|
Опрос
|
реклама
Быстрый переход
Аудитория браузера Brave выросла вчетверо и достигла 100 миллионов человек
05.10.2025 [05:37],
Анжелла Марина
Браузер Brave продолжает наращивать аудиторию и уже достиг отметки в 100 миллионов активных пользователей в месяц по состоянию на сентябрь 2025 года, тогда как ещё в 2021 году его ежемесячная аудитория составляла 50 миллионов человек, приводит данные статистики PCWorld. 
Источник изображения: Brave Brave ориентирован на конфиденциальность и уверенно набирает популярность. Генеральный директор компании Брендан Айх (Brendan Eich) заявил, что пользователи по всему миру отдают предпочтение конфиденциальности и контролю над своими действиями в интернете, отвергая слежку и злоупотребления со стороны крупных технологических компаний. Он подчеркнул, что все продукты Brave, включая поисковую систему, премиум-сервисы и рекламную платформу, были «созданы с учётом защиты приватности каждого». Параллельно с ростом функций и удобства использования браузера развивается и поиск Brave, предлагая новые возможности — теперь он может давать развёрнутые ответы на базе искусственного интеллекта, как ранее сообщал 3DNews. Поисковик, предлагающий альтернативу Google с акцентом на приватность, теперь обрабатывает более 20 миллиардов запросов в год. Это почти в 8,7 раза больше, чем 2,3 миллиарда обработанных запросов в 2021 году. Успех Brave связывают с его встроенными функциями безопасности, которые ставят во главу угла интересы пользователя. Среди них — блокировка рекламы и трекеров, запрет на использование JavaScript и файлов cookie, блокировка функции Windows Recall, а также возможность приватного просмотра через сеть Tor. В МВД РФ рассказали, где безопаснее всего хранить фото документов и пароли
03.10.2025 [08:07],
Владимир Фетисов
МВД РФ считает ненадёжным хранение фото документов и паролей в памяти телефона, поскольку это повышает риск кражи конфиденциальных данных. Оптимальным решением для этого считаются облачные хранилища с двухфакторной аутентификацией и шифрованием. Об этом пишет «Коммерсантъ» со ссылкой на собственные источники. 
Источник изображения: Glenn Carstens-Peters / Unsplash В ведомстве отметили, что сканы паспорта, СНИЛС, ИНН, водительских прав или банковских карт дают злоумышленникам возможность получения доступа к аккаунтам жертвы утечки данных. Кроме того, они могут быть задействованы для создания фейковых профилей и осуществления мошеннической деятельности. В МВД также указали на опасность записи паролей и кодов доступа в заметках или мессенджерах. Такие данные в случае попадания в руки злоумышленников позволят им взять под контроль цифровую жизнь жертвы, включая её банковские счета. Для хранения такой информации специалисты рекомендуют задействовать менеджеры паролей или же перенести их в офлайн, например, в записную книжку. Ещё в МВД напомнили о необходимости регулярной очистки истории сообщений из банковских приложений, поскольку уведомления о переводах и остатках средств на счетах раскрывают финансовые привычки и уровень дохода. Такая информация может облегчить работу мошенников. Личные переписки также нередко содержат номера карт, PIN-коды и ответы на секретные вопросы, т.е. данные, которые часто становятся целью злоумышленников. Присяжные в суде Сан-Франциско обязали Google выплатить более $425 млн за нарушение конфиденциальности
04.09.2025 [10:55],
Владимир Мироненко
В минувшую среду жюри присяжных вынесло по итогам слушаний в суде Сан-Франциско (США) вердикт, согласно которому компания Google должна будет выплатить $425,7 млн в качестве компенсации по коллективному иску о нарушении права пользователей на неприкосновенность частной жизни, пишет ресурс Bloomberg. 
Источник изображения: Solen Feyissa/unsplash.com Коллегия присяжных в составе восьми человек установила, что Google обманывала пользователей, продолжая сохранять и копировать их данные с помощью сторонних приложений, нарушая закон штата Калифорния о конфиденциальности, даже если пользователи отключали в настройках устройств параметр «История веб-поиска и приложений» (Web & App Activity). Истцы подчеркнули, что с 2016 года Google всё ещё могла получать данные о пользователях из таких сервисов, как Uber Technologies, PayPal Holdings, Venmo и Meta✴ Platforms, а также Instagram✴, использующих внутренние сервисы аналитики данных Google. Google продолжала собирать данные, несмотря на обещание пользователям контролировать их данные, утверждается в иске, поданном в июле 2020 года. «Обещания и заверения Google в отношении конфиденциальности — откровенная ложь», — заявили адвокаты истцов в иске. Всего было подано три коллективных иска к Google. В ходе судебного разбирательства Google утверждала, что чётко предупреждала пользователей о том, что отключение функции «История веб-поиска и приложений» означает, что их данные будут анонимизированы, но всё равно будут отслеживаться для предоставления сводной статистики сторонним приложениям. В заключительном заявлении адвокат Google Бенедикт Хур (Benedict Hur) из Cooley LLP сообщил, что как только пользователь отключает функцию отслеживания, ему открывается экран с вопросом «Вы уверены?», на котором говорится, что пользователи могут «узнать о данных, которые Google продолжает собирать, и почему», перейдя по дополнительной ссылке. «Не было никакого нарушения, утечки, неправомерного использования данных, обмена данными или продажи данных», — заявил адвокат. Присяжные признали Google ответственной по двум из трёх исков о нарушении конфиденциальности, поданных истцами. Они пришли к выводу, что Google действовала без злого умысла, а значит, дополнительные штрафные санкции начисляться не будут. Окружной судья Ричард Сиборг (Richard Seeborg) вынес приговор по коллективному иску от имени 98 млн пользователей Google, пострадавших от действий компании. При равном распределении между участниками группы пострадавших сумма компенсации составит около $4 на каждого участника. Изначально истцы требовали выплатить $31 млрд компенсации. Google объявила о намерении подать апелляцию на решение суда. «Это решение неверно истолковывает принципы работы наших продуктов, — заявил представитель компании Хосе Кастанеда (Jose Castaneda). — Наши инструменты обеспечения конфиденциальности дают людям контроль над своими данными, и когда они отключают персонализацию, мы уважаем этот выбор». Anthropic начнёт обучать ИИ на диалогах пользователей, но её можно попросить так не делать
29.08.2025 [11:04],
Павел Котов
Anthropic внесла важные изменения в политику обработки данных пользователей и предложила им до 28 сентября принять решение, хотят ли они использовать свою переписку с чат-ботом для обучения моделей искусственного интеллекта. 
Источник изображений: Anthropic Ранее Anthropic не использовала журналы чатов для обучения моделей — пользователей заверяли, что их запросы и ответы чат-ботов автоматически удаляются из систем в течение 30 дней «за исключением случаев, когда требования закона или политики [компании] предусматривают более продолжительный срок». Если запросы получали отметку как нарушающие правила обслуживания, то они хранились до двух лет. Теперь же она решила добавить в массивы обучающих данных обычную переписку и сессии с написанием программного кода — если пользователь даст согласие, эти данные будут храниться пять лет. Речь идёт только о потребительском сегменте сервиса, то есть о частных пользователях Claude Free, Pro и Max, в том числе тех, кто работает с Claude Code. У пользователей корпоративного сектора, в том числе сервисов Claude Gov, Claude for Work, Claude for Education, а также работающих через API компания собирать данные переписок для обучения ИИ не намерена. В стремлении убедить пользователей согласиться на новую политику обработки данных Anthropic отмечает, что так они «помогут нам повысить безопасность модели, сделав наши системы обнаружения вредоносного контента более точными и снизив вероятность реагирования на безобидные разговоры». Согласившись передавать журналы переписки на обучение ИИ, пользователи «также помогут нашим будущим моделям Claude улучшить такие навыки как программирование, анализ и рассуждения, что в конечном счёте приведёт к созданию более качественных моделей для всех». И действительно, отмечает TechCrunch, для обучения передовых моделей ИИ требуются колоссальные объёмы высококачественных разговорных данных, и доступ к миллионам чатов с Claude откроет ей источник материалов, способных улучшить позиции Anthropic как конкурента OpenAI и Google. 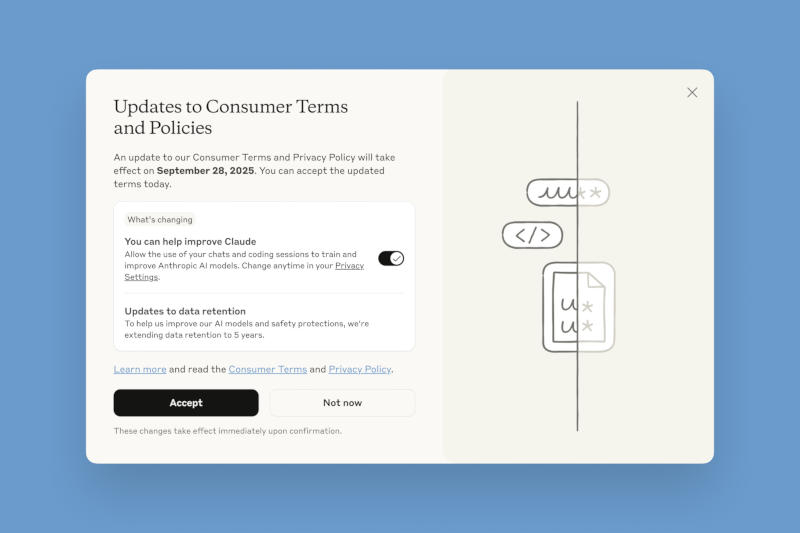 К нужному выбору компания подталкивает пользователей, делая нужные акценты в интерфейсе сервисов. Тем, кто только регистрируется, дают (или не дают) согласие при заполнении профиля; существующим же выводится всплывающее окно с заголовком «Обновления условий и политики для потребителей», включённым по умолчанию триггером согласия на передачу данных и большой чёрной кнопкой «Принять». Увидев такое окно, невнимательный или равнодушный пользователь может быстро нажать эту кнопку, не вдаваясь в подробности. Учёные придумали, как выявлять взломы аккаунтов без слежки и раскрытия личных данных
26.08.2025 [16:43],
Павел Котов
Исследователи из кампуса Cornell Tech при Корнельском университете (США) разработали механизм, который помогает обнаруживать факты взлома учётных записей, не принося в жертву конфиденциальность пользователей и не подвергая их компьютеры отслеживанию со стороны веб-сервисов. 
Источник изображения: KeepCoding / unsplash.com Система получила название CSAL (Client-Side Encrypted Access Logging) — её представили на симпозиуме по вопросам безопасности USENIX. В основе системы лежит метод проверки, позволяющий устанавливать, действительно ли вход в учётную запись осуществлялся с устройства пользователя. Сейчас крупные платформы регистрируют доступ к аккаунтам в ущерб конфиденциальности пользователей. Учёные обнаружили, что используемые сегодня журналы доступа регистрируют данные, передаваемые стороной клиента — идентификаторы устройств и IP-адреса, которые легко подделать. И даже после взлома учётной записи они позволяют вносить сведения, что вход осуществлялся со знакомого системе устройства. Механизм CSAL предлагает альтернативу с использованием криптографии. Вместо того, чтобы просто отправлять поставщику услуг представляемые клиентом данные, система защищает их сквозным шифрованием, используя ключ, который известен только настоящим клиентским устройствам. При входе на платформу операционная система клиента генерирует криптографический токен, содержащий идентификаторы устройства — данные шифруются и хранятся у поставщика услуг, а расшифровать и проверить источник входа может только сам пользователь. Таким образом, пользователь получает возможность обнаруживать факт несанкционированного доступа к своей учётной записи, не раскрывая идентифицирующую его информацию. Платформы же избавляются от необходимости хранить цифровые отпечатки устройств, которые часто используются для слежения. Система совместима с распространёнными протоколами безопасности и может с минимальными затратами интегрироваться в существующие рабочие процессы, утверждают создатели CSAL. Этот механизм она назвали возможностью уравновесить безопасность и конфиденциальность в управлении цифровыми учётными записями. Доработки не помогли: Windows Recall продолжает делать скриншоты с паролями и данными карт
06.08.2025 [19:39],
Сергей Сурабекянц
Сразу после анонса функция Recall в Windows 11 вызвала волну критики от экспертов по конфиденциальности и защите данных. Recall постоянно делает скриншоты экрана и сохраняет их, даже если они содержат конфиденциальные данные. Запуск Recall был отложен, а Microsoft сообщила о её доработке. Но исследователи The Register утверждают, что Recall «по-прежнему может захватывать данные кредитных карт и пароли — настоящий клад для мошенников». 
Источник изображений: Microsoft Microsoft интегрировала в Recall фильтр для распознавания ввода или отображения чувствительных данных и предотвращения создания их скриншотов, но пытливым умам сотрудников The Register удалось его обойти. Они выяснили, что Recall может делать скриншоты текущего баланса счетов, отображаемого на экране, избегая только данных для входа. «Таким образом, злоумышленник будет знать, услугами какого банка я пользуюсь и сколько у меня денег […], но не мои учётные данные или номер счёта», — сообщили исследователи. В ходе тестирования Recall иногда сохраняла данные кредитной карты, а иногда — нет. Функция надёжно распознала вводимые пароли и не записала их, но создала скриншоты файла с паролями. Очевидно, что Recall не всегда распознает, когда на экране отображаются пароли, и, следовательно, может их записывать. При входе в PayPal Recall сохранила скриншот экрана входа с именем пользователя, но без пароля. 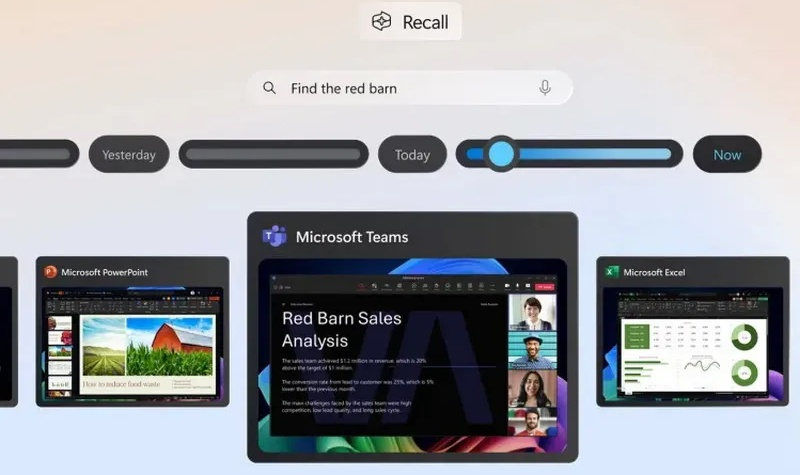 Исследователи The Register пришли к выводу, что, несмотря на все улучшения и доработки Microsoft, функция Windows Recall по-прежнему испытывает трудности с надёжным распознаванием конфиденциальных данных. Они полагают, что фильтрация конфиденциальной информации в Recall «хорошая, но недостаточная». Следует отметить, что Windows Recall хранит скриншоты в зашифрованном виде, поэтому посторонним лицам достаточно сложно их просмотреть. Тем не менее, чтобы избежать потенциальной утечки конфиденциальных данных, следует отключить Windows Recall и полностью исключить риски. Приватные диалоги с ChatGPT попали в поиск Google, и пользователи сами в этом виноваты
01.08.2025 [10:15],
Анжелла Марина
Многие пользователи ChatGPT по незнанию превратили свою приватную переписку с ботом в публичную. Их диалоги стали доступны в поисковых системах, включая Google, Bing и DuckDuckGo, по запросу site:chatgpt.com/share, сообщает PCMag. чтобы увидеть тысячи открытых диалогов, начиная от признаний в одиночестве и заканчивая вопросами о теории заговора. 
Источник изображения: Arkan Perdana / Unsplash Все эти беседы оказались в открытом доступе из-за функции, запущенной OpenAI в мае 2023 года, которая позволяет делиться ссылками на конкретные чаты. При общении с чат-ботом ChatGPT можно нажать на кнопку «Поделиться», после чего возникает диалог работы со ссылкой. Там есть галочка «Сделать этот чат доступным для обнаружения»: 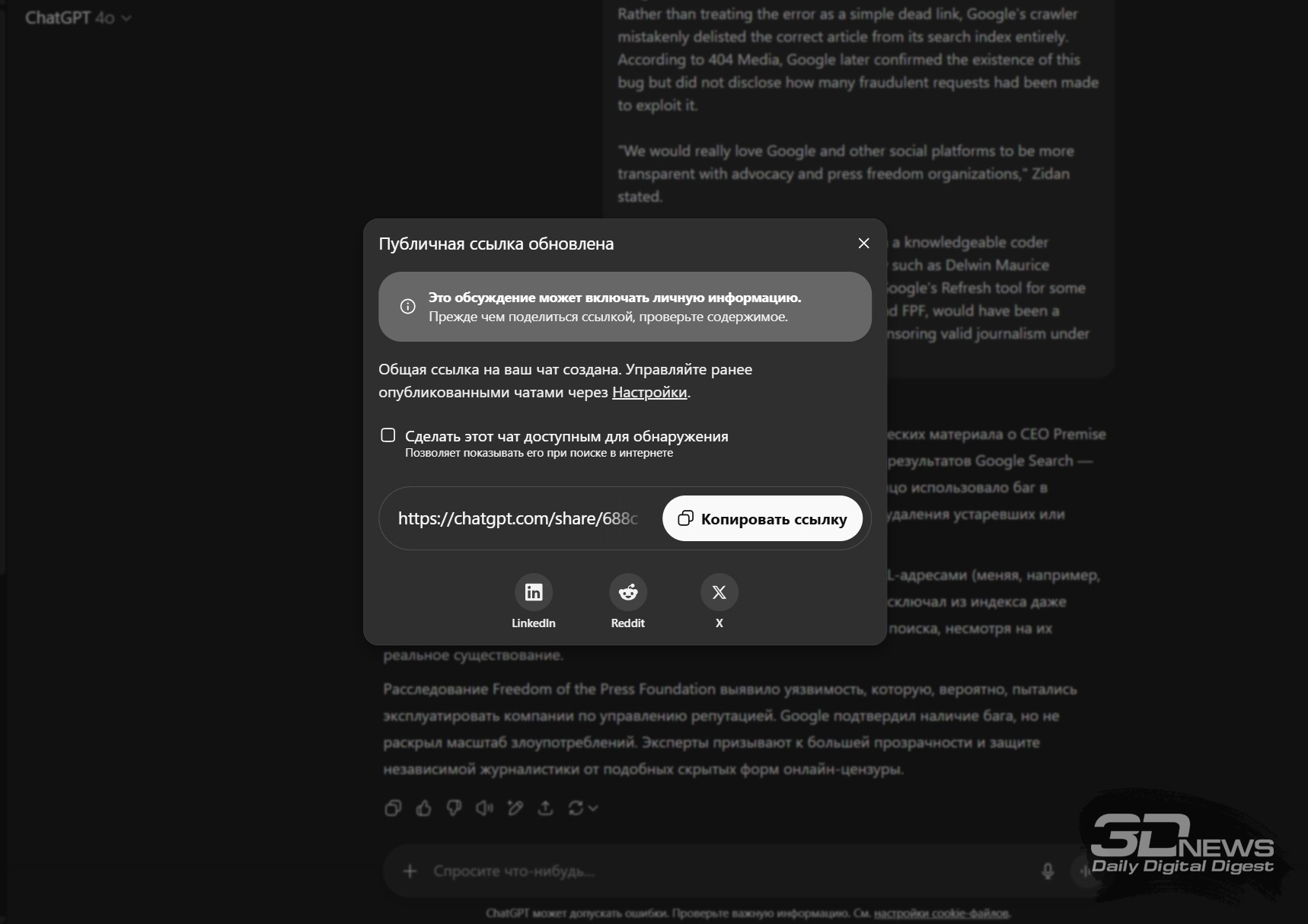 По умолчанию она не стоит, но, если её поставить и затем нажать «Копировать ссылку», всё содержимое диалога с нейросетью окажется проиндексированным Google, Bing, DuckDuckGo и, вероятно, другими поисковиками. При этом создание публичной ссылки не раскрывает имени пользователя или данные аккаунта. Но если в диалоге упоминаются конкретные имена, места или детали, переписку можно легко идентифицировать. Представители Google пояснили, что поисковые системы не инициируют индексацию этих страниц — ответственность за публикацию лежит на OpenAI. Пользователи могут в любой момент отредактировать или удалить общедоступные ссылки, а при удалении аккаунта все связанные чаты также исчезают. Однако до этого момента информация остаётся в интернете. 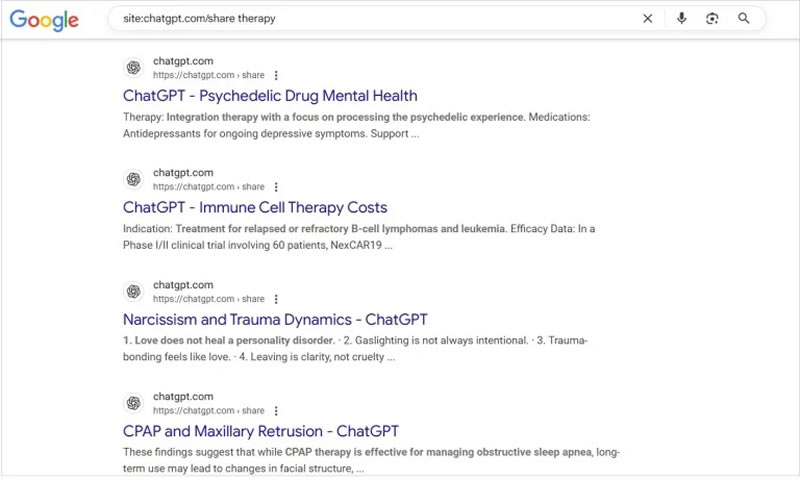
Источник изображения: pcmag.com Ранее TechCrunch сообщал, что глава OpenAI Сэм Альтман (Sam Altman) недавно отметил, что люди рассказывают ChatGPT о самых сокровенных вещах в жизни, особенно молодёжь, которая использует ИИ как терапевта или консультанта для решения личных и эмоциональных проблем. При этом OpenAI юридически обязана сохранять переписки и предоставлять их по запросу в рамках судебных разбирательств. Одновременно некоторые пользователи Reddit отмечают, что доступ к открытым чатам стал «золотой жилой» для специалистов по SEO, поскольку в них отражены реальные вопросы аудитории. Аналогичные проблемы с приватностью ранее возникали у Meta✴: в июне стало известно, что общие чаты с их ИИ попадали в ленту Discover, после чего компания добавила предупреждение перед публикацией. В феврале 2024 года после переименования Bard в Gemini пользователи также обнаружили, что чаты с сервисом появляются в поиске Google через параметр site:gemini.google.com/share, однако сейчас по этому запросу результатов не выдаётся. Также наблюдаются совпадения между ответами ChatGPT и результатами поиска Google, включая AI Overview (ИИ-сводки), что породило предположения о том, что ChatGPT может использовать данные из поисковой выдачи. На момент написания материала Google перестал выдавать списки диалогов по запросу site:chatgpt.com/share. Недоработки в системе защиты данных Spotify раскрыли музыкальный вкус знаменитостей и политиков
31.07.2025 [18:26],
Сергей Сурабекянц
Музыкальный сервис Spotify никогда не уделял много внимания конфиденциальности своих пользователей — по умолчанию все плейлисты и профили на платформе сделаны публичными. В результате в открытом доступе на недавно появившемся сайте Panama Playlists оказалась информация о музыкальных предпочтениях и другие данные известных лиц, включая руководителей технологических компаний и крупнейших политиков. 
Источник изображения: unsplash.com «Я нашёл настоящие аккаунты Spotify знаменитостей, политиков и журналистов. Многие используют свои настоящие имена. Немного поискав, я могу почти с уверенностью сказать: да, это они. Мы собираем данные их аккаунтов с лета 2024 года. Плейлисты, записи прослушиваний в прямом эфире — всё. Я знаю, какие песни они проигрывали, когда и сколько раз», — написал анонимный создатель сайта. Он утверждает, что таким образом хочет привлечь внимание пользователей к вопросам конфиденциальности Spotify. На сайте Panama Playlists содержатся разнообразные данные Spotify таких пользователей, как:
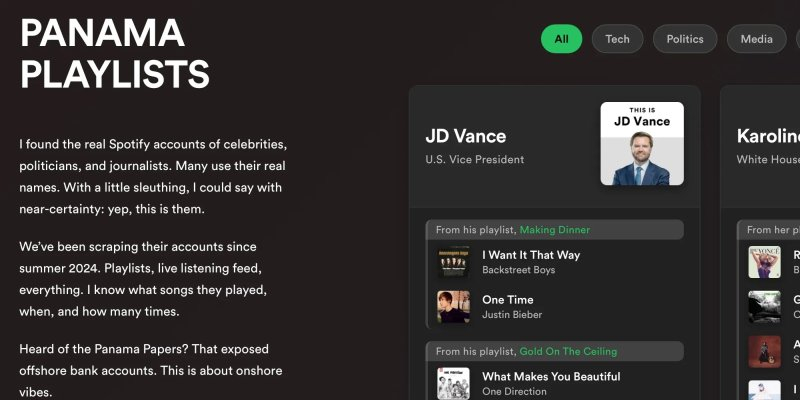
Источник изображения: Panama Playlists Технически эти данные не являются результатом утечки, поскольку, по-видимому, вся информация изначально была общедоступна. Автор сайта, обращаясь к пользователям, поднимает важный вопрос: знают ли они о своих настройках конфиденциальности в сервисе Spotify? Многие из опрошенных пользователей, похоже, были не на шутку удивлены таким отношением к своим персональным данным. «Этот сайт [Panama Playlists] существует благодаря тому, что Spotify изначально предполагает, что все хотят делиться всем со всем миром, и пользователям сложно защитить свою конфиденциальность. По умолчанию все плейлисты и профили сделаны публичными. Чтобы изменить это, пользователям нужно перейти в меню "Конфиденциальность и социальные сети" и переключить настройку "Публичные плейлисты" в режим "Частные". Однако это не сделает плейлисты закрытыми задним числом; вместо этого вам придётся делать всё это вручную для каждого плейлиста», — прокомментировала ситуацию обозреватель The Verge Элизабет Лопатто (Elizabeth Lopatto). Пользователям Spotify, вероятно, самое время проверить настройки конфиденциальности, чтобы убедиться, что они соответствуют их ожиданиям. Европа начала тестировать сервис проверки возраста для доступа к контенту 18+
15.07.2025 [18:14],
Павел Котов
В Евросоюзе стартовало тестирование пилотной версии приложения для проверки возраста — в нём принимают участие жители Дании, Греции, Испании, Франции и Италии. Цель проекта — упростить онлайн-платформам соблюдение норм по защите несовершеннолетних. 
Источник изображения: Alexey Larionov / unsplash.com Прототип приложения был представлен накануне вместе с рекомендациями по соблюдению требований европейского «Закона о цифровых сервисах» (DSA). Приложение разработано для того, чтобы при доступе к предназначенным для взрослых материалам в интернете пользователи могли подтверждать, что им исполнилось 18 лет. Это существенно упростит задачу владельцам подобных ресурсов — ранее на них возлагалась обязанность решать её собственными силами. С новым инструментом граждане сохранят полный контроль над своей персональной информацией, такой как точный возраст и идентификационные данные, заверили в Еврокомиссии, а сведения о просматриваемых ими материалах останутся конфиденциальными. Это временное решение, на смену которому придёт единый проект EU Digital Identity Wallet, запуск которого намечен на 2026 год. При этом Дания, Греция, Испания, Франция и Италия выпустят собственные национальные приложения для проверки возраста. EU Digital Identity Wallet даст «гражданам, резидентам и компаниям Европы возможность подтверждать свою личность при доступе к цифровым сервисам», а также обеспечит им «безопасное хранение, обмен и подписание цифровых документов». Европейские нормы в отношении проверки возраста не устанавливают конкретных требований, но владельцы ресурсов и онлайн-платформ обязаны защищать «здоровье, физическое, умственное и нравственное развитие» пользующихся их услугами несовершеннолетних, а также обеспечивать им «высочайший уровень конфиденциальности, безопасности и сохранности». Руководство по соблюдению этих норм призывает администрации онлайн-платформ принимать меры по устранению проблем, связанных с воздействием на детей вредоносного контента, с кибербуллингом, нежелательными контактами с незнакомцами, а также с функциями, вызывающими привыкание к платформам. Google открыла Gemini доступ ко всем приложениям на Android и толком не объяснила, как от этого отказаться
08.07.2025 [11:37],
Павел Котов
Google накануне, 7 июля, развернула изменения, благодаря которым помощник с искусственным интеллектом Gemini получил возможность взаимодействовать со сторонними приложениями, в том числе WhatsApp, даже если пользователи ранее запретили такие взаимодействия. Отказаться от этой функции очень непросто, и в Google простых инструкций не предоставили. 
Источник изображений: blog.google О нововведении Google сообщила пользователям в электронном письме, где сослалась на страницу поддержки — на ней говорится, что данные, к которым имеет доступ Gemini, «читают, комментируют и обрабатывают люди-рецензенты (включая поставщиков услуг)». В письме отсутствуют полезные рекомендации по действиям, которые следует предпринять, чтобы отказаться от указанных изменений; зато говорится, что пользователи могут блокировать приложения для взаимодействия с Gemini, но даже в этом случае собранные данные хранятся 72 часа. В письме не объясняется, можно ли полностью удалить Gemini с устройств под управлением Android; и, видимо, оно противоречит само себе относительно того, как это сделать, и возможно ли это вообще. В одном месте говорится, что изменения развёртываются в автоматическом режиме со вчерашнего дня, открывая Gemini доступ к таким приложениям как WhatsApp, «Google Сообщения» и «Google Телефон». Ниже по тексту указывается: «Если вы уже отключили эти функции, они останутся отключёнными». О возможности полностью удалить механизмы интеграции Gemini не сообщается нигде.  Пользователи одного из серверов соцсети Mastodon и журналисты Ars Technica заинтересовались вопросом, но в справочном разделе Google им удалось только найти инструкцию по настройке Gemini в учётной записи — минимум в одном из случаев само приложение на устройстве в явном виде отсутствовало. В стремлении прояснить ситуацию они обратились за помощью к Google, но в компании ответа на вопрос не дали, и, в частности, заявили: «Это обновление полезно для пользователей: теперь они могут пользоваться Gemini для выполнения повседневных задач на мобильных устройствах, в том числе для отправки сообщений, совершения телефонных звонков и установки таймеров при отключённой [настройке] Gemini Apps Activity. Когда Gemini Apps Activity отключена, их переписка не читается и не используется для улучшения наших моделей ИИ». Представитель компании также продублировал ссылку на одну из обнаруженных ранее страниц, содержимое которой не прояснило ситуацию. Дополнительно прояснить ситуацию попытались эксперты компании Tuta — поставщика конфиденциальных сервисов электронной почты и календаря. Они сделали вывод, что своей интеграцией Gemini в Android компания Google решила пойти по стопам Microsoft с её Internet Explorer в Windows — тогда всё закончилось затяжным судебным разбирательством. По версии Tuta, отключение Gemini Apps Activity предотвратит дальнейший сбор данных, а собранная ранее информация будет удалена за 72 часа; на устройства без установленного приложения Gemini оно самопроизвольно устанавливаться не станет. Один из способов защитить свою конфиденциальность — полное удаление Gemini с устройства, но для этого может понадобиться запуск отладки Android и работа с интерфейсом командной строки. Европейцы получат урезанную iOS 26 из-за неутихающего противостояния Apple и ЕС
30.06.2025 [19:12],
Сергей Сурабекянц
Сегодня на семинаре с должностными лицами и разработчиками ЕС в Брюсселе вице-президент Apple по юридическим вопросам Кайл Андер (Kyle Andeer) сообщил, что компании «пришлось принять решение об отсрочке выпуска продуктов и функций, о которых мы объявили в этом месяце для наших клиентов в ЕС». Он объяснил это решение стремлением обезопасить пользователей, если экосистема Apple будет открыта для конкурентов. Евросоюз требует от Apple соблюдения «Закона о цифровых рынках» (Digital Markets Act, DMA), который призван ограничить рыночные преимущества так называемых технологических компаний — «привратников» (gatekeepers) путём открытия их платформ для сторонних разработчиков. По мнению чиновников Евросоюза, этот закон призван обеспечить конкуренцию и справедливость на цифровых рынках Европы. Apple категорически не согласна с реализацией DMA и утверждает, что это ухудшает качество её продуктов, подвергает пользователей рискам безопасности и конфиденциальности и усложняет развёртывание обновлений в ЕС. Андер утверждает, что изменения, которые пришлось внести Apple, чтобы привести свои продукты в соответствие с правилами, «создают реальные риски конфиденциальности, безопасности и сохранности для наших пользователей». Apple заявила, что все ещё решает, какие функции пока окажутся недоступными в Евросоюзе, и работает над поиском решений для их скорейшего предоставления. Известно, что такие инструменты, как «Посещённые места» в приложении «Карты», не будут доступны жителям ЕС в момент выхода iOS 26 в конце этого года. Чиновник Евросоюза, присутствовавший на встрече с Кайлос Андером, подтвердил, что регулятор и Apple расходятся во мнениях относительно сферы действия DMA и потенциальных рисков безопасности. Сотни торговцев персональными данными уличили в нарушении законов США
26.06.2025 [11:11],
Владимир Мироненко
Electronic Frontier Foundation (EFF) и некоммерческая группа по защите прав на конфиденциальность Privacy Rights Clearinghouse (PRC) обратились в правоохранительные органы ряда штатов США с требованием провести расследование, почему «сотни» брокеров данных не зарегистрировались в государственных агентствах по защите прав потребителей, что является нарушением местного законодательства, пишет The Verge. 
Источник изображения: Steve Johnson / unsplash.com Брокеры данных — это компании, которые торгуют личной информацией пользователей, включая их имена, адреса, номера телефонов, финансовые сведения и многое другое. Потребители не контролируют их деятельность, которая может быть сопряжена с нарушением конфиденциальности данных. В прошлом месяце компания LexisNexis Risk Solutions сообщила о утечке данных, касающихся более 364 тыс. человек. В штатах Калифорния, Техас, Орегон и Вермонт приняли законы, которые требуют от брокеров регистрироваться в регулирующих органах и агентствах по защите прав потребителей, а также предоставлять сведения о том, какие данные они собирают. В письмах EFF и PRC, направленных генеральным прокурорам штатов, сообщается, что многие брокеры данных не зарегистрировали свой бизнес во всех четырёх штатах. Количество брокеров данных, которые указаны в одном реестре, но их нет в другом, включает 524 в Техасе, 475 в Орегоне, 309 в Вермонте и 291 в Калифорнии. В EFF отметили, что некоторые из этих несоответствий можно объяснить различием в определении каждым штатом статуса брокера данных. Также брокеры могут работать не во всех штатах, хотя, как правило, они собирают данные по всей стране. Вместе с тем следует учитывать и то, что некоторые компании игнорируют законы штата, не регистрируясь ни в одном штате. EFF и PRC предлагают правоохранительным органам провести расследование случаев отсутствия регистрации, которые «могут указывать на систематическое несоблюдение» законодательства в каждом штате. В настоящее время брокеры могут продавать персональные данные пользователей, взятые из приложений и других веб-сервисов, без их ведома. В прошлом году Бюро по защите прав потребителей в сфере финансов (CFPB) США намеревалось ввести запрет на продажу брокерами номера социального страхования, но в министерстве финансов отказались от этих планов. Как избежать оборотных штрафов по 152-ФЗ и не сломать маркетинг: объясняют эксперты рынка, регуляторы и юристы
23.06.2025 [10:00],
Сергей Карасёв
30 июня в 12:00 компания Sendsay проведёт бесплатный вебинар с участием регулятора, профильного юриста и эксперта по работе с персональными данными. Мероприятие ответит на самый острый вопрос бизнеса: как избежать оборотных штрафов по 152-ФЗ и не сломать маркетинг. Модератор мероприятия — руководитель отдела телекоммуникаций лидирующего федерального СМИ. С 30 мая 2025 года в России вступили в силу самые масштабные изменения в законе о персональных данных (152-ФЗ). Теперь любые компании, ИП и даже физлица, обрабатывающие персональные данные, обязаны уведомить Роскомнадзор и пересмотреть внутренние процессы работы с ПД — обновить документы, формы, проверить маркетинговые активности. За нарушения предусмотрены оборотные штрафы, а реальные проверки и наказания начнутся с 30 июня. При этом большинство представителей бизнеса не до конца понимают, что именно изменилось и как теперь работать с клиентскими базами без риска. Поэтому Sendsay, как сооснователь Ассоциации компаний по защите и хранению персональных данных, собрала свою экспертизу и пригласила на неформальный диалог основного регулятора этого закона — Роскомнадзор, а также профильного юриста по 152-ФЗ, чтобы доступным языком ответить представителям бизнеса, как действовать в новых условиях.  Тема вебинара: «Как избежать оборотных штрафов по 152-ФЗ и не сломать маркетинг: объясняют эксперты рынка, регуляторы и юристы». Эксперты обсудят:
Спикеры:
Модератор:
Вебинар пройдёт онлайн, 30 июня 2025 года в 12:00. У всех зарегистрировавшихся участников будет возможность задать свои вопросы. Ссылку на трансляцию пришлём на почту после регистрации на сайте вебинара: https://webinar.sendsay.ru/ Запись вебинара будет доступна всем зарегистрировавшимся. Если у вас остались вопросы, можете их задать по почте pr@sendsay.ru или телефону +79299872044 (Елена Петрякова, PR-директор CDP Sendsay) Генеральный партнер мероприятия: РАЭК Meta✴ AI показывает всем чужие переписки с интимными подробностями — формально с согласия самих пользователей
13.06.2025 [14:04],
Павел Котов
В приложении чат-бота Meta✴ AI раздел «Лента открытий» (Discover) стал показывать переписку других пользователей с искусственным интеллектом, где нередко приводятся персональные данные и прочая информация деликатного характера, обращает внимание Wired. Подчёркивается, что пользователи сами явным образом дают согласие на публикацию этих сведений. 
Источник изображения: Alex Suprun / unsplash.com В одной из переписок 66-летний одинокий мужчина из Айовы, как он себя описал, пытается выяснить, в каких странах женщины больше любят пожилых мужчин, и изъявил готовность переехать, если встретит молодую женщину. Meta✴ AI одобрил его намерения и посоветовал страны Средиземноморья, в том числе Испанию и Италию, а также Восточную Европу. Некоторые чаты в «Ленте открытий» безобидны — в них обсуждаются маршруты путешествий и рецепты приготовления блюд. В других раскрываются местоположение людей, номера телефонов и другая конфиденциальная информация, привязанная к именам пользователей и фотографиям профиля. Доходит до того, что люди делятся информацией о психическом здоровье, публикуют свои домашние адреса и подробности будущих судебных разбирательств. Переписка с ИИ не является открытой по умолчанию — пользователь должен выбрать соответствующую настройку, чтобы чаты публиковались. Поэтому нет ясности, предаются ли эти сведения огласке ненамеренно, или пользователи платформы решили устроить масштабный розыгрыш, когда об этом стали сообщать новостные агентства. Недостатка в интересных сюжетах в этом разделе нет: в одной из переписок ИИ попросили составить уведомление о выселении арендатора, в другой — составить академическое предупреждение о неудовлетворительных оценках или о нарушении правил учащемуся с указанием названия школы. Ещё один пользователь задал вопрос об ответственности своей сестры за мошенничество с налогами, раскрыв город, а в связанной с запросом учётной записи Instagram✴ указывались его имя и фамилия. Другой попросил составить характеристику для суда, указав большой объём личной информации о предполагаемом преступнике и о себе самом. 
Источник изображения: Paul Hanaoka / unsplash.com Люди активно раскрывают медицинскую информацию, обсуждая пищеварение, крапивницу с высыпанием на внутренней части бёдер, один поинтересовался подробностями операции на шее, указав свой возраст и род занятий — во многих случаях аккаунты привязаны к публичным профилям Instagram✴. В Meta✴ отметили, что переписка пользователя с ИИ является конфиденциальной, если он сам не пройдёт многоступенчатый процесс и явным образом её не раскроет. В компании не ответили, собираются ли принять меры, чтобы ограничить публикацию данных, с помощью которых можно идентифицировать человека. Но сообщили, что пользователь может указать ИИ запоминать информацию о себе, а ответы могут персонализироваться, исходя из информации, которую он предоставил на платформах Meta✴, и контенте, который ему понравился, или с которым он взаимодействовал. Люди могут не осознавать, что переданная ИИ информация перестаёт быть конфиденциальной, напоминают опрошенные Wired эксперты, — её дальнейшая судьба неизвестна, но она точно не остаётся между человеком и приложением; как минимум в Meta✴ к ней имеют доступ и другие люди. Сама же компания продолжает активно наращивать своё присутствие в области ИИ — аудитория Meta✴ AI на всех платформах превысила 1 млрд человек, признался недавно её гендиректор. «Все серверы Telegram принадлежат Telegram»: мессенджер опроверг обвинения в связях с ФСБ
11.06.2025 [10:04],
Владимир Мироненко
После выхода публикации BBC, в которой сообщалось о возможных связях Telegram с ФСБ, в пресс-службе мессенджера выступили с опровержением, отметив, что «Telegram никогда не раскрывал частные сообщения третьим лицам, а его шифрование никогда не было взломано». 
Источник изображения: Rubaitul Azad/unsplash.com В компании сообщили агентству BBC, что у Telegram, как и любой другой глобальной компании, имеются контракты с «десятками различных поставщиков услуг по всему миру», но ни у одного из них нет доступа к «данным Telegram или конфиденциальной инфраструктуре» мессенджера. «Все серверы Telegram принадлежат Telegram и обслуживаются сотрудниками Telegram», — подчеркнули в компании. Как пишет Forbes, в начале июня правозащитный проект «Первый отдел»✶ выступил с утверждением, что ФСБ возбуждает уголовные дела о госизмене на россиян, которые писали в боты украинских Telegram-каналов. По словам ресурса, эти сообщения россиян в Telegram были перехвачены в рамках оперативных мероприятий по уголовному делу, возбужденному весной 2022 года. Источник сообщил, что не знает, каким образом силовики получают доступ к переписке в Telegram, но в их практике накопилось множество дел, доказательная база в которых строилась на материалах из Telegram (например, переписка пользователей или информация об администрировании каналов). |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; ✶ Входит в реестр лиц, организаций и объединений, выполняющих функции иностранного агента; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






