







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexОсобо внимательные читатели (а это примерно 0,49%) при ознакомлении со статьёй, посвящённой Amazon EC2, наверняка обратили внимание, что по условиям акции даётся не только виртуальный сервер, но и немного места в Amazon S3. Почему бы не воспользоваться им и немного не поэкспериментировать? Если вы и в дальнейшем захотите пользоваться услугами Amazon S3, то надо будет прикинуть свои расходы с помощью специального калькулятора. Предварительно, конечно, лучше месяц попользоваться хранилищем в тестовых целях, чтобы посмотреть потом статистику по трафику и числу запросов. В любом случае цены на услуги у Amazon очень приятные. К тому же за входящий трафик с недавних пор платить не надо, а если хочется ещё немного сэкономить, то можно воспользоваться опцией Reduced Redundancy Storage — это чуть менее надёжное хранилище, которое тем не менее обеспечивает более чем достаточную сохранность данных. Процесс регистрации в облачных сервисах Amazon мы подробно рассмотрели в статье про EC2, так что останавливаться на этом пункте не будем.
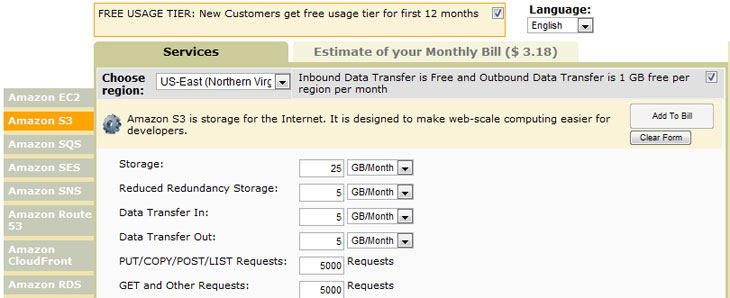
Теперь чуть ближе познакомимся с принципом организации данных в Amazon S3. Важно понять, что это не просто какой-то файловый сервер, пусть и где-то в облаке, а именно хранилище. То есть классические способы обращения по FTP, SMB, AFP, SSH и так далее в данном случае не работают. Точно так же нет как таковых каталогов, файлов и тому подобных вещей, хотя внешняя сторона сервиса для удобства пользователей позволяет работать с файлами и папками. Зато есть полноценная система управления правами доступа. На самом деле Amazon S3 оперирует объектами, причём не