|
Опрос
|
реклама
Быстрый переход
OpenAI представила Sora 2 — ИИ-генератор видео с реалистичной физикой и логикой, а также возможностью встроить в ролик самого себя
30.09.2025 [21:35],
Андрей Созинов
OpenAI анонсировала Sora 2 — флагманскую ИИ-модель для генерации видео и аудио, которую в компании позиционируют как огромный качественный скачок по сравнению с оригинальной Sora и сравнивают с GPT-3.5, ставшей революционной для генерации текста. Разработчики отмечают, что новая модель приближает ИИ-симуляцию мира к уровню, когда искусственный интеллект начинает «понимать» физику и динамику объектов почти так же, как человек. 
Источник изображения: OpenAI Если ранние модели для генерации видео часто создавали правдоподобную «картинку», но не справлялись с элементарной логикой движений — например, могли «телепортировать» баскетбольный мяч в корзину при промахе, то Sora 2 моделирует именно поведение объектов. Промах — значит, мяч отскочит от щита. Фигурист, делающий тройной аксель, может ошибиться и упасть. Система научилась имитировать не только успех, но и провал — ключевое требование для создания реальных симуляторов мира и продвинутых роботов. Разработчики обещают, что теперь не будет странных деформаций объектов и нарушений логики сцены в угоду соблюдению промпта. Контролируемость — ещё один акцент, отмечаемый OpenAI. Модель Sora 2 уверенно справляется со сложными многошаговыми сценами, удерживая непротиворечивое состояние объектов, локаций и света. В качестве примера приводятся ролики, где фигуристка выполняет сложную программу из нескольких элементов с котом на голове, или где герой аниме вовлечён в зрелищную битву. Всё это — с сохранением целостности мира, связности кадров и даже эмоций на лицах персонажей. Sora 2 умеет работать с несколькими стилями: реалистичным, кинематографичным и аниме. Как универсальная система генерации видео и аудио, Sora 2 способна создавать сложные фоновые звуковые ландшафты, речь и звуковые эффекты с высокой степенью реалистичности. Для этого достаточно короткой видеозаписи: модель точно воспроизведёт внешность, мимику и даже голос, органично интегрируя их в любую сцену. Эта возможность универсальна и работает для любого человека, животного или объекта, отмечает пресс-релиз OpenAI. Одновременно с выпуском Sora 2 компания OpenAI запускает социальное iOS-приложение Sora. В нём пользователи смогут генерировать ролики и делиться ими с друзьями, а также делать ремиксы на работы друг друга, находить новые видео в настраиваемой ленте Sora и добавлять себя или своих друзей с помощью функции «камео». С помощью «камео» можно попасть в любую сцену Sora с поразительной точностью — нужно только через само приложение записать короткое видео с собой и свой голос для подтверждения личности и захвата образа. «На прошлой неделе мы запустили приложение внутри OpenAI. Наши коллеги уже сообщили нам, что благодаря этой функции они завели новых друзей в компании. Мы считаем, что социальное приложение, построенное вокруг функции “камео”, — лучший способ ощутить всю магию Sora 2», — отметила OpenAI в пресс-релизе. OpenAI подчеркнула, что этическое и ответственное использование станет важной частью новой платформы. Пользователь сам будет решать, кто и как может использовать его «камео»; любое видео с участием пользователя можно удалить в любой момент. Контент с откровенно вредным содержанием или созданный без согласия людей блокируется на уровне алгоритмов и модераторов. Приложение Sora уже доступно для скачивания пользователям iPhone в США и Канаде, регистрация проходит через систему приглашений. Через несколько недель Sora 2 станет доступна в веб-версии. Базовая версия бесплатна и имеет «щедрые лимиты», а подписчики ChatGPT Pro вскоре получат доступ к экспериментальной модели Sora 2 Pro с повышенным качеством. Монетизация пока туманна: единственный план — брать деньги за дополнительные генерации при высоком спросе. Расширение географии сервиса и открытие доступа через API входят в планы на ближайшее время. Генератор видео Grok Imagine стал доступен бесплатно для всех
08.08.2025 [10:43],
Павел Котов
Специализирующийся на разработке технологий искусственного интеллекта стартап Илона Маска (Elon Musk) xAI оперативно подготовил ответ на выход новой флагманской модели OpenAI GPT-5 — компания сделала генератор видео Grok Imagine доступным бесплатно для всех желающих. Об этом говорится в сообщении администрации соцсети X. 
Источник изображения: x.com/X Grok Imagine является одним из немногих общедоступных и бесплатных генераторов видео на основе ИИ. Он создаёт короткие ролики на основе загружаемых пользователями изображений. Сервис работает на базе модели Aurora и генерирует ролики длиной до 15 секунд. Первоначально функция была доступна только для подписчиков SuperGrok в отдельном приложении Grok и для подписчиков Premium+ в соцсети X, но теперь ограничения для приложения Grok решили убрать. Сервис предлагает создание видео в трёх режимах: в Normal генерируются «профессиональные» ролики, Fun предназначается для забавного контента, а Spicy открывает доступ к созданию материалов деликатного характера, но с ограничениями и строгой модерацией. Есть мнение, что пока Grok Imagine по реалистичности видео и аудио уступает лидерам отрасли, таким как Google Veo 3 и OpenAI Sora. Воспользоваться генератором видео Grok Imagine можно в приложениях Grok для Android и iOS — достаточно обновить их до последней версии. Alibaba представила ИИ-генератор изображений Qwen-Image с высокой степенью грамотности
05.08.2025 [16:49],
Павел Котов
Alibaba представила модель искусственного интеллекта Qwen-Image 20B MMDiT, предназначенную для работы с изображениями — в ней разработчик значительно улучшил механизмы прорисовки сложных текстов и реализовал возможности точного редактирования изображений. 
Источник изображения: huggingface.co/Qwen Модель, доступ к которой откроется на платформе Qwen Chat в разделе «Генерация изображений», обладает расширенными возможностями рендеринга текста, в том числе многострочных макетов с семантикой на уровне абзацев и детализированными элементами. Поддерживаются языки на основе букв и иероглифов. Усовершенствованные механизмы многозадачного обучения помогли расширить возможности редактирования изображений с сохранением смыслового наполнения и визуального реализма. Новая Qwen-Image, уверяет Alibaba, обошла существующие решения в нескольких тестах по задачам на генерацию и редактирование изображений, включая GenEval, DPG, OneIG-Bench, GEdit, ImgEdit и GSO. Особых успехов удалось добиться в тестах на качество прорисовки текста, таких как LongText-Bench, ChineseWord и TextCraft — новая модель превзошла современные аналоги. Qwen-Image, в частности, справляется с точным отображением китайских иероглифов на вывесках магазинов с правильной глубиной резкости, с созданием детализированного английского текста на обложках книг и информационных слайдах, поддерживается работа с двуязычным контентом. Помимо обработки текста, модель свободно ориентируется в художественных жанрах от фотореализма до импрессионизма; поддерживаются различные операции при редактировании изображений, в том числе изменение стиля, добавление, удаление и улучшение деталей, а также редактирование текста и изменение поз у персонажей. В проекте Qwen-Image разработчики Alibaba, по их словам стремились способствовать развитию генерации изображений, снизить технические барьеры для создания визуальных материалов и вдохновить коллег на инновационные приложения. xAI запустила Grok Imagine — платный ИИ-генератор изображений и видео с «пикантным режимом»
04.08.2025 [19:36],
Сергей Сурабекянц
Компания xAI Илона Маска (Elon Musk) официально представила Grok Imagine — генератор изображений и видео, доступный для подписчиков тарифных планов SuperGrok и Premium+. Как и обещал Маск, позиционирующий Grok как ИИ, свободный от цензуры, Grok Imagine позволяет создавать контент, который обычно в интернете маркируется аббревиатурой NSFW (not safe/suitable for work — «небезопасно/неподходяще для демонстрации на работе»). 
Источник изображения: @elonmusk Grok Imagine преобразовывает текстовые или графические запросы в 15-секундные видеоролики с оригинальным звуком и предлагает «пикантный режим», позволяющий пользователям создавать контент сексуального характера, включая частичную наготу. Пример такого видео опубликовал в своём аккаунте X Илон Маск. Журналисты TechCrunch сообщили, что многие из опробованных ими (во имя журналистики, конечно!) пикантных запросов привели к появлению «модерированных» размытых изображений, однако изображения полуобнажённых тел им получить удалось. NSFW-контент неудивителен для xAI, учитывая выход в прошлом месяце пикантного аниме-компаньона Ani с искусственным интеллектом. Но так же, как необузданная натура Grok была забавной, пока он не начал изрыгать оскорбительный, антисемитский и женоненавистнический контент, появление Grok Imagine может повлечь за собой свои непредвиденные последствия. При этом в Grok Imagine предусмотрены серьёзные ограничения, особенно учитывая, что модель позволяет создавать контент с изображениями знаменитостей. Так, попытки журналистов TechCrunch сгенерировать изображение беременного Дональда Трампа (Donald Trump) успехом не увенчались — Grok Imagine создавал либо изображения Трампа с младенцем на руках, либо рядом с беременной женщиной. Grok Imagine стремится конкурировать с такими игроками, как Google DeepMind, OpenAI, Runway и китайские нейросети, но пока находится на начальном этапе развития. По отзывам тестировщиков, генерируемые им изображения и видео людей нередко выглядят мультяшно, особенно из-за неестественной текстуры кожи. Тем не менее, генератор впечатляет: изображения создаются за считаные секунды и продолжают формироваться автоматически по мере прокрутки страницы. Затем их можно анимировать в стилизованные видеоролики. Пользовательский интерфейс удобен и интуитивно понятен. Недавно Маск заявил о намерении создать Baby Grok — чат-бот, пригодный для работы с детским контентом. Учитывая, насколько скандально развивается «взрослая версия» Grok, подобное направление экспансии довольно рискованно. Тем не менее, с точки зрения охвата аудитории эта ставка вполне может себя оправдать. Популярность Baby Grok может стать дополнительным источником дохода для xAI и новой статьёй расходов для родителей. Google представила экспериментальный ИИ-генератор веб-приложений Opal
25.07.2025 [19:25],
Павел Котов
Специализированные инструменты для генерации программного кода при помощи искусственного интеллекта в последние несколько месяцев стали чрезвычайно популярными — многим работающим в этом направлении стартапам приходится почти отбиваться от желающих вложиться в них или даже поглотить. К модному тренду подключилась и Google, представившая экспериментальный проект Opal. 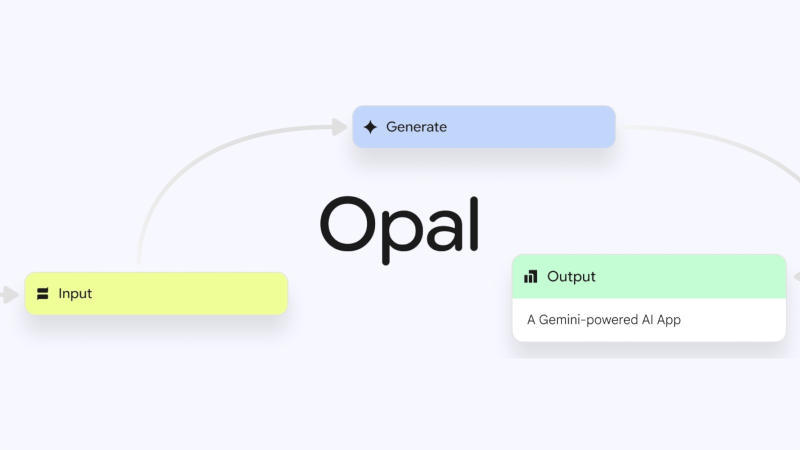
Источник изображения: Google Инструмент Opal доступен в экспериментальном разделе Google Labs и только в США. Он позволяет по текстовым запросам создавать небольшие веб-приложения либо с нуля, либо изменять присутствующие в библиотеке. Пользователю достаточно описать, что он хочет получить на выходе, и Opal при помощи различных моделей Google сделает работу за него. Когда мини-приложение готово, можно перейти в панель редактора и увидеть рабочую схему, в которой представлены ввод запроса, этапы генерации кода и вывод результата. В панели доступен выбор любого из этапов с описанием текущего процесса — его при необходимости можно отредактировать или добавить новый этапе с панели инструментов. Готовое приложение можно опубликовать и поделиться с другими пользователями, у которых есть учётные записи Google. В арсенале компании уже есть средства генерации приложений по текстовому описанию, но подробное визуальное представление рабочего процесса указывает, что Google, возможно, стремится охватить более широкую аудиторию. Прототипы приложений без необходимости писать код позволяют также генерировать платформы Canva, Figma и Replit. «Лучший на сегодня» ИИ-генератор изображений Google Imagen 4 стал доступен бесплатно для всех
25.06.2025 [12:23],
Владимир Мироненко
Компания Google представила ИИ-генератор изображений следующего поколения — Imagen 4, назвав его «лучшей на сегодняшний день моделью преобразования текста в изображение». «Imagen 4 предлагает значительно улучшенную визуализацию текста по сравнению с нашими предыдущими моделями и расширяет границы качества генерации изображений по тексту», — сообщила компания. 
