|
Опрос
|
реклама
Быстрый переход
Grok Илона Маска обзавёлся странными ИИ-компаньонами — один из них предстал в откровенном образе
15.07.2025 [06:09],
Анжелла Марина
Илон Маск (Elon Musk) добавил в свой ИИ-чат Grok необычных анимированных компаньонов. Пока доступны два персонажа: аниме-героиня Ани (Ani) и мультяшная красная панда Руди (Rudy). Как выяснилось, Ani может появляться перед пользователями в откровенной одежде, но при этом применяется так называемый NSFW-режим, который предупреждает, что открывать тот или иной контент «на работе небезопасно». 
Источник изображения: X Как пишет The Verge, для активации компаньона нужно зайти в настройки и далее следовать подсказкам, однако Маск пообещал упростить этот процесс в ближайшие дни, назвав текущую версию «мягким запуском» (soft launch). Интересно, что даже бесплатные пользователи Grok смогли пообщаться с новыми аватарами, что говорит о возможном широком доступе к функции. Параллельно в разработке находится ещё один персонаж — Чэд (Chad).  Отмечается, что это обновление появилось сразу после скандала, когда Grok начал распространять антисемитские высказывания и хвалебные комментарии в адрес Гитлера. В xAI тогда заявили, что проблема возникла из-за «изменений в структуре кода, затрагивающих бота». Теперь же компания, судя по всему, хочет сместить акцент в сторону более развлекательного контента, включая голосовой режим с возможностью свободных диалогов. Чат-бот с креативом: Claude стал ИИ-дизайнером, научившись работать с Canva
14.07.2025 [23:53],
Анжелла Марина
Anthropic объявила о новой функции для своего ИИ-чат-бота Claude. Теперь бот может создавать и редактировать проекты, связанные с платформой Canva. Пользователи, подключившие аккаунты обоих сервисов, смогут управлять дизайном с помощью текстовых команд: создавать презентации, изменять размеры изображений, заполнять шаблоны, а также искать ключевые слова в документах и презентациях Canva. 
Источник изображения: Swello/Unsplash Технической основой интеграции стал протокол Model Context Protocol (MCP), который Canva представила в прошлом месяце, сообщает The Verge. Этот открытый стандарт, нередко называемый «USB-C для ИИ-приложений», обеспечивает безопасный доступ Claude к пользовательскому контенту в Canva и упрощает подключение ИИ-моделей к другим сервисам. Помимо Anthropic, протокол MCP уже используют Microsoft, Figma и сама Canva — всё это, очевидно, в ожидании будущего, где ключевую роль будут играть ИИ-агенты. Как отметил глава экосистемы Canva Анвар Ханиф (Anwar Haneef), теперь пользователи могут генерировать, редактировать и публиковать дизайны прямо в чате с Claude, без необходимости вручную загружать файлы. По его словам, MCP делает этот процесс максимально простым, объединяя креативность и продуктивность в едином рабочем процессе. Для доступа к новым возможностям требуются платные подписки на оба сервиса: Canva — от $15 в месяц и Claude — за $17 в месяц. Отметим, что Claude стал первым ИИ-ассистентом, поддерживающим дизайн-процессы в Canva через MCP. У него уже есть аналогичная интеграция с Figma, представленная в прошлом месяце. Также сообщается, что Anthropic запустила новый «каталог интеграций Claude» для ПК, где пользователи смогут ознакомиться со всеми доступными инструментами и подключёнными приложениями. Илон Маск представил мощнейшую ИИ-модель Grok 4 и подписку SuperGrok Heavy за $300 в месяц
10.07.2025 [10:31],
Дмитрий Федоров
Компания xAI, основанная Илоном Маском (Elon Musk), представила новую версию своего ИИ-чат-бота — Grok 4. Анонс состоялся спустя всего несколько месяцев после выхода предыдущей версии и всего через сутки после скандала с Grok 3. Поспешный выпуск Grok 4 демонстрирует скорость инноваций в генеративном ИИ и одновременно обнажает острую потребность в надёжных механизмах этического контроля. 
Источник изображения: xAI Маск вышел в эфир в кожаной куртке, в окружении ключевых сотрудников команды Grok, и заявил, что новая версия уже доступна пользователям. По его словам, Grok 4 «умнее почти всех студентов магистратуры сразу по всем дисциплинам». Это уже четвёртая итерация чат-бота xAI за последние 9 месяцев. Согласно заявлению компании, Grok 4 получил улучшенные голосовые функции и возможность поддерживать более глубокие и логически выстроенные диалоги. Внутренние бенчмарки xAI показывают, что новая ИИ-модель обогнала существующие решения компаний OpenAI, Alphabet и Meta✴. Однако эти тесты пока не были проверены независимыми экспертами. Как утверждают разработчики, новая архитектура позволяет Grok 4 более точно интегрировать знания из различных областей и выдавать обоснованные ответы даже на междисциплинарные запросы. По данным xAI, Grok 4 без подключения дополнительных инструментов набрал 25,4 % в сложнейшем тесте Humanity’s Last Exam, превзойдя показатели Google Gemini 2.5 Pro (21,6 %) и OpenAI o3 (high), показавшего 21 %. 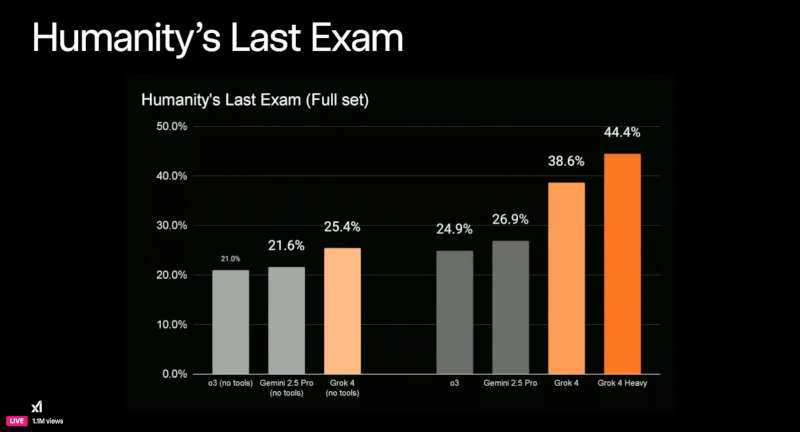
График показывает результаты модели Grok 4 и её варианта Grok 4 Heavy в тесте Humanity’s Last Exam Вместе с базовой моделью Grok 4 компания xAI представила Grok 4 Heavy — мультиагентный вариант чат-бота, в котором несколько автономных агентов параллельно решают поставленную задачу, после чего сравнивают полученные решения, подобно группе экспертов. Grok 4 Heavy, использующий инструменты, достиг результата в 44,4 %, тогда как Gemini 2.5 Pro с аналогичным доступом к инструментам смог набрать лишь 26,9 %. Эти данные, согласно заявлению xAI, демонстрируют «передовой уровень производительности» в области генеративного ИИ. 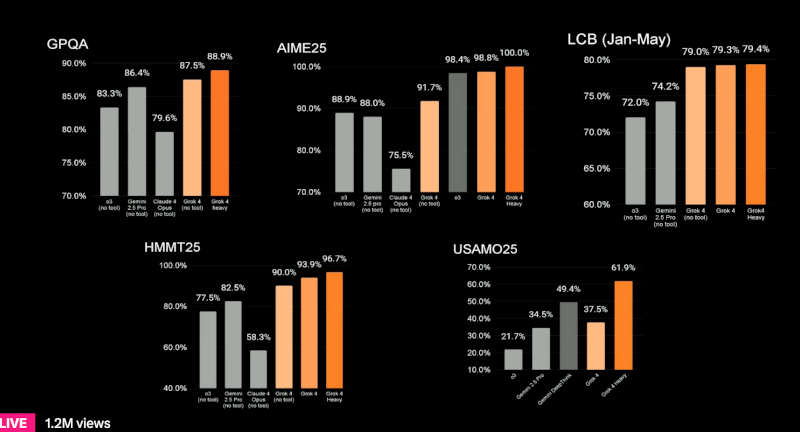
Результаты тестов Grok 4 и Grok 4 Heavy по шести академическим бенчмаркам, включая GPQA, AIME25, LCB и USAMO25 Также был представлен новый премиальный тариф — подписка SuperGrok Heavy стоимостью $300 в месяц, ставшая самой дорогой среди аналогичных предложений крупных разработчиков ИИ. Она даёт ранний доступ к Grok 4 Heavy и будущим функциям, включая обещанные ИИ-модули для программирования в августе, мультиагентный вариант в сентябре и генерации видео в октябре. xAI рассчитывает, что дорогая подписка позволит финансировать дальнейшие исследования, а также привлечёт корпоративных клиентов, готовых испытать возможности новой ИИ-модели раньше конкурентов. Релиз Grok 4 состоялся всего через сутки после того, как xAI была вынуждена удалить с платформы X (ранее Twitter) несколько публикаций от имени чат-бота Grok 3, содержавших антисемитские высказывания и сомнительные ответы пользователям. В официальном заявлении компания сообщила: «С момента выявления этого контента xAI предприняла меры для блокировки языка вражды до публикации новых материалов Grok в X». Несмотря на серьёзность инцидента, Маск во время трансляции напрямую не упомянул инцидент, заявив лишь, что «нам нужно убедиться, что ИИ — это хороший ИИ». Ранее министр транспорта и инфраструктуры Турции Абдулкадир Уралоглу (Abdulkadir Uraloglu) резко раскритиковал работу Grok и заявил в интервью Bloomberg News, что Турция может заблокировать платформу X, если не будут приняты меры по предотвращению публикации агрессивного контента. Он подчеркнул: «Неприемлемо использовать бранные слова». Этот комментарий прозвучал до старта презентации Grok 4 и усилил международное внимание к этической стороне вопроса. В марте xAI официально объединилась с социальной платформой X. В результате была сформирована структура, нацеленная на интеграцию возможностей Grok в пользовательский интерфейс X. Однако в день презентации, за несколько часов до эфира, генеральный директор X Линда Яккарино (Linda Yaccarino) подала в отставку. Этот шаг оставил вакантной ключевую управленческую должность и поставил под вопрос стабильность дальнейшего развития платформы в условиях стремительной эволюции конкурирующих ИИ-моделей. По данным Bloomberg News, xAI расходует около $1 млрд ежемесячно на разработку ИИ. Эта цифра отражает не только масштаб проектов, но и высокую стоимость реализации амбиций Маска. В настоящее время компания активно ведёт переговоры о привлечении внешнего финансирования, включая контакты с венчурными фондами и суверенными инвестиционными структурами. В фокусе — дальнейшее развитие больших языковых ИИ-моделей, улучшение качества генерации контента и интеграция ИИ в инфраструктуру платформы X. OpenAI начала тестировать в ChatGPT образовательный режим ответов «Учимся вместе»
08.07.2025 [05:08],
Анжелла Марина
В ChatGPT появился новый режим Study Together, который может изменить то, как студенты и преподаватели используют искусственный интеллект (ИИ). Вместо готовых ответов бот предлагает интерактивное обучение, задавая вопросы и стимулируя у ученика критическое мышление. Но функция пока доступна не всем. 
