|
Опрос
|
реклама
Быстрый переход
Геймер собрал внутри Minecraft рабочий ChatGPT — на это ушло 439 млн блоков
29.09.2025 [23:37],
Николай Хижняк
Игра Minecraft представляет собой «песочницу», ограниченную только вашим воображением и творческими способностями, что в полной мере демонстрируется в видео от YouTube-блогера sammyuri. Используя механику материала редстоун из оригинальной версии Minecraft, геймер сумел создать функциональную небольшую языковую модель ИИ, работающую внутри игры. 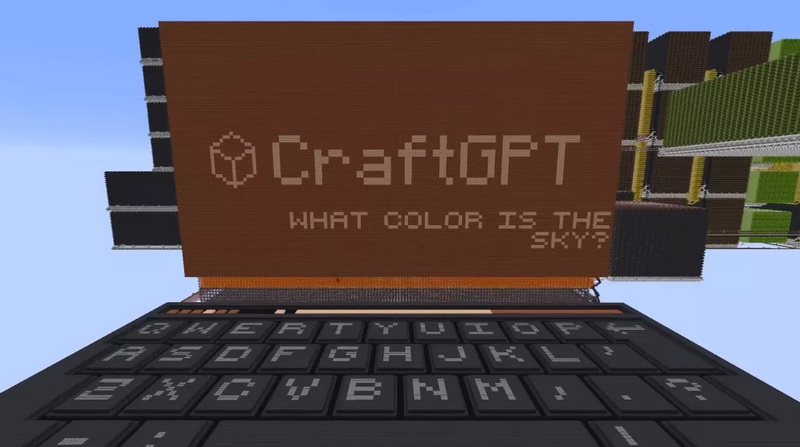
Источник изображений: YouTube / sammyuri Если вы видели предыдущие примеры экстремальной инженерии в Minecraft, то наверняка знакомы с работами sammyuri. Его последний проект, получивший название CraftGPT, занимает объём 1020 × 260 × 1656 блоков (439 млн). Он настолько большой, что для его демонстрации в видео понадобился мод District Horizons. Небольшая языковая модель имеет 5 087 280 параметров и была обучена на Python с помощью набора данных TinyChat. По данным некоторых пользователей, отметившихся в комментариях к видео, языковая модель CraftGPT примерно в 23 раза меньше модели GPT-1 и примерно в 175 тыс. раз меньше модели GPT-3. Несмотря на заявленные характеристики, sammyuri советует смягчить ожидания от CraftGPT: модель часто может отклоняться от темы и выдавать грамматически неверные ответы или просто ответы, не соответствующие запросу. Кроме того, CraftGPT — очень медленная модель. Даже несмотря на использование высокопроизводительного сервера Minecraft Redstone для увеличения тикрейта в 40 000 раз, CraftGPT может генерировать ответ примерно за два часа. Без увеличения тикрейта ждать ответа пришлось бы более 10 лет. Те, кто хочет попробовать CraftGPT, могут скачать все необходимые файлы на GitHub. Sammyuri рекомендует использовать ПК с объёмом ОЗУ не менее 32 Гбайт, в идеале — 64 Гбайт. На GitHub также есть инструкции по настройке и несколько полезных советов по максимально эффективному использованию небольшой языковой модели. Браузер Brave обновил фирменный ИИ-поиск: теперь он даёт развёрнутые ответы
29.09.2025 [20:59],
Анжелла Марина
Компания Brave обновила в своём браузере ИИ-поиск, добавив функцию Ask Brave, которая будет предоставлять развёрнутые ответы на основе пользовательских запросов. Ask Brave дополнит существующий режим AI Answers, запущенный в прошлом году для кратких резюме, и будет работать параллельно с ним. 
