|
Опрос
|
реклама
Быстрый переход
AMD представила мощнейший ИИ-ускоритель MI325X с 288 Гбайт HBM3e и рассказала про MI350X на архитектуре CDNA4
03.06.2024 [12:22],
Николай Хижняк
Компания AMD представила на выставке Computex 2024 обновлённые планы по выпуску ускорителей вычислений Instinct, а также анонсировала новый флагманский ИИ-ускоритель Instinct MI325X. 
Источник изображений: AMD Ранее компания выпустила ускорители MI300A и MI300X с памятью HBM3, а также несколько их вариаций для определённых регионов. Новый MI325X основан на той же архитектуре CDNA 3 и использует ту же комбинацию из 5- и 6-нм чипов, но тем не менее представляет собой существенное обновление для семейства Instinct. Дело в том, что в данном ускорителе применена более производительная память HBM3e.  Instinct MI325X предложит 288 Гбайт памяти, что на 96 Гбайт больше, чем у MI300X. Что ещё важнее, использование новой памяти HBM3e обеспечило повышение пропускной способности до 6,0 Тбайт/с — на 700 Гбайт/с больше, чем у MI300X с HBM3. AMD отмечает, что переход на новую память обеспечит MI325X в 1,3 раза более высокую производительность инференса (работа уже обученной нейросети) и генерации токенов по сравнению с Nvidia H200.  Компания AMD также предварительно анонсировала ускоритель Instinct MI350X, который будет построен на чипе с новой архитектурой CDNA 4. Переход на эту архитектуру обещает примерно 35-кратный прирост производительности в работе обученной нейросети по сравнению с актуальной CDNA 3. 
 Для производства ускорителей вычислений MI350X будет использоваться передовой 3-нм техпроцесс. Instinct MI350X тоже получат до 288 Гбайт памяти HBM3e. Для них также заявляется поддержка типов данных FP4/FP6, что принесёт пользу в работе с алгоритмами машинного обучения. Дополнительные детали об Instinct MI350X компания не сообщила, но отметила, что они будут выпускаться в формфакторе Open Accelerator Module (OAM). 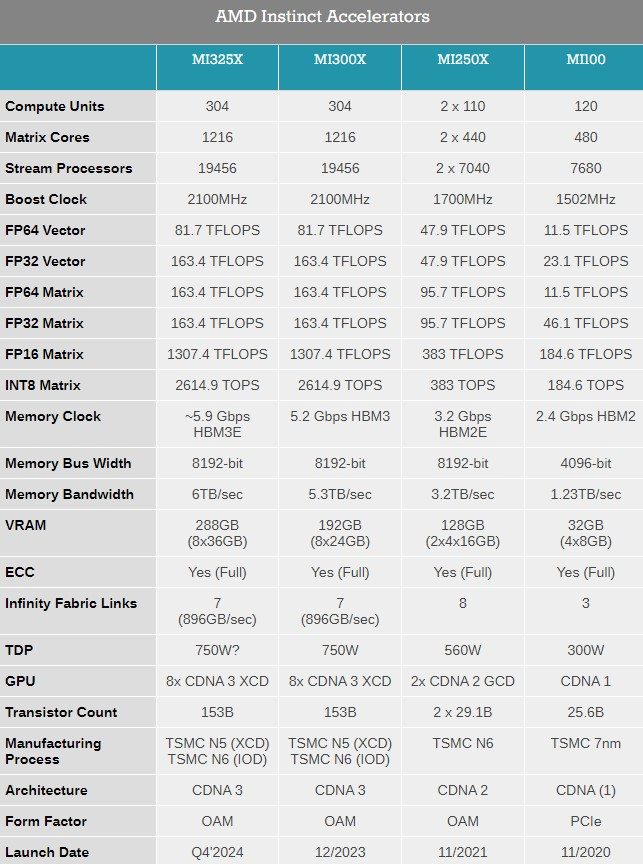
Источник изображения: AnandTech ИИ-ускорители Instinct MI325X начнут продаваться в четвёртом квартале этого года. Выход MI350X ожидается в 2025 году. Кроме того, AMD сообщила, что ускорители вычислений серии MI400 на архитектуре CDNA-Next будут представлены в 2026 году. Акции Nvidia упали на 10 % по сравнению с недавним историческим максимумом
10.04.2024 [19:50],
Сергей Сурабекянц
Nvidia вступила на «территорию коррекции»: её акции упали на 10 % по сравнению с последним историческим максимумом в $950 за акцию. Во вторник торги закрылись на отметке $853,54, падение за сессию составило 2 %. Аналитики связывают снижение стоимости акций Nvidia c представленным накануне компанией Intel ИИ-ускорителем Gaudi 3, «сокращением» моделей ИИ и перенаправлением инвестиций крупных клиентов на разработку собственного оборудования для ИИ. 
Источник изображения: Nvidia Nvidia за последние годы стала ключевым бенефициаром бума искусственного интеллекта благодаря ажиотажному спросу на её чипы, предназначенные для ресурсоёмких приложений ИИ. Ускорители компании являются ключевым компонентом множества центров обработки данных. Nvidia сообщила о росте в четвёртом квартале разводненной прибыли на акцию (non-GAAP) на 486 % благодаря беспрецедентной популярности генеративных моделей искусственного интеллекта. Однако последние две недели акции компании находятся под давлением. Падение курса ценных бумаг составило 10 % по сравнению с последним историческим максимумом, которого они достигли 25 марта. Сегодня акции Nvidia торговались с понижением на 0,7 % по состоянию на 9:45 утра по времени восточного побережья США (16:45 мск). Финансовые эксперты советуют инвесторам фиксировать прибыль, которая может составить более чем 200 % за последние 12 месяцев. 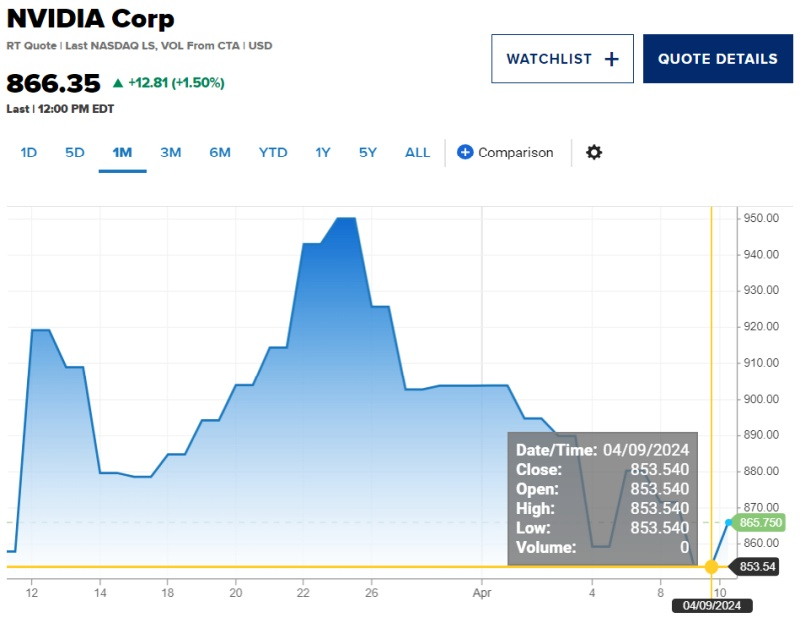
Источник изображения: cnbc.com Одной из возможных причин понижения курса акций Nvidia аналитики называют «сокращение» моделей искусственного интеллекта, включая альтернативы, такие как большая модель Mistral и система LLaMA от Meta✴. «Сочетание сокращения моделей, более устойчивого роста спроса, зрелых инвестиций в гиперскейлеры и растущего использования крупнейшими клиентами собственных чипов не сулит ничего хорошего для Nvidia в ближайшие годы», — полагают эксперты аналитической компании D.A. Davidson. Конкуренция в сфере ускорителей вычислений нарастает. Во вторник компания Intel представила свой новый чип для ускорения искусственного интеллекта под названием Gaudi 3. По утверждению компании, новый чип более чем в два раза энергоэффективнее, чем H100 — самый популярный из ныне выпускаемых ускорителей Nvidia, и может запускать модели искусственного интеллекта в 1,5 раза быстрее, чем H100. Хотя консенсус-оценки говорят о том, что спрос на графические процессоры Nvidia для технологий искусственного интеллекта в этом году будет высоким, в 2025 году ожидается замедление роста, а в 2026 году аналитики предрекают значительный спад для Nvidia, так как крупные покупатели чипов искусственного интеллекта, такие как Amazon и Microsoft, вероятно, направят большую часть своих инвестиций в собственное оборудование. Intel представила ИИ-ускорители Gaudi 3, которые громят NVIDIA H100 по производительности и энергоэффективности
09.04.2024 [23:06],
Владимир Чижевский
Сегодня на мероприятии Vision 2024 компания Intel представила множество новых продуктов, среди которых ИИ-ускорители Gaudi 3. По заявлениям создателей, они позволяют обучать нейросети в 1,7 раза быстрее, на 50 % увеличить производительность инференса и работают на 40 % эффективнее конкурирующих H100 от NVIDIA, которые являются самыми популярными на рынке. 
Источник изображений: Intel Gaudi 3 — третье поколение ускорителей ИИ, появившихся благодаря приобретению Intel в 2019 году компании Habana Labs за $2 млрд. Массовое производство Gaudi 3 для OEM-производителей серверов начнётся в третьем квартале 2024 года. Помимо этого, Gaudi 3 будет доступен в облачном сервисе Intel Developer Cloud для разработчиков, что позволит потенциальным клиентам испытать возможности нового чипа.  Gaudi 3 использует ту же архитектуру и основополагающие принципы, что и его предшественник, но при этом он выполнен по более современному 5-нм техпроцессу TSMC, тогда как в Gaudi 2 использованы 7-нм чипы. Ускоритель состоит из двух кристаллов, на которые приходится 64 ядра Tensor Processing Cores (TPC) пятого поколения и восемь матричных математических движков (MME), а также 96 Мбайт памяти SRAM с пропускной способностью 12,8 Тбайт/с. Вокруг установлено 128 Гбайт HBM2e с пропускной способностью 3,7 Тбайт/с. Также Gaudi 3 укомплектован 24 контроллерами Ethernet RDMA с пропускной способностью по 200 Гбит/с, которые обеспечивают связь как между ускорителями в одном сервере, так и между разными серверами в одной системе.  Gaudi 3 будет выпускаться в двух формфакторах. Первый — OAM (модуль ускорителя OCP) HL-325L, использующийся в высокопроизводительных системах на основе ускорителей вычислений. Этот ускоритель получит TDP 900 Вт и производительность 1835 терафлопс в FP8. Модули OAM устанавливаются по 8 штук на UBB-узел HLB-325, которые можно объединять в системы до 1024 узлов. По сравнению с прошлым поколением, Gaudi 3 обеспечивает вдвое большую производительность в FP8 и вчетверо — в BF16, вдвое большую пропускную способность сети и 1,5 раза — памяти.  OAM устанавливаются в универсальную плату, поддерживающую до восьми модулей. Модули и платы уже отгружены партнёрам, но массовые поставки начнутся лишь к концу года. Восемь OAM на плате HLB-325 дают производительность 14,6 петафлопс в FP8, остальные характеристики масштабируются линейно.  Второй формфактор — двухслотовая карта расширения PCIe с TDP 600 Вт. По заявлениям Intel, несмотря на заметно меньший TDP этой версии, производительность в FP8 осталась той же — 1835 терафлопс. А вот масштабируемость хуже — модули рассчитаны на работу группами по четыре. Gaudi 3 в данном формфакторе появятся в 4 квартале 2024 года. Dell, HPE, Lenovo и Supermicro уже поставили клиентам образцы систем с Gaudi 3 с воздушным охлаждением, а в ближайшее время должны появится модели с жидкостным охлаждением. Массовое производство начнётся лишь в 3 и 4 кварталах 2024 года соответственно. 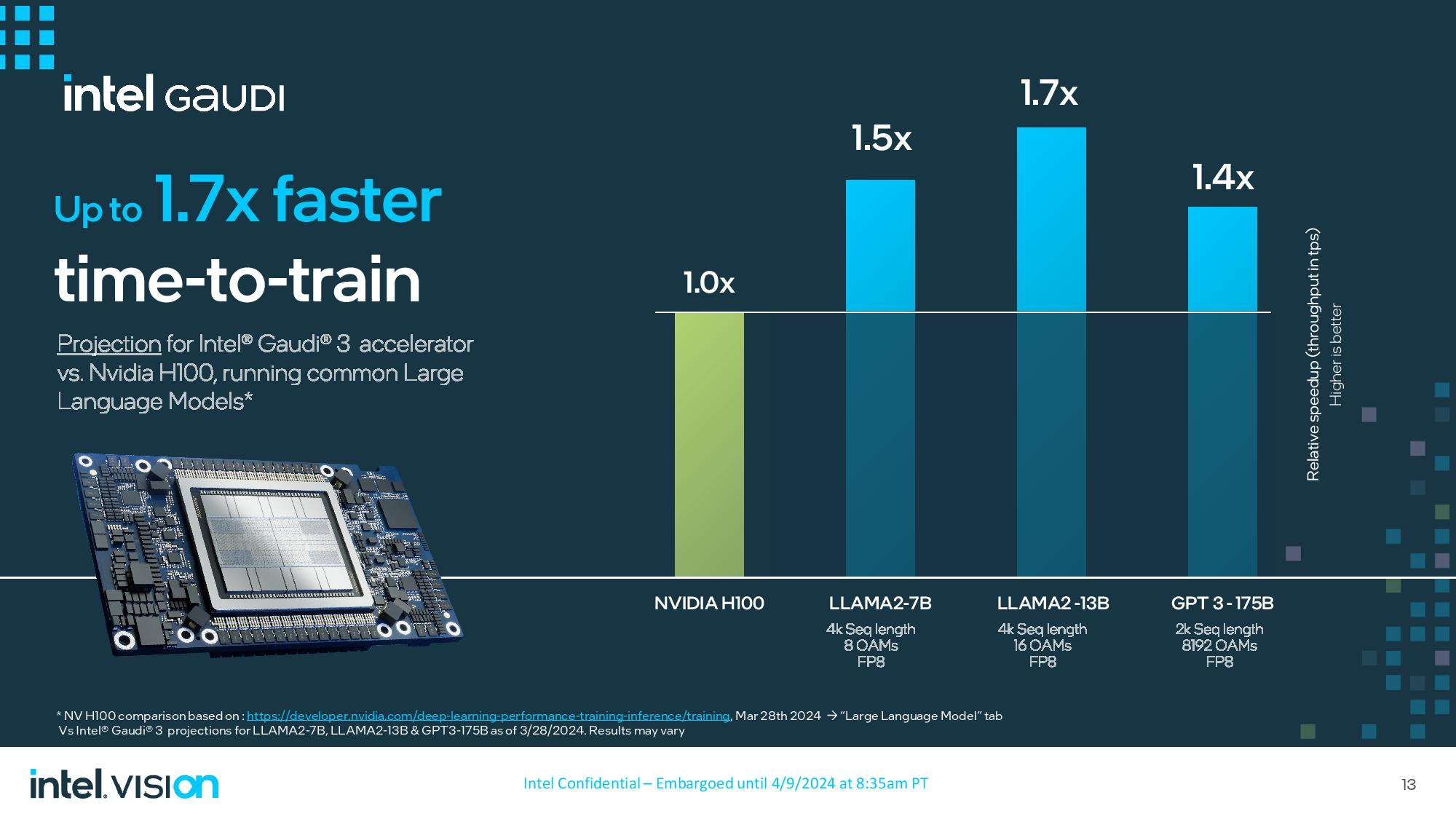 Intel также поделилась собственными тестами производительности, сравнив Gaudi 3 с системами на основе H100. По словам Intel, Gaudi 3 справляется с обучением нейросетей в 1,5–1,7 раза быстрее. Сравнение велось на моделях LLAMA2-7B и LLAMA2-13B на системах с 8 и 16 ускорителями, а также на модели GPT 3-175B на системе с 8192 ускорителями. Intel не стала сравнивать системы на Gaudi 3 с системами на H200 от NVIDIA, у которого на 76 % больше памяти, а её пропускная способность выше на 43 %. 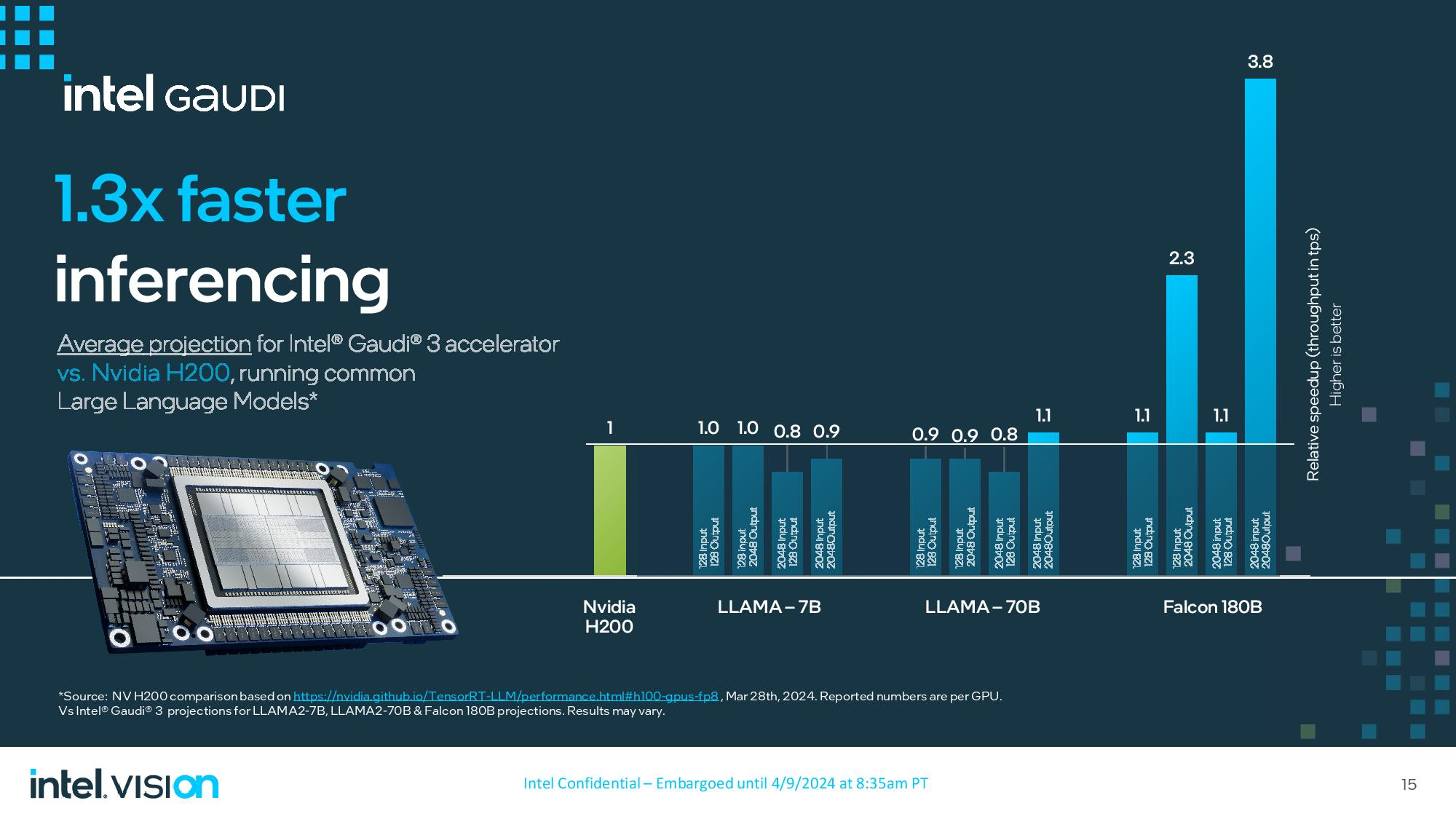 Intel сравнила Gaudi 3 с H200 в инференсе, но уже не кластерами, а отдельным модулем. В пяти тестах с LLAMA2-7B/70B производительность Gaudi 3 оказалась на 10–20 % ниже, в двух равна и в одном чуть выше H200. При этом Intel заявляет о 2,6-кратном преимуществе в энергопотреблении по сравнению с H100. NVIDIA представила самый мощный чип в мире — Blackwell B200, который откроет путь к гигантским нейросетям
19.03.2024 [00:12],
Андрей Созинов
Компания Nvidia в рамках конференции GTC 2024 представила ИИ-ускорители следующего поколения на графических процессорах с архитектурой Blackwell. По словам производителя, грядущие ИИ-ускорители позволят создавать ещё более крупные нейросети, в том числе работать с большими языковыми моделями (LLM) с триллионами параметров, и при этом будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. 
Источник изображений: Nvidia Архитектура GPU Blackwell получила название в честь американского математика Дэвида Блэквелла (David Harold Blackwell) и включает в себя целый ряд инновационных технологий для ускорения вычислений, которые помогут совершить прорыв в обработке данных, инженерном моделировании, автоматизации проектирования электроники, компьютерном проектировании лекарств, квантовых вычислениях и генеративном ИИ. Причём на последнем в Nvidia делают особый акцент: «Генеративный ИИ — это определяющая технология нашего времени. Графические процессоры Blackwell — это двигатель для новой промышленной революции», — подчеркнул глава Nvidia Дженсен Хуанг (Jensen Huang) в рамках презентации. Графический процессор Nvidia B200 производитель без лишней скромности называет самым мощным чипом в мире. В вычислениях FP4 и FP8 новый GPU обеспечивает производительность до 20 и 10 Пфлопс соответственно. Новый GPU состоит из двух кристаллов, которые произведены по специальной версии 4-нм техпроцесса TSMC 4NP и объединены 2,5D-упаковкой CoWoS-L. Это первый GPU компании Nvidia с чиплетной компоновкой. Чипы соединены шиной NV-HBI с пропускной способностью 10 Тбайт/с и работают как единый GPU. Всего новинка насчитывает 208 млрд транзисторов. 
Один из кристаллов Blackwell — в GPU таких кристаллов два По сторонам от кристаллов GPU расположились восемь стеков памяти HBM3E общим объёмом 192 Гбайт. Её пропускная способность достигает 8 Тбайт/с. А для объединения нескольких ускорителей Blackwell в одной системе новый GPU получил поддержку интерфейса NVLink пятого поколения, которая обеспечивает пропускную способность до 1,8 Тбайт/с в обоих направлениях. С помощью данного интерфейса (коммутатор NVSwitch 7.2T) в одну связку можно объединить до 576 GPU. Одними из главных источников более высокой производительности B200 стали новые тензорные ядра и второе поколение механизма Transformer Engine. Последний научился более тонко подбирать необходимую точность вычислений для тех или иных задач, что влияет и на скорость обучения и работы нейросетей, и на максимальный объём поддерживаемых LLM. Теперь Nvidia предлагает тренировку ИИ в формате FP8, а для запуска обученных нейросетей хватит и FP4. Но отметим, что Blackwell поддерживает работу с самыми разными форматами, включая FP4, FP6, FP8, INT8, BF16, FP16, TF32 и FP64. И во всех случаях кроме последнего есть поддержка разреженных вычислений. 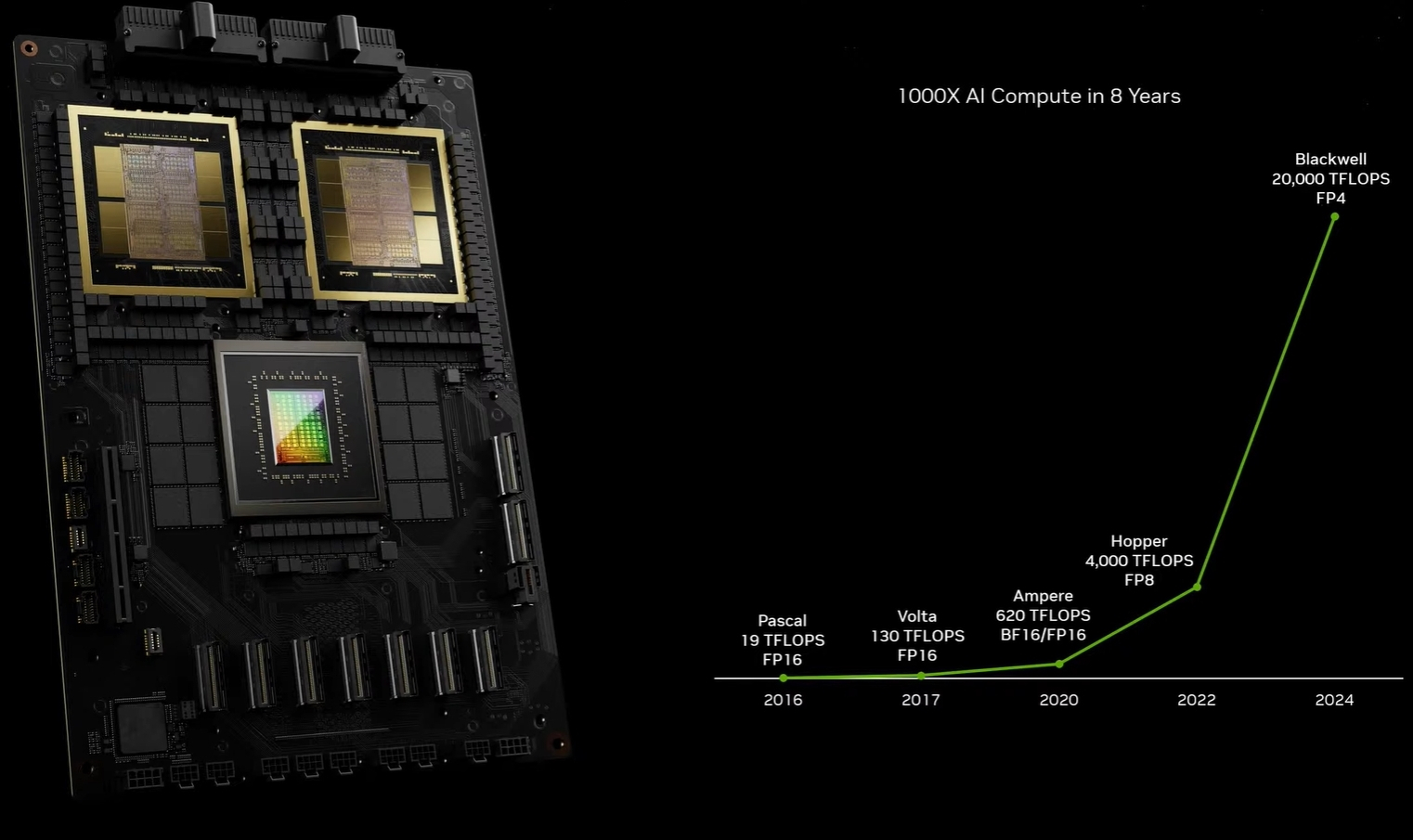 Флагманским ускорителем на новой архитектуре станет Nvidia Grace Blackwell Superchip, в котором сочетается пара графических процессоров B200 и центральный Arm-процессор Nvidia Grace с 72 ядрами Neoverse V2. Данный ускоритель шириной в половину серверной стойки обладает TDP до 2,7 кВт. Производительность в операциях FP4 достигает 40 Пфлопс, тогда как в операциях FP8/FP6/INT8 новый GB200 способен обеспечить 10 Пфлопс. Как отмечает сама Nvidia, новинка обеспечивает 30-кратный прирост производительности по сравнению с Nvidia H100 для рабочих нагрузок, связанных с большими языковыми моделями, а она до 25 раз более экономична и энергетически эффективна.  Ещё Nvidia представила систему GB200 NVL72 — фактически это серверная стойка, которая объединяет в себе 36 Grace Blackwell Superchip и пару коммутаторов NVSwitch 7.2T. Таким образом данная система включает в себя 72 графических процессора B200 Blackwell и 36 центральных процессоров Grace, соединенных NVLink пятого поколения. На систему приходится 13,5 Тбайт памяти HBM3E с общей пропускной способностью до 576 Тбайт/с, а общий объём оперативной памяти достигает 30 Тбайт.  Платформа GB200 NVL72 работает как единый GPU с ИИ-производительностью 1,4 эксафлопс (FP4) и 720 Пфлопс (FP8). Эта система станет строительным блоком для новейшего суперкомпьютера Nvidia DGX SuperPOD. 
На переднем плане HGX-система с восемью Blackwell. На заднем — суперчип GB200 Наконец, Nvidia представила серверные системы HGX B100, HGX B200 и DGX B200. Все они предлагают по восемь ускорителей Blackwell, связанных между собой NVLink 5. Системы HGX B100 и HGX B200 не имеют собственного CPU, а между собой различаются только энергопотреблением и как следствие мощностью. HGX B100 ограничен TDP в 700 Вт и обеспечивает производительность до 112 и 56 Пфлопс в операциях FP4 и FP8/FP6/INT8 соответственно. В свою очередь, HGX B200 имеет TDP в 1000 Вт и предлагает до 144 и 72 Пфлопс в операциях FP4 и FP8/FP6/INT8 соответственно. Наконец, DGX B200 копирует HGX B200 в плане производительности, но является полностью готовой системой с парой центральных процессоров Intel Xeon Emerald Rapids. По словам Nvidia, DGX B200 до 15 раз быстрее в задачах запуска уже обученных «триллионных» моделей по сравнению с предшественником.  Для создания наиболее масштабных ИИ-систем, включающих от 10 тыс. до 100 тыс. ускорителей GB200 в рамках одного дата-центра, компания Nvidia предлагает объединять их в кластеры с помощью сетевых интерфейсов Nvidia Quantum-X800 InfiniBand и Spectrum-X800 Ethernet. Они также были анонсированы сегодня и обеспечат передовые сетевые возможности со скоростью до 800 Гбит/с. Свои системы на базе Nvidia B200 в скором времени представят многие производители, включая Aivres, ASRock Rack, ASUS, Eviden, Foxconn, GIGABYTE, Inventec, Pegatron, QCT, Wistron, Wiwynn и ZT Systems. Также Nvidia GB200 в составе платформы Nvidia DGX Cloud, а позже в этом году решения на этом суперчипе станут доступны у крупнейших облачных провайдеров, включая AWS, Google Cloud и Oracle Cloud. Nvidia покажет ИИ-ускоритель нового поколения уже на следующей неделе в рамках GTC 2024
14.03.2024 [19:15],
Сергей Сурабекянц
Генеральный директор и соучредитель Nvidia Дженсен Хуанг (Jensen Huang) в понедельник 18 марта выйдет на сцену хоккейной арены Кремниевой долины, чтобы представить новые решения, включая ИИ-чипы нового поколения. Поводом для этого станет ежегодная конференция разработчиков GTC 2024, которая станет первой очной встречей такого масштаба после пандемии. Nvidia ожидает, что это мероприятие посетят 16 000 человек, что примерно вдвое превысит число посетителей в 2019-м. 
Источник изображения: Getty Images Рыночная капитализация Nvidia превысила $2 трлн в конце февраля, и теперь ей не хватает «всего» $400 млрд, чтобы превзойти Apple, которая занимает второе место по капитализации после лидера фондового рынка Microsoft. Аналитики ожидают, что выручка Nvidia в этом году вырастет на 81 % до $110 млрд, поскольку технологические компании на волне бума ИИ десятками тысяч скупают её новейшие ускорители ИИ для разработки и обучения чат-ботов, генераторов изображений и других нейросетей. Новое поколение высокопроизводительных ИИ-чипов от Nvidia, которое предположительно получит обозначение B100, должно стать основой для дальнейшего укрепления рыночных позиций компании. В рамках предстоящей GTC компания Nvidia вряд ли раскроет все характеристики и назовёт точную цену нового ускорителя, которая не в последнюю очередь зависит от размера партии и сроков поставки. Очевидно, B100 будет намного быстрее своего предшественника и, вероятно, будет стоить дороже, хотя цена актуальных H100 может превышать $20 000. Поставки нового чипа ожидаются позднее в этом году. 
Источник изображений: Nvidia Спрос на текущие ускорители Nvidia превысил предложение: разработчики программного обеспечения месяцами ждут возможности использовать кластеры ускорителей ИИ у облачных провайдеров. Реагируя на высокий спрос, акции Nvidia выросли на 83 % в этом году после более чем утроения их стоимости в прошлом. И даже после этого стремительного роста акции Nvidia торгуются с прибылью, в 34 раза превышающей ожидаемую. Аналитики значительно повысили оценки будущих доходов компании, но, если их прогнозы окажутся слишком оптимистичными, акции Nvidia рискуют ощутимо просесть в цене. «Самое большое беспокойство вызывает то, что цифры стали настолько большими и настолько быстрыми, что вы просто беспокоитесь, что они не продлятся долго, — считает аналитик Bernstein Стейси Расгон (Stacy Rasgon). — Чем больше у них появляется новых продуктов с более высокими характеристиками и более высокими ценами, тем больше у них возможностей для взлёта». Nvidia также, вероятно, представит на GTC 2024 множество обновлений своего программного обеспечения CUDA, которое предоставляет разработчикам инструменты для запуска своих программ на ускорителях компании, ещё сильнее привязывая их к чипам Nvidia. Глубокое погружение в использование CUDA усложняет для разработчика переход на «железо» конкурентов, таких как AMD, Microsoft и Alphabet.  В прошлом году Nvidia начала предлагать процессоры и программное обеспечение в виде облачных сервисов и продолжает развивать успех. Аналитики полагают, что «возможно, поставщики облачных услуг и программного обеспечения нервничают из-за того, что Nvidia действует на их игровой площадке». Nvidia располагает ощутимым технологическим преимуществом над китайскими конкурентами. США отрезали Китаю доступ к самым передовым чипам Nvidia, поэтому самыми передовыми китайскими ускорителями ИИ являются чипы Huawei, которые по производительности соответствуют процессорам Nvidia A100, выпущенным в далёком 2020 году. Ни один китайский ускоритель ИИ даже близко не может сравниться с флагманским чипом Nvidia H100, выпущенным в 2022 году, а предстоящий B100 ещё более увеличит отрыв. Эксперты полагают, что «со временем этот разрыв станет экспоненциально большим».  Купить ИИ-ускоритель NVIDIA H100 стало проще — очереди уменьшились, появился вторичный рынок
26.02.2024 [20:04],
Сергей Сурабекянц
Сроки поставки графических процессоров NVIDIA H100, применяемых в приложениях ИИ и высокопроизводительных вычислениях, заметно сократились — с 8–11 до 3–4 месяцев. Аналитики полагают, что это связано с расширением возможностей аренды ресурсов у крупных компаний, таких как Amazon Web Services, Google Cloud и Microsoft Azure. В результате некоторые компании, ранее закупившие большое количество процессоров H100, теперь пытаются их продать. 
Источник изображения: NVIDIA The Information сообщает, что некоторые фирмы перепродают свои графические процессоры H100 или сокращают заказы из-за снижения дефицита и высокой стоимости содержания неиспользуемых запасов. Это знаменует собой значительный сдвиг по сравнению с прошлым годом, когда приобретение графических процессоров NVIDIA Hopper было серьёзной проблемой. Несмотря на повышение доступности чипов и значительное сокращение сроков выполнения заказов, спрос на чипы ИИ всё ещё продолжает превышать предложение, особенно среди компаний, обучающих большие языковые модели (LLM). Ослабление дефицита ускорителей ИИ отчасти связано с тем, что поставщики облачных услуг упростили аренду графических процессоров NVIDIA H100. Например, AWS представила новый сервис, позволяющий клиентам планировать аренду графических процессоров на более короткие периоды, что привело к сокращению спроса и времени ожидания. Увеличение доступности ИИ-процессоров NVIDIA также привело к изменению поведения покупателей. Компании при покупке или аренде становятся более требовательными к ценам, ищут меньшие по размеру кластеры графических процессоров и больше внимания уделяют экономической жизнеспособности своего бизнеса. В результате рост сектора искусственного интеллекта значительно меньше, чем в прошлом году, сдерживается ограничениями из-за дефицита чипов. Появляются альтернативы устройствам NVIDIA, например, процессоры AMD или AWS, которые наряду с повысившейся производительностью получили улучшенную поддержку со стороны программного обеспечения. В совокупности с взвешенным подходом к инвестициям в ИИ, это может привести к более сбалансированной ситуации на рынке. Тем не менее, доступ к большим кластерам графических процессоров, необходимым для обучения LLM, до сих пор остаётся проблематичным. Цены на H100 и другие процессоры NVIDIA не снижаются, компания продолжает получать высокую прибыль и невероятными темпами наращивать свою рыночную стоимость. NVIDIA прогнозирует высокий спрос на ИИ-ускорители следующего поколения Blackwell. В поисках альтернатив Сэм Альтман (Sam Altman) из OpenAI пытается привлечь масштабное финансирование для создания дополнительных заводов по производству процессоров ИИ. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex