|
Опрос
|
реклама
Быстрый переход
В США стало незаконным использование в робозвонках сгенерированных ИИ голосов
08.02.2024 [23:09],
Владимир Фетисов
Федеральная комиссия по связи (FCC) США объявила незаконным использование сгенерированных искусственным интеллектом голосов в роботизированных звонках. Новое постановление ведомства позволит прокурорам штатов принимать соответствующие меры в отношении людей, использующих технологию клонирования голоса с помощью генеративных нейросетей. 
Источник изображения: Gerd Altmann / pixabay.com В постановлении FCC сказано, что сгенерированные с помощью ИИ голоса теперь считаются «искусственными или записанными заранее голосами» в соответствии с Законом о защите потребителей услуг телефонной связи. Это означает, что звонящие больше не смогут задействовать сгенерированные голоса при совершении неэкстренных звонков или без предварительного согласия потребителей. Упомянутый закон включает в себя ряд запретов на использование разных методов автоматического обзвона. Любопытно, что запрет на использование «искусственного или заранее записанного голоса» для распространения сообщений в законе был и прежде, но не было чёткого указания на то, что к этой категории относятся голоса, клонированные с помощью ИИ. «Злоумышленники используют голоса, сгенерированные искусственным интеллектом, для совершения нежелательных роботизированных звонков, чтобы вымогать деньги у людей, подражать знаменитостям и дезинформировать избирателей. Теперь у генеральных прокуроров штатов будут новые инструменты для борьбы с этим мошенничеством и обеспечения защиты общественности от мошенничества и дезинформации», — заявила председатель FCC Джессика Розенворсель (Jessica Rosenworcel). Прокуроры штатов и прежде могли наказывать мошенников, использующих роботизированные звонки для обмана граждан. Теперь же они смогут привлекать их к ответственности только лишь на основании использования голоса, клонированного с помощью ИИ. «Google Карты» получили ИИ, который поможет находить интересные места
02.02.2024 [17:24],
Владимир Фетисов
Google интегрировала ИИ-алгоритм в картографический сервис, чтобы помочь пользователям находить интересные места с помощью больших языковых моделей (LLM). Новая функция в «Google Картах» будет отвечать на запросы о рекомендациях по магазинам и ресторанам, используя LLM «для анализа обширных данных о более чем 250 млн мест и достоверной информации от сообщества, насчитывающего свыше 300 млн участников, чтобы быстро предлагать места, куда пойти». 
Источник изображения: Google Разработчики из Google не первый год прикладывают усилия для того, чтобы сделать из картографического сервиса компании инструмент, позволяющий искать и открывать новые места. Использование для этого генеративной нейросети кажется вполне логичным шагом. Согласно имеющимся данным, новая функция поиска мест в «Google Картах» работает очень похоже на то, что можно увидеть в ИИ-версии поисковика компании. Пользователю достаточно указать, какое место его может заинтересовать, например, «места с винтажной атмосферой». После этого ИИ-алгоритмы подберут подходящие варианты на основе анализа обширной информации из «Google Карт» о близлежащих заведениях, а также обработают имеющиеся в наличии фотоснимки, оценки и отзывы пользователей. В конечном счёте сервис подготовит несколько предложений, которые, наиболее удовлетворяют критериям запроса пользователя. Google заявила, что на этапе тестирования доступ к новой функции будет открыт для участников экспертного сообщества компании в США. Эта организация существует как минимум с 2019 года, а её члены пишут обзоры, делятся фотографиями, отвечают на вопросы, редактируют описание мест и проверяют достоверность информации в «Google Картах». После завершения этапа тестирования ИИ-поиск мест в картографическом сервисе Google станет доступен пользователям на территории США. Когда это нововведение появится за пределами домашнего рынка, пока неизвестно. Немцы придумали процессор, работающий на электрических полях, а не на токах
30.01.2024 [16:46],
Геннадий Детинич
Масштабирование вычислительных ресурсов для задач искусственного интеллекта сопряжено с внушительным ростом потребления и затрат на оборудование. Немецкий стартап Semron предлагает снизить зависимость от обоих факторов. Основатели компании представили новый управляющий элемент нейронной сети, который они назвали «мемконденсатор» (memcapacitors). Он работает на электрических полях, а не на токах. 
Источник изображения: ИИ-генерация Кандинский 3.0/3DNews Основателями компании Semron стали выпускники Дрезденского технологического университета Кай-Уве Демасиус (Kai-Uwe Demasius) и Арон Киршен (Aron Kirschen). Ещё в 2016 году они получили патент на управляющий элемент «мемконденсатор». Согласно их представлениям, отказ от запуска нейронных сетей на классических чипах с транзисторами, управляемыми электрическими токами, позволит создавать малопотребляющие и недорогие нейронные процессоры. «Из-за ожидаемого дефицита вычислительных ресурсов [для работы] искусственного интеллекта многие компании с бизнес-моделью, которая полагается на доступ к таким ресурсам, рискуют своим существованием. Например, это крупные стартапы, которые обучают свои собственные модели, — сообщил Киршен в интервью одному из авторов сайта TechCrunch. — Уникальные особенности нашей технологии позволят нам достичь уровня цен на современные чипы для устройств бытовой электроники, даже несмотря на то, что наши чипы способны работать с продвинутым искусственным интеллектом, чего нет у других». Проще говоря, Semron говорит о способности выпускать дешёвые чипы, сродни тем, что используются в смартфонах, гарнитурах и тому подобном носимом оборудовании, которые тем не менее смогу запускать мощные нейросети. 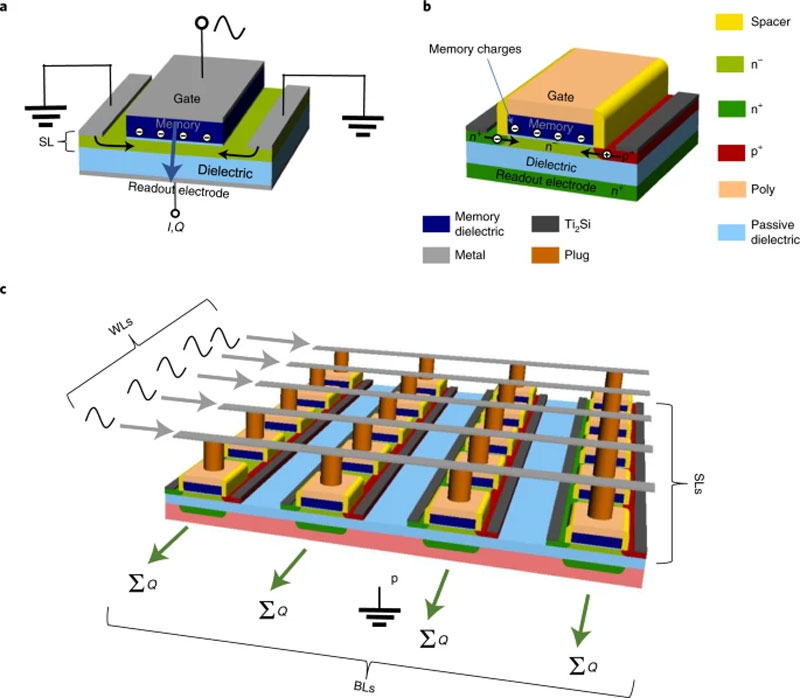
