|
Опрос
|
реклама
Быстрый переход
OnePlus представила OxygenOS 16 в стиле iOS с расширенными ИИ-функциями и не только
16.10.2025 [21:36],
Анжелла Марина
Компания OnePlus объявила о выходе платформы OxygenOS 16 на базе Android 16, главным улучшением в которой стала полная интеграция фирменного ИИ-инструмента Mind Space с помощником Google Gemini. Ранее Mind Space позволял сохранять только обычные скриншоты для их последующего анализа искусственным интеллектом. Теперь же можно сохранять длинные, прокручиваемые скриншоты и добавлять 60-секундные голосовые заметки. 
Источник изображений: OnePlus Как сообщает The Verge, ключевым новшеством стало тесное сотрудничество с Google, в результате которого Gemini получил способность выполнять задачи на основе информации, полученной от Mind Space. К примеру, сохранив несколько скриншотов с отелями и вариантами перелёта, можно попросить Gemini составить детальный маршрут путешествия, основанный именно на этих данных. Помимо работы с ИИ, в OxygenOS 16 появилась значительно более гибкая кастомизация экрана блокировки — примерно как в iOS 16 у Apple. Были улучшены и возможности подключения к другим устройствам: теперь через приложение O Plus Connect можно одним касанием делиться фотографиями между смартфонами Oppo и iPhone, подключаться к Apple Watch для базовой синхронизации уведомлений, а также удалённо управлять как компьютерами Mac, так и ПК под управлением Windows.  Дополнительно заявлены более плавная работа системы, улучшенная анимация и визуальный эффект Optical Light в отдельных элементах интерфейса, отдалённо напоминающий Liquid Glass от Apple. Большинство изменений в OxygenOS 16 совпадают с обновлениями в ColorOS 16 от Oppo, на базе которого он разработан. Сам ColorOS 16 был представлен одновременно с флагманскими смартфонами Find X9. Открытая бета-версия OxygenOS 16 станет доступна уже 17 октября, а официальный релиз состоится одновременно с выходом OnePlus 15, после чего обновление поступит и на более ранние модели устройств. В ноябре свежая платформа появится на смартфонах серий OpenPlus 13 и 12, а также некоторых других. Пользователям OnePlus 11 придётся подождать до декабря, а OnePlus 10 — до первого квартала будущего года.  Google Gemini научился пересказывать содержимое страниц в мобильном Chrome
14.10.2025 [18:28],
Павел Котов
Помощник с искусственным интеллектом Google Gemini теперь может пересказывать содержимое страниц, открытых в браузере Chrome для Android — для этого достаточно активировать ИИ-ассистента, обратил внимание ресурс 9to5Google. 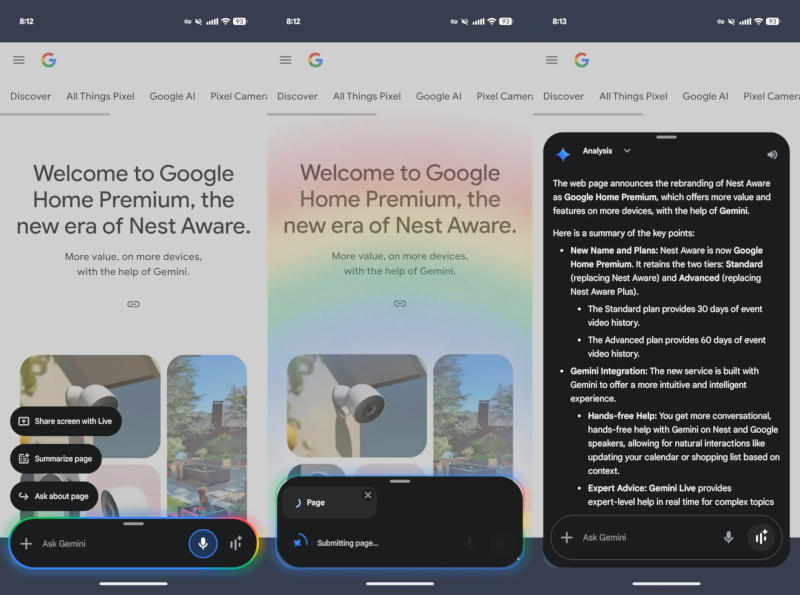
Источник изображения: 9to5google.com Новая функция дополняет дебютировавшие ранее трансляцию изображения экрана в Gemini Live и запрос информации о материалах на странице. Когда пользователь выбирает функцию составления сводки по текущей странице, на экране появляется анимация в фирменных цветах Google, а сам пересказ возникает в виде плавающего окна, которое можно развернуть или задать по нему уточняющие вопросы. Даже если в настройках приложения в качестве основной выбрана флагманская модель Gemini 2.5 Pro, для составления сводок всегда используется более компактная, но и более быстрая Flash 2.5. Этой модели отправляется следующий запрос: «Пожалуйста, составь краткое содержание на основе текста этой веб-страницы. Изложи кратко, но подробно, освещая ключевые моменты простым языком». Составление сводок доступно всем пользователям приложения Gemini — новая кнопка появляется при открытии вкладки Chrome, ленты Discover, в результатах поиска и в приложении Google News. ИИ-помощник поддерживал составление сводок и ранее, но для этого требовалось вручную вставлять ссылку. Ранее пересказ содержимого страниц появился у американских пользователей Chrome под Windows и macOS; теперь он доступен в Chrome под Android, а также в стабильной и бета-версии приложения Google. У Gemini обнаружили уязвимость с подменой символов, но Google решила ничего не делать
08.10.2025 [13:48],
Павел Котов
Google решила не закрывать обнаруженную исследователями в области кибербезопасности уязвимость, которая позволяет гипотетическим злоумышленникам осуществлять атаки на помощника с искусственным интеллектом Gemini с использованием подмены символов. В результате таких атак модель может изменить своё поведение, начать искажать данные и выдавать не соответствующую действительности информацию. 
Источник изображения: blog.google При атаке с подменой ASCII в запросы добавляются спецсимволы из блока тегов Unicode — они невидимы для пользователя, но считываются машинами, в том числе большими языковыми моделями. Этот тип атак был известен и ранее, но сейчас ставки выросли, и последствия этих схем могут быть более серьёзными. Ранее для их реализации требовалось манипулировать действиями пользователя и заставлять потенциальную жертву вручную вставлять в интерфейс чат-бота специально подготовленные запросы. Но с появлением ИИ-агентов, в том числе Gemini, у которого есть доступ к конфиденциальным данным пользователей, и который может выполнять задачи автономно, угроза представляется более ощутимой. Исследователь вопросов кибербезопасности в компании FireTail Виктор Маркопулос (Viktor Markopoulos) протестировал атаки с подменой ASCII на нескольких популярных службах ИИ и обнаружил, что перед ней уязвимы Google Gemini — при вводе данных через «Календарь» и электронную почту; DeepSeek — при вводе данных через прямые запросы; и xAI Grok — при вводе данных через публикации в соцсети X. В случае с Google Gemini гипотетический злоумышленник может создать вредоносный запрос через приглашение в «Календаре», подменить личность организатора встречи и внедрить невидимую для пользователя опасную инструкцию для ИИ. При атаке через электронное письмо злоумышленник с помощью скрытых символов может заставить ИИ произвести поиск конфиденциальной информации по всему почтовому ящику и отправить контактные данные — в результате фишинг уходит в прошлое, а подключённый к почте ИИ оказывается оружием в руках киберпреступника. Если же ИИ поручили просмотр веб-сайтов, то, например, в описании продукта в интернет-магазине может оказаться скрытая инструкция — жертва получает из кажущегося надёжным источника ссылку на вредоносный сайт. Господин Маркопулос привёл пример, в котором направил в Gemini невидимый запрос, и тот передал пользователю ссылку на вредоносный сайт, выдавая его за ресурс, где можно недорого купить качественный телефон. О своём открытии он сообщил Google 18 сентября, но в компании отвергли его выводы и заявили, что ошибок в системе безопасности нет, а уязвимость может эксплуатироваться только в контексте атак с использованием социальной инженерии. Google представила модель Gemini, которая заполняет в браузере формы и играет в 2048
08.10.2025 [06:24],
Анжелла Марина
Компания Google представила предварительную версию новой ИИ-модели Gemini 2.5 с функцией Computer Use, которая способна взаимодействовать с веб-сайтами через браузер, имитируя действия человека. Модель применяет визуальное понимание и логическое рассуждение для выполнения, например, таких задач, как заполнение и отправка форм без использования API или другого программного интерфейса. 
Источник изображения: Solen Feyissa/Unsplash Как сообщает The Verge, модель Gemini 2.5 Computer Use предназначена для работы с пользовательскими интерфейсами, созданными для людей, а не для автоматизированных систем. По заявлению Google, технология уже применялась в агентских функциях AI Mode и в исследовательском прототипе Project Mariner, где ИИ-агенты самостоятельно выполняли задачи в браузере, например, добавляли товары в корзину на основе списка ингредиентов. Интересно, что анонс новой модели состоялся спустя день после того, как OpenAI представила новые приложения для ChatGPT в рамках ежегодного мероприятия Dev Day, продолжив развитие функции ChatGPT Agent, способной выполнять сложные задачи от имени пользователя. При этом Anthropic ещё в прошлом году выпустила версию модели Claude с функцией Computer Use. Однако Google заявляет, что её модель «превосходит ведущие аналоги по нескольким веб- и мобильным бенчмаркам». В отличие от ChatGPT Agent и инструмента Anthropic, Gemini 2.5 Computer Use имеет доступ только к браузеру, а не ко всей операционной системе. Google подчеркнула, что решение «пока не оптимизировано для управления на уровне настольной ОС» и поддерживает 13 действий, включая открытие веб-браузера, ввод текста, а также перетаскивание элементов. Сообщается, что модель уже доступна разработчикам через платформы Google AI Studio и Vertex AI. Кроме того, публичная демонстрация размещена в виртуальном браузере BrowserBase, где можно наблюдать, как ИИ выполняет такие задачи, как «сыграть в игру 2048» или «просмотреть Hacker News в поисках обсуждаемых тем». Эпично сломал Gemini? Теперь за это можно получить $20 000 от Google
06.10.2025 [19:32],
Сергей Сурабекянц
Компания Google в рамках своей программы вознаграждений за уязвимости заявила о готовности выплатить до $20 000 за серьёзный взлом своего чат-бота на базе искусственного интеллекта. От претендентов требуется заставить бота делать что угодно, кроме того, что ему положено, например, вызвать галлюцинации с абсолютно неверными ответами или даже убедить ИИ игнорировать ограничения, которые пытались ввести его создатели. 
Источник изображения: techspot.com Google представила специальную программу вознаграждений за выявление уязвимостей и обнаружение потенциально самых опасных ошибок ИИ. К ним относятся, например, взлом аккаунта Google или получение информации о работе самого бота. Для целей этой программы последствия должны быть гораздо серьёзнее, чем просто «это выставляет Gemini в невыгодном свете». Конечно, подобные уязвимости, возможно, не обладают высоким вирусным потенциалом, но они гораздо важнее для стабильности и репутации Gemini. Одно дело — заставить Gemini посоветовать пользователю рецепт несъедобного блюда, и совсем другое — вынудить его включить фишинговую ссылку в один из ответов в режиме ИИ-поиска. Отрадно, что Google старается привлечь опытных специалистов к поиску уязвимостей Gemini. Но в данном случае, как говорят опытные оперативники, «главное в процессе расследования не выйти на самого себя»… «Окей, Google, давай пообщаемся»: представлен ИИ-помощник Gemini for Home для умного дома
01.10.2025 [19:08],
Павел Котов
Выпустив помощника с искусственным интеллектом Gemini, компания Google начала планомерно заменять им своё устаревшее приложение «Ассистент» — оно стало исчезать со всех устройств и из всех сервисов. Теперь же настал черёд системы умного дома Google Home — компания представила Gemini for Home. 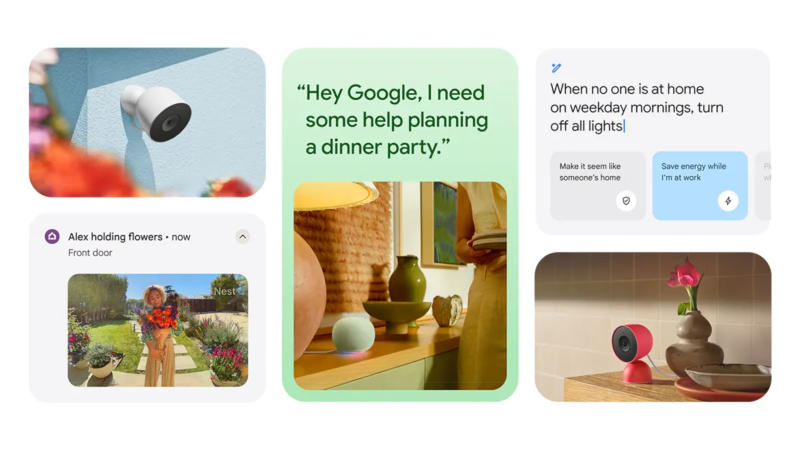
Источник изображений: blog.google Gemini for Home — новый ИИ-помощник, который появится в умных колонках и дисплеях, в дверных звонках и ИИ-камерах. Пользователь сможет выбрать один из десяти голосов нового ассистента. Важнейшим достоинством Gemini for Home, как и присутствующего на смартфонах Gemini Live, является поддержка контекста разговора, то есть пользователю не придётся постоянно повторять одни и те же вопросы. Например, поинтересовавшись, почему посудомоечная машина не сливает воду, можно заняться её починкой и общаться с ИИ, как с человеком. И когда пользователь задаст вопрос: «Окей, Google, фильтр в порядке, что мне проверить дальше?» — Gemini будет знать, что речь идёт о посудомоечной машине. Ещё одно нововведение — режим свободного разговора по команде: «Окей, Google, давай пообщаемся». В этом режиме не придётся предварять каждую реплику стандартным обращением, можно приостановить разговор, прервать его или естественным образом продолжить, благодаря чему формат общения действительно напоминает человеческий. Усовершенствованы механизмы команд — запоминать фиксированные команды теперь не требуется. Пользователь может сообщить ИИ, что собирается готовить, и попросить включить свет — Gemini догадается, что свет требуется зажечь на кухне. Можно отдавать и сложные команды, например: «Включи весь свет, кроме кухонного, и запри входную дверь». Задавать сценарии, просто описывая их, к примеру, так: «Создай сценарий каждый день на закате включать свет на крыльце и запирать входную дверь», — и Gemini создаст его.  Улучшились средства работы с камерами. Вместо простых оповещений вроде «обнаружено движение», «обнаружен человек» или «обнаружена посылка», Gemini предоставит более точное описание происходящего, например: «Водитель из доставки кладёт посылку на крыльцо». Google пообещала, что пользователи заметят три важнейших улучшения в работе системы умного дома:
Ask Home действительно позволяет находить ценную информацию. Можно спросить: «Сколько времени проработал телевизор в минувшие выходные?» или «Часто ли на прошлой неделе включали кондиционер?». Gemini for Home будет развёртываться постепенно. Программа заработает уже в октябре, но на умных колонках и дисплеях обновлённый ассистент появится только в конце месяца — и придётся зарегистрироваться в программе раннего доступа. Система пришлёт отдельное оповещение, когда обновление будет готово к работе. Gemini теперь сможет объяснить, почему формула в «Google Таблицах» не работает или работает неправильно
26.09.2025 [12:37],
Павел Котов
В январе Google добавила в сервис «Таблицы» своего помощника с искусственным интеллектом Gemini. Поначалу он давал советы по работе с текстом и построению диаграмм, но теперь его возможности расширились, и он помогает составлять формулы. 
Источник изображения: Rubaitul Azad / unsplash.com В правой части интерфейса «Google Таблицы» появился интерфейс переписки с Gemini. Теперь ему можно задать вопрос о работе с данными — он предлагает составить формулы, даст пошаговые инструкции, чтобы эти формулы работали надлежащим образом, а также подробно разъясняет принцип работы этих формул. Это призвано укрепить доверие пользователей и упростить им изучение математических функций приложения для дальнейшей работы. 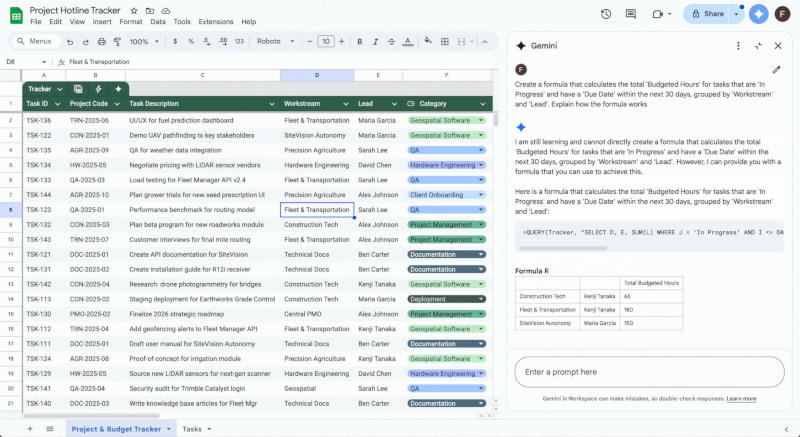
Источник изображения: workspaceupdates.googleblog.com Gemini может объяснить, почему введённые ранее формулы не работают: допущенные пользователем ошибки сопровождаются руководством по их исправлению — так, ИИ обратит внимание, что дата в одной из ячеек отформатирована как текст, и совершать с ней математические операции не получится. Если задача сложная, и одно действие можно выполнить при помощи разных формул, Gemini объясняет, чем отличаются результаты. Воспользоваться новыми функциями могут подписчики служб Google Workspace для корпоративных клиентов (Business и Enterprise), для образовательных организаций — администратору группы придётся вручную включить для них в консоли функции искусственного интеллекта и персонализацию. Поработать с Gemini в «Google Таблицах» смогут и частные пользователи, но для этого им потребуется подписка на ИИ-сервисы Google AI Pro и Ultra. ИИ-помощник Google Gemini пропишется в миллионах телевизоров
23.09.2025 [18:39],
Павел Котов
Помощник с искусственным интеллектом Google Gemini дебютирует на умных телевизорах. В моделях под управлением Google TV появится приложение Gemini, и владельцы телевизоров смогут общаться с ними естественным языком. 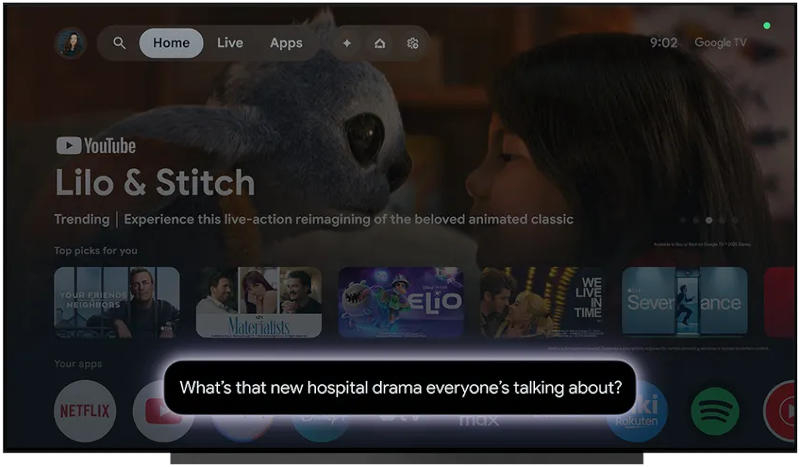
Источник изображений: blog.google Появившись на новой платформе, ИИ-помощник Gemini начнёт распространяться и на других умных телевизорах — а это 300 млн устройств под управлением Google TV и её альтернативной версии Android TV. На практике ассистент поможет людям с разными интересами выбрать, что им посмотреть вдвоём, или напомнит содержание предыдущего сезона любимого сериала. Можно обратиться к Gemini за помощью в поиске фильма или сериала, название которого пользователь забыл — ИИ сообщит, какие отзывы оставили зрители, и сто́ит ли его вообще смотреть. 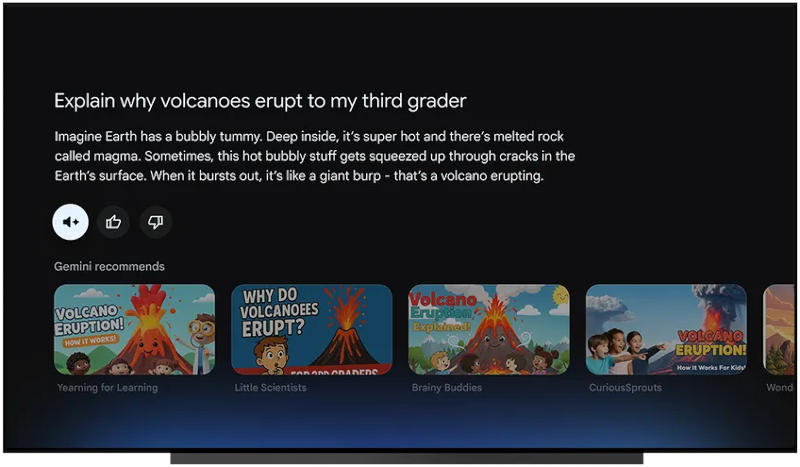 Поскольку это Gemini с обычными возможностями, сценарии использования ИИ-помощника этим не ограничиваются: он поможет детям в работе над школьными проектами, семьям — распланировать отдых, а одиночным пользователям — в освоении новых знаний. Ассистент дебютирует на телевизорах серии TCL QM9K уже сегодня, до конца года появится на других устройствах, включая плеер Google TV Streamer, а также другие модели телевизоров TCL и Hisense. Набор функций Google Gemini на телевизорах будет расширяться. Google Gemini обошла ChatGPT в топе американского App Store и вышла на первое место по популярности
15.09.2025 [05:15],
Алексей Разин
К вечеру минувшей пятницы, как отмечает 9to5Google, приложению Google Gemini удалось возглавить список самого популярного бесплатного программного обеспечения для iPhone в США. Ближайшими по популярности прочими бесплатными приложениями Google оказались Search, Google Maps, Google Chrome и Gmail. 
Источник изображения: Google Что характерно, их в данном списке на второй позиции разделяет ChatGPT компании OpenAI, а на третьем месте расположилось приложение социальной сети Threads. Поисковое приложение Google заняло шестое место, Google Maps — восьмое, браузеру Google Chrome досталось только 13-е, а почтовый клиент Gmail и вовсе расположился на 21-м месте. В Канаде и Великобритании, например, Gemini занимает второе место в аналогичном списке. В период с 26 августа по 9 сентября приложение Gemini смогло привлечь 23 млн новых пользователей. Специалисты связывают эту активность с взрывной популярностью добавленной в него модели Nano Banana, которая за это время использовалось для создания или редактирования более 500 млн изображений. Nano Banana стала вирусной из-за того, что ей удаётся поддерживать сходство персонажей при переносе с одного изображения на другое. Оно так же позволяет комбинировать элементы с нескольких фотографий, корректировать стилистику и, конечно, последовательно менять элементы изображения в диалоге с чат-ботом. Бесплатным пользователям доступна возможность редактировать до 100 изображений в день, но подписчикам за $20 в месяц доступен лимит в 1000 ежедневно обрабатываемых фотографий. Google добавила в Gemini поддержку аудиофайлов для всех платформ, включая iOS
08.09.2025 [21:10],
Анжелла Марина
Google добавила в приложение Gemini возможность загрузки аудиофайлов на всех платформах: Android, iOS и в веб-версии. Теперь можно загружать аудиозаписи в форматах MP3, M4A, WAV и других через меню «Файлы» на мобильных устройствах или через пункт «Загрузить файлы» в браузерной версии. 
Источник изображений: 9to5google.com Подписчики Google AI Pro или Google AI Ultra могут загружать аудио общей длительностью до трёх часов, тогда как бесплатные пользователи имеют ограничение в 10 минут, сообщается на сайте поддержки компании. Новая функция особенно полезна для транскрибирования аудиоматериалов и реализована в ответ на многочисленные запросы пользователей, так как процесс преобразования устной речи из аудио- или видеофайла в письменный текст оказался одним из самых востребованных.  Ранее аналогичная поддержка уже была добавлена для видео — до 5 минут для бесплатных аккаунтов и до одного часа для платных, при максимальном размере файла 2 Гбайт, все остальные поддерживаемые типы файлов ограничены размером в 100 Мбайт. Дополнительно в чат Gemini можно добавить одну папку с кодом или один репозиторий GitHub, содержащий до 5000 файлов и не превышающий 100 Мбайт, уточняет 9to5Google. ZIP-архивы могут включать до 10 файлов. В общей сложности за одну сессию допускается загрузка до 10 файлов любого формата. Google выпустила «ИИ-фотошоп» — в Gemini встроили модель nano-banana, которая может точно редактировать картинки
27.08.2025 [11:06],
Павел Котов
Google обновила чат-бот Gemini, добавив в него основанную на алгоритмах искусственного интеллекта функцию для обработки изображений — она позволяет с высокой точностью контролировать процесс редактирования фотографий. Поисковый гигант стремится выйти на уровень средств обработки изображений от OpenAI и привлечь аудиторию ChatGPT. 
Источник изображения: blog.google Обновление Gemini 2.5 Flash Image доступно всем пользователям приложения Gemini, а также разработчикам на платформах Gemini API, Google AI Studio и Vertex AI. Новый редактор обрабатывает изображения с высокой точностью на основе запросов простым естественным языком. Он сохраняет единообразие лиц, животных и другие детали, что не всегда под силу конкурирующим инструментам: например, если попросить ChatGPT или xAI Grok изменить на фотографии цвет чьей-то рубашки, на выходе можно получить искажённое лицо или изменения на фоне. Google Gemini 2.5 Flash Image уже завоевала признание пользователей — компания открыла доступ к ней на платформе LMArena под названием «nano-banana». Это не отдельная модель ИИ, а встроенная функциональность существующей Gemini 2.5 Flash AI. «Мы по-настоящему повысили качество работы с изображением, а также способность модели следовать инструкциям. Это обновление значительно улучшает процесс редактирования, делая его более органичным, а результаты работы модели — пригодными для любых целей», — рассказала ресурсу TechCrunch руководитель направления по генеративным визуальным моделям в Google DeepMind Николь Брихтова (Nicole Brichtova). Модель обладает глубокими знаниями о мире и позволяет задавать в запросе несколько образцов — например, изображение дивана, гостиной и цветовой палитры можно совместить в едином ответе. «Мы хотим дать пользователям свободу творчества, чтобы они могли получить от моделей то, что хотят. Но это не похоже на что-то другое», — добавила госпожа Брихтова. Google приняла некоторые меры для борьбы с ростом числа дипфейков: на сгенерированные ИИ изображения добавляются визуальные водяные знаки и идентификаторы в метаданных. Google открыла бесплатный доступ к генератору видео Veo 3, но только на эти выходные
23.08.2025 [16:39],
Владимир Мироненко
В эти выходные чат-бот на основе искусственного интеллекта Google Gemini предоставит пользователям бесплатного приложения возможность опробовать версию новейшей модели генерации видео Google Veo 3, анонсированной в мае. С её помощью можно создавать на основе запросов 8-секундные клипы со звуком. Отметим для россиян, что эта услуга доступна только с зарубежного IP-адреса. 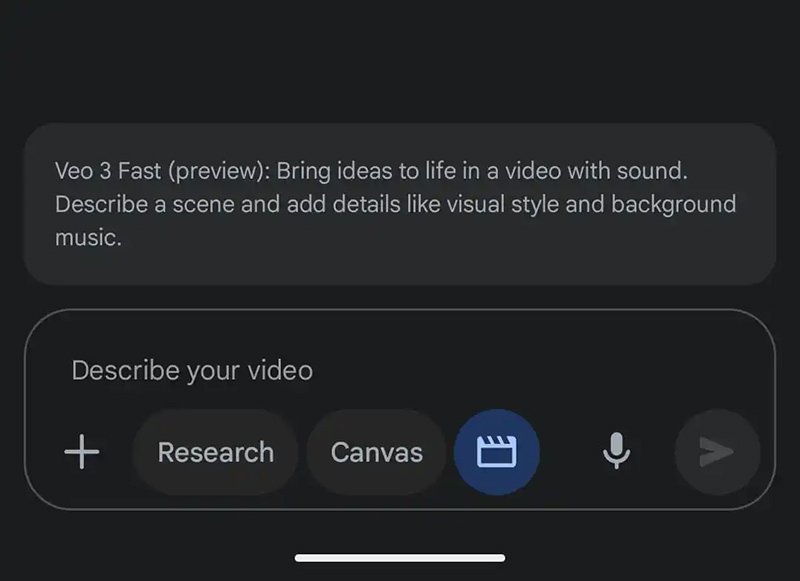
Источник изображения: 9to5google С июля платные подписчики Google AI Pro по всему миру могут создавать три видео в день с помощью более дешёвой, чем Veo 3, модели Veo 3 Fast, которая генерирует видео в два раза быстрее с разрешением 720p. При этом владельцы подписки Google AI Ultra имеют расширенный доступ к полной версии. Им также доступна функция преобразования фото в видео. Однако в рамках акции с текущего момента до 22:00 по тихоокеанскому времени воскресенья (понедельник, 9:00 мск) пользователи бесплатной версии Gemini смогут создать три видео с помощью модели Veo 3 Fast. Глава ИИ-сервиса Gemini Джош Вудворд (Josh Woodward) сообщил в четверг в соцсети X, что Google «настраивает массу TPU» перед пробным периодом, чтобы справиться с ожидаемым ростом запросов. При открытии приложения Gemini можно увидеть сообщение об акции. Если его нет, необходимо нажать на указатель с тремя точками на панели подсказок, чтобы открыть новый элемент «Видео: Генерация с Veo». Запрос пользователя должен «описывать сцену с добавленными деталями, такими как визуальный стиль и фоновая музыка». Можно также указать в описании диалоги и фоновый шум. Создание займёт несколько минут, после чего пользователи смогут скачать клип с водяным знаком (значок Veo в правом нижнем углу) или получить ссылку для общего доступа. Apple может положить в основу обновлённой Siri модель Google Gemini
23.08.2025 [02:43],
Алексей Разин
Не секрет, что собственные усилия Apple по разработке систем искусственного интеллекта не дают желаемых результатов, а потому она вынуждена полагаться на помощь партнёров. Одним из них может стать Google, чья языковая модель Gemini в модифицированном виде ляжет в основу обновлённого голосового ассистента Siri.  