали, что турбины, оснащённые системой искусственного интеллекта, автоматически подстраивающей угол атаки лопастей в реальном времени, повышают выработку энергии на 60 % по сравнению с ветряками с фиксированными лопастями. Также ИИ позволяет на 80 % снизить механическую нагрузку на лопасти, что продлевает срок службы установки. 
Модель с ротором высотой 1,7 м и диаметром 1,8 м вырабатывает 1 кВт·ч чистой энергии в год при средней скорости ветра 5,2 м/с Итальянский проект заинтересовал целый ряд инвесторов, среди которых — 360 Capital и CDP Venture Capital при поддержке фонда Acceleratori, фонда соинвестирования MiSE, фонда Toscana Next, а также NextSTEP One. Для ускорения перехода к полномасштабным изделиям компания получила финансирование в размере €2,7 млн. В случае успеха ветряки с ИИ появятся во многих городах Европы. Oracle купит 50 000 ИИ-ускорителей AMD — альтернатива Nvidia набирает обороты
14.10.2025 [20:08],
Владимир Фетисов
Компания Oracle Cloud Infrastructure на этой неделе объявила о планах по развёртыванию 50 тыс. графических ускорителей AMD с целью повышения уровня вычислительных мощностей для обеспечения нужд искусственного интеллекта. Реализация этого плана начнётся во второй половине 2026 года. На этом фоне акции AMD выросли в цене примерно на 2 %, тогда как ценные бумаги Oracle и Nvidia подешевели на 4 % и 3 % соответственно. 
Источник изображения: AMD Этот шаг стал очередным признаком того, что облачные провайдеры всё чаще обращаются к ИИ-ускорителям AMD, рассматривая их как альтернативу решениям Nvidia, которая занимает доминирующее положение в этом сегменте. Oracle задействует ускорители Instinct MI450, представленные AMD ранее в этом году. Это первые ИИ-ускорители компании, которые можно объединять в более крупные системы внутри одной стойки. Возможность задействовать до 72 ускорителей в стойке должна способствовать развёртыванию и обучению самых передовых нейросетей. Ранее в этом месяце OpenAI объявила о заключении многолетнего соглашения о стратегическом партнёрстве с AMD. В рамках достигнутых договорённостей компании планируют построить инфраструктуру на базе сотен тысяч ИИ-ускорителей AMD разных поколений общей мощностью 6 ГВт. Первый кластер мощностью 1 ГВт должен быть развёрнут уже в следующем году. Сделка также предусматривает вариант, при котором OpenAI сможет приобрести до 160 млн обыкновенных акций AMD (около 10 % от общего количества) по мере достижения контрольных целей. OpenAI исторически тесно связана с Nvidia, чьи ускорители использовались для создания ChatGPT. В настоящее время Nvidia доминирует в сегменте ускорителей для центров обработки данных, занимая более 90 % рынка, и продолжает инвестировать в OpenAI. На этом фоне руководство OpenAI заявило, что компании требуется как можно больше вычислительных мощностей, поэтому она готова использовать ускорители разных производителей. В дополнение к этому OpenAI совместно с Broadcom намерена разработать собственные ИИ-ускорители. Google Meet теперь умеет накладывать виртуальный макияж с помощью ИИ
14.10.2025 [19:52],
Сергей Сурабекянц
В Google Meet наконец-то появился фильтр макияжа на базе ИИ для пользователей, которые не хотят наносить настоящий макияж перед встречей. Этот новый инструмент поможет Google Meet конкурировать с другими приложениями для видеоконференций, такими как Microsoft Teams и Zoom, которые уже поддерживают функцию виртуального макияжа. 
Источник изображений: Google Meet Google Meet предлагает 12 различных вариантов макияжа на выбор. Они доступны в меню «Внешний вид» в разделе «Ретушь портрета», который появился в 2023 году и предоставляет пользователям такие возможности, как выравнивание тона кожи, осветление под глазами и отбеливание век. Google утверждает, что виртуальный макияж не зависит от движений пользователя на экране, что делает его более реалистичным. То есть, если пользователь сделает глоток кофе, фильтр останется на лице, а не переместится на кружку. После нанесения виртуального макияжа Google Meet запомнит предпочтения пользователя и применит их на будущих встречах. По умолчанию виртуальный макияж будет отключён, но его можно активировать в любой момент — как до начала, так и во время видеозвонка.
Виртуальный макияж в Google Meet на базе искусственного интеллекта стал доступен с 8 октября в мобильных приложениях и веб-браузерах. OpenAI превратится в чипмейкера — Broadcom поможет проложить «путь к будущему ИИ» на 10 ГВт
13.10.2025 [19:33],
Сергей Сурабекянц
OpenAI и Broadcom сегодня объявили о сотрудничестве по созданию и дальнейшему развёртыванию специализированных ИИ-ускорителей разработки OpenAI общей мощностью 10 ГВт. В своих чипах OpenAI планирует интегрировать опыт и знания, полученные в ходе создания передовых моделей ИИ, непосредственно в аппаратное обеспечение. Начало работ запланировано на вторую половину 2026 года, а завершение — на конец 2029 года. 
Источник изображения: unsplash.com Партнёрское соглашение предусматривает развёртывание полностью масштабируемых стоек на базе ИИ-ускорителей разработки OpenAI и сетевых решений Broadcom на объектах OpenAI и в партнёрских центрах обработки данных. Для Broadcom это сотрудничество подтверждает важность специализированных ускорителей и выбор Ethernet в качестве технологии для вертикального и горизонтального масштабирования сетей в центрах обработки данных искусственного интеллекта. «Партнёрство с Broadcom — критически важный шаг в создании инфраструктуры, необходимой для раскрытия потенциала ИИ и предоставления реальных преимуществ людям и бизнесу, — заявил глава OpenAI Сэм Альтман (Sam Altman). — Разработка собственных ускорителей дополняет более широкую экосистему партнёров, которые вместе создают потенциал, необходимый для расширения возможностей ИИ на благо всего человечества». «Сотрудничество Broadcom с OpenAI знаменует собой поворотный момент в развитии общего искусственного интеллекта, — считает президент и генеральный директор Broadcom Хок Тан (Hock Tan). — OpenAI находится в авангарде революции ИИ с момента появления ChatGPT, и мы рады совместно разработать и внедрить 10 гигаватт ускорителей и сетевых систем нового поколения, чтобы проложить путь к будущему ИИ». 
Источник изображения: Broadcom «Наше сотрудничество с Broadcom станет движущей силой прорывов в области ИИ и позволит полностью раскрыть потенциал этой технологии, — уверен соучредитель и президент OpenAI Грег Брокман (Greg Brockman). — Создавая собственный чип, мы можем интегрировать знания, полученные при создании передовых моделей и продуктов, непосредственно в аппаратное обеспечение, открывая новые возможности и уровень интеллекта». «Наше партнёрство с OpenAI продолжает устанавливать новые отраслевые стандарты в области разработки и внедрения открытых, масштабируемых и энергоэффективных кластеров ИИ, — полагает президент группы полупроводниковых решений Broadcom Чарли Кавас (Charlie Kawwas). — Специальные ускорители прекрасно сочетаются со стандартными сетевыми решениями […] Стойки включают в себя комплексное портфолио решений Broadcom для Ethernet, PCIe и оптических соединений, подтверждая наше лидерство в сфере инфраструктур искусственного интеллекта». В конце прошлого месяца Nvidia объявила о планах инвестировать до $100 млрд в OpenAI в течение следующего десятилетия. OpenAI планирует развернуть системы на базе ИИ-ускорителей Nvidia общей мощностью 10 ГВт, что на момент объявления эквивалентно от 4 до 5 миллионов графических процессоров. 
Источник изображения: Nvidia В начале октября было подписано соглашение между OpenAI и AMD, которое предусматривает приобретение компанией Сэма Альтмана до 10 % акций производителя чипов. AMD предоставила OpenAI право на покупку до 160 миллионов своих обыкновенных акций с контрольными сроками, привязанными к объёму развёртывания и к цене акций AMD. OpenAI в течение ближайших нескольких лет произведёт массированное развёртывание графических процессоров AMD Instinct нескольких поколений в дата-центрах OpenAI общей мощностью 6 ГВт. 
Источник изображения: AMD Количество активных пользователей OpenAI превысило 800 миллионов в неделю, а сама компания получила широкое распространение среди глобальных корпораций, малого бизнеса и разработчиков. OpenAI утверждает, что миссия компании — обеспечить, чтобы искусственный интеллект приносил пользу всему человечеству. Несмотря на это, многие эксперты полагают, что масштабные инвестиции в компанию лишь подтверждают опасения по поводу «циклического характера» некоторых сделок в сфере ИИ-инфраструктуры. ИИ спас США от рецессии, став единственным драйвером роста в 2025 году
12.10.2025 [15:12],
Владимир Фетисов
Беспрецедентный всплеск инвестиций в инфраструктуру для сферы искусственного интеллекта стал основным двигателем экономического роста США в нынешнем году. Эта тенденция наглядно демонстрирует, насколько сильно ИИ трансформирует экономику, а также заставляет специалистов задуматься над тем, насколько новая американская модель роста является устойчивой. 
Источник изображения: techspot.com Экономист из Гарварда Джейсон Фурман (Jason Furman) провёл анализ сложившейся ситуации. В результате он пришёл к выводу, что при исключении объёма расходов на технологическую инфраструктуру, годовой рост ВВП США в первом полугодии нынешнего года составил бы лишь 0,1 %. Это подчёркивает исключительное влияние инвестиций в цифровую инфраструктуру на общие экономические показатели. «Инвестиции в оборудование для обработки данных и программное обеспечение составляют 4 % от ВВП. Но на них пришлось 92 % роста ВВП в первом полугодии этого года. ВВП за вычетом этих категорий рос в первом полугодии с годовым темпом всего 0,1 %», — говорится в сообщении Фурмана. Результаты анализа экономиста указывают, что стремительный рост спроса на передовые вычислительные ресурсы спровоцировал масштабное увеличение капитальных затрат крупнейших технологических компаний США. Некоторые аналитики считают, что всплеск инвестиций в сферу строительства центров обработки данных для ИИ стал настолько выраженным, что впервые превзошёл потребительские расходы в США, которые традиционно составляют две трети ВВП страны, и стал основным фактором экономического роста. Фурман отметил, что влияние инвестиций в ИИ-инфраструктуру могло быть менее выраженным, если бы не повышенные процентные ставки и рост расходов на электроэнергию. «Если бы не бум в сфере ИИ, у нас, вероятно, были бы более низкие процентные ставки и стоимость электроэнергии, что дало бы некоторый дополнительный рост в других секторах. Грубо говоря, это могло бы компенсировать около половины того, что мы получили от бума в сфере ИИ», — считает Фурман. Резкий рост расходов отчётливо виден в стратегиях капитальных затрат отраслевых лидеров, таких как Microsoft, Google, Amazon, Meta✴ и Nvidia. Эти компании направили десятки миллиардов долларов на строительство, расширение и модернизацию своей инфраструктуры ЦОД. Компании инвестировали в покупку современного оборудования, специализированных ИИ-ускорителей, передовых систем управления энергопотреблением и др. Директор по инвестициям Morgan Stanley Wealth Лиза Шаллет (Lisa Shallet) в рамках собственного исследования пришла к выводу, что крупнейшие технологические гиганты за последние годы увеличили собственные капитальные затраты на ЦОДы для ИИ и связанную с ними инфраструктуру в четыре раза. При этом общий объём расходов приближается к $400 млрд в год. Она отметила, что стремительный рост расходов среди IT-гигантов составляет почти треть от всех капитальных затрат в масштабах отрасли. Это искажает общую экономическую картину и увеличивает примерно на 100 базисных пунктов реальный рост ВВП США. «Скорость роста и масштабы инвестиций искажают их совокупное экономическое влияние», — считает Шаллет. В других секторах экономический рост был значительно более сдержанным. Создание новых рабочих мест в первом полугодии заметно замедлилось. В это же время отрасли, такие как обрабатывающая промышленность, недвижимость, розничная торговля и традиционные услуги, внесли минимальный вклад в общий ВВП или даже оказали отрицательное влияние. Такая динамика вызывает опасения у аналитиков по поводу того, что без инвестиций в технологический сектор экономика США могла столкнуться с рецессией. Вопросы относительно дальнейшего экономического роста остаются открытыми. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex







