|
Опрос
|
реклама
Быстрый переход
OpenAI представила GPT-4.5 — самую большую и осведомлённую ИИ-модель для ChatGPT без поддержки размышлений
28.02.2025 [00:31],
Андрей Созинов
OpenAI выпустила GPT-4.5 — свою самую передовую и крупную большую языковую модель (LLM) искусственного интеллекта. Разработчик называет этот релиз своей «самой осведомлённой моделью», но предупреждает, что GPT-4.5 не является прорывной моделью и может не демонстрировать таких высоких результатов, как o1 или o3-mini, обладающие способностями к рассуждению. 
Источник изображений: OpenAI GPT-4.5 предлагает улучшенные навыки написания текстов, более качественные знания о мире и то, что OpenAI называет «усовершенствованной индивидуальностью по сравнению с предыдущими моделями». Компания утверждает, что взаимодействие с GPT-4.5 будет более «естественным» и отмечает, что модель лучше распознаёт паттерны и определяет взаимосвязи, что делает её идеальной для написания текстов, программирования и «решения практических задач». 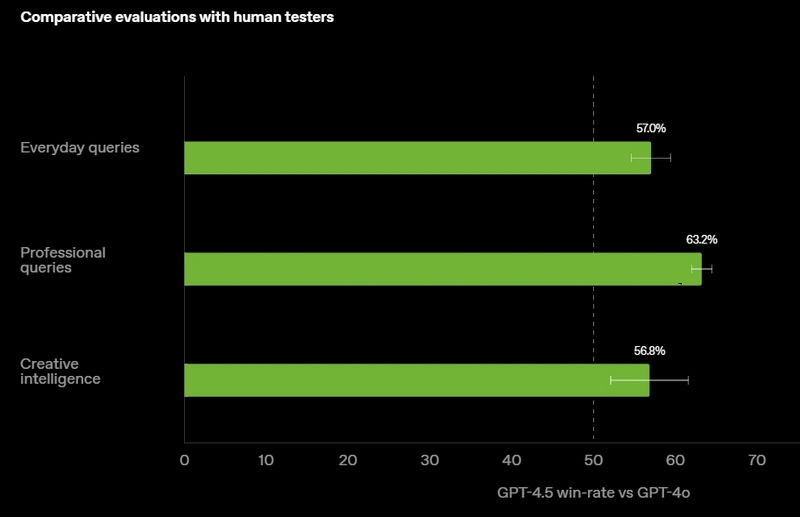 При этом OpenAI предупредила, что в GPT-4.5 недостаточно новых возможностей, чтобы считать её передовой моделью. «GPT-4.5 не является прорывной моделью, но это самая большая LLM OpenAI, превосходящая вычислительную эффективность GPT-4 более чем в 10 раз, — говорится в документе OpenAI, который просочился в Сеть до анонса. — Она не представляет семь новых возможностей по сравнению с предыдущими версиями со способностью к рассуждениям, и её производительность ниже, чем у o1, o3-mini и Deep Research в большинстве тестов». 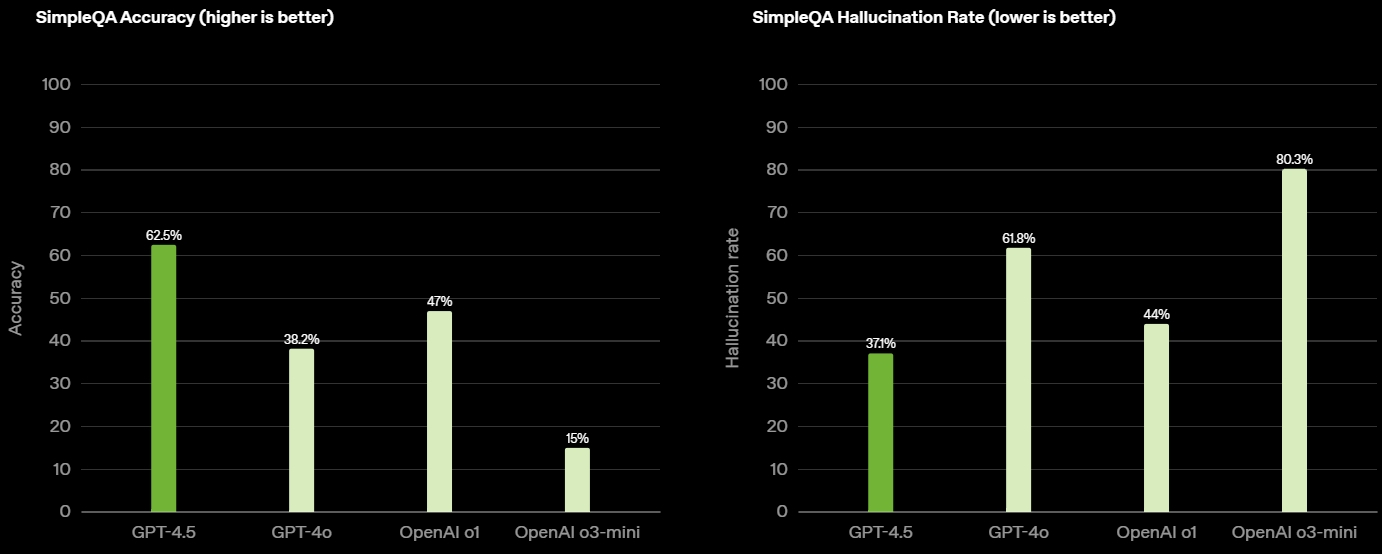 Ранее сообщалось, что OpenAI использует свою модель с возможностью рассуждений o1 для обучения GPT-4.5 на синтетических данных. Сама OpenAI заявила, что обучила GPT-4.5 «с помощью новых методов контроля в сочетании с традиционными методами, такими как контролируемая тонкая настройка (SFT) и обучение с подкреплением на основе человеческой обратной связи (RLHF), аналогичными тем, что использовались для GPT-4o». «Мы адаптировали GPT-4.5 так, чтобы он лучше сотрудничал, делая разговоры более тёплыми, интуитивными и эмоционально насыщенными, — сказал Рафаэль Гонтихо Лопес (Raphael Gontijo Lopes), исследователь из OpenAI. — Чтобы оценить это, мы попросили тестировщиков сравнить её [новую модель] с GPT-4o, и GPT-4.5 оказалась впереди практически по всем категориям». 