|
Опрос
|
реклама
Быстрый переход
ИИ Google Gemini получит доступ к истории поиска пользователя, а функция Deep Research станет бесплатной
13.03.2025 [22:37],
Анжелла Марина
В рамках обновления Gemini 2.0 компания Google улучшила несколько ключевых функций своей системы искусственного интеллекта. В частности, расширены возможности инструмента Deep Research, а также добавлена опция анализа истории поисковых запросов пользователей для персонализации рекомендаций. 
Источник изображения: Solen Feyissa / Unsplash Главное обновление, как рассказал ресурс Ars Technica, получила ИИ-модель Gemini 2.0 Flash Thinking Experimental, которая отвечает за многозадачное логическое рассуждение. Этот инструмент теперь сможет генерировать ответы в объёме до 1 миллиона токенов, а кроме того, пользователи смогут загружать файлы, получать более быстрые результаты и интегрировать Gemini с такими сервисами, как «Google Календарь», заметками, задачами и «Google Фото». Для повышения персонализации пользователям предлагается разрешить Gemini анализировать их историю поиска. При этом подчёркивается, что функция работает только с согласия пользователя и может быть отключена в любой момент, а в интерфейсе будет отображаться небольшой тизер, уведомляющий об использовании этой опции. Такой подход, по мнению Google, позволит нейросети лучше понимать интересы человека и давать более релевантные рекомендации. 
Источник изображения: arstechnica.com Ещё одно важное обновление касается инструмента Deep Research, который помогает собирать подробную информацию по заданной теме и выполнять её анализ. Обновлённая версия работает на новой модели Gemini 2.0 Flash Thinking Experimental, которая использует цепочки размышлений и может разбивать проблемы на промежуточные шаги, демонстрируя процесс сбора данных. Google уверяет, что теперь качество итоговых результатов станет выше. При этом Deep Research сделают бесплатным, но с некоторыми ограничениями. И как уточняется, воспользоваться этим инструментом без оплаты можно лишь несколько раз в месяц. Но что касается количества запросов, тот этот момент ещё компанией не озвучен. Стоит сказать и о том, что теперь без оплаты станут доступны Gems, представляющие из себя кастомных чат-ботов для выполнения конкретных задач. В Google предложили несколько шаблонов, таких как Learning Coach и Brainstormer, но пользователи могут создавать и собственные варианты Gems. Все игры для Android станут доступны на ПК, если разработчики будут не против
13.03.2025 [20:45],
Сергей Сурабекянц
В преддверии конференции разработчиков игр GDC, которая состоится на следующей неделе, компания Google объявила, что все мобильные игры для Android станут доступны в Google Play Games на ПК, если разработчик явно не откажется от этого. Это изменение может значительно увеличить количество игр на платформе, поскольку ранее политика Google, наоборот, требовала от разработчика или издателя согласия на размещение в Google Play Games на ПК. 
Источник изображения: Google Сервис Google Play Games был запущен в бета-версии в 2022 году, чтобы предоставить возможность запуска Android-игр на ПК. С тех пор Google последовательно расширяет доступность игр и развивает программу. Google также представила новый «значок играбельности» для мобильных игр, доступных на ПК. По словам генерального менеджера по играм в Google Play Аураша Махбода (Aurash Mahbod), отметка «оптимизировано» означает, что игра «соответствует всем нашим стандартам качества для отличного игрового опыта», а «играбельно» — что игра «соответствует минимальным требованиям для хорошей игры на ПК». Игры со значком «непроверено» отображаются в магазине только при целенаправленном поиске. Сами значки слегка напоминают их аналоги в Steam, показывающие степень совместимости со Steam Deck. Google также прикладывает серьёзные усилия для переноса нативных игр для ПК в службу Google Play Games на ПК. На сегодняшний день на платформе имеется уже более 50 таких игр. В этом году Google планирует открыть программу для всех разработчиков ПК-игр, которая позволит им переносить и размещать свои игры в Google Play Games на ПК. Google расширяет доступность Google Play Games на ПК — вместо ограниченного каталога игр для ноутбуков и настольных компьютеров AMD компания предложит полный. Махбод также сообщил, что Google «сотрудничает с OEM-производителями ПК, чтобы сделать Google Play Games доступным прямо из меню “Пуск” на новых устройствах, начиная с этого года». Кроме того, компания уже в этом месяце развернёт поддержку нескольких учётных записей Google Play Games на ПК. По словам Махбода, сервис Google Play Games на ПК станет общедоступным уже в этом году. Apple и Google мешают развитию мобильных браузеров, установили британские антимонопольщики
13.03.2025 [10:46],
Павел Котов
Рынок мобильных браузеров в Великобритании «не работает благополучно для потребителей и предприятий», гласит решение британского антимонопольного органа, и виноваты в этом, по его версии, Apple и Google. 
Источник изображения: Laurenz Heymann / unsplash.com Независимая экспертная группа завершила исследование рынка мобильных браузеров для британского Управления по конкуренции и рынкам (CMA) — она определила, что Apple проводит политику в отношении iOS, Safari и WebKit таким образом, что затрудняет конкуренцию для сторонних разработчиков браузеров, в результате чего сдерживается развитие рынка. Препятствия для конкурентов, по версии экспертов, создаёт также мобильная экосистема Google Android, хотя и в меньшей степени. Apple требует, чтобы все браузеры под iOS работали на разрабатываемом компанией движке WebKit; при этом у её собственного предустановленного браузера Safari есть преимущественный доступ к функциям по сравнению с альтернативными решениями; а его назначение в качестве браузера по умолчанию снижает осведомлённость пользователей о других продуктах. Схожая ситуация выявлена с Google Chrome, который идёт в качестве браузера по умолчанию на подавляющем большинстве устройство под Android. При этом Apple и Google предприняли некоторые шаги, чтобы упростить пользователям переход на альтернативные браузеры — они сделали это после того, как в минувшем ноябре было объявлено о предварительных выводах расследования. Расследование также показало, что средства, которые Google перечисляет Apple за установку своей системы по умолчанию на iPhone «значительно снижает финансовые стимулы для конкуренции». 
Источник изображения: Rubaitul Azad / unsplash.com Исходя из установленных фактов, CMA выдвинуло средства правовой защиты, направленные на оздоровление конкурентной среды на рынке мобильных браузеров Великобритании. В частности, Apple надлежит предоставить сторонним разработчикам возможность использовать на iOS альтернативные браузерные движки; Apple и Google следует выводить пользователям экран с выбором браузера во время настройки устройства; компаниям также предписывается разорвать соглашение о выплате средств от рекламных доходов. Пока все эти предложения не имеют юридической силы, но в ближайшие месяцы ситуация может измениться. В январе CMA также инициировало проверки в отношении мобильных экосистем Apple и Google с целью установить, следует ли присвоить им стратегический рыночный статус (SMS) в соответствии с «Законом о цифровых рынках, конкуренции и потребителях» (DMCC). Подобно европейскому «Закону о цифровых рынках» (DMA), документ даёт британским властям право предъявлять компаниям с «существенной и укоренившейся властью на рынке» более строгие антимонопольные требования. Этим компаниям может быть выдано предписание выполнить определённые действия, чтобы воспрепятствовать антиконкурентным мерам; нарушение норм DMCC грозит штрафом в размере до 10 % от годового оборота компании. «По итогам нашего углублённого расследования мы пришли к выводу, что конкуренция между различными мобильными браузерами работает не очень благополучно, и это сдерживает инновации в Великобритании. Я приветствую оперативные действия CMA по инициированию стратегических расследований в отношении статуса рынка мобильных экосистем Apple и Google. Изложенный нами сегодня обширный анализ поможет в этой работе по мере её продвижения», — заявила председатель независимой группы экспертов CMA Марго Дейли (Margot Daly). Google DeepMind дала роботам ИИ, с которым они могут выполнять сложные задания без предварительного обучения
12.03.2025 [20:41],
Сергей Сурабекянц
Лаборатория Google DeepMind представила две новые модели ИИ, которые помогут роботам «выполнять более широкий спектр реальных задач, чем когда-либо прежде». Gemini Robotics — это модель «зрение-язык-действие», способная понимать новые ситуации без предварительного обучения. А Gemini Robotics-ER компания описывает как передовую модель, которая может «понимать наш сложный и динамичный мир» и управлять движениями робота. 
Источник изображений: Google DeepMind Модель Gemini Robotics построена на основе Gemini 2.0, последней версии флагманской модели ИИ от Google. ПО словам руководителя отдела робототехники Google DeepMind Каролины Парада (Carolina Parada), Gemini Robotics «использует мультимодальное понимание мира Gemini и переносит его в реальный мир, добавляя физические действия в качестве новой модальности». Новая модель особенно сильна в трёх ключевых областях, которые, по словам Google DeepMind, необходимы для создания по-настоящему полезных роботов: универсальность, интерактивность и ловкость. Помимо способности обобщать новые сценарии, Gemini Robotics лучше взаимодействует с людьми и их окружением. Модель способна выполнять очень точные физические задачи, такие как складывание листа бумаги или открывание бутылки.  «Хотя в прошлом мы уже достигли прогресса в каждой из этих областей по отдельности, теперь мы приносим [резко] увеличивающуюся производительность во всех трёх областях с помощью одной модели, — заявила Парада. — Это позволяет нам создавать роботов, которые более способны, более отзывчивы и более устойчивы к изменениям в окружающей обстановке». Модель Gemini Robotics-ER разработана специально для робототехников. С её помощью специалисты могут подключаться к существующим контроллерам низкого уровня, управляющим движениями робота. Как объяснила Парада на примере упаковки ланч-бокса — на столе лежат предметы, нужно определить, где что находится, как открыть ланч-бокс, как брать предметы и куда их класть. Именно такой цепочки рассуждений придерживается Gemini Robotics-ER.  Разработчики уделили серьёзное внимание безопасности. Исследователь Google DeepMind Викас Синдхвани (Vikas Sindhwani) рассказал, как лаборатория использует «многоуровневый подход», при котором модели Gemini Robotics-ER «обучаются оценивать, безопасно ли выполнять потенциальное действие в заданном сценарии». Кроме того, Google DeepMind разработала ряд эталонных тестов и фреймворков, чтобы помочь дальнейшим исследованиям безопасности в отрасли ИИ. В частности, в прошлом году лаборатория представила «Конституцию робота» — набор правил, вдохновлённых «Тремя законами робототехники», сформулированными Айзеком Азимовым в рассказе «Хоровод» в 1942 году. В настоящее время Google DeepMind совместно с компанией Apptronik разрабатывает «следующее поколение человекоподобных роботов». Также лаборатория предоставила доступ к своей модели Gemini Robotics-ER «доверенным тестировщикам», среди которых Agile Robots, Agility Robotics, Boston Dynamics и Enchanted Tools. «Мы полностью сосредоточены на создании интеллекта, который сможет понимать физический мир и действовать в этом физическом мире, — сказала Парада. — Мы очень рады использовать это в нескольких воплощениях и во многих приложениях для нас».  Напомним, что в сентябре 2024 года исследователи из Google DeepMind продемонстрировали метод обучения, позволяющий научить робота выполнять некоторые требующие определённой ловкости действия, такие как завязывание шнурков, подвешивание рубашек и даже починка других роботов. Северокорейских хакеров обвинили в публикации вредоносов в Google Play
12.03.2025 [18:04],
Павел Котов
Хакерская группировка, предположительно связанная с властями КНДР, разместила несколько вредоносных приложений для Android в Google Play и обманом заставила некоторых пользователей платформы установить заражённое ПО. Об этом сообщила специализирующаяся на кибербезопасности компания Lookout. 
Источник изображений: lookout.com Кампания включала несколько образцов вредоносного ПО KoSpy; по крайней мере одно из заражённых приложений было скачано более десяти раз, гласит снимок экрана из магазина Google Play. Северокорейские хакеры, утверждают эксперты, часто используют свои навыки для кражи средств, но в данном случае их задачей является сбор данных — KoSpy является приложением-шпионом. Оно собирает «огромный объём конфиденциальной информации», в том числе SMS-сообщения, журналы вызовов, данные о местоположении устройства, файлы на устройстве, вводимые с клавиатуры символы, сведения о сетях Wi-Fi и списки установленных приложений. KoSpy записывает звук, делает снимки с помощью камер и скриншоты. Для получения «начальных конфигураций» использовалась облачная база данных Firestore в инфраструктуре Google Cloud.  Lookout сообщила о своих открытиях в Google, после чего проекты Firebase были деактивированы, приложения с KoSpy удалены, а сам вредонос добавили в систему автоматического обнаружения. Некоторые приложения с KoSpy эксперты Lookout обнаружили в альтернативном магазине приложений APKPure, но его администрация не подтвердила факта обращения специалистов по кибербезопасности. Предполагаемыми жертвами кампании являются лица из Южной Кореи — некоторые из обнаруженных заражённых приложений имели корейские названия, а также интерфейс на корейском и английском языках. В коде приложений обнаружены ссылки на доменные имена и IP-адреса, ранее связанные с другими вредоносными кампаниями, в которых обвиняли хакеров из КНДР. Google инвестировала в одного из главных конкурентов OpenAI больше, чем считалось ранее
12.03.2025 [13:05],
Павел Котов
Стартап из Сан-Франциско Anthropic часто рассматривается как независимый игрок в области ИИ, однако теперь у него обнаружились более глубокие связи с Google, чем считалось ранее. Об этом сообщила New York Times со ссылкой на судебные документы. 
Источник изображения: anthropic.com Google, которой принадлежат 14 % акций Anthropic, в этом году намеревается вложить в компанию ещё $750 млн через сделку по конвертируемому долгу. К настоящему моменту общая сумма вложений Google в Anthropic превышает $3 млрд. Несмотря на отсутствие права голоса, мест в совете директоров и прямого контроля над компанией, финансовая поддержка со стороны Google поднимает вопросы о том, насколько Anthropic независима в действительности. Стартапы в области ИИ всё чаще получают финансирование от технологических гигантов, и регулирующие органы проводят проверки с целью установить, не дают ли такие сделки несправедливых преимуществ участникам рынка. Ранее американский минюст отверг инициативу о принудительной продаже полученных таким путём акций. Google, которая и сама разрабатывает мощные проекты в области ИИ, финансирует собственных конкурентов, что явно указывает на хеджирование ставок — стремление защититься от проигрыша в конкурентной борьбе, извлечь прибыль при любом исходе такой борьбы и диверсифицировать риски. В Anthropic активно вкладывает средства и Amazon — к настоящему моменту размеры инвестиций от гиганта электронной коммерции достигли $8 млрд. И это придаёт особой остроты вопросу о том, что значат такие связи для Anthropic и других стартапов в области ИИ: всё меньше ясности, остаётся ли ещё смысл рассматривать их как независимые компании, или они уже являются дополнением к активам технологических гигантов. Google стала ещё на шаг ближе к выпуску смарт-очков после долгого перерыва
12.03.2025 [13:03],
Владимир Мироненко
Google близка к заключению сделки по покупке канадского стартапа AdHawk Microsystems, разрабатывающего технологии отслеживания движения глаз. Это поглощение позволит Google ускорить разработку платформы Android XR и, возможно, приступить к выпуску собственных умных очков и гарнитур, сообщил Bloomberg со ссылкой на информированные источники.  По словам источников, переговоры между компаниями находятся на завершающем этапе и могут привести к заключению договора уже на этой неделе. Google намерена приобрести стартап за $115 млн, из которых выплата $15 млн будет зависеть от достижения AdHawk оговоренных целевых показателей. Основанный в 2017 году стартап AdHawk из Ватерлоо (Онтарио) разработал очки MindLink на основе собственной технологии, позволяющей устройству определять направление взгляда пользователя. Энергоэффективные датчики AdHawk значительно превосходят решения конкурентов по скорости реагирования на движения зрачков. При этом компания занимается разработкой не только аппаратной части, но и программного обеспечения. AdHawk получила поддержку венчурных подразделений Samsung Electronics, Intel, HP и Sony Group, а также владельца бренда Ray-Ban — компании EssilorLuxottica SA, партнёра Meta✴ по выпуску умных очков. Google одной из первых проявила интерес к созданию умных очков, выпустив Google Glass более десяти лет назад. Однако носимое устройство так и не получило признания у потребителей, и проект был закрыт два года назад. Google сотрудничает с Samsung в разработке гарнитуры расширенной реальности (XR) Project Moohan, но интерес американской компании к созданию собственных умных носимых устройств вполне очевиден. Технология отслеживания направления взгляда является центральной в интерфейсе гарнитуры Vision Pro от Apple и станет важной составляющей интерфейса Samsung Moohan. Ранее в этом году Google купила подразделение HTC по разработке устройств расширенной реальности (XR) за $250 млн. После закрытия сделки сотрудники AdHawk присоединятся к команде разработчиков платформы Android XR для дальнейшей работы над носимыми устройствами. Google выпустила Gemma 3 — самую мощную модель ИИ для запуска на одной видеокарте
12.03.2025 [12:23],
Павел Котов
Google выпустила открытую модель искусственного интеллекта Gemma 3 — это новый представитель семейства моделей, на основе которых разработчики смогут создавать приложения, способные запускаться локально на рабочих станциях или даже смартфонах. Поддерживаются 35 языков, есть функции анализа текста, изображений и коротких видеороликов. 
Источник изображений: blog.google Google охарактеризовала Gemma 3 как «лучшую в мире модель для одного ускорителя» и заверила, что она демонстрирует результаты лучше, чем конкуренты от Meta✴, DeepSeek и OpenAI при работе на одной видеокарте; она оптимизирована для оборудования Nvidia и других ИИ-ускорителей. Обновился компонент анализа видео — теперь он поддерживает записи высокого разрешения и отличную от квадратной форму кадра; фильтр безопасности входных и выходных изображений ShieldGemma 2 реагирует на картинки деликатного характера и материалы с изображением жестокости. 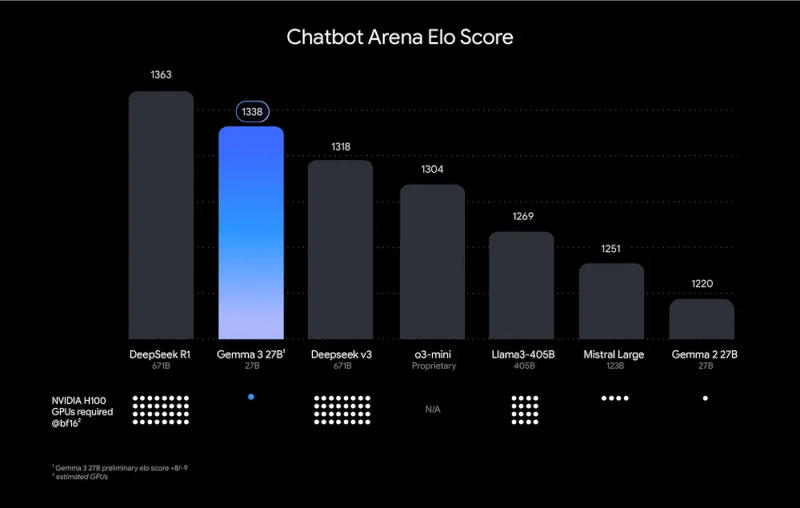 У Google это открытая модель ИИ уже третьего поколения, но потенциал этого направления помогла раскрыть китайская DeepSeek — её проекты продемонстрировали, что существует спрос на ИИ-решения с относительно невысокими системными требованиями. У Gemma 3 отмечаются значительные познания в области технических дисциплин, и Google провела дополнительное тестирование на возможность нецелевого использования модели, например, для создания вредных веществ — вероятность сбоя защитных механизмов в компании оценили как невысокую. Открытая лицензия Gemma 3 на деле является ограниченной: Google указала, для чего её разрешено использовать. Новая модель доступна, в частности, в Google Cloud. В рамках академической программы можно подать заявку на получение кредитов на сумму $10 000, если она будет использоваться в исследовательских целях. Google Pixel 10 и 10 Pro показались на качественных изображениях — отличия от актуальных Pixel 9 минимальны
11.03.2025 [18:44],
Павел Котов
Смартфоны Google Pixel 10 и 10 Pro выйдут предстоящей осенью, но их первые изображения стали достоянием общественности уже сейчас — рендеры на основе CAD-моделей опубликовали инсайдер OnLeaks и ресурс Android Headlines. Отличия от устройств девятой серии обещают быть минимальными. Google Pixel 10. Источник изображений: androidheadlines.com После нескольких эволюционных изменений во внешнем виде смартфонов Google дизайн Pixel 9 стал крупнейшим редизайном в линейке эталонных Android-устройств. Судя по всему, Google намерена сохранить это решение и для моделей нового поколения. Google Pixel 10 Опубликованные двумя источниками рендеры не являются официальными и, возможно, даже окончательными, поэтому к выходу Google Pixel 10 и 10 Pro что-то может измениться. Однако едва ли перемены будут радикальными. Google Pixel 10 Pro Устройства сохранили плоские грани, а приподнятые над задней панелью блоки камер никуда не исчезли. Даже размеры устройств изменились незначительно: если у Pixel 9 они составляли 152,8 × 72 × 8,5 мм, то у Pixel 10 — 152,8 × 72 × 8,6 мм. При этом на выступ камеры приходится 3,4 мм, так что в самой толстой точке корпус достигает 12 мм. Google Pixel 10 Pro Минимальные изменения в размерах означают, что смартфоны нового поколения можно будет использовать с аксессуарами предыдущих моделей. Так, чехлы для Pixel 9 и 9 Pro окажутся совместимыми с новыми устройствами. Габариты Pixel 10 Pro, если верить утечке, будут такими же, как у базовой модели, — 152,8 × 72 × 8,6 мм. Бывший гендир Google Эрик Шмидт возглавил аэрокосмический стартап Relativity Space
11.03.2025 [09:51],
Алексей Разин
Покинув пост генерального директора Google пятнадцать лет назад, Эрик Шмидт (Eric Schmidt) лишь недавно занял новую руководящую должность такого уровня, возглавив основанный девять лет назад аэрокосмический стартап Relativity Space. Об этом назначении сообщил вчера ресурс TechCrunch. 
Источник изображения: Relativity Space Тема получила огласку после публикации на страницах The New York Times, в которой рассказывалось о покупке Шмидтом крупного пакета акций стартапа, который фактически позволил ему получить контроль над компанией. Основатель Relativity Space Тим Эллис (Tim Ellis) при этом уступил Шмидту должность генерального директора, но продолжит участвовать в судьбе компании, являясь членом совета её директоров. На 2026 год намечен запуск ракеты-носителя Terran R, которая будет конкурировать с изделиями SpaceX, именуемыми Falcon 9 и Falcon Heavy. Ещё до первого пуска Terran R компания Relativity Space заключила с клиентами контракты на сумму почти $3 млрд, как сообщает The New York Times. Шмидт, который руководил Google на протяжении десяти лет, может предложить Relativity Space не только богатый управленческий опыт, но и выход на потенциальных инвесторов. Это тем более актуально, если учесть, что в прошлом году у компании возникли проблемы с финансированием своей деятельности. Компания использует инновационные подходы для строительства своих ракет, включая трёхмерные принтеры, роботов и искусственный интеллект. Ещё в 2023 году состоялся первый успешный полёт ракеты Terran 1, созданной с активным использованием напечатанных на трёхмерном принтере компонентов. Правда, ракета не смогла достичь земной орбиты, и дальнейшее её совершенствование компания решила прекратить, сосредоточившись на разработке преемницы — Terran R. Google обяжут продать Chrome, но позволят инвестировать в искусственный интеллект
09.03.2025 [01:59],
Анжелла Марина
Министерство юстиции США подтвердило, что Google придётся разделить свой бизнес, в частности продать браузер Chrome. По данным издания Engadget, это требование закреплено в новом судебном документе, который поддерживает решение федерального суда о том, что компания незаконно использовала монопольное положение на рынке поисковых систем. 
Источник изображения: Solen Feyissa / Unsplash В документе министерство пояснило, что продажа Chrome «навсегда прекратит контроль Google над этим важнейшим инструментом доступа к поиску» и даст конкурентам возможность интегрироваться с браузером, который для многих пользователей служит отправной точной входа в интернет. Также власти сохранили запрет, предложенный ещё при администрации Байдена, на установку поисковой системы Google на устройства Apple и устройства других производителей в качестве поиска по умолчанию, за который Google получала партнёрские выплаты. Запрет коснулся и браузера Mozilla Firefox. Одновременно было снято требование о продаже долей Google в ИИ-стартапах после того, как Anthropic заявила, что ей необходимо финансирование для успешного продолжения своей деятельности. Теперь, вместо полного запрета на инвестиции в искусственный интеллект, правительство потребовало от Google уведомлять федеральные и государственные органы о своих инвестициях в эту сферу. Ожидается, что Google представит собственное предложение по окончательному набору альтернативных мер. В своём предыдущем предложении, поданном в декабре, компания заявила, что первоначальные меры, предложенные Министерством юстиции, чрезмерны и выходят за рамки судебного решения, касающегося только соглашений с партнёрами относительно поисковой системы. В качестве альтернативы Google предложила сохранить возможность платить партнёрам за установку своего поиска, но при этом разрешить им сотрудничать и с другими поисковыми сервисами. Например, Apple могла бы устанавливать разные поисковые системы по умолчанию на iPhone и iPad. В то же время разработчики браузеров, могли бы устанавливать поисковые системы по умолчанию каждые 12 месяцев. Как отмечает The Washington Post, позиция Минюста может свидетельствовать о том, что администрация Трампа продолжит жёсткую антимонопольную политику в отношении крупных технологических компаний, несмотря на поддержку, оказанную ему в предвыборной компании со стороны ИТ-гигантов. Окончательное решение по делу примет судья Амит Мехта (Amit Mehta), который ранее признал Google монополистом. Заседание, на котором будут рассмотрены предложения обеих сторон, запланировано на апрель. В «Google Календаре» появится ИИ Gemini для удобного управления расписанием и планами
07.03.2025 [22:21],
Анжелла Марина
Google расширит возможности приложения «Календарь», добавив в него панель с чат-ботом Gemini, работающего на базе искусственного интеллекта (ИИ). Как сообщает TechCrunch, новая функция уже доступна в рамках программы Google Workspace Labs и поможет пользователям быстро управлять своим расписанием, используя всего лишь текстовые запросы. 
Источник изображения: Daniel Romero / Unsplash Чтобы воспользоваться функцией, нужно нажать на иконку Ask Gemini в правом верхнем углу окна Google Calendar. После этого можно выбрать предложенный вариант запроса или ввести свой собственный. Например, Gemini может предложить добавить какое-либо событие или найти запланированную встречу с определённым человеком. 
Источник изображения: Google Gemini в календаре позволяет задавать конкретные вопросы, например, «На какое время запланирована встреча с менеджером?» или «Сколько у меня встреч в понедельник?». Также можно создавать команды, с помощью которых Gemini добавит расписание тренировок на месяц вперёд. Основная цель функции состоит в ускорении и упрощении процесса работы с календарем, избавив пользователей от необходимости вручную искать информацию или добавлять события. Благодаря возможностям ИИ можно быстро получить нужные сведения и внести изменения в расписание с помощью простых текстовых команд. «Google Календарь» стал очередным приложением Workspace, получившим панель Gemini. Ранее она была добавлена в Gmail, Google Drive, Docs, Sheets, Slides и Chat. Пока опция работает в тестовом режиме и неизвестно, когда станет доступна для более широкого круга пользователей. В интернет утекли маркетинговые материалы и изображения Google Pixel 9a
07.03.2025 [18:32],
Сергей Сурабекянц
По слухам, Google представит смартфон Pixel 9a уже 19 марта — меньше чем через две недели. Сегодня инсайдеры опубликовали маркетинговые материалы и изображения будущего устройства. На фотографиях представлен Pixel 9a во всех четырёх цветах с обновлённым дизайном и заподлицо расположенными двойными камерами на задней панели. Источник изображений: gsmarena.com На изображении представлен Pixel 9A в четырёх официальных цветах — Obsidian (чёрный), Porcelain (белый), Peony (розовый) и Iris (фиолетовый). Следующее изображение намекает на защиту смартфона как минимум от капель дождя. Подчёркнута интеграция Google Gemini с такими приложениями, как «Карты», «Календарь» и YouTube. Также показана функция защиты от кражи, которая теперь стала неотъемлемой частью Android начиная с десятой версии. Ожидается, что Pixel 9a будет оснащён чипсетом Tensor G4, 6,3-дюймовым OLED-дисплеем с разрешением FHD+ и частотой обновления 120 Гц. Аккумулятор смартфона ёмкостью 5100 мА·ч будет поддерживать проводную зарядку мощностью 23 Вт и 7,5-ваттную беспроводную зарядку. На задней панели Pixel 9a будет размещена 48-мегапиксельная основная камера c датчиком 1/2" и 13-мегапиксельная широкоугольная камера. Pixel 9a будет работать под управлением Android 15 «из коробки». По слухам, Pixel 9a будет стоить $499 за версию с 8 Гбайт ОЗУ и 128-гигабайтным накопителем. Версия с тем же объёмом ОЗУ и накопителем на 256 Гбайт обойдётся в $599. Google отключился от российских точек обмена трафиком и центров обработки данных
07.03.2025 [17:35],
Павел Котов
Компания Google отключила соединения с некоторыми российскими центрами обработки данных (ЦОД) и точками обмена трафиком (IX). Информация о таких подключениях исчезла из базы PeeringDB, обратил внимание RB.ru. Мера грозит задержками в передаче данных и ростом цен на услуги. 
Источник изображения: Mitchell Luo / unsplash.com До середины июля 2024 года в базе были указаны сведения о наличии подключения Google к DataLine-IX и DataLine OST (входят в «Ростелеком»), inet2 и W-IX («Эр-Телеком»), MegaFon-IX, DATAIX, MSK-IX и Piter-IX4. В октябре информация об этом из PeeringDB исчезла. В PeeringDB подтвердили, что такой информации больше нет, и уточнили, что удалить её могли только сотрудники Google. В «МегаФоне» сообщили, что отключение Google от точки MegaFon-IX произошло по инициативе американской компании; отключение от W-IX «Эр-Телекома» также было следствием решения Google, подтвердил источник RB.ru. Администраторы некоторых других IX, однако, рассказали, что отключение Google было неполным. В компании «ГлобалНет» отметили, что физическое присоединение Google к DATAIX в России имеется, но американская компания перестала анонсировать и принимать маршруты через маршрутные серверы. Аналогичную ситуацию описали в MSK-IX и Piter-IX. Google могла принять такое решение по финансовым соображениям, считают опрошенные Forbes эксперты: присутствие на IX осуществляется на платной основе, а российское юрлицо американского поискового гиганта находится в состоянии банкротства. Из-за санкций и многомиллиардных штрафов Google лишилась возможности обслуживать серверы и оплачивать услуги — не контролируя ситуацию с обслуживанием серверов, компания могла отключиться от ряда точек обмена трафиком и публично отрицать своё присутствие на оставшихся. В результате этих мер скорость доступа к службам Google в России может снизиться, а качество сервисов — ухудшиться. Трафик будет идти через транзитную сеть, что означает рост задержек из-за увеличения числа переходов. Смартфоны на Android 16 получат виджеты на экраны блокировки уже в этом году
07.03.2025 [17:32],
Владимир Мироненко
Компания Google сообщила в блоге разработчиков платформы Android, что в этом году у смартфонов на Android 16 появятся виджеты на экране блокировки. Такие виджеты доступны у планшетов Pixel с прошлого года, но теперь Google добавит их на смартфоны и больше моделей планшетов. 
Источник изображения: Denny Müller/unsplash.com Компания подтвердила, что виджеты экрана блокировки будут добавлены в хранилище Android Open Source Project (AOSP) в первом квартальном обновлении после выхода Android 16, релиз которой состоится летом. ОС Android 16 сейчас находится на стадии бета-тестирования и должна выйти в июне. Хотя виджетов экрана блокировки для телефонов в последней бета-версии Android 16 нет, журналисту ресурса Android Authority Мишаалу Рахману (Mishaal Rahman) удалось активировать эту функцию, пишет The Verge. По словам Рахмана, текущая реализация функции для телефонов доступна только через режим заставки Android, для которого требуется, чтобы телефон находился на зарядке или был подключён к док-станции. Google отметила в блоге, что механизм запуска интерфейса виджетов будет настраиваться производителями устройств, поэтому можно будет встретить разные варианты запуска функции. Поскольку у смартфонов экран меньше, чем у планшета Pixel Tablet, виджеты у них будут располагаться по два вертикально. Поэтому потребуется листать, чтобы найти нужные. Все виджеты будут поддерживать размещение на экране блокировки по умолчанию, хотя разработчики приложений при желании смогут отключить эту функцию. Также сообщается, что при запуске отдельных приложений с помощью виджета пользователям, как и раньше, потребуется пройти аутентификацию с помощью отпечатка пальца, PIN-кода или разблокировки лицом. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