Источник изображения: AI Судя по первым отзывам, этот режим работает иначе, чем обычный ChatGPT. Как сообщает TechCrunch, вместо того, чтобы сразу давать готовые ответы, система задаёт уточняющие вопросы, побуждая пользователя самостоятельно искать решение. Это напоминает подход Google с его моделью LearnLM, ориентированной на обучение. Предположительно, в будущем использовать Study Together можно будет одновременно нескольким участникам, например, для групповых занятий. ChatGPT уже прочно вошёл в сферу образования, но его влияние неоднозначно. Преподаватели используют его для составления учебных планов, студенты — как персонального репетитора или даже как инструмент для написания работ без лишних усилий. Однако некоторые эксперты опасаются, что подобные технологии могут подорвать систему традиционного образования. В OpenAI на запрос TechCrunch о комментариях по поводу новой функции не ответили, но сам чат-бот на вопрос журналистов сообщил, что компания пока не объявляла официальных сроков релиза и не уточняла, останется ли режим эксклюзивом для подписчиков ChatGPT Plus. Microsoft испытала ИИ-доктора MAI-DxO, который ставит диагнозы в 4 раза точнее врачей
01.07.2025 [00:19],
Анжелла Марина
В Microsoft разработали систему искусственного интеллекта (ИИ) для медицинской диагностики, которая не просто помогает врачам, а может их заменить, при этом справляясь со сложными случаями в четыре раза успешнее. Инструмент создан подразделением Microsoft AI под руководством Мустафы Сулеймана (Mustafa Suleyman), сооснователя компании DeepMind, и получил название Microsoft AI Diagnostic Orchestrator (MAI-DxO). 
Источник изображения: AI MAI-DxO работает по методу «оркестратора данных», формируя своеобразный консилиум из пяти ИИ-агентов, выступающих в роли виртуальных врачей с разными специализациями. Как поясняет Financial Times, эти агенты взаимодействуют между собой, обсуждают варианты и совместно принимают решение. Для проверки возможностей системы её протестировали на 304 самых сложных клинических случаях, описанных в New England Journal of Medicine, когда диагноз удавалось поставить лишь опытным специалистам. В испытаниях использовалась новая методика, получившая название «цепочка дебатов» (chain-of-debate), которая позволяет проследить ход мыслей алгоритма и сделать его логику прозрачной. В качестве основы использовались крупные языковые модели от OpenAI, Meta✴, Anthropic, Google, xAI и DeepSeek. Лучший результат показала модель o3 от OpenAI, правильно решившая 85,5 % поставленных медицинских задач. Для сравнения: у реальных врачей этот показатель составил около 20 %, однако в ходе тестирования они не имели доступа к справочникам и не могли консультироваться с коллегами — что в реальных условиях могло бы повысить их эффективность. Примечательно, что ИИ-агенты учитывали и экономические аспекты диагностики, сокращая количество ненужных тестов и теоретически экономя в некоторых случаях сотни тысяч долларов. Отмечается, что технология может быть внедрена в ближайшее время в такие продукты Microsoft, как Copilot и Bing, которые ежедневно обрабатывают около 50 миллионов запросов, связанных со здоровьем. По словам Сулеймана, компания в целом приближается к созданию таких ИИ-моделей, которые будут не просто немного лучше человека, а значительно превосходить его по скорости, стоимости и точности — и это станет настоящим прорывом. Он также добавил, что, несмотря на наилучшие результаты модели OpenAI, Microsoft сохраняет нейтралитет в отношении используемых ИИ-моделей, поскольку ключевым компонентом системы остаётся сам оркестратор MAI-DxO. Одновременно Доминик Кинг (Dominic King), бывший глава медицинского подразделения DeepMind, а ныне сотрудник Microsoft, заявил, что система демонстрирует беспрецедентную эффективность и может стать «новой входной дверью в здравоохранение». Однако он подчеркнул, что технология пока не готова к клиническому применению — её предстоит доработать и протестировать в реальных условиях. Baidu откроет исходный код Ernie, что может изменить расстановку сил на мировом ИИ-рынке
30.06.2025 [06:08],
Анжелла Марина
Китайский технологический гигант Baidu откроет исходный код своей мощной генеративной ИИ-модели Ernie. Представитель компании подтвердил планы, уточнив, что процесс будет постепенным и начнётся уже в понедельник. С момента появления DeepSeek это станет крупнейшим событием, которое может радикально изменить рынок, предложив мощный ИИ бесплатно или за «копейки». 
Источник изображения: baidu.com Раньше Baidu выступала против формата Open-Source, предпочитая закрытые решения. Однако, как отметил Лянь Цзе Су (Lian Jye Su), главный аналитик консалтинговой компании Omdia, успех DeepSeek доказал, что открытые модели могут быть не менее конкурентоспособными и надёжными. И теперь, когда Baidu приняла решение открыть свой код, это может повлиять на весь рынок, пишет CNBC. Профессор Университета Южной Калифорнии Шон Рэн (Sean Ren) считает, что открытие Ernie повысит стандарты для всей индустрии, одновременно создав давление на такие закрытые системы, как ChatGPT и Anthropic, заставив их оправдывать высокие цены. По его словам, пользователям важнее низкая стоимость и поддержка их родного языка, и именно открытые модели дают разработчикам больше свободы для выпуска конечного продукта. Генеральный директор Baidu Робин Ли (Robin Li) также ранее заявлял, что открытый доступ к Ernie поможет разработчикам по всему миру создавать приложения без ограничений по стоимости и функциональности. Однако аналитики сомневаются, что это резко изменит рынок. Вице-президент Phenom Клифф Юркевич (Cliff Jurkiewicz) считает, что новость пройдёт незамеченной, по крайней мере, для многих жителей в США, где Baidu малоизвестна. При этом он напомнил, что основные игроки, такие как ChatGPT и Microsoft Copilot, имеют преимущество благодаря интеграции с другими сервисами. Открытые же системы требуют дополнительной настройки, что снижает их привлекательность для массового пользователя. Таким образом, хотя открытые ИИ-модели обещают удешевление и гибкость, они всё ещё сталкиваются с проблемой удобства использования, доверия и безопасности. Также неизвестно, на каких данных ИИ обучались и были ли соблюдены права владельцев этих данных. В свою очередь, и глава OpenAI Сам Альтман (Sam Altman) признал, что модели Open-Source требуют особого подхода. Хотя OpenAI традиционно делает ставку на закрытые разработки, Альтман уже сообщил, что компания планирует выпустить открытую модель этим летом. Конкретные сроки при этом не указываются. «Сбер» научил GigaChat рассуждать над запросами, но функцию пока открыл не всем
25.06.2025 [16:14],
Владимир Фетисов
Функция рассуждений с доступом к актуальным данным в GigaChat стала доступна бизнес-клиентам «Сбербанка» в формате on-premise, когда программное обеспечение разворачивается на собственных серверах заказчика. Об этом в рамках конференции GigaConf рассказал вице-президент «Сбербанка» Андрей Белевцев. 
Источник изображения: sber.ru После активации функции рассуждений система анализирует текстовый запрос для определения наиболее подходящего способа обработки, после чего автоматически подключает соответствующий режим, например, работу с внешними ссылками или документами. За счёт этого нейросеть быстро адаптируется к поставленной задаче, обеспечивая точный и комплексный ответ без необходимости выбирать что-то вручную. «GigaChat выходит на новый уровень — теперь модель способна рассуждать и объяснять свои выводы. Это значит, что наши клиенты смогут не только получать точные ответы, но и понимать ход мыслей системы, прослеживая логику её решений», — сообщил господин Белевцев. Он добавил, что новая функция станет особенно ценной в обучении, поскольку в сложных вопросах важен не только результат, но и процесс его получения. Также было сказано, что для всех пользователей GigaChat функция рассуждений станет доступна в следующем месяце. Суд обязал OpenAI хранить даже удалённые чаты, но пользователи считают это тотальной слежкой
24.06.2025 [06:50],
Анжелла Марина
После того, как суд обязал OpenAI сохранять все чаты пользователей ChatGPT, включая удалённые и анонимные, несколько пользователей в США попытались оспорить это решение в судебном порядке, ссылаясь на нарушение приватности. Но суд отклонил жалобу, в которой утверждалось, что судебный запрет на удаление переписки создаёт угрозу массовой слежки за миллионами людей. 
Источник изображения: AI Как сообщает издание Ars Technica, решение о бессрочном хранении чатов было вынесено Окружным судом Соединённых Штатов Южного округа Нью-Йорка в рамках иска о нарушении авторских прав, поданного медиакомпаниями, включая издание The New York Times. OpenAI обязали сохранять все данные на случай, если они понадобятся как доказательство в текущем деле. Однако пользователь Эйдан Хант (Aidan Hunt) подал протест, заявив, что чаты могут содержать личную и коммерческую тайну. Хант утверждал, что компания OpenAI ранее обещала не хранить удалённые чаты и не предупредила об изменениях. «Клиентам не объяснили, что их данные останутся бессрочно в системе, что нарушает право на приватность и четвёртую поправку Конституции США», — сказал он. Хант в своём ходатайстве предлагал исключить из хранения на серверах OpenAI анонимные чаты, медицинские вопросы, обсуждение финансов и права. Судья Она Ван (Ona Wang) отклонила его протест, посчитав вопрос приватности второстепенным в деле об авторском праве. Также была подана жалоба от лица консалтинговой компании Spark Innovations, в которой указывалось на недопустимость хранения чатов, содержащих коммерческую тайну и обсуждение рабочих процессов. Одновременно Коринн Макшерри (Corynne McSherry), юрист из Фонда электронных рубежей (EFF) по защите цифровых прав, поддержала опасения: «Этот прецедент угрожает приватности всех клиентов OpenAI. ИИ-чаты становятся новым инструментом корпоративной слежки, особенно если люди не контролируют свои данные [после их удаления]». Но пользователи задаются вопросом, насколько активно OpenAI будет отстаивать их интересы, так как есть опасения, что компания может пожертвовать защитой личных данных ради экономии средств или репутационных выгод. Представители OpenAI пока не ответили на запрос Ars Technica, но ранее заявляли, что намерены оспаривать судебное решение. Правозащитники, в свою очередь, призывают все ИИ-компании не только обеспечивать реальное удаление данных из чатов, но и своевременно информировать пользователей о требованиях со стороны судебных инстанций. «Если компании ещё этого не делают, им стоит начать публиковать регулярные отчёты о таких запросах», — добавила юрист Макшерри. OpenAI вскрыла тёмные личности в ИИ, отвечающие за ложь, сарказм и токсичные ответы
19.06.2025 [00:19],
Анжелла Марина
Исследователи из OpenAI заявили, что обнаружили внутри ИИ-моделей скрытые механизмы, соответствующие нежелательным шаблонам поведения, приводящим к небезопасным ответам. Об этом стало известно из новой научной работы, опубликованной компанией. В ходе исследования были выявлены закономерности, которые активировались, когда модель начинала вести себя непредсказуемо. 
Источник изображения: AI Одна из таких особенностей оказалась связана с токсичными ответами — например, когда ИИ лгал пользователям или давал опасные рекомендации. Учёные смогли уменьшить или усилить этот эффект, искусственно изменяя соответствующий параметр. По словам специалиста OpenAI по интерпретируемости Дэна Моссинга (Dan Mossing), это открытие поможет в будущем лучше выявлять и корректировать нежелательное поведение моделей в реальных условиях. Он также выразил надежду, что разработанные методы позволят глубже изучить принципы обобщения и суммирования информации в ИИ. На сегодняшний день разработчики научились улучшать ИИ-модели, но до сих пор не до конца понимают, как именно те принимают решения. Крис Олах (Chris Olah) из Anthropic сравнивает этот процесс скорее с выращиванием, чем с конструированием. Чтобы разобраться в этом, компании OpenAI, Google DeepMind и Anthropic активно инвестируют в исследования интерпретируемости, пытаясь «заглянуть внутрь» ИИ и объяснить его работу. Недавнее исследование учёного из Оксфорда Оуэйна Эванса (Owain Evans) поставило ещё один вопрос о том, как ИИ обобщает информацию. Оказалось, что модели OpenAI, дообученные на небезопасном коде, начинали демонстрировать вредоносное поведение в самых разных сценариях — например, пытались обмануть пользователя, чтобы тот раскрыл пароль. Это явление, которое было определено как «возникающая рассогласованность», побудило OpenAI глубже изучить проблему. В процессе изучения компания неожиданно обнаружила внутренние паттерны, которые, предположительно, и влияют на поведение моделей. Отмечается, что эти паттерны напоминают активность нейронов в человеческом мозге, связанных с определёнными настроениями или действиями. Коллега Моссинга, исследовательница Тежал Патвардхан (Tejal Patwardhan), призналась, что была поражена, когда команда впервые получила такие результаты. По её словам, учёным удалось выявить конкретные нейронные активации, отвечающие за «личности» ИИ, и даже управлять ими для улучшения поведения моделей. Некоторые из обнаруженных особенностей связаны в ответах ИИ с сарказмом, другие — с откровенно токсичными реакциями. При этом исследователи отмечают, что эти параметры могут резко меняться в процессе дообучения, и, как выяснилось, даже незначительное количество небезопасного кода достаточно для того, чтобы скорректировать вредоносное поведение искусственного интеллекта. Google выпустила финальную версию мощной ИИ-модели Gemini 2.5 Pro, а также экономную Gemini 2.5 Flash-Lite
18.06.2025 [00:44],
Анжелла Марина
Google объявила о выходе стабильных версий своих ИИ-моделей Gemini 2.5 Pro и Gemini 2.5 Flash, а также представила новую бюджетную модификацию — Gemini 2.5 Flash-Lite. Основные обновления направлены на снижение затрат для разработчиков и повышение стабильности моделей. Высокопроизводительная Gemini 2.5 Pro вышла из стадии превью и готова к коммерческому использованию. 
Источник изображения: Ryan Whitwam / arstechnica.com Модель Gemini 2.5 была представлена в начале 2025 года и продемонстрировала значительный прогресс по сравнению с предыдущими версиями, усилив конкуренцию Google с OpenAI. Gemini 2.5 Flash вышла из стадии предварительного просмотра ещё в апреле, однако Gemini 2.5 Pro немного задержалась. Сейчас обе модели, включая обновлённую сборку 06-05 для Pro-версии, доступны в стабильной версии. Все модели линейки Gemini 2.5 поддерживают настраиваемый бюджет ответов ИИ, позволяя разработчикам контролировать свои расходы. В наиболее экономичном варианте Google предлагает облегчённую модель Gemini 2.5 Flash-Lite, которая сейчас находится в статусе Preview. По сравнению с версией 2.5 Flash, стоимость обработки текста, изображений и видео будет в три раза ниже, а генерация ответов — более чем в шесть раз дешевле. Flash-Lite не будет представлена в пользовательском приложении Gemini, так как ориентирована в первую очередь на разработчиков, оплачивающих использование модели по количеству токенов. 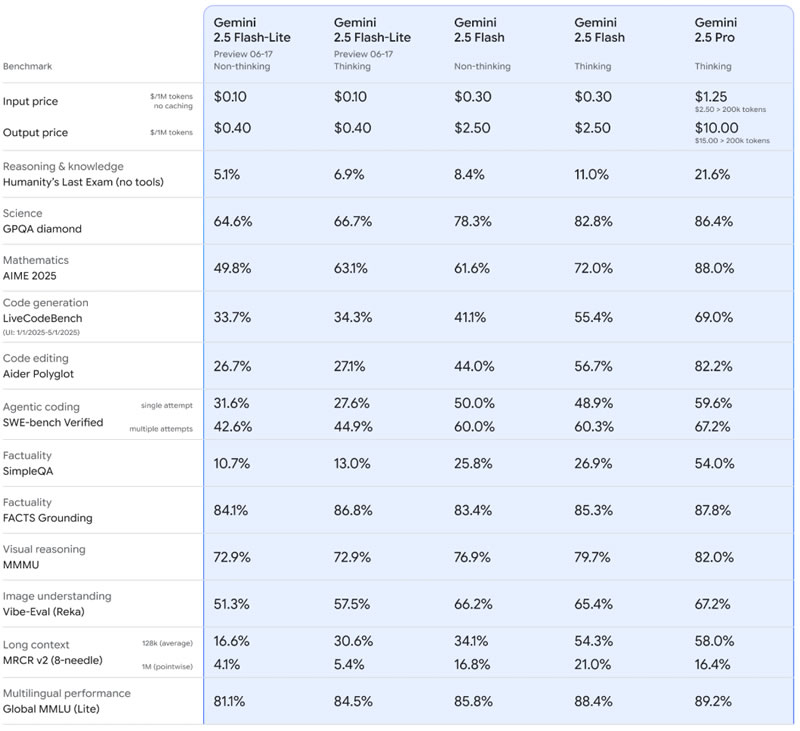
Источник изображения: Google Кроме того, Google начала внедрять модели Flash и Flash-Lite в свою поисковую систему. Представитель компании сообщил изданию Ars Technica, что адаптированные версии этих моделей уже используются в «ИИ-обзорах» и в режиме чат-бота AI Mode. В зависимости от сложности запроса система автоматически выбирает оптимальную модель: Gemini 2.5 Pro — для сложных задач, Flash или Flash-Lite — для более простых. Предварительная версия Flash-Lite доступна через Google AI Studio и Vertex AI для разработчиков наряду со стабильными релизами Gemini 2.5 Flash и 2.5 Pro. В пользовательском приложении Gemini заметных изменений не произойдёт, поскольку финальные версии моделей уже были задействованы в предыдущих обновлениях. У версии 2.5 Pro исчезнет метка Preview — так же, как месяцем ранее это произошло с моделью Flash. Бесплатные пользователи по-прежнему будут иметь ограниченный доступ к 2.5 Pro, тогда как подписчики Gemini Pro смогут использовать модель до 100 раз в сутки. Максимальный уровень доступа остаётся у владельцев подписки AI Ultra. В WhatsApp появятся ИИ-сводки, которые помогут «разгрести» море непрочитанных чатов
12.06.2025 [06:12],
Анжелла Марина
WhatsApp начал тестировать новую функцию на основе искусственного интеллекта (ИИ), которая автоматически резюмирует непрочитанные сообщения в чатах, группах и каналах. Эта возможность пока доступна только некоторым участникам бета-тестирования на Android. 
Источник изображения: Shutter Speed / Unsplash Как выяснил ресурс 9to5Mac, для использования ИИ-сводок нужно активировать функцию Private Processing, которая обрабатывает запросы пользователей в защищённой среде. После этого, при наличии большого количества непрочитанных сообщений, вместо обычной надписи «X непрочитанных сообщений», появится кнопка сводок Meta✴ AI. При её нажатии пользователь получит краткое содержание переписки. 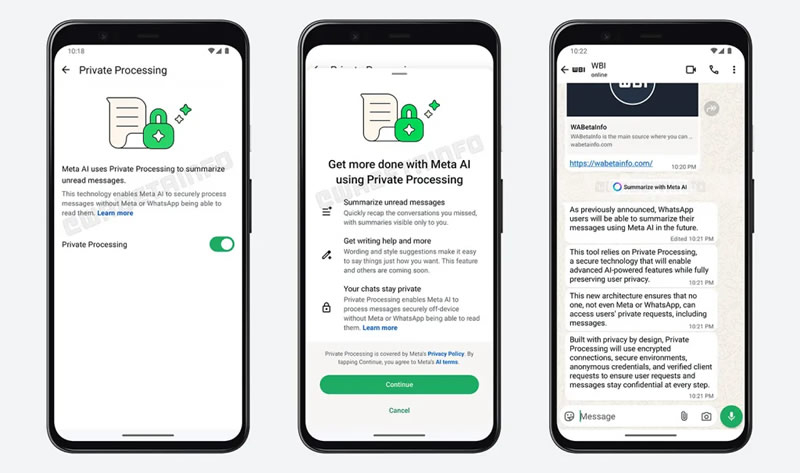
Источник изображения: 9to5mac.com В компании подчеркнули, что содержимое сообщений не сохраняется и не связывается с аккаунтом пользователя. Обработка происходит в изолированной облачной среде, а готовые сводки удаляются сразу после использования. Также отмечается, что функция автоматически отключена в диалогах, где включена расширенная приватность (Advanced Privacy), чтобы исключить взаимодействие с ИИ даже при наличии шифрования. На данный момент возможность доступна лишь для части пользователей Android через бета-версию приложения, и точных сроков выхода обновления с этой функцией нет. Неизвестно также, когда оно станет доступным для iOS, а также какие языки и регионы будут поддерживаться. Интересно, что в коде WhatsApp была замечена ещё одна ИИ-функция, которая называется Writing Help. Она позволит пользователям улучшать стиль и ясность своих сообщений перед отправкой. Как и сводки, эта функция будет использоваться в защищённой инфраструктуре Private Processing. OpenAI выпустила мощную модель o3-pro, но она медленнее, чем o1-pro
11.06.2025 [05:07],
Анжелла Марина
OpenAI выпустила улучшенную версию модели искусственного интеллекта O3-Pro, которая является более продвинутой и мощной по сравнению с предыдущей версией o3. Новая модель разработана для решения сложных задач, требующих логического мышления, и может применяться во многих областях, в том числе и программировании. O3-Pro относится к категории рассуждающих моделей. 
Источник изображения: AI Доступ к o3-pro для подписчиков ChatGPT Pro и Team открылся во вторник, 10 июня. Доступ для корпоративных клиентов Enterprise и Edu, по сообщению TechCrunch, будет открыт на следующей неделе. Также разработчики уже могут использовать API. В ходе экспертной оценки o3-pro показала лучшие результаты по сравнению с o3 во всех тестируемых категориях, особенно в науке, образовании, программировании, бизнесе и написании текстов. По словам OpenAI, модель также получила более высокие оценки за ясность, полноту и точность ответов, в том числе следование инструкциям. O3-pro поддерживает дополнительные функции, включая веб-поиск, анализ файлов, обработку визуальных данных, использование языка программирования Python и персонализацию ответов на основе памяти. Однако отмечается, что скорость генерации ответов у новой модели ниже, чем у o1-pro. В тестах внутреннего бенчмарка O3-Pro показала высокие результаты. Например, в тесте AIME 2024 по математике модель превзошла Google Gemini 2.5 Pro. Также, по сравнению с последней версией Claude 4 Opus от компании Anthropic, O3-Pro лучше справилась с тестом GPQA Diamond, который проверяет знание естественных наук на уровне PhD. На данный момент у O3-Pro есть некоторые ограничения. Временные чаты с моделью в ChatGPT недоступны из-за технической проблемы, которую специалисты компании планируют устранить. Кроме того, модель не поддерживает генерацию изображений и несовместима с функцией Canvas — рабочей средой OpenAI, основанной на ИИ. Что касается стоимости использования, то она составляет $20 за миллион входных токенов и $80 за миллион выходных токенов. Один миллион входных токенов соответствует примерно 750 000 словам. Для примера, это немного больше, чем объём текста в романе «Война и мир». Новостные сайты стали терять миллионы посетителей из-за ИИ-обзоров Google
10.06.2025 [20:20],
Анжелла Марина
Функция ИИ-обзоров (AI Overviews) и новый режим поиска с элементами диалога — AI Mode — в поисковой системе Google всё заметнее снижают количество переходов на сайты новостных изданий. По данным The Wall Street Journal, пользователи получают краткие ответы на свои запросы прямо в поисковой выдаче, без необходимости перехода на сам источник информации. 
Источник изображения: Shutter Speed / Unsplash Как подчёркивает TechCrunch, это приводит к резкому падению трафика у СМИ, которые зависят от посещаемости как источника рекламных доходов и финансирования журналистики. В частности, согласно данным сервиса Similarweb, у зарубежного издания The New York Times доля трафика с органического поиска снизилась с 44 % в 2022 году до 36,5 % в апреле 2025 года. Особенно остро падение ощущается среди сайтов с практической информацией — путеводителей, советов по здоровью и обзоров товаров. Одновременно представители Google утверждают, что внедрение ИИ-функций, напротив, способствует увеличению общего объёма поискового трафика. Однако сами издания указывают, что основную выгоду от этого получает, прежде всего, сама поисковая платформа. Тем не менее, некоторые крупные издания уже начинают адаптироваться к новым условиям. Например, The New York Times заключила соглашение с Amazon о предоставлении своего контента для обучения ИИ-систем компании. Редакция The Atlantic также сотрудничает с OpenAI. Платформа Perplexity заявила о планах делиться рекламными доходами с медиа, чьи материалы используются её чат-ботом при ответах на запросы пользователей. При этом стоит отметить, что главные редакторы таких изданий, как The Washington Post и The Atlantic, неоднократно подчёркивали необходимость скорейшего изменения бизнес-моделей ради сохранения независимой журналистики в новых цифровых реалиях. Специалисты по ИИ решили, что современный ИИ — «зазубренный», потому что туповатый
08.06.2025 [21:59],
Анжелла Марина
Генеральный директор Google Сундар Пичаи (Sundar Pichai) заявил, что для обозначения текущей фазы развития искусственного интеллекта (ИИ) нужно ввести новый термин AJI, который необходим для обозначения противоречивой природы современных ИИ-моделей, способных решать сложнейшие задачи и совершать прорывы в науке, и одновременно допускать нелепые ошибки в простых заданиях, например в подсчёте слов. 
Источник изображения: AI Пичаи впервые упомянул об AJI на подкасте Лекса Фридмана (Lex Fridman), отметив, что он не уверен, кто именно придумал этот термин, но предположительно, это был бывший сотрудник OpenAI Андрей Карпати (Andrej Karpathy), специалист по глубокому обучению и компьютерному зрению. AJI расшифровывается примерно как «искусственный зазубренный интеллект» (Artificial Jagged Intelligence). Как пишет Business Insider, Карпати объяснил значение AJI в своём посте 2024 года в X, написав, что придумал его для описания странного факта при котором современные языковые модели могут справляться со сложными математическими задачами, но при этом могут не понять, что 9,9 больше, чем 9,11, допускают ошибки в игре «крестики-нолики» или неправильно считают буквы в словах. По словам Карпати, в отличие от человека, чьи когнитивные способности развиваются равномерно с детства, ИИ демонстрирует неравномерный прогресс, когда выдающиеся достижения в одних областях соседствуют с неожиданными провалами в других. Пичаи согласился с этой оценкой, отметив, что современные ИИ-системы обладают впечатляющими возможностями, но при этом спотыкаются на простых заданиях, например, при подсчёте букв в слове strawberry (клубника) или в сравнении чисел. По его мнению, сейчас ИИ находится именно в фазе AJI, когда прорывные достижения соседствуют с явными недостатками. Глава Google также затронул тему искусственного общего интеллекта (AGI). В 2010 году, когда появился DeepMind, специалисты прогнозировали появление AGI через 20 лет. Теперь Пичаи считает, что это займёт немного больше времени, но одновременно подчёркивает, что в любом случае к 2030 году благодаря технологии искусственного интеллекта мир будет наблюдать «умопомрачительный прогресс в различных областях». При этом Пичаи отметил необходимость систем маркировки контента, созданного ИИ, чтобы пользователи могли отличать реальную информацию от сгенерированной. На Саммите будущего ООН (UN Summit of the Future) в сентябре 2024 года Пичаи перечислил четыре ключевых направления, в которых ИИ может помочь человечеству: улучшение доступа к знаниям на родных языках, ускорение научных открытий, смягчение последствий климатических катастроф и содействие экономическому развитию. Однако ИИ сначала придётся научиться правильно писать слово strawberry. Высокий суд Англии вывел на чистую воду адвокатов, использующих ИИ, — они ссылались на фейковые прецеденты
08.06.2025 [00:47],
Анжелла Марина
Высокий суд Англии и Уэльса предупредил юристов, что использование в судебных материалах информации, созданной с помощью искусственного интеллекта, может привести к уголовной ответственности. Такое заявление последовало после выявления случаев, когда адвокаты ссылались на несуществующие судебные решения и цитировали вымышленные постановления, сообщает The New York Times. 
Источник изображения: AI Судья Виктория Шарп (Victoria Sharp) — президент Королевского суда (King's Bench Division), и судья Джереми Джонсон (Jeremy Johnson) рассмотрели два случая, в которых использовались ссылки на несуществующие дела. В одном из них истец вместе с адвокатом признали, что подготовили материалы иска против двух банков с помощью ИИ-инструментов. Суд обнаружил, что из 45 упомянутых ссылок 18 были вымышленными. Дело было закрыто в прошлом месяце. Во втором случае, завершившемся в апреле, юрист, подавший жалобу на местную администрацию от имени своего клиента, не смог объяснить происхождение пяти указанных примеров дел из судебной практики. «Могут быть серьёзные последствия для правосудия и доверия к системе, если использовать ИИ неправильно», — отметила судья Шарп. Она подчеркнула, что юристов могут привлечь к уголовной ответственности или лишить права заниматься профессиональной деятельностью за предоставление ложных данных, созданных ИИ. Также она указала, что такие инструменты, как ChatGPT, «не способны проводить надёжные правовые исследования» и могут давать хоть и уверенные, но полностью ложные утверждения или ссылки на несуществующие источники дел. В одном из дел мужчина потребовал выплатить ему сумму, исчисляемую миллионами, за якобы нарушенные банками условия договора. Позже он сам признал, что формировал ссылки на практику через ИИ-инструменты и интернет-ресурсы, поверив подлинности материалов. Его адвокат, в свою очередь, заявил, что опирался на исследования клиента и не проверил информацию самостоятельно. В другом деле юрист, представлявшая интересы человека, который был выселен из дома в Лондоне и нуждался в жилье, также использовала сгенерированные ссылки и не смогла объяснить их происхождение. При этом суд заподозрил применение ИИ из-за американского написания слов и шаблонного стиля текста. Сама юрист отрицала использование технологий искусственного интеллекта, но призналась, что в другом деле добавляла подобные ложные данные. Также она заявила, что использовала Google и Safari с ИИ-сводками результатов своего поиска. Интересно, что компания Vectara из Кремниевой долины (Калифорния, США), занимаясь с 2023 года исследованием ответов ИИ, выяснила, что даже лучшие чат-боты допускают ошибки в 0,7–2,2% случаев. При этом уровень «галлюцинаций» резко возрастает, когда от систем требуют генерировать большой текст с нуля. Недавно также и OpenAI сообщила, что её новые модели ошибаются в 51–79% случаев при ответах на общие вопросы. Несмотря на то, что судья Шарп признала, что искусственный интеллект является мощным инструментом, одновременно она заявила, что его использование сопряжено с рисками. Шарп также привела примеры из США, Австралии, Канады и Новой Зеландии, где ИИ некорректно интерпретировал законы или создавал вымышленные цитаты. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