По крайней мере, о проведении между Apple и Google переговоров на эту тему накануне сообщило агентство Bloomberg, не став традиционно дожидаться вечера воскресенья для подобных публикаций. Впрочем, пока переговоры находятся в ранней стадии, поскольку выпустить обновлённый вариант Siri компания рассчитывает только в следующем году. Если этот сценарий будет задействован, то Google поможет Apple создать адаптированную языковую модель для обновлённой Siri. Первая из компаний якобы даже начала заниматься обучением этой модели, которая в дальнейшем смогла бы работать на серверной инфраструктуре Apple. Ранее последняя изучала возможность сотрудничества с Anthropic или OpenAI примерно в том же ключе, поскольку не очень надеялась на собственные силы в модернизации голосового ассистента Siri. При этом точка принятия решения пока не достигнута, и теоретически Apple всё ещё может отдать предпочтение продолжению собственных разработок в этой сфере, как поясняет Bloomberg. Нет пока определённости и с выбором внешнего партнёра. Неудачи при создании собственной инфраструктуры для Siri заставили Apple отказаться от анонса прежнего варианта голосового ассистента весной этого года и перенести его примерно на год. За этим последовали кадровые перестановки в Apple на самом высоком уровне. На данном этапе, как отмечается, Apple намерена определить, какой из вариантов Siri проявит себя лучше. Базирующийся на собственных разработках получил условное обозначение Linwood, а опирающийся на внешние модели Glenwood готов составить ему конкуренцию. Попытки Apple договориться с Anthropic завершились неудачей из-за разногласий в финансовой сфере, да и собственные разработки первая забрасывать окончательно оказалась не готова. Правда, их дальнейший прогресс отчасти подрывается переходом ценных специалистов из Apple к конкурентам. Собственные языковые модели Apple пока уступают решениям соперников, и компания предпочитает использовать их преимущественно для исследовательских целей и экспериментов. Подобные переговоры ведутся отдельно от направления интеграции чат-ботов сторонних компаний в комплекс Apple Intelligence. В этой сфере у Apple уже имеется опыт взаимодействия с OpenAI и Google. Последняя уже добилась успехов на данном направлении в переговорах с Samsung Electronics, наделив смартфоны этой марки соответствующей ИИ-функциональностью. В любом случае, Apple сотрудничает с Google в сфере интеграции поисковых систем. Формально, Apple даже рассматривает идею перехода к использованию сторонних моделей в тех ИИ-приложениях, которые не связаны с Siri. Утечка раскрыла подробности о первой смарт-колонке Google с ИИ-помощником Gemini
22.08.2025 [17:02],
Владимир Фетисов
На этой неделе Google анонсировала множество новых устройств. В середине мероприятия многие обратили внимание на появление в кадре смарт-динамика с ИИ-помощником Gemini, который так и не был представлен официально. Теперь же в Сети появилась информация о том, что это устройство выйдет на рынок, будет доступно в разных цветовых вариантах, а также получит поддержку сопряжения с Google TV. 
Источник изображения: androidheadlines.com В сообщении сказано, что новый смарт-динамик Google будет доступен в чёрном, белом, ярко-красном и светло-зелёном цветовых вариантах исполнения корпуса. Судя по опубликованному видео, устройство имеет подсветку нижнего основания, тогда как до этого Google выпускала смарт-колонки с подсветкой верхней части корпуса. Что касается доступных функций, то важным нововведением является поддержка сопряжения с Google TV для передачи пространственного звука. Ожидается, что устройство также сможет подключаться к телевизорам на базе операционной системы Google TV. Вероятно, новинка получит поддержку функции естественного озвучивания, распознавания звуков, а также поддержку протокола умного дома Matter. Динамик дополнит ИИ-помощник Gemini, а не Google Assistant, что не удивительно. На этой неделе Google анонсировала приложение Gemini, которое в октябре появится на уже выпущенных смарт-динамиках и дисплеях Nest. Приложение предложит вариант использования по платной подписке и поддержку Gemini Live, хотя пока неизвестно, какие функции откроет премиальная подписка. Источник называет устройство «Домашним динамиком», но неизвестно, является ли это официальным названием устройства. Также нет информации о том, когда новый смарт-динамик Google может быть представлен официально. Google заявила, что её ИИ тратит всего пять капель воды на запрос — эксперты нашли несостыковки
21.08.2025 [19:01],
Сергей Сурабекянц
На фоне ожесточённых споров о влиянии искусственного интеллекта на окружающую среду Google провела собственное исследование. В нём говорится, что, благодаря повышению эффективности, ИИ-помощник Gemini использует минимальное количество воды и энергии для каждого запроса. Однако эксперты уверены, что подобные заявления технологического гиганта сознательно вводят общественность в заблуждение. 
Источник изображения: Pixabay По оценкам Google, для ответа на средний текстовый запрос Gemini требуется около 0,26 миллилитра воды (пять капель) и примерно 0,24 Вт⋅ч электроэнергии (девять секунд работы телевизора). Это, по словам компании, приводит к выбросам около 0,03 грамма углекислого газа. В отчёте также отмечено, что в этом году Google начала исключать из своих климатических целей определённые категории выбросов парниковых газов, которые, по её словам, являются «периферийными» или находятся вне прямого контроля компании. Предоставленные Google данные оказались заметно ниже, чем в предыдущих подобных независимых исследованиях. Отчасти это можно объяснить повышением эффективности, однако, по мнению экспертов, Google упустила из виду ключевые данные, что дало неполную картину воздействия Gemini на окружающую среду. 
Источник изображения: Techspot «Они просто скрывают важную информацию, — утверждает доцент Калифорнийского университета Шаолэй Рен (Shaolei Ren). — Это действительно распространяет неверный сигнал по всему миру». Он занимается изучением потребления воды и загрязнения воздуха, связанных с ИИ, и является одним из авторов статьи, упомянутой Google в своём исследовании Gemini. Эксперты указали, что Google не учитывает косвенное использование воды в своих оценках. В исследовании учитывалась лишь та вода, которую ЦОД используют в своих системах охлаждения. Но фактически, большая часть воды, потребляемой ЦОД, приходится на электроэнергию, для выработки которой также требуются гигантские объёмы воды, что Google упускает из виду в данном исследовании. «Вы видите, по сути, лишь верхушку айсберга», — прокомментировал отчёт Google аспирант Института экологических исследований Амстердамского свободного университета Алекс де Врис-Гао (Alex de Vries-Gao). 
Источник изображения: unsplash.com Google утверждает, что указанный в её отчёте показатель расхода воды в 0,26 мл на средний запрос «на порядки меньше предыдущих оценок», которые в исследовании Рена достигали 50 мл. По мнению Рена, это сравнение вводит в заблуждение, так как он в своём исследовании учитывал как прямое, так и косвенное потребление воды ЦОД. Google не учитывает ещё один важный показатель, связанный с энергопотреблением и загрязнением окружающей среды. В отчёте компании представлен только «рыночный» показатель выбросов углерода, учитывающий обязательства компании по поддержке роста использования возобновляемых источников энергии в энергосетях. Более комплексный подход должен учитывать местоположение ЦОД и текущее соотношение чистой и грязной энергии в местной энергосети. Эксперты считают, что Google следовало использовать именно такой подход, следуя стандартам, установленным международным «Протоколом по парниковым газам». Google ссылается на предыдущее исследование, проведённое Реном и де Врис-Гао. Однако учёные утверждают, что Google сравнивает результаты, «как яблоки с апельсинами». Дело в том, что их предыдущие работы основывались на средних значениях, а Google использует медианные показатели, чтобы, как утверждает компания, «исключить искажение результатов выбросами, потребляющими чрезмерно много энергии». Компания также не сообщила количество слов или токенов для текстовых запросов, которые учитывались в отчёте. 
Источник изображения: unsplash.com Google ещё не представила свою новую работу на рецензирование, хотя представитель компании заявил, что компания планирует сделать это в будущем. По словам Google, компания стремится к большей прозрачности в отношении потребления воды, энергопотребления и выбросов углерода, а также предлагает более стандартизированные параметры для оценки воздействия на окружающую среду. Google утверждает, что идёт дальше предыдущих исследований, учитывая энергию, потребляемую простаивающими машинами и вспомогательной инфраструктурой центров обработки данных, например, системами охлаждения. Google утверждает, что за последний год значительно повысила энергоэффективность Gemini, добившись 33-кратного снижения потребления электроэнергии на один запрос. По данным компании, углеродный след медианной подсказки за тот же период сократился в 44 раза. «Мы гордимся инновациями, лежащими в основе нашего повышения эффективности, и намерены продолжать существенно совершенствоваться в ближайшие годы», — говорится в блоге Google. Однако, реальная картина выглядит более мрачной. Повышение эффективности может привести к увеличению загрязнения из-за опережающего роста потребления ресурсов искусственного интеллекта — к печальному явлению, известному как парадокс Джевонса. Так называемые «выбросы углерода, обусловленные амбициями» Google, выросли на 11 % в прошлом году и на 51 % с 2019 года, поскольку компания продолжает активно развивать ИИ. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex