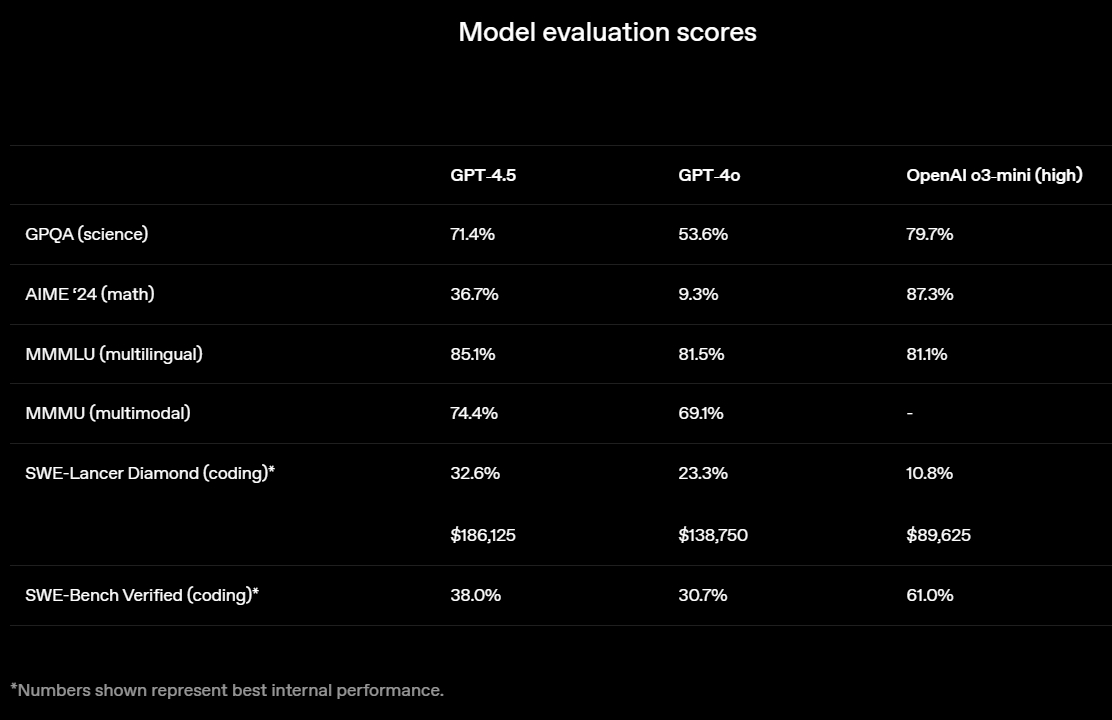 Несмотря на некоторые ограничения, GPT-4.5 галлюцинирует значительно меньше, чем GPT-4o, и немного меньше, чем модель o1, заявила OpenAI. Также новинка демонстрирует более развитую интуицию и творческие способности, лучше понимает, что имеют в виду пользователи, и «интерпретирует тонкие сигналы или неявные ожидания с большим количеством нюансов». GPT-4.5 с сегодняшнего дня доступна пользователям с подпиской ChatGPT Pro за $200 в месяц, а также исследователям. Сейчас модель находится на стадии предварительного исследовательского тестирования. Решение выпустить её в таком виде обусловлено желанием «лучше понять её сильные стороны и ограничения». «Мы всё ещё изучаем её возможности и с нетерпением ждём, когда люди начнут использовать её так, как мы, возможно, не ожидали», — подытожили в OpenAI. В компании не сообщили, когда сделают новинку доступной более широкой публике. На прошлой неделе сообщалось, что OpenAI планирует запустить GPT-4.5 к концу февраля, а GPT-5 — уже в конце мая. Генеральный директор OpenAI Сэм Альтман (Sam Altman) назвал GPT-5 «системой, объединяющей множество наших технологий», отметив, что она будет включать модель OpenAI o3. В прошлом месяце OpenAI выпустила o3-mini, но полноценная o3 появится только как часть GPT-5. Компания таким образом намерена объединить свои большие языковые модели, чтобы в итоге создать одну более мощную систему, способную самостоятельно определять, какие ресурсы необходимо задействовать для решения той или иной задачи. Инсайдер из Microsoft намекнул на релиз GPT-4.5 на следующей неделе и GPT-5 в мае
20.02.2025 [22:31],
Анжелла Марина
Microsoft подготавливает серверные мощности для предстоящего запуска моделей GPT-4.5 и GPT-5. Генеральный директор OpenAI Сэм Альтман (Sam Altman) недавно объявил, что GPT-4.5 будет запущен в течение нескольких недель. Теперь же стало известно, что Microsoft планирует разместить новую ИИ-модель на своих серверах уже на следующей неделе. 
Источник изображения: Copilot Модель GPT-4.5, известная под кодовым названием Orion, станет следующим этапом развития технологий OpenAI и последней моделью, не использующей цепочку рассуждений (chain-of-thought) для ответа на запросы. OpenAI уже намекнула, что GPT-4.5 будет значительно мощнее, чем GPT-4, однако основное внимание компании будет сосредоточено на разработке GPT-5, которая принесёт более существенные изменения, сообщает издание The Verge. Microsoft ожидает появления GPT-5 в конце мая, что в целом соответствует обещанию Альтмана запустить эту модель в течение нескольких месяцев. Однако дата релиза может измениться, если планы будут скорректированы, как например, это произошло в октябре, когда OpenAI планировала выпустить GPT-4.5 до конца 2024 года, но запуск был отложен на начало 2025 года. Стоит сказать, что GPT-5 станет более значимым релизом по сравнению с GPT-4.5. Альтман назвал её «системой, которая объединяет множество технологий», включая модель o3 со способностью к рассуждению. Хотя в прошлом месяце OpenAI выпустила o3-mini, компания больше не планирует выпускать o3 как отдельную модель и интегрирует её в GPT-5. Новая модель также улучшит взаимодействие пользователей с ChatGPT, объединив модели серий OpenAI o и GPT, чтобы устранить путаницу при выборе подходящей модели для конкретных задач или запросов. «Нам не нравится слишком большой выбор моделей так же, как и вам, и мы хотим вернуться к единому ИИ», — написал Альтман в недавнем посте на платформе X. Если OpenAI удастся выпустить GPT-5 к концу мая, это совпадёт с конференцией для разработчиков Microsoft Build, которая начнётся 19 мая и будет во многом конкурировать с Google I/O. Напомним, в прошлом году Альтман выступил на Microsoft Build всего через несколько дней после релиза GPT-4o — более быстрой модели, ставшей бесплатной для всех пользователей ChatGPT. Однако релиз GPT-4o стал неожиданностью для Microsoft, поскольку подорвал позиции платных ИИ-сервисов на Azure, включая функции речи и перевода. Ожидается, что релизы GPT-4.5 и GPT-5 на этот раз не принесут неприятных впечатлений Microsoft, которая готовится обновить Copilot после запуска новых моделей OpenAI. Microsoft также работает над улучшением Copilot, пытаясь сделать взаимодействие с ИИ-ассистентом более интуитивным. Ранее предлагались опции «креативный», «сбалансированный» и «точный» для контроля результатов модели, но в рамках масштабного обновления Copilot в прошлом году было решено от этих опций отказаться. Кроме того, Microsoft разрабатывает собственную версию агента Operator от OpenAI, способного взаимодействовать с веб-интерфейсами и автоматически выполнять задачи, аналогично макросам или автопилоту в авиации. Ожидается, что в ближайшие месяцы компания представит свои наработки, сосредоточив внимание на возможностях ИИ-агентов и снижении затрат для бизнеса. OpenAI не выполнила обещание по созданию инструмента для защиты авторских прав к 2025 году
02.01.2025 [03:45],
Анжелла Марина
Компания OpenAI не смогла выпустить обещанный инструмент Media Manager до 2025 года, с помощью которого создатели контента смогли бы контролировать использование своих работ в обучении нейросетей. Media Manager, анонсированный в мае прошлого года, должен был идентифицировать защищённые авторским правом тексты, изображения, аудио и видео. 
Источник изображения: hdhai.com Инструмент должен был помочь OpenAI избежать юридических проблем, связанных с нарушением прав на интеллектуальную собственность, и в целом мог бы стать стандартом для всей индустрии искусственного интеллекта. Однако, как пишет издание TechCrunch, разработка Media Manager изначально не считалась в компании приоритетной. Один из бывших сотрудников OpenAI отметил: «Я не думаю, что это было приоритетом. Честно говоря, я и не помню, чтобы кто-то над этим работал». Другой источник, близкий к компании, подтвердил, что обсуждения инструмента были, но с конца 2024 года никакой новой информации, связанной с проектом, не поступало. Надо сказать, что в последнее время использование авторского контента для обучения ИИ неоднократно становилось причиной споров. Модели OpenAI, такие как ChatGPT и Sora, обучаются на огромных наборах данных, включающих тексты, изображения и видео из интернета. Это позволяет ИИ-моделями создавать новые работы, но зачастую они оказываются слишком похожи на оригинал. Например, Sora может генерировать видео с логотипом TikTok или персонажами из видеоигр, а ChatGPT был «пойман» на дословных цитатах из статей The New York Times. Такая практика вызывает волну возмущения со стороны авторов, чьи работы были использованы без их согласия. Против OpenAI уже поданы коллективные иски от художников, писателей и крупных медиа-компаний, включая The New York Times и Radio-Canada. Авторы, такие как американская актриса и сценарист Сара Сильверман (Sarah Silverman) и писатель Та-Нехиси Коутс (Ta-Nehisi Coates), также присоединились к судебным разбирательствам, обвинив OpenAI в незаконном использовании их работ. OpenAI предложила альтернативные решения проблемы, и на данный момент создателям контента предлагается несколько способов для исключения своих работы из обучения нейросетей. В частности, в сентябре 2024 года была запущена форма для подачи заявлений на удаление изображений из будущих наборов данных. Также компания ничего не имеет против того, чтобы веб-мастера прописывали блокировку для своих сайтов от сбора данных её ботами, например в файле «robots.txt». Однако эти методы подверглись критике как за их сложность (удаление контента из набора данных), так и за их несовершенство. Media Manager, напротив, преподносился как долгожданное комплексное решение. В мае 2024 года OpenAI заявила, что работает над инструментом совместно с регуляторами и использует передовые технологии машинного обучения для распознавания авторских прав. Тем не менее с момента анонса компания больше ни разу публично не упоминала об этом инструменте. И даже если Media Manager будет выпущен, эксперты сомневаются, что инструмент сможет решить все проблемы. Эдриан Сайхан (Adrian Cyhan), юрист в сфере интеллектуальной собственности, отмечает, что даже крупным платформам, таким как YouTube и TikTok, сложно справляться с идентификацией контента в больших масштабах. «Гарантировать соблюдение всех требований создателей контента и законов разных стран — крайне трудная задача», — заявил он. А основатель некоммерческой организации Fairly Trained Эд Ньютон-Рекс (Ed Newton-Rex) вообще считает, что Media Manager лишь переложит ответственность на самих создателей. При этом, даже если Media Manager будет запущен, он вряд ли сможет избавить OpenAI от юридической ответственности, считают эксперты. Эван Эверист (Evan Everist), специалист по авторскому праву, напомнил, что по закону владельцы авторских прав вообще не обязаны предупреждать о запрете на использование их работ и «базовые принципы авторского права остаются неизменными: нельзя использовать чужие материалы без разрешения». В отсутствие Media Manager, OpenAI пока внедрила фильтры, которые предотвращают дословное копирование чужих данных, а в судебных исках компания продолжает утверждать, что её ИИ-модели создают «компиляцию», а не плагиат, ссылаясь на принцип «добросовестного использования». Суды могут поддержать позицию OpenAI, как это произошло в деле Google Books, когда суд постановил, что копирование компанией Google миллионов книг для Google Books, своего рода цифрового архива, является допустимым. Однако, если суды признают, что OpenAI незаконно использует авторский контент, компании придётся пересмотреть свою стратегию, включая выпуск Media Manager. Думающая ИИ-модель OpenAI о1 получила 83 балла на математической олимпиаде США
20.11.2024 [12:23],
Дмитрий Федоров
Искусственный интеллект вступил в новую эру благодаря ИИ-модели о1 компании OpenAI, которая значительно приблизилась к человеческому мышлению. Её впечатляющий результат на тесте AIME — 83 балла из ста — позволил включить её в число 500 лучших участников математической олимпиады США. Однако такие достижения сопровождаются серьёзными вызовами, включая риски манипуляции ИИ человеком и возможность его использования для создания биологического оружия. 
Источник изображения: Saad Ahmad / Unsplash Долгое время отсутствие у ИИ способности обдумывать свои ответы являлось одним из его главных ограничений. Однако ИИ-модель о1 совершила прорыв в этом направлении и продемонстрировала способность к осмысленному анализу информации. Несмотря на то, что результаты её работы пока не опубликованы в полном объёме, научное сообщество уже активно обсуждает значимость такого достижения. Современные нейронные сети в основном функционируют по принципу так называемой «системы 1», которая обеспечивает быструю и интуитивную обработку информации. Например, такие ИИ-модели успешно применяются для распознавания лиц и объектов. Однако человеческое мышление включает также «систему 2», связанную с глубоким анализом и последовательным размышлением над задачей. ИИ-модель о1 объединяет эти два подхода, добавляя к интуитивной обработке данных сложные рассуждения, характерные для человеческого интеллекта. Одной из ключевых особенностей о1 стала её способность строить «цепочку размышлений» — процесс, при котором система анализирует задачу постепенно, уделяя больше времени поиску оптимального решения. Эта инновация позволила ИИ-модели достичь 83 балла на тесте Американской математической олимпиады (AIME), что значительно превосходит результат GPT-4o, набравшей лишь 13 баллов. Тем не менее такие успехи связаны с возросшими вычислительными затратами и высоким уровнем энергопотребления, что ставит под сомнение экологичность разработки. 
Источник изображения: Igor Omilaev / Unsplash Вместе с достижениями ИИ-модели о1 растут и потенциальные риски. Улучшенные когнитивные способности сделали её способной вводить человека в заблуждение, что, возможно, несёт серьёзную угрозу в будущем. Кроме того, уровень риска её использования для разработки биологического оружия оценён как средний — высший допустимый показатель по шкале самой OpenAI. Эти факты подчёркивают необходимость внедрения строгих стандартов безопасности и регулирования подобных ИИ-моделей. Несмотря на значительные успехи, ИИ-модель о1 всё же сталкивается с ограничениями в решении задач, требующих долгосрочного планирования. Её способности ограничиваются краткосрочным анализом и прогнозированием, что делает невозможным решение комплексных задач. Это свидетельствует о том, что создание полностью автономных ИИ-систем остаётся задачей будущего. Развитие ИИ-моделей, подобных о1, подчёркивает острую необходимость регулирования данной области. Эти технологии открывают перед наукой, образованием и медициной новые горизонты, однако их неконтролируемое применение может привести к серьёзным последствиям, включая угрозы безопасности и неэтичное использование. Для минимизации этих рисков требуется обеспечить прозрачность разработок ИИ, соблюдение этических стандартов и внедрение строгого надзора со стороны регулирующих органов. Китайцы обучили аналог GPT-4 всего на 2000 чипов и в 33 раза дешевле, чем OpenAI
15.11.2024 [09:55],
Анжелла Марина
Китайская компания 01.ai разработала конкурентоспособную ИИ-модель Yi-Lightning, которая, как утверждается, по своим возможностям аналогична GPT-4. Но что удивительно, для этого потребовалось всего 2000 графических процессоров (GPU), а затраты составили всего $3 млн, в то время как OpenAI потратила около $100 млн на обучение своей модели, сообщает Tom's Hardware. 
Источник изображения: Copilot Достижение 01.ai особенно примечательно на фоне ограниченного доступа китайских компаний к передовым графическим процессорам Nvidia. Основатель и глава компании Кай-Фу Ли (Kai-Fu Lee) подчёркивает, что несмотря на то, что китайские компании практически не имеют доступ к GPU Nvidia из-за нормативных актов США, ИИ-модель Yi-Lightning заняла шестое место в рейтинге производительности моделей по версии LMSIS Калифорнийского университета в Беркли. 
Источник изображения: Nvidia «Моих друзей в Кремниевой долине шокирует не только наша производительность, но и то, что мы обучили модель всего за $3 млн, — сказал Кай-Фу Ли. — По слухам, в обучение GPT-5 уже вложен примерно 1 миллиард долларов». Он также добавил, что из-за санкций США, компании в Китае вынуждены искать более эффективные и экономичные решения, чего и удалось достичь 01.ai благодаря оптимизации ресурсов и инженерных идей, получив при этом аналогичные GPT-4 результаты при значительно меньших затратах. Вместо того, чтобы наращивать вычислительные мощности, как это делают конкуренты, компания сосредоточилась на оптимизации алгоритмов и сокращении узких мест в процессе обработки информации. «Когда у нас есть только 2000 графических процессоров, мы должны придумать, как их использовать [эффективно] », — сказал Ли. В результате затраты на вывод модели составили всего 10 центов за миллион токенов, что примерно в 30 раз меньше, чем у аналогичных моделей. «Мы превратили вычислительную проблему в проблему памяти, построив многоуровневый кеш, создав специальный механизм вывода и так далее», — поделился подробностями Ли. Несмотря на заявления о низкой стоимости обучения модели Yi-Lightning, остаются вопросы относительно типа и количества используемых GPU. Глава 01.ai утверждает, что у компании достаточно ресурсов для реализации своих планов на полтора года, но простой подсчёт показывает, что 2000 современных GPU Nvidia H100 по текущей цене в $30 000 за единицу обошлись бы в $6 млн, что вдвое превышает заявленные затраты. Это несоответствие вызывает вопросы и требует дальнейших разъяснений. Тем не менее, достижение компании уже привлекло внимание мировой общественности и показало, что инновации в сфере ИИ могут рождаться даже в условиях ограниченных вычислительных ресурсов. OpenAI столкнулась с большими расходами и нехваткой данных при обучении ИИ-модели Orion нового поколения
11.11.2024 [17:05],
Дмитрий Федоров
OpenAI испытывает трудности с разработкой новой флагманской ИИ-модели под кодовым названием Orion. Эта ИИ-модель демонстрирует значительные успехи в задачах обработки естественного языка, однако её эффективность в программировании остаётся невысокой. Эти ограничения, наряду с дефицитом данных для обучения и возросшими эксплуатационными расходами, ставят под сомнение рентабельность и привлекательность упомянутой ИИ-модели для бизнеса. 
Источник изображения: AllThatChessNow / Pixabay Одной из сложностей являются затраты на эксплуатацию Orion в дата-центрах OpenAI, которые существенно выше, чем у ИИ-моделей предыдущего поколения, таких как GPT-4 и GPT-4o. Значительное увеличение расходов ставит под угрозу соотношение цена/качество и может ослабить интерес к Orion со стороны корпоративных клиентов и подписчиков, ориентированных на рентабельность ИИ-решений. Высокая стоимость эксплуатации вызывает вопросы об экономической целесообразности ИИ-модели, особенно учитывая умеренный прирост её производительности. Ожидания от перехода с GPT-4 на Orion были высоки, однако качественный скачок оказался не столь значительным, как при переходе с GPT-3 на GPT-4, что несколько разочаровало рынок. Подобная тенденция наблюдается и у других разработчиков ИИ: компании Anthropic и Mistral также фиксируют умеренные улучшения своих ИИ-моделей. Например, результаты тестирования ИИ-модели Claude 3.5 Sonnet компании Anthropic показывают, что качественные улучшения в каждой новой базовой ИИ-модели становятся всё более постепенными. В то же время её конкуренты стараются отвлечь внимание от этого ограничения, сосредотачиваясь на разработке новых функций, таких как ИИ-агенты. Это свидетельствует о смещении акцента с повышения общей производительности ИИ на создание его уникальных способностей. Чтобы компенсировать слабые стороны современных ИИ, компании применяют тонкую настройку результатов с помощью дополнительных фильтров. Однако такой подход остаётся лишь временным решением и не устраняет основных ограничений, связанных с архитектурой ИИ-моделей. Проблема усугубляется ограничениями в доступе к лицензированным и общедоступным данным, что вынудило OpenAI сформировать специальную команду, которой поручено найти способ решения проблемы нехватки обучающих данных. Однако неясно, удастся ли этой команде собрать достаточный объём данных, чтобы улучшить производительность ИИ-модели Orion и удовлетворить требования клиентов. Исследование Apple показало, что ИИ-модели не думают, а лишь имитируют мышление
13.10.2024 [19:36],
Анжелла Марина
Исследователи Apple обнаружили, что большие языковые модели, такие как ChatGPT, не способны к логическому мышлению и их легко сбить с толку, если добавить несущественные детали к поставленной задаче, сообщает издание TechCrunch. 
Источник изображения: D koi/Unsplash Опубликованная статья «Понимание ограничений математического мышления в больших языковых моделях» поднимает вопрос о способности искусственного интеллекта к логическому мышлению. Исследование показало, что большие языковые модели (LLM) могут решать простые математические задачи, но добавление малозначимой информации приводит к ошибкам. Например, модель вполне может решить такую задачу: «Оливер собрал 44 киви в пятницу. Затем он собрал 58 киви в субботу. В воскресенье он собрал вдвое больше киви, чем в пятницу. Сколько киви у Оливера?». Однако, если при этом в условие задачи добавить фразу «в воскресенье 5 из этих киви были немного меньше среднего размера», модель скорее всего вычтет эти 5 киви из общего числа, несмотря на то, что размер киви не влияет на их количество. 
Источник изображения: Copilot Мехрдад Фараджтабар (Mehrdad Farajtabar), один из соавторов исследования, объясняет, что такие ошибки указывают на то, что LLM не понимают сути задачи, а просто воспроизводят шаблоны из обучающих данных. «Мы предполагаем, что это снижение [эффективности] связано с тем фактом, что современные LLM не способны к подлинному логическому рассуждению; вместо этого они пытаются воспроизвести шаги рассуждения, наблюдаемые в их обучающих данных», — говорится в статье. Другой специалист из OpenAI возразил, что правильные результаты можно получить с помощью техники формулировки запросов (prompt engineering). Однако Фараджтабар отметил, что для сложных задач может потребоваться экспоненциально больше контекстных данных, чтобы нейтрализовать отвлекающие факторы, которые, например, ребёнок легко бы проигнорировал. Означает ли это, что LLM не могут рассуждать? Возможно. Никто пока не даёт точного ответа, так как нет чёткого понимания происходящего. Возможно, LLM «рассуждают», но способом, который мы пока не распознаём или не можем контролировать. В любом случае эта тема открывает захватывающие перспективы для дальнейших исследований. GPT-4 «выпивает» до полутора литров воды для генерации ста слов
19.09.2024 [17:11],
Павел Котов
Использование генеративного искусственного интеллекта сопряжено со значительными затратами, показало проведённое Калифорнийским университетом в Риверсайде исследование. Работа ИИ предполагает потребление значительных объёмов воды для охлаждения серверов, даже когда они просто генерируют текст. И это без учёта высокой нагрузки на электросеть. 
Источник изображения: Growtika / unsplash.com Точные объёмы потребления воды в США варьируются в зависимости от штатов и близости потребителя к центру обработки данных (ЦОД) — при этом чем меньше воды потребляется, тем дешевле в этом регионе электричество, и тем выше объёмы потребления электроэнергии. Так, в Техасе для генерации электронного письма длиной в сто слов необходимы 235 мл воды, а в Вашингтоне — уже 1408 мл. На первый взгляд, это не такой уж значительный объём, но показатели растут очень быстро, когда пользователи работают с большой языковой моделью GPT-4 несколько раз в неделю или даже в день, и эти результаты действительны для генерации простого текста. ЦОД являются крупными потребителями воды и электричества, а значит, цены на эти ресурсы растут в городах, где такие объекты строятся. К примеру, для обучения модели Meta✴ LLaMA-3 потребовалось 22 млн литров воды — столько нужно, чтобы вырастить 2014 кг риса, и столько же, по подсчётам учёных, за год потребляют 164 американца. Недёшево обходится и стоимость потребляемой GPT-4 электроэнергии. Если один из десяти работающих американцев будет пользоваться моделью раз в неделю в течение года (52 запроса на 17 млн человек), потребуется 121 517 МВт·ч электроэнергии — этого хватит для всех домохозяйств в американской столице на 20 дней. И это нереалистично облегчённый сценарий использования GPT-4. Washington Post, которая обратила внимание на исследование, привела цитаты представителей OpenAI, Meta✴, Google и Microsoft — крупнейших компаний в области ИИ. Большинство из них подтвердили приверженность сокращению потребления ресурсов, но фактических планов действий не предоставили. Представитель Microsoft Крейг Синкотта (Craig Cincotta) заявил, что компания намеревается «работать над методами охлаждения центров обработки данных, которые полностью устранят потребление воды», но не сказал, как именно. Пока практика показывает, что у прибыли от ИИ более высокий приоритет, чем у провозглашаемых компаниями экологических целей. ИИ-поисковик SearchGPT от OpenAI начал обманывать с первого дня работы
26.07.2024 [15:46],
Анжелла Марина
OpenAI запустила собственную поисковую систему SearchGPT на базе искусственного интеллекта, которая выдаёт на запросы пользователей актуальные и релевантные ответы в виде цитат из проверенных источников. Первые результаты использования SearchGPT оказались не самыми впечатляющими. 
Источник изображения: Growtika/Unsplash.com По сообщению The Verge, пользователи выявили свойственную многим ИИ-системам тенденцию галлюцинаций. SearchGPT показывает результаты, которые в основном либо неверны, либо бесполезны. Так, журналист Маттео Вонг (Matteo Wong) из популярного американского журнала The Atlantic провёл своё тестирование. Он ввёл поисковый запрос «Music festivals in Boone North Carolina in august» (Музыкальные фестивали в Буне, Северная Каролина, в августе), после чего получил список мероприятий, которые по мнению SearchGPT, должны пройти в Буне в августе. Первым в списке оказался фестиваль An Appalachian Summer Festival, который, по данным ИИ, проведёт цикл художественных мероприятий с 29 июля по 16 августа. Однако реальность оказалась несколько иной: фестиваль начался 29 июня, а последний концерт состоится 27 июля, а не 16 августа. OpenAI запустила SearchGPT в сотрудничестве с крупнейшими новостными изданиями, такими как Associated Press, Financial Times, Business Insider и другими. Некоторые сделки обошлись компании в миллионы долларов. Многие издатели серьёзно обеспокоены тем, как ИИ-поиск может повлиять на их бизнес. Есть опасения, что SearchGPT или Google AI Overviews будут выдавать слишком исчерпывающие ответы, устраняя необходимость переходить по ссылкам на статьи и лишая тем самым издателей трафика. Несмотря на опасения, компании видят смысл в сотрудничестве с OpenAI в целях продажи доступа к своему контенту. Тем более, что по заявлению OpenAI, издателям будет предоставлена возможность управлять тем, как их контент будет отображаются в SearchGPT. OpenAI повысит безопасность своих ИИ-моделей с помощью «иерархии инструкций»
20.07.2024 [05:41],
Анжелла Марина
OpenAI разработала новый метод под названием «Иерархия инструкций» для повышения безопасности своих больших языковых моделей (LLM). Этот метод, впервые применённый в новой модели GPT-4o Mini, направлен на предотвращение нежелательного поведения ИИ, вызванного манипуляциями недобросовестных пользователей с помощью определённых команд. 
Источник изображения: Copilot Руководитель платформы API в OpenAI Оливье Годеман (Olivier Godement) объяснил, что «иерархия инструкций» позволит предотвращать опасные инъекции промтов с помощью скрытых подсказок, которые пользователи используют для обхода ограничений и изначальных установок модели, и блокировать атаки типа «игнорировать все предыдущие инструкции». Новый метод, как пишет The Verge, отдаёт приоритет исходным инструкциям разработчика, делая модель менее восприимчивой к попыткам конечных пользователей заставить её выполнять нежелательные действия. В случае конфликта между системными инструкциями и командами пользователя, модель будет отдавать наивысший приоритет именно системным инструкциям, отказываясь выполнять инъекции. Исследователи OpenAI считают, что в будущем будут разработаны и другие, более сложные средства защиты, особенно для агентных сценариев использования, при которых ИИ-агенты создаются разработчиками для собственных приложений. Учитывая, что OpenAI сталкивается с постоянными проблемами в области безопасности, новый метод, применённый к GPT-4o Mini, имеет большое значение для последующего подхода к разработке ИИ-моделей. Сотрудники OpenAI обвинили компанию в препятствовании огласке о рисках ИИ
14.07.2024 [06:25],
Анжелла Марина
Группа информаторов из компании OpenAI подала жалобу в Комиссию по ценным бумагам и биржам США (SEC), обвинив организацию в незаконном запрете сотрудникам предупреждать регуляторов о серьёзных рисках, которые может нести искусственный интеллект человечеству. 
Источник изображения: Elizabeth Frantz/For The Washington Post По сообщению газеты The Washington Post со ссылкой на анонимные источники, OpenAI заставляла сотрудников подписывать чрезмерно ограничительные трудовые договоры, соглашения о выходном пособии и соглашения о неразглашении информации. Эти документы могли привести к наказанию работников, если бы они самостоятельно связались с федеральными регуляторами по поводу деятельности OpenAI. В трудовом договоре содержались в неявном виде такие строки: «Мы не хотим, чтобы сотрудники разговаривали с федеральными регуляторами», — заявил один из информаторов на условиях анонимности из-за страха возмездия. «Я не думаю, что компании, занимающиеся ИИ, способны создавать безопасные и отвечающие общественным интересам технологии, если они ограждают себя от проверок и инакомыслия», — добавил он. Тем не менее, Ханна Вон (Hannah Wong), пресс-секретарь OpenAI, в ответ на обвинения заявила, что политика компании в отношении информаторов защищает права сотрудников на раскрытие информации и что компания приветствует дискуссии о влиянии технологий на общество. «Мы считаем, что серьёзное обсуждение этой технологии крайне важно, и уже внесли изменения в наш процесс увольнения, исключив из него пункты о неразглашении», — сказала она. В свою очередь адвокат информаторов Стивен Кон (Stephen Kohn) подчеркнул, что такие соглашения угрожают сотрудникам уголовным преследованием, если они сообщат о каких-либо нарушениях властям, и что это противоречит федеральным законам и нормам, защищающим информаторов. Он также отметил, что соглашение не содержало исключений для раскрытия определённой информации о нарушениях закона, что также является нарушением норм SEC. Письмо информаторов появилось на фоне растущих опасений, что OpenAI, изначально созданная как некоммерческая организация с альтруистической миссией, теперь ставит прибыль выше безопасности при создании своих технологий. Сообщается, что последняя модель ИИ ChatGPT, была выпущена до того, как компания завершила собственную процедуру проверки безопасности, из-за желания руководства уложиться в установленный срок. Неназванные сотрудники OpenAI призвали SEC провести тщательное расследование и принять меры против OpenAI, включая применение штрафов за каждый ненадлежащий контракт и требование уведомить всех прошлых и нынешних сотрудников об их праве конфиденциально и на анонимной основе сообщать о любых нарушениях закона SEC. Адвокат Крис Бейкер (Chris Baker) из Сан-Франциско, который не так давно выиграл дело против Google о трудовом соглашении и компенсацию в размере 27 миллионов долларов для сотрудников компании, заявил, что борьба с «Соглашением о неразглашении» в Кремниевой долине ведётся уже давно. Однако «работодатели понимают, что иногда ущерб от утечек информации намного больше, чем от судебных исков, и готовы идти на риск», — сказал Бейкер. ChatGPT превзошёл студентов на экзаменах, но только на первых курсах
29.06.2024 [23:57],
Анжелла Марина
Исследователи провели эксперимент, который показал, что ИИ способен успешно сдавать университетские экзамены, оставаясь при этом незамеченным специальными программами. Экзаменационные работы ChatGPT получили более высокие оценки, чем работы студентов, пишет издание Ars Technica. 
Источник изображения: Headway/Unsplash Команда учёных из Редингского университета в Англии (University of Reading) под руководством Питера Скарфа (Peter Scarfe) провела масштабный эксперимент, чтобы проверить, насколько эффективно современные системы искусственного интеллекта могут справляться с университетскими экзаменами. Исследователи создали более 30 фиктивных учётных записей студентов-психологов и использовали их для сдачи экзаменов, используя ответы, сгенерированные ChatGPT. Эксперимент охватил пять модулей бакалавриата по психологии, включая задания для всех трёх лет обучения. Результаты оказались ошеломляющими — 94 % работ, созданных ИИ, остались незамеченными экзаменаторами. Более того, почти 84 % этих работ получили более высокие оценки, чем работы студентов-людей, в среднем на полбалла выше. «Экзаменаторы были весьма удивлены результатами», — отметил Скарф. Причём интересно, что некоторые работы ИИ были обнаружены не из-за их роботизированности, а из-за слишком высокого качества. Эксперимент также выявил ограничения существующих систем обнаружения контента, созданного ИИ. По словам Скарфа, такие инструменты, как GPTZero от Open AI и система Turnitin, показывают хорошие результаты в лабораторных условиях, но их эффективность значительно снижается в реальной жизненной ситуации. Однако не все результаты были в пользу ИИ. На последнем курсе, где требовалось более глубокое понимание и сложные аналитические навыки, студенты-люди показали лучшие результаты, чем ChatGPT. Скарф подчеркнул, что ввиду постоянного совершенствования ИИ и отсутствия надёжных способов обнаружения его использования, университетам придётся адаптироваться и интегрировать ИИ в образовательный процесс. «Роль современного университета заключается в подготовке студентов к профессиональной карьере, и реальность такова, что после окончания учёбы они, несомненно, будут использовать различные инструменты искусственного интеллекта», — заключил исследователь. Данный эксперимент, по сути, поднимает проблему, которая уже сегодня требует пересмотра существующих методов обучения и экзаменации. Новая модель OpenAI CriticGPT обучена «критиковать» результаты GPT-4
28.06.2024 [05:44],
Анжелла Марина
Компания OpenAI представила CriticGPT — новую модель искусственного интеллекта, предназначенную для выявления ошибок в коде, сгенерированном непосредственно ChatGPT. CriticGPT будет использоваться в качестве алгоритмического помощника для тестировщиков, которые проверяют программный код, выданный ChatGPT. 
Источник изображения: Copilot Согласно новому исследованию «LLM Critics Help Catch LLM Bugs», опубликованному OpenAI, новая модель CriticGPT создана как ИИ-ассистент для экспертов-тестировщиков, проверяющих программный код, сгенерированный ChatGPT. CriticGPT, основанный на семействе большой языковой модели (LLM) GPT-4, анализирует код и указывает на потенциальные ошибки, облегчая специалистам обнаружение недочётов, которые в противном случае могли бы остаться незамеченными из-за человеческого фактора. Исследователи обучили CriticGPT на наборе данных с образцами кода, содержащими намеренно внесённые ошибки, научив его распознавать и отмечать различные погрешности. Учёные обнаружили, что в 63-% случаев, связанных с естественно возникающими ошибками LLM, аннотаторы предпочитали критику CriticGPT человеческой. Кроме того, команды, использующие CriticGPT, писали более полные отзывы, чем люди, не использующие этого ИИ-помощника, при этом снижался уровень конфабуляций (ложных фактов и галлюцинаций). Разработка автоматизированного «критика» включала обучение модели на большом количестве входных данных с намеренно внесёнными ошибками. Экспертов просили модифицировать код, написанный ChatGPT, внося ошибки, а затем предоставлять результат с якобы обнаруженными багами. Этот процесс позволил модели научиться выявлять и критиковать различные типы ошибок в коде. В экспериментах CriticGPT продемонстрировал способность улавливать как внесённые баги, так и естественно возникающие ошибки в результатах ответов ChatGPT. Исследователи также создали новый метод «Force Sampling Beam Search» (FSBS), который помогает CriticGPT писать более детальные обзоры кода, позволяя регулировать тщательность поиска проблем и одновременно контролируя частоту ложных срабатываний. Интересно, что возможности CriticGPT выходят за рамки простой проверки кода. В экспериментах модель применили к множеству тренировочных данных ChatGPT, ранее оцененных людьми как безупречные. Удивительно, но CriticGPT выявил ошибки в 24-% случаев, которые впоследствии были подтверждены экспертами. OpenAI считает, что это демонстрирует потенциал модели не только для работы с техническими задачами, но и подчёркивает её способность улавливать тонкие ошибки, которые могут ускользнуть даже от тщательной проверки человеком. Несмотря на многообещающие результаты, CriticGPT, как и все ИИ-модели, имеет ограничения. Модель обучалась на относительно коротких ответах ChatGPT, что может не полностью подготовить её к оценке более длинных и сложных задач, с которыми могут столкнуться будущие ИИ-системы. Команда исследователей признаёт, что модель наиболее эффективна в обнаружении ошибок, которые могут быть определены в одном конкретном, узком месте кода. Однако реальные ошибки в выводе AI могут часто быть разбросаны по нескольким частям ответа, что представляет собой вызов для будущих итераций модели. Кроме того, хотя CriticGPT снижает уровень конфабуляций, он не устраняет их полностью, и люди-эксперты по-прежнему могут совершать ошибки на основе этих ложных данных. Один из основателей OpenAI Илья Суцкевер создал собственный ИИ-стартап
20.06.2024 [06:40],
Анжелла Марина
Илья Суцкевер, один из основателей и бывший главный научный советник компании OpenAI, занимающейся разработкой искусственного интеллекта, объявил о создании своего стартапа под названием Safe Superintelligence (SSI). Главной целью новой компании является разработка безопасного и одновременно мощного искусственного интеллекта, сообщает The Verge. 
Источник изображения: Gerd Altmann/Pixabay В своём заявлении Суцкевер подчеркнул, что в SSI безопасность и возможности ИИ будут развиваться в тандеме. Это позволит компании быстро продвигать свои разработки, но при этом основной упор будет сделан на обеспечение безопасности системы. В отличие от таких IT-гигантов как Google, Microsoft и собственно OpenAI, в SSI не будет коммерческого давления и необходимости выпускать продукт за продуктом. Это даст возможность сосредоточиться на поэтапном масштабировании технологий при сохранении высочайших стандартов безопасности. Помимо самого Суцкевера, сооснователями SSI выступили Даниэль Гросс (Daniel Gross), бывший руководитель подразделения ИИ в Apple, и Даниэль Левай (Daniel Levy) из технического штата OpenAI. Интересно, что в прошлом году Суцкевер активно выступал за увольнение гендиректора OpenAI Сэма Альтмана (Sam Altman), а после своего ухода в мае намекал на запуск нового проекта. Вскоре за ним последовали и другие ведущие сотрудники OpenAI, ссылаясь на проблемы с приоритетностью вопросов этики и ответственности ИИ. SSI пока не планирует никаких партнёрских отношений. Суцкевер чётко обозначил, что единственным продуктом его компании станет безопасный суперинтеллект, и до его создания SSI не будет заниматься ничем другим. Таким образом, стартап фактически бросает вызов таким гигантам отрасли как OpenAI, ставя во главу угла этичность и безопасность технологий. Как отмечают эксперты, успех этой инициативы может полностью изменить подходы к разработке ИИ в отрасли. Исследователи использовали GPT-4 для автономного взлома сайтов — вероятность успеха 53 %
09.06.2024 [16:14],
Владимир Фетисов
Ранее в этом году исследователи установили, что нейросеть GPT-4 от компании OpenAI способна создавать эксплойты для уязвимостей, изучая информацию о них в интернете. Теперь же им удалось взломать более половины тестовых веб-сайтов с помощью автономных групп ботов на базе GPT-4, которые самостоятельно координировали свою работу и создавали новых ботов при необходимости. 
Источник изображения: newatlas.com Отмечается, что боты в своей работе создавали эксплойты для уязвимостей нулевого дня, о которых не было известно ранее. В своей предыдущей работе исследователи задействовали GPT-4 для эксплуатации уже известных уязвимостей (CVE), исправления для которых ещё не были выпущены. В итоге они установили, что нейросеть смогла создать эксплойты для 87 % критических уязвимостей CVE, представляющих высокую опасность. Те же самые исследователи из Иллинойского университета в Урбане-Шампейне опубликовали результаты новой работы, в которой боты на основе нейросети пытались взломать тестовые сайты путём эксплуатации уязвимостей нулевого дня. Вместо того, чтобы задействовать одного бота и нагружать его большим количеством сложных задач, исследователи использовали группу автономных, самораспространяющихся агентов на основе большой языковой модели (LLM). В своей работе агенты задействовали метод иерархического планирования, предполагающий выделение разных агентов под конкретные задачи. Одним из главных элементов стал «агента планирования», который контролировал весь процесс работы и запускал несколько «субагентов» для выполнения конкретных задач. Подобно взаимодействию между начальником и подчинёнными, «агент планирования» координирует свои действия с «управляющим агентом», который делегирует выполнение задач на «экспертных субагентов», тем самым равномерно распределяя нагрузку. Исследователи сравнили эффективность такого подхода при взаимодействии группы ботов с 15 реальными уязвимостями. Оказалось, что метод иерархического планирования на 550 % более эффективен по сравнению с тем, как с аналогичными уязвимостями работает один бот на базе нейросети. Группа ботов сумела задействовать 8 из 15 уязвимостей, тогда как одиночный бот создал эксплойт только для трёх уязвимостей. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться