|
Опрос
|
реклама
Быстрый переход
VK заплатит до 5 млн рублей тем, кто найдёт в мессенджере Max уязвимости и ошибки
01.07.2025 [19:02],
Сергей Сурабекянц
В соответствии с законом «О создании многофункционального сервиса обмена информацией» правительство планирует запуск национального мессенджера на базе платформы Max от российской компании VK. Министр цифрового развития России Максут Шадаев пообещал представить национальный мессенджер уже этим летом. Разработчики сервиса присоединились к программе для «белых хакеров» Bug Bounty и обещают премии до 5 млн рублей за найденные в приложении уязвимости. 
Источник изображения: max.ru Размер премий зависит от степени критичности выявленной проблемы. На первом месте — защищённость персональных данных пользователей. Уязвимости и ошибки можно искать в мобильном приложении, а также в версии для настольных компьютеров и в веб-интерфейсе. Программа VK Bug Bounty доступна на платформах Standoff Bug Bounty, BI.ZONE Bug Bounty и BugBounty.ru. Бета-версия Max была запущена в конце марта 2025 года, а в конце июня платформа достигла отметки в 1 млн ежедневных пользователей. Сервис должен обеспечить создание доверенной и безопасной среды для общения россиян, его можно будет использовать для удостоверения личности вместо бумажных документов. Ожидается, что в дополнение к функциям обмена данными сервис обеспечит доступ к государственным и муниципальным услугам. Также на платформе разместятся образовательные сервисы. В дальнейшем, после подключения сервиса к системе «Госключ», появится возможность использовать усиленную цифровую подпись. 24 июня Владимир Путин подписал Федеральный закон № 156-ФЗ «О создании многофункционального сервиса обмена информацией и о внесении изменений в отдельные законодательные акты Российской Федерации». Документ опубликован на официальном интернет-портале правовой информации. ИИ-поисковик Google научился понимать голосовые запросы, но доступна функция не всем
18.06.2025 [23:20],
Николай Хижняк
Google начала тестировать функцию Search Live в режиме поиска с ИИ — AI Mode. Новая функция позволяет задавать вопросы ИИ-чат-боту голосом прямо из поисковой системы. Открытое тестирование доступно пока только в США и исключительно для участников программы Google Labs по тестированию экспериментальных функций. На данный момент Search Live не поддерживает использование камеры смартфона, но Google планирует добавить такую возможность «в ближайшие месяцы». 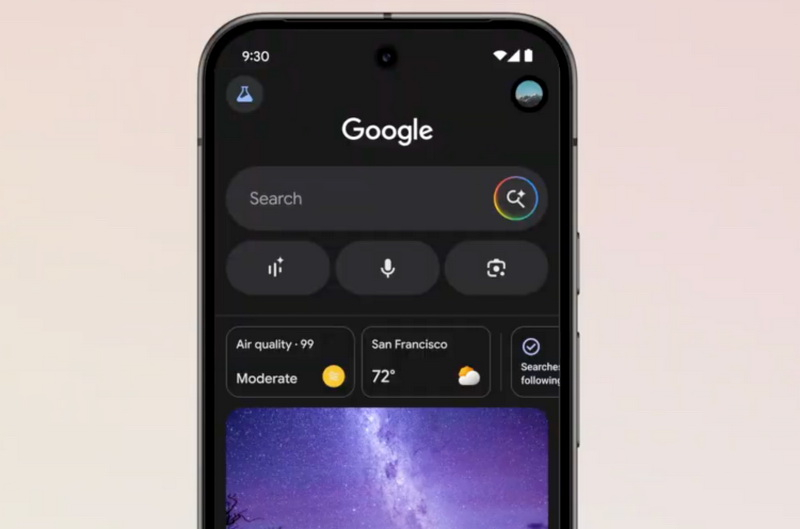
Источник изображений: Google Search Live позволяет взаимодействовать со специально адаптированной версией ИИ-помощника Gemini и выполнять поиск в интернете в режиме реального времени. Функция доступна в приложении Google для Android и iOS. В будущем Search Live получит поддержку камеры смартфона — пользователь сможет навести её на объект и задать голосом интересующий вопрос о нём. Google анонсировала функцию Search Live для режима поиска с ИИ AI Mode в прошлом месяце. Она является частью более широкой программы компании по трансформации своей поисковой системы и расширению его ИИ-возможностей. Сейчас компания, например, также экспериментирует с ИИ-функцией, которая превращает результаты поиска в подкаст. После запроса пользователя и вывода чат-ботом результатов, пользователь может использовать функцию Generate Audio Overview и ИИ предоставит ответ в аудиоформате в виде кратного подкаст-обзора по теме. Принять участие в тестировании Search Live можно через Google Labs (в России недоступен), после чего в приложении Google на Android или iOS станет активен новый значок Live. Затем чат-боту можно вслух задать, например, такой вопрос: «Как предотвратить появление складок на льняном платье, упакованном в чемодан?». Чат-бот предложит ответ, а пользователь сможет задать уточняющий вопрос, например: «Что делать, если оно всё равно мнётся?». Search Live также предложит ссылки на материалы с возможными решениями во время диалога.  Другие ИИ-компании также внедряют голосовые режимы в своих чат-ботах. Так, OpenAI представила расширенный голосовой режим для ChatGPT в прошлом году, а Anthropic запустила голосовую функцию в приложении Claude в мае. Apple также работает над большой языковой моделью для Siri, однако её выпуск был отложен — по словам старшего вице-президента Apple по программному обеспечению Крейга Федериги (Craig Federighi), компания пока не достигла «желаемого уровня надёжности». Google отмечает, что Search Live может работать в фоновом режиме, позволяя продолжать диалог с чат-ботом даже при переходе в другие приложения. Пользователь может также включить субтитры, чтобы видеть текстовую версию ответа, и при желании продолжить общение текстом. Кроме того, Search Live сохраняет историю прошлых разговоров в разделе поиска AI Mode. Google начала тестировать ИИ-функцию, которая превращает результаты поиска в подкаст
14.06.2025 [10:39],
Владимир Фетисов
Компания Google приступила к тестированию новой функции Audio Overviews, которая задействует генеративные нейросети для создания аудиообзоров на первой странице результатов поиска на мобильных устройствах. Экспериментальная функция позволит получить ответ в стиле подкаста, в котором ИИ обсуждает вопрос пользователя сам с собой. 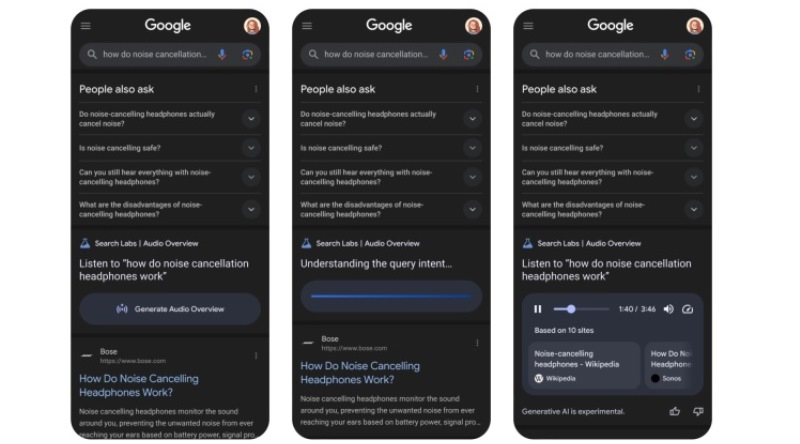
Источник изображения: Google При выполнении запроса, например: «Как работают наушники с шумоподавлением?», в разделе People also ask (аналог «Пользователи также интересуются») может появиться кнопка Generate Audio Overview. Нажатие запускает процесс генерации аудиофайла, в котором ИИ в формате разговора двух ведущих озвучивает краткий подкаст-обзор по теме. Генерация занимает в среднем 30–40 секунд. Аудиофайл встраивается прямо в выдачу поиска с помощью мини-плеера, позволяющего запускать и приостанавливать воспроизведение, настраивать скорость, отключать звук. Под плеером отображаются ссылки на источники, использованные при генерации: страницы с релевантным контентом, статьи и другие открытые материалы. Функция работает на базе языковой модели Gemini, ранее представленной как универсальная мультимодальная платформа для генерации текстов, изображений и аудио. Audio Overviews — продолжение интеграции этой модели в поисковые продукты Google. Ранее аналогичная функция была реализована в NotebookLM (генерация аудиосводок по пользовательским документам) и в рамках проекта Daily Listen, где ИИ формирует персонализированные новостные аудиосводки. Тестирование Audio Overviews проводится в рамках инициативы Search Labs и пока доступно только пользователям из США, выбравшим английский язык. На YouTube появится поиск объектов из коротких видео Shorts
30.05.2025 [12:56],
Павел Котов
На YouTube появится поддержка визуального поиска с «Google Объективом» в разделе Shorts. Бета-версию новой функции запустят в ближайшие недели — можно будет находить информацию о животных, растениях и предметах, попавших в кадр на коротких видео. 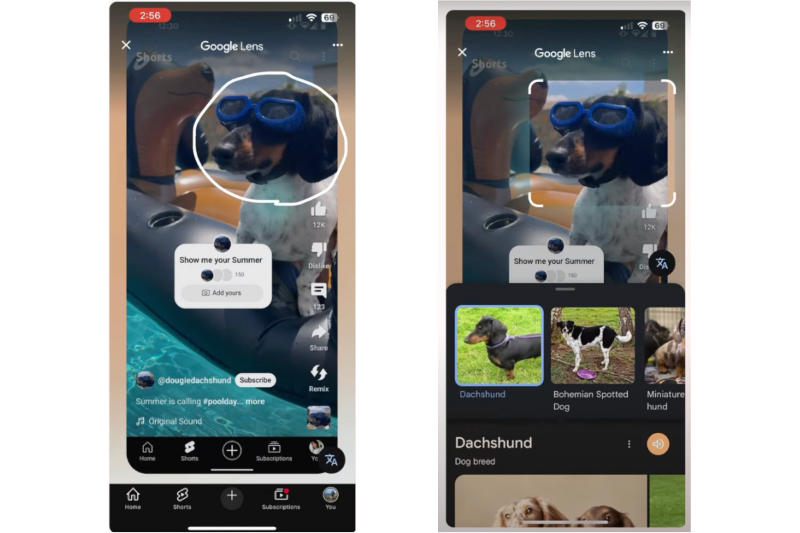
Источник изображения: youtube.com/@creatorinsider При просмотре видео, на заднем плане которого находится некая достопримечательность, YouTube выедет подсказку, что для её поиска можно воспользоваться «Объективом» и больше узнать о том, где было снято видео. Доступ к функции откроется в разделе коротких видео мобильного приложения YouTube: поставив ролик на паузу, можно будет нажать кнопку «Объектива» в верхнем меню, а затем обвести, выделить или нажать на элемент, который нужно найти. Приложение покажет визуальные совпадения и результаты поиска прямо поверх короткого видео. Выбрав один из результатов, можно будет «быстро вернуться к материалу, который вы смотрели». Google в последние месяцы начала расширять присутствие «Объектива» — он позволяет искать по видео и помогает разобраться, что купить в магазине. В случае YouTube «Объектив» будет работать без «биометрического распознавания лиц» для идентификации конкретных людей, но сможет выводить результаты для «известных общественных деятелей». На этапе пилотного проекта реклама в результатах поиска показываться не станет; партнёрских ссылок на покупки на начальном этапе тоже не будет. «Яндекс» тестируют функцию покупок в поиске без необходимости переходить в магазины
28.05.2025 [08:14],
Владимир Фетисов
«Яндекс» проводит закрытый эксперимент, в рамках которого тестируется кнопка чекаута в поисковике компании. Цель тестирования в проверке работоспособности функции, позволяющей пользователям оформлять заказы на товары в магазинах партнёров непосредственно из поисковой выдачи без необходимости переходить на сторонние сайты. Об этом пишет Forbes со ссылкой на источники в компании. 
Источник изображения: John / Unsplash В сообщении сказано, что при выборе товара в поисковике система будет перенаправлять пользователя в частично заполненную форму с данными для доставки, ПВЗ, платёжной информацией и возможностью оформить рассрочку. Конфиденциальная информация, включая данные банковских карт, защищается в «Яндекс ID». Компания также готова гарантировать безопасность покупок на онлайн-площадках, которые будут подключены к этой программе. На данном этапе механизм чекаута интегрируется через платформу «Яндекс Маркет» или специальные модули CMS (систем управления сайтом). В компании ссылаются на данные Tinkoff eCommerce, которые указывают на то, что до 70 % пользователей покидаю онлайн-корзину, не завершая покупки. В «Яндексе» считают, что прямой чекаут может снизить этот показатель, а также повысить конверсию и общий объём заказов. Аналитики «Яндекса» опросили 1289 россиян в возрасте от 18 до 64 лет, проживающих в городах с населением более 100 тыс. человек. В результате было установлено, что 59 % респондентов хотели бы иметь возможность быстрого оформления заказа без регистрации на сайте продавца. В дополнение к этому «Яндекс» намерен запустить индикатор ценовой прозрачности «ОК-цена». Он будет отображать, насколько цена того или иного товара соответствует рыночной. Данный инструмент анализирует стоимость аналогичных предложений, помогая пользователям убедиться в адекватности цен на интересующие их товары. «Яндекс» запустил «Вертикали Поиска» — теперь искать в интернете можно сразу по объектам
22.05.2025 [18:24],
Владимир Фетисов
В «Яндекс Поиске» появилась возможность осуществлять поиск по объектам: предложениям товаров, квартир или финансовых продуктов. Такие предложения собраны в «Вертикалях Поиска», где пользователям будет удобно ориентироваться, сравнивать и выбирать наиболее подходящие варианты. В дополнение к этому реализована возможность начать оформление услуги прямо в поиске. 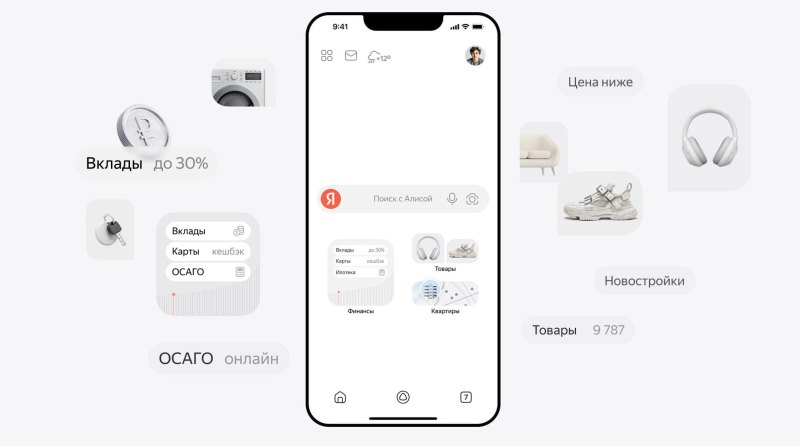
Источник изображений: «Яндекс» Чтобы ускорить процесс начала взаимодействия с «Вертикалями Поиска», разработчики обновили главную страницу мобильного приложения «Яндекс с Алисой». Теперь там появились кнопки «Квартиры», «Финансы» и «Товары». В дополнение к этому алгоритмы поисковика могут определить, когда пользователь выбирает какой-то товар или собирается что-то приобрести. В этот момент на экран выводятся тематические блоки с релевантными предложениями товаров и финансовыми продуктами. 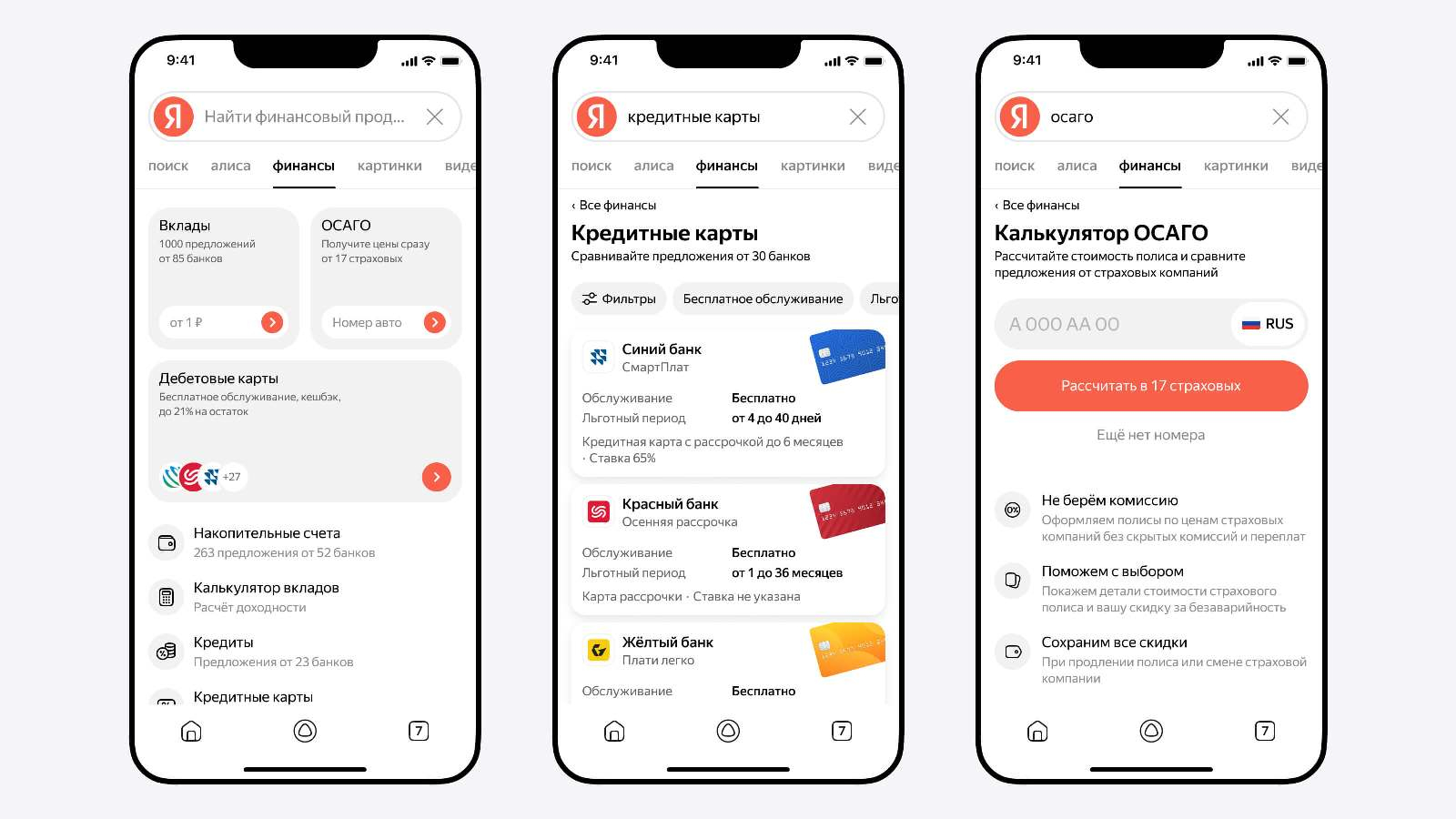 В разделе «Финансы» пользователи могут находить, сравнивать и следить за актуальными предложениями от банков, а также финансовых и страховых компаний. Такая информация может пригодиться при выборе вклада, дебетовой или кредитной карты, страховки, ипотеки и др. Для сравнения и подбора оптимальных вариантов предлагается задействовать фильтры. Полис ОСАГО стал первой из доступных услуг, начать оформление которой можно прямо в поиске. В дальнейшем количество таких продуктов будет увеличиваться. 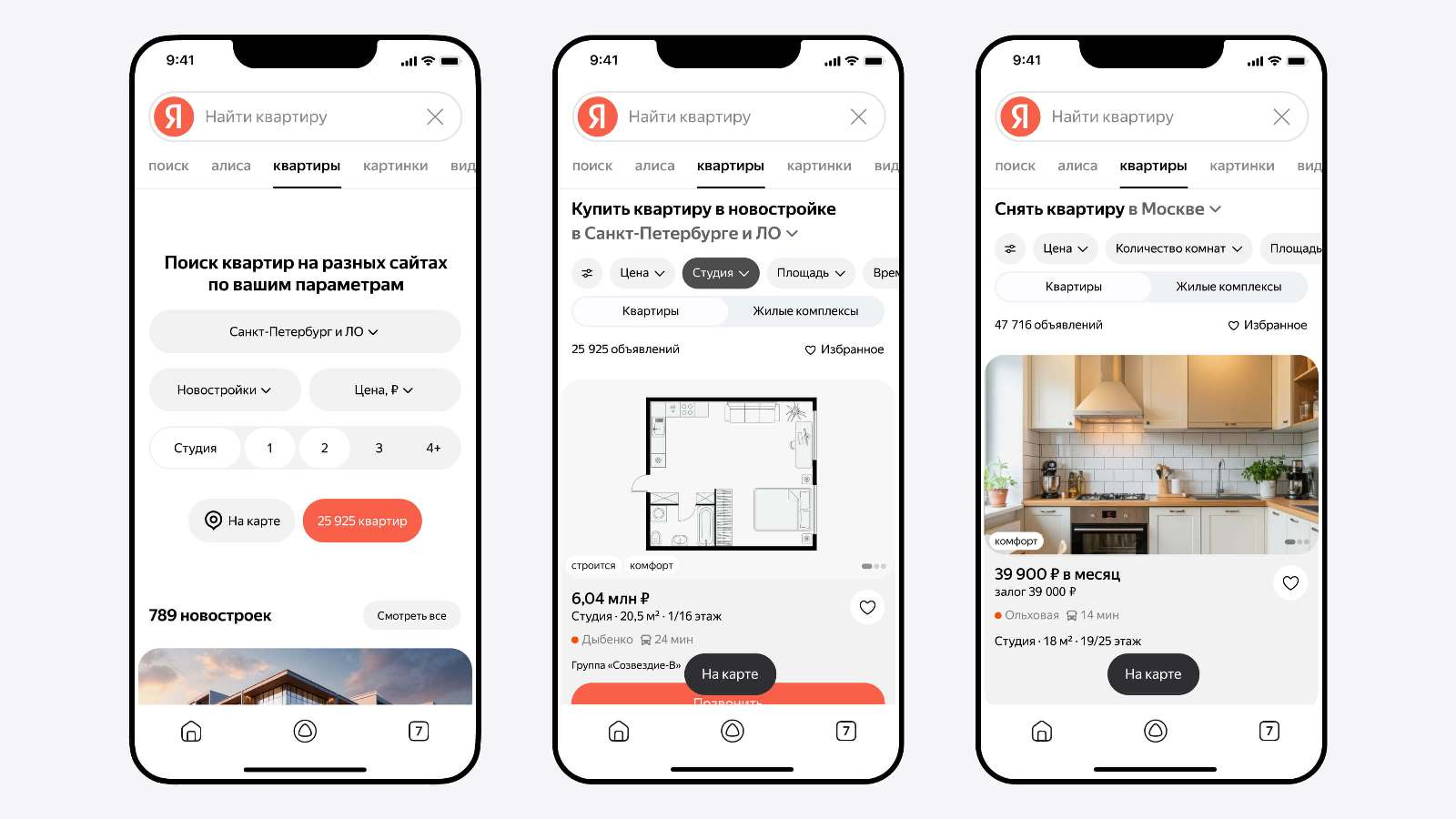 С помощью раздела «Квартиры» можно подобрать подходящие предложения по покупке и аренде недвижимости, как в новостройках, так и на вторичном рынке. Подбираются актуальные объявления с разных площадок, включая сайты застройщиков. Объявления с одинаковыми объектами объединяются в карточки, что позволяет видеть вариант с лучшей ценой. Поддерживаются фильтры, включая ценовой, по местоположению, количеству комнат и др. Отложить понравившиеся варианты можно в «Избранное», чтобы возобновить работу с ними, когда будет удобно. 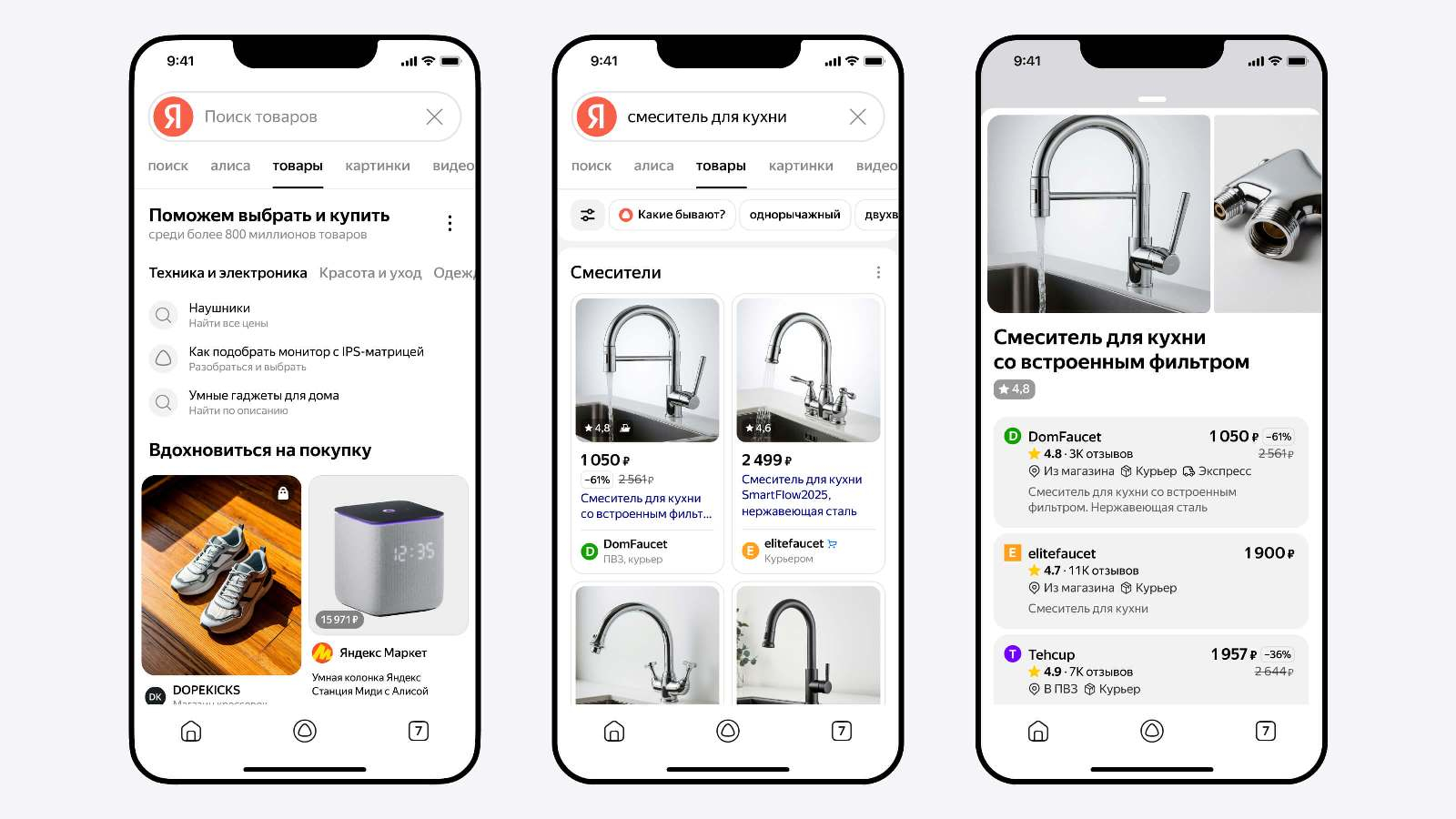 В разделе «Товары» открывается доступ к ассортименту предложений со всего Рунета. Для поиска наиболее подходящих предложений можно использовать подсказки, которые дают алгоритмы на базе искусственного интеллекта. Сервис анализирует множество предложений по каждому товару на онлайн-площадках и в маркетплейсах, объединяя одинаковые позиции в карточки. Благодаря этому не составит труда найти самое выгодное предложение. Помочь определиться с выбором может и виртуальный помощник «Алиса». На данный момент при поиске бытовой техники, электроники и товаров для ремонта пользователь может нажать кнопку «Какие бывают?», чтобы «Алиса» рассказала о характеристиках и других нюансах, которые следует учитывать при покупке того или иного товара. В дополнение к этому есть персонализированная лента, в которую попадают товары на основе интересов пользователя. Поисковик «Яндекса» теперь может рассуждать и генерировать тексты и изображения с помощью «Алисы»
22.05.2025 [17:11],
Павел Котов
Вместо появившемуся в прошлом году «Поиску с Нейро» в поисковой машине «Яндекса» теперь работает специальная версия «Алисы» — помощника с искусственным интеллектом. Она даёт пользователю в качестве ответа небольшую статью — полноценный структурированный текст, у которого есть подзаголовки, а также иллюстрации в формате изображений и видео. 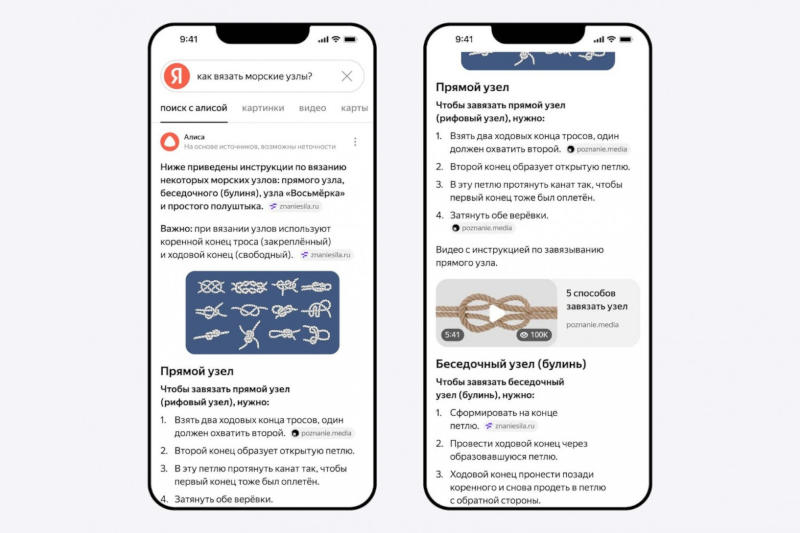
Источник изображений: «Яндекс» Также в «Поиске» появился режим рассуждений, который помогает глубже анализировать сложные вопросы — например, рассчитать стоимость строительства двухэтажного дома и составить смету. В таком режиме «Алиса» использует больше источников, проводит более детальный анализ и может представить данные в виде таблиц или наглядных сравнений. Пользователь также может проследить ход её рассуждений. Чтобы включить режим, нужно нажать кнопку «Рассуждать» под ответом. 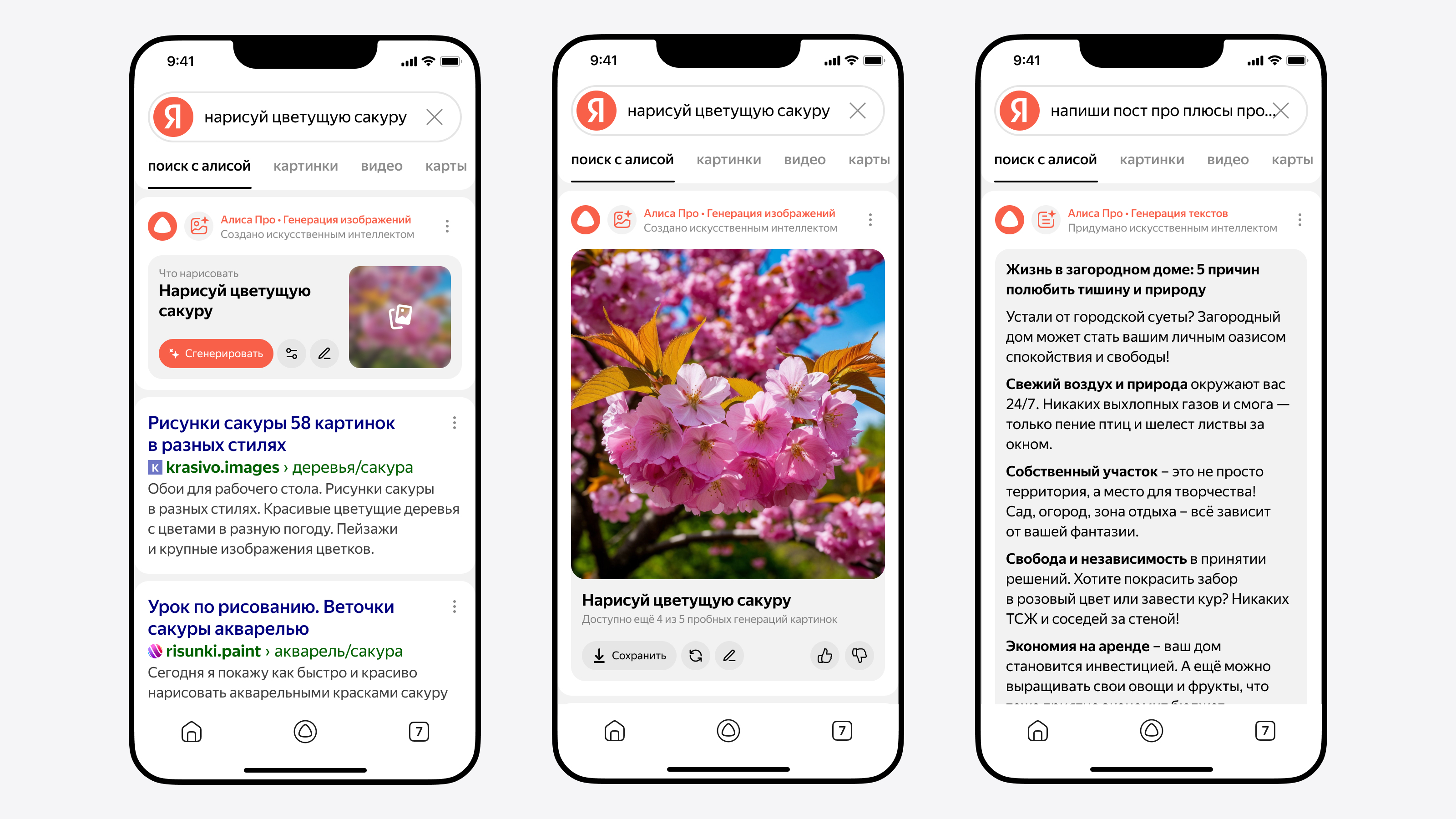 Ещё «Алиса» теперь умеет создавать тексты и изображения прямо в «Поиске». Можно попросить её придумать заголовок, поздравление или иллюстрацию для презентации — достаточно сформулировать запрос, например: «Напиши пост о плюсах загородной жизни». 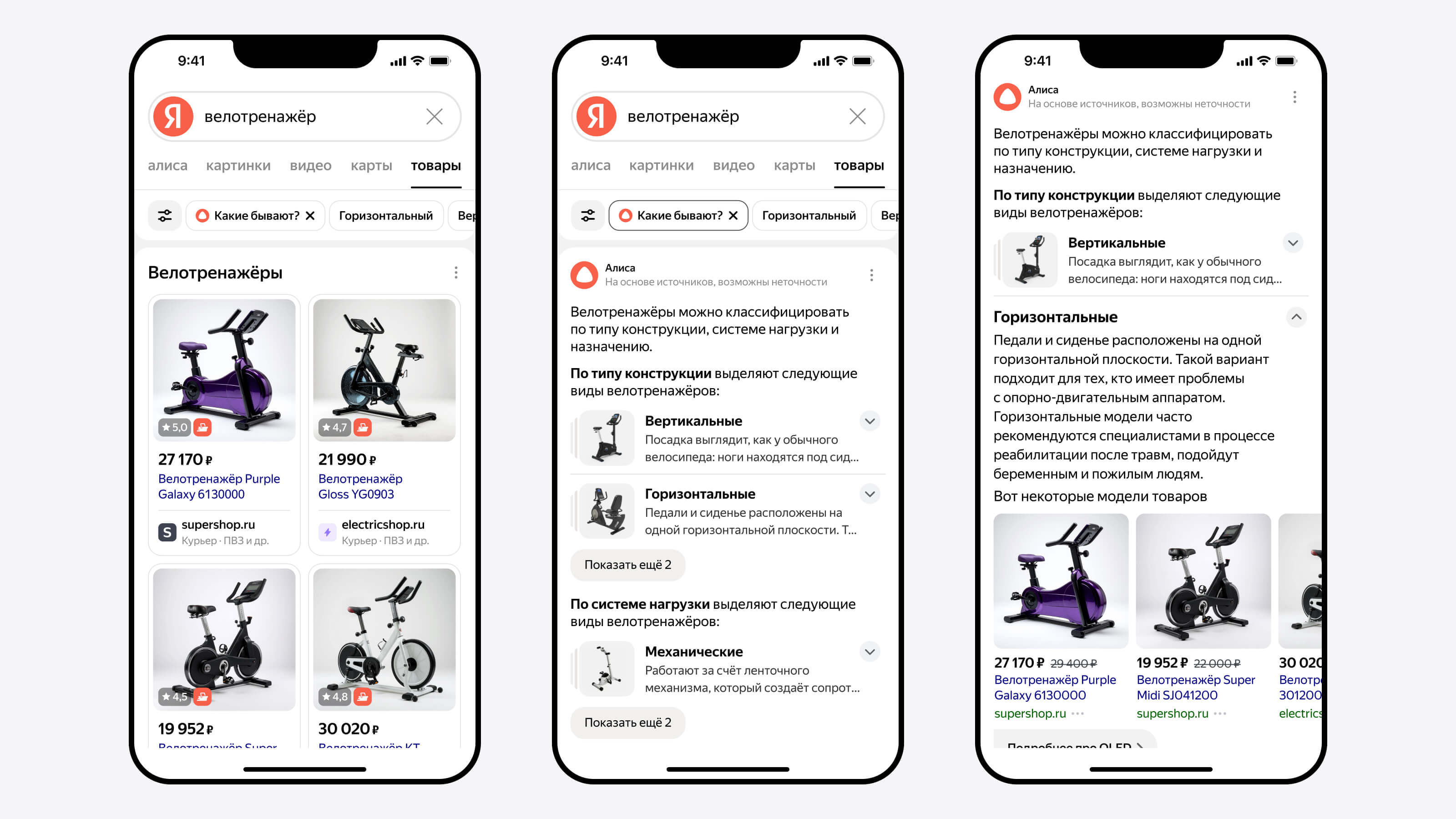 «Алиса» поможет сориентироваться при покупке бытовой техники, электроники и товаров для дома. Она объяснит ключевые характеристики и области применения. Чтобы получить советы, нужно нажать «Какие бывают» под поисковой строкой. Например, интересует велотренажёр — «Алиса» расскажет про типы конструкции и нагрузки. 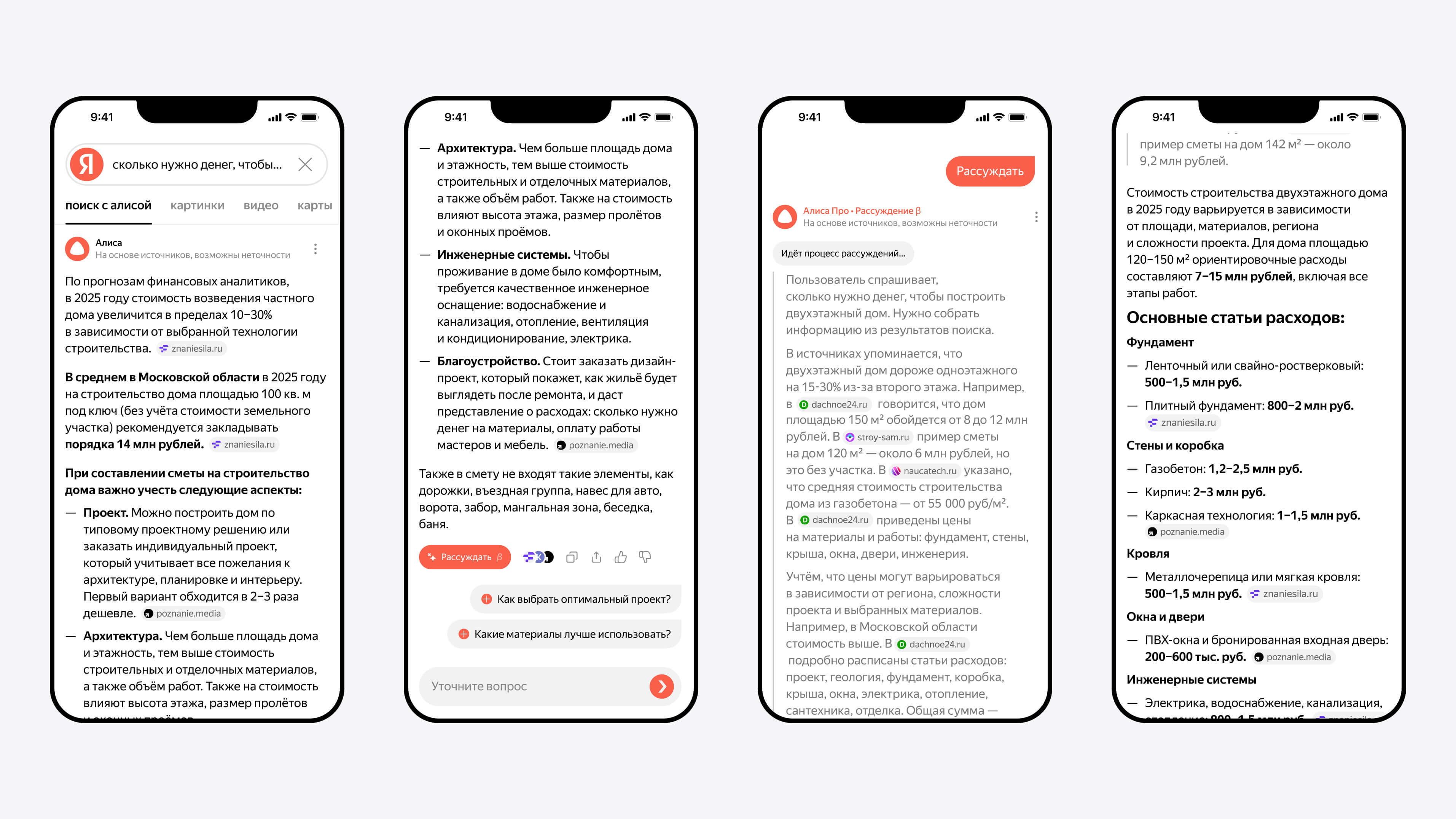 Все пользователи могут попробовать рассуждения и генерацию изображений, но с ограничением по числу запросов. Подписка «Алиса Про» снимает эти ограничения и включает доступ к самой мощной нейросети «Яндекса» — YandexGPT 5 Pro. Также теперь «Алиса» сможет помогать не только в «Поиске», но и на любых сайтах, просматриваемых через «Яндекс Браузер». Функция уже работает на ПК и скоро появится в мобильной версии. Автономная версия «Нейро», представленная чуть более года назад, работала на базе двух моделей ИИ. Первая, нейросетевая модель-рефазер, обрабатывала вопрос пользователя и производила несколько запросов к поисковой машине. Вторая, модель-генератор, изучала тексты всех страниц из выдачи и формулировала на их основе ответ. Схема оказалась востребованной среди пользователей, но в «Яндексе» остались не удовлетворены качеством ответов на некоторые сложные вопросы. Поэтому в новом воплощении ИИ-поиска была в корне переработана архитектура сервиса. Модель-рефазер заменили на модель-планер — она выстраивает по выдаче структуру будущего ответа и направляет запросы также в разделы поиска по картинкам и видео; эта модель не только обращается к собственной памяти, но и дополнительно обучается на документах из выдачи. В качестве модели-генератора использовали нейросеть новейшего семейства YandexGPT 5, которая прошла дополнительное обучение под задачи анализа информации и подготовки сводок. Её отличает более длинное контекстное окно, а также способность работать с разными форматами: текстом, изображениями и видео. На выходе получается связный и подробный структурированный ответ, обогащённый иллюстрациями и ссылками, чтобы пользователь мог более подробно изучить интересующий его вопрос. Модель-планер обучили определять, каким должен быть ответ на вопросы по разным темам — для этого ей предоставили наборы данных с упором на запросы повышенной сложности, при работе с которыми требуется извлекать и структурировать только нужную информацию. После основного обучения осуществлялось дополнительное — SFT (Supervised Fine-Tuning), а затем обучение с подкреплением, в котором использовались различные методы: CE RL (Cross-Entropy Reinforcement Learning) — генерация нескольких вариантов ответа и выбор лучшего на основе оценки; DPO (Direct Preference Optimization) — выбор лучшего ответа из нескольких, исходя из предпочтений человека; и GRPO (Generalized Reinforcement Preference Optimization) — выбор оптимального ответа с учётом улучшенного понимания контекста и нюансов человеческих предпочтений или усовершенствованный DPO. При обучении модели-генератора разработчики оптимизировали работу reward-моделей, которые оценивают качество обучаемой — их число довели до 16. Чтобы избежать перекоса генератора в сторону одной из этих моделей вознаграждений, использовали динамические веса на основе знаний о запросах, источниках и плане ответа и провели несколько стадий обучения с подкреплением. В итоге, подчеркнули в «Яндексе», качество обновлённого ИИ-поиска выросло на 79 % по сравнению с предыдущей версией — сказались более наглядная структура ответа, иллюстрации в виде картинок и видео, а также большее число подробностей в самом тексте. Microsoft представила NLWeb — открытый протокол для внедрения ИИ-поиска на сайты
21.05.2025 [06:51],
Вячеслав Ким
На конференции Build 2025 корпорация Microsoft анонсировала NLWeb — открытый протокол, позволяющий владельцам сайтов и приложений легко интегрировать поиск на основе искусственного интеллекта. Разработанный техническим директором Microsoft Раманатаном В. Гухой (Ramanathan V. Guha), NLWeb призван децентрализовать ИИ-взаимодействие в интернете, предоставляя разработчикам возможность создавать собственные чат-боты с использованием выбранных моделей ИИ и собственных данных. 
Источник изображения: Microsoft NLWeb предоставляет простой способ добавления функций взаимодействия в стиле ChatGPT на любой сайт или приложение. С помощью нескольких строк кода, выбранной модели ИИ и предоставленных данных можно создать кастомизированного чат-бота за считанные минуты. Протокол позволяет задавать вопросы на естественном языке и получать структурированные ответы, облегчая интеграцию ИИ-функций без необходимости в сложной инфраструктуре. В рамках презентации на конференции Build 2025 Гуха продемонстрировал, как NLWeb может быть использован на различных платформах, включая кулинарный сайт Serious Eats и ресурс розничного продавца одежды для активного отдыха. В обоих случаях ИИ-поиск учитывал предпочтения пользователя и предоставлял релевантные результаты, такие как вегетарианские блюда для праздника Дивали или подходящие куртки для холодного климата Квебека. Microsoft уже сотрудничает с компаниями, такими как TripAdvisor, Eventbrite и Shopify, для внедрения NLWeb, стремясь расширить его применение среди различных веб-ресурсов. Протокол также поддерживает Model Context Protocol (MCP), разработанный компанией Anthropic, что позволяет сайтам делать свой контент доступным для ИИ-агентов и других участников экосистемы MCP. Раманатан В. Гуха, известный своими работами над RSS, RDF и Schema.org, присоединился к Microsoft в 2024 году после почти двух десятилетий работы в Google. Его цель — предоставить разработчикам инструменты для создания более открытого и доступного интернета, где ИИ-взаимодействие не ограничивается крупными платформами, а становится доступным для всех участников веб-пространства. ИИ-поиск появился в приложениях Google для Android и iOS, но доступен пока не всем
17.05.2025 [11:48],
Павел Котов
Режим поиска с искусственным интеллектом стал доступен всем американским пользователям, участвующим в программе тестирования приложения Google на Android и iOS — конфигурация значков в области поисковой строки претерпела радикальные изменения, обратил внимание ресурс 9to5Google. 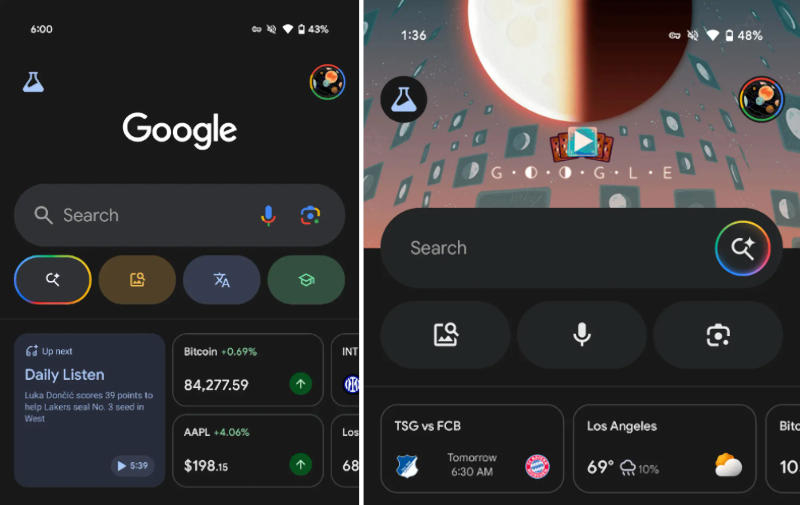
Старый (слева) и новый (справа) варианты поискового приложения Google. Источник изображений: 9to5google.com Значок запуска режима ИИ (AI Mode) переместился в правый край поисковой строки, заменив ранее размещённые там иконку микрофона для голосового поиска и ярлык «Google Объектива». Кнопка режима ИИ выполнена в виде увеличительного стекла с четырёхконечной звездой — логотипом Gemini. По периметру иконка окружена вращающимся кольцом с градиентными цветами Google. Оно напоминает обновлённый логотип компании в виде буквы «G», но не идентично ему. Анимация демонстрируется постоянно, а кнопка запуска остаётся на экране при прокрутке блока «Рекомендации». 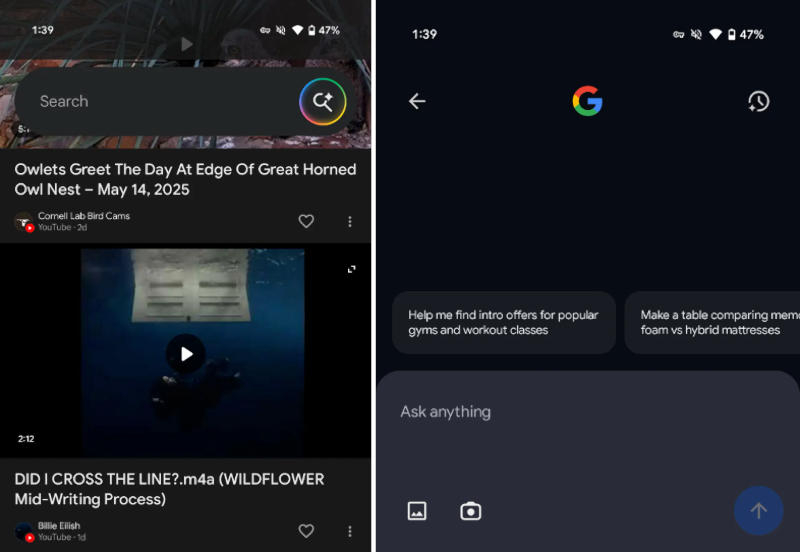 В рамках этих изменений радикальной перестройке подверглась и многоцветная карусель кнопок под поисковой строкой — она остаётся доступной только для тех, кто не участвует в программе тестирования. «Поиск по фотографиям» сохранился на своём месте, а вот «Перевод», «Домашнее задание» и звуковой поиск исчезли. Их заменили голосовой ввод и «Google Объектив», но уже без разноцветной стилистики. Google начала тестирование обновлённого интерфейса в апреле, в начале мая он появился в версии приложения для iOS, и теперь с ним может ознакомиться более широкая аудитория. Обновлённый вид приложения стал дополнением к режиму ИИ — фильтру, который прежде появился на странице поисковой выдачи. Ранее режим ИИ дебютировал в поисковом виджете Google. Google обновила дизайн поискового виджета на Android
09.05.2025 [12:07],
Владимир Фетисов
Компания Google изменила дизайн виджета панели поиска, который можно увидеть на домашнем экране устройств на базе Android. Прежде строка поискового виджета с закруглёнными краями содержала логотип в виде буквы «G» слева, а также ярлыки для активации микрофона и функции Google Lens справа. В новом дизайне добавился ярлык ИИ-функции Circle to Search, на котором сделан особый акцент. 
Источник изображения: Solen Feyissa/unsplash.com В целом же панель стала чуть шире, что соответствует концепции дизайна Material 3 Expressive, который стал основой будущей версии Android. Главное изменение заключается в появлении нового ярлыка и в том, что он выделен внутри отдельной от других ярлыков круглой области. 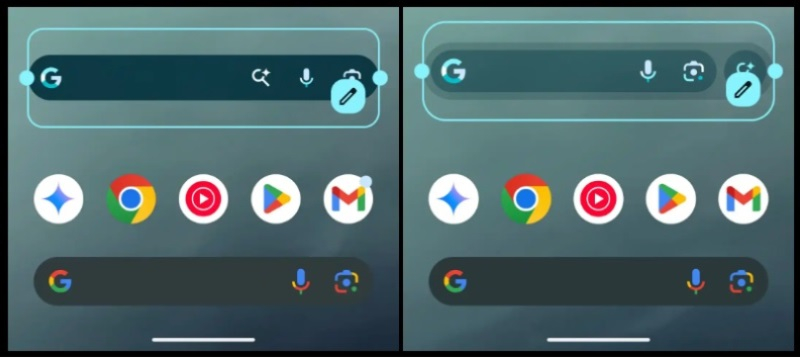
Источник изображения: 9to5google.com Пользователи могут задействовать функцию Circle to Search для выполнения разных задач, активировать ИИ-поиск AI Mode, выполнять перевод текстов, искать музыкальные композиции, просматривать актуальные погодные данные, использовать опцию перевод через камеру устройства и др. 
Источник изображения: 9to5google.com Минимальная ширина виджета, при которой он отображает все элементы, составляет 4×1, а не 3×1, как прежде. Сильнее всего внешний облик виджета меняется при изменении уровня его прозрачности. В настоящее время обновлённый дизайн виджета доступен в приложении Google 16.17, бета-версия которого стала доступна недавно. Очевидно, более широкое распространение виджет получит после завершения этапа тестирования. Google открыла доступ к интерактивному ИИ-поисковику, который станет ответом на SearchGPT и Perplexity AI
01.05.2025 [23:07],
Владимир Фетисов
Ранее в этом году Google анонсировала скорое появление AI Mode — поискового чат-бота на базе технологий искусственного интеллекта, который интегрирован в фирменное приложение компании. Теперь же было объявлено, что «небольшой процент» людей в США начнёт видеть вкладку AI Mode в поисковике Google «в ближайшие недели», благодаря чему они смогут протестировать этот инструмент в деле. 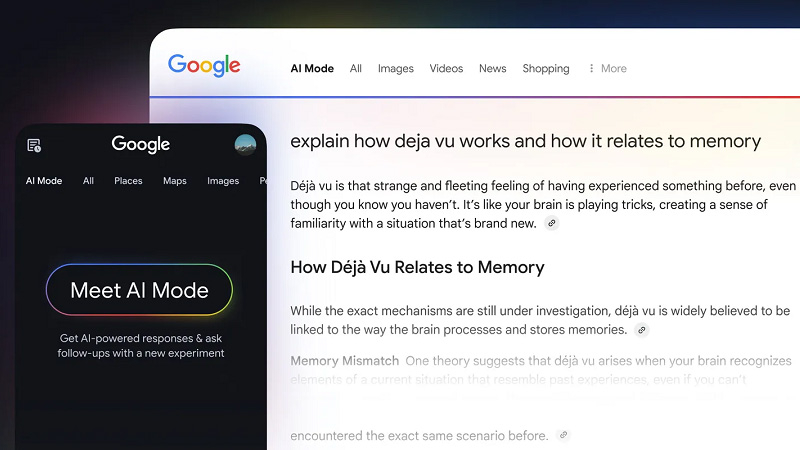 Источник изображения: Google Традиционные поисковые системы предоставляют список ссылок в ответ на пользовательские запросы. В отличие от этого AI Mode выдаёт ответы, сгенерированные нейросетью на основе найденной в поисковом индексе информации. Новый режим поиска также отличается от запущенных ранее ИИ-сводок, которые создаются генеративной нейросетью и выводятся в поисковике перед ссылками на сайты с искомой информацией. AI Mode представляет собой отдельную вкладку в интерфейсе поиска Google, расположенную рядом с традиционными разделами, такими как «Все», «Картинки» и «Видео». В отличие от стандартных результатов поиска, AI Mode предлагает ответы, сгенерированные искусственным интеллектом, на основе индекса поиска Google. Пользователи могут задавать сложные, многосоставные вопросы и получать подробные, контекстуализированные ответы, а также задавать уточняющие вопросы для более глубокого изучения темы. Новая функция также включает визуальные карточки с информацией о продуктах и местах, отображающиеся в правой части экрана, предоставляя ключевые данные, такие как часы работы, отзывы и цены. Кроме того, в левой части интерфейса доступна история предыдущих поисков, что облегчает навигацию и возвращение к ранее изученным темам. AI Mode интегрирует возможности модели Gemini AI, обеспечивая более продвинутые функции, включая обработку изображений и голосовых запросов, а также поддержку мультимодальных взаимодействий. Это делает AI Mode конкурентом другим инструментам поиска, основанным на искусственном интеллекте, таким как Perplexity и ChatGPT. Желающие протестировать новый инструмент пользователи могут самостоятельно активировать AI Mode через Google Labs и использовать его как на настольных компьютерах, так и на мобильных устройствах через приложение Google. Google планирует продолжить расширение функциональности AI Mode, включая более визуальные ответы, улучшенное форматирование и новые способы получения полезного веб-контента. Доминирование Google пошатнулось — его доля на мировом рынке поиска скатилась ниже 90 % впервые за десять лет
30.04.2025 [13:05],
Павел Котов
По итогам марта 2025 года доля Google на мировом поисковом рынке упала ниже 90 %, обращает внимание немецкая веб-платформа Tuta.com. В последний раз подобное наблюдалось десять лет назад, и теперь эффект может оказаться долгосрочным. 
Источник изображения: Mitchell Luo / unsplash.com В марте 2025 года доля Google в мировом поисковом трафике составила 89,71 %, гласят данные Statcounter — этот показатель взял курс на снижение в октябре 2024 года. В последний раз интернет-гигант демонстрировал подобное падение в 2015 году. Просадка показателей Google в сегменте ПК оказалась ещё более значительной: в мае 2023 года она демонстрировала максимальное значение в 87,65 %, после чего пошла на спад, и в марте 2025 года доля компании установила антирекорд — 79,10 %. В европейском регионе дела у Google ещё хуже: 87,08 % в мае 2023-го и 77,78 % в марте 2025 года. Учитывая масштабы деятельности Google, каждый процентный пункт в статистике соответствует более чем 50 млн пользователей, и потери доли компании на поисковом рынке равнозначны тому, что от её сервисов отказываются десятки миллионов человек по всему миру. Есть мнение, что для пользователей интернета всё большее значение приобретает вопрос конфиденциальности — немецкая поисковая служба Ecosia сообщила о росте аудитории на 250 % с конца 2024 года. В прошлом году федеральный суд США официально признал Google монополистом в области поисковых систем. Незаконными были признаны действия компании, которая платила своим партнёрам, в том числе Apple и Mozilla, за выбор Google в своих продуктах как поисковой системы по умолчанию. Недовольны деятельностью американских технологических гигантов и европейские власти: Apple и Meta✴ были оштрафованы соответственно на €500 млн и €200 млн за невыполнение требований действующего в регионе «Закона о цифровых рынках»; есть версия, что на очереди — Google и соцсеть X. Microsoft наконец запустила для всех ИИ-функцию Recall, которая делает скриншоты всех действий пользователя на ПК
25.04.2025 [23:05],
Николай Хижняк
Спустя почти год после первого анонса компания Microsoft начала массовое развёртывание спорной функции Recall на компьютерах Copilot Plus PC. Функция является частью обновления для Windows 11, которое также включает предварительный просмотр ранее анонсированных функций Click to Do и обновлённого поиска Windows на базе ИИ. 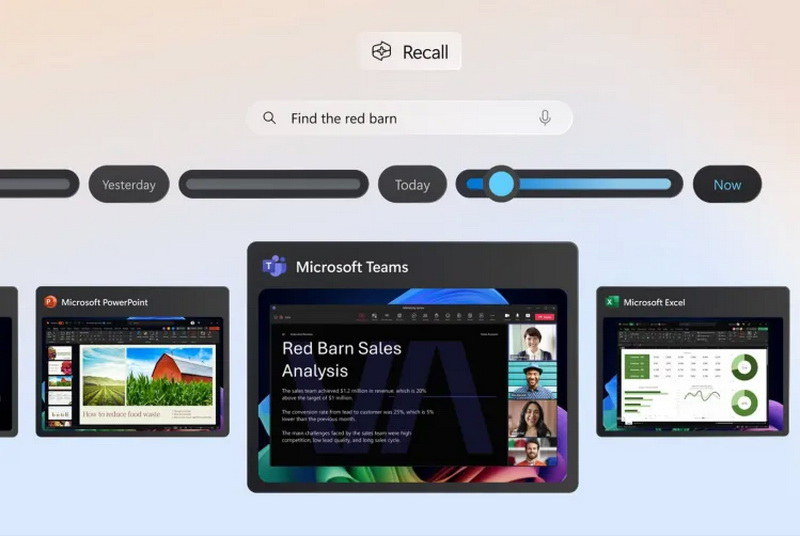
Источник изображений: Microsoft Microsoft сообщает, что апрельское обновление для Windows, не связанное с безопасностью, будет развёртываться постепенно. Те, кто хочет быть в числе первых, кто получит новые функции, могут в настройках «Центра обновления Windows» включить опцию «Получайте последние обновления, как только они будут доступны». После этого проверка обновлений должна позволить установить апрельский предварительный выпуск. И Recall, и Click to Do представлены как «предварительные возможности». Иными словами, их статус аналогичен открытой бета-версии Apple Intelligence для компьютеров Mac или «экспериментальным функциям», доступным для некоторых моделей ИИ Google Gemini. 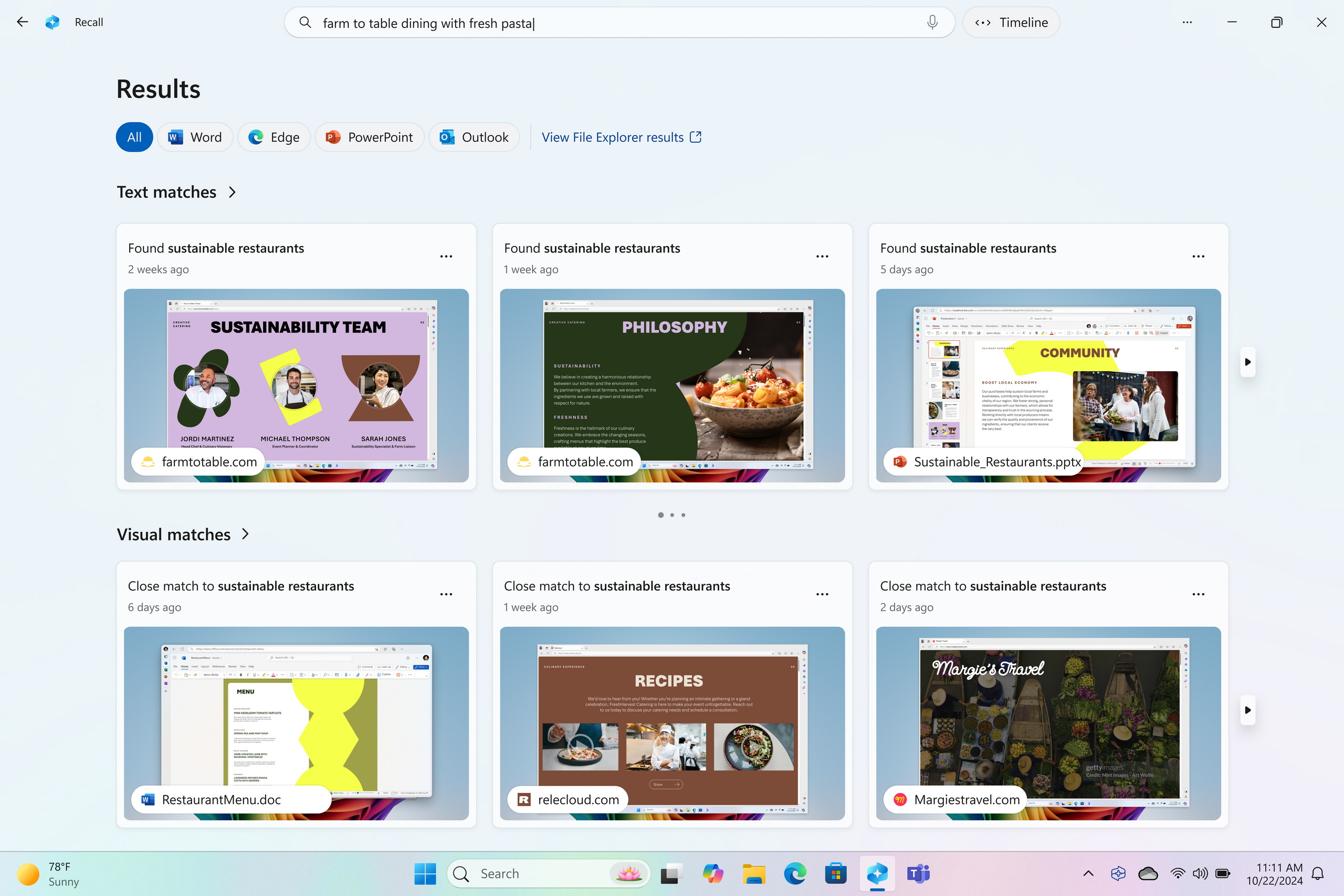 В рамках обновления наибольшее внимание привлекает функция Recall. Она разработана для того, чтобы пользователь имел быстрый доступ к информации, с которой он работал ранее. Функция с определённым интервалом делает снимки экрана и активностей пользователя на ПК, сохраняет их на локальном носителе (то есть на компьютере пользователя, а не в облаке) и использует эти данные для последующего поиска. 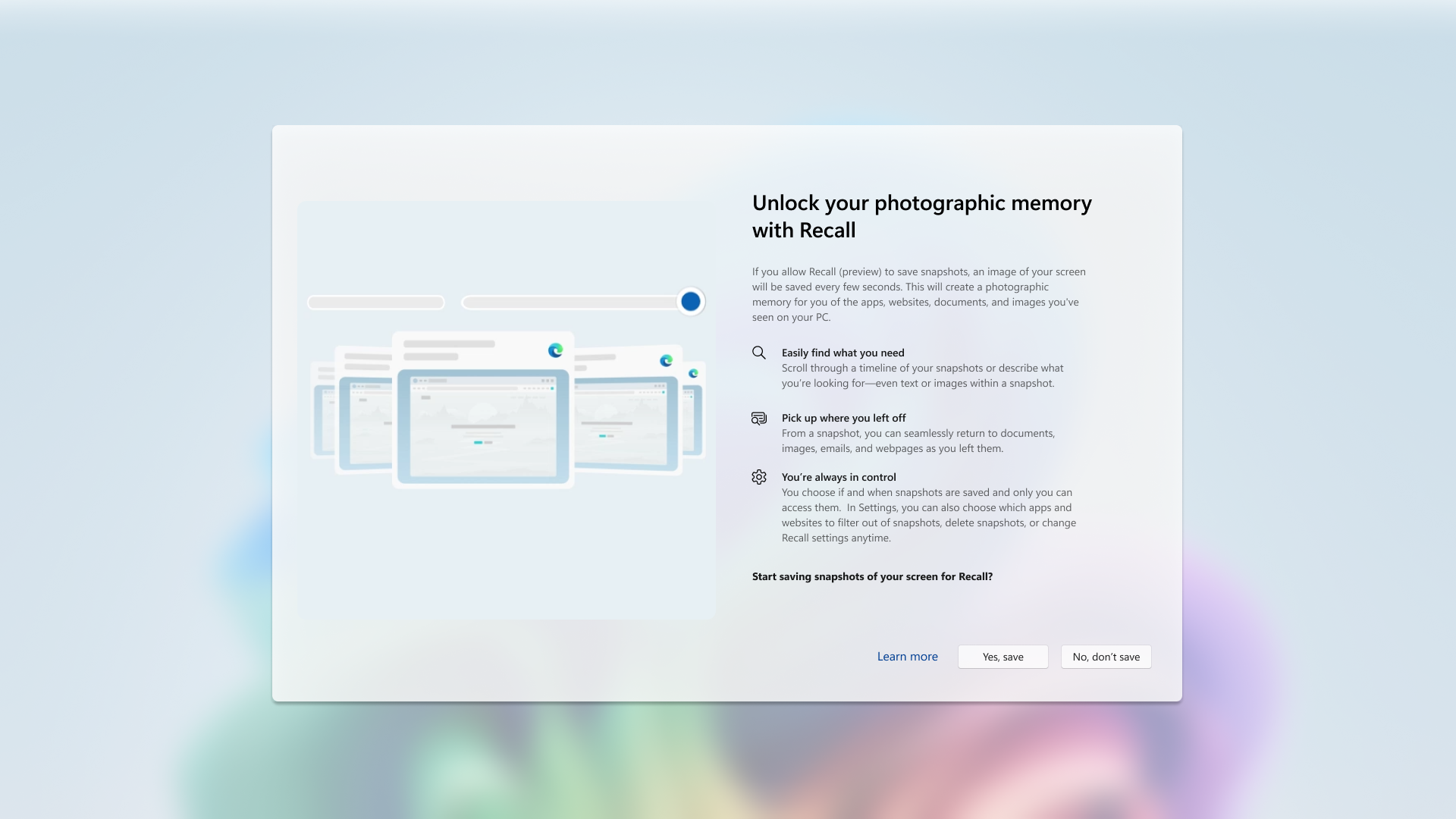 Устанавливать Recall необязательно — Microsoft сделала её полностью опциональной. Перед использованием функцию необходимо включить и настроить. Если этого не сделать, Recall не будет выполнять снимки экрана. Кроме того, Recall можно удалить со своего устройства через панель «Включение или отключение компонентов Windows» (найти её можно через поиск на панели задач). «При удалении любой функции Windows может сохранять временные копии неисполняемых двоичных файлов функции, которые со временем удаляются», — написал в блоге компании вице-президент Microsoft по Windows Experiences Навджот Вирк (Navjot Virk). 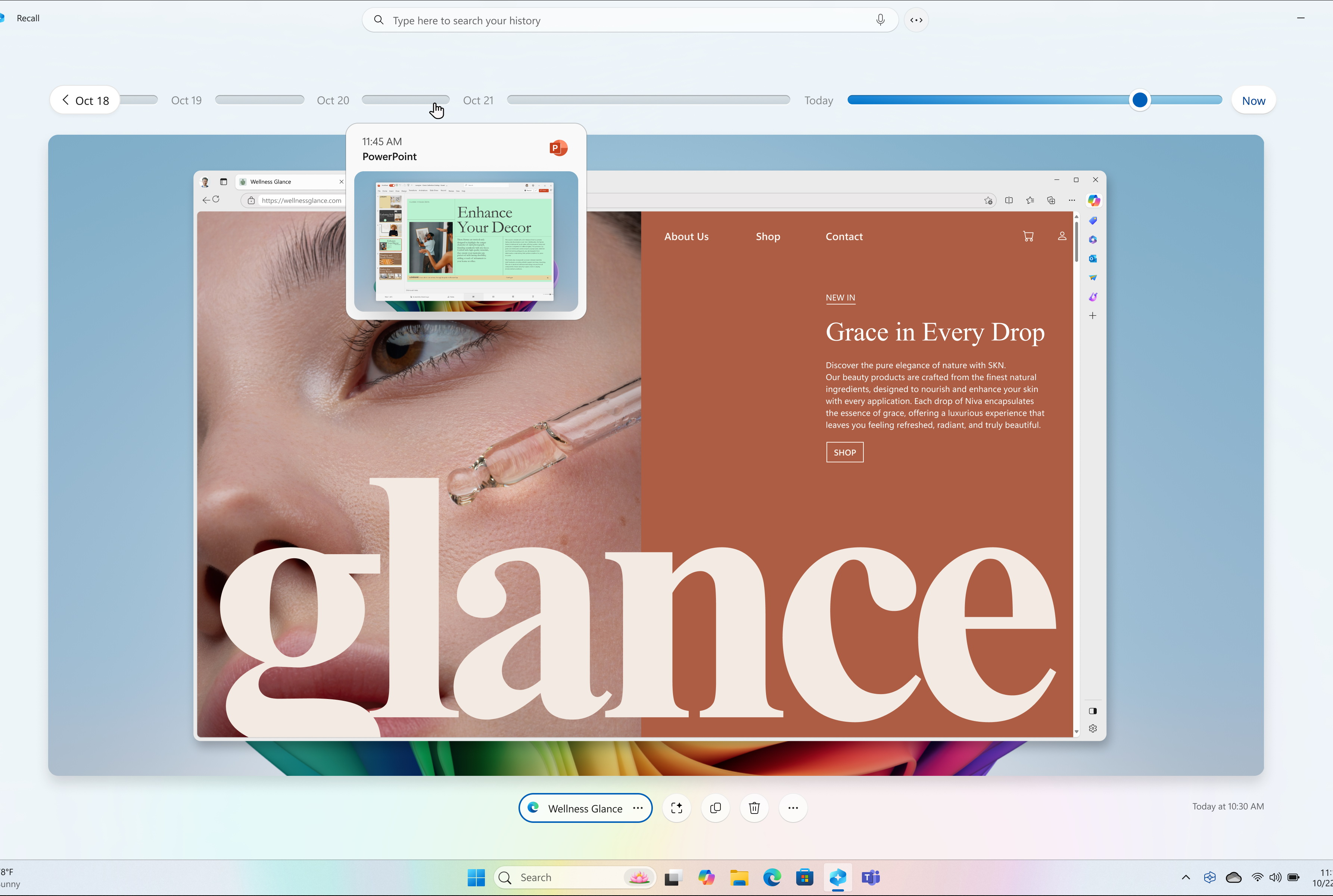 Recall вызвала жаркие споры среди пользователей с момента её первоначального анонса вместе с первыми ПК экосистемы Copilot Plus PC в мае 2024 года. Изначально она должна была стать частью Windows 11 уже в июне того же года, с началом продаж первых компьютеров Copilot Plus PC. Однако Microsoft несколько раз откладывала её выпуск после призывов экспертов по цифровой безопасности, утверждавших, что Recall может представлять риск для конфиденциальности данных пользователей. Как пишет Tom’s Hardware, знакомство с Recall в составе предварительных сборок ОС в рамках программы предварительной оценки обновлений Windows Insider показало, что функция сохраняет определённую конфиденциальную информацию, даже несмотря на наличие фильтров, предназначенных для предотвращения этого. С тех пор Microsoft усилила систему безопасности Recall, добавив шифрование снимков с помощью модуля Trusted Platform Module (TPM) ПК и авторизацию через Windows Hello для изменения настроек. Также появилась возможность добавлять в фильтры определённые приложения и веб-сайты, настраивать срок хранения снимков в Recall, а также удалять снимки, связанные с отдельными приложениями, веб-сайтами или временными диапазонами. 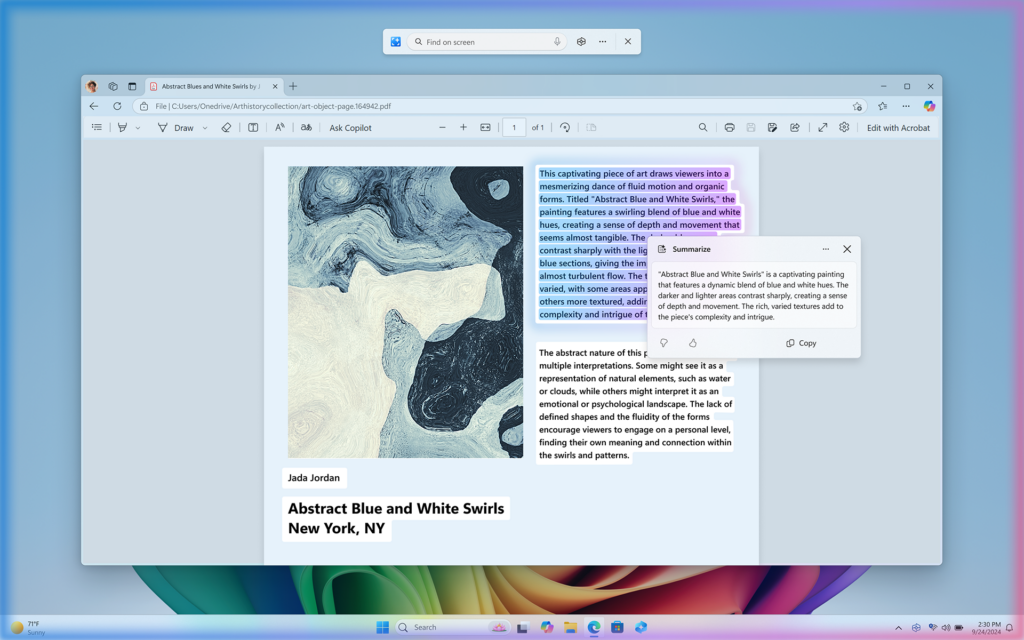 Функция Click to Do, выпущенная в качестве предварительной версии для участников программы Windows Insider прошлой осенью вместе с обновлением Windows 11 24H2, активируется комбинацией клавиш Windows + левая кнопка мыши (или свайпом вправо на сенсорном устройстве). Она открывает контекстное меню для соответствующих действий с использованием ИИ. Например, выделение текста и активация функции может предложить его резюмирование, а выбор изображения — возможность его редактирования или удаления. Действия с изображениями через Click to Do становятся доступны для всех ПК Copilot Plus PC с сегодняшнего дня. Функции работы с текстовыми файлами пока доступны только для устройств на базе процессоров Qualcomm Snapdragon. Поддержка систем с процессорами AMD Ryzen и Intel Core Ultra появится «в ближайшие месяцы», сообщает Microsoft. 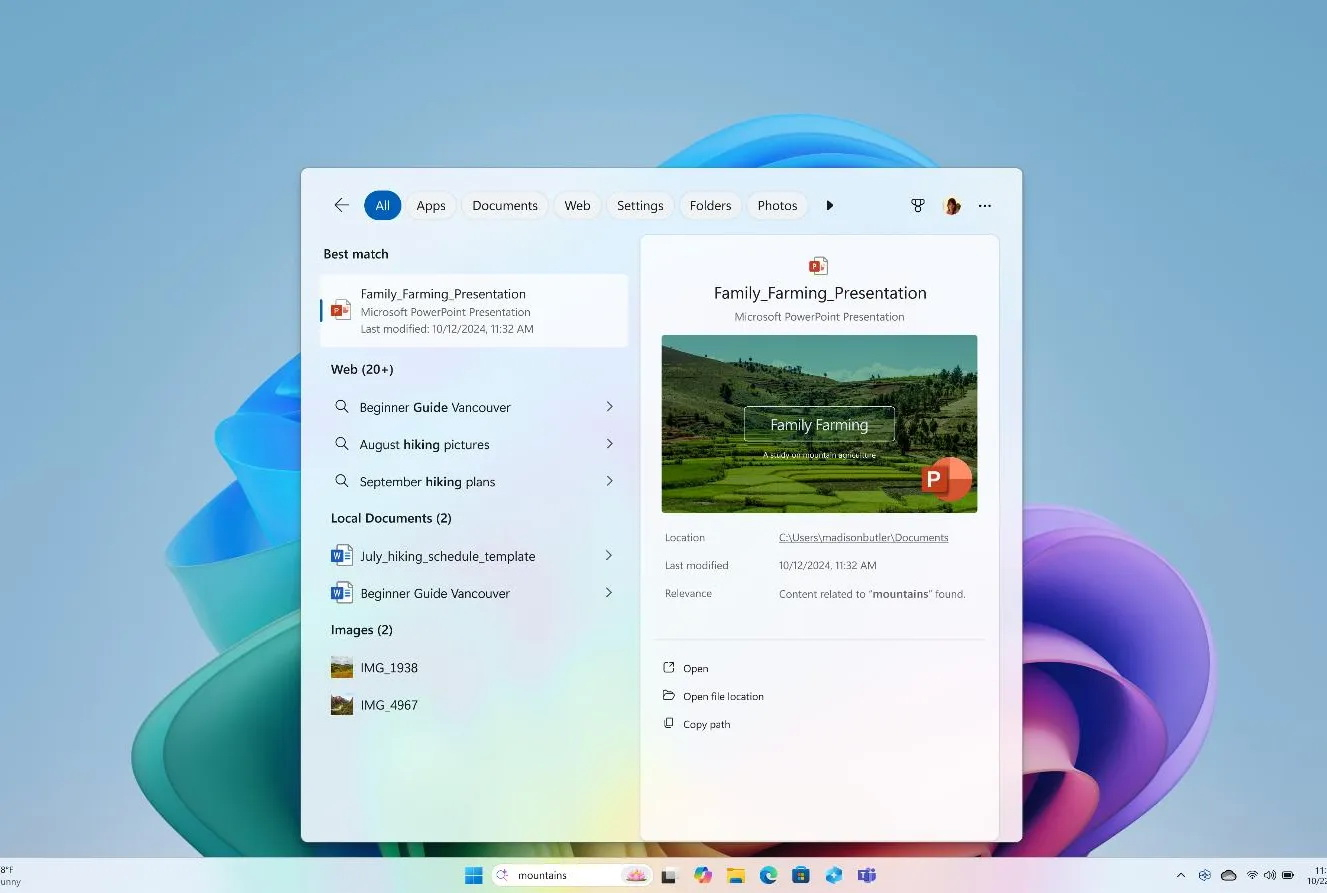 Времена, когда нужно было запоминать каждое имя того или иного файла, прошли. Улучшенный поиск Windows на ПК Copilot Plus PC теперь позволяет использовать естественный язык для описания того, что необходимо найти. Например, если вам нужен снимок «коричневой собаки», который вы сохранили где-то на своём компьютере, но не можете найти, — в поиске можно просто написать: «коричневая собака». Новая функция поиска будет встроена в существующее поле поиска Windows, а также в «Настройки» и «Проводник». Microsoft заявляет, что функция работает локально и требует наличия в составе Copilot Plus PC нейропроцессора (NPU) с производительностью от 40 TOPS и выше. «Нельзя дважды лизнуть барсука»: Google AI Overviews наделил смыслом абсурдные идиомы и вымышленные фразеологизмы
24.04.2025 [09:46],
Дмитрий Федоров
Функция AI Overviews, встроенная в поисковую систему Google и использующая генеративный ИИ (GenAI) для кратких ответов на запросы, уверенно интерпретирует вымышленные идиомы. Пользователи обнаружили, что достаточно ввести произвольную фразу и добавить слово «meaning» (англ. — значение), чтобы получить уверенное объяснение смысла этой фразы, независимо от её реальности. Система при этом не только интерпретирует бессмысленные конструкции как устойчивые выражения, но и указывает предполагаемое происхождение, иногда даже снабжая ответ гиперссылками, усиливающими эффект достоверности. 
Источник изображения: Shutter Speed / Unsplash В результате в интернете начали появляться примеры очевидных вымыслов, обработанных AI Overviews как подлинные фразеологизмы. Так, фраза «a loose dog won’t surf» (англ. — свободная собака не будет сёрфить) была истолкована как «шутливый способ выразить сомнение в осуществимости какого-либо события». Конструкция «wired is as wired does» (англ. — проводной — это то, что делают провода) ИИ объяснил как высказывание о том, что поведение человека определяется его природой, подобно тому как функции компьютера зависят от его схем. Даже фраза «never throw a poodle at a pig» (англ. — никогда не бросайте пуделя на свинью) была описана как пословица с библейским происхождением. Все эти объяснения звучали правдоподобно и были изложены AI Overviews с полной уверенностью. На странице AI Overviews внизу размещено уведомление о том, что в её основе используется «экспериментальный» генеративный ИИ. Такие ИИ-модели представляют собой вероятностные алгоритмы, в которых каждое последующее слово выбирается на основе максимально возможной предсказуемости, опираясь на данные обучения. Это позволяет создавать связные тексты, но не гарантирует фактологическую точность. Именно поэтому система оказывается способной логично объяснить, что могла бы означать фраза, даже если она лишена реального смысла. Однако это свойство приводит к созданию правдоподобных, но полностью вымышленных интерпретаций. Как пояснил Цзян Сяо (Ziang Xiao), специалист в области компьютерных наук из Университета Джонса Хопкинса (JHU), предсказание слов в таких ИИ-моделях строится исключительно на статистике. Однако даже логически уместное слово не гарантирует достоверности ответа. Кроме того, генеративные ИИ-модели, по данным научных наблюдений, склонны угождать пользователю, адаптируя ответы к предполагаемым ожиданиям. Если система «видит» в запросе указание на то, что фраза вроде «you can’t lick a badger twice» (англ. — нельзя дважды лизнуть барсука) должна быть осмысленной, она интерпретирует её как таковую. Это поведение наблюдалось в исследовании под руководством Сяо в прошлом году. Сяо подчёркивает, что такие сбои особенно вероятны в контекстах, где информации в обучающих данных недостаточно — это касается редких тем и языков с ограниченным числом текстов. Кроме того, ошибка может быть усилена каскадным распространением, поскольку поисковая система представляет собой сложный многоуровневый механизм. При этом ИИ редко признаёт своё незнание, поэтому, если ИИ сталкивается с ложной предпосылкой, он с высокой вероятностью выдаёт вымышленный, но правдоподобно звучащий ответ. Представитель Google Мэганн Фарнсворт (Meghann Farnsworth) объяснила, что при поиске, основанном на абсурдных или несостоятельных предпосылках, система старается найти наиболее релевантный контент на основе ограниченных доступных данных. Это справедливо как для традиционного поиска, так и для AI Overviews, которая может активироваться в попытке предоставить полезный контекст. Тем не менее AI Overviews не срабатывает по каждому запросу. Как отметил когнитивист Гэри Маркус (Gary Marcus), система даёт непоследовательные результаты, поскольку GenAI зависит от конкретных примеров в обучающих выборках и не склоннен к абстрактному мышлению. Google призналась, что платит Samsung «огромные деньги» за предустановку Gemini на Galaxy
22.04.2025 [17:57],
Сергей Сурабекянц
Недавно суд признал Google виновной в нарушении антимонопольного законодательства — компания платила производителям смартфонов за предустановку своей поисковой системы. Сегодня выяснилось, что Google аналогичным образом стала финансировать предустановку ИИ Gemini на устройства Samsung Galaxy. Этот факт признал вице-президент Google по платформам и партнёрским устройствам Питер Фицджеральд (Peter Fitzgerald) во время другого судебного разбирательства. 
Источник изображения: androidauthority.com На проходящих трёхнедельных слушаниях Министерство юстиции США в рамках антимонопольного дела против Google потребовало разделить компанию с рыночной капитализацией $1,81 трлн. Этот процесс может кардинально изменить облик технологического гиганта и существенно повлиять на расстановку сил в Кремниевой долине. На судебном процессе Фицджеральд сообщил, что ежемесячные платежи за предустановку Gemini на устройства Samsung Galaxy начались в январе, а контракт рассчитан как минимум на два года. Общая сумма не разглашается, но представитель Министерства юстиции заявил, что Google платит Samsung «огромные деньги». Кроме того, по словам Фицджеральда, контракт предусматривает получение Samsung процента от дохода от рекламы, отображаемой в Gemini. Эти показания могут доставить серьёзные юридические неприятности Google в дополнение к уже имеющимся. На днях Министерство юстиции США выиграло судебный процесс против компании, обвинив Google в монопольном положении в сфере рекламных технологий. Суд постановил, что Google «умышленно участвовала в серии антиконкурентных действий», а антиконкурентная практика технологического гиганта нанесла «существенный вред» клиентам и пользователям. Теперь суд приобщит к текущему судебному иску показания Фицджеральда, чтобы принять окончательное решение об изменениях, которые Google придётся внести в свой бизнес в случае юридического поражения. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






