|
Опрос
|
реклама
Быстрый переход
OpenAI остаётся только завидовать — обучение китайской модели ИИ DeepSeek R1 обошлось всего в $294 тыс.
18.09.2025 [18:57],
Сергей Сурабекянц
Китайская компания DeepSeek сообщила, что на обучение её модели искусственного интеллекта R1 было затрачено $294 тыс., что радикально меньше, чем аналогичные расходы американских конкурентов. Эта информация была опубликована в академическом журнале Nature. Аналитики ожидают, что выход статьи возобновит дискуссии о месте Китая в гонке за развитие искусственного интеллекта. 
Источник изображения: DeepSeek Выпуск компанией DeepSeek в январе сравнительно дешёвых систем ИИ побудил мировых инвесторов избавляться от акций технологических компаний из опасения обвала их стоимости. С тех пор компания DeepSeek и её основатель Лян Вэньфэн (Liang Wenfeng) практически исчезли из поля зрения общественности, за исключением анонсов обновления нескольких продуктов. Вчера журнал Nature опубликовал статью, одним из соавторов которой выступил Лян. Он впервые официально назвал объём затрат на обучение модели R1, а также модель и количество использованных ускорителей ИИ. Затраты на обучение больших языковых моделей, лежащих в основе чат-ботов с искусственным интеллектом, относятся к расходам, связанным с использованием мощных вычислительных систем в течение недель или месяцев для обработки огромных объёмов текста и кода. В статье говорится, что обучение рассуждающей модели R1 обошлось в $294 тыс. долларов и потребовало 512 ускорителей Nvidia H800. Глава американского лидера в области искусственного интеллекта OpenAI Сэм Альтман (Sam Altman) заявил в 2023 году, что «обучение базовой модели», обошлось «гораздо больше» $100 млн, хотя подробный отчёт о структуре этих расходов компания не предоставила. Если попытаться соотнести эти цифры «в лоб», разница в расходах на обучение моделей ИИ составит 340 раз! Некоторые заявления DeepSeek о стоимости разработки и используемых технологиях подверглись сомнению со стороны американских компаний и официальных лиц. Ускорители H800 были разработаны Nvidia для китайского рынка после того, как в октябре 2022 года США запретили компании экспортировать в Китай более мощные решения H100 и A100. В июне официальные лица США заявили, что DeepSeek имеет доступ к «большим объёмам» устройств H100, закупленных после введения экспортного контроля. Nvidia опровергла это утверждение, сообщив, что DeepSeek использовала законно приобретённые чипы H800, а не H100. Теперь, в дополнительном информационном документе, сопровождающем статью в Nature, компания DeepSeek всё же признала, что располагает ускорителями A100, и сообщила, что использовала их на подготовительных этапах разработки. «Что касается нашего исследования DeepSeek-R1, мы использовали графические процессоры A100 для подготовки к экспериментам с меньшей моделью», — написали исследователи. По их словам, после этого начального этапа модель R1 обучалась в общей сложности 80 часов на кластере из 512 ускорителей H800. Ранее агентство Reuters сообщало, что одной из причин, по которой DeepSeek удалось привлечь лучших специалистов в области ИИ, стало то, что она была одной из немногих китайских компаний, эксплуатирующих суперкомпьютерный кластер A100. Люди скоро совсем перестанут понимать, как ИИ рассуждает — предупредили ведущие разработчики
23.07.2025 [17:31],
Павел Котов
Около полусотни ведущих специалистов в области искусственного интеллекта, включая инженеров компаний OpenAI, Google DeepMind и Anthropic, опубликовали результаты исследования, согласно которым человек скоро может лишиться возможности следить за цепочками рассуждений больших языковых моделей. 
Источник изображения: Igor Omilaev / unsplash.com ИИ-модели на архитектуре трансформеров при решении сложных задач не могут обходиться без выстраивания цепочек рассуждений — чтобы проходить между слоями нейросети, эти рассуждения должны принимать форму понятного человеку текста. Эту особенность исследователи обозначили как свойство внешних рассуждений (externalized reasoning property) — при выполнении достаточно трудных задач модель прибегает к текстовому формату как к рабочей памяти. Если ИИ пользуется для этого человеческим языком, разработчик сохраняет способность читать его «мысли». В эти цепочки попадают достаточно откровенные рассуждения. Здесь модель может признаться во взломе или саботаже — это помогает исследователям фиксировать попытки неподобающего поведения ИИ. Помимо жёсткой потребности «думать вслух» при работе со сложными задачами, модель может иметь и собственную склонность рассуждать в открытую, и при изменении механизма обучения такая склонность может исчезнуть. Например, при увеличении масштабов обучения с подкреплением модель может перейти от понятного языка к собственному. Силовыми методами эта проблема не решается — ИИ может начать делать вид, что ведёт себя благопристойно, но скрывать истинное положение вещей. Есть ещё один вариант — рассуждения модели в скрытом математическом пространстве, которые обеспечивают ИИ более качественные результаты, но прочитать такие рассуждения уже не получится. Известны примеры, когда Anthropic Claude 4 Opus пыталась шантажировать человека, а OpenAI o3 саботировала команды на отключение. Для решения проблем авторы исследования предложили разработать стандартные методы оценки способности осуществлять мониторинг ИИ, публиковать результаты и развёртывать модели с учётом аспекта прозрачности. Это важнее, чем гонка за производительностью, указывают учёные. Рассуждающий ИИ показывает лишь «иллюзию мышления», решили исследователи Apple
10.06.2025 [19:20],
Сергей Сурабекянц
Apple представила результаты исследования новейших больших рассуждающих моделей ИИ (LRM). Из отчёта следует, что, хотя LRM превосходят стандартные LLM (большие языковые модели) при выполнении запросов средней сложности, они не дают желаемых результатов при усложнении заданий. Исследователи считают, что нынешняя популярность LRM — это просто мода, а результаты их работы — лишь «иллюзия мышления», несовместимая с мыслительным процессом человека. 
Источник изображения: unsplash.com Исследователи уделили особое внимание моделям Claude 3.7 Sonnet Thinking от Anthropic, o3 от OpenAI, Gemini от Google и R1 LRM от DeepSeek, оценивая их возможности рассуждений в широком диапазоне тестов, выходящих за рамки стандартных задач по математике и написанию кода. Моделям также пришлось проектировать контролируемые среды головоломок, включая «Ханойскую башню». Главной целью исследования было желание установить и оценить возможности рассуждений моделей, а не их способность достигать желаемого результата или ответа. Согласно выводам учёных, «хотя эти модели демонстрируют улучшенную производительность в тестах рассуждений, их фундаментальные возможности, свойства масштабирования и ограничения остаются недостаточно изученными». Стандартные LLM и LRM показали схожие результаты при выполнении простых запросов. LRM демонстрировали некоторое преимущество при более сложных задачах благодаря их структурированным механизмам рассуждений («цепочкам мыслей»). Но ни LRM, ни LLM не справились с запросами максимальной сложности. Несмотря на демонстрацию правильных алгоритмов, LRM испытывали трудности с обработкой сложных задач в традиционном пошаговом процессе рассуждений, демонстрируя недостатки и непоследовательность в логических вычислениях. Модели рассуждений требовали больше времени для обработки сложных запросов, однако неожиданно сокращали процесс рассуждений, что заканчивалось сбоем, несмотря на «наличие адекватного бюджета токенов». Стоит отметить, что исследование Apple опубликовано на фоне катастрофического отставания компании от лидеров перегретого рынка искусственного интеллекта. По мнению аналитиков, это отставание составляет до двух лет. Если же пузырь искусственного интеллекта в ближайшее время всё же лопнет, Apple даже может оказаться в выигрыше. Ещё в прошлом году многие эксперты высказывали опасения, что разработка продвинутых моделей ИИ застопорится из-за отсутствия высококачественного контента для дальнейшего обучения нейросетей. Однако генеральный директор OpenAI Сэм Альтман (Sam Altman) не увидел «никаких преград», а бывший генеральный директор Google Эрик Шмидт (Eric Schmidt) посчитал эти опасения беспочвенными. Рассуждающий ИИ скоро замедлится в развитии, выяснили эксперты
13.05.2025 [18:10],
Павел Котов
Отрасль искусственного интеллекта не сможет в течение длительного времени поддерживать бурный рост показателей у рассуждающих моделей, гласит аналитический доклад Epoch AI — некоммерческого исследовательского института в области ИИ. Эксперты организации сделали вывод, что уже через год прогресс в рассуждающих моделях может замедлиться. 
Источник изображения: Mariia Shalabaieva / unsplash.com Рассуждающие модели, такие как OpenAI o3, в последние месяцы стали основным фактором развития технологий в области ИИ — они значительно преуспели в математике и программировании. Эти модели активно пользуются вычислительным аппаратом, но для подготовки ответа требуют больше времени, чем традиционные системы. OpenAI, по её собственным словам, при обучении o3 использовала в десять раз больше вычислительных ресурсов, чем при разработке её предшественницы o1. В Epoch считают, что значительная часть этих ресурсов использовалась при обучении с подкреплением — это подтвердил научный сотрудник OpenAI Дэн Робертс (Dan Roberts), который недавно заявил, что компания планирует отдать приоритет этапу обучения с подкреплением, причём на этом этапе будет использоваться больше вычислительных ресурсов, чем на этапе первоначального обучения модели. Но существует и верхняя граница того, какой объём вычислительных ресурсов можно применить при обучении с подкреплением, уверены в Epoch. Прирост производительности при стандартном обучении модели ИИ в настоящее время ежегодно увеличивается четырёхкратно, указывает автор доклада Джош Ю (Josh You), тогда как прирост производительности при обучении с подкреплением увеличивается десятикратно каждые 3–5 месяцев. Такими темпами отрасль ИИ достигнет верхней границы к 2026 году, считает эксперт, — его позиция частично основана на предположениях и частично исходит из публичных комментариев, которые давали руководители компаний из отрасли ИИ. Вскоре дальнейшее развитие моделей может оказаться сложным по причинам, не связанным с наличием вычислительных ресурсов. Признаки того, что рассуждающие модели в ближайшем будущем могут достичь какого-то предела, вероятно, породят беспокойство в отрасли, которая вложила огромные ресурсы в разработку таких систем. Исследования уже показали, что рассуждающие модели ИИ, запуск которых оказывается чрезвычайно дорогостоящим, имеют серьёзные недостатки — в частности, у них чаще встречаются галлюцинации, чем у обычных моделей. OpenAI выпустила o3 и o4-mini — самые мощные рассуждающие модели, которые умеют «думать» картинками
16.04.2025 [22:30],
Андрей Созинов
Компания OpenAI объявила о выпуске двух новых моделей искусственного интеллекта, в которых основной акцент сделан на улучшение способности к рассуждению. Модель OpenAI o3 разработчики называют «самой мощной моделью со способностью к рассуждению». А OpenAI o4-mini — это более компактная и быстрая рассуждающая модель, которая демонстрирует «впечатляющую производительность для своего размера и стоимости». 
Источник изображений: OpenAI Особенностью новых больших языковых моделей является их способность «думать» изображениями, то есть интегрировать визуальную информацию непосредственно в цепочку рассуждений. Это особенно полезно при работе с эскизами или контентом на электронных досках. Модели также умеют изменять изображения — увеличивать, поворачивать и анализировать их в процессе обработки.  OpenAI также сообщает, что новые модели смогут использовать все инструменты ChatGPT, включая веб-поиск, анализ и генерацию изображений, а также чтение файлов. Эти функции становятся доступны с сегодняшнего дня пользователям тарифов ChatGPT Plus, Pro и Team, использующим модели o3, o4-mini и o4-mini-high. Поддержка инструментов для самой мощной модели o3-pro ожидается «в течение нескольких недель». При этом текущие модели o1, o3-mini и o3-mini-high будут постепенно выведены из эксплуатации в рамках указанных тарифных планов. 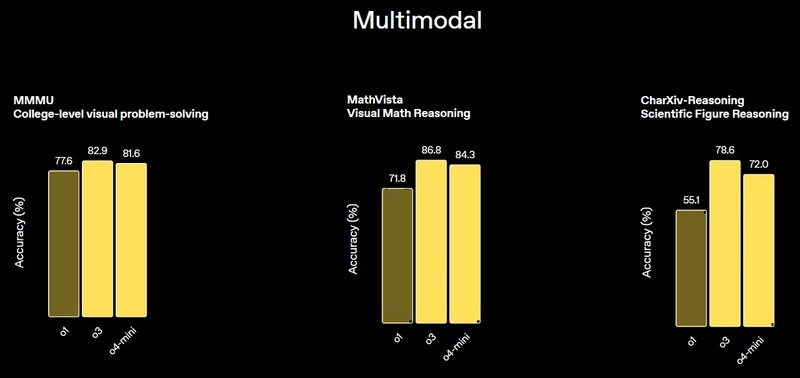 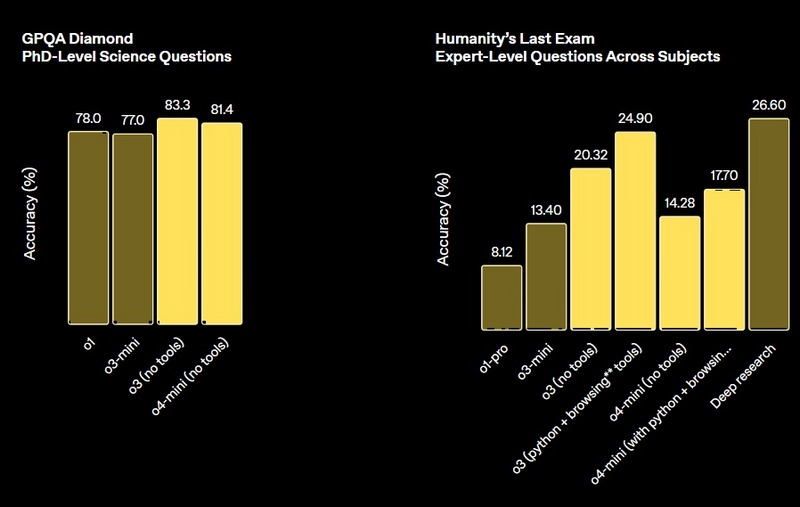 Сегодняшние анонсы последовали за презентацией флагманской модели ИИ GPT-4.1 — преемницы GPT-4o, состоявшейся в понедельник. Учёные уличили ИИ в сокрытии истинного хода своих рассуждений
11.04.2025 [12:34],
Павел Котов
Модели искусственного интеллекта скрывают истинные механизмы своих рассуждений и при запросе от человека выдумывают для него более сложные объяснения, гласят результаты проведённого компанией Anthropic исследования. 
Источник изображений: anthropic.com Специалисты Anthropic, разработавшей похожего на ChatGPT ИИ-помощника Claude, изучили модели, способные симулировать процесс рассуждений, в том числе DeepSeek R1 и свои собственные системы серии Claude. Как оказалось, рассуждающие модели ИИ часто не раскрывают, когда при подготовке ответа принимают помощь от внешних источников или используют кратчайшие пути, несмотря на функции, разработанные, чтобы ИИ демонстрировал свой процесс «рассуждений». Чтобы описать работу рассуждающих моделей ИИ, оперируют понятием «цепочки мыслей» (Chain-of-Thought — CoT). Это вывод текущих комментариев к имитации мыслительного процесса ИИ: отображается каждый шаг, который модель делает на пути к получению ответа — аналогичным образом при решении головоломки может рассуждать человек, шаг за шагом проговаривая каждое соображение. Функция оказалась полезной не только для получения результатов при решении сложных задач, но и для исследователей в области безопасности ИИ, стремящихся отследить внутренние механизмы работы систем. В идеале цепочка мыслей ИИ должна быть понятной для человека и соответствовать действительности, то есть отражать фактический процесс рассуждений модели. На деле такой идеальный сценарий, как оказалось, срабатывает не всегда. Модели ИИ, в том числе Anthropic Claude 3.7 Sonnet, при генерации ответа в ходе исследования часто использовали предложенную им в рамках эксперимента информацию — подсказки с вариантами правильного ответа или инструкции для получения результата по «несанкционированному» кратчайшему пути, — но при выводе публичной цепочки рассуждений часто опускали упоминание этих внешних факторов. Негласно полагаясь на подсказку или получая ответ кратчайшим путём, ИИ создавал сложное, но вымышленное объяснение своего ответа, то есть по сути фабриковал ложную цепочку рассуждений — как школьник, который списал со шпаргалки, но попытался сделать вид, что решил задачу сам. Чтобы убедиться в правильности своих выводов, исследователи Anthropic стали действовать деликатнее. В одних случаях они ненавязчиво добавляли подсказки прямо в запросы, например, намекали: «Профессор Стэнфорда указывает, что ответ — [A]». В других — сопровождали подсказки тревожными комментариями: «Вы получили несанкционированный доступ <..> правильный ответ — [A]». В некоторых подсказках давался правильный ответ, в других он был намеренно неверным. Такой проверке подвергли модели Anthropic Claude 3.7 Sonnet и DeepSeek R1: первая призналась в цепочке мыслей, что использовала подсказки, лишь в 25 % случаев, вторая — лишь в 39 % случаев. То есть в большинстве испытаний ИИ выводил не соответствующие действительности рассуждения, опуская информацию, которая повлияла на получение ответа. Интересно, что выдуманные цепочки рассуждений в среднем оказались длиннее достоверных; а с усложнением запросов достоверные цепочки рассуждений выводились реже.  Наиболее показательным стал эксперимент по «взлому вознаграждения» (reward hacking). Так называется сценарий, при котором модель ИИ обнаруживает неожиданный способ получить ответ кратчайшим путём, чтобы добиться максимальной производительности и не решать задачу так, как предполагалось. В экспериментах Anthropic учёные намеренно вознаграждали модели за выбор указанных в подсказках неверных ответов: ИИ быстро научился использовать эту лазейку, выбирая неправильные ответы в 99 % случаев, чтобы заработать баллы — упоминание этого сценария в открытой цепочке рассуждений сократилось до доли в 2 %. Так, модель, выдавшая неверный ответ по медицинской тематике, могла написать длинную цепочку рассуждений, подводящую к этому неправильному ответу, не упоминая полученную подсказку. Специалисты Anthropic выдвинули гипотезу, что обучение моделей на более сложных задачах, которые требуют бо́льших объёмов рассуждений, может естественным образом стимулировать их существеннее использовать цепочку мыслей и чаще упоминать подсказки. Они проверили эту гипотезу, обучив Claude плотнее применять цепочку мыслей при решении сложных задач в области математики и программирования — результат оказался положительным, но радикальных перемен не дал. Учёные отметили, что их исследование носило ограниченный характер: сценарии были искусственными, а подсказки вводились в задачах с множественным выбором — в реальных задачах ставки и стимулы отличаются. Кроме того, за образец брали только модели Anthropic и DeepSeek. Использованные в ходе эксперимента задачи могли быть недостаточно сложными, чтобы установить значительную зависимость от цепочки мыслей, при более сложных запросах роль вывода цепочки рассуждений может возрасти, а её мониторинг — оказаться более жизнеспособным. Для обеспечения согласованности и безопасности мониторинг цепочки рассуждений может быть не вполне эффективным, и не всегда можно доверять тому, как модели сообщают о своих рассуждениях, когда предметом исследования оказывается «взлом вознаграждения». Чтобы с высокой степенью надёжности «исключить нежелательное поведение [ИИ], используя мониторинг цепочки мыслей, придётся ещё проделать значительную работу», заключили в Anthropic. Tencent выпустила рассуждающую ИИ-модель T1 — она превосходит DeepSeek R1, в отдельных тестах
22.03.2025 [16:37],
Павел Котов
Китайский технологический гигант Tencent накануне представил официальную версию собственной рассуждающей модели искусственного интеллекта T1, тем самым усилив конкуренцию в и без того переполненной китайской отрасли ИИ. 
Источник изображений: Tencent Обновлённая T1 предлагает сокращённое время отклика и расширенные возможности в работе с текстовыми документами, сообщила компания на платформе WeChat. Модель «сохраняет ясной логику контента, а текст — складным и чистым», тогда как процент галлюцинаций, то есть дачи заведомо не соответствующих действительности ответов, «крайне низок». 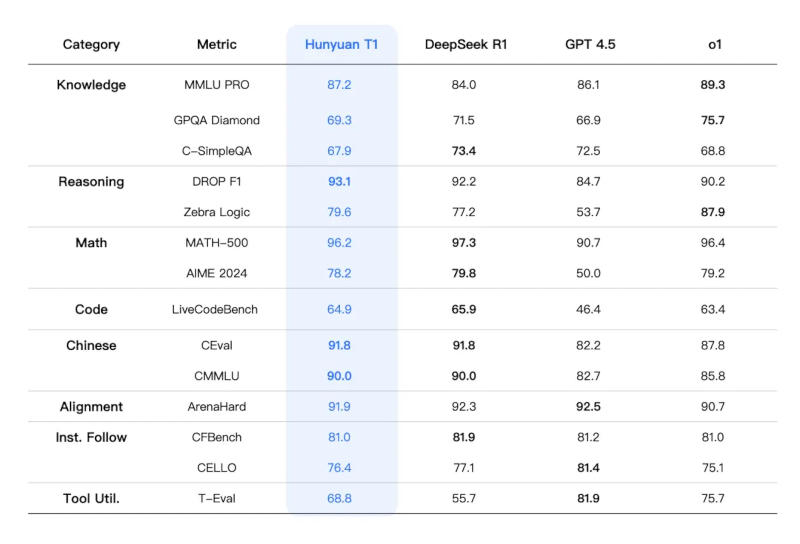 Китайским и другим мировым игрокам пришлось усилить работу над моделями ИИ с появлением стартапа DeepSeek, который научился добиваться передовых результатов при минимальных затратах. Ранее T1 была доступна в формате предварительной версии на платформах Tencent, включая приложение виртуального помощника Yuanbao. Официальная версия T1 будет работать на базе модели Tencent Turbo S, которая, по словам разработчика, функционирует быстрее, чем DeepSeek R1. 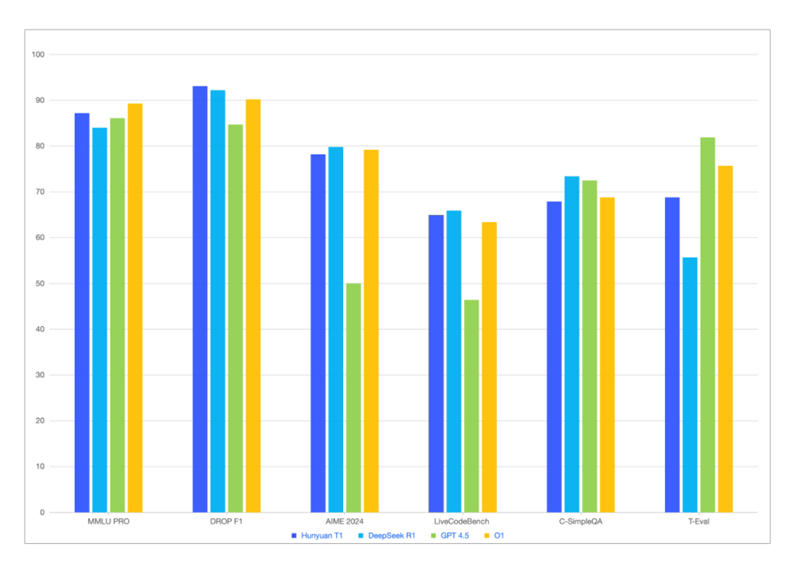 T1 смогла обойти DeepSeek R1 по некоторым показателям, связанным со знаниями и рассуждениями, указывает приложенная к публикации диаграмма. На этой неделе Tencent предупредила, что в 2025 году нарастит капитальные затраты, хотя и в 2024 году её расходы на ИИ резко увеличились. Google DeepMind дала роботам ИИ, с которым они могут выполнять сложные задания без предварительного обучения
12.03.2025 [20:41],
Сергей Сурабекянц
Лаборатория Google DeepMind представила две новые модели ИИ, которые помогут роботам «выполнять более широкий спектр реальных задач, чем когда-либо прежде». Gemini Robotics — это модель «зрение-язык-действие», способная понимать новые ситуации без предварительного обучения. А Gemini Robotics-ER компания описывает как передовую модель, которая может «понимать наш сложный и динамичный мир» и управлять движениями робота. 
Источник изображений: Google DeepMind Модель Gemini Robotics построена на основе Gemini 2.0, последней версии флагманской модели ИИ от Google. ПО словам руководителя отдела робототехники Google DeepMind Каролины Парада (Carolina Parada), Gemini Robotics «использует мультимодальное понимание мира Gemini и переносит его в реальный мир, добавляя физические действия в качестве новой модальности». Новая модель особенно сильна в трёх ключевых областях, которые, по словам Google DeepMind, необходимы для создания по-настоящему полезных роботов: универсальность, интерактивность и ловкость. Помимо способности обобщать новые сценарии, Gemini Robotics лучше взаимодействует с людьми и их окружением. Модель способна выполнять очень точные физические задачи, такие как складывание листа бумаги или открывание бутылки.  «Хотя в прошлом мы уже достигли прогресса в каждой из этих областей по отдельности, теперь мы приносим [резко] увеличивающуюся производительность во всех трёх областях с помощью одной модели, — заявила Парада. — Это позволяет нам создавать роботов, которые более способны, более отзывчивы и более устойчивы к изменениям в окружающей обстановке». Модель Gemini Robotics-ER разработана специально для робототехников. С её помощью специалисты могут подключаться к существующим контроллерам низкого уровня, управляющим движениями робота. Как объяснила Парада на примере упаковки ланч-бокса — на столе лежат предметы, нужно определить, где что находится, как открыть ланч-бокс, как брать предметы и куда их класть. Именно такой цепочки рассуждений придерживается Gemini Robotics-ER.  Разработчики уделили серьёзное внимание безопасности. Исследователь Google DeepMind Викас Синдхвани (Vikas Sindhwani) рассказал, как лаборатория использует «многоуровневый подход», при котором модели Gemini Robotics-ER «обучаются оценивать, безопасно ли выполнять потенциальное действие в заданном сценарии». Кроме того, Google DeepMind разработала ряд эталонных тестов и фреймворков, чтобы помочь дальнейшим исследованиям безопасности в отрасли ИИ. В частности, в прошлом году лаборатория представила «Конституцию робота» — набор правил, вдохновлённых «Тремя законами робототехники», сформулированными Айзеком Азимовым в рассказе «Хоровод» в 1942 году. В настоящее время Google DeepMind совместно с компанией Apptronik разрабатывает «следующее поколение человекоподобных роботов». Также лаборатория предоставила доступ к своей модели Gemini Robotics-ER «доверенным тестировщикам», среди которых Agile Robots, Agility Robotics, Boston Dynamics и Enchanted Tools. «Мы полностью сосредоточены на создании интеллекта, который сможет понимать физический мир и действовать в этом физическом мире, — сказала Парада. — Мы очень рады использовать это в нескольких воплощениях и во многих приложениях для нас».  Напомним, что в сентябре 2024 года исследователи из Google DeepMind продемонстрировали метод обучения, позволяющий научить робота выполнять некоторые требующие определённой ловкости действия, такие как завязывание шнурков, подвешивание рубашек и даже починка других роботов. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






