|
Опрос
|
реклама
Быстрый переход
«Наши GPU плавятся»: ажиотаж вокруг нового генератора картинок в ChatGPT заставил OpenAI ввести ограничения
27.03.2025 [22:21],
Владимир Мироненко
Представленная на днях функция 4o Image Generation генерации качественных изображений вызвала огромный интерес у пользователей. Ажиотаж даже вынудил OpenAI «временно» ограничить частоту отправки запросов на генерацию изображений, сообщил в соцсети X гендиректор компании Сэм Альтман (Sam Altman). «Очень забавно наблюдать, как людям нравятся изображения в ChatGPT, но наши графические процессоры плавятся», — отметил он в своём сообщении. 
Источник изображения: OpenAI Альтман не уточнил, какой предел скорости был установлен, лишь выразив надежду, что это ограничение не понадобится надолго, поскольку OpenAI пытается повысить эффективность обработки огромного числа запросов. Высочайший спрос уже заставил компанию отсрочить запуск обновлённого генератора изображений на базе GPT-4o для бесплатных пользователей ChatGPT — Альтман ранее пообещал, что бесплатные пользователи «скоро» смогут генерировать с его помощью до трёх изображений в день. Но, по-видимому, этого оказалось недостаточно, чтобы как-то снизить нагрузку на инфраструктуру OpenAI. Улучшенный инструмент генерации изображений использует мультимодальную большую языковую модель GPT-4o. Получающиеся с его помощью изображения выглядят качественно, более реалистично и лучше соответствуют запросам. Также имеются успехи в преодолении прошлых проблем, например, с отображением текста. В интервью ресурсу The Verge представитель компании назвал улучшение генерации как «шаговое изменение» по сравнению с предыдущими моделями. Тем не менее возникшие проблемы служат напоминанием о том, сколько технической мощности и энергии требуется для реализации функции генерации изображений в ChatGPT, отметил The Verge. OpenAI решила попридержать запуск 4o Image Generation для бесплатных пользователей
27.03.2025 [04:24],
Анжелла Марина
Компания OpenAI вынуждена перенести сроки предоставления доступа к встроенному генератору изображений в ChatGPT для пользователей бесплатной версии. Сэм Альтман (Sam Altman) в своём сообщении признал, что новый инструмент 4o Image Generation оказался популярнее, чем ожидалось, поэтому развёртывание для бесплатного использования будет отложено на некоторое время, сообщает The Verge. 
Источник изображения: OpenAI Новый ИИ-генератор изображений был интегрирован в ChatGPT буквально на днях. С его помощью можно создавать картинки непосредственно в приложении, используя новейшую модель рассуждений GPT-4o. Функция так понравилась пользователям, что они уже вовсю стали делиться в социальных сетях изображениями, в частности, стилизованными под работы студии Ghibli, — тренд, к которому присоединился даже сам Альтман. По словам разработчиков, 4o Image Generation отличается улучшенным рендерингом текста и использует для генерации изображений так называемый авторегрессионный подход, когда изображение создаётся последовательно, слева направо и сверху вниз, а не одномоментно целиком, что позволяет создавать картинки без каких-либо ошибок или искажений в тексте, чего раньше добиться в других генераторах не удавалось. В настоящее время доступ к функции имеют только подписчики платных тарифов ChatGPT Plus, Pro и Team. Когда именно пользователи бесплатной версии смогут опробовать новый ИИ-генератор, пока не совсем ясно из-за неожиданно высокого спроса на эту функцию. OpenAI представила функцию генерации точных изображений в ChatGPT на базе GPT-4o — она доступна бесплатно
26.03.2025 [01:03],
Анжелла Марина
OpenAI встроила функцию генерации точных изображений непоcредственно в ChatGPT. Новая функция, именуемая 4o Image Generation, опирается на мультимодальную большую языковую модель GPT-4o. Она понимает контекст, сложные инструкции, взаимодействия объектов и даже генерирует текстовые надписи без артефактов. Доступ для всех откроют сегодня. 
Источник изображений: OpenAI ChatGPT и прежде умел генерировать изображения с помощью нейросети Dall-E 3. Однако обновлённая функция работает куда лучше и точнее. Представитель OpenAI Тайя Кристиансон (Taya Christianson) уточнила, что лимиты для бесплатных пользователей останутся такими же, как у DALL-E, то есть три изображения в день. Доступ к DALL-E по-прежнему возможен через пользовательский интерфейс ChatGPT. Как отметил глава исследований Габриэль Го (Gabriel Goh), использование GPT-4o позволяет ИИ работать с любыми типами данных — текстом, изображениями, аудио и видео. Кроме того, Sora получила ключевое улучшение, заключающееся в корректном соотношении атрибутов и объектов (binding). Го объяснил, что большинство ИИ путаются при обработке 5–8 элементов. Например, ИИ может получить запрос нарисовать синюю звезду и красный треугольник, но создать красную звезду и нечто отличное от треугольника. 4o Image Generation справляется с 15–20 объектами без ошибок.  Пользователи также заметят улучшение в отрисовке текста, что позволяет генерировать на изображениях читаемый текст без опечаток. В существующих инструментах для генерации изображений текст часто искажался и достижение качественного рендеринга в этом смысле было серьёзной проблемой, так как даже небольшие ошибки в заголовках или текстовых элементах могут сделать всё изображение полностью непригодным. 
Генерация по запросу «Cделай очень красочную ризографию о том, как приготовить матча» (make a very colorful risograph on how to make matcha) Система также использует теперь нестандартный метод генерации. Изображения создаются последовательно, слева направо и сверху вниз, а не целиком, как это происходит в DALL-E. По мнению Го, это объясняет превосходство 4o Image Generation в работе с текстом и сложными сценами.  OpenAI продемонстрировала возможности 4o Image Generation на научных диаграммах, например, эксперимент Ньютона с призмой, комиксах и постерах. Также были показаны практические применения в создании изображений с прозрачным фоном для стикеров, меню ресторанов и логотипов. 4o Image Generation со всеми заданиями справилась успешно, не допустив в тексте никаких ошибок. Также 4o Image Generation способен редактировать загруженные пользователем изображения по простым запросам, добавляя на них элементы или наоборот убирая. 
Пример добавление элементов на фотографию с помощью GPT-4o Однако новая система генерирует изображения дольше, чем предыдущие, но OpenAI считает это оправданным компромиссом. «Хотя у нас определённо есть возможности для улучшения времени отклика, качество этих изображений, возможности, знание о мире действительно компенсируют дополнительные секунды ожидания», — сказали в компании.  Отвечая на вопросы о мерах безопасности, упоминая скандальные дипфейки Тейлор Свифт (Taylor Swift), созданные с помощью модели Microsoft, способность Grok от xAI изобразить Камалу Харрис (Kamala Harris) с оружием и удаление водяных знаков в Google Gemini, команда OpenAI подчеркнула наличие надёжных механизмов защиты от злоупотреблений. Директор по дизайну OpenAI Шеннон Джагер (Jackie Shannon) заявила, что инструмент предотвращает удаление водяных знаков, блокирует генерацию дипфейков, связанных с телом человека и отказывает в запросах на создание материалов с различным родом насилия над детьми (CSAM). Кроме того, Шеннон пояснила, что все сгенерированные изображения будут включать стандартные метаданные C2PA, чтобы отметить изображение как созданное OpenAI. Grok научится создавать видео: xAI поглотила разработчика ИИ-генератора видео Hotshot
17.03.2025 [22:57],
Владимир Фетисов
Принадлежащая американскому бизнесмену Илону Маску (Elon Musk) компания xAI стала владельцем стартапа Hotshot, который работает над созданием инструментов на базе искусственного интеллекта, предназначенных для генерации видео. О завершении сделки в своём аккаунте в соцсети X заявил Аакаш Састри (Aakash Sastry), соучредитель и генеральный директор Hotshot. 
Источник изображений: xAI «За последние два года мы небольшой командой создали три модели для генерации видео — Hotshot-XL, Hotshot Act One и Hotshot. Процесс обучения этих моделей помог нам понять, как в ближайшие годы будут меняться глобальные сферы образования, развлечения, общения и производительности. Мы рады продолжить масштабирование усилий в крупнейшем в мире кластере Colossus, как часть xAI», — сказано в сообщении Састри. Компания Hotshot была основана несколько лет назад в Сан-Франциско. Изначально стартап занимался разработкой ИИ-инструментов для генерации и редактирования изображений, но со временем переориентировался на модели искусственного интеллекта, позволяющие генерировать видео на основе текстовых подсказок. Ранее Hotshot удалось привлечь внимание инвесторов, но размер вложенных в стартап средств никогда не озвучивался публично. Переход Hotshot под контроль xAI может помочь стартапу в создании ИИ-моделей для генерации видео, которые станут конкурентами аналогов, таких как Sora от OpenAI или Veo 2 от Google. Ранее Маск намекал, что xAI работает над созданием инструментов генерации видео, которые в будущем планируется интегрировать с чат-ботом Grok. В начале этого года бизнесмен заявлял, что ожидает появление модели «Grok Video через несколько месяцев». AMD представила генератор кадров AFMF 2.1 для более качественного повышения FPS в любой игре
28.02.2025 [19:43],
Сергей Сурабекянц
Одновременно с анонсом видеокарт нового поколения Radeon RX 9070 XT и RX 9070 компания AMD представила и новые драйверы Adrenalin версии 25.3.1. Наряду с целым рядом других функций на основе искусственного интеллекта, новые драйверы включают технологию генерации кадров в играх Fluid Motion Frames 2.1 (AFMF 2.1) для повышения FPS. Это улучшенная версия технологии AMD Fluid Motion Frames 2, которая отличается повышенным качеством генерируемых кадров. 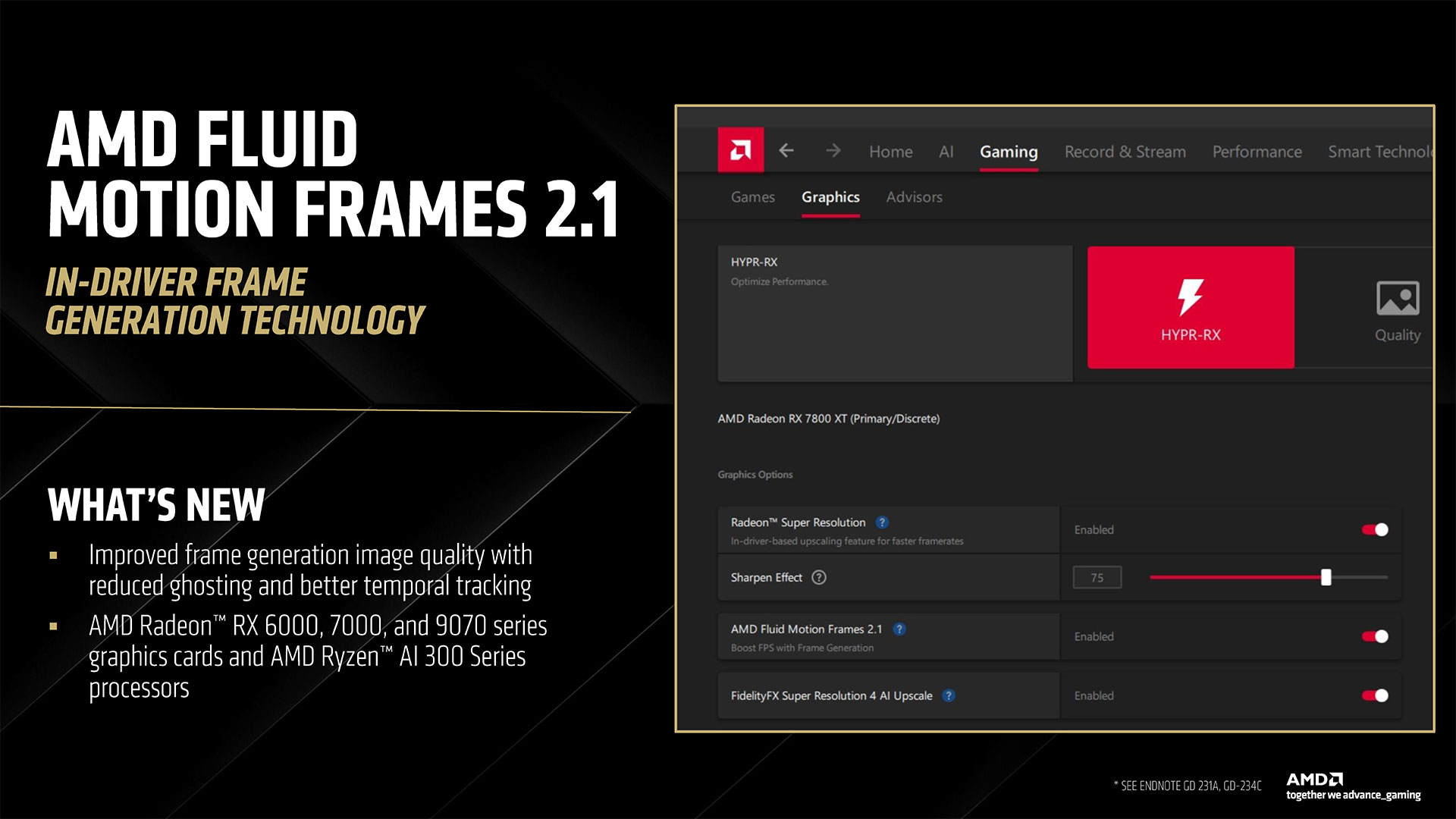
Источник изображений: AMD AMD утверждает, что с помощью технологии AFMF 2.1 удалось улучшить временное отслеживание, что обеспечивает более точно сгенерированные кадры. В отличие от одновременно представленной технологии Radeon Image Sharpening 2, AFMF 2.1 поддерживает не только видеокарты последнего поколения с архитектурой RDNA 4, а работает на всех видеокартах AMD, начиная с архитектуры RDNA 2, то есть на картах серии Radeon RX 6000 и более новых. По утверждению AMD, улучшенная технология Fluid Motion Frames 2.1 оптимизирует наложение текстур и уменьшает количество артефактов, связанных с наложением. Также уменьшаются ореолы вокруг контрастных объектов.  AMD отдельно отметила совместную работу функции AFMF 2.1 и программного стека HYPR-RX, который объединяет множество функций повышения производительности в играх. Компания представила результаты сравнительных тестов игр в нативном разрешении 4K с играми в разрешении 4K с включённым режимом качества FSR 2 и активированной функцией AFMF 2.1. Судя по графикам, частота кадров возрастает более чем в 2 раза. 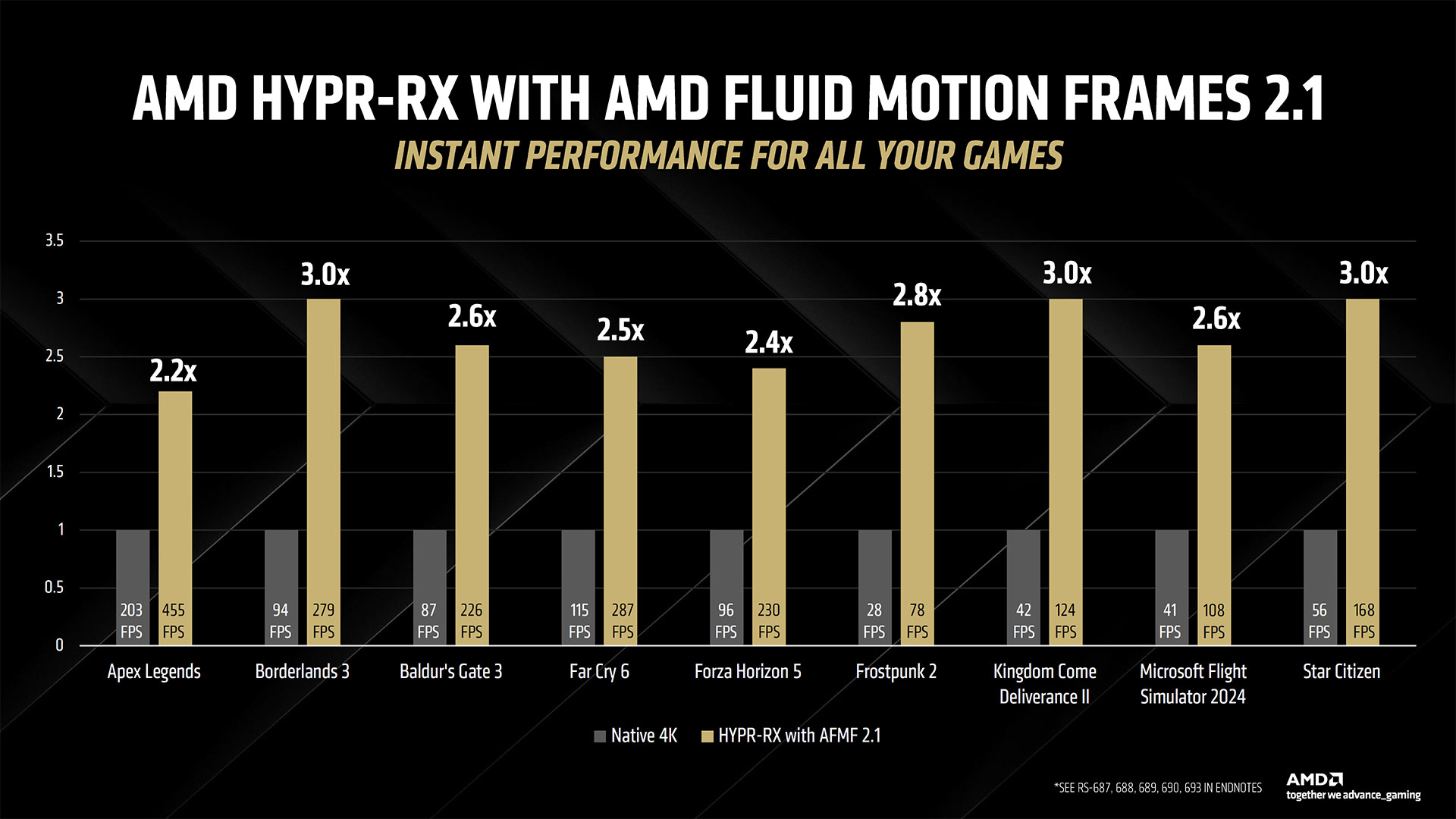 С помощью AFMF 2.1 AMD улучшила качество изображения своей технологии Frame Generation на уровне драйвера. В играх, не имеющих встроенной поддержки генерации кадров, технология Fluid Motion Frames 2.1 обеспечивает, по утверждению AMD, «повышенную игровую плавность». Alibaba снова ударила по OpenAI — вышел бесплатный ИИ-генератор реалистичных видео Wan 2.1
26.02.2025 [13:25],
Павел Котов
Китайский гигант в области электронной коммерции Alibaba сделал общедоступной разработанную им модель искусственного интеллекта для создания видео и статических изображений Wan 2.1. Этим шагом компания создала условия для её массового развёртывания и способствовала усилению конкуренции в области ИИ. 
