|
Опрос
|
реклама
Быстрый переход
Nvidia представила Blackwell Ultra с 288 Гбайт HBM3e — ИИ-ускоритель «для эпохи рассуждений»
19.03.2025 [11:20],
Андрей Созинов
Компания Nvidia в рамках открытия конференции GTC 2025 официально анонсировала ускоритель вычислений для центров обработки данных Blackwell Ultra B300, суперчип Grace Blackwell Ultra GB300, а также различные системы на его основе. Новинка «создана для эпохи рассуждений», то есть для новейших, более сложных и требовательных к ресурсам ИИ-моделей (LLM), способных размышлять над задачами. 
Источник изображений: Nvidia Nvidia уже традиционно не стала раскрывать всех деталей о новинке. В компании лишь отметили, что графические процессоры Blackwell Ultra (в составе GB300 и B300) физически отличаются от чипов Blackwell (в GB200 и B200). Отметим, что Blackwell Ultra B300 представляет собой классический ускоритель на GPU, тогда как Grace Blackwell Ultra GB300 — это связка из Arm-процессора Grace с 72 ядрами Neoverse V2 и двух графических процессоров Blackwell Ultra. 
Плата с парой CPU Grace и четырьмя Blackwell Ultra Nvidia отмечает увеличенный на 50 % объём набортной памяти. Blackwell Ultra получил 288 Гбайт HBM3e, что будет как раз кстати при работе с особенно крупными LLM. Объём памяти вырос благодаря использованию новых 12-ярусных стеков HBM3e — в Blackwell B200 применяются восьмиярусные стеки HBM3e, обеспечивающие 192 Гбайт памяти. По словам Nvidia, производительность Blackwell Ultra должна в 1,5 раза превышать производительность Blackwell в запуске уже обученных моделей (FP4 inference). Компания заявляет о производительности в 15 Пфлопс для вычислений FP4, а также о 30 Пфлопс для разреженных FP4. Для оригинального ускорителя Blackwell B200 эти показатели составляли 10 и 20 Пфлопс соответственно. 
GB300 NVL72 Nvidia предложит несколько готовых систем на базе новых ускорителей вычислений, которые начнут поступать в продажу во второй половине 2025 года. GB300 NVL72 — фактически это готовая серверная стойка, объединяющая 72 графических процессора Blackwell Ultra и 36 центральных процессоров Grace. Новинка, как и её предшественница GB200 NVL72, оснащена системой жидкостного охлаждения, использует NVLink пятого поколения, модули Nvidia ConnectX-8 SuperNIC и предлагает 18 Тбайт оперативной памяти LPDDR5X. Производительность достигает 1100 Пфлопс в FP4-вычислениях и до 1400 Пфлопс в разреженных вычислениях. 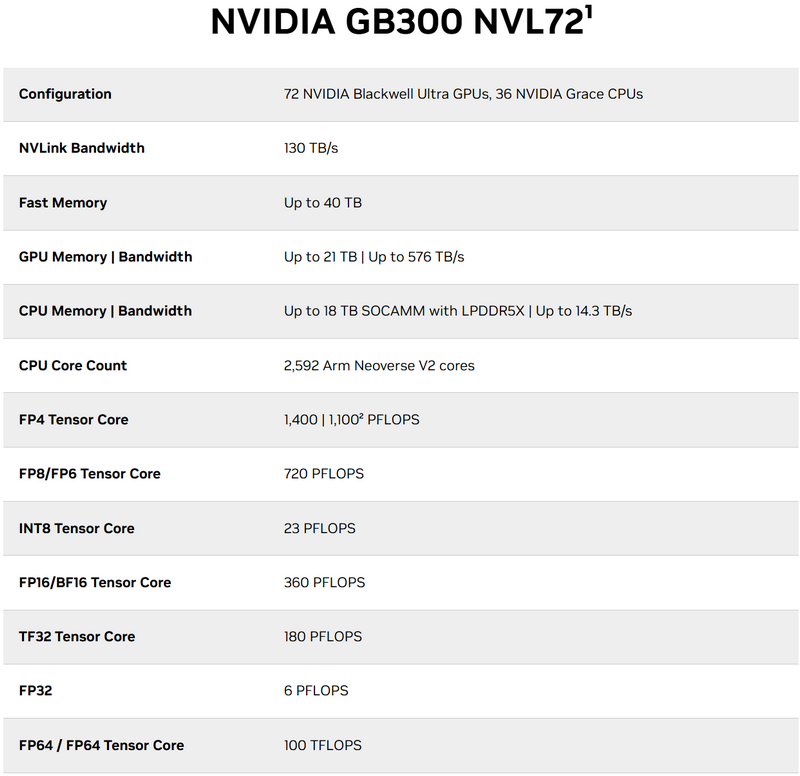 Nvidia особенно отмечает применение интерконнекта NVLink 5-го поколения, который соединяет отдельные чипы для создания «одного большого GPU». Он обладает пропускной способностью 1,8 Тбайт/с на GPU, а общая пропускная способность достигает 130 Тбайт/с. Начиная с Blackwell, NVLink также может использоваться в качестве интерфейса для соединения нескольких стоек, что ранее осуществлялось через InfiniBand со скоростью 100 Гбайт/с. Поэтому Nvidia заявляет о 18-кратном увеличении скорости для этого конкретного сценария. 
Blackwell Ultra DGX SuperPOD В домен NVLink можно подключить до 576 графических процессоров. Собственно, такую систему Nvidia тоже предложит — Blackwell Ultra DGX SuperPOD. Это кластер из восьми стоек NVL72, который включает 288 процессоров Grace, 576 чипов Blackwell Ultra, 300 Тбайт памяти HBM3e и FP4-производительность в 11,5 Экзафлопс. Наконец, Nvidia представила систему HGX B300 NVL16 — решение для тех, кому вместо Arm-процессора Grace нужен чип на x86-совместимой архитектуре. В системе имеется 16 графических процессоров B300A, соединённые через NVLink, и центральные x86-процессоры. Nvidia не уточняет, какие именно CPU применены, но в прошлом использовались чипы как от AMD, так и от Intel.  Ускорители вычислений и системы на базе Blackwell Ultra появятся на рынке во второй половине текущего года. Их предложат все крупные производители серверов, а также новинки будут доступны у основных облачных провайдеров. Ускорители Nvidia B300 прибавят в быстродействии 50 %, но ограничатся ростом TDP на 200 Вт
28.12.2024 [07:57],
Алексей Разин
Второе поколение ускорителей Nvidia с архитектурой Blackwell в лице B300, как сообщает Tom’s Hardware со ссылкой на SemiAnalysis, предложит рост быстродействия на 50 % по сравнению с GB200, но уровень TDP при этом увеличится только с 1200 до 1400 Вт. Чипы семейства B300, по оценкам аналитиков, появятся примерно через полгода после B200, поставки которых уже должны были начаться в этом квартале. 
Источник изображения: Nvidia Выпускать чипы B300 по прежней технологии 4NP будет компания TSMC, но это не помешает добиться роста производительности в вычислениях на 50 %. Ещё одним важным изменением станет использование чипами серии B300 двенадцатиярусных стеков памяти типа HBM3E. Оно обеспечит объём памяти в 288 Гбайт на один ускоритель и пропускную способность на уровне 8 Тбайт/с. Подобные изменения в совокупности позволят снизить затраты на обучение нейронных сетей до трёх раз по сравнению с предшественниками. Появление сетевого контроллера ConnectX-8 класса 800G позволит удвоить пропускную способность сетевого интерфейса относительно текущего ConnectX-7, а увеличение количества линий PCI Express с 32 до 48 штук расширит возможности интеграции данных ускорителей в серверных системах. Важным изменением при производстве ускорителей B300 станет и отказ Nvidia от поставок материнских плат или серверных систем строго в эталонном дизайне. Расширив доступ партнёров к производству таких ускорителей и систем, Nvidia увеличит объёмы поставок продукции. В целом, устройство систем на базе B300 и GB300 будет формироваться на принципах большей свободы, и клиенты от этого только выиграют. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться