|
Опрос
|
реклама
Быстрый переход
Завирусившийся новый генератор изображений в ChatGPT стал доступен всем пользователям
01.04.2025 [11:24],
Владимир Фетисов
Новый генератор изображений OpenAI, работающий на базе большой языковой модели GPT-4o, теперь доступен всем пользователям. Об этом на своей странице в социальной сети X написал гендиректор OpenAI Сэм Альтман (Sam Altman). До этого момента использовать новый ИИ-генератор изображений могли только платные подписчики ChatGPT. 
Источник изображения: OpenAI Бесплатные пользователи сервиса сейчас могут генерировать не больше двух изображений в сутки. Ранее Альтман упоминал о возможности введения лимита в три изображения в день. Инструмент генерации изображений OpenAI мгновенно стал сверхпопулярным сразу после его запуска в массы. Альтман заявлял, что спрос на генерацию картинок был так высок, что используемые компанией графические ускорители попросту «плавились». Генератор быстро стал известен тем, что его использовали для преобразования изображений в стиль японской анимационной студии Studio Ghibli. Это вызвало обеспокоенность по поводу нарушения авторских прав, поскольку создаваемые ИИ-генератором изображения были очень похожи на работы студии. Некоторые люди также использовали данный инструмент для создания поддельных квитанций, например, ресторанных счетов. В компании на это заявили, что все сгенерированные ИИ изображения содержат метаданные, указывающие на их происхождение. Вместе с этим OpenAI заявила о привлечении $40 млрд инвестиций, за счёт чего рыночная стоимость компании составила $300 млрд. В качестве основного инвестора в рамках этого раунда финансирования выступил Softbank. Компания также объявила, что ИИ-бот ChatGPT еженедельно используют более 500 млн человек по всему миру, тогда как количество ежемесячно активных пользователей выросло до 700 млн человек. Microsoft накрыла банду хакеров, которая обманом заставляла ИИ рисовать неподобающие фейки со знаменитостями
28.02.2025 [10:36],
Владимир Фетисов
Microsoft заявила об обнаружении американских и зарубежных хакеров, которые обходили ограничения генеративных инструментов на базе искусственного интеллекта, включая службы OpenAI в облаке Azure, для создания вредоносного контента, в том числе интимных изображений знаменитостей и другого контента сексуального характера. По данным компании, в этой деятельности участвовали хакеры из США, Ирана, Великобритании, Гонконга и Вьетнама. 
Источник изображения: Mika Baumeister / Unsplash В сообщении сказано, что злоумышленники извлекали логины пользователей сервисов генеративного ИИ из открытых источников и использовали их для собственных целей. После получения доступа к ИИ-сервису хакеры обходили установленные разработчиками ограничения и продавали доступ к ИИ-сервисам вместе с инструкциями по созданию вредоносного контента. Microsoft предполагает, что все идентифицированные хакеры являются членами глобальной киберпреступной сети, которую в компании именуют Storm-2139. Двое из них территориально находятся во Флориде и Иллинойсе, но компания не раскрывает личностей, чтобы не навредить уголовному расследованию. Софтверный гигант заявил, что ведёт подготовку соответствующих запросов в правоохранительные органы США и ряда других стран. Эти меры Microsoft принимает на фоне растущей популярности генеративных нейросетей и опасения людей по поводу того, что ИИ может использоваться для создания фейковых изображений общественных деятелей и простых граждан. Такие компании, как Microsoft и OpenAI, запрещают генерацию подобного контента и соответствующим образом ограничивают свои ИИ-сервисы. Однако хакеры всё равно пытаются обойти эти ограничения, что зачастую им успешно удаётся сделать. «Мы очень серьёзно относимся к неправомерному использованию искусственного интеллекта и признаём серьёзные и долгосрочные последствия злоупотребления изображениями для потенциальных жертв. Microsoft по-прежнему стремится защитить пользователей, внедряя надёжные меры ИИ-безопасности на платформах и защищая сервисы от незаконного и вредоносного контента», — заявил Стивен Масада (Steven Masada), помощник главного юрисконсульта подразделения Microsoft по борьбе с киберпреступлениями. Это заявление последовало за декабрьским иском Microsoft, который компания подала в Восточном округе Вирджинии против 10 неизвестных в попытке собрать больше информации о хакерской группировке и пресечь её деятельность. Решение суда позволило Microsoft взять под контроль один из основных веб-сайтов хакеров. Это и обнародование ряда судебных документов в прошлом месяце посеяло панику в рядах злоумышленников, что могло установить личности некоторых участников группировки. StabilityAI представила улучшенную ИИ-модель для генерации изображений Stable Diffusion 3.5
23.10.2024 [05:06],
Анжелла Марина
Компания StabilityAI представила новую версию ИИ-модели для генерации изображений Stable Diffusion 3.5 с улучшенным реализмом, точностью и стилизацией. По сообщению Tom's Guide, модель бесплатна для некоммерческого использования, включая научные исследования, а также для малых и средних предприятий с доходом до $1 млн. 
Источник изображения: StabilityAI Как и предыдущая версия SD3, Stable Diffusion 3.5 доступен в трёх конфигурациях: Large (8B), Large Turbo (8B) и Medium (2,6B). Все конфигурации оптимизированы для работы на обычном пользовательском оборудовании и их можно настраивать. В своём пресс-релизе StabilityAI признала, что модель Stable Diffusion 3 Medium, выпущенная в июне, не полностью соответствовала стандартам и ожиданиям сообщества. «После того как мы выслушали ценные отзывы, вместо быстрого исправления мы решили уделить время разработке версии, которая продвигает нашу миссию по трансформации визуальных медиа», — сказали в компании. Новые модели ориентированы на возможность гибкой настройки, высокую производительность и разнообразие результатов. Поддерживаются стилистические настройки, включая фотографию и живопись. Для указания определённого стиля можно также использовать хештеги, например, boho, impressionism или modern. Ещё можно выделять ключевые слова в запросе для получения более реалистичных изображений. Модель Stable Diffusion 3.5 Large лидирует на рынке по лучшему соответствию запросам и качеству изображений. Модель Turbo имеет минимальное время вывода результатов. Medium превосходит другие модели в плане баланса между качеством изображений и соответствия запросам, что делает её, по утверждению компании, самым эффективным выбором для создания контента. Все три конфигурации свободно доступны по лицензии Stability AI Community License. Для использования в коммерческих целях потребуется лицензия Enterprise License. AMD представила Amuse 2.0 — ПО для ИИ-генерации изображений для Ryzen и Radeon
29.07.2024 [00:20],
Николай Хижняк
AMD представила Amuse 2.0 — программный инструмент для ИИ-генерации изображений. Программа доступна в бета-версии. В перспективе её функциональность будет расширяться. Amuse 2.0 является своего рода аналогом инструмента AI Playground от Intel, использующего мощности видеокарт Intel Arc. Решение от AMD для генерации контента в свою очередь полагается на мощности процессоров Ryzen и видеокарт Radeon. 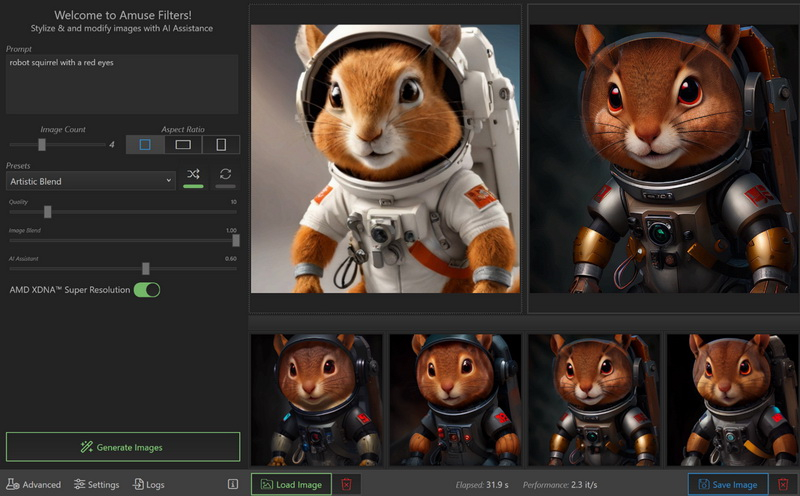
Источник изображений: AMD Приложение Amuse 2.0, разработанное с помощью TensorStack, отличается простотой использования, без необходимости загружать множество внешних компонентов, задействовать командные строки или запускать что-либо ещё. Для использования приложения достаточно лишь запустить исполняемый файл. 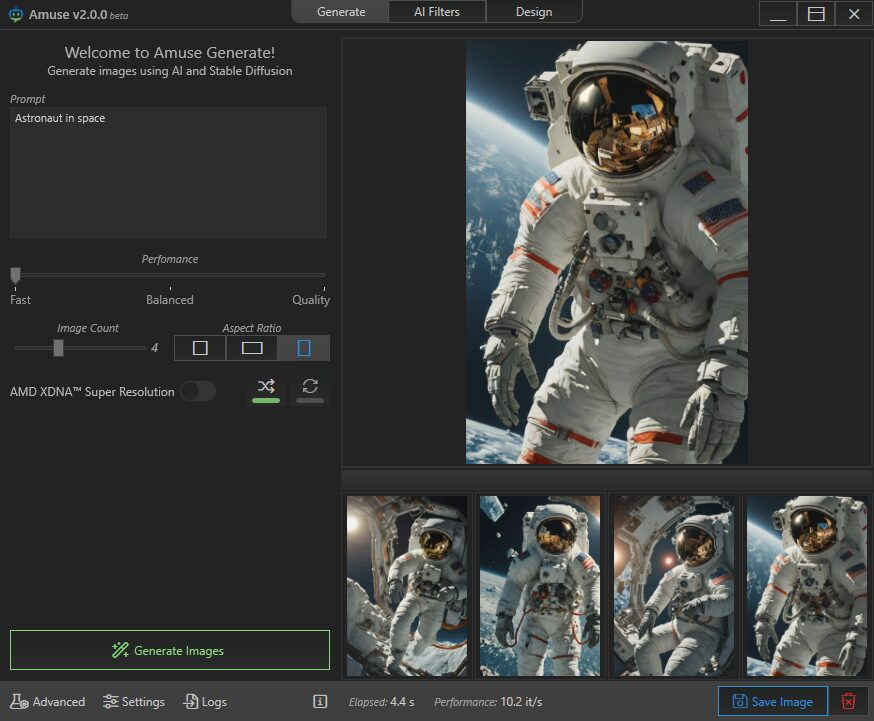 По сравнению с Intel AI Playground, Amuse 2.0 не поддерживает запуск чат-ботов на основе больших языковых моделей. В настоящее время приложение предназначено только для генерации изображений с помощью ИИ. Amuse 