







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Практикум по ИИ-рисованию, часть четвёртая: ComfyUI, или Приручение макаронного монстра
«Работает — не трогай» — известная всем первая заповедь программиста, сисадмина, да и любого айтишника в самом широком смысле слова. Для оператора ИИ-модели, создающей изображения по текстовым подсказкам, она в общем случае тоже справедлива. Речь здесь идёт не о неуклонном совершенствовании самих этих подсказок, конечно же, а о попытках улучшить работу интерпретирующей их рабочей среды. Тем более что, если применяемое ПО чем-то пользователя не устраивает, для исправления ситуации — даже когда это софт с открытым кодом, такой как рассматривавшийся нами на протяжении уже трёх «Мастерских» AUTOMATIC1111 (раз, два, три), — требуется квалификация посущественнее собственно пользовательской. 
Источник: ИИ-генерация на основе модели SDXL 1.0 Но вот какая незадача: некий софт — в данном случае рабочая среда для управления генеративной моделью, претворяющей текст в картинки, — может не то чтобы не работать совсем, а, скорее, ощутимо ограничивать (вследствие имманентно присущих ей особенностей) функциональные возможности этой самой модели. Взять ту же среду AUTOMATIC1111: за неполный год своего существования она стала для энтузиастов ИИ-рисования по всему миру едва ли не штатным инструментом для эксплуатации чекпойнтов, созданных на основе базисной генеративной модели Stable Diffusion 1.5 (путём дотренировки последней на дополнительных массивах аннотированных изображений). Однако в конце июля 2023-го, с выходом новейшей версии SD, уже не номерной (1.4, 1.5, 2.1, как было прежде), а литерной (с суффиксом XL), стало достаточно очевидно, что AUTOMATIC1111 в актуальном на тот момент своём состоянии не справляется с предоставлением полного доступа ко всем возможностям новой модели. Точнее, осознание это появилось у энтузиастов ИИ-рисования даже чуть раньше — ещё на этапе попадания в общий доступ бета-версии SDXL с условным индексом 0.9. Собственно, по этой причине многие поклонники Иизобразительных Иискусств продолжают считать SD 1.5 наиболее предпочтительным на сегодня вариантом: за долгие месяцы активной эксплуатации этой модели для неё разработаны довольно эффективные правила формулирования текстовых подсказок, а главное — создан обширнейший дополнительный инструментарий, включая апскейлеры (мини-нейросети для масштабирования исходной картинки с увеличением детализации), текстовые инверсии, LoRA, разнообразные модели ControlNet и множество прочего. 
Источник: ИИ-генерация на основе модели SDXL 1.0 Тем не менее коллектив Stability.ai, разработчика модели Stable Diffusion, делает самую серьёзную ставку на SDXL 1.0, прямо заявляя, что даже её базовая субмодель (смысл этого термина поясним чуть ниже) выдаёт результаты, ощутимо более привлекательные для контрольной группы, чем предыдущие разновидности. В отношении «Двоечки» (SD 2.0, а чуть позже и 2.1) таких заявлений не делалось, причём по вполне объективным причинам. Довольно быстро стало понятно, что смена текстового декодера (преобразователя текстовых подсказок в цифровые токены, по которым в дальнейшем уже и производится навигация в латентном пространстве) с CLIP на OpenCLIP сыграла с командой Stability.ai злую шутку: прямое использование подсказок от «Полуторки» для новой модели не давало изображений лучшего качества, поскольку декодировался их текст по-иному, — а ИИ-художественное сообщество к тому времени накопило уже столько опыта в обращении с SD 1.5, что отсутствие возможности с минимальными потерями перенести его на SD 2.1 стало для последней, в общем-то, приговором. До сих пор на портале Civitai, чрезвычайно популярном у энтузиастов генеративных изобразительных моделей, у самого востребованного чекпойнта для «Двоечки», rMada Merge, всего 8,7 тыс. загрузок и 1,5 тыс. «лайков», тогда как лидер в зачёте «Полуторок», DreamShaper, может похвастать 488 тыс. скачиваний и 32 тыс. отметок «нравится». Тут ещё надо иметь в виду, что для закачки чекпойнта с Civitai в общем случае нет необходимости регистрироваться, тогда как на сердечки рядом с названием модели могут нажимать только авторизованные пользователи. Разрабатывая SDXL, в Stability.ai учли этот момент, — и в результате текстовый декодер для «Оверсайза» представляет собой комбинацию OpenCLIP и исходной языковой модели CLIP, разработанной и активно применяемой другим пионером в области генеративного ИИ — компанией OpenAI (той самой, что стоит за ChatGPT). Формально программный код CLIP также открыт — зато массив изображений, на которых этот декодер тренировался, до сих пор остаётся проприетарным; смысл же OpenCLIP в том, что это, по сути, тот же CLIP, но натренированный на находящейся в открытом доступе базе аннотированных картинок LAION. 
В текстовой подсказке к этому изображению НЕ БЫЛО упоминания Алисы Вокс! (источник: ИИ-генерация на основе модели SDXL 1.0) Так или иначе, различий между SDXL и «номерными» версиями SD значительно больше, чем между версиями 1.5 и 2.1. Это автоматически означает, что и подбор слов в подсказках придётся вести по-иному (хотя «Оверсайз»-версия частично вернулась к использованию CLIP, так что в этом плане всё несколько проще), и все инструменты, от LoRA до ControlNet, потребуется воссоздавать с нуля. Однако эта работа уже идёт: судя по динамике появления новых моделей на сайте Civitai, среди самых первых пользователей SDXL оказалось так много очарованных широтой возможностей этой модели энтузиастов, что раскрытие всей полноты её потенциала уже не за горами. И, поскольку заданные AUTOMATIC1111 рамки пока чересчур тесны для адекватного знакомства со всеми этими возможностями, попробуем освоить — в самом первом приближении — принципиально иную по самой своей структуре рабочую среду под названием ComfyUI. ⇡#Два мира, два подходаДля начала укажем, что помимо ComfyUI в сообществе ИИ-художников активно используются по меньшей мере две локальных рабочих среды, готовые широко раскрыть потенциал SDXL: Fooocus (максимально упрощённый интерфейс, элементарная установка, возможность нажатием одной кнопки — без чрезмерного колдовства над текстовой подсказкой — задать выдачу изображения в стиле фотографического реализма, рисунка тушью или пиксельной графики) и SD.Next (мартовский, 2023 года, форк проекта AUTOMATIC1111 со множеством оптимизаций и расширенной поддержкой тренировки энтузиастами собственных моделей). Есть и другие, плюс к тому множество веб-сайтов предлагают теперь SDXL 1.0 в качестве модели по умолчанию — вот хотя бы mage.space и Clipdrop, для примера. 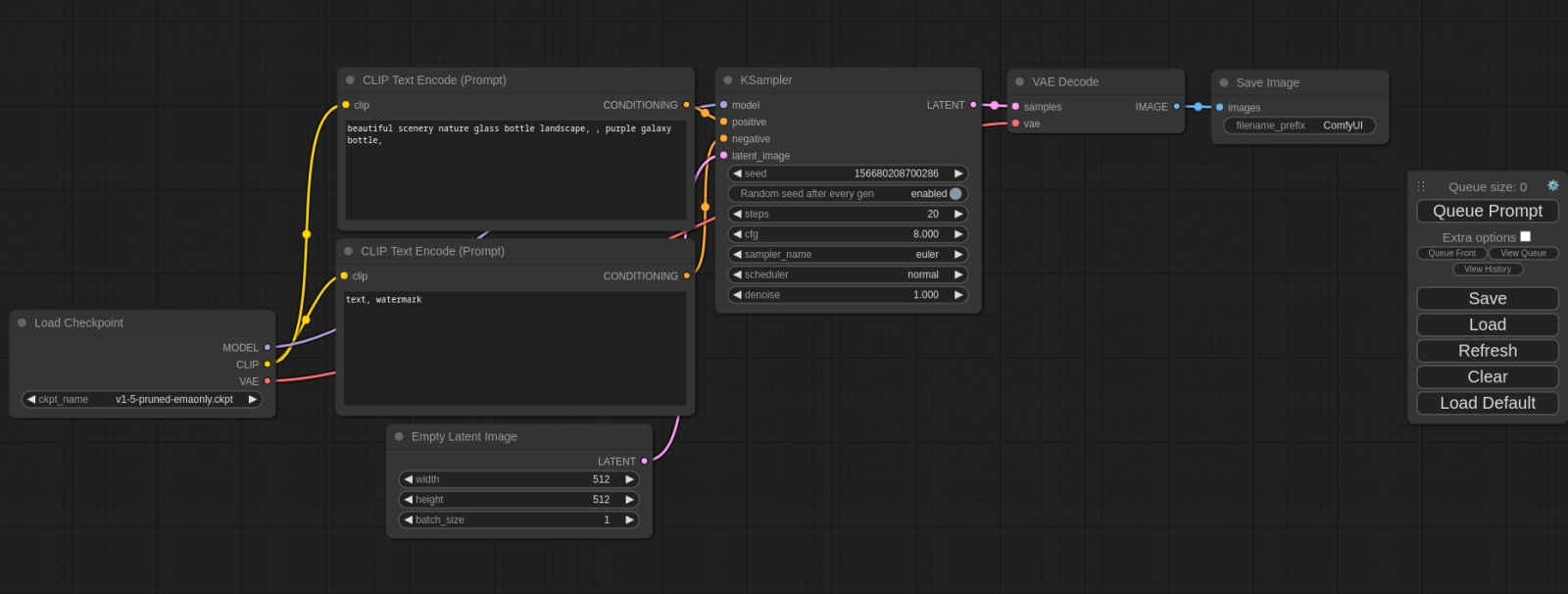
Базовая циклограмма, зашитая в «чистую» установку ComfyUI: обособленный, ни с чем не соединённый прямоугольник справа и есть, собственно, практически весь интерфейс данной рабочей среды (источник: GitHub) Но ComfyUI разительно отличается от всех прочих тем, как в ней организован процесс генерации изображений из текста. Суть в том, что в этой рабочей среде оператор не просто вводит данные в соответствующие поля, ставит галочки, нажимает кнопки и перемещает ползунки, — но собственноручно выстраивает последовательную многоэтапную процедуру (циклограмму) преобразования текста в картинку через латентное пространство, соединяя ответственные за отдельные операции узлы (nodes, ноды) логическими связями, по которым передаются те или иные данные. В сообществе энтузиастов генеративных изобразительных искусств почти сразу после появления ComfyUI в марте текущего года родилась саркастическая шутка: «AUTOMATIC1111 не так уж и автоматизирована, а работать с ComfyUI не слишком комфортно». Справедливости ради отметим, что название рассматриваемой рабочей среды вовсе не призвано подчёркивать эргономические достоинства её интерфейса (которого, на ошарашенный взгляд новичка, и вовсе по сути нет): просто Comfy — точнее, comfyanonymous, — это ник её создателя. Ныне, кстати говоря, присоединившегося к коллективу разработчиков Stable Diffusion по их же настоятельному приглашению, — именно ComfyUI стала теперь внутренней рабочей средой по умолчанию в Stability.ai. Один этот факт наверняка сделается для многих весомым аргументом в пользу переключения на данную рабочую среду если не прямо сегодня, то уже в обозримой перспективе — вне зависимости от того, страшит их «макаронный» интерфейс или нет. 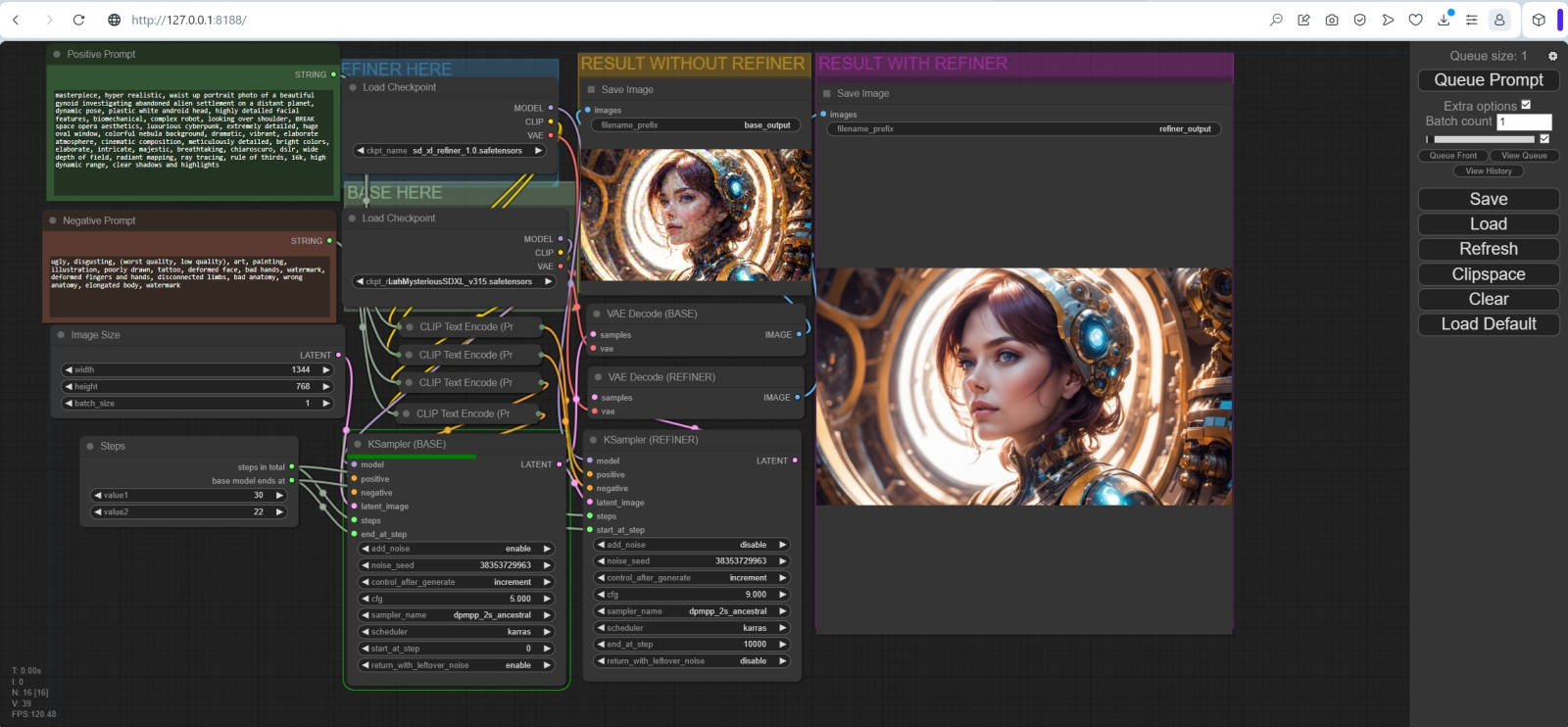
Для полного погружения в море возможностей SDXL циклограмма генерации картинок для этой модели должна обеспечивать последовательную работу двух чекпойнтов: основы (base) и доводчика (refiner) Да, сейчас вовсю тестируется предварительная версия AUTOMATIC1111 (которая после официального релиза должна получить номер 1.6.0; актуальная же стабильная на момент написания настоящей статьи — 1.5.1), которая, по слухам, будет гораздо лучше обращаться с XL-разновидностью этой популярной генеративной модели. Но с учётом прямой поддержки со стороны Stability.ai перспективы ComfyUI видятся более радужными. Вдобавок из-за особенностей внутренней архитектуры AUTOMATIC1111 эта среда-первопроходец значительно сложнее, чем более поздние проекты, поддаётся модификации, развитию, да и просто поддержке. Тот же comfyanonymous — благо код проекта открыт, так что его слова может проверить любой желающий, — так отзывается об «Автоматике»: «В коде A1111 ногу сломать можно; он слишком негибок, чтобы справляться со всеми новинками, что будут появляться в дальнейшем». И действительно, у ComfyUI есть такое безусловное достоинство, как невероятная в сравнении с AUTOMATIC1111 гибкость. Обеспечивается она именно за счёт того, что вместо использования готового интерфейса с вкладками, выпадающими меню и ползунками оператору (вот теперь уж точно не пользователю!) рабочей среды для ИИ-рисования предлагается самостоятельно составить циклограмму — протокол последовательного исполнения (workflow) — всей той работы, что предстоит проделать системе. Пусть путём не написания строк кода, а расстановки на интерфейсном поле нужных нод и соединения их соответствующими связями, — но именно запрограммировать, значительно глубже погрузившись тем самым в роль со-творца цифрового образа, чем в ходе эксплуатации более консервативной рабочей среды. 
Источник: ИИ-генерация на основе модели SDXL 1.0 К счастью, освоить потокоориентированное программирование (flow-based programming, FBP), базирующееся на графическом представлении нод (узлов), что исполняют различные действия, и на связывании их потоками движения данных, для не ИТ-специалиста значительно проще, чем справиться с каноничным написанием кода оператор за оператором. Концепция FBP восходит к концу 1960-х, а в последнее время она стала особенно популярна как принцип организации сред программирования LowCode/NoCode, не требующих (по крайней мере, теоретически) участия высококвалифицированных программистов для создания прикладных программных продуктов, полностью готовых к эксплуатации. В рамках этой концепции ноды выступают для операторов как некие чёрные ящики, до внутреннего устройства которых им нет дела. У каждой ноды есть входы и выходы, готовые принимать или, соответственно, выдавать данные определённых типов и в строго заданных форматах. Перенаправляя от одного узла к другому информационные потоки, оператор выстраивает из элементарных нод достаточно сложные конструкции — по тому же принципу, как из базовых полупроводниковых элементов (штрихов Шеффера) на поверхности микросхемы организуются — путём соединения их проводниками в нужном порядке — логические вентили, сумматоры и прочие составные элементы процессора. 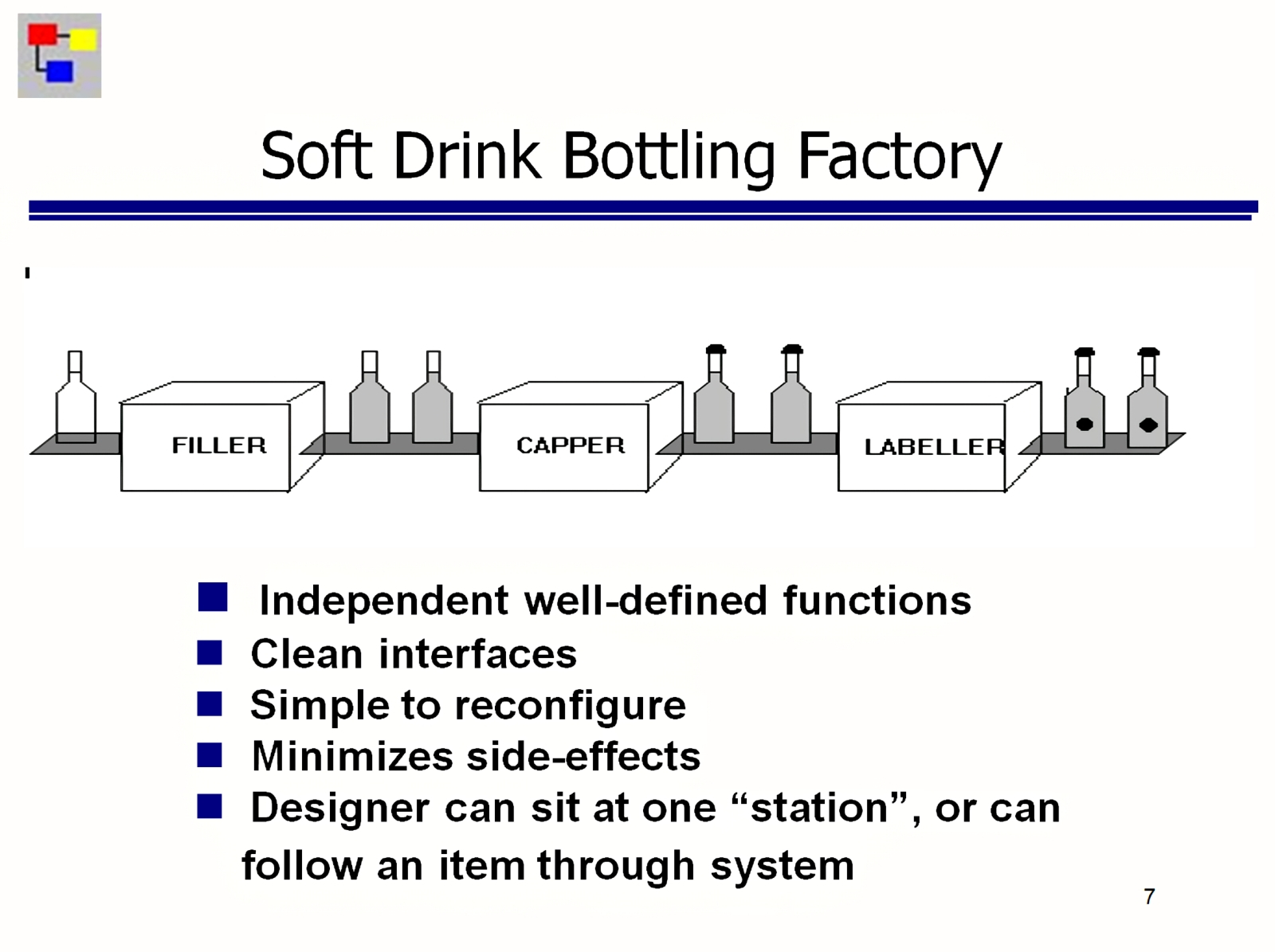
Пояснение принципа действия FBP-нод как чёрных ящиков на примере упаковочной линии на фабрике газировки: менеджеру процесса не надо знать, как именно реализуются наполнение, укупорка и наклеивание этикеток, — ему надо лишь в верном порядке соединить нужные узлы конвейерной лентой (источник: GitHub) И всё же при всех бесспорных достоинствах FBP-среды первое впечатление от взгляда на её интерфейс у любого, кто не знаком с азами NoCode-программирования, однозначное: «макаронный монстр». И вплоть до появления в открытом доступе чекпойнтов SDXL версии 0.9 доля энтузиастов ИИ-рисования, сознательно выбиравших ComfyUI для своих экзерсисов, была откровенно невелика. Надо, впрочем, отдать должное её создателю: с пугающими «макаронинами» рядовому оператору этой среды, по сути, нет особой необходимости слишком уж глубоко разбираться. Каждый PNG-файл, генерируемый на выходе ComfyUI, несёт в текстовых полях своего заголовка детальнейшее (в известной нотации JSON — JavaScript object notation) описание не только всей циклограммы, порождением которой он стал, но и взаимного расположения этих нод в интерфейсном поле ComfyUI. Иными словами, если энтузиасту, чурающемуся «макаронного монстра», понравился какой-то ИИ-рисунок, сгенерированный в этой рабочей среде, ему достаточно развернуть ComfyUI на своём ПК (либо в Google Colab, либо воспользоваться онлайновыми ресурсами, предоставляющими такую возможность), после чего перетащить мышкой из «Проводника» выбранную картинку прямо в интерфейсное поле. В результате система сама извлечёт все JSON-данные из заголовка — и воспроизведёт порождающую циклограмму данного рисунка один к одному. Включая все текстовые подсказки, значения затравок (seed) и CFG, вызовы нужных LoRA и апскейлеров, если те были задействованы, и т. п. 
Развитые циклограммы вроде тех, что предлагает проект Searge-SDXL, содержат как множество самописных (кастомных) нод, так и сразу множество доступных потоков исполнения, между которыми оператор волен переключаться в зависимости от того, что ему в данный момент требуется (источник: GitHub) И вот уже с этим практически одомашненным «макаронным монстром» обращаться значительно проще — принявшись, например, варьировать содержимое полей подсказки. Да, ряд ограничений имеется: скажем, не все веб-ресурсы при публикации закачанных на них PNG-файлов сохраняют заголовочные текстовые поля. Нередко вся сопроводительная информация (EXIF и прочие метаданные) в картинках автоматически вычищается, поскольку может содержать чувствительные данные — прежде всего GPS-координаты точки съёмки, если речь идёт о фото. Ещё один важный момент: часть использованных при создании картинки инструментов может в распоряжении скачавшего её оператора попросту отсутствовать: так, те же LoRA или апскейлеры, если они применялись автором исходной картинки, но не установлены на данном ПК, придётся загружать и развёртывать вручную. Если при формировании циклограммы использованы кастомные ноды — нужно будет установить и их. Но так или иначе однажды созданная кем-то удачная циклограмма когда-то уйдёт в народ — и станет широко применяться после этого теми, для кого FBP было и остаётся тёмным лесом. На известном любому энтузиасту ИИ-рисования сайте Civitai таких workflow уже предостаточно. И всё же для основной массы энтузиастов, которым от генеративной ИИ-модели всего-то и нужно, что изобразить по простенькой подсказке дракончика (ну или не дракончика), «макаронный» псевдоинтерфейс — циклограмма — сложноват, даже если не выстраивать его самостоятельно, а пользоваться чьим-то предварительно созданным. Выпадающие меню и селекторы AUTOMATIC1111, пусть и разбросанные по нескольким десяткам вкладок (если считать с подвкладками), смотрятся привычнее. Так, наверное, и суждено было бы ComfyUI оставаться рабочей средой не для всех, — если бы не холодный душ, пролившийся на верных поклонников AUTOMATIC1111 в момент выхода в открытый доступ XL-версии Stable Diffusion. Оказалось, что «не совсем автоматическая» среда в лучшем случае откровенно подтормаживает при работе с SDXL 0.9, а затем и 1.0, — а в худшем вовсе отказывается работать, вылетая из памяти с ошибкой. 
Источник: ИИ-генерация на основе модели SDXL 1.0 Уже в самые первые дни активной эксплуатации новейших чекпойнтов в AUTOMATIC1111 о затруднениях с исполнением базовой субмодели SDXL 1.0 отчитывались даже владельцы видеокарт с 16 Гбайт памяти — что уж говорить об обладателях более скромных аппаратных средств. Сперва многие грешили на то, что модель эта представлена в виде .safetensors-файла размером 6,6 Гбайт, тогда как типичный чекпойнт SD 1.5 занимает сегодня не более 2,3 Гбайт. Но всё равно даже 8 Гбайт видеоОЗУ теоретически должно было бы хватить для полной загрузки новой модели в видеопамять! И тем не менее AUTOMATIC1111, на тот момент (всего-то месяц назад от времени написания настоящей статьи), бесспорно, самая популярная рабочая среда для ИИ-рисования, с исполнением SDXL не справлялась. А ведь помимо основной субмодели (base, «база»), как мы укажем чуть ниже, в состав этой генеративной модели входит ещё одна, отделочная (refiner, «доводчик»), — чей файл .safetensors занимает дополнительно около 5,8 Гбайт. В AUTOMATIC1111 же версии 1.5.1 попросту не предусмотрено механизма для сопряжённого (а не просто последовательного, когда второму чекпойнту передаётся полностью готовый результат работы первого, — это важно!) исполнения двух этих субмоделей. Долго ли, коротко ли — выяснилось, что у ComfyUI подобного рода проблемы отсутствуют: и чекпойнты SDXL она загружает как следует, даже на аппаратной основе с 4 Гбайт видеоОЗУ, и работает с ними без вылетов по непонятным ошибкам, — да и скорость отработки одной и той же подсказки с полностью идентичными прочими параметрами выходит у неё существенно выше, чем у AUTOMATIC1111, когда ту всё-таки удаётся заставить адекватно взаимодействовать с SDXL. Счастливые обладатели GeForce RTX 3060 с 12 Гбайт видеоОЗУ рапортуют, что генерация одной картинки с разрешением 1024 × 1024 (стандарт для модели XL — в отличие от габарита 512 × 512, характерного для SD 1.5) в AUTOMATIC1111 не просто занимает всю доступную видеопамять, но ещё и принимается под конец активно обмениваться данными между VRAM и ОЗУ, тем самым ощутимо замедляя процесс. В то же время ComfyUI, чтобы исчерпать (и то не полностью) доступные 12 Гбайт видеопамяти, требуется генерировать одновременно, пакетом (batch), четыре SDXL-изображения 1024 × 1024 — с одними и теми же входными параметрами, но разными затравками. 
Наглядное пояснение того, насколько важен доводчик в SDXL: слева — изображение, произведённое целиком основной субмоделью; справа — генерация с теми же параметрами, 20% финальных шагов которой выполнены refiner и только первые 80% — base model Так что по крайней мере на данный момент — до появления версии 1.6.0 рабочей среды AUTOMATIC1111 — вердикт практически однозначен: чтобы в полной мере ощутить преимущества новейшей генеративной модели Stable Diffusion, логично сделать ставку на ComfyUI. Приятным бонусом к этому выбору пойдёт более полное и глубокое понимание подоплёки работы искусственного интеллекта по извлечению картинок из латентного пространства — что, в свою очередь, позволит сметливым энтузиастам усовершенствовать своё мастерство в части оптимизации составления текстовых подсказок и подбора иных параметров генерации. ⇡#Сотворчество против наследованияМежду SDXL и предыдущими версиями Stable Diffusion налицо принципиальная разница. Причём как количественная, так и качественная: если официальный чекпойнт SD 1.5 включает 0,98 млрд параметров (грубо говоря, каждый параметр — десятичная дробь; вес на одном из входов одного из перцептронов в одном из слоёв, образующих данную нейросеть), то SDXL 1.0 – уже 3,5 млрд только для базовой (base) субмодели, тогда как число параметров для отделочной (refiner) субмодели и вовсе достигает 6,6 млрд. Разбиение единой модели на два чекпойнта, действующих в связке, — существенная особенность SDXL, не учитывать которую при работе с этой версией генеративного ИИ — значит заведомо обрекать себя на получение априори менее качественных результатов, чем в принципе способна предложить такая система. В AUTOMATIC1111 вплоть до версии 1.5.1, последней стабильной на момент написания настоящей статьи, возможность именно сотворчества двух чекпойнтов не реализована. Наследование — дело другое: когда с вкладки «txt2img» картинка отправляется на «img2img» для апскейлинга, например, это как раз и есть применение второго чекпойнта к результату работы первого. 
Схематическое пояснение принципа работы основной модели и доводчика в режиме сотворчества (источник: Stability.ai) Основную и отделочную модели SDXL — если оператор захочет их использовать — в AUTOMATIC1111 именно так пока и приходится запускать: сперва основная производит преобразование текстовых подсказок в картинку, затем это изображение переправляется вручную на вкладку img2img (да, всего в одно нажатие соответствующей кнопки, — но не автоматически), и уже там, если есть настроение, к ней можно применить доводчик. Результат выходит обыкновенно действительно лучше — даже без масштабирования с повышением детализации, просто с сохранением исходных параметров картинки (1024 × 1024 точки, например), — но всё-таки чаще всего не настолько лучше, чтобы заморачиваться с дополнительным ручным запуском второй субмодели. Не случайно авторы дотренированных SDXL-чекпойнтов, что во множестве начали появляться на Civitai, частенько прямо указывают в описаниях своих моделей: “NO REFINER NEEDED”. Они понимают, что подавляющее большинство пользователей их чекпойнтов будут загружать те, как и версии для «Полуторки», в AUTOMATIC1111, — и не хотят усложнять жизнь своей потенциальной аудитории. Попробуем пояснить, чего же именно лишают себя те, кто не задействует для преобразования текста в картинки обе субмодели из состава SDXL 1.0, — и осознание это, хочется верить, многим поможет преодолеть неуверенность и боязнь в отношении ComfyUI, в которой, собственно, исполнение обеих этих субмоделей в сотворчестве реализуется с теми же лёгкостью и простотой, что и в наследовании. Официальная документация по Stable Diffusion XL разъясняет, что если базовая субмодель тренировалась исходно на собственно извлечение образов по текстовым подсказкам из латентного пространства, то отделочная (refiner) специализируется на таком удалении слабой зашумлённости с почти готовых изображений, чтобы в результате получались картинки с повышенным качеством на верхних частотах (to generate images of improved high-frequency quality). 
Слева — полностью готовое (без остаточного шума) изображение, выданное базовой субмоделью SDXL 1.0 за 20 шагов генерации; в центре — оно же, но с остаточным латентным шумом перед подачей на вход доводчика; справа — финальный результат после 5 шагов генерации в refiner model (источник: ИИ-генерация на основе модели SDXL 1.0) «Частота» здесь используется в смысле «обратный размер»: крупные элементы изображения — как большие волны — имеют низкую частоту встречаемости/повторяемости на рабочем поле генерации (допустим, 1024 × 1024 точки); мелкие — высокую. Настоящий бич генеративных моделей — как раз высокочастотные элементы: поскольку первичный полностью зашумлённый образ, извлекаемый из латентного пространства, чрезвычайно мал (128 × 128 точек в примере на приведённой выше диаграмме), мелкие детали на нём архитрудно оказывается выявлять в процессе преобразования текста в картинку. Как раз по этой причине доводчик (refiner), специально натренированный на порождение правдоподобных и уместных именно на данном изображении высокочастотных деталей, настолько ценен для модели, изначально ориентированной на генерацию крупноформатных — 1024 × 1024 — картинок. В его отсутствие пришлось бы заметно увеличивать габариты первичного образа, что существенно усложнило и удлинило бы процесс генерации. Упомянутая официальная документация указывает на два возможных способа применения базовой и отделочной субмоделей: сотворчество (романтично именуемое в тексте Ensemble of Expert Denoisers) и простое наследование. Первый метод (предложенный, кстати, под названием eDiff-I исследователями из NVIDIA) подразумевает доведение латентного образа до состояния «почти готов» — т. е. шум с изображения удалён не полностью, из назначенного для исполнения числа шагов (steps) выполнены 80-85%, — и передачу именно этой «непропечённой» картинки в отделочную субмодель (refiner). И вот уже та в меру своих обширных возможностей максимально качественно визуализирует все высокочастотные элементы, на промежуточном (замыленном) изображении скрывавшиеся под сравнительно некрупными мутными пятнами. 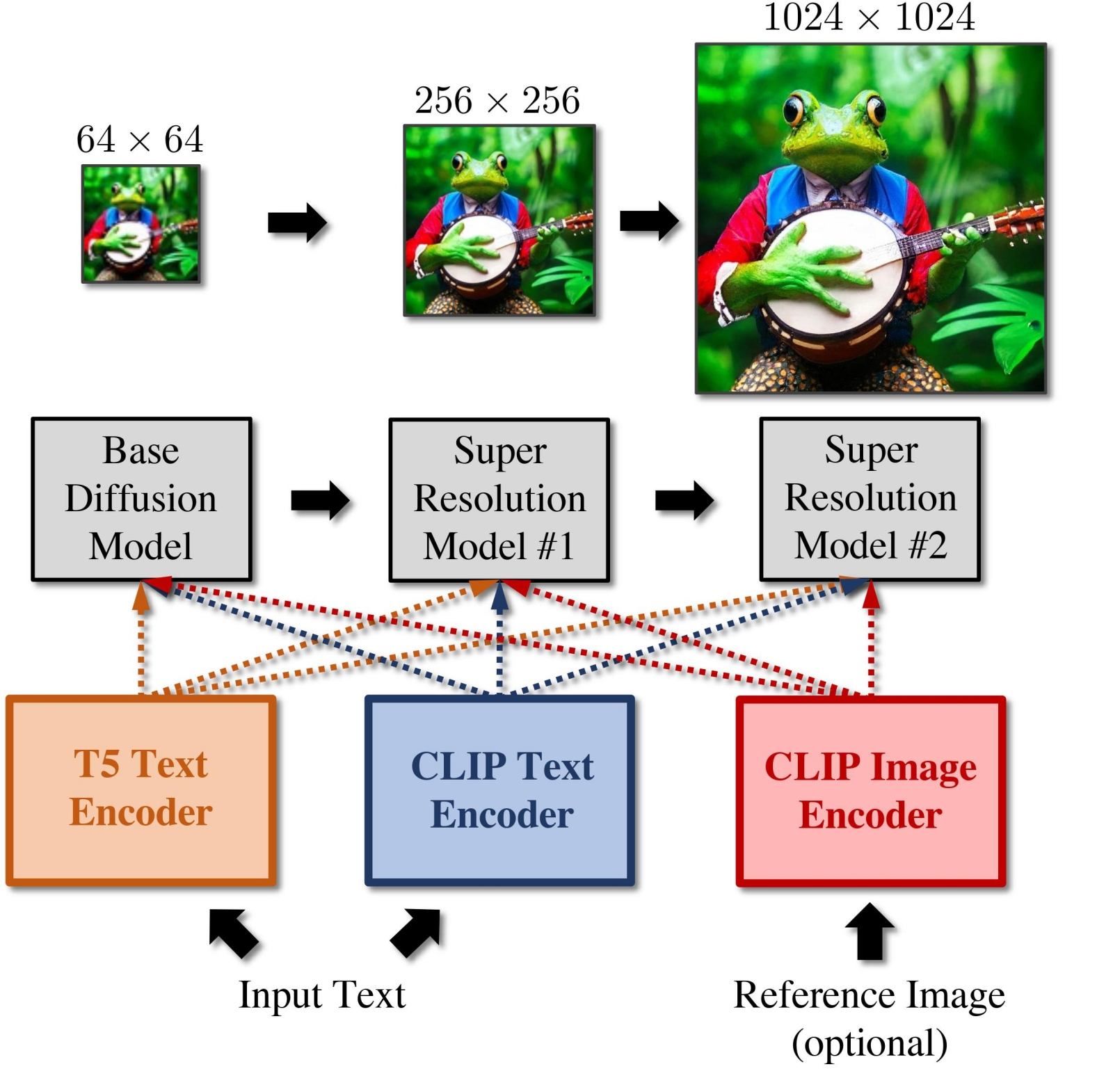
Реализация сотворчества генеративных моделей в подходе eDiff-I несколько отличается от той, что воплощена в SDXL, но общий принцип тот же (источник: NVIDIA) Второй метод — классический SDEdit (Stochastic Differential Editing), суть которого в том, что на вход второй субмодели в связке подаётся на 100% лишённый шума первой субмоделью образ — результат нормальной генерации с любым адекватным чекпойнтом. Получив этот образ, доводчик немного зашумляет его (поскольку собственно стохастический шум и является окошком в латентное пространство, через которое можно вытянуть недостающие высокочастотные детали), и далее происходит нормальная работа генеративной модели — удаление с получившейся картинки излишков шума путём итеративного решения стохастических дифференциальных уравнений. Вся разница между сотворчеством двух субмоделей и последовательной обработкой изображения — в том, что в первом случае доводчик (refiner) имеет дело с остатками натурально, что называется, присущего обрабатываемой картинке шума; того самого, что остаётся на ней с момента извлечения данной конкретной площадки — заготовки будущей картинки — из латентного пространства. Во втором же случае шум, необходимый для работы второй субмодели, добавляется, скажем так, искусственно: даже если формально затравка (seed) та же самая, прочие вводные для генерации почти наверняка другие (не говоря уже о системе внутренних параметров самой второй модели), так что результат выйдет несомненно иным, чем в первом случае. Не факт, кстати, что обязательно менее устраивающим оператора, — но иным. 
Источник: ИИ-генерация на основе модели SDXL 1.0 Так вот, сам принцип организации рабочей среды AUTOMATIC1111 отменно подходит для реализации последовательной связки двух субмоделей с передачей между ними полностью очищенного от латентного шума изображения. Код этой среды (опять-таки оговоримся, вплоть до актуальной ныне стабильной версии 1.5.1) в принципе не подразумевает возможности выдавать, пусть даже в качестве промежуточного результата, картинку с остатками латентного шума. А вот в ComfyUI — что благодаря, по сути, отсутствию интерфейса заставляет оператора самолично выстраивать циклограммы генерации образов, — для этого оказалось достаточно всего лишь написать соответствующую ноду. То бишь чёрный ящик (с точки зрения оператора, разумеется, а не создававшего её программиста), способный принимать на входе текстовые подсказки и иные параметры генерации, а на выходе выдавать изображение, очищенное от латентного шума не целиком, а лишь в указанных входными параметрами пределах. ⇡#Заводи моторОставим наконец необходимое, но поневоле несколько затянувшееся предисловие — и перейдём к собственно генерации ИИзображений при помощи чрезвычайно перспективной рабочей среды ComfyUI. Официальным источником информации об этом проекте с открытым кодом служит его страница на GitHub; где, в частности, публикуются сведения о новых релизах. Рассматриваемая среда кардинально отличается от AUTOMATIC1111 уже на этапе установки — тем, что развёртывается на ПК как полностью независимый пакет, не требующий предварительной инсталляции Git, Python и т. п.: всё необходимое уже присутствует в официальной сборке. Достаточно скачать её по приводимой на странице с релизами ссылке — в данном случае Download Link with stable pytorch 2.0 cu118 + xformers — и распаковать полученный ZIP-файл в любой удобный каталог (желательно, конечно же, на SSD, а не на магнитном жёстком диске). Ну, скажем, в нашем примере — в C:\Fun-n-Games\ComfyUI_windows_portable). Как и AUTOMATIC1111, ComfyUI — просто рабочая среда; собственно моделей (чекпойнтов) она не содержит. Их (напомним, две штуки — базу и доводчик) в виде файлов .safetensors потребуется загрузить с репозитория разработчика, Stability.ai, на сайте Hugging Face, по соответствующим ссылкам: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0 и https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0. В сумме файлы занимают около 13 Гбайт, так что стоит набраться терпения. 
Куда помещать закачанные субмодели? По умолчанию — в предназначенный для этого каталог внутри той папки, где развёрнут ComfyUI; в нашем случае это C:\Fun-n-Games\ComfyUI_windows_portable\ComfyUI\models\checkpoints. Однако как быть тем, кто уже пользуется AUTOMATIC1111 — и, допустим, захочет на собственном опыте удостовериться, что вплоть до версии 1.5.1 эта среда менее пригодна для работы с SDXL, чем ComfyUI? Копировать те же 13 Гбайт в соответствующую папку внутри каталога «Автоматика»? Это неэкономно — да и незачем, поскольку ComfyUI может пользоваться чекпойнтами и вне своего каталога по умолчанию.  Для этого в C:\Fun-n-Games\ComfyUI_windows_portable\ComfyUI\ предусмотрен файл-заготовка extra_model_paths.yaml.example. Копируем его с названием extra_model_paths.yaml в этот же самый каталог (или просто отрезаем суффикс «.example» в названии), открываем в любом текстовом редакторе, снимаем значок комментария (#) с третьей снизу строки, «checkpoints:», и прописываем туда путь к хранилищу чекпойнтов в составе AUTOMATIC1111. В нашем случае это C:\Fun-n-Games\Git\stable-diffusion-webui\models\Stable-diffusion. Теперь можно поместить обе субмодели SDXL в эту последнюю папку — и содержимое её отныне (включая, разумеется, чекпойнты для SD 1.5) будет доступно и AUTOMATIC1111, и ComfyUI. Аналогично можно поступить и с VAE (вариативным автокодировщиком, variational eutoencoder) — дополнительной мини-нейросетью, специально натренированной на повышение качества итогового изображения. Файл этой модели, sdxl_vae.safetensors, следует закачать со страницы https://huggingface.co/stabilityai/sdxl-vae/ и далее поместить либо в папку models/vae внутри установочного каталога ComfyUI, либо в аналогичную папку в инсталляции AUTOMATIC1111 — с прописыванием нужного пути в файле extra_model_paths.yaml.  Теперь счастливым обладателям видеокарт NVIDIA под Windows необходимо установить вручную ряд дополнительных пакетов из командной строки. Как и при установке AUTOMATIC1111, это несложно сделать, исполнив команду cmd из меню «Поиск» системной панели, а в открывшемся чёрном окошке запустив следующий скрипт: pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 xformers Если вдруг в системе не сконфигурирован должным образом пакет torch (а у тех, кто уже пользовался AUTOMATIC1111, тут всё должно быть в порядке), появится сообщение «Torch not compiled with CUDA enabled». В этом случае нужно отдать команду pip uninstall torch после чего повторить предыдущую.  Всё, что теперь остаётся, — связать ComfyUI зависимостями с другими развёрнутыми в системе пакетами. Для этого в «Проводнике», находясь в подпапке C:\Fun-n-Games\ComfyUI_windows_portable\ComfyUI, нужно вызвать контекстное меню правой кнопкой мыши, выбрать там «Git Bash here» и исполнить команду pip install -r requirements.txt Если в ПК установлен ГП NVIDIA, потребуется запустить файл run_nvidia_gpu.bat; если нет — run_cpu.bat. В последнем случае генеративная модель будет развёртываться в ОЗУ и использовать ядра ЦП, что позволит получать вполне адекватные изображения — правда, за гораздо большее время. Для систем с дискретной графикой AMD, с видеокартами Intel Arc и для компьютеров на чипах Apple Mac Silicon возможны варианты — они бегло рассмотрены на официальной странице проекта.  При первом запуске ComfyUI отчитывается об обнаружении всех папок с моделями, ранее загружавшимися нами для AUTOMATIC1111. Веб-интерфейс в данном случае доступен по адресу http://127.0.0.1:8188/.  Загрузившаяся по умолчанию циклограмма носит название default flow и представляет собой простейший вариант организации работы с нодами. Поле с разбросанными по нему объектами и связями можно приближать/удалять скроллингом, а также перемещать мышкой: либо зажимая левую кнопку где-нибудь на пустом месте и двигая манипулятор, либо нажав «Пробел» и перемещая мышь. С правой стороны экрана — столбец с кнопками, среди которых первым делом надо обратить внимание на последнюю, «Load Default». Если с непривычки или по неаккуратности что-то окажется совсем уж перекорёжено, именно она позволит восстановить всё вот в этом самом изначальном виде. А как только при помощи ComfyUI мы сгенерируем первое изображение, всё будет проще: чтобы воспроизвести один к одному задействованные для его получения ноды и связи, достаточно будет перетащить его мышкой из папки outputs, открытой в «Проводнике», в рабочее поле.  Кстати, крайняя справа нода в циклограмме по умолчанию, «Save Image», подразумевает автоматическое сохранение появляющихся там картинок. Изначально там нет окошка для вывода — оно появится после генерации первого изображения. Можно, потянув мышкой за правый нижний угол этой ноды, придать ей желаемые размер и форму. Есть и другой тип выходной ноды, которая просто демонстрирует картинку (а чтобы сохранить её при желании, оператору придётся нажать правой кнопкой и выбрать соответствующую опцию). Попробуем её добавить. 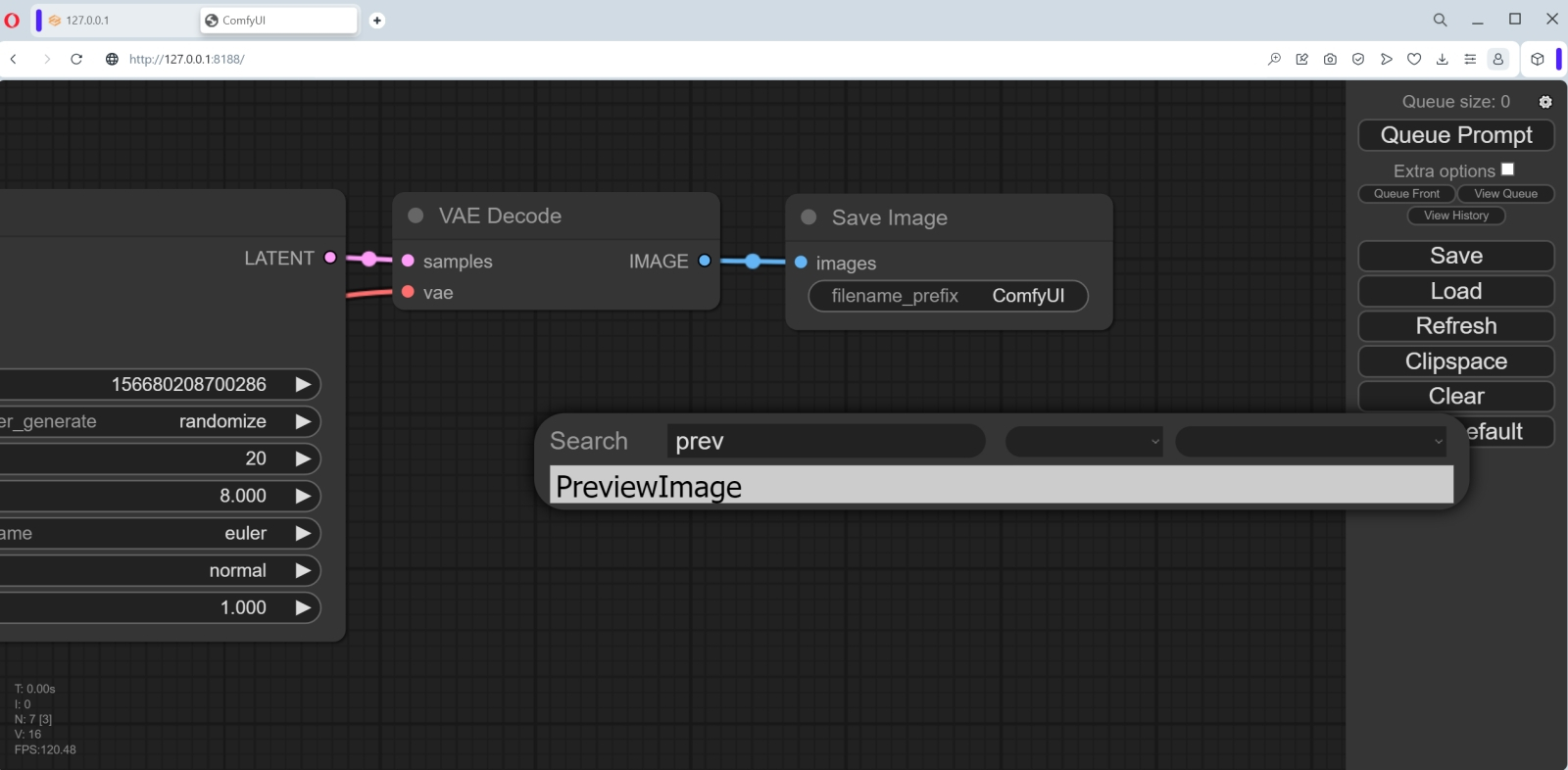 Для этого надо дважды щёлкнуть левой кнопкой мыши по любому свободному участку рабочего поля, после чего выбрать в появившемся меню (вот он, ненавязчивый интерфейс ComfyUI, — всё-таки имеется, пусть и в латентном виде!) опцию «PreviewImage». Сделать это с непривычки непросто, поскольку перечень доступных нод слишком уж велик. Зато тут есть окошко для ввода текста — и по мере набора в нём букв p, r, e число опций постепенно сокращается, пока не остаётся одна только «PreviewImage». Щелчок мышью — и на поле образуется новая нода под названием «Preview Image». В данном случае мы оставим обе ноды, и «Save Image», и «Preview Image», чтобы показать, что ComfyUI может оперировать несколькими окнами выдачи одновременно. Но если «Save Image» не нужна, её не составит труда удалить — щёлкнув по ней правой кнопкой и выбрав в открывшемся меню самую нижнюю опцию, «Remove».  Итак, у нас есть новая нода, «Preview Image», но она нерабочая — поскольку ни к чему не подсоединена. Подведём курсор к ноде «VAE Decode» (непосредственно перед «Save Image», если последняя не удалена) и нажмём левой кнопкой на яркую точку рядом с выходным параметром «IMAGE». Потянем, не отпуская, — и доведём растягивающуюся цветную линию до входного параметра «images» в новосозданной ноде «Preview Image». Собственно, так создание циклограмм и работает: ноды соединяются линиями, причём если в данном конкретном случае соединение в принципе невозможно (скажем, текст подсказки не может быть подан на вход, ожидающий числового значения), линия не присоединится к финальной точке. Ошибки практически исключены: либо составленная циклограмма заработает и выдаст хоть какой-то результат, либо не заработает вовсе.  Вернёмся к самой первой ноде, «Load Checkpoint», и посмотрим, что там выбрано. Поскольку на данном компьютере уже развёрнут AUTOMATIC1111, и ComfyUI в процессе настройки зависимостей обнаружила его репозитории, по умолчанию в данную ноду подгрузился первый по алфавиту из всех доступных чекпойнтов — aZovyaRPGArtistTools_v3.safetensors с этой вот страницы на Civitai. Это одна из популярных моделей для создания рисунков в псевдореалистичном стиле — вроде тех, какими иллюстрируют фэнтезийные романы, карты для настольных игр вроде MTG и т. п. Это чекпойнт, базирующийся на SD 1.5, — но тем интереснее будет сравнить, как с одними и теми же входными параметрами сработают ComfyUI и AUTOMATIC1111. 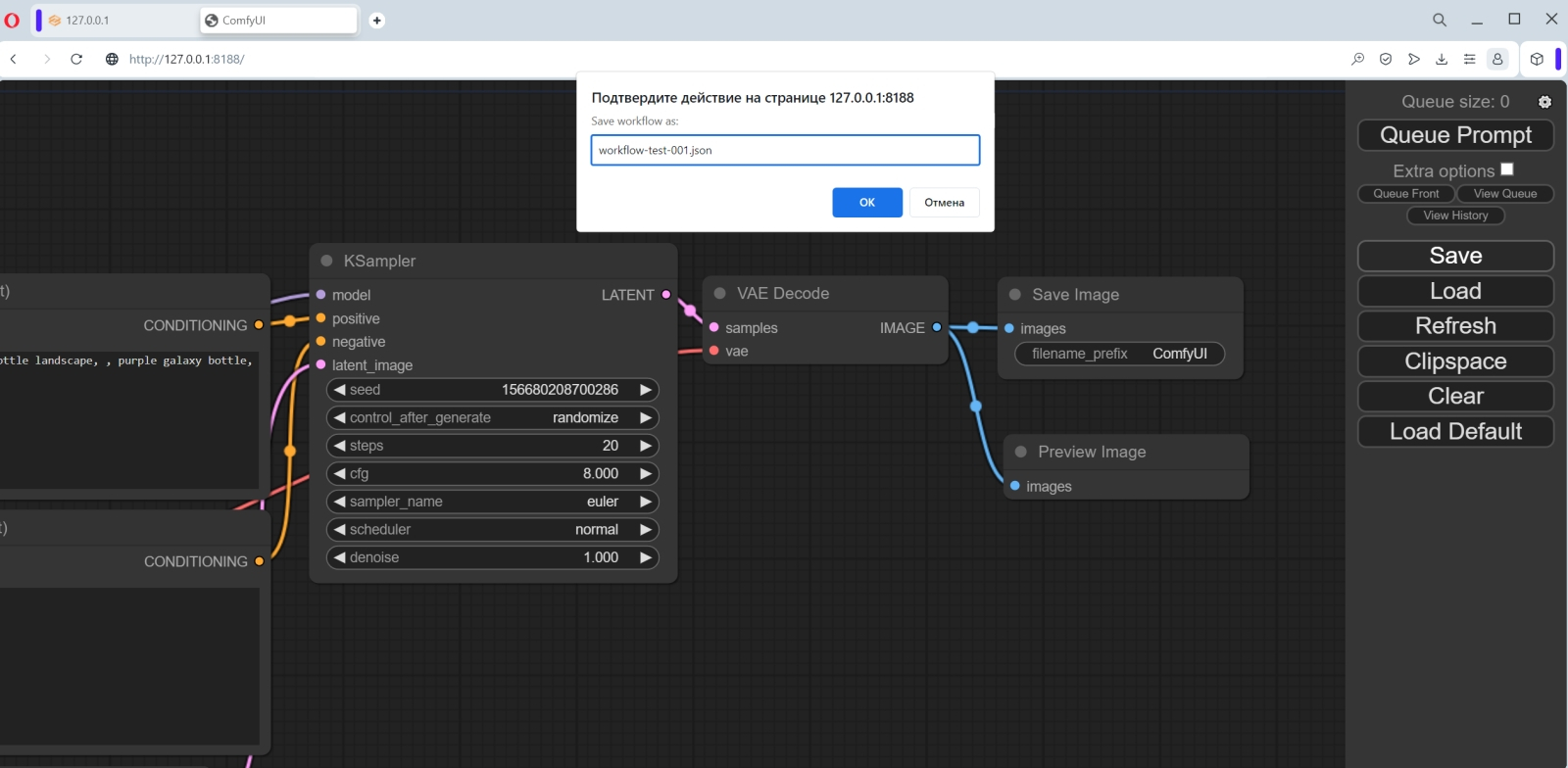 И кстати, сразу же воспользуемся удобнейшей возможностью ComfyUI — сохранением рабочего потока целиком. В отличие от AUTOMATIC1111, здесь не надо всякий раз судорожно проверять, стараясь воспроизвести однажды полученный результат, корректно ли указаны CFG, Clip skip, число шагов генерации и прочие величины: тут всё можно сохранить в файле формата JSON — ещё даже до того, как по выстроенной циклограмме сгенерирована первая картинка. При нажатии на кнопку Save на правой панели браузер сообщит, что данная страница запрашивает сохранение файла, — и в этом окошке можно задать для него имя.  Ну что же, нажимаем теперь на кнопку «Queue prompt» в самом верху правой панели или же просто «Ctrl»+«Enter» на клавиатуре — и циклограмма пойдёт на исполнение. Как видно, загрузка видеопамяти вполне щадящая. 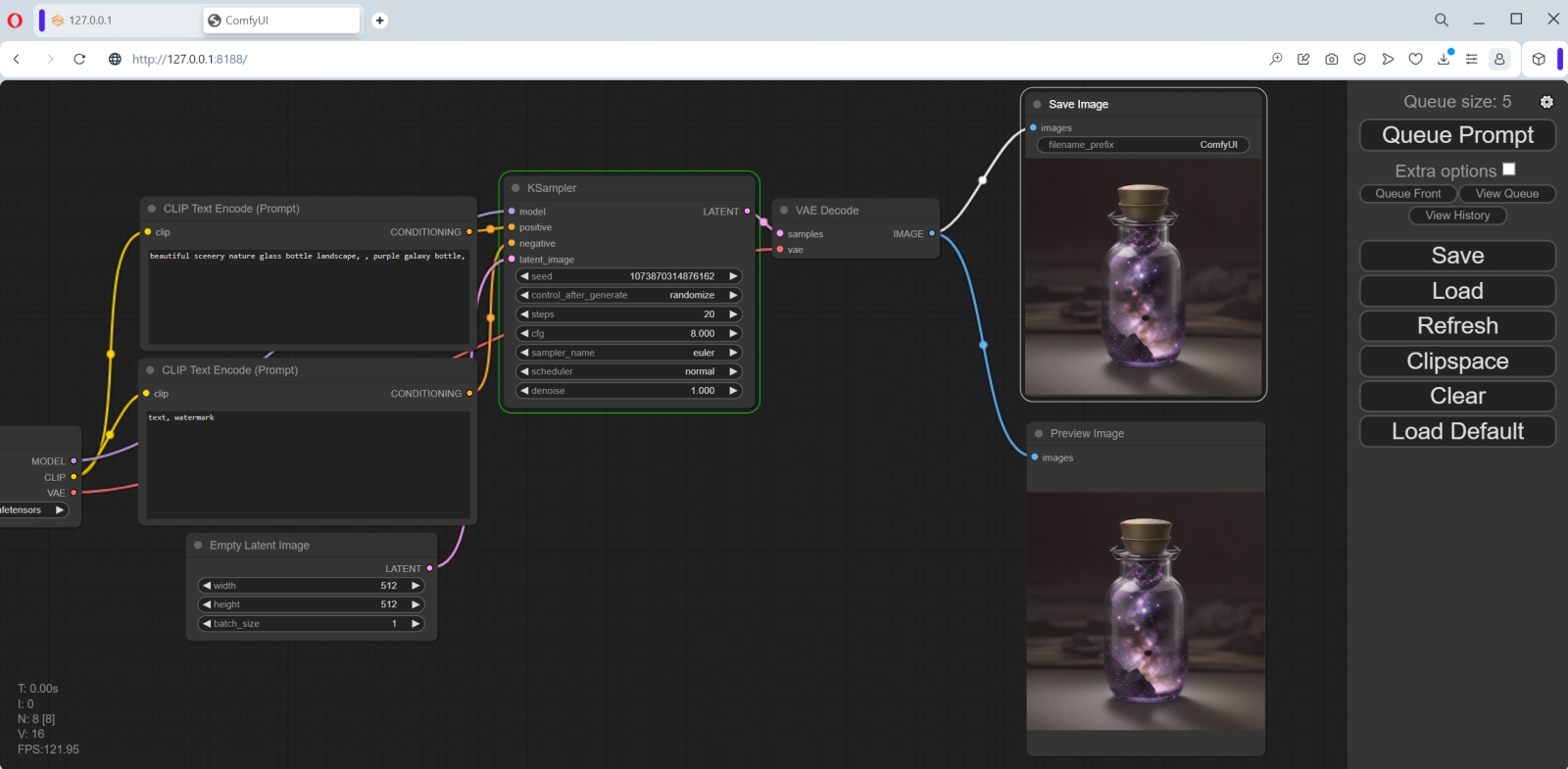 Текстовая подсказка по умолчанию описывает галактику в бутылке — и, как мы видим, соответствующая генерация пошла. В веб-интерфейсе можно наблюдать за её прогрессом: справа вверху, на макушке панели управления, идёт обратный отсчёт генераций в очереди; в верхней части ноды KSampler (обозначающей тот самый чёрный ящик с латентным пространством внутри, на входы которого поданы заданные пользователем параметры, а на выходе образуется картинка) движется слева направо зелёная полоска. Выходные картинки по мере их готовности можно наблюдать вживую. Готовые картинки с префиксом, указанным в шапке ноды «Save Image», сохраняются по умолчанию в каталог C:\Fun-n-Games\ComfyUI_windows_portable\ComfyUI\output. Время генерации одного изображения на ГП GeForce GTX 1070 — 8-9 секунд, загрузка ГП — около 68%. Теперь посмотрим, как с той же задачей справится AUTOMATIC1111. Выходим из окошка командной строки, в которой запущена ComfyUI, нажатием на «Ctrl»+«C» подтверждая свой выбор, и запускаем теперь AUTOMATIC1111. 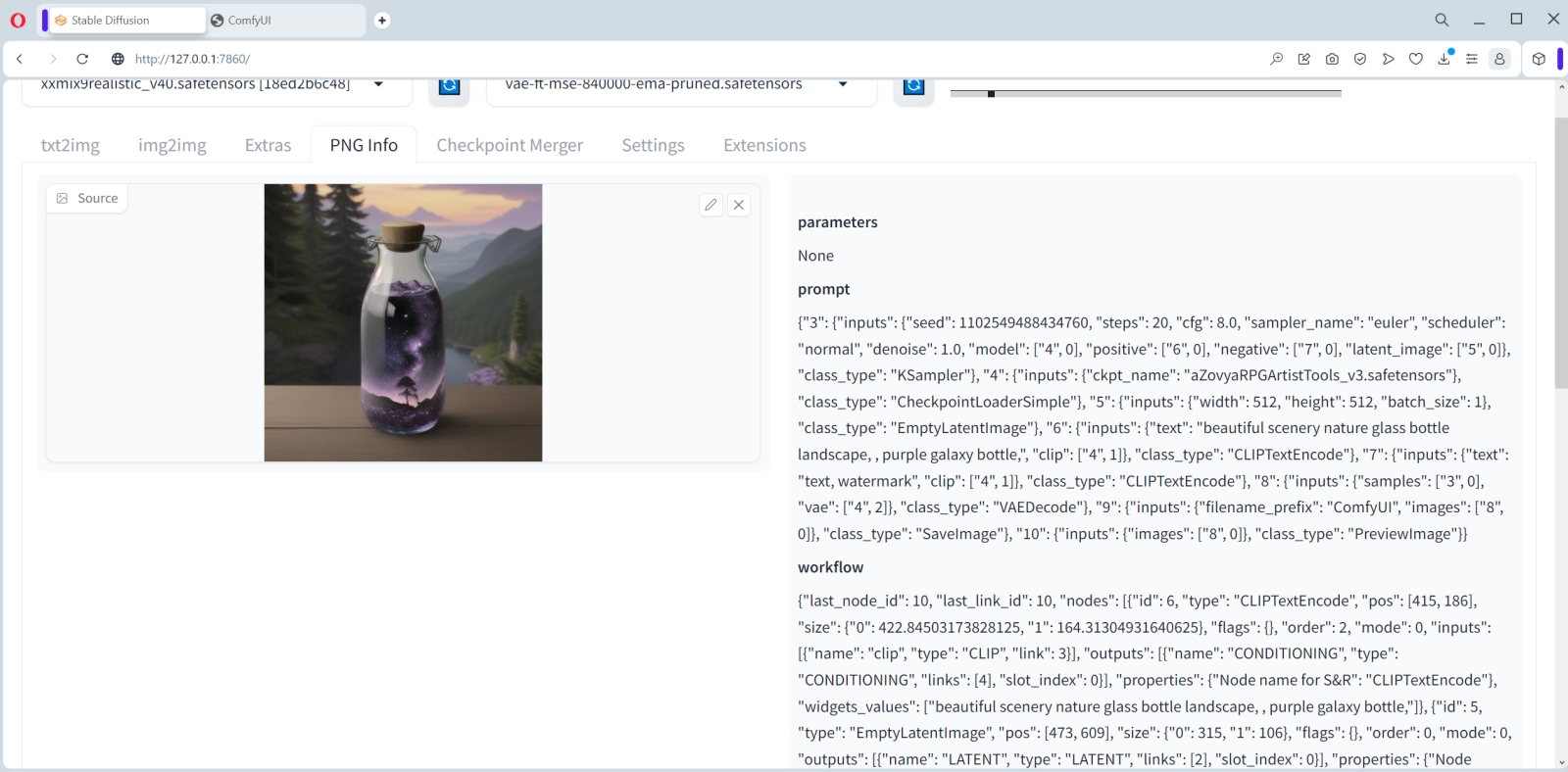 Попробуем загрузить инфо о сгенерированной в ComfyUI картинке через вкладку «PNG Info». Интересно получается: данные в файле есть, включая рабочий поток для его воспроизведения, — но формат явно иной, не поддерживаемый AUTOMATIC1111. Возможно, в грядущей версии 1.6.0 появится возможность автоматически переносить на вкладку «txt2img» сведения о параметрах генерации, произведённой в ComfyUI, — но пока придётся сделать это вручную. 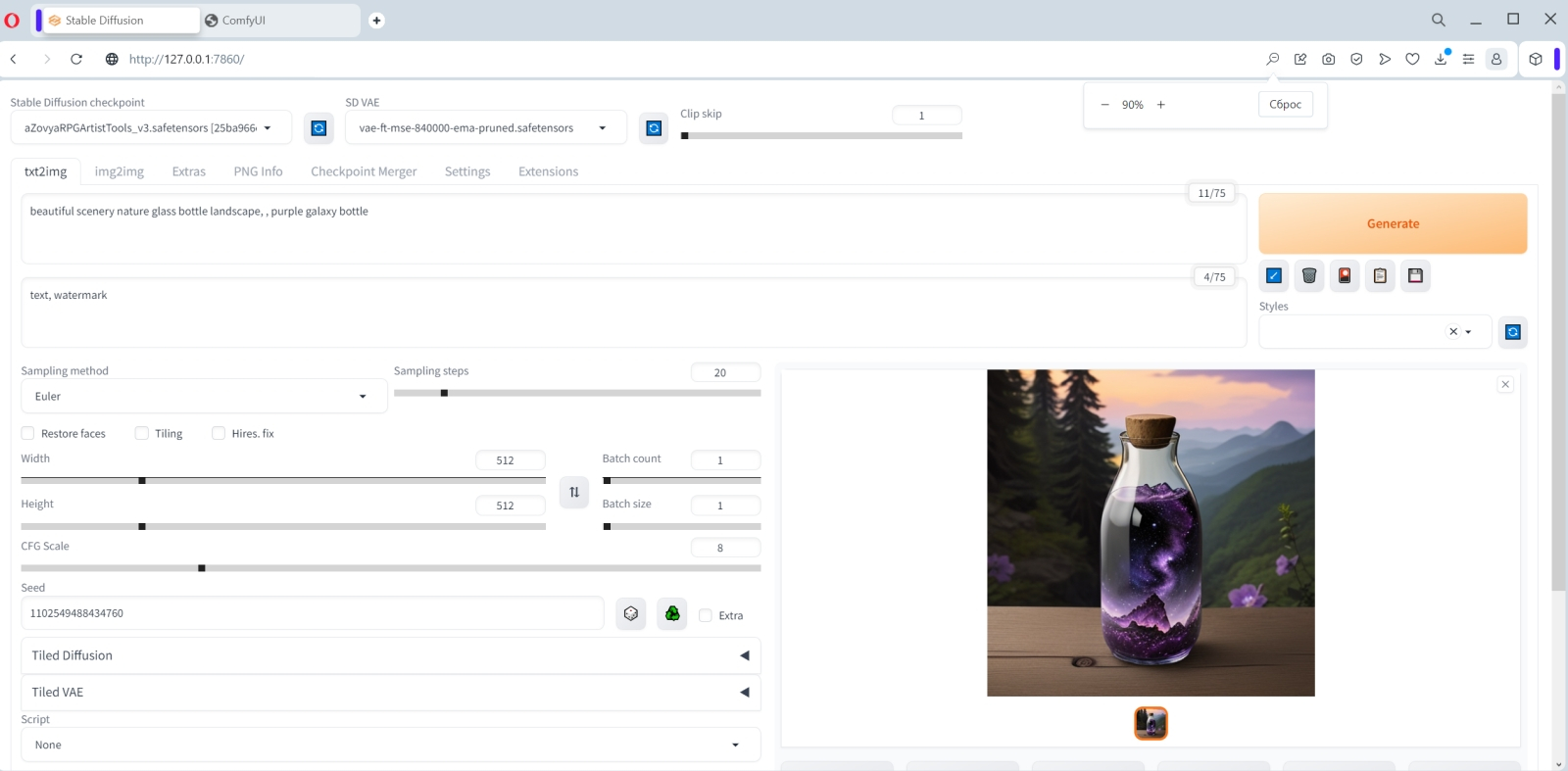 К счастью, вся информация, извлечённая «PNG Info» из JSON-записи в файле картинки, вполне поддаётся прочтению оператором, так что ввести нужные данные в поля на вкладе «txt2img» труда не составит. Итак, параметры: позитивная подсказка — beautiful scenery nature glass bottle landscape, , purple galaxy bottle (пробел, отграниченный запятой, — составная её часть; оставим на месте), негативная — text, watermark, Steps — 20, Sampler — Euler CFG scale — 8 Seed — 1102549488434760 Size — 512x512. Укажем здесь стандартную для SD 1.5 VAE и выставим «Clip skip» в 1, после чего запустим AUTOMATIC1111 на исполнение. Результаты: время генерации — 15,5 с; загрузка ГП — на уровне 53%. 
Слева — результат работы чекпойнта SD 1.5 в ComfyUI с базовой циклограммой; в центре — картинка, сгенерированная с теми же параметрами (+VAE vae-ft-mse-840000-ema-pruned) в AUTOMATIC1111, справа — тоже в AUTOMATIC1111, но без явного указания VAE В целом — очень похожие результаты генераций в обеих рабочих средах. Тем не менее разница есть, и возникает она вовсе не из-за VAE: если заменить явный выбор вариационного автокодировщика опцией «Automatic», изображение становится несколько более туманным, но детали его остаются прежними. Дело в том, что в AUTOMATIC1111 и ComfyUI чуть по-разному организована обработка векторов токенов, формируемых декодером CLIP. Тем не менее выигрыш во времени — пусть и за счёт небольшого гандикапа в утилизации ГП — для ComfyUI очевиден: почти в полтора раза для столь несложного набора входных параметров. Неудивительно, что многие энтузиасты ИИ-рисования, однажды дав себе труд разобраться в хитросплетениях (и в буквальном смысле тоже) циклограмм этой рабочей среды, начинают отдавать ей предпочтение перед AUTOMATIC1111 — даже для чекпойнтов, основанных на SD 1.5 А мы тем временем перейдём-таки к SDXL 1.0. Выйдем из AUTOMATIC1111 (не просто закрыв окошко в браузере, напомним на всякий случай, — надо и тут через «Ctrl»+«C» с подтверждением закрыть запущенный из командной строки сервер рабочей среды), запустим файл run_nvidia_gpu.bat ComfyUI. Кстати, после его запуска происходит автооткрытие нужной страницы (http://127.0.0.1:8188/) в браузере по умолчанию. 
Источник: скриншот сайта GitHub Напомним, что принципиальная особенность SDXL — в наличии двух чекпойнтов, действующих солидарно. Конечно, не так уж сложно нарисовать в интерфейсном поле ComfyUI нужные ноды и связи между ними вручную, но умудрённые энтузиасты уже позаботились обо всех начинающих, разместив на GitHub JSON-файл с предварительно настроенным потоком: ComfyUI-SDXL-Workflow. Скачаем его по приведённой ссылке (справа на странице — изображение стрелки вниз, утыкающейся в лежащую ничком квадратную скобку; нажимать для скачивания нужно именно на неё), сохраним туда, где при необходимости сможем быстро найти, и загрузим в ComfyUI через кнопку Load на правой панели. Файл называется Workflow ComfyUI SDXL 0.9.json, но смущаться не надо, — для версии 1.0 он точно так же подходит: различий по структуре рабочего потока между ними нет. 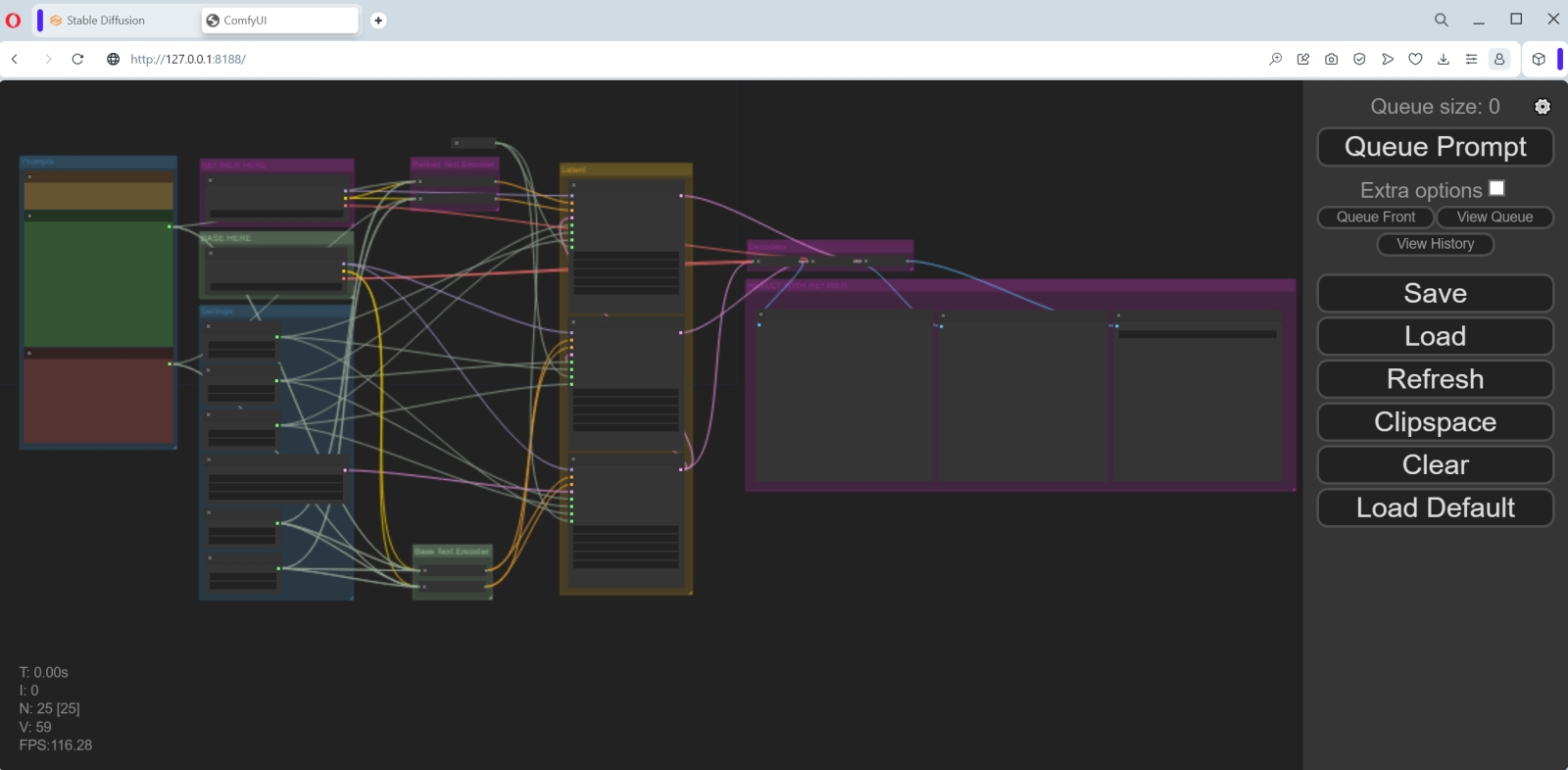 Выглядит, э-э, запутанно? На самом деле, всё логично — но постигать эту логику лучше последовательно, не торопясь.  Для начала изучим крайнюю левую колонку нод, объединённых в блок «Prompts». Сверху там располагается предупреждение («Please read!») о том, что для получения картинок более высокого качества следует сохранять предложенную структуру подсказок: для позитивной, к примеру, в первой строке надо дать общее описание создаваемой сцены (Splash art of an emo woman warrior), а далее, через разрыв строки, отделённый запятой, уже относящиеся к её общему виду команды (artistic, creative, contrasting, detailed, 8k, expressive). Кстати, и в том примере, что подгрузился в ComfyUI по умолчанию, такой разрыв (правда, в виде всего лишь пробела) присутствовал. Эмо-воительница — дело, конечно, хорошее, но давайте сперва воспроизведём на новейшей модели галактику в бутылке — а потом уже можно будет дать волю и более фривольным фантазиям. 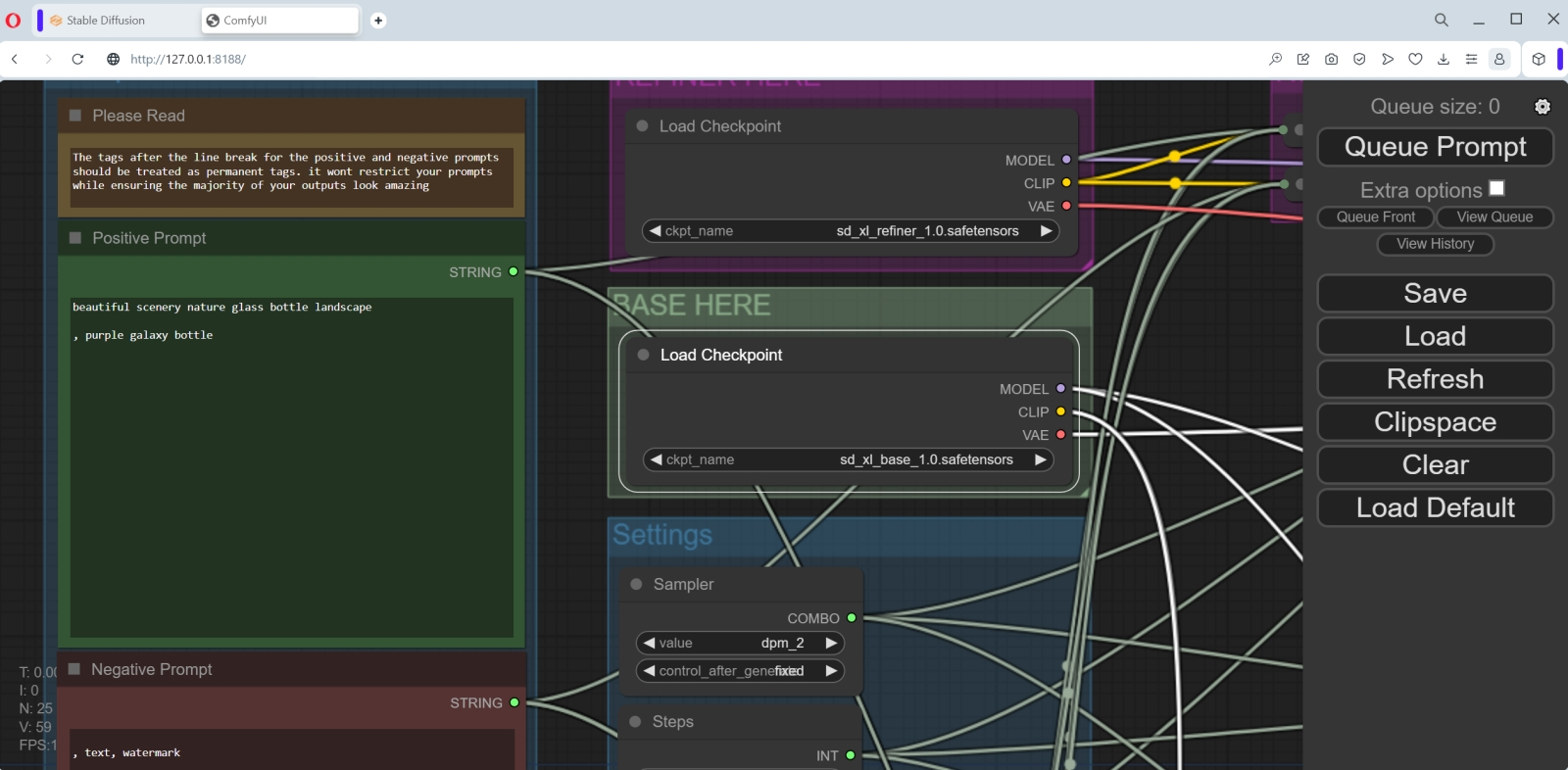 Итак, поменяем в ноде «Positive prompt» её содержимое на beautiful scenery nature glass bottle landscape
, purple galaxy bottle (обратите внимание на разрыв строки!), а «Negative prompt» -- на
, text, watermark (именно так: первая строка пустая, для её создания просто нажимаем на Enter; вторая начинается с запятой и пробела). Заодно актуализируем информацию в соседнем столбце нод, где верхние две представляют собой блоки вызова обеих моделей SDXL, доводчика (refiner) и базы. Здесь изначально указаны соответствующие файлы для версии 0.9, поскольку автор этого рабочего потока создавал его ещё до выхода финальной редакции новой модели. Поэтому следует, щёлкнув по полям с названиями чекпойнтов мышкой, выбрать для верхней ноды sd_xl_refiner_1.0.safetensors, а для нижней — sd_xl_base_1.0.safetensors.  Ниже в той же колонке идёт большой блок «Settings» с нодами различных настроек, которые читателям прежних наших материалов о генерации изображений по модели SD 1.5 в рабочей среде AUTOMATIC1111 должны быть хорошо знакомы. Попробуем привести их в соответствие с теми, с которыми ComfyUI в ходе своего первого запуска создавала галактики в бутылке. 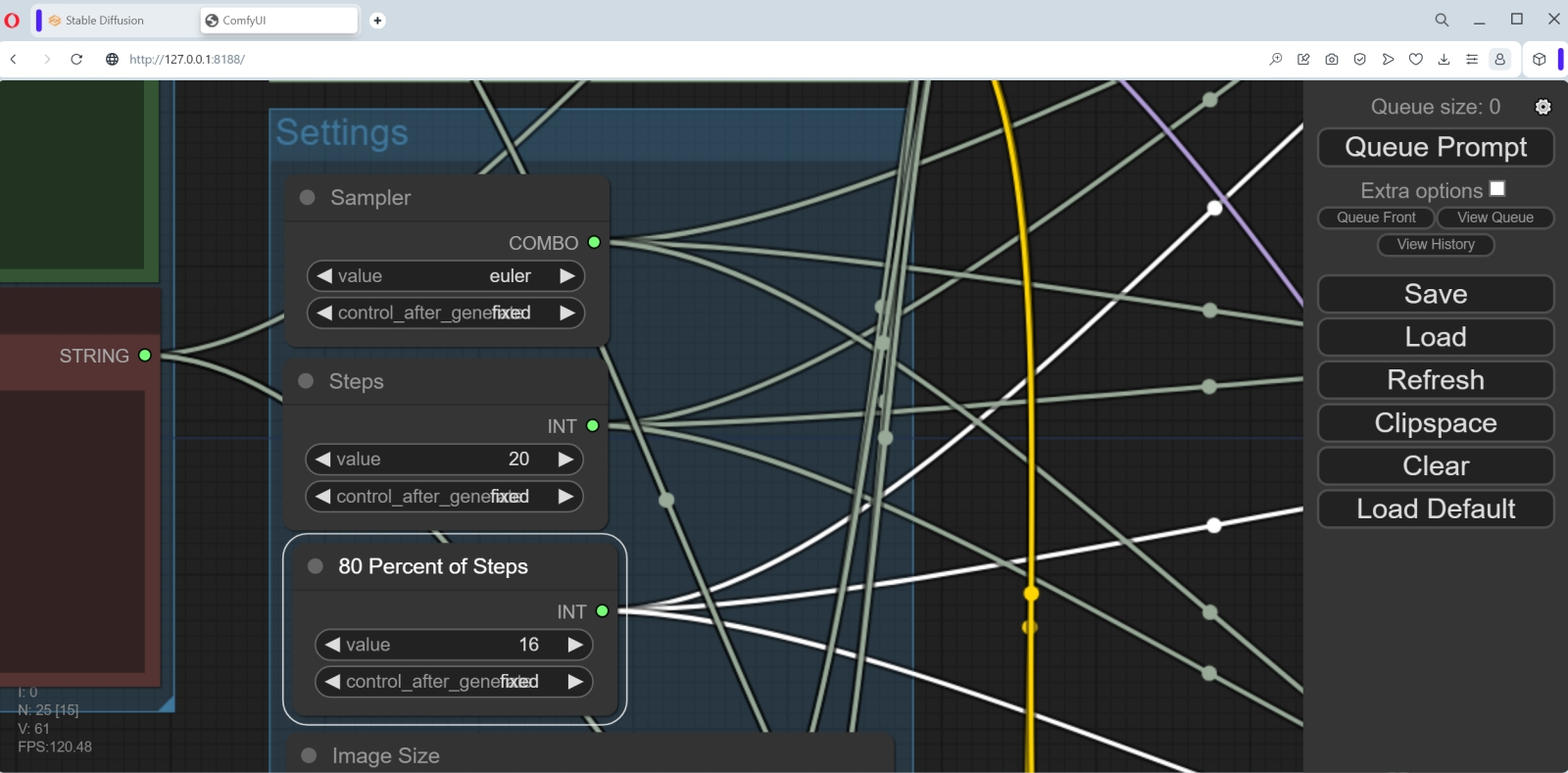 Семплер исходно указан dpm_2 — меняем его на euler. Число шагов 40 — пусть будет 20, как в прошлый раз. «80 percent of steps» — очевидно, 16 (80% от 40).  «Image size» пусть будет 1024 × 1024, стандарт для SDXL. Число изображений в серии (batch) — 1, ширина и высота учетверённой (по площади, имеется в виду) картинки — 4096 и 4096, конечно же. Учетверение это чисто служебное, будет производиться внутри «чёрного ящика» (ради ещё более чёткого выявления высокочастотных деталей картинки), — итоговое изображение всё равно окажется в размере 1024 × 1024.  В колонке правее с самого верха стоит неприметная нода «Noise seed». Она может отображаться в свёрнутом виде (один лишь заголовок в узкой плашке), но щелчок мышью по заголовку развернёт блок так, что откроются два поля для ввода параметров. В первое, «Value», поместим ту самую затравку, что была у полученной нами галактики в бутылке, — 1102549488434759. Ниже располагаются служебные мини-ноды, не предполагающие пользовательских настроек, — пары CLIPTextEncodeSDXLRefiner и CLIPTextEncodeSDXL. Интересующихся тем, что именно в этом месте делает создающая картинки нейросеть, отсылаем к краткому изложению самого понятия CLIP (в связи с параметром генерации «Clip drop») из второй части нашей «Мастерской» по ИИ-рисованию, а также к общему описанию этой модели. 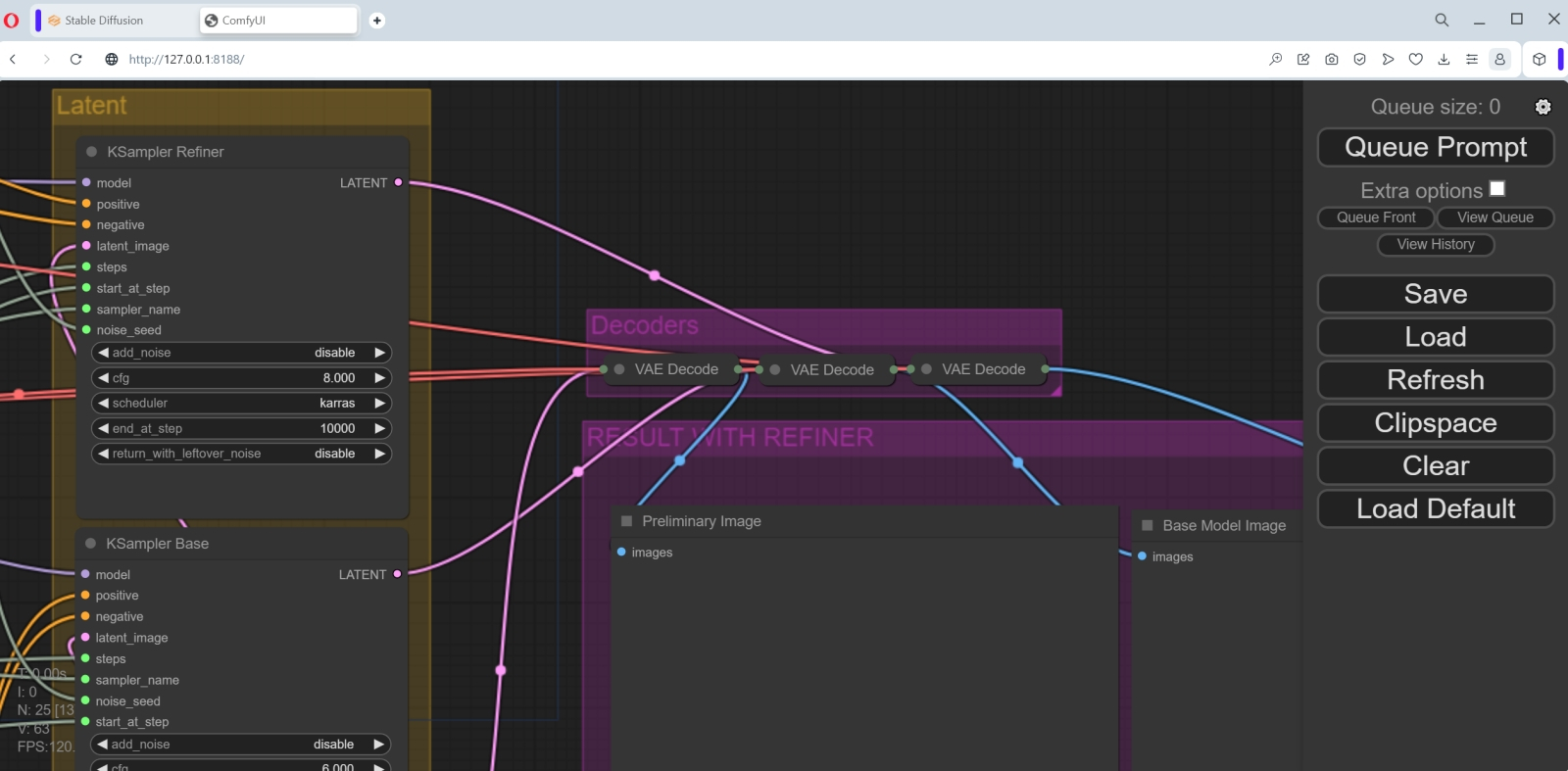 В следующей колонке расположены три ноды, задающие входные параметры чекпойнтов SDXL: доводчика (KSampler refiner), базы (KSampler Base) и предобработки (KSampler preliminary). От них розовые линии выдачи изображений ведут к соответствующим блокам постобработки VAE (в крайней колонке справа), а уже под теми располагаются три окошка для итоговых картинок. Точнее, в первом появится изображение, сгенерированное предварительным чекпойнтом, во втором — базой (на которую поступила в качестве одного из входных параметров латентная генерация из предварительной модели), а в третьем — доводчиком (который, в свою очередь, получил образ для дальнейшей обработки от базовой модели). По сути, KSampler Base — это визуализация (с полным удалением латентного шума) работы основной субмодели SDXL, тогда как KSampler preliminary передаёт на постобработку в доводчик ту же самую картинку, но зашумлённую примерно на 20% (поскольку общее число шагов, как можно увидеть в соответствующем поле, — 40, а передача производится после 32-го шага). Сохраним модифицированный рабочий поток в файл workflow-test-002.json и запустим его на исполнение, нажав кнопку «Queue Prompt». Тут надо набраться терпения: сперва вроде бы ничего не происходит, но загрузка ГП поднимается до 20-22%, а в окне командной строки, где запущен сервер SDXL 1.0, принимаются бежать служебные сообщения.  Затем нашему тестовому компьютеру пришлось туго: утилизация ГП подскочила до 80%, потом ещё выше, на какое-то время интерфейс ОС перестал откликаться на клавиатурные команды… В общем, собственно генерация первой картинки заняла тоже считаные секунды (8-9 — но лишь после того, как предварительно всё нужное было загружено в видеопамять; вот почему с SDXL имеет смысл работать именно пачками (batch), а не по одной картинке), а всего система проработала 808 секунд, пока не получила полностью готовое изображение 1024 × 1024, тратя на каждую итерацию по 3,19 с. 
Источник: ИИ-генерация на основе модели SDXL 1.0 Спору нет, изображение и впрямь замечательное. Но стоит ли овчинка выделки — для владельцев старых видеокарт, имеется в виду? Чекпойнты на базе SD 1.5 в AUTOMATIC1111 могут обсчитывать картинки дольше, но эта рабочая среда весьма умеренно кушает видеопамять — и не мешает сторонней работе на ПК (по крайней мере, тексты набирать и веб-страницы просматривать). Здесь же, похоже, стоит позакрывать вообще всё стороннее ПО, убрать в настройках браузера аппаратное ускорение — и в целом высвободить как можно больше видеопамяти, поскольку ComfyUI изрядно нагружает доступное ей «железо». Тем не менее SDXL вследствие своей кардинально обновлённой архитектуры набирает всё бóльшую популярность — и потому инструментарий для уверенной работы с этой генеративной моделью у каждого энтузиаста ИИ-рисования должен быть под рукой. В пользу же выбора именно ComfyUI в качестве такого инструментария говорит — помимо чисто технических соображений — то, что использовать полученный кем-то удачный результат в рамках этой рабочей среды чрезвычайно просто. Достаточно перенести картинку мышкой из «Проводника» в основное поле веб-интерфейса — и дело пойдёт: подбирать семплеры, менять чекпойнты, пробовать иные комбинации CFG и числа шагов можно едва ли не до бесконечности, не беспокоясь о том, что какой-то важный момент в ходе копирования исходных параметров упущен. 
Источник: ИИ-генерация на основе модели SDXL 1.0 Да, на первичное освоение ComfyUI понадобится определённое время, — зато потом обращаться с прирученным «макаронным монстром» будет с каждым разом всё проще и проще. Для этой рабочей среды есть уже и текстовые инверсии, и LoRA, и детально прописанные циклограммы на любой случай (от дорисовки/перерисовки до масштабирования с детализацией), и даже руководства по эффективному составлению подсказок. Притом с течением времени, судя по решительному настрою comfyanonymous и всего коллектива Stability.ai, либо сама ComfyUI, либо близкая к ней по духу среда имеет все шансы получить статус официально рекомендованной к использованию разработчиками Stable Diffusion. Понятно, что в мире ПО с открытым кодом конкуренция в любом случае будет оставаться высокой, — но создателям AUTOMATIC1111 и иных инструментов для локального (в смысле, не на облачном сервисе) ИИ-рисования уже сейчас приходится прилагать немалые усилия, чтобы соответствовать заданной ComfyUI высокой планке гибкости и эффективности. Причём всему сообществу энтузиастов генеративной компьютерной графики эта конкуренция идёт только на пользу. P.S.: По техническим причинам разместить изображения с метаданными на стайте 3DNews не представляется возможным. Интересующиеся могут скачать ZIP-архив с иллюстрирующими настоящую «Мастерскую» картинками, созданными в ComfyUI и содержащими собственные циклограммы, по этой ссылке. Часть их сгенерирована с использованием кастомных нод Searge SDXL: чтобы эти циклограммы заработали, потребуется установить соответствующее расширение для ComfyUI. P.P.S.: Пока статья готовилась к печати, автор AUTOMATIC1111 выкатил обновление 1.6.0-RC (release candidate) — так что, вполне вероятно, в самом скором времени и эта рабочая среда в стабильном своём релизе получит расширенную поддержку SDXL, включая сотворчество субмоделей с обменом зашумлёнными образами. Следите за дальнейшими выпусками нашей «Мастерской»! Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()




 Подписаться
Подписаться