так уж важно, что именно внутри объекта находится. У каждого объекта есть свой уникальный ключ, его идентифицирующий. Любой объект для избыточности хранится одновременно в нескольких местах внутри облака. Плюс ко всему регулярно проверяется целостность данных. Также Amazon S3 обладает возможностью сохранять предыдущие версии объектов, так что можно извлечь, например, более старый архив с бэкапом важных данных. Ну а раз уж речь идёт об облаке, то очевидно, что проблем с масштабированием и доступностью сервиса должно быть очень-очень мало. В пробном варианте нам доступен только стандартный доступ к серверам, находящимся в Америке, но в будущем лучше выбрать один из дата-центров, который географически расположен ближе к вам.
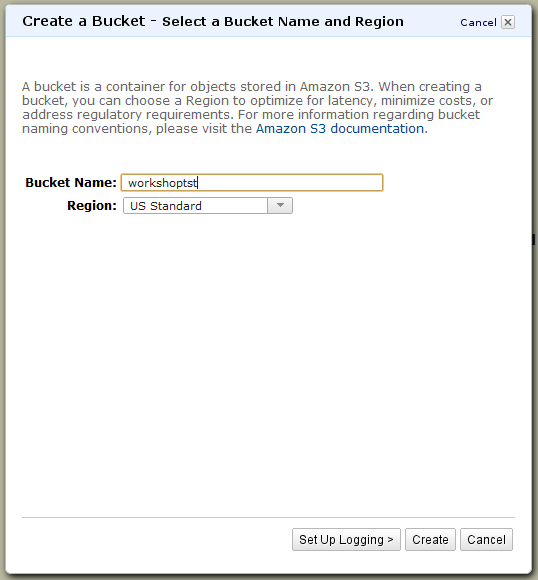
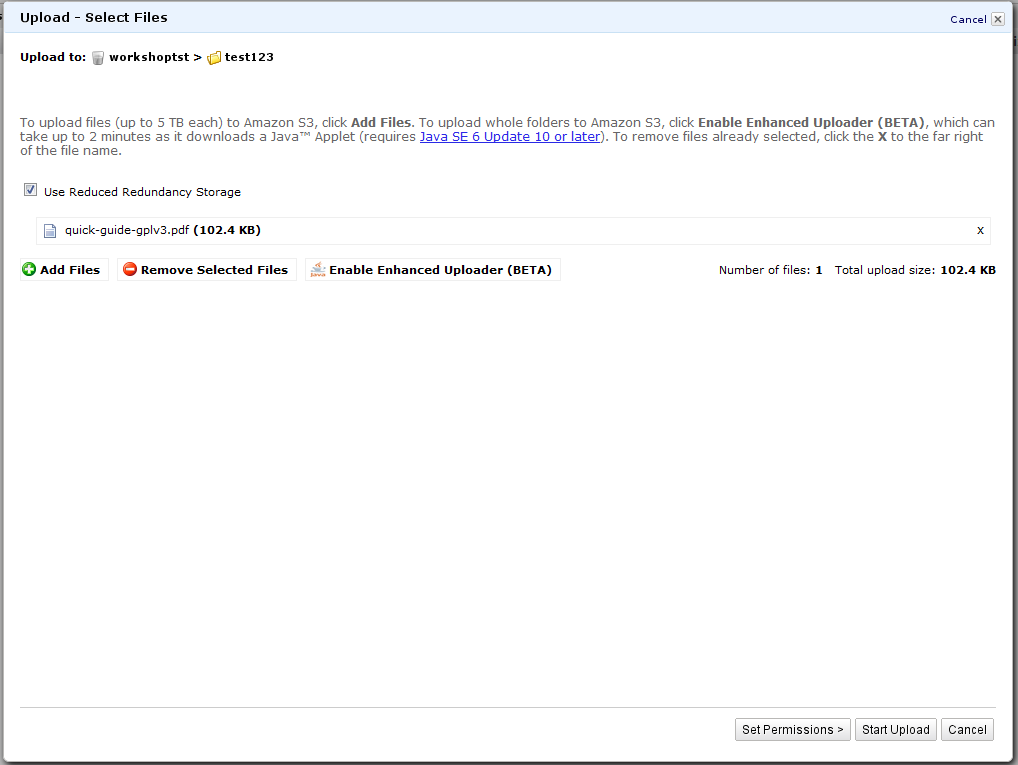
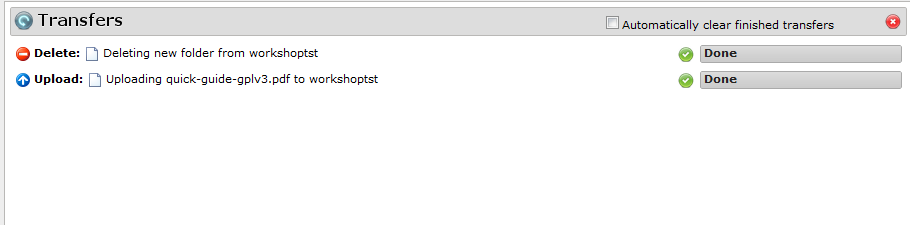
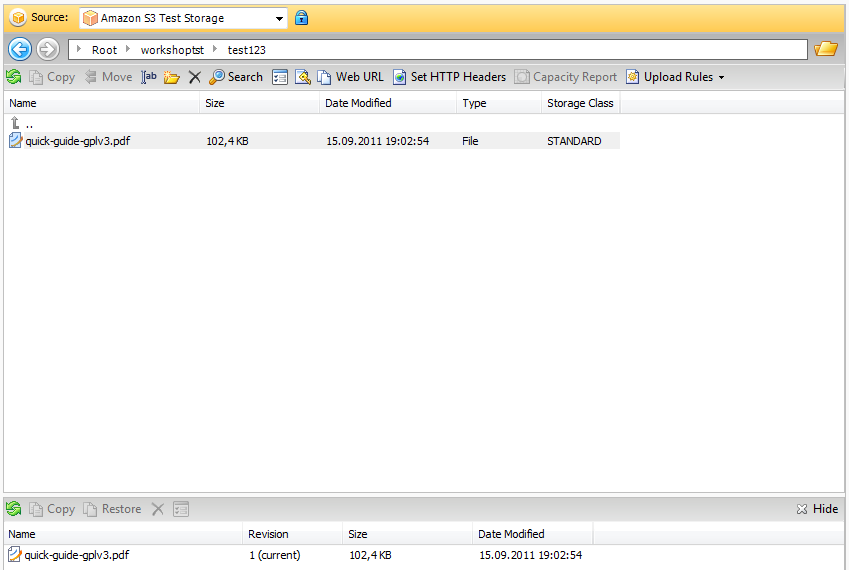
Итак, заходим в консоль управления Amazon S3. Здесь нам предлагается создать так называемый bucket («ведро») — контейнер, в котором хранятся сами объекты. Можно создавать сколь угодно объектов внутри контейнеров. Обратите внимание, что имя у контейнера должно быть уникальным среди всех имеющихся в S3 — в дальнейшем оно будет использоваться для доступа к нему извне. Для тестовых целей нам нужно выбрать регион US Standard. Внутри контейнера мы можем создавать папки и заливать в него файлы объёмом до 5 Гбайт каждый. При закачивании файла можно указать опцию Reduced Redundancy Storage, её же можно выбрать в свойствах папки, и тогда все файлы в этом каталоге будут автоматически помещены в менее надёжное хранилище. Ход каждой из операций и список последних действий доступен по клику на кнопку Transfers.
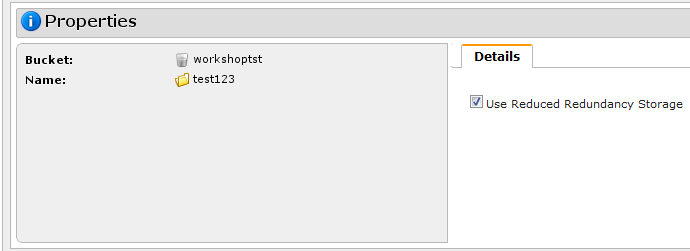
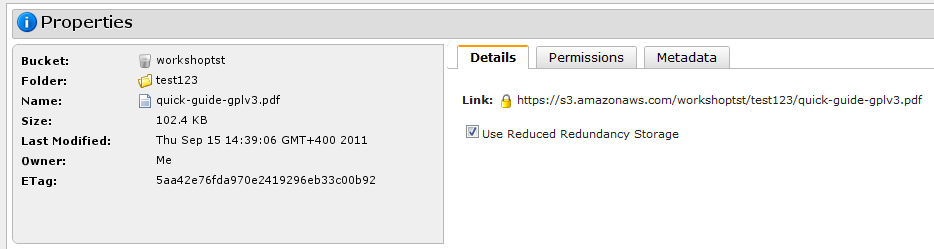
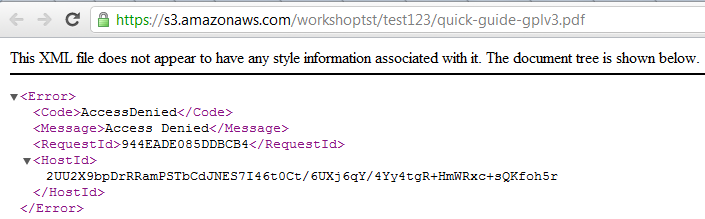
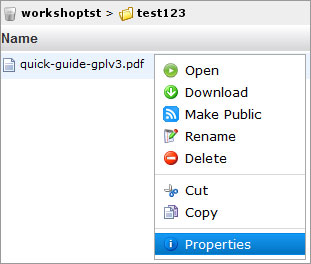
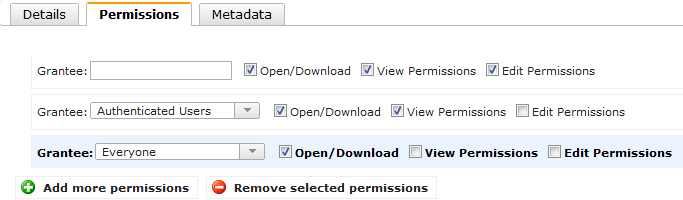
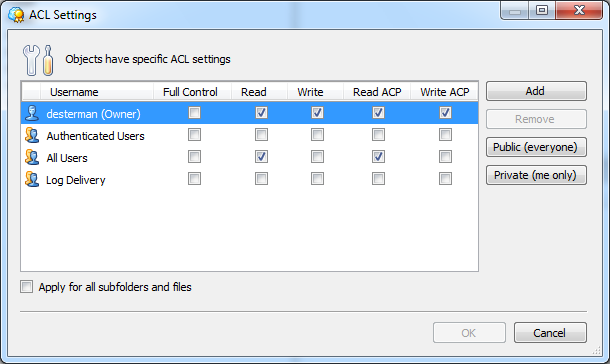
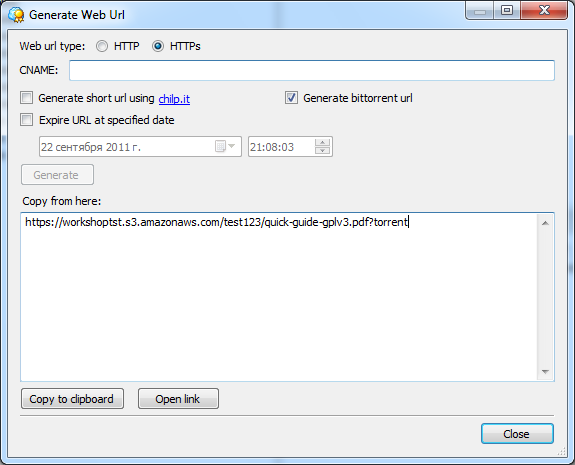
Файлы можно напрямую загружать из веб-интерфейса Amazon S3 или открывать в браузере, если последний, конечно, вообще способен их открыть. Также доступны простейшие операции по копированию, вырезанию, удалению и вставке объектов — они выполняются непосредственно на сервере, то есть никакой промежуточной закачки на ПК не идёт. В свойствах файла доступна http-ссылка на него, но по клику вместо файла вы увидите лишь сообщение об ошибке. Чтобы открыть доступ, нужно кликнуть правой кнопкой по нему в списке файлов и выбрать Make Public. Либо отредактировать права доступа непосредственно в свойствах файла. Таким образом можно быстро «расшарить» данные без использования файлообменников и с гарантированно высокой доступностью и скоростью отдачи. Ещё одна крайне полезная функция — доступ к файлам посредством BitTorrent. Так будет меньше тратиться трафик на сервере, а у пользователей окажется выше скорость скачивания. Нужно всего-то добавить в конец ссылки на файл ?torrent.
В принципе, никто не мешает сделать в S3 даже статический веб-сайт.
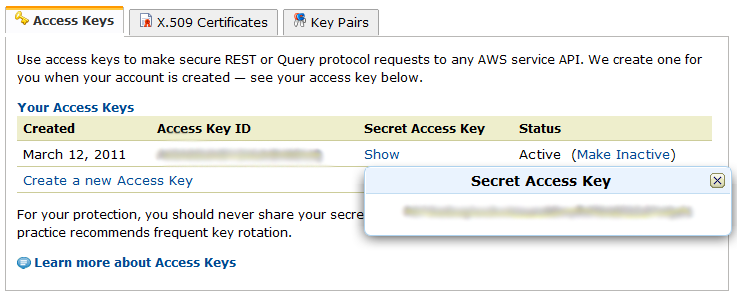
Веб-интерфейс консоли Amazon S3 хоть и продуман, но для работы с большим числом файлов не очень подходит. В качестве альтернативы можно воспользоваться дополнением к Firefox S3Fox, ещё одним онлайновым менеджером S3fm или же CloudBerry S3 Explorer. В любом случае нам придётся открыть доступ к хранилищу для этих клиентов. Делается это в панели управления аккаунтом Amazon в разделе Security Credentials. На вкладке Access Keys уже есть один ключ и пароль (надо кликнуть на Show), но можно добавить ещё один или деактивировать один из имеющихся. Никогда и никому не передавайте эти ключи, а также не забывайте периодически менять их.
Мы рассмотрим CloudBerry S3 Explorer как наиболее удобный S3-клиент под Wndows. Эта программа существует в платной и бесплатной версиях. За 40$ вам становятся доступны некоторые дополнительные полезные опции: шифрование, сжатие на лету, возможность загрузки файлов объёмом более 5 Гбайт (за счёт разбивки исходного файла на несколько частей и прозрачной работы с ним), удобная организация резервного копирования и так далее. У Pro-версии есть пробный период в 15 дней, а бесплатная при первом запуске попросит зарегистрироваться.
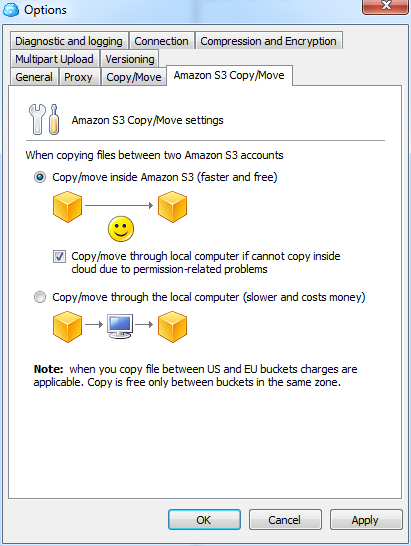
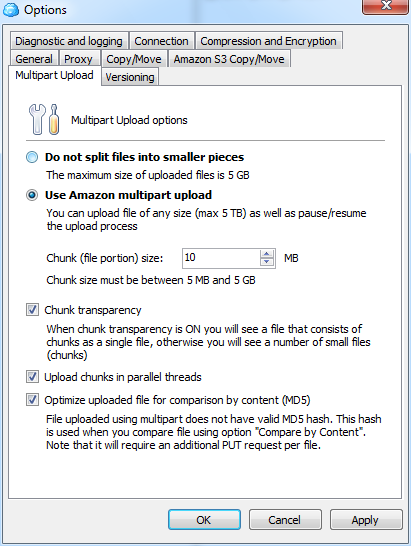
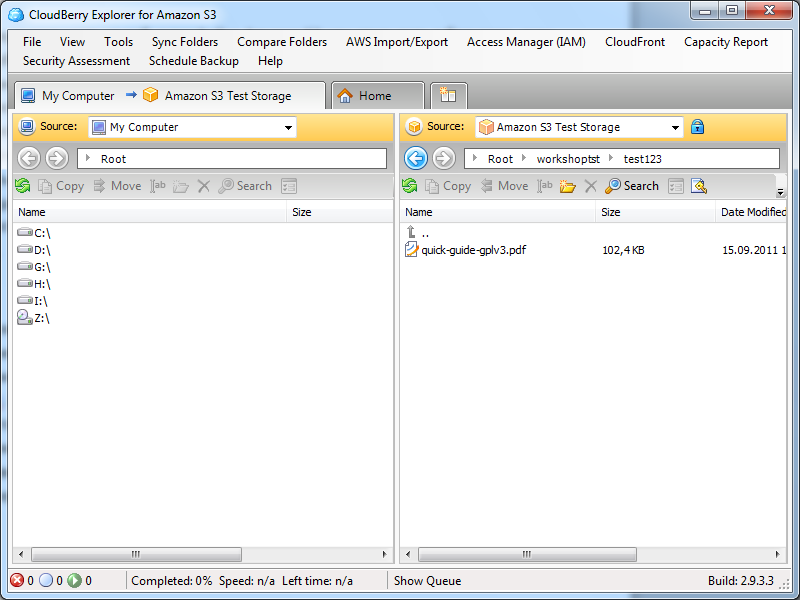
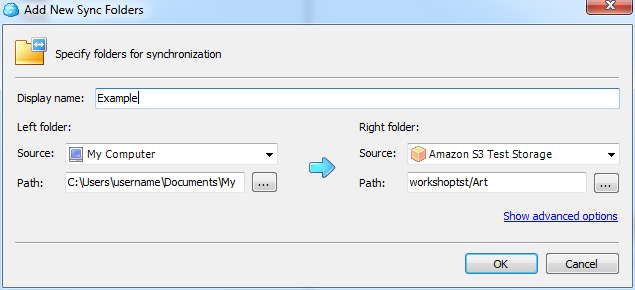
CloudBerry Explorer может работать не только с Amazon S3, но и с рядом других похожих сервисов. Первым делом нам надо добавить аккаунт S3 в меню File. Вводим пару из ключей доступа, проверяем соединение (Test connection) и сохраняем настройки. Теперь в левой или правой панели выбираем в выпадающем списке сверху только что созданный аккаунт S3. Всё, можно работать. Для объектов можно поменять настройки прав доступа, посмотреть предыдущие версии, быстро получить http-ссылку или torrent-файл для скачивания (а заодно воспользоваться сокращалкой URL и выставить время жизни ссылки), настроить синхронизацию между локальным каталогом и папкой в облаке, получить отчёт об использовании хранилища и многое-многое другое. Для Linux-систем можно воспользоваться консольным набором утилит S3tools.
Вообще у CloudBerry есть много продуктов для взаимодействия с облачными сервисами. Например, можно воспользоваться не Amazon S3, а Google Storage for Developers — аналогичным хранилищем от Google. Процедура регистрации в сервисе примерно такая же, да и расценки вполне нормальные. А до конца года вообще есть возможность получить бесплатно 5 Гбайт места в облаке. CloudBerry Explorer for Google Storage, кстати, позволяет хранить файлы и внутри Google Docs, обеспечивая такую же удобную работу с ними. На этом список облачных хранилищ, конечно же, не заканчивается — каждый волен выбрать то, что ему больше нравится. Напоследок хотелось бы напомнить о том, что важные данные перед загрузкой в облако лучше всё-таки шифровать и обязательно копировать куда-нибудь ещё. Ну и не забывайте следить за потреблением дискового пространства, трафика и запросов в любом облачном сервисе. На этом всё. Удачи!





 Подписаться
Подписаться