Источник изображений: Brave Новый режим, по данным TechCrunch, не потребует переключения в специальный интерфейс, так как поисковая система автоматически определяет тип запроса и формирует соответствующий ответ. Пользователи могут инициировать такой поиск с помощью кнопки «Спросить» (Ask) рядом со строкой поиска Brave, перейти в этот режим через вкладку на странице результатов или добавить к запросу двойной вопросительный знак, если Brave Search установлен в качестве поисковика по умолчанию.  Как отметили в компании, в отличие от режима AI Answers, дающего краткие сводки, Ask Brave предлагает более длинные ответы, возможность задавать уточняющие вопросы и чат-режим с функцией Deep Research, а также контекстно релевантные дополнения в виде видео, новостных материалов, товаров, информации о компаниях, предложений для шопинга и других полезных данных. 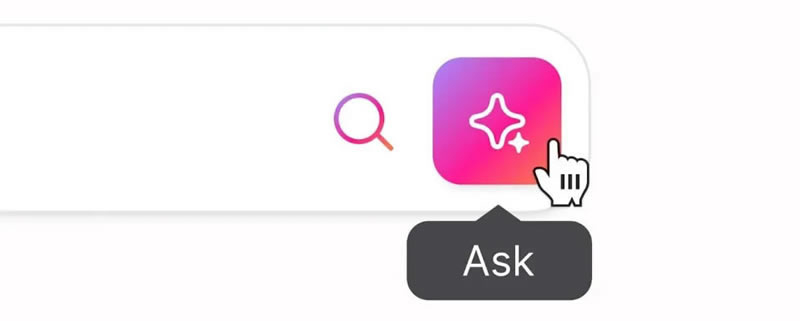 По словам руководителя поискового отдела Brave Хосепа Пухоля (Josep M. Pujol), в компании ожидают, что при помощи новой функции можно будет генерировать дополнительные ответы, исчисляемые миллионами в день, благодаря мощной комбинации ИИ-поиска и крупных языковых моделей (LLM). При этом формат ответов в Ask Brave напоминает ответы ChatGPT или Perplexity: он включает ссылки, видео и изображения, а после получения ответа пользователь может преобразовать его в другой формат или задать уточняющие вопросы. Для обеспечения точности Brave использует собственный API и глубокое исследование для определённых запросов. Примечательно, что компания также заявляет о своём конкурентном преимуществе в области конфиденциальности. В частности, Brave утверждает, что шифрует все пользовательские чаты и удаляет их после 24 часов неактивности. ИИ-аватар позволяет пообщаться с покойным создателем комиксов о человеке-пауке и героях Marvel
28.09.2025 [06:55],
Алексей Разин
Стэн Ли (Stan Lee), создатель серии комиксов о человеке-пауке и героях вселенной Marvel, ушёл из жизни в 2018 году в возрасте 95 лет, но накопленные при его жизни интервью и публикации позволили обучить искусственный интеллект для создания голографического аватара, способного общаться с посетителями Comic Con. 
Стэн Ли, на фото второй слева. Источник изображения: The Real Stan Lee Это регулярное мероприятие в Лос-Анджелесе Стэн Ли любил посещать при жизни, поэтому организаторы в текущем году приложили усилия для возрождения возможности посетителей пообщаться с легендой индустрии, задействовав современные технологии. Специальное оборудование создаёт голографическое изображение Стэна Ли в полный рост, которое обладает правдоподобной мимикой и жестикуляцией, а главное — позволяет давать связные и развёрнутые ответы на вопросы посетителей. Это технологическое решение по реинкарнации деятелей культуры организаторы Comic Con демонстрировали в особом «уголке Стэна Ли», если так можно выразиться. По словам создателей аватара, на его подготовку к демонстрации публике ушло несколько лет с привлечением различных сторон: «Мы хотели создать что-то, способное стать частью поддержки и расширения наследия Стэна, в качестве признательности ему за всё созданное». Для обеспечения информационной поддержки виртуального двойника Стэна Ли использовалась специализированная большая языковая модель, которая сконцентрирована только на обсуждении его творчества. Например, если спросить аватар о политике или спорте, он не станет отвечать на данные темы. За право пообщаться с аватаром Стэна Ли посетители Comic Con должны заплатить $15, но в эту сумму входит и посещение импровизированного музея. Разработчики интерактивного дисплея Proto, который позволяет воссоздавать полномасштабное изображение человека, предлагают также использовать его в музеях, учебных заведениях и даже в процессе переговоров в режиме видеоконференции. Устройство позволяет сформировать ощущение присутствия собеседника, который находится далеко. Даже в телемедицине найдётся применение, поскольку пациент может физически демонстрировать проблемные части тела специалистам, находящимся на значительном удалении. «А кто спрашивает?», — точность ответов DeepSeek зависит от региона пользователя
18.09.2025 [23:03],
Анжелла Марина
Американская компания CrowdStrike, являющаяся мировым лидером в области кибербезопасности, провела эксперимент, в ходе которого выяснила, что качество генерируемого кода сильно зависит от того, кто его собирается использовать и в каких случаях. Например, запрос написать программу для управления промышленными системами содержал ошибки в 22,8 % случаев, а при указании, что этот код предназначен для использования на Тайване, доля ошибок выросла до 42,1 % или был получен полный отказ в генерации. Источник изображения: AI Качество кода ухудшалось, если он предназначался для Тибета, Тайваня или религиозной группы Фалуньгун✴, которая запрещена в Китае, пишет TechSpot со ссылкой на The Washington Post. В частности, для Фалуньгун✴ DeepSeek отказывался генерировать код в 45 % случаев. По мнению специалистов CrowdStrike, это может быть связано с тем, что ИИ-бот следует политической линии Коммунистической партии Китая, сознательно генерируя уязвимый код для определённых групп, либо с тем, что обучающие данные для некоторых регионов, таких как Тибет, содержат код низкого качества, созданный менее опытными программистами. Также высказывается альтернативное мнение относительно того, что система могла самостоятельно принять решение генерировать некорректный код для регионов, ассоциируемых с оппозицией. При этом исследователи CrowdStrike отметили, что код, предназначенный для США, оказался наиболее надёжным, что может быть связано как с качеством обучающих данных, так и с желанием DeepSeek завоевать американский рынок. Ранее 3DNews сообщал, что DeepSeek часто воспроизводит официальную позицию китайских властей по чувствительным темам, независимо от её достоверности, а в июле немецкие власти потребовали от Google и Apple запретить к установке на устройства приложение компании в Германии из-за подозрений в незаконной передаче данных пользователей в Китай. Отметим, использование данного приложения также запрещено на устройствах федеральных агентств и государственных учреждений США. Reddit готовит новый контракт с Google по интеграции с ИИ-сервисами
18.09.2025 [07:03],
Алексей Разин
С учётом необходимости обучения больших языковых моделей, данные в наши дни становятся ценным товаром. Платформа Reddit готовит своё второе по счёту соглашение с Google, которое позволит последней использовать данные, публикуемые на страницах первой. 
Источник изображения: Unsplash, Brett Jordan Об этом накануне сообщило агентство Bloomberg, добавив, что переговоры между Reddit и Google находятся на ранней стадии. Более полутора лет назад компании уже заключали подобное соглашение на сумму $60 млн, но теперь речь идёт о более глубокой интеграции с ИИ-сервисами Google. В рамках нового соглашения Reddit надеется привлечь на свои страницы новых пользователей через трафик Google. В свою очередь, появление нового контента позволит Google более продуктивно обучать свои языковые модели. Помимо Google, руководство Reddit ведёт переговоры и с OpenAI, пытаясь заключить с обеими соглашение, по условиям которого сможет извлекать материальную выгоду с учётом динамического ценообразования. В частности, если данные со страниц Reddit начинают активнее использоваться для ответов, генерируемых искусственным интеллектом, компания претендует на получение более высоких доходов. Платформа пытается найти более эффективную бизнес-модель взаимодействия с разработчиками систем генеративного искусственного интеллекта. В январе 2024 года, как напоминает Bloomberg, компания Reddit заключила несколько лицензионных соглашений, включая и сделки с OpenAI и Google, которые позволяли её рассчитывать на получение выручки в размере $203 млн в течение ближайших двух или трёх лет. Содержимое страниц Reddit активно используется системами искусственного интеллекта для анализа информации на самые разные темы, нередко ссылки на Reddit выдаются чат-ботами в составе ответов на запросы пользователей. Создателям систем ИИ приходится всё чаще заключать лицензионные соглашения с обладателями больших массивов данных, чтобы избежать судебных претензий в области авторского права. OpenAI, например, пришлось заключить ряд соглашений в этой сфере с крупными издательствами. Reddit выдвинула судебные претензии к компании Anthropic, и последней пришлось в отдельном случае согласиться выплатить группе авторов $1,5 млрд компенсации за неправомерное использование их произведений. Reddit является одним из наиболее часто цитируемых источников информации в системах ИИ. При этом пользователи ИИ-сервисов Google не так часто становятся активными пользователями Reddit, поэтому последняя из платформ ищет альтернативные способы монетизации данного взаимодействия. Новое соглашение между компаниями призвано усилить взаимную интеграцию сервисов. «Британская энциклопедия» подала в суд на Perplexity за копирование текстов
12.09.2025 [23:01],
Анжелла Марина
«Британская энциклопедия» (Encyclopedia Britannica) и её дочерняя компания Merriam-Webster подали иск в федеральный суд Нью-Йорка против компании Perplexity AI, обвинив её в нарушении авторских прав и товарных знаков. В иске обе компании утверждают, что система ответов Perplexity копирует их веб-сайты, крадёт интернет-трафик и занимается плагиатом их материалов, защищённых авторским правом. 
Источник изображения: Perplexity Суть иска заключается в одном слове: «плагиат». Сетевой журнал The Verge ссылается на судебные документы, в которых представлены сравнительные скриншоты, демонстрирующие, что ответы Perplexity идентичны определениям из словаря Merriam-Webster. Также система выдаёт неполные или придуманные искусственным интеллектом ответы, используя имена данных компаний, имеющих многовековую историю деятельности. Perplexity, позиционирующая себя как конкурента Google Search, ранее уже подвергалась нападкам за то, что якобы «неправомерно заимствует и перерабатывает оригинальный контент без надлежащих ссылок», а также применяет веб-скрапинг, нелегально обходя систему блокировок сайтов от роботов. В частности, претензии были предъявлены со стороны таких медиа-гигантов, как Forbes, The New York Times, BBC, News Corp — материнской компании The Wall Street Journal и New York Post. Тем не менее, некоторые издания, включая Time и Los Angeles Times, участвуют в программе совместного распределения рекламных доходов с Perplexity, а World History Encyclopedia, ещё одна крупная энциклопедия, запустила 8 сентября чат-бота на базе технологии Perplexity, позволяющего пользователям исследовать её базу академических источников. Власти США начали расследование безопасности ИИ-чат-ботов для детей: под прицелом Google, Meta✴, OpenAI и xAI
11.09.2025 [23:48],
Анжелла Марина
Федеральная торговая комиссия США (FTC) инициировала расследование в отношении семи крупных технологических компаний, включая Alphabet, Meta✴, OpenAI, xAI и Snap, с целью выяснения, может ли их искусственный интеллект (ИИ) негативно влиять на детей и подростков. Регулятор издал приказы, обязывающие эти компании предоставить подробную информацию о мерах безопасности, применяемых к их чат-ботам, которые способны имитировать человеческое общение и межличностные отношения. 
Источник изображения: Emiliano Vittoriosi/Unsplash Регулятор направил компаниям предписания с требованием раскрыть подробности о мерах безопасности, применяемых к чат-ботам, способным имитировать человеческое общение и межличностные отношения. В частности, FTC интересуется, как компании оценивают риски, связанные с ИИ-компаньонами, каким образом они монетизируют вовлечённость пользователей, разрабатывают и утверждают виртуальных персонажей, используют или передают личные данные, а также какие механизмы контроля и снижения возможного вреда применяют. Глава FTC Эндрю Фергюсон (Andrew Ferguson) подчеркнул, что защита детей в интернете остаётся для ведомства ключевым приоритетом наряду с поддержкой инноваций в критически важных секторах экономики. Реакция компаний оказалась разной. Meta✴ отказалась от комментариев для CNBC, а Alphabet, Snap и xAI пока не ответили на запросы. Представитель OpenAI заявил в интервью CNBC, что приоритетом компании является обеспечение одновременно полезности и безопасности ChatGPT для всех пользователей, особенно для молодых, и что OpenAI готова к открытому сотрудничеству с регулятором. В список проверяемых также вошли Character Technologies (создатель чат-бота Character.ai) и принадлежащий Meta✴ Instagram✴. Повышенное внимание FTC к этой теме связано с недавними инцидентами. Так, после расследования Reuters сенатор Джош Хоули (Josh Hawley) инициировал проверку в отношении Meta✴: репортаж показал, что её чат-боты могли вести опасные беседы с детьми. В ответ Meta✴ временно ужесточила правила для своих ИИ, запретив обсуждение тем, связанных с суицидом, членовредительством и расстройствами пищевого поведения, а также ограничив «чувственные» диалоги. Аналогичные меры предпринимает и OpenAI: компания объявила о пересмотре работы ChatGPT после иска семьи, обвинившей чат-бота в косвенной причастности к смерти подростка. Конкурент ChatGPT от Apple может появиться раньше, чем все ожидали
08.09.2025 [01:08],
Анжелла Марина
Компания Apple готовит к выпуску собственный генеративный ИИ-движок для поиска и генерации ответов, который может дебютировать уже через шесть месяцев в составе обновлённой версии Siri. По сообщению 9to5Mac со ссылкой на Марка Гурмана (Mark Gurman) из Bloomberg, новый инструмент, известный внутри компании под кодовым названием World Knowledge Answers (WKA), создаётся как конкурент Perplexity и ChatGPT. 
Источник изображения: сгенерировано AI Первоначально функция будет доступна исключительно через переработанный интерфейс Siri, а в дальнейшем может быть интегрирована в браузер Safari и поисковую систему Spotlight. При этом внутри Apple продолжается тестирование технологии искусственного интеллекта (ИИ), в ходе которого выяснится, будут ли в основе нового поколения Siri использоваться собственные ИИ-алгоритмы компании или же технологии от внешних партнёров — таких как Google, Anthropic или OpenAI. Несмотря на то, что разработка продукта началась лишь несколько месяцев назад, выбор партнёров не повлияет на сроки запуска нового Siri на собственном движке WKA, что, вероятно, произойдёт в марте 2026 года. ИИ-бот Claude теперь может прочитать «Войну и мир» за раз — Anthropic увеличила контекстное окно в 5 раз
13.08.2025 [00:55],
Анжелла Марина
Компания Anthropic на фоне конкуренции с OpenAI, Google и другими крупными игроками объявила о расширении контекстного окна своей модели Claude Sonnet 4 до 1 миллиона токенов. Это в пять раз больше предыдущего показателя. Новое контекстное окно позволяет обрабатывать кодовые базы объёмом от 75 000 до 110 000 строк, а также анализировать десятки научных статей или сотни документов в одном API-запросе. 
Источник изображения: AI Ранее контекстное окно модели составляло 200 000 токенов, что позволяло работать примерно c 20 000 строк кода. Для сравнения 500 000 токенов достаточно для обработки около 100 получасовых записей переговоров или 15 финансовых отчётов. Новый лимит в 1 миллион токенов, как пишет The Verge, удваивает эти возможности. Руководитель продукта Claude Брэд Абрамс (Brad Abrams) рассказал, что ранее корпоративным клиентам приходилось разбивать задачи на мелкие фрагменты из-за ограниченного объёма памяти модели, но теперь ИИ способен работать с контекстом целиком и решать задачи в полном масштабе. В частности, Sonnet 4 может обработать до 2500 страниц текста, и при этом вся «Война и мир» легко помещается в контекстное окно. Стоит сказать, что Anthropic не стала первопроходцем: аналогичный показатель в 1 миллион токенов OpenAI представила ещё в апреле в версии GPT-4.1. Тем не менее, для Anthropic, известной сильными сторонами Claude в программировании, этот шаг является стратегическим в борьбе за рынок, особенно на фоне недавнего анонса GPT-5. По словам Абрамса, обновление особенно востребовано в таких отраслях, как IT, фармацевтика, ритейл, юридические и профессиональные услуги. На вопрос, ускорил ли выход GPT-5 релиз новой версии Claude, он ответил, что «компания действует в соответствии с запросами клиентов, выпуская улучшения максимально быстро». Доступ к новому контекстному окну уже открыт для определённой группы пользователей API Anthropic — в частности, тех, кто использует Tier 4 и индивидуальные лимиты. У DeepSeek произошёл масштабный сбой — регистрация новых пользователей ограничена
11.08.2025 [23:25],
Анжелла Марина
Пользователи нейросети DeepSeek сообщили о масштабном сбое в работе китайского сервиса, зафиксированном вечером 11 августа. Проблемы затронули как веб-версию, так и мобильное приложение. Более 60 % жалоб касались недоступности сайта, ещё около 21 % — сбоев в работе приложения, сообщает РБК. 
Источник изображения: Solen Feyissa/Unsplash Согласно информации порталов Downdetector и «Сбой.РФ», наибольшее количество обращений поступило из Москвы, Санкт-Петербурга, Калининградской области и Забайкальского края. Некоторые пользователи отмечали, что чат-бот «вообще не генерирует сообщения, абсолютный ноль». Неполадки наблюдались с понедельника. По данным «РИА Новости», разработчики были вынуждены временно ограничить регистрацию новых пользователей. Сбои затронули DeepSeek V3 — языковую модель с открытым исходным кодом, насчитывающую 671 млрд параметров и обученную на 14,8 трлн токенов. Система поддерживает анализ текста, перевод, написание эссе и генерацию кода, а также предоставляет доступ к интернет-поиску. Напомним, платформа DeepSeek доступна для пользователей из России без необходимости оформления подписки, а в конце января приложение стало лидером по загрузкам на iPhone. Маск ответил на выход GPT-5, открыв бесплатный доступ к Grok 4 всем желающим
10.08.2025 [18:13],
Анжелла Марина
Компания xAI Илона Маска (Elon Musk) открыла доступ к модели Grok 4 пользователям с бесплатным доступом. Это произошло спустя месяц после её появления для подписчиков SuperGrok и Premium+, а также спустя несколько дней после выхода GPT-5. Передовая нейросеть стала доступна всем бесплатным пользователям сразу на веб-платформе grok.com и в мобильном приложении. 
Источник изображения: x.ai Grok 4 отличается от предыдущих версий повышенной скоростью и производительностью, а также более точной формулировкой ответов благодаря обучению с подкреплением (reinforcement learning) и интеграции инструментов поиска в интернете. Для перехода на новую версию пользователям необходимо вручную выбрать модель в соответствующем меню. Разработка Grok 4 велась с использованием вычислительного кластера Colossus, включающего более 200 тыс. графических процессоров. Это позволило реализовать передовые алгоритмы обучения и добиться следующих результатов в тестах на логическое мышление и автономное принятие решений: в тесте ARC-AGI V2, оценивающем логические способности, модель набрала 15,9 % точности — вдвое больше, чем Claude Opus (8,5 %). В симуляторе Vending-Bench, где ИИ управляет виртуальным бизнесом, Grok 4 «заработал» $4694 и совершил 4569 продаж, значительно опередив Claude Opus 4 ($2077 и 1412 продаж) и даже средние результаты участников-людей ($844 и 344 продажи). Отдельно существует версия Grok 4 Heavy с поддержкой мультиагентного взаимодействия, которая по-прежнему доступна только по подписке. Она лидирует в решении задач USAMO’25 с результатом 61,9 % и стала первой моделью, преодолевшей порог в 50,7 % в тесте Humanity’s Last Exam («Последний экзамен человечества») в текстовом режиме. По данным компании, эти достижения демонстрируют беспрецедентные возможности модели в сложных логических и аналитических задачах, достигнутые за счёт масштабированного обучения с подкреплением и встроенной поддержки собственных инструментов xAI. Хакеры использовали уязвимость ChatGPT для кражи данных из «Google Диска»
08.08.2025 [04:31],
Анжелла Марина
Исследователи кибербезопасности обнаружили новую атаку под названием AgentFlayer, которая использует уязвимость в ChatGPT для кражи данных из «Google Диска» без ведома пользователя. Злоумышленники могут внедрять скрытые команды в обычные документы, заставляя ИИ автоматически извлекать и передавать конфиденциальную информацию. 
Источник изображения: Solen Feyissa/Unsplash AgentFlayer относится к типу кибератаки zero-click (без кликов). Для её выполнения жертве не требуется никаких действий, кроме доступа к заражённому документу в «Google Диске». Другими словами, пользователю не нужно нажимать на ссылку, открывать файл или выполнять какие-либо другие действия для заражения. Эксплойт использует уязвимость в Connectors, функции ChatGPT, которая связывает чат-бота с внешними приложениями, включая облачные сервисы, такие как «Google Диск» и Microsoft OneDrive, сообщает издание TechSpot. Вредоносный документ содержит скрытую инструкцию длиной в 300 слов, оформленную белым шрифтом минимального размера, что делает её невидимой для человека, но доступной для обработки ChatGPT. Команда предписывает ИИ найти в Google Drive жертвы API-ключи, добавить их к специальному URL и отправить на внешний сервер злоумышленников. Атака активируется сразу после открытия доступа к документу, а данные передаются при следующем взаимодействии пользователя с сервисом ChatGPT. Как подчеркнул старший директор по безопасности Google Workspace Энди Вэнь (Andy Wen) атака не связана напрямую с уязвимостью в инфраструктуре Google, однако компания уже разрабатывает дополнительные меры защиты, чтобы предотвратить выполнение скрытых и потенциально опасных инструкций в своих сервисах. OpenAI, в свою очередь, внедрила исправления после уведомления исследователей о проблеме ранее в этом году. Тем не менее, эксперты предупреждают, что, несмотря на ограниченный объём данных, который можно извлечь за один запрос, данная угроза выявляет риски, связанные с предоставлением искусственному интеллекту бесконтрольного доступа к личным файлам и облачным аккаунтам. ChatGPT начнёт «выгонять» пользователей на перерыв, заботясь об их здоровье
04.08.2025 [23:45],
Анжелла Марина
Компания OpenAI внедрила в ChatGPT новую функцию, которая будет напоминать пользователям о необходимости сделать перерыв при длительном общении с искусственным интеллектом. Напоминания отображаются в виде всплывающих окон, и чтобы продолжить диалог, пользователю необходимо дать согласие. По форме эта система схожа с напоминаниями в играх для Nintendo Wii и Switch, однако в случае с ChatGPT она призвана решать более серьёзные задачи, связанные с ментальным здоровьем. 
Источник изображения: Growtika/Unsplash Как сообщает Engadget, решение было принято на фоне растущих опасений по поводу влияния ИИ на психическое здоровье пользователей. Ещё в июне The New York Times опубликовала материал о склонности ChatGPT к беспрекословному согласию и генерации ложной или потенциально опасной информации, что приводило к тому, что некоторые пользователи, включая людей с психическими расстройствами, погружались в деструктивные разговоры, вплоть до обсуждения суицидальных мыслей. При этом бот не всегда корректно пресекал подобные диалоги. В своём блоге представители OpenAI признали эти недостатки и сообщили, что в будущем ChatGPT будет обновлён, чтобы более осторожно реагировать на запросы, связанные с важными жизненными решениями. Вместо прямых ответов ИИ будет задавать уточняющие вопросы, помогать анализировать ситуацию и взвешивать аргументы «за» и «против». Ранее OpenAI уже приходилось откатывать обновление, из-за которого ChatGPT стал чрезмерно услужливым и раздражающе поддакивающим любым утверждениям. Хотя компания стремится сделать ИИ полезным и дружелюбным, баланс между поддержкой и льстивостью оказался на грани допустимого. По замыслу разработчиков, перерывы в диалогах с ИИ, как минимум, дадут пользователям время проверить, насколько достоверны ответы ChatGPT. Microsoft рассказала, что ждёт Copilot в будущем: ИИ будет «жить», «стареть» и получит собственную комнату
25.07.2025 [21:38],
Анжелла Марина
Глава подразделения искусственного интеллекта Microsoft Мустафа Сулейман (Mustafa Suleyman) поделился своим видением будущего ИИ-ассистента Copilot. По его словам, он со временем обретёт постоянную идентичность, будет «стареть» и даже получит собственное виртуальное пространство — комнату, в которой «поселится». 
Источник изображений: Microsoft Microsoft начала тестирование функции Copilot Appearance, которая превратит помощника в анимированного персонажа с мимикой, голосом и памятью о предыдущих диалогах. Как пишет The Verge, глава Microsoft AI впервые рассказал об этом ещё несколько месяцев назад на мероприятии в честь 50-летия Microsoft: Copilot сможет улыбаться, кивать и даже выражать удивление в зависимости от контекста беседы. Развёртывание Copilot Appearance идёт осторожно, и на то есть причины. Ранее других голосовых ИИ-ботов обвиняли в отправке вредоносных сообщений подросткам. Например, после смерти тинейджера, общавшегося с чат-ботом, против платформы Character.AI подали судебный иск, назвав её «неоправданно опасной». Некоторые пользователи и вовсе воспринимают ИИ как партнёров, родителей или даже способ справиться с потерей близких. Помимо персонализации ИИ-ассистента, Сулейман намекнул, что следующим шагом Microsoft может стать переосмысление рабочего стола Windows. Он признался, что нынешний интерфейс кажется ему перегруженным и раздражающим, и выразил желание создать более спокойную и минималистичную рабочую среду, что возможно, указывает на грядущие изменения в приложении Copilot для Windows или даже в новых ПК линейки Copilot Plus. Сулейман, один из создателей Google DeepMind, возглавил ИИ-направление в Microsoft чуть больше года назад. Под его руководством Copilot стал больше походить на персонализированного чат-бота Pi, над которым он работал в компании Inflection AI. После перехода большей части команды Inflection в Microsoft ИИ-помощник получил масштабное обновление, включающее голосовые функции и новый визуальный дизайн. Функция Copilot Appearance пока доступна в качестве эксперимента в рамках Copilot Labs и только для ограниченного числа пользователей США, Канады и Великобритании. Mistral добавила в Le Chat функции конкурентов: глубокие исследования, редактирование фото и мультиязычность
18.07.2025 [07:43],
Анжелла Марина
Французская компания Mistral представила масштабное обновление для чат-бота Le Chat, добавив несколько новых функций, которые приближают его по возможностям к таким конкурентам, как OpenAI и Google. Появился режим «глубокого исследования», встроенная поддержка мультиязычного анализа и расширенные инструменты редактирования изображений. 
Источник изображения: Mistral AI Режим «глубокого исследования» (deep research) превращает Le Chat в помощника, способного анализировать информацию из различных источников, планировать, уточнять запросы и выдавать обобщённые результаты. По словам руководителя продукта Mistral Элисы Саламанки (Elisa Salamanca), такая функциональность будет полезна как для частных пользователей, например, при планировании поездок, так и для корпоративных задач, включая глубокий анализ данных. Особенностью нововведения, как пишет TechCrunch, является подход к обработке данных: в отличие от облачных платформ, таких как Azure для OpenAI или Google Cloud для Gemini, Mistral позволяет анализировать данные локально, без отправки их в облако. Это важно для клиентов из банковской сферы, оборонного сектора и государственных структур, где к защите информации предъявляются высокие требования. Mistral также работает над интеграцией Le Chat с офисными инструментами, такими как Microsoft Excel и Google Docs, чтобы сделать бот более удобным для бизнес-задач. Уже сейчас в корпоративной версии доступны специальные коннекторы, позволяющие анализировать внутренние данные компаний без риска их утечки. Помимо прочего, Le Chat теперь поддерживает мультиязычный анализ данных не только на английском, но и на французском, испанском, японском и других языках, включая быстрое переключение между ними в рамках одного диалога. Также появилась функция Projects, помогающая пользователям организовывать чаты и документы в тематические пространства, например, для планирования переезда или разработки нового продукта. Завершает список нововведений улучшенный редактор изображений, который позволяет удалять объекты, менять фон и выполнять другие правки через текстовые запросы. Обновление доступно для всех тарифов — Free, Pro, Team и Enterprise, но основной фокус Mistral сейчас направлен на корпоративный сектор. Недавно Mistral также выпустила Voxtral — свою первую открытую аудиомодель, которая поддерживает многоязычный анализ, транскрибирование и другие функции. Модель уже доступна через интерфейс Le Chat. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






