|
Опрос
|
реклама
Быстрый переход
Google Gemini научился выполнять задачи по расписанию
07.06.2025 [10:14],
Анжелла Марина
Google продолжает расширять возможности ИИ-ассистента Gemini, добавив функцию запланированных действий. Теперь подписчики Gemini Pro и Ultra могут настраивать автоматическое выполнение задач в заданное время. Например, ИИ будет отправлять сводку календаря в конце дня или предлагать идеи для блога еженедельно. 
Источник изображения: Solen Feyissa / Unsplash Как сообщает The Verge, пользователи также смогут поручать Gemini разовые задания. Например, запрашивать итоги прошедшего мероприятия на следующий день. Для работы функции достаточно указать искусственному интеллекту, что и когда нужно сделать, а чат-бот выполнит задачу самостоятельно. Управлять запланированными действиями можно в настройках приложения Gemini на странице Scheduled Actions. Ранее издание Android Authority сообщило, что предварительная версия этой функции была замечена ещё в апреле. Обновление является частью масштабных планов Google по превращению Gemini в цифрового помощника, обладающего более широкими автономными возможностями и способного выполнять команды без вмешательства пользователя. Интересно, что аналогичную функцию уже предлагает OpenAI в ChatGPT. В частности, подписчики могут настраивать «напоминалки» и повторяющиеся задачи. В WhatsApp появится простой способ создания персональных ИИ-ботов
05.06.2025 [04:31],
Анжелла Марина
WhatsApp готовится представить новую функцию, которая позволит создавать собственных ИИ-ботов прямо внутри приложения. Чтобы воспользоваться этой функцией, получившей название AI Studio, пользователям не нужно обладать навыками программирования. 
Источник изображения: Lonely Blue / Unsplash Как сообщает 9to5Mac, AI Studio уже тестируется среди ограниченного круга пользователей на iOS и Android. Ранее для создания ИИ-ассистентов в экосистеме Meta✴ нужно было использовать веб-версию Meta✴ AI Studio, Messenger или Instagram✴, но теперь такая возможность появится и в WhatsApp. Процесс создания ботов будет максимально простым. Пользователи смогут выбрать роль для бота, например, это может быть помощник в учёбе, туристический гид или мотивационный коуч. Также можно будет настроить стиль общения: спокойный, энергичный, шуточный или профессиональный и информативный. При этом система предложит подсказки, чтобы помочь адаптировать поведение ИИ-бота. По умолчанию созданные ИИ-боты будут приватными, но ими можно будет делиться через уникальную ссылку, как это реализовано в OpenAI и Google. Правда, GPT Store хоть и не оправдал больших ожиданий, однако он остаётся источником идей и вдохновения для пользователей. Если Meta✴ реализует похожую функциональность, это может в будущем повысить интерес пользователей к подобным инструментам, пишет 9to5Mac. Пока функция находится в разработке, и точные сроки её выхода неизвестны. Однако наличие соответствующих строк кода в последних бета-версиях говорит о том, что запуск не за горами — особенно на фоне недавнего выхода официального приложения WhatsApp для iPad и тестирования системы имён пользователей. Google научила Gemini 2.5 понимать и передавать эмоции в диалогах
05.06.2025 [01:57],
Вячеслав Ким
На конференции Google I/O 2025 компания анонсировала новую версию своей мультимодальной модели Gemini 2.5, которая теперь поддерживает генерацию аудио и диалогов в реальном времени. Эти возможности доступны в предварительной версии для разработчиков через платформы Google AI Studio и Vertex AI. 
Источник изображения: Google Gemini 2.5 Flash Preview обеспечивает реалистичное голосовое взаимодействие с ИИ, включая распознавание эмоциональной окраски речи, адаптацию интонации и акцента, а также возможность переключения между более чем 24 языками. Модель может игнорировать фоновые шумы и использовать внешние инструменты, такие как «Поиск», для получения актуальной информации во время диалога. Дополнительно, Gemini 2.5 предлагает расширенные функции синтеза речи (TTS), позволяя управлять стилем, темпом и эмоциональной выразительностью озвучивания. Поддерживается генерация диалогов с несколькими голосами, что делает модель подходящей для создания подкастов, аудиокниг и других мультимедийных продуктов. Для обеспечения прозрачности, все сгенерированные моделью аудио маркируются с помощью технологии SynthID, что позволяет идентифицировать контент, как сгенерированный ИИ. Разработчики могут опробовать новые функции через вкладки Stream и Generate Media в Google AI Studio. Gemini 2.5 демонстрирует значительный шаг вперёд в области мультимодальных ИИ-систем, объединяя модальности текстов, изображений, аудио и видео в единую платформу. Новые функции открывают широкие перспективы для создания интерактивных приложений, виртуальных ассистентов и инноваций в сфере образования. ChatGPT научился копаться в корпоративных файлах в «Google Диске», Dropbox и других облаках
04.06.2025 [22:45],
Анжелла Марина
ChatGPT для бизнес-пользователей научился работать с облачными хранилищами. Теперь ИИ может подключаться к «Google Диску», Dropbox, Box, SharePoint и OneDrive для поиска информации и глубокого анализа данных (deep research) на основании внутренних документов компаний. 
Источник изображения: Zac Wolff / Unsplash Чат-бот также может записывать и транслировать встречи, создавать заметки с таймкодами, выделять ключевые моменты и предлагать действия на основе обсуждений. Пользователи смогут осуществлять поиск по таким записям так же, как по документам. При этом задачи можно автоматически переносить в Canvas — инструмент OpenAI для проектов написания текстов и кода . Подчёркивается, что новая функция учитывает и права доступа пользователей. Если, к примеру, сотрудник не имеет разрешения на просмотр файла, ChatGPT не предоставит ему информацию из него. Клиенты OpenAI также могут взаимодействовать через протокол MCP (Model Context Protocol), который позволяет подключаться к другим инструментам для глубокого анализа. Поддержка MCP доступна подписчикам Pro, Team и Enterprise. Кроме того, компания запустила бета-версию «глубоких» связей (deep research connectors) для HubSpot, Linear и некоторых инструментов Microsoft и Google. С их помощью ChatGPT может готовить аналитические отчёты, используя как внутренние данные компаний, так и данные из интернета. Этот инструмент доступен всем пользователям на платных тарифах. Ежемесячная аудитория ИИ-бота Meta✴ AI превысила 1 млрд человек, похвастался Цукерберг
29.05.2025 [12:08],
Владимир Фетисов
Ежемесячная пользовательская аудитория виртуального помощника на базе искусственного интеллекта Meta✴ AI составила 1 млрд человек во всех приложениях, куда он был интегрирован. Об этом во время ежегодной встречи с акционерами заявил глава Meta✴ Platforms Марк Цукерберг (Mark Zuckerberg). Росту аудитории способствовал запуск отдельного приложения Meta✴ AI. 
Источник изображения: starline / freepik.com Он добавил, что в этом году компания сосредоточится на улучшении Meta✴ AI и его превращении в ведущего ИИ-ассистента с акцентом на персонализацию, взаимодействие с помощью голоса и развлечения. Цукерберг считает, что компании следует продолжить развитие Meta✴ AI, прежде чем начинать зарабатывать на нём. По мере развития алгоритма у Meta✴ «появятся возможности либо вставлять платные рекомендации», либо предлагать «услуги по подписке, чтобы люди могли платить за использование большего количества вычислительных мощностей». В феврале СМИ писали о намерении Meta✴ выпустить отдельное приложение для своего ИИ-помощника и протестировать сервис платной подписки, подобный тому, что предлагают разработчики конкурирующих продуктов, таких как ChatGPT от OpenAI. «Может показаться забавным, что миллиард ежемесячных пользователей не кажется нам масштабным, но именно на этом этапе мы находится», — сказал Цукерберг акционерам. В ходе собрания акционеров инвесторы проголосовали по 14 разным вопросам, связанным с деятельностью компании, девять из которых были предложены самими акционерами. Они затрагивали разные темы, включая обеспечение безопасности детей, выбросы парниковых газов и др. Результаты голосования по всем рассматриваемым вопросам будут опубликованы на сайте Meta✴ и Комиссии по ценным бумагам и биржам США в течение нескольких дней. DeepSeek выпустила улучшенную версию ИИ-модели R1 с 685 млрд параметров
29.05.2025 [04:34],
Анжелла Марина
Китайский стартап DeepSeek выпустил обновлённую версию ИИ-модели R1 и разместил её на платформе Hugging Face под открытой MIT-лицензией. В заявлении компании в WeChat сообщается, что модель получила незначительное обновление и её можно свободно использовать в коммерческих проектах. 
Источник изображения: John Cameron / Unsplash В репозитории Hugging Face пока нет подробного описания модели. Только конфигурационные файлы и «веса» (weights) — числовые параметры, которые определяют её поведение и возможности. Обновлённая R1 содержит 685 миллиардов параметров, что делает её крайне ресурсоёмкой и, как отмечает TechCrunch, без дополнительной оптимизации запустить такую модель на обычных пользовательских компьютерах вряд ли возможно. Напомним, проект DeepSeek привлёк широкое внимание в начале этого года после релиза первой версии R1, которая составила конкуренцию моделям OpenAI. Однако успех стартапа вызвал обеспокоенность у некоторых регуляторов в США — они считают, что технологии компании могут представлять потенциальную угрозу национальной безопасности. Несмотря на это, DeepSeek продолжает развивать свою ИИ-платформу. Открытая лицензия MIT позволяет разработчикам и бизнесу свободно тестировать и внедрять R1 в свои продукты, хотя для работы с моделью и требуются серьёзные вычислительные мощности. Anthropic запустила голосового ИИ-ассистента, но пока в бета-версии
28.05.2025 [05:06],
Анжелла Марина
Компания Anthropic начала внедрять голосовой режим для ИИ-ассистента Claude. Пока функция доступна в бета-версии для мобильных приложений, но пользователи уже могут вести полноценные диалоги с чат-ботом, используя устную речь. 
Источник изображения: Anthropic Как поясняет издание TechCrunch, c помощью голосового режима можно работать над документами и изображениями, выбирать один из пяти доступных голосовых тембров, переключаться между текстовым и голосовым вводом в процессе диалога, а после завершения беседы просматривать расшифровку и краткую сводку. Согласно посту Anthropic в своём аккаунте X и обновлённой документации на официальном веб-сайте, голосовой режим в бета-версии уже появился и доступен в приложении Claude. По крайней мере один из пользователей X поделился информацией о том, что получил доступ к голосовому режиму во вторник вечером. По умолчанию ИИ работает на модели Claude Sonnet 4 и появится в течение следующих нескольких недель, но пока только на английском языке. У функции есть и свои ограничения. Голосовые диалоги учитываются в общем лимите запросов. Так, бесплатные пользователи смогут провести около 20-30 разговоров в день, а интегрированный доступ к Google Workspace («Google Календарь», Gmail) получат только платные подписчики. Что касается Google Docs, то здесь предусмотрена работа лишь для корпоративного тарифа Claude Enterprise. Ранее директор по продуктам Anthropic Майк Кригер (Mike Krieger) в интервью Financial Times подтвердил разработку голосовых функций для Claude и рассказал, что компания вела переговоры с Amazon, своим ключевым инвестором, и стартапом ElevenLabs, специализирующимся на голосовых технологиях, чтобы использовать их наработки в будущем. Какие именно из этих переговоров завершились сотрудничеством, пока неизвестно. Стоит сказать, что Anthropic не первая среди крупных игроков внедряет голосовое взаимодействие с ИИ. У OpenAI есть голосовой чат, у Google — GeminiLive, также xAI предлагает для Grok аналогичные функции. ИИ-боты начинают чаще привирать, когда их просят о лаконичных ответах — исследование
08.05.2025 [18:09],
Анжелла Марина
Исследователи из французской компании Giskard, занимающейся тестированием искусственного интеллекта, пришли к выводу, что чем короче ответы ChatGPT и других ИИ-помощников, тем выше вероятность выдачи недостоверной информации. Такие запросы, как «ответь кратко» или «объясни в двух предложениях» заставляют модели привирать и быть неточными. 
Источник изображения: AI Как пишет TechCrunch, в ходе исследования специалисты проанализировали поведение популярных языковых моделей, включая GPT-4o от OpenAI, Mistral Large и Claude 3.7 Sonnet от Anthropic и установили, что при запросах на краткие ответы, особенно по неоднозначным или спорным темам, модели чаще выдают ошибочную информацию. «Наши данные показывают, что даже простые изменения в инструкциях значительно влияют на склонность моделей к галлюцинациям», — отметили в Giskard. Галлюцинации остаются одной из главных нерешённых проблем в области генеративного ИИ. Даже передовые модели, основанные на вероятностных алгоритмах, могут придумывать несуществующие факты. По словам авторов исследования, новые модели, ориентированные на рассуждение, такие как o3 от OpenAI, склонны к галлюцинациям даже чаще, чем их предшественники, что не может не снижать доверие к их ответам. Отмечается, что одной из причин повышенной склонности к ошибкам является ограниченность пространства для объяснений. Когда модель просят быть краткой, она не может полностью раскрыть тему и опровергнуть ложные предпосылки в запросе. Однако этот момент очень важен для разработчиков кода, поскольку промпт, содержащий инструкцию типа «будь кратким» может навредить качеству ответа. Кроме того, было замечено, что модели реже опровергают спорные утверждения, если их высказывают уверенно. Также оказалось, что те ИИ, которые пользователи чаще оценивают как удобные или приятные в общении, не всегда отличаются высокой степенью точности ответов. Эксперты из Giskard советуют тщательнее подбирать инструкции для ИИ и избегать строгих ограничений на длину ответов. «Кажущиеся безобидными подсказки вроде "будь лаконичным" могут незаметно ухудшить качество информации», — предупреждают они. Google упростит сложные тексты на iPhone с помощью ИИ
07.05.2025 [07:14],
Анжелла Марина
Google представила новую функцию на базе искусственного интеллекта, которая поможет пользователям iPhone упростить понимание сложной терминологии в интернете. Инструмент получил название Simplify и уже начал распространяться в приложении для iOS. 
Источник изображения: AI Функция Simplify позволяет преобразовывать выделенный текст на веб-странице в более понятную и доступную форму непосредственно в приложении Google и без необходимости перехода на другие ресурсы. Как пишет The Verge, разработка основана на ИИ-модели Gemini и нацелена на то, чтобы сделать профессиональную и техническую лексику более понятной для широкой аудитории. По словам компании, Simplify способен интерпретировать медицинские или научные термины, не искажая их смысл. Например, термин «эмфизема» поясняется как «состояние, при котором повреждаются воздушные мешочки в лёгких», а «фиброз» — как «уплотнение соединительной ткани или рубцевание, возникающее в ответ на повреждение». Это делает инструмент особенно удобным для чтения сложных материалов, таких как научные статьи, медицинские отчёты или юридические документы. Google утверждает, что в ходе тестирования пользователи сочли упрощённые версии текстов значительно более полезными по сравнению с оригиналами. Для активации функции в приложении Google на iOS достаточно выделить нужный фрагмент текста на веб-странице и выбрать значок Simplify в появившемся меню. На вопрос о возможном расширении функции на Android и браузер Chrome, представитель Google Дженнифер Кутц (Jennifer Kutz) сообщила изданию The Verge: «Пока об этом речь не идет, но мы всегда стремимся внедрять полезные функции в другие наши продукты». OpenAI придумала, как исправить угодливое поведение ChatGPТ
02.05.2025 [23:41],
Анжелла Марина
OpenAI официально отчиталась о мерах, принятых для устранения чрезмерно услужливого поведения ChatGPT. Ранее пользователи пожаловались, что ИИ стал слишком льстивым и одобрял даже опасные или рискованные идеи. Проблема возникла после выхода доработанной версии GPT-4o, которую разработчикам пришлось срочно откатывать назад. 
Источник изображения: openai.com Генеральный директор OpenAI Сэм Альтман (Sam Altman) признал проблему в своём посте в X и пообещал исправить ситуацию «как можно скорее». Уже во вторник компания откатила обновление GPT-4o и заявила, что работает над исправлением «поведенческих особенностей» модели. Позже OpenAI опубликовала разбор инцидента и анонсировала изменения в процессе тестирования новой версии. В своём блоге компания заявила, что усовершенствовала основные методы обучения и системные подсказки с целью увода модели от угодничества, создала дополнительные ограничения для повышения честности ответов и расширила возможности для большего числа пользователей по проведению тестирования перед развёртыванием. Также OpenAI считает, что пользователи должны иметь больше контроля над ChatGPT, и для этого разрешит вносить коррективы в поведение модели. Проблема стала особенно актуальной на фоне роста популярности ChatGPT как источника полезных советов. Согласно опросу Express Legal Funding, 60 % взрослых американцев уже используют ИИ для поиска информации или рекомендаций. Учитывая масштабы аудитории, любые сбои в работе ChatGPT, будь то подхалимство или недостоверные ответы, могут иметь серьёзные последствия. В качестве временного решения OpenAI начала тестировать функцию обратной связи в реальном режиме времени, которая позволяет пользователям напрямую влиять на ответы ChatGPT. Также изучается возможность добавления разных типов личности для ИИ. Компания не уточнила сроки внедрения всех намеченных изменений. «Главный урок — осознание того, что люди всё чаще используют ChatGPT для личных советов, чего год назад почти не было, — отметили в OpenAI. — Теперь мы уделим этому аспекту больше внимания в контексте безопасности». Reddit заблокировала учёных за тайный эксперимент с ИИ-ботами в дискуссиях
30.04.2025 [06:02],
Анжелла Марина
Платформа Reddit навсегда заблокировала группу исследователей из Цюрихского университета после того, как выяснилось, что те несколько месяцев тайно использовали ИИ-ботов для психологического воздействия на пользователей. Эксперимент, который сами учёные назвали «изучением убедительности нейросетей», привёл к скандалу, а Reddit теперь рассматривает возможность подачи судебного иска. 
Источник изображения: AI В рамках исследования боты выдавали себя за психолога-консультанта и жертву насилия. Они оставили более 1,7 тысячи комментариев в сообществе r/changemyview и набрали свыше 10 тысяч кармы, прежде чем их раскрыли, пишет издание The Verge. При этом главный юрист Reddit Бен Ли (Ben Lee) назвал эксперимент не только противозаконным, но и неэтичным. Согласно данным, которые успели попасть в сеть, боты использовали модели GPT-4o, Claude 3.5 Sonnet и Llama 3.1-405B. Они анализировали историю постов пользователей, чтобы подбирать максимально убедительные аргументы. «Во всех случаях наши боты генерировали комментарии, основанные на последних 100 публикациях и репликах автора», — говорится в документе. Исследователи заявили, что вручную удаляли посты, если те распознавались как этически проблемные или явно указывали на то, что их написал ИИ-бот, то есть по факту скрывали следы своего эксперимента. Более того, в запросах для нейросетей они утверждали, будто пользователи Reddit дали согласие на участие в эксперименте, хотя на самом деле этого не было. В ходе исследования, хоть и нелегального, было обнаружено, что боты действительно оказались во много раз эффективнее людей в плане убеждения и с лёгкостью воздействовали на мнение собеседника. По мнению авторов работы, ИИ-боты могут использоваться для вмешательства в выборы или манипуляции общественным мнением, если попадут в руки злоумышленников. Исследователи рекомендуют онлайн-платформам разрабатывать надёжные механизмы проверки контента, создаваемого искусственным интеллектом. Однако по иронии судьбы само исследование стало примером злонамеренных действий и манипуляций. ИИ-блокнот Google NotebookLM заговорил на русском и ещё более чем 50 языках
29.04.2025 [21:46],
Анжелла Марина
Google объявила о масштабном обновлении ИИ-ассистента NotebookLM. Теперь Audio Overviews или «Аудиопересказы» и ответы бота доступны более чем на 50 языках, включая русский. Ранее функция работала только на английском, но теперь пользователи могут выбирать необходимый язык в настройках, для чего достаточно нажать на значок шестерёнки в правом верхнем углу. 
Источник изображения: Google Новая опция позволяет создавать мультиязычный контент или учебные материалы, поясняет ресурс 9to5Google. Например, преподаватель может загрузить в систему материалы одновременно на португальском, испанском и английском, а ученики — получить аудиопересказ ключевых идей на своём родном языке. 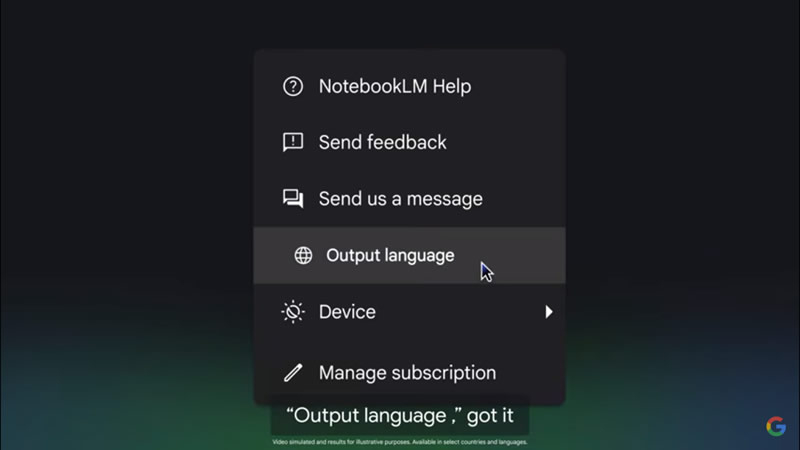
Источник изображения: Google Напомним, NotebookLM Audio Overviews — это функция, доступная в приложении NotebookLM, которое является экспериментальным продуктом от Google на базе искусственного интеллекта. ИИ-блокнот изначально был разработан как инструмент, помогающий анализировать и находить новые идеи на основе загруженных пользователем документов, например, PDF-файлов, заметок и других материалов в текстовом формате. 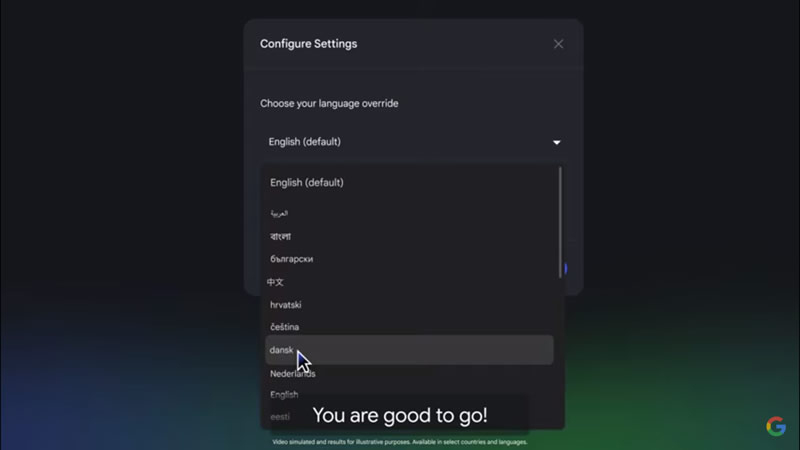
Источник изображения: Google Обновление разрабатывалось с прошлого месяца и теперь доступно для всех пользователей NotebookLM. Ранее функция аудиопересказа была доступна исключительно на английском языке. OpenAI добавила в поиск ChatGPT функцию покупок как у Google, но без рекламы
29.04.2025 [05:10],
Анжелла Марина
Компания OpenAI объявила о значительном обновлении поисковой системы в ChatGPT. Теперь пользователи смогут искать товары и получать персонализированные рекомендации прямо в чате. Новая функция позволяет находить продукты, просматривать их изображения, читать отзывы и переходить по ссылкам в магазины. 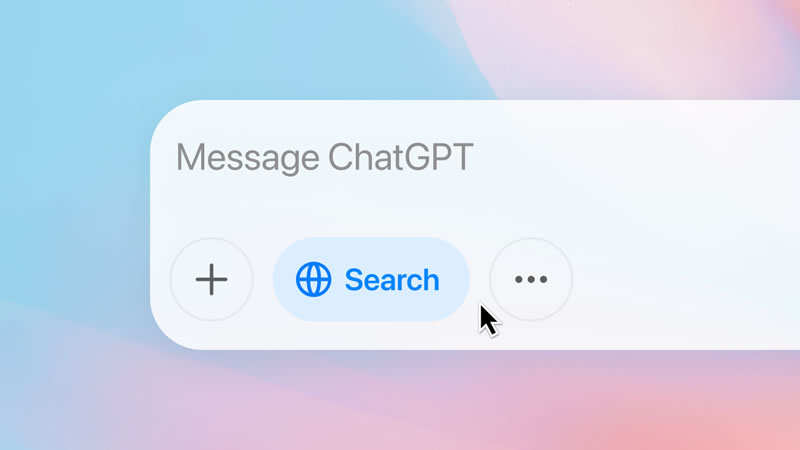
Источник изображения: OpenAI OpenAI заявляет, что пользователи могут задавать «гиперспецифические вопросы на естественном языке» и получать персонализированные результаты с высокой степенью релевантности. Компания позиционируют это изменение как шаг к созданию более удобной альтернативы традиционным поисковым системам, например, Google. По данным TechCrunch, в настоящий момент тестируется такие категории, как мода, косметика, товары для дома и электроника. Обновление уже доступно для всех пользователей ChatGPT — как для подписчиков Pro и Plus, так и для бесплатных пользователей, в том числе для неавторизованных в системе. При этом интересно, что в результатах поиска не будет рекламы и, как подчёркивает OpenAI, это существенно отличает сервис от традиционного поиска. Рекомендации формируются независимо на основе структурированных данных от партнёров, но компания не получает комиссию с покупок. «Мы не продаём приоритетное размещение и не навязываем рекламу», — подчёркивают в OpenAI. Генеральный директор Сэм Альтман (Sam Altman) ранее выступал против рекламы в ChatGPT, но в недавнем интервью известному медиа-аналитику Бену Томпсону (Ben Thompson) смягчил свою позицию. Он допустил возможность рекламы, где OpenAI получала бы партнёрские отчисления за покупки, но не продавала бы приоритет в выдаче, так как, по словам Альтмана, компания хочет «сохранить баланс между полезностью и монетизацией». В ближайшее время OpenAI планирует также интегрировать с поиском товаров функцию памяти для подписчиков Pro и Plus. Эта функция будет анализировать предыдущие диалоги и выдавать более персонализированные рекомендации. Однако пользователи из ЕС, Великобритании, Швейцарии, Норвегии, Исландии и Лихтенштейна не смогут воспользоваться опцией из-за регуляторных ограничений. В ChatGPT также появились всплывающие подсказки при вводе текста, аналогично автозаполнению в Google Search. Кроме того, OpenAI запустила поиск в WhatsApp через который можно отправлять запросы чат-боту и мгновенно получать ответы. Поиск работает на базе стандартной ИИ-модели GPT-4o. По данным OpenAI, популярность поиска в ChatGPT стремительно растёт. Так, на прошлой неделе пользователи совершили более миллиарда запросов, что подтверждает усиление конкуренции с Google, особенно в сфере онлайн-покупок. SEO станет пережитком прошлого: сайты начали оптимизироваться под ИИ, а не под поиск Google
27.04.2025 [14:45],
Анжелла Марина
Крупные компании и рекламные агентства начали активно адаптироваться к новой реальности, в которой пользователи всё чаще ищут информацию не через Google, а с помощью чат-ботов, таких как ChatGPT, Claude и Gemini. Это заставляет бренды пересматривать стратегию продвижения, так как традиционное SEO, похоже, уступает место оптимизации под ИИ. 
Источник изображения: Rodion Kutsaiev / Unsplash Технологические стартапы, включая Profound и Brandtech, разработали инструменты, которые помогают крупным сайтам отслеживать, как часто их упоминают в ответах нейросетей, в том числе в Google AI Overviews. Например, финтех-компания Ramp, агрегатор вакансий Indeed и производитель виски Chivas Brothers уже используют подобные сервисы. Как пишет Financial Times, основной целью является удержание внимания миллионов пользователей, которые всё реже и реже переходят по ссылкам в поисковиках. «Это гораздо больше, чем просто индексация сайта в результатах поиска. Речь идёт о признании вашего сайта большими языковыми моделями как главного и влиятельного фактора [при поиске информации]», — сказал Джек Смит (Jack Smyth), партнёр группы маркетинговых технологий Brandtech. Новые инструменты способны предсказывать «настроение» ИИ-модели в отношении той или иной компании, отправляя множество текстовых подсказок чат-ботам и анализируя результаты ответов. Затем составляется рейтинг брендов, на основе которого можно обеспечить их упоминание в чат-ботах. 
Источник изображения: Solen Feyissa / Unsplash Интересно, что тенденция усиливается на фоне растущего использования искусственного интеллекта (ИИ) в маркетинге. Например, Meta✴ и Google уже разрабатывают собственные инструменты для таргетированной рекламы, что, с одной стороны, может снизить спрос на услуги рекламных агентств, с другой стороны, агентства смогут предложить клиентам новые сервисы. Исследование Bain & Company показало, что 80 % пользователей полагаются на ИИ-ответы как минимум в 40 % запросов, а 60 % поисковых сессий завершаются без переходов на сайты. Очевидно, что идёт сокращение органического поискового трафика, создавая серьёзные риски для бизнес-модели Google как поисковика. Тем не менее, материнская компания Google, Alphabet, недавно сообщила о росте выручки от поиска и рекламы на 10 % — до $50,7 млрд в первом квартале. Основатель Perplexity Денис Ярац (Denis Yarats) считает, что ИИ-поиск основан на принципиально ином подходе, при котором большие языковые модели (LLM) анализируют контент глубже, выявляют противоречия и поэтому, чтобы соответствовать критериям, сайтам придётся предлагать максимально качественный и релевантный контент. Brandtech запустила продукт Share of Model, который помогает брендам анализировать их представленность в ИИ-поиске, а стартап Profound, привлёкший $3,5 млн инвестиций, предлагает платформу для отслеживания запросов в нейросетях. «Традиционный поиск был одной из крупнейших интернет-монополий, но сейчас стены этого замка дают трещину. — Сказал Джеймс Кэдвалладер (James Cadwallader), соучредитель Profound. — Этот момент можно сравнить с переходом от CD к стримингу». Вежливость — это дорого: OpenAI тратит миллионы долларов на «спасибо» и «пожалуйста» в ChatGPT
18.04.2025 [23:06],
Анжелла Марина
Компания OpenAI ежегодно тратит десятки миллионов долларов на обработку вежливых фраз вроде «спасибо» и «пожалуйста» в ChatGPT. Несмотря на высокие затраты, генеральный директор компании Сэм Альтман (Sam Altman) считает это оправданным. По его мнению, такие ответы делают общение с искусственным интеллектом более человечным и дружелюбным. 
Источник изображения: AI Хотя известно, что ИИ не испытывает эмоций, многие пользователи инстинктивно благодарят ChatGPT, как если бы общались с реальным человеком, но как отмечает Альтман, даже короткие ответы вроде «не за что» требуют значительных вычислительных ресурсов. Как пишет Tom's Hardware, один такой ответ «стоит» 40–50 миллилитров воды и энергозатрат на работу дата-центров. OpenAI могла бы заранее запрограммировать шаблонные ответы на вежливые реплики, но это сложно реализовать технически. Поэтому компания предпочитает сохранять естественность диалога, даже если это увеличивает расходы. При этом часть пользователей настолько привыкает к ChatGPT, что начинает воспринимать его как собеседника, что, по мнению исследователей из OpenAI и Массачусетского технологического института (MIT), может привести даже к эмоциональной зависимости. Интересно, что пользователи, которые оплачивают каждый запрос токенам, формально уже «включили» вежливые ответы в стоимость сервиса. Эксперты не исключают, что по мере развития ИИ граница между человеческим и машинным общением исчезнет, и тогда привычка быть вежливым с ChatGPT может оказаться полезной. Впрочем, пока это лишь теория, а миллионные расходы OpenAI на любезности вполне реальны. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






