|
Опрос
|
реклама
Быстрый переход
Анонсирована Stable Diffusion 3.0 — ИИ для рисования сменил архитектуру и научился писать
23.02.2024 [00:39],
Андрей Созинов
Компания Stability AI выпустила предварительную версию Stable Diffusion 3.0 — флагманской модели искусственного интеллекта следующего поколения для генерации изображений по текстовому описанию. Stable Diffusion 3.0 будет доступна в разных версиях на базе нейросетей размером от 800 млн до 8 млрд параметров. 
Источник изображений: Stable Diffusion 3.0 В течение последнего года компания Stability AI постоянно совершенствовала и выпускала несколько нейросетей, каждая из которых показывала растущий уровень сложности и качества. Выпуск SDXL в июле значительно улучшил базовую модель Stable Diffusion, и теперь компания собирается пойти значительно дальше. Новая модель Stable Diffusion 3.0 призвана обеспечить улучшенное качество изображения и лучшую производительность при создании изображений из сложных подсказок. Новая нейросеть обеспечит значительно лучшую типографику, чем предыдущие версии Stable Diffusion, обеспечивая более точное написание текста внутри сгенерированных изображений. В прошлом типографика была слабой стороной Stable Diffusion, собственно, как и многих других ИИ-художников. Stable Diffusion 3.0 — это не просто новая версия модели прежней Stability AI, ведь она основана на новой архитектуре. «Stable Diffusion 3 – это диффузионная модель-трансформер, архитектура нового типа, которая аналогична той, что используется в представленной недавно модели OpenAI Sora, — рассказал VentureBeat Эмад Мостак (Emad Mostaque), генеральный директор Stability AI. — Это настоящий преемник оригинальной Stable Diffusion».  Stability AI экспериментирует с несколькими типами подходов к созданию изображений. Ранее в этом месяце компания выпустила предварительную версию Stable Cascade, которая использует архитектуру Würstchen для повышения производительности и точности. Stable Diffusion 3.0 использует другой подход, используя диффузионные модели-трансформеры. «Раньше у Stable Diffusion не было трансформера», — сказал Мостак. Трансформеры лежат в основе большей части современных нейросетей, запустивших революцию в области искусственного интеллекта. Они широко используются в качестве основы моделей генерации текста. Генерация изображений в основном находилась в сфере диффузионных моделей. В исследовательской работе, в которой подробно описываются диффузионные трансформеры (DiT), объясняется, что это новая архитектура для диффузионных моделей, которая заменяет широко используемую магистраль U-Net трансформером, работающим на скрытых участках изображения. Применение DiT позволяет более эффективно использовать вычислительные мощности и превосходить другие подходы к диффузной генерации изображений. Еще одна важная инновация, которой пользуется Stable Diffusion 3.0 — это согласование потоков. В исследовательской работе по сопоставлению потоков объясняется, что это новый метод обучения нейросетей с помощью «непрерывных нормализующих потоков» (Conditional Flow Matching — CNF) для моделирования сложных распределений данных. По мнению исследователей, использование CFM с оптимальными путями транспортировки приводит к более быстрому обучению, более эффективному отбору образцов и повышению производительности по сравнению с диффузионными путями.  Улучшенная типографика в Stable Diffusion 3.0 является результатом нескольких улучшений, которые Stability AI встроил в новую модель. Как пояснил Мостак, качественная генерация текстов на изображения стала возможной благодаря использованию диффузионной модели-трансформера и дополнительных кодировщиков текста. С помощью Stable Diffusion 3.0 стало возможным генерировать на изображениях полные предложения со связным стилем написания текста. Хотя Stable Diffusion 3.0 изначально демонстрируется как технология искусственного интеллекта для преобразования текста в изображение, она станет основой для гораздо большего. В последние месяцы Stability AI также создаст нейросети для создания 3D-изображений и видео. «Мы создаем открытые модели, которые можно использовать где угодно и адаптировать к любым потребностям, — сказал Мостак. — Это серия моделей разных размеров, которая послужит основой для разработки наших визуальных моделей следующего поколения, включая видео, 3D и многое другое». OpenAI представила ИИ-генератор видео Sora, который выдаёт впечатляющие результаты
16.02.2024 [00:05],
Андрей Созинов
OpenAI представила новую нейросеть Sora для генерации видео. Компания утверждает, что Sora «может создавать реалистичные и фантазийные сцены по текстовым инструкциям». Модель преобразования текста в видео позволяет пользователям создавать на базе текстовых описаний фотореалистичные видео длиной до минуты с разрешением Full HD (1920 × 1080 точек). 
Источник изображения: OpenAI Sora способна создавать «сложные сцены с несколькими персонажами, определенными типами движения и точной детализацией объекта и фона», говорится в блоге OpenAI. Компания также отмечает, что нейросеть может понимать, как объекты «существуют в физическом мире», а также «точно интерпретировать реквизит и генерировать убедительных персонажей, выражающих яркие эмоции». Модель может генерировать видео на основе неподвижного изображения, заполнять недостающие кадры в существующем видео или расширять его. Среди демонстрационных роликов, созданных с помощью Sora и показанных в блоге OpenAI, сцена Калифорнии времен золотой лихорадки, видео, снятое как будто изнутри токийского поезда, и другие. Многие из них имеют некоторые артефакты, указывающие на работу искусственного интеллекта. Например, подозрительно движущийся пол в видеоролике о музее. Сама OpenAI говорит, что модель «может испытывать трудности с точным моделированием физики сложной сцены», но в целом результаты довольно впечатляющие. Пару лет назад именно генераторы текста в изображение, такие как Midjourney, лучше всего демонстрировали способности ИИ превращать слова в изображения. Но в последнее время генеративное видео стало улучшаться заметными темпами: такие компании, как Runway и Pika, продемонстрировали впечатляющие модели преобразования текста в видео, а Lumiere от Google, похоже, станет одним из главных конкурентов OpenAI в этой области. Как и Sora, Lumiere предоставляет пользователям инструменты для преобразования текста в видео, а также позволяет создавать видео из неподвижного изображения. В настоящее время Sora доступна только отдельным тестировщикам, которые оценивают модель на предмет потенциального вреда и рисков. OpenAI также предлагает доступ по запросу отдельным художникам, дизайнерам и кинематографистам, чтобы получить обратную связь. Компания отмечает, что существующая модель может неточно имитировать физику сложной сцены и неправильно интерпретировать некоторые случаи причинно-следственных связей. Ранее в этом месяце OpenAI объявила, что добавляет маркировку в свой инструмент преобразования текста в изображение DALL-E 3, но отмечает, что их можно легко удалить. Как и в случае с другими продуктами на базе ИИ, компании OpenAI придется бороться с последствиями того, что поддельные фотореалистичные видео, созданные ИИ, будут выдавать за настоящие. Больше видео, сгенерированных Sora, можно найти здесь. Google выпустила нейросеть Gemini 1.5 с огромнейшим контекстным окном — ИИ за раз осилит весь «Властелин колец»
15.02.2024 [21:20],
Андрей Созинов
Не прошло и двух месяцев с момента запуска передовой нейросети Gemini, а Google уже анонсировала её преемника. Сегодня была представлена большая языковая модель Gemini 1.5, которая сразу же стала доступна для разработчиков и корпоративных пользователей, а в скором времени начнется её распространение среди потребителей. Google ясно дала понять, что хочет использовать Gemini в качестве бизнес-инструмента, персонального помощника и не только.  В Gemini 1.5 много улучшений. Модель Gemini 1.5 Pro, которая ляжет в основу многих сервисов Google, превосходит Gemini 1.0 Pro на 87 % в тестах, и соответственно находится примерно на одном уровне с высококлассной Gemini 1.0 Ultra. При создании новой модели используется набирающий популярность подход «смесь экспертов» (Mixture of Experts — MoE), который подразумевает, что при отправке запроса запускается только часть общей модели, а не вся. Такой подход должен сделать модель более быстрой для пользователя и более эффективной для Google. 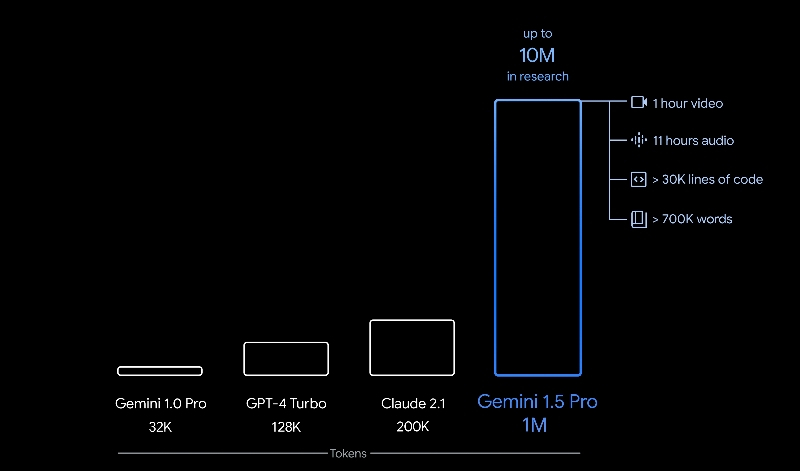 Но в Gemini 1.5 есть одна новая вещь, которая особенно радует всю компанию Google, начиная с генерального директора Сундара Пичаи (Sundar Pichai). Новая версия нейросети имеет огромное контекстное окно, что означает, что она может обрабатывать гораздо более объёмные запросы и просматривать гораздо больше информации одновременно. Размер окна составляет 1 миллион токенов, что намного больше 128 000 токенов у GPT-4 от OpenAI и 32 000 у текущей Gemini Pro. «Это примерно 10 или 11 часов видео, десятки тысяч строк кода», — отметил Пичаи. Ещё он добавил, что исследователи Google тестируют контекстное окно на 10 миллионов токенов — это, например, вся серия «Игры престолов» в одном запросе. В качестве примера Пичаи говорит, что в это контекстное окно можно вместить всю трилогию «Властелин колец». Это кажется слишком специфичным, но, возможно, кто-то в Google проверит, не обнаружит ли Gemini ошибок в преемственности, пытается разобраться в сложной родословной Средиземья. Или ИИ, возможно, сможет понять Тома Бомбадила. Пичаи также считает, что увеличенное контекстное окно будет очень полезно для бизнеса. «Это позволит вам использовать примеры, в которых вы можете добавить много личного контекста и информации в момент запроса, — говорит он. — Считайте, что мы значительно расширили окно запроса». Глава Google представляет себе, что кинематографисты могут загрузить весь свой фильм и спросить у Gemini, что скажут рецензенты, а компании смогут использовать Gemini для обработки массы финансовых документов. «Я считаю это одним из самых больших прорывов, которые мы совершили», — говорит он. Пока что Gemini 1.5 будет доступна только для бизнес-пользователей и разработчиков через Google Vertex AI и AI Studio. Со временем она заменит Gemini 1.0, а стандартная версия Gemini Pro — та, что доступна всем на сайте gemini.google.com и в приложениях Google, — будет заменена на 1.5 Pro с контекстным окном на 128 000 токенов. Чтобы получить миллион, придется доплатить. Google также тестирует безопасность и этические границы модели, особенно в отношении нового увеличенного контекстного окна. Сейчас Google находится в бешеной гонке за создание лучшего инструмента ИИ, в то время как компании по всему миру пытаются определить свою собственную стратегию ИИ и сотрудничать с OpenAI, Google или кем-то ещё. Буквально недавно OpenAI анонсировала «память» для ChatGPT и, похоже, готовится к выходу на рынок веб-поиска. Пока Gemini выглядит впечатляюще, особенно для тех, кто уже работает в экосистеме Google, компании предстоит еще много работы. В конце концов, говорит Пичаи, все эти 1.0 и 1.5, Pro и Ultra, а также корпоративные битвы не будут иметь значения для пользователей. «Люди будут просто потреблять лучший пользовательский опыт, — говорит он. — Это как пользоваться смартфоном, не обращая внимания на процессор под крышкой». Но на данный момент, по его словам, мы всё еще находимся на стадии, когда каждый знает, какой чип находится внутри его телефона, потому что это имеет значение. «Базовые технологии меняются так быстро», — говорит глава Google. — Людям не все равно». ИИ-бот ChatGPT научился запоминать факты о пользователях и их предпочтения
14.02.2024 [08:03],
Владимир Фетисов
Регулярная работа с чат-ботом на базе искусственного интеллекта может начать раздражать, поскольку для улучшения опыта взаимодействия пользователю каждый раз приходится объяснять некоторые факты о себе и своих предпочтениях. Компания OpenAI, являющаяся разработчиком ИИ-бота ChatGPT, намерена исправить это, сделав алгоритм более персонализированным за счёт добавления ему «памяти». 
Источник изображения: Growtika / unsplash.com Такой подход позволит ChatGPT со временем извлекать информацию о пользователе и его предпочтениях из диалогов с ним. Функция памяти работает двумя способами. Пользователь может прямо указать на свои предпочтения или иную информацию, которую ChatGPT должен запомнить. Если этого не делать, то чат-бот будет сам получать нужную информацию в процессе взаимодействия с пользователем. Цель разработчиков состоит в том, чтобы сделать ChatGPT более персонализированным и удобным. Во многих отношениях память является той функцией, которой действительно не хватает ChatGPT. Однако для её реализации алгоритм будет собирать информацию о пользователях, что может вызвать опасения по поводу конфиденциальности данных. OpenAI выбрала стратегию, которая во многом напоминает принцип работы разных интернет-сервисов. Речь идёт о наблюдении за действиями пользователя для постепенного формирования цифрового профиля. Такой метод работы неоднозначен, поскольку сразу возникают опасения по поводу того, что ChatGPT будет использовать собранные данные для дальнейшего обучения алгоритма и повышения уровня персонализации. OpenAI заявила, что пользователи будут иметь возможность контроля функции памяти ИИ-бота. Также отмечается, что алгоритм не будет запоминать конфиденциальные данные, например, информацию о здоровье. Можно спросить ChatGPT о том, что именно ему известно о пользователе, после чего эти данные при необходимости без особого труда удаляются из памяти. Если же пользователь не заинтересован в функции памяти, то её попросту можно отключить, но по умолчанию она будет активирована. На данный момент функция памяти ChatGPT находится на этапе тестирования и доступна ограниченному числу пользователей ИИ-бота. Когда именно она может стать общедоступной, пока неизвестно. NVIDIA представила Chat with RTX для запуска ИИ-чат-ботов локально на ПК
13.02.2024 [19:52],
Сергей Сурабекянц
NVIDIA выпустила предварительную версию приложения Chat with RTX, которое позволяет запускать локально на ПК чат-бота c генеративным ИИ на основе большой языковой модели (LLM). Чат-бот способен создавать сводки и выдавать релевантные ответы на основе видеороликов и документов пользователя. Chat with RTX работает на ПК под управлением Windows с видеокартами NVIDIA GeForce RTX 30-й или 40-й серии, оснащёнными как минимум 8 Гбайт видеопамяти. 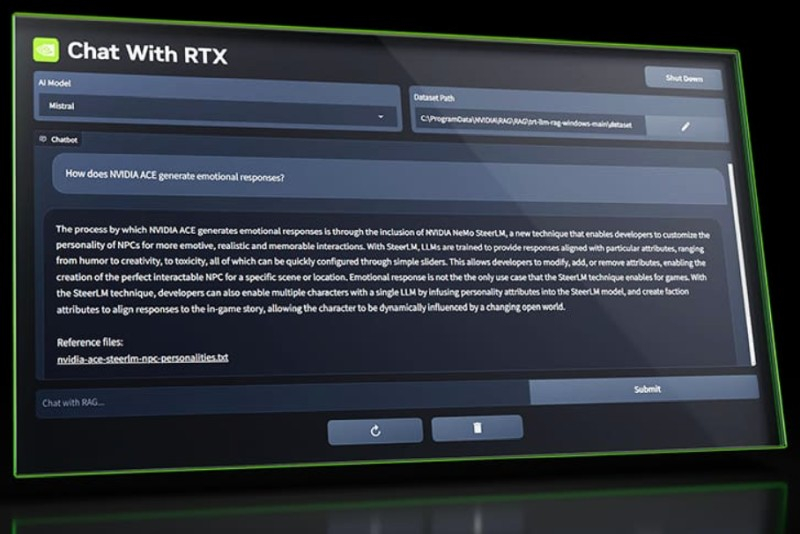
Источник изображений: NVIDIA Chat with RTX умеет обрабатывать видео YouTube — достаточно просто ввести URL-адрес, чтобы получить от чат-бота краткое содержание в текстовом виде. Chat with RTX позволяет выполнять поиск по расшифровке видео. По отзывам экспертов, поиск в видеороликах занимает считанные секунды. При этом отмечены случаи, когда чат-бот по непонятной причине использовал для поиска содержание другого ролика вместо запрошенного. Это явно указывает на ошибки ранней демоверсии. Исследователи находят Chat with RTX полезным при обработке PDF-файлов. Утверждается, что чат-бот от NVIDIA в этой задаче проявил себя лучше, чем Microsoft Copilot, без проблем извлекая ключевую информацию. Эксперты также отметили, что Chat with RTX даёт ответ практически мгновенно, без задержек, которые обычно наблюдаются при использовании облачных чат-ботов ChatGPT или Copilot. При помощи чат-бота тестировщикам удалось создать релевантный набор данных по судебному делу «FTC против Microsoft» и обобщить всю стратегию Microsoft в отношении Xbox Game Pass. При инсталляции Chat with RTX на ПК пользователя устанавливается веб-сервер и экземпляр Python, который использует LLM Mistral или Llama 2. Тензорные ядра на графическом процессоре NVIDIA RTX применяются для ускорения обработки запросов. Установка Chat with RTX на ПК с процессором Intel Core i9-14900K и видеокартой NVIDIA GeForce RTX 4090 продолжается около 30 минут. На диске приложение занимает около 40 Гбайт, а интерпретатор Python при работе потребляет около 3 Гбайт ОЗУ. После запуска пользователь получает доступ к чат-боту через веб-интерфейс, а в командной строке отображается ход выполнения и коды ошибок. 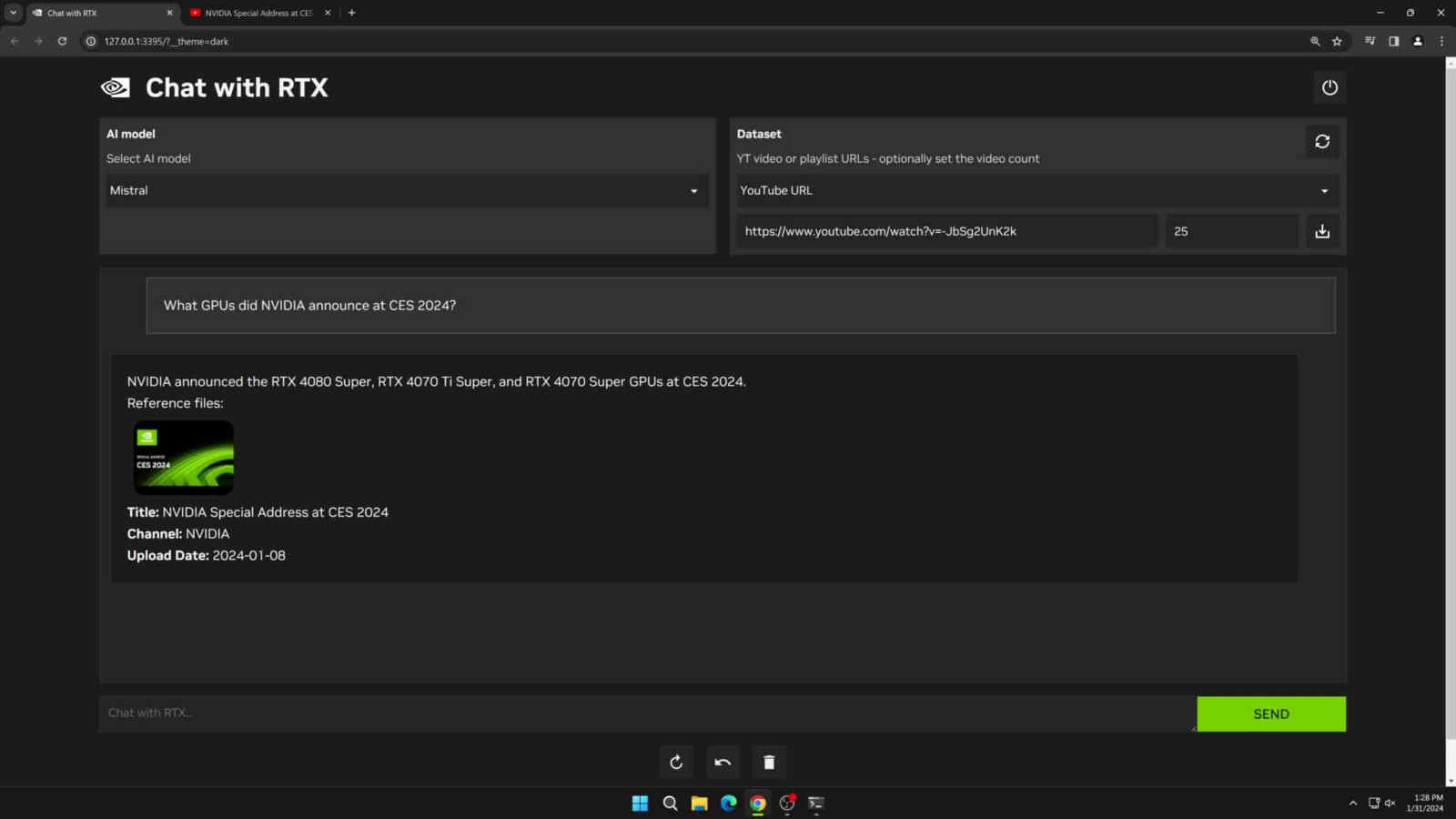 Эксперты отмечают, что Chat with RTX пока больше всего напоминает раннюю демоверсию для разработчиков и компьютерных энтузиастов. Существует целый ряд известных проблем и ограничений. Попытка проиндексировать с помощью Chat with RTX папку с 25 000 документов привела к сбою приложения, потребовавшему сброса всех настроек для восстановления работоспособности. Кроме того, чат-бот создал файлы JSON внутри всех папок, которые индексировал, что не всегда уместно. Chat with RTX также не запоминает контекст, поэтому новый запрос не может опираться на содержание предыдущего. Тем не менее, Chat with RTX — это хорошая техническая демонстрация возможностей и перспектив локально установленного на компьютере пользователя чат-бота с ИИ. Найдётся достаточно людей, которые не хотят для анализа личных данных использовать подписные облачные службы ИИ, такие как Copilot Pro или ChatGPT Plus. PayPal решила вдохнуть новую жизнь в платёжную систему при помощи ИИ
26.01.2024 [18:27],
Сергей Сурабекянц
Новый генеральный директор PayPal Алекс Крисс (Alex Chriss) заявил, что компания в этом году развернёт платформу на базе ИИ, которая позволит продавцам привлекать новых клиентов на основе их предыдущей истории покупок, используя данные торговых транзакций на общую сумму примерно в полтриллиона долларов по всему миру. Компания также запускает функцию оплаты в один клик. 
Источник изображения: unsplash.com Это первое крупное программное заявление Крисса, который приступил к работе в PayPal в сентябре 2023 года. Представленные им новые продукты на основе нейросети являются ещё одним примером того, как компании пытаются использовать энтузиазм инвесторов в отношении ИИ, который помог фондовым рынкам США достичь рекордных высот в этом месяце. Индекс S&P 500 поднялся до четвёртого рекордного максимума на закрытии торгов в среду, отчасти именно благодаря ралли акций технологических компаний на фоне всеобщего оптимизма в отношении ИИ. Эксперты надеются, что Крисс, который ранее был старшим руководителем компании-разработчика программного обеспечения Intuit, откроет новую страницу в истории PayPal и «оживит» акции компании, которые упали более чем на 22 % по сравнению с январём 2023 года из-за низкой рентабельности, не впечатлившей инвесторов. Крисс назвал 2024 год «переходным» для PayPal и пообещал существенно увеличить прибыльность компании. Продавцы смогут использовать отдельный инструмент на базе нейросети под названием «умные квитанции», чтобы рекомендовать покупателям персонализированные товары в квитанциях по электронной почте, а также начислять кэшбэк. PayPal представляет функцию оплаты «в один клик» под названием Fastlane, которая на ранних этапах тестирования увеличила скорость оплаты почти на 40 %, а также новые возможности для бизнес-профилей Venmo, сообщила компания. «Результаты инноваций… многообещающие и должны улучшить качество обслуживания потребителей и продавцов, — заявил аналитик BTIG Эндрю Харт (Andrew Harte). — Тем не менее, мы думаем, что инвесторы будут рассматривать какую-либо из них не как новаторскую информацию, а, скорее, как инициативы, над которыми, как они ожидали, компания уже работает». «Данные, которыми мы располагаем, и наша способность реально видеть, что покупают люди, и знать, на что пытаются ориентироваться продавцы, — вот где ИИ является огромной возможностью для нас», — заявил Крисс. Акции PayPal на последних торгах упали на 4,6 %, поскольку, кроме новостей от руководителя, инвесторы ждут реальных изменений от компании. Возможно, ситуация изменится уже 7 февраля, когда PayPal отчитается о результатах деятельности за четвёртый квартал. ИИ поможет выявлять ухудшение водительских навыков у пожилых людей
23.01.2024 [14:36],
Алексей Разин
Для Японии старение населения давно является серьёзной проблемой. Помимо прочего это снижает безопасность на дорогах. Бороться с этим предлагается не только за счёт внедрения автопилота, но и контроля за способностью престарелых граждан управлять транспортными средствами при помощи систем искусственного интеллекта. 
Источник изображения: Unsplash, Laura Gariglio Во всяком случае, как сообщает Nikkei Asian Review, японская компания NTT Data разрабатывает нейросеть соответствующего назначения. Следя за поведением водителя, она будет оценивать скорость движения, ускорения и замедления, а также обрабатывать другие данные, которые позволят своевременно выявить снижение способности конкретного человека безопасно управлять автомобилем в силу возрастных изменений. В качестве эксперимента NTT Data будет собирать статистику в одном из таксопарков японской столицы среди машин, управляемых водителями старше 65 лет, и накапливаться эта информация будет с января по июнь текущего года. Таксомоторы будут оборудованы соответствующими датчиками и устройствами GPS, а также модемами для передачи телеметрии в облачную систему NTT Data, которая и будет обрабатывать накапливаемую статистику. Особое внимание будет выделяться фактам резкого торможения или ускорения. Аномалии будут выявляться в сравнении с созданным профилем каждого водителя, учитывающим его нормальное поведение за рулём. Через несколько лет NTT Data планирует запустить в коммерческую эксплуатацию соответствующий облачный сервис, его клиентами смогут стать таксопарки и логистические компании, заботящиеся о безопасности перевозок. Со временем подключиться к этому сервису смогут и рядовые автолюбители. Компания собирается сотрудничать со страховщиками, чтобы те могли интегрировать данный сервис в свою экосистему. Предполагается, что для анализа когнитивных функций конкретного водителя будет достаточно статистики, накопленной за несколько дней активной работы. В дополнение к этому, прочими разработчиками для оценки профпригодности пожилых водителей будут использоваться технологии распознавания голоса и анализа выражений лица, а также движения зрачков. Искусственный интеллект скоро сможет правдоподобно имитировать почерк человека
16.01.2024 [10:17],
Алексей Разин
Уже сейчас нейросети способны правдоподобно воссоздавать голос человека и имитировать его мимику в соответствии с якобы произносимым текстом. Как считают учёные, вскоре искусственному интеллекту будут по плечу и задачи правдоподобного воспроизведения почерка человека, для этого нейросетям будет достаточно ознакомиться лишь с несколькими абзацами «исходного материала». 
Источник изображения: Unsplash, Hannah Olinger Команде специалистов Университета искусственного интеллекта имени Мухаммеда бен Заида в ОАЭ, как сообщает Bloomberg, уже удалось создать профильную нейросеть и опробовать её в деле. Эту разработку авторам даже удалось запатентовать в юрисдикции США. Пока использование данной нейросети сторонними клиентами не подразумевается, и авторы разработки уже выражают опасения по поводу способности недобросовестных пользователей применять её во вред обществу. Прежде чем этот инструмент начнёт распространяться, по мнению разработчиков, необходимо создать защитные механизмы, предотвращающие его некорректное с этической точки зрения применение. «Это всё равно что создать антивирус для вируса», — пояснили представители университета. Подобные соображения не мешают создателям нейросети планировать её коммерческое применение в течение ближайших месяцев, они уже ищут партнёров для реализации сопутствующего потенциала данной технологии. Помимо прочего, такая система могла бы распознавать рукописный текст — например, для обработки записей в историях болезни пациентов. На генерируемых нейросетью рукописях можно было бы обучать другие подобные системы. Пока нейросеть способна распознавать и генерировать рукописный текст на английском и французском языках, но в перспективе разработчики хотели бы добавить к ним и арабский. OPPO представила очень быструю нейросеть AndesGPT — она чуть-чуть уступает GPT-4 и поселится в смартфонах Find X7
27.12.2023 [19:03],
Сергей Сурабекянц
Сегодня компания OPPO представила множество новаторских технологий, которые дебютируют вместе со смартфонами серии Find X7. Одной из впечатляющих новаций стала ИИ-модель AndesGPT, представленная в вариантах со 180, 70 и 7 миллиардами параметров. Самая «компактная» версия и появится в грядущих флагманах OPPO. 
Источник изображения: Weibo Непосредственно в смартфонах Find X7 от OPPO будет использоваться нейросеть AndesGPT с 7 миллиардами параметров. Компания обещает, что AndesGPT обеспечит «сдвиг парадигмы возможностей искусственного интеллекта» благодаря таким нововведениям, как сжатие модели с квантованием в 4 бита, оптимизация механизма запуска ИИ Al Boost и совместная глубокая оптимизация модели с производителями чипов.  В практических сценариях AndesGPT должна проявить себя в обеспечении очень быстрого отклика. По утверждению OPPO, при обобщении текстового контента создание первого из 200 слов занимает всего 0,2 секунды, что опережает конкурентов в 20 раз. Для выжимки из 2000 слов AndesGPT демонстрирует быстрый ответ за 2,9 секунды, превосходя отраслевые стандарты в 2,5 раза. Нейросеть умеет генерировать рефераты объёмом до 14 000 слов, демонстрируя возможности моделирования, в 3,5 раза превосходящие его конкурентов. OPPO хвалит свою языковую модель с 7 миллиардами параметров за «улучшенное интеллектуальное понимание», что особенно заметно в функции сводки вызовов. AndesGPT «превосходно выделяет ключевые моменты из содержания звонков, предоставляя точные сводки с темами, ключевыми моментами и практическими элементами». По мнению OPPO, её нейросеть уступает, причём совсем немного, лишь GPT4 от OpenAI. 
Сравнение AndesGPT с другими нейросетями Нейросеть AndesGPT не ограничивается текстовыми приложениями, она также представляет полный спектр возможностей для генерации изображений. Компания заявляет, что AndesGPT «превосходно генерирует большие изображения с естественным светом и тенью, устанавливая новый стандарт локальной генерации изображений с 6-секундным интервалом — на 60 % быстрее, чем конкурирующие модели на той же платформе». Для смартфонов серии Find X7 компания OPPO также анонсировала технологию спутниковой связи «нового уровня» при помощи антенны с изменяемой диаграммой направленности. Теперь пользователи могут совершать спутниковые звонки традиционным способом, приложив телефон к уху, без необходимости поиска определённого угла или положения аппарата. Акции Google подскочили более чем на 5 % после анонса нейросети Gemini
08.12.2023 [13:06],
Владимир Фетисов
На этой неделе Google представила большую языковую модель Gemini, которая в перспективе должна стать главным конкурентом GPT-4 от OpenAI, а продукты на её основе — конкурентами ИИ-сервисов Microsoft. Для ценных бумаг компании 7 декабря, когда стоимость акций выросла более чем на 5 % до $136,93, стало лучшим днём с 29 августа. 
Источник изображений: Google Представитель торгового отдела банковской холдинговой компании Wells Fargo считает, что анонса нейросети Gemini должно быть достаточно, чтобы успокоить скептиков, которые считают, что Google проигрывает Microsoft гонку в сфере искусственного интеллекта. Он также отметил, что большой вопрос заключается в том, как компания видит монетизацию своей нейросети. Аналитики Bank of America отметили, что в этом году Alphabet находится под давлением из-за опасений по поводу возможностей Google в сфере искусственного интеллекта. Поэтому «хорошо раскрученная» конкурентная модель может иметь преимущества для её потребительской поисковой активности и корпоративных продаж облачных технологий. «Мы считаем, что Google обладает мощным потенциалом в сфере искусственного интеллекта, и данные, свидетельствующие о том, что Google обладает лучшими в своём классе собственными возможностями искусственного интеллекта, могут оказать положительное влияние на акции в первом полугодии 2024 года», — считают аналитики. Пока неясно, планирует ли Google монетизировать Gemini через все свои продукты в долгосрочной перспективе, хотя уже в этом месяце компания начнёт лицензировать использование алгоритма клиентами через Google Cloud. Руководство Google заявило, что Gemini превосходит алгоритм GPT-3.5 от OpenAI, но не были озвучены сравнительные данные с моделью GPT-4 Turbo. Тем не менее, Gemini показывает, что существуют возможности для дальнейшей монетизации ИИ. Например, Microsoft недавно запустила ИИ-помощника Copilot на базе ChatGPT, который встроен в Word, Excel и другие приложения офисного пакета компании, стоимостью $30 в месяц на пользователя. В октябре аналитики Piper Sandler заявили, что Copilot может принести Microsoft более $10 млрд ежегодного дохода к 2026 году. Аналитики JPMorgan сообщили, что хотя инвесторы Уолл-стрит в основном не обратили внимания на анонс Google, они воодушевлены, увидев Google в «этом важном технологическом сдвиге». Однако они отмечают, что «неопределённость в отношении путей монетизации в поиске» будет иметь место. Они считают, что запуск Gemini представляет собой значительную инновацию для Google, поскольку вскоре начнётся второй год коммерциализации и широкой доступности генеративных алгоритмов на базе нейросетей. «Сбер» обновил GigaChat — ИИ-чат-бот получил одну из крупнейших нейросетей на русском языке
23.11.2023 [15:48],
Владимир Фетисов
В рамках международной конференции по искусственному интеллекту AI Journey разработчики «Сбера» представили новую версию чат-бота GigaChat, основой которого стала одна из самых продвинутых больших языковых моделей (LLM) для русского языка с 29 млрд параметров. В скором времени доступ к API новой версии алгоритма получат бизнес-клиенты «Сбера», что позволит им создавать собственные решения на базе GigaChat, а также участники академического сообщества для проведения исследований. 
Источник изображения: sber.ru Использование новой LLM позволяет чат-боту лучше следовать инструкциям и выполнять сложные задания. Существенно повысилась качество суммаризации, рерайтинга, редактирования текстов и ответов на различные вопросы. Разработчики сравнили ответы новой и предыдущей моделей и зафиксировали общее повышение качества на 23 %. В дополнение к этому с фактологией новая модель справляется на 25 % лучше предшественницы. Для повышения качества работы LLM было проведено множество экспериментов по наращиванию эффективности её обучения. К примеру, использовался фреймворк для обучения больших языковых моделей с возможностью шардирования весов нейросети по видеокартам, за счёт чего удалось сократить потребление памяти на них. Результат внутренней оценки в бенчмарке Massive Multitask Language Understanding показал, что версия GigaChat с 29 млрд параметров превосходит самый популярный открытый аналог LLaMA 2 34B. «Обучение моделей, лежащих в основе GigaChat, — это масштабный и сложный вычислительный проект, прежде мы не делали ничего подобного. Суммарное количество вычислительных операций почти в 6 раз превысило количество операций при обучении модели ruGPT-3 с 13 млрд параметров в 2021 году. Также специально для GigaChat мы собрали и развиваем уникальный датасет, над которым работают сотни сотрудников «Сбера», помогая развивать и улучшать качество ответов в самых разных доменах. Благодаря этим усилиям пользователи с каждым новым релизом GigaChat получают максимум от сервиса для решения своих задач», — рассказал Андрей Белевцев, старший вице-президент, руководитель блока «Технологии» Сбербанка. Samsung представила ИИ Gauss для генерации картинок, текста и кода — он, вероятно, поселится в Galaxy S24
08.11.2023 [12:55],
Владимир Фетисов
На этой неделе компания Samsung официально представила собственную генеративную нейросеть под названием Gauss. Анонс нейросети состоялся в рамках ежегодного мероприятия Samsung AI Forum, который с 2017 года проходит в Сеуле и посвящён разработкам в сфере искусственного интеллекта. 
Источник изображения: Samsung Южнокорейский технологический гигант назвал свой генеративный ИИ-алгоритм в честь знаменитого математика Карла Фридриха Гаусса, который создал Закон нормального распределения, используемый в машинном обучении. В компании заявили, что название отражает видение Samsung в отношении ИИ-моделей, которое заключается в том, чтобы использовать все знания в мире для улучшения ИИ и повышения качества жизни потребителей по всему миру. Разработкой алгоритма Gauss занимались инженеры исследовательского подразделения Samsung Research. В настоящее время алгоритм задействован для повышения продуктивности работы сотрудников внутри компании, но в будущем его доступность будет расширена, и он появится в приложениях компании для потребителей. В основе Samsung Gauss лежат три модели: Gauss Language для обработки текстовых запросов, Gauss Image для генерации и обработки изображений, а также Gauss Code для помощи при написании программного кода. Gauss Language представляет собой генеративную нейросеть, предназначенную для повышения эффективности работы за счёт помощи при выполнении разных задач, включая написание электронных писем, обобщение содержания документов, перевод текстов и др. В состав алгоритма входит несколько языковых моделей, что позволяет использовать его как в облаке, так и на устройстве. Помощник по написанию программного кода под названием code.i создан для помощи в процессе программирования. В Samsung уверены, что он позволит разработчикам быстрее писать программный код, а интерактивный интерфейс ассистента обеспечит поддержку ряда полезных функций, таких как описание кода или создание тестовых примеров. Что касается Gauss Image, то эта модель предназначена для создания и редактирования изображений. С её помощью можно легко изменять стиль изображения, добавлять новые элементы, а также улучшать качество картинок с низким разрешением. OpenAI представила флагманскую нейросеть GPT-4 Turbo — мощнее и в разы дешевле GPT-4
07.11.2023 [00:40],
Николай Хижняк
Сегодня на своей первой конференции для разработчиков компания OpenAI представила GPT-4 Turbo — улучшенную версию своей флагманской большой языковой модели. Разработчики из OpenAI отмечают, что новая GPT-4 Turbo стала мощнее и в то же время дешевле, чем GPT-4. 
Источник изображения: CNET Языковая модель GPT-4 Turbo будет предлагаться в двух версиях: одна предназначена исключительно для анализа текста, вторая понимает контекст не только текста, но и изображений. Модель анализа текста доступна в виде предварительной версии через API, начиная с сегодняшнего дня. Обе версии нейросети компания пообещала сделать общедоступными «в ближайшие недели». Стоимость использования GPT-4 Turbo составляет 0,01 доллара за 1000 входных токенов (около 750 слов) и 0,03 доллара за 1000 выходных токенов. Под входными токенами понимаются фрагменты необработанного текста. Например, слово «fantastic» разделяется на токены «fan», «tas» и «tic». Выходные токены, в свою очередь, это токены, которые модель генерирует на основе входных токенов. Цена на GPT-4 Turbo для обработки изображений будет зависеть от размера изображения. Например, обработка изображения размером 1080 × 1080 пикселей в GPT-4 Turbo будет стоить 0,00765 доллара. «Мы оптимизировали производительность, поэтому можем предлагать GPT-4 Turbo по цене в три раза дешевле для входных токенов и в два раза дешевле для выходных токенов по сравнению с GPT-4», — сообщила OpenAI в своём блоге. Для GPT-4 Turbo обновили базу знаний, которая используется при ответе на запросы. Языковая модель GPT-4 обучалась на веб-данных до сентября 2021 года. Предел знаний GPT-4 Turbo — апрель 2023 года. Иными словами, на запросы, имеющие отношение к последним событиям (до апреля 2023 года), нейросеть будет давать более точные ответы. На основе множества примеров из интернета GPT-4 Turbo обучилась прогнозировать вероятность появления тех или иных слов на основе шаблонов, включая семантический контекст окружающего текста. Например, если типичное электронное письмо заканчивается фрагментом «С нетерпением жду…», GPT-4 Turbo может завершить его словами «… вашего ответа». Вместе с этим модель GPT-4 Turbo получила расширенное контекстное окно (количество текста, учитываемое в процессе генерации). Увеличение контекстного окна позволяет модели лучше понимать смысл запросов и выдавать более подходящие им ответы, не отклоняясь от темы. Модель GPT-4 Turbo имеет контекстное окно в 128 тыс. токенов, что в четыре раза больше, чем у GPT-4. Это самое большое контекстное окно среди всех коммерчески доступных моделей ИИ. Оно превосходит контекстное окно модели Claude 2 от Anthropic, которая поддерживает до 100 тыс. токенов. Anthropic утверждает, что экспериментирует с контекстным окном на 200 тыс. токенов, но ещё не внесла эти изменения в открытый доступ. Контекстное окно в 128 тыс. токенов соответствует примерно 100 тыс. словам или 300 страницам текста, что равносильно размеру романов «Грозовой перевал» Эмили Бронте, «Путешествия Гулливера» Джонатана Свифта или «Гарри Поттер и узник Азкабана» Джоан Роулинг. Модель GPT-4 Turbo способна генерировать действительный JSON-формат. По словам OpenAI, это удобно для веб-приложений, передающих данные, например для тех, которые отправляют данные с сервера клиенту, чтобы их можно было отобразить на веб-странице. GPT-4 Turbo в целом получила более гибкие настройки, которые окажутся полезными разработчикам. Более подробно об этом можно узнать в блоге OpenAI. «GPT-4 Turbo работает лучше, чем наши предыдущие модели, при выполнении задач, требующих тщательного следования инструкциям, таких как генерация определённых форматов (например, “всегда отвечать в XML”). Кроме того, GPT-4 Turbo с большей вероятностью вернёт правильные параметры функции», — сообщает компания. Также GPT-4 Turbo может быть интегрирован с DALL-E 3, функциями перевода текста в речь и зрительным восприятием, расширяя возможности использования ИИ. OpenAI также объявила, что будет предоставлять гарантии защиты авторских прав для корпоративных пользователей через программу Copyright Shield. «Мы теперь будем защищать наших клиентов и оплачивать понесённые расходы, если они столкнутся с юридическими претензиями о нарушении авторских прав», — заявила компания в своём блоге. Ранее то же самое сделали Microsoft и Google для пользователей их ИИ-моделей. Copyright Shield будет покрывать общедоступные функции ChatGPT Enterprise и платформы для разработчиков OpenAI. Для GPT-4 компания запустила программу тонкой настройки, предоставляя разработчикам еще больше инструментов для кастомизации ИИ под определённые задачи. По словам компании, в отличие от программы тонкой настройки GPT-3.5, предшественника GPT-4, программа тонкой настройки GPT-4 потребует большего контроля и руководства со стороны OpenAI, в основном из-за технических препятствий. Компания также удвоила лимит скорости ввода и вывода токенов в минуту для всех платных пользователей GPT-4. При этом цена осталась прежней: 0,03 доллара за входной токен и 0,06 доллара за выходной токен (для модели GPT-4 с контекстным окном на 8000 токенов) или 0,06 доллара за входной токен и 0,012 доллара за выходной токен (для модели GPT-4 с контекстным окном на 32 000 токенов). На следующей неделе OpenAI проведёт первую конференцию для разработчиков
04.11.2023 [15:57],
Владимир Фетисов
OpenAI, являющаяся разработчиком популярного ИИ-бота ChatGPT, в понедельник проведёт конференцию для разработчиков. Ожидается, что в рамках этого мероприятия будут анонсированы нововведения, которые сделают ИИ-модели компании более функциональными и доступными для разработчиков приложений. 
Источник изображения: Zac Wolff / unsplash.com Однодневное мероприятие, которое пройдёт в Сан-Франциско, свидетельствует о стремлении OpenAI выйти за пределы потребительского рынка, создав надёжную платформу для разработчиков в сфере ИИ. Генеральный директор OpenAI Сэм Альтман (Sam Altman) подогрел интерес к предстоящей конференции, пообещав участникам «много нового». После нескольких лет работы в относительной безвестности OpenAI в ноябре прошлого года выпустила на рынок ИИ-бота ChatGPT, который стал одним из самых быстрорастущих потребительских приложений за всю историю. Благодаря поддержке со стороны Microsoft, которая инвестировала в OpenAI миллиарды долларов, ChatGPT, способный генерировать тексты и изображения на основе небольших подсказок, создавать программный код и выполнять другие действия, быстрыми темпами завоевал популярность среди пользователей по всему миру. Касательно предстоящего мероприятия ожидается, что OpenAI объявит о снижении стоимости использования своих языковых моделей для разработчиков, а также объявит о новых возможностях машинного зрения для своего ИИ-алгоритма. Снижение затрат должно решить главную проблему для партнёров компании, чьи расходы при использовании большой языковой модели OpenAI растут быстрыми темпами. Возможности машинного зрения, которые позволят ИИ-модели анализировать изображения и составлять их описание, позволят разработчикам создавать приложения с новыми функциями и возможностью применения в разных сферах — от развлечений до медицины. Также ожидается, что OpenAI анонсирует новые возможности тонкой настройки GPT-4, наиболее совершенной языковой модели компании, запуск которой должен состояться осенью этого года. Это и другие нововведения призваны побудить сторонних разработчиков использовать технологию OpenAI для создания чат-ботов и разных приложений на базе нейросетей. По данным источника, одна из главных стратегических задач, поставленных Сэмом Альтманом, заключается в том, чтобы сделать OpenAI незаменимой для других разработчиков приложений. ИИ помог дозаписать новую песню The Beatles с вокалом Джона Леннона — она выйдет 2 ноября
27.10.2023 [18:05],
Владимир Фетисов
Стало известно, что 2 ноября состоится релиз последней песни легендарной группы The Beatles с вокалом Джона Леннона под названием Now and Then. В процессе её создания использовался ИИ-алгоритм компании WingNut Films, который применялся для обработки голоса Леннона на демо-записи этой песни, сделанной несколько десятилетий назад. 
Источник изображения: Business Wire Джон Леннон записал демо-версию Now and Then на аудиокассету в 1970-х годах, но она никогда официально не издавалась. В 2021 году режиссёр Питер Джексон снял документальный сериал The Beatles: Get Back, в процессе работы над которым для обработки партий музыкальных инструментов и голосов людей использовалась технология компании WingNut. Теперь же этот алгоритм задействовали для обработки голоса Леннона на демо-записи, благодаря чему удалось сохранить чёткость оригинального вокала, отделив его от играющей на записи музыки. Спустя несколько десятилетий после создания демо трек будет выпущен как официальная спродюсированная песня вместе с 12-минутным документальным фильмом The Last Beatles Song, посвящённым рассказу о создании этой музыкальной композиции. В него вошли комментарии Пола Маккартни, Ринго Стара, Джорджа Харрисона, а также сына Леннона Шона Оно-Леннона и Питера Джексона. В пресс-релизе, посвящённом предстоящей премьере, Пол Маккартни сказал, что был «весьма взволнован», услышав голос Леннона на «настоящей записи The Beatles» в 2023 году, а Ринго Старр описал процесс создания песни как «самый близкий к тому», чтобы вернуть Леннона в комнату. Документальный фильм The Last Beatles Song выйдет 1 ноября, песня Now and Then — 2 ноября, а видеоклип на неё — 3 ноября. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






