|
Опрос
|
реклама
Быстрый переход
ИИ-модель Llama запустили на ПК из прошлого тысячелетия на базе Windows 98
01.04.2025 [19:45],
Сергей Сурабекянц
На волне ажиотажа вокруг генеративного ИИ любопытный эксперимент поставил соучредитель венчурного фонда Andreessen Horowitz Марк Андрессен (Marc Andreessen). На днях он продемонстрировал, как небольшая ИИ-модель Llama от Meta✴ успешно работает на 26-летнем ПК Dell со 128 Мбайт ОЗУ под управлением Windows 98. По мнению Андрессена, человечество могло бы общаться с генеративным ИИ десятилетия назад, если бы подобный ИИ был создан в то время. 
Источник изображения: pcmag.com Андрессен не раскрыл конкретную модель Llama, использованную для тестирования, что затрудняет попытки повторить его эксперимент. Стоит отметить, что модель Llama AI от Meta✴ потребляет меньше вычислительной мощности по сравнению с массивом гораздо более крупных моделей, но при этом обладает довольно впечатляющими возможностями. Андрессен предположил, что запуск Llama на 26-летнем ПК Dell с Windows 98 означает, что люди могли бы осуществлять «человекоподобное взаимодействие» со своими компьютерами десятилетия назад, по крайней мере, если бы генеративный ИИ существовал тогда: «Все эти старые ПК могли бы быть буквально умными всё это время. Мы могли бы общаться с нашими компьютерами уже 30 лет». Он полагает, что такое взаимодействие могло бы осуществиться значительно раньше, если бы ключевые игроки воспользовались возможностью во время предыдущего бума искусственного интеллекта в 1980-х годах: «Многие умные люди в 80-х годах думали, что все это произойдёт тогда». 
Источник изображения: Andreessen Horowitz Утверждения Андрессена подтверждаются более ранним экспериментом Exo Labs, в результате которого исследователям удалось запустить модифицированную версию Llama 2 на ПК с Windows 98 на базе Pentium II. Достичь этого было непросто. Потребовались совместимые периферийные устройства PS/2, приемлемый способ передачи требуемых файлов на устаревшее устройство, а также компиляция современного кода для устаревшего устройства и адаптация самой модели. ИИ-модели Llama скачали более миллиарда раз, похвастался Марк Цукерберг
18.03.2025 [18:40],
Павел Котов
Количество загрузок открытых моделей искусственного интеллекта Llama достигло 1 млрд, сообщил глава компании Meta✴ Марк Цукерберг (Mark Zuckerberg). По состоянию на начало декабря 2024 года этот показатель составлял 650 млн, что соответствует росту более чем на 50 % за квартал. 
Источник изображения: Stefan Cosma / unsplash.com Модели семейства Llama лежат в основе ИИ-помощника Meta✴ AI, который присутствует на различных платформах компании, в том числе в Facebook✴, Instagram✴ и WhatsApp — Meta✴ стремится выстроить обширную систему продуктов в области ИИ. Компания бесплатно по собственной лицензии предоставляет как сами модели, так и инструменты для их тонкой настройки и кастомизации. Эти модели имеют некоторые ограничения для использования в коммерческих целях, но активно применяются в различных продуктах — например, оператором связи AT&T и потоковой службой Spotify. Впрочем, не обходится и без сложностей: сейчас Meta✴ пытается отбиться от судебного иска, в рамках которого её обвиняют в обучении ИИ на защищённых авторским правом материалах; в ЕС компанию заставили отложить, а то и вовсе отменить выпуск некоторых моделей из-за сомнений в отношении конфиденциальности данных. Кроме того, модели DeepSeek оказались по ряду критериев лучше, чем Llama. Meta✴ пытается воспользоваться опытом DeepSeek по снижению расходов на обучение ИИ. В этом году американская компания намеревается потратить на ИИ не меньше $65 млрд, а в ближайшие месяцы она хочет выпустить несколько моделей Llama, включая рассуждающие. Meta✴ также, вероятно, ведёт разработку ИИ-агентов — систем, способных самостоятельно выполнять сложные последовательности действий. Некоторые из продуктов она может представить на LlamaCon — первой проводимой Meta✴ конференции разработчиков генеративного ИИ; она намечена на 29 апреля. Следующие ИИ-модели Llama от Meta✴ получат улучшенные голосовые функции
07.03.2025 [19:00],
Сергей Сурабекянц
По информации Financial Times, Meta✴ планирует представить улучшенные голосовые функции в своей следующей флагманской большой языковой модели Llama 4, запуск которой ожидается через несколько недель. Разработчики уделили особое внимание возможности прерывать и перебивать модель в процессе диалога, аналогично голосовому режиму OpenAI для ChatGPT и опыту Gemini Live от Google. 
Источник изображения: Pixabay На этой неделе главный директор по продуктам Meta✴ Крис Кокс (Chris Cox) сообщил, что Llama 4 будет «всеобъемлющей» моделью, способной нативно интерпретировать и выводить речь, а также текст и другие типы данных. 
Источник изображения: Meta✴ Успех открытых моделей китайской ИИ-лаборатории DeepSeek, которые продемонстрировали впечатляющие результаты, заставил разработчиков Llama существенно ускориться. По слухам, Meta✴ даже организовала оперативные центры, чтобы попытаться выяснить, как DeepSeek удалось радикально снизить стоимость обучения, запуска и развёртывания моделей ИИ. Meta✴ проведёт LlamaCon — первую конференцию для разработчиков, посвящённую генеративному ИИ
19.02.2025 [06:32],
Анжелла Марина
Meta✴ объявила о проведении первой своей конференции для разработчиков, посвящённой генеративному искусственному интеллекту (ИИ). Мероприятие, получившее название LlamaCon в честь семейства моделей генеративного ИИ Llama от Meta✴, запланировано на 29 апреля. Как сообщает TechCrunch, компания планирует представить свои последние достижения в разработке ИИ-моделей с открытым исходным кодом для того, чтобы помочь разработчикам создавать «наилучшие приложения и программные продукты». 
Источник изображения: Meta✴ Meta✴ уже несколько лет придерживается открытого подхода к разработке технологий ИИ, стремясь создать экосистему приложений и платформ. Хотя точное количество созданных на базе Llama приложений или сервисов не раскрывается, ранее компания сообщала, что такие организации, как Goldman Sachs, Nomura Holdings, AT&T, DoorDash и Accenture, используют модель Llama. Как утверждает сама компания, её модель была загружена сотни миллионов раз, и не менее 25 партнёров, включая Nvidia, Databricks, Groq, Dell и Snowflake, предоставляют хостинг для Llama. Некоторые из них разработали дополнительные инструменты, позволяющие, например, ИИ-моделям ссылаться на проприетарные данные или работать с меньшей задержкой. Несмотря на очевидный успех, Meta✴ оказалась не готова к взрывному успеху китайской компании DeepSeek, которая выпустила ИИ-модель (также с открытым исходным кодом), способную конкурировать с разработками Meta✴. По слухам, Meta✴ считает, что одна из последних версий моделей DeepSeek может даже превзойти следующую версию Llama, релиз которой ожидается в ближайшие недели. Поэтому в компании даже якобы срочно стали заниматься анализом методов DeepSeek по снижению стоимости эксплуатации и развёртывания моделей, чтобы применить эти знания в своих разработках Llama. Ранее генеральный директор Meta✴ Марк Цукерберг (Mark Zuckerberg) анонсировал запуск нескольких моделей Llama в ближайшие месяцы, включая модели с функциями рассуждения, аналогичные o3-mini от OpenAI, а также модели с врождённной мультимодальностью. Он также коснулся темы ИИ-агентов (как у OpenAI), которые должны появиться в будущем и автономно выполнять определённые действия. «Я думаю, что этот год вполне может стать годом, когда Llama и открытые модели станут самыми продвинутыми и широко используемыми моделями ИИ, — заявил Цукерберг. — Мы хотим добиться того, чтобы Llama в этом году стала лидером». Тем временем Meta✴ сталкивается с юридическими и регуляторными вызовами. Компания вовлечена в судебный процесс, обвиняющий её в использовании защищённых авторским правом материалов книг для обучения ИИ-моделей без разрешения. Кроме того, несколько стран ЕС из-за опасений по поводу конфиденциальности данных вынудили Meta✴ отложить или полностью отменить планы по запуску моделей в регионе, что в целом создаёт дополнительные препятствия для амбиций компании в области разработки Llama. Дополнительные детали о конференции LlamaCon, которая станет первым событием компании, полностью сосредоточенном на генеративном ИИ, будут объявлены в ближайшее время, уточнили в Meta✴. При этом ежегодная конференция для разработчиков Meta✴ Connect, как и обычно, состоится в сентябре. Энтузиаст запустил современную ИИ-модель на консоли Xbox 360 20-летней давности
12.01.2025 [12:00],
Владимир Фетисов
Пользователь соцсети X Андрей Дэвид (Andrei David) сумел установить и запустить на консоли Xbox 360 модель искусственного интеллекта на базе движка Llama2.c, который написан на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). Сделать это энтузиаста побудила работа специалистов из EXO Lab, которые в конце прошлого года запустили большую языковую модель (LLM) Llama на 26-летнем компьютере с Windows 98. 
Источник изображения: Shutterstock Хотя энтузиаст использовал ИИ-модель на том же движке, что и EXO Lab, ему пришлось оптимизировать программный код для процессора консоли на архитектуре PowerPC и функций управления памятью. Основное отличие в том, что в PowerPC система с прямым порядком байтов в первую очередь сохраняет наиболее важные значения, тогда как используемый в ПК процессор Intel Pentium II в первую очередь сохраняет наименьшие значения. Для обеспечения правильной работы ИИ-модели Дэвиду пришлось добавить систему обмена байтами и обеспечить, чтобы все создаваемые и сохраняемые данные должным образом выравнивались по 128 байтам в памяти, чего требует подсистема памяти Xbox 360. В итоге энтузиаст запустил ИИ-модель на Xbox 360 с процессором Xenon на архитектуре PowerPC с 3 ядрами и рабочей частотой до 3,2 ГГц, а также 512 Мбайт оперативной памяти. Запуск большой языковой модели на основе Llama 2 на устройстве, которому уже несколько десятилетий, является существенным достижением. Однако один из пользователей платформы X заметил, что 512 Мбайт оперативной памяти в Xbox 360 должно хватить для запуска алгоритмов SmolLm от Hugging Face или 4-битной модели 0,5B Qwen2.5. «Вызов принят», — написал Дэвид в ответ на это. Это означает, что в будущем он попытается запустить на Xbox 360 другие ИИ-модели. Марк Цукерберг лично разрешил обучать ИИ-модели Llama на пиратских материалах
10.01.2025 [14:25],
Павел Котов
Гендиректор Meta✴ Марк Цукерберг (Mark Zuckerberg) лично разрешил подразделению Meta✴, ответственному за разработку моделей искусственного интеллекта Llama, использовать для их обучения массив данных, содержащий полученные незаконным путём книги и статьи. Об этом стало известно из документов, опубликованных в рамках судебного процесса писателя Ричарда Кадри (Richard Kadrey) против Meta✴. 
Источник изображения: Tingey Injury / unsplash.com Данный процесс — лишь одно из ряда дел, в рамках которых разрабатывающие системы ИИ технологические гиганты обвиняются в обучении моделей на защищённых авторским правом материалах без разрешения авторов. Ответчики традиционно уверяют, что их действия отвечают норме о добросовестном использовании контента — эта доктрина позволяет пренебрегать авторским правом для создания новых произведений и продуктов, если они в значительной мере отличаются от оригинала. Многие правообладатели с такой позицией не согласны. В новой порции рассекреченных документов (PDF) приводятся показания представителей Meta✴: выяснилось, что Марк Цукерберг лично одобрил использование компанией массива LibGen для обучения Llama. Проект LibGen, позиционирующий себя как агрегатор ссылок, в действительности предоставляет доступ к защищённым авторским правом работам, которыми управляют крупные издатели. В его отношении неоднократно подавались судебные иски, с него взыскивались десятки миллионов долларов за нарушения авторских прав, и в итоге проект был вынужден закрыться. Цукерберг, говорится в документах, одобрил использование LibGen для обучения как минимум одной модели Llama вопреки опасениям, которые выражали рядовые сотрудники и члены руководства Meta✴. Приводится внутренняя служебная записка, в которой отмечается, что работа с LibGen получила одобрение после «эскалации до MZ» — под этой аббревиатурой, очевидно, подразумевался глава компании. 
Источник изображения: Igor Omilaev / unsplash.com Сторона истца 8 января подала в суд заявление, в котором содержатся новые обвинения. В частности, утверждается, что Meta✴ могла попытаться скрыть это деяние и удалить сведения об использовании материалов LibGen — это предположительно сделал инженер Meta✴ Николай Башлыков (Nikolay Bashlykov), который написал скрипт, удаливший из книг в обучающем массиве информацию об авторских правах. Meta✴ также якобы удалила сведения об авторских правах и соответствующие метаданные из статей научных журналов в данном массиве. Более того, Meta✴ нарушила авторские права, скачав массив LibGen через протокол BitTorrent — в этот момент компания не только скачивала, но и одновременно «раздавала» эти данные, фактически распространяя пиратские материалы, утверждает сторона истца. Глава отдела генеративного ИИ в Meta✴ Ахмад Аль-Дахле (Ahmad Al-Dahle) дал разрешение скачивать данные LibGen через BitTorrent, хотя инженер Башлыков указывал, что это «может быть юридически недопустимо». Дело ещё далеко до завершения. Пока оно касается только ранних моделей Llama, а не последних выпусков. И если Meta✴ убедит суд в добросовестном использовании материалов, он может встать на сторону компании — в 2023 году несколько истцов так и не смогли доказать факта нарушения авторских прав, и их иски к Meta✴ были отклонены. Энтузиасты запустили современную ИИ-модель Llama на древнем ПК с Pentium II и Windows 98
30.12.2024 [17:19],
Владимир Фетисов
Специалисты из EXO Labs сумели запустить довольно мощную большую языковую модель (LLM) Llama на 26-летнем компьютере, работающем под управлением операционной системы Windows 98. Исследователи наглядно показали, как загружается старый ПК, оснащённый процессором Intel Pentium II с рабочей частотой 350 МГц и 128 Мбайт оперативной памяти, после чего осуществляется запуск нейросети и дальнейшее взаимодействие с ней. 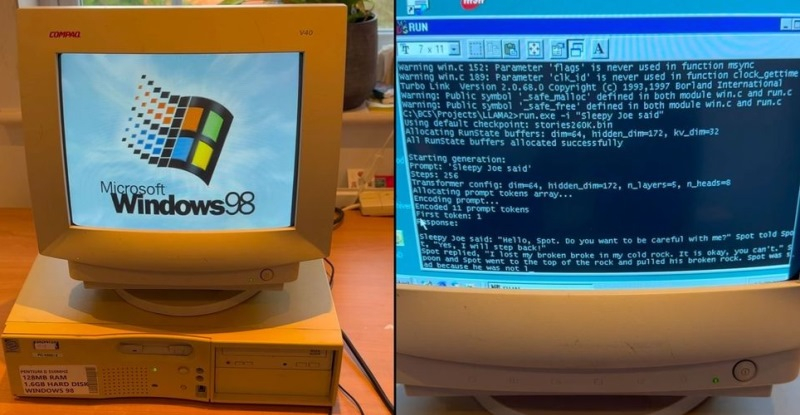
Источник изображения: GitHub Для запуска LLM специалисты EXO Labs задействовали собственный интерфейс вывода для алгоритма Llama98.c, который создан на базе движка Llama2.c, написанного на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). После загрузки алгоритма его попросили создать историю о Сонном Джо. Удивительно, но ИИ-модель действительно работает даже на таком древнем ПК, причём история пишется с хорошей скоростью. Загадочная организация EXO Labs, сформированная исследователями и инженерами из Оксфордского университета, вышла из тени в сентябре этого года. Согласно имеющимся данным, она выступает за открытость и доступность технологий на базе искусственного интеллекта. Представители организации считают, что передовые ИИ-технологии не должны находиться в руках горстки корпораций, как это происходят сейчас. В дальнейшем они рассчитывают «построить открытую инфраструктуру для обучения передовых ИИ-моделей, что позволит любому человеку запускать их где угодно». Демонстрация возможности запуска LLM на древнем ПК, по их мнению, доказывает то, что ИИ-алгоритмы могут работать практически на любых устройствах. В своём блоге энтузиасты рассказали, что для реализации поставленной задачи на eBay был приобретён старый ПК с Windows 98. Затем, подключив устройство в сеть с помощью разъёма Ethernet, они через FTP сумели передать в память устройства нужные данные. Вероятно, компиляция современного кода для Windows 98 оказалась более сложной задачей, решить которую помогла опубликованная на GitHub работа Андрея Карпатого. В конечном счёте удалось добиться скорости генерации текста в 35,9 токенов в секунду при использовании LLM размером 260K с архитектурой Llama, что весьма неплохо, учитывая скромные вычислительные возможности устройства. Meta✴ утёрла нос OpenAI: её ИИ оказался вдвое популярнее ChatGPT
07.12.2024 [13:19],
Павел Котов
Meta✴ представила ещё одну версию своей новейшей модели искусственного интеллекта — предназначенную для работы с текстом Llama 3.3 70B. Новинка показывает производительность на уровне прежнего флагмана Llama 3.1 405B, но предлагает более высокую эффективность: как видно из названия, у новой версии 70 млрд параметров против 405 млрд у старой. Компания также раскрыла размер аудитории своего помощника с ИИ — он оказался вдвое популярнее ChatGPT. 
Источник изображения: Igor Omilaev / unsplash.com «Используя последние достижения в области методов пост-обучения, <..> у этой модели повышена основная производительность при значительно меньших затратах», — рассказал в соцсети X Ахмад Аль-Дахле (Ahmad Al-Dahle), вице-президент по генеративному ИИ в Meta✴. Он также опубликовал диаграмму, которая демонстрирует, что Llama 3.3 70B превзошла Google Gemini 1.5 Pro, OpenAI GPT-4o и Amazon Nova Pro в ряде отраслевых тестов, включая MMLU — оценку способности модели понимать язык. 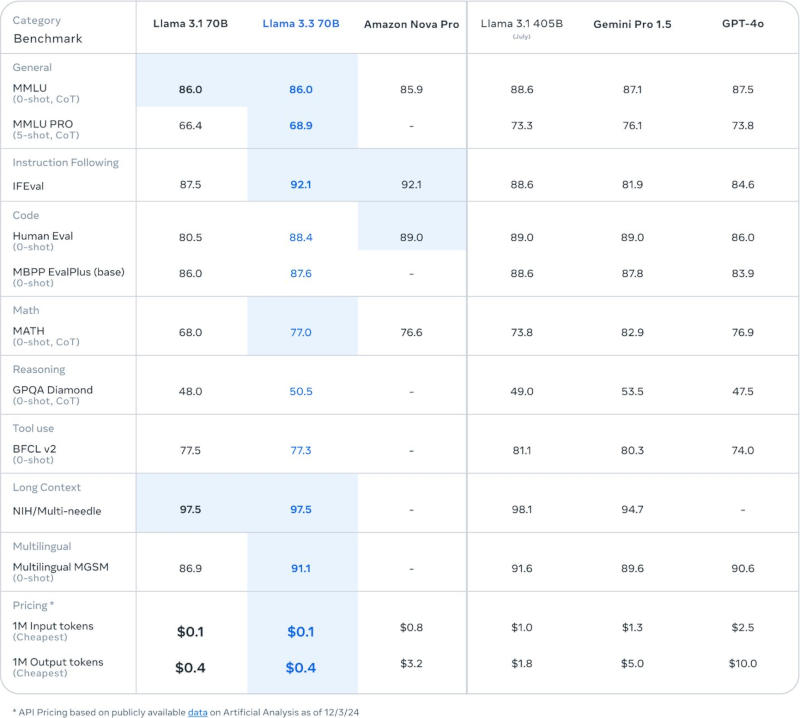
Источник изображения: x.com/Ahmad_Al_Dahle Новая модель опубликована с открытым исходным кодом, доступна для скачивания на платформе Hugging Face и в других источниках, включая официальный сайт Llama. Meta✴, впрочем, отчасти ограничила разработчикам возможность использовать модели Llama: для проектов, у которых более 700 млн пользователей, требуется специальная лицензия. При этом сами модели Llama, по сведениям Meta✴, были скачаны более 650 млн раз. Llama используется и самой компанией: на ней построен ИИ-помощник Meta✴ AI, у которого, по словам главы компании Марка Цукерберга (Mark Zuckerberg), почти 600 млн активных пользователей в месяц — вдвое больше, чем у ChatGPT. Ранее Цукерберг рассказал, что для обучения перспективных Llama 4 компании потребуется в десять раз больше вычислительных ресурсов, чем для актуальных Llama 3. В этих целях Meta✴ закупила более 100 тыс. ускорителей Nvidia — кластер такой мощности есть и у xAI Илона Маска (Elon Musk). Известно также, что во II квартале 2024 года капитальные затраты Meta✴ выросли почти на 33 % по сравнению с аналогичным периодом прошлого года и составили $8,5 млрд — средства были потрачены на серверы, центры обработки данных и сетевую инфраструктуру. «Больше, чем у кого-либо»: Цукерберг похвастался системой с более чем 100 тыс. Nvidia H100 — на ней обучается Llama 4
31.10.2024 [22:31],
Николай Хижняк
Среди американских IT-гигантов зародилась новая забава — соревнование, у кого больше кластеры и твёрже уверенность в превосходстве своих мощностей для обучения больших языковых моделей ИИ. Лишь недавно глава компании Tesla Илон Маск (Elon Musk) хвастался завершением сборки суперкомпьютера xAI Colossus со 100 тыс. ускорителей Nvidia H100 для обучения ИИ, как об использовании более 100 тыс. таких же ИИ-ускорителей сообщил глава Meta✴ Марк Цукерберг (Mark Zuckerberg). 
Источник изображения: CNET/YouTube Глава Meta✴ отметил, что упомянутая система используется для обучения большой языковой модели нового поколения Llama 4. Эта LLM обучается «на кластере, в котором используется больше 100 000 графических ИИ-процессоров H100, и это больше, чем что-либо, что я видел в отчётах о том, что делают другие», — заявил Цукерберг. Он не поделился деталями о том, что именно уже умеет делать Llama 4. Однако, как пишет издание Wired со ссылкой на заявление главы Meta✴, их ИИ-модель обрела «новые модальности», «стала сильнее в рассуждениях» и «значительно быстрее». Этим комментарием Цукерберг явно хотел уколоть Маска, который ранее заявлял, что в составе его суперкластера xAI Colossus для обучения ИИ-модели Grok используются 100 тыс. ускорителей Nvidia H100. Позже Маск заявил, что количество ускорителей в xAI Colossus в перспективе будет увеличено втрое. Meta✴ также ранее заявила, что планирует получить до конца текущего года ИИ-ускорители, эквивалентные более чем полумиллиону H100. Таким образом, у компании Цукерберга уже имеется значительное количество оборудования для обучения своих ИИ-моделей, и будет ещё больше. Meta✴ использует уникальный подход к распространению своих моделей Llama — она предоставляет их полностью бесплатно, позволяя другим исследователям, компаниям и организациям создавать на их базе новые продукты. Это отличает её от тех же GPT-4o от OpenAI и Gemini от Google, доступных только через API. Однако Meta✴ всё же накладывает некоторые ограничения на лицензию Llama, например, на коммерческое использование. Кроме того, компания не сообщает, как именно обучаются её модели. В остальном модели Llama имеют природу «открытого исходного кода». С учётом заявленного количества используемых ускорителей для обучения ИИ-моделей возникает вопрос — сколько электричества всё это требует? Один специализированный ускоритель может съедать до 3,7 МВт·ч энергии в год. Это означает, что 100 тыс. таких ускорителей будут потреблять как минимум 370 ГВт·ч электроэнергии — как отмечается, достаточно для того, чтобы обеспечить энергией свыше 34 млн среднестатистических американских домохозяйств. Каким образом компании добывают всю эту энергию? По признанию самого Цукерберга, со временем сфера ИИ столкнётся с ограничением доступных энергетических мощностей. Компания Илона Маска, например, использует несколько огромных мобильных генераторов для питания суперкластера из 100 тыс. ускорителей, расположенных в здании площадью более 7000 м2 в Мемфисе, штат Теннесси. Та же Google может не достичь своих целевых показателей по выбросам углерода, поскольку с 2019 года увеличила выбросы парниковых газов своими дата-центрами на 48 %. На этом фоне бывший генеральный директор Google даже предложил США отказаться от поставленных климатических целей, позволив компаниям, занимающимся ИИ, работать на полную мощность, а затем использовать разработанные технологии ИИ для решения климатического кризиса. Meta✴ увильнула от ответа на вопрос о том, как компании удалось запитать такой гигантский вычислительный кластер. Необходимость в обеспечении растущего объёма используемой энергии для ИИ вынудила те же технологические гиганты Amazon, Oracle, Microsoft и Google обратиться к атомной энергетике. Одни инвестируют в разработку малых ядерных реакторов, другие подписали контракты на перезапуск старых атомных электростанций для обеспечения растущих энергетических потребностей. OSI ввела строгие стандарты открытости для Meta✴ Llama и других ИИ-моделей
29.10.2024 [07:19],
Дмитрий Федоров
Open Source Initiative (OSI), десятилетиями определяющая стандарты открытого программного обеспечения (ПО), ввела определение для понятия «открытый ИИ». Теперь, чтобы модель ИИ считалась действительно открытой, OSI требует предоставления доступа к данным, использованным для её обучения, полному исходному коду, а также ко всем параметрам и весам, определяющим её поведение. Эти новые условия могут существенно повлиять на технологическую индустрию, поскольку такие ИИ-модели, как Llama компании Meta✴ не соответствуют этим стандартам. 
Источник изображения: BrianPenny / Pixabay Неудивительно, что Meta✴ придерживается иной точки зрения, считая, что подход OSI не учитывает особенностей современных ИИ-систем. Представитель компании Фейт Айшен (Faith Eischen) подчеркнула, что Meta✴, хотя и поддерживает многие инициативы OSI, не согласна с предложенным определением, поскольку, по её словам, «единого стандарта для открытого ИИ не существует». Она также добавила, что Meta✴ продолжит работать с OSI и другими организациями, чтобы обеспечить «ответственное расширение доступа к ИИ» вне зависимости от формальных критериев. При этом Meta✴ подчёркивает, что её модель Llama ограничена в коммерческом применении в приложениях с аудиторией более 700 млн пользователей, что противоречит стандартам OSI, подразумевающим полную свободу её использования и модификации. Принципы OSI, определяющие стандарты открытого ПО, на протяжении 25 лет признаются сообществом разработчиков и активно им используются. Благодаря этим принципам разработчики могут свободно использовать чужие наработки, не опасаясь юридических претензий. Новое определение OSI для ИИ-моделей предполагает аналогичное применение принципов открытости, однако для техногигантов, таких как Meta✴, это может стать серьёзным вызовом. Недавно некоммерческая организация Linux Foundation также вступила в обсуждение, предложив свою трактовку «открытого ИИ», что подчёркивает возрастающую значимость данной темы для всей ИТ-индустрии. Исполнительный директор OSI Стефано Маффулли (Stefano Maffulli) отметил, что разработка нового определения «открытого ИИ» заняла два года и включала консультации с экспертами в области машинного обучения (ML) и обработки естественного языка (NLP), философами, представителями Creative Commons и другими специалистами. Этот процесс позволил OSI создать определение, которое может стать основой для борьбы с так называемым «open washing», когда компании заявляют о своей открытости, но фактически ограничивают возможности использования и модификации своих продуктов. Meta✴ объясняет своё нежелание раскрывать данные обучения ИИ вопросами безопасности, однако критики указывают на иные мотивы, среди которых минимизация юридических рисков и сохранение конкурентного преимущества. Многие ИИ-модели, вероятно, обучены на материалах, защищённых авторским правом. Так, весной The New York Times сообщила, что Meta✴ признала наличие такого контента в своих данных для обучения, поскольку его фильтрация практически невозможна. В то время как Meta✴ и другие компании, включая OpenAI и Perplexity, сталкиваются с судебными исками за возможное нарушение авторских прав, ИИ-модель Stable Diffusion остаётся одним из немногих примеров открытого доступа к данным обучения ИИ. Маффулли видит в действиях Meta✴ параллели с позицией Microsoft 1990-х годов, когда та рассматривала открытое ПО как угрозу своему бизнесу. Meta✴, по словам Маффулли, подчёркивает объём своих инвестиций в модель Llama, предполагая, что такие ресурсоёмкие разработки по силам немногим. Использование Meta✴ данных обучения в закрытом формате, по мнению Маффулли, стало своего рода «секретным ингредиентом», который позволяет корпорации удерживать конкурентное преимущество и защищать свою интеллектуальную собственность. Meta✴ выпустила открытую ИИ-модель Llama 3.2 — она работает с текстом и изображениями
26.09.2024 [10:09],
Павел Котов
Всего через два месяца после выпуска большой языковой модели Llama 3.1 компания Meta✴ представила её обновлённую версию Llama 3.2 — первую открытую систему искусственного интеллекта, которая может обрабатывать как изображения, так и текст. 
Источник изображения: Gerd Altmann / pixabay.com Meta✴ Llama 3.2 позволяет разработчикам создавать передовые приложения с ИИ: платформы дополненной реальности с распознаванием видео в реальном времени; визуальные поисковые системы с сортировкой изображений на основе содержимого; а также системы анализа документов с подготовкой сводок по длинным фрагментам текста. Запустить новую модель разработчикам будет довольно просто, говорят в Meta✴ — потребуется добавить поддержку мультимодальности, «иметь возможность показывать Llama изображения и заставить её общаться». OpenAI и Google запустили собственные мультимодальные модели ИИ ещё в прошлом году, поэтому Meta✴ сейчас оказалась в положении догоняющей. Поддержка работы с изображениями играет важную роль — Meta✴ продолжает наращивать возможности ИИ на устройствах, включая очки Ray-Ban Meta✴. Пакет Llama 3.2 включает две модели, поддерживающие работу с изображением (с 11 и 90 млрд параметров) и две облегчённые текстовые модели (с 1 и 3 млрд параметров). Меньшие предназначены для работы на чипах Qualcomm, MediaTek и других Arm-процессорах — Meta✴ явно рассчитывает, что они будут применяться на мобильных устройствах. При этом выпущенная в июле Llama 3.1 по-прежнему является сильным предложением — одна из версий имеет 405 млрд параметров, и в генерации текста она должна превосходить более новые. Легендарный Winamp сегодня стал медиаплеером с открытым исходным кодом
24.09.2024 [21:13],
Владимир Фетисов
На этой неделе компания Llama Group открыла код плеера Winamp и перевела проект на модель совместного развития. Написанный на C++ и C исходный код приложения опубликован на GitHub под лицензией Winamp Collaborative License Version 1.0. В настоящее время сборка десктопной версии проигрывателя основана на Visual Studio 2019 и библиотеках Intel IPP v6.1.1.035. 
Источник изображения: forums.winamp.com Согласно имеющимся данным, переход на открытую модель разработки обусловлен реорганизацией в Llama Group, которая была проведена из-за финансовых проблем. По этой же причине в прошлом году компании пришлось продать проект Shoutcast, а также уволить команду разработчиков, которая занималась сопровождением классического приложения Winamp для Windows. При этом разработчики продолжили развитие одноимённого стримингового сервиса с подписками на музыкантов, а также мобильных версий Winamp для устройств на базе Android и iOS. Проект Winamp существует с 1997 года и является одним из самых долгоживущих мультимедийных проигрывателей, который всё ещё развивается. На фоне высокой популярности плеера для Windows появилось несколько клонов для Linux, таких как XMMS, XMMS2 и Beep Media Player. В 2022 году компания Radionomy Group, которая на тот момент владела разработчиком Winamp в лице Nullsoft, продала аудиобизнес компании Azerion и переименовалась в Llama Group. Позднее Llama Group объявила о перезапуске проекта Winamp в качестве музыкального стримингового сервиса. Текущая доступная версия Winamp Full имеет номер 5.9.2.10042. Meta✴ похвасталась ростом спроса на языковые модели Llama в 10 раз — всё благодаря их открытости
29.08.2024 [22:42],
Николай Хижняк
Компания Meta✴ сообщила, что количество загрузок её больших языковых моделей ИИ (LLM) Llama приближается к 350 млн. Это в 10 раз больше показателя загрузок за аналогичный период прошлого года. Примерно 20 млн из этих загрузок были сделаны только за последний месяц, после того как компания выпустила языковую модель Llama 3.1, которая, по заявлению Meta✴, позволит ей напрямую конкурировать с решениями компаний OpenAI и Anthropic. 
Источник изображения: Gerd Altmann / pixabay.com У некоторых крупнейших поставщиков облачных услуг, сотрудничающих с Meta✴, ежемесячное использование языковых моделей Llama выросло в десять раз с января по июль этого года. Также отмечается, что с мая по июль использование Llama на серверах её партнёров среди провайдеров облачных услуг выросло более чем вдвое по количеству токенов. Помимо Amazon Web Services (AWS) и Microsoft Azure, компания сотрудничает с Databricks, Dell, Google Cloud, Groq, Nvidia, IBM watsonx, Scale AI и Snowflake и другими, чтобы сделать свои LLM более доступными для разработчиков. Meta✴ считает, что успех её языковых моделей связан с тем, что они распространяются по открытой лицензии. По словам компании, открытое распространение её LLM позволило «расширить и разнообразить экосистему ИИ и предоставить разработчикам больше выбора». Когда Meta✴ выпустила Llama 3.1, глава компании Марк Цукерберг (Mark Zuckerberg) превозносил достоинства ИИ с открытым исходным кодом, назвав его «движением вперёд». Он также рассказал, что компания предпринимает шаги, чтобы сделать ИИ с открытым исходным кодом отраслевым стандартом. В своём последнем отчёте Meta✴ также рассказала, как её партнёры используют большие языковые модели. Например, оператор связи AT&T использует Llama для более точного пользовательского поиска. Один из крупнейших американских доставщиков еды DoorDash использует LLM, чтобы упростить работу своих инженеров по программному обеспечению. Языковая модель также используется для генерации живых реакций и цифровых существ в игре Peridot от компании Niantic. В свою очередь Zoom использует Llama, а также другие языковые модели, для работы ИИ-ассистента, который может подводить итоги встреч и делать умные заметки. Вышла крупнейшая ИИ-модель Llama 3.1 от Meta✴ — её самая большая версия имеет 405 млрд параметров
24.07.2024 [00:56],
Анжелла Марина
Компания Meta✴ объявила о выпуске крупнейшей на сегодня открытой языковой модели искусственного интеллекта Llama 3.1, насчитывающей более 400 миллиардов различных параметров. По заявлению генерального директора Meta✴ Марка Цукерберга (Mark Zuckerberg) модель может превзойти GPT-4 по производительности уже в ближайшее время, а к концу года станет самым популярным ИИ-помощником в мире. 
Источник изображения: Reuters Как сообщает издание The Verge, разработка новой модели потребовала больших инвестиций. Llama 3.1 значительно сложнее, чем более ранние версии, выпущенные всего несколько месяцев назад. Старшая версия ИИ-модели имеет 405 миллиардов параметров и была обучена с использованием более 16 000 ускорителей H100 от Nvidia. Meta✴ не раскрывает вложенных средств в её разработку, но, исходя из стоимости одних только чипов Nvidia, можно с уверенностью предположить, что речь идёт о сотнях миллионов долларов. Несмотря на высокую стоимость разработки, Meta✴ решила сделать код модели открытым (Open Source). В письме, опубликованном в официальном блоге компании, Цукерберг утверждает, что ИИ-модели с открытым исходным кодом обгонят проприетарные модели, подобно тому, как Linux стал операционной системой с открытым исходным кодом, которая сегодня управляет большинством телефонов, серверов и гаджетов. Одним из ключевых обновлений стало расширение географии доступности сервиса Meta✴ AI, который построен на Llama. Теперь ассистент доступен в 22 странах, включая Аргентину, Чили, Колумбию, Эквадор, Мексику, Перу и Камерун. Кроме того, если раньше Meta✴ AI поддерживала только английский язык, то сейчас добавлены французский, немецкий, хинди, итальянский, португальский и испанский. Однако стоит отметить, что некоторые из новых функций пока доступны только в определённых регионах или для конкретных языков. 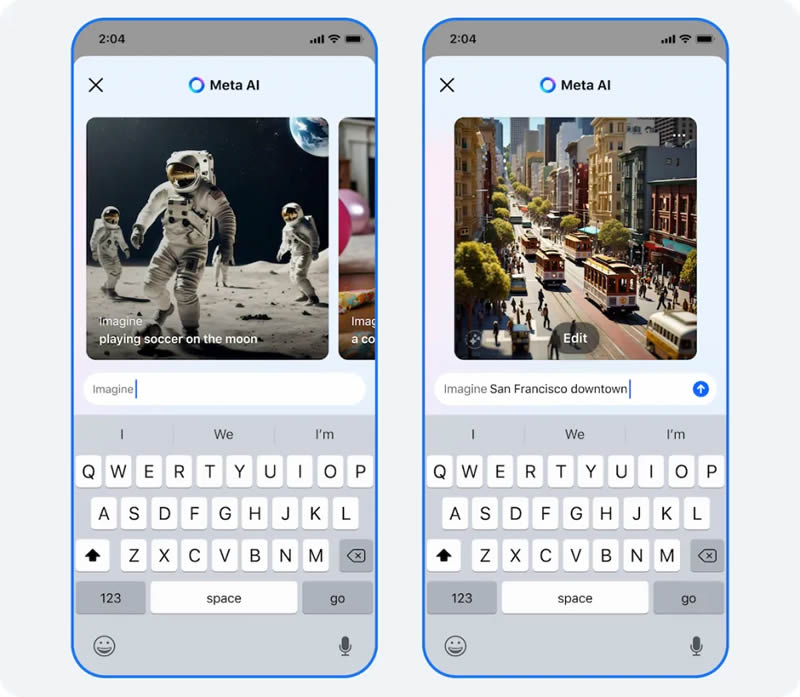
Источник изображения: Meta✴ Также появилась интересная функция Imagine me (представь меня), которая использует генеративную ИИ-модель Imagine Yourself, сообщает TechCrunch. Эта модель способна создавать изображения на основе фотографии пользователя и текстового запроса в требуемом контексте. Например, «Представь меня сёрфингистом» или «Представь меня на пляже». После чего искусственный интеллект сгенерирует соответствующее изображение. Функция доступна в бета-версии и активируется вводом фразы «Imagine me». 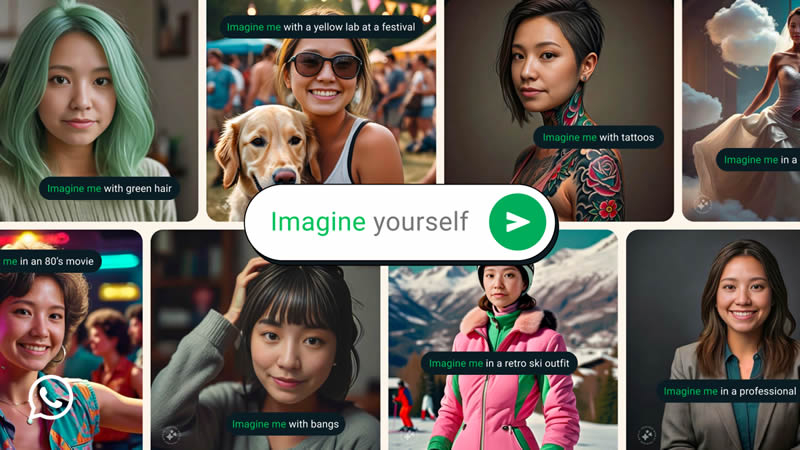
Источник изображения: Meta✴ В ближайшее время Meta✴ AI также получит новые инструменты редактирования изображений. Пользователи смогут добавлять, удалять и изменять объекты на изображениях с помощью текстовых запросов. А со следующего месяца разработчики обещают внедрить кнопку «Edit with AI» (редактирование с помощью ИИ) для доступа к дополнительным опциям тонкой настройки. Позднее появятся новые ярлыки для быстрой публикации изображений, созданных ИИ, в лентах, историях и комментариях в приложениях Meta✴. Напомним, запуск Meta✴ AI состоялся в сентябре 2023 года. Сервис основан на большой языковой модели Llama 2 и предоставляет пользователям возможность получать информацию, генерировать текст, делать переводы на различные языки и выполнять другие задачи с помощью искусственного интеллекта. Meta✴ бросила вызов ChatGPT — все сервисы компании получили «самого умного» ИИ-помощника
18.04.2024 [23:30],
Владимир Чижевский
Сегодня Meta✴ представила не только новое поколение собственных языковых моделей Llama 3, но и подключила их к поисковым строкам своих основных приложений — Facebook✴, Messenger, Instagram✴ и WhatsApp, пусть и не во всех странах. Кроме того, компания запустила отдельный сайт для своего чат-бота, meta✴.ai. 
Источник изображения: Meta✴ Meta✴ стремится не отставать, а то и превзойти конкурирующие продукты вроде ChatGPT от OpenAI, Gemini от Google и Claude от Anthropic, с которыми сегодня и сравнивала новое семейство больших языковых моделей Llama 3. Более того, Марк Цукерберг (Mark Zuckerberg) заявил, что Meta✴ AI «самый интеллектуальный ИИ-помощник из доступных для свободного пользователя». Meta✴ AI запустили ещё в прошлом году, и он по-прежнему поддерживает лишь английский язык, однако работает во многих странах, включая Австралию, Канаду, Гану, Ямайку, Малави, Новую Зеландию, Нигерию, Пакистан, Сингапур, Южную Африку, Уганду, Замбию и Зимбабве. Среди новых функций Meta✴ AI — возможность попросить ИИ найти определённую информацию в Google и Bing. Разработчики не просто ускорили генерацию изображений с помощью Meta✴ AI, но и наделили ИИ возможностью анимировать картинки, а также улучшили функцию размещения текста на генерируемых изображениях. Стремясь как можно сильнее расширить присутствие ИИ в своих продуктах, Meta✴ добавила его не только в поисковые строки, но и в индивидуальные и групповые чаты, и даже в ленты приложений. Например, увидев в ленте Facebook✴ фотографию северного сияния можно спросить ИИ, когда лучше отправиться в Исландию, чтобы наблюдать его своими глазами. Помимо этого, Meta✴ AI добавили в умные очки Ray-Ban, вскоре он появится и в VR-гарнитуре Meta✴ Quest. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться