|
Опрос
|
реклама
Быстрый переход
Intel планирует заработать до $1 млрд на продажах ПО к концу 2027 года
12.07.2024 [14:10],
Алексей Разин
Технический директор Intel Грег Лэвендер (Greg Lavender) в интервью Reuters заявил, что компания намеревается к концу 2027 года выручить от реализации программного обеспечения накопленным итогом до $1 млрд, предлагая клиентам разного рода подписки. Intel также прилагает усилия к продвижению в сфере ИИ программного обеспечения с открытым исходным кодом. 
Источник изображения: Intel Кроме прочего, Intel собирается предлагать разработчикам ПО подписку на свои облачные сервисы. Не исключено, что рубеж в $1 млрд кумулятивной выручки от реализации программного обеспечения Intel преодолеет ещё до конца 2027 года, как пояснил Лэвендер. Уже в 2021 году компания выручила от реализации ПО более $100 млн, как пояснил нынешний технический директор Intel, который тогда пришёл вслед за Патриком Гелсингером (Patrick Gelsinger) из VMware. С тех пор Intel уже удалось поглотить три компании, занимающиеся программным обеспечением. На фоне общей выручки в размере $54 млрд, которую компания получила по итогам 2023 года, указанная сумма в $1 млрд, распределённая на несколько лет, кажется не столь существенной, но для относительно нового источника выручки это довольно амбициозная цель. Intel приоритетными считает развитие ПО в сфере искусственного интеллекта, оптимизации производительности и информационной безопасности. Все три направления внутри компании поддерживаются инвестиционными ресурсами. Как попутно отметил технический директор Intel, компания наблюдает высокий спрос на свои ускорители семейства Gaudi 3 и надеется со временем стать вторым после Nvidia поставщиком соответствующих компонентов на рынок. Последняя, напомним, занимает по итогам прошлого года около 83 % рынка ускорителей вычислений, так что Intel и прочим конкурентам приходится бороться за его небольшую долю. Intel делает ставку на ПО с открытым исходным ходом, которое может работать на любых платформах с любыми ускорителями, тогда как экосистема Nvidia замкнута на среду CUDA, закрытую для сторонних разработчиков ускорителей. Intel является участницей консорциума UXL Foundation вместе с Qualcomm, Samsung и Arm, продвигая идею использования ПО с открытым исходным кодом для ускорения вычислений. Она также примкнула к продвигаемой OpenAI инициативе Triton по созданию среды разработки с открытым исходным кодом, которая позволяла бы повышать эффективность взаимодействия разнородных ускорителей вычислений в системах искусственного интеллекта. Это начинание поддерживается также компаниями AMD и Meta✴. Ускорители вычислений Intel могут работать в среде Triton как в нынешнем поколении, так и в будущем. По мнению технического директора Intel, распространение Triton уравняет шансы на успех всех участников рынка. Nvidia открыла исходный код RTX Remix
05.07.2024 [11:25],
Павел Котов
Nvidia 2 июня объявила о переводе инструмента RTX Remix, который используется для модификации игр эпохи DirectX8 и DirectX9 с целью добавления в них высококачественных текстур и поддержки трассировки лучей, в разряд проектов с открытым исходным кодом. Важнейшим нововведением стало внедрение Rest API для взаимодействия с ComfyUI — это позволяет любому желающему проводить модификацию игр и повышать качество изображения по текстовому описанию без технической подготовки. 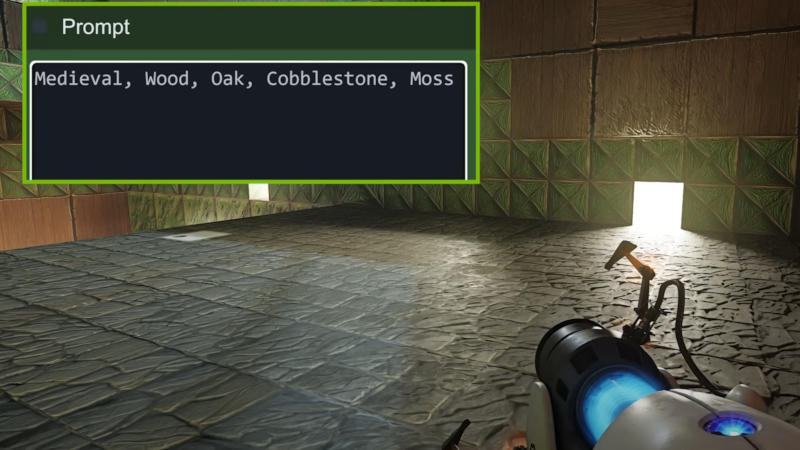
Источник изображения: youtube.com/@NVIDIAGeForce Nvidia показала новые возможности RTX Remix на примере игры Portal — оригинальной, а не официального ремастера с поддержкой трассировки лучей. RTX Remix позволяет проводить ремастеринг существующих текстур с добавлением физически корректного рендеринга (Physically based rendering — PBR). Дополнительная настройка внешнего вида игры производится посредством ввода запросов в текстовое поле для системы искусственного интеллекта. Теперь RTX Remix позволяет создавать простые фанатские ремастеры классических игр, появившихся до эпохи трассировки лучей. Благодаря открытому исходному коду Nvidia RTX Remix новое поколение ремастеров игр станет доступным и для владельцев видеокарт AMD, правда, пока они смогут запускать такие игры уже в завершённом виде. Чтобы пользователи графики AMD могли принять участие в создании таких проектов, сообществу придётся приложить значительные усилия — возможно, даже потребуется помощь самой Nvidia. Новые возможности RTX Remix наглядно демонстрируют, какую пользу может приносить ИИ на простом потребительском уровне. Одни представители игровой отрасли отвергают новые инструменты ИИ, другие стараются органично интегрировать их в рабочий процесс. Но в контексте RTX Remix впечатляет возможность через REST API обращаться к ComfyUI и Stable Diffusion почти мгновенно для создания ремастеров и обновления текстур классической игры с помощью простых текстовых запросов. AMD сделает открытым больше ПО Radeon и расширит документацию к своим GPU
03.04.2024 [17:28],
Павел Котов
AMD сообщила о намерении открыть исходный код большего количества своих программных продуктов Radeon и предоставить больше сведений о своих графических процессорах — интерес к ним растёт. 
Источник изображения: amd.com Рост интереса к видеокартам AMD Radeon связан с популярностью генеративного искусственного интеллекта и стремлением отрасли нарастить присутствие мощного оборудования, отличного от Nvidia. Как показала практика, «зелёные» не в состоянии выпускать ИИ-ускорители в достаточно крупных объёмах, чтобы удовлетворить спрос. Уже один этот факт является мощным фактором роста для AMD. AMD объявила, что планирует открыть исходный код большей части своего программного стека Radeon. Это, в частности, может значить, что открытым будет исходный код большей части ROCm (Radeon Open Compute Platform) — стека, который включает широкий набор моделей программирования, инструментов, компиляторов, библиотек и сред выполнения для разработки решений в области ИИ и высокопроизводительных вычислений на графических процессорах AMD. Но подробностей об этом компания пока не сообщила. 
Источник изображения: twitter.com/amdradeon Производитель также пообещал, что вскоре предоставит разработчикам дополнительную документацию по оборудованию. Это, в частности, поможет сторонним игрокам в реализации продукции AMD, а значит, будет способствовать и росту продаж компании. Рынок вычислений на графических процессорах также выиграет от появления более жизнеспособных вариантов на базе Radeon. AMD, наконец, сможет извлечь максимальную выгоду из бума ИИ. Intel, Google, Arm и другие объединились для борьбы с гегемонией Nvidia с помощью открытого ПО
26.03.2024 [00:56],
Владимир Мироненко
Как стало известно агентству Reuters, ряд крупных технологических компаний, включая Intel, Google, Arm, Qualcomm, Samsung и т.д., сформировала группу под названием The Unified Acceleration Foundation (UXL). Компании объединились для создания ПО с открытым исходным кодом, которое позволило бы разработчикам решений на базе искусственного интеллекта (ИИ) не быть привязанными к проприетарным технологиям Nvidia. 
Источник изображения: Nvidia В настоящее время более 4 млн разработчиков по всему миру используют программную платформу Nvidia CUDA для создания ИИ-приложений и других программ. UXL являются частью растущего сообщества компаний, борющихся с доминированием Nvidia в области ИИ. «На самом деле мы демонстрируем разработчикам, как перейти с платформы Nvidia», — сообщил в интервью Reuters Винеш Сукумар (Vinesh Sukumar), руководитель отдела ИИ и машинного обучения Qualcomm. В настоящее время проект включает открытый стандарт OneAPI, разработанный Intel, чтобы исключить необходимость использования определённых языков программирования, баз данных и другие инструментов, одним словам всех требований, которые вынуждают разработчиков использовать конкретную архитектуру, такую как платформа Nvidia CUDA. По словам руководителей группы, проект с открытым исходным кодом направлен на то, чтобы созданный компьютерный код работал на любой вычислительной машине, независимо от того, какой чип и оборудование в ней используются. Google в качестве одного из основателей UXL помогает определять техническое направление проекта, сообщил директор и главный технолог по HPC Билл Хьюго (Bill Hugo). По его словам, в первом полугодии 2024-го будут утверждены технические спецификации, а к концу года технические детали проекта должны достичь «зрелого» состояния. Помимо участников, UXL планирует привлекать провайдеров облачных вычислений, включая Amazon и Microsoft Azure, а также производителей чипов. По словам руководителей группы, с момента запуска в сентябре прошлого года UXL уже начала получать техническую информацию от её участников и сторонних компаний, заинтересованных в использовании технологии с открытым исходным кодом. UXL планирует заняться решением наиболее насущных вычислительных проблем, связанных с доминированием нескольких производителей чипов в сфере ИИ и HPC, чтобы в перспективе привлечь критическую массу разработчиков на свою платформу. Планы UXL также включают поддержку в дальнейшем оборудования и кода Nvidia. Илон Маск пообещал открыть исходный код чат-бота xAI Grok на этой неделе
11.03.2024 [13:39],
Алексей Разин
Конфликт миллиардера Илона Маска (Elon Musk) с основателями OpenAI вокруг гуманистических ценностей в сфере искусственного интеллекта привёл к достаточно неожиданным последствиям. Основанный Маском стартап xAI пообещал открыть исходный год своего чат-бота Grok на этой неделе. Примечательно, что частным пользователям X доступ к этому чат-боту предоставляется за $16 в месяц. 
Источник изображения: xAI Если xAI опубликует исходный год своего чат-бота Grok, то этот стартап присоединится к ряду компаний, которые это уже сделали, причём среди них оказалась запрещённая в РФ компания Meta✴ Platforms Марка Цукерберга (Mark Zuckerberg). Французский стартап Mistral также вошёл в число сторонников открытия свободного доступа к исходному коду своего чат-бота. Илон Маск давно продвигает идею свободного доступа к разработкам принадлежащих ему компаний. Многие из патентов Tesla с 2014 года доступны для использования всем желающим, хотя на практике выясняется, что использовать их безвозмездно всё же не получится. Как тогда отмечалось, на такой шаг Tesla пошла из стремления ускорить переход на электромобили. В прошлом году принадлежащая Маску социальная сеть X раскрыла часть исходного кода своих программных алгоритмов. Теперь к ним присоединится и стартап xAI, который работает в сфере систем генеративного искусственного интеллекта. Представлен первый процессор безопасности с открытым исходным кодом
15.02.2024 [12:07],
Андрей Созинов
Сегодня коалиция OpenTitan анонсировала первый коммерческий микропроцессор безопасности, построенный на одноимённой аппаратной платформе с открытым исходным кодом. По словам компании, это ещё одна веха в развитии открытого аппаратного обеспечения, которое набирает обороты благодаря открытой процессорной архитектуры RISC-V. 
Источник изображения: OpenTitan Чип под названием Earl Grey использует процессорное ядро на базе RISC-V и включает в себя ряд встроенных аппаратных модулей безопасности и криптографии. Проект был начат в 2019 году коалицией компаний, основанной Google и возглавляемой некоммерческой организацией lowRISC в Кембридже, Великобритания. По образцу программных проектов с открытым исходным кодом, он разрабатывается участниками со всего мира, как официальными партнерами проекта, так и независимыми инженерами. «Этот чип очень, очень интересен, — говорит один из создателей OpenTitan, генеральный директор zeroRISC Доминик Риццо (Dominic Rizzo). — Но есть и нечто гораздо большее — это разработка совершенно нового типа методологии. Вместо традиционной... командно-административной структуры — распределенная». Открытый исходный код «просто берет верх, потому что он обладает определенными ценными свойствами... Я думаю, мы видим начало этого в кремнии», добавил Риццо. Разработанная методология называется Silicon Commons. Разработка открытого аппаратного обеспечения сталкивается с проблемами, которых нет у программного обеспечения с открытым исходным кодом: более высокая стоимость, меньшее профессиональное сообщество и невозможность исправления ошибок в патчах после выпуска продукта, объясняет генеральный директор lowRISC Гэвин Феррис (Gavin Ferris). Фреймворк Silicon Commons предусматривает правила документирования, предопределенные интерфейсы и стандарты качества, а также структуру управления, определяющую, как различные партнеры принимают решения как единое целое. Еще одним ключом к успеху проекта, по словам Ферриса, стал выбор проблемы, решение которой стимулировало бы всех партнеров продолжать участвовать в проекте. Аппаратные модули безопасности подошли для этой работы как нельзя лучше из-за их коммерческой важности, а также из-за того, что они особенно подходят для модели с открытым исходным кодом. В криптографии есть понятие, известное как принцип Керкхоффса, который гласит, что единственное, что должно быть секретным в криптосистеме, это сам секретный ключ. Открытый доступ ко всему протоколу гарантирует, что криптосистема соответствует этому правилу. 
Источник изображения: lowRISC В OpenTitan используется аппаратный протокол безопасности Root-of-trust (RoT). Идея заключается в том, чтобы обеспечить источник криптографических ключей на кристалле, недоступный удаленно. Поскольку в противном случае ключ недоступен, система может быть уверена, что он не был подделан, обеспечивая основу для построения безопасности. Обычные проприетарные чипы также могут использовать технологию RoT. По мнению сторонников, открытый доступ к ней обеспечивает дополнительный уровень доверия. Поскольку любой желающий может проверить и изучить дизайн, теоретически вероятность того, что ошибки будут замечены, выше, а их исправление может быть проверено. Подобная защита на кристалле особенно актуальна для устройств, формирующих Интернет вещей (IoT), которые страдают от нерешенных проблем безопасности. Риццо и Феррис считают, что их чип представляет собой шаблон для разработки аппаратного обеспечения с открытым исходным кодом, который будут копировать другие коллективы. Помимо обеспечения прозрачной безопасности, открытые технологии экономят деньги компаний, позволяя им использовать готовые аппаратные компоненты вместо того, чтобы самостоятельно разрабатывать запатентованные версии одного и того же устройства. Это также открывает возможности для участия в проекте большего числа партнеров, включая академические институты, такие как партнер коалиции OpenTitan — Высшая техническая школа Цюриха. Благодаря участию академических кругов OpenTitan смог включить криптографические протоколы, которые безопасны для будущих квантовых компьютеров. «Как только методология будет доказана, ее подхватят другие, — говорит Риццо. — Если вы посмотрите, что произошло с программным обеспечением с открытым исходным кодом, то сначала люди думали, что это своего рода попытка вырваться на волю, а потом оказалось, что оно работает почти на каждом мобильном телефоне. Оно просто захватило власть, потому что обладает определенными ценными свойствами. И я думаю, что сейчас мы видим начало этого в кремнии». Apple незаметно выпустила нейросеть Ferret, которая работает с текстом и изображениями
26.12.2023 [13:37],
Павел Котов
Apple при поддержке учёных Корнеллского университета ещё в октябре выложила в открытый доступ собственную мультимодальную большую языковую модель Ferret, которая в качестве запросов может принимать фрагменты изображений. 
Источник изображения: Laurenz Heymann / unsplash.com Выход Ferret на GitHub в октябре не сопровождался со стороны Apple крупными объявлениями, но проект впоследствии привлёк участие специалистов отрасли. Принцип работы Ferret состоит в том, что модель изучает указанный фрагмент изображения, идентифицирует объекты на этом участке и очерчивает их рамкой. Распознанные на фрагменте изображения объекты система воспринимает как часть запроса, ответ на который предоставляется в текстовом формате. К примеру, пользователь может выделить на картинке изображение животного и попросить Ferret распознать его. Модель даст ответ, к какому виду относится животное, и ей можно будет задать дополнительные вопросы в контексте, уточнив информацию по другим объектам или действиям. 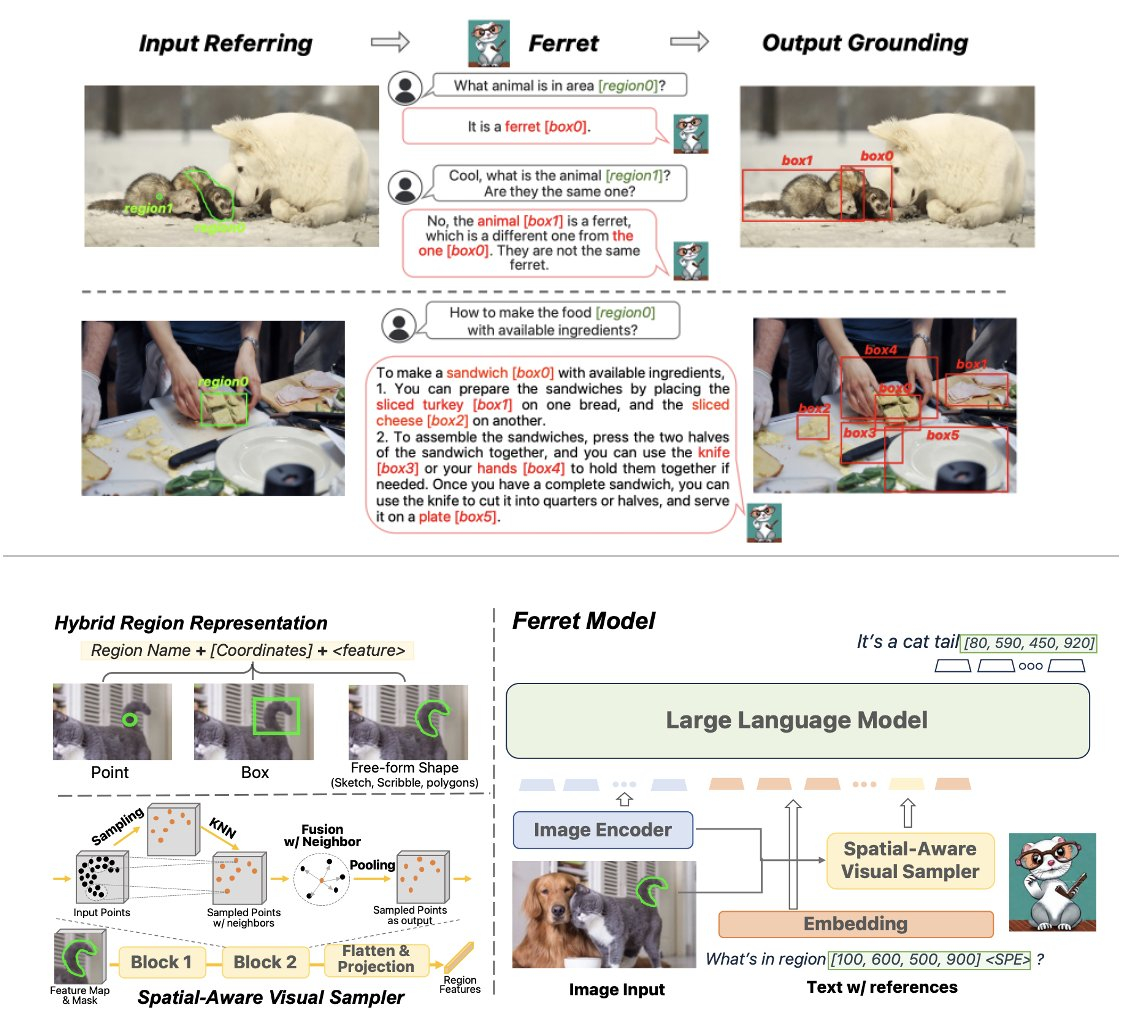
Источник изображения: twitter.com/zhegan4 Открытая модель Ferret — это система, способная «давать ссылки и обосновывать что угодно, где угодно и с любыми подробностями», пояснил исследователь из ИИ-подразделения Apple Чжэ Гань (Zhe Gan). Отраслевые эксперты отмечают важность выхода проекта в этом формате — он демонстрирует открытость традиционно закрытой компании. По одной из версий, Apple решилась на этот шаг, поскольку стремится конкурировать с Microsoft и Google, но не обладает сопоставимыми вычислительными ресурсами. Из-за этого она не смогла рассчитывать на выпуск собственного конкурента ChatGPT и была вынуждена выбирать между партнёрством с облачным гиперскейлером и выпуском проекта в открытом формате, как это ранее сделала Meta✴. «Яндекс» начал приём заявок на гранты для опенсорс-проектов в рамках Yandex Open Source
27.11.2023 [16:56],
Владимир Мироненко
«Яндекс» объявил о старте нового этапа ежегодной программы грантов Yandex Open Source, в рамках которой разработчики интересных и важных опенсорс-проектов получат гранты, которые можно будет использовать на платформу данных, инструменты для разработки и другие сервисы Yandex Cloud. Лучшие проекты получат гранты по 600 тыс. рублей каждый. 15 победителей Yandex Open Source 2024 будут определены до мая 2024 года.  Заявки на участие принимаются в трёх треках: обработка и хранение данных, разработка, машинное обучение. Каждый разработчик сможет принять участие в программе только с одним проектом. Рассмотрением заявок и определением победителей займётся программный комитет, состоящий из менеджеров и разработчиков опенсорс-решений Яндекса — YTsaurus, YDB, userver, Diplodoc и других. Комитет оценит актуальность и полезность каждого проекта, а также активность репозитория и потенциал развития. Претендовать на получение гранта в Yandex Open Source 2024 сможет независимый разработчик или группа разработчиков, а также сотрудники крупных компаний при условии, что проект разрабатывается вне основной работы и вне репозиториев, связанных с работодателем. Доступ к программе закрыт для сотрудников группы компаний «Яндекса», даже если будет предложен собственный сторонний проект. «Команды “Яндекса” не только выкладывают в опенсорс свои разработки, но и активно пользуются внешними решениями и помогают их развивать. Для нас это очень важно, так как мы верим, что технологии должны быть открыты и доступны для мира. А чтобы открытые проекты могли развиваться лучше и ещё быстрее, мы запускаем программу грантов», — сообщила директор по маркетингу опенсорс-технологий «Яндекса» Лейсан Зигангирова. Приём заявок на участие в программе Yandex Open Source 2024 продлится с 27 ноября по 29 февраля 2024 года. Затем, в течение месяца пройдёт их рассмотрение и 1 апреля 2024 года будут объявлены победители, которые получат гранты до 30 мая 2024 года. Узнать правила и подать заявку на грант можно на странице программы, а на сайте — ознакомиться с инициативой Yandex Open Source и проектами «Яндекса» с открытым исходным кодом. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






