|
Опрос
|
реклама
Быстрый переход
Голливудские агентства резко раскритиковали ИИ-генератор видео OpenAI Sora
10.10.2025 [11:45],
Владимир Фетисов
Агентство Creative Artist Agency присоединилось к тем, кто выступил с критикой в адрес OpenAI и её приложения для генерации видео Sora из-за нарушения авторских прав. В заявлении организации сказано, что упомянутый сервис представляет значительные риски для клиентов агентства и принадлежащей ему интеллектуальной собственности. 
Источник изображения: OpenAI Creative Artist Agency, представляющее интересы большого количества звёздных актёров, таких как Скарлетт Йоханссон (Scarlett Johansson) и Том Хэнкс (Tom Hanks), поставило под сомнение, считает ли OpenAI, что «люди, писатели, художники, актёры, режиссёры, продюсеры, музыканты и спортсмены заслуживают вознаграждения и упоминания за работу, которую они делают». «Или OpenAI считает, что может просто украсть контент, пренебрегая глобальными принципами авторского права и нагло игнорируя права создателей, а также многих людей и компаний, которые финансируют производство, создание и публикацию работы этих людей? На наш взгляд, ответ на этот вопрос очевиден», — говорится в заявлении агентства. Вместе с этим в Creative Artist Agency заявили, что агентство открыто для предложений OpenAI, направленных на решение возникшей проблемы, продолжая взаимодействовать с лидерами в области интеллектуальной собственности, профсоюзами, законодателями и политиками. «Контроль, разрешение на использование и компенсация являются фундаментальными правами этих работников. Всё, что не подразумевает защиту создателей и их прав, неприемлемо», — сказано в заявлении агентства. На прошлой неделе OpenAI выпустила приложение для генерации видео Sora, которое доступно для устройств на базе iOS с некоторыми ограничениями. Несмотря на это, всего за несколько дней ИИ-генератор скачали более 1 млн раз, благодаря чему он возглавил рейтинг App Store. Приложение позволяет генерировать на основе текстового описания короткие ролики, в том числе с участием персонажей, защищённых законодательством об авторском праве, что и стало причиной бурной реакции со стороны компаний, чья интеллектуальная собственность незаконно используется в Sora. United Talent Agency также раскритиковало приложение OpenAI, заявив, что использование сервисом защищённого авторским правом контента является эксплуатацией, а не инновацией. «В нашем бизнесе нет замены человеческому таланту, и мы будем продолжать бороться за наших клиентов, чтобы обеспечить их защиту. Когда речь идёт о Sora от OpenAI или любой другой платформе, которая стремится извлечь выгоду из интеллектуальной собственности и имиджа наших клиентов, мы солидарны с авторами», — сказано в заявлении агентства. Ранее OpenAI заявила, что ввела ряд защитных мер, которые должны предотвратить возможность генерации роликов с защищёнными авторским правом персонажами. В дополнение к этому компания проводит проверку уже созданных в Sora видео на предмет поиска материалов, которые не соответствует обновлённой политике OpenAI. «Мы удаляем сгенерированных персонажей из публичной ленты Sora и готовим обновления, которые предоставят правообладателям больше контроля над их персонажами и тем, как поклонники могут их использовать», — сообщил представитель OpenAI. Другие представители киноиндустрии также выразили недовольство тем, что сервис Sora использует контент, защищённый авторским правом. В их число входят агентство по подбору персонала WME, Disney и др. В интернете появилась система, которая заставит разработчиков ИИ платить за контент
10.09.2025 [18:38],
Сергей Сурабекянц
Представлен открытый стандарт лицензирования контента Really Simple Licensing (RSL), который даст медиакомпаниям возможность определять условия оплаты за сбор ботами данных для обучения ИИ. Новый стандарт позволит веб-издателям прямо в файле robots.txt на своих сайтах устанавливать условия использования их произведений. Многие крупные компании, в том числе Reddit, Yahoo, Medium, Quora, IGN и People Inc., уже объявили о поддержке RSL. 
Источник изображений: RSL Стандарт RSL основан на протоколе robots.txt, который позволял издателям давать инструкции поисковым роботам о том, к каким разделам сайта они могут получить доступ, а к каким — нет. Но вместо того, чтобы просто говорить «да» или «нет» конкретным ботам, сайты теперь могут добавлять условия лицензирования и выплаты роялти в свой файл robots.txt. Они также могут встраивать эти условия в онлайн-книги, видео и обучающие наборы данных, за которые необходимо получить компенсацию. За стандартом RSL стоит недавно созданная правозащитная организация RSL Collective, возглавляемая Экартом Вальтером (Eckart Walther), соавтором стандарта Really Simple Syndication (RSS) и Дугом Лидсом (Doug Leeds), бывшим генеральным директором IAC Publishing и Ask.com. «Цель — создать новую масштабируемую бизнес-модель для интернета, — сообщил Вальтер. — RSL берёт некоторые из этих ранних идей RSS и создаёт новый уровень для всего интернета, где определяются права лицензирования и права на компенсацию». 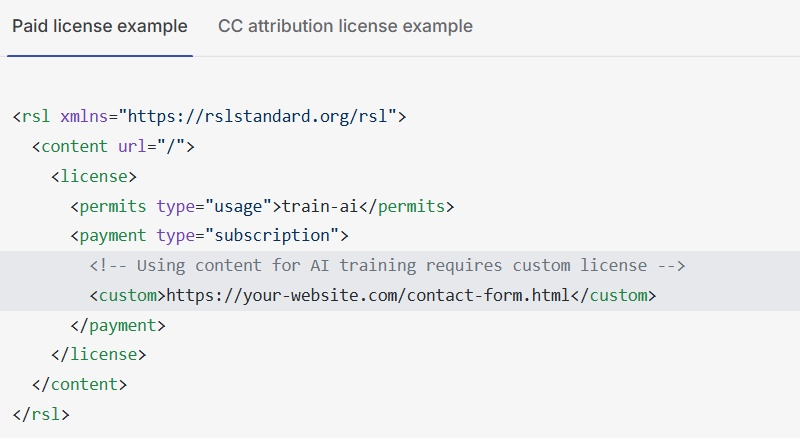 Стандарт RSL поддерживает различные модели лицензирования, включая бесплатные. Владельцы сайтов могут попросить компании, работающие с ИИ, оплатить подписку или назначить плату за каждое сканирование. Они также могут ввести плату за вывод, позволяя сайтам получать компенсацию, когда модель ИИ ссылается на их работу для генерации ответа. Боты, сканирующие сайты для других целей, например, для архивирования или включения в поисковые системы, могут работать в обычном режиме. Некоторые медиакомпании, включая Vox Media, материнскую компанию The Verge, News Corp, владеющую The Wall Street Journal, и The New York Times, уже заключили лицензионные соглашения с отдельными разработчиками ИИ, такими как OpenAI и Amazon. RSL Collective стремится упростить этот процесс, позволяя любому владельцу или создателю сайта получать оплату за свою работу без заключения множества отдельных соглашений. Как и в случае со многими другими стандартами, успех RSL зависит от того, насколько его поддержат крупные игроки отрасли. Разработчиков ИИ неоднократно обвиняли в игнорировании файлов robots.txt, и не существует простого способа подсчитать размер платы за вывод без их участия. RSL Collective делает ставку на то, что объединение усилий крупнейших веб-издателей сделает принятие стандарта более привлекательным. «Наша задача — выйти и убедить большую группу людей заявить, что это в ваших интересах. Это эффективно, поскольку вы можете договориться со всеми сразу, и юридически значимо, поскольку, если вы этого не сделаете, вы нарушите все сразу», — говорит Лидс. Стандарт RSL сам по себе не может блокировать посещение веб-сайта ботами, в отличие от системы «оплаты за сканирование», предлагаемой Cloudflare. RSL Collective в настоящее время работает с сетью доставки контента Fastly, чтобы допускать ботов ИИ на сайты только при согласии с политикой лицензирования. Fastly — это «вышибала у входа в клуб, и они не впустят людей без соответствующего удостоверения личности», — образно пояснил Лидс.  Лидс считает, что RSL Collective также может юридически обеспечивать соблюдение лицензий, что позволит, по его словам, «всем участникам организации коллективных прав участвовать в борьбе с любыми нарушениями» и совместно нести судебные издержки. Он сравнивает RSL с существующими организациями по защите цифровых прав, такими как группа по защите музыкальных прав ASCAP, которая собирает лицензионные сборы и распределяет их между участниками. Хотя традиционное лицензирование музыки пользуется особенно сильным и устоявшимся правовым прецедентом защиты авторских прав, несанкционированный сбор данных и использование медиафайлов для обучения систем ИИ всё ещё находятся в «серой зоне» правового регулирования. В настоящее время крупные игроки на рынке ИИ выступают ответчиками по судебным искам от Reddit, Getty Images и многих других онлайн-издателей. «Всегда стоял вопрос о том, соглашаются ли боты на условия, которые они не видят, — поясняют разработчики. — RSL меняет это принципиально, информируя поисковые роботы об условиях ещё до того, как они зайдут на сайт». Они рассчитывают, что новый стандарт лицензирования контента сможет создать интуитивно понятный способ навигации по лицензированию обучения ИИ. Apple ответит в суде за пиратство ради ИИ
07.09.2025 [18:12],
Владимир Мироненко
Компании Apple предстоит судебное разбирательство в связи с тем, что на неё подали в суд авторы книг, обвинившие компанию в нарушении авторских прав. По их словам, Apple использовала их произведения для обучения ИИ-модели без согласия правообладателей. 
Источник изображения: Sasun Bughdaryan/unsplash.com Основными истцами по иску являются авторы Грейди Хендрикс (Grady Hendrix) и Дженнифер Роберсон (Jennifer Roberson), которые сейчас собирают заявления других пострадавших, чтобы придать делу статус коллективного иска. Они утверждают, что Applebot, скрапер компании, имел доступ к пиратским «теневым библиотекам», состоящим из книг, защищённых авторским правом, включая их произведения. Как указано в иске, Apple «скопировала защищённые авторским правом работы» истцов «для обучения ИИ-моделей, чьи результаты конкурируют с этими самыми работами и размывают рынок для них — работами, без которых Apple Intelligence имела бы гораздо меньшую коммерческую ценность». «Такое поведение лишило истцов и группу контроля над своей работой, подорвало экономическую ценность их труда и позволило Apple добиться огромного коммерческого успеха незаконными способами», — говорится в документе. Это далеко не первый случай, когда компанию, разрабатывающую технологии генеративного ИИ, обвиняют в незаконном использовании контента без согласия правообладателей для обучения моделей. На OpenAI подали уже несколько исков, включая иск газеты The New York Times. Anthropic, создавшая ИИ-чат-бот Claude, недавно согласилась выплатить $1,5 млрд для урегулирования коллективного иска о пиратстве, поданного авторами. Warner Bros. подала в суд на Midjourney: сервис слишком хорошо генерирует Бэтменов и Суперменов
06.09.2025 [11:21],
Антон Чивчалов
Медиакомпания Warner Bros. Discovery (WBD) подала в суд на Midjourney за то, что та позволяет создавать изображения и видео с образами Бэтмена, Супермена, Джокера и других персонажей студии, что является нарушением авторских прав последней. Иск подан в федеральный суд Калифорнии, пишет Hollywood Reporter. 
Пример генерации образа Бэтмена сервисом Midjourney. Источник изображения: Hollywood Reporter Согласно иску WBD, ИИ-сервис Midjourney позволяет беспрепятственно генерировать образы персонажей, защищаемые законом об интеллектуальных и авторских правах. Помимо вышеупомянутых героев кинематографической вселенной, это также персонажи мультфильмов Looney Tunes и Cartoon Network. В Warner подспудно делают комплимент Midjourney, подчёркивая, что генерация очень качественная и практически неотличима от кадров из реальных фильмов. «Midjourney открыто и целенаправленно нарушает авторские права, и мы подаём иск, чтобы защитить наш контент, наших партнёров и наши инвестиции», — говорится в исковом заявлении. В качестве доказательств к иску прилагаются десятки примеров, где сгенерированные изображения совпадают с кадрами из фильмов, например, сцены с Бэтменом из культового фильма «Тёмный рыцарь». Даже если вводить нейтральные запросы без упоминания имён персонажей, например «битва супергероев», ИИ всё равно может генерировать изображения, очень похожие на персонажей вселенных Warner. По утверждению WBD, Midjourney нарушает авторские права ещё и с коммерческой выгодой для себя, поскольку сервис предлагает платную подписку по цене от $10 до $120 в месяц. Это не первый подобный иск крупной киностудии против Midjourney — ранее аналогичные иски подавали Disney и NBCUniversal. Сама Midjourney ранее отвергла обвинения в аналогичных исках от Disney и Universal, заявляя, что обучение модели на публично доступных изображениях — это «честное использование», а ответственность за выбор и генерацию контента лежит на пользователях, которые подписываются на соблюдение условий сервиса. В качестве компенсации WBD требует либо выплаты всех доходов, полученных Midjourney от использования её контента, либо компенсации в размере $150 тыс. за каждое своё произведение, использовавшееся для обучения нейросети. Anthropic согласилась выплатить $1,5 млрд по иску об авторских правах
06.09.2025 [08:32],
Алексей Разин
С момента распространения систем искусственного интеллекта материалом для их обучения служили различные произведения искусства, и владельцев авторских прав на них это не устраивало. В случае с Anthropic соответствующий иск от группы авторов дошёл до суда, и теперь компании предстоит выплатить авторам литературных произведений компенсацию в размере не менее $1,5 млрд. 
Источник изображения: Anthropic В конце июня, как отмечает NBC News, суд вынес предварительное решение, которое признавало использование компанией Anthropic литературных произведений, упоминаемых в иске, правомерным, поскольку результат подразумевал их существенную переработку. При этом суд постановил, что само по себе использование пиратских копий произведений, которые были получены Anthropic из нелегальных онлайн-библиотек Library Genesis и Pirate Library Mirror, было незаконным. Группа авторов при этом настаивала на выплате Anthropic компенсации в свой адрес из расчёта в среднем $3000 за каждое использованное литературное произведение, коих набралось не менее 500 000 штук. Таким образом, теперь компании предстоит в течение пяти рабочих дней направить в специальный фонд первые $300 000 компенсации после того, как решение суда вступит в законную силу. При этом сумма в $1,5 млрд является минимальным порогом компенсации. По факту, выплаты могут оказаться выше, поскольку Anthropic должна будет дополнительно перечислить в фонд по $3000 за каждое произведение сверх упомянутых 500 000, если обнаружится, что изначальный список не был исчерпывающим. Сумма компенсации станет крупнейшей в истории судебной практики по делам, связанным с нарушением авторских прав. Anthropic увернулась от иска за обучение ИИ на электронных книгах с помощью «исторического соглашения»
27.08.2025 [12:34],
Владимир Фетисов
Компания Anthropic добилась урегулирования коллективного иска, который был подан группой американских писателей, обвинивших разработчика в сфере ИИ в нарушении авторских прав. В судебном заявлении, которое Anthropic подала на этой неделе, сказано, что компания достигла договорённости в рамках «предложенного урегулирования», которое позволит ей избежать судебного разбирательства. 
Источник изображения: Anthropic Условия соглашения неизвестны, но отмечается, что речь идёт об иске о нарушении авторских прав, который в прошлом году подали писатели Андреа Бартц (Andrea Bartz), Чарльз Гребер (Charles Graeber) и Кирк Уоллес Джонсон (Kirk Wallace Johnson). Они обвинили Anthropic в том, что компания обучала ИИ-модели Claude на находящихся в открытом доступе данных, в том числе пиратском контенте. Anthropic сумела одержать победу в суде в июне, когда судья Уильям Алсуп (William Alsup) постановил, что обучение ИИ-моделей на данных книг, приобретённых законным путём считается легитимным. При этом он оставил возможность для дальнейших судебных разбирательств по данному вопросу. В июле Алсуп удовлетворил коллективный иск американских писателей, которые обвинили Anthropic в нарушении авторских прав и использовании пиринговой сети Napster для загрузки миллионов произведений. По данным источника, Anthropic должна была предстать перед судом по обвинению в пиратстве в декабре этого года. Компании грозили многомиллиардные штрафы. Ожидается, что мировое соглашение между Anthropic и группой истцов будет окончательно оформлено 3 сентября. «Это историческое соглашение принесёт пользу всем участникам группы. Мы с нетерпением ждём объявления деталей соглашения в ближайшие недели», — прокомментировал данный вопрос адвокат истцов Джастин Нельсон (Justin Nelson). Perplexity ответит в суде за использование материалов японских СМИ для обучения ИИ
26.08.2025 [14:52],
Алексей Разин
Информационные материалы, публикуемые новостными изданиями, являются важным источником дохода для многих медиагрупп, а потому они ревностно относятся к использованию своих публикаций для обучения больших языковых моделей. Японские Nikkei и Asahi Shimbun недавно подали в суд на Perplexity, обвинив её в нарушении авторских прав. 
Источник изображения: Unsplash, Neeqolah Creative Works Разрабатывающая системы искусственного интеллекта Perplexity сама поставила себя в уязвимое положение, организовав предоставление ответов на вопросы пользователей с прямым указанием первоисточников и цитированием. Этого оказалось достаточно, чтобы правообладатели уличили её в нарушении своих интересов, как это произошло в случае с судебным иском со стороны двух японских медиакорпораций. Рассмотрением дела займутся судебные инстанции в японской столице. Perplexity обвиняется истцами в неправомерном копировании их новостных материалов, размещении их на собственных серверах и обходе технических мер защиты, которые должны были предотвратить подобное использование интеллектуальной собственности. Каждое из двух японских издательств требует в качестве компенсации примерно по $15 млн, а также настаивает на удалении своих новостных материалов с серверов Perplexity. Помимо прочего, Nikkei обвиняет Perplexity в использовании публикаций, доступных только платным подписчикам. По данным Asahi, партнёрские материалы на страницах Yahoo News также использовались Perplexity с нарушением ряда японских законов и без разрешения правообладателей. Кроме того, японские медиакорпорации обвиняют компанию в искажении информации, содержавшейся в первоисточниках, что может нанести им существенный репутационный ущерб. В иске также отмечается, что подобные искажения способны дискредитировать саму основу журналистики, подразумевающую точное изложение фактов. Претензии к Perplexity в своё время выдвигало и японское издание Yomiuri. Американские и британские издания также ранее предъявляли претензии к Perplexity, обвиняя её в перетягивании читателей, поток которых позволяет онлайн-изданиям генерировать выручку за счёт размещения рекламы. С рядом таких СМИ компании пришлось заключить соглашения о разделении доходов в случае, если генерируемые ИИ-ответы ссылаются на материалы упоминаемых изданий: Time, Fortune и Der Spiegel. Сама Perplexity базируется в США, располагает примерно 30 млн пользователей и основной доход получает от подписки на свои услуги. Meta✴ обвинили в пиратстве порнофильмов для обучения ИИ
29.07.2025 [10:01],
Антон Чивчалов
Компания Meta✴ оказалась в центре нового судебного скандала: её обвиняют в распространении пиратского порнографического контента с целью обучения своего ИИ генерации «взрослого» видео. Как утверждают в компании Strike 3 Holdings, подавшей иск, при этом использовалась сеть BitTorrent. В Meta✴ обвинения отвергают и называют их необоснованными, передаёт Ars Technica. 
Источник изображения: dig.watch Истцом является холдинг Strike 3 Holdings (S3H), выпускающий порнографические фильмы, как утверждают в нём самом, «голливудского качества и уровня». в S3H утверждают, что Meta✴ с 2018 года распространила в одноранговой сети BitTorrent «как минимум 2396» фильмов для взрослых S3H без соответствующего разрешения. При этом в силу особенностей BitTorrent эти же ролики могли скачать и другие, совершенно посторонние люди, в том числе несовершеннолетние. Meta✴ якобы «целенаправленно отбирала» популярные фильмы в день их выхода, после чего они оставались доступными в сети в течение недель и даже месяцев. Также истцы утверждают, что в Meta✴ создали целую сеть из шести виртуальных облаков с анонимными IP-адресами с целью маскировки всей этой деятельности. Часть адресов были связаны с внутренними сетями Meta✴, но как минимум один — с домашним IP-адресом одного из сотрудников. В S3H считают, что всё это может говорить о том, что Meta✴ планирует создать генератор порнографических видеороликов на базе искусственного интеллекта. В иске суд просят запретить компании Цукерберга использовать контент подобного рода и выплатить компенсации правообладателю. В Meta✴ парируют обвинения тем, что нет никаких доказательств того, что она когда-либо выгружала пиратский контент через BitTorrent или одноранговые сети, при этом отмечая, что сейчас юристы компании изучают иск. Иск S3H не является чем-то совершенно новым: на Meta✴ уже подавали в суд за использование пиратских копий книг для обучения ИИ, которые также распространялись через сеть BitTorrent. Обучать ИИ на онлайн-библиотеках законно — так решил суд в деле авторов книг против Meta✴
26.06.2025 [13:52],
Владимир Мироненко
Meta✴ выиграла судебный процесс по иску авторов книг, включая Та-Нехиси Коутса (Ta-Nehisi Coates) и Ричарда Кадри (Richard Kadrey), обвинивших компанию в незаконном использовании контента онлайн-библиотеки — книг, научных статей и комиксов — для обучения своих ИИ-моделей Llama. Суд постановил, что использование онлайн-книг для обучения ИИ-моделей без согласия авторов является «добросовестным использованием». 
Источник изображения: Wesley Tingey/unsplash.com В деле Meta✴ речь шла о так называемой теневой онлайн-библиотеке LibGen, которая размещает большую часть своего контента без разрешения правообладателей. Компания утверждала, что контент библиотеки использовался для разработки преобразующей технологии, что было справедливым независимо от того, как она его получила. Окружной судья из Сан-Франциско Винс Чхабрия (Vince Chhabria) постановил, что использование Meta✴ этих материалов защищено положением закона об авторском праве и добросовестном использовании. Вместе с тем судья отметил, что его решение отражает неспособность авторов книг должным образом изложить свою позицию. «Это решение не означает, что использование компанией Meta✴ материалов, защищённых авторским правом, для обучения своих языковых моделей является законным, — сказал он. — Оно означает лишь то, что истцы привели неверные аргументы и не смогли представить доказательства в поддержку своей правоты». Чхабрия заявил, что «потенциально выигрышным аргументом» в иске к Meta✴ было бы указать на размывание рынка со ссылкой на ущерб, наносимый правообладателям ИИ-продуктами, которые могут «наводнить рынок бесконечным количеством изображений, песен, статей, книг и многого другого». «Люди могут побудить ИИ-модели генерировать эти результаты, используя лишь малую долю времени и креативности, которые потребовались бы в противном случае», — отметил судья. Он также предупредил, что ИИ может «значительно подорвать стимул людей создавать вещи по старинке». Это вторая победа за неделю у компаний в сфере ИИ, после того как в понедельник суд вынес решение в пользу стартапа Anthropic в аналогичном деле. Би-би-си угрожает Perplexity судом из-за нарушения авторских прав при обучении нейросетей
21.06.2025 [22:08],
Владимир Фетисов
Британская корпорация BBC (Би-би-си) пригрозила иском работающей в сфере искусственного интеллекта компании Perplexity. Для телекомпании это первая попытка пресечь деятельность технологических стартапов, использующих огромные запасы контента BBC для обучения нейросетей. 
Источник изображения: appshunter.io / Unsplash На этой неделе BBC направила письмо в адрес главы Perplexity Аравинда Шринивасу (Aravind Srinivas), в котором говорится, что у телекомпании есть доказательства того, что «базовая модель искусственного интеллекта» американского стартапа «была обучена с использованием контента BBC». Там также сказано, что компания может добиться судебного запрета, если базирующаяся в Сан-Франциско Perplexity не прекратит обучать свои алгоритмы на контенте BBC, а также не удалит все копии вещательных материалов компании, которые использовались для разработки ИИ-моделей, и не предоставит «предложение о финансовой компенсации» за нарушение авторских прав. Это первый случай, когда британская телекомпания обращается к разработчику в сфере ИИ. Однако это отражает растущую обеспокоенность по поводу того, что контент телекомпании, большая часть которого находится в свободном доступе, может свободно использоваться для обучения нейросетей. В Perplexity заявили, что требования BBC являются «манипулятивными и оппортунистическими» и что у компании нет «фундаментального понимания технологий, интернета и законодательства об интеллектуальной собственности». «[Эти заявления] также показывают, как далеко BBC готова зайти, чтобы сохранить незаконную монополию Google в своих собственных интересах», — добавили в компании. На самом деле Perplexity не разрабатывает и не обучает базовые языковые модели, но предоставляет интерфейс, через который пользователи могут взаимодействовать с ИИ-моделями других компаний, таких как OpenAI, Google и Anthropic. По данным источника, собственная нейросеть компании создана на базе языковой модели Meta✴ Llama и доработана для повышения точности и уменьшения частоты галлюцинаций, когда нейросети генерируют фейковые данные. BBC в Великобритании финансируется государством. Это означает, что потенциальное подписание лицензионных соглашений с разработчиками в сфере ИИ может стать источником дохода, в то время как самой компании приходится сокращать расходы из-за уменьшения объёмов финансирования. Осведомлённый источник сообщил, что телекомпания провела переговоры с крупными технологическими компаниями, такими как Amazon, о том, чтобы разрешить использовать контент BBC для обучения нейросетей. Perplexity, в число инвесторов которой входит основатель Amazon и владелец Washington Post Джефф Безос (Jeff Bezos), в настоящее время завершает очередной раунд финансирования, в рамках которого стартап оценивается в $14 млрд, что на $5 млрд больше, чем полгода назад. В арсенале Perplexity около 30 млн пользователей, преимущественно в США, а основным источником дохода являются подписки. В письме BBC в адрес Perplexity сказано, что часть контента компании дословно воспроизводится в ИИ-поисковике стартапа, и в поисковой выдаче даже отображаются ссылки на веб-сайт BBC. Речь, в том числе, о контенте, который был опубликован недавно. «Сервис Perplexity напрямую конкурирует с собственными сервисами BBC, избавляя пользователей от необходимости получать доступ к этим сервисам», — сказано в письме BBC. Руководители телекомпании особенно обеспокоены тем, что ИИ-компании злоупотребляют принадлежащим BBC контентом, что, по их словам, может нанести ущерб нейтральной и беспристрастной журналистике. Google давно использует контент YouTube для обучения ИИ и никогда этого не скрывала
20.06.2025 [13:52],
Сергей Сурабекянц
После выхода генератора видео Veo 3 создатели контента неожиданно осознали, что Google использует все двадцать с лишним миллиардов видеороликов YouTube для обучения своих моделей ИИ, так же, как ранее использовала их для улучшения других продуктов. Эксперты считают, что это может привести к кризису интеллектуальной собственности. Представитель YouTube подтвердил информацию, уточнив, что видеосервис «соблюдает определённые соглашения с создателями и медиакомпаниями». 
Источник изображения: unsplash.com «Мы всегда использовали контент YouTube, чтобы улучшить наши продукты, и это не изменилось с появлением ИИ, — заявил представитель YouTube. — Мы также осознаем необходимость в защитных барьерах, поэтому инвестировали в надёжные средства защиты, которые позволяют создателям защищать свой образ и подобие в эпоху ИИ — то, что мы намерены продолжать». Хотя YouTube никогда не скрывал факт использования контента для улучшения своих продуктов и обучения ИИ, авторы видеороликов и медиакомпании, похоже, ранее никогда не задумывались об этом. Опрос нескольких ведущих создателей и специалистов по интеллектуальной собственности показал, что никто из них не знал и не был проинформирован YouTube о том, что контент, размещённый на видеосервисе, может использоваться для обучения моделей ИИ Google. YouTube не раскрывает, какой процент из более чем двадцати миллиардов видео на платформе используются для обучения ИИ. Но, учитывая масштаб платформы, всего 1 % каталога составляет 2,3 миллиарда минут контента, что, по словам экспертов, более чем в 40 раз превышает объем обучающих данных, используемых конкурирующими моделями ИИ. Факт обучения ИИ с использованием видео пользователей YouTube заслуживает особого внимания после выпуска ИИ-видеогенератора Google Veo 3, создающего видеопоследовательности кинематографического уровня. Многие авторы теперь обеспокоены тем, что неосознанно помогают обучать систему, которая в конечном итоге может конкурировать или заменить их. 
Источник изображения: 9to5Google «Мы видим, как все больше создателей обнаруживают поддельные версии самих себя, распространяющиеся на разных платформах. Новые инструменты, такие как Veo 3, только ускорят эту тенденцию», — заявил глава компании Vermillio Дэн Нили (Dan Neely). Vermillio использует инструмент Trace ID собственной разработки, который оценивает степень совпадения видео, сгенерированного ИИ, с контентом, созданным человеком. Нили утверждает, что располагает достаточным количеством примеров близкого соответствия контента, созданного Veo 3, авторским материалам, размещённым на видеосервисе. Далеко не все создатели контента протестуют против использования своего контента для обучения ИИ. «Я стараюсь относиться к этому скорее как к дружескому соревнованию, чем как к противникам, — заявил Сэм Берес (Sam Beres), создатель канала YouTube с 10 миллионами подписчиков. — Я пытаюсь делать вещи позитивно, потому что это неизбежно, но это своего рода захватывающая неизбежность». Загружая видео на платформу, пользователь соглашается с условиями обслуживания YouTube, где, в частности, сказано: «Предоставляя контент сервису, вы предоставляете YouTube всемирную, неисключительную, безвозмездную, сублицензируемую и передаваемую лицензию на использование контента». Также в блоге компании открыто говорится, что контент YouTube может использоваться для «улучшения опыта использования продукта, в том числе с помощью машинного обучения и приложений ИИ». В декабре 2024 года YouTube объявил о партнёрстве с Creative Artists Agency с целью идентификации и управления ИИ-контентом, использующим образ артистов. Также создатели могут потребовать удалить видео, если оно использует их образ. YouTube позволяет создателям отказаться от обучения сторонних компаний, работающих с ИИ, включая Amazon, Apple и Nvidia, но пользователи не могут помешать Google обучать собственные модели. Однако условия использования Google включают пункт о возмещении ущерба — если пользователь сталкивается с нарушением авторских прав, Google возьмёт на себя юридическую ответственность и покроет связанные с этим расходы. ИИ стал экзистенциальной угрозой для интернет-СМИ: посетителей на сайтах вытесняют роботы
20.06.2025 [11:37],
Сергей Сурабекянц
Глава Cloudflare Мэтью Принс (Matthew Prince) в интервью изданию Axios заявил, что издатели сталкиваются с экзистенциальной угрозой со стороны ИИ и должны получать справедливую компенсацию за свой контент. «Люди стали больше доверять ИИ за последние шесть месяцев, что означает, что они не читают оригинальный контент, — сказал он. — Будущее интернета будет всё больше и больше похоже на ИИ, значит люди [и дальше] будут читать резюме вашего контента». 
Источник изображения: Walls.io / unsplash.com Число переходов со страниц поисковых систем на сайты с оригинальным контентом сокращается с каждым днём, поэтому многим издателям придётся пересмотреть свои бизнес-модели или вообще уйти с рынка. Принс привёл впечатляющие статистические данные. По его словам, десять лет назад соотношение проиндексированных поисковиком Google страниц к числу посетителей, перенаправленных со страницы поисковой выдачи на сайт издателя, составляло 2:1. С тех пор это соотношение постепенно увеличивалось, но после начала ИИ-бума стало расти угрожающими темпами. Шесть месяцев назад:
В настоящий момент:
Поисковые системы и чат-боты ИИ предоставляют ссылки на оригинальные источники, но издатели могут получать доход от рекламы только в том случае, если читатели переходят по ссылкам. «Люди не переходят по ссылкам», — констатировал Принс. Он уверен, что эта проблема касается любого создателя оригинального контента. Принс сообщил, что Cloudflare разработала инструмент, который должен «остановить копирование контента». AI Labyrinth использует контент, сгенерированный ИИ, для замедления, запутывания и траты ресурсов ИИ-сканеров и других ботов, которые не соблюдают директивы веб-серверов. Своим клиентам Cloudflare предлагает автоматическое развёртывание такого набора сгенерированных ИИ страниц при обнаружении «ненадлежащей активности» ботов. Суд «заблокировал» кнопку «Удалить» в ChatGPT
06.06.2025 [19:45],
Сергей Сурабекянц
OpenAI сообщила, что вынуждена хранить историю общения пользователей с ChatGPT «бессрочно» из-за постановления суда, вынесенного в рамках иска от издания The New York Times о защите авторских прав. Компания планирует обжаловать это решение, которое считает «чрезмерным вмешательством, отменяющим общепринятые нормы конфиденциальности и ослабляющим безопасность». 
Источник изображения: unsplash.com Издание The New York Times подало в суд на OpenAI и Microsoft за нарушение авторских прав в 2023 году, обвинив компании в «копировании и использовании миллионов» материалов для обучения моделей ИИ. Издание утверждает, что только сохранение данных пользователей до завершения судебного процесса сможет обеспечить предоставление необходимых доказательств в поддержку иска. В ноябре 2024 года стало известно, что инженеры OpenAI якобы случайно удалили данные, которые потенциально могли стать доказательством вины разработчика ИИ-алгоритмов в нарушении авторских прав. Компания признала ошибку и попыталась восстановить данные, но сделать это в полном объёме не удалось. Те же данные, что удалось восстановить, не позволяли определить, что публикации изданий были задействованы при обучении нейросетей. Поэтому в мае 2025 года суд обязал OpenAI сохранять «все выходные данные журнала, которые в противном случае были бы удалены», даже если пользователь запрашивает удаление чата или если законы о конфиденциальности требуют от OpenAI удаления данных. В соответствии с политикой OpenAI, если пользователь стирает чат, через 30 дней он удаляется без возможности восстановления. Теперь компании придётся хранить чаты до тех пор, пока суд не решит иначе. OpenAI сообщила, что постановление суда затронет пользователей бесплатной версии ChatGPT, а также владельцев подписок Pro, Plus и Team. Оно не повлияет на клиентов ChatGPT Enterprise или ChatGPT Edu, а также на компании, заключившие соглашение о нулевом хранении данных. OpenAI заверила, что данные не попадут в общий доступ, а работать с ними сможет «только небольшая проверенная юридическая и безопасная команда OpenAI» исключительно в юридических целях. «Мы считаем, что это был неуместный запрос, который создаёт плохой прецедент. Мы будем бороться с любым требованием, которое ставит под угрозу конфиденциальность наших пользователей; это основной принцип», — отреагировал генеральный директор OpenAI Сэм Альтман (Sam Altman). Ранее OpenAI обвинила The New York Times в «десятках тысяч попыток» получить эти «крайне аномальные результаты», «выявив и воспользовавшись ошибкой», которую сама OpenAI «стремится устранить». NYT якобы организовала эти атаки, чтобы собрать доказательства в поддержку утверждения, что продукты OpenAI ставят под угрозу журналистику, копируя авторские материалы и репортажи и тем самым отбирая аудиторию у создателей контента. The New York Times не одинока в своих претензиях в OpenAI. В мае 2024 года восемь интернет-изданий подали иск к OpenAI и Microsoft за незаконное использование статей для обучения ИИ. Истцы упрекают OpenAI в незаконном копировании миллионов статей, размещённых в изданиях New York Daily News, Chicago Tribune, Orlando Sentinel, Sun Sentinel, The Mercury News, The Denver Post, The Orange County Register и Pioneer Press для обучения своих языковых моделей. Знаменитая антипиратская кампания из 2000-х использовала спираченный шрифт
27.04.2025 [18:44],
Анжелла Марина
Нашумевшая антипиратская кампания 2000-х годов MPAA, запущенная Американской ассоциацией кинокомпаний и проходившая под лозунгом «Вы же не станете угонять машину? Так что и фильм пиратить не стоит», как оказалось сама нарушила авторские права. По данным Ars Technica, в материалах MPAA, предположительно, использовался нелицензионный шрифт, а именно копия оригинального шрифта FF Confidential. 
Шрифт FF Confidential. Источник изображения: fontsinuse.com В роликах, которые крутили перед показом фильмов в кинотеатрах и на DVD с 2004 по 2008 год, зрителей пугали последствиями пиратства. Один из роликов показывал, как девушка скачивает фильм, после чего на экране появлялась надпись, стилизованная под граффити: «You wouldn’t steal a car» (Вы бы не угнали машину). Однако шрифт надписи был идентифицирован как шрифт FF Confidential, созданный известным дизайнером Юстом ван Россумом (Just van Rossum) в 1992 году, о чём сообщил сайт Fonts in Use. Репортёр Мелисса Льюис (Melissa Lewis) из Центра расследовательской журналистики, обратила внимание, что энтузиасты ранее обнаружили очень похожий шрифт с названием XBand Rough. Льюис связалась с Россумом, и тот подтвердил, что XBand Rough является клоном его дизайна. 
Шрифт XBand Rough. Источник изображения: arstechnica.com Позднее некий пользователь под ником Rib проверил PDF-файл с архивного сайта кампании и с помощью программы FontForge выяснил, что в документе действительно использовался XBand Rough. При этом ван Россум в интервью популярному изданию TorrentFreak, освещающему тенденции в области протокола BitTorrent, заявил, что знал о существовании клона, но не подозревал, что MPAA применила его в своей кампании. «Это забавно», — прокомментировал он, но отказался давать дополнительные разъяснения. Пока неясно, насколько широко XBand Rough применялся в материалах MPAA. Возможно, его использовали только в отдельных документах, а не в основном ролике. Однако проверить это сложно — исходные файлы кампании недоступны. Юридические тонкости дела также осложняются различиями в законах об авторском праве. В США дизайн шрифтов (typeface) как таковой не защищён, но файлы шрифтов (font files) могут охраняться, поскольку считаются программным кодом. В Великобритании, где также транслировались антипиратские трейлеры, вопрос защиты авторских прав более сложен, хотя закон об авторских правах обычно защищает шрифты в течение 25 лет после первой публикации. В Германии, где находился головной офис оригинального издателя FontFont, шрифты находятся под защитой в течение первых 10 лет, а затем ещё 15 лет, если правообладатель платит взнос. «Большинство шрифтов очень похожи друг на друга, поэтому доказать их уникальность сложно», — пояснил адвокат из США по интеллектуальной собственности Джеймс Аквилина (James Aquilina). FF Confidential изначально выпустила студия FontFont, которую в 2014 году купила компания Monotype. Сейчас шрифт продаётся с пометкой о регистрации в USPTO (Ведомство по патентам и товарным знакам США). Аквилина отметил, что использование пиратских шрифтов в коммерческих проектах в целом не редкость. «Это происходит из-за популярности определённых шрифтов и желания добиться нужного стиля», — сказал он. Однако судебные иски по этому поводу встречаются нечасто, и правообладатели чаще преследуют распространителей, а не конечных пользователей. Одновременно происхождение XBand Rough, клона FF Confidential, остаётся загадкой. Название шрифта отсылает к игровой платформе XBAND (1994–1997), поэтому предполагается, что шрифт появился около 1996 года. Один из пользователей Bluesky даже выдвинул версию, что XBAND мог легально лицензировать FF Confidential, а затем переименовать его. А дальше XBand Rough просто случайно «утёк» в Сеть. MPA (бывшая MPAA) отказалась комментировать ситуацию, но, как отметили эксперты, законы об интеллектуальной собственности куда сложнее, чем сравнение «воровства фильмов с кражей автомобилей». OpenAI и Google поспорили с правительством Великобритании, что обучение ИИ в интернете «должно быть бесплатным»
06.04.2025 [11:05],
Владимир Мироненко
OpenAI и Google раскритиковали подготовленный правительством Великобритании «предпочтительный вариант» поправок в закон об авторских правах, которые касаются регулирования обучения ИИ-моделей с использованием общедоступного интернет-контента. 
Источник изображения: Steve Johnson/unsplash.com В ходе общественного обсуждения предложений правительства, закончившегося в феврале, было подано около 11 тыс. предложений со стороны компаний и пользователей. OpenAI и Google изложили свою позицию после того, как Комитет по науке, инновациям и технологиям парламента Великобритании направил им запрос по этому поводу, поскольку представители обеих компаний отказались дать свою оценку законопроекту перед парламентариями. Согласно предлагаемым правительством поправкам в закон, компании в сфере ИИ смогут обучать свои модели на общедоступном контенте в коммерческих целях без разрешения правообладателей, если только правообладатели не пожелают «сохранить свои права» и не откажут им в этом. Также поправки предполагают более жёсткие требования к прозрачности в деятельности компаний в сфере ИИ. В своих комментариях OpenAI заявила, что опыт других юрисдикций, включая ЕС, показывает, что закрепление за правообладателями права на отказ предоставления контента влечёт за собой «значительные проблемы внедрения», в то время как введение обязательства по соблюдения прозрачности может привести к исключению рынка из числа приоритетных среди разработчиков. «У Великобритании есть редкая возможность закрепиться в качестве европейской столицы ИИ, сделав выбор, который избежит политической неопределённости, будет способствовать инновациям и будет стимулировать экономический рост», — отметила компания. В свою очередь, Google заявила, что правообладатели уже сейчас могут эффективно осуществлять контроль, чтобы не допустить, чтобы веб-сканеры копировали контент в интернете, но предположила, что те, кто отказывает в предоставлении контента для обучения ИИ, не обязательно будут иметь право на вознаграждение, если он всё же будет замечен в данных для обучения модели. «Мы считаем, что обучение в открытом интернете должно быть бесплатным», — заявила компания, добавив, что «чрезмерные требования к прозрачности... могут помешать развитию ИИ и повлиять на конкурентоспособность Великобритании в этой сфере». Представитель правительства Великобритании сообщил ресурсу Politico, что окончательное решение по этому вопросу пока не принято. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






