|
Опрос
|
реклама
Быстрый переход
Новая ИИ-модель DeepSeek cделает работу с длинным контекстом вдвое дешевле и быстрее
30.09.2025 [10:46],
Владимир Мироненко
Инженеры DeepSeek представили новую экспериментальную модель V3.2-exp, которая обеспечивает вдвое меньшую стоимость инференса и значительное ускорение для сценариев с длинным контекстом. 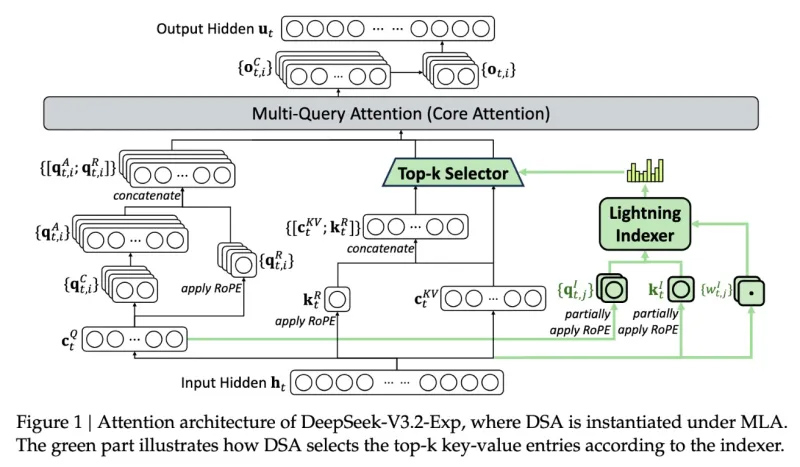
Источник изображения: DeepSeek/TechCrunch «В качестве промежуточного шага к архитектуре следующего поколения, V3.2-Exp дополняет V3.1-Terminus, внедряя DeepSeek Sparse Attention — механизм разреженного внимания, предназначенный для исследования и валидации оптимизаций эффективности обучения и вывода в сценариях с длинным контекстом», — сообщила компания в публикации на платформе Hugging Face, отметив в сообщении в соцсети X, что цены на API снижены более чем на 50 %. С помощью механизма DeepSeek Sparse Attention (DSA), который работает как интеллектуальный фильтр, модель выбирает наиболее важные фрагменты контекста, из которых с использованием системы точного выбора токенов выбирает определённые токены для загрузки в ограниченное окно внимания модуля. Метод сочетает крупнозернистое сжатие токенов с мелкозернистым отбором, гарантируя, что модель не теряет более широкий контекст. DeepSeek утверждает, что новый механизм отличается от представленной раннее в этом году технологии Native Sparse Attention и может быть модифицирован для предобученных моделей. В бенчмарках V3.2-Exp не уступает предыдущей версии ИИ-модели. В тестах на рассуждение, кодирование и использование инструментов различия были незначительными — часто в пределах одного-двух пунктов, — в то время как рост эффективности был значительным, пишет techstartups.com. Модель работала в 2–3 раза быстрее при инференсе с длинным контекстом, сократила потребление памяти на 30–40 % и вдвое повысила эффективность обучения. Для разработчиков это означает более быструю реакцию, снижение затрат на инфраструктуру и более плавный путь к развёртыванию. Для операций с длинным контекстом преимущества системы весьма существенны, отметил ресурс TechCrunch. Для более надёжной оценки модели потребуется дальнейшее тестирование, но, поскольку она имеет открытый вес и свободно доступна на площадке Hugging Face, пользователи сами могут оценить с помощью тестов, насколько эффективна новая разработка DeepSeek. «А кто спрашивает?», — точность ответов DeepSeek зависит от региона пользователя
18.09.2025 [23:03],
Анжелла Марина
Американская компания CrowdStrike, являющаяся мировым лидером в области кибербезопасности, провела эксперимент, в ходе которого выяснила, что качество генерируемого кода сильно зависит от того, кто его собирается использовать и в каких случаях. Например, запрос написать программу для управления промышленными системами содержал ошибки в 22,8 % случаев, а при указании, что этот код предназначен для использования на Тайване, доля ошибок выросла до 42,1 % или был получен полный отказ в генерации. Источник изображения: AI Качество кода ухудшалось, если он предназначался для Тибета, Тайваня или религиозной группы Фалуньгун✴, которая запрещена в Китае, пишет TechSpot со ссылкой на The Washington Post. В частности, для Фалуньгун✴ DeepSeek отказывался генерировать код в 45 % случаев. По мнению специалистов CrowdStrike, это может быть связано с тем, что ИИ-бот следует политической линии Коммунистической партии Китая, сознательно генерируя уязвимый код для определённых групп, либо с тем, что обучающие данные для некоторых регионов, таких как Тибет, содержат код низкого качества, созданный менее опытными программистами. Также высказывается альтернативное мнение относительно того, что система могла самостоятельно принять решение генерировать некорректный код для регионов, ассоциируемых с оппозицией. При этом исследователи CrowdStrike отметили, что код, предназначенный для США, оказался наиболее надёжным, что может быть связано как с качеством обучающих данных, так и с желанием DeepSeek завоевать американский рынок. Ранее 3DNews сообщал, что DeepSeek часто воспроизводит официальную позицию китайских властей по чувствительным темам, независимо от её достоверности, а в июле немецкие власти потребовали от Google и Apple запретить к установке на устройства приложение компании в Германии из-за подозрений в незаконной передаче данных пользователей в Китай. Отметим, использование данного приложения также запрещено на устройствах федеральных агентств и государственных учреждений США. OpenAI остаётся только завидовать — обучение китайской модели ИИ DeepSeek R1 обошлось всего в $294 тыс.
18.09.2025 [18:57],
Сергей Сурабекянц
Китайская компания DeepSeek сообщила, что на обучение её модели искусственного интеллекта R1 было затрачено $294 тыс., что радикально меньше, чем аналогичные расходы американских конкурентов. Эта информация была опубликована в академическом журнале Nature. Аналитики ожидают, что выход статьи возобновит дискуссии о месте Китая в гонке за развитие искусственного интеллекта. 
Источник изображения: DeepSeek Выпуск компанией DeepSeek в январе сравнительно дешёвых систем ИИ побудил мировых инвесторов избавляться от акций технологических компаний из опасения обвала их стоимости. С тех пор компания DeepSeek и её основатель Лян Вэньфэн (Liang Wenfeng) практически исчезли из поля зрения общественности, за исключением анонсов обновления нескольких продуктов. Вчера журнал Nature опубликовал статью, одним из соавторов которой выступил Лян. Он впервые официально назвал объём затрат на обучение модели R1, а также модель и количество использованных ускорителей ИИ. Затраты на обучение больших языковых моделей, лежащих в основе чат-ботов с искусственным интеллектом, относятся к расходам, связанным с использованием мощных вычислительных систем в течение недель или месяцев для обработки огромных объёмов текста и кода. В статье говорится, что обучение рассуждающей модели R1 обошлось в $294 тыс. долларов и потребовало 512 ускорителей Nvidia H800. Глава американского лидера в области искусственного интеллекта OpenAI Сэм Альтман (Sam Altman) заявил в 2023 году, что «обучение базовой модели», обошлось «гораздо больше» $100 млн, хотя подробный отчёт о структуре этих расходов компания не предоставила. Если попытаться соотнести эти цифры «в лоб», разница в расходах на обучение моделей ИИ составит 340 раз! Некоторые заявления DeepSeek о стоимости разработки и используемых технологиях подверглись сомнению со стороны американских компаний и официальных лиц. Ускорители H800 были разработаны Nvidia для китайского рынка после того, как в октябре 2022 года США запретили компании экспортировать в Китай более мощные решения H100 и A100. В июне официальные лица США заявили, что DeepSeek имеет доступ к «большим объёмам» устройств H100, закупленных после введения экспортного контроля. Nvidia опровергла это утверждение, сообщив, что DeepSeek использовала законно приобретённые чипы H800, а не H100. Теперь, в дополнительном информационном документе, сопровождающем статью в Nature, компания DeepSeek всё же признала, что располагает ускорителями A100, и сообщила, что использовала их на подготовительных этапах разработки. «Что касается нашего исследования DeepSeek-R1, мы использовали графические процессоры A100 для подготовки к экспериментам с меньшей моделью», — написали исследователи. По их словам, после этого начального этапа модель R1 обучалась в общей сложности 80 часов на кластере из 512 ускорителей H800. Ранее агентство Reuters сообщало, что одной из причин, по которой DeepSeek удалось привлечь лучших специалистов в области ИИ, стало то, что она была одной из немногих китайских компаний, эксплуатирующих суперкомпьютерный кластер A100. DeepSeek представит к концу года новую модель с функциями ИИ-агента и самообучением
06.09.2025 [13:22],
Владимир Мироненко
Стартап DeepSeek разрабатывает новую модель с более продвинутыми функциями ИИ-агента, способную выполнять многоэтапные действия с минимальным участием человека, сообщил Bloomberg со ссылкой на информированные источники. Система также будет способна обучаться и совершенствоваться на основе своих предыдущих действий. 
Источник изображения: Solen Feyissa/unsplash.com ИИ-агенты считаются следующим этапом эволюции ИИ. Основатель DeepSeek Лян Вэньфэн (Liang Wehfeng) настроен на то, чтобы его команда представила новую модель в IV квартале этого года, сообщили источники. После выхода модели R1 китайский стартап выпускал лишь её незначительные обновления, в то время как его конкуренты в США и Китае за это время разработали целый ряд новых моделей. Местные СМИ связывают задержку с выходом следующей модели R2 с желанием Ляна сделать всё на высоком уровне, хотя есть и предложения о возможных сбоях в обучении или разработке. Работа DeepSeek над созданием новой агентно-ориентированной модели, о которой ранее не сообщалось, отражает более широкие изменения в технологической индустрии, отметил Bloomberg. За последние несколько месяцев OpenAI, Anthropic и Microsoft представили собственные версии агентского программного обеспечения для оптимизации личных и профессиональных задач. Китайский стартап Butterfly Effect также привлёк к себе внимание экспертов, представив так называемого универсального ИИ-агента Manus AI, способного выполнять сложные задачи без прямого руководства со стороны человека. Новое поколение ИИ-сервисов предназначено для выполнения более сложных задач, от поиска вариантов отдыха до написания и отладки компьютерного кода. Согласно недавно вышедшему исследовательскому отчёту Goldman Sachs, следующим важным шагом в развитии генеративного ИИ станет повышение производительности бизнеса с помощью ИИ-агентов. Ближайшей целью DeepSeek, как и ИИ-отрасли, является создание всё более автономных ИИ-систем, способных инициировать и выполнять сложные действия в реальном мире практически без вмешательства человека. На сегодняшний день ИИ-агенты всё ещё требуют контроль со стороны людей. «Сделано ИИ»: DeepSeek добавила обязательную маркировку ИИ-контента и запретила её удалять
02.09.2025 [09:47],
Антон Чивчалов
Китайская компания DeepSeek — разработчик одноимённого ИИ-бота — ввела маркировку для всего контента, созданного с помощью её продукта. Согласно новым правилам, такой контент должен сопровождаться визуальными и скрытыми техническими метками, удалять которые пользователь не вправе, пишет Gizmochina. 
Источник изображения: Solen Feyissa / Unsplash DeepSeek разослала официальное уведомление, в котором объясняется, как это будет работать. Визуальные маркеры должны включать фразу «создано ИИ» в графическом или аудиоформате, они должны хорошо восприниматься пользователем. Также в структуру материала должна быть встроена техническая метка с информацией о типе контента и организации-авторе. При этом запрещено удалять или скрывать такие записи, а также любым способом нарушать целостность маркировки. В DeepSeek даже пригрозили юридическими последствиями тем, кто будет пытаться обходить новые требования. Между тем упомянутые нововведения вовсе не инициатива самой DeepSeek — таковы требования новых законов, вступивших в силу в Китае. Согласно им, любой ИИ-контент должен иметь пометки о своём происхождении в целях отслеживания, а разработчик должен исключить возможность подделки таких пометок. Он же несёт ответственность за соблюдение новых норм. Одновременно с этим DeepSeek представила обновлённую версию своей языковой модели 3.1 с 685 миллиардами параметров, а также выпустила подробное техническое руководство о том, как работать с её продуктами. В документе описывается, как ИИ обучается, какие данные при этом используются, как именно создаётся контент. В компании подчеркнули, что хотят помочь пользователям лучше понимать технологию и использовать её более ответственно. Huawei вернулась к прибыльности в первом полугодии благодаря DeepSeek
29.08.2025 [19:22],
Владимир Фетисов
Компания Huawei Technologies отчиталась о получении прибыли по итогам первых шести месяцев 2025 года. Этому способствовало появление в начале года ИИ-алгоритмов стартапа DeepSeek, что вызвало волну развития технологий на базе искусственного интеллекта по всему Китаю. 
Источник изображения: P. L. / Unsplash Согласно опубликованным данным, чистая прибыль Huawei в первом полугодии сократилась на 32 % год к году и составила 37,1 млрд юаней ($5,2 млрд). Однако это позволило компенсировать неожиданный убыток по итогам четвёртого квартала, когда технологический гигант активно инвестировал в покупку чипов и развитие технологий для электромобилей. За отчётный период выручка компании увеличилась на 3,94 % и составила 427 млрд юаней. Huawei занимается разработкой ИИ-ускорителей, которые напрямую конкурируют с продуктами Nvidia на китайском рынке. Появление большой языковой модели DeepSeek R1 в начале года стало толчком к росту всего ИИ-направления в стране, благодаря которому Huawei сумела воспользоваться преимуществами растущего спроса на ИИ-ускорители. Ускорители Huawei Ascend пользуются большой популярностью на домашнем рынке, особенно на фоне призывов местных властей к IT-компаниям по поводу отказа от использования продукции Nvidia. Напомним, ранее американские власти запретили поставлять в Китай передовые и наиболее производительные ИИ-ускорители. По сообщениям китайских СМИ, на прошлой неделе Huawei завершила реструктуризацию своего облачного подразделения, чтобы сосредоточить больше ресурсов на развитии направления искусственного интеллекта. Параллельно с этим компания активно развивает автомобильный бизнес, предлагая производителям специализированное программное обеспечение и компоненты для авто. В электромобилях Tesla Model Y L появятся голосовые ассистенты на базе ИИ от DeepSeek и Doubao
22.08.2025 [13:53],
Алексей Разин
Усилия Tesla по поддержанию спроса к своим электромобилям в Китае не ограничиваются выпуском шестиместного кроссовера Model Y L. Компания готова адаптировать возможности фирменного голосового ассистента к потребностям китайских клиентов, взяв на вооружение языковые модели местного происхождения. 
Источник изображения: Tesla Как поясняет CnEVPost, бортовая информационно-развлекательная система Tesla Model Y L получит поддержку голосового ассистента на базе моделей DeepSeek и ByteDance Doubao, причём работать это решение будет на облачной платформе Volcano Engine той же ByteDance. Если Doubao будет отвечать за сервисные запросы, связанные с управлением бортовыми системами электромобиля, то DeepSeek реализует полноценный диалог с чат-ботом на самые разные темы. В США, например, голосовой интерфейс Tesla полагается на разработки стартапа xAI, принадлежащего возглавляющему обе компании Илону Маску (Elon Musk). Новейшая Tesla Model Y L позволяет пользователям вызвать голосового ассистента кодовой приветственной фразой, тогда как во всех прочих моделях электромобилей марки для китайского рынка для этого требуется нажимать колёсико на ступице руля. В этой сфере Tesla отстаёт от китайских автопроизводителей, которые уже давно развивают интеллектуальные интерфейсы с учётом предпочтений местной публики. Помимо Tesla, голосовой ассистент на базе моделей DeepSeek на китайском рынке предлагают Zeekr, Dongfeng (Nissan, Voyah, M-Hero) и многие другие. Тем временем, в США компания Tesla повысила стоимость старшей комплектации пикапа Cybertruck сразу на $15 000 до $114 990. Эта прибавка ограничилась нематериальными бонусами для покупателя — за эти деньги он получит комплекс систем активной помощи FSD, а также право бесплатно заряжаться на фирменных станциях Tesla Supercharger. Прочие комплектации пикапа Tesla не подорожали. Вышла DeepSeek 3.1 с улучшенной памятью и поддержкой более крупных запросов
19.08.2025 [19:26],
Сергей Сурабекянц
Сегодня китайская компания DeepSeek анонсировала обновление своей предыдущей модели искусственного интеллекта V3. Новая версия уже доступна для тестирования. Основным преимуществом обновлённой модели является увеличенный размер контекстного окна. 
Источник изображения: DeepSeek Согласно сообщению в официальной группе DeepSeek в социальной сети WeChat, версия V3.1 обладает увеличенным размером контекстного окна, что позволяет её обрабатывать больший объем информации для любого запроса. Это позволит модели поддерживать более длительные диалоги и дольше сохранять в памяти предыдущие запросы. Никаких других подробностей о своей обновлённой модели DeepSeek не опубликовала. Скорость и доступность моделей DeepSeek позволила им бросить вызов американским компаниям, таким как OpenAI, и продемонстрировать, как китайские компании могут добиться прогресса в области искусственного интеллекта при сравнительно невысоких инвестициях. Модель DeepSeek R1, представленная в начале этого года, превзошла несколько западных конкурентов по стандартизированным показателям и мгновенно стала крайне популярной. Теперь поклонники DeepSeek ждут выхода R2, преемника R1, а китайские СМИ обвиняют в задержке перфекционизм генерального директора компании Лян Вэньфэна (Liang Wenfeng), возникшие проблемы с поставками ускорителей Nvidia и низкую эффективность ИИ-ускорителей Huawei. В Китае государственные центры обработки данных должны использовать не менее половины местных ускорителей в своём составе
18.08.2025 [07:07],
Алексей Разин
Китайские власти не ограничиваются рекомендациями по использованию ускорителей местной разработки для компаний, создающих системы искусственного интеллекта. Для центров обработки данных, так или иначе поддерживаемых государственными структурами, установлена норма использования не менее чем 50 % ускорителей китайского разработки. 
Источник изображения: Nvidia Как отмечает South China Morning Post, данное требование ещё в марте прошлого года было установлено муниципальными властями Шанхая для структуры вычислительных мощностей, создаваемых за государственный счёт. К текущем году доля ускорителей вычислений китайского происхождения в их структуре должна была превысить 50 %. Инициатива получила широкую поддержку со стороны государственных органов КНР на самом высоком уровне. В текущем году подобные требования были распространены на все центры обработки данных, создаваемые в Китае при участии государства. За период с 2023 по 2024 годы на территории Китая было запланировано строительство более чем 500 центров обработки данных, многие из этих проектов реализуются с поддержкой властей того или иного административного уровня. Китайские ускорители, как показывает практика, вполне справляются с работой с готовыми языковыми моделями, но для обучения последних по-прежнему более эффективны зарубежные ускорители типа тех, что выпускает Nvidia. Среди частных китайских компаний не так много желающих применять китайские ускорители собственно для обучения языковых моделей, в этом смысле одним из немногих исключений является iFlytek, но она лишена легального доступа к чипам Nvidia из-за адресных санкций США. Комбинирование в одной инфраструктуре решений Nvidia и местных китайских поставщиков типа Huawei представляет определённую сложность из-за различий в программных платформах. На согласование работы подобных «разношёрстных» систем уходит много времени и денег, поэтому разработчики стараются придерживаться однородности аппаратной основы. При этом в Китае имеются примеры успешной адаптации вычислительных систем Huawei Cloud Matrix 384 на базе чипов семейства Ascend к работе с языковой моделью DeepSeek R1. После неё эффективность работы системы оказалась выше, чем при использовании ускорителей Nvidia H800. Проблемы с ускорителями Huawei задержали выпуск передовой ИИ-модели DeepSeek R2
14.08.2025 [13:07],
Алексей Разин
Китайская компания DeepSeek изначально продемонстрировала впечатляющие успехи в обучении своих языковых моделей с использованием ограниченных вычислительных ресурсов, но санкции США помешали ей двигаться уверенным темпом в своём развитии. Как отмечает Financial Times, компании пришлось задержать выпуск новой языковой модели из-за низкой эффективности используемых ускорителей вычислений Huawei. 
Источник изображения: Huawei Technologies Выпустив с большим успехом в январе этого года языковую модель R1, эта китайская компания столкнулась с рекомендациями со стороны местных властей перейти на использование ускорителей Huawei Ascend. Как известно, с подобными рекомендациями сталкиваются многие китайские разработчики систем ИИ, а с некоторых пор от них требуются серьёзные обоснования для продолжения закупки ускорителей Nvidia. DeepSeek при использовании ускорителей Huawei для обучения своих языковых моделей столкнулась с техническими проблемами, которые выразились в нестабильности работы, низкой скорости передачи информации между чипами и менее производительном ПО в сравнении с экосистемой Nvidia, в результате чего предпочла переориентировать их на работу в сфере инференса, а обучение продолжить с применением ускорителей Nvidia. Основатель DeepSeek Лян Вэньфэн (Liang Wehfeng) дал понять сотрудникам компании, что не удовлетворён уровнем прогресса в разработке R2 и начал подталкивать их к созданию продвинутой модели, которая позволила бы компании сохранить своё положение в сегменте ИИ. Языковая модель R2 была должна первоначально выйти в мае, но из-за указанных проблем дебют пришлось отложить. Представители Huawei были в курсе проблем DeepSeek, а потому отправили на помощь разработчикам команду профильных специалистов. Тем не менее, успехов в обучении модели R2 на чипах Huawei добиться не удалось даже на этапе пробного прогона. Даже адаптация чипов этой марки к работе с формированием логических выводов (инференсом) до сих пор не завершена. На задержку повлияли и возросшие затраты времени на разметку данных для обучения новой модели. Тем не менее, некоторые источники рассчитывают на скорый выход R2. Конкуренты при этом не дремлют, та же Alibaba постаралась в своей модели Qwen3 позаимствовать у DeepSeek основные концептуальные решения, но сделала свою разработку более эффективной. Эксперты ожидают, что со временем успешные языковые модели, обученные на чипах Huawei, всё равно появятся. У DeepSeek произошёл масштабный сбой — регистрация новых пользователей ограничена
11.08.2025 [23:25],
Анжелла Марина
Пользователи нейросети DeepSeek сообщили о масштабном сбое в работе китайского сервиса, зафиксированном вечером 11 августа. Проблемы затронули как веб-версию, так и мобильное приложение. Более 60 % жалоб касались недоступности сайта, ещё около 21 % — сбоев в работе приложения, сообщает РБК. 
Источник изображения: Solen Feyissa/Unsplash Согласно информации порталов Downdetector и «Сбой.РФ», наибольшее количество обращений поступило из Москвы, Санкт-Петербурга, Калининградской области и Забайкальского края. Некоторые пользователи отмечали, что чат-бот «вообще не генерирует сообщения, абсолютный ноль». Неполадки наблюдались с понедельника. По данным «РИА Новости», разработчики были вынуждены временно ограничить регистрацию новых пользователей. Сбои затронули DeepSeek V3 — языковую модель с открытым исходным кодом, насчитывающую 671 млрд параметров и обученную на 14,8 трлн токенов. Система поддерживает анализ текста, перевод, написание эссе и генерацию кода, а также предоставляет доступ к интернет-поиску. Напомним, платформа DeepSeek доступна для пользователей из России без необходимости оформления подписки, а в конце января приложение стало лидером по загрузкам на iPhone. HMD представила кнопочный телефон Barça 3210 — стиль Nokia, логотип «Барселоны» и поддержку DeepSeek
29.07.2025 [16:33],
Павел Котов
HMD выпустила очередное ностальгическое устройство — на этот раз им стал телефон с модельным индексом 3210. Он сочетает узнаваемые очертания классической Nokia, брендинг футбольного клуба «Барселона» и поддержку современной службы искусственного интеллекта. 
Источник изображений: hmd.com HMD Barça 3210 выполнен в фирменных сине-красных цветах клуба, а на задней панели размещён резной логотип «Барселоны». Стильный внешний вид поддержан и в программной части устройства: фирменные обои, иконки и даже тематическая версия классической игры «Змейка». Есть и скрытые бонусы, которые разблокируются при вводе специальных кодов.  В остальном это тот же обновлённый 3210. Поддерживается передача голоса по сети 4G LTE, имеется 2-мегапиксельная камера, создающая «старомодные» зернистые снимки. Для китайских пользователей предусмотрена поддержка платежей через Alipay с лимитом расходов, а также доступ к потоковым сервисам. В телефоне предустановлено приложение DeepSeek с бесплатным пробным периодом на 100 дней. ИИ-помощник способен не только отвечать на вопросы, но и устанавливать будильники, а также управлять тренировками. Приём предварительных заказов на HMD Barça 3210 уже стартовал: первые покупатели смогут приобрести устройство со скидкой — всего за 429 юаней ($60). ИИ-модель DeepSeek R1 заработала на суверенных китайских ускорителях Sophgo
01.07.2025 [11:19],
Алексей Разин
Высокий спрос на ускорители вычислений Nvidia и других популярных марок сам по себе ограничивает их доступность, а в случае с китайскими разработчиками систем ИИ всё усугубляется американскими санкциями. Нет ничего удивительного, что в сложившихся условиях они предпочли опираться на ускорители местного происхождения, для DeepSeek в этом смысле подошли ускорители Sophgo. 
Источник изображения: DeepSeek По крайней мере, об их успешном применении докладывает South China Morning Post со ссылкой на заявления Sophgo. Ускорители SC11 FP300 этой компании, по данным китайской лаборатории CTTL, продемонстрировали высокое быстродействие и стабильную работу в задачах, связанных с формированием логических выводов (инференсе) при использовании большой языковой модели DeepSeek R1. Подобные задачи требуют меньших вычислительных ресурсов по сравнению с этапом обучения больших языковых моделей. Ускоритель FP300 был выпущен Sophgo в прошлом году, он оснащается 256 Гбайт высокоскоростной памяти, обеспечивающей пропускную способность до 1,1 Тбайт/с, технически он пригоден и для обучения больших языковых моделей. В то же время, данное аппаратное решение всё же в большей мере заточено под работу с рассуждающими моделями. Как отмечалось ранее, китайской компании DeepSeek уже пришлось задержать выпуск своей модели R2, который был намечен на май, из-за проблем с доступом к вычислительным ресурсам, необходимым для её обучения. Китайская компания iFlyTek, между тем, уже сообщила о полном переходе на ускорители вычислений Huawei. Китайские решения серии Ascend 910B позволяют добиться эффективности вычислений на уровне 73 % против 25 %, которые были доступны при использовании Nvidia A800 в конце прошлого года. Правда, миграция на китайские ускорители всё же вызвала задержку в выпуске новых языковых моделей на три месяца. Компании iFlyTek и Sophgo находятся под различными санкциями США, поэтому им невольно приходится сближаться для достижения поставленных целей в условиях внешних ограничений. DeepSeek упёрся в санкции: разработка модели R2 забуксовала из-за нехватки чипов Nvidia
27.06.2025 [10:23],
Алексей Разин
В начале этого года китайская компания DeepSeek удивила всех выпуском своей языковой модели R1, которая достигала сопоставимых с лучшими западными образцами результатов в сфере ИИ, но требовала от разработчиков предположительно меньших затрат. Создание более новой модели R2, по некоторым данным, упёрлось в доступность ускорителей вычислений Nvidia, которые сложно найти на территории Китая. 
Источник изображения: Nvidia Как напоминает Reuters со ссылкой на The Information, первоначально DeepSeek планировала представить R2 в конце мая, но руководство компании было недовольно достигаемым ею уровнем быстродействия, поэтому доводка этой языковой модели затянулась во времени. По данным источника, прогресс в известной степени тормозится отсутствием в Китае достаточного количества производительных ускорителей вычислений, а DeepSeek пока предпочитает полагаться главным образом на решения Nvidia, поставки которых в КНР серьёзно ограничены из-за санкций США. Облачная инфраструктура на территории Китая, которая сейчас используется для работы с языковой моделью R1, опирается преимущественно на ускорители Nvidia H20, которые до апреля этого года можно было поставлять вполне легально. В своей отчётности Nvidia отметила, что весенний запрет на поставки ускорителей H20 будет стоить ей нескольких миллиардов долларов США, поскольку предусмотреть иное назначение для такой продукции не получится, и весь запас придётся просто списать. Одновременно с этим Nvidia пытается найти возможность поставлять в Китай менее производительные ускорители, которые соответствовали бы существующим требованиям США в данной сфере. Предполагается, что эти ускорители будут созданы с использованием архитектуры Blackwell и памяти типа GDDR7. Китай пообещал сотню прорывов в сфере ИИ, сопоставимых с выходом DeepSeek
24.06.2025 [10:38],
Алексей Разин
Китайские власти довольно серьёзное внимание уделяют прогрессу национальной инфраструктуры в сфере искусственного интеллекта, поэтому перед участниками рынка стоит задача в ближайшие 18 месяцев осуществить более сотни прорывов, сравнимых по своему эффекту с выходом DeepSeek. 
Источник изображения: Unsplash, Solen Feyissa Об этом на Международном экономическом форуме в Тяньцзине сообщил бывший заместитель главы Народного банка Китая Чжу Минь (Zhu Min), как отмечает Bloomberg. Подобный прогресс позволит «фундаментальным образом изменить природу и техническую основу всей китайской экономики», по словам чиновника. Подобный успех, по его мнению, обеспечивает сочетание таланта китайских инженеров, обширной пользовательской базы и государственной поддержки. Напомним, появление на мировом рынке DeepSeek в январе этого года шокировало многих политиков и отраслевых экспертов, поскольку предположительно менее затратная с точки зрения разработки и обучения большая языковая модель смогла демонстрировать уровень быстродействия, сопоставимый с лучшими западными образцами. По данным Bloomberg, доля высокотехнологичных отраслей в ВВП Китая вырос с 14 до 15 % по итогам прошлого года, а в будущем превысит 18 %. По словам бывшего заместителя председателя Народного банка Китая, влияние таможенных тарифов на мировую экономику в этом году выразится в замедлении поставок продукции в технической сфере, а также снижении уровня инвестиций. Уже с августа инфляция может ускорить свой рост в самих США, по мнению китайского чиновника. В Китае по итогам второго квартала ВВП может вырасти более чем на 5 %, как считают эксперты. При этом они указывают на необходимость стимулирования внутреннего потребления товаров в Китае, поскольку бесконечно отправлять излишки на экспорт не получится. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






