







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexПопытки синтезирования человеческой речи и музыкальных инструментов имеют практически параллельную историю. Поэтому в этом материале я объединю эти истории воедино. То есть, одно вытекает из другого и так далее. Эта информация полезна как владельцам домашних и профессиональных синтезаторов, так и простым пользователям.
Виды синтеза
Синтезированные звуки можно получить разными путями и методами. Говоря о различных моделях синтезаторов/сэмплеров, программных и аппаратных, мы часто обращаем внимание на алгоритмы синтеза, вложенные в инструмент. На данный момент вы можете столкнуться с шестнадцатью основными видами синтезирования звуков, но на этом индустрия не останавливается и с каждым годом мы получаем новые методы и алгоритмы.
Аддитивный или суммирующий синтез (additive synthesis). Данный метод прекрасно иллюстрируют первые модели от Hammond, которые были основаны на принципе построения звучания реальных органов. В его основе лежит следующая идея - создание сложных гармонически насыщенных звуков из простых изменяющихся синусоидальных волн, различных по амплитуде и/или частоте.
Вычитающий синтез (substractive synthesis). Данный метод обратен предыдущему. В качестве исходного берется тембрально богатый, насыщенный гармониками звук, и потом, в результате сложной фильтрации из него формируется определенный тембр с характерной тоновой окраской. Вычитающий синтез активно использовался в аналоговых синтезаторах, а сейчас применяется в программных моделях для получения "аналогового эффекта".
Синтез с использованием частотной модуляции (Frequency Modulation (FM) synthesis). Основывается на последовательном и параллельном подключении генераторов простых сигналов и их взаимомодуляции. Схема соединения генераторов и параметры каждого сигнала (частота, амплитуда и закон их изменения во времени) определяет тембр звучания; а количество генераторов и степень тонкости управления ими определяет предельное количество синтезируемых тембров. Данный метод очень удобен с точки зрения дешевизны реализации, но при этом требует сложного программирования и тонкой настройки. Использовался в большинстве звуковых РС-карт в виде стандартных GM-устройств, а также активно популяризировался фирмой Yamaha и ее модельным рядом синтезаторов GX. Первое появление датируется 1981 годом и ассоциируется с ее разработчиком - фирмой Synclavier.
Direct Draw. В ряде синтезаторов используются осцилляторы, генерирующие звуковые волны со стандартными формами (синусоида, прямоугольная, пилообразная и т.п.). В варианте Direct Draw пользователь может самостоятельно рисовать любые формы. Данный метод еще не сильно изучен, хотя уже имеет место в ряде программного обеспечения и дорогих синтезаторах. По сути, нестандартную периодическую форму можно нарисовать в любом звуковом редакторе, и после использовать ее в качестве звукового фрагмента…
Таблично-волновой синтез (wavetable или PCM-synthesis). Этот метод базируется на использовании небольших сэмплированных "кусочков" звуковой волны. Их определенный набор позволяет создать звучание инструмента, смоделировать интересные звуки. Активно используется в PPG, Waldorf, Korg DW-8000, Ensoniq ESQ-1 и ряде других синтезаторов. Звуковые карты, использующие понятие "wavetable", на самом деле подразумевают другую технологию синтеза - сэмплинг (Sample Playback).
Гранулированный синтез (Granular synthesis). Является частным случаем таблично-волнового синтеза. Звук формируется из ультра-коротких сэмплированных фрагментов звуковой волны. В результате взаимодействия частоты их повторения и частотных составляющих сэмплированной звуковой формы, получается тембрально сложный монотонный звук, который впоследствии можно обрабатывать методами вычитающего синтезирования. Одна из первых реализаций подобного была в программе Ross Bencina AudioMulch, правдя в виде эффекта, а как законченный инструмент появилась в Propellerhead Reason.
Сэмплинг (Sample playback ). Данный метод базируется на использовании сэмплированных (записанных) инструментов и воспроизведении их в режиме обычного проигрывателя. Небольшие звуковые фрагменты загружаются в память (ROM или RAM) и воспроизводятся оттуда. Из этих фрагментов складывается звучание инструмента. Активно используется в сэмплерах и программных или программно-аппаратных (например, Turtle Beach Pinnacle) синтезаторах и звуковых картах. Так как раньше объем памяти не позволял обращаться с большими объемами памяти, то разработчики шли на ухищрения - понижали разрядность или частоту дискретизации либо записывали очень короткие фрагменты, зацикливая их. Теперь ситуация изменилась в прогрессивную сторону, и мы можем использовать не только качественно отсэмплированные библиотеки, но и создавать многослойные инструменты, включающие сразу несколько сэмплов на реализацию одного инструмента.
Ресинтезированный PCM (Resynthesized(RS)-PCM). Этот синтеза был введен фирмой Roland и основан на анализе сэмплированного звука и его последующего воссоздания аддитивным методом синтеза.
Линейно-арифметический синтез (Linear/Arithmetic (L/A) synthesis). Этот метод также был введен фирмой Roland в конце 80-х, начиная с модели D-50. За основу концепции L/A synthesis было взято смешивание небольшого фрагмента сэмпла "живого" инструмента (обычно атаки) с синтезированной волновой формой. Этот метод позволяет дать натуральную звуковую окраску, близкую к реальному звучанию, при этом получается выигрыш в меньшей загрузке аппаратных вычислительных мощностей. Атака инструмента - это один из самых сложных элементов при реализации натуральных звуков в синтезированном виде.
Передовое интегрирование (Advanced Integrated synthesis). Данный метод был впервые представлен в модели Korg M-1. Он использует сэмплированную атаку и другие волновые формы, которые впоследствии обрабатываются методами вычитающего синтеза, при этом для получения качественно новых звуков дополнительно могут использоваться сложные эффект процессоры.
Синтез переменной архитектуры (VAST - Variable Architecture Synthesis Technology). Разновидность DSP-синтеза, основанная на комбинировании мощных вычислений по формированию пэтчей, включая сэмплированные звуки, добавление сложных эффектов и открытую архитектуру. Это уникальный метод, который используется только в рабочих станциях и сэмплерах фирмы Kurzweil (начиная с Kurzweil K2000).
Z-Plane synthesis. Данный метод синтезирования является уникальной разработкой и впервые был представлен в звуковом модуле E-mu Systems Morpheus. Его суть состоит в следующем, берутся две волновые формы разных инструментов и одна промежуточная для плавного перетекания от первой к второй. Этот метод предусматривает очень сложные алгоритмы фильтрации, но при этом позволяет получить очень интересные новые звуки.
Синтез физического моделирования (Physical modeling synthesis). За основу данного метода берется очень сложная математическая модель, которая полностью описывает формирование звука в инструменте. Впервые этот вид синтезирования был представлен в модельном ряде синтезаторов Yamaha VL-1 и VL-7. Теперь используется повсеменстно, хотя до полноценного математического посвторения реальных физических процессов еще далеко - очень сложные расчеты. Но, стоит отметить, что производители уже добились хороших успехов в физическом моделировании духовых инструментов.
Формантный синтез (Formant synthesis). Формантный синтез является частным случаем физического моделирования. За его основу берется принцип формирования человеческой речи, где помимо основного тона и обертонов принято выделять формантную составляющую. Таким образом формируются речевые звуки используя как физическое моделирование, так и аддитивный метод формирования звуков.
Синтез по математической функции (Mathematical function synthesis). Также частный случай физического моделирования, с помощью которого можно вкладывать математические функции, объединять их в функциональные блоки, а из них создавать математические алгоритмические модели. Вернее сказать, что этот метод является одним из простейших разделов физического моделирования. Он хорошо подходит для эмуляции аналоговых синтезаторов. Первую реализацию подобного метода я встретил в программе-звуковом редакторе GoldWave, где вы можете просто описать математическими формулами генерируемый звук и относящиеся к нему эффекты. Как простейший пример можно привести и тон-генераторы в современных звуковых редакторах, где обычно указывается форма волны (функция) и значение частоты.
Спектральный синтез (Spectral synthesis). Это даже не метод, а скорее способ создания сложных гармонических звуков. За основу их построения берется обыкновенная спектрограмма (графическое представления зависимости частоты от амплитуды). На базе этой спектрограммы формируется инструмент. При этом данный способ позволяет самостоятельно рисовать на спектрограмме свои частотные полосы.
Немного истории… Синтезаторы речи
Другой принцип, широко используемый в устройствах вокодеров, - составление математической модели определенного голоса. Он предусматривает несколько полосных частотных составляющих или каналов, каждая из которых отвечает за реализацию частотного элемента человеческой речи. Когда мы произносим звук "а", то на спектрограмме отобразится одно взаимодействие частот и амплитуд гармонических составляющих, в варианте звука "п" ситуация меняется. Таким образом, разбив речевой спектр по частотным полосам и проанализировав взаимо соотношения частотных составляющих в каждой из них можно ресинтезировать человеческую речь.
И теперь история… В 1779 году русский профессор Кристиан Краценштейн (в других источниках упоминается как Кристиан Готтлиб) создал акустическую модель, позволяющую создавать гласные звуки, используя различные геометрические формы резонаторов как это показано на рисунке.
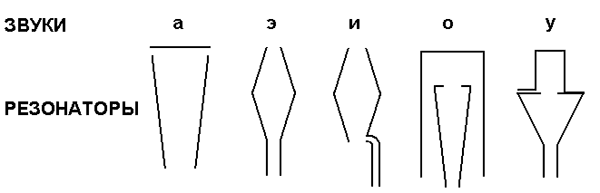
При этом можно было использовать аддитивный синтез, как в обычных органах. В 1791 году Вольфганг вон Кампелен (Volfgang von Kempelen) предатвил миру акустическо-механическую говорящую машину, которая воспроизводила определенные звуки и их комбинации. Шипящие и свистящие выдувались с помощью специального меха с ручным управлением. В середине 18 века это изобретение было улучшено ученым Чарльзом Уитстоуном (Charles Wheatstone), и уже могло воспроизводить гласные и большинство согласных звуков. А в 1846 году Джезеф Фабер представил свой говорящий орган, в котором была реализована попытка синтезирования не только речи, но и пения. В конце 18 века знаменитый ученый Александр Белл (Alexander Graham Bell) создал собственную "говорящую" механическую модель, очень схожую с конструкцией Уитстоуна. Начиная с 1920 года наступила эра электрических инструментов, при этом за основной вид синтеза оставался аддитивный. С развитием примитивных синтезаторов ученые получили уникальную возможность использовать генераторы звуковых волн, и на их базе строить алгоритмические модели.
Ключевой датой в развитии вокодеров является 1939. Именно в этом году ученый-изобретатель Хомер Дадли (Homer.W. Dudley) из Bell Laboratories представил миру устройство Parallel Bandpass Vocoder, над разработкой которого он трудился три года. Самая ранняя аналоговая модель называлась The VODER THE MACHINE THAT TALKS (VODER - машина, которая говорит).

Страница издания "Science News Letter" со статьей "Создана машина, которая говорит человеческим голосом". 14 января 1939 года.
Voder, представленный в 1939 году управлялся с помощью человека. Вот как описывает свои ощущения Ванневар Буш (Vannevar Bush) в своем научном труде "As We May Think" (1945 г.): "На мировой выставке 1939 года было показано устройство, называемое Voder. Девушка-оператор нажимала на его клавиши, и Voder воспроизводил звук, похожий на речь. Это происходило без использования человеческих голосов, нажатие на клавиши просто вызывало комбинации нескольких вибраций, созданных электронным способом, которые воспроизводились с помощью громкоговорителя". Кстати, данный труд Ванневара Буша посвящен интерактивному взаимодействию человека и компьютерных систем и очень интересен для прочтения. В 1940 году Хомер Дадли представил свою новую модель голосового синтезатора, именуемую The Vocoder (аббревиатура от Voice Operated reCorDER). А в 1948 году на выставке "Electronische Musik" (Германия) VODER был представлен как электронный инструмент будущего. Вот так и началась эра вокодеров.
Алгоритмические модели синтезаторов речи с того времени практически не изменилась. При этом как вы можете заметить эти системы развивались практически параллельно с аналоговыми синтезаторами.
Современные вокодеры
Современное понятие вокодера весьма размывчато. С одной стороны мы подразумеваем под ним синтез речи, с другой - кодирование и декодирование речевых сигналов для средств коммуникаций, с третьей - изменение тембральных составляющих. При этом существует разделение на вокодерные эффекты, применяющиеся в музыкальных творческих целях, и промышленные системы голосового кодирования, применяющихся в средствах коммуникаций.
В последних они делятся на два класса: фонемные (речеэлементные) и параметрические. В принципе фонемных лежит запоминание отдельных фраз, речевых оборотов. Благодаря этому запоминанию на воспроизводящий элемент передается не сама речь, а ее элементный номер. Это широко применялось и применяется в системах управления голосом, а также чтения текста с преобразованием в звук. В качестве простого примера можно привести звуковые схемы Windows, интерактивно реагирующие на то или иное событие. Если эти звуковые сигналы заменить на человеческую речь, то мы получим самый легкий пример речеэлементного вокодера. Системе сообщается не сам звук, а имя файла, который надо воспроизводить. Параметрические вокодеры состоят из фильтрового и генераторного подблоков. Первый подблок отвечает непосредственно за речевой спектр, второй - за тоновый спектр. В основе этого разделения лежит природа воспроизведения человеком различных звуков.
Сейчас многие говорят о голосовой связи посредством сети Интернет, и уже выпущено несколько моделей фразовых вокодеров для браузеров. Это прежде всего эмуляции телекоммуникационных вокодеров, которые выполняют задачу передачи человеческой речи на большие расстояния с малым сетевым траффиком. Другое применение - фонемные вокодеры для чтения текста. Например, преобразование текста html-страницы в речь. Поэтому Вы должны понять, что фразу "вокодер" звукорежиссер и телекоммуникационщик поймут по-разному. Хотя и в том, и в другом случаях природа устройств похожа, если не одинакова.
Основные типы вокодеров
Самые простые вокодеры - это полосные. Их реализацию можно увидеть во многих программных продуктах. В основе данного устройства лежит принцип разделения сигнала на полосы с помощью специальных фильтров. Чем больше полос, тем качественнее сигнал при передаче данных. Но для музыки имеют большое значение искажения, получаемые в определенных полосах, а также подмена тонального спектра речевых элементов на спектр другой природы.
Как простейшую имитацию вокодера такого типа можно привести пример с разделением звуковой формы на частотные полосы (с помощью фильтров или эквалайзеров), их обработки по отдельности и последующего сложения в новую волновую форму.
Другие типы вокодеров:
- Гомоморфные. При помощи гомоморфной обработки они позволяют разделить речевой сигнал на генераторную и фильтровую части.
- Формантные. Форманты - резонансные частоты голосового тракта, и в основе действия вокодера лежит их комбинация.
- Ортогональные - гармонические, раскладывают речь по определенному алгоритму, в частности, ряд Фурье.
- LPC-вокодеры или липредеры заключают в себе сложные алгоритмы линейного предсказания речи.
В основе устройств, используемых в музыкальной сфере, могут применяться любые алгоритмы вокодирования, а также их сочетания. Имеет место и разделение фильтров речевых сигналов и генераторной функции. Если фильтры, описывающие непосредственно речевые элементы, не трогать, а изменить только основной генерируемый(ые) тон(ы), то в результате мы можем получить речь с новым гармоническим наполнением.
Амплитудная управляющая и замена спектров. Морф
Как мы знаем, звуковая волна состоит из множества простых составляющих, разных по амплитуде и частоте. Современные программные вокодеры позволяют одному звуковому спектру менять амплитудные соотношения гармоник руководствуясь алгоритмическими моделями либо соотношениями другой звуковой формы. При этом данный метод уже применяется не только по отношению ко всему спектру в слышимом диапазоне, но и по более узким полосам. Данный эффект еще получил название Morph и прекрасно реализован в программе iZotope Ozone Spectron.
Суть данного преобразования проста. Мы берем исходный звуковой файл и выделяем в нем определенную частотную полосу. Потом загружаем файл-донор, из гармонического наполнения которого будет формироваться тембр нового звука. При запуске алгоритма на исполнение, все амплитудные соотношения, находящиеся в выделенной полосе исходного файла, будут управляющими для нового спектра. Таким образом, мы получаем скрипку, играющую в ритме ударных, либо орган с "боем", характерным для гитарного исполнителя.
В качестве тембровой составляющей может быть использован обыкновенный тон-генератор, либо любая другая более сложная модель синтеза, либо звуковой файл. При микшировании исходного звука и генерируемого тона мы можем получить смесь того и другого. Причем уникальной особенностью программных вокодеров является возможность изменения уровневого соотношения исходного тембра и тембра донора. В результате, мы можем добавлять в звучание инструментов легкую вокодерную "окраску", либо синтезировать принципиально новые звуки.
В следующей части этого материала мы рассмотрим лучшие современные программы вокодеров и синтезаторов речи. Продолжение следует…





