|
Опрос
|
реклама
Быстрый переход
Microsoft и Cloudflare хотят заново изобрести интернет и оставить Google не у дел
03.09.2025 [16:48],
Владимир Фетисов
Похоже, что для интернет-поисковиков наступает новая эра. Вместо привычных результатов в выдаче акцент смещается в сторону прямых ответов на запросы, генерируемых алгоритмами на базе искусственного интеллекта. На этом фоне Microsoft и Cloudflare объединились, чтобы переосмыслить то, как веб-сайты взаимодействуют с людьми и ИИ-агентами. 
Источник изображения: Robynne O / Unsplash Для достижения поставленной цели компании намерены объединить стандарт Microsoft NLWeb с ИИ-инфраструктурой Cloudflare AutoRAG. Этот шаг может бросить вызов доминированию Google и изменить представление о том, как пользователи взаимодействуют с веб-сайтами. Традиционно интернет-поиск строился на ключевых словах. Пользователь вводит запрос, после чего поисковик возвращает ранжированный список ссылок. Такая модель работала десятилетиями, но интернет продолжал развиваться, и постепенно искусственный интеллект занял лидирующую позицию в сфере поиска информации. Алгоритмы вроде ChatGPT, Claude и Copilot уже меняют то, как пользователи ищут информацию, поскольку многим нравится получать прямые ответы на вопросы вместо того, чтобы искать информацию, переходя по ссылкам. Microsoft и Cloudflare позиционируют NLWeb в сочетании с AutoRAG как инфраструктуру для поддержки перехода на новую схему поиска информации, которая позволит более эффективно работать с ИИ-алгоритмами. Ожидается, что в будущем объём интернет-трафика от ИИ-агентов будет сопоставим с аналогичным показателем от людей. NLWeb представляет собой новый стандарт, разработанный таким образом, чтобы веб-сайты могли открывать структурированные конечные точки для запросов на естественном языке. Проще говоря, NLWeb позволяет перейти на сайт и сформировать запрос. После этого сайт формирует прямой ответ на запрос, вместо того, чтобы заставлять пользователя перелистывать страницы в поисках нужной информации. Основная идея в том, чтобы сделать веб-сайты более похожими на диалоговые приложения, а не на набор страниц с информацией. Сервис AutoRAG сканирует веб-сайт, индексирует его содержимое и преобразует его во вложения, хранящиеся в управляемой базе данных. За счёт этого контент постоянно обновляется, и устраняется техническая необходимость в создании собственной векторной базы и контейнеров. Работая сообща, NLWeb и AutoRAG позволяют веб-сайтам отвечать на вопросы пользователей на естественном языке, получая запросы как от людей, так и от ИИ-агентов. Google доминирует в сегменте интернет-поиска, а ИИ-модель компании Gemini уже даёт ответы на поисковые запросы пользователей. Microsoft и Cloudflare используют иной подход, в связи с чем трафик может перетечь из Google в экосистему Microsoft, что приведёт к укреплению позиций Bing и Copilot. Однако сейчас генерируемые ИИ ответы далеко не всегда совершенны, а в некоторых случаях и вовсе доверять им не стоит. Использование генерируемых ИИ ответов также снижает видимость небольших сайтов, что отнимает деньги у людей, чей контент в первую очередь помогает в обучении инструментов на базе ИИ. ИИ-блокнот Google NotebookLM научился спорить сам с собой в формате аудиообзоров
03.09.2025 [12:46],
Николай Хижняк
Аудиообзоры в NotebookLM теперь доступны в четырёх различных форматах: «Глубокий обзор», «Краткий обзор», «Критика» и «Дебаты». В демо-ролике, опубликованном на странице команды NotebookLM в соцсети X показано, как десктопное приложение переключается между форматами, а голоса ИИ меняют тон соответствующим образом. 
Источник изображения: NotebookLM ИИ-помощник NotebookLM от Google предназначен для анализа и структурирования информации. Каждый новый аудиоформат привносит в NotebookLM что-то новое. «Глубокий обзор» представляет собой формат длинных аудиообзоров, в котором ИИ-ведущие подробно разбирают материал. Формат «Краткий обзор» — это краткое одно- или двухминутное резюме. Формат «Критика» представлен в виде экспертной оценки на тот или иной материал. А в формате «Дебаты» ИИ-ведущие обмениваются мнениями, чтобы подчеркнуть противоположные точки зрения. 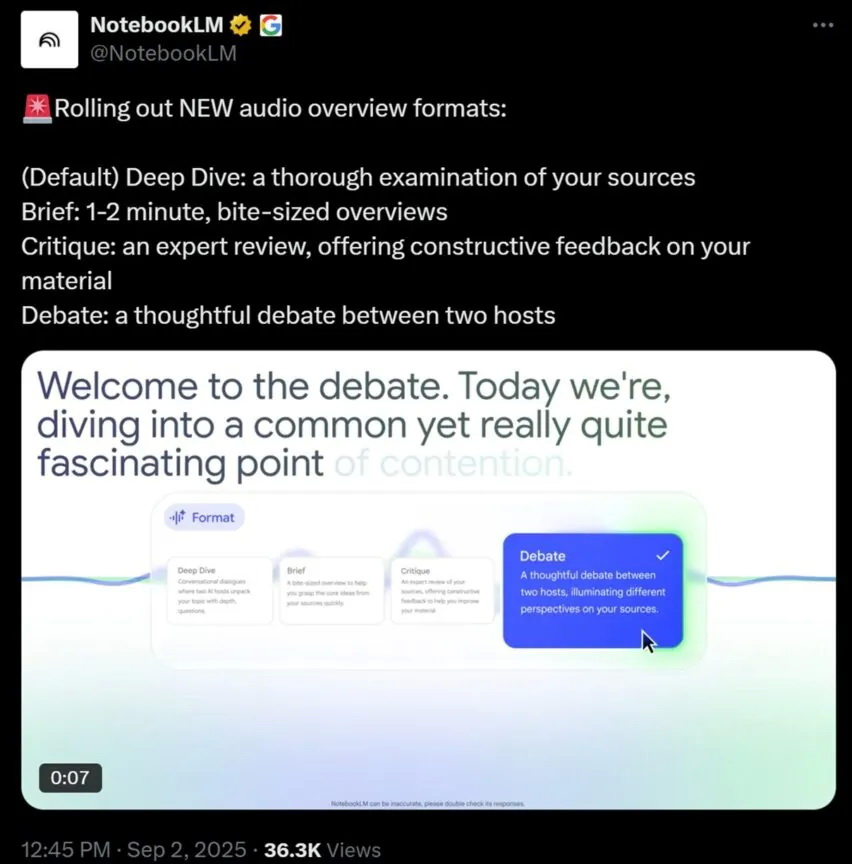 Ранее Google объявила о расширении функции видеобзоров в ИИ-помощнике NotebookLM. Теперь приложение поддерживает более 80 языков, включая русский, французский, немецкий, испанский и японский. Одновременно были улучшены аудиообзоры для неанглоязычных пользователей — они стали более подробными. ChatGPT получит родительский контроль и научится выявлять психологические проблемы у пользователей
03.09.2025 [11:38],
Антон Чивчалов
В OpenAI сообщили о планах внедрения в ChatGPT новых функций, направленных на улучшение реакций ИИ в ситуациях, когда пользователь испытывает эмоциональное или психологическое напряжение, а также новых средств родительского контроля, пишет Silicon Angle. 
Источник изображения: Nicolò Canu/Unsplash Первое обновление затронет так называемый маршрутизатор в GPT-5 — компонент ИИ, который анализирует запрос пользователя и решает, какая из языковых моделей лучше подходит для его обработки. В новой версии маршрутизатор сможет распознавать признаки острого психологического напряжения, и такие запросы будут направляться модели, «заточенной» для рассуждений и бесед с пользователями. Такая модель способна предоставлять «более полезные ответы», чем другие, говорят в OpenAI. Ещё одно нововведение — система родительского контроля. Родители смогут задавать возрастные ограничения, отключать историю чатов и получать уведомления о потенциально опасных запросах детей. А если система решит, что ребёнок находится в состоянии психологического напряжения, она может послать родителям уведомление. Эти функции заработают уже в течение месяца. В OpenAI говорят, что функции родительского контроля разрабатываются с участием специалистов в области развития подростков и психического здоровья. В частности, компания сотрудничает с международной сетью врачей Global Physician Network, в которую входят свыше 200 специалистов различного профиля. «Их работа напрямую влияет на наши исследования в области безопасности, обучение моделей и другие меры вмешательства», — говорится в заявлении компании. Новые инициативы OpenAI продолжают курс на повышение безопасности искусственного интеллекта, о чём было объявлено в прошлом месяце. Также в компании ведётся работа над улучшением блокировки потенциально опасных ответов ИИ. Anthropic получила оценку в $183 млрд — на 40 % дешевле OpenAI
02.09.2025 [22:07],
Николай Хижняк
Стартап в области искусственного интеллекта Anthropic, стоящий за семейством языковых моделей Claude и являющийся одним из главных конкурентов OpenAI, сообщил о привлечении $13 млрд дополнительного финансирования. Благодаря этому компания получила рыночную оценку в $183 млрд. 
Источник изображения: Anthropic В своём пресс-релизе Anthropic сообщила, что с начала 2025 года по август, то есть менее чем за девять месяцев текущего года, её доход от продаж вырос примерно с $1 млрд до более чем $5 млрд. Компания также заявила, что теперь у неё более 300 000 корпоративных клиентов, а за последний год список «крупных клиентов» — то есть тех, кто приносит более $100 000 выручки от текущих продаж, — увеличился в семь раз. Что касается Claude Code, агентного ИИ-помощника по программированию и одного из главных источников дохода компании, на который Anthropic делает ставку, продукт уже принёс более $500 млн выручки от текущих продаж, а количество пользователей выросло более чем в десять раз за три месяца с момента его «полного запуска». Среди инвесторов последнего раунда финансирования Anthropic отметились компании Qatar Investment Authority, TPG, Altimeter, Blackstone, Coatue, General Catalyst и другие. По словам Anthropic, полученные средства частично будут использованы для «удовлетворения растущего спроса со стороны предприятий, углубления исследований в области безопасности и поддержки международной экспансии» её продуктов. Добавим, что главный конкурент Anthropic в лице OpenAI в апреле получил оценку в $300 млрд, а в августе сообщалось, что в рамках нового раунда финансирования компания может быть оценена в $500 млрд. Представлен Dolby Vision 2 — «кинематографический» HDR, аутентичное сглаживание и ИИ-оптимизации
02.09.2025 [19:01],
Сергей Сурабекянц
Через десять лет после запуска формата Dolby Vision представлена обновлённая версия стандарта — Dolby Vision 2. Она включает новые инструменты Content Intelligence, которые используют нейросети для автоматической оптимизации изображения в зависимости от устройства и характера контента. По словам разработчика, представленное в Dolby Vision 2 интеллектуальное сглаживание изображения Authentic Motion — это «первый творческий инструмент управления движением». 
Источник изображения: Dolby Среди инструментов Content Intelligence — функция Precision Black, повышающая чёткость тёмных сцен с бережным сохранением замысла создателя фильма, и обновлённая функция Light Sense, изменяющая настройки изображения в зависимости от окружающего освещения и яркости контента. Функция Sports and Gaming Optimization обеспечит оптимальный показ спортивных трансляций и корректное отображение игрового контента. Телевизоры с поддержкой Dolby Vision 2 будут использовать двунаправленную тональную компрессию, которая предоставит создателям контента больше контроля над возможностями дисплея. Это позволит повысить яркость и чёткость изображения, а также обеспечить более насыщенные цвета. В обновлённом стандарте Dolby Vision 2 представлена технология сглаживания изображения Authentic Motion. По словам представителя Dolby, это «первый творческий инструмент управления движением», предоставляющий покадровый контроль для снижения нежелательного дрожания изображения и придания ему подлинно кинематографического вида без эффекта «мыльной оперы». Спецификация Dolby Vision 2 обратно совместима с первой версией стандарта, поэтому контент Dolby Vision будет корректно отображаться на устройствах, поддерживающих обе спецификации, а контент Dolby Vision 2 можно будет просматривать и на моделях предыдущего поколения. Однако распознавать и использовать дополнительные метаданные нового формата смогут только новейшие телевизоры с поддержкой Dolby Vision 2. По сравнению с оригинальной спецификацией Dolby Vision новая версия упростит определение возможностей телевизоров, разделив их на два уровня в зависимости от производительности. Dolby Vision 2 Max предлагает дополнительные премиум-функции для «самых производительных телевизоров», в то время как стандартная маркировка Dolby Vision 2 предназначена для более доступных моделей. Компания Hisense станет первым брендом, выпустившим телевизоры на базе чипа MediaTek Pentonic 800 с поддержкой стандарта Dolby Vision 2. Вероятно, в ближайшее время её примеру последуют и другие крупнейшие производители телевизоров. «Сделано ИИ»: DeepSeek добавила обязательную маркировку ИИ-контента и запретила её удалять
02.09.2025 [09:47],
Антон Чивчалов
Китайская компания DeepSeek — разработчик одноимённого ИИ-бота — ввела маркировку для всего контента, созданного с помощью её продукта. Согласно новым правилам, такой контент должен сопровождаться визуальными и скрытыми техническими метками, удалять которые пользователь не вправе, пишет Gizmochina. 
Источник изображения: Solen Feyissa / Unsplash DeepSeek разослала официальное уведомление, в котором объясняется, как это будет работать. Визуальные маркеры должны включать фразу «создано ИИ» в графическом или аудиоформате, они должны хорошо восприниматься пользователем. Также в структуру материала должна быть встроена техническая метка с информацией о типе контента и организации-авторе. При этом запрещено удалять или скрывать такие записи, а также любым способом нарушать целостность маркировки. В DeepSeek даже пригрозили юридическими последствиями тем, кто будет пытаться обходить новые требования. Между тем упомянутые нововведения вовсе не инициатива самой DeepSeek — таковы требования новых законов, вступивших в силу в Китае. Согласно им, любой ИИ-контент должен иметь пометки о своём происхождении в целях отслеживания, а разработчик должен исключить возможность подделки таких пометок. Он же несёт ответственность за соблюдение новых норм. Одновременно с этим DeepSeek представила обновлённую версию своей языковой модели 3.1 с 685 миллиардами параметров, а также выпустила подробное техническое руководство о том, как работать с её продуктами. В документе описывается, как ИИ обучается, какие данные при этом используются, как именно создаётся контент. В компании подчеркнули, что хотят помочь пользователям лучше понимать технологию и использовать её более ответственно. Белый дом приказал вернуть ИИ-бота xAI Grok «как можно скорее»
31.08.2025 [08:29],
Владимир Фетисов
Похоже, что Белый дом дал указание руководству Управления общих служб (GSA) США добавить ИИ-бота Grok принадлежащей Илону Маску (Elon Musk) компании xAI в список одобренных «как можно скорее». Об этом пишет журнал Wired со ссылкой на соответствующее электронное письмо, которое на этой неделе получили руководители правительственного агентства. 
Источник изображения: Mariia Shalabaieva/unsplash.com «Команда: Grok от xAI должен быть срочно возвращён в реестр по распоряжению Администрации президента. Кто-нибудь может немедленно связаться с Carahsoft и подтвердить это? <…> Это должны быть все продукты, которые у нас были ранее», — говорится в письме комиссара Федеральной службы закупок Джоша Грюнбаума (Josh Gruenbaum). Упомянутая в письме Carahsoft является крупным государственным подрядчиком, который занимается перепродажей технологий сторонних компаний. По данным источника, на этой неделе правительством США были внесены корректировки в контракт Carahsoft, в результате чего компания xAI снова попала в список одобренных властями. Уже к концу недели ИИ-алгоритмы Grok 3 и Grok 4 стали доступны на GSA Advantage — площадке по покупке продуктов и услуг для государственных учреждений. Это означает, что теперь, после проведения внутренних проверок, любое правительственное учреждение может внедрить Grok для федеральных служащих. Официальные представители Белого дома и GSA воздерживаются от комментариев по данному вопросу. Напомним, сотрудничество правительства с xAI было приостановлено летом этого года, после того, как интегрированный в соцсеть X ИИ-бот Grok начал распространять разного рода антисемитские убеждения. В июне сотрудники xAI встретились с представителями GSA и обсудили перспективы использования Grok правительством. Некоторые федеральные служащие были удивлены желанием властей внедрить в работу государственных учреждений ИИ-бота без цензуры, который отличается от аналогов непредсказуемым поведением. Samsung добавила ИИ-помощника Microsoft Copilot в свои новые телевизоры
31.08.2025 [07:56],
Владимир Фетисов
Компания Samsung официально объявила о начале внедрения ИИ-помощника Microsoft Copilot в свои телевизоры и смарт-дисплеи 2025 года в рамках программы по развитию платформы Samsung Vision AI. Пользователи смогут взаимодействовать с Copilot посредством голосовых команд или пульта дистанционного управления. Ассистент позиционируется как средство поиска контента на телевизорах Samsung, «адаптированного» под конкретного пользователя. 
Источник изображения: Samsung В компании добавили, что Copilot также появится на платформе Lifestyle Hub, которая выходит за рамки развлечений и охватывает разные сегменты, включая оздоровление, правильное питание, фитнес и др. Samsung считает голосового помощника Microsoft перспективным, поэтому намерена интегрировать его в новые телевизоры и смарт-дисплеи. Предсказуемым результатом перехода Samsung на использование функций Copilot в своих телевизорах станет постепенный отказ от Google Assistant. Этот помощник в целом за последний год был отодвинут на второй план, поскольку Google сосредоточила усилия на развитии ИИ-ассистента Gemini. Похоже, что разработчики намерены полностью отказаться от Google Assistant, поскольку он покидает даже те устройства, которые были созданы на его основе, например, дисплеи Nest. Что касается Samsung, то компания объявила о переходе на использование Copilot в начале этого года. Это произошло на фоне того, как один из конкурентов компании в лице LG также начал использовать ИИ-помощника Microsoft. Samsung уточнила, что доступность Copilot в новых телевизорах зависит от региона, но конкретные сроки внедрения ИИ-помощника названы не были. Стартап Илона Маска обвинил бывшего сотрудника в краже секретов для OpenAI
30.08.2025 [14:19],
Владимир Мироненко
Стартап Илона Маска (Elon Musk) в области искусственного интеллекта xAI подал в суд на бывшего сотрудника компании, якобы похитившего составляющую коммерческую тайну информацию о чат-боте Grok для передачи конкурирующей компании OpenAI, пишет Reuters. 
Источник изображения: xAI Иск xAI был подан в четверг в федеральный суд Калифорнии. В нём сообщается, что бывший сотрудник Сюэчэнь Ли (Xuechen Li) ранее в этом месяце украл конфиденциальную информацию, связанную с «передовыми ИИ-технологиями с функциями, превосходящими те, что предлагает ChatGPT», чтобы использовать секретные данные на своей новой работе в OpenAI. Как уточняет Reuters, OpenAI не является ответчиком в этом деле. Согласно иску, Сюэчэнь Ли приступил к работе в xAI в качестве инженера в прошлом году. Круг его обязанностей включал участие в обучении и разработке Grok. xAI утверждает, что Ли получил доступ к её коммерческим секретам в июле, вскоре после того, как принял предложение о работе в OpenAI и продал акции xAI на $7 млн. Эти сведения, как сообщается в иске, могут помочь OpenAI усилить продукт ChatGPT, добавив «более инновационный ИИ и оригинальные функции xAI». В иске также говорится, что Ли признался в краже файлов компании и «заметании следов» во время встречи 14 августа, и что позже на его устройствах были обнаружены дополнительные похищенные материалы, о которых он умолчал. В иске xAI выдвинуто требование о выплате неуказанной суммы денежной компенсации, а также о вынесении судебного запрета на переход Ли в OpenAI. Этот иск ещё больше ухудшил отношения Маска и OpenAI. В прошлом году он подал в суд на компанию и её гендиректора Сэма Альтмана (Sam Altman) за якобы отказ от первоначальной цели работать на некоммерческом поприще. В апреле OpenAI подала встречный иск против Маска, обвинив его в преследовании. Huawei вернулась к прибыльности в первом полугодии благодаря DeepSeek
29.08.2025 [19:22],
Владимир Фетисов
Компания Huawei Technologies отчиталась о получении прибыли по итогам первых шести месяцев 2025 года. Этому способствовало появление в начале года ИИ-алгоритмов стартапа DeepSeek, что вызвало волну развития технологий на базе искусственного интеллекта по всему Китаю. 
Источник изображения: P. L. / Unsplash Согласно опубликованным данным, чистая прибыль Huawei в первом полугодии сократилась на 32 % год к году и составила 37,1 млрд юаней ($5,2 млрд). Однако это позволило компенсировать неожиданный убыток по итогам четвёртого квартала, когда технологический гигант активно инвестировал в покупку чипов и развитие технологий для электромобилей. За отчётный период выручка компании увеличилась на 3,94 % и составила 427 млрд юаней. Huawei занимается разработкой ИИ-ускорителей, которые напрямую конкурируют с продуктами Nvidia на китайском рынке. Появление большой языковой модели DeepSeek R1 в начале года стало толчком к росту всего ИИ-направления в стране, благодаря которому Huawei сумела воспользоваться преимуществами растущего спроса на ИИ-ускорители. Ускорители Huawei Ascend пользуются большой популярностью на домашнем рынке, особенно на фоне призывов местных властей к IT-компаниям по поводу отказа от использования продукции Nvidia. Напомним, ранее американские власти запретили поставлять в Китай передовые и наиболее производительные ИИ-ускорители. По сообщениям китайских СМИ, на прошлой неделе Huawei завершила реструктуризацию своего облачного подразделения, чтобы сосредоточить больше ресурсов на развитии направления искусственного интеллекта. Параллельно с этим компания активно развивает автомобильный бизнес, предлагая производителям специализированное программное обеспечение и компоненты для авто. ИИ не устает и не забывает вопросы: в найме персонала он превзошёл людей
29.08.2025 [17:26],
Владимир Фетисов
На этой неделе исследователи из Школы бизнеса Бута Чикагского университета и Университета им. Эразма Роттердамского опубликовали результаты исследования, посвящённого изучению возможностей искусственного интеллекта по поиску кандидатов на работу. Исследование проводилось на основе 67 тыс. собеседований при приёме на работу, а его результаты не сулят ничего хорошего специалистам по подбору персонала — искусственный интеллект справляется с этими задачами не хуже человека. 
Источник изображения: Gabrielle Henderson / Unsplash Исследователи сотрудничали с компанией, занимающейся рекрутингом. Вместе они случайным образом распределили 67 тыс. соискателей, которым предстояло пройти собеседование с ИИ-агентом, человеком или же сделать самостоятельный выбор между ними. Отмечается, что собеседования проходили по телефону, и в начале разговора ИИ-агент предупреждал собеседника о том, что он разговаривает не с человеком. Во всех случаях окончательное решение о приёме на работу (на должности начального уровня по обслуживанию клиентов на Филиппинах) принимали люди — оно основывалось на том, насколько хорошо кандидаты показали себя во время собеседования и по результатам стандартного тестирования. Проведённые ИИ-агентом собеседования привели к увеличению количества предложений о работе на 12 % и повышению уровня удержания сотрудников на 17 % как минимум в первый месяц после приёма на работу. Исследователи установили, что голосовые агенты на базе ИИ охватывают значительно больше ключевых тем во время звонков, чем люди, проводящие собеседования. Такой подход позволяет рекрутерам получить больше актуальных данных для принятия решения о приёме человека на работу или отказе. Один из авторов исследования, Брайан Джабариан (Brian Jabarian), считает, что отчасти ИИ-агент хорошо справляется с проведением собеседований благодаря тому, что он меньше говорит и побуждает собеседника активнее высказываться. Кроме того, когда речь идёт о тысячах собеседований, люди-интервьюеры подвержены усталости, из-за чего могут забывать задавать те или иные важные вопросы. Некоторые из потенциальных кандидатов негативно восприняли предложение пройти собеседование с ИИ-агентом. Около 5 % из них завершили разговор раньше времени, потому что не хотели общаться с ботом. В 7 % случаев голосовой ИИ-агент столкнулся с техническими трудностями. Многие кандидаты оценили ИИ как «значительно менее естественного» собеседника. При этом 70 % соискателей, оставивших отзыв о собеседовании с ботом, сообщили, что для них это был положительный опыт. В то же время только 50 % людей высказались положительно о собеседовании с человеком-интервьюером. Такие результаты застали врасплох профессиональных рекрутеров, поскольку они ожидали, что ИИ будет справляться с задачей значительно хуже. Примечательно и то, что четыре из пяти людей предпочли пройти собеседование с ИИ-агентом — хотя это может быть связано и с тем, что в этом случае у них была возможность назначить удобное для себя время. Один из наиболее любопытных выводов, сделанных на основе исследования, связан с экономической эффективностью замены профессиональных рекрутеров алгоритмами на базе ИИ. Несмотря на то что боты на удивление хорошо справились со сложной работой, их использование не даёт гарантий возврата инвестиций, необходимых для интеграции. Хотя кандидаты имели возможность планировать время проведения собеседований, эта эффективность нивелировалась тем, что людям-рекрутерам в среднем требовалось примерно вдвое больше времени на изучение результатов интервью, проведённых ИИ-агентами. Вопрос о том, приведёт ли инвестирование в голосовых ИИ-агентов для собеседований к реальной экономии, во многом зависит от конкретной ситуации. Здесь играют роль тип вакансий, квалификация ИИ-агента для проведения интервью, объём найма, уровень зарплат рекрутеров и другие факторы. Вероятно, небольшие компании в регионах, где зарплаты рекрутеров невысоки, не смогут извлечь выгоду из использования ИИ-агентов. В то же время перспективы крупных компаний с большим числом соискателей и дорогостоящими рекрутерами выглядят более многообещающими. Meta✴ не забросила метавселенную — в Horizon Worlds появятся полноценные NPC с ИИ
29.08.2025 [12:44],
Антон Чивчалов
Разработчики, создающие контент для метавселенной Horizon Worlds, скоро смогут создавать NPC-персонажей с поддержкой ИИ. Такие виртуальные собеседники смогут вести реалистичные голосовые диалоги с игроками и реагировать на их действия, сообщает Engadget. 
Источник изображения: developers.meta.com Данное обновление от компании Meta✴ расширяет возможности редактора Character Builder в составе Worlds Desktop Editor. Оно обещает значительно расширить возможности взаимодействия в метавселенной за счёт генеративного ИИ. «В составе данного обновления мы расширяем Character Builder новыми инструментами, которые позволят вам определять различные характеристики ваших NPC, такие как имя, биография, черты характера, диалоги, а также тестировать их реакции», — говорится в официальном блоге Meta✴. Это будет первый раз, когда Meta✴ позволяет разработчикам создавать полноценных, настраиваемых NPC в Horizon Worlds. Ранее компания уже экспериментировала в этой области, но действия NPC были ограничены готовыми сценариями. Теперь возможности их кастомизации многократно расширяются. Meta✴ выложила видеоролик, где показано, как работать с новыми функциями. Точной даты выпуска нового решения пока нет, но в Meta✴ говорят «очень скоро». С большой вероятностью это станет известно на мероприятии Meta✴ Connect через несколько недель. Тем временем пользователи уже могут протестировать новых NPC в играх Bobber Bay Fishing и Profit or Perish. В WhatsApp появился ИИ-помощник по написанию сообщений
29.08.2025 [11:32],
Владимир Фетисов
Разработчики WhatsApp продолжают добавлять полезные функции, которые должны сделать процесс взаимодействия с мессенджером более комфортным. На этот раз была анонсирована функция Writing Help, которая задействует алгоритм на базе искусственного интеллекта для помощи в написании сообщений. 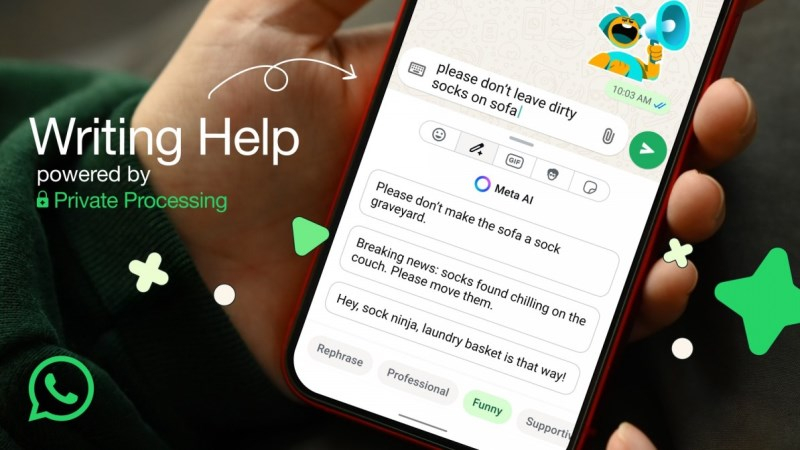
Источник изображения: gsmarena.com Новая функция позволит генерировать сообщения в разных стилях, например, профессиональном или шутливом. Пользователь может согласиться с предложенным вариантом или же проигнорировать его. Для активации функции Writing Help достаточно нажать на новую иконку в виде карандаша, которая появится среди доступных инструментов. Отмечается, что функция Writing Help задействует нейросеть для генерации сообщений в приватном формате, т.е. создаваемые алгоритмом тексты не передаются на удалённые серверы, и их не могут видеть сотрудники WhatsApp или Meta✴. По данным разработчиков, процесс обработки персональных данных был проверен с привлечением «коллег из сообщества безопасности». Функция Writing Help не является обязательной и по умолчанию она отключена. Если у пользователя есть сомнения по поводу конфиденциальности данных, генерируемых алгоритмом, то он может попросту не задействовать это нововведение. На данный момент функция Writing Help поддерживает английский язык и доступна в США, а также ряде других стран. Более масштабное распространение новой функции состоится позднее в этом году. Microsoft выпустила первые собственные ИИ-модели: одна генерирует речь, а другая — текст
29.08.2025 [00:43],
Николай Хижняк
До сих пор Microsoft в значительной степени полагалась на модели искусственного интеллекта компании OpenAI. Каждый раз, когда OpenAI представляла свои новейшие модели, Microsoft объявляла об их доступности в инфраструктуре Azure и во всех своих продуктах и сервисах. Сегодня Microsoft представила две собственные модели искусственного интеллекта: MAI-Voice-1 и MAI-1-preview. 
Источник изображения: Microsoft MAI-Voice-1 — это модель генерации речи. Она уже доступна в приложениях Copilot Daily (аудиосводка новостей и погоды на основе ИИ) и Podcasts. Чтобы ознакомиться со всеми возможностями этой голосовой модели, Microsoft создала новый интерфейс Copilot Labs, который каждый может попробовать уже сегодня. С помощью функции Copilot Audio Expressions пользователи могут вставить текстовый контент и выбрать голос, стиль и режим для создания высококачественного, выразительного звука. При необходимости можно скачать сгенерированный аудиофайл. Microsoft подчёркивает, что модель MAI-Voice-1 работает очень быстро и эффективно: она способна сгенерировать минуту аудио менее чем за секунду при использовании одного GPU. Модель MAI-1-preview доступна в виде публичной бета-версии на платформе LMArena для оценки сообществом. Это первая фундаментальная модель MAI, прошедшая комплексное обучение, и она даёт представление о будущих возможностях Copilot. MAI-1-preview — это модель MoE (смешанная модель экспертов), обученная на почти 15 000 специализированных ускорителях Nvidia H100. Это первая фундаментальная ИИ-модель Microsoft, прошедшая комплексное обучение собственными силами. Компания утверждает, что она эффективно выполняет инструкции и может давать полезные ответы на повседневные вопросы пользователей. Microsoft планирует внедрить MAI-1-preview для некоторых текстовых сценариев Copilot в ближайшие недели. При этом Microsoft уточняет, что MAI-1-preview не заменяет модели OpenAI в Copilot. Компания планирует использовать лучшие решения как собственной команды, так и партнёров, включая сообщество разработчиков ПО с открытым исходным кодом. Помимо платформы LMArena, модель MAI-1-preview также доступна через API для доверенных тестировщиков. Обнаружен первый ИИ-вирус — он запускает на локальном ПК нейросеть от OpenAI и просит её написать вредоносный код
28.08.2025 [08:32],
Антон Чивчалов
Компания Eset выявила, вероятно, первую в мире программу-вымогатель со встроенной языковой моделью искусственного интеллекта. Программа, получившая название PromptLock, способна динамически создавать скрипты Lua с помощью ИИ, пишет CyberInsider. 
Источник изображения: Flipsnack / unsplash.com По данным исследователей, в PromptLock используется локальная реализация модели gpt-oss:20b через API Ollama, что позволяет ей работать в средах Windows, macOS и Linux без необходимости создания отдельных версий. Такие способности повышают гибкость вируса и затрудняют его обнаружение. Код PromptLock написан на языке Go и классифицируется как Filecoder.PromptLock.A. Вредонос сканирует файловую систему и затем осуществляет выборочную эксфильтрацию данных и их шифрование по 128-битному алгоритму Speck. В самом коде PromptLock нет языковой модели, он подключается к ней через собственный сервер посредством прокси, что позволяет обходить сетевые ограничения. В коде программы присутствуют элементы, указывающие на потенциально разрушительные действия, однако они пока не реализованы до конца. По этой причине в Eset считают, что программа может быть экспериментальным образцом, не предназначенным для массового распространения. Что, впрочем, не уменьшает серьёзность находки — появление подобных решений говорит о новом этапе в развитии киберугроз, где ИИ становится инструментом уже не только защиты, но и атаки, отмечают в Eset. Интересно, что в коде PromptLock имеется жёстко заданный биткоин-адрес, связанный с автором биткоина Сатоси Накамото (Satoshi Nakamoto). По мнению специалистов, это может быть некой данью уважения к человеку со стороны создателей вируса, но также может быть отвлекающим манёвром. Специалисты отмечают аналогию PromptLock с другой программой — Lamehug, в которой также используется языковая модель HuggingFace для генерации команд. Однако PromptLock отличается полной автономией и независимостью от внешних API. За счёт подобной интеграции ИИ вирус умеет адаптироваться к окружению в реальном времени, подчёркивают в Eset. Администраторам сетей рекомендуется отслеживать выполнение Lua-скриптов, особенно связанных с шифрованием, и проверять исходящие соединения на наличие прокси с инфраструктурой Ollama. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






