|
Опрос
|
реклама
Быстрый переход
Представлен первый в мире настольный компьютер с живыми клетками человеческого мозга внутри
04.03.2025 [10:24],
Геннадий Детинич
На выставке MWC 2025 австралийский стартап Cortical Labs представил первый в мире настольный компьютер CL1, использующий живые клетки человеческого мозга. Уникальная система поддерживает жизнеспособность клеток и способствует их развитию в процессе самообучения. Компьютер функционирует автономно, не требуя подключения к классическим вычислительным устройствам. Предполагается, что искусственный интеллект на подобных платформах будет не только более энергоэффективным, но и интеллектуально продвинутым.  Cortical Labs была основана в Мельбурне в 2019 году и с тех пор разрабатывала гибридную платформу «клетки-кремний» совместно с учёными Университета Монаша (Австралия). В вычислениях, требующих сложных математических операций, мозг человека уступает традиционным кремниевым процессорам. Согласно недавним исследованиям, скорость работы человеческого мозга ниже, чем у 50-летнего процессора.  Однако в задачах, связанных с интуитивным поиском решений, человеческий интеллект по-прежнему остаётся вне конкуренции. Только летом 2022 года компьютерная система Frontier стоимостью $600 млн, занимавшая площадь 630 м², впервые превзошла человека в интуитивных вычислениях. Это доказывает, что биологические вычислительные системы ещё рано списывать со счетов.  Первым значимым достижением Cortical Labs стал гибридный процессор DishBrain, основанный на CMOS-матрице и колонии нейронов. Его обучили играть в Pong: нейроны росли на сетке электродов, а затем их стимулировали микроразрядами тока, поощряя успешные удары и «наказывая» промахи. Этот метод позволил сформировать устойчивые нейронные связи, ведущие к самообучению.  С тех пор компания значительно усовершенствовала свою платформу и теперь готова к массовому производству гибридных компьютеров. Первая модель CL1, представленная на MWC 2025 в Барселоне, представляет собой биореактор — систему жизнеобеспечения для колоний нервной ткани, растущих на кремниевом чипе. Конкретное количество клеток и их конфигурацию заранее предсказать невозможно, но для технического описания планируется использовать термин КОЕ (колониеобразующие единицы). Разработчики признают, что до конца не понимают, из каких именно клеток состоит их биологический процессор и в каком соотношении они должны присутствовать. В настоящее время компания использует два метода выращивания искусственной нервной ткани: получение индуцированных плюрипотентных стволовых клеток (iPSCs) из крови грызунов и человека, а также генетические модификации. Однако точный контроль этих процессов пока недостижим, что приводит к вариативности результатов.  Несмотря на это, технология уже готова к коммерческому внедрению. Cortical Labs планирует начать поставки CL1 во второй половине 2025 года. Ожидаемая стоимость одного компьютера — $35 000, что примерно в 2,5 раза дешевле аналогов. В конце года компания запустит облачный доступ к кластеру CL1, включающему четыре секции по 30 компьютеров каждая. Это будет первый опыт объединения биокомпьютеров в кластер, и его результаты пока сложно предсказать. Такая неопределённость отпугивает инвесторов, однако успешные продажи могут вернуть доверие финансовых кругов. Как отдельные устройства, так и облачный кластер рассматриваются компанией как эксперимент. Разработчики пока не имеют чёткого представления о том, как именно система должна работать и в каких областях будет наиболее эффективна. В идеале биокомпьютеры смогут потреблять меньше энергии и быстрее справляться с генеративными моделями. Например, энергопотребление стойки из CL1 составит около 1 кВт — значительно меньше, чем у классических серверов. 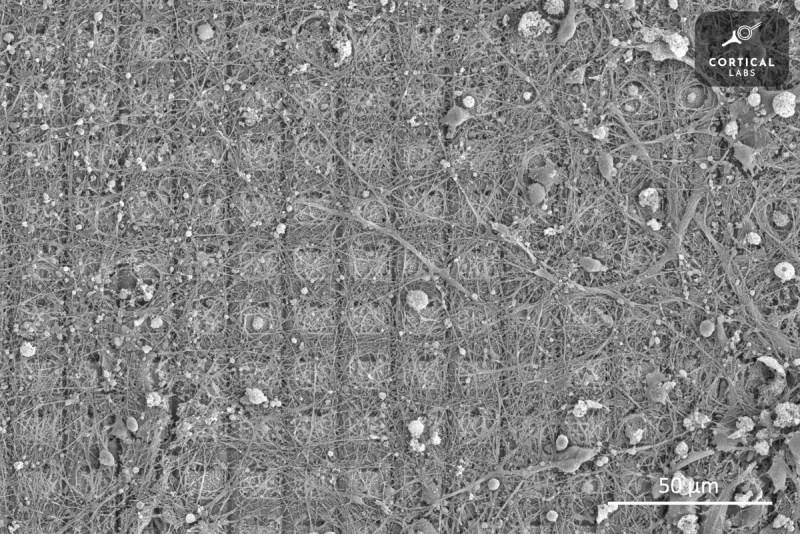
Нейроны DishBrain, растущие на массиве электродов. Источник изображения: Cortical Labs Помимо вычислительных задач, биологические компьютеры могут стать платформой для тестирования новых лекарств от нейродегенеративных заболеваний. Испытания на живых людях неэтичны, а использование колоний нервных клеток в компьютерах может стать альтернативным методом исследования. Это направление может оказаться самым ценным применением новой технологии, поскольку в конечном счёте здоровье человека важнее всего. Китайцы встроили оптическую нейронную сеть в торец оптоволокна — это подтолкнёт развитие квантовой связи, медицины и не только
18.02.2025 [10:53],
Геннадий Детинич
Дальнейшее развитие оптических технологий требует новых подходов в эпоху расцвета нейронных систем. Свойства света способствуют первичной обработке визуальной информации непосредственно в оптоволокне, что заставляет учёных искать способы воплотить такие механизмы на практике. О прорыве в этой сфере сообщили китайские учёные, которые сумели встроить оптическую нейронную сеть в торец оптоволокна для передачи изображений без искажений. 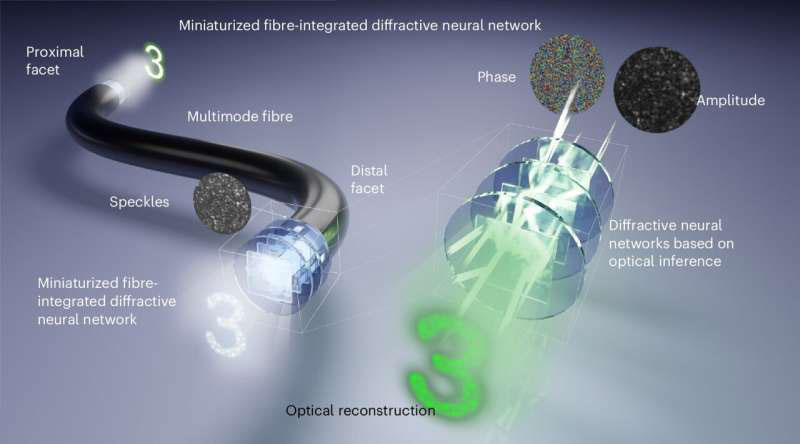
Источник изображения: USST Исследователи из Шанхайского университета науки и технологий (USST) опубликовали в журнале Nature Photonics статью, в которой рассказали о разработке технологии передачи изображений по оптоволокну для малоинвазивного эндоскопа. Учёные работали с многомодовым оптоволокном (MMF) как с более ёмким каналом, имеющим толщину с человеческий волос. Однако из-за склонности MMF к рассеиванию пришлось разработать ряд решений для его уменьшения. При этом высокая пропускная способность MMF рассматривалась как критически важный инструмент в таких областях, как квантовая информация и микроэндоскопия. В настоящее время компенсацию модовой дисперсии (рассеивания) осуществляют с помощью искусственных нейронных сетей и пространственных модуляторов света, однако эти методы дают лишь ограниченный успех в восстановлении искажённых изображений после их передачи по многомодовому оптоволокну. Учёные из USST поставили перед собой задачу преодолеть этот барьер, предложив принципиально новый подход. Исследователи разработали и интегрировали в дальний конец 35-сантиметрового оптоволокна многослойные оптические дифракционные нейронные сети. Внешне они представляют собой специально протравленные прозрачные пластинки, в которых свет преломляется определённым образом, фактически выполняя простейшие вычислительные операции со скоростью света. Такое решение позволяет обрабатывать оптическое умножение матриц и реализовывать больше связей в нейронных сетях без использования электрических схем. Это открывает возможности для таких задач, как оптическая классификация изображений, дешифрование и обнаружение фазы. 
Источник изображения: Nature Photonics 2025 Пластинки многослойных оптических дифракционных нейронных сетей были изготовлены со сторонами 150 мкм. Они позволили считывать и передавать по оптоволокну оптические изображения со сторонами 65 мкм с разрешением 4,9 мкм. В частности, учёные продемонстрировали способность системы различать группы клеток HeLa, не включённых в процесс обучения. При этом система обеспечивала высококачественную оптическую реконструкцию изображения, что подчёркивает потенциал интеграции миниатюризированных дифракционных нейронных сетей с многомодовым оптоволокном. Это создаёт беспрецедентную платформу для оптического вывода в микронном масштабе, прокладывая путь к созданию многофункциональных компактных фотонных систем, применимых в медицине, науке и квантовой фотонике. Нобелевскую премию по физике присудили отцам нейросетей и машинного обучения
08.10.2024 [15:18],
Геннадий Детинич
В основе ряда нейронных сетей, алгоритмов машинного обучения и искусственного интеллекта лежат глубокие открытия в области физики, о чём сегодня заявили представители Нобелевского комитета Каролинского института Стокгольма. Премия 2024 года за эти заслуги присуждена физику Джону Хопфилду (John Hopfield) и математику Джеффри Хинтону (Geoffrey Hinton). 
Источник изображения: nobelprize.org Джон Хопфилд родился 15 июля 1933 года, а докторскую степень по физике он получил в 1958 году в Корнеллском университете. Джеффри Хинтон родился 6 декабря 1947 года, а в 1978 году получил докторскую степень в Эдинбургском университете в сфере ИИ. Интересно отметить, что Хинтон приходится правнуком известному британскому математику Джорджу Булю (1815–1864). Сейчас он сотрудник Университета Торонто, Канада. Оба начали плотно работать над нейронными сетями с начала 80-х годов прошлого века. Джон Хопфилд стал известен в 1982 году как изобретатель ассоциативной нейронной сети, получившей его имя. Хинтон изобрёл метод, который позволял автоматизировать процесс извлечения данных для идентификации элементов изображений. Где во всём этом физика? Для создания нейросети Хопфилд воспользовался известным свойством атомов стремиться к наименьшему значению их энергии. Сеть Хопфилда описывается способом, эквивалентным поведению энергии в системе атомных спинов. Обучение происходит путем нахождения таких значений для соединений между узлами сети, чтобы сохранённые изображения имели низкую энергию. Тогда поиск сводится к такой обработке соединений между узлами, после которой энергия сети снижалась, и это вело бы к обнаружению наилучшего соответствия. Джеффри Хинтон использовал сеть Хопфилда в качестве основы для новой сети, использующей другой метод: машину Больцмана. С её помощью можно научиться распознавать характерные элементы в данных конкретного типа. Для этого Хинтон использовал инструменты статистической физики, науки о системах, построенных из множества похожих компонентов. Машина обучается путем подачи ей примеров, которые с большой вероятностью могут возникнуть при запуске машины. Машина Больцмана может использоваться для классификации изображений или создания новых примеров (рисунков), на которых она была обучена. «Работа лауреатов уже принесла наибольшую пользу. В физике мы используем искусственные нейронные сети в широком спектре областей, таких как разработка новых материалов с определенными свойствами», — прокомментировала награждение Эллен Мунс (Ellen Moons), председатель Нобелевского комитета по физике. Tesla показала, как роботы Optimus с помощью людей складывают аккумуляторы в контейнер
07.05.2024 [07:47],
Алексей Разин
На фоне первых демонстраций человекоподобных роботов Optimus, когда реальные прототипы удерживались на подставке, а способность танцевать обеспечивалась переодетым в робота человеком, последующие видео Tesla демонстрировали прогресс, но ощущение сырости изделия не покидало зрителей. В новом ролике компания показала, как обучает роботов Optimus выполнять полезную работу на конвейере. 
Источник изображения: Tesla, X В качестве одной из таких операций была выбрана укладка цилиндрических аккумуляторных ячеек типоразмера 4680 в специальный контейнер, компоновочно напоминающий кассету для яиц. На новом видео робот Optimus принимает поступающие по жёлобу аккумуляторные ячейки и укладывает их в контейнеры. Субтитры повествуют о том, что делать подобные манипуляции ему позволяет нейронная сеть, обучаемая просто по изображениям с двумерных камер, в ходе видеоролика также демонстрируется обстановка, в которой происходит обучение нескольких роботов одновременно. За каждым из них закреплён оператор, который смотрит на сортируемые предметы через некоторое подобие шлема дополненной реальности, а также позволяет электронике считывать данные о манипуляциях при помощи надетых на руку датчиков. По сути, на этапе обучения роботы должны получить возможность осуществлять подобные манипуляции самостоятельно. Как отмечает Tesla, дополнительно уделяется внимание способности робота сохранять равновесие во время всех манипуляций. В конце ролика демонстрируется робот Optimus, наматывающий круги по произвольной траектории по помещению лаборатории. Делается это, конечно же, в целях его обучения, и с каждым разом робот способен пройти всё больше и больше без посторонней помощи. 
Источник изображения: Tesla, X Представители Tesla в комментариях к видео отметили, что сейчас стараются заставить роботов Optimus двигаться быстрее и перемещаться не только по ровной поверхности, но и по более сложному ландшафту. Напомним, что Илон Маск (Elon Musk) недавно пообещал начать использование роботов Optimus на предприятиях Tesla к концу текущего года, а к концу следующего предложить их сторонним клиентам. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