Источник изображения: Alibaba Публикация ИИ-моделей с открытым исходным кодом — распространённый шаг в отрасли ИИ; одним из наиболее заметных игроков здесь стал стартап DeepSeek. Alibaba выпустила четыре варианта Wan 2.1: T2V-1.3B, T2V-14B, I2V-14B-720P и I2V-14B-480P — эти модели генерируют видео и статические картинки по текстовому запросу или по образцу, которым может служить изображение. Обозначения «1.3B» и «14B» указывают, что эти варианты содержат соответственно 1,3 млрд и 14 млрд параметров. Младшей модели T2V-1.3B для работы требуется всего 8,19 Гбайт видеопамяти, что делает её совместимой со многими потребительскими видеокартами. Разработчики заявляют, что эта модель может сгенерировать пятисекундный ролик в 480р на GeForce RTX 4090 примерно за 4 минуты (без оптимизаций). Модели доступны для пользователей по всему миру на платформах HuggingFace и ModelScope (входит в Alibaba Cloud) для академических, исследовательских и коммерческих целей. Последнюю версию модели ИИ для генерации видео Alibaba представила в январе — первоначально она называлась Wanx, впоследствии её переименовали в Wan. Проект получил высокую оценку в тестах Vbench, предназначенных для генераторов видео — в частности, она стала лидером по критерию взаимодействия объектов. Накануне Alibaba также выпустила предварительный вариант рассуждающей модели QwQ-Max, которая впоследствии также будет опубликована как проект с открытым кодом. В ближайшие три года компания намеревается вложить не менее 380 млрд юаней ($52 млрд) в поддержку облачных вычислений и инфраструктуры ИИ. AMD скоро выпустит улучшенный генератор кадров AFMF 2.1 для повышения FPS в любой игре
25.02.2025 [10:32],
Николай Хижняк
Компания AMD готовит к выпуску новую версию своей технологии генерации дополнительных кадров в играх — AMD Fluid Motion Frames (AFMF) 2.1. Она является частью технологического стека AMD HYPR-RX, входящего в состав драйвера Radeon и предназначенного для повышения производительности в играх путём одновременного включения функций масштабирования изображения и генерации кадров. 
Источник изображения: VideoCardz Технология AMD Fluid Motion Frames не требует интеграции в игры, так как работает на уровне драйвера. Пользователи могут самостоятельно выбирать, для какой именно игры использовать AFMF. Недостатком технологии является масштабирование и использование чересстрочной развёртки на весь кадр, включая элементы игрового меню и пользовательского интерфейса, что может снижать качество их отображения. AMD Fluid Motion Frames набирает популярность среди пользователей, которые находят её особенно полезной для старых игр, где не планируется внедрение других технологий для повышения FPS. В октябре прошлого года AMD выпустила AFMF 2.0, добавив в неё поддержку игр с OpenGL и Vulkan, чего не было в предыдущей версии. В AFMF 2.0 также появились профили производительности и внутриигровой задержки, улучшена работа в оконном безрамочном режиме, а также оптимизировано функционирование технологии в динамичных игровых сценах. С выпуском видеокарт GeForce RTX 50-й серии компания Nvidia представила технологию Smooth Motion, выполняющую аналогичную функцию AFMF, но работающую только на видеокартах GeForce. Обе технологии функционируют на уровне драйвера и не совместимы с видеокартами другого производителя. «AMD ведёт разработку AFMF 2.1, выпуск которой ожидается с выходом видеокарт серии Radeon RX 9070 в рамках обновления технологического стека HYPR-RX. Компания подтвердила прессе, что AFMF 2.1 улучшит качество генерируемых кадров», — пишет VideoCardz. Согласно доступной информации, AFMF 2.1 не использует тензорные или ИИ-ядра для работы и будет поддерживаться тем же оборудованием, что и AFMF 2.0. Поддержка программного генератора кадров Nvidia Smooth Motion появится у видеокарт GeForce RTX 40-й серии
02.02.2025 [01:31],
Николай Хижняк
С выпуском видеокарт GeForce RTX 50-й серии компания Nvidia также выпустила новую технологию Smooth Motion. Она представляет собой аналог технологии AMD Fluid Motion Frames — генератора кадров, реализованного на программного уровне. Технология создаёт один дополнительный кадр между двумя кадрами, отрисованными видеокартой, повышая тем самым плавность игрового процесса. 
Источник изображения: VideoCardz Технология Smooth Motion генерирует и масштабирует весь кадр целиком, что означает, что такие элементы, как игровой пользовательский интерфейс, текстовые подсказки или карта местности, также будут сгенерированы. Некоторые игровые элементы могут выглядеть не очень хорошо, поскольку при их генерации, в отличие от технологий DLSS Frame Generation (FG) или DLSS Multi Frame Generation (MFG), Smooth Motion не задействует векторы движения. Nvidia Smooth Motion обеспечивает качество изображения и задержку хуже, чем DLSS Frame Generation. Но, с другой стороны, геймерам не нужно ждать, пока разработчики игр интегрируют поддержку данной технологии, поскольку Nvidia Smooth Motion работает на уровне драйвера, а значит поддерживается всеми современными играми. 
Источник изображения: Nvidia Технология Nvidia Smooth Motion стала частью последней версии графического драйвера Nvidia Game Ready, а также приложения Nvidia App. Она официально поддерживается только видеокартами GeForce RTX 50-й серии, однако это лишь временная эксклюзивность. Согласно сообщению Nvidia, поддержка Smooth Motion в перспективе появится и на видеокартах GeForce RTX 40-й серии. «Nvidia Smooth Motion является новой технологией, работающей на уровне драйвера, поэтому требует времени для проверок и валидаций на уровне множества аппаратных продуктов. Поддержка технологии видеокартами GeForce RTX 40-й серии появится в рамках будущих обновлений», — говорит маркетинговый отдел Nvidia. Геймеры смогут включить Smooth Motion в настройках драйвера или в игровых профилях. «Да, качество изображения и задержка ввода могут быть не такими хорошими, как у FG или MFG, но есть множество сценариев, где она [технология Smooth Motion] будет отлично работать», — добавляет евангелист GeForce Джейкоб Фримен (Jacob Freeman) на своей странице в соцсети X. Примечательно, что Nvidia официально не анонсировала Smooth Motion для видеокарт RTX 50-й серии. Компания просто добавила её в последнюю версию драйвера GeForce Game Ready. Геймерам также следует знать, что технология работает исключительно с играми, основанными на DirectX 11 и DirectX 12. Nvidia научит старые видеокарты GeForce повышать FPS с помощью ИИ, но потом
20.01.2025 [17:56],
Николай Хижняк
В интервью Digital Foundry Брайан Катандзаро (Bryan Catanzaro), вице-президент по исследованиям в области прикладного глубокого обучения в Nvidia сообщил, что не исключает возможности в будущем внедрения функции генерации кадров силами ИИ для повышения FPS, ставшей частью технологии DLSS, в старые видеокарты Nvidia GeForce. 
Источник изображений: Digital Foundry / Nvidia С момента своего дебюта в 2018 году технология масштабирования с глубоким обучением (DLSS) от Nvidia эволюционировала уже до четвёртой версии. Её последняя итерация перешла на ИИ-модель типа трансформер, что позволило реализовать ряд новых функций, включая мультикадровую генерацию (Multi Frame Generation, MFG). Последняя позволяет создавать до трёх дополнительных кадров на каждый традиционно отрисованный кадр для повышения FPS.  Nvidia смогла реализовать некоторые новые технологии, включая реконструкцию лучей (DLSS Ray Reconstruction), супер-разрешение (Super Resolution) и технологию сглаживания, опирающуюся на искусственный интеллект (Deep Learning Anti-Aliasing, DLAA) на всех видеокартах GeForce RTX, начиная с 20-й серии. Однако генератор кадров (Frame Generation) первого поколения, изначально представленный как эксклюзивная функция видеокарт GeForce RTX 40-й серии, не поддерживается моделями GeForce RTX 30-й и RTX 20-й серий. Новый мультикадровый генератор так и вовсе изначально заявлен только для новейших GeForce RTX 5000. В разговоре с журналистами Брайан Катандзаро отметил, что не исключает появления функции генерации кадров у старых моделей видеокарт Nvidia. «Я думаю, что ключевым здесь является вопрос проектирования и оптимизации, а также конечного пользовательского опыта. Мы запускаем этот генератор кадров, лучший генератор кадров, коим является технология Multi Frame Generation, с видеокартами 50-й серии. А в будущем посмотрим, сможем ли что-то выжать для старого поколения оборудования», — прокомментировал представитель Nvidia.  На фоне заявления Катандзаро можно предположить, что первая версия генератора кадров может в перспективе появиться на видеокартах GeForce RTX 30-й серии. Однако маловероятно, что она появится у моделей GeForce RTX 20-й серии. При этом, скорее всего, мультикадровый генератор кадров останется эксклюзивом видеокарт RTX 50-й серии, поскольку для его работы требуется значительно больше вычислительной мощности, заточенной под ИИ, которую у этих карт обеспечивают новые тензорные ядра. Один из ведущих разработчиков Nvidia также поделился некоторой информацией о разработке DLSS. «Когда мы создавали Nvidia DLSS 3 Frame Generation, нам было абсолютно необходимо аппаратное ускорение для вычислений Optical Flow. Но у нас не было достаточного количества тензорных ядер и не было достаточно хорошего алгоритма Optical Flow. Мы не создавали алгоритм Optical Flow для работы в реальном времени на тензорных ядрах, который мог бы вписаться в наш запас вычислительной мощности. У нас был аппаратный ускоритель Optical Flow, который Nvidia создавала годами как эволюцию нашей технологии видеокодирования. Он также был частью нашей технологии ускорения работы компьютерного зрения для беспилотных автомобилей. Казалось бы, для нас имело смысл использовать его и для Nvidia DLSS 3 Frame Generation. Но сложность в любой аппаратной реализации алгоритма типа Optical Flow заключается в том, что его действительно трудно улучшить. Он такой, какой он есть, и те сбои, которые возникли из-за этого аппаратного Optical Flow, мы не могли исправить с помощью более умной нейронной сети, пока не решили просто заменить его и перейти на решение, полностью основанное на ИИ. Именно это мы и сделали для Frame Generation в DLSS 4». Nvidia рассказала, насколько карты GeForce RTX 5000 на самом деле быстрее RTX 4000
15.01.2025 [19:08],
Николай Хижняк
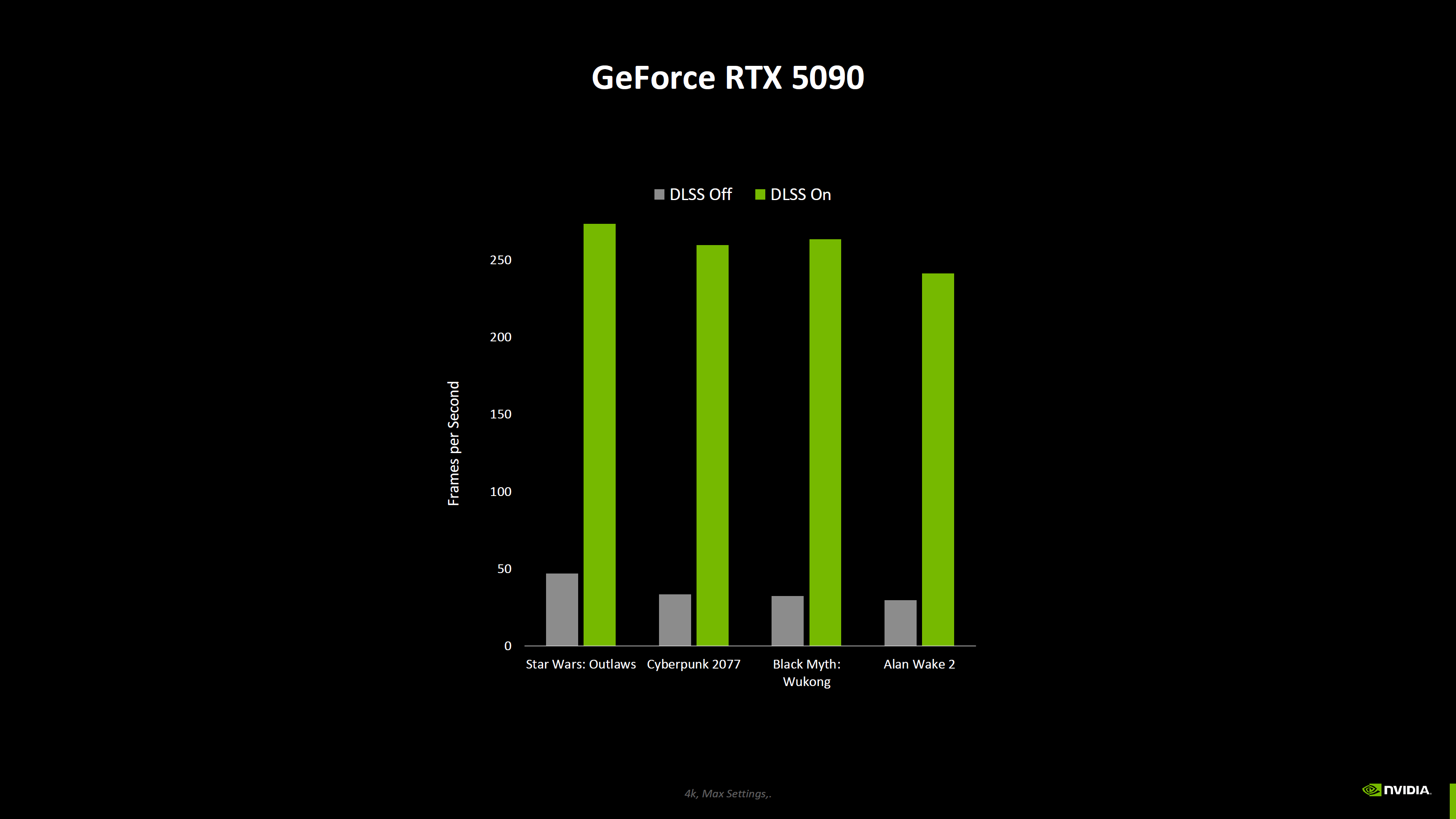
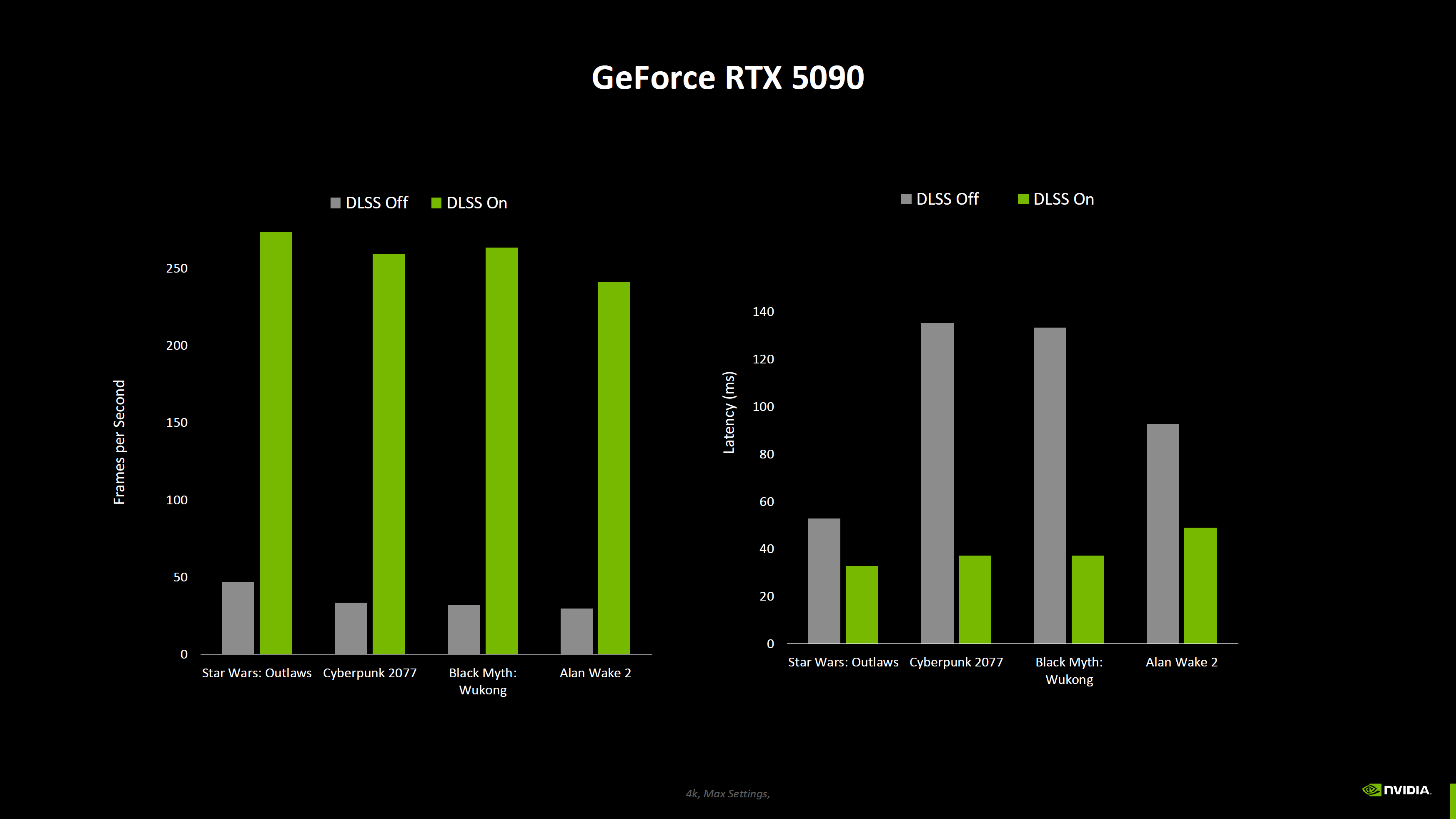
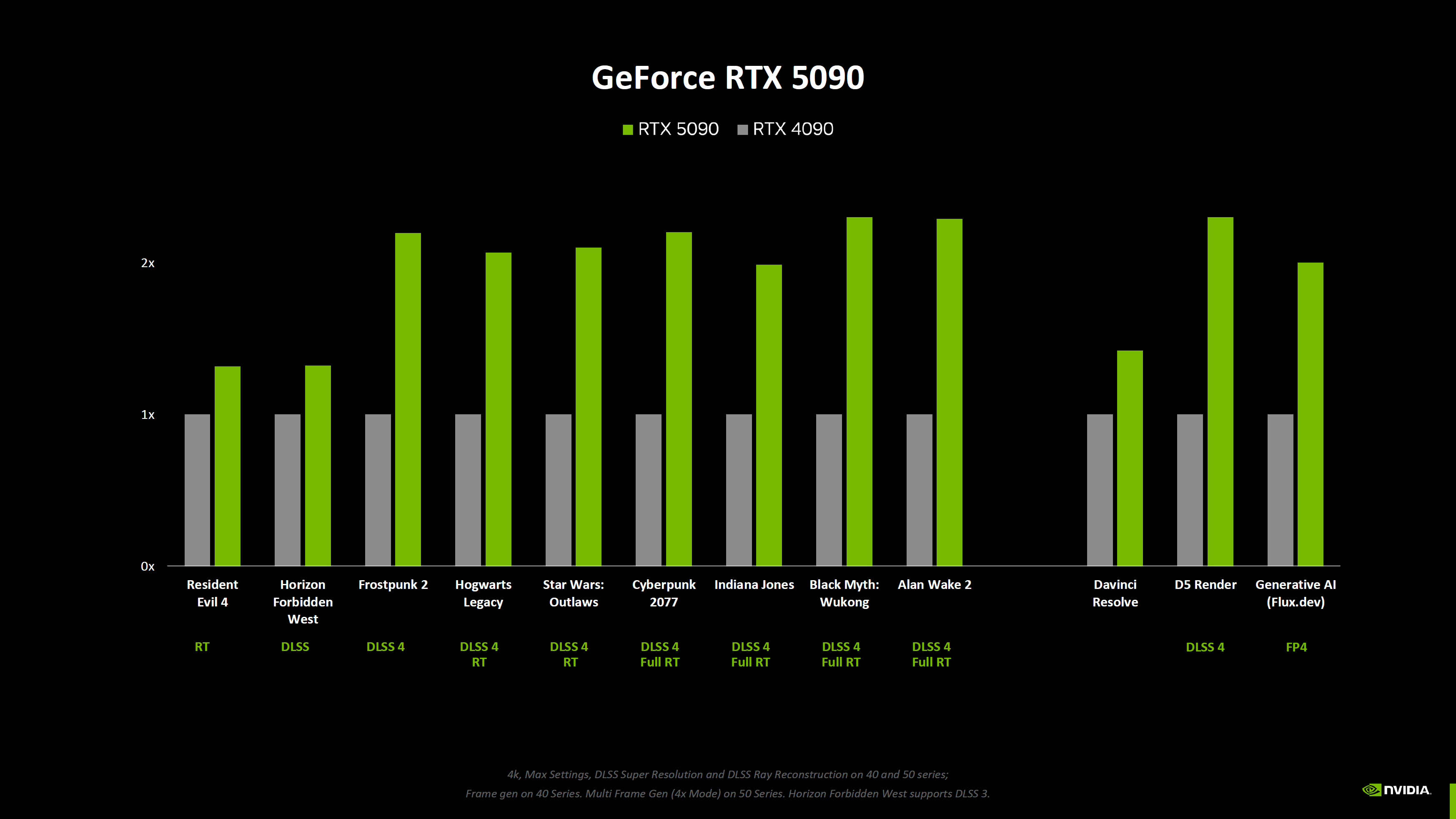
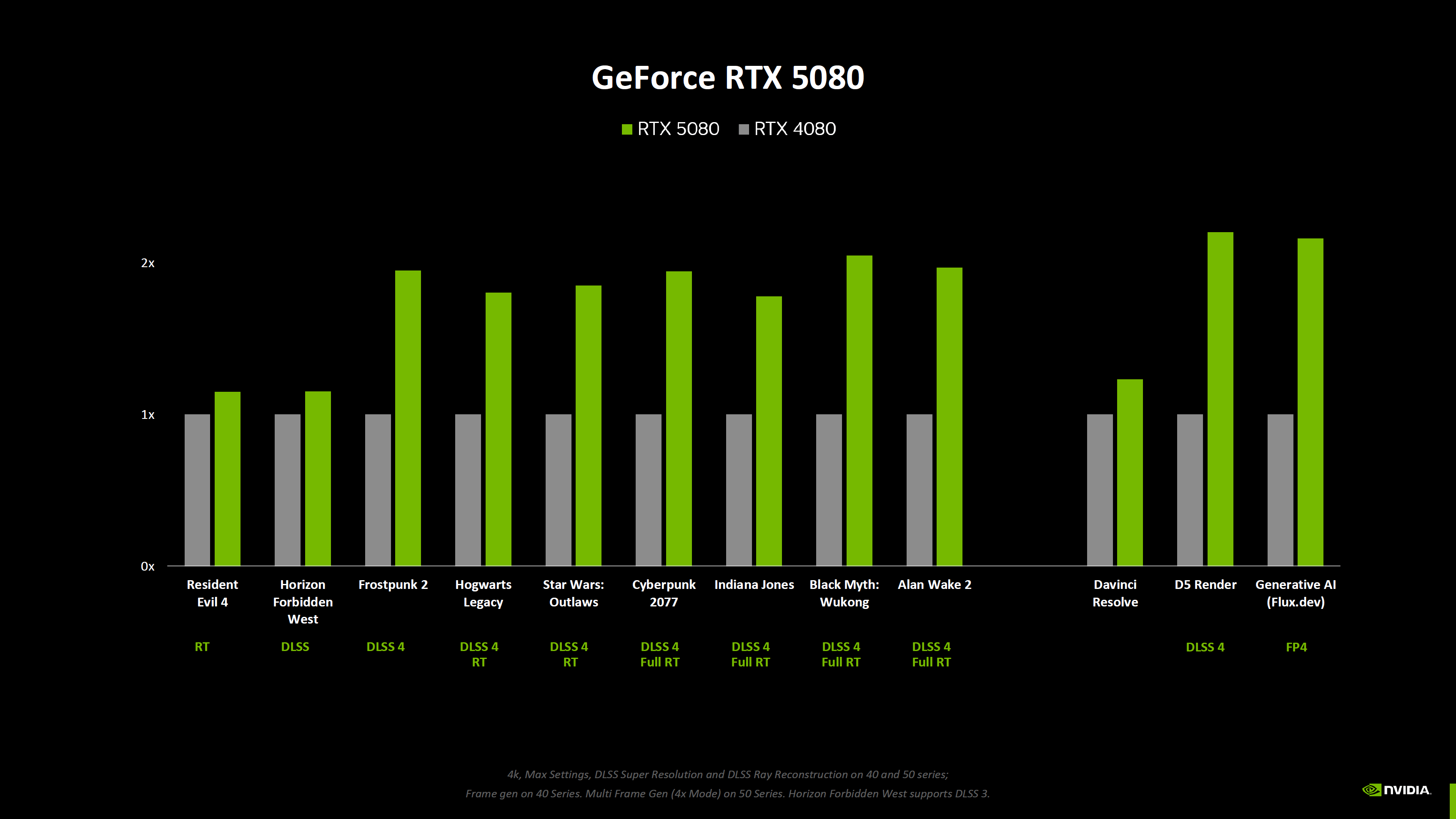
Nvidia опубликовала новые данные о производительности видеокарт GeForce RTX 50-й серии, включая результаты бенчмарков без использования технологии масштабирования DLSS 4, которая обеспечивает значительный прирост производительности по сравнению с видеокартами RTX предыдущего поколения. 
Источник изображений: Nvidia Nvidia поделилась информацией о производительности видеокарт GeForce RTX 5090, RTX 5080, RTX 5070 Ti и RTX 5070 в двух новых играх — Resident Evil 4 и Horizon Forbidden West. Первую компания тестировала только с трассировкой лучей (RT) и без использования технологии масштабирования DLSS. Во второй использовалась технология масштабирования DLSS, но не последняя версия DLSS 4 со встроенным мультикадровым генератором (Multi Frame Generation, MLG).
Портал ComputerBase скомпилировал результаты, демонстрирующие улучшение производительности в зависимости от увеличения числа шейдерных ядер для каждого класса графических процессоров. 
Источник изображения: VideoCardz по данным ComputerBase Согласно этим данным, GeForce RTX 5090 демонстрирует 33-процентный прирост производительности по сравнению с RTX 4090 в указанных играх (Resident Evil 4 и Horizon Forbidden West). Модель RTX 5080, в свою очередь, на 15 % быстрее, а RTX 5070 Ti и RTX 5070 — примерно на 20 % быстрее своих предшественников поколения Ada Lovelace. Новые графики Nvidia включают и другие игры, но эти результаты не подходят для сравнения, поскольку для новых карт компания использовала настройки с включённым мультикадровым генератором, а модели GeForce RTX 40-й серии его не поддерживают, что делает сравнение некорректным. 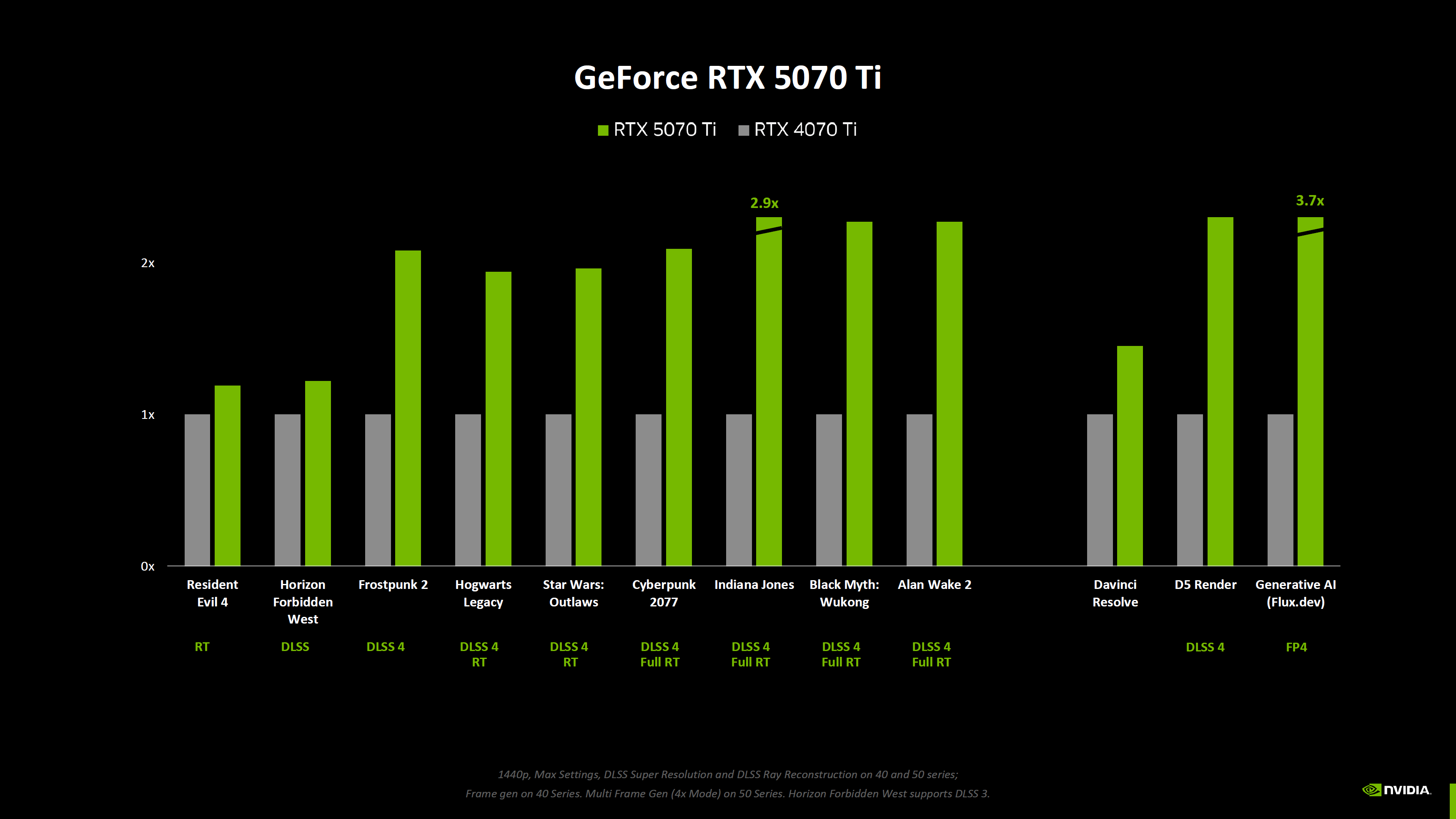
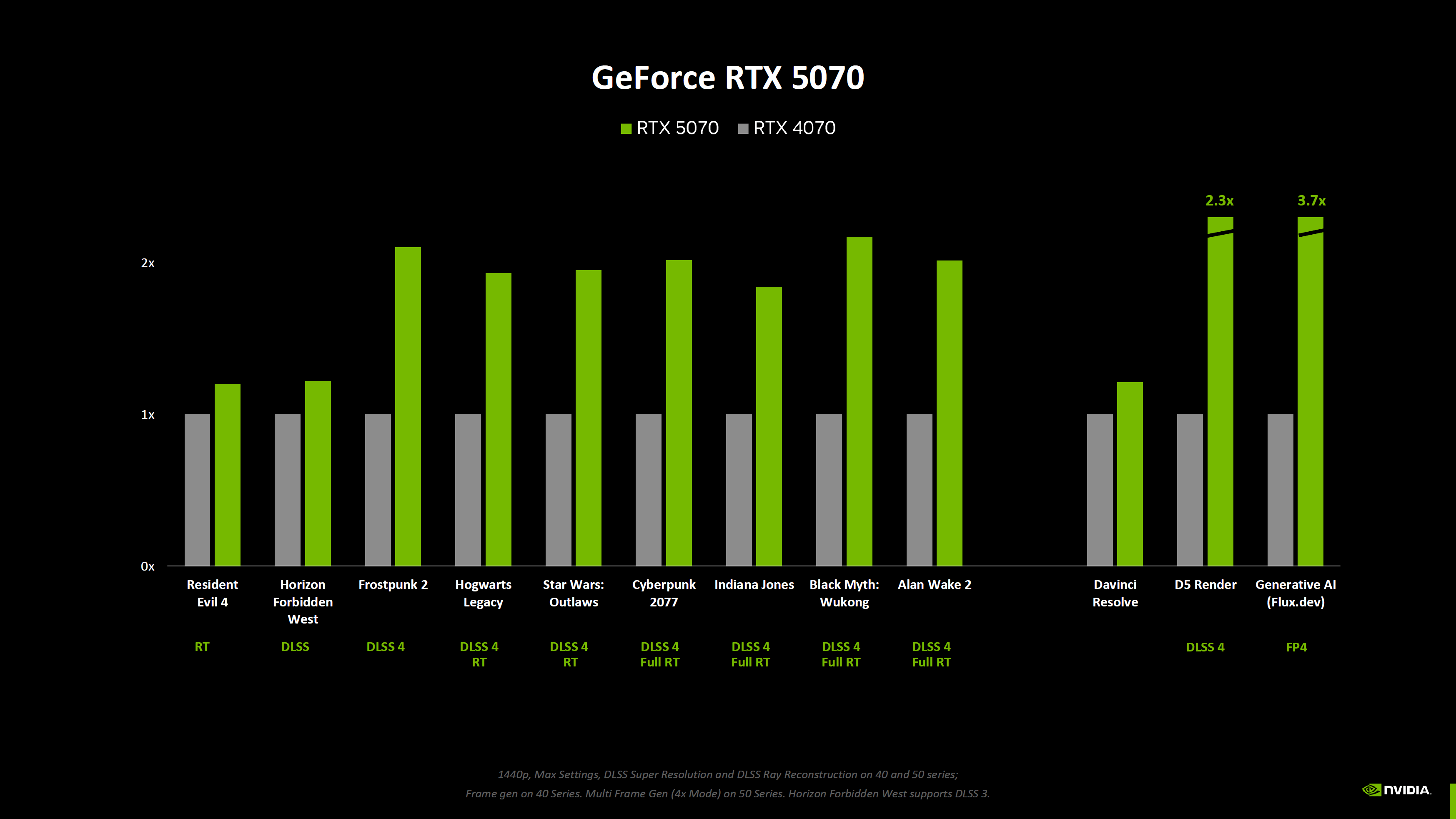 Результаты чистой растровой производительности новых видеокарт, скорее всего, станут известны после публикации первых независимых обзоров, которые ожидаются 24 января. Microsoft вернула старый ИИ-генератор картинок Bing Image Creator, потому что новый работал хуже
09.01.2025 [15:18],
Владимир Фетисов
Компания Microsoft решила откатить обновление ИИ-генератора изображений Bing Image Creator. Это произошло после того, как в течение нескольких недель пользователи сервиса активно жаловались на снижение качества его работы, которое возникло после обновления большой языковой модели DALL-E 3 18 декабря. Microsoft отказалась от комментариев по поводу причин решения откатить обновление. 
Источник изображения: Microsoft Сегодня корпоративный вице-президент Microsoft по поиску и искусственному интеллекту Жорди Рибас (Jordi Ribas) опубликовал пост в соцсети X, в котором сообщил, что разработчикам удалось воспроизвести «некоторые из обнаруженных проблем». Он также добавил, что было принято решение вернуться к использованию более старой версии модели DALL-E. В декабре Рибас сообщил о развёртывании обновления для модели DALL-E, которая является основой генератора изображений Bing Image Creator. Почти сразу после этого в интернете появились жалобы от пользователей сервиса, которые писали, что ИИ-генератор стал менее точно следовать текстовым подсказкам при создании изображений. На тот момент Рибас заявил, что качество работы обновлённого продукта «в среднем должно быть немного лучше», чем раньше. Жалобы пользователей стали появляться не только на форумах поддержки Microsoft, но и на других платформах, включая Reddit и форум OpenAI. Очевидно, что в конечном счёте Microsoft пришлось признать наличие проблемы и откатить обновление, чтобы вернуть Bing Image Creator к прежнему состоянию. Когда софтверный гигант может снова обновить языковую модель DALL-E, пока неизвестно. Google представила генератор картинок для тех, кто не любит писать — Whisk
17.12.2024 [12:54],
Павел Котов
Google анонсировала Whisk — основанный на искусственном интеллекте инструмент, который позволяет генерировать картинки, используя в качестве запроса другие изображения вместо длинных текстовых формулировок. 
Источник изображения: blog.google Работая с Whisk, можно загружать изображения, используя образцы картинок в качестве основной темы, сцены или стиля. При желании можно дополнить их текстовыми подсказками; а если нужных картинок не окажется под рукой, система предложит свои — вероятно, также сгенерированные ИИ. Получив результат, можно добавить его в избранное или скачать; либо улучшить его, дополнив или отредактировав текстовый запрос. Whisk предназначается для «быстрого создания визуального эскиза, а не дотошного редактирования с точностью до пикселя»; он может «промахнуться», признают в Google, поэтому позволяет редактировать исходные подсказки. В основу сервиса лёг последний вариант генератора изображений Imagen 3, который подразделение Google DeepMind анонсировало вместе с генератором видео Veo 2 — мощный конкурент OpenAI Sora пока доступен лишь ограниченному кругу пользователей экспериментальной платформы VideoFX. «Сбер» представил собственный ИИ-генератор видео по текстовому описанию Kandinsky 4.0 Video
12.12.2024 [23:02],
Владимир Фетисов
На проходящей на этой неделе конференции AI Journey «Сбер» представил бета-версию нейросети Kandinsky 4.0 Video, которая позволяет генерировать реалистичные видео на основе текстового описания или стартового кадра. Алгоритм может быть полезен не только обычным пользователям, но также дизайнерам, маркетологам и мультипликаторам, так как с его помощью можно создавать различные видео: от анимированных роликов с поздравлениями для близких до трейлеров и клипов. 
Источник изображения: fusionbrain.ai В компании отметили, что с момента релиза первой версии Kandinsky Video в прошлом году разработчики значительно улучшили многие характеристики алгоритма, включая качество создаваемых роликов и скорость генерации. Обновлённая нейросеть способна создавать ролики продолжительностью до 12 секунд с разрешением 1280 × 720 пикселей на основе текстового описания или изображения. Также поддерживается создание роликов с различным соотношением сторон. Улучшилось визуальное качество: повысились контрастность и чёткость кадров, композиция стала более выверенной, а движения объектов в кадре — реалистичными. В дополнение к этому разработчики анонсировали ускоренную версию нейросети — Kandinsky 4.0 Video Flash, которая способна генерировать ролики продолжительностью до 12 секунд с разрешением 720 × 480 пикселей всего за 15 секунд. На начальном этапе доступ к новой версии Kandinsky Video получат представители креативных индустрий, включая художников, дизайнеров и кинематографистов через портал fusionbrain.ai. Для обычных пользователей алгоритм станет доступен в первом квартале следующего года. OpenAI запустила ИИ-генератор видео по текстовым запросам Sora — он косячит так же, как и другие
10.12.2024 [01:30],
Андрей Созинов
Компания OpenAI в понедельник запустила Sora — свою революционную модель искусственного интеллекта для генерации видео по текстовым описаниям. С сегодняшнего дня новая модель стала доступна на сайте Sora.com для платных пользователей ChatGPT в США и «большинстве других стран». России в списке нет, как и стран ЕС.  Представленная сегодня версия под названием Sora Turbo может генерировать ролики длиной от 5 до 20 секунд в различных соотношениях сторон и разрешениях от 480p до 1080p. Каждая генерация обойдётся пользователю в определённое количество так называемых «кредитов». Например, видео в 480p стоит от 20 до 150 кредитов, ролик в 720p — от 30 до 540 кредитов, а видео в 1080p — от 100 до 2000 кредитов. Что именно влияет на цену, пока не уточняется. OpenAI сообщила, что подписчики базового тарифного плана ChatGPT Plus ($20 в месяц) получат 1000 кредитов в месяц. Это позволит сгенерировать до 50 «приоритетных видео» (то есть видео, которые генерируются быстро) в формате 720p и длительностью 5 секунд. В свою очередь, пользователи нового тарифа ChatGPT Pro за $200 в месяц получат 10 000 кредитов, которые смогут потратить на 500 приоритетных видео в формате 1080p и длительностью 20 секунд. Кроме того, более обеспеченные пользователи получат неограниченное количество низкоприоритетных генераций видео. Также пользователи с подпиской Pro смогут выполнять до пяти генераций одновременно и скачивать ролики без водяных знаков. OpenAI отмечает, что видео, созданные с помощью Sora, по умолчанию будут иметь видимые водяные знаки и метаданные C2PA, указывающие на их создание с помощью ИИ. Sora может создавать несколько вариантов видеоклипов на основе текстовой подсказки или изображения, а также редактировать существующие видео с помощью инструмента Re-mix. Интерфейс Storyboard позволяет пользователям создавать видео на основе последовательности подсказок, инструмент Blend объединяет два видео, сохраняя элементы обоих, а опции Loop и Re-cut дают возможность авторам дополнительно настраивать и редактировать свои видео и сцены. По словам видеоблогера Маркуса Браунли (Marcus Brownlee), известного как MKBHD, который получил доступ к предварительной версии Sora, система работает далеко не идеально. На создание среднего видеоролика в формате 1080p у него уходило «пара минут». Эта модель страдает от тех же недостатков, что и другие генераторы видео: ей не хватает постоянства объектов. В видеороликах Sora объекты перемещаются нелогично, исчезают и появляются вновь без видимой причины. Ноги — ещё один серьёзный источник проблем, отмечает Браунли. Если человек или животное с ногами долго ходит в ролике, Sora путает передние и задние ноги, а сами ноги могут «меняться местами». Также сообщается, что в Sora встроен ряд защитных механизмов, запрещающих генерировать видео с изображением людей младше 18 лет, содержащие насилие, «откровенные темы» или нарушающие авторские права третьих лиц. По словам Браунли, Sora также не создаёт видео на основе изображений с общественными деятелями, узнаваемыми персонажами или логотипами. Компания предупреждает, что «неправомерное использование загружаемых медиафайлов» может привести к запрету или приостановке работы аккаунта. По мнению блогера, новинка может быть полезна для генерации таких вещей, как заставки в определенном стиле, анимации, абстракции и стоп-кадры. Но он не стал бы рекомендовать её для создания фотореалистичных роликов. OpenAI подчёркивает, что это «ранняя версия Sora», в которой «будут ошибки». «Она не идеальна, но уже на том этапе, когда мы думаем, что она будет действительно полезна для дополнения человеческого творчества, — заявил Уилл Пиблз (Will Peebles), член технического персонала OpenAI и руководитель исследования Sora. — Мы не можем дождаться, когда увидим, что мир создаст с помощью Sora». Если у вас нет подписки на ChatGPT, вы всё равно сможете просматривать ленту видеороликов, созданных искусственным интеллектом другими пользователями с помощью Sora. В то время как модель станет доступна в США и многих других странах уже сегодня, генеральный директор OpenAI Сэм Альтман (Sam Altman) отметил, что запуск в «большинстве стран Европы и Великобритании» может «занять некоторое время». Чат-бот Grok от xAI Илона Маска обзавёлся генератором фотореалистичных изображений
08.12.2024 [06:24],
Алексей Разин
Концентрация нескольких динамично развивающихся компаний в руках Илона Маска (Elon Musk) приводит к их взаимной интеграции, а чат-бот Grok уже давно доступен подписчикам социальной сети X, а вчера он добрался и до бесплатных пользователей. Функциональность первого недавно дополнилась новым генератором изображений Aurora, который способен создавать фотореалистичные изображения, пусть и не лишённые недостатков. 
Источник изображения: X, EnsoMatt Бета-версия генератора изображений Aurora, как отмечает TechCrunch, стала доступна пользователям социальной сети X на вкладке Grok вчера. Доступ к этим возможностям не требует подписки, но имеет ограничения в бесплатном варианте. В частности, без подписки нельзя направить чат-боту Grok более 10 запросов за два часа, а количество генерируемых Aurora изображений ограничено тремя штуками в день. Кстати, некоторые пользователи X уже успели обнаружить, что лишены доступа к Aurora. Официально этот генератор изображений находится в бета-версии. Это уже второй генератор изображений для Grok компании xAI. Если в случае с первым, Flux, стартап Илона Маска сотрудничал с другими разработчиками, то история происхождения второго, Aurora, пока не раскрывается. По крайней мере, представители xAI только успели заявить, что принимали участие в настройке данной системы. Пользователи социальной сети X начали выкладывать образцы сгенерированных Aurora изображений, на одном из них можно лицезреть Адама Сэндлера (Adam Sandler) и его партнёра по сериалу Рэя Романо (Ray Romano), и если лица актёров на сгенерированных изображениях оказались похожими на настоящие, то с пальцами рук у генератора изображений возникли традиционные проблемы. Как отмечается, пейзажи и натюрморты у Aurora получаются гораздо лучше, но и там не обходится без дефектов. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex