







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Лингвистические технологии ABBYY. От сложного — к совершенному
Идея разобраться с одной из ключевых проблем теории искусственного интеллекта и решить задачу понимания вычислительной техникой человеческой речи зародилась в умах специалистов ABBYY пятнадцать лет назад. Именно тогда с подачи основателя компании Давида Яна стартовали сначала научно-исследовательские, а затем опытно-конструкторские и технологические работы по созданию системы машинного перевода нового поколения, впоследствии переросшей в отдельный проект Compreno (прежнее название — Natural Language Compiler) по решению множества задач, связанных с обработкой естественного языка. О серьезности намерений ABBYY совершить революцию в области компьютерной лингвистики свидетельствует не только многолетний труд более чем трехсот сотрудников компании, но и интерес к платформе со стороны Фонда развития Центра разработки и коммерциализации новых технологий (Фонд «Сколково»), отбирающего наиболее перспективные проекты и осуществляющего их поддержку. Не менее убедительной является и финансовая сторона дела: суммарные инвестиции фонда «Сколково» в Compreno — 475 млн рублей, что составляет половину финансирования проекта. Вторую часть (475 млн руб.) вносит сама ABBYY. Впечатляющие цифры, подчеркивающие размах и масштаб проекта. ⇡#Сумма технологийЧтобы разобраться в нюансах положенных в основу Compreno механизмов и логике их работы, необходимо понять фундаментальную концепцию проекта, заключающуюся в следующем. На каком бы языке цивилизованные люди ни говорили, у понятий, которые они обозначают словами, гораздо больше схожего, чем различного. Все мы живем в домах, пользуемся мебелью, телефонами, ездим на машинах, ходим на работу в офисы, летаем на самолетах и т.д. Эти понятия общие и не зависят от языка с точки зрения того, какими мы их себе представляем. Уловив эту связующую нить, в ABBYY построили независимую от конкретного языка универсальную семантическую иерархию понятий. Семантическая иерархия понятий представляет собой универсальное для всех языков дерево, толстые ветви которого являются более общими понятиями (например, «движение» ), а тонкие — более специфическими смысловыми значениями, структурированными от общего к частному («ползать», «летать», «ходить пешком», «бегать» и т.д.). Если речь идет про руководителя организации, то во главе данного лексического класса фигурирует понятие «лидер», а в подклассах представлены более частные понятия, такие, как «босс», «начальник», «руководитель», «шеф» и прочие слова и словосочетания, являющиеся своего рода листочками на дереве понятий.  ABBYY Compreno оперирует не словами, а значениями (понятиями). Одно значение может быть в одной ветке иерархии, а другое — в иной Такая древовидная структура обеспечивает наследование свойств от предков к потомкам и позволяет избегать неоднозначностей в процессе перевода предложений с одного языка на другой. Пояснение разработчики дают на примере значения слова «управление», в русском языке соответствующего нескольким понятиям на разных ветвях универсального семантического дерева: можно «управление» интерпретировать как департамент, а можно, к примеру, — как действие. И благодаря тому, что семантический класс «управление» в смысле некой организации представлен в одной ветке дерева, а как действия в другой, система автоматически подбирает правильное слово при переводе текста на английский язык, делая выбор в пользу department или management в зависимости от контекста фразы. Как следствие, служащие ядром Compreno семантические описания позволяют легко переводить текст с английского или русского языка в универсальный язык и с универсального — на любой другой, описания которого имеются в системе. Вторым крупным блоком платформы Compreno является синтаксис. Важно понимать, что синтаксис описывает то, каким образом понятия связаны друг с другом внутри одного или нескольких предложений. Для кодирования этих связей в языках используются члены предложения, согласования, порядок слов, падежи, различные служебные слова, союзы, предлоги и много всего остального. Синтаксис — это, образно говоря, большой конструктор из перечисленных элементов. В различных языках могут использоваться разные элементы конструктора. Например, в английском порядок слов является важной частью синтаксиса. Вопросительные предложения формируются одним образом, повествовательные — другим, и никак иначе. Бывают некоторые опциональные обстоятельства времени и места, которые ставятся в начало предложения, но обычно на первом месте находится подлежащее, на втором — сказуемое и дальше располагаются остальные части речи. В русском языке другая ситуация. Мы не завязываемся на порядок слов, но зато для нас важно согласование, что, собственно, и является едва ли не самым крупным камнем преткновения для людей, изучающих русский. Другая важная вещь, которую необходимо учитывать при синтаксическом разборе текста, — подстановки и связи между словами, имеющие место тогда, когда мы пропускаем какое-либо слово, но понимаем, что оно все равно есть. Яркий пример — фраза «Мальчик любит красные яблоки, а девочка зеленые». Ясно, что в отношении девочки речь идет про яблоки (а также про то, что она их любит), и мы прекрасно это поняли, хотя в тексте пара слов пропущена. Есть и другие, более сложные синтаксические связи, успешно разбираемые Compreno. Например: «Хоть мальчик и хотел поиграть, но он понимал, что у него мало времени». В данном случае мы два раза заменили слово «мальчик» местоимениями «он» и «него», и машине важно понимать, что это один и тот же объект, и восстанавливать пропущенные узлы. 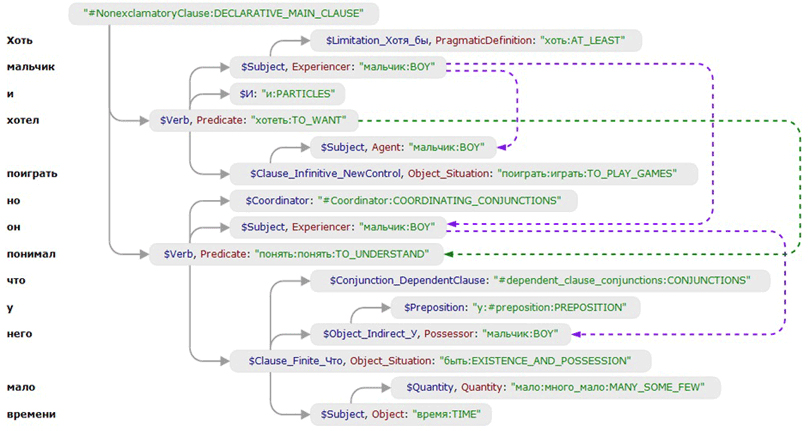 ABBYY Compreno стремится к определению смысла текста, написанного на обычном языке, позволяя машине «понять» этот текст и трансформировать его в универсальное представление, не зависящее от языка Блок Compreno, отвечающий за синтаксис, разбирает роли различных понятий в предложении и связывает их друг с другом. Система анализирует текст и выстраивает дерево связей, в котором главным является обычно какое-то действие. От него далее идут объект, субъект и прочие атрибуты, привязывающиеся либо к объекту, либо к субъекту и передающие заложенный в конкретном предложении смысл. Чтобы синтаксический разбор был максимально точным, Compreno использует семантический анализ, основанный на вышеописанной универсальной иерархии понятий. Все это в сумме предоставляет новый уровень свободы при обработке машиной текстов, позволяет ей «понимать» смысл исходного предложения и затем синтезировать этот смысл на другом языке. Наконец, третьей важной составляющей лингвистической платформы ABBYY является статистика, позволяющая системе правильно сочетать фразы и более полно разбираться с омонимией, когда одно и то же слово может означать разные вещи (типичный пример: «замок» и «замок»). Не менее важна статистическая информация и для корректного разбора предложений с двусмысленным толкованием. Например, провести грамотный анализ фразы «Эти типы стали есть в нашем цехе» можно только прибегнув к данным о частоте взаимоотношений между понятиями, вникнув тем самым в контекст речи или, иными словами, в предмет обсуждения. Если он о металлургии, то повествование идет про сталь, если про поведение людей, то логичным будет сделать выбор в пользу некоторых не очень хороших типов. В основу статистической модели Compreno положен внушительный набор текстов разной тематики и жанров, едва ли не ежедневно обрабатываемых системой. Причем текстовых данных не абы каких, а созданных либо переведенных с одного языка на другой именно человеком. Подобный подход снижает вероятность возникновения ошибок в процессе принятия системой решений и искажений при синтезе смысловых конструкций. Что же в итоге получилось? В итоге специалистам ABBYY удалось, объединив знания, воображение, идеи и опыт, построить на «трех китах» — семантической иерархии понятий, синтаксисе и статистике — модель языково-независимых данных об устройстве мира и модель доступа к этим данным. Как следствие, удалось максимально близко подойти к пониманию смысла текста компьютером и сделать возможным решение широкого пласта лингвистических задач. Каких именно? ⇡#Игры разумаГоворя о практической значимости платформы ABBYY Compreno, разработчики, прежде всего, акцентируют внимание на решении двух ключевых задач — автоматическом переводе текстов для множества языковых пар и интеллектуальном поиске информации. Первая задача, связанная с транслированием текстовых данных, крайне важна в век цифровых технологий, стирающих формальные границы и барьеры между странами. При постоянно возрастающих объемах многоязычной информации, необходимости вовлечения все большего количества участников из разных уголков мира в реализацию современных проектов критически важными становятся не только скорость получения перевода, но и качество получаемых на выходе текстов. С обеспечением последнего у существующих систем машинного перевода дела обстоят вовсе не так гладко, как может показаться на первый взгляд. Виной всему — многочисленные принципиальные ограничения в научных подходах, которые являются основой многих существующих машинных переводчиков. Эти ограничения связаны с невозможностью корректно обрабатывать исключения, объективной сложностью языковых конструкций, игнорированием семантики, неумением фиксировать реальные связи в предложении и прочими проблемами. Технология Compreno является инженерным воплощением фундаментальных лингвистических исследований многих учёных мира, аккумулирующим примерно 50-летний опыт. И благодаря этому Compreno умеет преодолевать перечисленные сложности и позволяет синтезировать текст по смыслу такой же, какой он был на оригинальном языке, или максимально похожий. Для оценки возможностей системы ниже представлен пример перевода кусочка статьи Google's «Babel fish» heralds future of translation средствами статистического переводчика и платформы ABBYY. Комментарии, как говорится, излишни. Исходник: If we tried manually to give the system those languages, it would be a hopeless task. The only possible way we could do this is to harness the power of machine computation. We build statistical models that are automatically training themselves and learning all the time. ABBYY Compreno: Если бы мы попытались вручную дать системе те языки, это было бы безнадёжной задачей. Единственный возможный способ, которым мы могли бы сделать это, состоит в том, чтобы использовать силу машинного вычисления. Мы создаём статистические модели, которые автоматически обучаются и учатся всё время. Статистический переводчик: Если бы мы попытались вручную, чтобы дать системе этих языков, то было бы безнадежной задачей. Единственно возможным путем мы могли бы сделать это, чтобы использовать возможности машины вычислений. Мы строим статистические модели, которые автоматически обучение себя и учитесь все время. Важность второй задачи — интеллектуального поиска — является следствием колоссального объема порождаемой человечеством информации, растущего в геометрической прогрессии и требующего иных подходов к анализу и поиску нужных данных. Сейчас поиск работает в основном с использованием словесной информации: при поиске документа мы сначала придумываем слова, которые должны в нем содержаться, затем вводим ключевые фразы, получаем удовлетворяющие критериям поиска данные и далее вручную выбираем интересующую нас информацию. Такой, ставший привычным поиск имеет ряд крупных недостатков. Во-первых, далеко не всегда можно сформулировать запрос, точно описывающий ту информацию, которую необходимо найти. Во-вторых, придумывая уточняющие слова, мы суживаем выборку и ограничиваем поиск. Наконец, перебирать все комбинации ключевых слов порой бывает крайне утомительно, а то и вовсе невозможно. Со всеми этими недостатками успешно справляются технологии ABBYY Compreno, позволяющие осуществлять смысловой поиск с использованием тех понятий и связей, которые были извлечены машиной из поискового запроса, сформулированного обычным языком.  Слоган «Мы помогаем людям понимать друг друга» прекрасно отражает суть технологий ABBYY Compreno «Эрудированность» платформы и сосредоточенный в ней огромный багаж знаний позволяют использовать Compreno для выполнения множества других прикладных задач. На ее основе компании могут создавать качественно новые решения для систем многоязычного поиска и классификации данных, извлечения фактов и установления связей между объектами, мониторинга, систем защиты от несанкционированного использования информации, автоматического реферирования и аннотирования документов, распознавания речи и многих других задач. Не менее перспективной и интересной сферой применения Compreno является решение задач, связанных с визуализацией текста. Яркий пример — создание мультипликационных роликов и фильмов на основе текстовых сценариев. Именно в этом направлении работает компания «Базелевс Инновации», также принимающая активное участие в проекте «Сколково» и уже добившаяся определенных результатов в создании программного комплекса для интерактивной трехмерной визуализации текстов. В ABBYY не без гордости заявляют, что в мире сейчас не существует настолько универсальной платформы, которая позволяет решить так много прикладных задач, требующих качественного лингвистического анализа текстов. ⇡#Планов громадьеНа сегодняшний день, как было сказано выше, в проекте участвуют более 300 специалистов, активно привлекаются молодые кадры, студенты кафедры ABBYY в МФТИ и выпускники ведущих вузов страны — МГУ, РГГУ, МГЛУ, СПбГУ и многих других. Если посмотреть на корни работы, то они кроются в серьёзных исследованиях российской и мировой лингвистики. Этот научный багаж используется специалистами ABBYY. В планах компании значатся привлечение к участию в проекте ведущих мировых специалистов в области языкознания и лингвистики и придание проекту международного статуса. В настоящий момент ABBYY реализует пилотные проекты по развертыванию программных решений на базе Compreno. Пока инициаторы проекта не раскрывают подробностей о разрабатываемых продуктах, но заверяют, что от их реализации и повсеместного внедрения в конечном итоге выиграют все — и производители софта, и потребители, то есть мы с вами. Пока еще рано говорить о том, как сильно изменит жизнь человечества амбициозный проект ABBYY Compreno в будущем. Однако можно с уверенностью утверждать, что уже в ближайшее время компьютерная лингвистика совершит значительный прогресс в области моделирования языка и перейдет на совершенно новую технологическую базу, фундамент которой закладывается сейчас.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()