2.0 использует модели Stable Diffusion и поддерживает процессоры Ryzen AI 300 (Strix Point), Ryzen 8040 (Hawk Point) и серию видеокарт Radeon RX 7000. Почему компания не добавила поддержку видеокарт Radeon RX 6000 и более ранних моделей, а также процессоров Ryzen 7040 (Phoenix), обладающих практически идентичными характеристиками с Hawk Point, неизвестно. Возможно, это изменится в будущем. 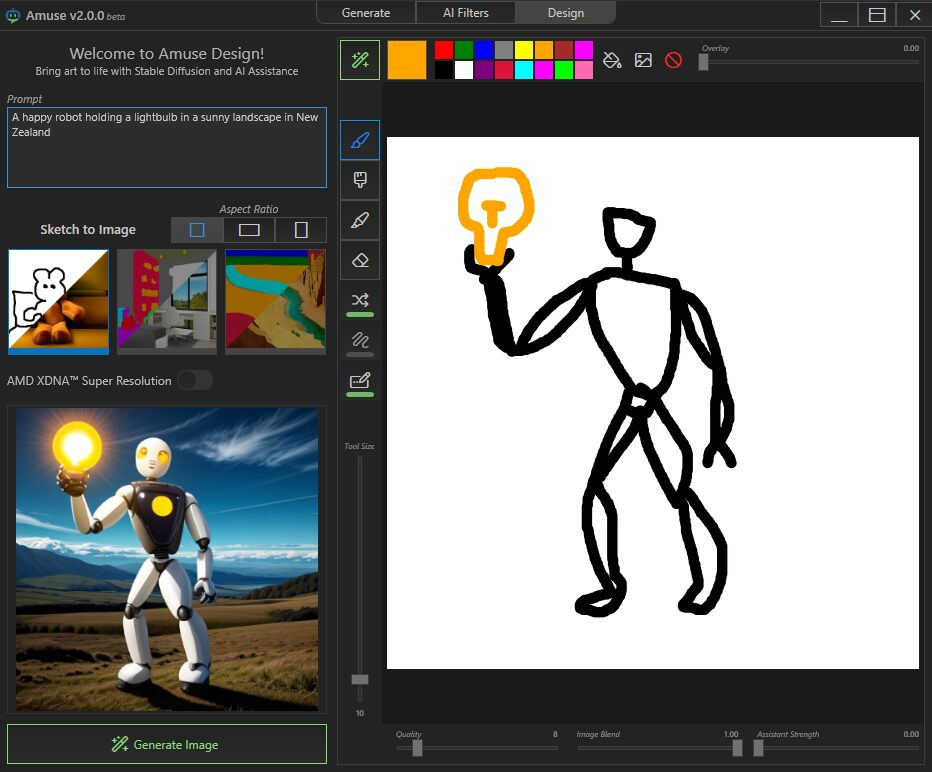 Для работы Amuse 2.0 AMD рекомендует использовать 24 Гбайт ОЗУ или больше для систем на базе процессоров Ryzen AI 300 и 32 Гбайт оперативной памяти для систем на базе Ryzen 8040. Для видеокарт Radeon RX 7000 требования к необходимому объёму памяти не указаны. 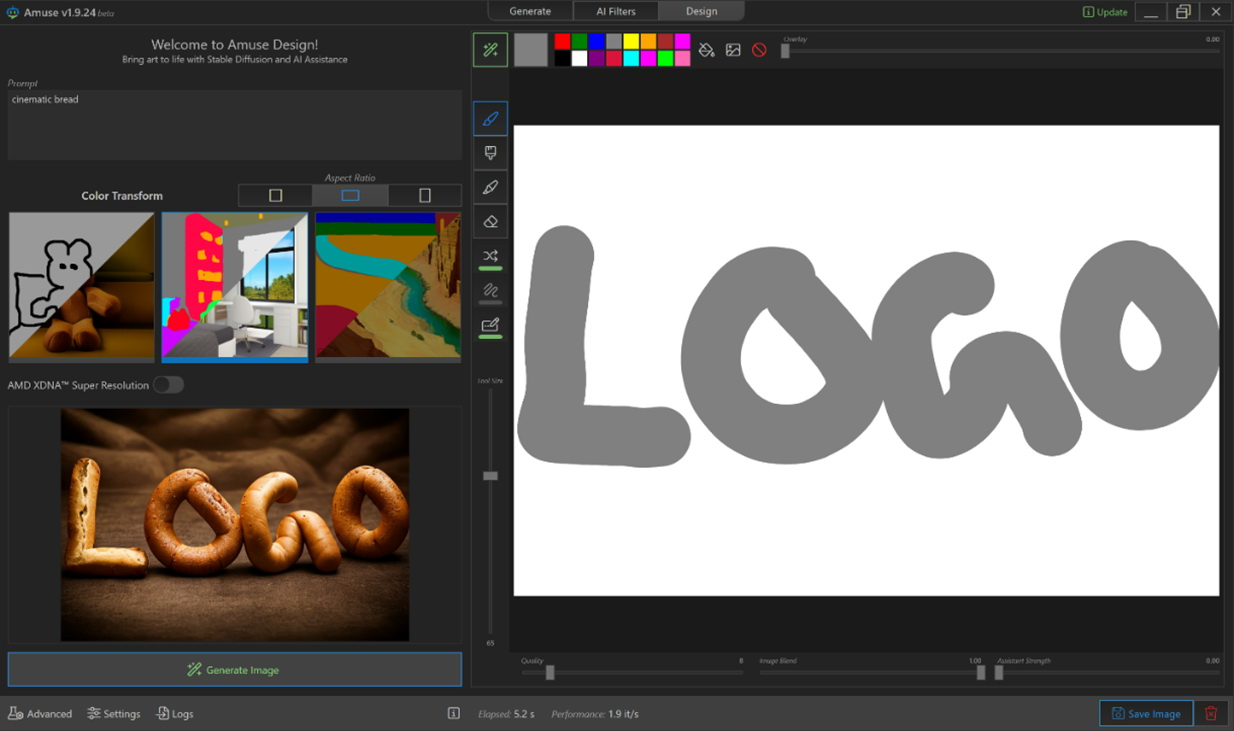 Возможности Amuse 2.0:
Стоит отметить, что инструмент поддерживает XDNA Super Resolution — технологию, позволяющую увеличивать масштаб изображений вдвое. Более подробно об Amuse 2.0 можно узнать по этой ссылке. В WhatsApp появился ИИ-генератор персонализированных аватаров, но доступен он пока не всем
04.07.2024 [15:52],
Владимир Фетисов
Пользователи мессенджера WhatsApp в скором времени смогут воспользоваться новой ИИ-функцией, которая позволит генерировать персонализированные аватары. На данном этапе такая возможность стала доступна некоторым пользователям бета-версии WhatsApp 2.24.14.7. 
Источник изображения: Dima Solomin / unsplash.com В сообщении сказано, что пользователи смогут делать аватары на основе собственных изображений и текстовых описаний. В опубликованном на этой неделе скриншоте есть краткое описание новой функции. В нём говорится, что пользователи могут представить себя «в любой обстановке — от леса до космоса». Опубликованные примеры сгенерированных аватаров выглядят достаточно типично для изображений, созданных ИИ-алгоритмом. Чтобы создать персонализированный аватар, пользователю потребуется «один раз сфотографировать себя». Этот снимок будет задействован для обучения ИИ-алгоритма созданию изображений, похожих на пользователя. После этого пользователю будет достаточно указать детали изображения, которое он хочет получить, в чате Meta✴ AI или в другом чате, задействовав команду «@Meta AI представь меня…». 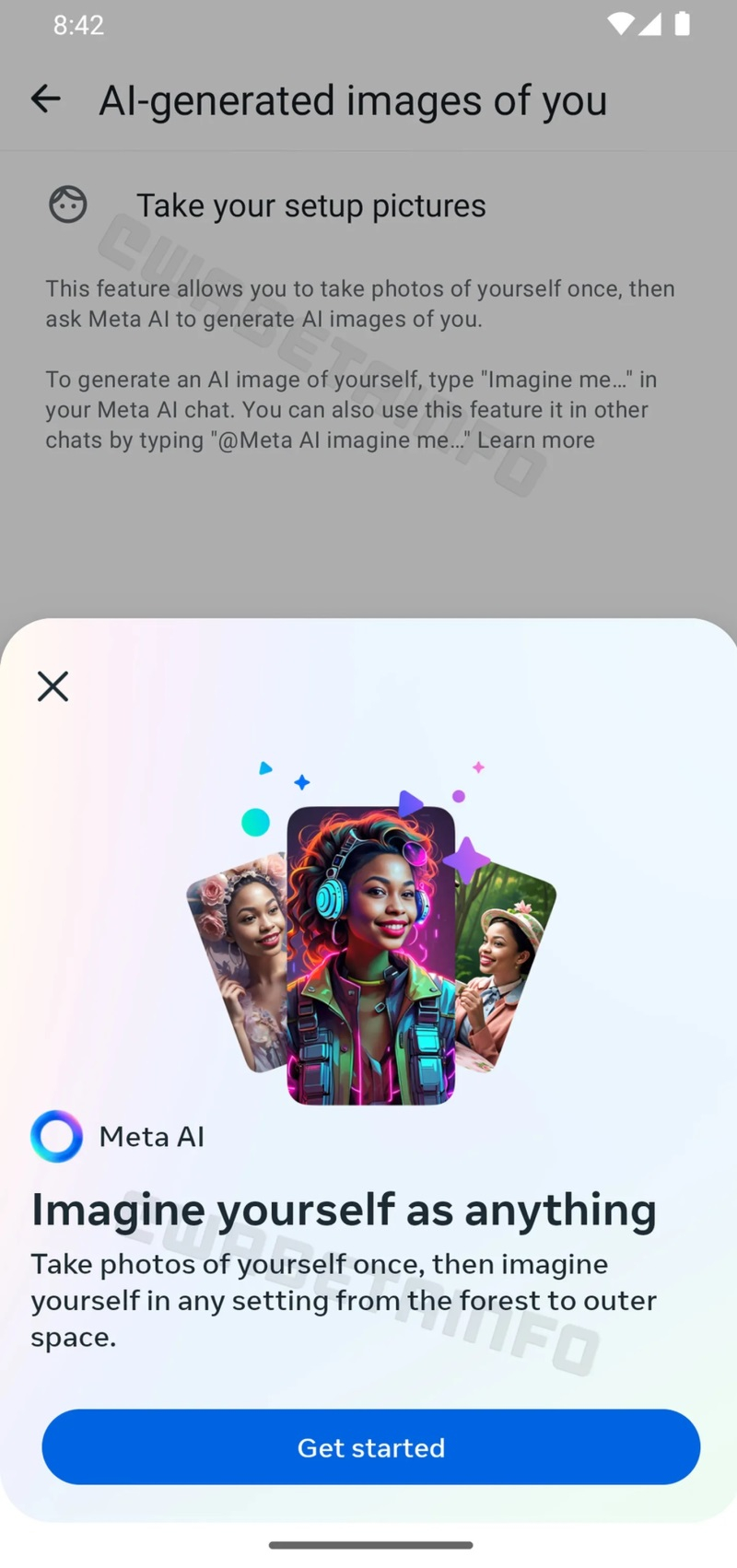
Источник изображения: WABetaInfo Согласно имеющимся данным, новая функция по умолчанию будет отключена. Для начала генерации персонализированных аватаров потребуется активировать соответствующую опцию в настройках приложения. Эталонные снимки, на основе которых создаются аватары, в любой момент можно удалить. Когда упомянутое нововведение станет общедоступным, пока неизвестно. Meta✴ выпустила ИИ-генератор 3D-моделей по текстовому описанию
03.07.2024 [19:43],
Владимир Фетисов
Исследовательское подразделение компании Meta✴ Platforms представило новый генеративный алгоритм 3D Gen, который позволяет создавать качественные 3D-объекты по текстовому описанию. По словам разработчиков, новая нейросеть превосходит аналоги по качеству создаваемых моделей и по скорости генерации. 
Источник изображений: 3D gen «Эта система может генерировать 3D-объекты с текстурами высокого разрешения», — говорится в сообщении Meta✴ в соцсети Threads. Там также отмечается, что нейросеть значительно превосходит аналогичные алгоритмы по качеству генерируемых объектов и в 3-10 раз опережает по скорости генерации. 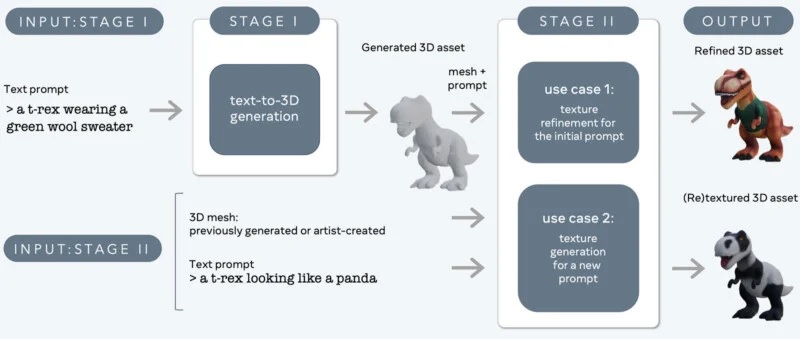 Согласно имеющимся данным, Meta✴ 3D Gen может создавать 3D-объекты и текстуры на основе простого текстового описания менее чем за минуту. Функционально новый алгоритм похож на некоторые уже существующие аналоги, такие как Midjourney и Adobe Firefly. Одно из отличий в том, что 3D Gen создаёт модели, которые поддерживают физически корректный рендеринг. Это означает, что создаваемые нейросетью модели могут использоваться в приложениях для моделирования и рендеринга реально существующих объектов.  «Meta 3D Gen — это двухступенчатый метод, сочетающий в себе два компонента: один для преобразования текста в 3D, а другой — для преобразования текста в текстуры», — говорится в описании алгоритма. По словам разработчиков, такой подход позволяет добиться «более высокого качества 3D-генерации для создания иммерсивного контента».  3D Gen объединяет две основополагающие языковые модели Meta✴ AssetGen и TextureGen. В Meta✴ заявляют, что, основываясь на отзывах профессиональных 3D-художников, новая технология компании предпочтительнее конкурирующих аналогов, которые также позволяют генерировать 3D-объекты по текстовому описанию. Adobe поменяет пользовательское соглашение на фоне скандала с доступом к контенту
11.06.2024 [19:02],
Владимир Фетисов
Ранее Adobe обновила соглашение, регулирующее правила взаимодействия пользователей с программными продуктами компании. Несколько расплывчатых формулировок указывали на то, что теперь Adobe официально может просматривать контент, который пользователи создали с помощью приложений компании и хранят в облаке. Это вызвало негативную реакцию сообщества, на фоне чего Adobe пришлось объясниться и пообещать внести в соглашение более понятные формулировки. 
Источник изображения: adobe.com «Ваш контент принадлежит вам и никогда не будет использоваться для обучения каких-либо инструментов генеративного искусственного интеллекта», — говорится в совместном заявлении директора по продуктам Adobe Скотта Бельски (Scott Belsky) и вице-президента по правовым вопросам Даны Рао (Dana Rao). Пользователи разных приложений компании, таких как Photoshop, Premiere Pro и Lightroom, были возмущены расплывчатыми формулировками. Люди посчитали внесённые в пользовательское соглашение изменения желанием Adobe использовать созданный пользователями контент для обучения генеративных нейросетей. Другими словами, создатели контента подумали, что Adobe намерена использовать ИИ для кражи их работ с целью последующей перепродажи. На этом фоне Adobe активно пытается убедить сообщество в том, что пользовательскому контенту ничего не угрожает, а внесённые в соглашение изменения ошибочно оказались недостаточно точными. «В мире, где клиенты беспокоятся о том, как используются их данные и как обучаются генеративные модели искусственного интеллекта, на компаниях, хранящих данные и контент своих клиентов, лежит обязанность заявить о своей политике не только публично, но и в своём пользовательском соглашении», — говорится в сообщении Бельски. Компания пообещала пересмотреть пользовательское соглашение, чтобы сделать его более понятным за счёт «более простого языка и примеров». В Adobe надеются, что такой подход поможет пользователям лучше понимать, о чём именно говорится в тех или иных пунктах соглашения. Компания уже отредактировала первоначальный текст изменений 6 июня, но это не повлияло на негативную реакцию сообщества. Компания утверждает, что клиенты могут защитить свой контент не только от нейросетей, им также доступен вариант отказа от участия в программе улучшения продуктов компании. Google анонсировала свой самый мощный ИИ-генератор изображений Imagen 3
14.05.2024 [22:03],
Владимир Фетисов
В рамках проходящей в эти дни в Маунтин-Вью конференции Google I/O состоялся анонс новой версии генеративной нейросети семейства Imagen. Речь идёт об алгоритме Imagen 3 — самом продвинутом генераторе изображений от Google на данный момент. 
Источник изображения: Google Глава исследовательского ИИ-подразделения Google Deep Mind Демис Хассабис (Demis Hassabis) во время презентации заявил, что Imagen 3 более точно понимает тестовые запросы, на основе которых он создаёт изображения, чем модель Imagen 2. Он отметил, что алгоритм работает более «креативно и детализировано», а также реже ошибается и создаёт меньше «отвлекающих артефактов». Вместе с этим Google попыталась развеять опасения по поводу того, что Imagen 3 будет использоваться для создания дипфейков. В процессе генерации изображений будет задействована технология SynthID, посредством которой на медиафайлы наносятся невидимые криптографические водяные знаки. Предполагается, что такой подход сделает бесполезными попытки использовать ИИ-генератор Google для создания фейкового контента. Частные пользователи могут оформить подписку на Imagen 3 через сервис Google ImageFX. Разработчики и корпоративные клиенты получат доступ к ИИ-генератору через платформу машинного обучения Vertex AI. Как и в прошлом, в этот раз Google не поделилась подробностями касательно того, какие данные использовались для обучения нового алгоритма. Microsoft начала тестировать ИИ-генератор изображений в Paint для Windows 11
28.09.2023 [17:51],
Владимир Фетисов
На этой неделе Microsoft выпустила очередную бета-версию графического редактора Paint для Windows 11. Помимо прочего, в ней реализована ИИ-функция Cocreator, с помощью которой можно генерировать изображения по текстовому описанию. Теперь же приложение стало доступно участникам программы предварительной оценки Windows Insider на каналах Dev и Canary. 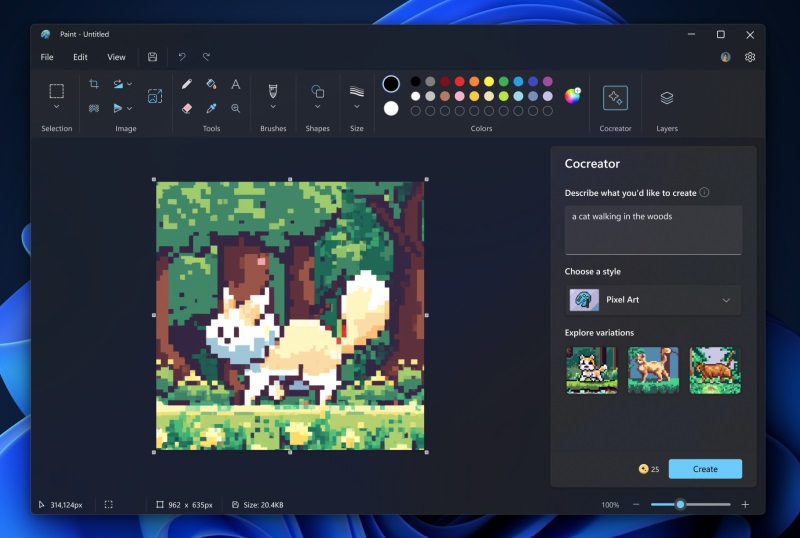
Источник изображений: Microsoft Функция генерации изображений по текстовому описанию опирается на работу нейросети DALL-E, созданной разработчиками из OpenAI. Она позволяет создавать уникальные изображения по короткому текстовому описанию. В дополнение к этому пользователь может выбрать стиль будущего изображения. После генерации пользователю будет предложено три варианта изображения. Выбрав один из них можно продолжить редактирование сгенерированной картинки, например, добавить слои, что также является нововведением для Paint. После загрузки Paint 11.2309.20.0 необходимо авторизоваться в своей учётной записи Microsoft. В Paint появилась кнопка Cocreator, нажав на которую пользователь будет добавлен к списку ожидания. Когда возможность использования инструмента Cocreator станет доступна, поступит соответствующее уведомление. В рамках тестирования Cocreator пользователям будут доступны 50 кредитов для генерации картинок. За каждое использование ИИ-функции списывается один кредит. 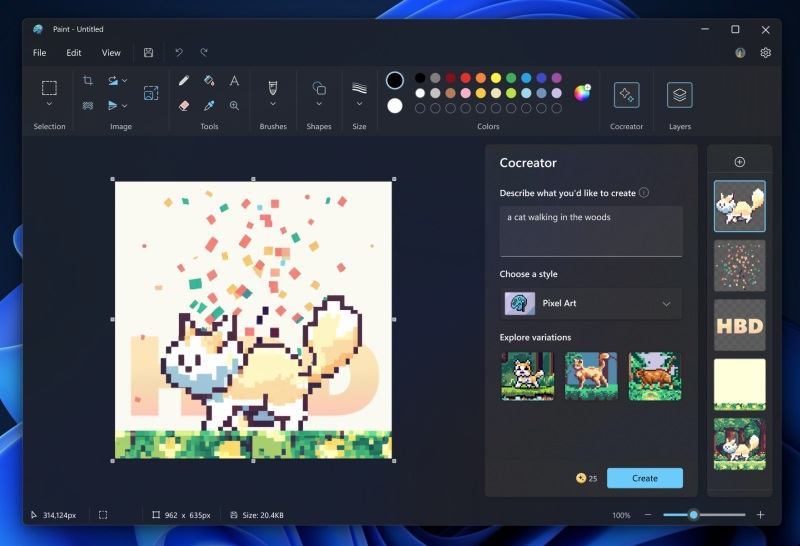 Microsoft планирует постепенно внедрять новую функцию, и в течение следующих нескольких недель она должна стать доступна всем пользователям Windows 11, установившим последнее функциональное обновление. Однако сейчас испытать функцию Cocreator могут только инсайдеры. WhatsApp начал тестировать ИИ для генерации стикеров
15.08.2023 [17:13],
Владимир Фетисов
Разработчики из Meta✴ Platforms продолжают интегрировать в мессенджер WhatsApp новые функции, которые могут стать популярными среди пользователей. На этот раз в бета-версии мессенджера для платформы Android появилась возможность использования нейросети для генерации стикеров по текстовому описанию. На данном этапе функция доступна ограниченному числе пользователей бета-версии WhatsApp для Android под номером 2.23.17.14. 
Источник изображения: geralt / Pixabay Какая именно нейросеть используется для генерации стикеров по текстовому описанию в WhatsApp, пока неизвестно. В описании лишь сказано, что стикеры генерируются с помощью «безопасной технологии, предлагаемой Meta✴». Ожидается, что пользователи смогут с помощью текстового описания создавать простые персонализированные изображения, которые можно будет задействовать в качестве стикеров. 
Источник изображения: WABetaInfo Пользователи смогут реагировать на сгенерированные стикеры и сообщать администраторам в случае, если те или иные картинки будут казаться им неуместными. Согласно имеющимся данным, созданные с помощью ИИ-алгоритма стикеры легко распознаются, что предполагает наличие водяных знаков, которыми они будут помечаться, или каких-то иных отметок, указывающих на то, что изображения созданы нейросетью. По данным источника, Meta✴ также работает над тем, чтобы интегрировать в Instagram✴ специальные метки, которыми будет помечаться контент, созданный с использованием нейросетей. Adobe научила Photoshop расширять и дорисовывать изображения с помощью ИИ
27.07.2023 [18:11],
Владимир Фетисов
В мае этого года Adobe интегрировала в бета-версию графического редактора Photoshop ИИ-инструмент, позволяющий пользователям масштабировать изображения, добавлять и удалять объекты с помощью текстовых команд. Теперь же разработчики добавили новые функции за счёт запуска универсального инструмента Generative Expand, который на этой неделе стал доступен участникам программы бета-тестирования Photoshop. 
Источник изображения: 9to5mac.com Новый инструмент может оказаться полезным для выполнения разных действий. С его помощью можно расширить обрабатываемое изображение с текстовой подсказкой или без неё для создания продолжения сцены. Достаточно выделить область рядом с обрабатываемым изображением или вокруг него, а ИИ-инструмент сгенирирует всё остальное. Если не указывать текстовую подсказку, то выделенная область будет заполнена объектами, которые логично вписываются в общую композицию. Если же указать текстовую подсказку, то ИИ дорисует окружение в соответствии с пожеланием пользователя. Ещё с помощью нового инструмента можно изменить соотношение сторон, например, сделав из горизонтального изображения картинку размером с обложку журнала. Доступна возможность получения точной композиции путём обрезки изображения в одном направлении и расширения в другом направлении, причём всё это осуществляется в рамках одного простого рабочего процесса. Generative Expand может многократно расширить обрабатываемое изображение, заполнить свободное пространство при повороте картинки и др. Новый ИИ-инструмент имеет массу других возможностей, которые помогут авторам контента при выполнении разных задач. Инструмент Generative Expand и функция генеративной заливки Adobe получили поддержку более 100 языков. На данном этапе они доступны в бета-версии Photoshop. Когда нововведения появятся в стабильной версии графического редактора, пока неизвестно. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться