|
Опрос
|
реклама
Быстрый переход
Биткоин рекордно подорожал до $112 000 — в том числе благодаря Nvidia
10.07.2025 [11:05],
Алексей Селиванов
Ралли на американском фондовом рынке способствовало росту курса криптовалюты. По данным Coin Metrics, вчера вечером биткоин подорожал до $112 052, обновив установленный 22 мая рекорд $111 999. 
Источник изображения: Traxer / Unsplash Рост произошел на фоне взлета акций технологических компаний. Так, вчера Nvidia стала первой компанией, чья рыночная капитализация на короткое время достигла $4 трлн. Технологический индекс Nasdaq Composite закрылся на рекордном уровне. Впрочем, несмотря на миллиарды долларов, поступившие в биржевые фонды на основе биткоина, флагманская криптовалюта торгуется в довольно узком диапазоне уже несколько недель. За последний месяц биткоин вырос всего на 2%, сообщает CNBC. Биткоин по-прежнему остаётся рисковым активом, чья стоимость растёт и падает вместе с акциями в зависимости от настроений инвесторов. Когда инвесторы покупают активы, ориентированные на рост (в том числе акции технологических компаний), биткоин и криптовалюты, как правило, растут вместе с ними. Некоторые аналитики считают, что по мере приближения даты принятия закона о криптовалютах в США биткоин может вырасти до $120 000. На момент написания заметки монета торговалась на уровне $111 408. Nvidia выпустит новый ИИ-ускоритель для Китая не раньше сентября
10.07.2025 [09:39],
Алексей Разин
Слухи уже давно приписывают Nvidia намерения создать новый ускоритель вычислений для Китая, который она смогла бы поставлять в страну легально после запрета на экспорт H20, наложенного властями США. По новым данным, компания сейчас активно обсуждает характеристики новинки с американскими чиновниками, а китайским клиентам новое решение предложит не ранее сентября. 
Источник изображения: Nvidia Издание Financial Times отмечает, что основатель и бессменный руководитель Nvidia Дженсен Хуанг (Jensen Huang) отправится в Китай на следующей неделе, где примет участие в конференции для поставщиков, и постарается встретиться с высокопоставленными чиновниками, чтобы заверить их в своей решимости продолжить поставки ускорителей Nvidia в КНР с учётом новых ограничений США. Ёмкость местного рынка глава компании оценивает в $50 млрд и не раз отмечал, что не хотел бы терять к нему доступ. При этом он же заявлял ранее, что за несколько лет из-за санкций США доля Nvidia на китайском рынке сократилась с 95 до 50 %. По некоторым данным, Хуанг рассчитывает встретиться во время своей поездки в Китай с премьер-министром страны Ли Цяном (Li Qiang). Как ожидается, Nvidia к сентябрю этого года формально представит своим китайским клиентам новый ускоритель вычислений, который будет использовать архитектуру Blackwell вместо Hopper у попавшего под запрет H20, и откажется от памяти HBM в пользу более медленной GDDR7. Интерфейсом NVLink, который позволяет эффективно масштабировать производительность ускорителей в кластерах, компании также наверняка придётся пожертвовать ради соблюдения требований властей США. Сроки выпуска ускорителя, который ранее фигурировал в публикациях под предполагаемым обозначением B30, будут зависеть от исхода переговоров Nvidia с властями США. Компания не хочет оказаться в ситуации, когда она потратит миллиарды долларов на создание нового продукта и выпуск первой крупной партии, а регуляторы в США опять запретят его поставки в Китай. Напомним, что запрет H20 уже обошёлся Nvidia в $5,5 млрд, которые пришлось списать безвозвратно. Клиенты Nvidia уже получают образцы B30, но этот ускоритель на местном рынке вряд ли повторит успех предшественника, с учётом заведомо более низкого уровня быстродействия. С другой стороны, в Китае полно разработчиков систем ИИ, которые не торопятся мигрировать на альтернативные платформы, оценивая высокие сопутствующие расходы. Для них дешевле вложиться в новые партии ускорителей Nvidia и оплачивать расходы на электроэнергию, чем переделывать всё программное обеспечение. Для охлаждения чипов Nvidia Blackwell компания Amazon решила использовать жидкостные системы собственной разработки
10.07.2025 [05:12],
Алексей Разин
Масштабы бизнеса так называемых «облачных гигантов» позволяют оправдывать созданные на заказ решения. Это касается не только вычислительных средств, но и сопутствующих систем. Так, столкнувшись с растущим тепловыделением ускорителей вычислений Nvidia, компания Amazon (AWS) решила оснастить их жидкостной системой охлаждения собственной разработки. 
Источник изображения: AWS По словам исполнительного вице-президента AWS Дейва Брауна (Dave Brown), на которого ссылается CNBC, готовые системы жидкостного охлаждения занимали бы слишком много драгоценного пространства в центрах обработки данных Amazon, а ещё их монтаж обещал растянуться на длительное время. Кроме того, серийные системы сторонних производителей не устраивали AWS по своим характеристикам и предполагали увеличенный расход воды, а потому компания решила создать свою. Те системы охлаждения, которые будут исправно функционировать в небольших центрах обработки данных, для Amazon не всегда подходят, как пояснил представитель компании, поскольку они имеют ограниченную производительность. Amazon разработала модульные системы жидкостного охлаждения рядной компоновки, которые могут устанавливаться как в строящиеся центры обработки данных, так и в уже существующие. В частности, новая система охлаждения нашла применение в инстансах семейства P6e, которые содержат стойки GB200 NVL72 с соответствующим количеством ускорителей Nvidia новейшего поколения Blackwell. Компания Amazon остаётся крупнейшим провайдером облачных услуг, поэтому разработка собственных инженерных решений оправдывает себя в подобных случаях. Nvidia стала первой компанией в истории с капитализацией $4 триллиона
09.07.2025 [17:16],
Павел Котов
Сегодня Nvidia поставила очередной рекорд рыночной капитализации — причём не только собственный, но и абсолютный. Впервые в истории компании удалось преодолеть планку в $4 трлн, опередив Microsoft и Apple. 
Источник изображения: BoliviaInteligente / unsplash.com Акции Nvidia сегодня подорожали более чем на 2 %, в результате чего рыночная капитализация производителя превысила $4 трлн. Инвесторы начали скупать акции технологического гиганта, выпускающего ускорители для систем искусственного интеллекта. Это первый в истории игрок, который сумел достичь такого результата. Теперь это самая дорогая компания в мире, обогнавшая Microsoft и Apple, которым удалось взять планку в $3 трлн ещё раньше. Microsoft также является одним из крупнейших и важнейших клиентов Nvidia. Nvidia была основана в 1993 году. Первоначально она занималась разработкой видеокарт для игровых компьютеров, но впоследствии стала специализироваться и на создании ИИ-ускорителей — на этом рынке она является ведущим производителем в мире. Отметку в $2 трлн она впервые преодолела в феврале 2024 года и достигла показателя в $3 трлн в июне того же года. До этого ближе всех к отметке $4 трлн удалось подобраться Apple, рыночная капитализация которой в декабре 2024 года составила $3,915 трлн. На текущий момент рыночную капитализацию более $1 трлн имеют следующие технологические компании: Microsoft ($3,756 трлн), Apple ($3,137 трлн), Amazon ($2,369 трлн), Alphabet ($2,151 трлн), Meta✴ ($1,842 трлн), Broadcom ($1,304 трлн) и TSMC ($1,199 трлн). Рыночная капитализация Tesla, которую традиционно причисляют к «клубу триллионеров», сейчас составляет $961,89 млрд. Новая статья: Обзор видеокарты GIGABYTE AORUS GeForce RTX 5060 Ti ELITE 16G: цена тишины
09.07.2025 [01:44],
3DNews Team
Данные берутся из публикации Обзор видеокарты GIGABYTE AORUS GeForce RTX 5060 Ti ELITE 16G: цена тишины Компактный компьютер Asus на суперчипе Nvidia Grace Blackwell выйдет 22 июля
05.07.2025 [15:15],
Павел Котов
Asus подтвердила дату выхода своего нового мини-ПК для систем искусственного интеллекта Ascent GX10 на платформе Nvidia Grace Blackwell GB200. О выпуске рабочей станции было объявлено вместе с приглашением на посвящённый устройству вебинар — в зависимости от региона, мероприятие пройдёт 22–23 июля 2025 года, передаёт VideoCardz.com. 
Источник изображения: asus.com Указанный Asus срок совпадает с летним графиком выпуска Nvidia систем серии GB10. Тайваньская компания одной из первых подтвердила выпуск мини-ПК GB200 в исполнении OEM-партнёра. Asus Ascent GX10 — компактная рабочая станция, предназначенная для разработки и инференса (запуска) ИИ. Система объединяет центральный процессор Nvidia Grace с ускорителем на архитектуре Blackwell — это одна из самых компактных и эффективных платформ в семействе GB200. Мини-ПК оснащается 128 Гбайт оперативной памяти LPDDR5X, шиной PCIe 5.0, предусматривается возможность подключать SSD NVMe, присутствует специальное решение для охлаждения. Asus Ascent GX10 также знаменует первый серьёзный шаг Nvidia в области настольных ПК, хотя и не напрямую. Центральные процессоры Grace на архитектуре Arm изначально ориентированы на высокопроизводительные системы и серверные рабочие нагрузки, и их интеграция в компьютеры малого формфактора, в том числе Ascent GX10, отчасти стирает грань между ЦОД и рабочими станциями. Решение обещает быть востребованным разработчиками, которым необходим локальный запуск систем ИИ без нужды в традиционных платформах на архитектуре x86. Примерно в то же время системы на базе GB200 готовят также Dell, Lenovo и другие производители. На рынке будет немало конкурирующих решений, в том числе на базе AMD Strix Halo (также с объёмом до 128 Гбайт памяти) — плюс Apple Mac Studio. США хотят ограничить поставки ИИ-чипов в Малайзию и Таиланд, потому что оттуда они нелегально мигрируют в Китай
04.07.2025 [20:09],
Алексей Селиванов
Администрация Дональда Трампа планирует ввести ограничения на экспорт передовых ИИ-процессоров в Малайзию и Таиланд. Цель — перекрыть лазейки, через которые эти чипы могут нелегально попадать в Китай. 
Источник изображений: Nvidia Проект нового плана Министерства торговли США призван заблокировать возможность Китаю закупать «запрещённые» процессоры через посредников в Малайзии и Таиланде, пишет Bloomberg. Напрямую Китаю нельзя покупать американскую полупроводниковую продукцию с 2022 года. На протяжении нескольких лет чиновники в Вашингтоне спорят, кому и на каких условиях можно продавать американские ИИ-чипы. С одной стороны, весь мир хочет использовать продукты Nvidia, а США заинтересованы, чтобы системы ИИ строились на базе американских технологий до того, как Китай предложит альтернативу. С другой — как только полупроводники покидают территорию США и союзников, риски их попадания в Китай или удалённого доступа к ним китайских компаний резко возрастают. Юго-Восточная Азия привлекает высокое внимание американских корпораций. Компании вроде Oracle активно вкладываются в дата-центры в Малайзии, а статистика показывает резкий рост импорта чипов в страну за последние месяцы. Под давлением Вашингтона власти страны пообещали усилить проверку импортных партий чипов. Именно на экспорт полупроводников в Малайзию сейчас опираются обвинения в соседнем Сингапуре, где прокуратура предъявила трём мужчинам обвинения в мошенничестве. Они продали клиентам серверы с передовыми чипами Nvidia, изначально поставленные из Сингапура в Малайзию, скрыв реальный маршрут поставки. По словам знакомых с ситуацией источников, в окончательном варианте постановления Минторга США планируется включить ряд послаблений для компаний, имеющих крупные производственные мощности в Малайзии и Таиланде. Например, фирмам из США и нескольких союзных стран разрешат ввозить ИИ-чипы без лицензий ещё в течение нескольких месяцев после публикации правила. Кроме того, в списке лицензионных исключений сохранятся положения, призванные предотвратить сбои в цепочках поставок: многие производители рассчитывают на заводы в Юго-Восточной Азии для ключевых операций, например упаковки чипов перед установкой в конечные изделия. Большинство новейших видеокарт по-прежнему продаются с наценкой в 12–57 % — особенно GeForce RTX 5090 и 5080
04.07.2025 [19:20],
Алексей Селиванов
Сегодня найти видеокарту по рекомендованной цене крайне затруднительно, причём независимо от страны проживания. Реальность такова, что если хочется собрать новый компьютер с современной видеокартой, нужно закладывать бюджет с запасом. Некоторые модели сегодня продаются в полтора раза дороже рекомендованных цен, хотя от момента анонса прошёл уже не один месяц.  В Gamers Nexus проанализировали сотни предложений на популярных американских площадках вроде Newegg, Amazon и Best Buy. Из 420 предложений видеокарт только 56 продавались по рекомендованной цене, причём в наличии оказалось и того меньше — 20 штук. К тому же некоторые продавцы отметили, что больше не будут завозить ускорители по этим ценам. 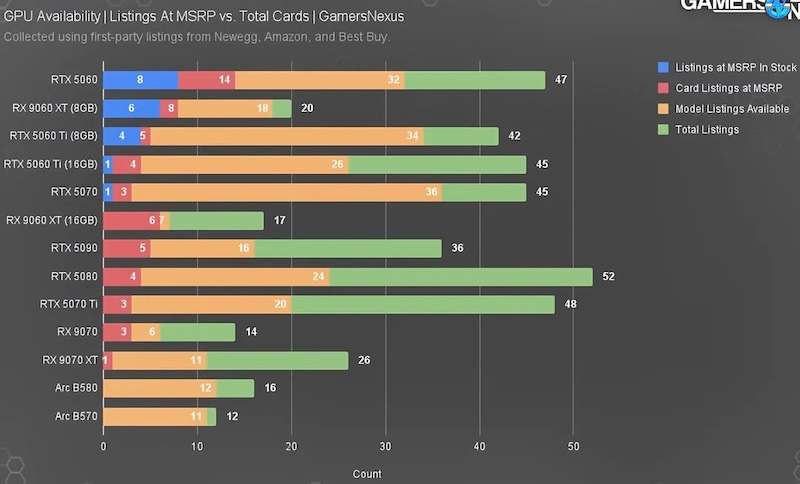
Источник изображения: Gamers Nexus / YouTube Энтузиасты сравнили реальные цены всех актуальных ускорителей (кроме новой GeForce RTX 5050) с рекомендованными. Выяснилось, что в среднем видеокарты в США стоят на 28 % дороже — наценка достигает в среднем $134. Хуже всего дела обстоят с GeForce RTX 5090 и RTX 5080, которые продаются дороже рекомендованных цен более чем на 50 %. То же касается Intel Arc B580 и B570. Лишь у GeForce RTX 5060 Ti с 16 Гбайт памяти и у большинства 8-гигабайтных моделей средняя наценка не превысила 20 %. А из 20 карт, которые всё ещё продавались по рекомендованной цене, только у одной GeForce RTX 5070 было 16 Гбайт. 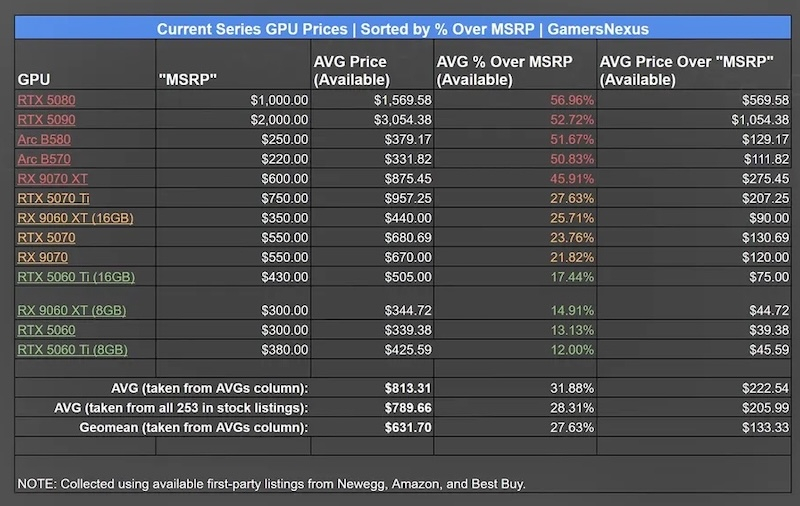
Источник изображения: Gamers Nexus / YouTube В среднем видеокарты по цене в диапазоне от $400 до $800 продаются на 25 % выше рекомендованных цен. В качестве исключения можно назвать Radeon RX 9070 XT, которую предлагают на 46 % дороже. В Tom's Hardware подчеркнули, что приведённые данные отражают только цены в США. Но тенденция характерна для любого региона: опираться на рекомендованные производителями GPU цены бессмысленно. В любом случае придется раскошелиться куда больше, чем многие рассчитывают перед покупкой видеокарты. Раскрыты российские цены GeForce RTX 5050 — не такая уж бюджетная
04.07.2025 [12:38],
Андрей Созинов
В ассортименте российских онлайн‑магазинов стали появляться первые видеокарты GeForce RTX 5050. Пока что приобрести ни одну из новинок нельзя и точная дата старта продаж не раскрывается, но зато можно ознакомиться с ценами, которые традиционно выше рекомендованной. 
Источник изображения: Nvidia На данный момент в каталоге магазина DNS представлены сразу пять моделей GeForce RTX 5050, и все с двухвентиляторными системами охлаждения. От Palit выставлены версии GeForce RTX 5050 Dual и Dual OC — вторая отличается заводским разгоном графического процессора до 2647 МГц. Также магазин предлагает три варианта видеокарты в исполнении компании MSI: GeForce RTX 5050 Shadow 2X OC, Ventus 2X OC и Gaming OC. Между собой они отличаются оформлением и конструкцией систем охлаждения. Все модели обладают заводским разгоном GPU, а наибольший разгон у модели Gaming OC — 2632 МГц. 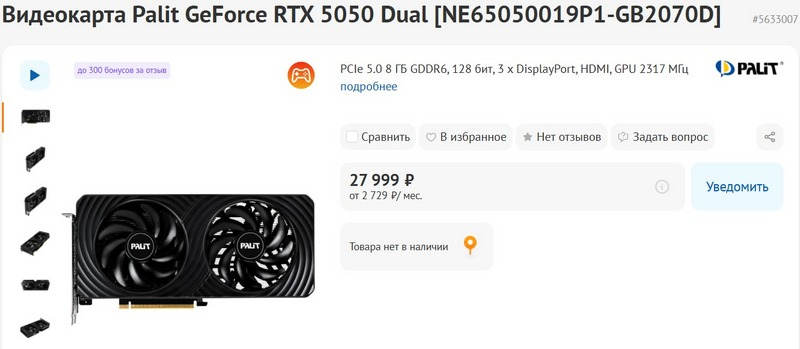 Что касается цен, то они начинаются с отметки в 27 999 рублей и достигают 30 999 рублей. Напомним, что рекомендованная цена GeForce RTX 5050 в США составляет $249 или примерно 19,6 тыс. рублей по курсу ЦБ. Заметим, что в другие крупные магазины пока не выставили товарные карточки для RTX 5050 — скорее всего это произойдёт уже на старте продаж, который ожидается позже в этом месяце. 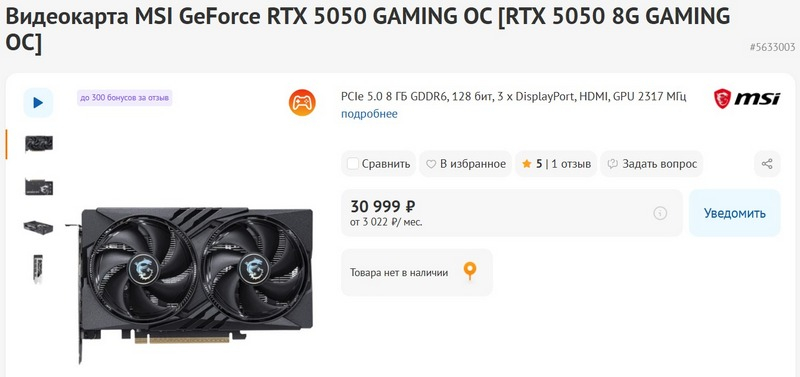 Напомним, что в основе GeForce RTX 5050 используется графический процессор GB207-300 с 2560 ядрами CUDA, 20 RT-ядрами, 80 текстурными блоками и 80 тензорными ядрами. Базовая частота GPU составляет 2,31 ГГц, а эталонная Boost-частота — 2,57 ГГц. Карта оснащена 8 Гбайт памяти GDDR6 с пропускной способностью 320 Гбайт/с. Заявленное энергопотребление — 130 Вт. GeForce RTX 5050 позиционируется как бюджетный вариант для игр в разрешении 1080p с поддержкой трассировки и DLSS 4. По заявлениям Nvidia, новинка примерно на 60 % производительнее, чем RTX 3050, а первые тесты показали, что RTX 5050 быстрее GeForce RTX 3060, но уступает по производительности GeForce RTX 4060 и Intel Arc B580. CoreWeave стала первым облачным клиентом Nvidia, запустившим эксплуатацию ускорителей Blackwell Ultra
04.07.2025 [04:59],
Алексей Разин
В формировании облачной вычислительной инфраструктуры принимают участие сразу несколько компаний, поэтому о начале эксплуатации систем на основе ускорителей Nvidia GB300 NVL72 (Blackwell Ultra) заявили одновременно сама Nvidia, провайдер CoreWeave, который их получил и установил, а также Dell, которая занималась их поставками. 
Источник изображения: Nvidia По словам CoreWeave, переход на ускорители Blackwell Ultra позволит клиентам ощутить сокращение времени реакции рассуждающих языковых моделей в десять раз, а производительность в пересчёте на ватт потребляемой электроэнергии увеличится в пять раз. В одной стойке GB300 NVL72 содержатся 72 графических процессора Blackwell Ultra и 36 центральных процессоров Grace. По словам Dell, данные системы собираются и проходят тестирование на территории США. Данные заявления вызвали рост курса акций CoreWeave на 6 %, акции Dell Technologies подорожали примерно на 2 %, а ценные бумаги Nvidia укрепились в цене и того меньше, но она накануне приблизилась к абсолютному мировому рекорду по величине капитализации среди публичных компаний, так что ей грех жаловаться на отсутствие внимания инвесторов. По данным Nvidia, ускорители поколения Blackwell Ultra способны в единицу времени создавать в 50 раз больше ИИ-контента, чем базовый вариант Blackwell. В мае руководство Nvidia подчеркнуло, что поставки Blackwell Ultra начнутся в третьем квартале, и стоило наступить июлю, как нашёлся первый клиент компании в лице CoreWeave, заявивший о доступности соответствующих решений. Относительно небольшому провайдеру облачных вычислительных мощностей помогло то, что Nvidia является акционером CoreWeave. Nvidia сегодня может отобрать у Apple звание самой дорогой компании в истории
03.07.2025 [20:25],
Анжелла Марина
Капитализация Nvidia сегодня может установить абсолютный исторический рекорд. В течение сегодняшней торговой сессии она достигла $3,92 трлн, тем самым превзойдя рекорд Apple в $3,915 трлн, сообщает Reuters. Теперь осталось только зафиксировать достижение на закрытии сессии. Инвесторы воодушевлены, а акции компании растут благодаря высочайшему спросу на технологии искусственного интеллекта. 
Источник изображения: Nvidia Nvidia, которая изначально стала известна как разработчик графических процессор для видеоигр, теперь является ключевым поставщиком чипов для обучения нейросетей. Акции компании выросли на 2,2 % и составили $160,6 на утренних торгах в четверг, позволив превзойти предыдущий рекорд Apple ($3,915 трлн), установленный в декабре 2024 года. Microsoft сегодня заняла второе место с капитализацией $3,7 трлн после роста акций на 1,4 % до $498. Apple сохранила третью позицию и поднялась на 0,5 %, а её стоимость составила $3,19 трлн. Гонка технологических гигантов — Microsoft, Amazon, Meta✴, Alphabet и Tesla — за лидерство в сфере ИИ и наращивание вычислительной мощности дата-центров продолжает подогревать интерес к высокопроизводительным ускорителям вычислений Nvidia. За четыре года рыночная стоимость компании выросла почти в восемь раз — с $500 млрд в 2021 году до почти четырёх триллионов сейчас. По данным ведущего мирового поставщика инфраструктуры и данных для финансовых рынков LSEG, сейчас Nvidia стоит больше, чем фондовые рынки Канады и Мексики вместе взятые, а также превосходит совокупную капитализацию всех публичных компаний Великобритании. Акции Nvidia торговались с коэффициентом P/E (цена/прибыль) на уровне 32, что ниже среднего показателя в 41 за последние пять лет. Это говорит о том, что рост прибыли компании опережает даже существенное повышение курса её акций. С апреля котировки Nvidia выросли более чем на 68 %, восстановившись после падения, вызванного заявлениями Дональда Трампа (Donald Trump) о новых глобальных пошлинах. Рост акций связан с ожиданиями, что администрация Белого дома смягчит торговые ограничения. Nvidia выпустила драйвер с поддержкой GeForce RTX 5050
01.07.2025 [18:59],
Николай Хижняк
Компания Nvidia выпустила свежий пакет графического драйвера GeForce Game Ready 576.88 WHQL. В него добавлена поддержка настольной и мобильной версий видеокарты GeForce RTX 5050. 
Источник изображения: Nvidia Новое программное обеспечение также расширяет поддержку технологии DLSS 4 для игр Mecha Break, Diablo IV и Monster Hunter Wilds. Список исправленных проблем:
Список известных проблем:
Скачать драйвер GeForce Game Ready 576.88 WHQL можно через приложение Nvidia App или с официального сайта Nvidia. Nvidia подтвердила, что скоро прекратит выпускать драйверы для видеокарт GeForce GTX 700, 900 и 1000
01.07.2025 [13:35],
Павел Котов
Следующая основная ветка драйверов Nvidia станет последней с поддержкой трёх устаревших архитектур графических процессоров, официально подтвердил производитель. Это решение повлияет на несколько моделей видеокарт GeForce и профессиональные продукты. 
Источник изображения: nvidia.com Начиная с версии 580 (сейчас актуальной является 576.80), Nvidia начнёт прощаться с видеокартами на базе архитектуры Maxwell (GeForce GTX 700, GTX 900), а также GTX 10 на архитектуре Pascal. В список попала также TITAN V — единственная потребительская видеокарта на базе архитектуры Volta. Но полностью Nvidia свернёт выпуск драйверов для старых видеокарт только с выпуском драйверов серии 590. В сообщении на официальном форуме Nvidia говорится о прекращении поддержки устаревших видеокарт на системах семейства Linux, но ветки драйверов для этих платформ являются общими с драйверами для Windows. Таким образом, компания, вероятно, относительно скоро прекратит выпуск драйверов Game Ready для одной из последних оставшихся линеек продуктов GeForce GTX — поддержка сохранится только для видеокарт серии GeForce GTX 16 на архитектуре Turing. Таким образом, неактуальными станут архитектуры, которым от 8 до 11 лет. Не всем геймерам интересны новейшие игры, и не все могут позволить себе новые комплектующие для компьютера, но даже с учётом этого удивительно, что эти видеокарты поддерживались настолько долго. Сроков выхода ветки драйверов 580 в Nvidia не уточнили — на это могут уйти ещё несколько месяцев. Nvidia начала бесплатно раздавать подписки Adobe Creative Cloud, но данные карты ввести придётся
30.06.2025 [18:57],
Сергей Сурабекянц
В рамках сотрудничества Nvidia с Adobe компания предоставляет владельцам видеокарт GeForce RTX трёх последних поколений бесплатный доступ к Adobe Creative Cloud, включающий в себя популярные инструменты для редактирования фотографий и видео, такие как Photoshop, Premiere Pro, After Effects. Подписки ограничены по сроку действия — один месяц для владельцев видеокарт GeForce серий RTX 3000 и 4000, два месяца — для владельцев серий RTX 5000. 
Источник изображения: Adobe Эксклюзивно для владельцев видеокарт серии GeForce RTX 5000 доступно ещё одно вознаграждение под названием Substance 3D, которое даёт доступ к пяти различным приложениям Adobe вместе с огромной библиотекой ресурсов для разработки игр, включая такие инструменты, как 3D Sampler, 3D Designer и 3D Painter. В целом это довольно солидное предложение, даже если рассматривать только Adobe Creative Cloud, подписка на который обычно стоит $69 в месяц. 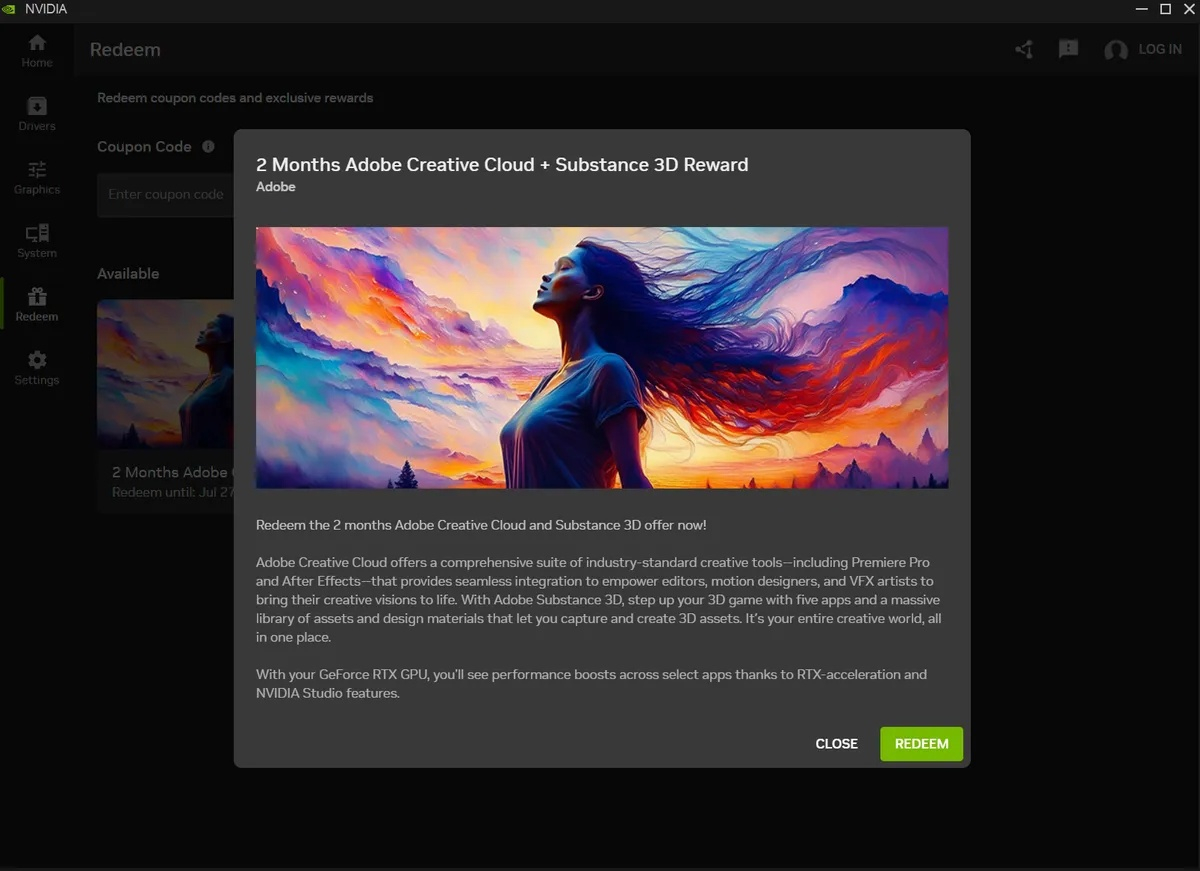 Условием для получения пробной версии на один или два месяца является предоставление платёжные реквизитов, с пользователя автоматически будет взиматься стандартная плата за подписку в размере $69 в месяц после окончания бесплатного периода. Чтобы средства не списывались, необходимо вовремя отменить подписку. Предложение действует только для новых пользователей. Зарегистрированным клиентам, которые ранее уже пользовались продуктами Adobe воспользоваться бесплатным периодом подписки не получится. Высокопоставленные руководители Nvidia за последние 12 месяцев выручили более $1 млрд на продаже акций компании
30.06.2025 [07:05],
Алексей Разин
Сделки с акциями публичных компаний являются привычной частью жизни их руководителей, поскольку они часть своего вознаграждения получают ценными бумагами, которые по истечении времени должны продавать. Динамика курса акций Nvidia способствовала тому, что сотрудникам компании, которые продавали их за последние 12 месяцев, удалось в совокупности выручить более $1 млрд. 
Источник изображения: Nvidia Как поясняет Financial Times, из этой суммы более половины пришлось на текущий месяц, поскольку в этом периоде акции Nvidia обновили исторический максимум и в очередной раз сделали компанию самой дорогой среди публичных. Основатель и бессменный руководитель Nvidia Дженсен Хуанг (Jensen Huang) воздерживался от продажи акций своей компании с сентября прошлого года, но на прошлой неделе вернулся к соответствующей активности. Впрочем, эти действия генерального директора были частью плана по продаже акций, согласованного с советом директоров и акционерами ещё в марте текущего года. Первый квартал был не очень благоприятным с точки зрения динамики курса акций Nvidia, но сейчас всё складывается более выгодным образом для желающих заработать на их продаже. Скорее всего, в случае с главой компании превышение курсом акций отметки в $150 стало сигналом к возобновлению продаж. Ему пришлось выждать 90 дней с момента утверждения плана продаж в марте, чтобы соблюсти все необходимые формальности. До конца текущего года Хуанг может в общей сложности реализовать 6 млн акций Nvidia. По текущему курсу это позволит ему выручить не менее $900 млн. Общее благосостояние главы компании оценивается Forbes в $138 млрд, что позволяет ему замыкать десятку самых состоятельных людей планеты. На прошлой неделе капитализация Nvidia выросла до рекордных $3,8 трлн. В уходящем месяце высокопоставленные сотрудники Nvidia также объявили о начале продаж принадлежащих им акций. Член совета директоров Марк Стивенс (Mark Stevens) в начале месяца объявил о намерениях продать 4 млн акций, с тех пор ему удалось выручить на продаже некоторой части из них $288 млн. Исполнительный вице-президент Nvidia Джей Пури (Jay Puri) в прошлую среду продали акций компании на сумму $25 млн. Два других члена совета директоров, Тенч Кокс (Tench Coxe) и Брук Сивэлл (Brook Seawell), реализовали акций на сумму $143 млн и $48 млн соответственно. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex