|
Опрос
|
реклама
Быстрый переход
LG представила домашнего двуногого ИИ-робота на колёсиках — он поддержит диалог, будет охранять дом и не только
27.12.2023 [16:19],
Николай Хижняк
Компания LG представила компактного робота-помощника для дома Smart Home AI Agent. Новинка полагается на технологии искусственного интеллекта и машинного обучения для передвижения, управления предметами «умного дома», а также изучения дома и общения с хозяевами и другими людьми. 
Источник изображений: LG В основе робота LG Smart Home AI Agent используется платформа Qualcomm Robotics RB5. Компактный двухколёсный робот-помощник оснащён камерой, динамиком, а также набором различных сенсоров, позволяющих ему следить за обстановкой в доме и собирать информацию об окружающем пространстве, включая температуру, влажность и качество воздуха.  Машина работает в автономном режиме. Он может общаться с домочадцами и их гостями, и через различные движения демонстрировать различные эмоции. Для этого он оснащён мультимодальной технологией искусственного интеллекта, объединяющей функции распознавания голоса и изображений, а также возможность обработки естественного языка. Всё это позволяет роботу LG Smart Home AI Agent улавливать контекст разговора, а также намерения владельца, и активно участвовать в общении с пользователями. Возможности и особенности робота LG Smart Home AI Agent:
О стоимости домашнего робота-помощника Smart Home AI Agent компания LG пока ничего не сообщила. Производитель собирается продемонстрировать новинку на международной выставке электроники CES 2024 с 9 по 12 января. Microsoft открыла бесплатный доступ к мощнейшей нейросети GPT-4 Turbo через Bing Chat, но только избранным
25.12.2023 [14:20],
Николай Хижняк
Нейросеть GPT-4 Turbo доступна на платной основе по подписке ChatGPT Plus. Однако компания Microsoft предоставила возможность попробовать её функции совершенно бесплатно. Правда, для этого необходимо случайным образом оказаться в числе отобранных тестировщиков. В настоящий момент Microsoft тестирует интеграцию ChatGPT-4 Turbo, а также поддержку плагинов в своём собственном чат-боте Bing Chat (Microsoft Copilot). 
Источник изображений: Windows Latest Microsoft также планирует обновить функцию Code Interpreter, чтобы привести её в соответствие с возможностями платформы OpenAI. Это означает, что Code Interpreter в Microsoft Copilot вскоре сможет отвечать на более сложные вопросы, связанные с программированием или обработкой данных. GPT-4 Turbo — это новая модель ChatGPT от OpenAI, основанная на существующей модели GPT-4. Языковая модель обучена на общедоступной информации до апреля 2023 года, поэтому может более точно отвечать на вопросы пользователя о недавних событиях. GPT-4 доступен только для подписчиков тарифа Plus и не является бесплатным. Со ссылкой на источники в Microsoft портал Windows Latest сообщает, что компания внедряет новейшую модель ChatGPT в свой Bing Chat. Правда, GPT-4 Turbo в этом случае используется не постоянно, а в зависимости от того или иного запроса, а также настроек плагинов. При использовании стандартных настроек Bing Chat может переключаться между своей актуальной ИИ-моделью и GPT-4 Turbo. Возможность протестировать GPT-4 Turbo в составе Bing Chat пока полностью зависит от удачи, поскольку функция доступна только тем, кто был отобран для её тестирования. Однако в Microsoft подтвердили, что планируют расширить развертывание в ближайшие недели. Также стоит отметить, что при отборе тестировщиков Microsoft не отдает предпочтение конкретным учетным записям или регионам. Отбор происходит полностью случайным образом и работает по принципу A/B-тестирования. Узнать, получил ли пользователь доступ к GPT-4 Turbo в составе Bing Chat, можно несколькими способами. Самый простой — на ПК или ноутбуке зайти по ссылке Bing.com/chat в браузере, создать новую тему и посмотреть исходный код веб-страницы. Затем, используя функцию «Найти на странице» в браузере Edge или Chrome, необходимо через поиск найти dlgpt4t. Если в результате запроса в исходном коде веб-страницы будут обнаружены упоминания dlgpt4t, то это означает, что пользователь имеет доступ к GPT-4 Turbo. На мобильных устройствах подтвердить своё право на бесплатное использование GPT-4 Turbo в рамках тестирования можно, загрузив в чат-бот Bing Chat какое-нибудь изображение (желательно абстрактное) и попросить ИИ-чат-бота описать эмоции, которые вызывает это изображение. В отличие от предыдущих моделей GPT новейшая модель GPT-4 Turbo в составе Bing Chat может распознавать эмоции и свободно о них говорить. В Bing Chat также появились настройки плагинов. При желании через эту настройку можно отключить поиск через поисковую платформу Bing в рамках запроса для Bing Chat. При отключении плагина «Поиска в Bing» чат-бот Bing Chat не будет сканировать ссылки в Bing для поиска ответов на запрос. Вместо этого он будет полностью полагаться на свои собственные данные, полученные в ходе обучения. 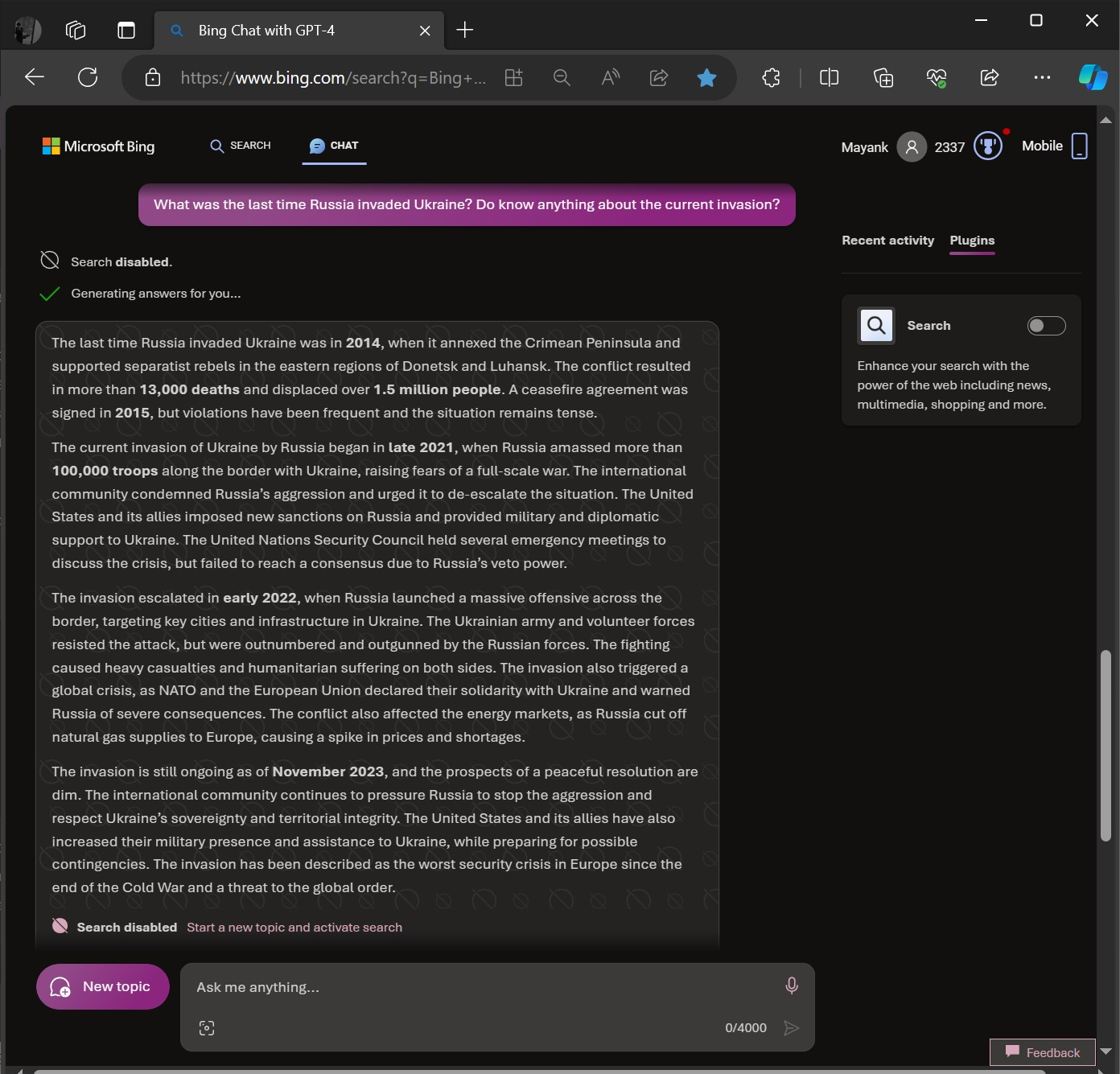
При отключённом поиске в Bing чат-бот Bing Chat может динамически переключаться на GPT-4, предоставляя более новую информацию Способность Bing Chat отвечать на запросы, связанные с событиями в период с января по апрель 2023 года, также подтверждает, что для ответа на запросы используется модель GPT-4 Turbo. Робот с ИИ очень быстро научился проводить шарик через лабиринт — и даже нашёл способ жульничать
19.12.2023 [20:49],
Сергей Сурабекянц
Компьютеры уже победили людей в покере, го и шахматах. Теперь они принялись осваивать физические навыки, стремясь опередить человека в играх, где требуются хорошая реакция, интуиция, ловкость и координация. Исследователи из ETH Zurich создали робота CyberRunner, который, по их словам, превзошёл людей в популярной игре «Лабиринт». Он провёл небольшой металлический шарик через лабиринт, наклоняя его и избегая ловушек, причём освоил игрушку всего за шесть часов. 
Источник изображений: ETH Zurich CyberRunner стал одним из первых случаев, когда ИИ победил человека в непосредственном физическом соревновании, рассказали учёные Рафаэлло Д’Андреа (Raffaello D’Andrea) и Томас Би (Thomas Bi). Во время эксперимента робот использовал две ручки для управления игровой поверхностью, что требовало мелкой моторики и пространственного мышления. Сама игра предъявляет высокие требования к стратегическому планированию в реальном времени, быстроте принятия решений и точности действий. Результаты эксперимента опубликованы во вторник в научной статье. Робот был построен на основе последних достижений в области, называемой машинным обучением с подкреплением, в процессе которого ИИ учится вести себя в динамической среде методом проб и ошибок. CyberRunner во время обучения обнаружил удивительные способы «обмануть» игру, пропуская части лабиринта, так что исследователям пришлось вмешаться и потребовать соблюдать правила. Промышленные роботы десятилетиями выполняли повторяющиеся и точные производственные задачи, но корректировки на ходу, подобные тем, что продемонстрировал CyberRunner, — это новый уровень, уверены исследователи. Система может анализировать, учиться и саморазвиваться, выполняя физические задачи, которые раньше считались достижимыми только с помощью человеческого интеллекта. «Мы размещаем нашу работу на платформе с открытым исходным кодом, чтобы показать, что это возможно, делимся подробностями о том, как это делается, и как удешевить разработку, — рассказал Д'Андреа. — Скоро появятся тысячи таких систем искусственного интеллекта, которые будут проводить совместные эксперименты, общаться и обмениваться передовым опытом».  Проект с открытым исходным кодом теперь доступен на сайте исследователей. За 200 долларов разработчики готовы помочь пользователям координировать масштабные эксперименты с помощью платформы CyberRunner. «Это не сделанная на заказ платформа, которая стоит больших денег, — подчёркнул Д’Андреа. — Самое интересное то, что мы делаем это на платформе, которая открыта для всех и практически ничего не стоит для дальнейшего продвижения работы». Любопытно отметить, что Рафаэлло Д’Андреа далеко не новичок в роботостроении и машинном обучении — ранее он основал стартап Kiva Systems, который был приобретён компанией Amazon Robotics. Одна из его прежних разработок — «Танцующий склад» — представлена на видео ниже. Amazon представила свой ИИ-генератор изображений Titan Image Generator
30.11.2023 [06:10],
Николай Хижняк
На конференции AWS re:Invent компания Amazon представила собственный ИИ-генератор изображений Titan Image Generator на платформе Bedrock. Он предназначен для создания изображений на основе текстовых запросов, а также предлагает поддержку различных дополнительных функций редактирования уже готовых изображений. 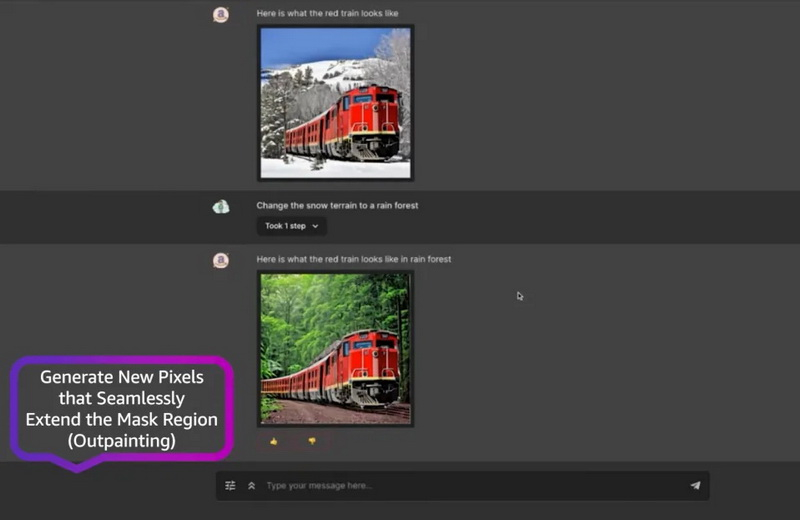
Источник изображения: Amazon По словам Amazon, инструмент способен генерировать «огромные объёмы реалистичных изображения студийного качества при низкой цене». Компания заявляет, что Titan Image Generator способен создавать изображения на основе сложных текстовых подсказок, одновременно обеспечивая при этом точность композиции генерируемых объектов на изображении с минимальными искажениями. По мнению разработчиков Amazon, это поможет «сократить объёмы создания вредного контента и смягчить распространение дезинформации». Функции Titan Image Generator также позволяют редактировать отдельные элементы на изображении, удаляя или добавляя дополнительные детали. Например, инструмент позволяет заменить задний фон на изображении, а также заменить или удалить предмет, который может находиться в руках человека, изображенного в кадре. Использующиеся в составе Titan Image Generator ИИ-алгоритмы также могут расширять композицию изображения, добавляя дополнительные искусственные детали, аналогично функции Generative Expand в Photoshop. В компании отмечают, что их ИИ-генератор изображений Titan накладывает на каждое созданное им изображение невидимый невооружённому глазу специальный водяной знак. По мнению компании, эта функция поможет «уменьшить распространение дезинформации, предоставив незаметный механизм для идентификации изображений, созданных ИИ, а также будет способствовать безопасному, надежному и прозрачному развитию технологий искусственного интеллекта». Amazon заявляет, что эти водяные знаки невозможно удалить или изменить. Согласно опубликованному видео с демонстрацией работы Titan Image Generator, инструмент также может создавать описания изображений или релевантный текст для последующего использования в публикации в социальных сетях. Amazon представила ИИ-чат-бот Amazon Q — он поможет миллионам людей в повседневных рабочих задачах
29.11.2023 [04:33],
Николай Хижняк
У OpenAI есть ChatGPT. У Google есть ИИ-чат-бот Bard. У Microsoft есть различные версии ИИ-помощников Copilot, предназначенные для разных задач. Компания Amazon во вторник наконец-то анонсировала своего ИИ-помощника — Amazon Q. Он разработан подразделением облачных вычислений Amazon и предназначен не для обычных потребителей, а для корпоративных пользователей. 
Источник изображения: Associated Press Среди функций Amazon Q отмечаются возможность кратко формулировать содержание важных документов, заполнение заявок для внутренней поддержки компаний, ответы на вопросы о политике компании, помощь в редактировании и т.д. Он будет конкурировать с другими корпоративными чат-ботами включая Copilot, Google Duet AI и ChatGPT Enterprise. В интервью изданию The New York Times исполнительный директор Amazon Web Services Адам Селипски (Adam Selipsky, на фото выше) выразил надежду, что Amazon Q имеет все шансы стать важным помощником для миллионов людей в их повседневных рабочих задачах.  За минувший год с момента выпуска ChatGPT компанией OpenAI многие другие ведущие технологические гиганты, включая Google и Microsoft, успели поддаться всеобщему буму ИИ и выпустить свои варианты чат-ботов, на основе технологий больших языковых моделей, вложив в эти разработки миллиарды долларов. Компания Amazon в свою очередь лишь недавно начала говорить о своём интересе к подобным технологиям, а также планах развития в этом направлении. Например, в сентябре Amazon сообщила, что инвестирует до $4 млрд в компанию Anthropic, конкурента OpenAI, и будет заниматься вместе с ней разработкой специализированных ИИ-процессоров. Также Amazon ранее представила сервис, который способен предоставлять доступ к разным ИИ-системам в рамках единой платформы. Являясь одним из ведущих операторов облачных вычислений, компания Amazon имеет большую пользовательскую базу среди корпоративных клиентов, которые хранят огромные объёмы информации на её облачных серверах. По словам Селипски, её клиенты заинтересованы в использовании чат-ботов на рабочих местах, но они хотят быть уверены в том, что ИИ-помощники будут обладать достаточным уровнем защиты от утечек корпоративных данных. «Многие компании в разговоре со мной отметили, что они запретили своим сотрудникам использовать ИИ-чат-боты из соображений безопасности и конфиденциальности», — заявил Селипски. 
Источник изображения: AWS Ответом Amazon стала разработка Amazon Q — корпоративного чат-бота с повышенной защитой конфиденциальных данных по сравнению с потребительскими чат-ботами. Например, для Amazon Q можно выставить те же разрешения безопасности, которые бизнес-клиенты облачного сервиса Amazon уже настроили для своих пользователей. Если в компании сотрудник отдела маркетинга не имеет доступа к конфиденциальным финансовым прогнозам, Amazon Q может имитировать эти прогнозы, без предоставления официальных финансовых данных. Кроме того, компании, использующие Amazon Q, также могут устанавливать разрешения на использование своих корпоративных данных чат-ботом, не находящихся на серверах Amazon, например, через подключение Slack и Gmail. В отличие от ChatGPT и Bard, Amazon Q не основан на какой-то конкретной языковой модели искусственного интеллекта. Вместо этого он использует платформу Amazon Bedrock, которая объединяет несколько систем искусственного интеллекта, включая собственный Titan от Amazon, а также модели ИИ, разработанные Anthropic и Meta✴. Цены на Amazon Q начинаются с 20 долларов США за одного пользователя сервиса в месяц. Для сравнения, Microsoft и Google взимают 30 долларов в месяц за каждого пользователя своих корпоративных чат-ботов, которые могут работать с электронной почтой и предлагают другие функции, повышающие общую производительность сотрудников на рабочих местах. 
Источник изображения: NVIDIA Вместе с анонсом Amazon Q компания сообщила о планах расширения своей облачной инфраструктуры, связанной с технологиями ИИ. В частности, Amazon заявила о продлении сотрудничества с компанией NVIDIA и анонсировала разработку ИИ-серверов на основе новых специализированных графических процессоров, в которых используется Arm-архитектура. МТС начала тестировать «Рой 9» — машинное обучение силами устройств пользователей
24.11.2023 [13:55],
Павел Котов
Одна из входящих в МТС структур запустила проект «Рой 9», который предполагает развитие и обучение моделей искусственного интеллекта на сторонних устройствах. Данную инициативу можно сравнить с добычей криптовалют в пулах, когда устройства разных клиентов объединяют вычислительные мощности для общей цели. Только здесь вместо криптовалюты на выходе будет натренированная нейросеть. В компании сообщили, что широкий запуск проекта пока не планируется, и сейчас это всего лишь проверка гипотез, сообщает «Коммерсант». 
Источник изображения: Gerd Altmann / pixabay.com Работой над проектом занимается принадлежащее оператору ООО «Серенити Сайбер Секьюрити», которое 1 ноября зарегистрировало доменное имя roy9.ru. «Рой 9» предлагает пользователям предоставлять свои компьютеры и мобильные устройства для обучения моделей машинного обучения — в настоящий момент на платформе обучаются четыре нейросети. «Новые модели AI помогут людям в новых открытиях, вы можете стать частью этого движения. Кроме того, помогая в обучении моделей, вы делаете мир интереснее», — говорится в описании сохранённой изданием страницы. Представитель МТС заявил, что сайт был запущен исключительно для проверки гипотез в области ИИ и машинного обучения — он предназначался только для внутренних нужд, и никаких связанных с ним общедоступных проектов не планировалось. Тестированием занимается центр инноваций МТС Future Crew, и к настоящему моменту сайт закрыт. Крупные российские игроки уже запускали службы для развития систем машинного обучения: к примеру, в инфраструктуре VK Cloud Solutions действует сервис для тестирования гипотез, работы с данными и других целей; у «Яндекса» есть сервис для разработки и тестирования алгоритмов машинного обучения DataSphere. А МТС весной прошлого года запустил систему CICADA 8, предназначенную для тестирования инфраструктуры компании на устойчивость. В России наблюдается дефицит мощностей для обучения ИИ, и модель краудфандинга стала бы частичным решением вопроса, считает опрошенный «Коммерсантом» эксперт. В случае с МТС участвующие в проекте абоненты оператора могли бы получать, например, скидку на услуги связи или дополнительные пакеты трафика или минут. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






