|
Опрос
|
реклама
Быстрый переход
AMD по примеру Nvidia возобновит поставки своих ИИ-ускорителей Instinct в Китай
15.07.2025 [21:05],
Николай Хижняк
Представитель AMD в разговоре с порталом Tom’s Hardware подтвердил, что компания возобновит поставки ИИ-ускорителей MI308 в Китай. Это специализированная модификация ускорителей серии Instinct MI300, разработанная специально для соответствия экспортным правилам, установленным Министерством торговли США. 
Источник изображения: AMD Ранее сегодня глава Nvidia Дженсен Хуанг (Jensen Huang) публично подтвердил, что компания немедленно приступает к подготовке возобновления продаж своих ИИ-ускорителей Hopper H20 в Китае. Nvidia рассчитывает получить разрешение на продажу этих специализированных GPU, изготовленных по индивидуальному заказу, после того как в апреле они были запрещены к продаже в Китае обновлёнными экспортными правилами США. AMD и Nvidia ясно дали понять, что китайский рынок критически важен для их бизнеса, поскольку они разрабатывают специализированные GPU для центров обработки данных с учётом ограничений правительства США. Однако проектирование и выпуск таких вариантов графических чипов — процесс небыстрый: их разработка, производство, сборка и настройка занимают месяцы. После завершения разработки и установки необходимой прошивки устройства фактически становятся программно заблокированными в соответствии с экспортными ограничениями, что часто затрудняет их продажу за пределами рынков, для которых эти ограничения были введены. «Мы планируем возобновить поставки, как только получим одобрение по лицензии. Министерство торговли недавно сообщило нам, что заявки на получение лицензий на экспорт продукции MI308 в Китай будут переданы на рассмотрение», — заявил представитель AMD в разговоре с Tom’s Hardware. Обе компании оказались под давлением в связи с масштабным экспортным контролем на поставки технологий, связанных с ИИ, введённым ещё предыдущей администрацией президента США Джо Байдена и продолженным нынешней администрацией президента Дональда Трампа. Последняя, хоть и сузила ограничения, всё же включила в список запрещённых к поставке чипов такие модели, как H20 и MI308. Согласно оценке AMD, экспортные ограничения могут обойтись ей примерно в $800 млн в виде нераспроданных запасов, невыполненных обязательств по заказам и оставшихся резервов. Хотя это значительно меньше, чем масштабное списание Nvidia в размере $5,5 млрд, потери всё же заметно ударят по чистой прибыли AMD. После сегодняшнего объявления акции AMD подскочили на 5,7 % вслед за аналогичным ростом акций Nvidia. AMD потеряет $800 млн из-за новейших ограничений на поставки ускорителей вычислений в Китай
17.04.2025 [05:04],
Алексей Разин
Повышенное внимание к Nvidia, которая является крупнейшим поставщиком вычислительных средств для систем искусственного интеллекта, вполне объяснимо. Новейшие запреты со стороны США вынудят списать её только в этом квартале $5,5 млрд, но от ограничений пострадает и конкурирующая AMD, которая свой ущерб оценила в $800 млн. 
Источник изображения: AMD Напомним, что 9 апреля власти США ввели запрет на поставки в Китай ускорителей вычислений Nvidia H20 и сопоставимых с ними по быстродействию альтернатив американского происхождения. Хотя подобная деятельность афишировалась значительно меньше, чем в случае с Nvidia, но AMD также поставляла в Китай свои адаптированные к требованиям США ускорители вычислений, носящие обозначение Instinct MI308. В своём недавнем официальном заявлении AMD упоминает, что потери компании от введения новых ограничений достигнут $800 млн. Это существенная сумма, с учётом пропорционально меньшего оборота компании AMD в целом по сравнению с Nvidia. По словам представителей AMD, компания попытается получить экспортные лицензии, которые помогут ей продолжить обслуживание китайских клиентов в этой сфере, но успех этой затеи гарантироваться не может. Акции Nvidia на торгах в среду опустились в цене примерно на 7 %, акции AMD просели даже немного сильнее. Сейчас на долю Nvidia приходится почти 90 % рынка ускорителей вычислений в серверном сегменте. AMD представила мощнейший ИИ-ускоритель MI325X с 288 Гбайт HBM3e и рассказала про MI350X на архитектуре CDNA4
03.06.2024 [12:22],
Николай Хижняк
Компания AMD представила на выставке Computex 2024 обновлённые планы по выпуску ускорителей вычислений Instinct, а также анонсировала новый флагманский ИИ-ускоритель Instinct MI325X. 
Источник изображений: AMD Ранее компания выпустила ускорители MI300A и MI300X с памятью HBM3, а также несколько их вариаций для определённых регионов. Новый MI325X основан на той же архитектуре CDNA 3 и использует ту же комбинацию из 5- и 6-нм чипов, но тем не менее представляет собой существенное обновление для семейства Instinct. Дело в том, что в данном ускорителе применена более производительная память HBM3e.  Instinct MI325X предложит 288 Гбайт памяти, что на 96 Гбайт больше, чем у MI300X. Что ещё важнее, использование новой памяти HBM3e обеспечило повышение пропускной способности до 6,0 Тбайт/с — на 700 Гбайт/с больше, чем у MI300X с HBM3. AMD отмечает, что переход на новую память обеспечит MI325X в 1,3 раза более высокую производительность инференса (работа уже обученной нейросети) и генерации токенов по сравнению с Nvidia H200.  Компания AMD также предварительно анонсировала ускоритель Instinct MI350X, который будет построен на чипе с новой архитектурой CDNA 4. Переход на эту архитектуру обещает примерно 35-кратный прирост производительности в работе обученной нейросети по сравнению с актуальной CDNA 3. 
 Для производства ускорителей вычислений MI350X будет использоваться передовой 3-нм техпроцесс. Instinct MI350X тоже получат до 288 Гбайт памяти HBM3e. Для них также заявляется поддержка типов данных FP4/FP6, что принесёт пользу в работе с алгоритмами машинного обучения. Дополнительные детали об Instinct MI350X компания не сообщила, но отметила, что они будут выпускаться в формфакторе Open Accelerator Module (OAM). 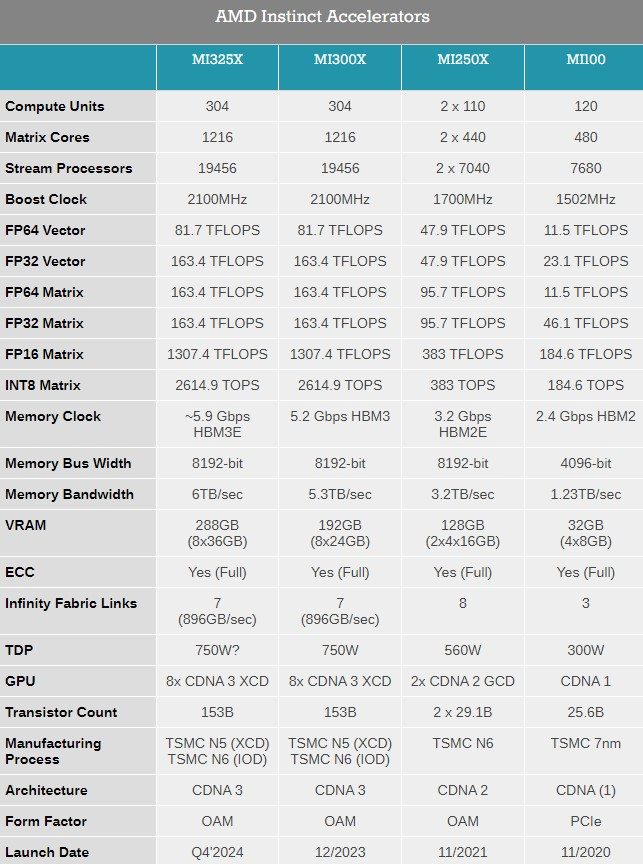
Источник изображения: AnandTech ИИ-ускорители Instinct MI325X начнут продаваться в четвёртом квартале этого года. Выход MI350X ожидается в 2025 году. Кроме того, AMD сообщила, что ускорители вычислений серии MI400 на архитектуре CDNA-Next будут представлены в 2026 году. AMD становится серверной компанией, а продажи Radeon и чипов для консолей упали вдвое
01.05.2024 [01:09],
Андрей Созинов
Компания AMD опубликовала финансовый отчёт за первый квартал текущего года. Финансовые показатели немного превзошли ожидания аналитиков Уолл-стрит, однако на большинстве направлений компания показала спад по сравнению с предыдущим кварталом. Акции AMD уже отреагировали падением на 7 % на расширенных торгах.  Чистая прибыль AMD в первом квартале текущего года составила $123 миллиона. Это значительно лучше показателя за первый квартал 2023 года — тогда компания сообщила о чистом убытке в $139 миллионов. Однако по сравнению с предыдущим кварталом, то есть четвёртой четвертью 2023 года, чистая прибыль обвалилась на 82 %. 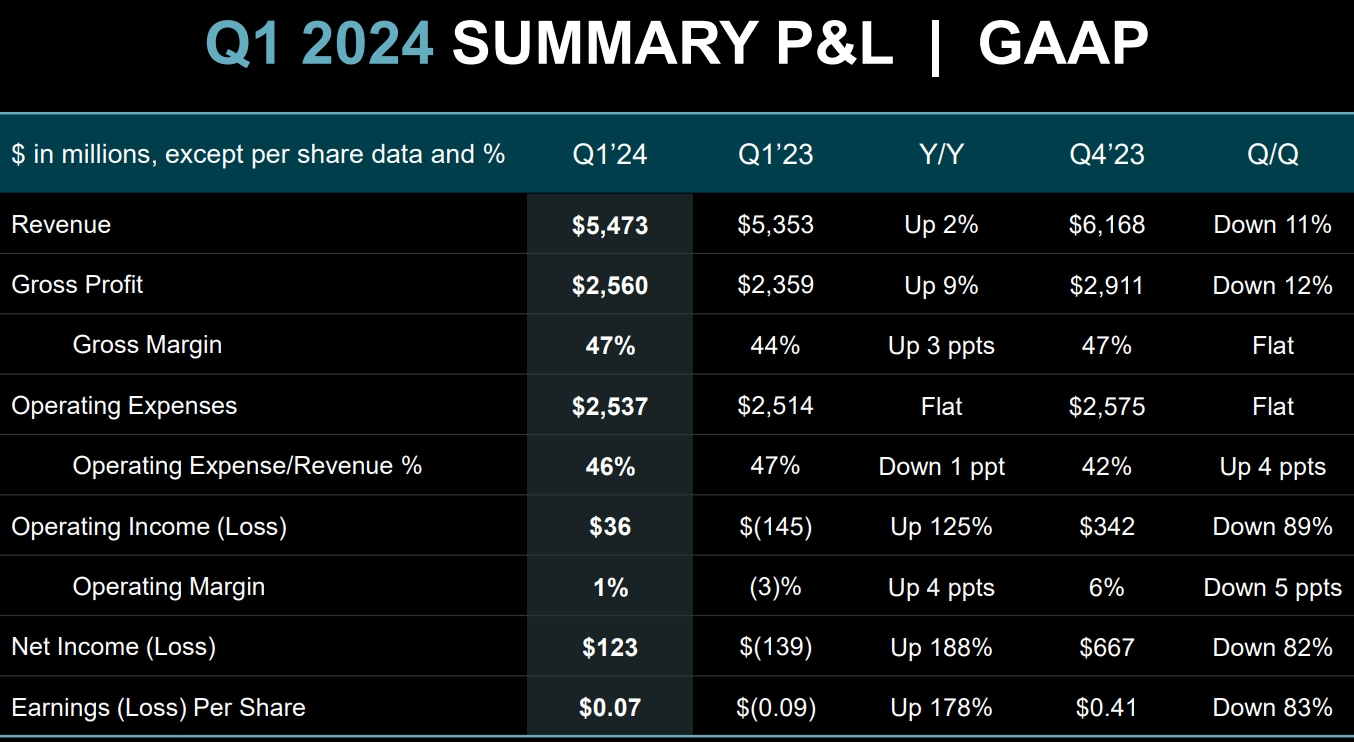
Источник изображений: AMD Выручка AMD в первой четверти 2024 года выросла в годовом сравнении примерно на 2 %, до $5,47 млрд. Однако по сравнению с предыдущим кварталом снова отмечается спад, но не столь значительный как для прибыли — на 11 %. При этом AMD превзошла ожидания аналитиков, которые прогнозировали ей $5,46 млрд выручки. 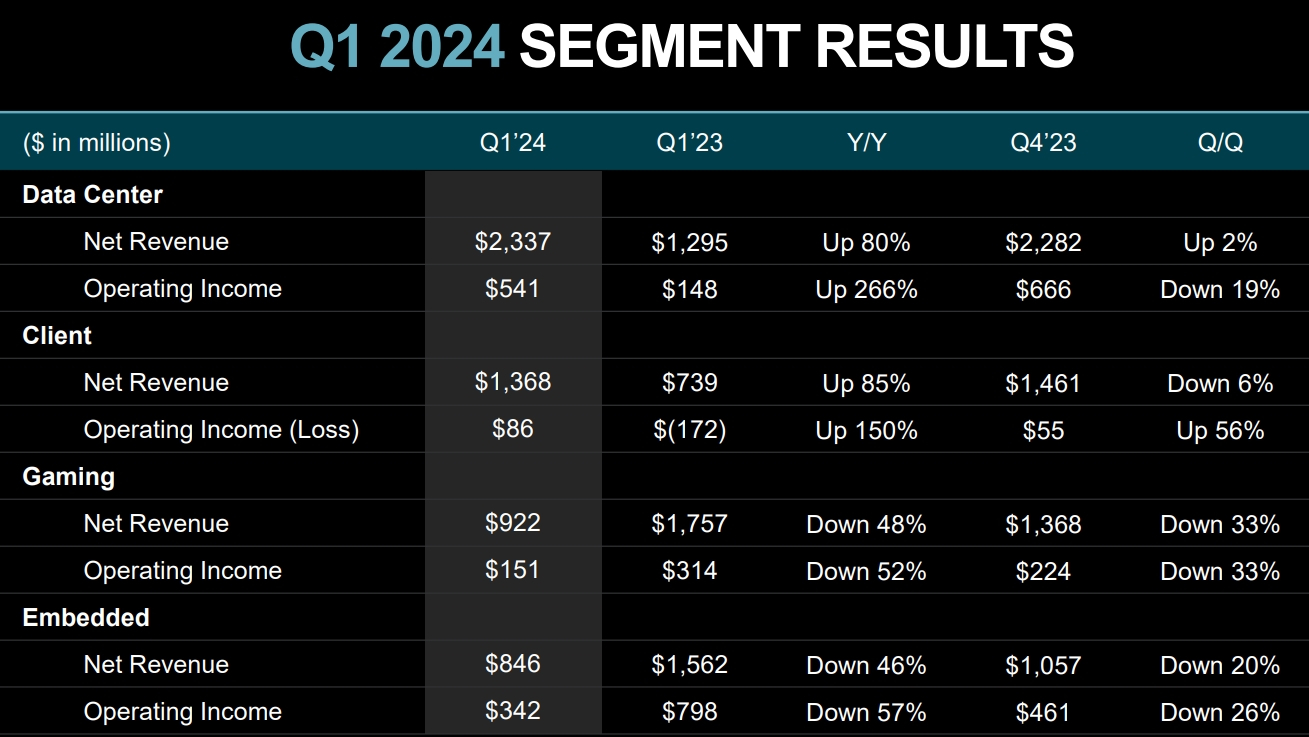 В большинстве сегментов AMD показали спад по сравнению с прошлым кварталом, что главным образом обусловлено сезонными колебаниями спроса — в конце года продажи обычно растут, а вот в начале слабеют. Единственным сегментом, показавшим рост по сравнению с предыдущим кварталом, оказалось направление продуктов для центров обработки данных: AMD заявила о последовательном росте выручки в данном сегменте на 2 %, до $2,3 млрд. А в годовом сравнении выручка и вовсе подскочила на 80 %. Такой рост обеспечили продажи ускорителей вычислений Instinct MI300, которые конкурируют с ускорителями от Nvidia на бурно развивающемся рынке ИИ-систем. AMD заявила, что с момента запуска в четвертом квартале 2023 года продала ускорителей Instinct MI300 на более чем $1 миллиард. В AMD отметили, что чипы MI300X используются компаниями Microsoft, Meta✴ и Oracle, а компания Lenovo не так давно анонсировала серверы с данными ускорителями. В целом по итогам 2024 года AMD планирует выручить $4 млрд от реализации ускорителей вычислений, что на $500 млн больше предыдущего прогноза. Тем не менее, Nvidia за один только первый квартал выручила на серверном направлении $18,4 млрд, поэтому прогресс AMD на этом фоне не кажется впечатляющим. 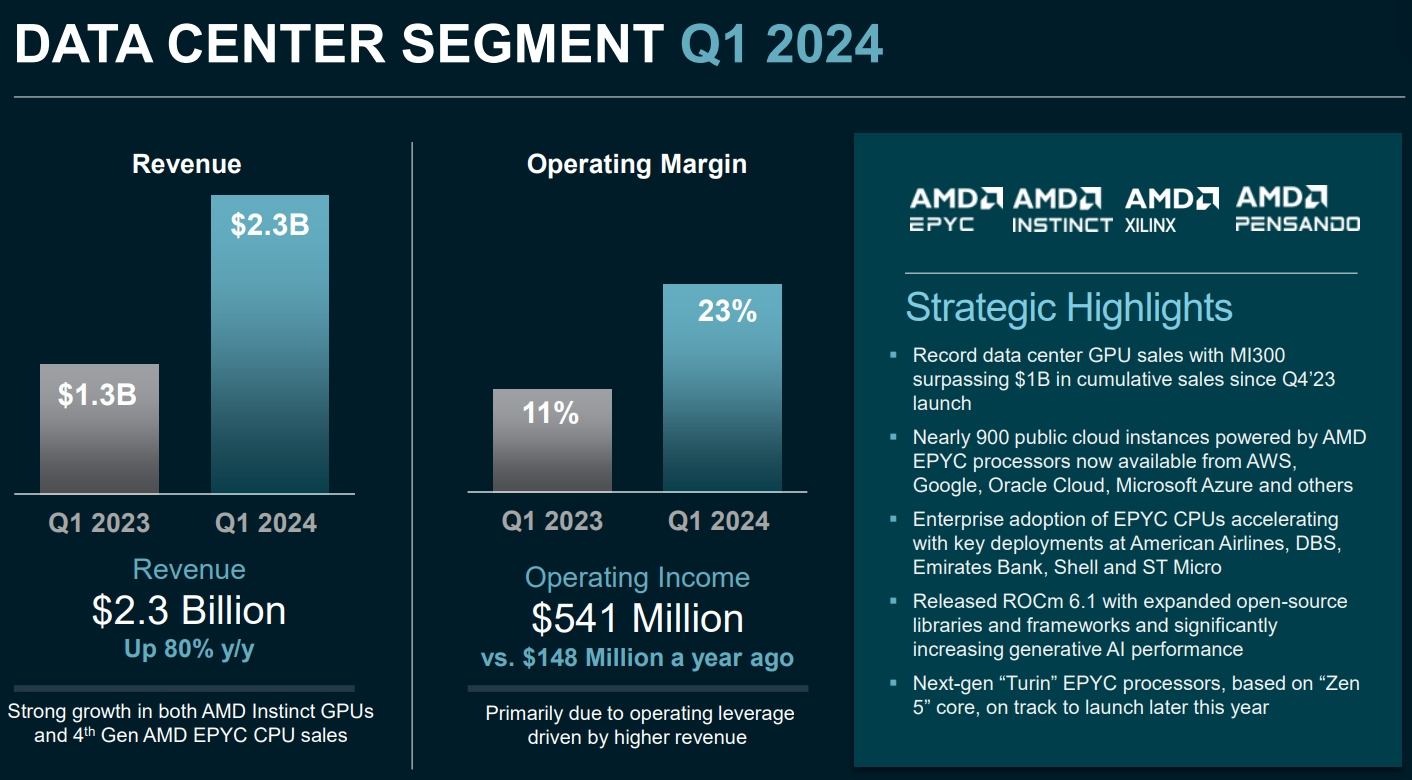 Также укрепить позиции AMD в серверном сегменте помог высокий спрос на центральные процессоры EPYC — AMD указывает, что их всё больше применяют корпоративные клиенты и облачные провайдеры, а также они активно используются в ИИ-системах.  Самым слабым сегментом у AMD в прошлом квартале стал игровой, который показал спад выручки на 48 % в годовом исчислении до $922 млн. Последовательно продажи сократились на внушительные 33 %. По словам компании, падение было вызвано снижением продаж чипов для игровых консолей, а также видеокарт для игровых компьютеров.  Основной бизнес AMD — процессоры для ПК — показал рост в годовом сравнении на 85 % до $1,37 млрд. Это говорит о том, что прошлогодний спад на рынке ПК позади и потребители снова стали активнее покупать компьютеры. Заметим, что в последовательном выражении здесь наблюдался спад, на 6 %. В данном сегменте AMD делает ставку на свежие чипы Ryzen 8000-й серии, которые способны локально запускать ИИ-приложения. Это открывает им путь в так называемые AI PC, на которые ставят многие компании в отрасли — ИИ-возможности должны стимулировать продажи новых ноутбуков и настольных ПК. На направлении встраиваемых решений, которое представлено главным образом продуктами, созданными с помощью приобретённой в 2022 году компании Xilinx, компания AMD отчиталась о снижении продаж на 46 % в годовом исчислении до $846 миллионов. Последовательное снижение выручки составило 20 %. На текущий квартал компания AMD прогнозирует последовательный рост выручки до $5,7 млрд, что совпадает с ожиданиями аналитиков. В годовом сравнении это будет соответствовать росту на 6 %. Наконец, AMD не забыла напомнить, что позже в этом году планирует выпустить серверные процессоры EPYC Turin на базе Zen 5, а во второй половине года ожидается выход процессоров для ноутбуков Strix Point также на Zen 5. Также в AMD отметили, что уже начали поставлять клиентам тестовые образцы процессоров EPYC Turin, так что их выход действительно не за горами. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex