
Источник: ИИ-генерация на основе модели FLUX.1
⇡#ИИ съел пустоту (ко всеобщему удовольствию)
В елизаветинской Англии ещё до начала промышленной революции (но в её непосредственном преддверии) овцы, по меткому выражению Томаса Мора, съели людей, — имеется в виду изгнание землевладельцами арендаторов-пахарей с земель, которые отдавались под овечьи пастбища ради наращивания производства шерсти; процесс, известный историкам как огораживания. В Лос-Анджелесе же осенью 2024-го предназначенные в основном для решения ИИ-задач центры обработки данных поедают пустоту в теряющих арендаторов бизнес-центрах — вновь разогревая спрос на деловую недвижимость, со времён ковидного кризиса прозябавший на тревожно низком для арендодателей уровне. Новые клиенты настолько активно занимают бывшие офисы, переоборудуя опенспейсы под машинные залы, а избыточные при малом числе сотрудников лифтовые шахты — под теплоотводящие стволы градирен, что даже летом, в традиционный сезон сокращения спроса на коммерческую недвижимость в центрах крупных городов, доля доступных для аренды площадей в отдельных бизнес-районах американского мегаполиса снижалась до давным-давно невиданных 3%. Арендаторов особенно привлекает высокая доступность электроэнергии в деловых центрах — этот критерий в принципе начинает выходить на первое место для устроителей новых ЦОДов: по оценке Goldman Sachs, к 2030 г. дата-центры (прежде всего — исполняющие ИИ-задачи) будут потреблять до 11% всего вырабатываемого в США электричества против нынешних примерно 3%.

Источник: ИИ-генерация на основе модели FLUX.1
⇡#Умный бот — друг программиста. Или нет?
Как измерить эффективность привлечения искусственного интеллекта к решению программистских задач? Вопрос не праздный, если учесть, в какие суммы обходится исполнение и в особенности тренировка ИИ-моделей; соответственно, и инвестиции заказчиков, занятых разработкой ПО, в привлечение умных ботов (из облака либо локальных) на помощь живым кодерам выходят немалыми. Исследователи из Uplevel, проведя довольно обширный опрос, выяснили, что влияние ИИ-инструментов на труд применяющих их в повседневной работе программистов статистически незначимо — если в качестве основной метрики брать среднее время, затраченное на добавление очередной порции кода в репозиторий (pull request cycle time). Более того: использование, скажем, умного помощника программиста GitHub Copilot привело к росту количества багов в готовом коде на 41% — соответственно, хотя скорость генерации текста программ и вправду повысилась, сразу же выросло и время, необходимое на отладку.
Снижению темпов творческого выгорания разработчиков применение ИИ-помощника также в целом не поспособствовало, так что и аргумент «боты возьмут на себя рутинные задачи, оставив человеку лишь свободный творческий полёт» тоже выходит не очень-то состоятельным. Аналитики Uplevel, впрочем, вовсе не рекомендуют наотрез отказываться от умных помощников: программистский ИИ-инструментарий непрерывно совершенствуется и вполне вероятно, что уже после ближайших обновлений всё-таки научится выдавать более корректный — и лучше постижимый кожаными мешками — код (поскольку сейчас, указывает целый ряд экспертов, сгенерированные LLM программы порой настолько сложны для человеческого восприятия, что проще бывает переписать тёмный фрагмент вручную целиком, чем разбираться в его внутренней — машинной — логике). К тому же ближе к концу октября стало известно, что в самой Google уже более четверти всего кода пишет ИИ, — и ничего ведь, работает!
Интересно в этой связи, что руководство проекта GitHub Copilot — знакомого уже множеству кодеров ИИ-помощника, что ранее базировался исключительно на разработках OpenAI, — под самый конец октября объявило о скором, буквально в течение считаных недель, предоставлении пользователям доступа и к конкурентному семейству GPT инструментарию: имеются в виду модели Claude 3.5 Sonnet компании Anthropic и Gemini 1.5 Pro от Google. Кроме того, арсенал готовых к работе ИИ-кодеров на платформе GitHub дополнят «способная к рассуждениям» модель GPT o1-preview и o1-mini, специально натренированная на решение более сложных программистских задач. Возможность не делать ставку только на одну модель, а переключаться по мере надобности между теми, что в данный момент пользователь сочтёт наиболее подходящими, призвана ещё более увеличить гибкость и широту применения GitHub Copilot.

Источник: ИИ-генерация на основе модели FLUX.1
⇡#Мой аватар свяжется с вашим аватаром
В числе задач, которые ИИ уже на нынешнем этапе развития способен, как выясняется, вполне эффективно брать на себя, — интервьюирование претендентов на замещение самых разных должностей, от работников первой линии в универмагах до программистов и даже до самих специалистов по работе с персоналом (по крайней мере, начального уровня). HR-аватары, которых предлагает среди прочего бизнес-заказчикам компания Fairgo.ai, готовы выйти на связь с кандидатом «в любое время и где угодно» онлайн, в том числе в формате видеочата — правда, сгенерированное ИИ видео демонстрируется при этом лишь на начальном этапе беседы; детальный же опрос претендента ведётся уже исключительно в аудиорежиме, чтобы не создавать избыточной нагрузки на серверы провайдера такой услуги. В утешение тем, кто не готов доверять решение своей судьбы бездушным аватарам, разработчики специально оговариваются, что принимать или отклонять кандидатуру собеседника умный бот в любом случае не уполномочен. Его задача — составить текстовую запись проведённого с претендентом разговора на основе вопросов, предварительно сформулированных клиентом, и переправить её этому самому клиенту, — чтобы затем уже человек принимал обоснованное решение, не тратя время на прямой контакт с соискателями (которых на вакансии, открытые популярными работодателями, ясное дело, может быть куда больше, чем способны в привычном режиме обработать за разумное время живые сотрудники HR-отдела).
Да что там менеджеры по персоналу — современный ИИ делает ненужным и самогó среднего пользователя, сидящего за ПК! Как утверждают в Anthropic, новейшая версия генеративного ИИ этой компании, Claude Sonnet 3.5, уже по сути представляет собой ИИ-агент — умный инструмент для автоматизации исполнения стандартных задач на персональном компьютере, которые прежде были по плечу лишь биологическому пользователю. «Мы обучили Claude распознавать происходящее на экране, а затем применять доступные программные инструменты для выполнения определённых задач. Когда разработчик поручает Claude использовать некое ПО и предоставляет соответствующий доступ, Claude на основании сделанных в ходе работы самого пользователя скриншотов решает, в каком направлении, как далеко сдвинуть курсор — и в какой позиции щёлкнуть, чтобы добиться требуемого результата», — сообщают разработчики. Получая от пользователя команды — например, какую форму заполнить и откуда брать данные для каждого из её полей, — ИИ самостоятельно ретранслирует их в последовательность команд и действий с программным интерфейсом, после чего исправно выполняет. Да, пока не идеально, — но где вы видели идеальных биологических «профессиональных пользователей ПК»?

Источник: ИИ-генерация на основе модели FLUX.1
⇡#Разблокирован титул: «Пустозвон»
А как ещё назвать вдохновлённого сверхидеей торжества искусственного разума человека, который предлагает вполне приземлённым, видавшим виды коммерсантам вот прямо сейчас, чем скорее, тем лучше, понастроить где только возможно три-четыре десятка новых фабрик по выпуску самых передовых микросхем — с тем, чтобы завалить планету явно недостающими ей высокопроизводительными серверными GPU? Ну да, признаёт выдвинувший эту идею гендиректор OpenAI Сэм Альтман (Sam Altman), обойдётся предлагаемое им миру удовольствие примерно в 7 трлн долл. США (для сравнения: текущие бюджетные расходы этой сверхдержавы за истекшую к концу октября часть 2024 года приближаются к 6,8 трлн долл.), но цель-то однозначно оправдывает средства! «Нет», — отрезали в ответ бизнесмены из TSMC, Samsung и SK hynix, к которым американский визионер обращался с такого рода предложением ещё прошлой зимой в ходе своего азиатского турне. А ближе к середине осени 2024-го New York Times стало известно, что высшее руководство лидирующего в мире тайваньского чипмейкера назвало Альтмана, выслушав его прожект, довольно-таки деликатно — «пустозвоном» или «болтунишкой» (podcasting bro).
На самом деле, за настойчивым стремлением Альтмана сделать как можно более доступными аппаратные средства для исполнения ИИ-моделей кроется вполне практический резон. Как сообщило в октябре издание Tom’s Hardware со ссылкой на блог Tech Fund, некий анонимный высокопоставленный программный архитектор из Alphabet признал недавно, что мощные GPU в облачных ИИ-ЦОДах выходят из строя, бывает, и через год после начала интенсивной эксплуатации, а к концу третьего года после установки в сервер (работающий, как правило, 60-70% всего времени под максимальной нагрузкой, ибо очень уж высок спрос на облачные ИИ-услуги) отказывать могут и до трети всех приобретённых исходно ускорителей. Частично не выдерживают такого режима работы собственно графические процессоры, рассеивающие до 700 Вт тепла каждый; частично — работающая с ними в связке память HBM. Но в любом случае ИИ-ускоритель, в отличие от серверного ЦП, сетевой карты, накопителя или иного оборудования, слишком часто не дотягивает до стандартного для дата-центров срока фактической эксплуатации «железа» в 3-5 лет. Если же учесть практически полную загруженность заказами передовых фабрик той же TSMC по меньшей мере на год вперёд, становится куда понятнее горячность неугомонного главы OpenAI в деле обеспечения притока на рынок дополнительных объёмов подходящих для ИИ-вычислений аппаратных средств.

⇡#Горячее «железо»
На фоне мягкой по форме, но доходчивой рекомендации китайских властей локальным компаниям не применять графические платы Nvidia для решения своих ИИ-задач Huawei приступила к поставкам своих новейших серверных ускорителей Ascend 910C — и ввергла тем самым глобальных экспертов в нешуточное недоумение: где же эти, предположительно «7-нм», чипы могут изготавливать в заявленных количествах — десятками и сотнями тысяч? Понятно, что материковая SMIC оказалась способна обеспечить «7-нм» системами-на-кристалле флагманские смартфоны всё той же Huawei, но всё-таки серверный графический ускоритель, заявленный как прямой конкурент Nvidia A100, — это куда более серьёзная СБИС. Тем более что предыдущий чип этой серии, Ascend 910B, Huawei, согласно официальному заявлению её представителей, «никогда не выпускала» — а, если верить (подкреплённому результатами пристального исследования) предположению специалистов лаборатории TechInsights, заказала его через подставную фирму у тайваньской TSMC уже после введения Минторгом США санкций. В результате разразившегося скандала тайваньский чипмейкер принялся расторгать договоры со всеми заказчиками, которых можно хотя бы заподозрить в попытках нарушить экспортные санкции США в интересах Huawei Technologies, — и оздоровлению глобального рынка аппаратных ИИ-платформ это совершено точно не способствует.
OpenAI, в свою очередь, занята отнюдь не одним только семитриллионным прожектёрством — и деятельно прорабатывает, по информации Reuters, совместно с Broadcom дизайн-проект собственного чипа для ИИ-вычислений, — изготавливать который планируется на мощностях всё той же TSMC ориентировочно в 2026 году. Речь при этом идёт о микросхеме, ориентированной прежде всего на исполнение (inference) генеративных моделей, а не на их обучение, которое требует куда более изрядных вычислительных мощностей. Очевидно, в обозримом будущем — особенно с учётом ограниченности доступных в мире «3-нм» и ещё более мелкомасштабных полупроводниковых производств — большого смысла конкурировать с ведущими поставщиками «тяжёлых» серверных ИИ-ускорителей даже для OpenAI нет. Зато на поле предоставления услуг исполнения генеративных моделей, локального либо в облаке, посостязаться с нынешними грандами смысл имеется: инвестиций в такую активность потребуется меньше, а возврата их можно ожидать сравнительно скоро.

Источник: ИИ-генерация на основе модели FLUX.1
⇡#А денежки врозь
Мировой ИТ-рынок в целом на данный момент если и не стагнирует, то демонстрирует довольно-таки сдержанный рост, особенно по части инвестиций в новые НИОКР, зато в сегменте ИИ с притоком денежных средств и в октябре всё было в полном порядке. Даже Microsoft научилась зарабатывать на искусственном интеллекте — в основном за счёт сдачи в аренду облачных мощностей Azure для запуска на них сторонних ИИ-разработок, включая продукты OpenAI. Кстати, в саму эту формально независимую компанию редмондский гигант вложил уже почти 14 млрд долл. и пока что только наращивает эти инвестиции — очевидно, надеясь всё-таки увидеть их возврат с прибылью уже в каком-то обозримом будущем. Тем более что та же OpenAI три четверти своей выручки получает от платных пользователей разработанных ею моделей — а значит, если общий интерес к ИИ не примется вдруг снижаться, с увеличением числа таких пользователей можно ожидать и пропорционального роста доходов. Правда, и затраты, прежде всего на электроэнергию, вырастут, но тут есть надежда и на малые модульные ядерные реакторы, и на природный газ.
К слову, хотя долларовые потоки в ИИ-сектор и не ослабевают, на всех подвизающихся там игроков средств уже начинает недоставать. Как сообщает Financial Times, получившая недавно в ходе очередного раунда привлечения внешнего финансирования 6,6 млрд долл. OpenAI попросила инвесторов воздержаться от вложения средств в напрямую конкурирующие с ней крупные проекты — такие как Anthropic или xAI. Требования к эксклюзивности финансовой поддержки стартапов (а компания под управлением Сэма Альтмана, даром что стоимость её оценивается почти в 160 млрд долл., до сих пор по ряду параметров числится стартапом) по определённому направлению в ИТ-отрасли практически неслыханны, — напротив, инвесторы чаще предпочитают вкладываться в несколько параллельных проектов.
Сам факт такой постановки вопроса со стороны OpenAI свидетельствует об особом её положении в ИИ-сегменте, по крайней мере с точки зрения потенциальных инвесторов, — и должен подвигнуть её прямых конкурентов к ещё более стремительному совершенствованию собственных моделей. В «чёрный список» компаний, которые не должны получать финансирование из тех же источников, что уже подпитывают деньгами OpenAI, вошли, помимо xAI и Anthropic, Perplexity, Glean и Safe Superintelligence — последнюю основал бывший коллега Альтмана Илья Суцкевер (Ilya Sutskever). Впрочем, эти условные ИИ-аутсайдеры не то чтобы совсем уж страдают от нехватки средств: так, покинувшую OpenAI в сентябре Миру Мурати (Mira Murati), что занимала там должность технического директора, уже осаждают венчурные инвесторы с предложениями финансирования ещё не созданного ею ИИ-стартапа, а сооснователь всё той же пресловутой OpenAI Дарк Кингма (Durk Kingma) в октябре был принят на работу в Anthropic — компанию, которая благодаря своим успешным разработкам также не бедствует.
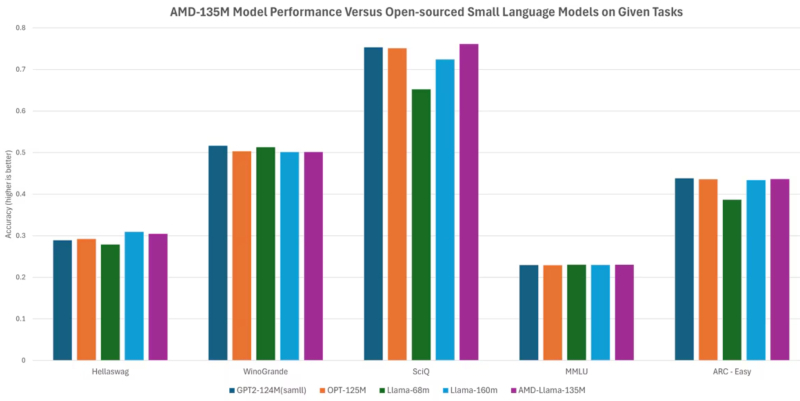
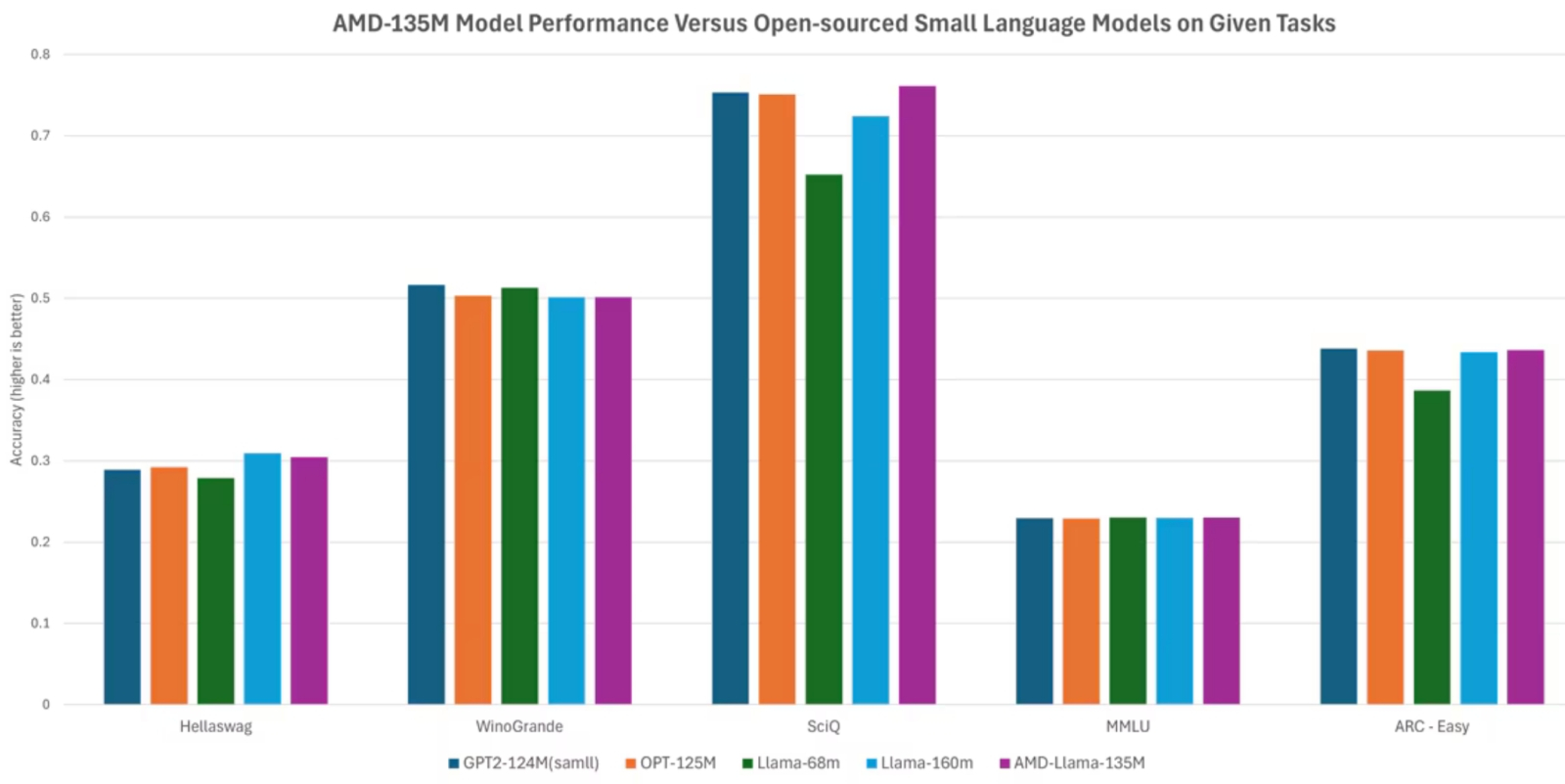
Сопоставление AMD-Llama-135M с рядом популярных языковых моделей при исполнении нескольких тестов ИИ-производительности (источник: AMD)
⇡#Больше моделей для бога моделей
К выполнению каких только задач не привлекают теперь ИИ — например, кто мог бы подумать, что место для генеративной функциональности отыщется в таком непритязательном графическом редакторе, как Microsoft Paint? А вот нашлось, и теперь новейшая его версия, которая должна появиться на Copilot Plus PC ещё до конца 2024 г., благодаря умному инструменту Paint Cocreator (со встроенной модерацией, разумеется, — а то ишь, примутся что ни попадя рисовать!) сможет создавать изображения по текстовым подсказкам или эскизам. Кроме того, Super-Resolution позволит масштабировать изображения с повышением качества, Generative Erase — удалять с них ненужные объекты, Generative Fill — добавлять те, которых на оригинале не было, и т. д.
Умный локальный помощник Copilot разработки всё той же Microsoft тоже получил в октябре серьёзное обновление функциональности — теперь он обрёл полноценный голосовой интерфейс, научился распознавать отображаемые на экране визуальные данные (содержимое просматриваемых пользователем веб-страниц, например), принял на себя функции анонсирующего прогноз погоды диктора и даже глубокого мыслителя. Насколько именно глубокого, предстоит узнать первым пользователям ИИ-инструмента (пока ещё находящегося в испытательной стадии) Think Deeper, который якобы позволяет находить ответы даже на действительно сложные вопросы, выстраивая цепочки рассуждений и последовательно производя логические умозаключения.
Не отстают от лидеров генеративного направления и другие компании, понимающие, что нельзя уступать столь прибыльный сегмент без боя. Nvidia представила в начале октября целое семейство больших языковых моделей NVLM, в том числе NVLM-D 1.0 с 72 млрд параметров, не уступающую, по заверениям разработчиков, Llama 3-V от Meta* с её 405 млрд параметров — и даже готовую посостязаться с GPT-4o, популярнейшим (благодаря актуальной версии бота ChatGPT) детищем OpenAI. В свою очередь, AMD презентовала — для разнообразия — малую языковую модель (SLM) AMD-135M с умозрительным декодированием (speculative decoding). Одна из её составных частей, AMD-Llama-135M, была обучена на 670 млрд токенов, а затем дополнительно отъюстированная версия модели, AMD-Llama-135M-code, прошла дополнительную тренировку ещё на 20 млрд токенов. Смысл «малых» языковых моделей — в отказе от универсальности LLM и в концентрации на определённом круге задач, в данном случае — прикладных программистских. Принцип её работы — то самое умозрительное декодирование — следующий: сперва более общий вариант, в данном случае AMD-Llama-135M, генерирует несколько возможных ответов на заданный вопрос, а затем дополнительно натренированная на массиве специализированных данных версия, AMD-Llama-135M-code, сопоставляет предложенные ответы и выбирает среди них наиболее адекватный операторскому запросу. Таким образом, утверждают разработчики, сокращается время исполнения и снижается нагрузка на аппаратные мощности (по сравнению с тем, когда и первичную генерацию вариантов, и их сравнение проводит одна и та же более крупная модель) — не в ущерб качеству получаемых результатов.
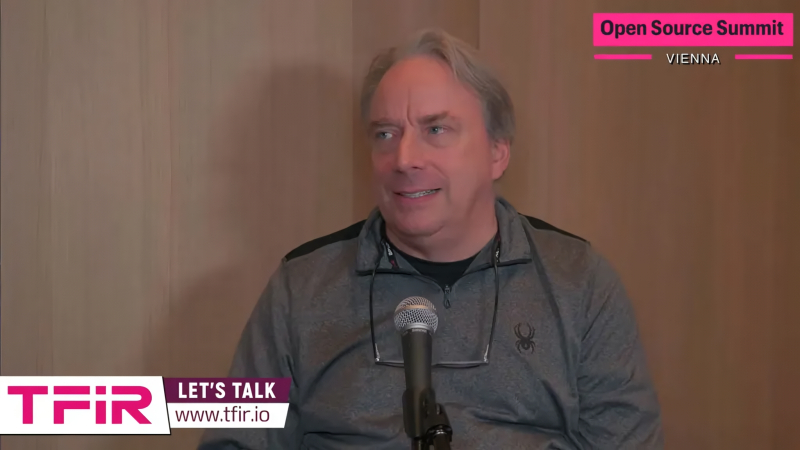
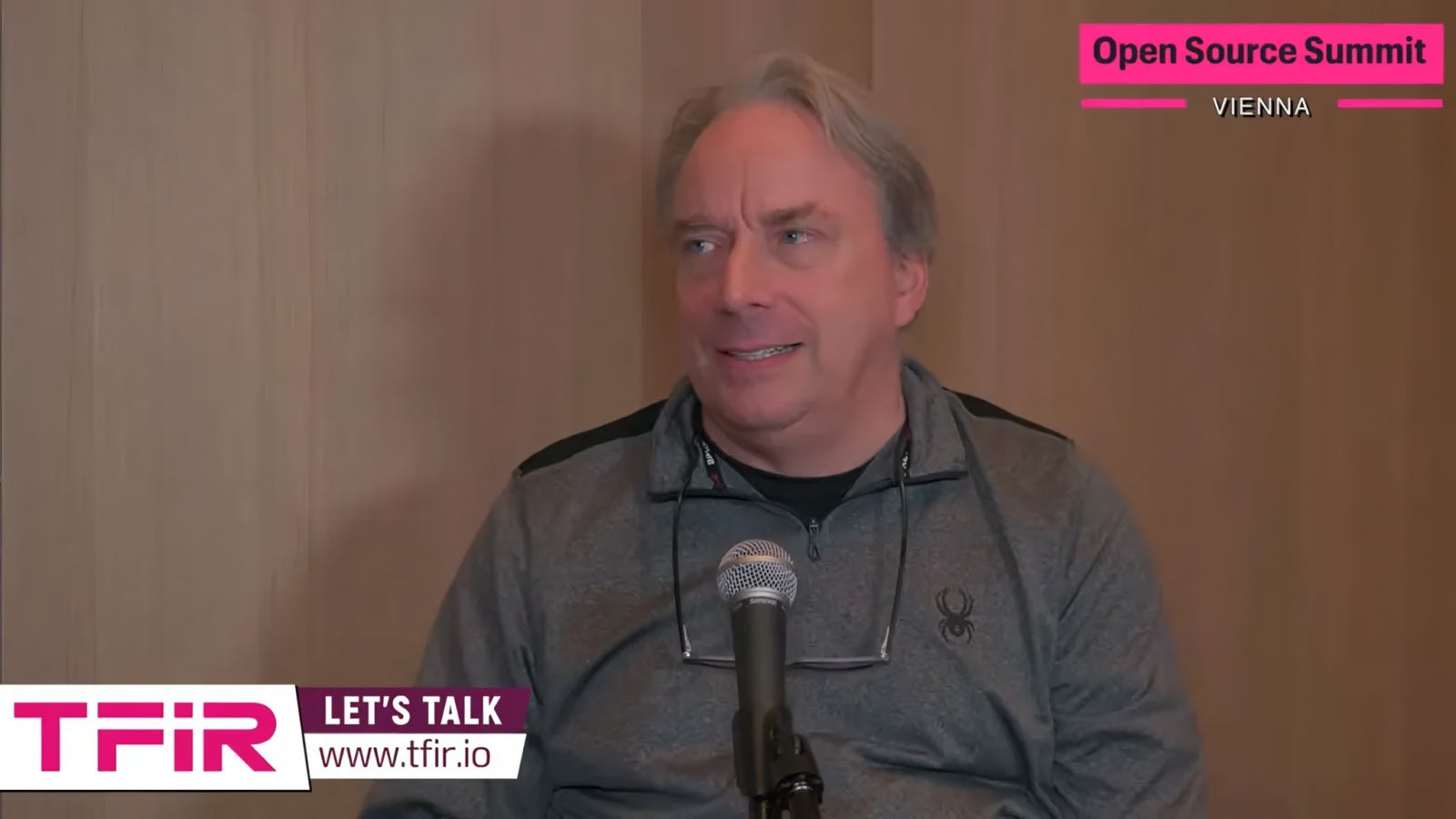
Твоё лицо, когда удалил упоминания о российских программистах из списка разработчиков ядра Linux, а после раскритиковал шумиху вокруг ИИ (источник: TFiR)
⇡#Маркетинг или реальность?
«ИИ на 90% — маркетинг, и только на 10% реальность», — горячо заявил Линус Торвальдс (Linus Torvalds) в ходе очередного слёта сообщества разработчиков ПО с открытым кодом (Open Source Summit), что проходил в октябре в австрийской Вене. Собственно, скептицизм этой культовой для мира Linux фигуры в отношении искусственного интеллекта никогда не был секретом, но в этом выступлении он подвёл под свои взгляды достаточно основательную базу: «Я не сомневаюсь, что у ИИ огромный потенциал, и считаю это направление по-настоящему интересным. Уверен, что однажды эта технология способна будет изменить мир, но в то же время я попросту не выношу всю ту шумиху, что поднята сейчас вокруг ИИ, и именно из-за неё не хочу даже приближаться к этой теме». Торвальдс считает, что весь сконцентрировавшийся сегодня на искусственном интеллекте сегмент глобального ИТ-рынка находится в крайне невыгодной позиции — и что эта тема привлекает чересчур много нездорового внимания.
Как ни парадоксально, с основателем Linux-движения солидарны и воротилы с Уолл-стрит: крупнейшие американские инвесторы чем дальше, тем сильнее ощущают беспокойство по поводу темпов, которыми мировые ИТ-гиганты наращивают инвестиции во всё более мощные и энергетически прожорливые дата-центры. Дело не в самих по себе величинах затрат, а в крайне низкой и не слишком твёрдо гарантированной их окупаемости. По крайней мере, сейчас вложения в новые ИИ-ЦОДы, в электростанции и ЛЭП для них, в тренировку всё более крупных языковых моделей производятся в расчёте на то, что спрос на ИИ в самых разных отраслях экономики будет как минимум не снижаться от нынешнего довольно высокого уровня, а в идеале ещё и увеличиваться. Но расчёты эти сопряжены с крайне высокими рисками: так, по оценке Visible Alpha, инвестиции одной только Microsoft в серверную инфраструктуру для ИИ лишь за один квартал в текущем году превышают её совокупные затраты за весь 2019-й.
Рост объёмов доступных для организации ИИ-вычислений ресурсов попросту не поспевает за спросом на них — и это, как ни странно, пугает инвесторов ещё больше. Ведь если на рынке одновременно оперируют и заказчики, которые уже интенсивно привлекают генеративные модели для оптимизации своих бизнес-процессов, и те, кто поневоле продолжает действовать по старинке (просто потому, что им объективно недостаёт вычислительных мощностей), — и если первые в среднем не опережают вторых кардинально ни по выручке, ни по чистой прибыли (особенно по прибыли, ведь затраты на энергоёмкий ИИ весьма велики), то через какое-то время клиенты примутся задавать неудобные вопросы: а где, собственно, обещанное визионерами LLM безусловное технологическое превосходство? Высокохудожественные изображения котиков в смешных шляпах по текстовому запросу, даже анимированные, даже синтетически озвученные, — вот они, пожалуйста; а сверхприбыли-то ожидаемые где?

Афиша спектакля «McNeal» (источник: Lincoln Center Theater)
⇡#Не смейте меня генерировать!
Оскароносец, Железный Человек и просто Холмс, а точнее, Роберт Дауни-младший (Robert Downey Jr.) не просто запретил голливудским студиям сейчас или когда-либо в будущем воспроизводить его образ при помощи ИИ-технологий, но пригрозил «засудить всех будущих администраторов», которым придёт в голову отдать своим подчинённым такого рода распоряжение. Речь здесь именно о будущих исполнительных директорах MCU или иной студии, которая заполучит права на сыгранных актёром персонажей, поскольку тот уверен, что нынешнее их руководство на такой шаг ни в коем случае не пойдёт. «И даже когда я умру, мои адвокаты будут крайне активны», — добавил Дауни-младший, явно давая понять, что твёрдо обдумал этот вопрос и принял все соответствующие решения. Более того, сейчас он занят на театральной сцене — в идущей на Бродвее пьесе «McNeal», — где как раз рассматриваются не самые однозначно благотворные для отдельно взятого человека и для человечества в целом последствия решений, принимаемых по части ИИ активно развивающими это направление большими корпорациями.
И воплотивший образ Железного Человека актёр далеко не одинок в своём неприятии искусственных генераций творческого характера: уже более 30 тыс. художников, музыкантов и иных творцов, включая довольно известных, поддержали онлайн-петицию под названием Statement on AI training, которая отвергает несанкционированное использование компаниями созданных подписантами в ходе того или иного творческого акта художественных образов — будь то картина, музыкальное произведение, воплощение персонажа пьесы на сцене и т. п. Причём не только для создания нового, производного от этих образов контента, но и даже для тренировки с их помощью генеративных моделей. Причина проста и понятна — чем больше публика потребляет порождённого ИИ контента, тем меньше она склонна платить живым создателям использованных для его тренировки прототипов; а это, в свою очередь, сокращает потенциально объёмы вновь порождаемых людьми художественных образов. Направленные финским стартапом Saidot главам ведущих ИИ-компаний и верхушке Европейского союза перчатки с шестью пальцами тоже можно считать предупреждением об опасностях чрезмерно быстрого развития искусственного интеллекта — мешающего предвидеть и заблаговременно купировать связанные с ним опасности и риски.
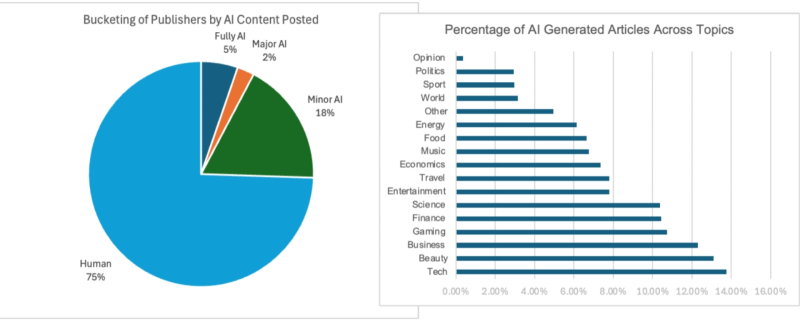
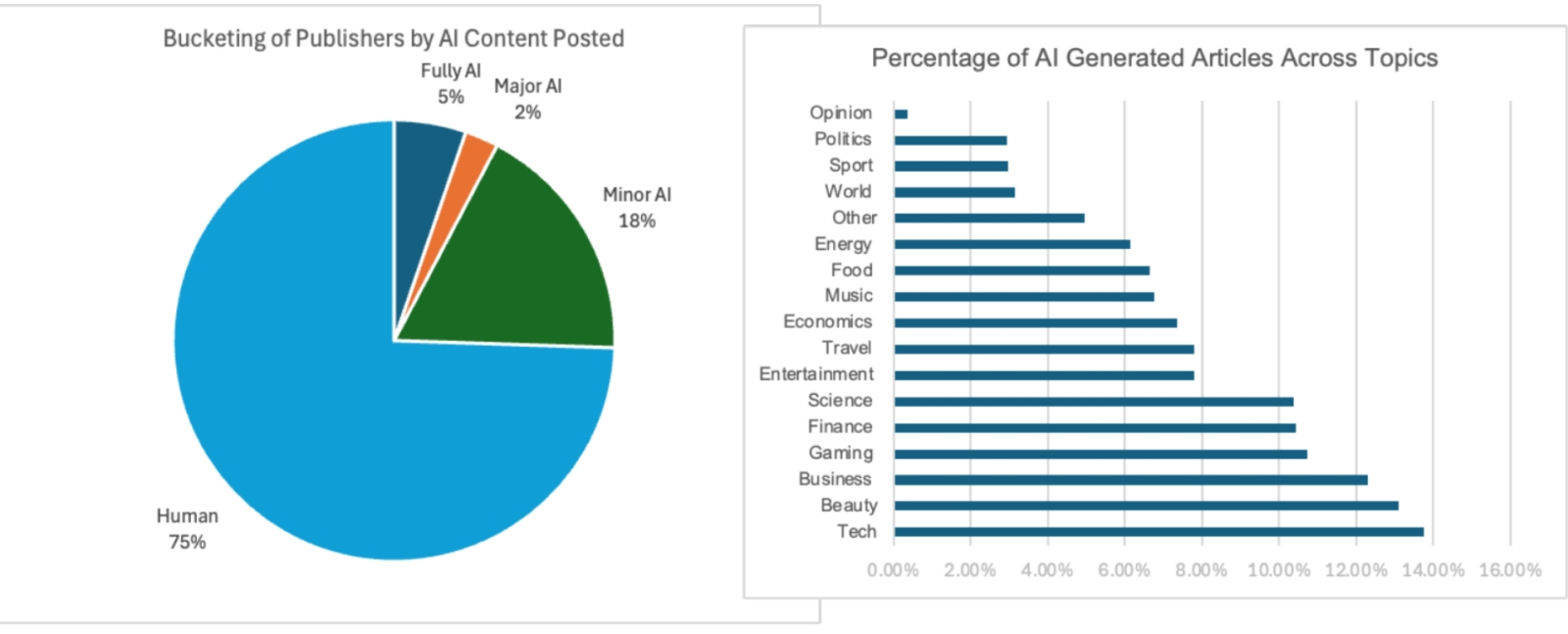
Три четверти текстовых новостных материалов в англоязычной Сети сгенерированы людьми целиком и полностью, а по доле тех, к созданию которых хотя бы в минимальной степени привлекается ИИ, лидирует — что ни чуточки не удивительно — тематика техники/технологий (источник: Pangram Labs)
⇡#Хляби разверзлись — а никто и не заметил
Что будет с привычным для нас Интернетом, когда его заполонят созданные ИИ-ботами тексты? Вопросом этим обеспокоенные эксперты задавались ещё на заре генеративной революции, осенью 2022-го, и мнения высказывали порой самые пессимистичные — предрекалось, к примеру, полное отмирание (полу)анонимных открытых платформ вроде Reddit или Medium, на которых регистрация требует всего лишь подтверждения по электронной почте (хотя бы даже временной) и не предполагается предварительная модерация постов. Да и классической авторской/редакционной журналистике будет, как считали многие, нанесён непоправимый урон, — ведь по меньшей мере контрактные новостники наверняка не удержатся от соблазна переложить на сверкающие плечи роботов нудный труд по перелицовке общедоступных текстов.
На деле, как выясняется, мутный поток сгенерированных бездушными ботами текстов действительно захлестнул определённые сегменты Интернета — однако ситуация и там, и в Сети в целом по-прежнему далека от катастрофической. Ещё летом исследователи из Pangram Labs опубликовали результаты анализа почти 900 тыс. материалов с более чем 26 тыс. англоязычных онлайн-ресурсов — и выяснили, что не более четверти текстов в среднем подвергаются даже минимальной ИИ-корректировке, а сгенерированных ботами от начала до конца и вовсе лишь около 7%. Да, кое-где дела обстоят значительно хуже: так, на популярной открытой платформе Medium эта доля доходит до 47% — но, как заявил её CEO Тони Стаблбайн (Tony Stubblebine) в октябрьском интервью Wired, «это не имеет ни малейшего значения: всё равно писанину ботов никто в здравом уме читать не станет». И такая позиция вполне осмысленна, хотя бы ситуативно: по крайней мере, на нынешнем уровне развития генеративного ИИ произведённый им «человекоподобный» текст сразу же неприятно режет глаз, и интерес к такому материалу у биологических читателей по ту сторону монитора стремительно угасает. Оставлять такого рода материалы без внимания для редакции оказывается дешевле и проще, чем вводить хоть пре-, хоть постмодерацию: раз ущерба для живых посетителей никакого, а реклама на порождённых ботами страничках всё равно крутится, какой смысл суетиться?
Тем более что на такого рода открытых платформах наибольшее число просмотров получают статьи, рекомендуемые одними читателями другим, — либо напрямую, отправкой ссылки, либо всевозможными пометками-«лайками» с выводом в видимый для всех топ. Понятно, что и тут умные боты, в особенности хорошо имитирующие действия человека за ПК, могут быть использованы для накрутки, — но в этом случае биологические посетители всё равно обнаружат, что их пытаются объегорить, и своими «дизлайками» достаточно быстро восстановят статус-кво. Так что, по крайней мере, пока живых читателей у популярного сайта больше, чем ботов (а ИИ-боты — удовольствие, напомним, недешёвое, они весьма энергетически и финансово затратны), беспокоиться о качестве генерируемого самими же посетителями на нём контента и впрямь, наверное, не следует. Да, если когда-либо в будущем найдёт своё реальное воплощение «теория мёртвого Интернета» (Dead-internet theory), в котором умных ботов на порядки больше, чем людей, — тогда разговор будет иной. Но пока до этого, судя по изысканиям Pangram Labs, ещё далеко.
И более того: сгенерированный ИИ-контент вовсе не обязательно должен рассматриваться как мусорный — в этом искренне убеждён глава Meta* Марк Цукерберг (Mark Zuckerberg), который считает, что пользователи его соцсетей просто-таки тоскуют по высококачественным текстам, музыке, видеороликам, статичным изображениям и прочим порождениям генеративных моделей; прежде всего, из разрабатываемого силами его программистов семейства Llama. Цукерберг не согласен с устоявшимся категоричным обозначением такого контента как «ИИ-помоев» (AI slop), — напротив, уже сегодня вирусящиеся в Facebook* картинки, к примеру, нередко оказываются на поверку сгенерированными искусственным интеллектом. И они исправно приносят своим создателям (точнее, тем, кто придумал либо удачно где-то подрезал для них подходящие подсказки) вполне материальные бонусы; до 10 долл. за 1 тыс. «лайков». Так что тут многое зависит от точки зрения: возможно, боты, исправно выводящие в топы других ботов, для соцсетей и впрямь — идеальные пользователи?

Источник: ИИ-генерация на основе модели FLUX.1
⇡#Явление суперразума откладывается; пока — до 2035-го
По крайней мере, так считает Масаёси Сон (Masayoshi Son), генеральный директор SoftBank, который в ходе конференции в саудовском Эр-Рияде заявил, что искусственный мозг, «превосходящий возможности человеческого в десять тысяч раз», будет создан именно к этому сроку. Речь идёт о самом общем описании этой недоступной пока технологии; неясно даже, будет ли этот «мозг» воплощён на отличной от полупроводников аппаратной основе — или же всё-таки смоделирован в цифровом виде не некоем x86- или ARM-суперкомпьютере. Правда, оговорился глава японской корпорации, для воплощения в жизнь этого пророчества потребуются изрядные инвестиции в эволюционное развитие ИИ от нынешнего его (не самого выдающегося, прямо скажем, хотя и крайне многообещающего) состояния до грядущего суперразума, — не менее 900 трлн долл. в актуальных сегодня ценах. На этом фоне жалкие 7 трлн, о которых мечтал ещё совсем недавно Сэм Альтман, представляются, скажем прямо, ничтожной суммой, однако и та на начальном этапе пригодится; ибо в отсутствие действительно обширного производственного потенциала для выпуска всё новых ИИ-чипов (одновременно с довольно вялым прогрессом нейроморфных вычислений на отличной от полупроводников аппаратной базе) развитие генеративных моделей грозит ещё надолго застрять на достигнутой в наши дни стадии.
А вот Робин Ли (Robin Li), глава китайского цифрового гиганта Baidu, предупредил, что на пути к светлому ИИ-будущему (вне зависимости от того, достигнут своей цели создатели искусственного суперразума или нет) высокотехнологичную индустрию ждут немалые потери. За последние 18-20 месяцев, по его наблюдениям, доставившие немало хлопот разработчикам проблемы с галлюцинациями генеративных моделей если не полностью сошли на нет, то оказались в значительной мере купированы. Однако именно это и создаёт предпосылки для вызревания биржевого пузыря, точь-в-точь грозящего повторить судьбу пресловутого «пузыря доткомов» на рубеже веков. Тогда ставшие внезапно доступными всем сети цифровых коммуникаций привлекли огромное количество бизнесменов, 99% компаний которых затем обанкротились, не сумев справиться с валом заказов и стремительно выросшими запросами потребителей. Та же судьба, уверен Ли, ожидает теперь 99% выбравших ИИ-стезю предпринимателей, — и для мирового ИТ-рынка это тоже может оказаться крайне серьёзным ударом.

Ну что; потенциал есть, конечно, но над кистями рук ещё работать и работать… да и не только над кистями. А вот фактура картонки бесспорно хороша. Подсказка: «pretty girl lying on grass, holding a hand-written cardboard sign that reads "Finally, I am lying!"», затравка: 538536405 (источник: ИИ-генерация на основе модели Stable Diffusion 3.5 Large)
⇡#Рисовать!
Компания Stability AI, не так давно разочаровавшая энтузиастов ИИ-рисования откровенно недоработанной моделью SD3M, решила в октябре исправить своё реноме, выпустив под весьма толерантной в том числе и к ограниченному (с выручкой до 1 млн долл. в год) коммерческому использованию лицензией сразу три весьма привлекательные на первый взгляд модели — Stable Diffusion 3.5 в вариантах Large, Turbo и Medium. Даже наиболее крупная модель, Large, с её 8,1 млрд параметров вполне пригодна для локальной генерации. Turbo представляет собой «ускоренную» версию, оптимизированную для быстрой, всего за 4 шага, выпечки картинок, тогда как Medium с 2,5 млрд параметров может похвастать переработанной архитектурой мультимодальных диффузных преобразователей Multimodal Diffusion Transformer (MMDiT-X) и готовностью генерировать взаимосогласованные по композиции, колористике и прочим параметрам картинки в широком диапазоне разрешений — от 0,25 до 2 Мпикс.
Что сразу привлекло сообщество, уже успевшее слегка подустать от чрезмерной дистиллированности (при всех её безусловных достоинствах) модели FLUX.1, немалую роль в создании которой сыграли бывшие же сотрудники Stability AI, так это как раз отсутствие в SD 3.5 аналогичных жёстких оптимизаций. Да, в исходной версии модель эта далеко не всегда генерирует субъективно близкие к эстетическому идеалу изображения — в отличие от FLUX.1, в особенности от её доступной исключительно через API версии [pro], — зато в жертву этой условной безупречности не были принесены вариативность модели и её готовность к дальнейшим модификациям. Имеются в виду создаваемые сообществом модели LoRA, ControlNet и проч., с тренировками которых на базе FLIX.1 как раз не всё получается гладко, поскольку дистиллированный набор весов с большим скрипом поддаётся тонкой юстировке. Именно по причине отсутствия подобных ограничений, уверены энтузиасты, SD 3.5 от Stability AI имеет все шансы сделаться «новой SDXL», сформировав вокруг себя целую экосистему созданных сообществом дополнений — и задав новый стандарт максимально открытого (насколько это в принципе возможно для модели с обнародованными лишь итоговыми весами, но не исходным массивом тренировочных изображений) инструмента для локальной, а не привязанной к облачным сервисам ИИ-генерации.
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex

















 Подписаться
Подписаться
Все комментарии премодерируются.