|
Опрос
|
реклама
Быстрый переход
Суперкомпьютер Aurora на Intel не смог стать самым мощным в мире — лидером остался Frontier на AMD
13.05.2024 [18:29],
Николай Хижняк
Суперкомпьютер Aurora на базе процессоров Intel не смог обогнать суперкомпьютер Frontier на базе чипов AMD в свежем рейтинге самых быстрых суперкомпьютеров в мире Top500, заняв в нём второе место. Однако Aurora вырвался в лидеры в бенчмарке HPL-MxP, предназначенном для оценки ИИ-производительности. Таким образом, Aurora является самым быстрым ИИ-суперкомпьютером в мире с производительностью 10,6 AI Эфлопс. 
Источник изображения: Argonne National Laboratory Суперкомпьютер Aurora по-прежнему не может работать в полную силу. Сообщается, что машина сталкивается с различными проблемами в работе комплектующих, системы охлаждения, рабочими ошибками и нестабильностью сетевой инфраструктуры. Aurora был анонсирован девять лет назад. В первой итерации систему так и не собрали. Вторая версия суперкомпьютера была анонсирована пять лет назад, а последние компоненты машины были установлены лишь 11 месяцев назад. Суперкомпьютер Aurora разделён на 10 624 кластеров, в которых совокупно содержатся 21 248 центральных и 63 744 графических процессоров. Согласно последним данным, Аргоннская национальная лаборатория (ANL), в которой установлен этот суперкомпьютер, снова не смогла оценить весь потенциал его производительности в тесте Linpack, на результатах которого составляется рейтинг самых мощных суперкомпьютеров в мире Top500. При работе 87 % компонентов Aurora (9234 активных кластеров из 10 624 имеющихся) Aurora продемонстрировал производительность на уровне 1,012 Эфлопс, преодолев экзафлопсный барьер быстродействия. Это закрепило его на втором месте в списке Top500. Первое участие Aurora в рейтинге производительности состоялось шесть месяцев назад. Тогда у суперкомпьютера работала лишь половина из имеющихся вычислительных блоков, что позволило ему продемонстрировать результат в 585,34 Пфлопс. 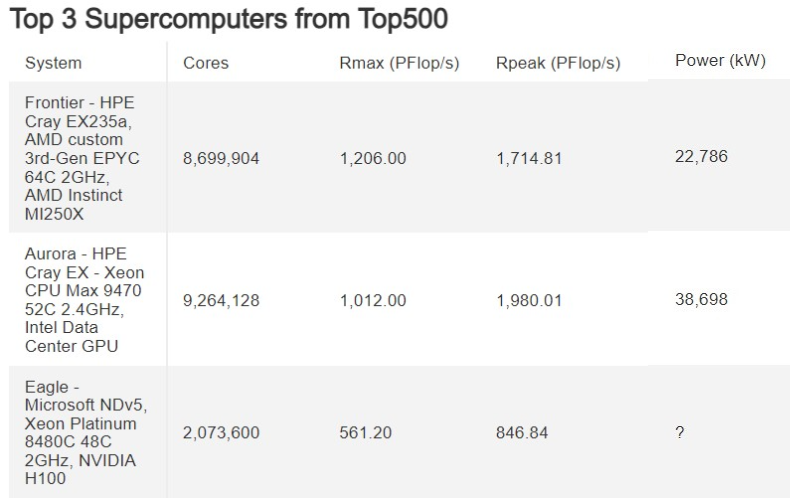
Источник изображения: Tom's Hardware Предполагается, что при полной мощности Aurora будет быстрее Frontier в вычислительном тесте производительности Linpack. Однако суперкомпьютеру ещё требуется дополнительная настройка для соответствия заявленным характеристикам. В настоящий момент Frontier с результатом 1,206 Эфлопс примерно на 19 % быстрее Aurora. Однако, как пишет Tom’s Hardware, с учётом линейной масштабируемости Aurora по-прежнему не смог бы выиграть у Frontier даже после задействования его неиспользовавшихся 13 % вычислительных блоков. 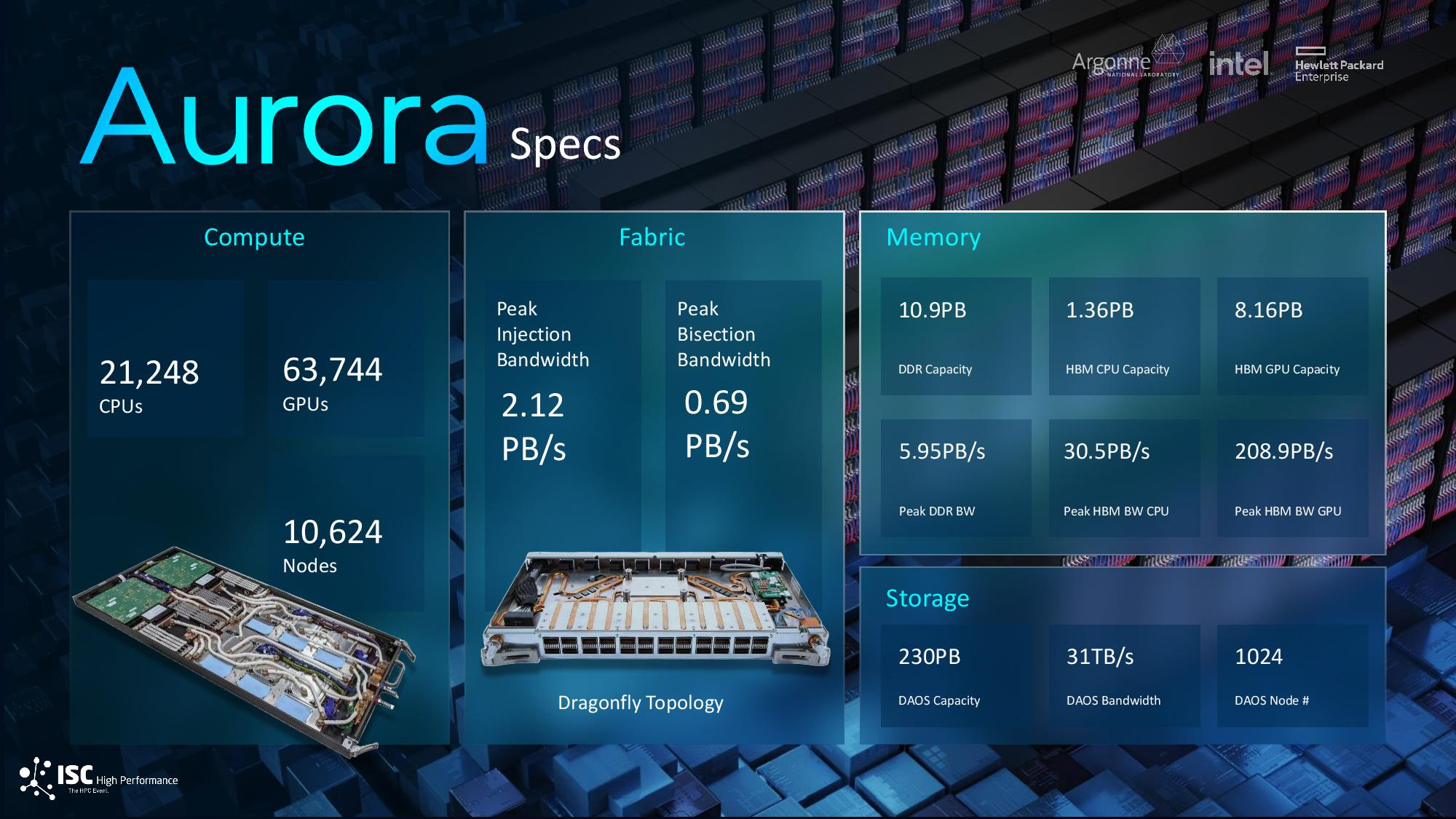 Intel широко расхваливала теоретическую пиковую производительность Aurora на уровне 2 Эфлопс (Rpeak), но производительность суперкомпьютеров измеряются показателем устойчивой производительности (Rmax). Frontier обеспечивает 70 % от своей пикового быстродействия в виде устойчивой производительности в Linpack, тогда как у Aurora показатель устойчивой производительности составляет 51 % от пиковой. Возможно, в будущем после всех необходимых доработок ситуация изменится в лучшую сторону. В Аргоннской национальной лаборатории надеются, что это рано или поздно произойдёт. Там отмечают, что для Aurora заявлен контрактный целевой показатель производительности, который выше, чем у Frontier.  И всё же Aurora удалось обогнать всех конкурентов в тесте ИИ-производительности HPL-MxP со смешанной точностью, где он продемонстрировал результат 10,6 Эфлопс при использовании 89 % своих вычислительных блоков. В этом тесте предпочтение отдаётся вычислениям более низкой точности (FP32 и FP16), чем в Linpack (FP64). Считается, что HPL-MxP лучше отражает производительность в реальных рабочих нагрузках ИИ и растущем числе других приложений, связанных с этой средой. В свою очередь FP64 в значительной степени отражает производительность систем, связанных с научными вычислениями. Однако лидерство Aurora в HPL-MxP может быть подорвано уже в ближайшее время. На горизонте маячит суперкомпьютер Alps Швейцарского национального компьютерного центра (CSCS) на базе суперчипов Nvidia Grace Hopper. Данная система пока не участвовала в рейтинге, однако для неё заявляется ИИ-производительность на уровне 20 Эфлопс. Ожидается, все 10 752 суперчипа Grace Hopper будут установлены на неё к концу июня текущего года. 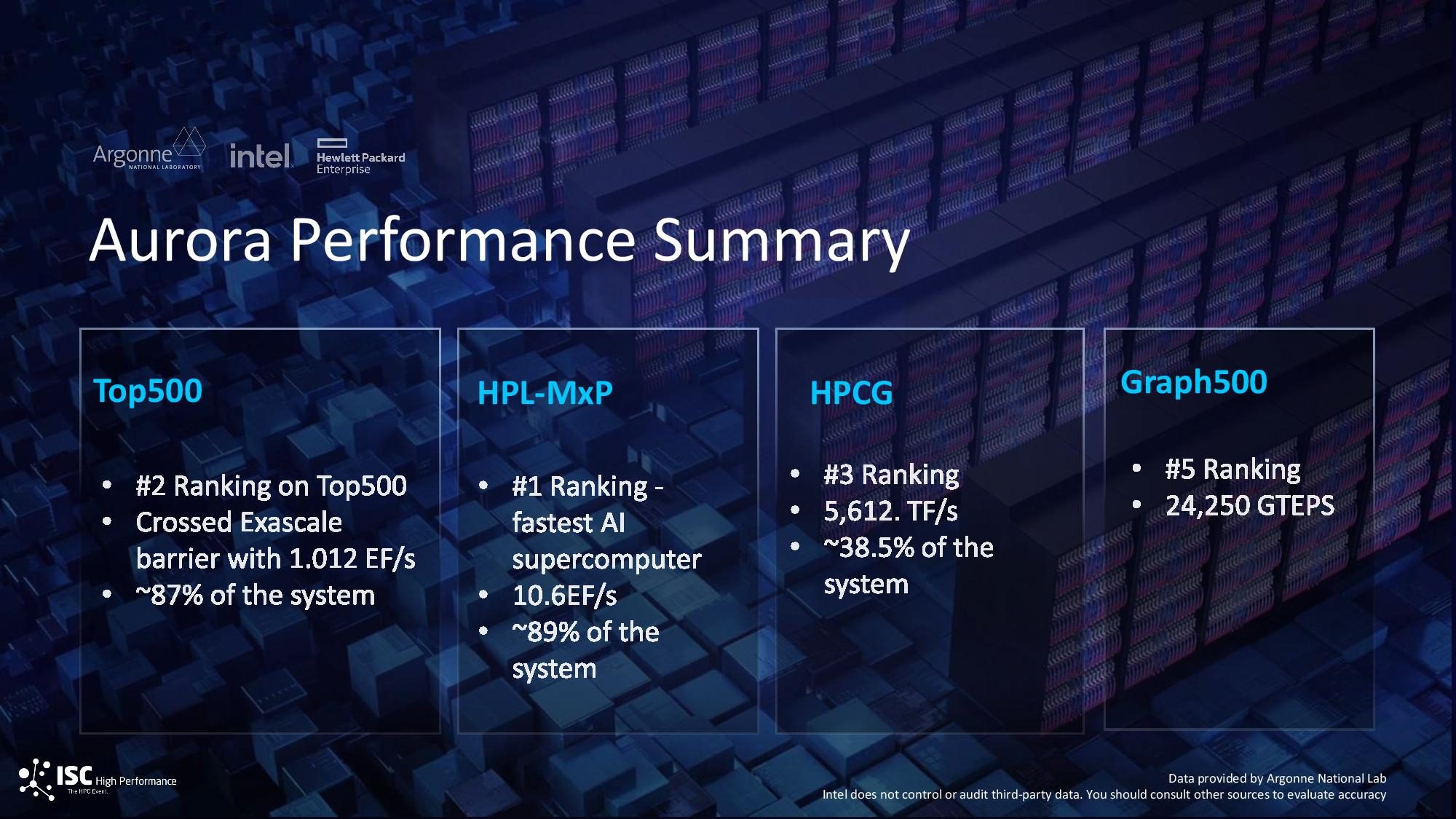 В тесте HPCG (High Performance Conjugate Gradients), также более репрезентативном для приложений с реальными рабочими нагрузками, чем Linpack, суперкомпьютер Aurora тоже продемонстрировал впечатляющую эффективность. С учётом работы всего 38,5 % от общего числа вычислительных блоков он занял третье место в данном тесте. В бенчмарке Graph500, предназначенном для оценки производительности систем в работе с большими наборами данных, Aurora занял пятое место. Правда, здесь ANL не указала, какой объём системы использовался для этого теста. Aurora не попал в список самых энергоэффективных суперкомпьютеров Green500, и это совсем неудивительно. Его пиковое энергопотребление составляет до 60 МВт, что вдвое больше энергопотребления Frontier (29 МВт). С момента установки последних блоков оборудования, входящих в состав Aurora, прошло 10 месяцев. Однако система до сих пор не заработала в полную силу. За прояснением ситуации Tom’s Hardware обратился в Intel. «Поскольку мы завершили поставку последнего вычислительного узла в конце июня 2023 года (10 месяцев назад), сейчас мы работаем с Аргоннской национальной лабораторией и HPE над полной стабилизацией и настройкой системы, вычислительных узлов, системой хранения данных, коммутационной структурой, системой электропитания и системой охлаждения. Мы также активно работаем над решением проблем стабильности, проявляющихся в аппаратных сбоях, ошибках программного обеспечения, неисправностях системы охлаждения, проблемах с электропитанием, стабильностью сетевой инфраструктуры, операционных ошибках, а также над экологическими факторами», — отметил в разговоре с Tom's Hardware представитель Intel. Аргоннская национальная лаборатория и Intel пока не готовы говорить о том, когда Aurora станет полностью работоспособным. Частному лицу удалось купить у правительства США суперкомпьютер на 8 тысячах Xeon, причём по дешёвке
05.05.2024 [01:50],
Анжелла Марина
Суперкомпьютер Cheyenne, использовавшийся для научных исследований, продан с аукциона всего за $480 тысяч из-за поломок оборудования, хотя изначальная стоимость системы оценивалась минимум в $25 млн. Покупатель получил в своё распоряжение 8064 процессоров Intel Xeon Broadwell и 313 Тбайт оперативной памяти DDR4-2400 ECC. 
Источник изображения: @ Gsaauctions.gov На состоявшемся на днях онлайн-аукционе правительства США был продан суперкомпьютер Cheyenne по смехотворно низкой цене, что вызвало волну интереса и вопросов. Как так получилось, что многомиллионная государственная система была продана менее чем за полмиллиона долларов? Почему правительство решило избавиться от мощного вычислительного ресурса, обеспечивавшего важные научные исследования? И что новый владелец собирается делать с 8 тысячами процессоров, тоннами оперативной памяти и десятками серверных стоек? История Cheyenne началась 7 лет назад, когда правительство штата Вайоминг инвестировало десятки миллионов долларов в строительство мощного суперкомпьютера для нужд университетов и научно-исследовательских институтов. Система использовалась для моделирования погоды, изучения климатических изменений и других наукоёмких вычислений. Но за годы напряжённой работы оборудование сильно износилось и стало часто выходить из строя, из-за чего власти приняли решение о замене устаревшего Cheyenne на новый суперкомпьютер. Однако вместо утилизации старой системы чиновники решили выставить её на онлайн-аукцион. Это решение вызвало недоумение в научном сообществе. Ведь несмотря на высокую степень износа, Cheyenne всё ещё обладал колоссальной вычислительной мощностью. Согласно описанию аукциона, в суперкомпьютере отказал всего 1 % узлов, то есть десятки тысяч ядер и сотни терабайт оперативной памяти сохранили свою работоспособность. А значит, при правильном обслуживании и ремонте компьютер мог бы послужить ещё не один год. Кроме того, продажа Cheyenne по такой низкой цене, это, по мнению критиков, фактически подарок частному лицу за счет налогоплательщиков. Сумма в полмиллиона долларов даже близко не компенсирует вложенные в систему средства. Учитывая, что новый суперкомпьютер Derecho обошелся бюджету в $35-40 млн, продажа Cheyenne с 98-% дисконтом выглядит как минимум странно. Возможно, чиновники надеялись, что никто не станет тратить деньги на старую поломанную технику. Однако это оказалось не так — аукцион привлек 27 участников, а победитель заплатил почти полмиллиона. Теперь у него есть тысячи дорогущих серверных процессоров и модулей памяти, которые, например, можно перепродать по частям с большой выгодой. Выигранный на аукционе суперкомпьютер включает в себя 8064 процессора Intel Xeon E5-2697 v4 с 18 ядрами/36 потоками и частотой 2,3 ГГц, стоимость которых на eBay составляет около $50 за штуку. В сочетании с этой армадой процессоров имеется 313 ТБ оперативной памяти, распределённой между 4890 ECC-совместимыми модулями емкостью по 64 Гбайт, которые стоят около $65 за штуку на вторичном рынке. Покупатель суперкомпьютера получил также 30 серверных стоек весом в десятки тонн, которые ему придется вывезти самостоятельно, так как государство не предоставляет транспортировку в подобных случаях. TSMC начала выпускать гигантские чипы для суперкомпьютера Tesla Dojo
03.05.2024 [16:47],
Алексей Разин
Недавнее упоминание TSMC о методах производства чипов с высокой степенью интеграции для суперкомпьютера Tesla Dojo, который Tesla будет использовать для развития своих систем искусственного интеллекта, имело вполне прагматичный повод. Как стало известно на этой неделе, TSMC уже приступила к производству чипов Tesla, использующих метод упаковки CoW-SoW.  По данным тайваньских СМИ, компания TSMC уже приступила к производству чипов Dojo D1 для нужд компании Tesla. По своей вычислительной производительности они будут превосходить существующие системы более чем в 40 раз. Новая технология упаковки позволяет создавать логические процессоры в масштабе целой кремниевой пластины типоразмера 300 мм. В массовом производстве TSMC собирается освоить данный метод упаковки и интеграции к 2027 году. На одной пластине процессоры Dojo объединяются в массив размером 5 на 5 штук. До 60 микросхем памяти типа HBM могут располагаться на такой кремниевой пластине. Tesla собирается вложить в развитие суперкомпьютера Dojo в Нью-Йорке не менее $500 млн. На этом пути её мешают различные препятствия. Например, в декабре прошлого года штат компании покинули два крупных специалиста по разработке данного суперкомпьютера. Предполагается, что запуск Dojo будет иметь критическое значение для вывода на рынок роботизированного такси Tesla, формальный анонс которого намечен на 8 августа текущего года. Если суперкомпьютер Dojo расположится в Нью-Йорке, то его вычислительный компаньон, построенный на ускорителях Nvidia, будет работать рядом со штаб-квартирой компании в штате Техас. Центр обработки данных в Остине будет потреблять до 100 МВт мощности. Microsoft и OpenAI построят ИИ-суперкомпьютер Stargate за $100 миллиардов
30.03.2024 [12:19],
Павел Котов
Microsoft и OpenAI разрабатывают проект Центра обработки данных нового поколения с бюджетом $100 млрд и суперкомпьютером для искусственного интеллекта. Объекту присвоено кодовое наименование Stargate, а начало работы над ним намечено на 2028 год. 
Источник изображения: Colin Behrens / pixabay.com О масштабном совместном проекте Microsoft и OpenAI сообщил ресурс The Information и «три человека, которые участвовали в частных беседах по поводу этого предложения». Один из источников лично обсуждал вопрос с главой OpenAI Сэмом Альтманом (Sam Altman) и ознакомился с предварительными сметами расходов Microsoft: строительство нового ЦОД и ИИ-суперкомпьютера обойдётся в $100 млрд, то есть в сто раз дороже ряда наиболее крупных и мощных ЦОД на планете. План по разработке и строительству суперкомпьютеров Microsoft и OpenAI включает пять этапов — сейчас компании находятся в середине третьего, а значительная часть бюджетов двух последующих будет направлена на приобретение ИИ-ускорителей в необходимых объёмах. Четвёртый этап, о котором будет объявлено в 2026 году, включает создание суперкомпьютера для OpenAI. Пятый предполагает строительство крупнейшего на рынке суперкомпьютера Stargate с миллионами чипов для ИИ — его планируют завершить к 2030 году. В действительности расходы на объект могут превысить $115 млрд, передаёт The Information, и это втрое превышает расходы Microsoft на серверы, здания и другое оборудование в 2023 году. «Мы всегда планируем новое поколение инфраструктурных инноваций, чтобы продолжать раздвигать границы возможностей ИИ», — прокомментировал проект представитель Microsoft агентству Reuters. В конце минувшего года Microsoft представила два собственных ИИ-чипа, а Nvidia недавно анонсировала самый мощный ускоритель Blackwell B200 — он, по словам главы компании Дженсена Хуанга (Jensen Huang), обойдётся от от $30 000 до $40 000. AMD наняла бывшего директора Национальной лаборатории Ок-Ридж для продвижения ИИ-суперкомпьютеров на Instinct и EPYC
05.03.2024 [12:06],
Алексей Разин
На протяжении многих лет заказчиком строительства самых производительных суперкомпьютерных систем в США являлась Национальная лаборатория Ок-Ридж, относящаяся к Министерству энергетики США. Её бывший директор Томас Закария (Thomas Zacharia) теперь займёт пост старшего вице-президента AMD, помогая компании развивать партнёрские отношения в сфере высокопроизводительных вычислений. 
Источник изображения: AMD Об этом назначении компания AMD сообщила на текущей неделе. В пресс-релизе отдельно подчёркивается наличие у Томаса Закарии 35-летнего опыта работы в данном научно-исследовательском учреждении, который может быть полезен AMD для продвижения своих систем искусственного интеллекта на рынках разных стран. Этого ветерана отрасли компания собирается привлекать для развития частно-государственного партнёрства в сфере создания систем искусственного интеллекта. Полное наименование должности Закарии подразумевает курирование стратегических партнёрских проектов и публичной политики в данной сфере. Компания хочет сотрудничать с государственными структурами разных стран, некоммерческими организациями и компаниями, чтобы предлагать им адаптированные под нужды конкретных клиентов серверные системы, предназначенные для работы с искусственным интеллектом. Томас Закария взаимодействовал с AMD на этапе строительства суперкомпьютера Frontier, и уже тогда получил представление о технологических возможностях компании и потенциале команды управленцев. Построенный на ускорителях AMD Instinct и центральных процессорах EPYC суперкомпьютер Frontier первым в истории преодолел барьер производительности вычислений в один эксафлопс, он с мая 2022 года считается самым мощным в мире. Томас Закария получил высшее образование в Индии по профилю инженера-механика, а затем прошёл магистратуру в области материаловедения в США, и там же получил степень доктора технических наук. Путин поручил нарастить мощность отечественных суперкомпьютеров на порядок
29.02.2024 [15:55],
Владимир Фетисов
Президент России Владимир Путин поручил правительству разработать и осуществить реализацию мер, направленных на увеличение вычислительных мощностей отечественных суперкомпьютеров. Об этом было сказано во время оглашения послания Федеральному Собранию, а на официальном сайте Кремля уже опубликован список поручений, сформированный по итогам конференции «Путешествие в мир искусственного интеллекта». 
Источник изображения: pixabay.com «Правительству Российской Федерации: разработать и реализовать комплекс мер, направленных на увеличение вычислительных мощностей суперкомпьютеров, находящихся в Российской Федерации, определив конкретные параметры увеличения этих мощностей», — сказано в перечне поручений президента. Кабинет министров также должен разработать механизмы использования архивов государственных и муниципальных органов и библиотечных фондов для создания наборов данных, которые могут быть использованы на безвозмездной основе. Ответственным за исполнение поручений назначен премьер-министр России Михаил Мишустин, а доклад об исполнении поручений глава государства ждёт к 1 марта. «Так, в 2030 году совокупная мощность отечественных суперкомпьютеров должна быть увеличена не менее чем в 10 раз. Это абсолютно реалистичная задача<…> В целом, необходимо развивать всю инфраструктуру экономики данных. Я прошу правительство предложить конкретные меры поддержки компаний и стартапов, которые производят оборудование для хранения и обработки данных, а также создают программное обеспечение», — сказал Владимир Путин во время оглашения послания Федеральному Собранию. Стоит отметить, что на данный момент в суперкомпьютерный рейтинг TOP500 входит лишь семь отечественных суперкомпьютеров. Самый мощный из них, принадлежащий «Яндексу» «Червоненкис» находится на 36-м месте в рейтинге с производительностью 21,5 Пфлопс. При этом лидер рейтинга, американский экзафлопсный суперкомпьютер Frontier превосходит российскую систему по производительности более чем в 50 раз. Что касается самих поручений президента, то правительству предстоит реализовать выполнение следующих шагов:
Отметим, что в этом году в стране началась реализация национального проекта, направленного на развитие экономики на основе данных, генерируемых в цифровых системах — как бизнеса, так и государства. Этот проект является продолжением национального проекта «Цифровая экономика». Помимо прочего новая инициатива предполагает разработку программы по созданию и закупке комплектующих, а также созданию суперкомпьютеров на территории России. NVIDIA запустила девятый по мощности суперкомпьютер в мире — Eos получил 4608 ИИ-ускорителей H100
17.02.2024 [13:07],
Павел Котов
NVIDIA официально представила суперкомпьютер Eos, предназначенный для приложений искусственного интеллекта. Он оснащён 576 системами NVIDIA DGX H100, каждая из которых включает 8 ускорителей H100 — всего 4608 единиц. Системы подключены с использованием архитектуры NVIDIA Quantum-2 InfiniBand (400 Гбит/с). Также суперкомпьютер включает 1152 процессора Intel Xeon Platinum 8480C, каждый из которых предлагает 56 ядер. 
Источник изображения: nvidia.com Суперкомпьютер NVIDIA Eos предлагает производительность для ИИ-приложений в 18,4 Эфлопс (FP8), а также обеспечит около 9 Эфлопс в рассчётах FP16 и 275 Пфлопс в FP64. Компания анонсировала его почти год назад и рассказывала подробнее о нём на выставке Supercomputing 2023 в ноябре минувшего года — теперь он готов начать работу. Разработчик отмечает, что Eos способен справиться с самыми большими рабочими нагрузками в области ИИ для обучения больших языковых моделей, рекомендательных алгоритмов, квантового моделирования и многого другого. Суперкомпьютер занимает девятое место в рейтинге TOP500. Высокую производительность NVIDIA Eos обеспечивают мощные ускорители и интерфейсы компании NVIDIA, а также её ПО, такое как NVIDIA Base Command и NVIDIA AI Enterprise. «Архитектура Eos оптимизирована для рабочих нагрузок ИИ, требующих сверхмалой задержки и высокой пропускной способности соединений внутри кластера ускорителей, что делает её идеальным решением для предприятий, стремящихся масштабировать свои комплексы ИИ. В то время как корпорации и разработчики по всему миру стремятся задействовать возможности ИИ, Eos становится основным ресурсом, который обещает ускорить путь к приложениям на базе ИИ для каждой организации», — отметила NVIDIA. Мощь 52 ускорителей NVIDIA H200 за 1/100 стоимости — Tachyum начнёт массово выпускать 192-ядерные чипы Prodigy в этом году
29.01.2024 [18:31],
Николай Хижняк
Компания Tachyum сообщила, что в этом году начнёт массовое производство универсального процессора Prodigy, сочетающего вычислительные и графические ядра, а также нейродвижок TPU. Производитель обещает, что новинка обеспечит выдающийся уровень производительности и сможет потягаться с самыми мощными ускорителями вычислений NVIDIA. 
Источник изображения: Tachyum Разработчик заявляет, что её 192-ядерный чип, выполненный на основе 5-нм технологического процесса, обеспечивает в 4,5 раза более высокую производительность, чем любой другой процессор, предназначенный для вычислительных нагрузок в облачной среде. Кроме того, он до трёх раз быстрее любого GPU, предназначенного для высокопроизводительных вычислений и до шести раз энергетически эффективнее специализированных GPU для ИИ-задач. Tachyum анонсировала чип Prodigy Universal Processor в 2022 году и пообещала с его помощью трансформировать узкоспециализированные ЦОДы в универсальные компьютерные центры, способные обеспечить необходимую вычислительную мощность и эффективность для различных ИИ-нагрузок. В декабре 2023 года компания выпустила видео, показывающее способность Prodigy эмулировать работу в x86-совместимых приложениях. Однако есть одно существенное «но»: несмотря на внушительные цифры производительности и заявления Tachyum, процессоры Prodigy существуют только на бумаге и в виде эмулируемой с помощью FPGA платформы с небольшим количеством ядер. «Успехи, которых нам удалось достичь при корректировке нашего плана выпуска продуктов, привели нас к 2024 году, полному ожиданий, поскольку мы движемся к началу массового производства Prodigy и реализации многомиллиардного канала продаж. Мы с нетерпением ждём возможности выполнить наше обещание и обязательство по преобразованию обычных центров обработки данных в универсальные вычислительные центры в ближайшем будущем», — заявил генеральный директор и основатель Tachyum Радослав Данилак (Radoslav Danilak). Поскольку в составе Prodigy Universal Processor используются функциональные компоненты, предназначенные для разных типов нагрузок, он может динамически переключаться между вычислительными кластерами, исключая необходимость в использовании разнонаправленного и дорогостоящего аппаратного обеспечения для отдельных типов ИИ-нагрузок в составе вычислительной системы. По крайней мере, так говорится в свежем пресс-релизе компании. Там же заявляется, что всего один процессор Prodigy Universal Processor стоимостью $23 000 способен сравниться по производительности в задачах обучения ИИ с системой из 52 специализированных ускорителей NVIDIA H200, являющихся одними из лучших на рынке. Компания заявила, что стоимость такого количества графических процессоров в составе семи серверов Supermicro GPU составит 2 349 028 долларов или в 100 раз больше, чем одна система с Prodigy Universal Processor и 2 Тбайт оперативной памяти DDR5. Tachyum также заявила, что уже планирует разработку более передового универсального процессора Prodigy 2 на базе 3-нм техпроцесса, который получит поддержку интерфейсов PCIe 6.0 и CXL, и будет оснащаться набортной высокопроизводительной памятью HBM3. Его планируется выпустить где-то в 2026 году. Aurora на базе Intel стал вторым мощнейшим суперкомпьютером в мире — лидером остался вдвое более мощный Frontier на AMD
14.11.2023 [16:19],
Павел Котов
Проект Top500 обновил рейтинг самых быстрых суперкомпьютеров в мире. Первое место сохранила система Frontier на базе процессоров и ускорителей AMD с производительностью 1,194 Эфлопс. А вот второе место претерпело изменения. Здесь, уступив лидеру более чем вдвое, оказался основанный на чипах Intel суперкомпьютер Aurora Аргоннской национальной лаборатории (США) — он показал 585,34 Пфлопс. 
Источник изображения: intel.com Intel осуществила мощную атаку на рейтинг суперкомпьютеров, добавив в список 20 новых систем на чипах Sapphire Rapids. В то же время места в Top500 активно занимают системы на AMD EPYC — на этих процессорах работают уже 140 суперкомпьютеров в списке, а за год их число выросло на 39 %. Intel и Аргоннская лаборатория продолжают работу по расширению Aurora: на момент выхода последней версии рейтинга суперкомпьютер составляли 10 624 процессора и 31 874 графических ускорителя Intel, обеспечивших производительность в 585,34 Пфлопс при суммарной мощности 24,69 МВт. Для сравнения, лидер рейтинга в лице Frontier на чипах AMD имеет производительность в 1,194 Эфлопс, более чем двукратно опережая систему на втором месте и потребляя при этом относительно скромные 22,70 МВт энергии. Из-за этого Aurora не попал в рейтинг самых энергоэффективных суперкомпьютеров Green500, а Frontier удерживает здесь восьмое место. Ожидается, что в конечном итоге Aurora выйдет на производительность в 2 Эфлопс — её обеспечат 21 248 процессоров Xeon Max и 63 744 графических ускорителя Max Ponte Vecchio в 166 стойках и 10 624 вычислительных модулях. Это будет самый крупный массив графических процессоров в мире. Суперкомпьютер работает на узлах HPE Cray EX с сетевыми соединениями HPE Slingshot-11. Тем временем AMD занимается строительством суперкомпьютера El Capitan в Ливерморской национальной лаборатории имени Лоуренса (США), который, как ожидается, превысит показатель в 2 Эфлопс, и, возможно, Aurora уже не поднимется до первого места. 
Источник изображения: olcf.ornl.gov Впервые о суперкомпьютере Aurora было объявлено в 2015 году. Его строительство планировали завершить в 2018 году — тогда ожидалось, что он будет работать на процессорах Knights Hill, выход которых впоследствии был отменён. В 2019 году был анонсирован обновлённый проект Aurora с производительностью около 1 Эфлопс, который намеревались завершить к 2021 году. Но в конце 2021 года проектную производительность повысили до 2 Эфлопс, а сроки продлили до 2024 года. Третьим в рейтинге оказался новый суперкомпьютер Eagle (561,20 Пфлопс) от Microsoft, развёрнутый в облаке Azure — облачный суперкомпьютер обогнал прежнего серебряного лауреата в лице японского суперкомпьютера Fugaku (442,01 Пфлопс), который опустился на четвёртое место. А замкнула пятёрку финская система LUMI с 379,70 Пфлопс. Поставлена первая коммерческая система на «кремниевом мозге» IBM
30.03.2016 [14:45],
Геннадий Детинич
Компания IBM официальным пресс-релизом сообщила, что Ливерморская национальная лаборатория им. Лоуренса стала первым покупателем единственного в мире компьютера, имитирующего работу головного мозга. Уникальная система базируется на разработке IBM по созданию нейросинаптического процессора. Проект стартовал в 2008 году по заказу агентства DARPA. Ожидалось, что IBM создаст процессор, способный на оперативный анализ данных на поле боя. Процессор должен был работать по алгоритмам, имитирующим работу головного мозга. Соответственно, в основе разработки лежит архитектура, отличная от классической неймановской логики. 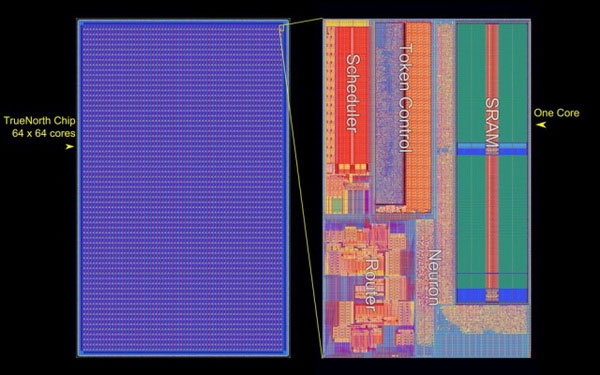
Структура кристалла процессора IBM TrueNorth (IBM) После серии изысканий в 2011 году компания IBM представила процессор TrueNorth. Решение выпускалось с использованием 45-нм техпроцесса SOI-CMOS и содержало 256 аналогов нейронов. Кроме этого одно ядро содержало 262 тысяч программируемых аналогов синапсов, а в другом находились 65 тысяч обучаемых синапсов. Естественно, все эти «нейроны и синапсы» представляли собой электронные цепи из обычных кремниевых транзисторов, но связанных между собой специальной логикой по типу ячеистых сетей. 
Процессор IBM TrueNorth второго поколения (IBM) Второе поколение процессоров TrueNorth вышло в 2014 году. Производством процессора с использованием 28-нм техпроцесса занималась компания Samsung. Новый процессор включал уже один миллион цифровых нейронов и 256 млн программируемых синапсов. При всём этом процессор TrueNorth — это чип с 5,4 млрд транзисторов. Что поразительно, довольно большое число транзисторов не сказалось на потреблении процессора. В ходе вычислений с производительностью 46 млрд синаптических операций в секунду процессор потребляет всего 70 милливатт (0,8 вольт). Ливерморской лаборатории передан компьютер на базе 16 таких процессоров и его потребление составляет всего 2,5 Вт — как у планшета. 
16-ядерная система на «когнитивных» процессорах IBM TrueNorth, проданная Ливерморской лаборатории Кроме компьютера компания IBM включила в поставку набор необходимого программного обеспечения как для работы системы, так и для разработки программ. Ожидается, что имитирующий работу мозга компьютер поможет решить ряд сложных для традиционной логики задач. В лаборатории не скрывают, что основным направлением деятельности с использованием «познающей» системы станет изучение проблем по заказам Национальной администрации по ядерной безопасности (National Nuclear Security Administration), которая занимается широким спектром вопросов контроля над распространением ядерного вооружения. Также в лаборатории будут прорабатывать варианты создания суперкомпьютеров будущего с 50-кратно увеличенной производительностью по отношению к современным системам. 
Ведущий разработчик «когнитивного» процессора IBM, Дхармендра Модха (Dharmendra S. Modha) Кстати, по неофициальным данным, которые приводит сайт The Wall Street Journal, система IBM обошлась лаборатории всего в один млн долларов США. В принципе, неплохо для IBM за систему с 16-ядерным процессором. Компаниям Intel и AMD такое даже не снилось. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