Концептуальное строение мемконденсатора. Источник изображения: Nature Чипы Semron предполагают многослойную организацию, что позволит значительно масштабировать решения. Элементарная ячейка памяти или вычислительного элемента на базе мемконденсатора должна содержать диэлектрик с эффектом памяти (заряда или ёмкости). Например, это может быть сегнетоэлектрик. В зависимости от величины заряда в ячейку будет записан тот или иной весовой коэффициент, который будет использоваться в расчетах. В свою очередь, этот диэлектрик с памятью разделяет два электрода, наводящих друг на друга электрические поля. «Сцепка» этих полей будет зависеть от записанного в ячейку коэффициента — насколько промежуточный слой будет экранировать электромагнитное поле, что послужит величиной для расчётов. Будем надеяться увидеть разработку в кремнии. Основатели компании опубликовали ряд работ в престижных научных журналах и обещают вскоре показать работу мемконденсаторов на практике. OpenAI сделала нейросети GPT-4 Turbo прививку от лени
26.01.2024 [12:51],
Владимир Фетисов
Компания OpenAI обновила большую языковую модель GPT-4 Turbo для более тщательного выполнения таких задач, как генерация программного кода, а также «уменьшения случаев "лени", когда модель отказывается выполнять задачу». Что именно было обновлено, разработчики не уточнили. 
Источник изображения: Growtika / unsplash.com Не так давно часть пользователей ChatGPT обратила внимание на то, что чат-бот зачастую попросту отказывается выполнять поставленную задачу, что, вероятно, было связано с длительным отсутствием обновлений языковой модели. Нынешнее обновление распространяется только на самую мощную нейросеть компании GPT-4 Turbo, которая была обучена на данных до апреля 2023 года и в настоящее время доступна только в предварительной версии. Пользователи более широко распространённой модели GPT-4, которая обучена на данных до сентября 2021 года, всё ещё могут сталкиваться с проблемами, когда алгоритм отказывается выполнять задачу. В сообщении OpenAI сказано, что более 70 % пользователей GPT-4, которые используют для взаимодействия с моделью API компании, перешли на GPT-4 Turbo из-за того, что алгоритм обучался на более свежих данных. Компания также планирует в ближайшие месяцы продолжить выпуск обновлений для GPT-4 Turbo, что позволит использовать больше мультимодальных подсказок при взаимодействии с алгоритмом. В дополнение к этому разработчики запустили две меньшие ИИ-модели, которые в компании называют моделями «вложения». Речь идёт о моделях text-embedding-3-small и text-embedding-3-large, которые уже доступны пользователям. Автопилотом Tesla FSD скоро начнёт управлять ИИ
25.01.2024 [13:22],
Алексей Разин
На квартальной отчётной конференции Tesla Илон Маск (Elon Musk) не упустил возможности похвалить прогресс возглавляемой им компании в сфере совершенствования систем активной помощи водителю, главной из которых остаётся комплекс FSD. Недавно компания начала распространять его версию под номером 12, которая опирается на искусственный интеллект в принятии решений, а не только на распознавание образов. 
Источник изображения: Tesla Впервые, как пояснил Илон Маск, искусственный интеллект будет применяться компанией не только для распознавания объектов, но и для принятия решений при построении траекторий управляемых транспортных средств, а также отправки команд системе рулевого управления и торможения. По словам главы компании, для перехода к такой модели FSD пришлось заменить около 330 000 строк кода на C++ нейросетями. Всё это делает Tesla, по его мнению, самой эффективной компанией среди использующих технологии искусственного интеллекта. Она просто вынуждена была выжать максимум из так называемого аппаратного обеспечения третьего поколения, к которому относятся бортовые компьютеры на нейронных процессорах Tesla собственной разработки. Позже Маск напомнил, что первое поколение систем для автопилота было построено на компонентной базе Mobileye, во втором она перешла на продукцию NVIDIA, и только в третьем начала применять собственные нейронные процессоры FSD. Кстати, глава компании не стал скрывать, что помимо уже существующих нейронных процессоров четвёртого поколения она разрабатывает и процессоры пятого поколения. Между ними с точки зрения производительности и эффективности достигается огромный прогресс, но когда именно компоненты пятого поколения выйдут на рынок, Маск уточнять не стал. Когда главу Tesla спросили, интересуются ли другие компании возможностью получить доступ к платформе FSD за деньги на условиях лицензирования, он пожаловался на некоторую осторожность и мнительность потенциальных клиентов, с которыми уже ведутся предварительные переговоры. Не исключено, что их плоды станут известны уже в текущем году. Если бы Маск был главой какого-то другого автопроизводителя, он непременно бы лицензировал технологии Tesla, как без лишней скромности резюмировал миллиардер. Позже он предположил, что технологию FSD могли бы лицензировать для своих нужд китайские автопроизводители, но пока Tesla больше склоняется к идее сотрудничества с ними с точки зрения разделения доступа к сети своих зарядных станций Supercharger, как это происходит сейчас в Северной Америке. Зашла на квартальном отчётном мероприятии и речь об ускорителях вычислений NVIDIA, потребность в которых сейчас испытывают многие разработчики систем искусственного интеллекта. Маск уклончиво заявил, что соответствующие чипы NVIDIA компания Tesla старается закупать в достаточных количествах. В ближайшее время разработки в сфере ИИ будут полагаться как на платформу NVIDIA, так и на фирменный суперкомпьютер Dojo. Последний, по словам Маска, является долгосрочным проектом и должен продемонстрировать свою эффективность в более отдалённой перспективе. Возвращаясь к теме выхода 12-й версии FSD, представители Tesla пояснили, что сейчас она тестируется сотрудниками компании на своих электромобилях этой марки, но в ближайшие недели начнёт распространяться среди участников программы бета-тестирования в Северной Америке, которая насчитывает около 400 000 участников. «Великолепная семёрка» IT-гигантов на волне ИИ-бума обеспечила мощный рост фондового рынка США
22.01.2024 [21:39],
Сергей Сурабекянц
«Великолепную семёрку» американских технологических компаний составляют Apple, Microsoft, Alphabet, Amazon, NVIDIA, Tesla и Meta✴. В пятницу индекс S&P 500 закрылся на историческом максимуме после стремительного роста акций этих лидеров технологической отрасли. Инвесторы воодушевлены потенциалом ИИ, который принёс 62 % от общего прироста в размере 26 % за 2023 год. Без вклада «великолепной семёрки» годовой рост в четвёртом квартале снизился бы по всему индексу. 
Источник изображения: Pixabay По мнению аналитиков Bank of America, шесть из этих семи компаний, за исключением Tesla, чьи доходы, как ожидается, снизятся, обеспечат основной рост индекса S&P 500, после опубликования отчётов за четвёртый квартал в течение ближайших двух недель. Их акции показали средний рост в 105 % по сравнению с прошлым годом. Передовые технологии обещают огромный прирост производительности и оказывают влияние на целые отрасли промышленности. 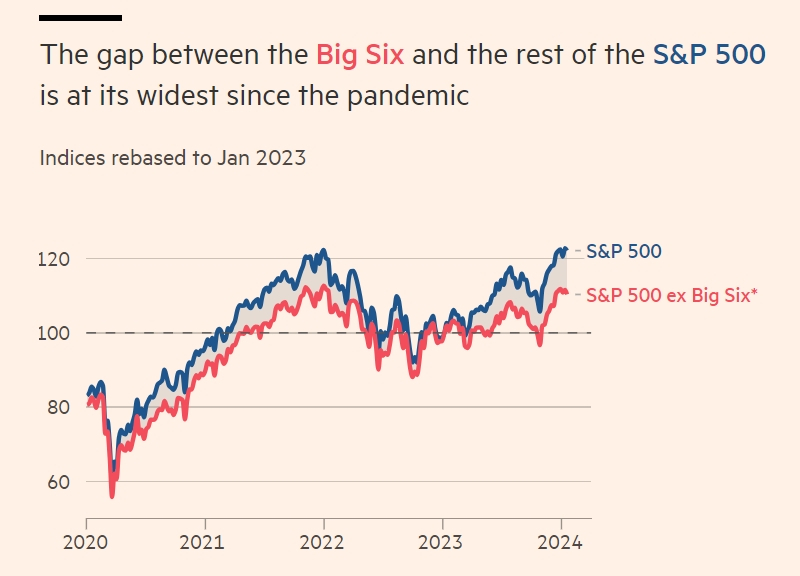
Разрыв между компания из «великолепной семёрки» и остальными участниками S&P 500 / Источник изображения: FactSet Microsoft и NVIDIA до сих пор находятся в авангарде ИИ-революции. Microsoft инициировала целую серию сделок между крупными технологическими компаниями и стартапами в области ИИ, объявив в прошлом году об инвестициях в OpenAI в размере $10 млрд, став крупнейшим спонсором создателя чат-бота ChatGPT. Доходы от ИИ-помощника Copilot и службы облачных вычислений Azure послужат для инвесторов барометром о перспективах ИИ-отрасли в 2024 году. Недавние кадровые «пятнашки» в OpenAI, похоже, мало повлияли на интерес инвесторов к Microsoft, которая в этом месяце снова обогнала Apple и заняла первое место в мире по рыночной стоимости. Между тем, акции NVIDIA, производителя лидирующих на рынке чипов ИИ, в прошлом году выросли на 239 %, что даёт компании все шансы превзойти рыночную капитализацию Amazon в $1,6 трлн. «Все инвесторы будут сосредоточены на доходах Microsoft в последнюю неделю января, потому что это предварительный просмотр того, что будет с остальным софтом и чипами для ИИ в течение следующих 12–18 месяцев, — уверен аналитик Wedbush Securities Дэниел Айвз (Daniel Ives). — Это ключевой период, закладывающий основу для определения того, кто победит в гонке вооружений ИИ». В мае 2023 года Google выпустила чат-бота Bard — свой первый автономный потребительский ИИ-продукт, а в декабре последовала мощная нейросеть под названием Gemini. Эксперты считают, что компания вынуждена лавировать между своим поисковым бизнесом и внедрением продуктов генеративного ИИ, которые вполне могут уничтожить её чрезвычайно прибыльную бизнес-модель. Amazon не спешит объявлять о крупных инвестициях в нейросети, но готовит к выпуску продукты, которые можно рассматривать как попытку наверстать упущенное. «Microsoft явно лидирует в интеграции OpenAI, и такие компании, как Alphabet и Amazon, делают все возможное, чтобы наверстать упущенное», — утверждает старший аналитик Baird Колин Себастьян (Colin Sebastian). По прогнозам, Amazon в ближайшее время начнёт «тотальное наступление, чтобы догнать ИИ». В ноябре компания запустила Amazon Q, ИИ-помощника для пользователей своих облачных сервисов. По слухам, в этом году Apple нарастит усилия по созданию собственных систем искусственного интеллекта, а новая модель iPhone сможет запускать большие языковые модели, несмотря на ограниченную память мобильных устройств. В октябре компания без особой помпы запустила нейросеть с открытым исходным кодом Ferret, способную распознавать изображения. Amazon Web Services, Microsoft и Google выиграли от роста глобальных корпоративных расходов на облачные сервисы, в то время как Meta✴ и Google получили поддержку от увеличения рекламных и потребительских расходов, поскольку опасения по поводу экономического спада в конце 2023 года не оправдались. 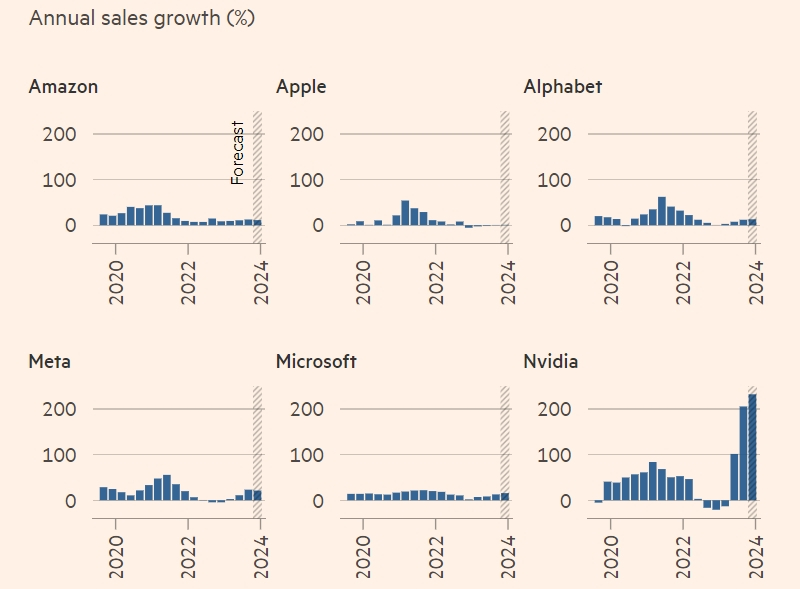
Годовой рост продаж компаний из «великолепной семёрки» / Источник изображения: FactSet Одновременно с ростом доходов в этом месяце в компаниях, включая Google и Amazon, прошли сокращения сотен рабочих мест для снижения затрат и одновременного увеличения инвестиций в ИИ. Конечно, пока масштаб увольнений гораздо меньше, чем в январе 2023 года, когда Google, Meta✴, Microsoft и Amazon уволили от 6 до 13 процентов своих работников, что сигнализирует о более устойчивом начале года для всего технологического сектора. Аналитики прогнозируют, что доходы NVIDIA, Amazon, Meta✴, Google, Microsoft и Apple замедлятся до 33 % в годовом исчислении в первом квартале этого года. Ожидается, что за потоком инвестиций в ИИ в 2023 году последует интеграция этой технологии в большее количество приложений в этом году, что может радикально изменить ландшафт успешных продуктов ИИ. ИИ-гаджет Rabbit R1 сможет давать актуальные ответы без ограничений с помощью алгоритмов Perplexity
19.01.2024 [12:09],
Владимир Фетисов
Разработчики ИИ-гаджета Rabbit R1, ставшего хитом выставки CES 2024, объявили о сотрудничестве со стартапом Perplexity, занимающимся ИИ-алгоритмами. В рамках совместной работы в гаджет R1 будет интегрирован «разговорный ИИ, работающий на основе ответов». В отличие от больших языковых моделей (LLM), которые могут ссылаться на данные только до определённой даты в прошлом, алгоритм в R1 сможет давать «актуальные ответы без каких-либо ограничений по знаниям». 
Источник изображений: Rabbit По словам соучредителя Perplexity Аравинда Сриниваса (Aravind Srinivas), первые 100 тыс. покупателей гаджета R1 также станут обладателями годовой подписки Perplexity Pro. В рамках данной подписки пользователи получают доступ к различных популярным LLM, включая GPT-4, Claude 2.1 и Gemini, между которыми можно быстро переключаться в зависимости от предпочтений и задач. Обычная стоимость подписки на помощника по поиску с ИИ Perplexity Pro составляет $20 в месяц. В одном из сообщений Rabbit в соцсети X также упоминалось, что алгоритм Perplexity будет работать в R1 «вместе с другими ведущими LLM», которые пока не были названы, и без подписки. Напомним, гаджет Rabbit R1 имеет в оснащении небольшой дисплей, вращающуюся камеру и колесо прокрутки, которое помогает взаимодействовать со встроенным ИИ-помощником. Устройство позволяет задействовать единый интерфейс платформы Rabbit OS для управления различными мобильными приложениями и сервисами разных разработчиков: музыкой, оформлением заказов на доставку еды, заказами такси, отправкой сообщений и др. Гаджет стоит $199 и с момента его анонса уже было оформлено более 50 тыс. предварительных заказов на покупку R1. ИИ показал, что отпечатки пальцев не так уникальны, как считалось прежде
16.01.2024 [20:43],
Геннадий Детинич
Считается, что рисунок линий на подушечках пальцев никогда не повторяется даже у одного человека, не говоря о других людях. На этом строится вся криминалистика и биометрические датчики. Группа исследователей решила проверить это утверждение с помощью обучаемой нейросети и с удивлением обнаружила, что отпечатки пальцев вовсе не так уникальны, как считалось. 
Чем «горячее» область, тем больше сходства с отпечатками других пальцев одного человека. Источник: Gabe Guo/Columbia Engineering Это вряд ли заставит заново пересмотреть уголовные дела, где основными уликами были оставленные на месте преступления отпечатки пальцев. Но это может помочь с делами, где нет полного набора отпечатков, а новые всё всплывают и всплывают. Учёные из Колумбийского университета с помощью нейросетей, обычно используемых для распознавания лиц, проанализировали отпечатки пальцев 60 тыс. граждан США из открытой правительственной базы. После обучения нейросеть с вероятностью 77 % смогла идентифицировать другие отпечатки пальцев человека по одному из известных ей отпечатков. Сети достаточно было увидеть один отпечаток пальца, чтобы она сразу же представила все остальные. Новый анализ отпечатков пальцев по открытой базе с усовершенствованным алгоритмом позволил найти общие моменты, присущие всем отпечаткам пальцев одного человека. Эти особенности рисунка папиллярных линий сосредоточены в центре подушечек. На каждом пальце одного человека они имеют много одинаковых особенностей — изгибов и поворотов — сообщили учёные, что раньше никем не анализировалось. Со временем нейросеть стала лучше определять, когда два разных отпечатка принадлежат одному и тому же человеку. Хотя каждый отпечаток на одной руке по-прежнему уникален, между ними было достаточно сходства, чтобы искусственный интеллект смог сопоставить и находить общее. Алгоритм и методика, предложенные учёными, пока не подходят для уверенной идентификации человека лишь по одному отпечатку пальцев с помощью сканирования любого другого. Настоящее чудо может произойти, если нейросети скормить данные о миллионах и миллиардах людей. Но у скромного коллектива учёных нет доступа к таким базам. Разве что их методикой воспользуются заинтересованные государственные структуры. Американские разработчики ИИ провели секретные переговоры с Китаем об опасности новых технологий
14.01.2024 [17:54],
Владимир Фетисов
Американские компании OpenAI, Anthropic и Cohere, работающие в сфере искусственного интеллекта, ведут секретные переговоры с китайскими экспертами по безопасности в этой области. Это происходит на фоне всеобщей обеспокоенности относительно того, что ИИ-алгоритмы могут использоваться для распространения дезинформации и угрожать социальной сплочённости общества. Об этом пишет Financial Times со ссылкой на собственные осведомлённые источники. 
Источник изображения: Gerd Altmann / pixabay.com В сообщении сказано, что в июле и октябре прошлого года в Женеве прошли встречи с участием североамериканских экспертов и учёных, специализирующихся на политической составляющей в сфере ИИ-разработок, а также представителей Университета Цинхуа и ряда других учреждений, поддерживаемых правительством Поднебесной. Осведомлённый источник рассказал, что в рамках этих встреч сторонам удалось обсудить риски, связанные с новыми технологиями, а также стимулировать инвестиции в исследования в области безопасности в сфере ИИ. Отмечается, что основной целью этих встреч был поиск безопасного пути для разработки более сложных ИИ-технологий. «У нас нет возможности устанавливать международные стандарты безопасности и согласовывать ИИ-разработки без достижения договоренности между участниками этой группы. Если они согласятся, будет проще привлечь остальных», — сообщил осведомлённый источник. Издание отмечает, что эти не афишированные переговоры являются редким признаком китайско-американского сотрудничества на фоне гонки за превосходство между двумя державами в области передовых технологий, таких как искусственный интеллект и квантовые вычисления. Что касается самих переговоров, то их организовала консалтинговая компания Shaikh Group и их проведении было известно в Белом Доме, а также правительствах Великобритании и Китая. «Мы увидели возможность объединить ключевых игроков из США и Китая, работающих в сфере искусственного интеллекта. Нашей главной целью было подчеркнуть уязвимости, риски и возможности, связанные с широким внедрением ИИ-моделей, которые используются во всём мире. Признание этих фактов, на наш взгляд, может стать основой для совместной научной работы, что в конечном счёте приведёт к разработке глобальных стандартов безопасности для ИИ-моделей», — прокомментировал данный вопрос Салман Шейх (Salman Shaikh), исполнительный директор Shaikh Group. Участники переговоров обсудили возможности в плане технического сотрудничества сторон, а также более конкретные политические предложения, которые легли в основу дискуссий во время заседания Совета Безопасности ООН по ИИ в июле 2023 года и британского ИИ-саммита в ноябре 2023 года. По словам источников, успех прошедших встреч позволил разработать план дальнейших переговоров, в рамках которых будут изучаться конкретные научно-технические предложения, направленные на то, чтобы привести сферу ИИ в соответствие с правовыми кодексами, а также нормами и ценностями каждого общества. Ещё не выпущенные ИИ-гаджеты Rabbit R1 уже перепродают на eBay с двукратной наценкой
13.01.2024 [13:36],
Владимир Фетисов
Неожиданным хитом выставки CES 2024 стал ИИ-гаджет Rabbit R1, который позволяет взаимодействовать с мобильными приложениями с помощью алгоритмов на основе нейросетей. Всего через сутки после презентации разработчики объявили, что им удалось продать 10 тыс. устройств R1. Хотя поставки начнутся лишь через пару месяцев, некоторые из первых покупателей уже выставили на eBay ИИ-гаджеты от Rabbit, рассчитывая перепродать их по более выгодной цене. 
Источник изображения: Rabbit Гаджет R1 оснащён 2,88-дюймовым дисплеем, вращающейся камерой для съёмки фото и видео, а также колесом прокрутки, которое помогает в навигации и взаимодействии со встроенным ИИ-помощником. Аппаратной основой устройства стал микропроцессор MediaTek с рабочей частотой 2,4 ГГц, 4 Гбайт оперативной памяти и накопитель ёмкостью 128 Гбайт. В качестве операционной системы задействована собственная разработка Rabbit OS с интегрированными ИИ-алгоритмами. Гаджет позволяет использовать единый интерфейс для управления разнообразными приложениями и сервисами разных разработчиков: музыкой, оформлением заказов на доставку еды, отправкой сообщений и др. Авторы R1 считают, что в будущем этот гаджет может стать потенциальной заменой смартфонов. Что касается стоимости ИИ-гаджета, то его можно предзаказать на официальном сайте Rabbit за $199. Проблема в том, что ввиду неожиданно высокой популярности за первые двое суток с момента презентации были распроданы две партии R1 по 10 тыс. единиц каждая. Согласно имеющимся данным, покупатели устройств из первой партии начнут получать R1 в марте, а из второй — в апреле-мае 2024 года. Гаджет всё еще можно заказать на сайте Rabbit, но получить его удастся не раньше мая-июня. 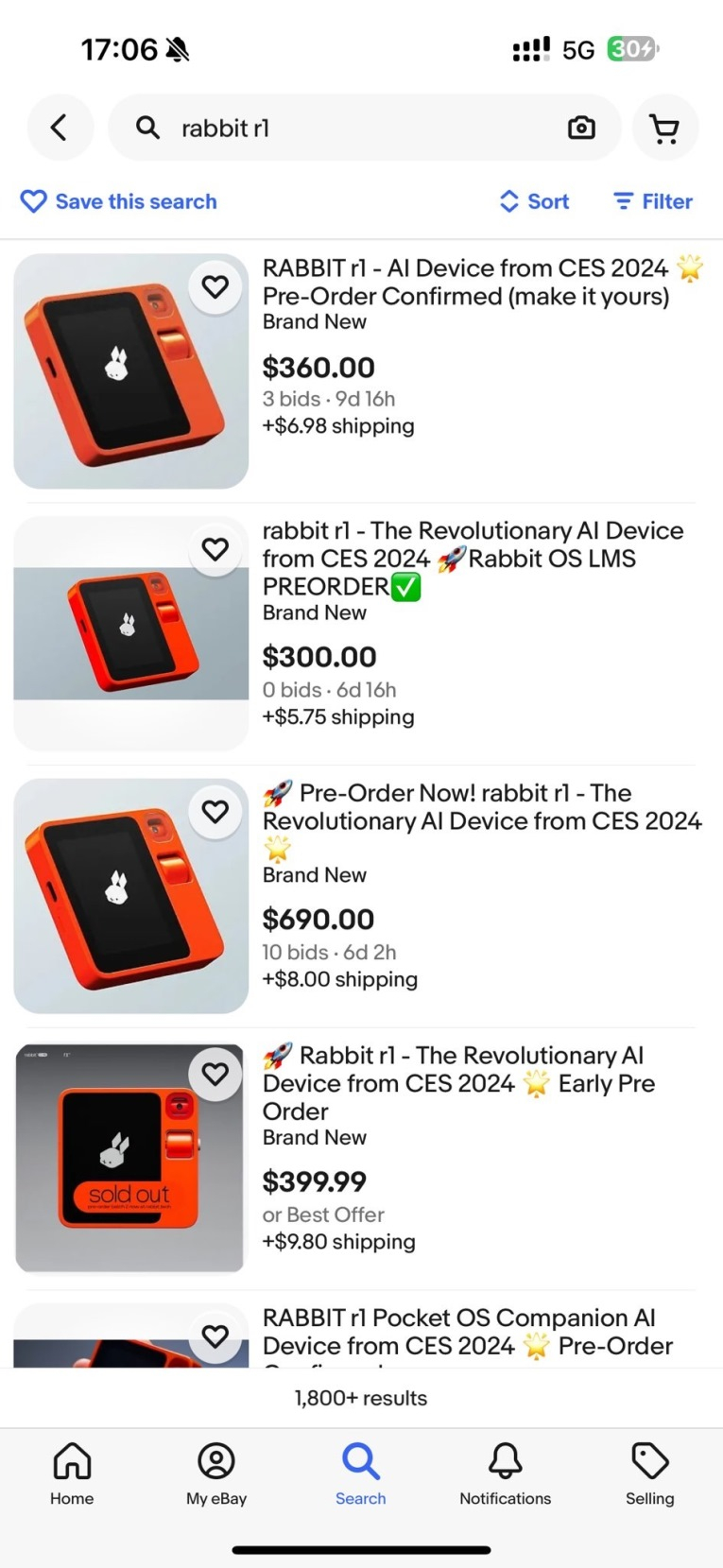
Источник изображения: Jesse Lyu / X Этим и решили воспользоваться некоторые люди, успевшие заказать устройства из первых партий. Они предлагают купить R1 на платформе eBay по значительно более высокой цене от $300 до $690. Авторы таких лотов обещают отправить устройство покупателям сразу же после того, как получат свои предзаказанные R1. Такая предприимчивость некоторых покупателей не понравилась разработчикам. Основатель и генеральный директор Rabbit Джесси Лю (Jesse Lyu) опубликовал в своём аккаунте в соцсети X снимок экрана с несколькими лотами R1 на eBay. «Чёрт возьми, нет. Не делайте этого», — на писал Лю в комментарии к фото. Очевидно, компания не ожидала, что спрос на R1 будет настолько высоким, из-за чего в данный момент она не в состоянии удовлетворить спрос в полной мере. Rabbit за сутки продала 10 тыс. ИИ-гаджетов R1 — в 20 раз больше, чем ожидалось
11.01.2024 [13:40],
Владимир Фетисов
ИИ-стартап Rabbit представил на выставке CES 2024 устройство R1, предназначенное для взаимодействия с мобильными приложениями при помощи алгоритмов на основе нейросетей. Теперь стартап объявил, что всего за сутки с момент презентации было продано более 10 тыс. устройств R1 стоимостью $199. Соответствующее сообщение появилось в аккаунте Rabbit в соцсети X (бывшая Twitter). 
Источник изображений: Rabbit «Когда мы создавали R1, мы сказали себе, что будем рады, если в день запуска продадим 500 устройств. За 24 часа мы уже превзошли этот показатель в 20 раз!», — говорится в сообщении Rabbit. Что касается самого гаджета R1, то в его конструкции предусмотрен 2,88-дюймовый дисплей, вращающаяся камера для съёмки фото и видео, а также колесо прокрутки, помогающее в навигации и взаимодействии со встроенным ИИ-помощником. Согласно имеющимся данным, аппаратной основой R1 стал микропроцессор MediaTek с рабочей частотой 2,4 ГГц, 4 Гбайт оперативной памяти и накопитель на 128 Гбайт. Роль программной платформы исполняет Rabbit OS с интегрированными ИИ-алгоритмами. Платформа позволяет через единый интерфейс управлять музыкой, заказывать доставку и такси, отправлять сообщения и др. Хотя первая партия устройств Rabbit R1 полностью распродана, желающие стать обладателем необычного гаджета могут оформить предзаказ на официальном сайте стартапа. По данным производителя, поставки новинки начнутся в апреле-мае этого года. Тем же кто успел заказать R1 из первой партии, устройство будет доставлено в марте. Microsoft добавит ИИ даже в «Блокнот» — функция Cowriter поможет с обработкой текста
11.01.2024 [01:46],
Владимир Фетисов
Похоже, что в этом году Microsoft планирует также активно интегрировать функции на основе искусственного интеллекта в свои продукты, как это было в году минувшем. На этой неделе стало известно о планах софтверного гиганта добавить в «Блокнот» для Windows 11 функцию под названием Cowriter, которая будет задействовать нейросети для корректировки текста. 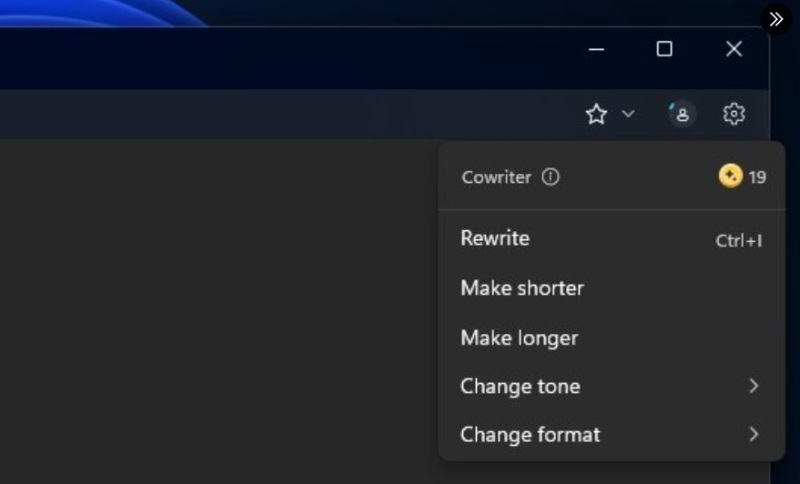
Источник изображения: @PhantomOcean3 / X Инсайдеры @PhantomOcean3 и @teroalhonen поделились скриншотами новой версии «Блокнота» и файлов, связанных с текстовым редактором. Речь идёт о версии «Блокнота» 11.2312.17.0, в которой и были обнаружены упоминания функции Cowriter. Хотя на данный момент инструмент не работает, не трудно догадаться, для чего именно он предназначен. 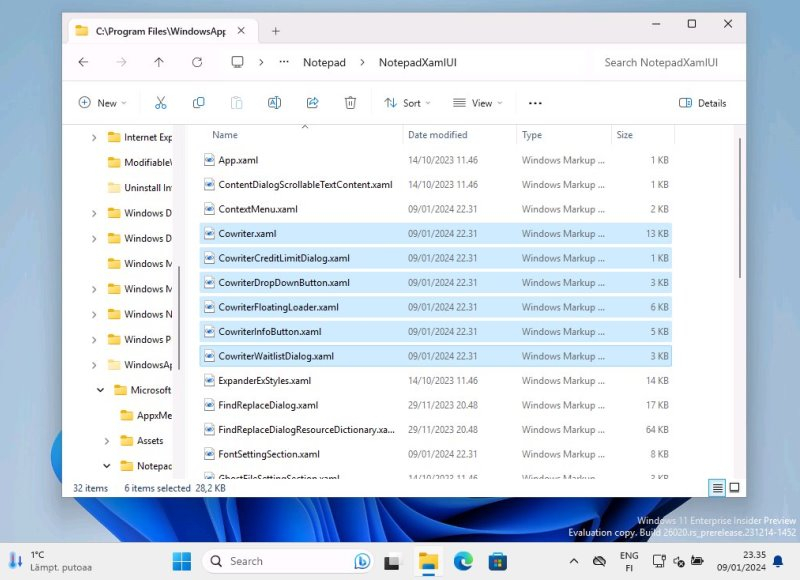
Источник изображения: @teroalhonen / X Предполагается, что инструмент Cowriter будет задействовать нейросети для корректировки набираемого текста, изменения его длины, фона или даже форматирования. Вероятно, в скором времени Microsoft анонсирует новую функцию, после чего она станет доступна участникам программы предварительной оценки Windows Insider. Когда разработчики планируют добавить Cowriter в стабильные версии «Блокнота», пока неизвестно. ИИ больно ударит по сотрудникам Google — грядут сокращения в отделе продаж
25.12.2023 [16:37],
Владимир Фетисов
По сообщениям сетевых источников, компания Google рассматривает возможность смены направления деятельности или увольнения части сотрудников отдела продаж, чья работа была автоматизирована за счёт запуска инструментов на основе искусственного интеллекта. Ранее в этом году поисковый гигант запустил «новую эру рекламы на основе ИИ» как способ улучшения взаимодействия рекламодателей с компанией. 
Источник изображения: JHVEPhoto / Shutterstock Согласно имеющимся данным, в настоящее время рекламное подразделение Google насчитывает около 30 тыс. сотрудников, причём почти половина из них занимается продажей рекламы для определённых рекламных сервисов Google. Необходимость в этих сотрудниках фактически отпала после запуска ряда ИИ-инструментов. Ожидается, что в долгосрочной перспективе замена сотрудников на ИИ поможет Google нарастить прибыль. Стоит отметить, что не только в рекламном бизнесе большое количество людей может лишиться своих мест из-за технологий на основе искусственного интеллекта. По мере того, как нейросети становятся всё более продвинутыми, на некоторые должности, традиционно занимаемые людьми, потенциально может претендовать ИИ. По данным исследования хостинговой компании Hostinger, искусственный интеллект может заменить людей некоторых профессий в сферах здравоохранения, транспорта и финансовых услуг, среди прочего. Ожидается, что в сфере здравоохранения, особенно в таких областях, как выполнение административных задач в больницах, искусственный интеллект придёт на смену человеку быстрее всего. Будущее соучредителя OpenAI Ильи Суцкевера в компании остаётся под вопросом
09.12.2023 [13:20],
Владимир Фетисов
После возвращения Сэма Альтмана (Sam Altman) на должность генерального директора OpenAI произошло немало событий, одним из которых стал роспуск совета директоров. Однако неясной остаётся судьба главного научного сотрудника компании Ильи Суцкевера (Ilya Sutskever), который, как сообщалось, сыграл важную роль в смещении Альтмана с должности. 
Источник изображения: Viralyft / unsplash.com По данным издания Business Insider, ссылающегося на собственные источники в OpenAI, на этой неделе Суцкевер не появлялся в офисе компании в Сан-Франциско, хотя его имя продолжает фигурировать в системах компании, таких как Slack, а картины Ильи продолжают дополнять интерьер офиса. Один из источников отметил, что будущее Суцкевера в компании ещё не обсуждалось руководством официально. «Илья всегда будет играть важную роль. Но, вы знаете, есть много других людей, готовых взять на себя ответственность, которую исторически нёс Илья», — добавил представитель компании, пожелавший сохранить конфиденциальность. Другой источник сообщил, что в настоящее время обсуждается возможность выделения Суцкеверу новой должности, и что есть желание «найти для него роль». При этом он отметил, что определённости относительно будущего главного научного сотрудника OpenAI в компании пока нет. Это не выглядит удивительным, учитывая, что Суцкевер сыграл важную роль в увольнении Альтмана с поста гендиректора, вслед за которым ушёл соучредитель OpenAI Грег Брокман (Greg Brockman), а многие сотрудники компании пригрозили последовать их примеру. Суцкевер входил в совет директоров, который принял решение об увольнении Альтмана. Однако его значение и влияние в компании, а также статус соучредителя делают Суцкевера более значимой фигурой по сравнению с любым другим членом совета директоров. Продолжающийся кризис в OpenAI подтверждает недавний пост Суцкевера в соцсети X, где он написал: «За последний месяц я усвоил много уроков. Одним из таких уроков является то, что фраза «избиения будут продолжаться до тех пор, пока не улучшится моральный дух» применяется чаще, чем имеет на то право». Эта фраза часто используется в мемах для ироничного обозначения цикла, когда низкая мораль порождает наказание, делающее её ещё более низкой. Также известно, что Суцкевер нанял адвоката, которым стал Алекс Вайнгартен (Alex Weingarten) из Willkie & Gallagher. Адвокат отказался комментировать вопросы сотрудничества с Суцкевером, сообщив лишь, что его клиент желает лучшего для компании. Официальные представители OpenAI также воздерживаются от комментариев по данному вопросу. Google представила ИИ-модель Gemini — она должна стать главным конкурентом GPT-4
06.12.2023 [22:11],
Владимир Фетисов
Google объявила о запуске модели искусственного интеллекта Gemini, которая станет основой ИИ-функций компании и бросит вызов конкурентам, включая ChatGPT от OpenAI. По словам гендиректора Google Сундара Пичаи (Sundar Pichai), появление нового алгоритма знаменует начало новой эры искусственного интеллекта в компании. 
Источник изображений: Google «Одна из самых важных особенностей этого момента в том, что вы можете работать над одной базовой технологией и улучшать её, и это сразу будет распространяться на все наши продукты», — сказал господин Пичаи. Гендиректор Google отметил, что запуск языковой модели Gemini является огромным шагом вперёд и в конечном счёте это окажет влияние практически на все продукты компании. Gemini представляет собой нечто большее, чем одна языковая модель. Существует более лёгкая версия ИИ-модели Gemini Nano, которая предназначена для автономной работы на устройствах с Android. Кроме того, существует более мощная версия Gemini Pro, которая в будущем станет основой многих сервисов Google, а с сегодняшнего дня является основой чат-бота Bard. В дополнение к этому Google создала ИИ-модель Gemini Ultra, которая является самой мощной языковой моделью компании и в основном предназначена для использования в центрах обработки данных и интеграции с корпоративными приложениями. 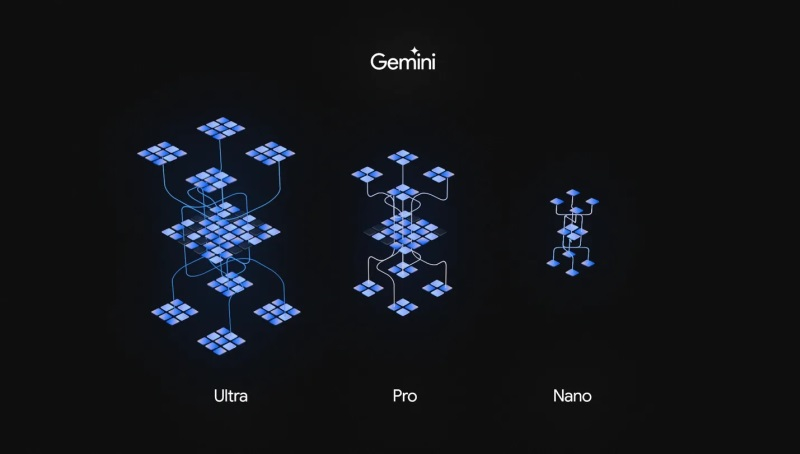 На потребительский рынок компания выводит свою ИИ-модель сразу несколькими способами. Чат-бот Bard теперь работает на основе Gemini Pro, а пользователи Pixel 8 Pro получат доступ к нескольким новым функциям благодаря интеграции с Gemini Nano. Возможность использования Gemini Ultra появится в следующем году. Разработчики и корпоративные клиенты смогут получить доступ к Gemini Pro через Google Generative AI Studio или Vertex AI в Google Cloud, начиная с 13 декабря. На данный момент Gemini может обрабатывать запросы на английском языке, но, очевидно, что в дальнейшем, появится поддержка других языков. По словам Сундара Пичаи, эта ИИ-модель в конечном счёте будет интегрирована в поисковую систему Google, рекламные продукты компании, браузер Chrome и другие сервисы. Похоже, что Google, являющаяся создателем большей части основополагающих технологий, способствовавших нынешнему буму в сфере ИИ, и уже около десяти лет называвшая себя компанией, ориентированной на искусственный интеллект, готова дать отпор запущенному год назад ChatGPT, который оказался настолько хорош, что явно заставил нервничать IT-гиганта. В рамках презентации Gemini гендиректор Google DeepMind Демис Хассабис (Demis Hassabis) рассказал, что Google провела тщательное сравнение своей языковой модели с GPT-4, наиболее актуальной версией нейросети, лежащей в основе ChatGPT. «Мы провели очень тщательный сравнительный анализ систем. Я думаю, что мы существенно опережаем конкурента по 30 из 32 показателей», — сказал Хассабис, указывая на 32 хорошо себя зарекомендовавших теста сравнения больших языковых моделей. Он также отметил, что в некоторых тестах превосходство Gemini над GPT-4 минимально, тогда как в других оно более ощутимо. В этих тестах наиболее явным преимуществом Gemini стала способность понимать видео и аудио, а также взаимодействовать с ними. По большому счёту, Google так и задумывала, поскольку компания не создавала отдельные ИИ-модели для обработки изображений и аудио, как сделала OpenAI, создав DALL-E и Whisper. С самого начала Google работала над созданием единой модели, способной распознавать изображения и звуки. На данный момент базовые версии Gemini поддерживают ввод и вывод текста, но более мощные версии алгоритма, такие как Gemini Ultra, могут работать с изображениями, видео и аудио. Конечно, эти модели всё ещё галлюцинируют, они не лишены предубеждений и других проблем, но со временем Google планирует улучшить их понимание окружающего мира. Несмотря на проведённые разработчиками тесты, главную проверку Gemini проведут рядовые пользователи, которые захотят использовать алгоритм для поиска информации, создания контента, написания программного кода и многого другого. В плане генерации кода алгоритм Google использует новую систему AlphaCode 2, которая, по словам представителей компании, работает лучше по сравнению с 85 % аналогами конкурентов и на 50 % лучше по сравнению с оригинальным алгоритмом AlphaCode. Не менее важно для Google и то, что Gemini, вероятно, является максимально эффективной моделью. Она обучалась с использованием тензорных процессоров Google, благодаря чему может работать быстрее и эффективнее, чем предыдущие алгоритмы компании, такие как PaLM. Наряду с новой языковой моделью Google представила ускорители TPU v5p, которые предназначены для использования в центрах обработки данных для обучения и запуска больших языковых моделей. Презентация Gemini даёт понять, что Google рассматривает новый алгоритм как масштабный проект и одновременно большой шаг вперёд для всей компании. Gemini — это ИИ-модель, к которой Google шла годами, возможно, даже та, которую ей следовало выпустить до того, как мир захватил ChatGPT. Google приложили массу усилий, чтобы обеспечить безопасность и надёжность Gemini, проведя внутреннее и внешнее тестирование алгоритма, но и это, по словам руководителей компании, не гарантирует, что нейросеть будет работать безошибочно. В течение многих лет Сундар Пичаи и другие руководители Google поэтически рассуждали о потенциале искусственного интеллекта. Сам Пичаи не раз говорил, что ИИ окажет на человечество более сильное влияние, чем огонь или электричество. Первое поколение модели Gemini, скорее всего, не изменит мир. В лучшем случае она поможет компании догнать ChatGPT, но руководство Google, уверено, что это начало чего-то большего. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






