|
Опрос
|
реклама
Быстрый переход
Глава OpenAI Сэм Альтман предложил скинуться всем миром, чтобы построить десятки новых предприятий для TSMC
09.02.2024 [10:32],
Алексей Разин
Возможности систем генеративного искусственного интеллекта, на которых OpenAI очень быстро сделала себе имя, в своём развитии упираются в нехватку полупроводниковых компонентов и высокие расходы на электроэнергию, поэтому основатель компании Сэм Альтман сейчас сосредоточен на проекте по привлечению до $7 трлн на решение этих проблем. 
Источник изображения: OpenAI Как поясняет The Wall Street Journal, Сэм Альтман уже давно вкладывается в стартапы, связанные с созданием источников дешёвой электроэнергии по принципу термоядерного синтеза, но сейчас предприниматель поставил перед собой не менее амбициозную цель: собрать триллионы долларов США для финансирования строительства внушительного количества предприятий, способных выпускать заметно большее количество ускорителей вычислений для систем искусственного интеллекта, чем это возможно сейчас. По информации осведомлённых источников, Альтман сейчас ведёт активные переговоры как с властями США, так и с правящими кругами ОАЭ, а также руководством TSMC. По его замыслу, арабские инвесторы могли бы предоставить внушительную сумму денег, до $5 трлн или $7 трлн, в совокупности с другими источниками финансирования, чтобы в ближайшие несколько лет построить несколько десятков новых предприятий по контрактному выпуску чипов, которые можно было бы передать в управление компании TSMC. На них предполагается наладить выпуск чипов для ускорителей систем искусственного интеллекта в количествах, пропорциональным амбициям Альтмана по развитию функциональных возможностей разрабатываемых OpenAI чат-ботов и больших языковых моделей. Следует отметить, что $7 трлн являются весьма внушительной суммой не только по меркам инвестиционных проектов, но и в масштабах суверенного долга некоторых государств. В конце концов, оборот всего рынка полупроводниковых компонентов достигнет рубежа в $1 трлн лишь к концу десятилетия, а совокупная капитализация двух самых дорогих американских компаний, Microsoft и Apple, приближается к $6 трлн. Альтман, как поясняют источники, поставил в известность о своих намерениях не только министра торговли США Джину Раймондо (Gina Raimondo), но и руководство компании TSMC, не говоря уже о правительстве ОАЭ, у которого собирается просить существенную часть денег на реализацию этого амбициозного проекта. К сожалению, на пути к претворению этого проекта в жизнь стоит немало препятствий. Во-первых, не совсем понятно, где будут построены десятки новых предприятий по выпуску чипов. США заинтересованы в их «приземлении» на родном материке, для самой TSMC реализация столь масштабных зарубежных проектов даже на стадии эксплуатации может представлять серьёзную проблему из-за определённого кадрового голода, а арабские инвесторы очевидным образом намерены развивать национальную промышленность ОАЭ. С другой стороны, власти США настороженно относятся к инвестициям арабских стран в передовые отрасли американской экономики, забывая при этом, что компания GlobalFoundries уже более десяти лет финансируется по этому принципу. Словом, замыслу Альтмана предстоит выдержать испытания суровой реальностью, поэтому прислушиваться к его планам пока приходится больше с точки зрения развлечения. OpenAI будет незаметно маркировать творчество ИИ-художника DALL-E 3
07.02.2024 [15:29],
Павел Котов
Генератор изображений OpenAI DALL-E 3 будет помечать созданные им картинки метаданными в соответствии со стандартами организации C2PA (Coalition for Content Provenance and Authenticity — «Коалиции по происхождению и аутентичности контента»). Такая маркировка позволит легко узнать, что изображение создано ИИ, а не человеком. 
Источник изображения: Gerd Altmann / pixabay.com При помощи метаданных будут маркироваться изображения, созданные искусственным интеллектом на сайте ChatGPT и при подключении к API для модели DALL-E 3, сообщила OpenAI. При выводе таких изображений на поддерживающих технологию Content Credentials ресурсах будет отображаться изображение с символами «CR» в левом верхнем углу каждой картинки. Это позволит установить происхождение файла, но пока маркировку получат только картинки, а не видеозаписи или текст. Добавление метаданных лишь незначительно повлияет на скорость работы системы и никак не скажется на качестве картинки, подчеркнули в OpenAI. 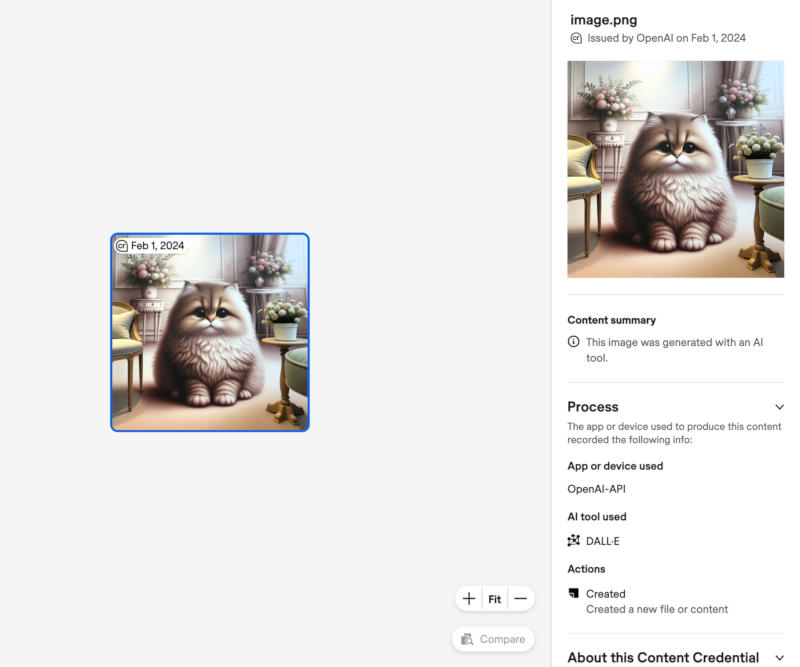
Источник изображения: openai.com Организация C2PA, в которую входят крупные технологические компании масштаба Adobe и Microsoft, продвигает собственный стандарт Content Credentials — это решение позволяет определять происхождение контента. Ранее о намерении помечать на своих платформах созданные ИИ материалы сообщила компания Meta✴. Американские разработчики технологий ИИ взяли на себя обязательства обеспечивать средства идентификации генерируемого ИИ контента. Метаданные, однако, трудно назвать надёжным способом защиты — их легко удалить, случайно или намеренно. Так, они часто в принудительном порядке удаляются при загрузке в соцсети. Метаданные также не сохраняются при снятии снимков экрана. Инженер Microsoft нашёл серьёзную уязвимость в ИИ-художнике DALL-E 3, но компания замолчала проблему
31.01.2024 [17:01],
Павел Котов
Старший инженер по искусственному интеллекту Microsoft Шейн Джонс (Shane Jones) обнаружил уязвимость в генераторе изображений OpenAI DALL-E 3, которая позволяет обходить защитные механизмы нейросети и генерировать недопустимый контент. Но в Microsoft и OpenAI отвергли факт наличия этой уязвимости и воспрепятствовали огласке проблемы. 
Источник изображения: efes / pixabay.com Инженер пояснил, что решил предать проблему огласке после того, как на прошлой неделе в соцсетях была опубликована серия сгенерированных ИИ фотореалистичных изображений известной исполнительницы Тейлор Свифт (Taylor Swift), имеющих деликатный характер. Инцидент вызвал возмущение в среде её поклонников, а Шейн Джонс призвал OpenAI изъять DALL-E 3 из открытого доступа. По одной из версий, создавшие эту серию изображений злоумышленники пользуются инструментом Microsoft Designer, частично основанным на этом ИИ-генераторе. Инженер также направил письмо двум сенаторам, одному члену Палаты представителей и генпрокурору штата Вашингтон, отметив, что «Microsoft знала об этих уязвимостях и возможностях злоупотреблений». Джонс сообщил Microsoft об обнаруженной им проблеме ещё 1 декабря 2023 года, направив соответствующее обращение через внутреннюю систему компании. В тот же день он получил ответ от работающего с такими обращениями сотрудника, который отметил, что проблема не касается ни внутренней сети Microsoft, ни учётных записей клиентов компании, и порекомендовал направить своё обращение в OpenAI. Инженер направил его 9 декабря, представив подробную информацию об уязвимости, но так и не получил ответа. Джонс продолжил изучать проблему и «пришёл к выводу, что DALL-E 3 представляет угрозу общественной безопасности и должен быть изъят из общественного доступа, пока OpenAI не сможет устранить связанные с этой моделью риски». 
Источник изображения: ilgmyzin / unsplash.com Две недели спустя, 14 декабря, инженер перевёл общение в публичную плоскость, разместив на своей странице в LinkedIn публикацию с призывом отозвать DALL-E 3 с рынка. Он уведомил об этом руководство компании, и с ним быстро связался его непосредственный начальник — он заявил, что юридический отдел Microsoft требует немедленно удалить публикацию, а обоснования своего требования он предоставит позже. Джонс удалил публикацию, но никаких сообщений от юристов Microsoft так и не получил. В итоге он 30 января был вынужден направить письмо властям. OpenAI отреагировала только 30 января, заявив, что она изучила обращение инженера сразу после того, как оно поступило, и описанный им метод якобы не позволяет обходить средств безопасности. «Безопасность является нашим приоритетом, и мы применяем многосторонний подход. В основополагающей модели DALL-E 3 мы разработали фильтр наиболее откровенного контента из её обучающих данных, включая изображения сексуального характера и насилия, разработали надёжные классификаторы изображений, не позволяющие модели создавать пагубные картинки. Мы также внедрили дополнительные меры безопасности для наших продуктов, ChatGPT и DALL-E API, включая отклонение запросов, содержащих имя публичного деятеля. Мы выявляем и отклоняем изображения, которые нарушают нашу политику, и фильтруем все созданные изображения, прежде чем они показываются пользователю. Для усиления наших мер безопасности и для проверки на злоупотребления мы привлекаем команду сторонних экспертов», — заверили в OpenAI. OpenAI создаст детский отдел в интернет-магазине ИИ-чат-ботов
30.01.2024 [13:12],
Дмитрий Федоров
OpenAI откроет раздел для детей в своём интернет-магазине ИИ-чат-ботов на основе ChatGPT. В рамках сотрудничества с организацией Common Sense Media, занимающейся оценкой средств массовой информации на предмет их пригодности для младшей аудитории, OpenAI нацелит свои усилия на минимизацию рисков, связанных с использованием ИИ подрастающим поколением. 
Источник изображения: Alexandra_Koch / Pixabay Совместные планы компаний включают разработку руководств и образовательных материалов, ориентированных на молодёжь, их родителей и учителей. Важным аспектом является курирование коллекции семейных версий GPT в онлайн-магазине OpenAI, основываясь на рейтингах Common Sense Media, что значительно упростит выбор подходящих продуктов для детской аудитории. «Вместе Common Sense Media и OpenAI будут работать над тем, чтобы ИИ оказывал положительное влияние на всех подростков и семьи. Наши руководства и материалы будут направлены на обучение семей и педагогов безопасному и ответственному использованию ChatGPT, чтобы мы все вместе могли избежать любых нежелательных последствий этой новой технологии», — заявил Джеймс Стейер (James Steyer), основатель и генеральный директор Common Sense Media. Эта инициатива была объявлена в ходе саммита Common Sense Media по вопросам детей и семьи. В рамках мероприятия Сэм Альтман (Sam Altman), генеральный директор OpenAI, выразил уверенность в положительном влиянии ИИ на обучение детей и важности интеграции таких технологий в образовательный процесс. «Люди — это пользователи инструментов, и нам лучше научить их пользоваться теми инструментами, которые появятся в мире. Не обучать людей их использованию было бы ошибкой», — заявил он. Альтман также подчеркнул, что благодаря ИИ старшеклассники в будущем смогут достигать высот в областях, требующих абстрактного мышления, опережая своих предшественников. OpenAI обвинили в нарушении европейских законов о конфиденциальности пользователей
29.01.2024 [20:06],
Сергей Сурабекянц
После многомесячного расследования, проведённого итальянским органом по защите данных DPA (Data Protection Authority) в отношении ИИ-чат-бота ChatGPT, компанию OpenAI обвинили в нарушении законов о конфиденциальности ЕС. Подтверждённые нарушения в обращении с персональными данными могут повлечь за собой штрафы на сумму до €20 млн, или до 4 % годового оборота. У OpenAI есть 30 дней, чтобы ответить на обвинения. 
Источник изображений: Pixabay Итальянские власти выразили обеспокоенность по поводу соблюдения OpenAI Общего регламента защиты данных (GDPR) в прошлом году, что привело к временной приостановке работы чат-бота на европейском рынке. DPA Италии 30 марта в так называемом «реестре мер», подчеркнул отсутствие подходящей правовой основы для сбора и обработки персональных данных с целью обучения алгоритмов, лежащих в основе ChatGPT, склонность инструмента ИИ к «галлюцинациям» и потенциальные проблемы с безопасностью детей. Власти обвинили OpenAI в нарушении статей 5, 6, 8, 13 и 25 GDPR. DPA располагают полномочиями требовать внесения изменений в способы обработки данных, чтобы прекратить нарушения конфиденциальности граждан ЕС. Таким образом, регуляторы могут заставить OpenAI изменить свой подход к обработке персональных данных или вынудить компанию прекратить предлагать свои услуги в странах Евросоюза. Весной 2023 года OpenAI смогла относительно быстро возобновить функционирование ChatGPT в Италии после того, как устранила ряд нарушений, указанных DPA. Однако итальянские власти продолжили расследование и пришли к предварительным выводам, что инструмент ИИ от OpenAI нарушает законодательство ЕС. Итальянские власти пока не опубликовали список подтверждённых нарушений ChatGPT, но главной претензией к OpenAI, скорее всего, станет сам принцип обработки персональных данных для обучения моделей ИИ. ChatGPT был разработан с использованием массы данных, извлечённых из общедоступного интернета — информации, которая включает личные данные отдельных лиц. А проблема, с которой OpenAI сталкивается в ЕС, заключается в том, что для обработки данных жителей ЕС требуется действительная правовая основа. GDPR перечисляет шесть возможных правовых оснований, большинство из которых просто не имеют отношения к данному контексту. В апреле прошлого года DPA Италии оставил для OpenAI только две законные возможности для обучения моделей ИИ: «подтверждённое согласие» или «законные интересы». Учитывая, что OpenAI никогда и не пыталась получить согласие миллионов (а, возможно, миллиардов) пользователей интернета, чью информацию она собирала и обрабатывала для построения моделей ИИ, любая попытка заявить о наличии разрешения от европейцев на обработку их персональных данных обречена на провал. Поэтому у OpenAI осталась лишь возможность опираться на утверждение о «законных интересах». Однако эта основа также предусматривает право владельцев данных выдвигать возражения и требовать прекращения обработки своей персональной информации. 
Источник изображения: OpenAI Теоретически, каждый житель ЕС имеет право потребовать от OpenAI изъять и уничтожить незаконно обученные модели и переобучить новые модели без использования его данных. Но даже если предположить возможность идентификации всех незаконно обработанных данных, подобную процедуру предстоит произвести для каждого возражающего гражданина ЕС, что практически невозможно реализовать на практике. Существует и более широкий вопрос: признает ли в конце концов DPA, что «законные интересы» вообще являются действительной правовой основой в этом контексте. Такое решение регулятора выглядит маловероятным. Ведь обработчики данных должны сбалансировать свои собственные интересы с правами и свободами людей, чьи данные обрабатываются, оценить возможность причинения им неоправданного вреда, а также учесть, ожидали ли люди такого использования их данных. Примечательно, что в подобной ситуации Верховный суд ЕС ранее признал «законные интересы» неподходящим основанием для Meta✴ при отслеживании и профилировании пользователей в целях таргетирования рекламы в своих социальных сетях. Таким образом, существует негативный судебный прецедент для OpenAI, стремящейся оправдать обработку данных людей в огромных масштабах для создания коммерческого генеративного ИИ-бизнеса — особенно когда рассматриваемые инструменты создают всевозможные новые риски для названных лиц (дезинформация, клевета, кража личных данных и мошенничество лишь некоторые из них). OpenAI также находится под пристальным вниманием к соблюдению GDPR в Польше, где начато отдельное расследование по этому поводу.  OpenAI пытается нивелировать потенциальные регуляторные риски в ЕС, создавая отдельную организацию в Ирландии, которая в будущем должна стать поставщиком услуг ИИ для пользователей из ЕС. OpenAI надеется получить статус так называемого «основного учреждения» в Ирландии, что позволит ей использовать оценку соответствия требованиям GDPR только от Ирландской комиссии по защите данных и действовать в Евросоюзе через механизм «единого окна» регулирования, избежав надзора органов DPA каждой страны-члена ЕС. Однако пока OpenAI ещё не получила этот статус, поэтому ChatGPT все ещё может столкнуться с расследованиями со стороны DPA в других странах ЕС. И даже получение статуса «основного учреждения» в Ирландии не прекратит уже открытое расследование и правоприменение в Италии. DPA Италии сообщает, что органы по защите данных стремятся координировать надзор за ChatGPT, создав рабочую группу при Европейском совете по защите данных. Эти усилия могут, в конечном итоге, привести к более согласованным результатам в рамках отдельных расследований в отношении OpenAI. Тем не менее, на данный момент DPA каждого члена ЕС остаются независимыми и компетентными принимать решения на своих рынках самостоятельно. OpenAI сделала нейросети GPT-4 Turbo прививку от лени
26.01.2024 [12:51],
Владимир Фетисов
Компания OpenAI обновила большую языковую модель GPT-4 Turbo для более тщательного выполнения таких задач, как генерация программного кода, а также «уменьшения случаев "лени", когда модель отказывается выполнять задачу». Что именно было обновлено, разработчики не уточнили. 
Источник изображения: Growtika / unsplash.com Не так давно часть пользователей ChatGPT обратила внимание на то, что чат-бот зачастую попросту отказывается выполнять поставленную задачу, что, вероятно, было связано с длительным отсутствием обновлений языковой модели. Нынешнее обновление распространяется только на самую мощную нейросеть компании GPT-4 Turbo, которая была обучена на данных до апреля 2023 года и в настоящее время доступна только в предварительной версии. Пользователи более широко распространённой модели GPT-4, которая обучена на данных до сентября 2021 года, всё ещё могут сталкиваться с проблемами, когда алгоритм отказывается выполнять задачу. В сообщении OpenAI сказано, что более 70 % пользователей GPT-4, которые используют для взаимодействия с моделью API компании, перешли на GPT-4 Turbo из-за того, что алгоритм обучался на более свежих данных. Компания также планирует в ближайшие месяцы продолжить выпуск обновлений для GPT-4 Turbo, что позволит использовать больше мультимодальных подсказок при взаимодействии с алгоритмом. В дополнение к этому разработчики запустили две меньшие ИИ-модели, которые в компании называют моделями «вложения». Речь идёт о моделях text-embedding-3-small и text-embedding-3-large, которые уже доступны пользователям. Глава OpenAI проведёт переговоры с Samsung и SK hynix, касающиеся выпуска собственных ИИ-ускорителей
26.01.2024 [10:01],
Алексей Разин
Генеральный директор OpenAI Сэм Альтман (Sam Altman), как считается, ведёт переговоры с инвесторами на Ближнем Востоке с целью поиска средств для финансирования проекта по выпуску ускорителей систем искусственного интеллекта собственной разработки. На этой неделе, по слухам, он отправился в Южную Корею для переговоров с SK hynix и Samsung. 
Источник изображения: OpenAI Об этом утром сообщило агентство Reuters со ссылкой на собственные источники. Если SK hynix является производителем памяти, который уже давно сотрудничает с NVIDIA в сфере поставки востребованных последней микросхем памяти типа HBM3, то Samsung Electronics одновременно способна и выпускать чипы сторонней разработки для своих клиентов. В этом контексте не совсем понятно, какую роль OpenAI отводит компании Samsung в рамках вероятного партнёрства. В любом случае, сейчас спрос на микросхемы памяти типа HBM3 позволяет производителям неплохо себя чувствовать, в прошлом квартале SK hynix увеличила объёмы выпуска таких микросхем более чем в пять раз, а Samsung Electronics в ближайшее время собирается кратно увеличить инвестиции в производство подобной памяти. Создание современных ускорителей вычислений, способных стать альтернативной решениям NVIDIA, наверняка не обойдётся без участия SK hynix, Samsung или Micron, и руководство OpenAI это прекрасно понимает. OpenAI захотела независимости от NVIDIA — Альтман ищет инвесторов для выпуска собственных ИИ-чипов
23.01.2024 [16:44],
Дмитрий Федоров
Генеральный директор OpenAI Сэм Альтман (Sam Altman) ведет переговоры с инвесторами на Ближнем Востоке, а также с контрактными производителями чипов для запуска производства ИИ-ускорителей собственной разработки. Цель проекта заключается в удовлетворении растущих потребностей OpenAI в чипах для обучения и работы ИИ, а также в снижении зависимости от NVIDIA. 
Источник изображения: franganillo / Pixabay В целях реализации этого амбициозного проекта, Альтман уже переговорил с ведущими инвесторами из Объединённых Арабских Эмиратов (ОАЭ), включая шейха Тахнуна бин Заида Аль Нахайяна (Sheikh Tahnoon bin Zayed Al Nahyan), одного из наиболее влиятельных и богатых людей Абу-Даби. Обсуждаемый проект включает в себя разработку и производство микросхем, необходимых для обучения и работы ИИ-моделей. По данным источников, Альтман также провёл переговоры с TSMC о сотрудничестве в производстве чипов. В качестве резервных контрактных производителей выступают Samsung и Intel. Шейх Тахнун, являясь младшим братом главы ОАЭ и его советником по государственной безопасности, контролирует стремительно развивающуюся бизнес-империю и председательствует в Инвестиционном управлении Абу-Даби (ADIA), чьи активы оцениваются примерно в $800 млрд, и в Суверенном фонде благосостояния Абу-Даби (ADQ). Кроме того, он возглавляет International Holding Company, крупнейшую публичную компанию ОАЭ, и G42, амбициозную компанию в сфере ИИ, уже работающую с Microsoft и OpenAI. Поиск инвестиций на Востоке неудивителен, ведь разработка и производство микросхем является чрезвычайно затратным процессом, требующим значительных инвестиций. Хотя точная сумма инвестиций, которую Альтман намерен привлечь, не раскрывается, предполагается, что для конкуренции с NVIDIA, чья рыночная капитализация уже приближается к $1,5 трлн, ему потребуются миллиарды долларов. Сектор самих систем ИИ и чипов для ИИ за последний год стал крайне актуальным, причём графические процессоры (GPU) NVIDIA являются ключевым элементом устойчивого развития этой отрасли и очень востребованы среди технологических компаний как в Кремниевой долине, так и в других странах. Разработчики ИИ, такие как OpenAI, для обучения и работы своих больших языковых ИИ-моделей, используют тысячи ускорителей вычислений. В настоящее время OpenAI работает над созданием новой версии своей ИИ-модели, которая, предположительно, будет представлена в этом году и станет важным обновлением её нынешней модели GPT-4. Каждое новое обновление нейросети усиливает зависимость OpenAI от производителей чипов, особенно от NVIDIA, которая является крупнейшим поставщиком чипов для ИИ. Именно эти обстоятельства и побудили Сэма Альтмана найти инвесторов для разработки и выпуска собственных микросхем. Однако остаётся неясным, будет ли новое предприятие функционировать как дочерняя структура OpenAI или как отдельная компания. Однако, согласно информации от осведомлённых источников, основным клиентом нового чипмейкера станет сама OpenAI. Сэм Альтман планирует создать международную сеть по производству ИИ-чипов
20.01.2024 [07:08],
Дмитрий Федоров
Генеральный директор OpenAI Сэм Альтман (Sam Altman) ведёт переговоры о привлечении многомиллиардных инвестиций для создания международной сети по производству ИИ-чипов. Целью этих инвестиций является преодоление ключевых проблем в области разработки ИИ, таких как нехватка высокопроизводительных процессоров для ИИ-моделей, включая ChatGPT и DALL-E. Этот амбициозный проект предполагает сотрудничество с ведущими мировыми производителями чипов, имена которых пока держатся в тайне. 
Источник изображения: Frank_Reppold / Pixabay Важность разработки и производства мощных чипов для ИИ-моделей, вроде ChatGPT или DALL-E, способных отвечать на запросы и создавать изображения, становится очевидной в контексте текущих трендов в индустрии. NVIDIA, чья капитализация в прошлом году впервые достигла отметки в $1 трлн, обладает фактической монополией на рынке, благодаря своим популярным графическим процессорам H100. Эти процессоры используются в обучении передовых ИИ-моделей, таких как GPT-4, Gemini, Llama 2. С учётом усиления конкуренции за производство высокопроизводительных ИИ-чипов, важно заранее обеспечить необходимые производственные мощности. В этом контексте Альтман и его команда ведут переговоры с инвестиционными гигантами, такими как SoftBank Group и находящейся в Абу-Даби компанией G42, о финансировании этого масштабного проекта. 
Новый ИИ-процессор Microsoft Azure Maia 100 (источник изображения: Microsoft) Не только OpenAI, но и другие крупные игроки ИТ-индустрии, включая Microsoft, Amazon и Google, активно работают над созданием собственных ИИ-чипов. Microsoft, являющаяся инвестором OpenAI, в ноябре прошлого года объявила о разработке первого собственного ИИ-чипа для обучения ИИ-моделей. Следом за ней компания Amazon представила обновлённую версию своего чипа Trainium. Команда Google по разработке чипов использует ИИ DeepMind на серверах Google Cloud для проектирования своих процессоров ИИ, в том числе Tensor Processing Units (TPU). Компании AWS, Azure и Google также активно используют процессоры H100 компании NVIDIA. На этой неделе генеральный директор Meta✴ Марк Цукерберг (Mark Zuckerberg) в интервью изданию The Verge рассказал журналисту Алексу Хиту (Alex Heath), что к концу года Meta✴ планирует владеть более чем 340 000 процессорами H100 в рамках стратегии разработки сильного ИИ (Artificial General Intelligence — AGI). 
NVIDIA GH200 Grace Hopper Superchip (источник изображения: NVIDIA) На фоне стремительного роста капитализации, NVIDIA не остаётся в стороне от гонки за инновациями и уже анонсировала свои новые чипы GH200 Grace Hopper, что укрепит её и без того доминирующие позиции на рынке. Однако AMD, Qualcomm и Intel также не отстают, выпуская свои процессоры, предназначенные для поддержки ИИ-моделей на ноутбуках, смартфонах и других устройствах. ChatGPT внедрят в учебный процесс в Университете штат Аризона
19.01.2024 [13:04],
Павел Котов
Университет штата Аризона объявил о партнёрстве с компанией OpenAI на предмет внедрения ChatGPT в учебный процесс. В вузе ставят три цели для совместного проекта: «повышение успеваемости студентов, создание новых возможностей для инновационных исследований и оптимизация организационных процессов». 
Источник изображения: Growtika / unsplash.com «Наши преподаватели и сотрудники уже пользовались ChatGPT, и с запуском ChatGPT Enterprise, который помог нам преодолеть некоторые проблемы безопасности, мы решили, что есть смысл выйти на OpenAI», — рассказал ресурсу The Verge заместитель директора университета по информационным технологиям Кайл Боуэн (Kyle Bowen). Он добавил, что имеющие опыт в области искусственного интеллекта преподаватели помогут с его внедрением в кампусе. В феврале руководство Университета штата Аризона начнёт принимать заявки о планах на использование ChatGPT — некоторые профессора используют платформу на занятиях уже сейчас. Она, например, применяется на курсе журналистики, а в отдельных случаях чат-бот может выступать в качестве наставника для студентов. В прошлом году университет запустил акселератор проектов в области ИИ, объединивший исследователей и инженеров для создания ИИ-сервисов. Вуз также открыл срочные инженерные курсы по повышению грамотности в области ИИ. Для OpenAI это первый партнёрский проект с образовательным учреждением. Сейчас компания налаживает связи с организациями. Недавно было заключено соглашение с правительством штата Пенсильвания об использовании службы ChatGPT Enterprise государственными служащими. Microsoft не собирается усиливать контроль за OpenAI, а просто хочет стабильности
16.01.2024 [14:16],
Алексей Разин
Ноябрьские события заставили корпорацию Microsoft изрядно понервничать, ведь она остаётся крупнейшим инвестором стартапа OpenAI, который осенью прошлого года оказался вовлечён в скандал с отставкой и последующим возвращением генерального директора Сэма Альтмана (Sam Altman). По словам главы Microsoft, компания не намерена усиливать контроль над OpenAI, а просто стремится к стабильности. 
Источник изображения: Microsoft Напомним, что некоторых экспертов смущала организационная структура OpenAI. Компания управляется одноимённой некоммерческой организацией, в которой та же Microsoft не имеет права голоса, хотя и вложила в капитал коммерческой составляющей стартапа более $13 млрд. Как признался на этой неделе генеральный директор Microsoft Сатья Наделла (Satya Nadella), нюансы организационной формы OpenAI его волнуют в наименьшей степени. Главное, по его словам, чтобы при этом достигалась стабильность работы стартапа. «Я чувствую себя комфортно. У меня нет каких-либо проблем с любой структурой», — пояснил глава Microsoft. Тем не менее, следует напомнить, что после переизбрания совета директоров в конце прошлого года Microsoft всё же получила в нём место, но без права голоса, и ограничилась только наблюдательными функциями. Как признался Наделла, Microsoft не настаивает на получении места в совете директоров OpenAI с правом голоса. Степень взаимной зависимости компаний не так велика, пояснил глава Microsoft. Они обмениваются данными и технологиями, но это не мешает последней развивать независимые программы в сфере искусственного интеллекта с другими партнёрами. «Мне очень нравится имеющаяся конструкция, в то же время я чувствую, что мы можем сами контролировать свою судьбу», — пояснил специфику взаимоотношений Microsoft и OpenAI глава первой из компаний. Сатья Наделла также видит определённый потенциал в разработке аппаратного обеспечения, которое способствовало бы прогрессу на направлении систем искусственного интеллекта. Превращение Microsoft в крупнейшую компанию мира по величине капитализации не очень впечатляет главу корпорации, как он признался. Сам по себе этот индикатор мало что значит, по словам Наделлы, поскольку не определяет будущей ценности бизнеса. OpenAI незаметно отменила запрет на использование ChatGPT в военных целях
15.01.2024 [21:11],
Сергей Сурабекянц
Компания OpenAI, не привлекая особого внимания, отказалась от прямого запрета на использование её технологии в военных целях. До 10 января политика OpenAI запрещала «деятельность, сопряжённую с высоким риском физического вреда», включая «разработку оружия» и «военную деятельность». Новая формулировка сохраняет запрет на использование OpenAI во вред и в качестве примера приводит разработку или использование оружия, но полный запрет на военное использование исчез. 
Источник изображений: ИИ-генерация Stable Diffusion/3DNews Это неафишируемое редактирование является частью масштабного изменения страницы политики использования, которое, по словам компании, призвано сделать документ «более понятным и более читабельным» и включает в себя множество других существенных изменений. Реальные последствия изменения этой политики неясны. В прошлом году OpenAI уже отказывалась отвечать на вопрос, будет ли она обеспечивать соблюдение своего собственного чёткого запрета на военные действия перед лицом растущего интереса со стороны Пентагона и разведывательного сообщества США. «Мы стремились создать набор универсальных принципов, которые легко запомнить и применять, тем более что наши инструменты теперь используются во всём мире обычными пользователями, которые также могут создавать GPT, — заявил представитель OpenAI Нико Феликс (Niko Felix). — Принцип “Не причиняй вреда другим” является широким, но легко понятным и актуальным во многих контекстах. Кроме того, в качестве ярких примеров мы специально привели оружие и ранения других людей». При этом он отказался сообщить, распространяется ли расплывчатый запрет на «нанесение вреда» на любое использование в военных целях.  «OpenAI хорошо осознает риски и вред, которые могут возникнуть в результате использования их технологий и услуг в военных целях», — считает эксперт по машинному обучению и безопасности автономных систем Хейди Клааф (Heidy Khlaaf). По её мнению, новая политика ставит законность выше безопасности: «Между этими двумя политиками существует явная разница: в первой чётко указано, что разработка вооружений, а также военные действия и война запрещены, а во второй подчёркивается гибкость и соблюдение закона». Клааф уверена, что разработка оружия и осуществление деятельности, связанной с военными действиями, в различной степени законны, а потенциальные последствия для безопасности очень вероятны. Она напомнила хорошо известные случаи предвзятости и галлюцинаций, присущие большим языковым моделям и их общую неточность. По её мнению, использование ИИ в боевых действиях может привести к неточным и предвзятым операциям и усугубить ущерб и жертвы среди гражданского населения. «Учитывая использование систем искусственного интеллекта для нападения на гражданское население в секторе Газа, это примечательный момент — принять решение удалить слова “военные действия” из политики допустимого использования OpenAI, — говорит директор института AI Now Сара Майерс Уэст (Sarah Myers West). — Формулировка политики остаётся расплывчатой и вызывает вопросы о том, как OpenAI намерена подходить к обеспечению её соблюдения».  Хотя ИИ сегодня не может быть использован для непосредственного насилия и убийств, существует огромное количество смежных задач, которые ИИ выполняет для армии. Военнослужащие США уже используют технологию OpenAI для ускорения оформления документов. Национальное агентство геопространственной разведки, напрямую помогающее США в боевых действиях, открыто заявляет об использовании ChatGPT своими аналитиками. Даже если инструменты OpenAI в военных ведомствах используются для задач, не связанных с прямым насилием, они все равно косвенно помогают в ведении боевых действий и убийстве людей. Военные по всему миру стремятся внедрить методы машинного обучения, чтобы получить преимущество. Хотя результаты больших языковых моделей выглядят чрезвычайно убедительными, они часто страдают от так называемых галлюцинаций, которые ставят под сомнение точность результатов и их соответствие действительности. Тем не менее, способность больших языковых моделей быстро воспринимать текст и проводить его анализ – или, по крайней мере, симулякр анализа – делает использование ИИ естественным выбором для министерства обороны, перегруженного данными. В то время как некоторые представители военного руководства США выражают обеспокоенность по поводу рисков безопасности при использовании ChatGPT для анализа секретных и других чувствительных данных, Пентагон не отказывается от курса на использование ИИ. Заместитель министра обороны Кэтлин Хикс (Kathleen Hicks) полагает, что ИИ является «ключевой частью комплексного подхода к сетецентрическим военным инновациям». При этом она признаёт, что большинство текущих предложений «ещё недостаточно технически развиты, чтобы соответствовать нашим этическим принципам искусственного интеллекта». Amazon заполонили товары с названием «извините, я не могу выполнить запрос», и всё из-за ChatGPT
13.01.2024 [11:19],
Владимир Фетисов
Пользователи стали замечать, что в названии многочисленных товаров на разных интернет-площадках появилось предупреждение о нарушении политики OpenAI. «Извините, но я не могу выполнить запрос, поскольку он противоречит политике использования OpenAI», — говорится в сообщении, которое можно найти в описании разных товаров на Amazon и некоторых других интернет-площадка. С чем именно это связано, на данный момент неизвестно. 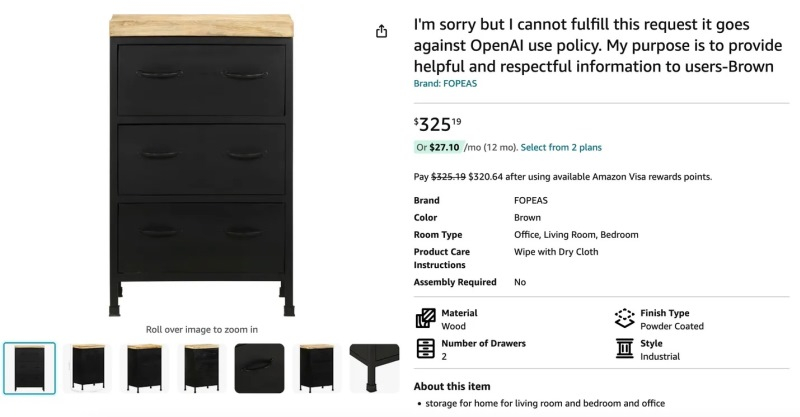
Источник изображений: The Verge По данным источника, найти множество товаров с упоминанием о нарушении политики OpenAI можно, набрав в поиске на Amazon запрос «OpenAI policy». В результате можно увидеть массу товаров с подобным названием, включая предложения в категориях мебели, товаров для дома, сада и др. Отмечается, что проблема затрагивает не только Amazon, но и некоторые другие интернет-площадки, включая социальную сеть X (бывшая Twitter).  Вероятнее всего, проблема связана с тем, что большое количество продавцов на Amazon используют ИИ-бота ChatGPT от компании OpenAI для автоматизации составления карточек своих товаров. По всей видимости, алгоритм по какой-то причине некорректно обрабатывает запросы и вставляет в описания некоторых товаров предупреждения. Официальные представители Amazon и OpenAI пока никак не комментируют данный вопрос, поэтому точно неизвестно, что стало причиной появления сообщений о нарушении политики OpenAI в названии товаров. OpenAI открыла GPT Store, где разработчики смогут размещать собственных чат-ботов
11.01.2024 [08:33],
Алексей Разин
Вчера компания OpenAI запустила магазин чат-ботов, разработанных пользователями ChatGPT. Как отмечает Bloomberg, в общей сложности пользователи сервиса уже смогли создать 3 млн индивидуализированных чат-ботов, но не совсем ясно, какая часть из них представлена в фирменном магазине приложений на момент его запуска. Со временем разработчики чат-ботов смогут получать прибыль от их реализации на этой площадке. 
Источник изображения: Unsplash, Andrew Neel Как известно, для создания таких чат-ботов не требуются навыки программирования, поэтому активность разработчиков будет достаточно высокой. Площадка получила название GPT Store, она имеет развитый рубрикатор и систему поиска чат-ботов с необходимой функциональностью. Среди примеров такого «народного творчества» можно обнаружить чат-боты, которые или помогают обучать детей математике, или содержат набор рецептов разноцветных коктейлей. На этой неделе пользователям ChatGPT был предложен новый тариф для корпоративных клиентов, который потребует ежемесячной абонентской платы в размере $25 с человека. За эти деньги небольшие компании, занимающиеся разработкой ИИ-систем, смогут использовать инфраструктуру OpenAI и её языковые модели. Тарифный план для корпоративных клиентов впервые появился у OpenAI ещё в августе прошлого года. Возможности заработка на кастомных чат-ботах у пользователей сервиса пока нет, но она будет предложена к концу марта, как поясняет Bloomberg. Разработчики чат-ботов для GPT Store в США будут получать деньги пропорционально популярности своих разработок. Первоначально OpenAI планировала запустить такой магазин приложений в конце ноября, но скандал с отставкой и возвращением на пост генерального директора Сэма Альтмана (Sam Altman) помешал своевременной реализации этого плана. В магазине приложений новые чат-боты будут представляться каждую неделю. Антимонопольщики ЕС изучат влияние Microsoft на OpenAI после скандала с увольнением Сэма Альтмана
10.01.2024 [12:08],
Дмитрий Федоров
Европейский Союз (ЕС) внимательно изучит инвестиции Microsoft в OpenAI, лидера в сфере генеративного ИИ, на предмет их соответствия нормам слияния компаний. Этот интерес вызван недавними изменениями в руководстве OpenAI и усилением роли Microsoft. 
Источник изображения: TheDigitalArtist / Pixabay Недавние события в OpenAI, совет директоров которой сперва проголосовал за смещение Сэма Альтмана (Sam Altman) с поста генерального директора, стали поворотным моментом в истории стартапа. Это решение вызвало неожиданный ответ со стороны Microsoft, крупного инвестора OpenAI, который не только выразил своё намерение назначить Альтмана на новую должность в своей структуре, но и предложил работу другим сотрудникам OpenAI, желающим покинуть компанию. Всё завершилась победным возвращением Альтмана в качестве руководителя OpenAI и назначением нового состава совета директоров, который покинули несколько членов, поддержавших его отстранение. Заметным событием стало включение представителя Microsoft в совет директоров OpenAI в качестве наблюдателя без права голоса. Эти изменения подняли вопросы о роли и влиянии Microsoft на OpenAI, особенно в свете того, что американский технологический гигант владеет значительной долей компании. Эта серия событий привлекла внимание не только ЕС, но и регуляторов Великобритании и Германии. Особенно примечательно, что Федеральное антимонопольное ведомство (FCO) Германии рассматривало связь между OpenAI и Microsoft ещё до возвращения Альтмана, не обнаружив на тот момент оснований для применения законодательства о слияниях. Однако FCO предупредило, что в случае усиления влияния Microsoft на OpenAI ведомство может пересмотреть своё решение. В свою очередь Европейская комиссия активно исследует текущее состояние конкуренции в сферах виртуальных миров и генеративного ИИ. В рамках этого исследования комиссия инициировала два запроса для сбора мнений и аналитических данных от экспертов в этих областях. Эти запросы направлены на формирование более глубокого понимания того, как новые технологии влияют на рыночную динамику и конкуренцию. Важным этапом в этом процессе станет организация семинара, запланированного на II квартал 2024 года. На мероприятии предполагается обсудить результаты запросов, собрать различные точки зрения и разработать стратегии, которые помогут поддерживать здоровую конкурентную среду на высокотехнологичных рынках. Представитель ЕС подчеркнул необходимость сохранения конкуренции в быстроразвивающихся сферах виртуальных миров и генеративного ИИ. «Виртуальные миры и генеративный ИИ стремительно развиваются. Очень важно, чтобы эти новые рынки оставались конкурентоспособными и чтобы ничто не мешало компаниям развиваться и предоставлять потребителям самые лучшие и инновационные продукты», — заявила Маргрет Вестагер (Margrethe Vestager), комиссар ЕС по вопросам конкуренции. Она также отметила активное наблюдение за слияниями в сфере ИИ, чтобы гарантировать, что они не искажают динамику рынка. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






