|
Опрос
|
реклама
Быстрый переход
Sony пригрозила 700 компаниям судом за несанкционированное использование музыки для обучения ИИ
17.05.2024 [19:54],
Сергей Сурабекянц
Sony Music Group разослала предупреждения более чем 700 технологическим компаниям и службам потоковой передачи музыки о недопустимости использования защищённого авторским правом аудиоконтента для обучения ИИ без явного разрешения. Компания признает «значительный потенциал» ИИ, но «несанкционированное использование контента в обучении, разработке или коммерциализации систем ИИ» лишает её и её артистов контроля и «соответствующей компенсации». 
Источник изображения: Pixabay В части разосланных писем Sony Music прямо утверждает, что имеет «основания полагать», что получатели письма «возможно, уже совершили несанкционированное использование» принадлежащего компании музыкального контента. В портфолио Sony Music — множество известных артистов, среди них Harry Styles, Beyonce, Adele и Celine Dion. Компания стремится защитить свою интеллектуальную собственность, включая аудио- и аудиовизуальные записи, обложки, метаданные и тексты песен. Компания не раскрыла список адресатов, получивших «письма счастья». «Мы поддерживаем артистов и авторов песен, которые берут на себя инициативу по использованию новых технологий в поддержку своего искусства, — говорится в заявлении Sony Music. — Эволюция технологий часто меняла курс творческих индустрий. ИИ, скорее всего, продолжит эту давнюю тенденцию. Однако это нововведение должно гарантировать уважение прав авторов песен и записывающихся исполнителей, включая авторские права». Получателям в указанный в письме срок предлагается подробно описать, какие песни Sony Music использовались для обучения систем ИИ, как был получен доступ к песням, сколько копий было сделано, а также почему копии вообще существовали. Sony Music подчеркнула, что будет обеспечивать соблюдение своих авторских прав «в максимальной степени, разрешённой применимым законодательством во всех юрисдикциях». Нарушение авторских прав становится серьёзной проблемой по мере развития генеративного ИИ, уже сейчас потоковые сервисы, подобные Spotify, наводнены музыкой, созданной искусственным интеллектом. В прошлом месяце в США был опубликован проект закона, который, в случае его принятия, заставит компании раскрывать, какие песни, защищённые авторским правом, они использовали для обучения ИИ. В марте 2024 года Теннесси стал первым штатом США, который принял юридические меры для защиты артистов, после того как губернатор Билл Ли (Bill Lee) подписал «Закон об обеспечении безопасности голоса и изображений» (Ensuring Likeness Voice and Image Security, ELVIS). Google представила мощнейший серверный ИИ-процессор Trillium — почти в пять раз быстрее предшественника
14.05.2024 [22:21],
Николай Хижняк
В рамках конференции Google I/O компания Google представила шестое поколение своего фирменного тензорного процессора (Tensor Processing Unit) с кодовым названием Trillium. Он предназначен для центров обработки данных, ориентированных на работу с искусственным интеллектом. По словам компании, новый чип почти в пять раз производительнее предшественника. 
Источник изображения: The Verge «Промышленный спрос на компьютеры для машинного обучения вырос в миллион раз за последние шесть лет и каждый год продолжает увеличиться в десять раз. Я думаю, что Google была создана для этого момента. Мы являемся новаторами в разработке чипов для искусственного интеллекта уже более десяти лет», — заявил генеральный директор Alphabet Сундар Пичаи (Sundar Pichai) в разговоре с журналистами. Разрабатываемые Alphabet, материнской компанией Google, специализированные чипы для центров обработки данных, ориентированных на ИИ, представляют собой одну из немногих жизнеспособных альтернатив решениям компании Nvidia. Вместе с программным обеспечением, оптимизированным для работы с тензорными процессорами Google (TPU), эти решения позволили компании занять значительную долю на рынке. По данным издания Reuters, Nvidia по-прежнему доминирует на рынке чипов для ИИ-дата-центров с долей 80 %. Значительная часть от оставшихся 20 % приходятся на различные версии TPU от Google. В отличие от Nvidia, компания Google не продаёт свои процессоры, а использует их сами и сдаёт в аренду облачные вычислительные платформы, которые на них работают. Для шестого поколения TPU под названием Trillium компания заявляет прибавку вычислительной производительности в 4,7 раза по сравнению с TPU v5e в задачах, связанных с генерацией теста и медиаконтента с помощью больших языковых моделей ИИ (LLM). При этом Trillium на 67 % энергоэффективнее, чем TPU v5e, отмечают в компании. Как пишет портал TechCrunch, значительного увеличения производительности у Trillium компания смогла добиться благодаря увеличения количества используемых матричных умножителей (MXU), а также повышения тактовой частоты чипа. Кроме того, компания удвоила для Trillium пропускную способность памяти. Более конкретных технических деталей Trillium не приводится. Вычислительные мощности нового процессора станут доступны для клиентов облачных сервисов Google к «концу 2024 года», отмечают в компании. Однако от решений Nvidia компания Google не отказывается. В рамках конференции Google I/O также было заявлено, Google станет одним из первых облачных провайдеров, который с начала будущего года будет предлагать облачные услуги на базе специализированных ИИ-ускорителей нового поколения Nvidia Blackwell. Более половины сотрудников в полупроводниковой отрасли США склонны к смене места работы
12.05.2024 [05:50],
Алексей Разин
В американской полупроводниковой отрасли не хватает квалифицированных специалистов, и это ощущается даже на этапе строительства объектов. Эксперты McKinsey выяснили, что существующие сотрудники американских предприятий полупроводниковой отрасли более чем в половине случаев склонны к смене работы в течение ближайших трёх или шести месяцев. 
Источник изображения: Micron Technology Эти данные, как сообщает Bloomberg, были получены представителями агентства McKinsey в результате социологического опроса сотрудников американских компаний полупроводниковой отрасли. В прошлом году доля желающих сменить место работы в течение ближайших трёх или шести месяцев превысила 50 %, тогда как в 2021 году она не превышала 40 %. Респонденты в качестве самой распространённой причины такого настроя называли отсутствие карьерного роста, на втором месте фигурировало отсутствие гибкости в организации работы. Строительство предприятия TSMC в штате Аризона уже обнажило одну из проблем, с которыми сталкивается пытающаяся возродиться на новом уровне национальная полупроводниковая промышленность. Квалифицированных рабочих не хватает уже на уровне строительства, а для возведения подобных объектов требуются особые навыки. Если учесть, что смежные отрасли промышленности США переживают бум строительства новых объектов, то конкуренция за квалифицированных строителей будет только усиливаться. Старение существующих кадров также является проблемой для полупроводниковой отрасли США. Около трети специалистов уже достигла возраста 55 лет. Сотрудники при этом начинают демонстрировать признаки недовольства условиями работы. По некоторым прогнозам, к 2030 году дефицит кадров в полупроводниковой отрасли США будет измеряться 70 000 позициями. Востребованы будут как строители специфического профиля, так и инженеры и техники, которые задействованы как при пуско-наладочных работах, так и при оперативном функционировании оборудования предприятий по выпуску чипов. Сейчас программы подготовки кадров в США рассчитаны на выпуск 12 000 инженеров и 31 500 техников к 2029 году. Если учесть, что только одно передовое предприятие требует 1350 инженеров и 1200 техников, становится очевидной перспектива кадрового голода. К решению этой проблемы власти США и местный бизнес должны подходить более ответственно, как считают эксперты McKinsey. OpenAI позволит правообладателям запретить использование контента для обучения ИИ
08.05.2024 [12:34],
Павел Котов
OpenAI сообщила, что разрабатывает инструмент под названием Media Manager, который позволит создателям и владельцам контента отметить свои работы для компании и указать, как можно ли их включать в массив данных для исследований и обучения ИИ, или же нельзя. 
Источник изображения: Growtika / unsplash.com Инженеры OpenAI намереваются разработать этот инструмент к 2025 году. Сейчас компания сотрудничает с «создателями контента, правообладателями и регуляторами» над выработкой стандарта. «Создание первого в своём роде инструмента, который поможет нам идентифицировать текст, аудио и видео, защищённые авторским правом, в нескольких источниках и отразить предпочтения создателей, потребует передовых исследований в области машинного обучения. Со временем мы планируем внедрить дополнительные возможности и функции», — сообщила OpenAI в своём блоге. Media Manager, вероятно, станет ответом компании на критику в отношении её подхода к разработке искусственного интеллекта. Она в значительной степени использует общедоступные данные из интернета, но совсем недавно несколько крупных американских изданий подали на OpenAI в суд за нарушение прав интеллектуальной собственности: по версии истцов, компания украла содержимое их статей для обучения моделей генеративного ИИ, которые затем коммерциализировались без компенсации и упоминания исходных публикаций. OpenAI считает, что невозможно создавать полезные модели ИИ без защищённых авторским правом материалов. Но в стремлении унять критику и защититься от вероятных исков компания предприняла несколько шагов, чтобы пойти навстречу создателям контента. В прошлом году она позволила художникам удалять свои работы из наборов обучающих данных для генераторов изображений, а также ввела директиву для файла robots.txt, которая запрещает её поисковому роботу копировать содержимое сайтов для дальнейшего обучения ИИ. OpenAI продолжает заключать соглашения с крупными правообладателями на предмет использования их материалов. ИИ научил робопса балансировать на шаре — он тренирует роботов эффективнее, чем люди
07.05.2024 [12:23],
Павел Котов
Группа учёных Пенсильванского университета разработала систему DrEureka, предназначенную для обучения роботов с использованием больших языковых моделей искусственного интеллекта вроде OpenAI GPT-4. Как оказалось, это более эффективный способ, чем последовательность заданий в реальном мире, но он требует особого внимания со стороны человека из-за особенностей «мышления» ИИ. 
Источник изображения: eureka-research.github.io Платформа DrEureka (Domain Randomization Eureka) подтвердила свою работоспособность на примере робота Unitree Go1 — четвероногой машины с открытым исходным кодом. Она предполагает обучение робота в симулированной среде, используя рандомизацию основных переменных: показатели трения, массы, демпфирования, смещения центра тяжести и других параметров. На основе нескольких пользовательских запросов ИИ сгенерировал код, описывающий систему вознаграждений и штрафов для обучения робота в виртуальной среде. По итогам каждой симуляции ИИ анализирует, насколько хорошо виртуальный робот справился с очередной задачей, и как её выполнение можно улучшить. Важно, что нейросеть способна быстро генерировать сценарии в больших объёмах и запускать их выполнение одновременно. ИИ создаёт задачи с максимальными и минимальными значениями параметров на точках отказа или поломки механизма, достижение или превышение которых влечёт снижение балла за прохождение учебного сценария. Авторы исследования отмечают, что для корректного написания кода ИИ требуются дополнительные инструкции по безопасности, в противном случае нейросеть при моделировании начинает «жульничать» в стремлении к максимальной производительности, что в реальном мире может привести к перегреву двигателей или повреждению конечностей робота. В одном из таких неестественных сценариев виртуальный робот «обнаружил» что способен передвигаться быстрее, если отключит одну из ног и начнёт передвигаться на трёх. Исследователи поручили ИИ соблюдать особую осторожность с учётом того, что обученный робот будет проходить испытания и реальном мире, поэтому нейросеть создала дополнительные функции безопасности для таких аспектов как плавность движений, горизонтальная ориентация и высота положения туловища, а также учёт величины крутящего момента для электродвигателей — он не должен превышать заданных значений. В результате система DrEureka справилась с обучением робота лучше, чем человек: машина показала 34-процентный прирост в скорости движения и 20-процентное увеличение расстояния, преодолеваемого по пересечённой местности. Такой результат исследователи объяснили разницей в подходах. При обучении задаче человек разбивает её на несколько этапов и находит решение по каждому из них, тогда как GPT проводит обучение всему сразу, и на это человек явно не способен. В результате система DrEureka позволила перейти от симуляции напрямую к работе в реальном мире. Авторы проекта утверждают, что могли бы дополнительно повысить эффективность работы платформы, если бы сумели предоставить ИИ обратную связь из реального мира — для этого нейросети потребовалось бы изучать видеозаписи испытаний, не ограничиваясь анализом ошибок в системных журналах робота. Среднему человеку требуются до 1,5 лет, чтобы научиться ходить, и лишь немногие способны передвигаться верхом на мяче для йоги. Обученный DrEureka робот эффективно справляется и с этой задачей. ИИ переплюнет по энергопотреблению Индию уже к 2030 году, спрогнозировал глава Arm
17.04.2024 [21:42],
Николай Хижняк
Технологиям искусственного интеллекта требуются огромные объёмы электроэнергии. По мнению главы компании Arm Рене Хааса (Rene Haas), это может привести к тому, что уже к концу текущего десятилетия общие объёмы потребляемой системами ИИ энергии превзойдут объёмы энергопотребления Индии, самой густонаселённой страны в мире. 
Источник изображения: Gerd Altmann / pixabay.com По словам Хасса, поиск способов предотвратить прогнозируемое утроение энергопотребления к 2030 году имеет первостепенное значение, если человечество хочет достигнуть целей, которые возлагаются на ИИ. «Мы по-прежнему находимся на раннем этапе развития возможностей [искусственного интеллекта]. Чтобы эти системы стали лучше, им потребуется дополнительное обучение — этап, который включает в себя бомбардировку программного обеспечения огромными наборами данных. Этот процесс рано или поздно столкнётся с пределом наших энергетических мощностей», — рассказал Хаас в интервью Bloomberg. Хаас формально ставит себя в один ряд с растущим числом людей, выражающих обеспокоенность по поводу возможного ущерба, который ИИ может нанести мировой энергетической инфраструктуре. Но он также заинтересован в том, чтобы отрасль перешла на использование чипов с Arm-архитектурами, которые всё больше завоёвывают популярность в центрах обработки данных. Технологии компании, которые к настоящему моменту получили широкое распространение в смартфонах, разработаны с целью более эффективного использования энергии по сравнению с традиционными серверными чипами. Arm рассматривает ИИ в качестве одного из основных драйверов своего роста. Технологии компании уже используются в процессорах, являющихся основой серверных систем AWS, Microsoft и Alphabet, разработавших собственные чипы для снижения своей зависимости от Intel и AMD. По словам Хааса, используя больше чипов, изготовленных по индивидуальному заказу, компании могут сократить ограничивающие факторы и повысить энергоэффективность их систем. Такая стратегия может снизить энергопотребление центров обработки данных более чем на 15 %. Однако отрасль нуждается в более масштабных технологических прорывах. Сроки поставок ИИ-ускорителей Nvidia H100 сократились до 2–3 месяцев
10.04.2024 [20:59],
Николай Хижняк
Cроки поставок ИИ-ускорителей Nvidia H100 сократились с 3–4 до 2–3 месяцев (8–12 недель), сообщает DigiTimes со ссылкой на заявление директора тайваньского офиса компании Dell Теренса Ляо (Terence Liao). ODM-поставщики серверного оборудования отмечают, что дефицит специализированных ускорителей начал снижаться по сравнению с 2023 годом, когда приобрести Nvidia H100 было практически невозможно. 
Источник изображения: Nvidia По словам Ляо, несмотря на сокращение сроков выполнения заказов на поставки ИИ-ускорителей, спрос на это оборудование на рынке по-прежнему чрезвычайно высок. И несмотря на высокую стоимость, объёмы закупок ИИ-серверов значительно выше закупок серверного оборудования общего назначения. Окно поставок в 2–3 месяца — это самый короткий срок поставки ускорителей Nvidia H100 за всё время. Всего шесть месяцев назад он составлял 11 месяцев. Иными словами, клиентам Nvidia приходилось почти год ждать выполнение своего заказа. С начала 2024 года сроки поставок значительно сократились. Сначала они упали до 3–4 месяцев, а теперь до 2–3 месяцев. При таком темпе дефицит ИИ-ускорителей может быть устранён к концу текущего года или даже раньше. Частично такая динамика может быть связана с самими покупателями ИИ-ускорителей. Как сообщается, некоторые компании, имеющие лишние и нигде не использующиеся H100, перепродают их для компенсации огромных затрат на их приобретение. Также нынешняя ситуация может являться следствием того, что провайдер облачных вычислительных мощностей AWS упростил аренду ИИ-ускорителей Nvidia H100 через облако, что в свою очередь тоже частично помогает снизить на них спрос. Единственными клиентами Nvidia, которым по-прежнему приходится сталкиваться с проблемами в поставках ИИ-оборудования, являются крупные ИИ-компании вроде OpenAI, которые используют десятки тысяч подобных ускорителей для быстрого и эффективного обучения своих больших языковых ИИ-моделей. Языковые модели ИИ сразились друг с другом в импровизированном турнире по Street Fighter III
05.04.2024 [18:24],
Николай Хижняк
На хакатоне Mistral AI, прошедшем в Сан-Франциско на минувшей неделе, разработчики Стэн Жирар (Stan Girard) и Quivr Brain представили тест LLM Colosseum с открытым исходным кодом, основанный на классическом аркадном файтинге Street Fighter III. Тест предназначен для определения самой эффективной языковой модели ИИ в не совсем традиционной, но зрелищной манере. 
Источник изображений: YouTube / Matthew Berman ИИ-энтузиаст Мэтью Берман (Matthew Berman) решил провести с помощь теста LLM Colosseum своеобразный турнир между языковыми моделями, о чём он поделился в своём видео. В нём же Берман показал один из поединков между ИИ. Кроме того, он рассказал, как можно установить этот проект с исходным кодом на домашний ПК или Mac и оценить его самостоятельно. Это не совсем типичный тест LLM. Как правило, маленькие языковые модели имеют преимущество в задержке и скорости, что приводит к победе в большинстве виртуальных боёв. В файтингах очень важна скорость реакции игроков на ответные действия своих оппонентов. То же правило работает и в случае противостояния ИИ против ИИ. 
Источник изображений: OpenGenerativeAI team Языковая модель в реальном времени принимает решение, как ей сражаться. Поскольку LLM представляют собой текстовые модели, их обучили в игре Street Fighter III с помощью текстовых подсказок. ИИ сначала дали проанализировать контекст игры в целом, а затем подсказали, как реагировать на то или иное игровое действие в той или иной ситуации, не забыв про вариативность ходов. ИИ обучили приближаться или отдаляться от противника, а также использовать различные приёмы вроде огненного шара, мегаудара, урагана и мегаогненного шара. 
Источник изображения: OpenGenerativeAI team Продемонстрированный на видео бой между ИИ выглядит динамично. Оппоненты действуют стратегически, блокируют удары противника и используют специальные приёмы. Однако к настоящему моменту проект LLM Colosseum позволяет использовать только одного игрового персонажа, Кена. Согласно тестам Жирара, лучшей языковой моделью в турнире Street Fighter III оказалась GPT 3.5 Turbo от OpenAI. Среди восьми участников она достигла самого высокого рейтинга ELO — 1776. В отдельной серии тестов, организованных Банджо Обайоми (Banjo Obayomi), специалистом по продвижению продуктов AWS компании Amazon, спарринги проводились между четырнадцатью языковыми моделями в рамках 314 индивидуальных матчей. Здесь в конечном итоге победила языковая модель claude_3_haiku от Anthropic с рейтингом ELO 1613. Университет Кюсю поможет TSMC с кадрами и исследованиями в Японии
01.04.2024 [10:01],
Алексей Разин
В данный момент известно, что тайваньская компания TSMC не ограничится единственным построенным на территории Японии предприятием по контрактному производству чипов, поэтому сотрудничество с местными академическими учреждениями является для неё предсказуемым шагом. Университет Кюсю поможет TSMC готовить квалифицированных специалистов и проводить прикладные исследования. 
Источник изображения: TSMC Как отмечает Nikkei Asian Review, в рамках договорённости TSMC отправит инструкторов в образовательный центр Университета Кюсю, чтобы те поделились с местными преподавателями информацией, необходимой для формирования учебных планов и выработки методики подготовки будущих сотрудников японских предприятий TSMC. Стороны также рассматривают возможность сотрудничества в сфере разработок и исследований. Географическая близость Университета Кюсю к площадке, на которой TSMC и её японские партнёры строят свои предприятия, сыграет на руку в реализации этого проекта. Власти Японии уже одобрили строительство второго предприятия TSMC в этом регионе, но с условием методологической помощи со стороны компании по разработке учебных планов представителями Университета Кюсю. У последнего есть договорённости с тайваньскими университетами, поэтому взаимодействием только с TSMC дело не ограничится. Представители японской полупроводниковой отрасли считают, что остров Кюсю в ближайшие десять дет будет ежегодно нуждаться в 1000 новых специалистов в сфере полупроводникового производства. Университет Кумамото уже начал подстраивать свои планы под потребности местной полупроводниковой отрасли. Microsoft и Intel сформулировали определение «ПК с искусственным интеллектом»
27.03.2024 [17:24],
Николай Хижняк
Intel и Microsoft представили на проходящей конференции в Тайбэе своё универсальное определение «ПК с искусственным интеллектом». В понимании обоих производителей, далеко не все актуальные модели ПК и ноутбуков, представленных сегодня на рынке, ему соответствуют, даже несмотря на то, что они оснащены новейшими процессорами с ИИ-ускорителями и ИИ-помощником Copilot на базе большой языковой модели, который входит в состав операционной системы Windows 11. 
Источник изображений: Intel В октябре прошлого года компания Intel запустила программу AI PC Acceleration Program, призванную побудить независимых разработчиков программного обеспечения, а также производителей аппаратных средств присоединиться к расширению экосистемы ПК, оснащённых технологиями искусственного интеллекта. На конференции в Тайбэе производитель процессоров сообщил, что будет более активно помогать разработчикам ПО и аппаратных средств в рамках этого процесса. Intel представила специальные комплекты разработчиков на базе NUC с новейшими процессорами Core Ultra (Meteor Lake) для разработки программных решений с поддержкой ИИ, а также поделилась чётким определением «ПК с искусственным интеллектом», каким его представляет компания Microsoft.  Стремительное развитие технологий искусственного интеллекта и машинного обучения в течение последних лет открыло огромные возможности для внедрения новых аппаратных и программных функций в проверенную временем платформу ПК. Однако само по себе определение «ПК с искусственным интеллектом» или ИИ ПК по-прежнему оставалось расплывчатым. Ведущие мировые производители процессоров, включая Intel, AMD, Apple уже разработали и выпустили свои аппаратные решения, оснащённые специальными блоками ускорения работы ИИ-алгоритмов (NPU), которые располагаются на кристаллах чипов рядом с обычными ядрами CPU и GPU. На рынке скоро также должны появиться ноутбуки на базе процессоров Qualcomm, тоже оснащённых такими ИИ-ускорителями. Однако у каждой компании имеется свой взгляд на то, что представляет собой компьютер с искусственным интеллектом.  Ранее Intel уже заявляла, что к концу 2025 году планирует оснастить 100 млн ПК по всему миру своими процессорами с NPU. Для достижения этих целей производитель заручился поддержкой более сотни независимых поставщиков программного обеспечения и уже к концу 2024 года планирует вывести на рынок более 300 различных приложений с поддержкой искусственного интеллекта. Согласно прогнозам аналитического агентства Canalys, конкуренция на рынке ПК с технологиями ИИ в ближайшие годы будет усиливаться. И если к концу 2024 года доля поставок ПК с поддержкой искусственного интеллекта составит 19 % от общемировых объёмов поставок компьютеров, то 2027 эта доля вырастет уже до 60 %.  В новом совместно разработанном Microsoft и Intel определении говорится, что компьютер с искусственным интеллектом будет поставляться с нейронным сопроцессором (NPU), центральным и графическим процессорами, поддерживающими ИИ-помощника Microsoft Copilot, а также будет иметь физическую клавишу вызова ИИ-помощника Copilot непосредственно на клавиатуре, которая заменит правую клавишу Windows. Copilot — это чат-бот с искусственным интеллектом, созданный на основе LLM (большой языковой модели) и в данный момент активно внедряющийся компанией Microsoft в её операционную систему Windows 11. В настоящее время он работает через облачные сервисы, но, как сообщается, компания планирует реализовать локальную обработку Copilot непосредственно на ПК для повышения его производительности и оперативности. Озвученное Intel и Microsoft определение «ПК с искусственным интеллектом» означает, что большинство уже выпущенных ноутбуков на процессорах Intel Meteor Lake и AMD Ryzen AI последних поколений, поставляющихся без выделенной клавиши вызова Copilot, на самом деле не соответствуют официальным критериям Microsoft. В то же время можно ожидать, что все ключевые производители ПК и ноутбуков рано или поздно скорректируют характеристики своих решений для соответствия этим требованиям.  Хотя Intel и Microsoft сейчас занимаются совместным продвижением нового определения ИИ ПК, у самой Intel есть более простое определение для таких систем. В нём описывается ПК с CPU, GPU и NPU, в котором каждый из этих компонентов имеет свои собственные возможности ускорения выполнения задач, специфичных для искусственного интеллекта. Intel предлагает распределять рабочие нагрузки ИИ между указанными компонентами в зависимости от типа необходимых вычислений. При этом на NPU компания предлагает возлагать нагрузки ИИ с низкой интенсивностью, с которыми он сможет справляться с высокой степенью энергоэффективности. Сюда можно отнести, например, обработку фотографий, а также аудио и видео. NPU сможет ускорить выполнение этих задач непосредственно на компьютере, а не полагаясь на специальные облачные сервисы. В Intel отмечают, что таким образом получится одновременно увеличить время автономности систем с NPU, повысить их производительность, а также реализовать высокий уровень конфиденциальности данных за счёт хранения всей информации на локальном компьютере, а не в Сети. Использование NPU в низкоинтенсивных нагрузках также освободит ресурсы центрального и графического процессоров, которые можно будет использовать для других задач. Возможности CPU и GPU предлагается использовать при более интенсивных ИИ-нагрузках, где мощностей NPU может оказаться недостаточно. При необходимости ресурсы NPU и GPU также можно будет использовать одновременно, например, для запуска ресурсоёмких языковых моделей. 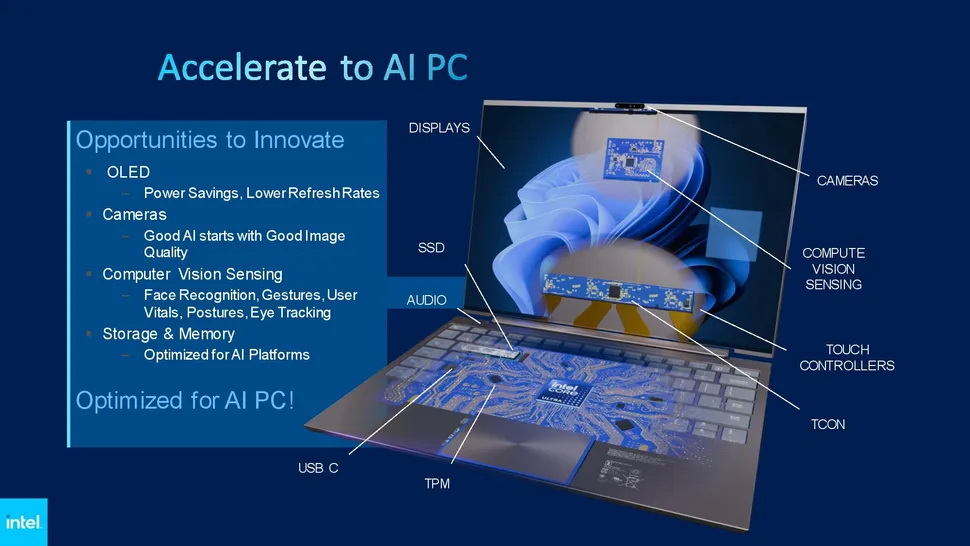 Разные модели искусственного интеллекта имеют разные требования к объёму используемой памяти и скорости компонентов, которые необходимы для их работы. Одни могут создавать более сложные и точные языковые модели, другие обеспечивают более высокую скорость выполнения поставленных задач. Intel говорит, что вопрос доступного объёма памяти у ПК станет ключевым для запуска LLM. Некоторые модели требуют 16 Гбайт ОЗУ, другим требуется вдвое больше. В перспективе это может привести к значительному увеличению стоимости потребительских компьютеров с ИИ, особенно в сегменте ноутбуков, однако Microsoft пока не определила минимальные требования к доступной памяти. Очевидно, что компания продолжит сотрудничество с производителями ПК и ноутбуков, чтобы найти нужный компромисс. Для каждого сегмента потребительских устройств, вероятно, будут выставлены свои требования. Но вполне можно ожидать, что даже в системах начального уровня с искусственным интеллектом появится больше памяти, а ПК с 8 Гбайт ОЗУ будут встречаться крайне редко или вообще исчезнут. 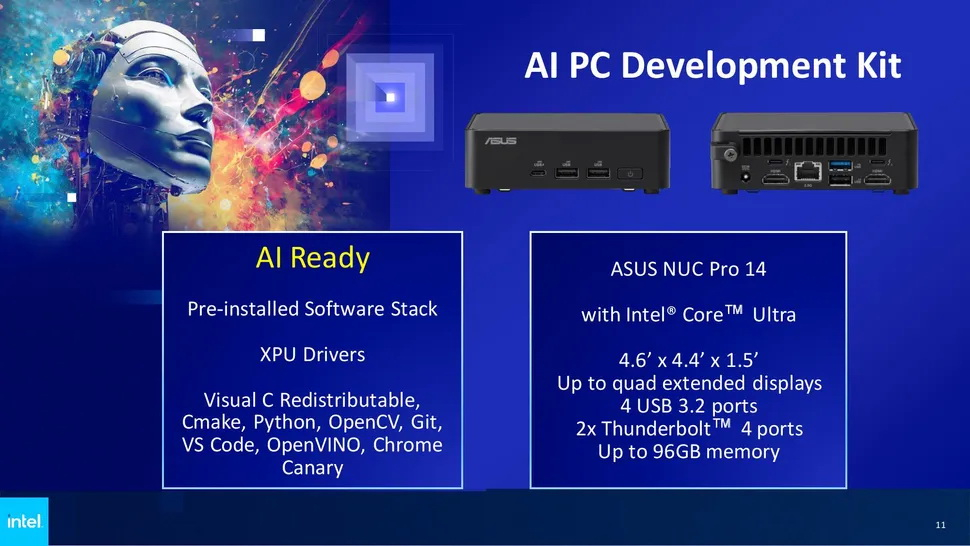 Что касается специальных комплектов разработчиков программного обеспечения с поддержкой ИИ, то для них Intel представила системы ASUS NUC Pro 14, оснащённые процессорами Core Ultra (Meteor Lake). Это компактные неттопы, оснащённые несколькими портами USB 3.2, а также интерфейсами Thunderbolt, предлагающие до 96 Гбайт ОЗУ. Более подробные характеристики указанных систем компания не сообщает, однако отмечает, что они также предлагают набор предустановленного специального программного обеспечения, инструментов, компиляторов и драйверов, необходимых для разработки программ с поддержкой ИИ. Установленные инструменты включают, среди прочего, Cmake, Python и OpenVino. Платформа Intel также поддерживает ONNX, DirectML и WebNN и другие средства для разработки и оптимизации программного обеспечения. Intel отмечает, что на её оборудовании с использованием OpenVino уже разработано более 280 различных открытых и оптимизированных ИИ-моделей, на базе ONNX — 173 моделей, а на базе Hugging Face — 150. При этом самые популярные модели скачиваются более 300 тыс. раз в месяц.  Компания уже сотрудничает с десятками крупных поставщиков программного обеспечения по вопросу интеграции ИИ в их продукты. В их числе Zoom, Adobe, Autodesk и многие другие. Однако Intel хочет расширить экосистему разработчиков, добавив к ней небольшие независимые команды и даже разработчиков-одиночек. Именно для них компания подготовила специальные комплекты разработчиков. Первые устройства для разработки программного обеспечения с ИИ-функциями будут выдаваться на текущей конференции в Тайбэе. В перспективе Intel также хочет предоставить указанные комплекты разработчиков тем, кто в силу разных причин не может участвовать в подобных мероприятиях. Однако эта часть программы AI PC Acceleration Program пока не началась из-за различных ограничений в разных странах и других логистических проблем.  Intel планирует предлагать комплекты разработчиков по льготной цене, однако конкретных деталей по этому поводу производитель не предоставил. В перспективе компания также планирует предоставлять разработчикам доступ к аналогичным аппаратным средствам на базе своих будущих платформ. Также компания планирует укрепить сотрудничество с различными университетами, представляя их факультетам информатики указанные комплекты разработчика. Для поддержки сообщества разработчиков на сайте Intel также имеется специальный центр знаний, в котором содержатся видеоуроки, инструкции, различная документация, дополнительные материалы и даже образцы кода. Для независимых поставщиков аппаратного обеспечения в рамках программы Open Labs компания Intel предлагает круглосуточный доступ к своим ресурсам для тестирования и оптимизации аппаратных средств, а также ранним образцам её оборудования в лабораториях в США, Китае и Тайване. Компания заявляет, что в рамках программы Open Labs более ста различных команд разработчиков уже представили около 200 различных аппаратных компонентов. ChatGPT обрёл тело — OpenAI и Figure сделали умного робота-гуманоида, который полноценно общается с людьми
13.03.2024 [22:40],
Николай Хижняк
Американский стартап Figure показал первые плоды сотрудничества с компанией OpenAI по расширению возможностей гуманоидных роботов. Figure опубликовала новое видео со своим роботом Figure 01, ведущим диалог с человеком в режиме реального времени. Машина на видео отвечает на вопросы и выполняет его команды. 
Источник изображения: Figure Стремительный темп развития проекта Figure 01 и компании Figure в целом не может не впечатлять. Бизнесмен и основатель стартапа Бретт Эдкок (Brett Adcock) «вышел из тени» год назад, после того как компания привлекла внимание крупных игроков на рынке робототехники и технологий искусственного интеллекта, включая Boston Dynamics, Tesla Google DeepMind, Archer Aviation и других, и поставила цель «создать первого в мире коммерчески доступного гуманоидного робота общего назначения». К октябрю того же года Figure 01 «встал на ноги» и продемонстрировал свои возможности в выполнении базовых автономных задач. К концу всё того же 2023 года робот обрёл возможность обучаться выполнению различных задач. К середине января Figure подписала первый коммерческий контракт на использование Figure 01 на автомобильном заводе компании BMW в североамериканском штата Северная Каролина. В прошлом месяце Figure опубликовала видео, на котором Figure 01 выполняет работу на складе. Практически сразу после этого компания анонсировала разработку второго поколения машины и объявила о сотрудничестве с OpenAI «по разработке нового поколения ИИ-моделей для гуманоидных роботов». Сегодня Figure поделилась видео, в котором демонстрируются первые результаты этого сотрудничества. Через свою страницу в X (бывший Twitter) Адкок сообщил, что встроенные в Figure 01 камеры отправляют данные в большую визуально-языковую модель ИИ, обученную OpenAI, в то время как собственные нейросети Figure «также через камеры робота захватывает изображение окружения с частотой 10 Гц». Алгоритмы OpenAI также отвечают за возможность робота понимать человеческую речь, а нейросеть Figure преобразует поток полученной информации в «быстрые, низкоуровневые и ловкие действия робота». Глава Figure утверждает, что во время демонстрации робот не управлялся дистанционно и видео показано с реальной скоростью. «Наша цель — научить мировую модель ИИ управлять роботами-гуманоидами на уровне миллиардов единиц», — добавил руководитель стартапа. При таком темпе развития проекта ждать осталось не так уж и долго. Cerebras представила гигантский процессор WSE-3 c 900 тысячами ядер
13.03.2024 [19:58],
Николай Хижняк
Американский стартап Cerebras Systems представил гигантский процессор WSE-3 для машинного обучения и других ресурсоёмких задач, для которого заявляется двукратный прирост производительности на ватт потребляемой энергии по сравнению с предшественником. 
Cerebras WSE-3. Источник изображений: Cerebras Площадь нового процессора составляет 46 225 мм2. Он выпускается с использованием 5-нм техпроцесса компании TSMC, содержит 4 трлн транзисторов, 900 000 ядер и объединён с 44 Гбайт набортной памяти SRAM. Его производительность в операциях FP16 заявлена на уровне 125 Пфлопс. Один WSE-3 составляет основу для новой вычислительной платформы Cerebras CS-3, которая, по утверждению компании, обеспечивает вдвое более высокую производительность, чем предыдущая платформа CS-2 при том же энергопотреблении в 23 кВт. По сравнению с ускорителем Nvidia H100 платформа Cerebras CS-3 на базе WSE-3 физически в 57 раз больше и примерно в 62 раза производительнее в операциях FP16. Но учитывая размеры и энергопотребление Cerebras CS-3, справедливее будет сравнить её с платформой Nvidia DGX с 16 ускорителями H100. Правда, даже в этом случае CS-3 примерно в 4 раза быстрее конкурента, если речь идёт именно об операциях FP16. 
Cerebras CS-3 Одним из ключевых преимуществ систем Cerebras является их пропускная способность. Благодаря наличию 44 Гбайт набортной памяти SRAM в каждом WSE-3, пропускная способность новейшей системы Cerebras CS-3 составляет 21 Пбайт/с. Для сравнения, Nvidia H100 с памятью HBM3 обладает пропускной способностью в 3,9 Тбайт/с. Однако это не означает, что системы Cerebras быстрее во всех сценариях использования, чем конкурирующие решения. Их производительность зависит от коэффициента «разрежённости» операций. Та же Nvidia добилась от своих решений удвоения количества операций с плавающей запятой, используя «разреженность». В свою очередь Cerebras утверждает, что добилась улучшения примерно до 8 раз. Это значит, что новая система Cerebras CS-3 будет немного медленнее при более плотных операциях FP16, чем пара серверов Nvidia DGX H100 при одинаковом энергопотреблении и площади установки, и обеспечит производительность около 15 Пфлопс против 15,8 Пфлопс у Nvidia (16 ускорителей H100 выдают 986 Тфлопс производительности). 
Одна из установок Condor Galaxy AI Cerebras уже работает над внедрением CS-3 в состав своего суперкластера Condor Galaxy AI, предназначенного для решения ресурсоёмких задач с применением ИИ. Этот проект был инициирован в прошлом году при поддержке компании G42. В его рамках планируется создать девять суперкомпьютеров в разных частях мира. Две первые системы, CG-1 и CG-2, были собраны в прошлом году. В каждой из них сдержится по 64 платформы Cerebras CS-2 с совокупной ИИ-производительностью 4 экзафлопса. В эту среду Cerebras сообщила, что построит систему CG-3 в Далласе, штат Техас. В ней будут использоваться несколько CS-3 с общей ИИ-производительностью 8 экзафлопсов. Если предположить, что на остальных шести площадках также будут использоваться по 64 системы CS-3, то общая производительность суперкластера Condor Galaxy AI составит 64 экзафлопса. В Cerebras отмечают, что платформа CS-3 может масштабироваться до 2048 ускорителей с общей производительностью до 256 экзафлопсов. По оценкам экспертов, такой суперкомпьютер сможет обучить модель Llama 70B компании Meta✴ всего за сутки. Помимо анонса новых ИИ-ускорителей Cerebras также сообщила о сотрудничестве с компанией Qualcomm в вопросе создания оптимизированных моделей для ИИ-ускорителей Qualcomm с Arm-архитектурой. На потенциальное сотрудничество обе компании намекали с ноября прошлого года. Тогда же Qualcomm представила свой собственный ИИ-ускорители Cloud AI100 Ultra формата PCIe. Он содержит 64 ИИ-ядра, 128 Гбайт памяти LPDDR4X с пропускной способностью 548 Гбайт/с, обеспечивает производительность в операциях INT8 на уровне 870 TOPS и обладает TDP 150 Вт. 
Источник изображения: Qualcomm В Cerebras отмечают, что вместе с Qualcomm они будут работать над оптимизацией моделей для Cloud AI100 Ultra, в которых будут использоваться преимущества таких методов, как разреженность, спекулятивное декодирование, MX6 и поиск сетевой архитектуры. «Как мы уже показали, разрежённость при правильной реализации способна значительно повысить производительность ускорителей. Спекулятивное декодирование предназначено для повышения эффективности модели при развёртывании за счёт использования небольшой и облегченной модели для генерации первоначального ответа, а затем использования более крупной модели для проверки точности этого ответа», — отметил гендиректор Cerebras Эндрю Фельдман (Andrew Feldman). 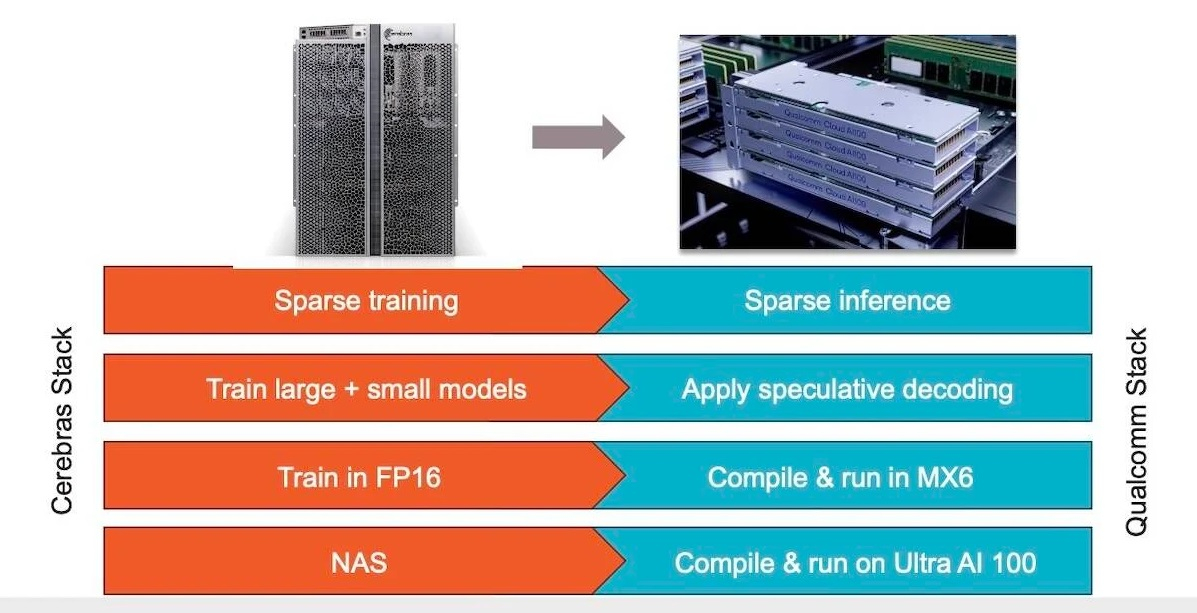 Обе компании также рассматривают возможность использования метода MX6, представляющего собой форму сжатия размера модели путём снижения её точности. В свою очередь, поиск сетевой архитектуры представляет собой процесс автоматизации проектирования нейронных сетей для конкретных задач с целью повышения их производительности. По словам Cerebras, сочетание этих методов способствует десятикратному повышению производительности на доллар. В Китае искусственный интеллект навёл порядок на железной дороге — она заработала лучше, чем новая
13.03.2024 [12:10],
Геннадий Детинич
Чат-боты, сгенерированные картинки, видео и другие подобные развлечения с искусственным интеллектом — это интересно и местами полезно. Но более важным станет практическое внедрение ИИ в производство, транспорт и материальную экономику в целом. В конечном итоге выиграет тот, кто буквально будет «пахать и строить» на ИИ, заменив человека в производственной сфере. Китай сделал важный шаг к этому: благодаря ИИ там смогли навести порядок на железной дороге. 
Источник изображения: Xinhua Простой обыватель даже не может себе представить, чего стоит содержать дорогу, инфраструктуру и парк техники в порядке, а также обеспечивать движение составов. Это потенциально убыточные мероприятия с огромной ответственностью. Китай, как и другие страны, вскоре ощутит проблемы со стареющим населением. При этом железнодорожная сеть в стране растёт и предполагает соединение высокоскоростными ж/д магистралями все города с населением свыше 500 тыс. человек. Скорость подвижного состава также растёт, что делает человеческий фактор наиболее слабым звеном. Протокол управления данными для внедрения ИИ-алгоритмов на железной дороге в Китае был внедрён оператором национальной сети железных дорог — китайской государственной компанией China State Railway Group — в 2022 году. Доступ к данным должен был быть ограничен и защищён от стороннего вмешательства и утечек. Алгоритмы управления были проверены людьми, и только после этого они были внедрены. Масштабные испытания начались в 2023 году. Результат ошеломил — железная дорога стала работать даже лучше, чем новая (сразу после ввода участков и составов в строй). Датчики установлены на объектах инфраструктуры, на колёсные пары, на вагоны, чтобы учитывать вибрации, ускорение и амплитуды и это не говоря об обычной сигнальной автоматике. Объём собираемых для анализа данных достиг 200 Тбайт, а ведь это не картинки или видео, а обычные состояния регистров. Человек и сколь угодно большой коллектив не смог бы оперативно обрабатывать такой объём информации. Всё это данные о 45 тыс. км путей — это длиннее, чем экватор Земли. Обслужить всё это не хватит никакой рабочей силы. Размещённая в Пекине система искусственного интеллекта в режиме реального времени обрабатывает огромные объёмы данных со всей страны и может предупреждать ремонтные бригады о нештатных ситуациях в течение 40 минут с точностью до 95 %. Рекомендации обычно направлены на предотвращение неисправностей — на профилактику потенциальных проблем. ИИ во всём этом потоке данных научили находить связи между событиями, которые недоступны для осознания в реальном масштабе времени. За прошедший год ни одна из действующих высокоскоростных железнодорожных линий Китая не получила ни единого предупреждения о необходимости снижения скорости из-за серьёзных проблем с неровностями пути, в то время как количество мелких неисправностей на путях сократилось на 80 % по сравнению с предыдущим годом. Алгоритмы действуют настолько чётко, что даже повышают плавность хода в условиях сильных ветров и на мостах, снижая амплитуду колебаний составов и уменьшая нагрузку на пути и инфраструктуру. Звучит, как фантастика. Подобные решения не только уменьшают потребность в обслуживающем персонале, но также снижают финансовую нагрузку на содержание железных дорог и, что самое важное, повышают безопасность движения. В Китае признают своё отставание от США в плане развития искусственного интеллекта, но если США не сможет конвертировать возможности ИИ в повышение производительности труда в материальной сфере, то это их преимущество будет лишь иллюзией. Все ведущие большие языковые модели ИИ нарушают авторские права, а GPT-4 — больше всех
06.03.2024 [18:36],
Сергей Сурабекянц
Компания по изучению ИИ Patronus AI, основанная бывшими сотрудниками Meta✴, исследовала, как часто ведущие большие языковые модели (LLM) создают контент, нарушающий авторские права. Компания протестировала GPT-4 от OpenAI, Claude 2 от Anthropic, Llama 2 от Meta✴ и Mixtral от Mistral AI, сравнивая ответы моделей с текстами из популярных книг. «Лидером» стала модель GPT-4, которая в среднем на 44 % запросов выдавала текст, защищённый авторским правом. 
Источник изображений: Pixabay Одновременно с выпуском своего нового инструмента CopyrightCatcher компания Patronus AI опубликовала результаты теста, призванного продемонстрировать, как часто четыре ведущие модели ИИ отвечают на запросы пользователей, используя текст, защищённый авторским правом. Согласно исследованию, опубликованному Patronus AI, ни одна из популярных книг не застрахована от нарушения авторских прав со стороны ведущих моделей ИИ. «Мы обнаружили контент, защищённый авторским правом, во всех моделях, которые оценивали, как с открытым, так и закрытым исходным кодом», — сообщила Ребекка Цянь (Rebecca Qian), соучредитель и технический директор Patronus AI. Она отметила, что GPT-4 от OpenAI, возможно самая мощная и популярная модель, создаёт контент, защищённый авторским правом, в ответ на 44 % запросов. Patronus тестировала модели ИИ с использованием книг, защищённых авторскими правами в США, выбирая популярные названия из каталога Goodreads. Исследователи разработали 100 различных подсказок, которые можно счесть провокационными. В частности, они спрашивали модели о содержании первого абзаца книги и просили продолжить текст после цитаты из романа. Также модели должны были дополнять текст книг по их названию. Модель GPT-4 показала худшие результаты с точки зрения воспроизведения контента, защищённого авторским правом, и оказалась «менее осторожной», чем другие. На просьбу продолжить текст она в 60 % случаев выдавала целиком отрывки из книги, а первый абзац книги выводила в ответ на каждый четвёртый запрос. Claude 2 от Anthropic оказалось труднее обмануть — когда её просили продолжить текст, она выдавала контент, защищённый авторским правом, лишь в 16 % случаев, и ни разу не вернула в качестве ответа отрывок из начала книги. При этом Claude 2 сообщала исследователям, что является ИИ-помощником, не имеющим доступа к книгам, защищённым авторским правом, но в некоторых случаях всё же предоставила начальные строки романа или краткое изложение начала книги. Модель Mixtral от Mistral продолжала первый абзац книги в 38 % случаев, но только в 6 % случаев она продолжила фразу запроса отрывком из книги. Llama 2 от Meta✴ ответила контентом, защищённым авторским правом, на 10 % запросов первого абзаца и на 10 % запросов на завершение фразы. 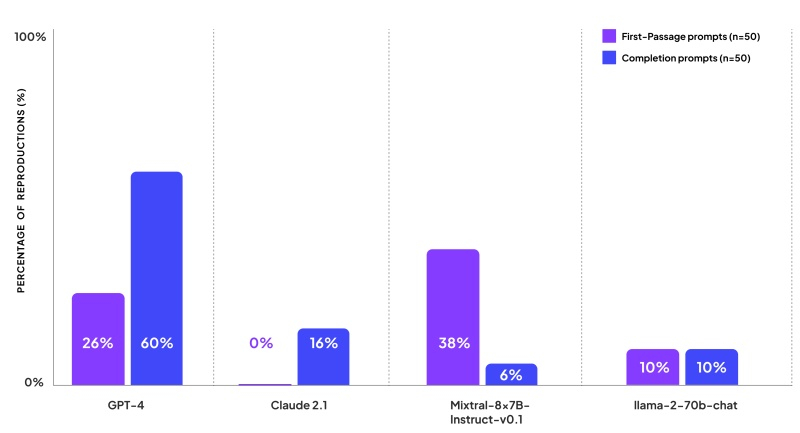
Источник изображения: Patronus AI «В целом, тот факт, что все языковые модели дословно создают контент, защищённый авторским правом, был действительно удивительным, — заявил Ананд Каннаппан (Anand Kannappan), соучредитель и генеральный директор Patronus AI, раньше работавший в Meta✴ Reality Labs. — Я думаю, когда мы впервые начали собирать это вместе, мы не осознавали, что будет относительно просто создать такой дословный контент». Результаты исследования наиболее актуальны на фоне обострения отношений между создателями моделей ИИ и издателями, авторами и художниками из-за использования материалов, защищённых авторским правом, для обучения LLM. Достаточно вспомнить громкий судебный процесс между The New York Times и OpenAI, который некоторые аналитики считают переломным моментом для отрасли. Многомиллиардный иск новостного агентства, поданный в декабре, требует привлечь Microsoft и OpenAI к ответственности за систематическое нарушение авторских прав издания при обучении моделей ИИ.  Позиция OpenAI заключается в том, что «поскольку авторское право сегодня распространяется практически на все виды человеческого выражения, включая сообщения в блогах, фотографии, сообщения на форумах, фрагменты программного кода и правительственные документы, было бы невозможно обучать сегодняшние ведущие модели ИИ без использования материалов, защищённых авторским правом». По мнению OpenAI, ограничение обучающих данных созданными более века назад книгами и рисунками, являющимися общественным достоянием, может стать интересным экспериментом, но не обеспечит системы ИИ, отвечающие потребностям настоящего и будущего. ChatGPT научился читать свои ответы вслух
05.03.2024 [10:12],
Николай Хижняк
Компания OpenAI добавила в свой ИИ-бот ChatGPT функцию «Чтение вслух», которая озвучивает ответы на запросы пользователей с помощью одним из пяти голосов. Функция может пригодиться, например, в дороге, когда отвлечься на экран устройства для чтения ответа на запрос может оказаться невозможно. Новая функция «Чтение вслух» уже доступна как в веб-версии ChatGPT, так и в приложениях ChatGPT для iOS и Android. 
Источник изображения: Unsplash, Andrew Neel Функция «Чтение вслух» поддерживает 37 языков и автоматически определяет язык ответа. Она доступна как для чат-ботов на базе GPT-4, так и для GPT-3.5. Следует добавить, что аналогичные возможности для своих ИИ-моделей ранее добавила компания Anthropic, один из основных конкурентов OpenAI. В сентябре минувшего года ChatGPT запустил функцию голосового запроса, благодаря которой пользователи могут голосом проговаривать запрос для чат-бота, не печатая его в форме. Новая же функция позволяет настроить чат-бота таким образом, чтобы он всегда устно отвечал на запросы пользователя. Для работы функции «Чтение вслух» в мобильных приложениях необходимо нажать и удерживать поле введённого запроса. В результате откроется специальный плеер «Чтение вслух», где можно выбрать настройки воспроизведения, приостановки или перемотки аудио-ответа. В веб-версии чат-бота для активации функции «Чтение вслух» под текстом ответа отображается значок динамика. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться