|
Опрос
|
реклама
Быстрый переход
Настольные суперкомпьютеры Nvidia DGX Spark на суперчипе GB10 снова не вышли в назначенные сроки
08.10.2025 [15:01],
Николай Хижняк
Nvidia, судя по всему, снова задерживает выпуск своего суперчипа для ИИ — GB10. Как пишет VideoCardz, компания могла перенести выпуск предназначенного для компактных рабочих станций DGX Spark процессора, на четвёртый квартал этого года. Эти системы ориентированы на ИИ-разработчиков, исследователей и других специалистов, занимающихся созданием прототипов, настройкой и доработкой больших ИИ-моделей. 
Источник изображения: VideoCardz По мнению VideoCardz, GB10 на архитектуре Blackwell, вероятно, является ближайшим конкурентом AMD Strix Halo — однопроцессорной системы, разработанной в первую очередь для задач ИИ и сочетающей в себе два кристалла CPU, а также мощный графический процессор. Каждый чип Nvidia GB10 оснащён 128 Гбайт унифицированной памяти LPPDR5X, явно предназначенной для задач обучения ИИ. Изначально Nvidia планировала выпустить рабочие станции DGX Spark в мае, затем выпуск был смещён на июль. Лето прошло, но в продаже новинки до сих пор так и не появились, на что указывает полное отсутствие каких-либо обзоров или демонстраций систем. На пороге четвёртого квартала на странице продукта на официальном сайте Nvidia по-прежнему отображается всё то же сообщение «Уведомите меня» о поступлении DGX Spark в продажу. 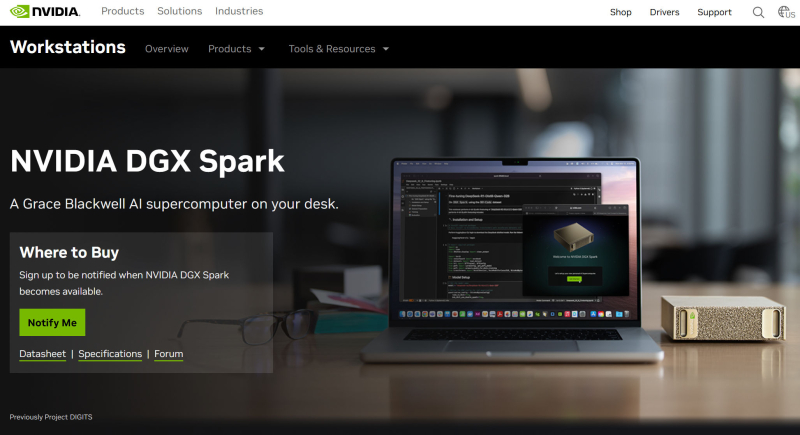
Источник изображения: Nvidia Партнёры Nvidia в лице Asus и HP в свою очередь подтверждают, что их системы DGX Spark должны выйти в четвёртом квартале, хотя никто не называет конкретных дат. VideoCardz отмечает, что за пределами Nvidia никто точно не знает, когда DGX Spark поступит в продажу. Например, британский магазин электроники Scan UK, изначально указывавший, что компактные рабочие станции поступят в продажу 15 сентября, а затем 30 сентября, теперь даже не называет дату. 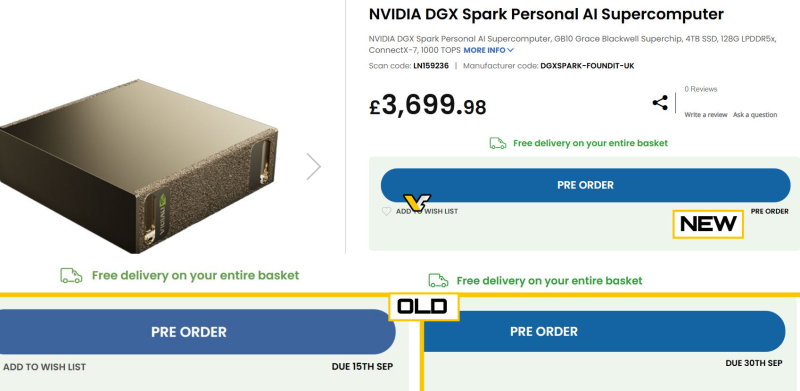
Источник изображения: VideoCardz / Scan UK Ранее ходили слухи, что Nvidia также собиралась представить SoC серии N1 для потребительских ноутбуков и настольных компьютеров, но ни на CES, ни на Computex компания не анонсировала такой продукт. Более того, Nvidia никогда официально не подтверждала такие планы. Недавно генеральный директор Nvidia сообщил, что суперчип GB10 носит внутреннее кодовое название «N1», что подтверждает ранние слухи о том, что эти два чипа не просто похожи по характеристикам, а фактически являются одним и тем же. Возможно, имя «N1» изначально предназначалось для внутреннего использования, и Nvidia вообще не планировала выпускать продукт с именно таким названием на потребительский рынок. Fujitsu внедрит технологии Nvidia в суперкомпьютеры на собственных процессорах
03.10.2025 [11:34],
Алексей Разин
Некоторое время назад Nvidia представила инициативу NVLink Fusion, которая позволит сторонним разработчикам полупроводниковых компонентов добиваться более эффективной интеграции чипов Nvidia в свои системы. Очередным партнёром по внедрению NVLink в этом смысле для Nvidia станет японская компания Fujitsu. 
Источник изображений: Fujitsu Строго говоря, содержательный пресс-релиз на страницах сайта Fujitsu перечисляет многие сферы сотрудничества с Nvidia, включая и область квантовых вычислений, но решение о соединении процессоров Monaka компании Fujitsu и GPU компании Nvidia при помощи NVLink Fusion стоит особняком. Первые плоды сотрудничества двух компаний появятся к 2030 году. Для совместных заявлений на эту тему основатель Nvidia Дженсен Хуанг (Jensen Huang) даже отправился в японскую столицу, где разделил сцену с главой Fujitsu Такахито Токитой (Takahito Tokita). Финансовые условия сотрудничества Nvidia и Fujitsu остались за рамками заявлений. По словам главы первой из компаний, Fujitsu буквально создаст аппаратное решение, позволяющие «объединить» свои центральные процессоры с технологиями Nvidia. К 2030 году Fujitsu при поддержке партнёров, в число которых вошла и Nvidia, намеревается построить суперкомпьютер Fugaku NEXT, производительность которого превысит предшественника в пять или десять раз. 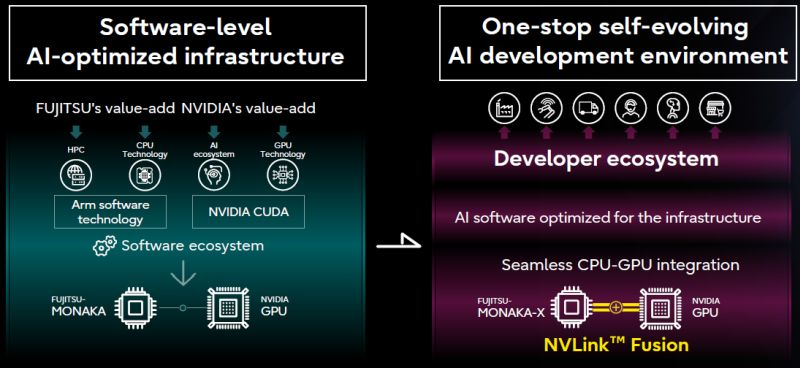 Как признался Хуанг, создание Fugaku NEXT будет только первым шагом на пути реализации множества совместных инициатив Fujitsu и Nvidia. Интеграция с технологиями Nvidia позволит Fujitsu увеличить рыночный охват для своих решений. Японская компания также продвигает идею «ИИ-суверенитета» нации и готова прилагать к её реализации максимум усилий со своей стороны. Кроме того, у Fujitsu за счёт интеграции с частью экосистемы Nvidia откроются перспективы на европейском рынке ИИ. По словам главы компании, её японскую штаб-квартиру регулярно посещают делегации из Европы, интерес к решениям Fujitsu на этом рынке очень высок. Fujitsu и Nvidia при участии разнообразных партнёров также собираются разрабатывать большие языковые модели для робототехники, промышленной автоматизации, торговли, автономного транспорта и здравоохранения. В Европе появился первый экзафлопсный суперкомпьютер Jupiter — в мировом рейтинге он занял четвёртое место
06.09.2025 [14:03],
Анжелла Марина
В Германии, в Юлихском исследовательском центре (Jülich Supercomputing Center) близ Кёльна, состоялось официальное открытие первого в Европе суперкомпьютера Jupiter, преодолевшего порог экзафлопсной производительности (10¹⁸ операций в секунду). 
Источник изображения: Forschungszentrum Jülich/YouTube На церемонии присутствовали канцлер Германии Фридрих Мерц (Friedrich Merz), федеральный министр по вопросам исследований, технологий и космоса Дороте Бэр (Dorothee Bär), министр-президент земли Северный Рейн-Вестфалия Хендрик Вюст (Hendrik Wüst) и министр культуры и науки Инна Брандес (Ina Brandes), информирует The Register. Открытие касалось пока только модуля Booster — кластера графических процессоров, предназначенного для масштабных симуляций и обучения ИИ, включающего около 6000 вычислительных узлов, каждый из которых оснащён четырьмя суперчипами Nvidia GH200 Grace Hopper и объединён сетевым оборудованием Quantum-2 InfiniBand от Nvidia. Этот модуль позволил Jupiter занять первое место в Европе и четвёртое в мире по производительности, а его тестовый модуль Jedi годом ранее возглавил рейтинг Green500 как самый энергоэффективный суперкомпьютер планеты.  Как заявила еврокомиссар по вопросам стартапов, исследований и инноваций Экатерина Захариева (Ekaterina Zaharieva), этот суперкомпьютер «открывает новую главу для науки, искусственного интеллекта и инноваций, укрепляя цифровой суверенитет Европы и обеспечивая её исследователей мощными вычислительными ресурсами». Несмотря на достижение, система ещё не завершена полностью. Модуль общего назначения (Cluster Module), предназначенный для рабочих процессов, не требующих использования ускорителей, ожидается не раньше конца 2026 года. Он будет основан на европейском процессоре Rhea1 от компании SiPearl, финальный дизайн которого был готов только в июле этого года. Этот чип содержит 80 ядер Arm Neoverse V1, в кластере планируется использовать 1300 узлов, каждый с двумя такими процессорами.  Пока Европа отстаёт в экзафлопсной гонке от США, которые достигли этого рубежа три года назад с системой Frontier, а также от Китая, который, как полагают, уже имеет подобные системы, но не раскрывает детали. Проект Jupiter реализуется консорциумом ParTec-Eviden, а его общая стоимость, включая шесть лет эксплуатации, оценивается в 500 миллионов евро. Финансирование поровну разделено между инициативой EuroHPC JU и немецкими министерствами. Вся система размещается в модульном дата-центре площадью 2300 квадратных метров, что позволяет при необходимости легко её расширять и модифицировать. Tesla закрыла проект по созданию ИИ-суперкомпьютера Dojo на гигантских чипах
08.08.2025 [05:14],
Алексей Разин
Агентство Bloomberg накануне сообщило, что компанию Tesla покинет руководитель группы специалистов, которые создавали суперкомпьютер Dojo, вместе с этим около 20 его теперь уже бывших коллег сформировали новую компанию DensityAI, в штате которой надеются найти применение своим профильным навыкам. 
Источник изображения: Nvidia Прежде всего, стало известно об уходе из Tesla Питера Бэннона (Peter Bannon), который руководил строительством фирменного суперкомпьютера Dojo. Около двадцати бывших специалистов Tesla по суперкомпьютерам основали компанию DensityAI, а оставшаяся часть коллектива была перераспределена по другим проектам внутри Tesla, как сообщают источники. Бэннон в 2016 году перешёл на работу в Tesla из компании Apple. До недавних пор он занимал в Tesla пост вице-президента по разработке аппаратного обеспечения. До сих пор считалось, что создание собственного суперкомпьютера Dojo для Tesla является одним из приоритетов в гонке по развитию технологий искусственного интеллекта. Мощности Dojo планировалось использовать для обучения технологий автопилота электромобилей Tesla и человекоподобных роботов Optimus. В ответ на сообщение Bloomberg о роспуске команды Dojo генеральный директор Tesla Илон Маск (Elon Musk) сказал: «Для Tesla не имеет смысла разделять свои ресурсы и масштабировать два совершенно разных дизайна чипов искусственного интеллекта. Tesla AI5, AI6 и последующие чипы будут отлично подходить для запуска обученных нейросетей и, по крайней мере, довольно хороши для обучения. Все усилия сосредоточены на этом». Маск имеет в виду чип AI6 следующего поколения Tesla, который будет производиться Samsung в рамках сделки на $16,5 млрд. Эти чипы будут обеспечивать принятие решений в режиме реального времени на борту автомобилей и роботов Tesla. Закрытие Dojo фактически положит конец амбициозным планам Tesla по созданию собственной внутренней архитектуры обучения ИИ и консолидирует усилия компании на платформах AI5 и AI6. Хотя Маск говорит, что фирменные чипы «довольно хороши» для обучения, теперь компания будет в значительной степени полагаться на ускорители вычислений Nvidia и других поставщиков. Начало производства AI5 запланировано на 2026 год, а AI6 — на 2027 год. Это уже не первый случай ухода из Tesla видных специалистов в отдельных областях. Ранее компанию покинул Милан Ковач (Milan Kovac), который руководил разработкой человекоподобных роботов Optimus. Компания также лишилась главы по разработке программного обеспечения Дэвида Лау (David Lau). В июне стало известно об уходе из Tesla одного из давних соратников Tesla Омеада Афшара (Omead Afshar). Илон Маск на недавней квартальной отчётной конференции дал понять, что при разработке будущих поколений чипов типа AI6 компания будет придерживаться принципа унификации, чтобы использовать их как в собственных центрах обработки данных, так и в человекоподобных роботах, не говоря уже о бортовых системах электромобилей. AMD похвасталась, что её чипы стали основой для трети мощнейших суперкомпьютеров мира
06.08.2025 [14:16],
Алексей Разин
На квартальной конференции представители AMD старались всячески подчеркнуть, что трудности с увеличением выручки в серверном сегменте носят временный характер, и в целом дела у компании на этом направлении идут очень хорошо. По меньшей мере, компоненты AMD уже используются более чем в трети мощнейших суперкомпьютеров мира, а доля компании на рынке серверных процессоров растёт уже 33 квартала подряд. 
Источник изображения: AMD По сути, число 33 с этой точки зрения стало для компании магическим. Выручка от реализации центральных процессоров семейства EPYC в прошлом квартале обновила рекорды как в сегменте облачных вычислений, так и на корпоративном направлении. Эти процессоры пользуются высоким спросом, как подчеркнула на отчётном мероприятии глава AMD Лиза Су (Lisa Su). Это тем более заметно в контексте развития инфраструктуры искусственного интеллекта и появления новых сфер применения данных технологий и самих процессоров. По словам Лизы Су, развитие инфраструктуры ИИ повышает спрос на вычислительные ресурсы общего назначения, которые могут предоставить многоядерные центральные процессоры. Во втором квартале значительно вырос объём поставок процессоров EPYC новейшего поколения Turin, а спрос на их предшественников и не думает снижаться, оставаясь стабильным. Доля AMD на рынке центральных процессоров серверного применения непрерывно растёт уже 33 квартала подряд — то бишь, уже более восьми лет. В сегменте суперкомпьютеров AMD есть чем похвастаться. Во-первых, на её компонентах построены две мощнейшие системы в списке Top 500, а именно — El Capitan и Frontier. Во-вторых, более трети мощнейших суперкомпьютеров мира используют компоненты AMD. В-третьих, на решениях этой марки построены 12 из 20 лучших суперкомпьютерных систем Green 500 с точки зрения энергоэффективности. Экс-глава Intel вложился в стартап, создающий сверхпроводниковые чипы для суперкомпьютеров
23.06.2025 [14:04],
Алексей Разин
Спектр интересов Патрика Гелсингера (Patrick Gelsinger) после его отставки с поста генерального директора Intel в начале декабря прошлого года то и дело становится предметом обсуждения в прессе, и очередной поддерживаемый им стартап интригует своей миссией. Компания Snowcap Compute собирается создавать чипы для суперкомпьютеров, которые обладают свойством сверхпроводимости. 
Источник изображения: Snowcap Compute В свою очередь, состояние сверхпроводимости позволит заметно снизить энергопотребление таких чипов, хотя достигаться оно будет традиционно при сверхнизких температурах, что также требует серьёзных энергозатрат на их поддержание. Так или иначе, как поясняет Reuters, представители Snowcap Compute убеждены, что игра будет стоить свеч, поскольку эффективность итоговых вычислительных систем будет покрывать дополнительные затраты на мощное охлаждение. Соотношение производительности и энергопотребления для разрабатываемых стартапом чипов будет в 25 раз выше, чем у лучших представителей текущего поколения ускорителей. Генеральный директор Snowcap Compute Майкл Лафферти (Michael Lafferty) поясняет: «Энергоэффективность — это хорошо, но продажами движет производительность. То есть, мы одновременно поднимаем производительность и опускаем уровень энергопотребления». Предполагается, что для выпуска чипов с подобными свойствами понадобится доступ к нитриду ниобия-титана — сплаву, составляющие которого нужно получать из Бразилии и Канады. Первые образцы готовых чипов компания рассчитывает получить к концу следующего года, но наладить выпуск полноценных вычислительных систем на их основе удастся лишь значительно позже. Нюанс заключается в том, что поддержку стартапу на данном этапе оказал бывший глава Intel Патрик Гелсингер, вложивший через связанный с ним венчурный фонд Playground Digital часть из $23 млн, собранных инвесторами. Кроме того, Гелсингеру за это полагается и место в совете директоров Snowcap Compute, поэтому в жизни стартапа бывший руководитель Intel будет принимать самое непосредственное участие. Сам Гелсингер подчеркнул: «Многие дата-центры сегодня ограничены в своём масштабировании только количеством доступной энергии». Жизнь после «Яндекса» есть: Nebius Group Аркадия Воложа создала второй суперкомпьютер, и он попал в топ-15 мира
11.06.2025 [21:15],
Анжелла Марина
У нидерландской компании Nebius Group (бывшая Yandex NV), возглавляемой сооснователем «Яндекса» Аркадием Воложом, появился ещё один суперкомпьютер. Речь идёт об ISEG 2, который занял 13-е место в рейтинге TOP500 самых мощных суперкомпьютеров в мире. 
Источник изображения: AI FP64-производительность ISEG 2 составляет 202,4 Пфлопс (в пике 338,49 Пфлопс) и насчитывает 718 848 вычислительных ядер. Система оснащена процессорами Intel Xeon Platinum 8468 (48 ядер, 96 потоков), ускорителями Nvidia H200 и интерконнектом InfiniBand NDR400. ISEG 2 размещён в Исландии. Как отметила компания в своём аккаунте X, система стала самым мощным коммерчески доступным суперкомпьютером в Европе и второй по производительности коммерческой системой в мире, что подтверждается данными TOP500. Напомним, первый суперкомпьютер ISEG, названный в честь сооснователя «Яндекса» Ильи Сегаловича (Ilya Segalovich), дебютировал в рейтинге TOP500 в ноябре 2023 года, заняв 16-е место. Его пиковая вычислительная мощность составила 86,79 Пфлопс, а фактическая — 46,54 Пфлопс. На данный момент компьютер находится на 39-й позиции рейтинга. ISEG размещён в бывшем дата-центре «Яндекса» в Финляндии. Nvidia построит на Тайване штаб-квартиру и мощный суперкомпьютер с 10 000 ускорителями Blackwell
19.05.2025 [11:40],
Алексей Разин
Свой приуроченный к выступлению на Computex 2025 визит на Тайвань основатель и бессменный руководитель Nvidia Дженсен Хуанг (Jensen Huang) использовал для заявления о намерениях потратить внушительные средства на строительство здесь локальной штаб-квартиры компании и мощного суперкомпьютера. 
Источник изображения: Nvidia Тайвань он назвал «крупнейшим регионом по производству электроники», отметив его важное значение в формировании мировой компьютерной экосистемы. Подразделение тайваньской Foxconn (Big Innovation Company) поможет Nvidia построить для нужд местной вычислительной инфраструктуры современный суперкомпьютер, использующий 10 000 новейших ускорителей вычислений семейства Blackwell. На его строительство уйдёт несколько сотен тысяч долларов, по предварительным оценкам. Примечательно, что пользоваться этим суперкомпьютером, помимо прочих, будет тайваньская компания TSMC, которая остаётся основным контрактным производителем чипов Nvidia. С помощью современного суперкомпьютера TSMC будет совершенствовать имеющиеся и разрабатывать новые технологические процессы в сфере литографии. Хуанг также подчеркнул, что Nvidia становится тесно в пределах имеющегося офиса компании на Тайване, она построит новое здание местной штаб-квартиры Constellation в одном из районов Тайбэя. Не исключено, что на этой площадке будет осуществляться более тесное взаимодействие с тайваньскими партнёрами Nvidia, особенно в контексте инициативы по продвижению интерфейса NVLink Fusion, позволяющего интегрировать собственные вычислительные решения компании со сторонними. В Китае Nvidia также готовится открыть локальный исследовательский центр, но связанные с разработкой графических процессоров ценные данные она передавать его сотрудникам не будет. Autonomous представила дизайнерский домашний ИИ-суперкомпьютер за $40 000 — его функциональность вызывает вопросы
16.05.2025 [01:28],
Анжелла Марина
Компания Autonomous из США представила первую в своём роде рабочую станцию Brainy с очень высокой производительностью, предназначенную для ускорения разработки искусственного интеллекта (ИИ). Устройство создано для исследователей, разработчиков и стартапов, которые стремятся выйти за рамки возможностей облачных решений и работать с самыми сложными ИИ-моделями локально, а значит быстро и безопасно. 
Источник изображений: Autonomous Система Brainy создана для самых сложных задач в области ИИ и оснащена видеокартами Nvidia RTX 4090. Её производительность превышает один петафлопс в максимальной конфигурации, которые могут включать от двух до восьми GPU. Это позволяет обучать модели с 70 миллиардами параметров, добиваться результатов уровня суперкомпьютеров прямо с рабочего стола и оптимизировать обучение ИИ-моделей. Как отмечает TechPowerUp, станция особенно эффективна для тонкой настройки больших языковых моделей (LLM), задач компьютерного зрения и других областей глубокого обучения. Autonomous разработала Brainy, чтобы решить проблемы дорогих облачных GPU-решений. Хотя облачные сервисы, как известно, обладают высокой гибкостью, их оплата по мере использования может стать чрезмерно затратной для долгосрочных проектов. Autonomous предлагает альтернативу в виде локальной мощности, повышенной безопасности данных и значительной экономии. По оценкам компании, владельцы Brainy могут сэкономить тысячи долларов уже в первый год по сравнению с арендой облачных мощностей. Ещё одним преимуществом Brainy является стабильность работы. Система исключает такие типичные для облака проблемы, как очереди, внезапные отключения и задержки из-за интернета. Кроме того, пользователи могут начать с конфигурации из двух видеокарт и при необходимости расширить её до восьми. Готовые проекты можно легко перенести в облако или дата-центр без дополнительных настроек. 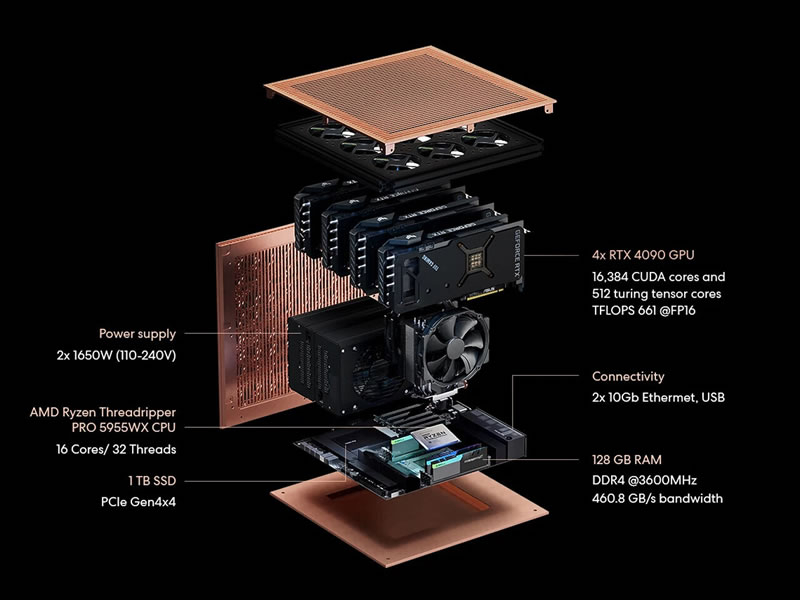 Производитель отмечает, что Brainy поддерживает популярные фреймворки, включая PyTorch и TensorFlow, а также технологии Nvidia — CUDA, cuDNN и TensorRT. Все эти возможности ускоряют разработку ИИ-моделей и научных вычислений. Ко всему прочему, Autonomous входит в программу Nvidia Inception, что даёт ей доступ к ресурсам и обучению для оптимизации Brainy, а также позволяет предложить клиентам конкурентные цены. По словам компании, с помощью станции стартапы и организации смогут быстрее разрабатывать ИИ-решения в таких сферах, как медицина, образование, логистика и финансы. Помимо видеокарт Nvidia системы Autonomous Brainy предлагают процессоры AMD Ryzen Threadripper — в базовой модели это 24-ядерный Ryzen Threadripper 3960X, тогда как в более продвинутых конфигурациях предлагаются более свежие 16-ядерные Ryzen Threadripper 5955WX. А самая мощная версия и вовсе оснащена 16-ядерным чипом AMD Epyc 9124. Объём оперативной памяти составляет соответственно 96, 128 и 192 Гбайт. Заметим, что в одной из конфигураций видеокарты не смогут работать в полную силу. В частности, у Ryzen Threadripper 5955WX имеется лишь 80 линий PCIe, а на шесть видеокарт нужно 96 линий. А ещё ведь надо выделить четыре линии для SSD. Так что даже у флагманской модели со 128 линиями PCIe 4.0 будет их дефицит. Также вызывает беспокойство охлаждение: не будет ли видеокартам тесно в корпусе. Что касается стоимости, то системы Autonomous Brainy предлагаются по цене от $9000 до $40 000.  Суперкомпьютер Colossus Илона Маска запустили на полную мощность — он потребляет, как 300 000 домов
08.05.2025 [18:17],
Павел Котов
Первая фаза проекта xAI Memphis Supercluster Илона Маска (Elon Musk) вышла на полную мощность — ИИ-суперкомпьютер готов подключиться к местной подстанции и основной электросети. Площадка будет получать 150 МВт от операторов Memphis Light, Gas and Water (MLGW) и Tennessee Valley Authority (TVA), и столько же — от аккумуляторов Tesla Megapack, предназначенных для работы в качестве резервного источника энергии на случай отключения сети и в периоды повышенного спроса. 
Источник изображения: xAI ИИ-кластер Илона Маска начал работу в июле прошлого года со 100 000 ускорителями Nvidia H100; оборудование на объекте установили за 19 дней, хотя в обычных условиях на это ушли бы четыре года, рассказал тогда глава Nvidia Дженсен Хуанг (Jensen Huang). Из-за высокой скорости развёртывания пришлось пойти на некоторые ухищрения — в том числе запустить систему без подключения к электросети: на объекте установили газотурбинные генераторы. Первоначально сообщалось, что их было 14 штук мощностью по 2,5 МВт каждый, но местные жители говорили о более чем 35 генераторах. Завершение первого этапа проекта означает, что суперкомпьютер теперь может полностью работать на энергии, поставляемой TVA, которая примерно на 60 % формируется из возобновляемых источников — речь идёт о гидро-, солнечной, ветряной и ядерной энергетике. Это позволило xAI отключить около половины ранее запущенных генераторов, временно обеспечивавших питание Colossus. Однако остальная часть генераторов продолжит работу до запуска второй подстанции на 150 МВт, намеченного на осень этого года. Общая мощность кластера составит 300 МВт — этого хватило бы для снабжения электричеством около 300 000 домов. В TVA заверили, что смогут выполнить свои обязательства без ущерба для других клиентов. Первые 100 000 ускорителей Nvidia H100 заработали в Colossus в июле 2024 года, в феврале их количество увеличилось до 200 000, но в перспективе Маск намерен довести число ускорителей до миллиона. Объекту потребуется значительно больше энергии, и пока неясно, сможет ли TVA обеспечить такие объёмы без перебоев для местного населения. Volvo выпустит самый мощный суперкомпьютер на колёсах
20.02.2025 [10:50],
Дмитрий Федоров
Volvo готовит электрический седан ES90 — автомобиль с самой высокой вычислительной производительностью. Построенный на платформе SPA2 и использующий технологический стек Superset, электромобиль оснащён парой суперкомпьютеров Nvidia Drive AGX Orin. Система с производительностью 508 триллионов операций в секунду (TOPS), обеспечивает мгновенную обработку данных с сенсоров, управляет системами активной безопасности на основе ИИ в реальном времени и оптимизирует распределение энергии. 
Источник изображений: Volvo Car Corporation Система на базе двух Orin представляет собой значительное усовершенствование по сравнению с предыдущими решениями Volvo. Новый суперкомпьютер обеспечивает восьмикратное увеличение производительности по сравнению с Nvidia Xavier, который использовался в 2018 году, когда Volvo объявила о стратегическом партнёрстве с Nvidia. Возросшая вычислительная мощность позволит значительно улучшить алгоритмы машинного обучения: объём данных, обрабатываемых нейросетями Volvo, увеличится с 40 млн до 200 млн параметров. Это создаст основу для более точного восприятия окружающей среды электромобилем, сокращения времени отклика на дорожные ситуации и повышения эффективности автопилота. Технологический стек Superset, лежащий в основе ES90, представляет собой инженерную модульную платформу, предназначенную для будущих автомобилей Volvo. Этот унифицированный подход позволит компании создавать новые модели на единой архитектуре, сокращая затраты на разработку и ускоряя внедрение передовых технологий.  Superset включает в себя ключевые модули: систему автономного вождения, управление энергопотреблением, мониторинг окружающей среды и беспроводные обновления программного обеспечения (ПО). Благодаря этому ES90 сможет получать новые функции, совершенствоваться со временем и оставаться актуальным даже после выхода на рынок.  Концепция программно-определяемых автомобилей стала индустриальным стандартом после успеха Tesla — первой компании, внедрившей транспортные средства с возможностью обновления через мобильный интернет или Wi-Fi. Volvo также движется в этом направлении, но сталкивается с технологическими трудностями.  Ранее представленный электрический внедорожник EX90 с одним чипом Nvidia Drive AGX Orin должен был стать первой моделью компании, использующей стек Superset, однако его запуск был отложен из-за проблем с ПО. Когда модель всё же вышла на рынок, оказалось, что в ней отсутствовали многие из обещанных функций. Volvo рассчитывает, что с ES90 ей удастся преодолеть эти трудности и создать полностью адаптивный автомобиль.  Volvo заявляет, что функции помощи водителю, системы безопасности и даже запас хода батареи будут улучшаться со временем благодаря оптимизации алгоритмов и выпуску новых версий ПО. Более того, ES90 и EX90 будут использовать единую технологическую платформу, что позволит синхронизировать обновления между моделями и обеспечит их долгосрочную поддержку. Учёные впервые заглянули внутрь нейтронных звёзд, совершив прорыв в их моделировании на суперкомпьютерах
14.01.2025 [19:39],
Геннадий Детинич
Внутри нейтронных звёзд происходят экстремальные физические процессы, которые, вероятно, никогда не удастся изучить напрямую. Более того, это настолько компактные объекты, что они невидимы в телескопы. Всё, чем располагает наука, — это косвенные данные о нейтронных звёздах и возможность грубого моделирования их свойств на компьютерах. Однако при определённых усилиях точность таких моделей можно довести до высочайшего уровня. 
Комбинированное изображение Крабовидной туманности с нейтронной звездой в видимом, инфракрасном и рентгеновском диапазоне. Источник изображения: NASA До ближайшей нейтронной звезды от Земли около 400 световых лет. У нас нет, и в течение тысяч лет не появится технологий, позволяющих отправить туда исследовательскую станцию. На таком расстоянии никакой телескоп не сможет разглядеть нейтронную звезду диаметром всего 20 км. Кроме того, в земных условиях невозможно воспроизвести физические параметры внутри нейтронной звезды, где плотность вещества в несколько раз превышает плотность атомных ядер. Качественный прорыв в моделировании нейтронных звёзд, вероятно, станет возможным с появлением мощных квантовых симуляторов. Однако уже сегодня у нас есть суперкомпьютеры и развитая квантовая математика, что может быть достаточным для углублённого анализа физики нейтронных звёзд. По крайней мере, об этом недавно заявили учёные из Университета Колорадо в Боулдере и Массачусетского технологического института. Внутренние свойства нейтронной звезды, такие как давление и плотность, определяются уравнениями квантовой хромодинамики (КХД), которые описывают сильное взаимодействие между протонами, нейтронами и составляющими их кварками. Однако эти уравнения нельзя решить для всей нейтронной звезды. Упрощая ряд переменных, учёные могут решать уравнения для внешнего слоя звезды и её ядра, но промежуточный слой до сих пор описывался лишь аппроксимацией. Прямого решения не существовало. Чтобы обойти это ограничение, исследователи применили другой подход — квантовую хромодинамику на решётке. Но и здесь не обошлось без уловки. КХД на решётке также не позволяет напрямую решать уравнения для всего объёма нейтронной звезды. Уравнения становятся решаемыми, если принять во внимание изоспин — характеристику, отличающую протоны от нейтронов знаком зарядовых состояний. Используя предложенную модель описания нейтронных звёзд, учёные установили пределы размеров этих объектов и получили новые строгие ограничения для свойств их внутренней части. Одним из выводов этой работы стало предположение, что массы нейтронных звёзд могут превышать две солнечные массы, что ранее считалось теоретическим пределом для таких объектов. Расчёты на суперкомпьютере предоставили множество интересных данных. Однако без следующего шага — подтверждения вычисленных свойств нейтронных звёзд с помощью астрофизических наблюдений — эти результаты остаются перспективной гипотезой и инструментом для поиска новых путей их изучения. И это уже немалое достижение. Nvidia представила настольный ИИ-суперкомпьютер Project Digits на суперчипе Grace Blackwell за $3000
07.01.2025 [10:23],
Андрей Созинов
Nvidia представила персональный ИИ-суперкомпьютер. В мае этого года компания начнёт продажи системы под названием Project Digits, в основе которой лежит новый суперчип GB10 Grace Blackwell. Он обладает достаточной вычислительной мощностью для запуска сложных моделей ИИ (LLM) и при этом достаточно компактен, чтобы поместиться на столе и работать от стандартной розетки. Ранее для такой вычислительной мощности требовались гораздо более крупные и энергоёмкие системы. 
Источник изображений: Nvidia «ИИ станет основным в каждом приложении для каждой отрасли. Благодаря Project Digits суперчип Grace Blackwell станет доступен миллионам разработчиков, — заявил генеральный директор Nvidia Дженсен Хуанг (Jensen Huang). — Размещение суперкомпьютера ИИ на столах каждого специалиста по обработке данных, исследователя ИИ и студента даст им возможность участвовать в формировании эпохи ИИ». Система Project Digits, размером с традиционный настольный мини-ПК вроде Mac mini, может работать с моделями ИИ, содержащими до 200 миллиардов параметров, а её стартовая цена составляет 3000 долларов. Для ещё более требовательных приложений две системы Project Digits могут быть объединены для работы с моделями, содержащими до 405 миллиардов параметров (лучшая модель Meta✴, Llama 3.1, как раз имеет 405 миллиардов параметров). 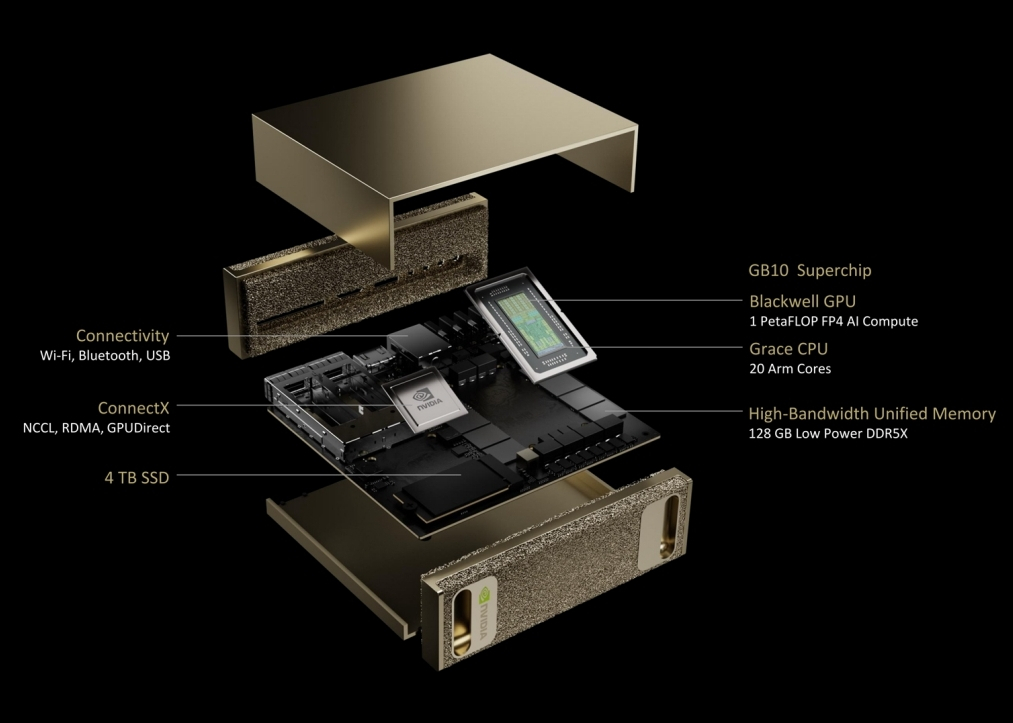 Чип GB10 Grace Blackwell обеспечивает производительность до 1 петафлопа с точностью FP4, то есть он способен выполнять 1 квадриллион операций в секунду для обучения и запуска ИИ-моделей. Система оснащена графическим процессором с ядрами Nvidia CUDA последнего поколения и тензорными ядрами пятого поколения. Он подключён через NVLink-C2C к центральному процессору Grace с 20 энергоэффективными ядрами на архитектуре Arm. В разработке GB10 участвовала компания MediaTek, помогая оптимизировать энергоэффективность и производительность. Каждая система оснащается 128 Гбайт унифицированной когерентной оперативной памяти и до 4 Тбайт NVMe-накопителя. Пользователи также получат доступ к библиотеке программного обеспечения Nvidia для ИИ, включая наборы для разработки, инструменты оркестрации и предварительно обученные модели, доступные в каталоге Nvidia NGC. Система работает на базе Linux Nvidia DGX OS и поддерживает такие популярные фреймворки, как PyTorch, Python и Jupyter Notebooks. Разработчики могут настраивать модели с помощью фреймворка Nvidia NeMo и ускорять рабочие процессы в области науки о данных с помощью библиотек Nvidia RAPIDS.  Пользователи могут разрабатывать и тестировать свои модели ИИ локально на Project Digits, а затем развёртывать их в облачных сервисах или инфраструктуре центров обработки данных, которые используют ту же архитектуру Grace Blackwell и программную платформу Nvidia AI Enterprise. Заметим, что это далеко не первый «потребительский» ИИ-суперкомпьютер Nvidia. В декабре компания анонсировала версию своего компьютера Jetson за 249 долларов для приложений ИИ, ориентированную на любителей и стартапы, под названием Jetson Orin Nano Super, который способен справляться с LLM до 8 миллиардов параметров. Китай засекретил новые суперкомпьютеры и делает вид, что не развивается в этой сфере
28.12.2024 [13:27],
Павел Котов
Китайское компьютерное общество (Chinese Society of Computer Science) опубликовало список сотни самых производительных суперкомпьютеров в стране, который, возможно, не отражает истинного положения вещей. Как и в прошлом году, в него не попали системы экзафлопсного класса; более того, в нём не оказалось новых систем по сравнению с прошлогодней редакцией. 
Источник изображения: Top500.org Единственным отличием списков сотни мощнейших суперкомпьютеров Китая за 2023 и 2024 годы стал некоторый рост их совокупной производительности. Китайские организации могут намеренно скрывать сведения о самых мощных системах, чтобы не провоцировать новых санкций со стороны США. В тройке лидеров сейчас оказались те же суперкомпьютеры с центральными и графическими процессорами, что и в 2023 году. Первое место, по официальной версии, принадлежит машине, развёрнутой в 2023 году, — у неё 15 974 400 ядер центрального процессора и производительность до 487,94 Пфлопс в тесте Linpack. Она мощнее японского суперкомпьютера Fugaku (442 Пфлопс, FP64), но значительно уступает экзафлопсным американцам El Capitan (1,742 Эфлопс), Frontier (1,353 Эфлопс) и Aurora (1,012 Эфлопс). Вторым стал суперкомпьютер, запущенный в 2022 году — у него 460 000 ядер центрального процессора и 208,26 Пфлопс; третьей оказалась система на 285 000 ядер центрального процессора и производительностью 125,04 Пфлопс по версии Linpack. Разница в совокупной производительности в официальных списках сотни наиболее мощных суперкомпьютеров минимальна: в 2023 году она была 1,398 Эфлопс, а в 2024 году выросла до 1,406 Эфлопс. Но ещё в прошлом году эксперт в области суперкомпьютеров Джек Донгарра (Jack Dongarra) заявил, что в Китае есть по крайней мере три машины экзафлопсного класса с производительностью от 1,3 до 1,7 Эфлопс, а также машина на 2 Эфлопс с x86-процессорами Hygon. Официальных подтверждений информации не последовало, но слова господина Донгарры в отрасли воспринимаются всерьёз. Информация об этих системах и спецификации машин из официального рейтинга не публикуются, вероятно, чтобы скрыть поставщиков компонентов для суперкомпьютеров. Аналитики, как правило, достаточно проницательны, чтобы установить, какое оборудование может использоваться, и кто может его поставлять — есть версия, что в этих системах установлены стандартные компоненты, и многие из них поставляются по «серым» каналам в обход американских санкций. Но в десятке лидеров есть и системы на процессорах и графических ускорителях китайской разработки. Суперкомпьютеру Илона Маска выделили 150 МВт — теперь он заработает почти во всю мощь
24.12.2024 [16:18],
Павел Котов
Американская федеральная корпорация TVA (Tennessee Valley Authority) одобрила выделение суперкомпьютеру Colossus компании xAI Илона Маска (Elon Musk) мощности в 150 МВт, что позволит запустить объект почти в полную силу. 
Источник изображения: x.com/xai Вычислительный кластер для систем искусственного интеллекта xAI Colossus сможет запустить почти все свои 100 000 ускорителей Nvidia — ранее число работающих компонентов ограничивалось доступной для предприятия мощностью. Огромный запрос объекта на электричество вызывал обеспокоенность у местных заинтересованных сторон относительно воздействия на энергосистему всего региона. Компания Илона Маска xAI впервые запустила суперкомпьютер в июле 2024 года, и уже тогда ему требовалось значительно больше энергии, чем было доступно — первоначально было выделено лишь 8 МВт. Команда Маска попыталась восполнить пробел, используя собственные источники питания, и ещё до конца лета местная ресурсоснабжающая компания Memphis Light, Gas & Water (MLGW) модернизировала действующую подстанцию, чтобы обеспечить объекту 50 МВт, но и этого было мало. Для одновременного запуска всех 100 000 ИИ-ускорителей требуется примерно 155 МВт мощности, то есть с выделенной властями квотой его потребности будут почти удовлетворены. MLGW и TVA провели работу с местными жителями и заверили их, что возросший уровень энергопотребления со стороны объекта xAI не окажет отрицательного влияния на надёжность электроснабжения в районе Мемфиса. Гендиректор MLGW Дуг Макгоуэн (Doug McGowen) отметил, что при новой квоте мощность остаётся в пределах прогнозируемой пиковой нагрузки компании, и в случае необходимости у TVA будет закуплена дополнительная мощность. Чтобы удовлетворить возросшие с развитием отрасли ИИ потребности в электроэнергии, крупные технологические компании, включая Amazon, Google, Microsoft и Oracle, начали вкладываться в альтернативные источники, в том числе в ядерную энергетику. Однако последняя сможет быть развернута не менее чем через пять лет. До этого времени потребителям придётся использовать для питания центров обработки данных существующую инфраструктуру, что вызывает опасения по поводу её способности справляться с растущим спросом. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