Источник изображений: Google Developers Blog Imagen 4 доступен в виде платной предварительной версии через API Gemini, а также для ограниченного бесплатного тестирования — в Google AI Studio. В настоящее время семейство Imagen 4 включает две модели: Imagen 4 и Imagen 4 Ultra. Модель преобразования текста в изображение Imagen 4 разработана для решения широкого спектра задач генерации изображений с существенным улучшением качества — особенно при работе с текстом — по сравнению с Imagen 3. Стоимость использования Imagen 4 составляет $0,04 за одно сгенерированное изображение.  Флагманская модель Imagen 4 Ultra предназначена для создания изображений, максимально точно соответствующих текстовым подсказкам пользователя, что позволяет добиться лучших результатов по сравнению с другими ведущими генеративными моделями. Стоимость одного изображения, созданного с помощью Imagen 4 Ultra, составляет $0,06. Все изображения, созданные моделями Imagen 4, получают маркировку в виде невидимого цифрового водяного знака SynthID. Adobe выпустила мобильное приложение со всеми генеративными ИИ-инструментами Firefly
17.06.2025 [18:08],
Владимир Фетисов
Платформа генеративных ИИ-сервисов Adobe Firefly теперь доступна на устройствах, работающих под управлением Android и iOS. Новое мобильное приложение Firefly позволяет пользователям генерировать изображения и видео по текстовому описанию, а также экспериментировать с популярными ИИ-инструментами для редактирования фотографий. 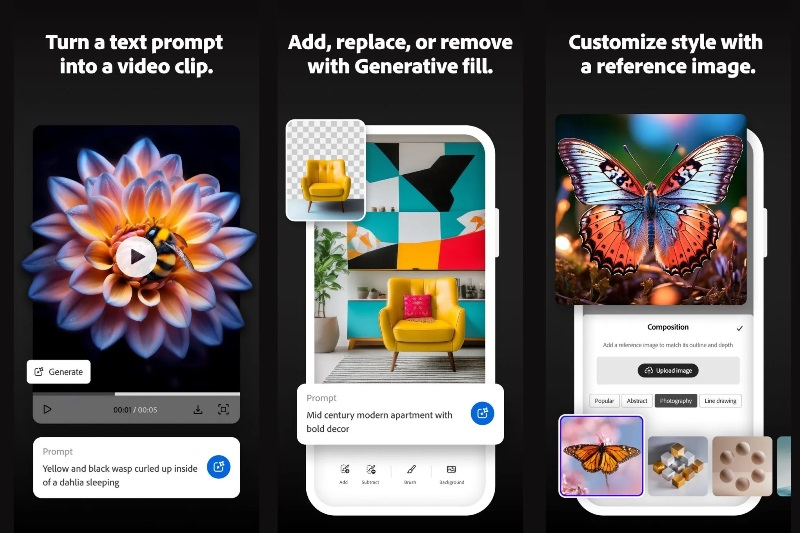
Источник изображения: Adobe Приложение Firefly для Android и iOS включает в себя фирменные алгоритмы Adobe для преобразования текста в изображения и видео, а также генеративные функции, такие как Generative Fill и Generative Expand, которые ранее были доступны в Photoshop. В дополнение к этому пользователи приложения могут взаимодействовать с ИИ-моделями сторонних разработчиков, такими как Google Imagen 3 и Imagen 4 для создания картинок, Veo 2 и Veo 3 для создания видео, а также генератором изображений OpenAI. Созданный в приложении Firefly контент автоматически синхронизируется с учётной записью пользователя на платформе Creative Cloud, что упрощает его дальнейшее размещение в интернете или обработку в других приложениях Adobe. Как и в случае с веб-приложением Firefly, для взаимодействия с некоторыми ИИ-инструментами необходимы кредиты Firefly, которые можно получить в рамках ежемесячных обновлений или путём оформления одного из платных тарифов Creative Cloud. Вместе с этим Adobe расширила возможности генерации видео в публичной бета-версии платформы интерактивных досок Firefly Boards. Теперь пользователи могут повторно микшировать загруженные клипы и генерировать новые кадры с помощью ИИ-модели Firefly, а также сторонних инструментов, таких как Veo 3 от Google. В ближайшее время разработчики также внедрят на платформу больше партнёрских ИИ-моделей от сторонних разработчиков для увеличения количества доступных функций. OpenAI пришлось идти на крайние меры, чтобы справиться с ажиотажем вокруг генерации картинок в стиле Ghibli
13.06.2025 [14:59],
Владимир Мироненко
Популярность ИИ-решений OpenAI среди пользователей сейчас зашкаливает, и каждый новый продукт пользуется буквально ажиотажным спросом. По словам главы OpenAI Сэма Альтмана (Sam Altman), компании пришлось пойти на необычные меры, чтобы справиться со спросом на создание изображений в стиле японской студии Ghibli Хаяо Миядзаки (Hayao Miyazaki) с помощью генератора изображений в ChatGPT. 
Источник изображения: Growtika/unsplash.com Сэм Альтман тогда пошутил, что шумиха вокруг этой функции чуть не расплавила графические процессоры компании, вынудив её на время ввести ограничения на частоту отправки запросов на генерацию изображений, чтобы смягчить проблему. Он буквально умолял пользователей снизить частоту генерации изображений, объясняя просьбу тем, что команде OpenAI нужна передышка и время для отдыха. Из-за всплеска спроса на картинки в стиле Ghibli от GPT-4o Image Generation аудитория чат-бота ChatGPT менее чем за час увеличилась на 1 млн пользователей. Популярность сервиса объясняется тем, что он позволяет получать более реалистичные изображения по сравнению с другими инструментами, такими как технология генерации изображений DALL-E 3. В недавнем интервью ресурсу Bloomberg Сэм Альтман признал, что компания была вынуждена идти на «неестественные» меры, чтобы справиться с вирусным эффектом Ghibli. «Я не думаю, что это случалось с какой-либо компанией раньше, — говорит Альтман. — Я видел вирусные моменты, но я никогда не видел, чтобы кто-то сталкивался с таким массовым наплывом использования продукта». Альтман рассказал, что создание изображения с помощью нового генератора изображений компании требует значительных вычислительных ресурсов, и чтобы справиться со всплеском спроса, OpenAI пришлось сделать много вещей, в том числе позаимствовать вычислительные мощности у исследовательского подразделения OpenAI, а также отсрочить запуск новых функций. «У нас нет сотен тысяч графических процессоров, которые просто простаивают без дела», — сообщил Альтман, добавив, что если бы у OpenAI было больше графических процессоров, она могла бы лучше справляться с резкими скачками спроса, и ей бы не пришлось прибегать к экстремальным мерам, таким как ограничения по скорости и задержка предоставления новых функций для бесплатных пользователей. Adobe обновила ИИ-генератор изображений Firefly и переработала его веб-приложение
24.04.2025 [14:11],
Владимир Фетисов
Adobe объявила о запуске новой версии ИИ-модели Firefly для генерации изображений, а также алгоритма генерации векторной графики и обновлённого веб-приложения, в котором собраны все генеративные модели компании, а также некоторые нейросети конкурентов. В дополнение к этому разработчики продолжают трудиться над созданием мобильного приложения Firefly. 
Источник изображения: Rubaitul Azad / Unsplash Большая языковая модель Firefly Image Model 4, по данным Adobe, превосходит своих предшественниц по качеству генерируемых изображений, скорости обработки запросов и возможностям по настройке параметров создаваемого контента. Поддерживается генерация изображений с разрешением до 2K. Существует также более производительная версия алгоритма Image Model 4 Ultra, которая может создавать сложные сцены с множеством мелких структур и большим количеством деталей. Представитель Adobe рассказал, что разработчики сделали новые ИИ-модели более производительными, чтобы они могли генерировать более детализированные изображения. Помимо прочего, более качественной стала генерация текста на изображениях, а также появилась возможность создавать несколько изображений в том же стиле, что и исходное. Вместе с этим компания открыла доступ всем желающим к своему ИИ-генератору видео Firefly, бета-тестирование которого началось в прошлом году. Алгоритм позволяет создавать видео на основе текстового описания или изображения, менять ракурсы камеры, указывать начальный и конечный кадры, настраивать элементы стиля анимации и др. ИИ-модель может создавать ролики в формате 1080p. ИИ-модель Firefly для создания векторной графики может генерировать пригодные для дальнейшего редактирования векторные иллюстрации, а также итерировать и генерировать варианты логотипов, паттернов и др. Доступ ко всем новым ИИ-моделям Adobe можно получить в обновлённом веб-приложении Firefly. Там также нашлось место генератору изображений GPT от OpenAI, моделям Imagen 3 и Veo 2 от Google, а также алгоритму Flux 1.1 Pro от Flux. Пользователи могут переключаться между этими алгоритмами по своему усмотрению. Adobe также проводит публичное тестирование нового продукта под названием Firefly Boards, который представляет собой холст для творчеств и реализации идей. С его помощью можно генерировать или импортировать изображения, редактировать их, в том числе совместно с другими пользователями платформы. Firefly Boards также будет доступен в веб-приложении Firefly. В дополнение к этому Adobe открыла доступ к API Text-to-Image и Avatar API, а также объявила о начале бета-тестирования API Text-to-Video. Получить доступ к этим и другим программным интерфейсам компании можно через платформу Firefly Services. Adobe и Figma взяли на вооружение передовой генератор изображений от OpenAI
24.04.2025 [12:58],
Павел Котов
Обновлённый генератор изображений OpenAI 4o Image Generation в составе ChatGPT привлёк внимание широкой аудитории благодаря своей способности создавать картинки в стиле студии аниме Ghibli. Теперь компания открыла доступ к «изначально мультимодальной модели» через API — доступ к платформе gpt-image-1 уже начали бронировать для себя крупные партнёры. 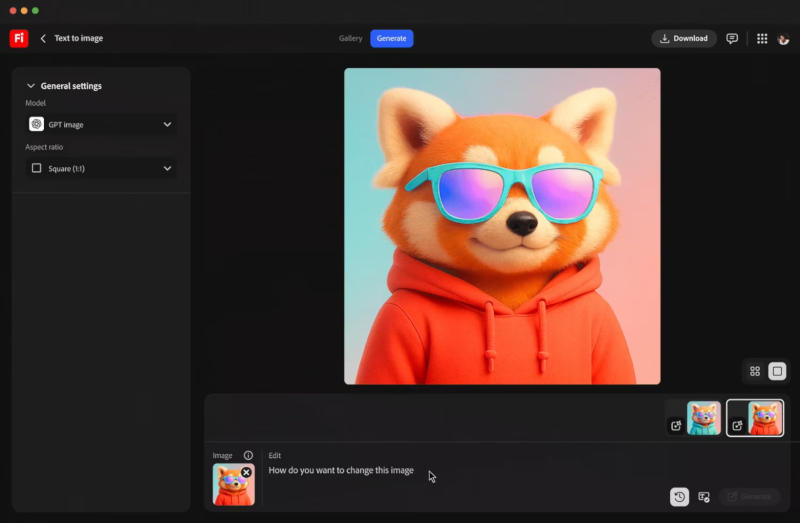
Источник изображения: openai.com «Универсальность модели позволяет ей создавать изображения в различных стилях, в точности придерживаться запросов пользователей, применять знания о мире и правильно воспроизводить текст, раскрывая бесчисленное множество сценариев практического применения в различных областях», — говорится в блоге OpenAI. Поработать с моделью смогут пользователи сервисов Adobe и Figma, которые уже включили её поддержку в свои наборы инструментов. Adobe добавила её в приложения Firefly и Express; с сегодняшнего дня генератор изображений gpt-image-1 доступен также в Figma Design, где по простым текстовым запросам он сможет корректировать стили, добавлять или удалять объекты, расширять фоновые изображения и производить множество других операций. OpenAI добавила, что продолжает сотрудничать с другими партнёрами, которые помогут ей раскрыть новые сценарии применения генератора изображений — среди них значатся, в частности, Canva, GoDaddy и Instacart. ИИ обрёл человеческое лицо: Character.AI представила модель AvatarFX для превращения ботов в анимированных персонажей
23.04.2025 [16:50],
Павел Котов
Платформа Character.AI, которая специализируется на общении и ролевых играх пользователей с созданными искусственным интеллектом персонажами, представила модель для генерации видео AvatarFX. Источник изображения: x.com/character_ai Пока AvatarFX доступна в формате закрытого бета-тестирования; она позволяет анимировать персонажей на платформе в различных стилях и с различными голосами — эти персонажи могут быть любыми: от человекоподобных до животных из 2D-мультфильмов. В отличие от конкурирующих решений вроде OpenAI Sora, AvatarFX — не просто генератор видеороликов по текстовым запросам. Пользователи могут создавать видео на основе существующих статических изображений, например, анимировать фотографии реальных людей. Подобные решения создают широкое пространство для злоупотреблений, указывает ресурс TechCrunch: недобросовестные пользователи могут начать загружать фотографии знаменитостей или тех, с кем знакомы в реальной жизни, чтобы виртуальный персонаж сказал или сделал нечто компрометирующее. Технологии создания убедительных дипфейков существуют уже не первый год, но их включение в популярные потребительские продукты масштаба Character.AI лишь усугубляет угрозу. В прошлом году трагедией закончилось общение созданного на платформе Character.AI ИИ-персонажа «Игры престолов» с 14-летним американским подростком. В ответ на это администрация сервиса добавила в приложение родительский контроль и дополнительные средства безопасности. Комментариев по поводу возможных злоупотреблений AvatarFX в компании не дали. AMD представила Amuse 3.0 — приложение для ИИ-генерации изображений на Ryzen и Radeon
15.04.2025 [18:45],
Николай Хижняк
Компания AMD представила Amuse 3.0 — программный инструмент для ИИ-генерации изображений. Платформа разработана в партнёрстве с компанией TensorStack AI. Она использует мощности процессоров AMD Ryzen AI и видеокарт Radeon RX для создания изображений и коротких видеороликов локально на ПК. 
Источник изображений: TechPowerUp / AMD AMD заявляет, что платформа Amuse 3.0 способна генерировать изображения печатного качества и видеоролики чернового качества (низкого разрешения) длиной до 6 секунд. Amuse 3.0 поддерживает более 100 новых моделей ИИ, включая Stable Diffusion 3.5 и FLUX. 
 Каждая из этих моделей была тщательно оптимизирована для работы с аппаратным обеспечением AMD, что привело к увеличению скорости вывода до 4,3 раз по сравнению с универсальными моделями. Для платформы заявлена поддержка видеофильтров на основе ИИ. Amuse 3.0

Смотреть все изображения (6)



Смотреть все изображения (6) AMD заявляет, что производительность Amuse 3.0 по сравнению с универсальной базовой платформой генерации изображения Olive Optimize в 4,3 раза выше и была достигнута на видеокарте Radeon RX 9070 XT. Компания также добавила данные о производительности процессоров Ryzen AI со встроенным NPU мощностью 50 TOPS, с которыми оптимизированные модели AMD показали себя в 3,3 раза быстрее при генерации изображений. Каждый десятый человек на Земле теперь пользуется ChatGPT, и его популярность только растёт
14.04.2025 [13:42],
Дмитрий Федоров
Число еженедельных активных пользователей ChatGPT приблизилось к одному миллиарду. Такой рост совпал с мартовским обновлением функции генерации изображений, что вызвало всплеск интереса к ИИ-сервису. В прошлом месяце ChatGPT стал самым загружаемым в мире приложением за исключением игр, а общее количество его установок составило 46 млн. 
Источник изображения: Growtika / Unsplash Во время беседы на сцене конференции TED куратор мероприятия Крис Андерсон (Chris Anderson) задал Сэму Альтману (Sam Altman), генеральному директору OpenAI, вопрос о числе пользователей ChatGPT. Альтман ответил, что последняя озвученная цифра составляла 500 млн еженедельных активных пользователей, и добавил, что аудитория продолжает стремительно расти. Андерсон заметил, что в частной беседе Альтман упоминал о двукратном росте за несколько недель. Альтман это не опроверг. Альтман также сообщил, что ChatGPT пользуются около 10 % населения Земли. Поскольку сегодня на Земле живут более 8 млрд человек, это примерно 800 млн пользователей. После запуска 30 ноября 2022 года бесплатной исследовательской версии ChatGPT на основе ИИ-модели GPT-3.5, он достиг отметки в 100 млн пользователей всего за два месяца, став самым популярным приложением в истории. Для сравнения: TikTok для этого потребовалось девять месяцев, а Instagram✴ — два с половиной года. К августу 2024 года число еженедельных активных пользователей ChatGPT достигло 200 млн. Последующий резкий рост был вызван обновлением 25 марта, в котором были улучшены возможности генерации изображений. После этого социальные сети наводнили изображения и видео, выполненные в различных художественных стилях, наиболее популярным из которых оказался стиль японской анимационной студии Studio Ghibli. Альтман отметил, что спрос оказался настолько высоким, что фактически «плавил» графические процессоры компании. Хорошей новостью для OpenAI стало то, что обновление привлекло миллион новых пользователей ChatGPT всего за один час. Согласно данным аналитической платформы Appfigures, в марте ChatGPT стал самым скачиваемым неигровым приложением в мире. Количество установок выросло на 28 % по сравнению с февралем и достигло 46 млн. Взрывному успеху способствовало не только улучшение генератора изображений, но и, вероятно, снятие некоторых ограничений в работе сервиса. 
Источник изображения: TED На фоне популяризации генеративного ИИ усиливаются опасения по поводу его влияния на рынок труда. Всё больше компаний сокращают персонал, поскольку задачи, ранее выполнявшиеся людьми, теперь выполняют ИИ-системы. На вопрос о том, заменит ли ИИ человека, Альтман ответил: «Можно сказать: „О, Боже, оно делает всё, что делаю я. Что же со мной будет?“ Или вы можете сказать, как во времена всех других технологических революций в истории: „Хорошо, теперь есть новый инструмент. Я могу делать гораздо больше. Что я смогу делать?“ Конечно, ожидания от человека, занимающего определённую должность, возрастают, но возможности расширяются настолько значительно, что, я думаю, соответствовать этим ожиданиям возможно». Представлена Midjourney V7 — ИИ-генератор изображений стал идеально понимать запросы и поразил качеством
04.04.2025 [15:46],
Павел Котов
Midjourney представила альфа-версию основанного на искусственном интеллекте генератора изображений V7. В отличие от OpenAI ChatGPT эта модель не была оптимизирована для создания картинок в стиле Ghibli, но это не мешает ей генерировать эстетически приятные работы, пишет TechCrunch. 
Источник изображения: x.com/midjourney Прежде чем начать работу с Midjourney V7, пользователю придётся оценить около двух сотен изображений, чтобы система создала для него профиль «персонализации» — это помогает настроить модель в соответствии с визуальными предпочтениями конкретного человека; в данном проекте персонализация впервые включена по умолчанию. По окончании настройки можно начинать работу с V7 как на сайте Midjourney, так и на сервере компании в Discord. При её разработке использовалась «совершенно иная архитектура», рассказал гендиректор Midjourney Дэвид Хольц (David Holz). Модель доступна в двух вариантах: есть более ресурсоёмкий Turbo; и Relax с режимом Draft Mode, при котором изображения генерируются в десять раз быстрее, и задействуются вдвое меньше вычислительных ресурсов. «Черновые» изображения Draft Mode имеют более низкое качество, чем созданные в стандартном режиме картинки, но их можно улучшить и повторно отрисовать в один щелчок мыши. Модель имеет как преимущества, так и недостатки, предупредил господин Хольц, поэтому для достижения оптимального результата пользователям рекомендуется экспериментировать с составлением запросов. Midjourney — необычная компания. Её открыл в 2022 году Дэвид Хольц, некогда соучредитель производителя периферии Leap Motion; отличительной чертой стартапа является полное отсутствие внешнего финансирования. В конце 2023 года компания сообщила, что ожидает получить около $200 млн прибыли. В прошлом году Midjourney объявила о наборе сотрудников в проект по разработке оборудования; при этом она продолжала обучение ранее анонсированных моделей для генерации видео и трёхмерных объектов. Картинки в стиле Ghibli перегрузили серверы OpenAI — выпуск новых функций замедлен
02.04.2025 [00:41],
Анжелла Марина
Генеральный директор OpenAI Сэм Альтман (Sam Altman) заявил, что из-за высокой популярности нового инструмента генерации изображений в ChatGPT компания столкнулась с перегрузкой оборудования, из-за чего выход новых продуктов и функций придётся ограничить. 
Источник изображения: Mariia Shalabaieva / Unsplash По словам Альтмана, OpenAI пытается справиться с ситуацией, но пользователям следует ожидать как минимум задержек в релизах, а также перебоев в работе сервисов и замедления работы платформы. Тем не менее, как отмечает TechCrunch, компания уверяет, что держит ситуацию под контролем. «Что-то будет ломаться, а обслуживание иногда будет медленным, поскольку мы справляемся с проблемами, связанными с пропускной способностью, — написал Альтман. — Мы стараемся решать проблемы оперативно, чтобы всё действительно работало». Напомним, выпущенный недавно новый генератор изображений вызвал буквально ажиотаж благодаря способности имитировать различные стили, в частности популярный стиль анимационной студии Studio Ghibli. Однако компания не успевает справляться с наплывом пользователей, а сотрудники вынуждены работать допоздна и даже в выходные, чтобы поддерживать работоспособность системы. Чтобы снизить нагрузку на свои серверы, OpenAI задержала запуск нового инструмента генерации изображений для бесплатных пользователей ChatGPT, а возможность создания видео с помощью Sora временно отключена для новых пользователей. Компания не уточняет, когда проблемы с перегрузкой будут окончательно решены и пока продолжает работать над улучшением инфраструктуры. В понедельник ChatGPT зафиксировал регистрацию в сервисе одного миллиона новых пользователей всего за один час. Также отметим, что на сегодня системой пользуются 500 миллионов еженедельных пользователей и 20 миллионов подписчиков, что значительно больше по сравнению с концом 2024 года, когда показатели составляли 300 миллионов и 15,5 миллиона соответственно. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex








