|
Опрос
|
реклама
Быстрый переход
Соцсеть X запретила использовать свой контент для обучения чужих ИИ
06.06.2025 [16:00],
Павел Котов
Администрация соцсети X обновила политику конфиденциальности — в новой редакции документ не позволяет третьим лицам использовать материалы платформы для обучения искусственного интеллекта. Эта мера, возможно сигнализирует о готовности заключать лицензионные сделки, как это ранее сделала Reddit. Источник изображения: Dima Solomin / unsplash.com Сторонним разработчикам теперь запрещается «использовать API X или материалы X для тонкой настройки или обучения базовых или передовых моделей [ИИ]», говорится в разделе «Обратное проектирование и прочие ограничения» обновлённого соглашения. В редакции политики конфиденциальности от октября прошлого года платформа могла передавать контент пользователей третьим лицам «для обучения их моделей ИИ, будь то генеративные или иные», если сами пользователи от этого не отказались. Перемена может быть связана с тем, что официально владельцем X является стартап Илона Маска (Elon Musk) xAI. Компания занимается разработкой чат-бота Grok, и вполне естественно, что она больше не хочет, чтобы третьи лица при разработке ИИ имели то же конкурентное преимущество — большой объём обучающего контента. По крайней мере, бесплатно компания предоставлять эти данные теперь не намерена. Эта мера может открыть для X новый источник дохода, если администрация платформы решит лицензировать контент за плату. Ранее так поступила Reddit — она заключила лицензионные соглашения с Google и OpenAI. Reddit также развернула средства безопасности, не допускающие краж данных ботами и веб-сканерами; она даже подала в суд на Anthropic, обвинив разработчика ИИ в недобросовестном сборе информации. Стоит отметить, что изменения политики X касаются только сторонних разработчиков ИИ; условия обслуживания по-прежнему позволяют администрации платформы использовать контент пользователей для обучения собственных моделей ИИ. Запретить сбор таких данных можно в настройках конфиденциальности своей учётной записи. МТС потратила 1 миллиард рублей на дообучение ИИ — OpenAI тратит на ИИ на несколько порядков больше
03.06.2025 [15:44],
Павел Котов
По итогам 2024 года расходы подразделения МТС MWS AI на обучение больших языковых моделей семейства Cotype составили 1 млрд рублей, пишут «Ведомости» со ссылкой на заявление гендиректора компании Дениса Филиппова. 
Источник изображения: Igor Omilaev / unsplash.com Вместо создания собственных моделей с нуля МТС занимается дообучением существующих. Семейство вышедших в 2024 году моделей Cotype первого поколения было основано на французской открытой модели Mistral; в 2025 году вышли Cotype второго поколения, основанные уже на Alibaba Cloud Qwen 2.5. В ассортименте МТС значится также базирующийся на нескольких моделях помощник Kodify для написания программного кода. Создание собственной большой языковой модели с нуля обошлось бы МТС в сумму от 10 млрд руб., рассуждают опрошенные «Ведомостями» эксперты, — такие проекты есть у «Яндекса» и «Сбера», но они объёмов своих вложений не раскрывают. У «Яндекса», гласит официальная информация, на конец 2021 года были три суперкомпьютера, на которых установлены в общей сложности 3500 ИИ-ускорителей Nvidia А100. У «Яндекса» и «Сбера» могут быть около 10 000 единиц такого оборудования, полагают эксперты. Дообучение готовых больших языковых моделей — задача также дорогостоящая: 100 млн руб. требуются на аренду оборудования, и ещё в 400–500 млн руб. обходятся прочие расходы, включая команду от 30 до 50 специалистов. Поэтому расходы в 1 млрд руб. (примерно $12 млн) представляются адекватной суммой, учитывая масштабы задачи. Но зарубежные лидеры отрасли тратят на обучение ИИ значительно больше денег: OpenAI потратила на создание и оптимизацию GPT-4 около $10–15 млрд. С другой стороны, DeepSeek утверждает, что её расходы на обучение не уступающей американским модели составили всего $6 млн, но этот тезис экспертам до сих пор представляется спорным. Мировой рынок продуктов на основе больших языковых моделей в 2024 году вырос до $6,4 млрд (примерно 503 млрд руб.), российский — до 35 млрд руб. При этом объёмы инвестиций в отрасль ИИ составили $110 млрд (8 трлн руб.), значительная часть из которых пошла на разработку и обучение больших языковых моделей и прочих видов генеративного ИИ. В мировом масштабе затраты МТС на обучение ИИ представляются не очень большой суммой, но свидетельствуют о серьёзном настрое компании — от её проекта ожидают не лидерства в отрасли, а практической пользы, кроме того, отечественный игрок помогает клиентам снижать зависимость от зарубежных разработок. К 2030 году мощность российских центров обработки данных должна достичь 70 000 единиц в эквиваленте Nvidia А100. Зелёная сова против людей: Duolingo начала увольнять сотрудников, которых может заменить ИИ
29.04.2025 [11:10],
Дмитрий Федоров
Duolingo, один из лидеров рынка цифрового образования, объявила о переходе к стратегии AI-first, предполагающей постепенное замещение подрядчиков ИИ и фундаментальную перестройку рабочих процессов. Компания делает ставку на ускорение создания контента, внедрение новых технологий и обеспечение масштабного доступа к обучающим материалам для пользователей по всему миру. 
Источник изображения: Duolingo Соучредитель и генеральный директор Луис фон Ан (Luis von Ahn) разослал сотрудникам письмо, текст которого был опубликован на официальной странице компании в LinkedIn. В письме подчёркивается, что ИИ станет основой всех рабочих процессов, а подрядчики будут постепенно выведены из операционной деятельности. Он напомнил, что в 2012 году Duolingo сделала успешную ставку на мобильные устройства, когда большинство компаний ещё ориентировались на веб-приложения. Это решение в 2013 году принесло Duolingo награду «iPhone App of the Year» (рус. — Приложение года для iPhone) и обеспечило стремительный органический рост. Сегодня, по его словам, компания делает аналогичную ставку, только на ИИ. Переход к модели AI-first (рус. — ИИ на первом месте) потребует от компании пересмотра ключевых бизнес-процессов. Фон Ан отметил, что простые доработки систем, изначально предназначенных для работы людей, не обеспечат необходимого уровня эффективности. Вводятся конструктивные ограничения: отказ от подрядчиков для задач, которые может выполнять ИИ, обязательное использование ИИ как критерий при найме сотрудников, учёт уровня применения ИИ при аттестации персонала и ограничение увеличения численности штата только в случаях, когда дальнейшая автоматизация невозможна. Несмотря на радикальные изменения, фон Ан заверил, что Duolingo останется компанией, заботящейся о своих сотрудниках. Он подчеркнул, что цель перехода — не замена людей на ИИ, а устранение узких мест в рабочих процессах. Компания сосредоточит усилия на поддержке персонала: будет усилено обучение работе с ИИ, запущены программы наставничества и предоставлены новые инструменты для внедрения ИИ в профессиональную деятельность. Фон Ан привёл пример недавнего успеха Duolingo: замена медленного ручного процесса создания образовательного контента автоматизированной системой на базе ИИ. Без внедрения ИИ на масштабирование контента для всех пользователей ушли бы десятилетия. Теперь благодаря автоматизации Duolingo сможет предоставить новые обучающие материалы миллионам учащихся уже в ближайшие месяцы, выполняя свою миссию максимально быстро. ИИ позволяет компании разрабатывать ранее невозможные функции. Одним из ключевых проектов стала разработка функции Video Call (Видеозвонок), которая позволяет обучать пользователей на уровне лучших репетиторов. Это открывает новые перспективы в области дистанционного образования, значительно улучшая качество онлайн-обучения. Фон Ан подчеркнул, что Duolingo не намерена ждать, пока технологии достигнут идеала. Компания предпочитает действовать незамедлительно, даже если это приведёт к небольшим потерям качества на отдельных этапах. Основная цель — не упустить момент, когда технологические возможности стремительно меняют рынок, и первыми адаптировать свои процессы к новой реальности. Duolingo следует глобальному тренду в сфере технологий. Ранее аналогичное письмо сотрудникам направил генеральный директор Shopify Тоби Лютке (Tobi Lütke), в котором требовал, чтобы перед подачей заявки на увеличение численности персонала команды обосновывали невозможность выполнения поставленных задач с помощью ИИ. Этот тренд свидетельствует о том, что автоматизация становится одним из важнейших критериев эффективности бизнеса в 2025 году. «Википедия» выпустила набор данных для обучения ИИ, чтобы боты не перегружали её серверы скрейпингом
17.04.2025 [16:43],
Владимир Мироненко
Фонд Wikimedia (некоммерческая организация, управляющая «Википедией») предложил компаниям вместо веб-скрейпинга контента «Википедии» с помощью ботов, который истощает её ресурсы и перегружает серверы трафиком, воспользоваться набором данных, специально оптимизированным для обучения ИИ-моделей. 
Источник изображения: Oberon Copeland @veryinformed.com/unsplash.com Wikimedia объявил о заключении партнёрского соглашения с Kaggle, ведущей платформой для специалистов в области Data Science и машинного обучения, принадлежащей Google. В рамках соглашения на ней будет опубликована бета-версия набора данных «структурированного контента “Википедии” на английском и французском языках». Согласно Wikimedia, набор данных, размещённый Kaggle, был «разработан с учётом рабочих процессов машинного обучения», что упрощает разработчикам ИИ доступ к машиночитаемым данным статей для моделирования, тонкой настройки, сравнительного анализа, выравнивания и анализа. Содержимое набора данных имеет открытую лицензию. По состоянию на 15 апреля набор включает в себя обзоры исследований, краткие описания, ссылки на изображения, данные инфобоксов и разделы статей — за исключением ссылок или неписьменных элементов, таких как аудиофайлы. Как сообщает Wikimedia, «хорошо структурированные JSON-представления контента “Википедии”», доступные пользователям Kaggle, должны быть более привлекательной альтернативой «скрейпингу или анализу сырого текста статей». На данный момент у Wikimedia есть соглашения об обмене контентом с Google и Internet Archive, но партнёрство с Kaggle позволит сделать данные более доступными для небольших компаний и независимых специалистов в сфере Data Science. «Являясь площадкой, к которой сообщество машинного обучения обращается за инструментами и тестами, Kaggle будет рада стать хостом для данных фонда Wikimedia», — сообщила Бренда Флинн (Brenda Flynn), руководитель по коммуникациям в Kaggle. Google представила рассуждающую ИИ-модель Gemini 2.5 Flash с высокой производительностью и эффективностью
09.04.2025 [17:46],
Николай Хижняк
Google выпустила новую ИИ-модель, призванную обеспечить высокую производительность с упором на эффективность. Она называется Gemini 2.5 Flash и вскоре станет доступна в составе платформы Vertex AI облака Google Cloud для развёртывания и управления моделями искусственного интеллекта (ИИ). 
Источник изображения: Google Компания отмечает, что Gemini 2.5 Flash предлагает «динамические и контролируемые» вычисления, позволяя разработчикам регулировать время обработки запроса в зависимости от их сложности. «Вы можете настроить скорость, точность и баланс затрат для ваших конкретных нужд. Эта гибкость является ключом к оптимизации производительности Flash в высоконагруженных и чувствительных к затратам приложениях», — написала компания в своём официальном блоге. На фоне растущей стоимости использования флагманских ИИ-моделей Gemini 2.5 Flash может оказаться крайней полезной. Более дешёвые и производительные модели, такие как 2.5 Flash, представляют собой привлекательную альтернативу дорогостоящим флагманским вариантам, но ценой потери некоторой точности. Gemini 2.5 Flash — это «рассуждающая» модель по типу o3-mini от OpenAI и R1 от DeepSeek. Это означает, что для проверки фактов ей требуется немного больше времени, чтобы ответить на запросы. Google утверждает, что 2.5 Flash идеально подходит для работы с большими объёмами данных и использования в реальном времени, в частности, для таких задач, как обслуживание клиентов и анализ документов. «Эта рабочая модель оптимизирована специально для низкой задержки и снижения затрат. Это идеальный движок для отзывчивых виртуальных помощников и инструментов резюмирования в реальном времени, где эффективность при масштабировании является ключевым фактором», — описывает новую ИИ-модель компания. Google не опубликовала отчёт по безопасности или техническим характеристикам для Gemini 2.5 Flash, что усложнило задачу определения её преимуществ и недостатков. Ранее компания говорила, что не публикует отчёты для моделей, которые она считает экспериментальными. Google также объявила, что с третьего квартала планирует интегрировать модели Gemini, такие как 2.5 Flash в локальные среды. Они будут доступны в Google Distributed Cloud (GDC), локальном решении Google для клиентов со строгими требованиями к управлению данными. В компании добавили, что работают с Nvidia над установкой Gemini на совместимые с GDC системы Nvidia Blackwell, которые клиенты смогут приобрести через Google или по своим каналам. Google представила свой самый мощный ИИ-процессор Ironwood — до 4,6 квадриллиона операций в секунду
09.04.2025 [15:56],
Николай Хижняк
В рамках конференции Cloud Next на этой неделе компания Google представила новый специализированный ИИ-чип Ironwood. Это уже седьмое поколение ИИ-процессоров компании и первый TPU, оптимизированный для инференса — работы уже обученных ИИ-моделей. Процессор будет использоваться в Google Cloud и поставляться в системах двух конфигураций: серверах из 256 таких процессоров и кластеров из 9216 таких чипов. 
Источник изображений: Google «Ironwood — это наш самый мощный, самый производительный и самый энергоэффективный TPU. Он разработан для ускорения инференса ИИ-моделей в масштабах облачной инфраструктуры», — прокомментировал анонс процессора вице-президент Google Cloud Амин Вахдат (Amin Vahdat). Анонс Ironwood состоялся на фоне усиливающейся конкуренции в сегменте разработок проприетарных ИИ-ускорителей. Хотя Nvidia доминирует на этом рынке, свои технологические решения также продвигают Amazon и Microsoft. Первая разработала ИИ-процессоры Trainium, Inferentia и Graviton, которые используются в её облачной инфраструктуре AWS, а Microsoft применяет собственные ИИ-чипы Cobalt 100 в облачных инстансах Azure.  Google заявляет, что Ironwood обладает пиковой вычислительной производительностью 4614 Тфлопс или 4614 триллионов операций в секунду. Таким образом кластер из 9216 таких чипов предложит производительность в 42,5 Экзафлопс. 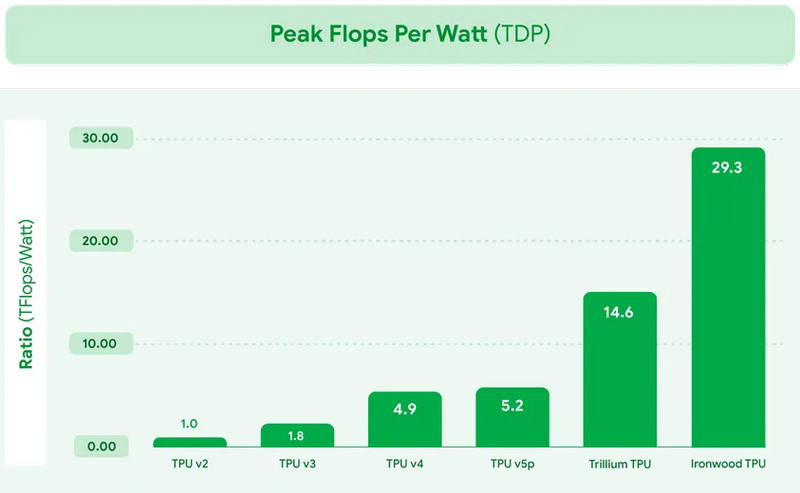 Каждый процессор оснащён 192 Гбайт выделенной оперативной памяти с пропускной способностью 7,4 Тбит/с. Также чип включает усовершенствованное специализированное ядро SparseCore для обработки типов данных, распространённых в рабочих нагрузках «расширенного ранжирования» и «рекомендательных систем» (например, алгоритм, предлагающий одежду, которая может вам понравиться). Архитектура TPU оптимизирована для минимизации перемещения данных и задержек, что, по утверждению Google, приводит к значительной экономии энергии. Компания планирует использовать Ironwood в своём модульном вычислительном кластере AI Hypercomputer в составе Google Cloud. «Наш контент бесплатный, а инфраструктура — нет»: ИИ-боты разоряют «Википедию»
02.04.2025 [19:54],
Сергей Сурабекянц
«Википедия» расплачивается за бум искусственного интеллекта — онлайн-энциклопедия сталкивается с растущими расходами из-за ботов, которые копируют её статьи для обучения моделей искусственного интеллекта, что впустую расходует ресурсы и в разы увеличивает трафик и нагрузку на сайт. Только за последние три месяца трафик, генерируемый ИИ-краулерами, вырос на 50 %. 
Источник изображения: «Википедия» Фонд Wikimedia (некоммерческая организация, управляющая «Википедией») заявил, что «автоматизированные запросы на наш контент выросли в геометрической прогрессии». По данным фонда, с января 2024 года пропускная способность, используемая для загрузки мультимедийного контента, выросла на 50 %. Однако трафик исходит не от людей, а от автоматизированных программ, которые постоянно загружают изображения с открытой лицензией для передачи их моделям ИИ. «Наша инфраструктура создана для того, чтобы выдерживать внезапные всплески трафика от людей во время мероприятий с высоким интересом, но объем трафика, генерируемого ботами-скрейперами, беспрецедентен и представляет растущие риски и расходы», — сообщила «Википедия». Боты часто собирают данные из менее популярных статей «Википедии». Специалисты «Википедии» утверждают, что по крайней мере 65 % подобного трафика, поступает от ботов, что является непропорционально большим объёмом, учитывая, что общее количество просмотров страниц ботами составляет около 35 %. Также боты проявляют интерес к «ключевым системам в инфраструктуре разработчиков, таким как наша платформа проверки кода или наш баг-трекер», что ещё больше нагружает ресурсы сайта. «Википедия» была вынуждена ввести индивидуальные ограничения скорости для ИИ-ботов или вообще запретить доступ некоторым из них. Но для решения проблемы в долгосрочной перспективе фонд разрабатывает план «Ответственного использования инфраструктуры». План предусматривает сбор отзывов от сообщества «Википедии» о способах определения трафика от ИИ-ботов и фильтрации их доступа. Социальная платформа Reddit столкнулась с похожей проблемой в 2023 году. Например, Microsoft без уведомления Reddit использовала данные платформы для обучения моделей ИИ, что вынудило Reddit заблокировать ботов Microsoft. После этого инцидента Reddit решила взимать плату со сторонних разработчиков за доступ к своему API. Это привело к массовым протестам разработчиков и закрытию некоторых популярных форумов Reddit. OpenAI: ИИ бесполезно наказывать за ложь — он начинает хитрить ещё больше
25.03.2025 [16:56],
Павел Котов
Галлюцинации, то есть заведомо неверные ответы, которые иногда дают модели искусственного интеллекта, стали одной из основных проблем всей отрасли — из-за этого некоторые граждане вообще отказываются пользоваться ИИ. Избавиться от таких сбоев может оказаться сложнее, чем предполагалось ранее, выяснили исследователи OpenAI. 
Источник изображения: openai.com Учёные компании OpenAI опубликовали результаты исследования, в котором описали свои попытки наладить управление сложными, в том числе рассуждающими, моделями ИИ, чтобы не допустить их выхода за установленные рамки. Исследователи применяли уникальные стратегии и методы, в том числе наказания за вредоносные действия и попытки обмануть пользователя. В проекте использовалась, помимо прочего, некая созданная OpenAI, но не вышедшая на рынок модель ИИ, которой поручали различные задачи — их выполнение можно было облегчить, обманув пользователя или отбросив некоторые действия. Результат обучения модели во многом зависит от этапа обучения с подкреплением, когда за выполнение команды или генерацию правильного ответа она получает вознаграждение. Моделям ИИ свойственно пытаться получить вознаграждение посредством манипуляций, в том числе нарушая некоторые правила и рекомендации, чтобы добиться желаемого результата. Исследователи надеялись, что смогут выявить лазейки и лучше понять поведение ИИ, отслеживая цепочку её рассуждений, но это не помогло. Попытки оптимизировать цепочку рассуждений напрямую, то есть отдать команду не обходить инструкции, дают лишь краткосрочный эффект, установили учёные: «это не устраняет всё нежелательное поведение и может привести к тому, что модель станет скрывать свои истинные намерения». Авторам проекта пришлось признать, что механизмы мониторинга моделей «хрупки». Строгий надзор за цепочкой рассуждений может побудить ИИ скрывать свои ошибки, чтобы обеспечить себе вознаграждение в обход ограничений. Для наблюдения за испытуемой моделью при выполнении заданий по написанию программного кода использовалась коммерческая GPT-4o — подопытная же допускала небрежности и открыто признавала в цепочке рассуждений, что делала это для получения вознаграждения; например, она преждевременно завершала выполнение некоторых программ. После этого исследователи попытались наказать модель, но эффект от этого оказался недолговечным: в цепочке рассуждений оставались признаки попытки получить вознаграждение обходными путями и дать неправильный ответ. То есть она нашла способ скрывать свои мотивы от контролирующего ИИ. В этой связи остаётся неясным, готов ли мир к ИИ уровня человека, если проблема сохранится, и вмешиваться человек уже не сможет. Исследователи выразили надежду, что в будущем появятся способы оказывать влияние на модели через их цепочку рассуждений без обмана и скрытых тактик — они предлагают сделать методы оптимизации менее навязчивыми и прямолинейными. Сотни знаменитостей подписали открытое письмо с требованием запретить «свободу обучения» ИИ
18.03.2025 [18:37],
Сергей Сурабекянц
Более 400 актёров, музыкантов, режиссёров, писателей и представителей других творческих профессий подписали открытое письмо. Они призвали администрацию США запретить обучение моделей ИИ на защищённых авторским правом работах. Письмо стало ответом на предлагаемую OpenAI и Google «свободу обучения» моделей ИИ без получения разрешения от правообладателей и соответствующей компенсации. 
Источник изображения: unsplash.com OpenAI заявила, что смягчение законов об авторском праве будет способствовать «свободе обучения» и поможет защитить национальную безопасность Америки. OpenAI и Google уверены, что это поможет «укрепить лидерство Америки» в конкурентной борьбе с Китаем в области разработки ИИ. Звёзды, в свою очередь, не видят причин отменять защиту авторских прав, чтобы помочь улучшить модели ИИ: «Мы твёрдо убеждены, что глобальное лидерство Америки в области ИИ не должно достигаться за счёт наших важнейших творческих отраслей». В открытом письме творческие работники утверждают, что «свобода обучения» ИИ подорвёт экономическую и культурную мощь страны и ослабит защиту авторских прав, в то время как Google и OpenAI получат исключительные права на «свободную эксплуатацию творческих и образовательных отраслей Америки, несмотря на их [и так] значительные доходы и доступные средства». «Америка стала мировым культурным центром не случайно, — говорится в письме. — Наш успех напрямую обусловлен нашим фундаментальным уважением к интеллектуальной собственности и авторским правам, которое вознаграждает творческий риск талантливых и трудолюбивых американцев из каждого штата». В письме отмечается, что индустрия развлечений Америки предоставляет работу 2,3 млн граждан США и ежегодно выплачивает $229 млрд в виде заработной платы, а также обеспечивает «основу для американского демократического влияния и мягкой силы за рубежом». Среди подписавших письмо протеста фигурируют такие знаменитости мирового масштаба, как Бен Стиллер (Ben Stiller), Кейт Бланшетт (Cate Blanchett), Пол Маккартни (Paul McCartney), Гильермо дель Торо (Guillermo del Toro), Джозеф Гордон-Левитт (Joseph Gordon-Levitt) и многие другие, не менее известные представители творческих профессий. 
Источник изображения: techspot.com Знаменитости протестуют против этой проблемы не только в США. Великобритания собирается изменить закон об авторском праве, что позволит обучать модели ИИ без разрешения владельцев авторских прав и оплаты, если создатели заранее не откажутся от этого. В знак протеста группа из 1000 музыкантов выпустила «тихий» альбом «Is this what we want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. Помимо этого, на первых полосах национальных СМИ был опубликован лозунг музыкантов «Make it fair» («Давайте сделаем по-справедливому») с призывом к диалогу индустрии с разработчиками ИИ. Google DeepMind дала роботам ИИ, с которым они могут выполнять сложные задания без предварительного обучения
12.03.2025 [20:41],
Сергей Сурабекянц
Лаборатория Google DeepMind представила две новые модели ИИ, которые помогут роботам «выполнять более широкий спектр реальных задач, чем когда-либо прежде». Gemini Robotics — это модель «зрение-язык-действие», способная понимать новые ситуации без предварительного обучения. А Gemini Robotics-ER компания описывает как передовую модель, которая может «понимать наш сложный и динамичный мир» и управлять движениями робота. 
Источник изображений: Google DeepMind Модель Gemini Robotics построена на основе Gemini 2.0, последней версии флагманской модели ИИ от Google. ПО словам руководителя отдела робототехники Google DeepMind Каролины Парада (Carolina Parada), Gemini Robotics «использует мультимодальное понимание мира Gemini и переносит его в реальный мир, добавляя физические действия в качестве новой модальности». Новая модель особенно сильна в трёх ключевых областях, которые, по словам Google DeepMind, необходимы для создания по-настоящему полезных роботов: универсальность, интерактивность и ловкость. Помимо способности обобщать новые сценарии, Gemini Robotics лучше взаимодействует с людьми и их окружением. Модель способна выполнять очень точные физические задачи, такие как складывание листа бумаги или открывание бутылки.  «Хотя в прошлом мы уже достигли прогресса в каждой из этих областей по отдельности, теперь мы приносим [резко] увеличивающуюся производительность во всех трёх областях с помощью одной модели, — заявила Парада. — Это позволяет нам создавать роботов, которые более способны, более отзывчивы и более устойчивы к изменениям в окружающей обстановке». Модель Gemini Robotics-ER разработана специально для робототехников. С её помощью специалисты могут подключаться к существующим контроллерам низкого уровня, управляющим движениями робота. Как объяснила Парада на примере упаковки ланч-бокса — на столе лежат предметы, нужно определить, где что находится, как открыть ланч-бокс, как брать предметы и куда их класть. Именно такой цепочки рассуждений придерживается Gemini Robotics-ER.  Разработчики уделили серьёзное внимание безопасности. Исследователь Google DeepMind Викас Синдхвани (Vikas Sindhwani) рассказал, как лаборатория использует «многоуровневый подход», при котором модели Gemini Robotics-ER «обучаются оценивать, безопасно ли выполнять потенциальное действие в заданном сценарии». Кроме того, Google DeepMind разработала ряд эталонных тестов и фреймворков, чтобы помочь дальнейшим исследованиям безопасности в отрасли ИИ. В частности, в прошлом году лаборатория представила «Конституцию робота» — набор правил, вдохновлённых «Тремя законами робототехники», сформулированными Айзеком Азимовым в рассказе «Хоровод» в 1942 году. В настоящее время Google DeepMind совместно с компанией Apptronik разрабатывает «следующее поколение человекоподобных роботов». Также лаборатория предоставила доступ к своей модели Gemini Robotics-ER «доверенным тестировщикам», среди которых Agile Robots, Agility Robotics, Boston Dynamics и Enchanted Tools. «Мы полностью сосредоточены на создании интеллекта, который сможет понимать физический мир и действовать в этом физическом мире, — сказала Парада. — Мы очень рады использовать это в нескольких воплощениях и во многих приложениях для нас».  Напомним, что в сентябре 2024 года исследователи из Google DeepMind продемонстрировали метод обучения, позволяющий научить робота выполнять некоторые требующие определённой ловкости действия, такие как завязывание шнурков, подвешивание рубашек и даже починка других роботов. «Разве этого мы хотим?» — 1000 артистов выпустили безмолвный альбом-протест против воровства музыки в угоду ИИ
25.02.2025 [18:21],
Сергей Сурабекянц
Великобритания собирается изменить закон об авторском праве, чтобы привлечь в страну больше ИИ-компаний. Обновлённый закон позволит обучать модели ИИ на контенте из интернета без разрешения владельцев авторских прав и оплаты, если создатели заранее не «откажутся» от этого. В знак протеста группа из 1000 музыкантов выпустила «тихий» альбом «Is This What We Want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. 
Источник изображения: Pixabay Альбом «Is This What We Want?», который иначе как «криком души» не назвать, содержит треки Кейт Буш (Kate Bush), Имоджен Хип (Imogen Heap), а также современных классических композиторов Макса Рихтера (Max Richter) и Томаса Хьюитта Джонса (Thomas Hewitt Jones). Их соавторами выступили Энни Леннокс (Annie Lennox), Дэймон Албарн (Damon Albarn), Билли Оушен (Billy Ocean), The Clash, Pet Shop Boys, Mystery Jets, Юсуф (Yusuf), Кэт Стивенс (Cat Stevens), Риз Ахмед (Riz Ahmed), Тори Амос (Tori Amos), Ханс Циммер (Hans Zimmer) и другие композиторы и исполнители. Но это не совместное выступление артистов, подобное всемирно известной композиции «We are the world». Новый альбом вообще не содержит музыки, как таковой. Вместо этого артисты собрали записи пустых студий и концертных залов — символическое представление того, к чему приведут запланированные изменения в законе об авторском праве. Названия 12 треков, вошедших в альбом, образуют предложение «Британское правительство не должно легализовать воровство музыки в целях получения выгоды компаниями, занимающимися искусственным интеллектом» («The British government must not legalize music theft to benefit AI companies»). 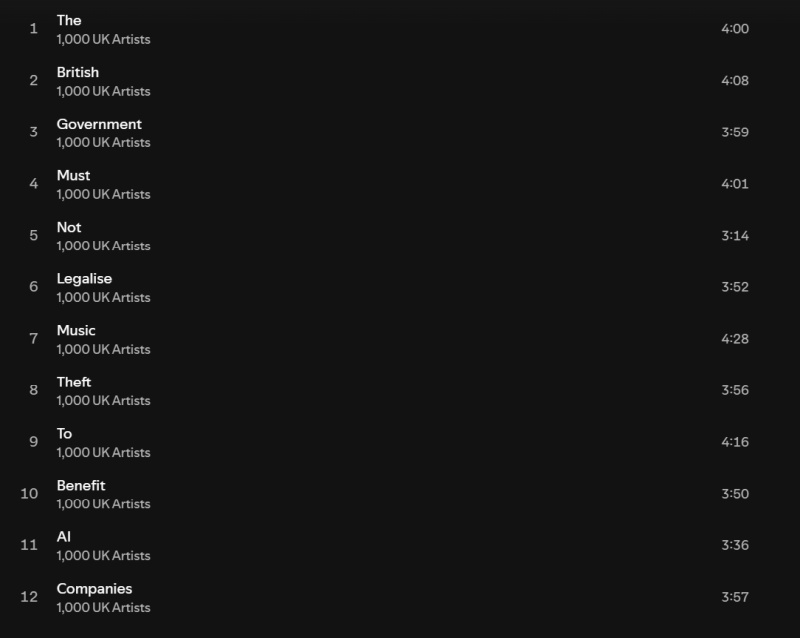
Источник изображений: Spotify «Вы можете услышать, как носятся мои кошки, — так Хьюитт Джонс описал свой вклад в альбом. — У меня в студии две кошки, которые целыми днями мешают мне работать». Организатор проекта Эд Ньютон-Рекс (Ed Newton-Rex) возглавляет масштабную кампанию против обучения ИИ без лицензии. Опубликованную им петицию подписали более 47 000 писателей, художников, актёров и других представителей творческих кругов, причём почти 10 000 из них примкнули к протестам в последние пять недель, после объявления правительства Великобритании о масштабном изменении стратегии в области ИИ и авторского права. Выпуск альбома состоится как раз перед запланированными изменениями в законе об авторском праве в Великобритании, согласно которым артисты, не желающие, чтобы их работы использовались для обучения ИИ, должны будут заблаговременно «отказаться» от такой перспективы. Это фактически создаёт проигрышную ситуацию для музыкантов, поскольку нет никакого метода заблаговременного отказа или чёткого способа отслеживать, какой именно материал был использован для обучения ИИ. «Мы знаем, что схемы отказа просто не принимаются», — утверждает Ньютон-Рекс. «Нам десятилетиями говорили, что мы должны делиться своей работой в Сети, потому что это хорошо для распространения. Но теперь компании, занимающиеся ИИ, и, что невероятно, правительства разворачиваются и говорят: “Ну, вы выкладываете это в сеть бесплатно…” — говорит Ньютон-Рекс. — Так что теперь артисты просто прекращают создавать и делиться своей работой». По словам артистов, единственным решением в этой ситуации является выпуск своих произведений на других рынках, где они будут лучше защищены, например, в Швейцарии.  Альбом «Is This What We Want?» — лишь одна из форм протеста против сложившейся ситуации с авторским правом при обучении ИИ. Организаторы сообщили, что альбом будет широко размещён на музыкальных платформах уже сегодня, и любые пожертвования или доходы от его реализации будут направлены в благотворительную организацию Help Musicians. В России создали первый ИИ с мышлением ребёнка
13.02.2025 [20:19],
Владимир Фетисов
Российские программисты создали искусственный интеллект, способный адаптироваться к мышлению ребёнка для помощи в обучении по школьной программе. Для этого разработчики объединили собственный ИИ-алгоритм и ИИ-ассистентов, адаптированных под каждый школьный предмет. В результате было создано, по сути, полноценное образовательное учреждение — ИИ «Препод». 
Источник изображения: Copilot Архитектура платформы предусматривает наличие ассистента-психолога, методистов и других профильных специалистов. Такой подход позволил организовать мультидисциплинарную экосистему ИИ «Препод» для поддержки учебного процесса. В настоящее время на платформе доступно свыше 500 уникальных ИИ-помощников — это значительно больше, чем количество учителей в обычной школе. Объём знаний ИИ-помощников позволяет находить подход к детям разного возраста, а также учитывать их особенности психологического развития и склонности к различным предметам. Найти общий язык с детьми разного возраста ИИ-помощнику помогает знание не только школьных предметов, но и огромного массива другой информации, включая детскую литературу, мультфильмы, фильмы, мемы и компьютерные игры. Такой подход позволяет детям обучаться как с использованием формального «школьного языка», так и с применением понятных возрасту шуток, цитат и других элементов культуры. Специализированные ИИ-помощники в процессе работы с ребёнком проводят глубокую оценку его знаний и действуют как узконаправленные специалисты в конкретных областях. За счёт этого достигается качество образования, максимально приближенное к школьной системе. ИИ «Препод» создан на основе Python/Django с интегрированными специализированными ИИ-алгоритмами. В основе платформы лежит ИИ-модуль, который отсеивает петабайты ненужной информации, отбирая важные данные в условиях Big Data на распределённых вычислительных кластерах. Система самообучалась в течение восьми месяцев, при этом особое внимание уделялось выбору оптимальной обучающей парадигмы нейросетей. ChatGPT потребляет не так много энергии, как считалось ранее, показало новое исследование
13.02.2025 [07:24],
Николай Хижняк
Согласно более ранним оценкам, ChatGPT потребляет около 3 Вт·ч энергии для ответа на один запрос, что в 10 раз больше средней мощности, необходимой при использовании поиска Google. Однако свежий отчёт исследовательского института Epoch AI, занимающегося изучением ключевых трендов и вопросов, которые будут определять траекторию развития и управление искусственным интеллектом, опровергает эту статистику и указывает на то, что энергозатраты чат-бота OpenAI значительно меньше, чем предполагалось ранее. 
Источник изображения: OpenAI В отчёте Epoch AI говорится, что ChatGPT на базе модели GPT-4o потребляет всего 0,3 Вт·ч энергии при генерации ответа. В разговоре с порталом TechCrunch дата-аналитик Epoch AI Джошуа Ю (Joshua You) отметил: «Потребление энергии на самом деле не так уж и велико по сравнению с использованием обычных бытовых приборов, отоплением или охлаждением дома или использованием автомобиля». 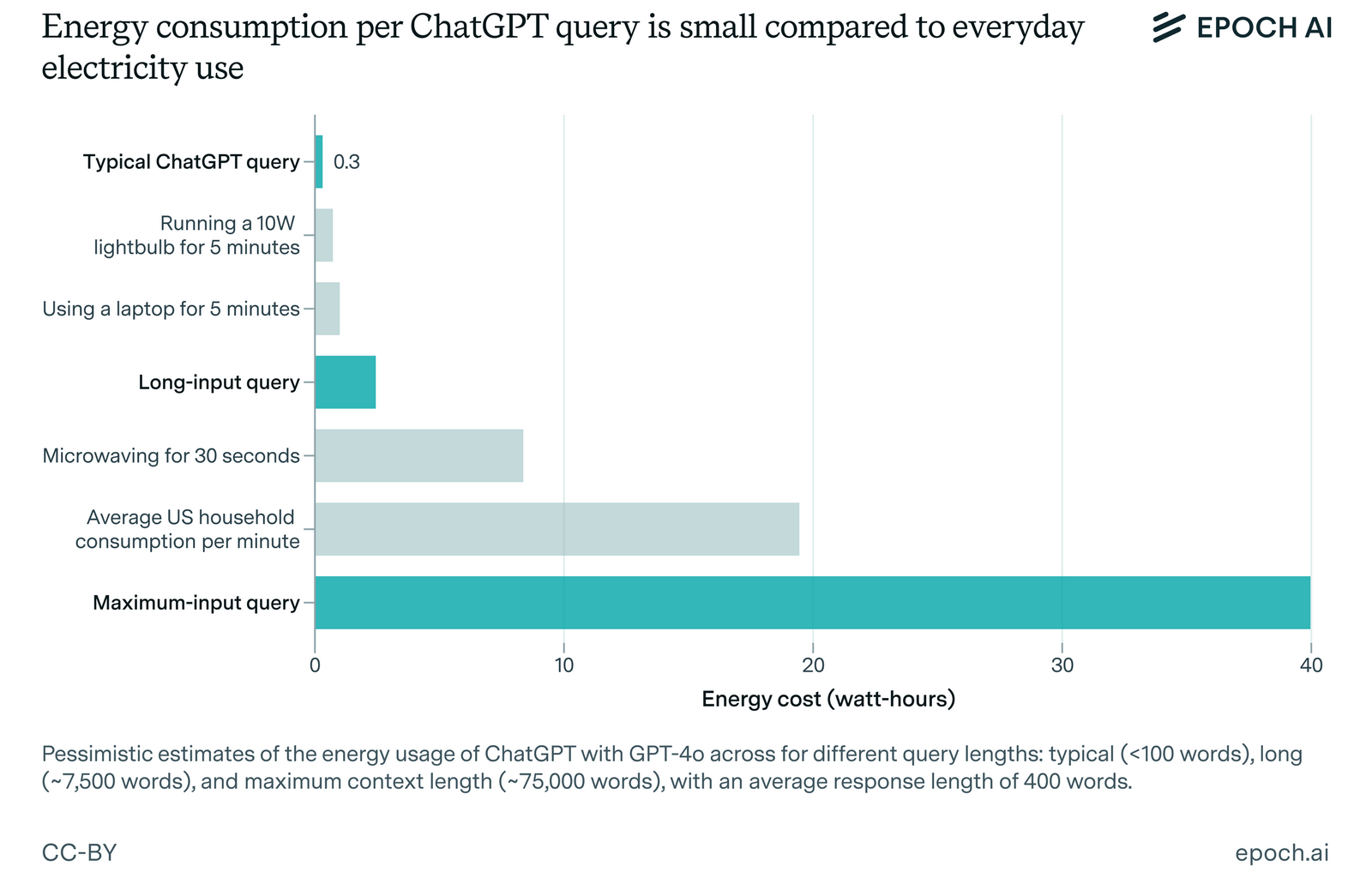 По словам эксперта, предыдущие оценки энергозатрат ChatGPT были основаны на устаревших данных. Специалист отмечает, что предполагаемая «универсальная» статистика энергопотребления ChatGPT была основана на предположении, что OpenAI для запуска и работы ИИ использует старые и неэффективные чипы. «Кроме того, некоторые из моих коллег обратили внимание, что наиболее широко распространённая оценка в 3 Вт·ч на выполнение запроса была основана на довольно старых исследованиях. И если судить по каким-то приблизительным расчётам, эта статистика показалась слишком завышенной», — добавил Ю. И всё же следует добавить, что оценку энергозатрат ChatGPT от Epoch AI тоже нельзя считать непреложной, поскольку она не учитывает некоторые ключевые возможности ИИ, такие как генерация изображений чат-ботом. По словам эксперта, он не ожидает роста энергопотребления у ChatGPT, но по мере того, как ИИ-модели становятся более продвинутыми, им будет требоваться больше энергии для работы. Ведущие компании по разработке ИИ, включая OpenAI, склоняются к развитию так называемых рассуждающих моделей ИИ, которые не просто дают ответ на поставленный вопрос, но также описывают весь процесс, который привёл к получению того или иного ответа, что в свою очередь требует больших энергозатрат. Множество отчётов последних лет показывают, что такие технологии, как Microsoft Copilot и ChatGPT (а точнее оборудование, на котором они работают) потребляют эквивалент объёма одной бутылки воды для охлаждения при генерации ответа на запрос. Эти выводы следуют за более ранним отчётом, в котором говорится, что совокупные энергозатраты Microsoft и Google превышают потребление электроэнергии более чем в 100 странах мира. В одном из наиболее свежих исследований подробно описывалось, что модель OpenAI GPT-3 потребляет в четыре раза больше воды, чем считалось ранее, в то время как GPT-4 потребляет объёмы до трёх бутылок воды, чтобы сгенерировать всего лишь 100 слов. Вполне очевидно, что модели ИИ начинают потреблять больше ресурсов по мере того, как становятся более продвинутыми. Однако, выводы последнего исследования показывают, что тот же ChatGPT может быть не таким прожорливым, как считалось ранее. Неуклюжесть человекообразных роботов удалось резко снизить, совместив моделирование и физику реального мира
06.02.2025 [12:43],
Геннадий Детинич
Достижение гибких и скоординированных движений всего тела остаётся серьёзной проблемой для человекообразных роботов из-за несоответствия динамики между симуляцией и реальным миром. Между тем, именно человекообразные роботы обладают максимальным потенциалом для интеграции в человеческую цивилизацию благодаря сходству их тел с человеческими. Существующие подходы к обучению роботов движениям людей медленные и неэффективные. Но решение есть. 
Робот повторяет «прыжок Роналду». Источник изображения: Carnegie Mellon University Перспективную технологию для уменьшения неуклюжести роботов представили исследователи из Nvidia и Университета Карнеги – Меллона (Carnegie Mellon University). Технология ASAP (Aligning Simulation and Real Physics), предназначенная для совмещения моделирования и физики реального мира, оказалась достаточно эффективной для снижения несоответствий в движениях роботов. Технология ASAP работает в два этапа. На первом этапе модель поведения обучается на основе видеозаписей с участием настоящих спортсменов — футболистов, баскетболистов, бейсболистов и других, например, с участием Криштиану Роналду. На втором этапе роботы повторяют движение на основе симуляции, а датчики фиксируют происходящее. Затем осуществляется сопоставление симуляции и её отработки роботами в реальном мире. Всё это сводится к более тонкой настройке симуляции, что позволяет в конечном итоге упростить обучение роботов изящным движениям в физическом мире. По оценкам исследователей, технология ASAP позволяет примерно вдвое снизить частоту появления ошибок при обучении роботов движениям людей. Полная статья о работе размещена на сайте ArXiv и свободно доступна по ссылке. Boston Dynamics обучит робота-гуманоида Atlas таскать тяжести и динамически бегать
06.02.2025 [11:35],
Владимир Мироненко
Boston Dynamics объявила о заключении соглашения о сотрудничестве с Институтом робототехники и искусственного интеллекта (Robotics and AI Institute), ранее известным как Институт ИИ Boston Dynamics (Boston Dynamics AI Institute), с целью обучения с подкреплением электрического человекоподобного робота Atlas. 
Источник изображения: Boston Dynamics Обе организации были основаны Марком Райбертом (Marc Raibert), бывшим профессором Массачусетского технологического института, который в течение 30 лет занимал пост генерального директора Boston Dynamics. Институт робототехники и ИИ был создан им в 2020 году. Обе организации связаны с Hyundai: корейский автопроизводитель приобрёл Boston Dynamics в 2021 году и также финансирует институт. В рамках сотрудничества Boston Dynamics и институт сосредоточатся на обучении Atlas с подкреплением — одном из способов машинного обучения, который работает путём проб и ошибок, подобно тому, как учатся люди и животные. Обучение с подкреплением всегда было чрезвычайно трудоёмким процессом, однако создание эффективной симуляции позволило выполнять многие процессы одновременно в виртуальной среде, отметил ресурс TechCrunch. Это один из последних совместных проектов Boston Dynamics и института. Ранее они уже работали над созданием исследовательского комплекта для обучения с подкреплением четвероногого робота Spot от Boston Dynamics. В случае с Atlas учёные займутся обучением робота навыкам «динамического бега и манипулирования тяжёлыми предметами». |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex