|
Опрос
|
реклама
Быстрый переход
«Яндекс» представил «Нейроэксперта» — ИИ, который соберёт базу знаний по ссылкам и файлам пользователя
03.04.2025 [10:52],
Павел Котов
Компания «Яндекс» представила сервис «Нейроэксперт», который доступен в формате бета-версии. Он позволяет загружать документы, таблицы, презентации, аудио- и видеофайлы, а также отправлять ссылки, из которых составляется база знаний с возможностью найти ответ на любой вопрос. Воспользоваться сервисом может любой желающий. 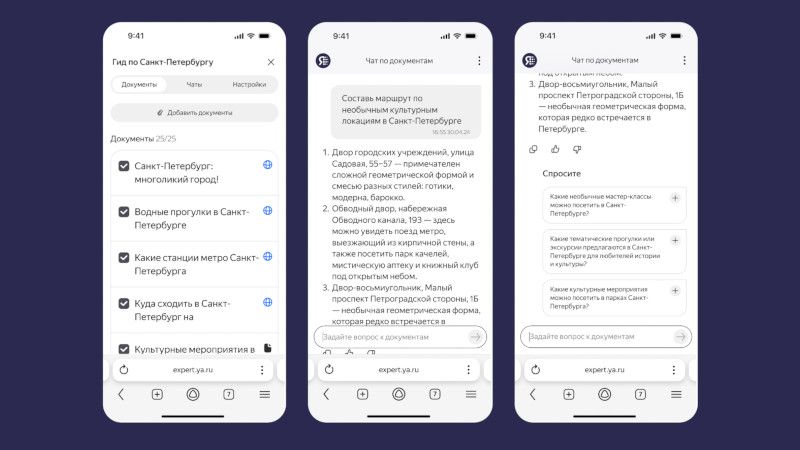
Источник изображений: «Яндекс» База знаний на платформе «Нейроэксперт» похожа на папку в облачном хранилище — ею можно поделиться по ссылке. Пользователь загружает информацию и задаёт о ней вопросы в режиме диалога; ответы система готовит только на основе предоставленных данных. На этапе бета-тестирования загружаются до 25 файлов и ссылок — это могут быть документы, таблицы, аудиосообщения из мессенджера или другие данные. По завершении бета-тестирования можно будет добавлять больше исходных данных. Сервис пригодится тем, кто работает с большими объёмами информации. Преподаватель может загрузить свои лекции и передать базу данных студентам, которые при подготовке к экзаменам найдут в ней ответы на свои вопросы. «Нейроэксперт» окажется полезным, например, если требуется создать отчёт, а необходимые данные размещены в одной из множества презентаций — искать информацию вручную не придётся. Сервис поможет принять решение о покупке, если загрузить в него ссылки с описанием товаров и видеообзоры. Можно, наконец, загрузить «Нейроэксперту» правила настольной игры и задать ему вопрос при возникновении спорного момента. 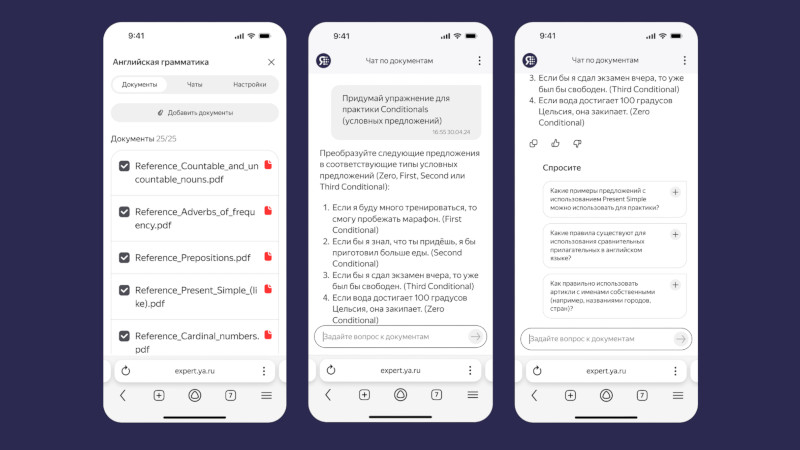 Особенно полезным сервис окажется для бизнес-клиентов — его можно будет подключить к внутренним базам знаний и документации. «Нейроэксперт» поможет систематизировать работу, будет способствовать адаптации и повышению эффективности работников компании. Подключить предварительный вариант корпоративного «Нейроэксперта» можно по заявке. Для работы сервиса использованы несколько созданных «Яндексом» технологий. Для поиска данных по графикам и диаграммам используется визуально-языковая модель (VLM); за обработку аудио и видео отвечает технология распознавания речи (ASR); текст на картинках обрабатывает технология оптического распознавания символов (OCR). Обработку данных от этих систем и подготовку ответа осуществляет большая языковая модель YandexGPT 5 Pro: знания о мироустройстве и правилах языка помогают ей понимать запрос и готовить качественные ответ — при этом фактические данные она берёт из загруженных материалов. Знания модели и сведения из файлов объединяет ещё один компонент — RAG-система (Retrieval Augmented Generation). 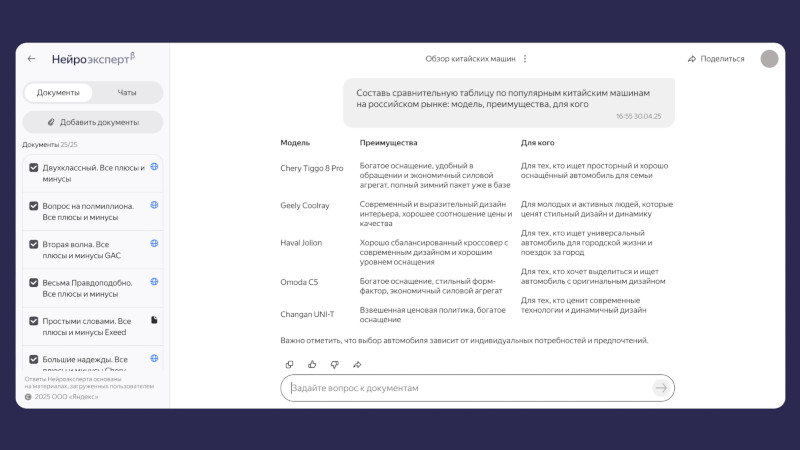 Аналоги «Нейроэксперта» уже есть у зарубежных разработчиков: Google NotebookLM, Perplexity Spaces и ChatGPT Projects. «Яндекс» планирует реализовать две модели монетизации сервиса: расширенные возможности для оформивших подписку пользователей и интеграция «Нейроэксперта» в информационные системы заказчика. Учёные успешно испытали логические вентили на фотонах — это приближает появление оптических процессоров
03.09.2024 [19:31],
Павел Котов
Учёные Байройтского университета (Германия) и Мельбурнского университета (Австралия) разработали переключаемый оптический блок для хранения и считывания двоичной информации при помощи света. Проект обещает стать большим шагом на пути к построению полностью оптического компьютера, в котором для обработки и хранения данных используются фотоны, а не электроны, как в актуальных чипах. 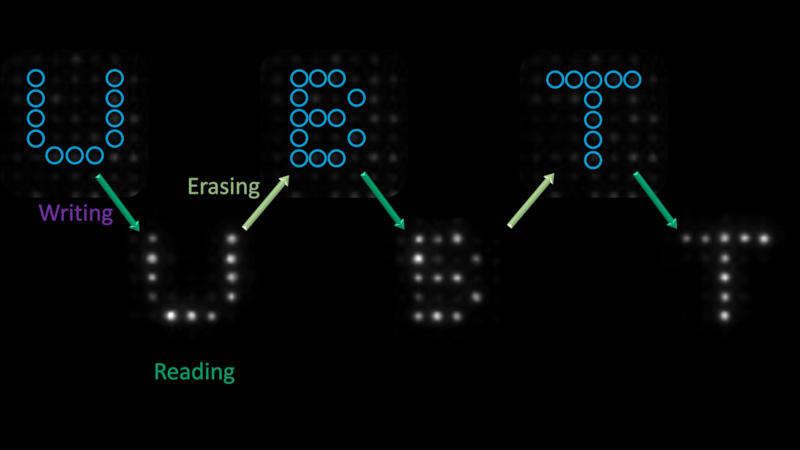
Источник изображения: phys.org Учёные применили эти логические вентили для обработки информации исключительно с использованием света — они произвели несколько циклов чтения, записи и стирания на полимерных сферах, чтобы записать алфавит на одном и том же участке массива микроструктур. Учёные работают над созданием полностью оптического логического вентиля уже более десяти лет, и данный проект представляет собой пример практического применения этой технологии. Он поможет перенести обработку и хранение данных с электронов на фотоны и снизить потребляемую мощность систем. Фотонные вычисления сулят и другие выгоды: можно работать не только с силой сигнала (количеством фотонов), но также с длиной волны (цветом) и поляризацией (направлением колебаний) — что даст широкий набор сигналов. Один оптический вентиль сможет обрабатывать сразу несколько сигналов, что в перспективе позволит удвоить, утроить или даже вчетверо повысить вычислительную мощность одного оптического процессора. Фотоны движутся быстрее и эффективнее электронов. Поэтому для передачи данных на большие расстояния используются оптоволоконные кабели. Их применение в логических вентилях способно стать важным практическим шагом в использовании фотонов при обработке данных. Microsoft создала ИИ, который облегчит работу с таблицами в Excel — он понимает запросы на естественном языке
18.07.2024 [17:51],
Павел Котов
Сотрудники, умеющие качественно работать с электронными таблицами Excel, ценятся достаточно высоко. Но исследователи Microsoft разработали решение, способное как минимум отчасти их заменить. Большая языковая модель SpreadsheetLLM предназначена для управления электронными таблицами при помощи команд естественным языком. 
Источник изображения: Rubaitul Azad / unsplash.com SpreadsheetLLM анализирует и интерпретирует данные в электронных таблицах при помощи ИИ, решая большинство связанных с ними задач — для этого производится сериализация данных, то есть включение в поток адресов, значений и форматов ячеек. Инструмент содержит компонент SheetCompressor, который сжимает электронные таблицы для их передачи модели ИИ. Он состоит из трёх модулей: первый анализирует структуру таблицы и отбрасывает нетабличное содержимое; второй преобразует данные в более эффективное представление; третий агрегирует данные. У SpreadsheetLLM есть некоторые ограничения. Она игнорирует цвета ячеек, а они могут иметь какое-то значение, и не осуществляет семантического сжатия для содержимого ячеек, выраженного естественным языком. Но и этого хватает, чтобы на 96 % сократить потребление токенов при запросе к ИИ, что означает экономию вычислительных ресурсов. В итоге пользователи без надлежащей технической подготовки могут отправлять к SpreadsheetLLM запросы естественным языком и добиваться поставленных задач. Но основная задача проекта — не заменить человека, а оказать ему помощь в финансах, бухгалтерском учёте и других областях, связанных с обработкой данных. Модель включает фреймворк Chain of Spreadsheet (CoS) для анализа содержимого нескольких таблиц. SpreadsheetLLM может работать со структурированными и неструктурированными данными электронных таблиц — исследователи указывают, что этот аспект способен уменьшить инциденты с «галлюцинациями» в ответах ИИ. Пока проект находится на стадии исследования, и к выходу в качестве коммерческого продукта он ещё не готов. Facebook✴ объявила, что будет обучать ИИ на фото и постах пользователей — личные переписки не тронут
28.05.2024 [17:25],
Анжелла Марина
Социальная сеть Facebook✴ объявила о внесении изменений в политику конфиденциальности, касающихся использования фотографий и сообщений пользователей для обучения искусственного интеллекта. Нововведения вступят в силу 26 июня 2024 года. 
Источник изображения: rawpixel.com / freepik.com Как сообщает PCWorld, начиная с упомянутой даты, сообщения, изображения и другой публичный контент миллионов пользователей Facebook✴ по умолчанию будут доступны для анализа нейросетям компании Meta✴ (материнская структура Facebook✴). Это нужно для улучшения работы инструментов генеративного ИИ. При этом личные сообщения и переписка использоваться не будут — к ним доступ по-прежнему будет ограничен. Эксперты отмечают, что подобный шаг был вполне ожидаем. Компания Марка Цукерберга (Mark Zuckerberg) уже несколько лет наращивает инвестиции в разработку технологий ИИ, для обучения которых требуются огромные массивы различных данных. Опасения вызывает то, что теперь Facebook✴ фактически получает доступ к информации людей без их непосредственного одобрения. Хотя сама компания утверждает, что нововведение пойдет на пользу не только ей, но и пользователям, часть аудитории социальной сети уже высказала своё недовольство. В связи с этим Meta✴ подчеркивает, что у каждого пользователя есть «право на возражение». Это можно сделать с помощью специальной формы, которая предлагается на странице помощи. В форме надо указать свои данные и причину возражения. Далее Meta✴ обязана рассмотреть возражение и оценить его в соответствии с действующим законодательством о защите данных. Однако даже если возражение будет одобрено, Facebook✴ все равно может использовать часть данных для обучения ИИ, например, когда другие люди делятся контентом пользователя или упоминают его в своих сообщениях. Использование публикаций участников социальной сети для обучения ИИ можно было предвидеть уже к концу прошлого года. Однако новое, беспрецедентное по масштабам соглашение, вступает в силу впервые. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






