|
Опрос
|
реклама
Быстрый переход
Австралия запретила пользоваться DeepSeek в госучреждениях
04.02.2025 [18:21],
Павел Котов
Австралия вслед за Тайванем запретила использовать службы искусственного интеллекта китайской DeepSeek во всех государственных системах и на всех принадлежащих государственным учреждениям устройствах. 
Источник изображения: Solen Feyissa / unsplash.com Все продукты, приложения и службы DeepSeek подлежат немедленному удалению из государственных систем по соображениям национальной безопасности, заявил министр внутренних дел Австралии Тони Бёрк (Tony Burke). Оценка угроз, проведённая спецслужбами страны, показала, что решения китайской компании представляют неприемлемый риск, заявил чиновник. Стартап DeepSeek, начавший работу всего 20 месяцев назад, в январе стал сенсацией, выпустив мобильное приложение с чат-ботом на основе рассуждающего ИИ — при решении задач система показывает ход «мыслительного процесса». Компания уверяет, что на обучение своих моделей ИИ она тратит чрезвычайно малые суммы. Приложение оказалось в лидерах мировых рейтингов загрузок. Но в отношении безопасности сервиса есть некоторые сомнения. «ИИ — технология, полная потенциала и возможностей, но правительство не станет колебаться, когда наши органы обнаруживают угрозу национальной безопасности», — гласит заявление господина Бёрка. Китайское происхождение сервиса на принятие решения не повлияло, заверил он, — власти обеспокоила исключительно «угроза для австралийского правительства и наших активов». На частных лиц инициатива правительства не распространяется, но министр призвал сограждан задуматься о том, как используются их данные, и принять меры, чтобы «осмыслить своё присутствие онлайн и защитить свою конфиденциальность». OpenAI пока не будет подавать в суд на DeepSeek
04.02.2025 [04:31],
Николай Хижняк
OpenAI не планирует подавать в суд на китайскую компанию DeepSeek на фоне ранее озвученных подозрений Microsoft и OpenAI в отношении последней в том, что она могла использовать их данные для обучения своей нейросети R1. Об этом заявил сам глава OpenAI Сэм Альтман (Sam Altman). 
Источник изображения: Solen Feyissa / unsplash.com «У нас нет планов прямо сейчас судиться с DeepSeek. Мы собираемся продолжать делать отличные продукты и лидировать в мире по мощности модели, я думаю, это хорошо работает», — передаёт слова Альтмана издание Nikkei. Ранее DeepSeek выпустила собственную модель искусственного интеллекта R1, создание которой, согласно её разработчикам, обошлась значительно дешевле по сравнению с западными аналогами. При этом она не проигрывает им по характеристикам. На прошлой неделе сообщалось, что Microsoft и OpenAI заподозрили DeepSeek в краже данных при разработке R1. Позже Альтман назвал R1 «впечатляющей моделью» и заявил, что «появление нового соперника нас реально вдохновляет». Затем SemiAnalysis выразили предположение, что DeepSeek могла потратить куда больше средств на создание R1, чем было заявлено изначально. Нынешнее заявление Альтман сделал во время поездки в Японию, где встречался премьер-министром страны Сигэру Исибой (Shigeru Ishiba) и главой японского холдинга SoftBank Масаёси Соном (Masayoshi Son). OpenAI и SoftBank объявили о создании совместного предприятия в Японии SB OpenAI Japan, которое будет развивать ИИ-сервисы. Ожидается, что это будет самый масштабный проект по предоставлению ИИ-инструментов американского стартапа корпоративным клиентам за пределами США. DeepSeek за неделю стал вторым по популярности чат-ботом в мире, обогнав Google Gemini
04.02.2025 [01:22],
Анжелла Марина
Китайская компания DeepSeek стремительно завоёвывает позиции на рынке искусственного интеллекта, став вторым по популярности чат-ботом в мире. За неделю трафик платформы вырос на 614 %, обогнав Gemini и Character AI, а число посетителей достигло отметки в 49 миллионов визитов ежедневно по данным сервиса мониторинга трафика Similarweb. 
Источник изображения: Copilot Успех DeepSeek особенно примечателен на фоне предыдущих показателей. Месяц назад сайт насчитывал всего около 300 тысяч посещений в сутки, но уже к концу января аудитория взлетела до 33,4 миллиона пользователей, передаёт PCMag. Этот скачок не только потряс рынок технологий, но и вызвал волну беспокойства среди инвесторов, что даже привело к снижению котировок американских технологических акций. Особенно пострадали акции Nvidia, упавшие на 17,8 %. Согласно Similarweb, глобальный трафик платформы продолжает оставаться высоким, хотя DeepSeek всё ещё уступает лидеру рынка — ChatGPT, который собирает более 130 миллионов посещений в день. 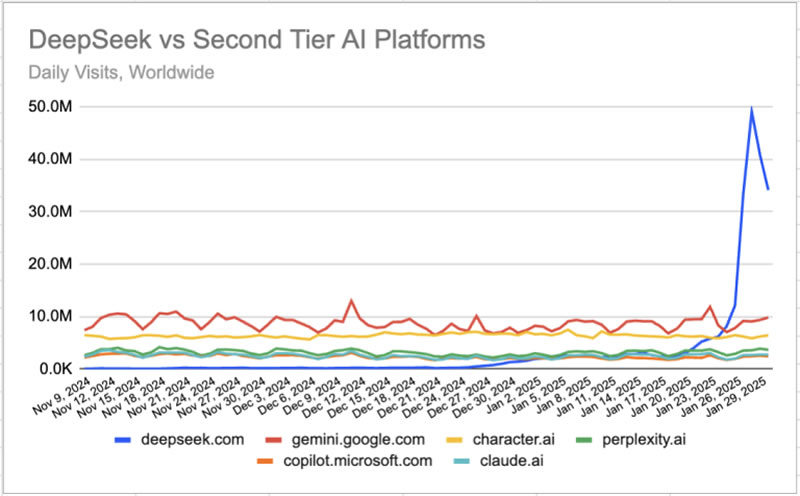
Источник изображения: Similarweb Как отмечают эксперты, основным драйвером успеха DeepSeek стал запуск открытой модели V3, которая привлекла внимание разработчиков и компаний по всему миру. Обучение V3 обошлось в $5,5 млн — значительно меньше, чем затраты на аналогичные решения из США. При этом её возможности сопоставимы с функционалом ChatGPT, но с важным отличием: модель можно свободно загрузить и запустить на локальных серверах. Это делает её привлекательной для организаций, желающих внедрять ИИ-технологии без необходимости полагаться на облачные сервисы. 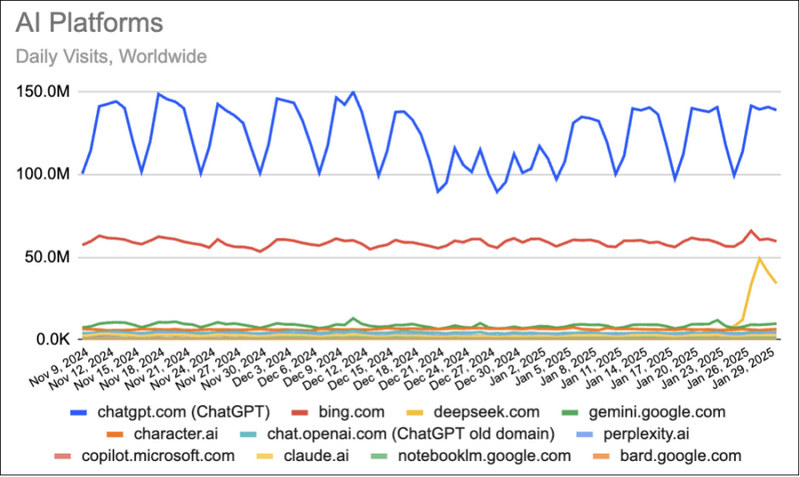
Источник изображения: Similarweb Несмотря на впечатляющие достижения, DeepSeek пока не смогла обогнать поисковую систему Microsoft Bing, где используется ИИ-ассистент Copilot на базе технологий OpenAI. Однако аналитики подчёркивают, что успех платформы в США также очевиден. «В США DeepSeek достиг пика в 4,9 миллиона ежедневных посещений 28 января, а затем стабилизировался на уровне 2,4 миллиона посещений, что на 813,3 % больше, чем неделей ранее», — сообщает Similarweb. Тем не менее, будущее DeepSeek может оказаться менее оптимистичным из-за усиления конкуренции. Например, недавно OpenAI представила новую функцию Deep Research, позволяющую создавать подробные исследовательские отчёты на основе данных из сотен источников. Кроме того, платформа всё чаще сталкивается с критикой в отношении политики конфиденциальности и цензуры, что может повлиять на лояльность пользователей. Однако текущие показатели демонстрируют, что DeepSeek остаётся одним из самых перспективных игроков в развивающейся «семимильными» шагами ИИ-индустрии. Аналитики SemiAnalysis ударили по мифу о дешёвом ИИ, раскрыв реальные масштабы DeepSeek
03.02.2025 [04:23],
Анжелла Марина
Китайский стартап DeepSeek привлёк всеобщее внимание, заявив о создании конкурентоспособной модели искусственного интеллекта (ИИ) с минимальными затратами. Компания утверждала, что на обучение мощной нейросети DeepSeek V3 было потрачено всего $6 млн и использовано 2048 графических процессоров (GPU). Однако аналитики SemiAnalysis опровергают это утверждение, заявив, что компания располагает 50 000 GPU Nvidia и на создание инфраструктуры потратила не менее $1,6 млрд. 
Источник изображения: Nvidia Согласно данным экспертов, DeepSeek управляет крупной вычислительной инфраструктурой, включающей около 50 000 GPU Hopper. Среди них числятся 10 000 единиц H800 и 10 000 более мощных H100, а также дополнительные партии H20. Эти ресурсы распределены между несколькими центрами обработки данных и используются для обучения ИИ, научных исследований и финансового моделирования. Общие капитальные затраты на серверы составили около $1,6 млрд, а операционные расходы оцениваются в $944 млн, указывают аналитики. Напомним, DeepSeek появилась как дочерний проект китайского хедж-фонда High-Flyer, который с 2023 года выделил стартап в отдельное направление, сосредоточенное на технологиях ИИ. В отличие от большинства стартапов, которые арендуют мощности у облачных провайдеров, компания имеет собственные дата-центры, что даёт полный контроль в плане оптимизации ИИ-моделей и позволяет быстрее внедрять инновации. К тому же, поскольку DeepSeek остаётся полностью самофинансируемой организацией, любые решения принимаются быстрее и гибче, делая компанию более эффективной по сравнению с традиционными игроками рынка. Особого внимания заслуживает кадровая политика. Компания нанимает специалистов исключительно из Китая, делая акцент на навыках и способности решать сложные задачи, а не на формальных дипломах. При этом зарплаты некоторых исследователей в DeepSeek превышают $1,3 млн в год, что позволяет привлекать таланты из ведущих университетов страны. Хотя DeepSeek позиционирует себя как новатора, способного бросить вызов лидерам отрасли, аналитики SemiAnalysis подчёркивают, что успех компании основан на многомиллиардных инвестициях, технических прорывах и сильной команде, а заявления о «революционном бюджете», затраченном на ИИ-модель, могут быть преувеличены. GeForce RTX 5090 лучше всех видеокарт для ПК подходят для запуска ИИ-модели DeepSeek, заявила Nvidia
02.02.2025 [18:52],
Владимир Фетисов
Nvidia позиционирует свои новые видеокарты GeForce RTX 50-й серии не только как отличные решения для игр, но и как мощные ускорители для работы с ИИ. Компания не осталась в стороне от шумихи вокруг китайской ИИ-модели DeepSeek и на днях заявила, что её новые видеокарты позволяют «запускать языковые модели DeepSeek быстрее, чем что-либо на рынке ПК». 
Источник изображения: Nvidia На этой неделе Nvidia пережила самое крупное однодневное падение рыночной капитализации среди американских компаний за всю историю. Многие связывают это со стремительным ростом популярности ИИ-модели R1 от китайского стартапа DeepSeek. Этот алгоритм по производительности сопоставим с OpenAI GPT-4o, но для его обучения было затрачено значительно меньше средств и использовалось менее передовое оборудование. Алгоритмы DeepSeek обучаются с использованием графических ускорителей Nvidia H800, тогда как американским разработчикам доступны более производительные H100 и H200, активно применяемые такими компаниями, как OpenAI, xAI и другими. Тем не менее успех китайского стартапа доказывает, что доступ к самым передовым ускорителям Nvidia не всегда необходим для достижения высоких результатов в сфере ИИ. Однако в своей публикации Nvidia отмечает, что её новые видеокарты GeForce RTX 50-й серии являются лучшим вариантом для запуска ИИ-моделей DeepSeek, обеспечивая максимальную производительность. Любопытно, что ранее на этой неделе AMD заявила, что её Radeon RX 7900 XT быстрее GeForce RTX 4090, но данные Nvidia это опровергают. 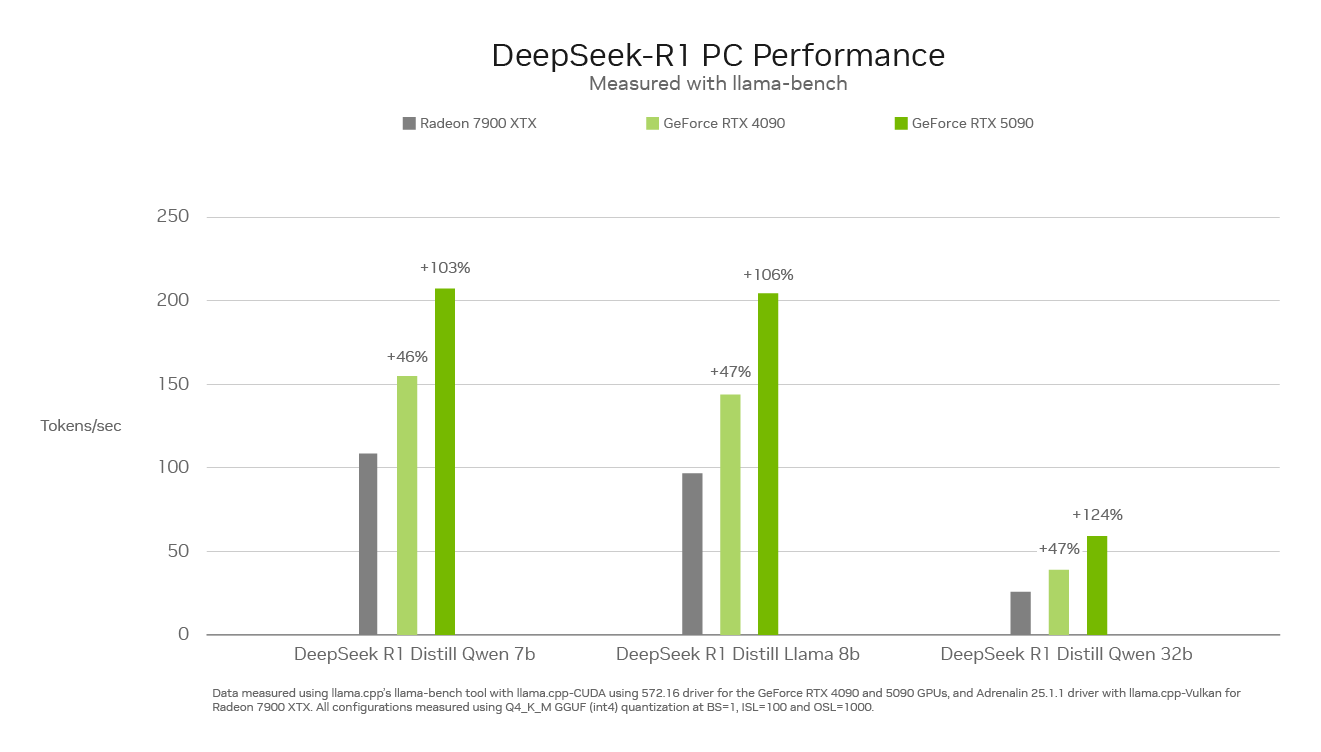 Отметим, что другие технологические компании также стремятся извлечь выгоду из неожиданного взлёта популярности DeepSeek. Рассуждающая ИИ-модель R1 уже доступна в облаке AWS и на платформе Microsoft Azure. Параллельно с этим Microsoft и OpenAI изучают вероятность того, что DeepSeek использовала для обучения своих ИИ-моделей данные OpenAI, о чём ранее писали СМИ. Также Nvidia показала работу DeepSeek в своём пакете микросервисов NIM для простого развёртывания ИИ. Популярность DeepSeek растёт, хотя чат-бот провалил все тесты на безопасность ИИ
02.02.2025 [07:07],
Анжелла Марина
Китайская компания DeepSeek, создавшая бюджетный чат-бот с высокой производительностью, оказалась в центре внимания из-за серьёзных проблем с безопасностью своей модели. Несмотря на активный рост популярности, новый чат-бот DeepSeek R1 показал катастрофические результаты при попытках блокировать вредоносные запросы, сообщает PCMag.  Исследователи компании Cisco смогли взломать модель DeepSeek R1 со 100-% успешностью, используя автоматизированный алгоритм в сочетании с 50 запросами, связанными с киберпреступностью, дезинформацией и незаконной деятельностью. Чат-бот не смог отклонить ни одного опасного запроса и стал выдавать запрещённые инструкции. Если сравнивать китайского чат-бота в плане безопасности с конкурентами, то статистика оказалась не в пользу DeepSeek. Так, модель GPT-4o от OpenAI смогла отклонить 14 % вредоносных запросов, Google Gemini 1.5 Pro — 35 %, а Claude 3.5 показала результат в 64 %. Лидером стала предварительная версия OpenAI o1, которая заблокировала 74 % атак. По мнению Cisco, причина такого «поведения» DeepSeek кроется в низком бюджете, затраченном на разработку. Компания утверждает, что на создание модели было потрачено всего $6 млн, тогда как, например, обучение GPT-5 обошлось примерно в полмиллиарда долларов. Несмотря на слабую защиту от атак, DeepSeek демонстрирует строгую цензуру на политически чувствительные темы, связанные с Китаем. Например, на вопросы о положении уйгуров, подвергающихся гонениям по данным ООН, и о протестующих на площади Тяньаньмэнь в 1989 году, бот отвечает: «Извините, это выходит за рамки моих возможностей. Давайте поговорим о чём-то другом». Интересно, что проблемы с безопасностью и цензурой пока не влияют на популярность DeepSeek. По данным Similarweb, количество пользователей чат-бота выросло с 300 тысяч до 6 миллионов в день. А Microsoft и Perplexity уже начали интегрировать DeepSeek, который базируется на открытом исходном коде, в свои разработки. Власти Тайваня запретили чиновникам использовать DeepSeek из соображений безопасности
02.02.2025 [06:50],
Алексей Разин
С точки зрения властей КНР Тайвань является мятежным островом, над которым они хотели бы восстановить контроль. По этой причине власти Тайваня ждут от соседей какого-то подвоха, а потому использование разработок китайского стартапа DeepSeek государственными служащими и компаниями, имеющими стратегическое значение для Тайваня, было запрещено. 
Источник изображения: Unsplash, John Cameron Министерство цифровых технологий Тайваня, как сообщает Bloomberg, в пятницу заявило, что «работа DeepSeek вызывает озабоченность в сфере безопасности, связанные с трансграничной передачей информации и утечкой данных». Подобные опасения регулярно возникают в юрисдикции геополитических оппонентов КНР при распространении китайских информационных технологий по миру. Явным примером является попытка американских властей запретить деятельность китайской социальной сети TikTok в США из-за подобных опасений. В Италии едва набравшую популярность ИИ-платформу DeepSeek уже запретили, власти Великобритании пока ограничились предупреждением в адрес своих граждан и представителей бизнеса, Министерство обороны США запретило сотрудникам использовать DeepSeek. Компании в различных странах по своей личной инициативе запретили сотрудникам пользоваться разработками DeepSeek. Подобная ситуация возникали и на заре распространения американского ChatGPT, когда прецедент с использованием сотрудником Samsung конфиденциальных корпоративных данных для содействия в разработках со стороны чат-бота привёл к запрету на подобные действия для всего штата компании. По словам тайваньских чиновников, DeepSeek «угрожает национальной информационной безопасности», поскольку имеет китайские корни. Соответственно, запрещено вводить конфиденциальную или официальную информацию через интерфейс этой платформы. Это требование распространяется не только на тайваньских чиновников, но и на представителей компаний, формирующих критическую инфраструктуру острова. Китайский ИИ-чат-бот DeepSeek лидирует по загрузкам во всём мире, больше всего скачиваний — в Индии
01.02.2025 [16:59],
Владимир Мироненко
Чат-бот AI Assistant на основе искусственного интеллекта китайского стартапа DeepSeek возглавил список самых загружаемых мобильных приложений в 140 странах, причем наибольший процент новых пользователей приходится на Индию, пишет Bloomberg. 
Источник изображения: DeepSeek По данным сервиса аналитики Appfigures, которые не включают сторонние магазины приложений в Китае, 26 января приложение AI Assistant вышло на первое место в интернет-магазине App Store компании Apple и с тех пор удерживает лидирующую позицию во всем мире. При это на Индию приходится 15,6 % всех загрузок на разных платформах с момента запуска чат-бота. Согласно исследованию Sensor Tower, приложение AI Assistant также занимает первое место в магазине приложений Android Play Store компании Alphabet в США, которое оно удерживает с 28 января. Sensor Tower сообщила, что за первые 18 дней с момента запуска приложение стартапа DeepSeek было скачано 16 млн раз, что почти вдвое превышает 9 млн скачиваний, зафиксированных у ChatGPT компании OpenAI после выхода. Вместе с тем число пользователей ChatGPT значительно превышает аудиторию AI Assistant, у которого могут возникнуть проблемы с дальнейшим ростом, поскольку правительства и компании обеспокоены потенциальными последствиями его использования для кибербезопасности. Сотни фирм и государственных подрядчиков заблокировали DeepSeek в качестве меры предосторожности, сообщило агентство Bloomberg News на этой неделе. DeepSeek могла тайно получать ускорители Nvidia через Сингапур в обход санкций, заподозрили власти США
31.01.2025 [07:05],
Алексей Разин
Сложно было отрицать, что успехи китайского ИИ-стартапа DeepSeek вызвали в США не только восхищение конкурентов, но и озабоченность чиновников. Microsoft заподозрила, что обучение языковых моделей DeepSeek могло происходить за счёт нелегального доступа к данным OpenAI, а ещё власти США подозревают, что китайская компания могла получить доступ к ускорителям Nvidia в обход санкций через посредников в Сингапуре. 
Источник изображения: Nvidia В прошлом году Сингапуру удалось избежать тотального запрета на получение и транзитную отгрузку ускорителей вычислений американского происхождения, но в начале этого года администрация Байдена успела ограничить подобные поставки через введение квот. Без экспортной лицензии США в Сингапур можно поставить не более 1700 ускорителей Nvidia, но даже такая партия потребует уведомления американских властей. Более крупную партию они могут просто заблокировать. Nvidia регистрирует в Сингапуре до 20 % всей своей выручки, но поясняет, что фактически поставляет в крохотное государство гораздо меньше продукции, чем можно было подумать. Через сингапурские компании просто проходит оплата за поставку продукции Nvidia, а фактически отгрузка осуществляется во множество других стран, включая западные. Считается, что DeepSeek для обучения своей модели V3, представленной в прошлом месяце, использовала 2048 ускорителей Nvidia серии H800. Их поставки в Китай были под запретом с конца 2023 года, но установить, каким образом DeepSeek получила доступ к этим ускорителям, затруднительно. Сейчас, по данным Bloomberg, американские чиновники предполагают, что китайские разработчики использовали посредников в Сингапуре для получения ускорителей вычислений, запрещённых к ввозу в Китай напрямую. Nvidia поспешила заявить, что контролирует поставки ускорителей и придерживается экспортных ограничений, наложенных США. Как стало известно недавно, новая администрация США хочет включить ускорители Nvidia H20, которые пока можно ввозить в Китай легально, в расширенный список экспортного контроля. Потенциальный министр торговли США Ховард Лютник (Howard Lutnick) заявил, что не намерен поощрять использование китайской стороной «американских инструментов» для соперничества в сфере искусственного интеллекта. По его словам, доступ Китая к определённым категориям ускорителей вычислений американского происхождения нужно перекрыть. Microsoft открыла доступ к DeepSeek R1 своим клиентам в GitHub и Azure
30.01.2025 [13:05],
Владимир Мироненко
Компания Microsoft на удивление оперативно предоставила доступ своим клиентам к продвинутой ИИ-модели DeepSeek R1 со способностью к размышлению, пишет The Verge. Теперь она является частью каталога моделей на Azure AI Foundry и GitHub, что позволяет клиентам Microsoft интегрировать её в свои приложения ИИ. 
Источник изображения: Solen Feyissa/unsplash.com «Одним из ключевых преимуществ использования DeepSeek R1 или любой другой модели на Azure AI Foundry является скорость, с которой разработчики могут экспериментировать и интегрировать ИИ в свои рабочие процессы», — отметила Аша Шарма (Asha Sharma), корпоративный вице-президент Microsoft по ИИ. По её словам, DeepSeek R1, анонс которой привёл к резкому падению акций многих технологических компаний США на этой неделе из-за возможности обучения с гораздо меньшими затратами по сравнению с ведущими моделями OpenAI, прошла строгие проверки защищённости в формате Red Teaming и безопасности, включая автоматизированные оценки поведения модели и обширные проверки безопасности для снижения потенциальных рисков. Microsoft также вскоре сделает уменьшенную версию R1 доступной для локального запуска на ПК Copilot Plus, и вполне возможно, что R1 появится в других сервисах на базе ИИ от Microsoft. Ранее появились сообщения о том, что OpenAI и Microsoft проводят расследование по поводу возможного использования китайской компанией API OpenAI для обучения своих моделей. Переписки с ИИ-ботом DeepSeek и другие конфиденциальные данные попали в открытый доступ
30.01.2025 [11:44],
Павел Котов
Американская компания Wiz, которая специализируется на вопросах кибербезопасности, рассказала, что обнаружила в открытом доступе базу данных ClickHouse китайской лаборатории искусственного интеллекта DeepSeek — среди имеющейся в ней информации оказалась переписка с чат-ботом и другая конфиденциальная информация. 
Источник изображения: wiz.io Эксперты Wiz провели сканирование ресурсов DeepSeek и выяснили, что китайская компания оставила незащищёнными несколько миллионов строк данных. В этом наборе оказались программные ключи API и журналы переписки — DeepSeek сохраняет запросы, которые пользователи отправляют чат-боту с ИИ. Также база содержала значительный объем истории чатов, внутренних данных и конфиденциальной информации, включая эксплуатационные данные, которые позволяли повышать привилегии пользователя без обхода механизмов защиты. Wiz уведомила о своей находке китайскую компанию, и та оперативно закрыла незащищённую информацию. «Они убрали её менее чем за час. Но это было так просто обнаружить, что мы сочли себя не единственными, кто это нашёл», — рассказали в Wiz. В Wiz уточнили, что ClickHouse — разработанная «Яндексом» система управления базами данных с открытым исходным кодом, предназначенная для быстрых аналитических запросов к большим наборам данных. Система широко используется для обработки данных в реальном времени, хранения журналов и аналитики больших данных. Выпущенный DeepSeek виртуальный помощник с ИИ взволновал общественность в Китае и вызвал переполох в США. Китайской компании удалось добиться того же, чего и OpenAI, но при значительно более скромных затратах. Инвесторы в Америке поставили под сомнение устойчивость бизнес-моделей и рентабельность американских гигантов в области ИИ, в том числе Nvidia и Microsoft. К понедельнику приложение DeepSeek обогнало ChatGPT в Apple App Store, что спровоцировало масштабную распродажу акций технологических компаний. Radeon RX 7900 XTX обогнала GeForce RTX 4090 в работе с ИИ-моделью DeepSeek R1
29.01.2025 [23:58],
Николай Хижняк
Компания AMD заявила, что её флагманская видеокарта Radeon RX 7900 XTX обеспечивает более высокую производительность по сравнению с GeForce RTX 4090 и RTX 4080 Super в работе с ИИ-моделью DeepSeek R1. По словам генерального менеджера подразделения клиентских процессоров AMD и графики Radeon Дэвида Макафи (David McAfee), их флагман на архитектуре RDNA 3 обходит RTX 4090 до 13 %, а модель RTX 4080 Super — до 34 % в этих задачах. 
Источник изображений: AMD AMD протестировала три видеокарты с несколькими конфигурациями DeepSeek R1. Модель Radeon RX 7900 XTX обеспечила наиболее значительное превосходство над RTX 4090 в работе с ИИ-моделью DeepSeek R1 Distill Qwen 7B (7 млрд параметров), где обошла представителя поколения Ada Lovelace на 13 %. В трёх других конфигурациях LLM карта AMD также оказалась эффективнее конкурента: в двух задачах Distill Llama 8B (8 млрд параметров) её превосходство составило 11 %, а в Distill Qwen 14B (14 млрд параметров) она была на 2 % быстрее. Модель GeForce RTX 4090 оказалась быстрее Radeon RX 7900 XTX лишь в одной конфигурации LLM — Distill Qwen 32B (32 млрд параметров), где её превосходство составило 4 %. AMD также сравнила ИИ-производительность Radeon RX 7900 XTX с GeForce RTX 4080 Super. В работе с ИИ-моделью DeepSeek R1 Distill Qwen 7B (7 млрд параметров) «красная» карта показала 34-процентное превосходство над конкурентом. В задачах Distill Llama 8B и Distill Qwen 14B преимущество видеокарты AMD сократилось до 27 и 22 % соответственно. 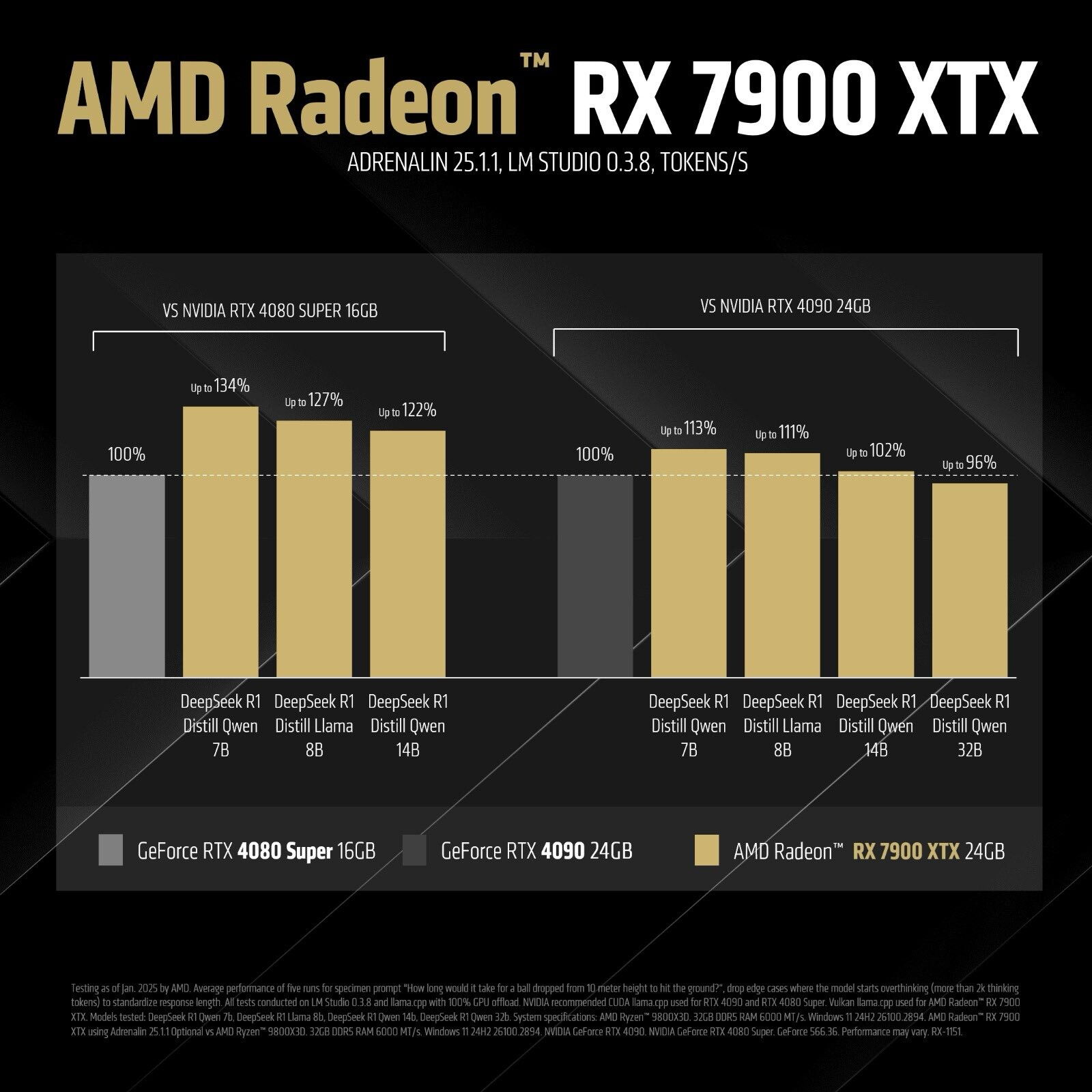 Как пишет портал Tom’s Hardware, результаты тестов, предоставленных AMD, следует воспринимать с некоторой долей скепсиса. Во-первых, речь идёт о внутренних тестах компании, а не о независимых испытаниях. Во-вторых, неизвестно, как были настроены видеокарты Nvidia для этих тестов. В конце концов, не все рабочие нагрузки ИИ требуют использования всех вычислительных возможностей GPU. Например, Stable Diffusion может не задействовать вычисления FP8 или код TensorRT для обработки. Карты Radeon RX 7900 XTX нечасто применяются в качестве специализированных ускорителей ИИ, однако их архитектура вполне позволяет это делать. RDNA 3 в составе Radeon RX 7900 XTX способна выполнять матричные операции, поддерживая вычисления BF16 и INT8. AMD даже официально использует словосочетание «ускоритель ИИ» в рекламных материалах об архитектуре RDNA 3, чтобы продемонстрировать её возможности в задачах искусственного интеллекта. В составе графического процессора Radeon RX 7900 XTX присутствуют 192 блока ускорения ИИ. Ранее AMD также опубликовала инструкцию, как использовать новую ИИ-модель DeepSeek R1 на её потребительском аппаратном обеспечении, включая видеокарты Radeon RX 7900 XTX. AMD показала, как запустить думающую ИИ-модель DeepSeek R1 на обычном ПК
29.01.2025 [23:13],
Николай Хижняк
Компания AMD опубликовала инструкции по локальному запуску продвинутой ИИ-модели DeepSeek R1 со способностью к размышлению на пользовательских ПК. Правда, необходима система на процессоре Ryzen с ИИ-ускорителем (NPU) XDNA, либо компьютер с настольной видеокартой Radeon RX 7000. Также для запуска требуется драйвер Adrenalin 25.1.1. 
Источник изображения: AMD Как утверждается, только недавно была представлена «высокоэффективная» малая версия ИИ-модели DeepSeek R1, достаточно компактная для работы на потребительском оборудовании. Стоит отметить, что в целом модели DeepSeek отличаются небольшими запросами к железу — например, модель DeepSeek-V3 изначально обучалась на кластере всего из 2048 ускорителей Nvidia H800. В инструкции AMD описывается всё, что нужно для локального запуска DeepSeek R1 на пользовательской системе на базе аппаратного обеспечения AMD. В LM Studio есть установщик больших языковых моделей в один клик, специально разработанный для процессоров Ryzen AI. Его же пользователи AMD могут использовать для установки R1. В ролике компания также показывает, как приложение должно быть настроено для конкретного оборудования, а также объясняет, какое максимальное количество параметров LLM поддерживается тем или иным оборудованием. Последнее в значительной степени зависит от объёма доступной памяти. Например, видеокарты Radeon RX 7600 XT, RX 7700 XT, RX 7800 XT, RX 7900 GRE и RX 7900 XT поддерживают модели до DeepSeek-R1-Distill-Qwen-14B с 14 млрд параметров. Флагманская карта Radeon RX 7900 XTX позволяет запускать модели до DeepSeek-R1-Distill-Qwen-32B с 32 млрд параметров. А модель Radeon RX 7600, имеющая на борту всего 8 Гбайт памяти, поддерживает запуск моделей до DeepSeek-R1-Distill-Llama-8B с 8 млрд параметров. Ноутбуки на базе процессоров Ryzen 8040 и Ryzen 7040 с 32 Гбайт ОЗУ, а также системы на базе процессоров Ryzen AI 9 HX 370 и Ryzen AI 9 365, оснащённые 24 или 32 Гбайт оперативной памяти, могут запускать модели до DeepSeek-R1-Distill-Llama-14B. Ноутбуки на базе Ryzen AI Max+ 395 поддерживают модели до DeepSeek-R1-Distill-Llama-70B с 70 млрд параметров, но только при наличии 64 или 128 Гбайт ОЗУ. Версии лэптопов с 32 Гбайт памяти могут запускать модели до DeepSeek-R1-Distill-Qwen-32B с 32 млрд параметров. Новая модель искусственного интеллекта DeepSeek R1 в одночасье покорила мир, поскольку затраты на её обучение оказались в 11 раз ниже, чем у передовых ИИ-моделей конкурентов. Два дня назад она стала причиной рекордной потери рыночной капитализации Nvidia в размере 589 миллиардов долларов. Модель DeepSeek R1 полагается на экстремальные уровни оптимизации, чтобы обеспечить 11-кратный рост эффективности. DeepSeek R1 работает не только на ускорителях Nvidia и AMD, но также сообщается о поддержке ускорителей Huawei Ascend. DeepSeek пропал из App Store и Google Play в Италии — до этого власти решили выяснить, как сервис обрабатывает персональные данные
29.01.2025 [19:06],
Павел Котов
Китайская лаборатория DeepSeek, которая обрела популярность благодаря выпуску революционных моделей искусственного интеллекта, предлагающих возможности, аналогичные американским, но при более скромных затратах на обучение, привлекла внимание итальянских властей — они обеспокоены «возможной угрозой для данных миллионов людей» в стране. Приложение DeepSeek уже исчезло из итальянских разделов App Store и Google Play. 
Источник изображения: Solen Feyissa / unsplash.com Приложение DeepSeek стало самым популярным на платформе Apple App Store, и итальянское Управление по защите данных (Garante) обратилось к китайской компании с просьбой предоставить информацию о чат-боте, который может представлять угрозу конфиденциальности жителей страны. Надзорный орган отвечает за применение норм «Общего регламента по защите данных» (GDPR) в Италии. Garante сообщило, что связалось с офисами DeepSeek в Ханчжоу и Пекине и запросило информацию о том, какие персональные данные собирает чат-бот с ИИ. Ведомство поинтересовалось, каковы цели сбора данных и хранятся ли они на серверах, физически расположенных на территории Китая. В «Политике конфиденциальности» DeepSeek действительно указано, что сервис передаёт персональные данные, связанные со страной проживания пользователя, и хранит их «на защищённых серверах, расположенных в Китайской Народной Республике». Однако отмечается, что «это будет делаться в соответствии с требованиями применимых законов о защите данных». Итальянский регулятор также запросил, какие данные используются для обучения системы искусственного интеллекта DeepSeek. Если производится сканирование веб-страниц, то каким образом зарегистрированные и незарегистрированные пользователи информируются об обработке персональных данных. DeepSeek дали 20 дней на ответ Garante. Расследование в отношении китайской лаборатории уже проводят Microsoft и OpenAI; изучать вопрос начали и американские власти. Любопытно, что спустя несколько часов после того, как Garante запросило у DeepSeek информацию об обработке персональных данных, приложение исчезло из итальянских разделов магазинов Apple App Store и Google Play. Официальных комментариев от Apple и Google по этому вопросу не последовало. Microsoft заподозрила DeepSeek в обучении ИИ на данных, украденных у OpenAI
29.01.2025 [12:17],
Павел Котов
Компании Microsoft и OpenAI проведут расследование на предмет того, не совершила ли организация, связанная с китайской лабораторией искусственного интеллекта DeepSeek, кражу данных у OpenAI. Об этом сообщило агентство Bloomberg со ссылкой на собственные источники. 
Источник изображения: deepseek.com Эксперты отдела безопасности Microsoft ещё осенью обратили внимание, что некие лица, которые, по мнению корпорации, могут быть связаны с DeepSeek, запрашивают большие объёмы данных через API OpenAI, рассказали источники Bloomberg. OpenAI продаёт доступ к API — этот инструмент позволяет сторонним разработчикам интегрировать модели искусственного интеллекта OpenAI в свои приложения. Microsoft как технологический партнёр и крупнейший инвестор OpenAI уведомила компанию о происходящем. Эта деятельность может нарушать условия обслуживания OpenAI или указывать, что связанная с китайской лабораторией компания пыталась обойти ограничения на объём данных, который могут получить клиенты OpenAI. Ранее DeepSeek представила открытую модель ИИ R1, имитирующую ход мыслей человека. Проект всколыхнул рынок, на котором доминируют OpenAI и другие американские компании, в том числе Google и Meta✴. По словам создателей, модель может конкурировать или превосходит проекты ведущих американских разработчиков, а её обучение обошлось радикально дешевле. В результате возникла угроза американскому доминированию в отрасли ИИ, и в понедельник, 27 января, рыночная капитализация технологических компаний США, включая Microsoft, Nvidia, Oracle и Alphabet, просела почти на $1 трлн. Накануне, 28 января, советник президента США Дональда Трампа (Donald Trump) по вопросам ИИ Дэвид Сакс (David Sacks) заявил, что есть «существенные доказательства» использования моделей OpenAI при разработке технологий DeepSeek. В интервью господин Сакс рассказал о методе дистилляции, позволяющий одной модели ИИ обучаться на данных другой для развития аналогичных возможностей. «Мы знаем, что компании из КНР — и прочие — постоянно пытаются произвести дистилляцию моделей ведущих американских компаний в области ИИ. Как ведущий разработчик ИИ мы принимаем контрмеры для защиты нашей интеллектуальной собственности, включая тщательный процесс развёртывания передовых возможностей у выпускаемых моделей, и уверены, что по мере движения вперёд критически важно тесно сотрудничать с правительством США, чтобы наиболее эффективным образом защитить самые функциональные модели от попыток неприятеля и конкурентов завладеть американскими технологиями», — прокомментировали заявление Сакса в OpenAI. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






